
Abstract
Purpose
The Pittsburgh Sleep Quality Index (PSQI) is a widely used measure for assessing sleep impairment. Although it was developed as a unidimensional instrument, there is much debate that it contains multidimensional latent constructs. We examined the dimensionality of the underlying factor structure of PSQI in Singapore, a rapidly industrialising Asian country with multi-ethnicities representing the Chinese, Malays and Indians.
Methods
The PSQI was administered through an interviewer-based questionnaire in two separate population-based cross-sectional surveys. An explanatory factor analysis (EFA) was first used to explore the underlying construct of the PSQI in both studies. Then, a confirmatory factor analysis (CFA) was conducted to evaluate an optimal factor model by comparing against other possible models identified in EFA.
Results
There are three correlated yet distinguishable factors that account for an individual’s sleep experience from the same best-fit model obtained in both studies: perceived sleep quality, daily disturbances and sleep efficiency. Our three-factor structure of PSQI is superior to the originally intended unidimensional model. Our model also shows the best-fit indices when compared to the previously reported single-factor, two-factor and three-factor (by Cole et al.) models in a multi-ethnic Asian population.
Conclusion
There is strong evidence that the PSQI contains a three-factor rather than a unidimensional structure in a multi-ethnic Asian population. Scoring the PSQI along their multidimensional perspectives may provide a more accurate understanding of the relationship between sleep impairment and health conditions rather than using a single global score.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Sleep impairment is being increasingly recognised as a serious problem in modern society. Commercial activity has extended beyond traditional trading hours, shift-work has become more common, and the separation of on- and off-duty hours has increasingly blurred. Furthermore, noise and light pollution also affect the sleep quality of residents living in densely populated urban areas, where more than half of the world’s population resides. These factors contribute to sleep impairment, and studies have reported high prevalence of sleep impairment from 10.0 to 35.5 % in different communities [1–4]. In Singapore, Yeo et al. has reported that the prevalence of insomnia was 15.3 % in 1996 [5]. Sleep impairment is associated with an increased risk of hypertension, obesity, depression and cardiovascular diseases [6, 7] and affects daily activities such as driving [8] and work [9].
The Pittsburgh Sleep Quality Index (PSQI) is a 19-item self-reported questionnaire that measures the quality and patterns of sleep during the past 1 month [10]. Although the PSQI was initially developed as a clinical tool to evaluate sleep quality in psychiatric practice, it is now also widely used in general population-based epidemiologic studies. There has been much debate that the PSQI contains multidimensionality instead of being a unidimensional scale of measure. Multiple studies have shown that a scoring method based on two [11, 12] or three [13–15] factors may provide a better assessment of sleep quality. For example, Cole et al. examined the factor structure of the PSQI using a cross-validation approach and identified the presence of a three-factor structure based on a confirmatory factor analysis [14]. Another study with Nigerian students [15] also confirmed Cole’s findings.
Factor structure is influenced both by the intrinsic quality of the instrument, as well as the population on which the instrument is applied [16, 17]. Most of these factor analysis studies were conducted outside Asia namely in the USA and Europe [11–15], and their results might not apply to Asian populations such as that of Singapore. The aim of this study is to establish the factor structure of PSQI, which is administered in serial national representative cross-sectional surveys for the surveillance of the health state of the Singapore population. Two different population-based surveys were used to obtain an optimal factor model of PSQI in the Singapore population, which is a multi-ethnic Asian society representing East (Chinese), South-East (Malay) and South Asian (Indian) ethnicities.
Methods
Study design
The first study is a community-based cross-sectional study conducted in Queenstown housing estate, Singapore (Queenstown study) by medical students from National University of Singapore (NUS) as part of their training curriculum. The inclusion criterion was Singapore citizens or permanent residents aged at least 21 years who were willing to provide informed consent. A three-stage sampling method was used to randomly select the participants. In the first stage, 30.0 % of the Housing Development Board (HDB) blocks were randomly selected out of 270 HDB blocks in Queenstown estate. In the second stage, 1140 household units were randomly selected from 90 HDB blocks from the first stage. In the third stage, the interviewer randomly selected one participant from each household when there was more than one eligible participant by using the Kish grid method. Out of the 1140 participants randomly selected, 489 agreed to participate, 412 declined and 239 did not respond. The overall response rate was 42.9 %.
The second study is Singapore Health (SH) 2012, a national representative study of the Singapore adult population, consisting of a main questionnaire administered at participant’s home, a health examination and administration of sub-questionnaires (containing the PSQI) at designated health examination centres. The data from the National Database of Dwellings, maintained by the Department of Statistics, was used to draw up the sampling frame for the entire population of Singapore. Here, a two-stage randomisation was employed. In the first stage, a sampling frame of 14,200 households was randomly chosen from the database and all these households were enumerated. The enumeration response rate was 46.0 % and entailed the collection of demographic data of all the members of each household, where the inclusion criteria was Singaporeans or permanent residents aged 18 to 79 years living in these households. In the second stage, 6000 individuals were then randomly selected based on the list of individuals enumerated, with oversampling of Malays and Indians. The study overall response rate was 40.0 %, but only 1976 of them who had completed the PSQI at the health examination centres were used in the analysis.
The PSQI was administered through a standard questionnaire by trained interviewers in both studies with other information collected on demographics, medical and psychosocial conditions.
Statistical analysis
Following the scoring guidelines provided by Buysse et al. [10], the 19 items of the PSQI are grouped into seven sleep components: subjective sleep quality, sleep latency, sleep duration, habitual sleep efficiency, sleep disturbances, use of sleeping medications and daytime dysfunction. Each of these seven components are equally weighted in a 0–3 scale and aggregated into a single global PSQI score ranging from 0 to 21.
We compared the characteristics of the two study populations. For continuous data, the median and range was reported and for categorical data, proportion was used. Mann-Whitney U test (two-tailed) was performed to test the differences in medians and the chi-squared test was used to test for differences in proportion. Fisher’s exact test was used whenever the cell frequency was below 5. We assumed the two study populations did not overlap. Subsequently, an EFA and CFA were conducted separately on the two studies to evaluate an appropriate factor model for PSQI.
In EFA, two methods of estimation, principal components analysis (PCA) and maximum likelihood estimation (MLE), were used to calculate the factor loadings and to determine the correlation between each component to its corresponding factor, as well as to establish the number of factors to be retained in the model. The factor loadings were then subjected to a varimax rotation to aid in the interpretability and to evaluate against the cutoff criteria of 0.40 proposed by Steven et al. [18]. In addition, a variable factor map and individual map were plotted using the package FactoMineR in R [19] to better understand the contribution of each PSQI component to the latent factors [20]. This was followed by CFA to evaluate the fit of various models to identify the model with the best fit. We also compared our best-fit model against Cole’s three-factor model [14] and the Buysse’s single-factor model [10].
Multiple fit indices were used to evaluate the adequacy of the model fit: we considered the fit to be good if the goodness-of-fit index (GFI) and adjusted goodness-of-fit index (AGFI) were 0.90 or higher [21], comparative fit index (CFI) was 0.95 or higher [22] and the root mean square error of approximation (RMSEA) was 0.05 or lower (0.05 < RMSEA < 0.08 indicates adequate model fit) [23]. Then, the models were compared against one another based on the following: delta chi-squared (∆χ 2) statistics [24], Bayesian information criteria (BIC) [25] and consistent Akaike information criteria (CAIC) [20]. When comparing the fit indices between two models, the model with a lower χ 2 statistics, BIC and CAIC would be preferred. Furthermore, Raftery had shown in his paper that a difference of at least 10 in the BIC of two models would render the model with higher BIC to be rejected [25].
All analyses were performed using the statistical programming language R [26].
Results
Table 1 shows the characteristics of the two study populations. Of the 489 participants in the Queenstown study, 290 (59.3 %) were females and 199 (40.7 %) were males. The median age was 47 years. The majority were Chinese (73.6 %) followed by Malays (9.0 %), Indians (9.8 %) and others (7.6 %). Of the 1976 participants in SH 2012, 1021 (51.7 %) were females and 955 (48.3 %) were males. The median age was 43 years, which was slightly younger than the Queenstown study. In addition, majority of the participants were Chinese (35.1 %) and Malays (35.0 %), followed by Indians (24.4 %) and others (5.5 %). Most of the characteristics were significantly different between the two study populations except for sleeping medication use, proportion of hypertension, diabetes mellitus and cancer; this is probably due to the different study designs used in recruitment of the study populations.
Table 2 provides the Spearman’s correlations and the descriptive statistics for the seven PSQI components in both studies. Each component score ranged from 0 to 3. Among the inter-component correlations in the Queenstown study, sleep duration and habitual sleep efficiency were found to have the highest correlation (r = 0.48) and use of sleep medications and sleep duration had the lowest correlation (r = 0.02). The mean global PSQI score was 5.04 (SD = 3.29, Cronbach’s alpha = 0.67). Using the recommended cutoff of 5 for the global PSQI score, 35.0 % of the participants have poor sleep quality.
Among the inter-component correlations in SH 2012, similarly sleep duration and habitual sleep efficiency had the highest correlation (r = 0.36). However, unlike in the other study, use of sleep medications and sleep efficiency had the lowest correlation (r = 0.05). The mean global PSQI score was 4.21 (SD = 2.77, Cronbach’s alpha = 0.64). Using the recommended cutoff of 5 for the global PSQI score, 24.7 % of the participants have poor sleep quality, lower than the proportion from the Queenstown study.
Exploratory factor analysis
In EFA of both datasets, both two-factor and three-factor models fitted the data well with interpretability. In the two-factor model, the first factor was labelled sleep efficiency and the second factor was labelled perceived sleep quality. Two of the components, sleep duration and sleep efficiency, were loaded highly on the first factor, while the rest of the components had good loadings on the second factor.
In the three-factor model of the Queenstown study, the same component under each factor was identified in both the MLE and PCA methods. The factors were labelled as sleep efficiency, perceived sleep quality and daily disturbances. Components habitual sleep efficiency and sleep duration had strong loadings on the first factor sleep efficiency. Sleep latency and sleep disturbance had relatively high loading on the factor daily disturbances and the rest of the components were loaded onto the factor perceived sleep quality. A second three-factor model was also identified through the variable map: in this model, subjective sleep quality was grouped with sleep latency under the factor perceived sleep quality; sleep disturbances, sleeping medication use and daytime dysfunction under the factor daily disturbances and finally, habitual sleep efficiency and sleep duration were grouped together under the factor sleep efficiency.
In SH 2012, a similar three-factor structure was observed and each factor was labelled in the same manner as the Queenstown study. The components habitual sleep efficiency and sleep duration were loaded highly on the first factor using the PCA method, while daily disturbances, subjective sleep quality and daytime dysfunction were loaded onto the second factor; finally, the rest of the components were loaded onto the third factor. The MLE and variable mapping method also identified the same components under each of these three factors; in particular, the grouping of the components was identical to the variable mapping method as the Queenstown study.
Confirmatory factor analysis
We also compared our models with that of Cole’s three-factor model and Buysse’s single-factor model. Table 3 shows the summary of the model fits. In the Queenstown study, the three-factor model obtained from the variable map produced the best fit; hence, only this model was evaluated as the best model obtained in the EFA. For SH 2012, the three-factor model obtained from the PCA did not provide a good fit compared to the three-factor model from variable mapping and MLE; hence, only the latter was evaluated as the best model.
For the Queenstown study, Buysse’s single-factor model had resulted in the poorest fit (χ 2 = 128.2, P < 0.01; GFI = 0.93; AGFI = 0.86; CFI = 0.78; RMSEA = 0.13; BIC = 214.9; CAIC = 27.5). Although applying Cole’s three-factor model did not result in the most desirable fit indices, it was more appropriate than the single-factor model (χ 2 = 47.6, P < 0.01; GFI = 0.97; AGFI = 0.93; CFI = 0.93; RMSEA = 0.08; BIC = 152.8; CAIC = 31.5). The fit of a three-factor model was clearly better than using a single-factor or a two-factor model. The best three-factor model derived from EFA had a good fit for all the indices except for RMSEA which only had an adequate fit and a significant χ 2 statistics (χ 2 = 36.1, P < 0.01; GFI = 0.98; AGFI = 0.95; CFI = 0.95; RMSEA = 0.07; BIC = 141.3; CAIC = −43.0). The difference in BIC between our best model and Cole’s model had a difference of at least 10 [25], suggesting that our three-factor model would be preferred over Cole’s model.
For SH 2012, Buysse’s model resulted in the poorest fit (χ 2 = 245.2, P < 0.01; GFI = 0.96; AGFI = 0.93; CFI = 0.85; RMSEA = 0.09; BIC = 351.4; CAIC = 124.9). Similar to the Queenstown study, Cole’s three-factor model did not have the best-fit indices, although it outperformed the Buysse’s model (χ 2 = 70.6, P < 0.01; GFI = 0.99; AGFI = 0.97; CFI = 0.96; RMSEA = 0.05; BIC = 199.6; CAIC = −23.8). The fit of a three-factor model was superior to that of a two-factor model. The fit statistics for our best three-factor model by EFA had good fit for all the indices except for a significant χ 2 statistics (χ 2 = 63.8, P < 0.01; GFI = 0.99; AGFI = 0.98; CFI = 0.97; RMSEA = 0.05; BIC = 192.8; CAIC = −30.7). However, the difference in BIC between our best model and Cole’s model had a difference of only about 7 (<10) which failed to provide adequate evidence to conclude that our best three-factor model is preferred over Cole’s model.
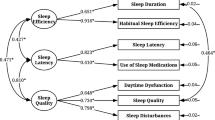
In the three-factor model for Queenstown study, each PSQI component score and its corresponding factor had relatively large standardised path coefficients that ranged from 0.37 (sleep disturbance to daily disturbances factor) to 0.72 (subjective sleep quality to perceived sleep quality factor, and habitual sleep efficiency to sleep efficiency factor), while the correlations between the three factors ranged from 0.27 to 0.89. In the three-factor model for SH 2012, each PSQI component score and its corresponding factor had relatively large standardised path coefficients that ranged from 0.26 (sleep medication use to daily disturbances factor) to 0.67 (habitual sleep efficiency to sleep efficiency factor), while the correlations between the three factors ranged from 0.39 to 0.90 (Fig. 1).

Best three-factor model obtained in EFA with standardised path coefficients between factor solution and the PSQI component in the a Queenstown study and b SH 2012
Discussion
We have shown that there exists a three-factor structure of the PSQI underlying an individual’s sleep experience in the Singapore population. This same conclusion is reached from the analyses of two separate studies conducted in Singapore with two distinct study populations recruited using different study designs. For the Queenstown study, the study population was mostly Chinese, while for SH2012, the three ethnicities were equally sampled. Despite differences in the distribution of ethnicities, we obtained the same best three-factor structure in both studies, indicating that there is unlikely to be any bias in the evaluation of sleep quality among the three ethnicities. This also supports the theory of PSQI containing multidimensional factor structures instead of a unidimensional one.
The Cronbach’s alpha [27] which is a measure of the internal consistency, usually taken to be at least 0.80 [28], was relatively low in both of our studies (0.67 in the Queenstown study, 0.64 in the SH 2012). Our low Cronbach’s alpha was similar to Mariman et al. [29] of 0.64, and this is not surprising given our findings of a three-factor structure is in sharp contrast with the Cronbach’s alpha (0.83) reported by the team that developed the PSQI [10].
Our finding is consistent with most other studies in the USA and Europe which show that contrary to the intentions of the developers of the instrument, the PSQI is not unidimensional [13–15]. Our three-factor model derived from EFA appears to perform better than Cole’s model. The main difference was that the component sleeping medication use was loaded onto the factor perceived sleep quality in our model instead of daily disturbances in Cole’s model.
A large proportion of participants in both our studies reported that they did not use any sleeping medication during the past month (94.9 % in the Queenstown study, 96.7 % in the SH 2012 study). Insufficient numbers of participants with sleep medication use may render the analyses of this component unreliable. The standardised path coefficients for sleeping medication use to its factor is one of the lowest in both of our studies (Fig. 1), suggesting a weak dependency between the component and its factor. This difference could be due to a lack of power from insufficient sample sizes. Alternatively, it may also be due to underlying inherent differences in the study populations, in particular their perception of the effect and consequences of the use of sleep medications, the diverse nature of sleep problems, and the varying sleeping behaviours in different populations. Possible future research work may involve validating the three-factor model against a gold standard and to confirm if the factor structure differs between Western and Asian populations.
Strengths and limitations
The strengths of this study are the following: we evaluated the factor structure of PSQI in two different population-based studies with different study designs. The statistical analysis performed separately on the two studies had arrived at the same finding of a distinct three-factor structure, suggesting that a three-factor model of the PSQI in a multi-ethnic Asian population is robust. Our study is also the largest that we know of, using data from a total of 2465 participants. We also used data from healthy community-dwelling individuals rather than from disease cohorts. Disease and its sequelae such as pain may affect the experience of sleep, in that results from these cohorts may not apply to the general populations.
We highlight limitations that may affect the interpretation of our results. First, the overall response rates for the Queenstown study and SH 2012 were 42.9 and 40.0 %, respectively. While these were comparable to other population-based studies in Singapore [30], the relatively low response rate may affect the generalisability of our results. Second, our three-factor model showed only an adequate fit criterion with RMSEA, and the χ 2 statistics were statistically significant in the Queenstown study. However, other fit indices such as GFI, AGFI, CFI, BIC and CAIC suggested that our model had a good fit with the data.
Conclusion
In summary, this study evaluates the structure of PSQI in the multi-ethnic Asian city-state of Singapore. We show that PSQI has a distinct three-factor structure (sleep efficiency, perceived sleep quality and daily disturbances) in the Singapore population, using data from two distinct population-based surveys. In population-based studies that use the PSQI to evaluate sleep quality, validating cutoffs and scoring the PSQI along these three factors may provide a more accurate understanding of the relationship between sleep impairment and health conditions rather than using a single global score.
References
Ohayon MM (2008) Nocturnal awakenings and comorbid disorders in the American general population. J Psychiatr Res 43(1):48–54
Kim K, Uchiyama M, Okawa M, Liu X, Ogihara R (2000) An epidemiological study of insomnia among the Japanese general population. Sleep 23(1):41–47
Weyerer S, Dilling H (1991) Prevalence and treatment of insomnia in the community: results from the Upper Bavarian Field Study. Sleep 14(5):392–398, Epub 1991/10/01
Hohagen F, Rink K, Kappler C, Schramm E, Riemann D, Weyerer S et al (1993) Prevalence and treatment of insomnia in general practice. A longitudinal study. Eur Arch Psychiatry Clin Neurosci 242(6):329–336
Yeo BK, Perera IS, Kok LP, Tsoi WF (1996) Insomnia in the community. Singap Med J 37(3):282–284
Budhiraja R, Roth T, Hudgel DW, Budhiraja P, Drake CL (2011) Prevalence and polysomnographic correlates of insomnia comorbid with medical disorders. Sleep 34(7):859–867
Sarsour K, Morin CM, Foley K, Kalsekar A, Walsh JK (2010) Association of insomnia severity and comorbid medical and psychiatric disorders in a health plan-based sample: insomnia severity and comorbidities. Sleep Med 11(1):69–74
Maia Q, Grandner MA, Findley J, Gurubhagavatula I (2013) Short and long sleep duration and risk of drowsy driving and the role of subjective sleep insufficiency. Accid Anal Prev 59:618–22
Nakashima M, Morikawa Y, Sakurai M, Nakamura K, Miura K, Ishizaki M et al (2011) Association between long working hours and sleep problems in white-collar workers. J Sleep Res 20(1 Pt 1):110–116
Buysee DJ, Reynolds CF, Monk TH, Berman SR, Kupfer DJ (1989) The Pittsburgh Sleep Quality Index: a new instrument for psychiatry practice and research. Psychiatr Res 28:198–213
Jimenez-Genchi A, Monteverde-Maldonado E, Nenclares-Portocarrero A, Esquivel-Adame G, de la Vega-Pacheco A (2008) Reliability and factorial analysis of the Spanish version of the Pittsburg Sleep Quality Index among psychiatric patients. Gac Med Mex 144:491–496
Magee CA, Caputi P, Iverson DC, Huang X-F (2008) An investigation of the dimensionality of the Pittsburgh Sleep Quality Index in Australian adults. Sleep Biol Rhythms 6:222–227
Carpenter JS, Andrykowski MA (1998) Psychometric evaluation of the Pittsburgh Sleep Quality Index. J Psychosom Res 45:5–13
Cole JC, Motivala SJ, Buysse DJ, Oxman MN, Levin MJ, Irwin MR (2006) Validation of a 3-factor scoring model for the Pittsburgh Sleep Quality Index in older adults. Sleep 29:112–116
Aloba OO, Adewuya AO, Ola BA, Mapayi BM (2007) Validity of the Pittsburgh Sleep Quality Index (PSQI) among Nigerian university students. Sleep Med 8:266–270
Panayides et al (2013) Using Rasch measurement to create a quality of sleep scale for a non-clinical sample based on the Pittsburgh Sleep Quality Index (PSQI). Eur J Psychol 9(1):113–135
Pittsburgh Sleep Quality Index (PSQI), Sleep Medicine Institute, University of Pittsburgh. http://www.sleep.pitt.edu/content.asp?id=1484&subid=2316 Accessed 16 May 2014
Stevens JP (1992) Applied multivariate statistics for the social sciences, 2nd edn. Erlbaum, Hillsdale, NJ
Lê S, Josse J, Husson F (2008) FactoMineR: An R package for multivariate analysis. J Stat Softw 25(1):1–18
Bollen KA, Long JS (1993) Testing structural equation models. Sage, Newbury Park, CA
Bentler PM, Bonett DG (1980) Significance tests and goodness-of-fit in the analysis of covariance structures. Psychol Bull 88:588–606
Hu L, Bentler PM (1998) Fit indices in covariance structure modeling: sensitivity to underparameterized model misspecification. Psychol Methods 3:424–453
Schumacker RE, Lomax RG (2004) A beginner’s guide to structural equation modeling, 2nd edn. Lawrence Erlbaum Associates, Inc, Mahwa, NJ
Long JS (1983) Confirmatory factor analysis. Sage, Newbury Park, CA
Raftery AE (1993) Bayesian model selection in structural equation models. In: Bollen KA, Long JS (eds) Testing structural equation models. Sage, Newbury Park, CA, pp 163–180
R Core Development Team: R: A language and environment for statistical computing. http://www.R-project.org Accessed 16 May 2014
Cronbach LJ (1951) Coefficient Alpha and the internal structure of tests. Psychometrika 16:297–334
Cortina JM (1993) What is coefficient alpha? An examination of theory and applications. J Appl Psychol 78:98–104
Mariman A, Vogelaers D, Hanoulle I, Delesie L, Tobback E, Pevernagie D (2012) Validation of the three-factor model of the PSQI in a large sample of chronic fatigue syndrome (CFS) patients. J Psychosom Res 72(2):111–113. doi:10.1016/j.jpsychores.2011.11.004
Weng FC (2010) National Health Survey 2010, Singapore: Epidemiology & Disease Control Division, Ministry of Health. http://www.moh.gov.sg/content/moh_web/home/Publications/Reports/2011/national_health_survey2010.html. Accessed 16 May 2014
Acknowledgments
The Singapore Health (SH) survey is funded by the Ministry of Health, Singapore. The funder did not play a role in the design, conduct or analysis of the study as well as the drafting of this manuscript. The authors would also like to thank the group of Community Health Project (CHP) medical students of year 2012 from the National University of Singapore (NUS) for going out to conduct the surveys to collect data for the Queenstown study. We would also like to gratefully acknowledge Dr. Choi Hyungwon (NUS) for reading and providing editorial comments for our manuscript.
Ethical standards
Ethics review requirement was waived by the National University of Singapore (NUS) Institutional Review Board (IRB) as anonymous data was collected for the Queenstown study. For SH 2012, ethics was reviewed and approved by the NUS IRB prior to implementation. All subjects had given their informed consent prior to their inclusion in the study.
Conflict of interest
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Koh, H.W.L., Lim, R.B.T., Chia, K.S. et al. The Pittsburgh Sleep Quality Index in a multi-ethnic Asian population contains a three-factor structure. Sleep Breath 19, 1147–1154 (2015). https://doi.org/10.1007/s11325-015-1130-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11325-015-1130-1