
Abstract
In previous papers, decoding schemes which did not use machine learning considered additive white Gaussian noise or memoryless impulse noise. The decoding methods applying deep learning to reduce computational complexity and decoding latency didn’t consider the impulse noise. Here, we apply the Long Short-Term Memory (LSTM) neural network (NN) decoder for Polar codes under the Markov Gaussian memory impulse noise channel, and compare its bit error rate with the existing Polar code decoders like Successive Cancellation (SC), Belief Propagation (BP) and Successive Cancellation List (SCL). In the simulation results, we first find the optimal training SNR value 4.5 dB in the Markov Gaussian memory impulse noise channel for training the proposed LSTM based Polar code decoder. The optimal training SNR value is different from that 1.5 dB in the AWGN channel. The bit error rate of the propose LSTM based Polar code decoder is one third that of the previous non-deep-learning-based decoder SC/BP/SCL in Markov Gaussian memory impulse noise channels. The execution time of the proposed LSTM-based method is 5 ~ 12 times less and thus has much less decoding latency than that of SC/BP/SCL methods because the proposed LSTM-based method has inherent parallel structure and has one shot operation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Polar code was proposed in [1]. It, concatenated with Cyclic Redundancy Check (CRC), is adopted as the channel code of the 5G control channel [2]. Its decoding methods include Successive Cancellation (SC) [1], Belief Propagation (BP) [3] and Successive Cancellation list (SCL) [4]. SC decoding is simpler but it does not have parallel structure. BP decoding is an iterative message passing procedure and has parallel structure and doesn’t need many iterations. In addition to the additive white Gaussian noise (AWGN) considered in most Polar code decoding papers, the non-Gaussian noise such as the impulse noise has a more serious impact on communication systems.
The impulse noise exists in wired and wireless communications channels by experimental measurements [5,6,7] such as urban outdoor/indoor mobile [8, 9], power-line communications [10, 11] because of man-made electromagnetic interference etc.
The impulse noise is different from the AWGN. The energy of impulse noise is often tens of times that of the AWGN. Impulse noise models can be divided into memory noise channels like Markov-Gaussian channel models [10, 12,13,14,15], and memoryless noise channels like Bernoulli-Gaussian (BG) [16,17,18] and Additive White (Middleton) Class A Noise (AWAN) [19,20,21,22]. The works on the Polar code decoding in the impulse noise channels are [19, 23, 24]. Tseng et al. [19, 23] used SC to decode the Polar code in the memoryless impulse noise channels with different cases like known statistical features, position or not [24]. Compared the SC and BP on Polar code with memoryless impulse noise with different situation like [23].
Deep learning is popular in many areas like image classification [25], speech recognition [26], and radio resource allocation [27, 28]. Machine learning needs separate feature extraction. Deep learning has embedded feature extraction and uses deep nueural network (DNN) composed of multiple layers of nonlinear processing units. The DNN learns data representation with multiple abstraction levels. Deep learning can learn complex structures in training sets to adjust the neuron weights [29]. There are special cases of DNN. The convolutional neural network (CNN) realizes spatial correlations [30, 31]. The recurrent neural network (RNN) [32] realizes the temporal correlations and is suited to sequential data [33]. To solve the gradient explosion problem of RNN, a Long Short-Term Memory (LSTM) model [34] that can be remembered for a long time emerges from RNN.
Recent years, many researchers try to use deep learning for channel coding [35,36,37,38,39,40,41]. Kim et al. [35] used RNN and Neural Recursive Systematic Convolutional (N-RSC) to train convolutional codes and Turbo codes on the AWGN channel and test it on the non-AWGN channel which show better performance than convolutional Turbo decoder. Liang et al. [36] proposed LDPC decoder using BP-CNN, CNN extracts the feature of the color noise (correlated noise is similar to spatial correlation of an image) and removes the BP decoding error in a way similar to image denoising. It showed BP-CNN is better than the BP decoder under the general color noise environment. Cammerer et al. [37] partitioned the 128 bit long Polar code encoding graph in to blocks and trained separately. These neural network decoders are connected to BP decoding. Gruber et al. [38] used deep neural network for decoding Polar and random code with 16–64 bit codeword length and showed the performance of Polar code is better than random code. Irawan et al. [39] extended [38] to fading channels for (16, 8) Polar code. Lyu et al. [40] compared DNN, CNN, and RNN for Polar code decoding. Gross et al. [41] proposed to partition Polar encoding graph too but to connect to SC decoding instead. It showed the same performance and 43.5% reduction in latency than [37] for a (128, 64) Polar code. The above deep learning Polar cod decoding papers, however, did not consider the impulse noise.
The main objective or research problem that this paper want to address is deep learning based Polar code decoding in the memeory impulse noise channels. We considered short Polar code (16,8), the same as the prior works [38, 39] for comparison. For longer code length, we could add more layers in DNN/CNN, or stack more LSTM cells in every time step [40]. The impulse channels exist in realistic environment [5,6,7,8,9,10,11] but it requires more complicated statistics for Polar code decoding like known statistical features (average number of impulses in a code word), the positions of the impulses in a codeword, the state transition probability to and from the states with the impulse noise or not, etc. [15, 19, 23], so the other existing works do not consider the impulse noise channel.
The reasons why deep learning or LSTM is selected for Polar code decoding are as follows. First, non-deep learning-based Polar code decoding required iterative operations and has no parallel structure, so it has high computation complexity and thus high decoding latency [38]. The deep learnning for Polar code decoding has inherently parallel structure and is a one-shot operation [38]. That is, there is no iterative steps and thus reduce the complexity by 30% or more [42, 43]. Second, Polar decoding is a sequential decoding problem [43]. That is, there is long time dependency within the codeword [44] and LSTM is built for exploiting the temporal correlation. Finally, the memory impulse noise we considered in this paper has temporal memory, this is one more reason to select LSTM which is naturally fit to deal with temporal correlation for Polar code decoding.
In this paper, we propose LSTM (deep learning) based decoder for Polar code in the memory impulse noise channel. The contribution is as follows:
-
1.
Previous papers [19, 23, 24] which did not use deep learning only considered the memoryless impulse noise and AWGN.
-
2.
Previous papers [38,39,40,41,42,43,44] which decoded using deep learning didn’t consider the impulse noise.
-
3.
We find the optimal training SNR value 4.5 dB in the memory impulse channel, which is different from that 1.5 dB in the AWGN channel in [38, 40]. Based on the optimal training SNR value we found, the bit error probabilityt of the proposed LSTM-based decoding method is one third of that of the previous non-deep-learning based schemes for the testing SNR range 0 ~ 6 dB.
-
4.
The proposed LSTM-based method is 5 ~ 12 times less and thus has much less decoding latency than that of SC/BP/SCL methods because the proposed LSTM-based method has inherently parallel structure and has one shot operation- no iterative operations.
2 System Model
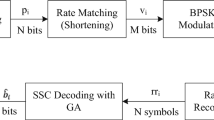
The Polar code encoder and decoder block diagram is shown in Fig. 1. The decoder is replaced by LSTM based Polar coder decoder.

Polar code decoder system model
2.1 Markov-Gaussian (MG) Impulse Noise Channel Model
The MG noise model is shown in Fig. 2. The MG channel is a hybrid two state Markov chain and generated by a Gaussian process, while state1 (j = 1) represents the Gaussian noise only, state2 (j = 2) represents the impulse noise. MG channel model describes the burst channel, we assume that the received signal:
where \(x\) is the transmitted signal with bit energy \({E}_{b}\), \(\omega\) is the noise, and it has two states, \({state}_{1}\) is the AWGN, and \({state}_{2}\) is the impulse noise. Then, the probability density functions (PDF) of \(\upomega\) is:
where \({\sigma }_{G}^{2}\) is the variance of the Gaussian noise, and \(R\) is the impulse noise power over the Gaussian noise power. The SNR is defined as \(\frac{{E}_{b}}{{\sigma }_{G}^{2}}\).

State diagram of Markov-Gaussian noise model
The channel state transition probabilities are expressed as:
\({state}^{*}\) is the next state.
The state transition probability matrix of the MG impulse noise channel is as follows:
The matrix element must satisfy:
and \({P}_{state1}\), \({P}_{state2}\) can be expressed as:
According to [12, 15, 16], we set the matrix M as:
2.2 Polar Code
The Binary Discrete Memoryless Channel (B-DMC) is assumed channel splitter and channel combining to make channel polarization [1]
2.2.1 Channel Polarization
Channel polarization is the repeated use of any B-DMC in a recursive manner, and through channel splitting and channel combination. The original independent B-DMC is turned into a polarized channel with a certain relationship, and so many the sub -channels will have different reliabilities. When the encoding length N is larger, the more polar sub-channels, the channel capacity of some polar sub-channels will approach 1 and become the perfect channel. The rest sub-channels are the opposite. Their channel capacity will approach zero, making it a poor channel for pure noise. The transmission of the polarization code is to use the channel whose channel capacity is close to 1 to transmit the message, and the channel closer to 0 will transmit the frozen bits.
2.2.2 Encoder
The encoder is to form a butterfly architecture for channel merging and select a sub-channel with better channel capacity for message transmission. The polarization code encoding method with length N which is u through the generator matrix form \({G}_{N}\) and then through each channel:
\({G}_{N}\) is the matrix with code length N, \({G}_{N}\) is generated using the matrix \(\mathrm{F}=[\begin{array}{cc}1& 0\\ 1& 1\end{array}]\) via Kronecker power:
\({F}^{\otimes n}\) Kronecker power is define as:
Only the sub-channel with the better channel capacity is selected for transmission, and the remaining sub-channels transmit frozen bits known in advance by the encoding and decoding end, so (11) can be rewritten in more details:
A is the set of original signals, \({A}^{c}\) is set of frozen bits (= zeros).
2.2.3 Decoder
Assume a parameter (N, K, A, \({A}^{c}\)), The encoder makes \({\mathrm{u}}_{i}\) into \({\mathrm{d}}_{i}\) and transmits it through the channel C. The decoder uses the two parameters known in advance with the encoder, The first one is the transmits message A, the second is the frozen bit \({A}^{c}\), and estimate \({\mathrm{u}}_{i}\) with the received signal \({\mathrm{y}}_{i}\), then get the predicted result \(\widehat{{u}_{i}}\). The decoder has already known the location and information of the frozen bit, so the \({\widehat{u}}_{{A}^{c}}\) must be equal to \({u}_{{A}^{c}}\), we only need to estimate the remaining information to get \({\widehat{u}}_{A}\).
Three common decoding methods will be used in this work to compare: Successive Cancellation (SC), Belief Propagation (BP), Successive Cancellation List (SCL).
Due to the limitation of space, we only describe SC in details. Please refer to references [3, 4] for details of BP and SCL.
SC decoding method was proposed in [1]. It can be known from the encoding principle that the construction of the Polar code is the choice of the channel, and this selection method is selected according to the optimal SC performance as the standard. The channel has the channel reliability, SC decoding is to judge the log likelihood ratio (LLR) of each bit from small to large, each step of decoding will need to use the previous results, so under the condition of correct decoding, the channel capacity will be reached, and the longer the Polar code, the easier the channel capacity is reached.
The estimated value \(\widehat{{u}_{i}}\) during decoding will be determined according to (15).\({y}_{1}^{N}\) is the first bit of receive signal with length N. As mentioned before, when it is a frozen bit, \({u}_{i}\) must be equal to \(\widehat{{u}_{i}}\). Where \({h}_{i}\) is the decision equation decoded for this:
\({L}_{1,i}\) is the LLR of \(\widehat{{u}_{i}}\):
W is the set of channel after channel polarization, \(W(\mathrm{y}|\mathrm{u}=0)\) is the channel transmission probability.
The SC decoding recursion can be expressed as (18):
L is LLR, \({\mathrm{L}}_{\mathrm{j},\mathrm{i}}\)’s j and i respectively represent the jth recursion in the coding structure and the ith bit in this structure. \(1\le \mathrm{j}\le \mathrm{n}, 1\le \mathrm{i}\le \mathrm{N}\).
We define two functions:
and (18) can be rewritten as:
when (18) updates, it is estimated one by one, and the result of previous bit will use in the next bit.
After receiving \({y}_{1}^{N}\), the decoder can first calculate the initial LLR \({L}_{n,i}\), and it is updated by the operation of (18) to obtain \({L}_{1,i}\) and use (15, 16) to estimate \(\widehat{{u}_{i}}\). After estimating \(\widehat{{u}_{i,j}}= {\mathrm{S}}_{\mathrm{i},\mathrm{j}}\), The decoder could use (22, 23) to push back \({\mathrm{S}}_{\mathrm{i}+1,\mathrm{j}}\) and \({\mathrm{S}}_{\mathrm{i},\mathrm{j}+{2}^{\mathrm{i}-1}}\),. After the calculation and update of formula (18), the decoder could calculate \({L}_{1,i}\) of the next message, and use (15) and (16) to estimate the next \(\widehat{{u}_{i}}\).
As shown in Fig. 3, first go the orange line using f function defined in (19) with \({L}_{\mathrm{1,1}}\) and \({L}_{\mathrm{1,2}}\) to calculate the LLR of \(\widehat{{u}_{1}}\) and use (15), (16) to estimate the \(\widehat{{u}_{1}}\). Next, we go the blue line using g function defined in (20) with \(\widehat{{u}_{1}}\) and \({L}_{\mathrm{1,1}}\) and \({L}_{1,2}\) to get the LLR of \(\widehat{{u}_{2}}\), then put it to (15), (16) to estimate \(\widehat{{u}_{2}}\).

Unit structure SC decoding
3 The Proposed Deep-learning Based Decoding for Polar Code
3.1 Long Short-Term Memory(LSTM)
In this work, we use a 2-layer LSTM with a hidden layer size set to 256 and use sigmoid as the output process as shown in Fig. 4. \({Y}^{t}\) is the training data (the received signal after impulse noise, and the orginal imformation bit) with different SNR and t is the time. A LSTM cell in Fig. 4 is shown in Fig. 5.

Two layer LSTM model

LSTM cell model
\({C}_{0}^{t}\) is the value in the memory cell (cell state) of the first layer LSTM cell in the time t which is a vector, \({h}_{0}^{t}\) is the first output solution of first LSTM cell (hidden state) in the time t. Next, \({C}_{0}^{t}\) and \({h}_{0}^{t}\) will put into second layer of LSTM Cell to help training. \({h}_{0}^{t}\) size is (128,256) which mean the size of data 128 and the hidden layer size of prediction output 256.
Finally, We get the hidden state output\({h}_{1}^{T}\), T mean the final time of t. We do the matrix multiplication with \({h}_{1}^{T}\) and put it to the sigmoid to get the the\(\widehat{u}\), which is (128, 8).
This is sigmoid function, the output is 0 ~ 1.
Z is the real input of LSTM, which is y and h multipe with weight W and weight U and add bias.
G(Z) is the value into the input gate.
\({Z}^{i}\) is the control value, which decide whether G(Z) can put in memory cell, the value of \(\mathrm{S}({Z}^{i})\) will approximate 0 or 1
\({Z}^{o}\) is the control value, which decide whether the tanh multiply memory cell value can be output, the value of \(\mathrm{S}({Z}^{o})\) will approximate 0 or 1
\({Z}^{f}\) is the control value, which decide whether the value can be forgot or not, the value of S(\({Z}^{f})\) will approximate 0 or 1
(30) is the value in the memory cell, cell state, we can see if S(\({Z}^{f})=0\), then the value of input will replace the value of cell (forget), if S(\({Z}^{f})=1\) it will add up with input become new value.
(31) is the hidden state output, which is the real output, it is control by \({Z}^{o}\) if \(S({Z}^{o})\) is 0, then we can’t transmit the output.
3.2 Training Data
The purpose of the decoding is to find the optimal map function, \({f}^{*}=Y\to X\), Y is the set of all possible y and U is the set of all possible of u. \({f}^{*}\) should satisfy maximum a posteriori (MAP) criterion:
In deep learning, if want to train the neural network, we need a lot of data and then define the loss function.
-
I.
Generating training samples: To train the NN, we generate a large number of received signals y, and the real information bits x. The received vector y is x plus the impulse noise. Taking y as the training data and x as the labeled output to train the model to estimate y to obtain \(\widehat{{u}_{i}}\).
-
II.
Loss function: It is a very important parameter in NN. It measures the difference between the labeled output and the neural network (NN) output. In this paper, we define loss function as:
$$L_{MSE} = \frac{1}{K}\mathop \sum \limits_{i = 0}^{K - 1} \left( {u_{i} - \hat{u}_{i} } \right)^{2}$$(33)where \(u_{i} = \left\{ {0,1} \right\}\) is the i-th labeled output (correct information bit). \(\hat{u}_{i}\) is the i-th of NN output (estimated information bit).
3.3 Validation
During training, the signal-to-noise ratio (SNR) \({\rho }_{t}\) during training must be defined. Because in the actual decoding stage, the SNR is unknown and will change with time, the performance of our NN decoder will be greatly affected by the SNR during training, so we use a performance metric—the normalized validation error (NVE) [38]
where \({\rho }_{v,s}\) represents the s-th SNR in a set of S different verification samples, \({BER}_{NND}({\rho }_{t},{\rho }_{v,s})\) represents the BER obtained by NN decoder training SNR \({\rho }_{t}\). \({BER}_{MAP}({\rho }_{v,s})\) is the BER of MAP decoding at the SNR \({\rho }_{v,s}\). The intention of this method is measuring the performance of NN decoder trained on a specific SNR compared to MAP decoding in different ranges of SNR. From (34), we can know that the less the NVE, the better the NN decoder, and there will be an optimal \({\rho }_{t}\). So, we train the NN decoder with datasets of different \({\rho }_{t}\) in our work, and choose the optimal \({\rho }_{t}\) which results in the least NVE.
In Fig. 6, we can see the SNR of 4.5 dB has the best performance, we choose this SNR as our NN decoder’s training SNR, so there is only one NN model and training data are of SNR 4.5 dB, and testing data are of SNR in 0 ~ 6 dB (13 different SNR values). The optimal training SNR in the impulse noise channel is different from that in the AWGN channel. In the prior work [38], the optimal training SNR is 1.5 dB, not 4.5 dB, for the same testing SNR range 0–6 dB.

NVE training \({E}_{b}/{N}_{0}\) for 16 bit length codes in impulse noise
4 The Numerical Results
4.1 Setting Environment of the Proposed Method and Comparing Methods
We compare the following schemes: NN (proposed), SC (comparing), BP (comparing), SCL (comparing), MAP (comparing). The common setting environment/ parameters of all schemes are listed in Table 1. We use the same (16,8) Polar code as prior works without impulse noise [38, 39].
The unique setting environment/ parameters for each method is as follows. The number of iterations for BP method is 100. We try 50,100, 200 iterations [24] and found 100 and 200 iterations have similar performance, so we set 100 iterations for BP method. The list size for SCL method is 2. We try list size 2,4,8,16 [4] and find they have similar performance so I select list size 2 for SCL method. In this work we don’t set the CRC for SCL. The hyperparameters for the proposed NN method are listed in Table 2.
One important finding is that the optimal training SNR in the impulse noise channel is different from that in the AWGN channel. In the prior work [38], the optimal training SNR is 1.5 dB, not 4.5 dB in Fig. 6, for the same testing SNR range 0–6 dB (Table 1).
4.2 Simulation Results
4.2.1 In the AWGN
Figure 7 shows the BERs of the proposed deep learning based decoding scheme (NN) and previous non-deep-learning based schemes SC/BP/SCL and the MAP bound are close to each other’s.

AWGN
4.2.2 In the Impulse Noise
For Markov Gaussian memory impulse noise channel with state transition matrix in (10), we compare the BERs of the proposed deep learning based decoding scheme (NN) and previous non-deep-learning based schemes SC/BP/SCL and the MAP bound in Fig. 8.

Impulse noise
We can see all decoders under the impulse noise has a BER gap with the MAP bound, but the BER of proposed NN decoder is about one third of that of SC, SCL, and BP. One finding is that the NN decoder could learn to a degree the memory impulse noise. For comparison SC/BP/SCL/MAP perform poorly when the noise model in not exactly AWGN. Thus, the proposed NN decoded is more suited to memory impulse noise channel than previous SC/BP/SCL decoding schemes.
Another finding is that the proposed LSTM-based method is 5 ~ 12 times less and thus has much less decoding latency than that of SC/BP/SCL methods because the proposed LSTM-based method has inherent parallel structure and has one shot operation- no iterative operations.
5 Conclusion
Deep learning-based Polar code decoding method has parallel structure in nature and has lower execution time and thus decoding latency. However, prior works do not consider memory impulse channels which has more complicated statistical model about average number of impulses in a codeword and the positions of the impulses in a codeword etc. In this paper, we propose the use LSTM for the Polar code decoding under the Markov Gaussian memory impulse noise channels. For the SNR range 0 ~ 6 dB, we find the optimal SNR value 4.5 dB, which is different from the 1.5 dB in the AWGN channel found in [38, 40]. The data set with training SNR 4.5 dB is used to train the proposed LSTM-based Polar code decoding method. The bit error probability of the proposed LSTM-based method is only one-third that of the conventional SC/BP/SCL decoding schemes under Markov Gaussian channels, and 5 ~ 12 times faster in execution time and decoding latency.
Availability of data and material
Not applicable.
Code availability
Not applicable.
References
Arikan, E. (2009). Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Transactions on Information Theory, 55(7), 3051–3073.
Hui, D., Sandberg, S., Blankenship, Y., Andersson, M., & Grosjean, L. (2018). Channel coding in 5G new radio: A tutorial overview and performance comparison with 4G LTE. IEEE Vehicular Technology Magazine, 13(4), 60–69.
Arikan, E. (2010). Polar codes: A pipelined implementation. In: Proceedings of 4th ISBC, (pp. 11–14).
Tal, I., & Vardy, A. (2015). List decoding of polar codes. IEEE Transactions on Information Theory, 61(5), 2213–2226.
Wang, X., & Rong, C. (2001). Blind turbo equalization in Gaussian and impulsive noise. IEEE Transactions on Vehicular Technology, 50(4), 1092–1105.
Axell, E., Wiklundh, K. C., & Stenumgaard, P. F. (2015). Optimal power allocation for parallel two-state Gaussian mixture impulse noise channels. IEEE Wireless Communications Letters, 4(2), 177–180.
Axell, E., Eliardsson, P., Tengstrand, S. Ö., & Wiklundh, K. (2017). Power control in interference channels with class a impulse noise. IEEE Wireless Communications Letters, 6(1), 102–105.
Blackard, K., & RappaportBostian, T. C. (1993). Measurements and models of radio frequency impulsive noise for indoor wireless communications. IEEE Journal on Selected Areas in Communications, 11(7), 991–1001.
Blankenship, T., et al. (1997). Measurements and simulation of radio frequency impulsive noise in hospitals and clinics. In: Proceedings of 1997 IEEE 47th vehicular technology conference (VTC), vol.3, (pp. 1942–1946).
Tseng, D.-F., Mengistu, F. G., Han, Y. S., Mulatu, M. A., Chang, L.-C., & Tsai, T.-R. (2014). Robust turbo decoding in a Markov Gaussian channel. IEEE Wireless Communications Letters, 3(6), 633–636.
Tseng, S.-M., Lee, T.-L., Ho, Y.-C., & Tseng, D.-F. (2017). Distributed space-time block codes with embedded adaptive AAF/DAF elements and opportunistic listening for multihop power line communication networks. International Journal of Communication Systems, 30(1), e2950.
Fertonani, D., & Colavolpe, G. (2009). On reliable communications over channels impaired by bursty impulse noise. IEEE Transactions on Communications, 57(7), 2024–2030.
Cheffena, M. (2012). Industrial wireless sensor networks: Channel modeling and performance evaluation. EURASIP Journal of Wireless Communications Networking, 2012(297), 1–8.
Alam, M., Labeau, F., & Kaddoum, G. (2016). Performance analysis of DF cooperative relaying over bursty impulsive noise channel. IEEE Transactions on Communications, 64(7), 2848–2859.
Tseng, S.-M., Wang, Y. C., Hu, C. W., & Lee, T. C. (2018). Performance analysis of CDMA/ALOHA networks in memory impulse channels. Mathematical Problems in Engineering, 2018, 9373468.
Ghosh, M. (1996). Analysis of the effect of impulse noise on multicarrier and single carrier QAM systems. IEEE Transactions on Communications, 44(2), 145–147.
Shongwe T, Vinck, AJH, Ferreira, H. C. (2014). On impulse noise and its models. In Proceedings of 18th IEEE international symposium on power line communications and its applications, (pp.12–17).
Han B, Schotten, H. D. (2018). A fast blind impulse detector for Bernoulli-Gaussian noise in underspread channel. In: Proceedings of 2018 IEEE international conference on communications (ICC) (pp. 1–6).
Tseng D.-F, Lin, Y-D, Tseng, S-M. (2020) Practical polar code construction over memoryless impulse noise channels. In: Proceedings of 2020 IEEE 91st vehicular technology conference (VTC2020-Spring), (pp. 1–5,).
Middleton, D. (1977). Statistical-physical models of electromagnetic interference. IEEE Transactions on Electromagnetic Compatibility, EMC-19(3), 106–127.
Laere V Bette, S., Moeyaert, V. (2016). Poster: ITU-T G. 9903 performance against middleton class-A impulsive noise. In: Proceedings of 2016 symposium on communications and vehicular technologies (SCVT) (pp. 1–6).
Al-Rubaye, G., Tsimenidis, C. C., & Johnston, M. (2018). Performance evaluation of T-COFDM under combined noise in PLC with log-normal channel gain using exact derived noise distributions. IET Communications, 13(6), 766–775.
Chen W. (2018). Polar code over memoryless impulse noise channels. M.S. paper, Department of Electrical Engineering, National Taiwan University of Science and Technology, Taipei, Taiwan.
Lin Y.-D. (2019), Polar code over different decoding method for performance analysis comparison. M.S. paper, Department of Electrical Engineering, National Taiwan University of Science and Technology, Taipei, Taiwan.
Krizhevsky A., Sutskever, I, Hinton, G. E.,. (2012). ImageNet classification with deep convolutional neural networks. In: Proceedings of advances in neural information processing systems,(pp. 1090–1098).
Hinton, G., Deng, L., Yu, D., Dahl, G., Mohamed, A.-R., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T., & Kingsbury, B. (2012). Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29(6), 82–97.
Tseng, S.-M., Chen, Y.-F., Tsai, C.-S., & Tsai, W.-D. (2019). Deep-learning-aided cross-layer resource allocation of OFDMA/NOMA video communication systems. IEEE Access, 7, 157730–157740.
Tseng, S.-M., Tsai, C.-S., & Yu, C.-Y. (2020). Outage-capacity-based cross layer resource management for downlink NOMA-OFDMA video communications: Non-deep learning and deep learning. IEEE Access, 8, 140097–140107.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521, 436–444.
LeCun Y, Denker J. S, Henderson D, Howard R. E, Hubbard W, Jackel L. D. (1990). Handwritten digit recognition with a back-propagation network. In: Proceedings of advances in neural information processing systems, (pp. 396–404).
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of IEEE, 86(11), 2278–2324.
Werbos, P. (1990). Backpropagation through time: What it does and how to do it. Proceedings of the IEEE, 78(10), 1550–1560.
Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of conference on empirical methods in natural language processing, (pp. 1724–1734,).
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Kim, H, Jiang, Y., Rana, R., Kannan, S., Oh, S., Viswanath, P. (2018). Communication algorithms via deep learning. In: Proceedings of international conference on learning representations (ICLR).
Liang, F., Shen, C., & Wu, F. (2018). An iterative BP-CNN architecture for channel decoding. IEEE Journal of Selected Topics in Signal Processing, 12(1), 144–159.
Cammerer, S, Gruber, T., Hoydis, J., ten Brink, S. (2017) Scaling deep learning-based decoding of polar codes via partitioning. In: Proceedings of 2017 IEEE Global Communications Conference, (pp. 1–6).
Gruber, T, Cammerer, S., Hoydis, J., ten Brink, S. (2017). On deep learning-based channel decoding. In: Proceedings of 2017 51st annual conference on information sciences and systems (CISS), (pp. 1–6).
Irawan, A., Witjaksono, G., Wibowo, W. K. (2019). Deep learning for polar codes over flat fading channels. In: Proceedings of 2019 international conference on artificial intelligence in information and communication (ICAIIC) (pp. 488–491).
Lyu, W., Zhang, Z., Jiao, C., Qin, K., Zhang, H. (2018). Performance evaluation of channel decoding with deep neural networks. In: Proceedings of 2018 IEEE international conference on communications (ICC), (pp. 1–6).
Doan, N., Hashemi, S. A., Gross, W. J. (2018). Neural successive cancellation decoding of polar codes. In: Proceedings of 2018 IEEE 19th international workshop on signal processing advances in wireless communications (SPAWC), (pp. 1–5).
Gross, W., Doan, N., Mambou, E. N., & Hashemi, S. A. (2020). Deep learning techniques for decoding polar codes. In F.-L. Luo (Ed.), Machine learning for future wireless communications (pp. 287–301). Wiley.
Chen, C. -H., Teng, C-F, Wu, A-Y (2020). Low-complexity LSTM-assisted bit-flipping algorithm for successive cancellation list polar decoder. In: Proceedings of 2020 IEEE International conference on acoustics, speech and signal processing (ICASSP), (pp. 1708–1712).
He, B., Wu, S., Deng, Y., Yin, H., Jiao, J., Zhang, Q. (2020). A machine learning based multi-flips successive cancellation decoding scheme of polar codes. In: Proceedings of 2020 IEEE 91st vehicular technology conference (VTC2020-Spring), (pp. 1–5).
Funding
This study was funded by the Ministry of Science and Technology, Taiwan, (Grant Number MOST 109–2221-E-027-087).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tseng, SM., Hsu, WC. & Tseng, DF. Deep Learning Based Decoding for Polar Codes in Markov Gaussian Memory Impulse Noise Channels. Wireless Pers Commun 122, 737–753 (2022). https://doi.org/10.1007/s11277-021-08923-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08923-0