
Abstract
Purpose
Current markerless registration methods for neurosurgical robotics use the facial surface to match the robot space with the image space, and acquisition of the facial surface usually requires manual interaction and constrains the patient to a supine position. To overcome these drawbacks, we propose a registration method that is automatic and does not constrain patient position.
Methods
An optical camera attached to the robot end effector captures images around the patient’s head from multiple views. Then, high coverage of the head surface is reconstructed from the images through multi-view stereo vision. Since the acquired head surface point cloud contains color information, a specific mark that is manually drawn on the patient’s head prior to the capture procedure can be extracted to automatically accomplish coarse registration rather than using facial anatomic landmarks. Then, fine registration is achieved by registering the high coverage of the head surface without relying solely on the facial region, thus eliminating patient position constraints.
Results
The head surface was acquired by the camera with a good repeatability accuracy. The average target registration error of 8 different patient positions measured with targets inside a head phantom was \(1.39\pm 0.33\,\hbox {mm}\), while the mean surface registration error was \(0.35\,\hbox {mm}\).
Conclusion
The method proposed in this paper achieves automatic markerless registration in multiple patient positions and guarantees registration accuracy inside the head. This method provides a new approach for establishing the spatial relationship between the image space and the robot space.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In recent years, surgical robotics have been used in neurosurgery to assist in locating planned surgical trajectories. Their performance is more accurate and stable and, unlike the manual approach to the surgical navigation system, does not present the drawback of human fatigue [1]. To locate surgical trajectories as planned in the image space, registration between the image space and the robot space is needed. The registration methods of neurosurgical robotics can be divided into two main categories: marker-based and markerless. In marker-based methods, preoperative images with fiducials on the patient’s head [2,3,4] must be scanned to acquire the fiducial coordinates in the image space so that the transformation of the two spaces can be computed using point matching algorithms [5]. Markerless registration is performed through surface matching between the patient’s surface extracted from the preoperative images and that acquired in the robot space during operation. Fiducials are not needed, and the preoperative images obtained for diagnosis or surgical planning can therefore be used for registration, simplifying the preparation procedure and reducing the preparation time and cost.
Markerless registration methods have been adopted in some neurosurgical robotic systems. Existing markerless registration methods for neurosurgical robotic systems are implemented by matching facial surfaces [6,7,8]. The miniature surgical robot Renaissance uses a surface scanner to scan the patient’s facial features and employs a registration jig fixed on the robot base to achieve registration [6]. ROSA performs markerless registration using a laser range scanner to acquire the facial surface after coarse registration via anatomic landmarks [7]. Shin proposed a facial surface acquisition method using stereo cameras with a projector attached to the robot end effector [8]. There are two main factors that underlie the facial matching strategy: first, the skin of the facial region is typically thin, resulting in individual surface relief [9]; second, the commonly used matching algorithm, i.e., the iterative closest point (ICP) [10], require an initial alignment that can be obtained by matching facial anatomic landmarks [11]. To obtain effective facial surface and anatomic landmarks, the limitations of the position of the acquisition device (which is usually fixed) requires constraints on the patient position (usually supine [7]). In addition, when the facial region is the only registration region, the accuracy inside the head decreases with an increasing distance to the face [12, 13]. Furthermore, in obtaining the initial alignment, manually locating and touching anatomic landmarks can be time-consuming [12] and requires more interactions with the surgical robot.
To overcome these disadvantages, we propose a new automatic markerless registration method based on an optical camera attached to the robot end effector. First, the optical camera captures the patient’s head from multiple views via the movement of the end effector around the head, and a dense point cloud of the patient’s head surface with high coverage is acquired following multi-view stereo vision reconstruction. Second, since the acquired head surface contains color information, a specific mark that is manually drawn on the patient’s head prior to image capture can be extracted to accomplish coarse registration instead of facial landmarks. During the fine registration procedure, we employ the geometric constraints provided by the high-coverage dense point cloud of the head surface to achieve final registration. Because there is no need to locate facial landmarks or the complete facial surface, patients can be placed in any patient position during the procedure. Phantom experiments have been performed, and the target registration error (TRE) measured inside the head phantom was employed to validate that the accuracy of the proposed method was comparable to other markerless registration methods. This method provides a new way to establish the relationship between the image space and the surgical robot space using an automatic procedure.
Method
Overall framework
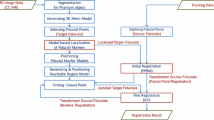
An optical camera is mounted on the robot end effector. During surgery, the camera captures images from multiple angles around the patient’s head, via the movement of the robot end effector. A three-dimensional (3D) scene can be reconstructed in the robot base coordinates through multi-view stereo vision algorithms, and the head surface is extracted from the 3D scene with high coverage and color information. Accordingly, the head surface in the image coordinates is extracted from the preoperative images. Two regions, with similar shapes and corresponding positions, can be automatically extracted from the head surfaces in the robot base coordinates and in the image coordinates. Matching the two regions achieves coarse registration of the two whole head surfaces. Finally, fine registration is performed with these two head surfaces to obtain a transformation from the image coordinates to the robot coordinates. The workflow of the proposed registration method is illustrated in Fig. 1.

Workflow of the registration method. The processes in the left and right blue dashed box are performed in the robot base coordinates and image coordinates, respectively. The position of the camera relative to the end effector is determined via hand–eye calibration (A). During surgery, the camera captures images from multiple angles with the movement of the end effector around the patient’s head (B). Combined with the calibration results and each pose of the end effector when capturing an image, a three-dimensional (3D) scene can be reconstructed in the robot base coordinates using multi-view stereo vision algorithms. After removing irrelevant objects in the scene, the head surface is obtained, with high coverage and color information (C). Taking advantage of the color information, the mark can be automatically extracted from the head surface and then extended to a specific region (D). Accordingly, the head surface in the image coordinates (F) is extracted from the preoperative images (E). Then, a template region is obtained by segmenting a specific area of the head surface following defined rules (G), which is used for coarse registration with the mark region. Matching the two regions based on similar shapes and corresponding positions achieves coarse registration of the two whole head surfaces (H). Finally, fine registration is performed with these two head surfaces to obtain the transformation from the image coordinates to the robot coordinates (I)
Intraoperative surface acquisition
Stereo vision triangulates 3D points that are associated with corresponding point pairs in images, according to the relative positions of the camera. In the proposed method, we take advantage of the fact that the camera can move with the robot end effector to capture images of the patient’s head from multiple views to achieve multi-view stereo vision. Features of the skin texture are detected in images and are used as corresponding point pairs. The position of the camera relative to the end effector is determined via hand–eye calibration. The hand–eye calibration is performed via the method proposed by Radu [14], and camera calibration is accomplished with Zhang’s method [15] to correct distortions of the images associated with both hand–eye calibration and later 3D reconstruction. Once the calibrations are completed, the results can be continuously used as long as the relative position of the camera and the robot end effector are maintained. Because of the prior hand–eye calibration, the capture position of the camera in the robot base coordinates can be calculated. Therefore, multi-view stereo vision can be used to reconstruct the patient’s head surface in the robot base coordinates. Moreover, the color information acquired from this method can be utilized to achieve automatic registration.
During the acquisition procedure, via the movement of the robot end effector around the patient’s head, images are captured when the camera is in a number of different positions (called capture positions in the following text). Because the patient’s head is placed in a fixed region of the robot workspace in each surgery (shown in Fig. 2), the capture positions and the movement between the capture positions are stored as presets. The capture positions are adjusted by manually controlling the robot so that the camera faces the rectangular box. To provide high coverage of the head surface for registration, the capture positions are distributed along two arcs. Under these capture positions, the whole rectangular box is in the field of view and it accounts for larger than half of the field of view. The capture trajectory for capturing the left, up and right facets of the rectangular box is approximately \(180^{\circ }\), and it is approximately \(90^{\circ }\) for capturing the up and top facets. Therefore, four of the five facets (except the down facet) can be captured so that nearly four-fifths of the head surface can be reconstructed.

Schematic diagram of the surface acquisition setup. The capture trajectories are shown as dotted lines. Right is opposite the left facet, and down is opposite the up facet
The 3D scene can be reconstructed through the patch-based multi-view stereo (PMVS) algorithm [16]. Each image corresponds to a pose of the robot, which is represented by the transformation \({}_{\mathrm{E}}^{\mathrm{R}} T_{{i}}\) from the robot end effector coordinates \(\left\{ E \right\} \) to the robot base coordinates \(\left\{ R \right\} \). From the method described in [14], we can deduce the projection matrix corresponding to each image, i.e., the projection from the robot base coordinates to the imaging plane satisfies
where \(M_1\)is the projection matrix given in the hand–eye calibration; Y is the result of hand–eye calibration; B is given by \(B={ }_{\mathrm{E}}^{\mathrm{R}} T_{{i}}^{-1} { }_{\mathrm{E}}^{\mathrm{R}} {T}_1 \); and \({n}-1\) is the total number of the images. PMVS reconstructs the 3D point cloud from images according to their projection matrix \({M}_{{i}} \). Because \({M}_{{i}} \) is from the robot base coordinates to the imaging plane, the point cloud is reconstructed in the robot base coordinates. In addition to the head surface, the point cloud contains other objects in the surgical scene; therefore, we extract the head surface using the random sampling consistency (RANSAC) method with a sphere template, segmented with a larger radius to extract all of the points belonging to the head surface.
Registration
The basic idea is to match two partial regions with similar shapes and corresponding positions as a coarse registration of the whole head surface; these regions are obtained from the head surface reconstructed via stereo vision and that extracted from the preoperative images. A template region is formed by segmenting the head surface in image coordinates according to different patient positions. Accordingly, a hand-drawn mark is used to delimit a specific region of the head surface in robot base coordinates. Then, fine registration is performed between the two whole head surfaces, both of which contain tens of thousands of points with high coverage.
Design and extraction of the template and the mark
A principle of the design is that when the patient is placed in any surgical position, at least one mark can be easily captured by the camera. Therefore, four templates are designed according to the four orientations, for the front, rear, left and right of the patient’s head. The designed templates and their corresponding marks are shown in Fig. 3; the templates are indicated by the yellow regions. The templates are strip areas from superior (S) to inferior (I), since it is easy for surgeons to locate the position according to anatomic landmarks on the front and rear midline as well as the connection line between the vertex and the ear. The hand-drawn mark is a cross pattern that consists of a long line and a short line, which will form a strip after it is extended. The long line starts from the vertex and lies on the front and rear midline for Template_1 and Template_2. For Template_3 and Template_4, it lies from the vertex to the ear. The short line lies perpendicular to the long line, and the intersection is approximately at the middle. The length of the long line is approximately 100 millimeters, and the short one is approximately half of the length of the long one.

Design of templates and marks. S, I, A, P, R and L represent superior, inferior, anterior, posterior, right and left, respectively

Workflow for the mark region
The segmentation rules for the templates include three steps; using Template_1 as an example, the segmentation rules are:
-
1.
Segment the portion within a length of 100 mm from the S to the I direction [after measuring several medical image datasets, the length is determined to be the region that roughly maintains a simple shape to use principal component analysis (PCA)];
-
2.
Bisect the result from the previous step in the anterior (A) and posterior (P) direction, retaining the portion near the A direction;
-
3.
Divide the result of the previous step in the right (R) and left (L) direction into three equal portions, retaining the middle portion.
When the patient’s head is placed in any patient position, surgeons select a template with a corresponding mark that can be completely captured by the camera. Then, a mark is drawn in the corresponding region on the head surface using a marking pen.
A workflow for extracting the mark is shown in Fig. 4; the processing results are shown on the right. The mark is extracted according to color information and the prior information that the mark corresponds to the upward exposure. PCA is performed for the mark, and then, the mark is extended in the three main directions to form a region with a shape similar to that of the template region.
Coarse registration
Because of the similar shapes of the template region and the mark region, the initial alignment is performed by aligning each principal direction after the PCA is completed. According to the prior position and shape information for the head, the symmetry problem of PCA is checked, and the initial alignment transformation \({ }_{\mathrm{R}}^{\mathrm{I}} {T}_{\mathrm{o}} \) is updated by rotating the mark \(180^{\circ }\) along the normal of the symmetry plane.
Then, the ICP algorithm is used to better match these two regions; the result is denoted by \({ }_{\mathrm{R}}^{\mathrm{I}} {T}_{\mathrm{c}} \). The strategy of the ICP algorithm is the same as that of fine registration.
Fine registration
After the proposed coarse registration is performed, the two head surfaces exhibit a relative position to each other that is sufficient to use ICP to achieve fine registration. When establishing the correspondences, we adopt a point-to-surface distance strategy because it is more efficient and stable [17]. In addition, since the head surface intraoperatively constructed from images may contain a few points of another object, such as the head frame, an outlier removal strategy based on the mean distance is used during each iteration. The result of the fine registration is \({ }_{\mathrm{R}}^{\mathrm{I}} {T}_{\mathrm{f}} \).
Finally, the \({ }_{\mathrm{I}}^{\mathrm{R}} {T}\) transformation mapping from the image coordinates to the robot coordinates is calculated as follows:
Experiments
In the experiments, we used a 6-axis articulated robot (VS060A3, Denso, Japan), a CCD camera (CM3-U3-28S4C-CS, Point Grey Research, Canada) with dimensions of \(44\times 35\times 19.5\hbox { mm}^{3}\) and a workstation (CPU core i7, 6G RAM). The head phantom was generated via 3D printing (3DP-110F Single, Cubicon, Korea) from a set of human computed tomography (CT) images. The workstation was used to control camera capture, data processing and robot motion. The head phantom was placed in a region of \(220\hbox { mm} \times 200\hbox { mm}\times 200\hbox { mm}\) in the workspace of the robot. The illumination was approximately 300 lux (similar to that in the operation room without opening the shadowless lamp), and the images were \(1928\times 1448\) pixels. When using the PMVS algorithm, the resolution was set to four times smaller to increase the speed of computation.
Head surface acquisition
The repeatability accuracy and the coverage of the camera-based acquisition method was validated. Additionally, the suitable number of images for reconstruction was investigated by examining the completeness of the head phantom surfaces.
The phantom was placed without changing the position during the repeatability experiment. The robot end effector with the camera moved to 80 different positions, and 80 images were captured. These positions were distributed in two orthotropic arcs (shown in Fig. 2) and were divided into four groups by capturing the left, right, up and top facets of the rectangular box; there were 20 images in each group. Ten reconstructions were reconstructed using n randomly chosen images; n / 4 images were from each group. Phantom surfaces were extracted from the reconstructions and meshed, as denoted by \({S}n_i\left( {n=8,12,16,20,24,28;i=1,2,\ldots ,10} \right) \). The time consumption and the number of points of the phantom surfaces were recorded.
Repeatability accuracy
The signed distances from all the points in \({S}n_i \) to the surface \({S}n_{i-1} \) were calculated. Because the phantom surfaces were reconstructed from different images, they had regions that did not overlap with each other. Therefore, distances larger than 2 mm were excluded because they were classified as non-overlapping regions. The mean value and the standard deviation of the distances with 2 mm were calculated, denoted by \(D_i\) and \(\hbox {Std}_i\left( {i=1,2,\ldots ,9} \right) \), respectively. \(\overline{D} \) was the repeatability accuracy of S n, and \(\overline{\hbox {Std}} \) was calculated.
Completeness
To investigate how many images were suitable for the acquisition of the head surface, the completeness of the reconstructed phantom surfaces using different number of images was measured. A phantom surface point cloud, which was extracted from the reconstruction using all 80 images, was seen as a complete surface, denoted by S80. The distances from all the points in S80 to the surface \({S}n_i \) were calculated. The completeness was defined as the percentage of the number of points out of the total number of points in S80 whose distances were smaller than 2 mm.
Coverage
The proposed registration method would use the setup shown in Fig. 5; therefore, the coverage of the acquired point cloud was validated using this setup.

Registration setup of the optical camera-based surgical robot for neurosurgery
Registration
The automatic registration accuracy of multiple patient positions and the stability of this method were validated.

Head phantom for the registration accuracy experiment. a Appearance of the phantom, b the internal targets and pins and c a CT slice of the phantom
Registration accuracy
To measure TRE inside the head, we designed a head phantom consisting of a scalp surface shell and 13 internal targets on a base, as shown in Fig. 6. The targets were randomly distributed inside the head and were designed as a conical pivot on the top of each cylinder, allowing a robot probe to be placed in the center position of the target. The base and surface shell were compactly connected by pins, with a repeatability of the assembly and disassembly of 0.21 mm. To avoid the influence of deformation by the force from the Mayfield clamp, the phantom base was directly fixed on the test bench. Through the registration procedure, the surface shell was mounted on the base. Then, with the surface shell removed, the internal targets could be picked by the robot probe. It should be noted that for easy fixation and measurement in all experiments, the phantom was placed upright and facing different directions, simulating different patient positions that were used in clinical settings. A total of eight patient positions were tested; each was rotated approximately \(45^{\circ }\).

Variations of the mark region (shown in white color)
CT images were scanned with a voxel size of \(0.5\times 0.5\times 0.8\,\hbox {mm}^{3}\). We picked each target (Fig. 6c) in the images five times, using the average as the target in the image coordinates, denoted by \({ }^{\mathrm{I}} \mathbf t _{{i}}\). The targets in the robot base coordinates were picked by the probe mounted on the robot end effector, and this operation was performed by manually controlling the robot for four different robot configurations to calculate a mean value, denoted by \({ }^{\mathrm{R}} \mathbf{t }_{{i}} \). The probe was calibrated based on its machining dimensions. Then, the probe was substituted for the camera for registration to obtain the transformation \({ }_{\mathrm{I}}^{\mathrm{R}} {T}\). The number of images was 20. The termination criteria were as follows: iterations exceeded 20,000 times, or the incremental position change fell below \(10^{-6}\). The TRE of the 13 targets was measured as follows:
In addition, we calculated the surface registration error (SRE, i.e., the distance from the points on the reconstructed head surface to the surface extracted from the CT images). SRE was calculated as follows:
where \({ }^{\mathrm{R}}{} \mathbf p _{{i}} \) is the point on the operative acquisition head surface; \({ }^{\mathrm{I}}{} \mathbf p _{{i}} \) is the closest point on the surface extracted from the CT images after registration; \({ }_{\mathrm{R}}^{\mathrm{I}} T\) is the transformation from robot coordinates to image coordinates; \(\mathbf n _{{i}} \) is the normal of \({ }^{\mathrm{I}}{} \mathbf p _{{i}} \); and N is the number of points on the operative acquisition head surface that participate in the registration.
Registration stability
To validate the stability of the proposed method that is affected by the hand-drawn mark, a mark region was simulated for registration and the TRE was calculated. The data were the same as the data in the registration accuracy section.
If the hand-drawn mark was not drawn properly (i.e., with a different length, width, position or the lines were not direct), after being extracted and extended, variations (such as those shown in Fig. 7) would occur for the mark region. The extracted marks from the acquired phantom surface in the registration accuracy section were defined as the initial mark. Then, the length, width and angular deflection were generated randomly 100 times while obeying a uniform distribution. The length was between (− 70, − 25) mm and (25, 70) mm from the center along the first principle axis of the PCA of the initial mark; the width was between (− 30, − 5) mm and (5, 30) mm along the second principle axis; and the angular deflection was rotated around the third principle axis by (\(-10^{\circ },10^{\circ })\).
Then, the new mark region was segmented and matched with its corresponding template region. Once the whole registration completed, the TRE was calculated using the 13 internal targets.
Results
Surface acquisition
The repeatability accuracy represented by the signed distance is represented in Fig. 8 by the blue line. The standard deviation is represented by the red line.

Repeatability accuracy of the reconstructions using different numbers of images
The completeness of the reconstructions using different numbers of images is shown in Fig. 9. A case illustrating the completeness is shown in Fig. 10. In Fig. 10a, S80 had a completeness of \(100\%\), and in Fig. 10b, \({S12}_6 \) was constructed using 12 images. Figure 10c shows the distance from the points in S80 to the surface \({S12}_6 \), where the red color represents distances greater than 2 mm for non-overlapping regions.

Completeness of constructions using different numbers of images

A case illustrating completeness. a S80, b \({S12}_6 \), and c distance from (a) to (b)

Time consumption and number of points acquired using different number of images. a Time consumption of the reconstructions; b number of points of the acquired phantom surfaces

Acquired point cloud. a, b Different views of the point cloud
The time consumption of the ten reconstructions using different numbers of images is shown in Fig. 11a. The number of points after segmenting for the phantom surfaces is shown in Fig. 11b.
Coverage
The capture procedure required nearly 2 min. The results of the acquisition are shown in Fig. 12. It can be seen in the figure that the point cloud contains the face, vertex and lateral parts of the phantom surface. The point cloud also contains part of the Mayfield frame.
Registration
Registration accuracy
In the 8 registration experiments, the coarse registration procedure took from 7 to 29 s; the fine registration procedure took from 23 to 60 s; and the whole registration process took from 33 to 69 s. The corresponding templates and the serial numbers are summarized in Table 1. The reconstructed head surface from each experiment is shown in Fig. 13. Among the 8 series of experiments, the registration results from (g) are shown in Fig. 14 as an example, where (a) is the coarse registration result and (b) is the fine registration result. Figure 14c shows the distance between the two head surfaces after registration. Table 2 lists the TRE of coarse registration, the TRE and SRE of fine registration, and the standard deviation, maximum and minimum of the fine registration TRE. The average fine registration TRE for all 8 series was \(1.39\,\hbox {mm}\pm 0.33\,\hbox {mm}\), and the average SRE was 0.35 mm.

Head surfaces acquired in eight different patient positions, observed from a fixed viewpoint

An example showing the registration between the head surface extracted from the CT images and that reconstructed from the images captured. a The coarse registration result, and b is the fine registration result. c The distance between the two head surfaces after registration

Coarse registration TRE of each serial number

Fine registration TRE of each serial number
Registration stability
The statistical results of the 100 times of registration for each serial number are shown in Figs. 15 and 16 as box plots for coarse registration TRE and fine registration TRE, respectively. From the results, using the variation of the mark regions within the range in the experiment, coarse registration TRE can be achieved below 11 mm. Figure 7 shows some of the variations within the given range. The maximums of fine registration TRE of all the \(100\times 8\) tests are from 1.34 to 2.33 mm except two outliers in serial (g).
Discussion
Herein, we propose a markerless registration method to be used in neurosurgical robotics. An optical camera attached to the robot end effector is employed to acquire both position and color information for the surgical patient’s head surface. The repeatability accuracy and completeness of the acquired head surface were measured. Coarse registration is performed via surface registration between two partial areas with similar shapes and the corresponding positions, rather than using facial anatomic landmarks. TRE inside the phantom was measured in multiple patient positions, and the stability of the registration was validated.
Registration under multiple patient positions is achieved in the proposed method. According to the literature [7], surface registration was impossible for the patient in the prone position because the face could not be registered by the robot. From some cases of our experiment, the facial region could not be completely acquired, but nearly four-fifths of the head surface was used for matching, and the registration was guaranteed by geometric features of the whole head. According to our results, there was no significant relationship between patient positions. In addition, based on the report that the accuracy decreases when the targets are located farther from the registration region [12, 18] and the finding in the literature [13] that the average TRE using the entire head surface to register is smaller than using the facial region, the proposed method has a potential advantage of achieving better accuracy in posterior areas than the methods that only use the facial area. The mean TRE, which was measured using 13 targets randomly distributed inside the head phantom, of \(1.39\pm 0.33\,\hbox {mm}\) and the standard deviation indicate relatively stable results. This accuracy is similar to that of other markerless methods [6, 8, 19] in which measurements were performed in vitro. To improve the acquisition accuracy, considering the workflow, more optimized and accurate methods of hand–eye calibration and robot calibration can be adopted. In addition, improving the accuracy of the surface extraction from CT scans can reduce the measurement error of the TRE.
This method provides an automatic process from coarse registration to fine registration. The color information of the intraoperative head surface is used to delimit a specific region. Combined with the designed template, the coarse registration can be achieved automatically, rather than manually picking facial anatomic landmarks. In the registration stability experiment, the variations of the mark regions, caused by inaccurate hand-drawn marks in a real-world situation, were simulated. From the results, the hand-drawn mark is allowed not rigorous obeying the instruction described in the section of Design and extraction of the template and the mark, and the registration method is stable using the hand-drawn mark. In addition, outliers can be rectified by intraoperative validation after the registration procedure and then performing registration again using a variation of the mark region; the intraoperative validation is not concerned in this paper.
To our knowledge, there are no previous reports of utilizing a single optical camera in the markerless registration procedure for neurosurgical robotics. Optical cameras have been used for registration in both augmented reality navigation [20,21,22] and surgical robotics [8, 23,24,25,26]. They are employed as a stereo vision system consisting of two cameras. Without specifically designed markers [23,24,25,26], the corresponding points are natural features [20, 21] or beam patterns projected on the patient’s face [8, 22], which allow markerless registration. A sparse facial point cloud and a teeth contour were reconstructed with a stereo vision camera in [20] and [21], respectively. In our method, images captured at multiple camera positions can be seen as multi-view stereo vision, and the reconstructed head surface is a dense point cloud. From Fig. 11b, ten thousands of points can be acquired for the phantom surface by this method. Moreover, additional devices, such as projectors [8, 22], are unnecessary because this method uses features of skin texture as corresponding point pairs. Additionally, because the range of capture positions is greater than that in other methods where the stereo vision system is placed at an invariant position during surgery, the coverage of the point cloud acquired by our method is greater than the other methods described above. To acquire high coverage of the head surface, the size of the acquisition device should allow the robot end effector to flexibly move around the patient’s head. Therefore, color 3D scanners, such as Go!SCAN (Creaform, Canada), are not appropriate in our situation because of the size requirements. Based on the repeatability accuracy (Fig. 8), the signed distance is distributed around zero, which means the points are evenly distributed on both sides of the other phantom surface being compared. As the number of images used increases, the standard deviation decreases, which means the points from both sides of the phantom surface are closer to each other, but this benefit decreases after using 20 images. The result of the completeness experiments (Fig. 9) shows that the completeness is close to \(95\%\) when using 20 images to reconstruct, and the increasing trend becomes stable. Considering that the time consumption of construction increases as the increasing number of images increases, as shown in Fig. 11a, acquiring 20 images around the head for this situation of registration in neurosurgery is recommended.
Instead of using auxiliary features such as markers and structured light, correspondences in this method are found by matching textural features on the skin surface. Thus, suitable illumination is required when capturing images. This requirement is readily satisfied in clinical settings because the illumination in our experimental conditions was set to 300 lux measured by HT-8318 (Hcjyet, China), which was near 290 lux we measured in the operating room without opening the shadowless lamp. Additionally, the described registration method is limited to surgeries in which the patient’s head is fully shaved. It provides an acceptably accurate alternative for this kind of surgery when a patient needs to be shaved to reduce the risk of infection. At present, validation of the proposed method has been performed only on a phantom head. Thus, we will validate this method on real people in an actual clinical situation in future work. To avoid disturbing the surgical workflow, the placement of the robot is also a problem to be solved in the future.
Conclusion
The proposed markerless registration method used in neurosurgical robotics allows an automatic procedure in any patient position. The accuracy of the method is comparable with that of other markerless registration methods that are acceptable for certain surgeries.
References
Taylor RH, Menciassi A, Fichtinger G, Dario P (2008) Medical robotics and computer-integrated surgery. In: Siciliano B, Khatib O (eds) Springer handbook of robotics. Springer, pp 1199–1222
Varma T, Eldridge P (2006) Use of the NeuroMate stereotactic robot in a frameless mode for functional neurosurgery. Int J Med Robot Comput Assist Surg 2(2):107–113
Bekelis K, Radwan TA, Desai A, Roberts DW (2012) Frameless robotically targeted stereotactic brain biopsy: feasibility, diagnostic yield, and safety: clinical article. J Neurosurg 116(5):1002–1006
Meng F, Ding H, Wang G (2014) A stereotaxic image-guided surgical robotic system for depth electrode insertion. In: 2014 36th annual international conference of the IEEE engineering in medicine and biology society. IEEE, pp 6167–6170
Horn BK (1987) Closed-form solution of absolute orientation using unit quaternions. JOSA A 4(4):629–642
Joskowicz L, Shamir R, Freiman M, Shoham M, Zehavi E, Umansky F, Shoshan Y (2006) Image-guided system with miniature robot for precise positioning and targeting in keyhole neurosurgery. Comput Aided Surg 11(4):181–193
Lefranc M, Capel C, Pruvot-Occean A-S, Fichten A, Desenclos C, Toussaint P, Le Gars D, Peltier J (2015) Frameless robotic stereotactic biopsies: a consecutive series of 100 cases. J Neurosurg 122(2):342–352
Shin S, Cho H, Yoon S, Park K, Kim Y, Park S, Kim L, Lee D (2015) Markerless surgical robotic system for intracerebral hemorrhage surgery. In: 2015 37th annual international conference of the IEEE engineering in medicine and biology society (EMBC). IEEE, pp 5272–5275
Raabe A, Krishnan R, Wolff R, Hermann E, Zimmermann M, Seifert V (2002) Laser surface scanning for patient registration in intracranial image-guided surgery. Neurosurgery 50(4):797–803
Besl PJ, McKay ND (1992) A method for registration of 3-D shapes. IEEE Trans Pattern Anal Mach Intell 14(2):239–256
Medtech S (2010) Premarket notification 510 (K) submission rosa surgical device. Montpellier, France, pp 6–10
Shamir RR, Freiman M, Joskowicz L, Spektor S, Shoshan Y (2009) Surface-based facial scan registration in neuronavigation procedures: a clinical study: clinical article. J Neurosurg 111(6):1201–1206
Fan Y, Jiang D, Wang M, Song Z (2014) A new markerless patient-to-image registration method using a portable 3D scanner. Med Phys 41(10):101910-1–101910-13
Horaud R, Dornaika F (1995) Hand-eye calibration. Int J Robot Res 14(3):195–210
Zhang Z (2000) A flexible new technique for camera calibration. IEEE Trans Pattern Anal Mach Intell 22(11):1330–1334
Furukawa Y, Ponce J (2010) Accurate, dense, and robust multiview stereopsis. IEEE Trans Pattern Anal Mach Intell 32(8):1362–1376
Chen Y, Medioni G (1992) Object modelling by registration of multiple range images. Image Vis Comput 10(3):145–155
Ledderose GJ, Hagedorn H, Spiegl K, Leunig A, Stelter K (2012) Image guided surgery of the lateral skull base: testing a new dental splint registration device. Comput Aided Surg 17(1):13–20
Lefranc M, Capel C, Pruvot AS, Fichten A, Desenclos C, Toussaint P, Le Gars D, Peltier J (2014) The impact of the reference imaging modality, registration method and intraoperative flat-panel computed tomography on the accuracy of the ROSA® stereotactic robot. Stereotact Funct Neurosurg 92(4):242–250
Lee J-D, Huang C-H, Huang T-C, Hsieh H-Y, Lee S-T (2012) Medical augment reality using a markerless registration framework. Expert Syst Appl 39(5):5286–5294
Wang J, Suenaga H, Hoshi K, Yang L, Kobayashi E, Sakuma I, Liao H (2014) Augmented reality navigation with automatic marker-free image registration using 3-D image overlay for dental surgery. IEEE Trans Biomed Eng 61(4):1295–1304
Zeng B, Meng F, Ding H, Wang G (2017) A surgical robot with augmented reality visualization for stereoelectroencephalography electrode implantation. Int J Comput Assist Radiol Surg 12(8):1355–1368
Deacon G, Harwood A, Holdback J, Maiwand D, Pearce M, Reid I, Street M, Taylor J (2010) The Pathfinder image-guided surgical robot. Proc Inst Mech Eng H 224(5):691–713
Jerbic B, Nikolic G, Chudy D, Svaco M, Sekoranja B (2015) Robotic application in neurosurgery using intelligent visual and haptic interaction. Int J Simul Model 14(1):71–84
Wei J, Wang T, Liu D (2011) A vision guided hybrid robotic prototype system for stereotactic surgery. Int J Med Robot Comput Assisted Surg 7(4):475–481
Meng C, Wang T, Chou W, Luan S, Zhang Y, Tian Z (2004) Remote surgery case: robot-assisted teleneurosurgery. In: 2004 IEEE international conference on robotics and automation, 2004. Proceedings. ICRA’04. IEEE, pp 819–823
Acknowledgements
The authors acknowledge the support of the National Natural Science Foundation of China (61361160417, 81271735) and the National Key Technology R&D Program of China (2016YFC0105800, 2017YFA0205904).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
This article does not contain patient data.
Rights and permissions
About this article

Cite this article
Meng, F., Zhai, F., Zeng, B. et al. An automatic markerless registration method for neurosurgical robotics based on an optical camera. Int J CARS 13, 253–265 (2018). https://doi.org/10.1007/s11548-017-1675-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11548-017-1675-5