
Abstract
A rodent behavior analysis system is presented, capable of automated tracking, pose estimation, and recognition of nine behaviors in freely moving animals. The system tracks three key points on the rodent body (nose, center of body, and base of tail) to estimate its pose and head rotation angle in real time. A support vector machine (SVM)-based model, including label optimization steps, is trained to classify on a frame-by-frame basis: resting, walking, bending, grooming, sniffing, rearing supported, rearing unsupported, micro-movements, and “other” behaviors. Compared to conventional red-green-blue (RGB) camera-based methods, the proposed system operates on 3D depth images provided by the Kinect infrared (IR) camera, enabling stable performance regardless of lighting conditions and animal color contrast with the background. This is particularly beneficial for monitoring nocturnal animals’ behavior. 3D features are designed to be extracted directly from the depth stream and combined with contour-based 2D features to further improve recognition accuracies. The system is validated on three freely behaving rats for 168 min in total. The behavior recognition model achieved a cross-validation accuracy of 86.8% on the rat used for training and accuracies of 82.1 and 83% on the other two “testing” rats. The automated head angle estimation aided by behavior recognition resulted in 0.76 correlation with human expert annotation.

Top view of a rat freely behaving in a standard homecage, captured by Kinect-v2 sensors. The depth image is used for constructing a 3D topography of the animal for pose estimation, behavior recognition, and head angle calculation. Results of the processed data are displayed on the user interface in various forms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
New and rapid developments in neuroscience, psychology, genetics, and pharmacology have led to growing demands for automated analysis of animal behavioral in scientific and preclinical research experiments, while maintain to surpassing the accuracy of expert human observer [1]. Key applications of such algorithms include research on addiction and drug abuse and a variety of medical interventions, such as development of new medications [2]. Being small, low cost, and easy to breed mammals, rodent species, such as rats and mice, have been widely used in experiments, further supported by the fact that their genome sequences are widely available [3, 4]. At present, most physical behavioral assessment is conducted by expert human annotations, making the process labor-intensive, tedious, and yet subjective. As a result, manual assessment of rodent behavior suffers from being time consuming, costly, low throughput (one animal at a time), and poorly reproducible.
Because of these issues, researchers conducting in vivo experiments on behaving animals are becoming increasingly interested in automatic behavior analysis systems, where advancements in computing power, computer vision, sensors, and machine learning techniques are well exploited, resulting in a flurry of research and developments on automated behavior analysis in both academic and industrial domains.
Shi et al. [5, 6] developed a video processing system to recognize rat behaviors, including grooming, rotating, and rearing and controlled a robotic rat to interact with real rats based on the recognition outcome. In reference [7], Jhuang et al. described a trainable computer vision system enabling the automated recognition of eight mouse behaviors from a side-view consumer grade camcorder, with an overall accuracy of 77.3%. Using the heavily annotated Caltech Resident-Intruder Mouse dataset (CRIM13), Burgos-Artizzu et al. [8] developed a behavior recognition method with novel trajectory features and spatiotemporal features, reaching a recognition rate of 61.2% on 13 categories. Dam et al. [9] presented an automated system for recognizing up to nine types of rat behavior, without requiring on-site training. This system was later integrated into EthoVision® XT by Noldus Information Technology. Besides Noldus, other companies including CleverSys Inc. and ViewPoint Behavior Technology also offer computer vision-based products on rodent behavior analysis, but those systems are quite costly and mainly focus on tracking in narrowly defined setups. Patel et al. [10] reported their open source toolbox for automating the scoring of several common behavior tasks used by the neuroscience community on mouse models. Brodkin et al. [11] created an instrument, named Behavioral Spectrometer, for measuring mouse behavior, aimed at identifying different mouse models and providing detailed description of its behavior. Besides a color CCD camera, it required other sensors, such as a row of photo-beams and an accelerometer under an instrumented floor, which increased the overall cost and complexity of the setup. Lorbach et al. [12] introduced the first, publicly available rat social interaction dataset, RatSI, and demonstrated that cross-dataset experiments provide more insight in the performance of classifiers. Ren et al. [13] leveraged the transferability of CNNs to build high accuracy models in classifying rodent behavior in spatial memory experiments. Crispim-Junior et al. [14] proposed a framework for behavior classification in laboratory rats based on a hybrid set of visual features (morphological and kinematic) which distribution over time is modeled using descriptive-statistic features.
For most of the abovementioned work, the use of optical cameras makes sufficient lighting a necessity. To overcome this limitation, considering the fact that most rodents are nocturnal animals and demonstrate more activity and natural behavior in dark environments, researchers have adopted infrared sensors. Among them, Microsoft Kinect®, which is equipped with both red-green-blue (RGB) and infrared (IR) depth cameras, is popular because of its high-resolution imaging and cost-effectiveness, resulting in its usage in a variety of computer vision applications [15,16,17,18].
Using Kinect, Lee et al. [19, 20] were able to track the rat position and orientation in real-time, inside a wirelessly powered homecage for long-term behavioral experiments. Ou-Yang et al. [21] introduced a locomotion measurement and pose reconstruction system based on depth images for locomotion analysis of rodents, immune to interference from the visible-light spectrum. But the reconstruction of shaded parts of the rat was omitted since the IR camera was still bounded by the rectilinearity of light (shining in straight line). To overcome this limitation, Matsumoto et al. [22, 23] combined images, captured by multiple depth cameras at different viewpoints, to reconstruct the 3D rat model and used a physics-based fitting algorithm to estimate the positions of rat body parts during both sexual behavior and novel object-recognition tests. Nakamura et al. [24] proposed a gait analysis system for mice from beneath an opaque infrared pass filter by tracking footprints and 3D paw-tip positions in the depth sensor coordinates. Xu et al. [25] proposed a unified paradigm based on Lie group theory for pose estimation, tracking, and action recognition of articulated objects and evaluated the algorithm in lab animals including mouse with depth image from a top-mount Primesense Carmine depth camera. The depth sensor enabled Rezaei et al. [26] to develop an automatic system for extracting respiration patterns in small rodents. Combining adaptive Gaussian mixture model (GMM) with principle component analysis (PCA), they also presented a tracking system for detecting caged vole’s location and pose over time [27].
Monteiro et al. [28] developed a depth map-based approach for recognition of behavior of singly housed mice, where decision trees were used to produce rules of identifying walking, resting, rearing, and micro-movement occurrences, with a limited level of accuracy. By combining videos from a depth sensor, a top view camera and a side view camera, Hong et al. [29] described an integrated hardware/software platform for automatically detecting and scoring innate social behaviors between mice in a homecage environment. Despite the high complexity of the system, only three behaviors (aggression/attack, mounting/mating, and social/close investigation) were considered, to achieve satisfactory classification accuracies.
In our previous work, using Kinect v1, we developed an image processing algorithm to provide an automated tracking and behavior recognition mechanism for freely moving animal experiments [30]. The system tracked the position of the center of the animal body and classified its behavior into five categories: standstill, walking, grooming, rearing, and rotating. We integrated this algorithm into the EnerCage-HC2 system, which is a smart wirelessly powered experimental arena for longitudinal experiments on freely behaving small animal subjects, and validated it in reference [31].
In this paper, we are presenting a significantly improved version of our rodent behavior recognition technology that is fully automated and runs not only faster to be in real-time but also more robust against changes in the environment lighting conditions, both of which are further supported by the Kinect v2 upgrades. The novel aspects of this paper include the following: (1) our system is based on Kinect depth imaging sensor (3D), which enables stable, fast, and accurate object tracking and contour extraction compared to the aforementioned RGB (2D) camera-based systems; (2) pose detection algorithm for extracting nose and tail base points from the rodent body contour; (3) enhanced feature extraction methods utilizing new 3D features; (4) increased number of recognized behaviors in the classification algorithm from five to nine behaviors; (5) clarifying feature analysis and SVM classifier training with newly designed label optimization steps to improve the overall recognition accuracy; and (6) a method for head angle estimation when the rat is not rearing. We have evaluated the new algorithm on three freely behaving rats and assessed the stability of the trained model from one animal on other animal subjects. Section 2 gives an overview of the automated behavior analysis system. Section 3 describes the image processing methods used for rodent position tracking and pose estimation. Section 4 describes the proposed behavior recognition model. Experimental results are presented in Sect. 5, followed by concluding remarks.
2 Methods
2.1 Data acquisition
Figure 1a shows the experimental setup used for in vivo data acquisition of the automated behavior analysis system. A Microsoft Kinect v2 was mounted at the height of 110 cm above the bottom of a standard rat homecage (46 × 24 × 20 cm3), using PVC pipes, and connected via USB 3.0 to a PC laptop with Intel i7 processor and 8 GB RAM, running at 2.4 GHz. The depth stream was captured at 512 × 424 pixels resolution and 30 frames/s (fps), and restored as 16 bit raw data. To prevent rats from jumping out of the cage, a custom-designed cover, made of transparent acrylic sheet, was added to the homecage, as shown in Fig. 1b, with many holes to allow for air circulation without interfering with the Kinect operation. Moreover, bedding material was spread evenly at the bottom of the homecage.

a Experimental setup for data collection with Kinect v2. The animal subjects (rats) were freely moving in a standard homecage as part of the EnerCage-HC2 system [32]. b A transparent acrylic cover prevents the rats from jumping out of the homecage. 1 × 1-cm2 holes are created in the sheet to allow for air circulation. Two distances between the holes, 0.1 and 2.5 cm, were tested and the later was selected for better transparency to IR sensors
Three 11-week-old male Sprague-Dawley rats, weighing 330–350 g, were used in this experiment, generating ~ 3 h (168 min) of simultaneous 2D/3D video recording (~ 300,000 frames). The experiment, which was conducted as part of the evaluation of the EnerCage-HC2 system, was approved by the Institutional Animal Care and Use Committees (IACUC) at Emory University and Georgia Tech. During the experiment, a wirelessly powered headstage was mounted on each rat to apply electrical stimulation via a pair of monopolar stainless steel electrodes, implanted in the primary motor cortex of the rat brain (GPi). A detailed description of the EnerCage-HC2 can be found in reference [32]. The stimulating headstage was included in this experiment to change the animal subject’s behavior and test the effectiveness of our automated Kinect-based algorithm in quantifying the changes in rats’ behavior due to electrical stimulation.
2.2 System overview
Figure 2 shows the simplified block diagram of the automated behavior analysis system for freely moving rodents. The top view of the animal subject freely behaving in a standard homecage is captured by Kinect in both color (2D) and depth (3D) from a 1920 × 1080 pixel RGB camera and the 512 × 424 pixel IR sensor, respectively. The acquired data is fed into a real-time image processing algorithm that is implemented in C++ environment. The 3D depth image is used for pose estimation, behavior recognition, and head angle calculation. For pose detection, first the rodent contour is extracted, and the animal pose is determined in terms of multi-point tracking of the nose, center of body, and base of the tail. In behavior recognition, we use a supervised learning model based on SVM to classify the rodent’s behaviors. The 2D/3D feature extraction technique uses the results of pose estimation. The output of the SVM classifier is further improved with label optimization steps before generating the final behavior recognition results, using which the algorithm estimates the head angle for non-rearing frames. The processing results are displayed on a user interface (UI) in various forms, including an ethogram, and stored in the PC along with the raw data.

Block diagram of the automated behavior recognition system for rodents, based on a Kinect v2 3D imaging system
2.3 Pose estimation
2.3.1 Rat body contour
In conventional RGB camera-based systems, the behavior analysis of rodents starts with extracting the animal shape for pose estimation or feature calculation, and their performance is influenced by the lighting condition during recording and the contrast level between animals and their background. The current system, however, uses depth imaging to enable stable, fast, and accurate body contour extraction from the 16-bit depth value per pixel, which represents the distance (in mm) of the closest object within that pixel from the Kinect aperture. The flowchart for this process is illustrated in Fig. 3, including the extracted results in each step. While the algorithm directly utilizes the 16-bit depth image, we have converted the depth image to 8-bit grayscale only for visualization in the UI and in Fig. 3, using the following relationship, such that the pixels closer to the Kinect appear brighter,
where g(i,j) and d(i,j) are the grayscale and depth values of the pixel at coordinates (i,j), respectively, and dupper = 1100 mm and dlower = 850 mm are the upper and lower boundaries of the range of distances, where the rat body might appear.

Flowchart of the image processing algorithm used for acquiring the shape of the rat body (body contour). Sixteen-bit depth images are converted to 8-bit grayscale for visualization. The extracted contour is then used for calculating the three key points: nose, body center, and tail base. The algorithm for calculating the neck point and head angle θh is explained in Sect. 2.4.4
Background subtraction
This step extracts the foreground mask, ID-R, by performing a direct subtraction between the current depth image, ID, and a background reference image, IREF. Because both Kinect and the experimental arena are fixed during the experiment, and changes in illumination do not affect the depth frames, we can assume that the background depth image is nearly unchanged during recording and thus calculate IREF by averaging a certain number of depth images, e.g., 100 frames, when the animal subject is not yet placed in the arena. Using depth images eliminates the need for high color contrast between the animal and its surrounding in 2D image-based methods.
Noise filtering
This step tries to smooth and reduce the “salt and pepper” type noise as well as structural noise introduced by the Kinect sensor. Here, we have chosen median filter with 5 × 5 kernel size over Gaussian and bilateral filters, considering computational efficiency and the filtering effects.
ROI extraction
The region of interest (ROI) is extracted using the boundary information of experimental arena, which was a standard homecage in this study. Coordinates of the arena can be either manually identified by the user or detected automatically using the RGB image before the experiment. In the latter case, small square-shaped markers with two predefined colors were placed on two opposite corners of the arena, and template matching method was used to locate them. The ROI is then mapped onto the depth space using the coordinate mapper, provided in the Kinect SDK.
Thresholding
A threshold is applied to separate the potential rat body area from the bottom of the arena and convert the result to a binary image, IBINARY. Considering small changes in the height of the bedding material, we chose 10 mm to be the threshold that differentiates the target from the background.
Contour finding and removal
Contours are extracted from IBINARY to identify the potential rat body contour. False targets are removed based on contour size. Morphological operations, including three iterations of erosion, followed by three iterations of dilation, both using a 3 × 3 rectangular structuring element, are performed to smooth the body contour as well as remove the animal tail [33]. After this step, the largest contour from the remaining ones (usually only one contour remains) is considered to be the rat body contour.
2.3.2 Key points
After obtaining the rat body contour, the coordinates of three key points, nose, body center, and base of tail, are calculated to identify the rat posture. We calculate centroid of the rat body contour to be its body center point (xc, yc),
where moments of the contour points, Mij, are calculated by points with pixel intensity I(x,y) = 1 in IBINARY,
This center point is also used to track the rat position in real-time.
To extract the nose and tail base points, the geometric characteristics of rat body contour are considered, where (1) the nose point usually lies at a vertex of the head triangle, (2) the tail base point lies at the other side of body curve from the nose, and (3) the geometric center of the body lies closer to the tail point than to the nose point. Thus, we find the nose point, (xn, yn), as the point in contour that has the longest distance from the centroid,
Instead of making the point in contour that has the shortest distance from the centroid or the longest distance from the nose to be the tail base point, we propose a new formula that takes into consideration both the tail-center and tail-nose distances. In this case, tail base point, (xt, yt), is a point in the contour that has the largest sum of distances to the center point and to the nose point,
2.4 Behavior recognition
We used supervised learning techniques to perform automatic rat behavior recognition on 3D and 2D features extracted from the depth images. More specifically, we trained a support vector machine (SVM)-based multi-class classifier using datasets with manual labels as the ground truth, to learn an inferred function that best categorizes new examples. Since Kinect captures images at 30 fps, to make the system operate in real-time on a PC with average specifications and considering the speed of rat physical movements, both pose estimation (rodent contour extraction and multi-point tracking) and SVM-based behavior recognition are computed and deduced once in every three frames, resulting in a processing rate of 10 fps. An alternative method is to use the average of every three frames to reduce noise in the following computations.
2.4.1 Feature extraction
In rat behavior recognition, the classifier performance is highly affected by feature engineering and the quality of extracted features [34]. Therefore, we carefully designed the features to best represent the rat body contour as follows:
-
Body area, S, is computed simply by counting all the pixels inside the animal body contour.
-
Body radius, R, is the longest distance between rodent body center and body contour, which is often the distance between the nose and body center points.
-
Circularity, E, is the square proportion relationship between S and R, i.e., S/R2.
-
Ellipticity, ρ, is calculated after fitting an ellipse to the rat body contour, as the ratio between the long and short axes of the ellipse.
-
Body angle, θb, is calculated with respect to the triangle formed by the three key points, as shown in Fig. 3.
-
Speed of the three key points: nose speed vn, body center speed vc, and tail base speed vt, are denoted by the distance these points travel from the previous frame.
These eight features are defined in 2D, because they are mainly extracted from the processed binary image, IBINARY with respect to the x-y plane of the experimental arena. However, IBINARY itself is generated from the 3D depth image. Since the subject image frames also form a time sequences, we further extend the 2D feature set to include the changes in features 1~5 compared to the previous frame to consider the temporal info as well. Hence, a total of 13 types of 2D features are calculated.
Depth image not only indicates the shape of the animal for calculating contour-based features that are also used in conventional systems, but also provides 3D features that directly use of the depth/height information in the z-axis:
-
Maximum height, Hmax, is obtained by finding the point within the animal body contour that has the highest height.
-
Body volume, V, of the animal body, found by integrating the height over the 2D body contour.
-
Average height, Haver, of body points can then be calculated by dividing the body volume with body area, i.e., V/S.
Similar to 2D features, the temporal changes of these features in consecutive frames are also calculated, yielding a total of six 3D features. Besides being used as input vectors of the behavior recognition classifier, some of these extracted features are meaningful by themselves and can be plotted over time for researchers to describe the animal posture or various activities.
2.4.2 Behavior type
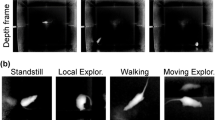
To train the classifier, the types of rodent behaviors must be defined clearly to generate ground truth labels for each frame. After reviewing the wide range of rodent behavior types [6,7,8,9, 28, 35], discussing with animal behavior experts, and considering the constraints of the homecage experimental arena that we used to conduct our in vivo study, we defined the following nine behaviors of interest.
-
(1)
Resting/Standstill: the subject rests in one place without moving its body, limbs, or head.
-
(2)
Walking: subject body clearly moves from one place to another, particularly moving forward, where the nose is pointing.
-
(3)
Bending/Rotating: subject body bends or turns away from the spine with an obvious angle, θx > 30°.
-
(4)
Grooming: subject body cuddles and its head curls.
-
(5)
Rearing Unsupported: subject rises up on its hind limbs, in an upright posture with its forelimbs off the ground.
-
(6)
Rearing Supported: subject stands on hind limbs with its paws leaning against a wall or vertical object.
-
(7)
Sniffing/Surveying: subject moves its head for exploring and foraging the environment, while not rearing. This includes sniffing air, the cage walls, or any other objects.
-
(8)
Micro-movements: the subject stays at a certain place, while making small movements in certain body parts. To make the human labeling more specific, we only identify the following behaviors to be in this category: digging, chewing, nibbling.
-
(9)
Other: any behavior type that is not described above, such as twitching or body shaking during stimulation.
These are the behaviors that are currently labeled manually in most neurobehavioral research labs to indicate the physical, cognitive, psychosocial, and emotional state of the animal subjects. Since the homecage used in our study was not equipped with a feeder or water bottle, over the course of the experiment, behaviors such as eating or drinking are excluded from the current algorithm. However, these two behaviors are easily recognizable based on the animal location and orientation near the food and water dispensers in conjunction with the aforementioned features, determined by including the feeder or water bottle into the background reference image.
2.4.3 Classification model
The SVM constructs a hyperplane or set of hyperplanes in a high- or infinite-dimensional space, which can be used for optimally classifying the input feature vectors into different categories [36]. Here, we use a nonlinear classifier with a radial basis function (RBF) kernel,
which is implemented using LIBSVM [37]. Section 3.2.3 discusses how the RBF kernel parameter, γ, and the soft margin parameter, C, are chosen from the training dataset.
To improve the classification performance, label optimization steps based on spatial and temporal optimization are added. We found that the SVM classifier often confuses the “rearing unsupported” with “rearing supported.” To reduce this error, the position-based optimization makes use of the tracking results by checking the animal position for the frames that are classified as “rearing supported” to estimate the animal distance from the homecage walls. If the distance is more than L, the label is changed to “rearing unsupported” based on the fact that the subject hands are too short to lean against the wall at that distance. The temporal optimization then processes the outputs through a majority filter with window length, W, making the assumption that the animal behavior remains the same within a short period of time, e.g., 0.3~0.5 s. Both L and W are chosen empirically, depending on the animal species. The output after those steps indicates the final recognized animal behavior.
2.4.4 Head angle estimation
Head rotation angle is used for quantifying certain rodent behavior, particularly during neuromodulation [38, 39]. For instance, we used this angle (manually) in evaluation of the EnerCage-HC2 system, which was used to wirelessly stimulate the globus pallidus (GPi) region of the rat brain to induce head turning behavior [39]. Here, we utilize the pose estimation results from Sect. 2.3, together with behavior recognition results, to estimate the rodent head angle, θh, shown in Fig. 3 right inset. Considering that the line connecting the body center and tail base points represents the orientation of the rodent body, this line is extended by a fraction of the tail-center distance to identify a new point, which is indicating the neck position. Hence, coordinates of the neck point (xneck, yneck) can be estimated from
where a is the constant that can be either empirically defined or derived from to the subject body contour features.
Once the neck point is identified, the neck angle, θneck, is calculated as the angle between the tail-center line and the neck-nose line, as shown in Fig. 3, which also shows that θh is the complementary angle of θneck. Therefore, θh, can be found from
where d denotes the distance between corresponding key points. In practice, we swept a from 0 to 2 and compared the results of this simple algorithm with manual annotations of recorded images to choose a value with the lowest error.
When the rodent rears on its hind limbs, either supported or unsupported, its body no longer lies in the x-y plane, resulting in the contour derived from the top view to be insufficient for estimating the head angle. Even human observers find it difficult to determine θh in these body postures. Therefore, this algorithm is only valid for non-rearing frames, which is applied in an automated fashion when the classified behavior recognition results are available to identify the non-rearing frames.
3 Experimental results
3.1 Pose estimation
3.1.1 Multi-point extraction errors
The extraction accuracy is analyzed for the three key points by comparing the automated results with manually labeled ones. For this purpose, a total of 4000 frames of depth images were annotated by two human observers to locate the center, nose, and tail base points. For each frame, we used the average coordinates of the two observers as the ground truth.
The extraction errors were first calculated in pixel and then converted to centimeters, given the knowledge of Kinect setup and homecage geometry. The error in locating the center point was the lowest (mean ± SD = 1.3 ± 0.9 cm), followed by that of tail base points (1.7 ± 1.6 cm) and then nose points (1.9 ± 1.9 cm), which make sense in terms of the speed of movement and ease of localization. This may be partly due to the blurring effect of the morphological operations, which attenuate the sharpness of nose point. Also, the headstage might have contributed to the error of the nose point in certain head orientations. Considering dimensions of the homecage and rat body, this level of accuracy in automatically locating the key points is sufficient in determining the animal subject’s position and posture.
3.1.2 Position tracking
The position tracking results are presented in two ways: animal trajectories and heat maps. Figure 4a, b compares rat #2’s trajectories derived from depth videos, before (normal condition) and during stimulation, over 20 min. When plotting these trajectories, the position was updated every 0.5 s with respect to the homecage boundaries. Clearly, rat #2 was more active under stimulation, creating a denser trajectory, and spent more time in the center of the homecage. The distance that the animal subject travels during a certain period, as well as average speed are calculated from these trajectories. Table 1 shows the summary of these results for the entire datasets collected on all three rats. It can be seen that the distance traveled by rat #2 has increased from 87.6 to 206.8 m, despite a shorter duration, corresponding to a considerable increase in the average speed of movement from 4.71 to 12.6 m/min. Similar increments in distance traveled and average speed were observed in the other two rats.

Rat #2 trajectories recorded by automated tracking within the standard homecage over 20 min: a normal condition, b under stimulation. Lower part: center point tracking results for rat #2 as heat maps, c normal condition, d under stimulation. The homecage was divided into a 23 × 12 grid of 2 × 2 cm2 bins to count the number of frames for each bin, inside which the center point appeared. Counts were normalized and then smoothed by 5-fold bicubic interpolation for smoother display
Statistical heat maps, plotted in Fig. 4c, d, represent the rat #2’s position information during normal and stimulated conditions, respectively, in a way that is clearer than the raw trajectories over the same periods in Fig. 4a, b. It can be seen that in normal condition, rat #2 preferred to stay within a specific part of the homecage, while during stimulation, several hot spots exist near the center of the homecage. With a combination of subject trajectory, heat map, and numerical features in Table 1, the proposed system offers a comprehensive view of the animal subjects’ activities just from the position information.
3.2 Behavior recognition
3.2.1 Data preparation
The videos were annotated by a trained researcher as the ground truth for rat behaviors. The depth video from rat #2 was used for training and cross validation, while data from the other rats was used as testing set to judge the feasibility of subject-independent classification by using the same trained model among different rats from the same family (similar shapes and sizes). For comparison, we trained the classifier in three ways:
-
(1)
Using 2D features only: following reference [30], with contour-based features and increased number of behaviors.
-
(2)
Using 3D features only.
-
(3)
Using all the available features.
3.2.2 Feature analysis
To analyze the effectiveness of our extracted 19 features, PCA was applied to the features resulted from the training set, which explained variances are shown in Fig. 5. We treated the 2D, 3D, and combined features as separate groups. For the combined features, the first 10 principle components contribute to 91% of the total explained variance. The first three PCA dimensions of the combined feature group are plotted in Fig. 6 to show the interaction between main dimensions, which span most of the feature space.

Variance accounted for by the each principal component for each group of features. Bars show the explained variance by each component, and the line shows the cumulative variance accounted for. For 2D and combined features, the first 10 principle components are plotted

The first three principal components of the combined features. The behavior type numbers in the color bar legend are consistent with the numbers assigned to behaviors in Sect. 2.4.2
3.2.3 Training the support vector classifier
The RBF kernel used in nonlinear SVM has a hyper-parameter, γ, which controls how much influence a single support vector will have on deciding the class of the data points [37]. Figure 7a shows the validation curves vs. γ values on the training set. If γ is chosen too small, under-fitting is observed, as both the training and cross-validation scores stay low. As γ increases, at some point, high values in both scores are obtained, indicating good candidates for γ value. Even though larger γ further increased the training scores, it made the classifier over-fit and caused a decrease in validation scores. Figure 7 roughly suggests that good γ values should lie within 10−2~10−1.

a Training and cross-validation scores of the SVM for different values of the kernel parameter, γ. b Learning curves of SVM using different feature settings. Stratified 6-fold cross-validation was used
The other RBF kernel hyper-parameter, C, controls the cost of misclassification on the training data. To find the best combination, grid search was performed on exponentially growing sequences of C and γ (C = 2−3, 2−1, …, 27, γ = 2−8, 2−6, …, 22). To identify the best region on the grid, we conducted a fine search within the ranges and picked the parameter pairs with best cross-validation accuracy, as listed in Table 2.
3.2.4 Recognition results
Using parameter pairs in Table 2, we trained the SVM classifier using all depth frames from rat #2. Figure 7b shows the learning curves during the training process. As the number of training examples increased, the gap between the training and validation scores narrowed, at the end, both scores became stable, indicating possible convergence.
In label optimization steps, we empirically picked L = 6 and W = 5 to optimize the outputs of the trained SVM and generate the final classification results. This trained model was used for classifying new data from rats #1 and #3. Table 3 shows the accuracy scores of our proposed model. Considerable improvements in accuracies were achieved by adding 3D features to the 2D features. Those results indicate the effectiveness of the trained model in classifying new data from different rats of the same family. The label optimization steps generally improved the SVM results by ~ 2%.
Table 4 shows the main classification metrics: precision, recall, and F1-score [40], for each type of behavior in the trained model, using combined features and label optimization. For the training data from rat #2, both precision and recall scores are good. For rat #1, the three highest recalls were of behaviors: “rearing supported” (RS), “resting,” and “rearing unsupported” (RU), while for rat #3, behavior types “rearing supported,” “bending,” and “rearing unsupported” had the three highest recalls. The high accuracies in “rearing” frames can be explained by the use of 3D features aided by the position-based optimization, as the main difference between RS and RU lies in the rat’s position. Low recall rates for “grooming” might be the result of the fact that the duration of “grooming” was quite short in the training video, resulting in an imbalanced class distribution.
Our trained model behaved slightly better on depth data of rat #3 than that of rat #1. To further analyze the classification output, the normalized confusion matrix on rat #3 dataset is shown in Fig. 8. Main errors include misclassifying “grooming” as either “bending” (0.324) or “resting” (0.168), and misclassifying “other” as either “rearing supported” (0.287) or “micro-movements” (0.193). Moreover, “walking” and “sniffing” are sometimes mistaken as “micro-movements” (0.144 and 0.191, respectively) by the classifier.

Normalized confusion matrix of behavior classification results for rat #3. Rows denote truth labels and columns denote predicted labels (RU: rearing unsupported, RS: rearing supported)
Ethograms are widely used in rodent behavior analysis to show the sequence of animal behavior over time. Figures 9a, b compares the manual and automatically generated ethograms of rat #3 over 15 min under normal and stimulation conditions, respectively. The total corresponding time intervals for each behavior are also registered on the right columns, in seconds. Comparing the two ethograms, it is clear that the rat was more active under stimulation, spending significantly less time on “resting” and “micro-movements” and more time on the other behaviors. Moreover, the labels generated by the system are in strong agreement with the manual labels and clearly capable of showing the differences between the two conditions.

Ethograms of ground truth and automatic behavior recognition over 15 min of testing video of rat #3. a Normal condition, b under stimulation. The sum of time intervals for each behavior is also listed on the right columns in seconds (red: manual, blue: algorithm)
3.2.5 Estimation accuracy of head rotation angle
To assess the accuracy of the head orientation estimation algorithm, we used the pose estimation data in Sect. 3.1.1 and compared with human annotation of the neck point. For each frame, the annotated coordinates of nose, tail base, and neck points are used to calculate the ground truth for the head angle. We tested different values of a (0.1, 0.2, 0.3, …, 2.0) and found a = 0.6 to yield the best correlation. In this case, the difference between all frames used is 15.0° ± 14.5° (mean ± SD), with a correlation of 0.48. After excluding the rearing frames (RS and RU), provided by the behavior recognition algorithm, the errors were reduced to 10.8° ± 9.9°, and the correlation increased to 0.76, suggesting a considerably more reliable output.
Figure 10 shows a sample head angle estimation output from one of the rat #1 video streams, where the green line indicates the rearing behaviors. When the rat is not rearing, the head angle curve from the algorithm shows a good correlation with the manual curve.

Comparison between manual annotation and algorithm results of head angle estimation from rat #1 video clip
4 Discussion
The in vivo study within the EnerCage-HC2 system showed the ability of our Kinect-based automated rodent behavior analysis system in tracking, multi-point pose estimation, including head angle, and recognition of up to nine types of behaviors. Adding the newly designed 3D features increased the overall recognition accuracy to a competitive level (82~83%), as shown in Table 5, which benchmarks the performance of the proposed system against others reported in the literature to show its effectiveness. Considering the influence of different setups in the recorded datasets, species, behavior types of interest, and subjective human annotations, it is not easy to have a fair comparison among recognition accuracies. Our system has the highest overall accuracy compared with those that classify 5~13 types of behavior. The only two systems that have better accuracies classify much smaller types of behaviors (3 vs. 9). Moreover, only this work includes the ability to estimate the head angle, using an algorithm based on the key recognized points on the animal body, further aided by behavior recognition results.
A key advantage of using IR depth stream from the Kinect is that the system would be independent of the ambient lighting to a high extent, with consistent image quality under both bright and dark conditions. This is especially helpful for experiments involving nocturnal species, like rats and mice. Requiring only a single Kinect sensor with simple mounting (see Fig. 1), our system is low-cost and easy to setup. Yet, it is quite effective and can facilitate both fundamental and preclinical research on freely behaving animal subjects. While our proposed system has been validated on rats, by adjusting the operating distance between Kinect and the arena, it can be trained and used for other rodents with similar body shapes, such as mice, voles, and guinea pigs.
Our system also has some limitations. For example, the trained model has low accuracy in “grooming” and “other” behaviors. Adding other pieces of info, such as features extracted from the RGB stream, might be helpful. The animal behaviors are considered as time sequences, while the SVM-based classification model mainly operates on a frame-by-frame basis. Although short-term temporal information was integrated in the feature sets in terms of inter-frame differences, and the label optimization steps did improve the recognition performance, there is room for further enhancement by integrating graphical models, such as Hidden Markov Model (HMM), in this system for time series analysis. When operating in bright condition, we also plan to combine the RGB stream to reduce the error in pose estimation. For more accurate behavioral analysis, we also have plans for tracking more key points on the animal, such as the four limbs.
5 Conclusions
A Kinect-based system that integrates both pose estimation and SVM-based classification to recognize in real-time freely moving rodents’ behavior has been presented. Three key points of the rodent body, center, nose, and tail base, are identified, marked in the depth image, and combined with other features for pose/behavior analysis. The behavior recognition module uses both 2D and 3D features that are directly extracted from the IR depth image and is trained to classify nine different behaviors on a frame-by-frame basis. We further extended the pose estimation to reliably calculate the head rotation angle, aided by behavior recognition results. The use of depth image enables the system to produce consistent outputs regardless of the ambient lighting condition. The functionality of the system was validated in vivo with data collected from three freely behaving rats, while receiving wireless neural stimulation in the primary motor cortex within the EnerCage-HC2 system.
References
Tecott LH, Nestler EJ (2004) Neurobehavioral assessment in the information age. Nat Neurosci 7:462–466
van Meer PJK, Graham ML, Schuurman H (2015) The safety, efficacy and regulatory triangle in drug development: impact for animal models and the use of animals. Eur J Pharmacol 759:3–13
Baker M (2011) Animal models: inside the minds of mice and men. Nature 475:123–128
Rat Genome Sequencing Project Consortium (2004) Genome sequence of the Brown Norway rat yields insights into mammalian evolution. Nature 428:493–521
Shi Q, Miyagishima S, Fumino S et al (2010) Development of a cognition system for analyzing rat’s behaviors. In: IEEE Int Conf Robotics and Biomimetics (ROBIO), pp 1399–1401
Shi Q, Ishii H, Konno S et al (2012) Image processing and behavior planning for robot-rat interaction. In: IEEE RAS & EMBS Int. Conf. Biomedical Robotics and Biomechatronics (BioRob), pp 967–973
Jhuang H, Garrote E, Yu X, Khilnani V, Poggio T, Steele AD, Serre T (2010) Automated home-cage behavioural phenotyping of mice. Nat Commun 1(68):1–9
Burgos-Artizzu XP, Dollár P, Lin D et al (2012) Social behavior recognition in continuous videos. In: IEEE Conf. Computer vision and pattern recognition (CVPR 2012), pp 1322–1329
van Dam EA, van der Harst JE, ter Braak CJF et al (2013) An automated system for the recognition of various specific rat behaviours. J Neurosci Methods 218(2):214–224
Patel TP, Gullotti DM, Hernandez P, O'Brien WT, Capehart BP, Morrison B, Bass C, Eberwine JE, Abel T, Meaney DF (2014) An open-source toolbox for automated phenotyping of mice in behavioral tasks. Front Behav Neurosci 8:349
Brodkin J, Frank D, Grippo R, Hausfater M, Gulinello M, Achterholt N, Gutzen C (2014) Validation and implementation of a novel high-throughput behavioral phenotyping instrument for mice. J Neurosci Methods 224:48–57
Lorbach M, Kyriakou EI, Poppe R et al (2017) Learning to recognize rat social behavior: Novel dataset and cross-dataset application. J Neurosci Methods. in press, available online
Ren Z, Noronha A, Ciernia AV et al (2017) Who moved my cheese? Automatic annotation of rodent behaviors with convolutional neural networks. In: IEEE Winter Conf. Applications computer vision (WACV), pp 1277–1286
Crispim-Junior CF, de Azevedo FM, Marino-Neto J (2017) What is my rat doing? Behavior understanding of laboratory animals. Pattern Recogn Lett 94:134–143
Han J, Shao L, Xu D, Shotton J (2013) Enhanced computer vision with Microsoft Kinect sensor: a review. IEEE Trans Cybern 43(5):1318–1334
Hu M, Chen C, Cheng W et al (2015) Real-time human movement retrieval and assessment with Kinect sensor. IEEE Trans Cybern 45(4):742–753
Whitmire E, Latif T, Bozkurt A (2013) Kinect-based system for automated control of terrestrial insect biobots. In: Int. Conf. IEEE EMBC, pp 1470–1473
Wiltschko AB, Johnson MJ, Iurilli G, Peterson RE, Katon JM, Pashkovski SL, Abraira VE, Adams RP, Datta SR (2015) Mapping sub-second structure in mouse behavior. Neuron 88(6):1121–1135
Lee B, Kiani M, Ghovanloo M (2014) A smart homecage system with 3D tracking for long-term behavioral experiments. In: Int. Conf. IEEE EMBC, pp 2016-2019
Lee B, Kiani M, Ghovanloo M (2015) A smart wirelessly powered homecage for long-term high-throughput behavioral experiments. IEEE Sensors J 14(9):4905–4916
Ou-Yang TH, Tsai ML, Yen CT, Lin TT (2011) An infrared range camera-based approach for three-dimensional locomotion tracking and pose reconstruction in a rodent. J Neurosci Methods 201(1):116–123
Matsumoto J, Urakawa S, Takamura Y, Malcher-Lopes R, Hori E, Tomaz C, Ono T, Nishijo H (2013) A 3D-video-based computerized analysis of social and sexual interactions in rats. PLoS One 8(10):e78460
Matsumoto J, Nishimaru H, Ono T, Nishijo H (2017) 3D-video-based computerized behavioral analysis for in vivo neuropharmacology and neurophysiology in rodents. In: Philippu A (ed) In Vivo Neuropharmacology and Neurophysiology. Neuromethods, vol 121. Humana Press, New York
Nakamura A, Funaya H, Uezono N, Nakashima K, Ishida Y, Suzuki T, Wakana S, Shibata T (2015) Low-cost three-dimensional gait analysis system for mice with an infrared depth sensor. Neurosci Res 100:55–62
Xu C, Govindarajan LN, Zhang Y, Cheng L (2017) Lie-X: depth image based articulated object pose estimation, tracking, and action recognition on lie groups. Int J Comput Vis (IJCV) 123(3):454–478
Rezaei B, Lowe J, Yee JR et al (2016) Non-contact automatic respiration monitoring in restrained rodents. In: Int. Conf. IEEE EMBC, pp 4946–4950
Rezaei B, Huang X, Yee JR, Ostadabbas S (2017) Long-term non-contact tracking of caged rodents. In: 42nd IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP’17), pp 1952–1956
Monteiro JP, Oliveira HP, Aguirar P, Cardoso JS (2014) A depth-map approach for automatic mice behavior recognition. In: IEEE Int. Conf. Image Processing (ICIP), pp 2261–2265
Hong W, Kennedy A, Burgos-Artizzu XP, Zelikowsky M, Navonne SG, Perona P, Anderson DJ (2015) Automated measurement of mouse social behaviors using depth sensing, video tracking, and machine learning. PNAS 112(38):E5351–E5360
Wang Z, Mirbozorgi SA, Ghovanloo M (2015) Towards a Kinect-based behavior recognition and analysis system for small animals. In: IEEE biomed. Circ. Sys. Conf. (BioCAS), pp 683–686
Jia Y, Wang Z, Canales D et al (2016) A wirelessly-powered homecage with animal behavior analysis and closed-loop power control. In: Int Conf IEEE EMBC, pp 6323–6326
Jia Y, Mirbozorgi SA, Wang Z, Ghovanloo M (2017) Position and orientation insensitive wireless power transmission for EnerCage-Homecage system. IEEE Trans Biomed Eng 64(10):2439–2449
Gonzalez RC, Woods RE (2008) Digital image processing, 3rd edn. Prentice Hall, Upper Saddle River
Lorbach M, Poppe R, van Dam EA et al (2015) Automated recognition of social behavior in rats: the role of feature quality. In: Int. Conf. Image analysis processing (ICIAP 2015), pp 565–574
Fuzesi T, Daviu N, Cusulin JIW et al (2016) Hypothalamic CRH neurons orchestrate complex behaviours after stress. Nat Commun 7:1–13
Hsu CW, Lin CJ (2002) A comparison of methods for multiclass support vector machines. IEEE Trans Neural Netw 13(2):415–425
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2(2):1–27
Kelland MD, Asdourian D, Kelland DZ (1988) Inhibition and excitation of neck and shoulder muscles during unilateral electrical stimulation of the rat neostriatum. Behav Brain Res 30:1–13
Chen L, Chan SCY, Yung WH (2002) Rotational behavior and electrophysiological effects induced by GABAB receptor activation in rat globus pallidus. Neuroscience 144(2):417–425
Goutte C, Gaussier E (2005) A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In: 27th European Conf. Advances inform. Retrieval research, pp 345–359
Acknowledgements
This work was supported in part by the National Institutes of Health award 1R21EB018561 and the National Science Foundation under award ECCS-1407880 and ECCS-1408318. The authors would like to thank Prof. Rainnie and members of his lab at the Emory University Department of Psychiatry for their assistance in conducting the in vivo experiments.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The experiment, which was conducted as part of the evaluation of the EnerCage-HC2 system, was approved by the Institutional Animal Care and Use Committees (IACUC) at Emory University and Georgia Tech.
All procedures performed in studies involving animals were in accordance with the ethical standards of the institution or practice at which the studies were conducted.
Rights and permissions
About this article

Cite this article
Wang, Z., Mirbozorgi, S.A. & Ghovanloo, M. An automated behavior analysis system for freely moving rodents using depth image. Med Biol Eng Comput 56, 1807–1821 (2018). https://doi.org/10.1007/s11517-018-1816-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-018-1816-1