
Abstract
The complexity of motion estimation in the High Efficiency Video Coding (HEVC) standard is very high as it uses a number of prediction block sizes. The test zonal search (TZS) mechanism is used as motion estimation algorithm in the fast search mode of HM encoder, the reference software for HEVC. In this paper, we present schemes for reducing the complexity of the TZS algorithm for uni-prediction in HEVC. The proposed mechanisms help in reducing complexity of grid, raster and refinement search stages of TZS. The performance of the proposed mechanisms is tested independently and also combined in the fast search mode of HM-16.18. The motion estimation time and the number of search points in the combined algorithm are reduced by 68.14% and 77.10% with a BD-rate of 0.30% and a BD-PSNR of \(-0.007\) dB in comparison with the original fast search mode in the low-delay P main profile. The proposed complexity reduction schemes are compared with those adopted in other recently proposed fast motion estimation algorithms and the performance of the proposed scheme is found to be superior in terms of the reduction in motion estimation time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Joint Collaborative Team on Video Coding (JCT-VC) has developed High Efficiency video Coding (HEVC) with the goal of improving the compression ratio [1]. As compared to H.264 [2], its earlier standard, HEVC provides nearly 50% bit rate reduction, albeit at the cost of a high computational complexity due to the adoption of advanced video coding tools like advanced motion vector prediction (AMVP), large-sized coding tree units (CTUs), recursive quad-tree structure partitioning of CTU, use of an interpolation filter for fractional pixel motion estimation and variable transform sizes. There is a need for reducing the complexity of HEVC without significantly affecting the video quality and amount of compression.
The motion estimation (ME) block of HEVC is comparatively more complex than the other components. ME is carried out for different block sizes with the individual blocks organized in a recursive quad-tree structure. Though full search motion estimation provides an optimal solution, its complexity is very high contributing to around 80–90% of the total encoding complexity. In the fast search mode of the HM encoder, the test zonal (TZ) search algorithm [3] is employed to reduce the motion estimation time without any significant effect on bit rate and video quality [4].
The TZ search algorithm includes four stages, namely motion vector prediction, grid search, raster search and refinement search stages. In the HM encoder, the various stages are implemented as follows:
Motion vector prediction In this stage among zero MV predictor, AMVP and upper depth predictor, the best predicted motion vector (PMV) is found based on the minimum rate-distortion (RD) cost. Upper depth predictor is not used in the older versions of the HM encoder.
In Fig. 1, the prediction motion vector PMV2 is a better predicted motion vector as compared to the predicted motion vector PMV1. Because PMV2 is same as MV, the actual motion vector, when RD cost calculation is done with diamond pattern with stride distance \(s=1, 2\) and 4, the minimum cost search point will not change for three consecutive strides. Hence, grid search can be terminated. In grid search for PMV1, the MV is near to its diamond pattern with \(s=8\). So, cost calculation continues till \(s=64\).

Grid search with each search point numbered
Grid search stage The PMV position obtained from motion vector prediction is used as the search centre in the grid search stage. Diamond search patterns are used by default in this stage with stride distances of 1, 2, 4 and so on in powers of 2 up to the maximum search range. These patterns are used to find the search point corresponding to the minimum RD cost. In the HM encoder, for diamond search patterns, the number of search points (n) for different stride distances (s) is as given in (1). For a search range of 64, there are at most \(4 + 3\times 8 + 3\times 16 = 76\) search points. In this stage if the minimum RD cost is not changed for three consecutive strides, then grid search is terminated
In Fig. 1, if the minimum cost search point does not change for three consecutive strides, it is highly likely that the actual motion vector is near to this search point. In the TZ search of HM encoder, grid search is terminated if the minimum cost search point does not change three consecutive strides, thereby optimizing the grid search in terms of complexity.
Raster search stage Raster search is used only if in grid search the distance of the minimum cost search point from the search centre is greater than 5. Raster search is similar to full search with the search window downsampled by a raster distance both horizontally and vertically. In the HM encoder, the raster distance is set to 5 by default. With the search range of 64, the search area is of size \((2\times 64 + 1)\times (2\times 64 + 1) = 129\times 129\). Therefore, the search area has a total of \(\mathrm{{ceil}} \left( \frac{129}{5}\right) \times \mathrm{{ceil}} \left( \frac{129}{5}\right) = 26\times 26 = 676\) search points.
Refinement search stage Star refinement or raster refinement search is used in the refinement search stage of the TZ search algorithm. In HM encoder, star refinement is enabled by default. Initially, the refinement search centre is the search point corresponding to the minimum RD cost obtained in the previous stages. Starting from the refinement search centre, the search process is carried out with diamond pattern strides as in grid search. After obtaining the minimum cost search point, refinement search is terminated if the this search point is same as the refinement search centre. If the distance of the minimum cost search point from the refinement search centre is one, then a two-point search is carried out to check whether the minimum cost search point changes. Refinement search is terminated if there is no change after two-point search. If the distance of the minimum cost search point from the refinement search centre is greater than 1 or if the distance is 1 and the minimum cost search point changes with two-point search, then refinement search is again performed with the new refinement search centre at the minimum cost search point. Refinement search is repeated till the minimum cost search point is at a distance of 0 from the refinement search centre or with a distance of 1 with the additional condition that the minimum cost search point does not change with two-point search.
Table 1 shows the percentage of the number of search points \((\%N)\) and complexity in terms of the number of \(4 \times 4\) blocks \((\%C)\) in the grid, raster and refinement search stages. In this table, the ’Others’ column includes the complexity involved in calculating the best PMV among AMVP, zero motion vector predictor and the upper depth predictor. The number of search points in the raster search stage is large compared to the grid search stage. For a bigger search range, there is a huge difference in number of search points between these two stages. Though the complexity involved in the raster search stage is much higher than the grid search and refinement search stages, the number of search points and the number of \(4 \times 4\) blocks for a sequence in raster search are comparable to that of grid search. This is because raster search is enabled for prediction blocks (PBs) belonging to regions having high motion and multi-directional motion. For sequences like Kimono, Cactus, BasketballDrive, BasketballDrill, BQMall, RaceHorsesC, BasketballPass and RaceHorses, the number of \(4 \times 4\) blocks is larger for raster search compared to grid search. The BQSquare sequence has a lower number of \(4 \times 4\) blocks for raster search compared to grid search. Therefore, it is necessary to reduce the number of search points in both grid search and raster search stages.
This paper proposes four different schemes to reduce the ME complexity for the TZ search algorithm in uni-prediction. The proposed methodologies include an adaptive search range algorithm and schemes to reduce the complexity of grid search, raster search and star refinement search. The rest of the paper is organized as follows. In Sect. 2, recently proposed fast motion estimation algorithms are described in brief. Section 3 presents schemes for reducing the motion estimation complexity in uni-prediction. Experimental results are presented in Sect. 4, and the paper concludes in Sect. 5.
TZ search can be used for fast motion estimation in uni-prediction of HEVC. In bi-prediction of HM encoder, full search is used within a search range of 4. The proposed schemes are limited to TZ search, which is used for fast motion estimation in the HM encoder. The TZ search algorithm gives a better trade-off between complexity reduction (compared to full search) and the bit rate and PSNR (not a significant change in bit rate and PSNR compared to full search). There is no significant difference in performance of TZ search and full search motion estimation algorithms in terms of bit rate and PSNR. But TZ search has huge reduction in complexity compared to full search.
2 Related work
2.1 Fast search pattern-based motion estimation
Fast search pattern-based motion estimation algorithms like 2D-logarithmic search [5], cross search [6], three-step search [7], four-step search [8], diamond search [9] and hexagonal search [10] lead to significant reduction in the motion estimation complexity. However, when these fast search patterns are used for video sequences having high motion activity, the quality and the amount of compression are reduced due to the local minimum problem of these fast search patterns.
2.2 Adaptive search range algorithm
To find the best match reference block for the current macroblock, the search operation is carried out over all the reference macroblocks in the search window. Many adaptive search range algorithms reduce the motion estimation complexity by reducing the size of the search window based on the neighbouring information [11,12,13,14,15,16,17]. [11] also uses the sum of absolute difference (SAD) at the search centre to estimate the search range with the aim of reducing the motion estimation complexity for the full search algorithm. The linear adaptive search range in [12] is able to reduce the search range in uni-prediction with a minor increment in (Bjontegaard delta bitrate) BD-rate of 0.7% on an average. The scheme proposed by Nalluri et al. [13] uses the motion vector difference (MVD) of the spatial, temporal and upper depth neighbours for setting the search range. The algorithm presented in [14] is based on neighbouring MVDs modelled using a Laplace distribution. The mechanism proposed in [15] is based on neighbouring MVDs and models the MVDs of all the macroblocks in the previous frame with a Cauchy distribution. Cauchy distribution can be used to model the global search range in terms of MVDs of the previous frame. The local search range is based on the global search range and the MVDs of spatial and collocated neighbouring blocks as given in [15].
[16] uses the depth information for adapting the search range. Our previous work [17] generates a better prediction of search range by using MVDs of the neighbouring blocks, modelled using a Cauchy distribution and the SAD at the search centre.
2.3 Motion estimation termination
The early stop search algorithm adopted in [11] and [18] terminates the ME process if the current search point in the spiral search pattern has the minimum RD cost. The termination criterion is based on a threshold obtained from the minimum RD cost among the costs of neighbouring blocks. Termination of the grid search stage is done in the HM encoder if the diamond patterns in the previous two strides and the current stride do not have the minimum RD cost.
2.4 Partial distortion search
Partial distortion search (PDS)-based mechanisms reduce the motion estimation complexity by using SADs of sub-sampled blocks [19]. The normalized partial distortion search mechanism used in [20] leads to further reduction in the motion estimation complexity. The adjustable partial distortion search used in [21] can be used to vary degrees of motion estimation complexity with variations in the video quality. Block size-based sub-sampling factors are used in [22]. Additionally, in adjusted [22] thresholds over multiple reference frame are adjusted leading to further reduction in motion estimation complexity.
For reducing the motion estimation complexity of TZ search, in [23] grid search is replaced by rotating pentagon search, which reduces the motion estimation time to a certain extent. The search range is repeatedly reduced in [24] by using a quadratic function in order to get an optimal motion vector (MV). This method reduces the complexity with a slight loss of coding efficiency. The fast and low complexity motion estimation approach proposed in [25] for ultra-high-definition videos greatly reduces the motion estimation complexity compared to the full search algorithm at the expense of a minor degradation in coding efficiency. Search ranges based on video characteristics and the successive elimination algorithm are used in [26]. This method also leads to a minor degradation in the coding efficiency.
By classifying the current prediction block as one with smooth, medium or complex motion and employing a different motion estimation strategy for each class, [27] is able to reduce the ME complexity with negligible effect on the coding efficiency. [28] uses two AMVPs and the predicted motion vectors of blocks at a lower depth to reduce the complexity of bottom up integer motion estimation without significantly affecting the coding efficiency.
3 Motion estimation complexity reduction schemes for uni-prediction
In terms of compression and video quality, the TZ search algorithm, a highly optimized ME strategy, has a performance similar to that of full search, though it a much lower complexity.
3.1 Adaptive search range algorithm
Use of better predictors will make the search range prediction more accurate, providing a better trade-off between complexity, BD-rate and BD-PSNR. X and Y components of MVD are obtained as given in (2)
where \(\mathrm{{MVD}}_X\) and \(\mathrm{{MVD}}_Y\) are MVDs, \(\mathrm{{MV}}_X\) and \(\mathrm{{MV}}_Y\) are the motion vectors and \(\mathrm{{PMV}}_X\) and \(\mathrm{{PMV}}_Y\) are predicted motion vectors in x and y directions, respectively.
The distance of the MVD from the PMV, d(X, Y), is obtained as given in (3)
\(\mathrm{{SR}}_1\), the spatial search range predictor is obtained from the length of MVD which is the distance of the MV from the PMV as given in (4)
where \(d_\mathrm{{L}}\), \(d_\mathrm{{U}}\) and \(d_{\mathrm{{UR}}}\) are the length of MVDs of left, upper and upper right block. \(k_1\) is a constant.
As specified in (5) the second search range predictor, \(\mathrm{{SR}}_2\) is obtained using the MVD distribution of the previous frame. The MVDs of a frame are represented accurately by a Cauchy distribution [15]. X and Y components of the predicted search range are denoted by \(C_{X}\) and \(C_{Y}\)
where \(k_2\) is a constant. For each frame in RA mode, there are up to two neighbouring frames chosen for search range prediction. One is the immediate neighbouring frame in the forward direction, and the other is the immediate neighbouring frame in the backward direction that are already coded before the current frame. Each of \(C_X\) and \(C_Y\) is obtained as the maximum of the predicted search ranges of the forward and backward directions.
Current block’s motion vector is proportional to the SAD corresponding to the PMV position \((\mathrm{{SAD}}_{\mathrm{{PMV}}})\). This means the high motion prediction block (PB) has high \(\mathrm{{SAD}}_{\mathrm{{PMV}}}\) value, and the low motion PB has low \(\mathrm{{SAD}}_{\mathrm{{PMV}}}\) value. In the beginning of TZ search, PMV is chosen from AMVP, zero motion and upper depth predictors based on the minimum RD cost. This PMV is used as the search centre for grid search.
The third search range predictor, \(SR_3\), is obtained from the \(\mathrm{{SAD}}_{\mathrm{{PMV}}}\) normalized by block size and is given in (6)
where \({n_1 \times n_2}\) is the block size. Low-resolution sequences have smaller value of \(k_3\) and high-resolution sequences have larger value.
In the proposed adaptive search range mechanism, a total of four search ranges are used. Three of the search ranges are the same as in our previous work [17]. \(\mathrm{{SR}}_4\), the fourth search range is derived from the deviation of the predicted motion vector (PMV) with respect to the motion vectors of the neighbouring blocks.
The fourth search range predictor is obtained from the predicted motion vector deviation (PMVD). MVD is the deviation of PMV from the actual MV. PMVD is defined as the maximum of the deviations of PMV from motion vectors of the neighbouring blocks. PMVD is used for predicting the search range. PMVD over x and y directions is calculated as given in (7). \(\mathrm{{SR}}_4\), the search range, is predicted as the maximum of PMVDs in x and y directions
where n is the number of neighbouring blocks considered for calculating the PMVD, (\(\mathrm{{PMV}}_{X}\), \(\mathrm{{PMV}}_{Y}\)) is the PMV of the current block and (\(\mathrm{{MV}}_{X(i)}\), \(\mathrm{{MV}}_{Y(i)}\)) represents MV of the ith neighbouring block
We first define a search range, \(\mathrm{{SR}}_I\) as given in (9). In this equation, \(C_{0.996}\) is defined as the search range predicted from the Cauchy distribution with a probability of 0.996. The final search range is computed as specified in (10)
In the above equations, the values of \(k_1\), \(k_2\), \(k_3\), \(k_4\) and a have an effect in motion estimation complexity and coding efficiency. The value of these parameters is adjusted in order to obtain a better trade-off between complexity and coding efficiency.

Grid search with each search point numbered
3.2 Motion estimation complexity reduction in the grid search stage
The complexity of the grid search stage is reduced by early termination of the ME process as well as by skipping half of the search points as discussed below.
Early termination of ME If the best minimum search point is not changed for one or two consecutive diamond pattern strides, then the grid search is terminated to reduce the grid search complexity. This is done if the number of neighbours is greater than 1. Let \({\mathrm{{AMVP}}}_1\) and \({\mathrm{{AMVP}}}_2\) be the motion vectors of the best two neighbouring blocks obtained from advanced motion vector prediction and \(J_{\mathrm{{PMV}}}\) be the RD cost of the centre of the grid search stage. The grid search stage is terminated if the search point corresponding to the minimum RD cost is not changed for one diamond pattern stride, and if the following criteria are satisfied
here, T, the threshold is fixed based on the size of the prediction block.
If the termination of grid search when minimum RD cost does not change for one stride is done all the time, then there would be a significant reduction in quality and compression. To take care of the quality and compression, grid search is terminated if the minimum RD cost is not changed after one stride when \({\mathrm{{AMVP}}}_1\) and \({\mathrm{{AMVP}}}_2\) are equal. This implies that the deviation between these two AMVPs is equal to 0. Even a small deviation between \({\mathrm{{AMVP}}}_1\) and \({\mathrm{{AMVP}}}_2\) can be used as it helps in terminating grid search more frequently, but it leads to slight loss in coding efficiency.
If the best minimum search point is not changed for two diamond pattern stride, grid search is terminated provided the following criterion is satisfied
where \(\mathrm{{SR}}_1\) and \(\mathrm{{SR}}_4\) are the search ranges obtained from the spatial neighbours and PMV deviation. This implies that the grid search stage can be terminated quickly if these two search ranges are zero.
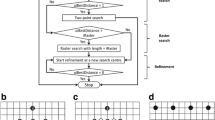
Half round in the grid search stage In the grid search stage, all the search points of diamond strides are used for the calculation of SAD and RD cost as shown in Fig. 2. Since the search point in the current round having the minimum RD cost is likely to be near the minimum cost search point of the previous round, only the search points near the minimum cost search point of the previous round are considered for the calculation of SAD and RD cost in this round.
For a diamond pattern stride having N search points, \((\frac{N}{2}+1)\) search points near the minimum RD cost search point of the previous round are used for calculating the SAD and RD cost. From Fig. 2, if the minimum RD cost is in round 4 at the search point number 8 and the current round, r is 5, then the search points numbered from 4 to 12 of round 5 are used for calculating the SAD and RD cost. Other search points in round 5 are skipped.

Raster search represented in two-level scanning of search points with dark colour and grey colour search points representing level 1 and level 2, respectively, for a \(\mathrm{{SR}}_{\mathrm{{raster}}} = 10\) and b \(\mathrm{{SR}}_{\mathrm{{raster}}} = 20\)
3.3 Motion estimation complexity reduction in the raster search stage
Search range reduction for raster search Raster search is used only if the search point in the grid search stage corresponding to the minimum RD cost falls beyond a distance of 5 from the search centre. Otherwise, it is not used. The use of raster search over the complete search range increases the complexity to a greater extent even if the best match search point is not much far away from the search centre. The search point having the minimum RD cost is likely to be near the search centre. If the minimum cost search point in the grid search stage is far from the search centre, the minimum cost search point obtained in the raster search stage is more likely to be far away from the minimum cost search point of the grid search stage. This implies that it is not required to perform raster search always over the entire search range. The search point having the minimum RD cost in the grid search is used as the search centre in the raster search stage. The search range for raster search is chosen selectively based on how far the minimum RD cost search point is from its search centre in the grid search stage as given in (14)
In the grid search stage, two search points are chosen. If these two search points are nearby, then the search range is reduced for the raster search stage. If these two search points are far away from each other, then reducing the search range for raster search creates a local minimum problem. In order to determine whether the two minimum cost search points are nearby, search points in the diamond pattern stride are numbered as shown in Fig. 2. If the distance between the numbers allotted to these two search points is in between 4 and 12, then the minimum cost search point is considered to be in the direction of the minimum cost search point in the grid search stage. If these two best minimum search points are far away, i.e. the difference between the two search point numbers is greater than 4 and less than 12, then adaptive raster search is disabled and the search centre in the grid search stage is used as the search centre of raster search.
Two-level scanning order of raster search In Fig. 3a, b, the distance between two adjacent search points is 5. The SAD and RD cost are calculated at level 1 search points represented in dark colour in the order they are numbered. The level 1 search points are covered in a spiral scan manner in clockwise direction. We have chosen clockwise in our implementation. It does not make a difference in performance even if the patterns in grid, raster and refinement search are implemented anticlockwise. After calculating the RD cost at one search point in level 1, a threshold \(T_{L1}\) is computed as given in (15). In this equation, \(J_{\mathrm{{min}}}\) is the minimum of all the previously calculated RD costs of level 1 and level 2 search points and PBsize, which is the size of the PB equals \(n_{1}\times n_{2}\). RD costs at the eight neighbouring search points represented in grey colour and connected by dotted lines are calculated if the criterion given in (16) is satisfied
where \(J_{L1}\) is the RD cost at the current level 1 search point.
As shown in Fig. 3a for \(\mathrm{{SR}}_{\mathrm{{raster}}} = 10\), there are four level 1 search points. There are three level 2 search points corresponding to the two adjacent level 1 search points. And, the search centre for raster search is common for the four adjacent level 1 search points. If there are any level 2 search points corresponding to the previous level 1 search point and the current level 1 search point, and if those level 2 search points are already used for RD cost calculation, then these search points are not used again. For \(\mathrm{{SR}}_{\mathrm{{raster}}} = 20\) as shown in Fig. 3b, there are no level 2 search points common to two adjacent level 1 search points. For \(\mathrm{{SR}}_{\mathrm{{raster}}} > 20\), level 1 search points as given in Fig. 3b, which are considered in a spiral scan manner, can be extended over the search range and its corresponding level 2 search points are used for RD cost calculation only if the RD cost at level 1 satisfies the criterion given in (16).
3.4 Motion estimation complexity reduction in star refinement search
Adaptive search range in star refinement search In star refinement search stage of the TZS algorithm, diamond patterns with strides varying from 1 to 64 in multiples of 2 are used for finding the minimum RD cost. The minimum RD cost search point in this stage is more likely to be near the minimum RD cost search point obtained so far in the grid and raster search stages. Therefore, the search range can be reduced even at this stage as follows

Search points of diamond pattern strides of star refinement search represented in red lines and the diamond pattern strides of grid search represented in grey lines for best minimum in grid search at \((-1, -1)\) represented in red shaded circle
Redundant search point skip in refinement search If the best minimum is near the search centre in the grid search stage, then there are few search points in the refinement search stage that are already used for calculating the RD cost during grid search. This gives us the information that these search points do not correspond to the minimum RD cost. Therefore, RD cost calculation is skipped at these search points. In Fig. 4, the search points of the grid search stage are represented in black colour and grey colour within the diamond pattern strides represented in grey colour. In this figure, the minimum search point is at motion vector difference of \((-1, -1)\), represented in red colour. The search points in the star refinement stage are represented in grey colour and blank circles within the diamond strides of red colour. Grey colour search points are common to both grid and star refinement search stages. Therefore, only search points represented by blank circles are used for RD cost calculation in the star refinement stage.
4 Experimental results
The proposed methods are implemented individually and then are combined in the HEVC reference software HM-16.18 [4] in the fast search mode. The schemes presented in [27] and [28] are implemented in HM-16.18 for fair comparison with the proposed scheme. The HM encoder is used in Visual studio 2013 in the release mode in an Intel Xeon 12-Core 2.5 GHz processor with 32-GB RAM. LD-P configuration uses only uni-prediction, and it is predicted from the previous frames only. Complexity is less in LD-P profile. LD-B configuration uses both uni-prediction and bi-prediction, and it is predicted from the previous frames only. Due to the use of bi-prediction, complexity increases although it provides better compression. The RA main configuration uses both uni-prediction and bi-prediction, and it is predicted from both previous and future frames in hierarchical structure. Due to the use of hierarchical structure, compression is high, but it has high complexity compared to other profiles if same number of reference frames are used in each reference list (same number even in LD-P and LD-B profile). Simulations are carried out in the LDP main configuration as specified in HEVC common test conditions [29]. Class B, C and D sequences obtained from [30] are used for evaluating the performance of the proposed and other existing algorithms. For each of the test sequences, the first hundred frames are used in the experimentation. In addition to Bjontegaard Delta PSNR (BD-PSNR) and Bjontegaard delta bitrate (BD-rate) [31], four other measures are used to evaluate the performance of the schemes. The additional measures are the percentage reduction in number of search points \((\varDelta N)\), percentage reduction in the number of \(4 \times 4\) blocks \((\varDelta C)\), percentage reduction in motion estimation time \((\varDelta MET)\) and the percentage reduction in encoding time \((\varDelta ET)\). These are calculated as follows:
where the subscripts HM and Proposed denote the performance measures corresponding to the HM encoder and the proposed algorithm, respectively. Each of the measures \(\mathrm{{MET}}_{\mathrm{{Proposed}}}\) and \(\mathrm{{ET}}_{\mathrm{{Proposed}}}\) includes the overhead time due to the proposed scheme. It may be noted that the number of \(4 \times 4\) blocks used for SAD calculation better reflects the complexity of an algorithm as compared to the number of search points covered. Because, for one search point in motion estimation, PBs of different sizes have different numbers of \(4 \times 4\) blocks, e.g. a PB of size \(64 \times 64\) has 256 \(4 \times 4\) blocks and a PB of size \(8 \times 4\) has only two \(4 \times 4\) blocks.
The schemes proposed for complexity reduction of uni-prediction, and the grid, raster and the refinement search stages are first implemented individually and then combined in the HM-16.18 encoder. The performance in terms of the different measures is shown for each of these methods and the combined method. In this paper, BD-PSNR and BD-rate are computed for the luminance component.
The Cauchy parameter is set to 2 as given in [32], and the probability constant is set to 99.2% [15]. The values of \(k_1\), \(k_2\), \(k_3\), \(k_4\) are set to 1 and a is set to 8. From Table 2, it is found that the proposed ASR algorithm for uni-prediction has reduced the number of search points, number of \(4 \times 4\) blocks, motion estimation time and encoding time by 37.87%, 46.15%, 37.28% and 5.78%, respectively. When compared with ESR [17] with the parameters \(k_1\), \(k_2\), \(k_3\), \(k_4\) scaled by 1.4, the proposed algorithm provides nearly the same BD-rate on an average with reduced motion estimation complexity. In our previous work [17], we did not use the upper depth MVD as the fourth search range predictor. Table 3 reports results obtained by using the ESR algorithm [17] as well as ESR when the upper depth MVD is used as the fourth search range predictor, both implemented in HM-16.18 in the LD-P main profile. We observe that the ASR algorithm is better than ESR using upper depth MVD as the fourth search range predictor. In [17] ESR is implemented in HM-16.6 with upper depth PMV disabled in the predicted motion vector stage of TZ search. So the complexity reduction is high. In the current work, upper depth PMV is enabled by default in the beginning of the TZ search algorithm.
From Table 4, it is found that the grid search complexity reduction scheme has reduced the number of search points, motion estimation time, number of \(4 \times 4\) blocks and encoding time by 44.82%, 34.83%, 34.86% and 4.92% on an average. From Table 5, it is observed that the raster search complexity reduction scheme has reduced these number of search points, motion estimation time, number of \(4 \times 4\) blocks and encoding time by 25.49%, 24.59%, 32.96% and 3.60% on an average. In Table 6, refinement search complexity reduction has reduced the number of search points, motion estimation time, number of \(4 \times 4\) blocks and encoding time by 12.73%, 12.20%, 16.28% and 1.84% on an average.
Table 7 shows the results of MCBFME and the proposed scheme implemented in HM-16.18 with AMP SPEED-UP enabled by default is shown. Reduction in motion estimation time, number of search points and the number of \(4 \times 4\) for MCBFME and the proposed scheme are 41.65%, 62.57% and 68.20% and 68.14% 77.10% and 77.16% on an average. In Table 8, the results of BMVP and the proposed scheme implemented in HM-16.18 with AMP SPEED-UP disabled are shown. The average reduction in motion estimation time, number of search points and the number of \(4 \times 4\) blocks for BMVP and the proposed scheme are 48.69%, 39.33% and 66.02% and 66.96%, 76.64% and 75.23%. Encoding time reduction of the proposed scheme in HM-16.18 with AMP SPEED-UP enabled and disabled is 9.64% and 8.99%, respectively.
5 Conclusion
The proposed scheme leads to an appreciable reduction in the number of \(4\times 4\) blocks and motion estimation time without greatly affecting the coding efficiency. Experimental results clearly demonstrate that the proposed grid, raster and refinement search complexity reduction schemes reduce the motion estimation complexity significantly at the respective stages without significantly affecting the video quality and the bitrate. The schemes proposed in this paper are different from existing work as: (1) the grid search MV distance is used for search range reduction in raster search, (2) both grid search MV distance and raster search MV distance are used for search range reduction in refinement search, (3) search points that are already covered in grid search are skipped in refinement search when the grid search MV distance is in between one or two, (4) the early termination criteria proposed for grid and refinement search terminate the stages earlier than in TZ search used in the HM encoder, and (5) a mechanism is proposed for reducing the number of search points in raster search.
References
Sullivan, G.J., Ohm, J.R., Han, W.J., Wiegand, T.: Overview of high efficiency video coding (HEVC) Standard. IEEE Transactions on Circuits and Systems for Video Technology 22(12), 1648–1667 (2012)
Wiegand, T., Sullivan, G.J., Bjontegaard, G., Luthra, A.: Overview of the H.264/AVC video coding standard. IEEE Transactions on Circuits and Systems for Video Technology 13(7), 560–576 (2003)
Nalluri, P., Alves, L.N., Navarro, A.: Fast motion estimation algorithm for HEVC. IEEE Second International Conference on Consumer Electronics (ICCE), Berlin (2012)
HEVC test model. https://hevc.hhi.fraunhofer.de/trac/hevc (2018)
Jain, J., Jain, A.: Displacement measurement and its application in interframe image coding. IEEE Transactions on Communications. 29(12), 1799–1808 (1981)
Ghanbari, M.: The cross-search algorithm for motion estimation. IEEE Transactions on Communications. 38(7), 950–953 (1990)
Koga, T., Iinuma, K., Hirano, A., Iijima, Y., Ishiguro, T.: Motion compensated interframe coding for video-conferencing. In: Proceedings, National Telecommunications Conference, pp. G5.3.1-G5.3.5 (1981)
Po, L.M., Ma, W.C.: A novel four-step search algorithm for fast block motion estimation. IEEE Transactions on Circuits and Systems for Video Technology 6(3), 313–317 (1996)
Zhu, S., Ma, K.K.: A new diamond search algorithm for fast-block matching motion estimation. IEEE Transactions on Image Processing 9(2), 287–290 (2000)
Zhu, C., Lin, X., Chau, L.P.: Hexagon-based search pattern for fast block motion estimation. IEEE Transactions on Circuits and Systems for Video Technology 12(5), 349–355 (2002)
Ismail, Y., McNeely, J.B., Shaaban, M., Mahmoud, H., Bayoumi, M.A.: Fast motion estimation system using dynamic models for H.264/AVC video coding. IEEE Transactions on Circuits and Systems for Video Technology 22(1), 28–42 (2012)
Du, L., Liu, Z., Ikenaga, T., Wang, D.: Linear adaptive search range model for uni-prediction and motion analysis for bi-prediction in HEVC. In: IEEE International Conference on Image Processing (ICIP), pp. 3671-3675 (2014)
Nalluri, P., Alves, L.N., Navarro, A.: Complexity reduction methods for fast motion estimation in HEVC. Signal Processing: Image Communication 39, 280–292 (2015)
Ko, Y.H., Kang, H.S., Lee, S.W.: Adaptive search range motion estimation using neighboring motion vector differences. IEEE Transactions on Consumer Electronics 57(2), 726–730 (2011)
Dai, W., Au, O.C., Li, S., Sun, L., Zou, R.: Adaptive search range algorithm based on Cauchy distribution. In: IEEE Visual Communications and Image Processing (VCIP), pp. 1-5 (2012)
Lee, T.K., Chan, Y.L., Siu, W.C.: Adaptive search range for HEVC motion estimation based on depth information. IEEE Transactions on Circuits and Systems for Video Technology 27(10), 2216–2230 (2017)
Varma, K.C.R.C., Kumar, M.V.P., Mahapatra, S.: Search range reduction for uni-prediction and bi-prediction in HEVC. J. Real-Time Image Proc. 16, 1351–1364 (2019)
Ismail, Y., McNeely, J.B., Shaaban, M., Bayoumi, M.A.: A generalized fast motion estimation algorithm using external and internal stop search techniques for H.264 video coding standard. In: IEEE International Symposium on Circuits and Systems, (ISCAS), pp. 3574–3577. IEEE, Seattle, WA (2008)
Liu, B., Zaccarin, A.: New fast algorithms for the estimation of block motion vectors. IEEE Transactions on Circuits and Systems for Video Technology 3(2), 148–157 (2012)
Cheung, C.K., Po, L.M.: Normalized partial distortion search algorithm for block motion estimation. IEEE Transactions on Circuits and Systems for Video Technology 10(3), 417–422 (2000)
Cheung, C.H., Po, L.M.: Adjustable Partial Distortion Search Algorithm for Fast Block Motion Estimation. IEEE Transactions on Circuits and Systems for Video Technology 13(1), 100–110 (2003)
Varma, K.C.R.C., Kumar, M.V.P., Mahapatra, S.: A low complexity block matching algorithm for fast motion estimation in High Efficiency Video Coding. In: IEEE National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), pp. 1-4 (2015)
Jeong, J.H., Parmar, N., Sunwoo, M.H.: Enhanced test zone search algorithm with rotating pentagon search. In: IEEE International SoC Design Conference (ISOCC), pp. 275-276 (2015)
Gao, L., Dong, S., Wang, W., Wang, R., Gao, W.: A novel integer-pixel motion estimation algorithm based on quadratic prediction. In: IEEE International Conference on Image Processing (ICIP), pp. 2810-2814 (2015)
Kim, S., Park, C., Chun, H., Kim, J.: A novel fast and low-complexity motion estimation for UHD HEVC. Picture Coding Symposium (PCS), IEEE, pp. 105-108 (2013)
Chen, Y.W., Hsiao, M.H., Chen, H.T., Liu, C.Y., Lee, S.Y.: Content-aware fast motion estimation algorithm. Journal of Visual Communication and Image Representation 19(4), 256–269 (2008)
Fan, R., Zhang, Y., Li, B.: Motion Classification-Based Fast Motion Estimation for High-Efficiency Video Coding. IEEE Transactions on Multimedia 19(5), 893–897 (2017)
Kim, T.S., Rhee, C.E., Lee, H.J., Chae, S.I.: Fast integer motion estimation with bottom-up motion vector prediction for an HEVC encoder. IEEE Trans. Circuits Syst. Video Technol. 28(12), 3398–3411 (2017)
Bossen, F., Common, H.: Test conditions and software reference configurations. JCTVC-L1100 (2013)
Test sequences. ftp://ftp.tnt.uni-hannover.de (2012)
Bjontegaard, G.: Improvements of the BD-PSNR model. ITU-T SG16, VCEG-AI11, July (2008)
Kamaci, N., Altunbasak, Y., Mersereau, R.M.: Frame bit allocation for the H.264/AVC video coder via Cauchy-density based rate and distortion models. IEEE Transactions on Circuits and Systems for Video Technology 15(8), 994–1006 (2005)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Varma, K.C.R.C., Mahapatra, S. Complexity reduction of test zonal search for fast motion estimation in uni-prediction of High Efficiency Video Coding. J Real-Time Image Proc 18, 511–524 (2021). https://doi.org/10.1007/s11554-020-00983-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11554-020-00983-y