
Abstract
Visual inspection of electroencephalogram (EEG) recordings for epilepsy diagnosis is very time-consuming. Therefore, much research is devoted to developing a computer-assisted diagnostic system to relieve the workload of neurologists. In this study, a kernel version of the robust probabilistic collaborative representation-based classifier (R-ProCRC) is proposed for the detection of epileptic EEG signals. The kernel R-ProCRC jointly maximizes the likelihood that a test EEG sample belongs to each of the two classes (seizure and non-seizure), and uses the kernel function method to map the EEG samples into the higher dimensional space to relieve the problem that they are linearly non-separable in the original space. The wavelet transform with five scales is first employed to process the raw EEG signals. Next, the test EEG samples are collaboratively represented on the training sets by the kernel R-ProCRC and they are categorized by checking which class has the maximum likelihood. Finally, post-processing is deployed to reduce misjudgment and acquire more stable results. This method is evaluated on two EEG databases and yields an accuracy of 99.3% for interictal and ictal EEGs on the Bonn database. In addition, the average sensitivity of 97.48% and specificity of 96.81% are achieved from the Freiburg database.

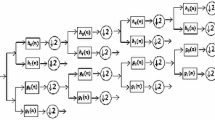
Visual inspection of EEG recordings for epilepsy diagnosis is very time-consuming. Therefore, many researchers are devoted to developing a computer-assisted diagnostic system to relieve the workload of neurologists. In this paper, a kernel version of the robust probabilistic collaborative representation based classifier (R-ProCRC) is proposed for the detection of epileptic EEG signals. The kernel R-ProCRC jointly maximizes the likelihood that a test EEG sample belongs to each of the two classes, i.e., seizure and non-seizure, and uses the kernel function method to map the EEG samples into the higher dimensional space to relieve the problem that they are linearly non-separable in the original space. The main procedures of the proposed method are exhibited in the two figures as following,
Fig. 1 The main procedures of the proposed method. (a) The schematic diagram of EEG classification based on the Freiburg database. (b) The detailed procedures of the kernel R-ProCRC
This method has been evaluated on two different types of EEG databases and shows superior performance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Epileptic seizures are a common chronic brain disease characterized by abrupt, recrudescent, and uncontrolled neuronal discharges [1]. This neurological disorder is primarily caused by genetics and external injuries, which can lead to self-injuries or more [2]. The electroencephalogram (EEG) collects the electrical activities of the brain, which has become a reliable tool in the diagnosis of epilepsy [3]. Large amounts of EEG data are required to be identified by visual observation of well-trained neurophysiologists. However, this is a subjective as well as a tedious process [4]. Therefore, the development of automatic detection of EEG recordings provides a new way to alleviate the pressure of neurologists.
For the diagnosis of epilepsy, the offline epileptic seizure detection is an indispensable procedure that can be retrospect to the 1970s. To date, a large number of automated seizure detection algorithms have been introduced based on the classification of EEG data. The broadly applied technique, proposed by Gotman [5], broke down EEG signals into half waves and utilized the peak amplitude, slope, duration, and sharpness as features [6]. Orhan et al. [7] developed a method that adopted k-means clustering and a multilayer perception neural network model for the discriminant analysis. As the development of nonlinear dynamics theory, a number of nonlinear features, including higher order spectra [8], approximate entropy [9], largest Lyapunov exponent [10], and pattern match regularity statistic [11], were also used for seizure detection and gained promising results.
Since EEG signals are non-stationary by nature and have paroxysmal and transient characteristics, the wavelet transform has become a powerful approach in EEG analysis, which can express the signal as a linear combination of a specific series of wavelet functions. In contrast to the short-time Fourier transform (STFT), the wavelet transform uses a variable window size to overcome the resolution drawback of STFT [12, 13]. Long time windows are employed at low frequencies to obtain high-frequency resolution and short time windows are adopted at high frequencies to acquire high time resolution. Hence, the wavelet transform can provide particular frequency information and time information at different frequency scales and localize transient changes in both time and precisely frequency domains [14].
The sparse representation that stems from compressed sensing has been extensively applied in many fields, especially in pattern recognition. Wright et al. [15] proposed a method of sparse representation-based classification (SRC) for robust face recognition via encoding a query face over the training template set. The classification can be performed by evaluating the represented residual. After that, Zhang et al. [16] developed the SRC to the collaborative representation-based classifier (CRC) which replaced l1-minimization with l2-minimization and obtained the competitive accuracy and lower complexity. Zhou et al. introduced the SRC and CRC to discriminate ictal EEGs from interictal EEGs [17] and to detect seizure events in long-term EEG signals [18]. Although the SRC and the CRC can achieve competitive accuracy, they still lack intrinsic explanations. Recently, a clear probabilistic explanation of classification mechanism of the CRC is given in [19], and a robust probabilistic collaborative representation-based classifier (R-ProCRC) is also presented for face recognition.
Because of the nonlinear reparability of the EEG data, it is difficult to find an effective linear technique to classify the EEG data in the original sample space. In this study, the kernel function method is applied to map the EEG epoch to a high-dimensional space, which combined with the R-ProCRC can more effectively capture the nonlinear relationships of EEG samples. The performance of the kernel R-ProCRC is evaluated on the two different EEG databases, and the detection results indicate that there is the potential for clinical application of the proposed method.
The remainder of this paper is organized as follows. In Section 2, the two different EEG databases are briefly described, and the detailed introduction of the proposed method composed of preprocessing, kernel R-ProCRC, and post-processing is given. Section 3 displays the experimental results and a discussion of the performance is followed in Section 4. Section 5 concludes this work.
2 Materials and methods
2.1 EEG database
The two EEG databases are used to evaluate the proposed method in this study. One is from the Department of Epileptology, Bonn University, Germany, and another is from the Epilepsy Center of the University Hospital of Freiburg, Germany. The dataset from Bonn University is comprised of five subsets (denoted Z, O, N, F, and S), which are digitized at 173.61 Hz per second. Each subset contains 100 single-channel EEG segments of 23.6-s duration. Sets Z and O contain scalp EEG segments which are recorded from five healthy volunteers whose eyes are open and closed. Sets N and F are collected in seizure-free intervals from five epileptic patients. Epochs in set F are obtained from the epileptogenic zone, and those in set N are extracted from the hippocampal formation of the opposite hemisphere of the brain, while set S includes epileptic seizure epochs from all channels. A more detailed description of this database is discussed in [20].
Three different classification experiments are constructed for the Bonn database to evaluate the classifying capacity of the proposed method. First, set F (interictal) and set S (ictal) are elected for classification, which is the most likely to be used in clinical practice. Then, for the classification of two databases, set Z (normal) and set S (ictal) are also solved. Thirdly, we select four databases and divide those into two classes: the first class comprises sets Z, N, and F, while set S is in the second class.
The data from the University Hospital of Freiburg are acquired using a Neurofile NT digital video-EEG system with 128 channels, a 256-Hz sampling rate, and a 16-bit analog-to-digital converter. The whole database includes intracranial EEG recordings of 21 patients suffering from medically intractable focal epilepsy, which are recorded during presurgical epilepsy monitoring with invasive electrodes [21]. The seizure onset and offset are determined by epileptologists. In addition, three focal and three extrafocal channels were previously chosen by certified epileptologists for all the patients. The Freiburg database is summarized in Table 1.
In this study, both three focal channels and three extrafocal channels were used for seizure detection. For each patient, no more than three seizure events are selected according to the time order (except patients 5, 15, and 19) and the twice number of non-seizure data are selected for training. In total, 0.76 h of seizure data and 1.52 h of non-seizure data are chosen to train the classifier. In addition, 2.05 h of seizure data comprised of 1844 epochs and 560.05 h of non-seizure data comprised of 504,042 epochs are selected to assess the performance of the proposed method. In the aggregate, 564.38 h EEG data are used in this work.
The amount of data in the Bonn database is much smaller than that in the Freiburg database and the sampling frequency of the two databases is different. In addition, the EEG data in the Bonn database were selected and cut out from continuous EEG recordings after visual inspection for artifacts, e.g., due to muscle activity or eye movements. But the data in the Freiburg database were the original continuous long-term EEG data. So the seizure detection task on the Freiburg database is much more difficult than the EEG classification on the Bonn database. Only when good results are obtained on the Bonn database by the proposed kernel R-ProCRC, it is possible for this method to yield well detection results on the Freiburg database which contains much more EEG data with noise. Therefore, the experiment on the Bonn database can be regarded as the verification of the proposed method prior to the experiment of the Freiburg database that can be seen as the final proof of whether this method can be applied in practice.
2.2 Preprocessing
In this study, the procedures of the preprocessing based on the Freiburg database and the Bonn database are different. For Freiburg database, the original long-term EEG data are decomposed into 4-s segments using a sliding window without overlap. Next, the discrete wavelet transform with five decomposition levels is utilized to preprocess the EEG segments. Because of the sampling frequency of the Freiburg database is 256 Hz, the EEG segments can be split into five detail coefficients (D1 − D5) corresponding to 64–128 Hz, 32–64 Hz, 16–32 Hz, 8–16 Hz, and 4–8 Hz, and the approximation coefficients (A5) represent 0–4 Hz. In this work, the Daubechies-4 wavelet is adopted as the wavelet function, which has been proven by many previous studies as more effectively capturing the characteristics of EEG signals [14, 22, 23]. Considering that seizures usually occur between 3 and 29 Hz, the coefficients D3, D4 and D5 are selected to reconstruct the sub-signals XD3, XD4 and XD5 to detect epileptic seizure in EEGs.
The differential operator, which is defined as fn − fn ‐ 1, can capture significant changes such as spike and sharp waves contained in the EEG signals. It is able to heighten the contrast of the seizure activities and the background which contains interictal EEGs [24, 25]. In this study, the differential operator is carried out on the XD3, XD4, and XD5, which is defined as
where fn is the EEG signals, D′ represents the first-order derivative with respect to n, and every patient has their own w. For Freiburg database, continuous 1-h EEG data comprised of the seizures was used to determine the parameter w in the training stage. We adjusted the w to get the best results in advance for each patient. For Bonn database, we adjusted the value of w in the 10-fold cross-validation experiment to get the best results. After the above preprocessing steps, three outputs acquired from the differential operator are used to do the classification.
For the Bonn database, sets Z, N, F, and S are used in this work, and all of them contain 100 segments of 4096 points. First, each segment is divided into four epochs with the same length of 1024 points. Next, each EEG epoch is decomposed into one detail coefficient D1 and one approximation coefficient A1 by the discrete wavelet transform with one decomposition levels. The differential operator is then executed on the approximation coefficient A1, whose outputs are applied for the subsequent seizure detection.
The EEG data in the Bonn database is the artificially selected pure EEG data and the data in the Freiburg database is the raw long-term EEG recordings. So, there is a slight difference in the way of processing data in the two databases using wavelet transform. The choice of different wavelet decomposition levels is also based on the differences in EEG data between the two databases.
2.3 The kernel robust probabilistic collaborative representation-based classifier
The main procedures of the proposed method are exhibited in Fig. 1. In the following sections, a detailed description of each step will be given.

(a) The schematic diagram of EEG classification based on the Freiburg database. (b) The detailed procedures of the kernel R-ProCRC
2.3.1 The robust probabilistic collaborative representation-based classifier
Suppose that the training samples are composed of K classes of training sets X = [X1, X2, …, Xk], where \( {X}_i=\left[{x}_{\mathrm{i}}^1,{x}_{\mathrm{i}}^2,\dots, {x}_{\mathrm{i}}^{{\mathrm{n}}_{\mathrm{i}}}\right] \) represents the data matrix of the ith class and the column of Xi denotes the ni sample vector. We define the linear subspace that is collaboratively spanned by the training samples in X as S. The label set of each class in X is denoted by lx. For any data point in the subspace S, it can be represented by all training sample as
where \( a=\left[{a}_1^{\mathrm{T}},{a}_2^{\mathrm{T}},\dots, {a}_{\mathrm{k}}^{\mathrm{T}}\right] \) and ai are the coding vectors associated with the ith class.
The confidence of different data points belonging to lx is determined by the representation coefficients a (in terms of magnitude). If x falls into the ith class, it can be coded as a linear combination by the training samples of the same class: x = Xiai. The probability of lx is different between different data points, where l(x) denotes the label of x. A Gaussian function is selected to define the probability:
where c is a constant and the \( {\left\Vert a\right\Vert}_2^2 \) represents the square of the l2-norm of a. P(l(x) ∈ lx) should be higher if the l2-norm of a is smaller, vice versa.
The probability of the sample inside the subspace S has been defined in Eq. (3). However, not all the test sample y will fall into the subspace, whose probability P(l(y) ∈ lx) can be represented with the following methods. First, we select a sample x in subspace S and compute two probabilities P(l(x) ∈ lx) and P(l(x) = l(y)) which denotes the probability that y and x have the same class label. We then can obtain:
Using l1-norm to characterize, the loss function can enhance the robustness of classification [15]. So the Laplacian kernel is chosen to define the similarity of y and x:
where κ is a constant. With Eq. (3)~Eq. (5), we obtain:
Moreover, the logarithmic operator is applied to Eq. (6) to obtain the maximum of the probability P(l(y) ∈ lX):
where λ = c/κ. To measure the probability that x has the same class as xk, the Gaussian kernel is adopted to define it as
where δ is a constant and the \( {\left\Vert x-{X}_{\mathrm{k}}{\alpha}_{\mathrm{k}}\right\Vert}_2^2 \) represents the square of the l2-norm of x − Xkαk. A testing sample y whose probability that l(y) = k can be computed as:
In consideration of k ∈ lX, the probability P(l(y) = l(x)| l(x) ∈ lX) in Eq. (5) and k are independent of each other. We readily have P(l(y) = l(x)| l(x) ∈ k) = P(l(y) = l(x)| l(x) ∈ lX). With (7)–(9), we obtain:
where γ = δ/κ. By computing the maximum of the probability defined in Eq. (10) for each class, some corresponding data points can be found to satisfy the requirement. Assume that, a common x is found to maximize the joint probability P(l(y) = 1, …, l(y) = K) as well as each event l(y) = k is independent. The class label of y can be determined as
The logarithmic operator is applied in Eq. (11) and the solution vector \( \widehat{\alpha} \) can be formulated as:
where the parameters γ and λ can be tuned. For Freiburg database, continuous 1-h EEG data containing the seizure of training set is used to be classified in the training stage. And we adjusted the γ and λ to achieve the best results for this 1-h EEG data. The γ and λ are determined by this way for each patient. For Bonn database, we adjusted the values of γ and λ in the 10-fold cross-validation experiment to get the best results. In this work, we found that γ = 5 and λ = 0.001 are the best values.
With a more detailed view of Eq. (11), it can be seen that all classes share the common part \( \left({\left\Vert y- X\alpha \right\Vert}_1+\lambda {\left\Vert \alpha \right\Vert}_2^2\right) \). Thus, we can only compute the remaining portion of Eq. (11), that is,
where \( \widehat{\alpha} \) is the solution vector obtained in Eq. (12). The final identity of y can be defined as
The above model is the R-ProCRC. Additionally, the sparse coefficient vector can be easily solved by the iterative reweighted least square (IRLS) algorithm. Here, a diagonal weighting matrix WX is introduced as:
where X(i, :) denotes the ith row of X. With Eqs. (12) and (15), we have:
Next, the representation coefficient is computed as
The representation coefficient α is updated alternatively until convergence or after an appropriate number of iterations which is set as five in this study.
2.3.2 The kernel R-ProCRC
Many experimental results of kernel-based methods in the fields of machine learning have shown satisfactory classification performance [26, 27]. The inseparable samples are mapped from the original linear space into the high-dimensional feature space, which may become linearly separable.
The mapping mentioned above is defined as Φ : Rm → RF. The inner products between the transformed feature samples ϕ(xi) and ϕ(xj) in the feature space RF can be calculated in the original input space:
where K(, ) denotes the definition of the kernel function in Eq. (18). Both training samples and testing samples can be mapped into the high-dimensional space and represented as K(Xc, X) and K(Xc, y). The center matrix Xc is obtained by selecting training sets following the theory of k-means clustering [27]. First, the mean sample of the training set of each class \( {X}_{\mathrm{i}}=\left[{x}_{\mathrm{i}}^1,{x}_{\mathrm{i}}^2,\dots, {x}_{\mathrm{i}}^{{\mathrm{n}}_{\mathrm{i}}}\right] \) can be computed as: \( {u}_{\mathrm{i}}=\left({\sum}_{j=1}^{n_{\mathrm{i}}}{x}_{\mathrm{i}}^{\mathrm{j}}\right)/{n}_{\mathrm{i}} \). Next, we select the nearest 3ni/4 samples from ui to generate the matrix \( {X}_{\mathrm{c}}^{\mathrm{i}}=\left[{u}_{\mathrm{i}},{x^{\prime}}_{\mathrm{i}}^1,{x^{\prime}}_{\mathrm{i}}^2,\dots, {x^{\prime}}_{\mathrm{i}}^{\left(3{n}_{\mathrm{i}}/4\right)}\right] \). After the above steps, we obtain the center matrix \( {X}_{\mathrm{c}}=\left[{X}_{\mathrm{c}}^1,{X}_{\mathrm{c}}^2,\dots, {X}_{\mathrm{c}}^{\mathrm{k}}\right] \).
When the kernel trick is plugged into the R-ProCRC, the parameter β (which is the representation coefficient in the space RF) can be recalculated as
The algorithm of the kernel R-ProCRC is illustrated as follows:
-
1)
Generate the center matrix Xc.
-
2)
Using the Gaussian RBF kernel, map X and y into the high feature space to gain the K(Xc, X) and K(Xc, y). The Gaussian RBF kernel is applied in this work.
-
3)
Normalize each column of K(Xc, X) and K(Xc, y) using unit l2-norm and compute the sparse representation coefficient β by the IRLS algorithm according to Eq. (19).
-
4)
Calculate the residual of each class:
In addition, we also compare the performance of the proposed method with different kernel functions, which include the linear kernel, sigmoid kernel, and polynomial kernel. The results of the comparison are given in the Sec. 3.
The linear kernel has a fast calculation speed and fewer parameters. When samples are linearly separable, the linear kernel can achieve a satisfactory classification result. And the linear kernel is defined as:
where Xc is the center matrix, and M denotes the training samples or testing samples.
The sigmoid kernel is widely used in cases where the samples are linearlyinseparable. It is also one of the most commonly used activation functions for neural networks and can map variables to between 0 and 1. The sigmoid kernel can be formulated as:
where tanh is the hyperbolic tangent function, Xc is the center matrix, and M denotes the training samples or testing samples, a is a scalar and c is a displacement parameter.
The polynomial kernel can represent the similarity of vectors in a feature space over polynomials of the original variables. It is often used to map linearly inseparable samples from the original space to the feature space. However, it has more parameters than the sigmoid kernel. When the order of the polynomial kernel is high, it will have a large computational complexity. The polynomial kernel is computed as:
where Xc is the center matrix, and M denotes the training samples or testing samples, b is a free parameter and d is the order of the polynomial kernel.
2.4 Post-processing
In this study, number 0 denotes the seizure activity and number 1 denotes the normal or non-seizure segment. The outputs of the classifier are not exactly equal to 0 or 1. Therefore, the post-processing procedure is necessary to obtain the final detection results.
If a test sample belongs to the class of seizure, its representation vector α in regard to the ictal training set should be much larger than that associated with the interictal training set. In addition, its residual with respect to the ictal training set should have smaller values than that associated with the interictal training set. Figure 2 shows a case where an ictal segment is detected.

The sparse coefficients and residuals of an ictal segment acquired from patient 4. a The sparse coefficients located in the left side of the vertical dashed line are in regard to the interictal training samples, while the remainder in regard to the ictal training samples. b The residuals of this ictal segment in regard to the interictal and ictal training samples
For the Freiburg database, after a test sample is represented by two class of training samples, two residuals corresponding to the ictal and interictal training sets can be acquired. In order to make the classification result more accurate, the difference variable is applied to this study, which is defined as the value of the residual with respect to the interictal training set minus that with the ictal training set.
In order to remove the isolated misjudgment points and the small fluctuations caused by noise, the moving average filter (MAF) is first applied to the decision variables, which can be defined as:
where x represents the input signal, y is the output signal, and N + 1 is the smoothing length that is specific for each patient. For each patient, 1-h continuous EEG data comprised of seizures was used to determine the parameter N in the training phase. We adjusted the N to achieve the best recognition rate for this 1-h EEG data. The value obtained from the MAF is compared to a suitable threshold, which is set as zero in this study. After that, binary decisions are acquired.
The multichannel integration is also applied to improve the correct detection rates. Figure 3 presents the procedures of the multichannel integration. The data of six electrodes are applied for the seizure detection and each EEG epoch is decomposed into three sub-signals XD3, XD4, and XD5 in the preprocessing stage. If there are at least two signed “1” in six channels, it will be marked as “seizure.” After that, three decisions corresponding to the three sub-signals are obtained. If the seizures are detected in at least two decisions, the testing epoch will be labeled as “seizure.” In addition, if there is only one seizure in the three decisions, the current epoch is also defined as a “seizure” when it adjoins an epoch, which is marked as seizure. Otherwise, it is labeled as “non-seizure.” Subsequently, the MAF is applied again to remove burrs and sporadic false detections.

The procedures of the multichannel integration
The start and the end of a seizure activity are changing slowly, which makes it difficult to detect the beginning and ending of the seizure. Moreover, the smoothing technique may also make the start and end of seizures obscure. Hence, a collar technique is used to compensate the epoch which is mistaken as non-seizure [28]. In this process, each detected seizure event is extended l epochs on both sides (Fig. 4(h)). The parameter l is adjusted for each patient in the training stage to get the best classification result. And the number of l does not exceed 5. Then, the number of l is fixed in the testing stage. The procedure of post-processing is exhibited in Fig. 4. In addition, the post-processing is only applied to the continuous EEG recordings from the Freiburg database in this work. For the Bonn database, the testing sample is categorized as the class that has the minimum represented residual.

The post-processing scheme of 1-h EEG data with one seizure from patient 4. (a) The difference variable with channel 1. (b) The smoothed output after the moving average filtering. (c) The decisions with channel 1 after threshold judgment. (d), (e) The decisions with another two channels after threshold judgment. (f) The decisions after the multichannel integration. (g) The smoothed output after the second moving average filtering. (h) The final classification results after the collar operation
3 Results
The proposed method is evaluated comprehensively based on different EEG databases and different assessment criteria. All the experiments are executed in the MATLAB8.1 environment on an Intel core processor with 3.40 GHz. The segment-based approach is employed for all of the databases, and the event-based approach is employed for the Freiburg database to appraise the performance of the proposed algorithm. For the segment-based criterion, the labels of the epochs judged by the algorithm are compared with those marked by the experts. The three statistical measures are introduced in this level, which are expressed as:
-
Sensitivity: True positive/the total number of seizures identified by the experts. The true positive (TP) denotes the seizure marked by the classifier as well as EEG experts.
-
Specificity: True negative/the total number of non-seizures identified by the experts. The number of non-seizures labeled by the detector as well as the experts is defined as true negative (TN).
-
Recognition accuracy: Number of accurately marked epochs/total number of epochs.
For the Freiburg database, the wavelet transform with five scales is conducted on EEG epochs and the coefficients of scales 3, 4, and 5 are selected to reconstruct the sub-signals for the multichannel decision. After that, the query samples are represented sparsely by the training samples using the kernel R-ProCRC method and the residuals in regard to the seizure and non-seizure training samples are calculated. A post-processing procedure is conducted on the residuals to obtain the final detection results.
For the segment-based level, the experimental results of the Freiburg dataset are listed in Table 2. It can be observed that the optimal sensitivity of 100%, specificity of 99.98%, and recognition accuracy of 99.98% are achieved for different patients. From the last row of Table 2, it can be noted that all of the mean values of the three statistical measurements are over 96%. Moreover, the sensitivity values of the 12 patients, exceeding half of the total number of patients, reach 100%. The lowest sensitivity of 87.18% is obtained for patient 15. All of the patients except patient 10 have specificities larger than 94%. Patient 10 achieves an unsatisfactory specificity of 75.01% owing to the electrode disconnection and reconnection.
Furthermore, the event-based evaluation approach is also employed to verify the feasibility of the proposed method in clinical practice. At this level, the two measures (the number of true detections and the false detection rate) must be calculated. The true detection denotes the seizure event detected by this method overlapping that is marked by the EEG experts. The events detected only by the classifier but not the experts are defined as false detections. Table 3 displays the results on the event-based level. At this level, the 52 seizure events are used to evaluate the performance of this approach. Except for one seizure event of patient 10, all others are detected by the proposed method. Most patients have a satisfactory false detection rate, and more than half of the patients achieve a false detection rate of less than 0.1/h. In addition, the majority of the false detections are caused by high-amplitude activities that are easily misjudged as seizures.
In order to comprehensively demonstrate the performance of the proposed approach, the Bonn dataset is also used in this study. The K-fold cross validation is adopted to acquire stable and convincing classification results. The original dataset is divided into K subsets equally, and the K − 1 subsets are selected to train the model, while the remaining one is treated as the testing samples. That is, the process of classification is executed K times in turn. K is set to ten in this work.
The experimental results based on the Bonn dataset are depicted in Table 4. For F-S classification, the sensitivity of 99%, the specificity of 99.5% and the accuracy of 99.3% are acquired, which manifest the remarkable classification capacity of the proposed approach. All of the three classifications have the recognition accuracies over 99%, which proves that the proposed method can classify ictal and interictal EEGs accurately. In addition, for the F-S classification problem, Table 5 gives the results of the proposed method with different kernel functions including the linear kernel, sigmoid kernel, and polynomial kernel. It can be seen that the method with Gaussian RBF achieves the best result, which indicates that the Gaussian RBF is more adaptive than the others for the classification between seizure and non-seizure epochs. Compared with the linear function, the Gaussian kernel function is more suitable for linearly inseparable data, and it has fewer parameters than the polynomial kernel function, which implies the Gaussian kernel function has a lower complexity.
4 Discussion
In this study, a novel automatic seizure detection method based on the kernel R-ProCRC is introduced, which creates a classification by calculating the maximum probability that the testing sample falls into each class. The choice of distinct characteristics and an appropriate classifier is significant for the conventional detection method. Nonetheless, the work of feature selection and extraction is complicated and it is not clear whether the features selected can effectively help the classification. Compared with the conventional method, the selection of features is no more necessary in this method, which is only needed to sparsely represent the testing samples through the training set and make a comparison of the residuals with respect to the two categories. The kernel R-ProCRC, based on a probability framework, can make full use of training samples to judge the category of the testing samples.
In general, the classification of the seizure and non-seizure EEG signals is complicated, because they are irregular and nonlinear in nature and contain many seizure-like activities throughout the entire recordings. To prepare for the consequent classification, the preprocessing is employed to process the raw EEG signals. The wavelet transform can decompose the EEG signal into sub-signals on the different frequency bands, which offers a wealth of time information and frequency information. Hence, it can sufficiently remove the high-frequency noise, which is conducive for the differential operator that is further applied to the signal. But some short seizures may also be filtered due to the wavelet filtering and then misclassified as a non-seizure. The differential operator can capture the abrupt change at the boundary of the seizure and non-seizure, and amplify it to make the contrast of high-frequency components and the low-frequency background more prominent. In addition, it is a linear operator and therefore suitable for the real-time system. From Fig. 5, it can be seen that the contrast of the onset activities and the background that comprises interictal EEGs are clearly heightened. This property is conducive to improving the detection accuracy of the proposed method.

The performance of differential operator for 10-min EEG signal from patient 4 in the Freiburg database. a The EEG signal before the different operator. b The EEG signal after the different operator. The signals between the two vertical dashed lines are ictal signals
In order to assess the performance of the proposed method comprehensively, two different databases are employed, which include the Bonn database and Freiburg database. Many previous papers on seizure detection also adopt these databases to evaluate their algorithms. Majumdar et al. [24] proposed a method that combined the differential operator with the windowed variance to identify the seizure onset in continuous EEG signals. There are 369 h of interictal data and 59 h of ictal data are applied to evaluate the performance. Their method obtains the sensitivity of 91.25% with 59 seizures, which only used 15 patients in the study. Raghunathan et al. [29] put forward a multistage detection method to identify the morphologies of seizures. Their method takes advantage of wavelet filtering and combines the variance and coastline as EEG features, which obtains a sensitivity of 87.5% from five patients with 24 seizures. In the work of Yuan et al. [17], the kernel CRC are employed, which is evaluated on 21 patients including 60 seizures and achieves the sensitivity of 96.03%. In this study, the kernel R-ProCRC exploits a probabilistic collaborative representation framework to jointly maximize the probability that a test EEG sample belongs to seizure or non-seizure, where the feature extraction is no longer required. Compared with the work of Majumdar et al. and Raghunathan et al., our method used more EEG data to assess the performance of detecting epileptic seizure in EEGs. In addition, our method yields a much higher sensitivity than their method. Table 6 gives a detailed comparison of the Freiburg database between the previous algorithms and this approach.
Table 7 shows a comparison between the proposed method and the other previous methods based on the Bonn database. First, for the classification of normal (Z) and ictal (S) EEGs, this approach obtained an average accuracy of 99.30% using the 10 fold cross-validation, which is the second best result listed in Table 7. Tzallas et al. [32] employed the artificial neural network for the classification and gained the best accuracy of 100%. The classification of interictal (F) and ictal (S) is the most significant among these three classifications, which is much closer to clinical applications. For F-S classification, the result obtained from this method is better than the others. The second best result is 98.63% in the work of Yuan et al. [18], in which the SRC is combined with the kernel trick for the EEG classification. Thirdly, for ZNF-S classification, the proposed method still yields the best accuracy of 99.20%, which has 1.45% of improvement compared with Guo’s work. In their work, they employed wavelet transform to process the raw EEG signals and applied line length feature to locate the seizure onset [36]. The competitive results suggest that the proposed method can become a potential approach for detecting the seizures in clinical application.
5 Conclusion
In this study, a novel method based on the kernel version of R-ProCRC is presented to detect seizure events in EEG signals. When a test EEG sample comes, the kernel ProCRC can effectively take full advantage of the training samples to represent it and deduce its label. Most previous work only evaluated their method on one EEG database, which cannot verify the generalization ability of the algorithm for different EEG data. In this study, our method is evaluated on the two different databases. The experimental results of the two databases show that the proposed method has a remarkable adaptability in different types of EEG signals. Additionally, the feature extraction is no longer required in this method, which simplifies the process of epilepsy detection.
References
Fisher RS, WVE B, Blume W, Elger C, Genton P, Lee P, Engel J (2005) Epileptic seizures and epilepsy: definitions proposed by the International League Against Epilepsy (ILAE) and the International Bureau for Epilepsy (IBE). Epilepsia 46(4):470–472. https://doi.org/10.1111/j.0013-9580.2005.66104.x
Behnam M, Pourghassem H (2017) Seizure-specific wavelet (Seizlet) design for epileptic seizure detection using CorrEntropy ellipse features based on seizure modulus maximas patterns. J Neurosci Methods:27684–27107
Zhang T, Chen W, Li M (2017) AR based quadratic feature extraction in the VMD domain for the automated seizure detection of EEG using random forest classifier. Biomed Signal Process:31550–31559
Acharya UR, Fujita H, Sudarshan VK, Bhat S, Koh JE (2015) Application of entropies for automated diagnosis of epilepsy using EEG signals: a review. Knowl-Based Syst:8885–8896
Gotman J (1982) Automatic recognition of epileptic seizures in the EEG. Electroencephalogr Clin Neurophysiol 54(5):530–540. https://doi.org/10.1016/0013-4694(82)90038-4
Aarabi A, Fazel-Rezai R, Aghakhani Y (2009) A fuzzy rule-based system for epileptic seizure detection in intracranial EEG. Clin Neurophysiol 120(9):1648–1657. https://doi.org/10.1016/j.clinph.2009.07.002
Orhan U, Hekim M, Ozer M (2011) EEG signals classification using the K-means clustering and a multilayer perceptron neural network model. Expert Syst Appl 38(10):13475–13481. https://doi.org/10.1016/j.eswa.2011.04.149
Acharya UR, Sree SV, Suri JS (2011) Automatic detection of epileptic EEG signals using higher order cumulant features. Int J Neural Syst 21(05):403–414. https://doi.org/10.1142/S0129065711002912
Srinivasan V, Eswaran C, Sriraam N (2007) Approximate entropy-based epileptic EEG detection using artificial neural networks. IEEE Trans Inf Technol Biomed 11(3):288–295. https://doi.org/10.1109/TITB.2006.884369
Übeyli ED (2010) Lyapunov exponents/probabilistic neural networks for analysis of EEG signals. Expert Syst Appl 37(2):985–992. https://doi.org/10.1016/j.eswa.2009.05.078
Yuan Q, Zhou W, Zhang L, Zhang F, Xu F, Leng Y, Wei D, Chen M (2017) Epileptic seizure detection based on imbalanced classification and wavelet packet transform. Seizure:5099–5108
Kıymık MK, Güler IN, Dizibüyük A, Akın M (2005) Comparison of STFT and wavelet transform methods in determining epileptic seizure activity in EEG signals for real-time application. Comput Biol Med 35(7):603–616. https://doi.org/10.1016/j.compbiomed.2004.05.001
Tzallas AT, Tsipouras MG, Fotiadis DI (2009) Epileptic seizure detection in EEGs using time–frequency analysis. IEEE Trans Inf Technol Biomed 13(5):703–710. https://doi.org/10.1109/TITB.2009.2017939
Subasi A (2007) EEG signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst Appl 32(4):1084–1093. https://doi.org/10.1016/j.eswa.2006.02.005
Wright J, Yang AY, Ganesh A, Sastry SS, Ma Y (2009) Robust face recognition via sparse representation. IEEE Trans Pattern Anal Mach Intell 31(2):210–227. https://doi.org/10.1109/TPAMI.2008.79
Zhang L, Yang M, Feng X (2011) Sparse representation or collaborative representation: which helps face recognition? In: IEEE Int Conf Computer Vision. p. 471–478
Yuan S, Zhou W, Yuan Q, Li X, Wu Q, Zhao X, Wang J (2015) Kernel collaborative representation-based automatic seizure detection in intracranial EEG. Int J Neural Syst 25(02):1550003. https://doi.org/10.1142/S0129065715500033
Yuan Q, Zhou W, Yuan S, Li X, Wang J, Jia G (2014) Epileptic EEG classification based on kernel sparse representation. Int J Neural Syst 24(04):1450015. https://doi.org/10.1142/S0129065714500154
Cai S, Zhang L, Zuo W, Feng X (2016) A probabilistic collaborative representation based approach for pattern classification. In: IEEE Int Conf on Computer Vision and Pattern Recognition. p. 2950–2959
Andrzejak RG, Lehnertz K, Mormann F, Rieke C, David P, Elger CE (2001) Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: dependence on recording region and brain state. Phys Rev E 64(6):061907. https://doi.org/10.1103/PhysRevE.64.061907
Maiwald T (2004) Comparison of three nonlinear seizure prediction methods by means of the seizure prediction characteristic. Physica D 194(3):357–368
Kalayci T, Ozdamar O (1995) Wavelet preprocessing for automated neural network detection of EEG spikes. IEEE Eng Med Biol Mag 14(2):160–166. https://doi.org/10.1109/51.376754
Khan Y, Gotman J (2003) Wavelet based automatic seizure detection in intracerebral electroencephalogram. Clin Neurophysiol 114(5):898–908. https://doi.org/10.1016/S1388-2457(03)00035-X
Majumdar KK, Vardhan P (2011) Automatic seizure detection in ECoG by differential operator and windowed variance. IEEE Trans Neural Syst Rehab Eng 19(4):356–365. https://doi.org/10.1109/TNSRE.2011.2157525
Majumdar K (2012) Differential operator in seizure detection. Comput Biol Med 42(1):70–74. https://doi.org/10.1016/j.compbiomed.2011.10.010
Liu Q (2016) Kernel local sparse representation based classifier. Neural Process Lett 43(1):85–95. https://doi.org/10.1007/s11063-014-9403-4
Yang S, Han Y, Zhang X (2012) A sparse kernel representation method for image classification. In: (IJCNN). p. 1–7, DOI: https://doi.org/10.1007/s00253-018-9238-4
Temko A, Thomas E, Marnane W, Lightbody G, Boylan G (2011) EEG-based neonatal seizure detection with support vector machines. Clin Neurophysiol 122(3):464–473. https://doi.org/10.1016/j.clinph.2010.06.034
Raghunathan S, Jaitli A, Irazoqui PP (2011) Multistage seizure detection techniques optimized for low-power hardware platforms. Epilepsy Behav:22S61–22S68. https://doi.org/10.1016/j.yebeh.2011.09.008
Nigam VP, Graupe D (2004) A neural-network-based detection of epilepsy. Neurol Res 26(1):55–60
Guo L, Rivero D, Seoane JA, Pazos A (2009) Classification of EEG signals using relative wavelet energy and artificial neural networks. In: Proceedings of the first ACM/SIGEVO Summit on Genetic and Evolutionary Computation: ACM. p. 177–184
Tzallas A, Karvelis P, Katsis C, Fotiadis D, Giannopoulos S, Konitsiotis S (2006) A method for classification of transient events in EEG recordings: application to epilepsy diagnosis. Meth Inf Med 45(6):610–621
Wang Y, Zhou W, Yuan Q, Li X, Meng Q, Zhao X, Wang J (2013) Comparison of ictal and interictal EEG signals using fractal features. Int J Neural Syst 23(06):1350028. https://doi.org/10.1142/S0129065713500287
Yuan Q, Zhou W, Li S, Cai D (2011) Epileptic EEG classification based on extreme learning machine and nonlinear features. Epilepsy Res 96(1):29–38
Ocak H (2009) Automatic detection of epileptic seizures in EEG using discrete wavelet transform and approximate entropy. Expert Syst Appl 36(2):2027–2036. https://doi.org/10.1016/j.eswa.2007.12.065
Guo L, Rivero D, Dorado J, Rabunal JR, Pazos A (2010) Automatic epileptic seizure detection in EEGs based on line length feature and artificial neural networks. J Neurosci Methods 191(1):101–109. https://doi.org/10.1016/j.jneumeth.2010.05.020
Funding
This work was jointly financially supported by the National Natural Science Foundation of China (No. 61501283, No. 61701279, No. 61701270 and No. 61401259), the Shandong Provincial Natural Science Foundation (No. ZR2015PF012 and No. ZR2017PF006), and the China Postdoctoral Science Foundation (No. 2015 M582129 and No. 2015 M582128).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yu, Z., Zhou, W., Zhang, F. et al. Automatic seizure detection based on kernel robust probabilistic collaborative representation. Med Biol Eng Comput 57, 205–219 (2019). https://doi.org/10.1007/s11517-018-1881-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-018-1881-5