
Abstract
This paper presents an Ethernet based hybrid method for predicting random time-delay in the networked control system. First, db3 wavelet is used to decompose and reconstruct time-delay sequence, and the approximation component and detail components of time-delay sequences are figured out. Next, one step prediction of time-delay is obtained through echo state network (ESN) model and auto-regressive integrated moving average model (ARIMA) according to the different characteristics of approximate component and detail components. Then, the final predictive value of time-delay is obtained by summation. Meanwhile, the parameters of echo state network is optimized by genetic algorithm. The simulation results indicate that higher accuracy can be achieved through this prediction method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The time-delay is an important factor which influences the networked control system performance[1]. So analyzing and predicting the network time-delay is very important.
Currently, the networked control system time-delay prediction researches are mainly divided into the following directions. Auto regressive (AR) and auto regressive and moving average (ARMA)[2–4]. AR and ARMA methods are complex processes to figure out parameters, prediction model is difficult to online recursive, so it is not suitable for network time-delay whose dynamic change range is large. The neural network, which has the ability of nonlinear identification and operates quickly, can be used to predict time-delay[5–7]. But the problem is that it is easy to fall into the local optimal value and that the performance excessively relies on the input time-delay sequence correlation coefficient. Support vector machine (SVM) can be used for strong nonlinear network time-delay prediction[8, 9]. But the parameters of SVM are not identified easily. Analyzing the time-delay data, studying the distribution and predicting are also few of the main of the research directions[10–12]. But the problem of prediction based on the statistical analysis is that it is difficult to confirm the distribution parameters, and at the same time, the prediction precision is hard to guarantee because of the randomness of time-delay.
This paper focusses on how to use wavelet transform to decompose and reconstruct the original time-delay sequences. Then the approximate and detail components of time-delay sequence are obtained. The approximate component has long-range dependence with the non-linear characteristics, so it is suitable to use the genetic algorithm (GA) to optimize parameter of echo state network (ESN) model; while the detail components have the characteristics of being short-range dependence and unstable, so it is suitable to use auto-regressive integrated moving average model (ARIMA) to predict. The real predictive time-delay value is obtained by adding the predictive value of each component. With each component predicted separately with its own model, this method has a precise prediction. As a result, the simulation experiment verifies the validity of this method.
2 Wavelet transform
Wavelet transform decomposes the signal through orthogonal basis[13]. Discrete wavelet transform consists of a series of parameters.
in which 〈*, *〉 is the inner-product, c j (k) is approximation component, d j (k) is detail component, scaling function ϕ jk (t) is obtained by translation and expansion of mother wavelet ϕ(k):
in which ϕ jk (t) is a low-pass filter which can separate the low frequency components from input signal. The wavelet transform can decompose signal into the large time scale approximate component and different small scale detail component sets.
The fast discrete orthogonal wavelet transform Mallat algorithm[14] is used to decompose and reconstruct time-delay sequence. According to the decomposition algorithm, a j is seen as a time-delay sequence to be decomposed, then the following equation can be obtained:
where H is the low-pass filter and G is the high-pass filter. The Mallat algorithm is as following:
in which H* and G* is the dual operator of H and G.
After using Mallat algorithm to decompose and reconstruct the time-delay sequence, the approximate component has the characteristics of being long associated and non-linear, thus ESN model is used to predict. The detail components have the characteristics of being short-range dependence and unstable, thus it is suitable to use ARIMA model to predict.
3 ARIMA model
The ARIMA model’s basic idea is to turn non-stationary time series into stationary sequences by calculating differences. The differential frequency parameter is d. The ARMA model is used with p, q to establish the stationary sequence model, then the original sequence is obtained through inverse transform. The ARIMA model predicting equation, with p, d, q as parameters, can be expressed as
in which y t is the time series of sample values, ϕ t and θ t is the model parameters, and ε t is the independent normal distribution of white noise.
Calculate the autocorrelation function (ACF) and the partial autocorrelation function (PAC) of the original sequence after time series are smoothed.
Autocovariance is given by
Autocorrelation function is defined as
Partial autocorrelation function is
The parameter identification of time series can be obtained by the least squares estimation. The optimum parameter model can be obtained by combining p, d, q with Akaike information criterion (AIC), defined as follows:
in which L is the maximum likelihood parameter of the model, n is the independent model parameter format.
4 Genetic algorithm to optimize the echo state network
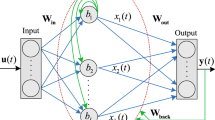
ESN has greater improvement than traditional algorithms in nonlinear system identification. Assuming the system has K input units, N internal processing units and L output units, the value of input unit, output unit, and internal state at time k respectively is
Compared with the traditional neural network, the ESN hidden layer is neurons dynamic reservoir (DR). In order to make DR internally have dynamic memory capacity, usually the connectivity of weight W is varied from 5% to 10% and its spectral radius is less than 1. The ESN learning step is
in which f and f out are DR internal neurons and output layer neuron activation function respectively, and W in, W, W out and W back respectively stand for N × K order matrix from the input layer to the reserve pools, N × N order matrix of the reserve pool, L×(K+N+L) order matrix from the reserve pool to the output layer, and N × L connection weight matrix from output feedback to the reserve pool.
The performance of ESN is determined by four parameters of the reserve pool:
-
1)
SR, which is internal connection power spectral radius of the reserve pool and the largest Eigen value of W absolute value.
-
2)
N, size of the reserve pool, which is connected with the number of samples, greatly influences the performance of network.
-
3)
IS, input unit scale of the reserve pool. The stronger the object is nonlinear, the larger IS becomes.
-
4)
SD, the sparse degree of the reserve pool. SD stands for the percentage of interconnected neuron in total neurons (N).
The reserve pool parameters will cause different effects on prediction accuracy. At the same time, ESN input layer number and input series embedding dimension m are important parameters. The paper uses genetic algorithm to optimize parameters and improve the precision of prediction.
ESN time-delay prediction needs the parameters m, SR, N, IS, SD, and the search target of GA is to find the appropriate m, SR, N, IS, SD in order to improve the prediction precision of time-delay. Therefore, the fitness function is related to the accuracy of the time-delay prediction model. Set mean square error (MSE) of time-delay prediction of the i-th groups as
In (13), n is the number of the time-delay sequence, y i and \({\hat y}_{i}\) are the actual value of the i-th time-delay and the prediction value of the ESN algorithm.
The prediction method in the paper can be expressed as follows:
-
Step 1. Code the parameters m, SR, N, IS, SD.
-
Step 2. Create the initial population.
-
Step 3. Set MSE value between predictive value and the actual value as the fitness function.
-
Step 4. Sample time-delay sequences are used to train ESN. The time-delay prediction accuracy of each parameter and individual fitness value are recorded.
-
Step 5. Select the individual with the best performance from the groups as the next generation. The new population is generated through the operator of selection, crossover and mutation of the rest individuals.
-
Step 6. If the ending condition is favourable, output the best parameters: m, SR, N, IS and SD.
5 Hybrid networked time-delay prediction model
In this paper, db3 wavelet is selected on the basis of experiment results and [15], and the decomposition number is related to signal-to-noise ratio, three level decomposition and reconstruction is used to guarantee real-time and forecast accuracy of the algorithm. The network time-delay hybrid prediction model can be represented in Fig. 1.

Time-delay hybrid prediction model
From Fig. 1, the hybrid prediction method have the following steps:
-
Step 1. For the input time-delay sequences d 1, d 2, ⋯, d N , db3 wavelet decomposition and reconstruction should be performed three times and approximate component A3 and the three detail components D1, D2, D3 are obtained.
-
Step 2. ESN is used to train approximate components A3. GA algorithm is used to optimize ESN optimal prediction parameters.
-
Step 3. ARIMA model is used to train three detail components. Calculating three model parameters p, d, q with AIC criterion.
-
Step 4. After ESN and ARIMA model have been established, decompose and reconstruct the test time-delay sequence according to the Step 1. Enter the training mode. Respectively predict the next step time-delay. Combine the four predictive outputs to obtain the final forecasting result.
6 Simulation
The 1100 group time-delay data is obtained by using delay measurement software. The first 1000 data sets are used for training the model. The last 100 groups of data are used for testing. Fig. 2 is a waveform graph of 1000 groups time-delay data, approximate component is Ca3 and detail components are Cd1, Cd2, Cd3. As seen from the graph, the approximation component is close to the actual time-delay. With the increase of decomposition order, the time-delay series becomes smooth. Detail components of sample time-delay data are used to build ARIMA training model. According to AIC criteria, we obtain the following prediction model, which is shown in Table 1.

Three layer decomposition and reconstruction of time-delay sequence. (a) The original series; (b) Ca3; (c) Cd1; (d) Cd2; (e) Cd3
Fig. 3 shows a comparison between the actual value of detail components after wavelet transform and predicted values. From the graph, we can know through established model, the predictive value of detail components training time-delay data fit well the real time-delay values.

The comparison between the prediction and real delay value of sample data’ detail component. (a) Cd1; (b) Cd2; (c) Cd3
The paper uses genetic algorithm to optimize parameters of ESN. Parameter SR, N, IS, SD, m to be optimized are coded as binary. Since the parameters are in the range of (0, 255), each parameter can use the 8-bit encoding. However, in order to increase the calculation accuracy, the code length in this paper is chosen as 10. Population is 20. Evolutionary iteration number is 200. Parameters change range is m ∈ [1, 20], SR ∈ [0.01, 1], N ∈ [10, 200], IS ∈ [0.01, 1], SD ∈ [0.01, 1]. Crossover probability is 0.8. Mutation probability is 0.1. Fitness function is MSE between the predictive value and the actual value of time-delay. GA-optimized parameters are: m is 8, SR is 0.6303, N is 169, IS is 0.0303, SD is 0.4397. The fitness curve is shown in Fig. 4. Fig. 5 is the comparison between actual value and ESN prediction value of approximate component of sample time-delay data.

The fitness curve of GA optimized ESN

The comparison between the actual value and the ESN prediction value of approximate component of sample data
When ARIMA and ESN prediction model has been established, the model is verified with 100 groups of time-delay data. Figs. 6 and 7 are the contrast between real value and tested value of detail components and the approximate component.

The comparison curve between the actual value and the prediction value of testing detail components. (a) Cd1; (b) Cd2; (c) Cd3

The comparison between the actual value and the prediction value of testing approximate components
Fig. 8 is the comparison curve of the actual value and the final prediction value which is added by wavelet decomposition and reconstruction.

The comparison curve of the final prediction value and the actual value of testing data
From Figs. 6–8, we can know that the final time-delay predictive value fit the real value of time-delay very well. In order to prove the effectivity of the method used in this paper, Fig. 9 shows ARIMA, least squares support vector machine (LSSVM) and Elman neural network predict on the same time-delay sequence. In ARIMA algorithm, the prediction model is ARIMA(4, 0, 6), in LSSVM algorithm, parameter optimization is obtained by cross-validation method, the parameters of prediction model are γ = 0.662 and σ 2 = 220.64. The number of input layer of Elman neural network is 10, the number of hidden layer is 10, and the number of output layer is 1. The largest number of iterations is 2000.

The comparison of the prediction and the real delay through other methods. (a) ARIMA; (b) LSSVM; (c) Elman
Table 2 is MSE comparison between several time-delay prediction methods. Table 3 is mean absolute percent error (MAPE) comparison between the several time-delay prediction methods.
From the compared graphs, MSE and MAPE of prediction time-delay values and actual values show that the method in this paper is better than other methods in accuracy and curve fitting degrees. The reason why the precision of prediction has been improved in this method lies in that after the original time-delay sequences are transformed by wavelet transformation, approximate component and detail components are obtained. Due to the difference of the approximate component and detail components, ESN and ARIMA model are used to train and predict.
7 Conclusions
This paper presents a hybrid prediction method of random time-delay for the networked control system. Through wavelet transforming, the approximate component and detail components of time-delay sequences can be obtained. ESN and ARIMA are used respectively to predict the approximate component and detail components. Finally, actual predictive values are obtained. The simulation results show that this method is effective. At the same time, compared with other prediction methods, this method has a higher prediction precision.
References
B. D. Qu. H ∞ State Feedback delay-dependent control for discrete systems with multi-time-delay. International Journal of Automation and Computing, vol. 2, no. 2, pp. 107–113, 2005.
W. G. Shi, C. Shao, Z. Y. Sun. Improved GPC network-control algorithm based on AR model time-delay prediction. Control and Decision, vol. 27, no. 3, pp. 477–480, 2012.
M. Yang, J. F. Ru, X. R. Li, H. M. Chen, A. Bashi. Predicting Internet end-to-end delay: A multiple-model approach. In Proceedings of the 25th IEEE International Conference on Computer Communications, IEEE, Barcelona, pp. 1–5, 2006.
H. Y. Li, H. Wang, C. Gui. Internet time-delay prediction based on auto-regressive and neural network model. In Proceedings of International Conference on Communications, Circuits and Systems, IEEE, Guilin, China, pp. 1758–1761, 2006.
D. Liu, J. H. Du, Y. Zhao, N. L. Song. Study on the time-delay of Internet-based industry process control system. In Proceedings of the 5th World Conference on Intelligent Control and Automation, IEEE, Piscataway, USA, pp. 1376–1380, 2004.
B. Rahmani, B. Markazi, N. Mozayani. Real time prediction of time delays in a networked control system. In Proceedings of the 3rd International Symposium on Communications, Control and Signal Processing, IEEE, St Julians, pp. 1242–1245, 2008.
N. Sadeghzaedh, A. Afshar, M. B. Menhaj. An MLP neural network for time delay prediction in networked control systems. In Proceedings of the 2008 Chinese Control and Decision Conference, IEEE, Yantai, Shandong, pp. 5314–5318, 2008.
C. M. Li, J. Xiao, Y. Zhang. Time delay estimation and adaptive control of networked control systems. Journal of Southwest Jiaotong University, vol. 42, no. 2, pp. 175–180, 2007.
X. X. Li, X. H. Fu. A predictive algorithm for time delay Internet-based network control. Chinese Journal of Scientic Instrument, vol. 29, no. 4, pp. 590–593, 2008.
T. Karagiannis, M. Molle, M. Faloutsos. Long-range dependence ten years of Internet traffic modeling. IEEE Internet Computing, vol. 8, no. 5, pp. 57–64, 2004.
S. H. Wang, B. G. Xu, Q. Y. Wang. Delays analysis for teleoperation over Internet and Smith predictor with adaptive time-delay control. In Proceedings of IEEE International Conference on Robotics and Biomimetics, IEEE, Piscataway, USA, pp. 664–669, 2005.
X. H. Fu, X. Fu. A predictive algorithm for time delay Internet network. In Proceedings of the IEEE International Conference on Electronics, Communications and Control, IEEE, Ningbo, China, pp. 666–669, 2011.
Y. T. Wei, J. K. Wang, C. R. Wang, K. Zhang. Network traffic prediction algorithm based on wavelet transform and combinational models. Journal of Northeastern University (Natural Science), vol. 32, no. 10, pp. 1382–1385, 2011.
S. Mallat. A Wavelet Tour of Signal Processing, 2nd ed., Burlington, USA: Academic, 1999.
I. Daubechies. Ten Lectures on Wavelets, USA: Society for Industrial and Applied Mathematics, 1992.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by National Natural Science Foundation of China (No. 61034005).
Rights and permissions
About this article

Cite this article
Tian, ZD., Gao, XW. & Li, K. A Hybrid Time-delay Prediction Method for Networked Control System. Int. J. Autom. Comput. 11, 19–24 (2014). https://doi.org/10.1007/s11633-014-0761-1
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11633-014-0761-1