
Abstract
To solve blurring and poor visual effects after enhancement of low-light images by conventional low-light algorithms, this paper proposes a MER-Retinex (multi-scale expansion reconstruction retinex) algorithm that integrates attention mechanism and multi-scale expansion pyramid reconstruction. It includes two parts: decomposition and enhancement module. In the decomposition module, two U-shaped networks are used to decompose the image into reflectance and illumination, then, use multi-layer convolution to expand the field of perception and improve the ability to decompose the image to obtain reflectance and illumination. In the enhancement module, a U-shaped network is used to fuse multi-scale expansion pyramids with a multi-attention mechanism to enrich image information, increase image brightness and fuse the processed global information with local information to enhance the recovered image details. In the enhanced reconstruction section, super-resolution techniques are used to enhance and denoise image feature details. Experimental analysis of the MER-Retinex algorithm was carried out on the LOL dataset. The PSNR of the algorithm in this paper was 25.26 and the NIQE was 3.43. The algorithm in this paper can effectively solve the problems of blurred images and poor visual effects, and has improved in both subjective perception and objective evaluation indexes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The quality of images and videos under low-light conditions can be greatly affected in terms of brightness and colour saturation, making it difficult for images or videos to be observed or processed properly. Therefore, image enhancement under low-light conditions is an important area in computer vision, such as recognition detection [1,2,3] and mine work [4, 5], which need to maintain normal operation under low-light conditions. Currently, low-light image enhancement algorithms are mainly divided into traditional low-light image enhancement algorithms [6,7,8,9,10,11,12] and low-light image enhancement algorithms based on deep learning [13,14,15,16,17,18,19]. The traditional low-light image enhancement algorithms are represented by histogram equalization and model-based optimization algorithms, the basic idea of which is to transform or adjust the distribution of image pixels by grey scale. Low-light image enhancement algorithms based on deep learning are represented by the classical algorithms of convolutional neural networks, which mainly train the mapping relationships of low-light images to achieve image enhancement. From the existing research results, the low-light image enhancement algorithm based on deep learning is more robust, has better scalability, has certain advantages in practical applications and has made good research progress. For example, in 2018, to address the problem of dark information being compressed in low-light image enhancement algorithms, Wei et al. researchers proposed the Retinex-Net [20] algorithm, which uses Retinex theory to achieve decomposition and enhancement of images, recovering some of the dark information and proposing LOL datasets, but the algorithm suffers from certain chromatic aberration problems. In 2019, to address the problem that image enhancement will produce chromatic aberration, Zhang et al. proposed the KinD algorithm [21], which uses multiple loss functions for constrained adjustment of low-light images on the basis of the Retinex-Net algorithm, but the enhanced images of this algorithm have blurred edges. To solve the edge blurring problem, in 2020, Zhu et al. proposed a low-light image enhancement algorithm for EEMEFN introducing edge information [22], which uses edge information to refine the initial image, but it is still difficult to handle low-light images in different scenes. In 2021, Jiang et al. proposed the EnlightenGAN algorithm [23], a low-light image enhancement algorithm based on generative adversarial networks (GAN), which enhances by training a generator and discriminator neural network with a self-attentive mechanism and self-regularized perceptual loss. In 2022, Ma et al. proposed the SCI algorithm [24], which discards the complex network design and introduces a self-calibration module with weight sharing. From the existing research results of low-light image enhancement algorithms based on deep learning, the image features under different illumination were fused to improve the robustness of low-light image enhancement algorithms. However, the existing research results did not effectively solve the problems of blurred low-light images and low brightness, and the low-light image enhancement effect still needs further improvement.
To solve the problems of blurred images and poor visual effects in low-light image enhancement techniques, this paper proposes a MER-Retinex algorithm that incorporates an attention mechanism and multi-scale expansion pyramid reconstruction. It includes two parts: decomposition and enhancement. In the decomposition module, a dual U-shaped network architecture is proposed to decompose the image into reflectance and illumination, respectively. The feature maps of different sizes are fused with each other through multi-layer convolution combined with jump connections, so that the contextual information between different perceptual field feature maps is fully utilized, and finally the reflectance and illumination are fed into the enhancement network. This module enriches image information and facilitates image enhancement. In the enhancement network, a multi-scale expansion pyramid module is added using a U-shaped network, in which a null convolution is used and a multi-attention mechanism is fused, in which the feature images are fully exploited and the image is enhanced using a light enhancement loss function. The super-resolution reconstruction section is used for feature extraction, nonlinear mapping and reconstruction, in which the image details are further reconstructed and denoised. The feature map is extracted in the feature layer. The details are mapped in the nonlinear mapping layer. Finally, the information mentioned in the above section is integrated in the reconstruction section to achieve the effect of denoising and de-blurring.
2 Analysis of the MER-Retinex algorithm model
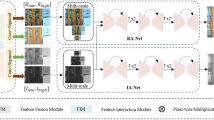
Conventional low-light image enhancement algorithms fuse and enhance different light images by extracting features of different sizes according to the algorithm itself, but there are problems such as loss of details and blurring after multiple fusions, thus causing a lack of visual enhancement effect. To address this problem, the MER-Retinex algorithm is proposed in this paper, and the overall architecture of the algorithm is shown in Fig. 1. It is mainly composed of two parts: the decomposition network and the enhancement network. The decomposition network uses two U-shaped networks to decompose the image into reflectance and illumination, respectively, where the normal light image and the low-light image share parameters to extract the reflected light and illumination information of the normal light and low-light images, so that the information is fused. In the enhancement network part, the U-shaped network combines multi-scale expansion pyramid and multi-attention mechanism. And multi-scale expansion pyramid uses expansion convolution to extract detailed information from images with different perceptual field features. Multi-attention mechanism improves the network’s ability to capture image information for the purpose of image enhancement. Super-resolution reconstruction is used in the enhancement reconstruction module to fuse feature information to remove noise from the image and obtain a clearer and smoother enhanced image.

Overall framework of MER-Retinex
2.1 Decomposition network
The main disadvantage of low-light image enhancement algorithms is the lack of information on picture features, and it is important to obtain good information on reflectance and illumination. Retinex theory suggests that the visual system can obtain a realistic and stable perception of colour by contrasting differences in colour and luminance in different areas of the surrounding environment. When we decompose the picture, we can think in terms of both reflectance and illumination, and the process can be expressed as:
Among equation, \(\left( m,n\right) \) is the position coordinate of the pixel, \({\varvec{T}}\) represents input image, \({\varvec{F}}\) represents reflectance, \({\varvec{Z}}\) represents light.
According to equation, this paper proposes a decomposition network part to perform image decomposition using the reflection consistency and luminance smoothing consistency of the paired images. The structure diagram of the decomposition network is shown in Fig. 1a. Paired datasets are used in training, and normal light images provide relevant weight parameters to low-light images, so that low light images learn normal light image information. In this case, the decomposition network works in parallel using two U-shaped networks, which are divided into up-sampling and down-sampling. Up-sampling is achieved by two layers of 3\(\times \)3 convolution plus maximum pooling together with one layer of 3\(\times \)3 convolution. Down-sampling is made up of three layers of 3\(\times \)3 convolution, with the two U-networks working independently and finally feeding the results into the augmented network. The decomposition network works to facilitate the subsequent augmentation network, while improving the training speed and generalization ability of the network.

Structure of a multi-scale expanding pyramid
2.2 Enhanced network
Conventional low-light image enhancement techniques tend to have problems such as weak brightness and blurring. To address these issues, this paper uses a U-shaped network with a multi-scale expansion pyramid and a multi-attention mechanism in the enhancement network part, and a super-resolution reconstruction technique in the enhancement reconstruction part. In the enhancement network module, the global and local feature map information is fully extracted for brightness enhancement, detail enhancement and smoothing of image information. The structure of the enhancement network is shown in Fig. 1b. After reflectance and illumination fusion, an expansion pyramid operation is performed to expand the perceptual field of the network and improve the efficiency of the network in extracting feature information. At the same time, the multi-attention mechanism is then used to suppress background interference, preserve richer contextual information and improve the representation of feature information.

Multi-attention structure diagram
2.2.1 Multi-scale expansion pyramids
In the low-light image enhancement algorithm, the global and local information of the image plays a crucial role, which contains rich feature details. In this paper, we propose a multi-scale expansion pyramid (MEP) structure to extract feature image information of different perceptual fields, and the multi-scale expansion pyramid structure diagram is shown in Fig. 2. The first layer in the multi-scale expansion pyramid consists of a multi-attention mechanism and 1\(\times \)1 ordinary convolution. The multi-attention mechanism extracts feature information and maintains the original perceptual field detail information. Meanwhile, 1\(\times \)1 convolution reduces the number of channels to maintain the effective performance of the network and improve the generalization ability. The middle three branches consist of a 3\(\times \)3 convolution of voids with void rates of 12, 24 and 36 to obtain different scales of receptive field information and to achieve successive extraction of multi-scale features. Diverse expansion rates are able to cover different scales of the feature map, providing the network with the ability to extract detailed information at different scales. Finally, global average pooling is used to obtain global perceptual field information. The above feature maps are combined and stacked, and the global and local information is fused using 1\(\times \)1 ordinary convolution.
2.2.2 Multi-attention mechanism
Since feature maps at different scales correspond to different feature information, the common fusion methods do not effectively solve the information bias; therefore, this paper proposes a multi-attention mechanism, and the structure of the multi-attention mechanism (MAM) is shown in Fig. 3. Firstly, the channel attention mechanism is parallel to the spatial attention mechanism, and the input feature map is passed through the channel attention mechanism and the spatial attention mechanism, so that its number of parameters gradually decreases and invalid information interference is reduced. The channel attention mechanism is a parallel action of maximum pooling and global average pooling, and the channel attention mechanism is implemented by merging the fully connected layer channel descent and ascent to the sigmoid function, and finally fusing the initial feature map. The spatial attention mechanism utilizes the spatial information of the feature image and is achieved by parallel stacking of maximum pooling and global average pooling then merging with the initial feature map through the action of 1\(\times \)1 convolution and sigmoid function.
In order to further improve the model to focus more on the information contained in the feature map, the ECA attention mechanism is added after the channel attention mechanism and the spatial attention mechanism in parallel. The ECA attention mechanism is implemented through global average pooling, 1\(\times \)1 convolution and sigmoid function. The multi-attention mechanism is added to the overall network architecture after the second and third convolution layers of the augmented network, respectively. Also after the second and third layers of the symmetric adjacent interpolation and deconvolution, as well as in the multi-scale expansion pyramid mentioned above. The multi-attention mechanism effectively enhances the detail information of the feature map and improves the efficiency of the network.
2.2.3 Super-resolution reconstruction
In low-light image enhancement algorithms, most of them have the problem of noise and non-smoothness. To address this problem, this paper proposes a fusion super-resolution reconstruction method, and the super-resolution reconstruction (SR) module is shown in Fig. 4. An image is input from the enhancement module, and an image after processing resolution is output after three convolution layers, whose roles are feature extraction, nonlinear mapping and reconstruction, respectively. Firstly, the filter convolution of the feature block extraction module consists of a 1\(\times \)1 convolution with a relu activation function that extracts feature blocks from the low-resolution image and represents each block as a high-dimensional vector that consists of a set of feature maps equal to the number of dimensions of the vector. Secondly, the filter of the nonlinear mapping module consists of a 1\(\times \)1 convolution with a relu activation function that nonlinearly maps each high-dimensional vector to another high-dimensional vector, each mapped vector being conceptually a representation of a high-resolution feature block. Finally, a 1\(\times \)1 convolution is used in the reconstruction module to combine the feature maps into the final smoothed image. Combined the above operations to generate the final super-resolution image.

Super-resolution reconstruction structure diagram
2.3 Loss function
In image decomposition, the reflectance and illumination of the image need to be consistent and smooth, and for this problem, a relevant loss function is proposed in the decomposition module. The decomposition module loss function consists of four components, which are the reflectance similarity loss function \(L_{\textrm{xs}}^{d}\), illumination smoothness loss function \(L_{\textrm{ph}}^{\textrm{d}}\), reciprocal consistency loss function \(L_{\textrm{yz}}^{d}\) and reconstructing the loss function \(\mathcal{L}_{\textrm{cg}}^{d}\). The total loss function of the decomposition module is \(L^{\textrm{d}}=0.01^*L_{x s}^{d}+0.15*L_{p h}^{d}+0.2*L_{y z}^{d}+L_{c g}^{d}\).
Gradient loss and similarity of the enhanced image is often an issue to be considered when enhancing low-light images. To address this issue, the relevant loss functions are designed in the enhancement module, which are the mean square error function MSE, structural similarity index function SSIM, gradient loss function Grad. The total loss function of the enhancement module is \(\mathcal{L}^{\textrm{R}}=M S E(R_{L},R_{H})+\lambda _{R}^{S}S S I M(R_{L},R_{H})+\lambda _{R}^{G}G r a d(R_{L},R_{H})\), where \(\lambda _{R}^{S}\) and \(lambda_{R}^{{G}}\) are 0.5; \(R_{H}\) is the reflectance extracted from the standard diagram by the decomposition module, \(R_{H}\) for shared data. The decomposition loss function is mainly used for the decomposition of reflectance and illumination, and the loss function of the enhancement module is mainly used for illumination, detail enhancement and noise removal of the image.
3 Experiments and analysis of results
3.1 Data sets and evaluation indicators
In order to verify the effectiveness of the method designed in this paper, the LOL dataset was chosen to train the algorithm in this paper. The LOL dataset consists of 500 pairs of low-light images and enhanced images. Each pair of images is obtained from the same original image with different exposure times. The images in this dataset cover a variety of scenes, including indoor and outdoor, human and non-human objects, natural and artificial light sources, etc.
In order to verify the validity of the algorithm in this paper, evaluation metrics are used for validation. Evaluation metrics are divided into reference and non-reference metrics, peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and mean square error (MSE) are reference metrics, and natural image quality evaluator (NIQE) is a non-reference evaluation metric. PSNR stands for peak signal-to-noise ratio, which is the degree of proximity between two image pixels, the higher the value of PSNR, the better the quality of the image. SSIM is a structural similarity index, which is used to evaluate the overall architecture, brightness, etc., of two images, the higher the value the better the image quality. Mean square error is the comparison between the reference image and the noise of the enhanced image, the smaller the value, the smaller the error, the better the image quality. NIQE is a natural image quality assessor with high accuracy and stability for image quality evaluation, the smaller the value, the higher the image quality.
3.2 Experimental setup
The algorithmic model optimized in this paper is based on the TensorFlow-GPU2.4 [25] framework with Python version 3.7. The environment used in the training experiments was the NVIDIA GeForce RTX 3060, and the Adam optimizer [26] was used during the model training. The specific parameters are shown in Table 1.
3.3 Analysis of experimental results

Comparison of average performance of different algorithms on LOL dataset
3.3.1 Comparison of performance
To test the quantitative metrics of our algorithm, Table 2 presents the comparison of the PSNR, SSIM, MSE and NIQE [27] values of our MER-Retinex algorithm with different low-light enhancement algorithms (Such as LightenNet(A), Retinex-Net(B), KinD(C), KinD++(D), DRBN(E), Zero-DCE(F), Zero-DCE++(G). RRDNet(H), SCI(I)) for the LOL dataset. The algorithm performs best in the NIQE, MSE and PSNR evaluation metrics, the SSIM evaluation index is slightly weak. The main reason for the unsatisfactory SSIM metrics compared to other algorithms is that this paper’s algorithm uses smoothing operations to soften the image during the denoising of the image in the super-resolution reconstruction part, which makes the detailed structure of the image deviate, resulting in unsatisfactory SSIM metrics.
In order to evaluate this paper’s algorithm more comprehensively, in addition to quantitatively analysing each evaluation metric, we also analysed its distribution using box plots, as shown in Fig. 5. In the figure, we use the LOL large dataset as the algorithm test data source, and measure the average performance of the algorithm with the four metrics of PSNR, SSIM, MSE and NIQE, and use the algorithms of LightenNet, Retinex-Net, KinD, KinD++, DRBN, Zero-DCE, Zero-DCE++, RRDNet and SCI as comparisons, and it can be seen that the algorithm of this paper achieves the ideal results in the four metrics in comparison with the above-mentioned algorithms, and also indicates that the algorithm of this paper has a good performance in terms of the average performance.
To test the performance effectiveness of the algorithm in this paper on different datasets, a test comparison was conducted on LIME dataset, MEF dataset and DICM dataset. Table 3 shows the NIQE values of different algorithms on LIME dataset, MEF dataset and DICM dataset, with the best results in bold font, which shows that the algorithm in this paper has the best metrics. Taken together, the algorithm in this paper has a significant improvement in objective evaluation.
To test the effectiveness of each module of the algorithm in this paper, ablation experiments were conducted and the results are shown in Table 4. The ablation experiments were evaluated using the PSNR with reference evaluation metric and the NIQE without reference evaluation metric to compare the effect of each network structure on image quality on the LOL dataset.
To test the effectiveness of the multi-attention mechanism, the base decomposition was retained for ablation experiments with the augmentation module. By adding the multi-attention mechanism to the base module to enhance the model’s ability to perceive picture features, the PSNR metric of the model improved to 19.50 and the NIQE metric improved to 3.62 compared to the base module.
To test the effectiveness of the multi-scale inflation pyramid, the PSNR metric of the model was improved to 24.49 and the NIQE metric to 3.49 by adding the multi-scale inflation pyramid to the base module and the multi-attention mechanism to enhance the model’s integration of contextual information.
To test the effectiveness of super-resolution reconstruction, super-resolution reconstruction was added to the base module, multi-attention mechanism with multi-scale expansion pyramid to effectively remove noise from the images, and the PSNR index of this model was improved to 25.26 and NIQE index to 3.43.
3.3.2 Qualitative experimental comparison
The curve change of the loss function can reflect the performance change during the training of the model, as Fig. 6 shows the loss function curve during the training of the MER-Retinex algorithm in this paper. Figure 6a shows the loss function curve during training of the decomposition network. It can be seen that the value of the loss function decreases significantly during the training process from 1.0 to 0.4, the model performance keeps improving; the loss function curve fluctuates in the range of 0.4-\(-\)0.1 and the model keeps running smoothly. Figure 6b shows the loss function curve during training of the augmented network. It can be seen that there is a significant decrease in the training loss function from 5.5 to 0.5, and the model performance keeps improving; the loss function curve fluctuates in the range of 0.5 to 0.1, and the model keeps running smoothly.

Loss function graph

Visual comparison chart
To verify whether the algorithm in this paper is effective in practical applications, Fig. 7 shows the visual comparison graph of the MSE-Retinex algorithm in this paper with different low-light enhancement algorithms. From Fig. 7, it can be seen that the MSE-Retinex algorithm in this paper has a significant improvement in terms of brightness compared to LightenNet [28];the denoising effect is better compared with Retinex-Net [20] algorithm; clearer compared with KinD [21]and KinD++ [16] algorithms; more vivid colours compared with DRBN [29] algorithm; more vivid colours compared with Zero-DCE [30] algorithm, Zero-DCE++ [31], RRDNet [32] and SCI [24] algorithms for luminance enhancement. From the above results, it can be seen that the image enhancement effect of the method proposed in this paper is more in line with the visual effect in practical human applications, and the visual effect is ideally enhanced in comparison with other algorithms.
To test the greyscale distribution of the algorithm in this paper, a greyscale histogram visualization was used, as shown in Fig. 8. On the left is a comparison of the low-light image with the enhanced image, and on the right is a comparison of the greyscale histogram of the low-light image with the enhanced image. The greyscale histogram visualization shows the greyscale distribution of the image in the form of a histogram. It can be seen that the greyscale distribution of the low-light image is concentrated in the denser part of the grey scale. And the enhanced image with the MER-Retinex algorithm proposed in this paper has a more uniform distribution of greyscale indicators, which makes up for the defects of the low-light image from the subjective visual point of view.

Comparison of greyscale histograms

Local zoom comparison
In order to verify the visual effectiveness of the algorithm for noise removal in this paper, Fig. 9 shows a local zoom comparison. The circled part on the left is the local zoom after the basic decomposition and enhancement module, while the circled part on the right is the local zoom after the enhancement of the MSE-Retinex algorithm in this paper. It can be seen that the noise is significantly removed and the image is smoother and more detailed with the algorithm.
4 Conclusions
In order to improve the performance of the algorithm in low-light image enhancement and to address the problems of low brightness and blurring of low-light images, MER-Retinex optimization algorithm proposed in this paper incorporates an attention mechanism and multi-scale expansion pyramid reconstruction. It mainly consists of the following two modules: the decomposition module and the enhancement module. The decomposition module consists of two U-shaped networks working in parallel, and the enhancement network module consists of a multi-scale expansion pyramid module, a multi-attention mechanism module and a super-resolution reconstruction module. Firstly, in the decomposition module, two U-shaped networks are used to decompose the image into reflectance and illumination, respectively, using jump connections and shared data to obtain feature-rich reflectance and illumination. Secondly, in the enhancement network module, multi-scale expansion pyramids and attention mechanisms are fused to obtain rich image information, improve image brightness and fuse the processed global information with local information. In the reconstruction part, the images are denoised using super-resolution techniques. The results show that the MER-Retinex algorithm has good results for low-light image enhancement. Experimental analysis of the MER-Retinex algorithm was carried out on the LOL dataset, and the PSNR and NIQE metrics of this paper’s algorithm were 25.26 and 3.43, respectively. Although the algorithm in this paper has improved the effect of low-light image enhancement, how to train and optimize the network structure model using unpaired low illumination image data is still the main direction of future research.
Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Fan, Y., Wang, Y., Yan, X., Gong, L., Guo, Y., Wei, M.: Face recognition-driven low-light image enhancement. J. Graph. 43(6), 1170 (2022)
Xiang, X., Yao, J., Huang, B., Yang, S., Wu, X.: Traffic sign detection and recognition under complicated illumination. J. Comput. Aided Des. Comput. Graph. 35(2), 10 (2023)
Shu, Z., Zhang, Z., Song, Y., Wu, M., Yuan, X.: Low-light image object detection based on improved yolov5 algorithm. Laser Optoelectron. Prog. 60(4), 8 (2023)
Wang, M., Li, J., Zhang, C.: Deep neural network-based image enhancement algorithm for low-illumination images underground mines. Coal Sci. Technol. 1, 1 (2022). https://doi.org/10.13199/j.cnki.cst.2022-1626
Wang, H., Cao, W., Wang, H., Li, Z., Xiang, F., Tao, L., Wang, H., Zhang, C., Geng, Y.: A method for enhancing low light images in coal mines based on retinex model containing noise. J. Mine Autom. 49(4), 8 (2023)
Zhang, Z., Wang, S., Xiong, S., Hu, L., Hu, X.: Image enhancement algorithm based on wavelet transform and clahe. Mod. Electron. Tech. 45(3), 4 (2022)
Cheng, H.D., Shi, X.J.: A simple and effective histogram equalization approach to image enhancement. Digit. Signal Process. 14(2), 158–170 (2004)
Ibrahim, H., Kong, N.S.P.: Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(4), 1752–1758 (2007)
Abdullah-Al-Wadud, M., Kabir, M.H., Akber Dewan, M.A., Chae, O.: A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(2), 593–600 (2007). https://doi.org/10.1109/TCE.2007.381734
Land, E.H.E.: Lightness and retinex theory. J. Opt. Soc. Am. 61(1), 1–11 (1971)
Bindhu, A., Uma, M.O.: Color corrected single scale retinex based haze removal and color correction for underwater images. Color Res. Appl. 45, 1084–1093 (2020)
Shen, L., Yue. Z., Feng. F., et al. Msr-net: low-light image enhancement using deep convolutional network[J]. arXiv preprint (2017). arXiv:1711.02488
Huixian Huang, F.C.: Low-illumination image enhancement method based on attention mechanism and retinex. Laser Optoelectron. Prog. 57(20), 8 (2020)
Han, W., Dong, X., Xing, G., Wang, H.: Research and improvement of the algorithm for low illumination image enhancement. J. Inf. Eng. Univ. 23(2), 6 (2022)
Guo, X., Li, Y., Ling, H.: Lime: low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 26(2), 982–993 (2017). https://doi.org/10.1109/TIP.2016.2639450
Zhang, Y., Guo, X., Ma, J., Liu, W., Zhang, J.: Beyond brightening low-light images. Int. J. Comput. Vis. 129, 1013–1037 (2021)
Zhu, G., Ma, L., Liu, R., Fan, X., Luo, Z.: Collaborative reflectance-and-illumination learning for high-efficient low-light image enhancement. In: 2021 IEEE International Conference on Multimedia and Expo (ICME), pp. 1–6 (2021)
Zhao, L., Lu, S.-P., Chen, T., Yang, Z.-Y., Shamir, A.: Deep symmetric network for underexposed image enhancement with recurrent attentional learning. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 12055–12064 (2021)
Wang, L.-W., Liu, Z.-S., Siu, W.-C., Lun, D.P.-K.: Lightening network for low-light image enhancement. IEEE Trans. Image Process. 29, 7984–7996 (2020)
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement (2018). arXiv:1808.04560
Zhang, Y., Zhang, J., Guo, X.: Kindling the darkness: a practical low-light image enhancer. In: Proceedings of the 27th ACM International Conference on Multimedia (2019)
Zhu, M., Pan, P., Chen, W., Yang, Y.: Eemefn: low-light image enhancement via edge-enhanced multi-exposure fusion network. In: AAAI Conference on Artificial Intelligence (2020)
Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., Yang, J., Zhou, P., Wang, Z.: Enlightengan: deep light enhancement without paired supervision. IEEE Trans. Image Process. 30, 2340–2349 (2019)
Ma, L., Ma, T., Liu, R., Fan, X., Luo, Z.: Toward fast, flexible, and robust low-light image enhancement. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5627–5636 (2022)
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur, M., Levenberg, J., Monga, R., Moore, S., Murray, D.G., Steiner, B., Tucker, P.A., Vasudevan, V., Warden, P., Wicke, M., Yu, Y., Zhang, X.: Tensorflow: a system for large-scale machine learning (2016). arXiv:1605.08695
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2014). CoRR arXiv:1412.6980
Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind’’ image quality analyzer. IEEE Signal Process. Lett. 20, 209–212 (2013)
Li, C., Guo, J., Porikli, F., Pang, Y.: Lightennet: a convolutional neural network for weakly illuminated image enhancement. Pattern Recogn. Lett. 104, 15–22 (2017)
Yang, W., Wang, S., Fang, Y., Wang, Y., Liu, J.: From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3060–3069 (2020)
Guo, C., Li, C., Guo, J., Loy, C.C., Hou, J., Kwong, S.T.W., Cong, R.: Zero-reference deep curve estimation for low-light image enhancement. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1777–1786 (2020)
Li, C., Guo, C., Loy, C.C.: Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 44, 4225–4238 (2021)
Zhu, A., Zhang, L., Shen, Y., Ma, Y., Zhao, S., Zhou, Y.: Zero-shot restoration of underexposed images via robust retinex decomposition. In: 2020 IEEE International Conference on Multimedia and Expo (ICME), pp. 1–6 (2020)
Funding
This work was supported by the Jiangsu Graduate Practical Innovation Project (No. SJCX22_1685), the Major Project of Natural Science Research of Jiangsu Province Colleges and Universities (No: 19KJA110002), the Natural Science Foundation of China under Grant (No. 61673108), the Natural Science Research Project of Jiangsu University (No. 18KJD510010).
Author information
Authors and Affiliations
Contributions
All authors have made substantial contributions to the conception, design and revision of the paper.
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, R., Wang, R., Wang, Y. et al. Research on low-light image enhancement based on MER-Retinex algorithm. SIViP 18, 803–811 (2024). https://doi.org/10.1007/s11760-023-02801-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02801-x