
Abstract
We sought to apply social disorganization/social capital theory to the prediction of larceny victimization among community-dwelling residents. Based on social disorganization theory, we empirically derived an index of “social distance” by calculating averaged differences in sociodemographic characteristics (social class, stage of life course, size of hometown of origin) between residents. Our study was based on a postal questionnaire mailed to 1,000 residents of Arakawa Ward, Tokyo, Japan. Based on social capital theory, we also tested if neighborhood-level social ties could buffer the association between social distance and larceny victimization. Using multilevel analyses, we found that higher neighborhood-level social distance was associated with increased larceny victimization, independently of the respondents’ own background sociodemographic characteristics. Additionally, area-level supportive networks buffered the adverse effect of social distance on larceny victimization. By contrast, we also found that network size magnified the probability of victimization in neighborhoods characterized by large social distances between residents.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Shaw and McKay’s (1942) social disorganization theory remains central to the field of criminology, with recent theoretical extensions such as Bursik and Grasmick’s (1995) systemic model and Sampson et al. (1997) theory of collective efficacy. Social disorganization theory was originally developed to explain variations in the crime rate among neighborhoods in US cities. The theory posits that, in neighborhoods characterized by marked heterogeneity of residents’ characteristics (e.g., social class, race/ethnicity), common values are harder to realize, and interactions among residents as well as effective social control become more difficult. Such neighborhoods are also posited to suffer from higher crime rates. In previous American studies, it is suggested that racial/ethnic diversity in particular is an important factor driving social disorganization (Green et al. 1998; Massey and Denton 1987; Sampson 1984; South and Deane 1993). The degree of heterogeneity along additional dimensions such as incomes, educational attainment, marital status, age, and hometown of origin is similarly hypothesized to influence the level of interactions between residents (Elder 1999; Fischer 1982; Hipp and Perrin 2009; Simon et al. 1997), and social disorder is increased in such neighborhoods (Hipp 2010).
Evidence on the above findings has mainly accumulated in the USA where the population is marked by considerable diversity, despite the degree of residential segregation. By contrast, evidence on the interrelationships between resident heterogeneity, social disorganization, and crime remains spare outside the USA. The purpose of the present study was to provide a validation of social disorganization theory in a non-US context. We sought to examine whether the degree of social heterogeneity between neighborhood residents was linked to crime victimization in Japan. Because heterogeneity by race/ethnicity is extremely low in Japan, race/ethnicity is not considered to be a major factor in social disorganization in Japanese society (In fact, the National Census of 2005 revealed that only 1.2 % of people living in Japan were classified as being of non-Japanese ethnicity.). Hence, the present study focused on diversity along other social dimensions such as socioeconomic status, hometown of origin, marital status, age, and presence of children.
Social Capital and Crime
A second strand of theory that we sought to examine was the hypothesized relationships between social disorganization, social capital, and crime. According to the political scientist Robert Putnam (1995), social capital consists of “features of social organization such as networks, norms, and social trust that facilitate coordination and cooperation for mutual benefit” (1995, p. 67). Close network ties within a group generate higher levels of trust and give rise to the norm of reciprocity. Trust and reciprocity in turn encourage cooperative behaviors that translate to the prevention of crime within communities (Putnam 1995, 2000). In the field of criminology, a wealth of empirical data have demonstrated the relationships between community stocks of social trust, network connections, social participation, and lower crime rates (Kennedy et al. 1998; Lederman et al. 2002; Martin 2002; Messner et al. 2004; Rosenfeld et al. 2001). Researchers have drawn a strong connection between social capital and social disorganization theory. For example, Sampson (1988, 1995) identified paucity of social capital as one of the characteristics of local communities that were socially disorganized and showed that low social ties (friendship networks and social participation) and mistrust hampered the ability of residents to exert effective social control over unsupervised or delinquent youths who were at risk of committing crime. Based on Bursik and Grasmick’s (1995) systemic model, Rose and Clear (1998) demonstrated that residential instability and racial/ethnic heterogeneity adversely impacted the formation of social capital and thereby the ability of the community to exercise social control over crime. Using General Social Survey data, Rosenfeld et al. (2001) found that social capital encouraged both informal and formal social control and thereby reduced crime victimization. Other researchers noted the conceptual overlap between social capital and social disorganization, and together, they helped to explain the effects of neighborhood structural features on crime rates (McCulloch 2003).
Bridging Social Capital and Social Disorganization Theory
One important distinction between social capital theory and social disorganization theory is that the latter treats residential heterogeneity as an impediment to the realization of common values as well as the ability of the community to engage in collective action. In contrast, social capital theory distinguishes between bonding and bridging forms of social capital (Bellair 2000; Putnam 2000). Bonding capital refers to the network resources generated by residents who are similar to each other with respect to background characteristics such as social class and race/ethnicity. Thus, socially organized neighborhoods—as originally described by Shaw and MacKay—are those with strong bonding capital, characterized by residential homogeneity. However, social capital theory also posits that bridging forms of capital—i.e., network resources generated by residents who are dissimilar to each other in terms of background characteristics—might be effective from the point of view of crime prevention. At any given level of social disorganization (i.e., neighborhoods with greater heterogeneity in the compositional characteristics of residents), we posit that the existence of bridging social capital tends to buffer the deleterious effects of social disorganization on crime incidence. That is, in neighborhoods where residents’ diversities are large, social capital has the potential to serve as a lubricant that unites people who have different social backgrounds. Thus, the second purpose of the present study was to explore whether social capital buffered influences of social disorganization—in other words, whether the presence of social capital allowed disadvantaged neighborhoods to “catch-up” to the level of non-disadvantaged neighborhoods in terms of crime prevention.
In the present study, we used two types of social network measures as indicators of social capital. The first is the number of supportive networks within neighborhoods that are engaged in helping each other on a routine basis and attend neighborhood meetings together. Our second indicator is the presence of passing acquaintances who greet each other on the street. The latter can be rephrased as network size in the neighborhood. Having a lot of supportive networks in socially disorganized neighborhood may connect people who have different backgrounds and generate efficacy against crime. Broad network size in a socially disorganized neighborhood may function as “weak ties” (Granovetter 1973) and allow the residents time to foster ties with others in the broader community beyond their small neighborhood (Hipp 2010).
The Types of Social Characteristics’ Diversity Influencing Crime
The purpose of testing the above ideas using Japanese data is to provide a test of the generalizability of the findings reported mainly from Europe and America. Especially American society is characterized by marked heterogeneity of race/ethnicity and social economic status unlike the situation in Japan. However, because social diversity along dimensions such as economic disparity has risen markedly in Japanese society during the past two decades (Kuramitsu 2008; Otake 2005), it is important to conduct research on the effects of heterogeneity on crime rates in Japan. Income inequality forms one obvious dimension of social distance among residents in a locality. Income inequality increases crime by creating strains and conflicts among people and decreasing interactions among neighborhood residents (Hipp 2007; Morenoff et al. 2001).
While previous studies in Japan reported that wage inequality was associated with rates of larceny and robbery (Park 1993a, b, 1994), there are few studies examining the effects of diversity along other social dimensions. Educational disparity contributes to widening the social distance between residents because schooling contributes to the formation of different tastes and political opinions and hence less frequent social interactions (Hipp 2010; Bourdieu 1984). Age heterogeneity is yet another dimension of social distance because different birth cohorts experience different life events that generate distinct attitudes and outlooks (Elder 1999; Hipp and Perrin 2009). Similarly, marital status and presence of children are also important factors determining social distance among neighborhood residents. Because people who are married and parents who have children differ in their life styles and concerns from those who are single or childless, they form distinct constituencies within a community whose interests may (sometimes) be at direct variance from each other. For example, women with young children develop their networks through events mainly at preschool (Small 2008). Finally, hometown of origin may be a marker for distinct cultural identities (in Japanese society, associated with different dialects, as well as regional customs and folkways) that may set residents apart from one another (Wirth 1956a, b).
According to Hipp (2010), the degree of heterogeneity among neighborhood residents (and hence, the extent of social disorganization of a community) can be operationalized and quantified according to an index of “social distance,” calculated as the averaged difference of all pair-wise comparisons of social characteristics among individuals residing within a geographic boundary. The present study also used the index of social distance in order to examine the effects of social characteristics’ diversity among residents (i.e., social disorganization) on crime in Japanese context.
Methods
Data
In 2009, we mailed a questionnaire survey to 1,000 residents of Arakawa Ward in Tokyo, Japan. The Arakawa Ward is located in northeastern metropolitan Tokyo and has a population of 191,207. Subjects were chosen by a two-stage random sampling from among eligible voters. At first, we randomly sampled 17 neighborhood areas from all 52 areas in Arakawa Ward. In the second stage, we randomly sampled 60 individuals from each neighborhood area. Finally, 20 people of our sample were omitted because of move, demise, etc. The response rate was 50.6 % (n = 496).
In order to explore the influences of contextual explanatory variables on crime, we conducted multilevel analyses using both individual- and neighborhood-level data. The present study’s neighborhood-level unit of analysis was choumoku that is a small areal unit of neighborhoods in Japan (average areal size of target areas of this survey was 0.17507 km2). The choumoku is comparable to towns and villages in the USA. In the analyses, we used data from all respondents by imputing the missing values using a multiple imputation method. As a result, we had 496 individuals nested within 17 neighborhoods.
Dependent Variable
In the present study, crime victimization was measured by asking whether respondents experienced the following larceny crimes in their neighborhood in the past 5 years: burglaries, auto theft, car break-in, and snatching of possessions. Respondents who have experienced at least one of these were coded as 1 otherwise coded as 0.
Sociodemographic Variables
Perceived social class, educational attainment, size of hometown of origin, age, marital status, and presence of children were selected as sociodemographic variables. Race/ethnicity of the study participants was not included because of ethnic homogeneity (=native Japanese) in this study population (As previously noted, in 2005, only 1.2 % of people living in Japan were of non-Japanese ethnicity.).
We measured respondents’ perceived social class as a proxy for household income because response rates to survey questions inquiring about income are typically very low in Japanese society (Mizoguchi 1992; Shigekawa 1997). Perceived social class was assessed by asking the following question: “If current Japanese society is divided into five layers, which group do you think you belong to?” Responses were selected from one of five predetermined categories (1 = lowest, 2 = upper lower, 3 = lower middle, 4 = upper middle, 5 = high). We treated perceived social class as a continuous variable in the analyses. Educational attainment was obtained from responses to the question asking them to mark one response from six categories as their educational background (1 = elementary school, 2 = junior high school, 3 = high school, 4 = 2-year college/technical college, 5 = 4-year college, 6 = graduate school). The educational attainment variable was treated as a continuous variable in the analyses. Size of hometown of origin was assessed by responses to the item: “What size city were you living when you were 15 years old?” Respondents were asked to mark one response out of three categories (1 = village, 2 = small and medium cities, 3 = metropolis). For marital status, respondents who were married and living with their spouse at the time of survey were coded as 1 otherwise coded as 0. For presence of children, we coded respondents who had children and were living together at the time of survey as 1 and zero for those who did not.
In addition, as control variables, we measured sex of the respondents, duration of residence in the community, and type of housing. For type of housing, detached (free-standing) homes were coded as 1 otherwise coded as 0 (sex, duration of residency, and the type of housing were not used for calculating social distance indices described below).
Calculating Social Distance Indices
To calculate the social distance index, each of the individual sociodemographic characteristics were first transformed into z scores with a mean of 0 and standard deviation of 1. Following the approach by Hipp (2010), individual-level social distance index was calculated with the following equation:
That is where sd ij is social distance between individual i and individual j. K represents the K number of sociodemographic variables being measured. x ik and x jk are the value of i’s sociodemographic variable K and the value of j’s sociodemographic variable K, respectively. ϕ is the weight assigned to each sociodemographic variable, whereas greater empirical evidence might allow weighting ϕ K differently for each measure; as with Hipp (2010), we adopted the simplest assumption of weighting them equally. The difference of each demographic variable between individual i and individual j was calculated, and the average of them was used as the total social distance between i and j. The above calculation was applied to all dyads nested within the same neighborhood. Although Hipp (2010) used 11 households derived from micro-neighborhoods as his “neighborhood-level” units and calculated the above social distances for all pair-wise comparisons among these 11 households, in the present study, we calculated the social distance for all possible pair-wise comparisons among people living in the same choumoku.
We used the average of social distance per individual as the individual-level social distance variable. For the neighborhood-level, we used the average of the individual social distances within each neighborhood. In the present study, in addition to the above social distance index using all sociodemographic variables, we also examined indices derived from specific background variables such as “social economic status (SES)” (average of social distance of perceived social class and educational background), “size of hometown of origin,” and “life stage” (average of social distance of age, marital status, and presence of children).
The theoretically possible minimum value of social distance index is 0. A score of 0 social distance index means that the respondent shares exactly the same values of sociodemographic variables as his or her neighbors. We used absolute values of social distances; a high score on the social distance index means larger differences between the participant and his or her neighbors in the selected sociodemographic characteristics. Area-aggregated social distance variables indicate the average degree of homo/heterogeneity among people living in the same neighborhood.
Social Capital Variables
For social capital variables, supportive network and network size were assessed. Supportive network was measured by responses to two items: “Number of acquaintances who cooperate with you on a routine basis” and “Number of acquaintances who go to neighborhood events or meetings with you.” In the analysis, we used the sum of these two items. The size of personal network was measured by responses to two items: “Number of acquaintances whom you greet when meeting on the street” and “Number of acquaintances with whom you talk casually.” Supportive network and network size are scale-free items. In the analyses, because distributions of this type of scale are power-low distribution or lognormal distribution (Barabasi 2002; Watts 2003), we translated these network items into natural logarithms. We used these network indices as individual-level independent variables and their average per choumoku as neighborhood-level independent variables.
Statistical Analysis
First, we imputed the missing values by using a multiple imputation method. We conducted the Data Augmentation method based on Markov Chain Monte Carlo (MCMC) using the mi impute command in STATA, created 20 datasets in which the missing values were imputed, and conducted our multilevel analyses using these 20 datasets.
Multilevel logistic regression model was used with individual-level as level 1 and the neighborhood-level as level 2. The software used was STATA. A two-level, random-intercept, and fixed-slope model was fitted. We conducted two analyses. First, we examined the main effects of total social distance on larceny victimization at both the individual- and neighborhood-level, as well as the interaction terms between neighborhood-level social distance and the two network items. Second, we tested the main effects of each specific social distance indicator (i.e., “SES,” “size of hometown of origin,” and “life course stage”) on larceny victimization. In the analyses, individual-level perceived social class, supportive network, network size, and social distance indices were centered on the group mean, and those at neighborhood-level were centered on the grand mean. As previously mentioned, in the analyses, we used 20 datasets in which the missing values were imputed by the Data Augmentation method. Therefore, for descriptive statistics and odds ratios reported below, the average values of estimators estimated from each dataset were used.
Results
Table 1 contains the descriptive statistics for individual-level variables. Because multiple imputed dataset was used, each statistic shows the 95 % confidence interval (CI) instead of the standard deviation. Although the mean values of neighborhood-level variables (perceived social class, supportive network, network size, and social distance indices) were little different from those of individual-level because they were aggregated values of individual-level variables, 95 % CIs were different between the levels.
The effects of the total social distance and their interaction effects with network variables on larceny victimization are shown in Table 2. Although the variance inflation factors (VIF) in this model were relatively high (the averages of the interaction terms’ VIFs estimated from the 20 datasets were 5.33 for the total SD × supportive network and 4.28 for the total SD × network size), these values were lower than the recommended threshold value of 6 (Cohen et al. 2003).
As predicted, neighborhood-level social distance was significantly positively associated with larceny victimization. However, there was no association between individual-level social distance and larceny victimization. While the effects of neighborhood-level supportive network and network size were not significant, we found a significant interaction between neighborhood-level social distance and supportive networks. Interestingly, there was a positive interaction between social distance and network size.
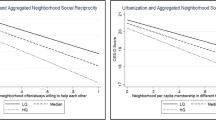
These significant neighborhood-level interaction effects are illustrated in Figs. 1 and 2. The vertical axes show the predicted probability of larceny victimization when neighborhood-level social distance and social networks were set to their minimum or maximum values, while all other independent variables were held at the average values. These figures provide additional support for the significant interaction effects between social distance and social networks. Figure 1 suggests that neighborhood-level supportive networks buffer the adverse effects of social distance on larceny victimization. By contrast, in a neighborhood where residents have a more extensive web of weak ties, their risk of larceny victimization is increased in the presence of greater social distance in the neighborhood (Fig. 2).

Interaction effect of neighborhood-level supportive network and total social distance on larceny victimization

Interaction effect of neighborhood-level network size and total social distance on larceny victimization
Next, we examined each specific dimension of social distance (Table 3). Because a full model that simultaneously involved all specific social distance indices was not statistically viable (due to multicollinearity), we analyzed each social distance index separately. Again, although the interaction terms indicated relatively high VIFs, none of them exceeded the threshold value of 6 recommended by Cohen et al. (2003).
Model 2 in Table 3 shows that social distance based on SES was associated with larceny victimization. In addition, the interaction effects between SES social distance and social network indices were marginally significant. This suggests that the adverse effect of larger social distance based on SES is buffered by supportive social ties and, on the other hand, is strengthened by mere acquaintanceship social ties. While social distance based on size of hometown also shows a marginal positive effect on larceny in model 3, its interactions with network variables were not significant. In model 4, life stage social distance also had significant main and interaction effects on larceny victimization in the same way as in models 1 and 2.
Discussion
We summarize our key findings. First, all social distance indices (total social distance, SES social distance, city size of hometown social distance, and life stage social distance) at the neighborhood-level were independently associated with increased probability of larceny victimization. That is, neighborhood-level social distance appeared to be associated with higher risk of larceny victimization independently of the individual’s absolute values of sociodemographic characteristics. For example, the result for SES social distance is consistent with previous studies that examined the effects of income inequality on crime victimization in Japan (e.g., Park 1993a, b, 1994). The present study additionally demonstrated that neighborhood diversity based on other social characteristics also affected the probability of residents’ crime victimization. Model 4 concerning life stage social distance (i.e., the diversity among residents’ age, marital status, and presence of children) also suggests that greater diversity in residents’ life stage makes the community more disorganized. While diversities in some social characteristics among residents in Japan are relatively smaller compared to the USA, our findings confirm that neighborhood social distance also matters in the Japanese context. On the other hand, we did not find that the individual-level indices of social distance were associated with individual victimization.
The second major finding of our study is that neighborhood-level supportive networks buffered the adverse effects of social distance on larceny victimization. In other words, the risk from social distance becomes potentiated if neighborhoods do not have a lot of supportive networks. This is consistent with the theory of bridging social capital, which posits that linking social ties within a community can serve as a “glue” to bring together people who have different social backgrounds, thereby assisting in the control of crime. Our findings are consistent with previous studies on the relationship between social disorganization, social capital, and crime which have explored the importance of strong social ties for crime control (e.g., Sampson and Groves’s (1989) local friendship networks). On the other hand, the main effects of neighborhood-level network indices were not statistically significant. This finding is not consistent with studies which reported that social ties in neighborhood helped to reduce the number of crime or fear of crime (e.g., Bellair 1997; Ross and Jang 2000; Rountree and Warner 1999).
Interestingly, we also observed that network size potentiates (rather than buffers) the deleterious effect of total social distance, SES social distance, and life stage social distance on larceny risk. That is, in the neighborhood that has many weak social ties, the risk from social distance was increased. Although network diversity enhances certain positive actions (e.g., the diffusion of information), it may also increase the opportunity for exposure to crime if people’s social distance is large. Indeed Takagi et al. (2010) have previously shown that network size at the neighborhood-level positively affected individual burglary victimization, using Japanese empirical data. Although it was not a study specifically focused on social ties among community-dwelling adults, Patacchini and Zenou (2008) showed that criminal behavior among teenagers was influenced by their weak ties who were not their friends. They found that increasing the percentage of weak ties induced more transitions from non-crime to crime and thus the crime rate in the economy increased. That is, an abundance of weak ties increases the opportunity to access people who exhibit criminal tendency or who hold information that is relevant to crime. This may be applicable to the neighborhood context—i.e., in neighborhoods with an abundance of weak ties, informal social control may be hampered and the adverse effect of social distance may be magnified due to an increase in undesirable contacts, interactions, and information.
There are two implications of the present study. First, our findings suggest that the rise in economic disparities in Japan during the last two decades will have an adverse impact on rates of crime victimization. Our findings also suggest that crime victimization may also arise because of social heterogeneity induced by factors other than income and wealth—such as the influx of foreign workers.
Second, our findings suggest that local social ties can buffer the impact of social distance. In Japan, a direct relationship between social capital and crime has been empirically hard to demonstrate. Many studies using Japanese data have failed to detect a relationship between neighborhood-level social ties and individual-level crime victimization. In the present study, we focused on the interaction effects between social distance and supportive network, and we showed that social ties are significantly protective in places where social distance is high. Research on social capital has been developed primarily in European and American societies where social diversity is relatively high compared to Japanese society. The present paper suggests that in Japan, social ties are also important for protection against crime, but they are important when interacted with local social heterogeneity.
Two limitations should be noted about our study. First, the analyses were cross-sectional and, hence, we could not exclude the possibility of reverse causality. To some extent, people choose where to settle, and it is possible that people who wish to live in safety sort themselves into neighborhoods where they can be surrounded by others who share similar sociodemographic characteristics (and with whom they can socialize). Prospective studies that take into account this type of selective mobility would help to strengthen causal inference. The second limitation of the present study is that the sample was derived from just one metropolitan area in Japan. That is, our sample was not a representative sample of people in Japan. Our findings may not generalize to other areas or neighborhoods with different population characteristics.
In summary, we have found an association between neighborhood social distance and larceny victimization in Japanese society which is characterized by relative homogeneity compared to American society. Additionally, we have revealed that supportive networks in neighborhood can potentially buffer the detrimental effects of social distance on crime victimization (while network size magnifies it).
References
Barabasi, A. L. (2002). Linked: the new science of networks. Cambridge: Perseus Book Group.
Bellair, P. E. (1997). Social interaction and community crime: examining the importance of neighbor networks. Criminology, 35, 677–704.
Bellair, P. E. (2000). Informal surveillance and street crime: a complex relationship. Criminology, 38, 137–167.
Bourdieu, P. (1984). Distinction: a social critique of the judgment of taste. Cambridge: Harvard University Press.
Bursik, R. J., & Grasmick, H. (1995). Neighborhoods and crime: the dimensions of effective community control. New York: Lexington Books.
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences. Mahwah: Erlbaum.
Elder, G. H. (1999). Children of the great depression: social change in life experience. Boulder: Westview Press.
Fischer, C. S. (1982). Two dwell among friends: personal networks in town and city. Chicago: University of Chicago Press.
Granovetter, M. (1973). The strength of weak ties. American Journal of Sociology, 78, 1360–1380.
Green, D. P., Strolovitch, D. Z., & Wong, J. S. (1998). Defended neighborhoods, integration, and racially motivated crime. American Journal of Sociology, 104, 372–403.
Hipp, J. R. (2007). Income inequality, race, and place: does the distribution of race and class within neighborhoods affect crime rates? Criminology, 45, 665–697.
Hipp, J. R. (2010). Micro-structure in micro-neighborhoods: a new social distance measure, and its effect on individual and aggregated perceptions of crime and disorder. Social Networks, 32, 148–159.
Hipp, J. R., & Perrin, A. J. (2009). The simultaneous effect of social distance and physical distance on the formation of neighborhood ties. City & Community, 8, 5–25.
Kennedy, B. P., Kawachi, I., Prothrow-Stith, D., Lochner, K., & Gupta, V. (1998). Social capital, income inequality, and firearm violent crime. Social Science and Medicine, 47, 7–17.
Kuramitsu, T. (2008). Widening gap and its countermeasure in Japanese society. Journal of Economic Policy Studies, Kagawa University, 4, 23–47 (in Japanese).
Lederman, D., Loayza, N., & Menendez, A. M. (2002). Violent crime: does social capital matter? Economic Development and Cultural Change, 50, 509–539.
Martin, D. (2002). Spatial patterns in residential burglary: assessing the effect of neighborhood social capital. Journal of Contemporary Criminal Justice, 18, 132–146.
Massey, D. S., & Denton, N. A. (1987). Trends in the residential segregation of Blacks, Hispanics, and Asians: 1970–1980. American Sociological Review, 52, 802–825.
McCulloch, A. (2003). An examination of social capital and social disorganization in neighborhoods in the British household panel study. Social Science & Medicine, 56, 1425–1438.
Messner, S. F., Baumer, E. P., & Rosenfeld, R. (2004). Dimensions of social capital and rates of criminal homicide. American Sociological Review, 69, 882–903.
Mizoguchi, T. (1992). Contemporary problems of statistical survey in Japan. Tokyo: Iwanami Shoten (in Japanese).
Morenoff, J. D., Sampson, R. J., & Raudenbush, S. W. (2001). Neighborhood inequality, collective efficacy, and the spatial dynamics of urban violence. Criminology, 39, 517–559.
Otake, F. (2005). Inequality in Japan: dreams and future of unequal society. Tokyo: Nihon Keizai Shinbun (in Japanese).
Park, W. (1993a). Trends of the crime rate in the postwar Japan: a time-series regression approach (1). Hougaku Shinpou, 99, 165–230 (in Japanese).
Park, W. (1993b). Trends of the crime rate in the postwar Japan: a time-series regression approach (2). Hougaku Shinpou, 99, 221–266 (in Japanese).
Park, W. (1994). Trends of the crime rate in the postwar Japan: a time-series regression approach (3). Hougaku Shinpou, 99, 169–195 (in Japanese).
Patacchini, E., & Zenou, Y. (2008). The strength of weak ties in crime. European Economic Review, 52, 209–236.
Putnam, R. D. (1995). Bowling alone: America’s declining social capital. Journal of Democracy, 6, 65–78.
Putnam, R. D. (2000). Bowling alone: the collapse and revival of American community. New York: Simon & Schuster.
Rose, D. R., & Clear, T. R. (1998). Incarceration, social capital, and crime: implications for social disorganization theory. Criminology, 36, 441–479.
Rosenfeld, R., Messner, S. F., & Baumer, E. P. (2001). Social capital and homicide. Social Forces, 80, 283–309.
Ross, C. E., & Jang, S. J. (2000). Neighborhood disorder, fear, and mistrust: the buffering role of social ties with neighbors. American Journal of Community Psychology, 28, 401–420.
Rountree, P. W., & Warner, B. D. (1999). Social ties and crime: is the relationship gendered? Criminology, 37, 789–814.
Sampson, R. J. (1984). Group size, heterogeneity, and intergroup conflict: a test of Blau’s inequality and heterogeneity. Social Forces, 62, 618–639.
Sampson, R. J. (1988). Local friendship ties and community attachment in mass society: a multilevel systemic model. American Sociological Review, 53, 766–779.
Sampson, R. J. (1995). The community. In J. Q. Wilson & J. Petersilia (Eds.), Crime (pp. 193–216). San Francisco: Institute for Contemporary Studies.
Sampson, R. J., & Groves, W. B. (1989). Community structure and crime: testing social-disorganization theory. American Journal of Sociology, 94, 774–802.
Sampson, R. J., Raudenbush, S. W., & Earls, F. (1997). Neighborhoods and violent crime: a multilevel study of collective efficacy. Science, 277, 918–924.
Shaw, C., & McKay, H. (1942). Juvenile delinquency and urban areas. Chicago: University of Chicago Press.
Shigekawa, J. (1997). Features of missing values in the panel survey on consumption behavior. Research on Household Economics, 33, 76–83 (in Japanese).
Simon, B., Hastedt, C., & Aufderheide, B. (1997). When self-categorization makes sense: the role of meaningful social categorization in minority and majority members’ self-perception. Journal of Personality and Social Psychology, 73, 310–320.
Small, M. L. (2008). Unanticipated gains: origins of network inequality in everyday life. New York: Oxford University Press.
South, S. J., & Deane, G. D. (1993). Race and residential mobility: individual determinants and structural constraints. Social Forces, 72, 147–167.
Takagi, D., Tsuji, R., & Ikeda, K. (2010). Crime control by local communities: focusing on social capital and cooperative behaviors in neighborhoods. Japanese Journal of Social Psychology, 26, 36–45 (in Japanese).
Watts, D. J. (2003). Six degrees: the science of a connected age. New York: W. W. Norton.
Wirth, L. (1956a). Life in the city. In L. Wirth (Ed.), Community life and social policy (pp. 206–217). Chicago: University of Chicago Press.
Wirth, L. (1956b). Urbanism as a way of life. In P. Kasinitz (Ed.), Metropolis: center and symbol of our times (pp. 58–82). New York: New York University Press.
Acknowledgments
This research was supported by a grant received by the first author from the Japan Society for the Promotion of Science (Grant Number: DC2 22-8772).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Takagi, D., Kawachi, I. Neighborhood Social Heterogeneity and Crime Victimization in Japan: Moderating Effects of Social Networks. Asian Criminology 9, 271–284 (2014). https://doi.org/10.1007/s11417-014-9191-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11417-014-9191-9