
Abstract
Emotion recognition through physiological signals is of great importance for the examination of psychological states and the development of biofeedback-based applications. Thanks to the emergence of the concept of metaverse and the integration of physiological signal trackers into smart devices, this field of study has become a necessity and a subject of interest to researchers. In this study, an algorithm is proposed for emotion detection according to the two-category (valence–arousal) emotion model. ECG signal recordings from the MAHNOB-HCI database were used in the study. First, the noise on the ECG signals is eliminated in the preprocessing step. R peaks were detected by applying the Pan–Tompkins algorithm to the preprocessed ECG signals. Then, for each recording, the P-QRS-T fragment and the maximum and minimum values of the P, Q, R, S, and T waves were obtained as morphological features and combined with selected heart rate variability features to obtain a feature vector. By applying an automated feature engineering algorithm to this feature vector, new feature vectors with increased weight of distinctive features and increased number of samples are obtained as output. These features are classified with three different learning algorithms: support vector machines, feedforward neural network, and bidirectional long short-term memory. As a result of the study, good results were obtained with the bidirectional long short-term memory algorithm compared to the literature. According to these results, with bidirectional long short-term memory, the accuracy obtained was 78.28% for the valence category and 83.61% for the arousal category.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Intelligent human–computer systems are highly demanded today in order to increase the ability to interact with people and to understand human communication accurately. Emotional information processing is of great importance in human–computer interaction and emotion detection [1]. Recognizing people's emotions and gaining emotional intelligence is of great importance for the emotional and correct interaction (human–computer interaction, HCI) between human and computer [2]. Today, with the emergence of the concept of Metaverse, studies in this field have increased. Studies have shown that biomedical signals are affected by emotional changes. The aim of the researchers here is to create emotion detection systems with balanced performance in terms of both accuracy and response speed. Therefore, the recent challenge in this area is to consider fewer physiological signals [3,4,5]. Emotion detection methods are designed by analyzing biomedical signals produced by the autonomic nervous system (such as electrocardiography and galvanic skin response). In addition, physiological signals are directly affected by emotional changes. According to the results of many studies in the literature, one of the most accurate ways to detect emotion is the use of biomedical signals [6]. At this point, since the biomedical signals are nonlinear and nonstationary, appropriate features must be selected to increase the accuracy of the system.
Among these physiological signals, emotion detection based on the analysis of short-term ECG (electrocardiography) signal, computer games, and multimedia biofeedback systems will be useful in applications such as detecting emotional responses to changing stimuli in psychiatric studies [7]. ECG signals are signals that allow monitoring the electrical activity of the heart.
Studies have shown that biomedical signal characteristics affect classification performance. In addition, the long computation time of the emotion detection algorithm to emotion recognition/classification poses a challenge for real-time emotion recognition applications. At this point, feature extraction and feature selection are important steps because ideal feature extraction will enhance the classification and the improvement of the evaluated indicators [6]. In these studies, classification with as few features as possible will be beneficial in terms of transaction costs.
Regarding emotional states, Plutchik proposed eight different emotions as fear, anger, sadness, disgust, curiosity, surprise, pleasure, and joy. The rest of the emotions are a mix of these emotions (for instance, a mix of sadness and curiosity) [8]. From another point of view, emotions are divided into four regions, in the arousal and valence planes. Here, on the valence axis, it ranges from very positive emotions to negative emotions, or in other words, the left side expresses negative emotions and the right side expresses positive emotions. In the axis of arousal; it ranges from the least activating to the activating emotions from the lower side of the axis upwards. For example, it ranges from sleepiness to excitement. Here, emotions are classified as positive or negative on the valence axis, and high and low on the arousal axis [9].
There are many studies in the literature related to sentiment analysis, especially those using physiological signals, which have been one of the areas that researchers have shown great interest in. In these studies, the physiological signal used, the database, the extracted features, and the classification methods vary. Below are summaries of some recent studies in the literature:
Ferdinando et al. applied standard empirical mode decomposition and bivariate empirical mode decomposition to ECG signals recorded in the MAHNOB-HCI database, and obtained features based on the statistical distribution of the instantaneous frequency calculated using the Hilbert transform of the intrinsic mode function. They used SVM and KNN for classification and achieved the highest performance metrics with KNN, obtaining accuracies of 59.7 and 55.8% for arousal and valence, respectively [7].
Hsu et al. extracted features in the time and frequency domains from ECG signals recorded in the MAHNOB-HCI database and used an SFFS-KBCS-based feature selection algorithm. They also reduced the dimensionality of the features using GDA. They used LS-SVM for classification and obtained results of 49.2 and 44.1% for arousal and valence, respectively [10].
Ben and Lachiri used ECG, respiration volume, skin temperature, and galvanic skin response signals recorded in the MAHNOB-HCI database to extract 169 features. They used SVM for classification and obtained accuracies of 64.23 and 68.75% for arousal and valence, respectively [11].
Siddharth et al. conducted a classification experiment using LSTM with physiological signals from four different datasets, including DEAP, MAHNOB-HCI, AMIGOS, and DREAMER. They also evaluated the performance of the algorithm extensively by using transfer learning to show that their proposed method overcomes inconsistencies between datasets. Using the ECG signal from the MAHNOB-HCI dataset with their proposed method, they achieved accuracies of 79% for both arousal and valence [12].
Baghizadeh et al. limited the physiological signals recorded in the MAHNOB-HCI database and obtained various features in the time, frequency, and time–frequency domains by applying the Poincaré map to R-R, QT, and ST intervals of the ECG signals. They used three classifiers, KNN, SVM, and MLP, for classification and achieved the best average accuracies of 82.17 ± 4.73 and 78.07 ± 3.59 for arousal and valence categories, respectively, with KNN [13].
In the proposed model, using the ECG signals from the MAHNOB-HCI database, preprocessing and feature extraction are performed, and new feature generation is performed with automated feature engineering. Using three different learning methods: support vector machines (SVM), feedforward neural network (FNN), and bidirectional long short-term memory (BiLSTM); classification was performed for both valence and arousal levels. The relevant sections are given in detail in the Materials and Methods section.
2 Material and method
2.1 MAHNOB-HCI database
MAHNOB database; it is a database designed to elicit emotional responses to content, such as amusement or disgust, in order to learn about the natural behavior of healthy adults when interacting with a computer during multimedia viewing. Within the scope of this experiment, camera, microphone, and eye tracker were used (color and monochromatic at six different angles) to see the reactions of the participants, and different physiological signals were recorded within the scope of the experiment. These recorded biomedical signals are EEG (electroencephalography), ECG, GSR (galvanic skin response), body temperature, and respiration (RESP) signal. Signals were recorded at 1024 Hz and down-sampled to 256 Hz [14].
In this study, since the classification process was based on arousal and valence, two-class emotion categorization was performed as shown in Table 1 according to the value of r.
Here, the r value is the evaluation score that the subjects entered from the keyboard, and these values can be found for each record in the database.
Two classes were converted into rating points according to the r scale and labeled. As shown in Fig. 1, the data show a balanced distribution when divided into two classes in the valence and arousal categories.

Data distribution pie chart for valence and arousal category
Within the scope of the study, it is aimed to perform the classification process over the ECG signal.
2.2 Methods
In the study, firstly, the ECG records obtained from the database were segmented into 15-s recordings due to their different lengths. Then, the preprocessing step was carried out to remove the noise on the raw ECG signals. After detecting the R peaks with the Pan–Tompkins algorithm; P, Q, R, S, and T waves were detected. On these detected waves, first the P–QRS–T fragment with a length of 281 samples, then the maximum–minimum values of the P, Q, R, S, and T waves with a length of 10 samples are obtained. Thus, morphological features with a total length of 291 samples were extracted. In addition, HRV (heart rate variability) features of five samples were obtained and added, and a feature vector with a total length of 297 samples was created. Finally, the normalization process was applied on the obtained feature vector. Afterwards, feature generation was carried out with feature engineering in order to increase both the number of obtained features and increase the accuracy of the classification algorithm.
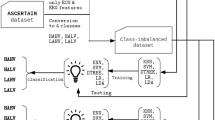
Then with SVM, FNN, and BiLSTM; two separate classification studies, namely valence and arousal, were carried out. The block diagram of the method used is shown in Fig. 2.

The methodology used in the study for emotion classification
2.2.1 ECG signal preprocessing
There are basically three types of noise in the ECG signal: (1) baseline drift, (2) power line interference, and (3) high-frequency noise.
Causes of baseline shift are breathing, movement of the patient, inability to place the electrodes completely. It is seen as the signal moving on a DC voltage. The frequency range of this noise is below 0.5 Hz [15]. For this reason, a 0.5-Hz cutoff frequency Butterworth filter was used for this noise.
The frequency range of power line interference usually varies around 50 Hz [15]. For power line noise, an IIR (infinite impulse response) notch filter with a cutoff frequency of 50 Hz is used.
ECG signals are a low-frequency biomedical signal seen between 0.5 and 100 Hz, but the weighted information content is considered below 40 Hz. High-frequency content outside this frequency may be electrical noise from the heart muscle or nervous activities from different parts of the body, or the noise of other high-frequency devices in the environment [16, 17]. For this reason, a Butterworth filter with a passband corner frequency of 40 Hz and a stopband corner frequency of 60 Hz is used for high-frequency noise.
2.2.2 Detection of ECG signal P, Q, R, S, and T waves
The ECG signal is a biomedical signal consisting of P, Q, R, S, and T waves. Each wave results from one step of the electrical activity of the heart. These waves are used in clinical diagnosis and signal processing studies. In order to detect the other wave peaks of the ECG signal and to extract the morphological features, first of all, the QRS complex that occurs with the contraction of the ventricles during the heartbeat must be detected. In this study, the Pan–Tompkins algorithm, which has been effective for years due to its high accuracy, has been used for the detection of QRS complexes [18].
There are certain periods between P, Q, R, S, and T waves in the ECG signal. Between P and Q, it can take 120–200 ms at most, and between S and T widths between 80 and 120 ms [19]. The QRS complexes detected in the proposed study were divided into two separate vectors as right and left vectors. First, the P wave is detected by finding a 250-ms window maximum point to the left of the QRS complex. On the right side of the QRS complex, the maximum point is sought with a window of 150 ms, and the T wave is detected. From here on, the minimum point between the onset of QRS and the P wave is determined as the Q wave, and the minimum point between the onset of QRS and the T wave is determined as the S wave. Finally, the maximum point between the Q wave and the S wave was determined as the R peak, as shown in Fig. 3.

Detected P, Q, R, S, and T waves
2.2.3 ECG signal morphological features
For an ECG signal, the P–QRS–T fragment refers to the electrical activity in one beat of the heart. The morphological features here basically correspond to the positions, durations, amplitudes and shapes of certain waves, or deviations in the signal [20]. In this study, to detect the changes in the amplitudes and durations of P, Q, R, S, and T waves in recordings containing different emotional states, it is intended to extract a P–QRS–T fragment representing each ECG recording.
Therefore, a total of 281 samples long P–QRS–T fragment with 110 samples from the left of the R peak and 170 samples from the right would be sufficient [17]. This is approximately 1 s for recordings at a sampling frequency of 256 Hz. A normal person's heart rate will be between 60 and 100 bpm (beats per minute). The extracted P–QRS–T fragments for each recording were averaged, and this average was differentiated to increase the salience of the change points on the signal. In this way, a feature vector representing each record was created. In addition, the maximum and minimum amplitude range values for each of the P, Q, R, S, and T waves were added to the feature vector.
2.2.4 ECG signal heart rate variability features
Heart rate variability (HRV) is a method used in the clinic, as well as a measurement of the activity of the central autonomic nervous system (sympathetic and parasympathetic impulses) toward the myocardium. These parameters are average heart rate, standard deviation of all R-R intervals (SDNN), mean squared of consecutive differences (RMSSD), and number of intervals of R-R intervals greater than 50 ms (NN50), pNN50 as the ratio of NN50 number to all R-R intervals can be counted as parameters [21]. It is expected that emotion change and arousal level will affect HRV parameters with the effect of the autonomic nervous system, therefore, the HRV features mentioned in the proposed study were also used.
2.2.5 Automated feature engineering
Feature engineering is an important part of machine learning and classification studies, and its purpose is to obtain a new enriched representation of the data with the additional variables produced. The aim is to predict more accurate classification models with the new predicted variables. It is also done by transforming the original (existing) feature space to create a new feature space by learning a predictive relationship between associated features [22]. These new features can be differences, ratios, or other transformations of existing features with mathematical operators [23].
In this study, gencfeatures, an automated feature engineering algorithm in MATLAB environment, was used. The purpose of this algorithm; it is to automatically generate new features that give the best results by using mathematical operators to make the feature vector entered as input suitable for linear classification. Mathematical operators used are the difference, proportioning, z-score (standardization), logarithm, square root, exponentiation, and trigonometric functions. This function automatically creates a new feature vector in the direction of increasing the weight of the features that have a high effect on the classification among the input features according to the classification type determined by the related mathematical operators [24, 25].
Since a two-class classification study will be performed as an estimator here, a linear estimator has been applied. With this algorithm, output attributes of 450 samples are automatically generated from 297 sample-long input features. The sample count 450 has been empirically chosen, based on the experience with the data, and the number of samples of the output features can be adjusted as desired. Details can be studied in the literature [25]. The output attributes here are completely different from the input, and operations with mathematical operators used to automatically obtain new attributes can be seen.
2.2.6 Support vector machines
SVM is a classification algorithm designed for binary classification, but can also be used in multi-class classification studies. SVM is a supervised classification method [26] that divides d-dimensional data into two classes by separating them with a hyperplane [27,28,29,30].
2.2.7 Feedforward artificial neural networks
FNNs are one of the most widely used types of neural networks. In FNN, neurons are arranged in layers and are fully interconnected. Basically an FNN: It consists of an input, a series of hidden and output layers. Connections between neurons are shown as weights. Neurons in the network consist of an addition function and an activation function (such as Sigmoid, Tangents Hyperbolics, and Softmax) [31,32,33].
In this study the sigmoid function is used as the activation function that follows all layers except the last layer. The last fully connected layer performs classification according to the output of the network.
2.2.8 Bidirectional long short-term memory
In traditional recurrent neural network (RNN) and long short-term memory (LSTM) network models, it propagates forward only, so the information at time t depends only on the information before time t. For this reason, the BiLSTM model is obtained by combining two independent RNNs and replacing the hidden layers with LSTM cells.
Unlike LSTM, BiLSTM (bidirectional LSTM) has two hidden layers (forward and reverse) connected to the outputs. This structure works by considering past and future situations to improve accuracy [34, 35].
The first layer of the BiLSTM architecture model created within the scope of this study is the feature input. Since there are 450 samples of features, the multi-channel feature input layer consisting of 450 channels is used. The next BiLSTM layer has 100 hidden LSTM cells. In addition, the softplus layer is used because it increases the stability during training.
The next layer, the batch normalization layer, allows the layers in the network to wait for the previous layers to learn, that is, simultaneous learning. It allows the network to be used with a high learning speed and also makes the network more stable and organized. Finally, there is the classification layer with the softmax function together with the fully connected layer.
In the proposed model, hyper parameters; it was determined and trained as 0.001 learning rate for 100 epochs by using 100 batch size with Adam Optimizer [36].
3 Experimental results
Accuracy, sensitivity, and specificity values were calculated to evaluate the performance of the models used in the proposed study. Here, the accuracy is calculated as shown in Eq. 1 and shows the ratio of the signals detected by the algorithm correctly. Sensitivity is calculated as shown in Eq. 2 and gives the correct rate of detecting high and positive emotion ECG signals for this study. Specificity, on the other hand, is calculated as in Eq. 3, showing the rate of accurately detecting low and negative emotional ECG signals. In addition, 10-fold cross validation was used when separating the training and test data.
where TP (true positive); the number of correctly classified, high or positive emotional ECG signals. TN (true negative); the number of correctly classified, low or negative emotional ECG signals. FP (false positive); the number of ECG signals classified as high or positive despite having a low or negative emotion. FN (false negative); the number of ECG signals that are classified as low or negative despite having a high or positive emotion.
In order to understand the effectiveness of automated feature engineering while performing the classification study: First of all, the features were classified by SVM, FNN, and BiLSTM without applying feature engineering right after the normalization process. Then, after feature generation with feature engineering, they were classified with SVM, FNN, and BiLSTM, which have the same parameters. The results given in Table 2 show the effectiveness of automated feature engineering by significantly increasing the classification performance criteria.
When the table is examined, accuracy metrics of all classification algorithms increased for both arousal and valence. In addition, it can be seen that the BiLSTM algorithm working with feature engineering gets the best results. While the most unsuccessful among the other methods before feature engineering was applied, the highest accuracy was obtained after feature engineering.
4 Discussion
In studies in the literature, for emotion detection; it is seen that different databases, features, and classification algorithms are used. Table 3 shows the comparison of the best results obtained within the scope of the study and the results in the literature.
If Table 3 is examined, it is seen that the proposed method gives very good results with a small number of features and feature engineering obtained from the time domain. These features were produced by using automated feature engineering with a length of 297 samples and a feature length of 450 samples. Since the best results were obtained with BiLSTM within the scope of this study, only BiLSTM is included in the table. When examined the results of the study of Baghizadeh et al. [13], it is seen that the proposed method for classification is more successful. Considering that only the ECG signal is used, the success metrics of the proposed method show that it can be considered successful when compared with the studies in the literature.
5 Conclusion
In this study, a machine learning-based method has been proposed to detect emotion using ECG signals. In the study, signal recordings obtained from the MAHNOB-HCI database and obtained by watching movie segments containing various emotional states were used. Butterworth filter is used to remove high-frequency noise and baseline drift of ECG signals. In addition, preprocessing was completed using an IIR notch filter to remove 50-Hz power line interference. Then, morphological and HRV features were obtained from the preprocessed ECG signals. These features have lower computational cost and complexity compared to feature extraction techniques such as wavelet transform and Fourier transform. In the next step, features are produced with automated feature engineering. One of the main purposes of the study is to develop a method with high accuracy rates by obtaining a small number of features and low processing load with automated feature engineering. Automated feature engineering increases the classification accuracy of input features by using mathematical operators to weigh heavily impacted features. Table 2 shows that automated feature engineering improves the accuracy of all classification models. Considering that only ECG signals are used, the accuracy rates of 83.61% for arousal with BiLSTM and 78.28% for valence, compared to the literature, were quite good.
Emotion detection studies are increasing day by day, when the concept of metaverse emerged and started to become widespread. In addition, these biofeedback systems are tried to be integrated into many multimedia tools such as computer games. With the development of technology, biological signal tracking systems are being integrated into smart devices. This will also make real-time emotion detection possible.
Data availability
The data used in the studies in this article can be accessed from https://mahnob-db.eu/hci-tagging/.
References
Soleymani, M., Lichtenauer, J., Pun, T., Pantic, M.: A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 3, 42–55 (2012)
Smitha, K.G., Vinod, K.P.: Hardware efficient FPGA implementation of emotion recognizer for autistic children. In: IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), pp. 1–4 (2013)
Kim, K.H., Bang, S.W., Kim, S.R.: Emotion recognition system using short-termmonitoring of physiological signals. Med. Biol. Eng. Comput. 42, 419–427 (2004). https://doi.org/10.1007/BF02344719
Kim, J., André, E.: Emotion recognition based on physiological changes in musiclistening. IEEE Trans. Pattern Anal. Mach. Intell. 30, 2067–2083 (2008). https://doi.org/10.1109/TPAMI.2008.26
Picard, R.W., Vyzas, E., Healey, J.: Toward machine emotional intelligence: analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 23, 1175–1191 (2001). https://doi.org/10.1109/34.954607
Koelstra, S., Patras, I.: Fusion of facial expressions and EEG for implicit affective tagging. Image Vis. Comput. 31(2), 164–174 (2013)
Ferdinando, H., Seppänen, T., Alasaarela, E.: Comparing features from ECG pattern and HRV analysis for emotion recognition system. In: 2016 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), pp. 1–6. IEEE (2016)
Plutchik, R.: The nature of emotions: human emotions have deep evolutionaryroots, a fact that may explain their complexity and provide tools for clinicalpractice. Am. Sci. 89, 344–350 (2001)
Lang, P.J.: The emotion probe: studies of motivation and attention. Am. Psychol. 50, 372 (1995). https://doi.org/10.1037/0003-066X.50.5.372
Hsu, Y.L., Wang, J.S., Chiang, W.C., Hung, C.H.: Automatic ECG-based emotion recognition in music listening. IEEE Trans. Affect. Comput. 11(1), 85–99 (2017)
Wiem, M.B.H., Lachiri, Z.: Emotion classification in arousal valence model using MAHNOB-HCI database. Int. J. Adv. Comput. Sci. Appl. 8(3) (2017)
Siddharth, S., Jung, T.-P., Sejnowski, T.J.: Utilizing deep learning towards multi-modal bio-sensing and vision-based affective computing. IEEE Trans Affect Comput. (2019)
Baghizadeh, M., Maghooli, K., Farokhi, F., Dabanloo, N.J.: A new emotion detection algorithm using extracted features of the different time-series generated from ST intervals Poincaré map. Biomed. Signal Process. Control 59, 101902 (2020)
Lichtenauer, J., Soleymani, M.: MAHNOB-HCI-tagging database. (2011)
Zhao, Z.D., Chen, Y.Q.: A new method for removal of baseline wander and power line interference in ECG signals. In: 2006 International Conference on Machine Learning and Cybernetics, pp. 4342–4347. IEEE (2006)
Sangaiah, A.K., Arumugam, M., Bian, G.B.: An intelligent learning approach for improving ECG signal classification and arrhythmia analysis. Artif. Intell. Med. 103, 101788 (2020)
Bassiouni, M.M., El-Dahshan, E.S.A., Khalefa, W., Salem, A.M.: Intelligent hybrid approaches for human ECG signals identification. SIViP 12(5), 941–949 (2018)
Pan, J., Tompkins, W.J.: A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 32, 230–236 (1985). https://doi.org/10.1109/tbme.1985.325532
Chaudhuri, S., Pawar, T.D., Duttagupta, S.: Ambulation analysis in wearable ECG. Springer (2009)
Yeh, Y.C., Wang, W.J., Chiou, C.W.: Feature selection algorithm for ECG signals using range-overlaps method. Expert Syst. Appl. 37(4), 3499–3512 (2010)
Tsuji, H., Larson, M.G., Venditti, F.J., Manders, E.S., Evans, J.C., Feldman, C.L., Levy, D.: Impact of reduced heart rate variability on risk for cardiac events: the Framingham Heart Study. Circulation 94(11), 2850–2855 (1996)
Guyon, I., Elisseeff, A.: An introduction to feature extraction. In: Guyon, I., Nikravesh, M., Gunn, S., Zadeh, L.A. (eds.) Feature extraction, pp. 1–25. Springer (2006)
Heaton, J.: An empirical analysis of feature engineering for predictive modeling. SoutheastCon 2016, 1–6 (2016). https://doi.org/10.1109/SECON.2016.7506650
Zhang, C., Cao, L., Romagnoli, A.: On the feature engineering of building energy data mining. Sustain. Cities Soc. 39, 508–518 (2018)
Sunnetci, K.M., Alkan, A.: Biphasic majority voting-based comparative COVID-19 diagnosis using chest X-Ray images. Expert Syst. Appl. p. 119430 (2023)
Boswell, D.: An introduction to support vector machines (2002)
Alkan, A.: Analysis of knee osteoarthritis by using fuzzy c-means clustering and SVM classification. Sci. Res. Essays 6(20), 4213–4219 (2001)
Sunnetci, K.M., Ulukaya, S., Alkan, A.: Periodontal bone loss detection based on hybrid deep learning and machine learning models with a user-friendly application. Biomed. Signal Process. Control 77, 103844 (2022)
Caputo, M., Denker, K., Franz, M. O., Laube, P., Umlauf, G.: Support vector machines for classification of geometric primitives in point clouds. In: International Conference on Curves and Surfaces, pp. 80–95. Springer, Cham (2014)
Fausett, L.V.: Fundamentals of neural networks: architectures, algorithms, and applications. Prentice Hall (1994)
Faris, H., Aljarah, I., Mirjalili, S.: Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl. Intell. 45(2), 322–332 (2016)
Alkan, A., Sahin, Y. G., Karlik, B.: A novel mobile epilepsy warning system. In: Australasian Joint Conference on Artificial Intelligence, pp. 922–928. Springer, Berlin, Heidelberg (2006)
Chen, Y., Xu, W., Zhu, W., Ma, G., Chen, X., Wang, L.: Beat-to-beat heart rate detection based on seismocardiogram using BiLSTM network. In: 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), pp. 1503–1507 (2021)
Xu, G., Meng, Y., Qiu, X., Yu, Z., Wu, X.: Sentiment analysis of comment texts based on BiLSTM. IEEE Access 7, 51522–51532 (2019). https://doi.org/10.1109/ACCESS.2019.2909919
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980. (2014)
Subramanian, R., Wache, J., Abadi, M.K., Vieriu, R.L., Winkler, S., Sebe, N.: ASCERTAIN: emotion and personality recognition using commercial sensors. IEEE Trans. Affect. Comput. 9(2), 147–160 (2016)
Katsigiannis, S., Ramzan, N.: DREAMER: a database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices. IEEE J. Biomed. Health Inform. 22(1), 98–107 (2017)
Gjoreski, M., Lustrek, M., Gams, M., Mitrevski, B.: An inter-domain study for arousal recognition from physiological signals. Informatica (Slovenia) 42, 61–68 (2018)
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
FEO worked in methodology, software, investigation, writing—original draft, conceptualization, and resources. AA worked in methodology, investigation, writing—original draft, conceptualization, and resources. TS worked in methodology, writing—original draft, conceptualization, and resources.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Oğuz, F.E., Alkan, A. & Schöler, T. Emotion detection from ECG signals with different learning algorithms and automated feature engineering. SIViP 17, 3783–3791 (2023). https://doi.org/10.1007/s11760-023-02606-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02606-y