
Abstract
Communication overhead is a major concern in wireless sensor networks because of inherent behavior of resource constrained sensors. To degrade the communication overhead, a technique called data aggregation is employed. The data aggregation results are used to make crucial decisions. Certain applications apply approximate data aggregation in order to reduce communication overhead and energy levels. Specifically, we propose a technique called semantic correlation tree, which divides a sensor network into ring-like structure. Each ring in sensor network is divided into sectors, and each sector consists of collection of sensor nodes. For each sector, there will be a sector head that is aggregator node, the aggregation will be performed at sector head and determines data association on each sector head to approximate data on sink node. We propose a doorway algorithm to approximate the sensor node readings in sector head instead of sending all sensed data. The main idea of doorway algorithm is to reduce the congestion and also the communication cost among sensor nodes and sector head. This novel approach will avoid congestion by controlling the size of the queue and marking packets. Specifically, we propose a local estimation model to generate a new sensor reading from historic data. The sensor node sends each one of its parameter to sector head, instead of raw data. The doorway algorithm is utilized to approximate data with minimum and maximum bound value. This novel approach, aggregate the data approximately and efficiently with limited energy. The results demonstrate accuracy and efficiency improvement in data aggregation.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Wireless sensor networks [3] consist of a large number of sensor nodes which are densely deployed in a harsh environment for detecting relevant quantities, monitoring and collecting the data, assessing and evaluating the information, formulating meaningful user displays and performing decision making [11]. Nowadays, wireless sensor networks are widely used in applications such as military surveillance, battle fields etc. A wireless network contains tiny resource bounded sensors, which are furnished with non-rechargeable batteries, so transmission consumes lots of energy. Hence to avoid this constraints, communication overhead has to be degraded [11, 26]. In large sensor networks, huge amount of data is being generated, which results in data redundancy. To overcome this problem a technique called as data aggregation [23] has to be taken into account. This data aggregation technique [21] efficiently reduces data redundancy and saves energy [4]. In many applications of wireless sensor networks, it is unnecessary to collect entire data set from resource constrained WSN. In wireless sensor network, sending huge amount of data directly to sink may cause several difficulties. The problem occurs here are the data quality gets lost because of packet loss and collecting large amount of data leads excessive communication traffic. Due to this the 10 lifetime of sensor nodes gets decreased.so the data aggregation strategy [19] must be designed cautiously to minimize energy consumption and to increase the lifetime of the network as much as possible. For persistent data collection in wireless sensor networks with constrained bandwidth, approximate data aggregation [18] is a wise choice. A recent application of wireless sensor networks needs to collect the data efficiently and approximately due to constraints in communication bandwidth and energy budget [27].
In this paper, we consider the problem of data collection in physical environments where different sensors containing data are correlated. The correlated data being collected can be biased by approximately fusing the data inside the network and reduces the energy consumption and number of transmission for data collection process. To achieve this, the data aggregation tree semantic correlation tree (SCT) that adventures correlation strategies can be expanded. The semantic correlation tree [11, 29] is also called spatial correlation tree. This method suggests a sector based data aggregation scheme. SCT divides a sensor network into ring like structure. It considers a circular wireless sensor network in which the sink will be placed at the center. By utilizing SCT [3, 12], the network is divided into ‘n’ concentric rings, where each ring has the same width. Each ring in sensor network is divided into sectors, and each sector consists of same number of sensor nodes. For each sector, there will be a sector head that is aggregator node, the aggregation will be performed at sector head. The node which has more energy will be chosen as sector head. After the tree construction, the aggregated data will be transmitting to the sink by sector head.
In SCT, assumed that every sensor nodes must know their own geographical position. First sink broadcast its message to the sensor node, the message consist of the sink position, total number of nodes in an network, number of rings and sector, total number of nodes the sector containing. Once the node receives a message, each sensor node will discover which ring and sector the node belongs to. This SCT is described in Fig. 1.

Ring structure of SCT
Once the network is divided into circles and sectors, the aggregator node for each sector must be collected. The aggregator node will be chosen by finding a node which is closer to the geometric center of the lower arc of the sector is selected as an aggregator node. When a node in a sector has a data to send, first it calculates the geometric center and then sends the data to the node nearest to the center. If the node receives first packet, it takes the roll of data aggregator and broadcast the message to its entire neighbor and announcing that it is the aggregator for that sector. By receiving this message all its neighboring nodes will route their own packets to this aggregator node. The role of aggregator node will be shifted after few rounds to achieve load balancing [11]. If the aggregator node during transmission, the node which has more energy will be chosen as a aggregator node. The advantages of SCT are it requires low overhead to maintain the tree and does not require any centralized coordination and also addresses load balancing and node failures.
2 Related Works
2.1 Approximate Data Collection in Sensor Networks Using Ken Method
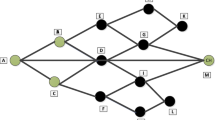
The Ken method in wireless sensor network is a robust approximate technique. The core challenge of this method is to maximize the lifetime of the network by minimizing energy consumption. Ken uses a replicated dynamic probabilistic model to reduce the communication between sensor node and base station. The key idea is to maintain a pair of dynamic probabilistic model over the network attributes. One copy is within the base station and another copy is within a sensor node. The base station computes the values expected by sensor net attributes according to the model. This method is also well suited to detect anomalous, in addition to data collection. The sensor node detects that the received value is not within a required error bound and it will route back the data to base station. The dis-advantage of using this technique is robust to communication failure that is, if the data lost during transmission it cannot be recovered. The advantage of this technique is that the readings which are visible to the user are with in fixed error bound [8] (Fig. 2).

Ken approach
2.2 Directed Diffusion : An Accessible and Robust Communication Model for Senosr Networks
Directed diffusion is a data centric approach, which is used for information gathering and broadcasting in wireless sensor networks. The main objective of this method is reduction in energy consumption [2]. To accomplish this, it will keep interact with their neighboring nodes and by using this interaction it will grasp a robust multipath delivery. The main elements used here are interest and gradients. In directed diffusion method sink broadcast its interest to its neighbor and it propagates throughout the network. Each node maintains interest cache, when a node receives an interest it will check for the matching entry in interest cache. If any matching entry is found it reply to the interest as gradient (the gradient is the response message). In this scenario the transmission will be reduced because of interested neighbor will be responded. The disadvantage of using this method, it’s not suitable for long term large scale wireless sensor networks [15, 16].
2.3 Similarity Based Adaptive Framework (SAF)
The similarity based adaptive framework method reduces the amount of communication in wireless sensor networks. SAF uses time series model [6] to predict the sensor reading. The idea of this technique is to build this model in each node and transmit to the root of the network called sink. The SAF method detects data similarities among the nodes and groups them into clusters [5]. Its main goal is to conserve energy by reducing transmission. The disadvantage of using this method is, it’s only taking an advantage of temporal [1] correlation with in the sensor data without considering the similar readings of nearby sensor nodes [10].
2.4 Model Driven Data Acquistion in Sensor Networks Using Bar-B-Q Method (BBQ)
Bar-B-Q method is a query based approach. This method is used to extract data from sensor networks. It is the first method which extracts data from sensor network by using Gaussian joint distribution model [7]. Gaussian model is used here to find correlations among sensor readings [20] by using the data extracted from the sensor networks. It has several drawbacks because of using Gaussian joint distribution model. First it is not suitable for large scale wireless sensor networks. Second, it needs to gather complete data set, gathering of complete data set is too energy consuming [22].
2.5 Constraint Chaining (CONCH) for Energy Efficient Continuous Monitoring in Sensor Networks
Constraint chaining is a continuous monitoring scheme. This scheme uses a spatial and temporal correlation [14, 20] to attain energy saving. In a sensor network, the values monitored are either spatially or temporarily correlated, it suggest that it’s not needed to report every value in every time if it is not changed from the existing value. The main intension is to build a minimal cost spanning forest in sensor network. Spanning a forest [5] is an input and it will assign reporter and updater at the edge, the role of the reporter is to report the base station if there is a change in value and the updater job is to update the value reported by the reporter. The disadvantage of using this technique is that it goes through update message overhead when the readings changes often [17, 24, 25].
2.6 Approximate Data Collection (ADC)
In wireless sensor network approximate data collection is a clever choice due to some bounds in energy and communication bandwidth. The method ADC divides a sensor network into cluster [1] and each cluster have its own cluster head and it determine data association on cluster heads, then performs approximation on sink node by using an parameter updated by an data model. The disadvantage of using this model is if the cluster head lost its energy then the entire communication will get stuck [12, 27].
3 Proposed Work
3.1 Local Estimation Model
The local estimation model is used to reduce the communication cost among sensor nodes and its cluster heads. By exploiting this local estimation model, the sensor node will estimate a newly generated reading from its historic data. Each sensor node sends its parameter of the local estimation data to its cluster head, instead of sending raw sensor readings. If the difference between the original value and the estimated value is smaller than a prespecified threshold, the sensor node doesn’t upload its data to cluster head. Consequently, the communication cost will be reduced. The sensor node will send an update message only when the difference between the original value and the estimated value exceeds the given threshold.
3.1.1 Local Estimation Updating
The model should be self-adaptive to environmental changes. To maintain the accuracy of the local estimation model, each node will periodically check the correctness of its local estimation model. If the estimation error is not within a required bound then we call it as an anomaly. The anomalies can be detected by each sensor node based on the history of its sensor data. The anomalies can be an outsider, which is temporarily different from its data model. Only when the distribution is changed, the local estimation model should be updated.
Notations used in local estimation algorithm are defined in Table 1.
The local estimation data gets updated according to the local estimation update message received and also checks for the estimation error. According to all local estimation update message (UM) received, the algorithm updates the message.
The local estimation algorithm is given by,

3.2 Doorway Algorithm
The doorway algorithm is based on random early detection (RED) gateway [27]. This algorithm is proposed mainly to reduce the congestion [9, 13] and also the communication cost among sensor nodes and cluster head. The doorway algorithm will avoid congestion by controlling the size of the queue and marking packets.
The local estimation model [10] is utilized to generate a new sensor reading from its historic data. The sensor node sends each one of its parameter to sector head, instead of raw data. The doorway algorithm is utilized to calculate the average queue size. It compares the average size of the queue with two threshold value it sets, that is maximum bound value and minimum bound value [28]. Based on the following criteria it will decide whether to transmit or drop. The following scenarios are:
-
If the average queue size is less than the minimum bound value, none of the packets will be marked.
-
If the average queue size is greater than the maximum bound value, the each and every packets will be marked and later it will be dropped.
-
If the average queue size is between the minimum bound value and maximum bound value, the arrived packets will be marked with the probability ‘pb’.
Queue length and time value comparison is shown in Fig. 3.
Notations used in doorway algorithm are defined in Table 2.
The doorway algorithm is given by,


Graph for finding queue limit
4 Simulation Results
Doorway algorithm is simulated in GloMoSim network simulator, a scalable discrete-event simulator developed by UCLA. This software provides a high fidelity simulation for wireless communication with detailed propagation, radio and MAC layers. The GloMoSim library is used for protocol development in sensor networks. The library is a scalable simulation environment for wireless network systems using the parallel discrete event simulation language PARSEC. Doorway algorithm is simulated in an area of \(1,000\times 1,000\) \(\hbox {m}^{2}\) and 300 sensor nodes. Simulations are performed with random distribution of sensor nodes. The performance of doorway algorithm implementation in SCT is compared with the cluster head approach. Some of parameters used in simulation are in Table 3.
The doorway algorithm is utilized to calculate the average queue size. It compares the average size of the queue with maximum threshold bound value and minimum threshold bound value with the help of historical data whish is received from the previous transactions. If the average queue size is between the minimum threshold bound value and maximum threshold bound value, received data will be considered as approximate data value and SCT node never send the sensed value to sink node. Therefore, we may reduce transmission energy level. If the received data greater than maximum threshold bound value or less than minimum threshold bound value, that value is called legitimate value and SCT node send the sensed value to sink node. compared with historical data.
In Fig. 4, the graph shows that the efficiency and accuracy obtained is high by implementing the algorithm called doorway in SCT. The doorway algorithm is utilized to calculate the average queue size. It compares the average size of the queue with maximum threshold bound value and minimum threshold bound value with the help of historical data which is received from the previous transactions. If the average queue size is between the minimum threshold bound value and maximum threshold bound value, received data will be considered as approximate data value and SCT node never send the sensed value to sink node. Therefore, we may reduce transmission energy level. If the received data greater than maximum threshold bound value or less than minimum threshold bound value, that value is called legitimate value and SCT node send the sensed value to sink node. Efficiency percentage is ratio between energy level of approximate value and energy level of legitimate value. Accuracy percentage is ratio between approximate value and legitimate value.

Graphs for SCT efficiency and accuracy
In Fig. 5, The X-axis represents number of nodes in an terrain and Y-axis represents efficiency in terms of percentage. Efficiency percentage is ratio between energy level of approximate aggregation value and energy level of legitimate value. The graph shows that efficiency of the SCT structure.

Simulation graph for SCT efficiency
In Fig. 6, the proposed doorway algorithm is implemented in cluster head based structure and compared with SCT structure. The X-axis represents number of nodes in an terrain and Y-axis represents efficiency in terms of percentage. Efficiency percentage is ratio between energy level of approximate aggregation value and energy level of legitimate value. The graph shows that efficiency of the SCT structure is better than cluster head (CH) structure.

Comparing efficiency between SCT and cluster head
In Fig. 7, The X-axis represents number of nodes in an terrain and Y-axis represents accuracy in terms of percentage. Accuracy percentage is ratio between approximate value and legitimate value. The graph shows that accuracy of the SCT structure.

SCT accuracy
In Fig. 8, the proposed method implemented in CH based structure and compared with SCT structure. The X-axis represents number of nodes in an terrain and Y-axis represents accuracy in terms of percentage. Accuracy percentage is ratio between approximate value and legitimate value. The graph shows that accuracy of the SCT structure is better than CH structure.

Comparison between SCT and cluster head accuracy
Figure 9 represents accuracy and efficiency results of both SCT structure and cluster head structure. X-axis represents number of nodes in an terrain and Y-axis represents accuracy and efficiency in terms of percentage. The graph results proves that SCT structure is more accurate and efficient than cluster head based structure.

Comparison graph for SCT and CH
5 Conclusion
Wireless sensor network are power controlled network. For transmitting and receiving data in wireless sensor networks require more energy than computation. Data aggregation is a technique which reduces energy consumption and also communication overhead by removing redundancy in the data. Data aggregation accuracy is essential for some application in wireless sensor network, Therefore, the proposed SCT, which divides sensor network into ring-like structure. SCT considers a circular wireless sensor network in which the sink will be placed at the center. Each ring in sensor network is divided into sectors, and each sector consists of same number of sensor nodes and for each sector there will be sector head. The aggregation will be performed at sector head by implementing doorway algorithm and determine data association in each sector head then transmit a required data to sink by eliminating redundant data and data which is not in a limited bound. This novel approach reduces the amount of message transmission in wireless sensor network and makes our approach more efficient.
References
Abbasi, A. A., & Younis, M. (2007). A survey on clustering algorithms for wireless sensor networks. Computer Communication, 30(14–15), 2826–2841.
Akyildiz, I. F., Vuran, M. C., & Akan, O. B. (2004). On exploiting spatial and temporal correlation in wireless sensor networks. In Proceedings of the WiOpt’04: Modeling and optimization in mobile, ad Hoc and, wireless networks (pp. 71–80).
Akyildiz, I. F., Su, W., & Sankarasubramaniam, Y. (2002). Wireless sensor networks: A survey. Computer Networks, 38(4), 393–422.
Anastasi, G., Conti, M., Di Francesco, M., & Passarella, A. (2009). Energy conservation in wireless sensor networks: A survey. Elsevier on Ad Hoc Networks, 7(3), 537–568.
Arun Kalav, D., & Gupta, S. (2012). Congestion control in communication network using RED, SFQ and REM algorithm. International Refereed Journal of Engineering Sciences, 1(2), 41–45.
Box, G., & Jenkins, G. M. (1994). Time series analysis: Forecasting and control. Englewood Cliffs, NJ: Prentice Hall.
Chatterjea, S., & Havinga, P. (2008). An adaptive and autonomous sensor sampling frequency control scheme for energy-efficient data acquisition in wireless sensor networks. In Proceedings of the IEEE 4th international conference on distributed computing in sensor systems (DCOSS ’08) (pp. 60–78).
Chu, D., Deshpande, A., Hellerstein, J.M., & Hong, W. (2006). Approximate data collection in sensor networks using probabilistic models. In IEEE Proceedings of the 22nd international conference on data engineering (ICDE ’06) (p. 48).
Deshmukh, W. (2007). A physical estimation based continuous monitoring scheme for wireless sensor networks. Computer Science Theses. Paper, 45.
Deshpande, A., Guestrin, C., Madden, S., Hellerstein, J., & Hong, W. (2004). Model-driven data acquisition in sensor networks. In Proceedings of the 13th international conference on very large data bases (VLDB ’04) (Vol. 30, pp. 588–599).
Ezhumalai, P., Manoj Kumar, S., Arun, C., & Sridaharan, D. (2009). Tree based aggregation algorithm design issues in wireless sensor networks. Wireless Sensor Network, 1, 306–315.
Fasolo, E., Rossi, M., Widmer, J., & Zorzi, M. (2007). In-network aggregation techniques for wireless sensor networks: A survey. IEEE on Wireless Communications, 14(2), 70–87.
Guestrin, C., Krause, A., & Singh, A. P. (2005). Near-optimal sensor placements in Gaussian processes. In Proceedings of the 22nd international conference on machine learning (ICML ’05) (pp. 265–272).
Guo, W., Xiong, N., Vasilakos, A. V., & Chen, G. (2011). Multi-source temporal data aggregation in wireless sensor networks. Wireless Personal Communications, 56(3), 359–370.
Intanagonwiwat, C., Govindan, R., & Estrin, D. (2000). Directed diffusion: A scalable and robust communication paradigm for sensor networks. In Proceedings on mobile computing (pp. 56–67).
Intanagonwiwat, C., Govindan, R., Estrin, D., Heidemann, J., & Silva, F. (2002). Directed diffusion for wireless sensor networking. IEEE/ACM Transaction on Networking, 11(1), 2–16.
Krause, A., Rajagopal, R., Gupta, A., & Guestrin, C. (2009). Simultaneous placement and scheduling of sensors. In Proceedings of the international conference on information processing in sensor networks (IPSN ’09) (pp. 181–192).
Li, H., Lin, K., & Li, K. (2011). Energy-efficient and high-accuracy secure data aggregation in wireless sensor networks. Elsevier Computer Communications, 34(4), 591–597.
Maraiya, K., Kant, K., Gupta, N. (2011). Wireless sensor network: A review on data aggregation. International Journal of Scientific & Engineering Research, 2(4).
Raichana, M. B., & Kulkarni, M. S. (2012). Performance analysis of networks using RED for congestion control. International Journal of Advanced Research in Computer Science and Electronics Engineering, 1(5), 109–117.
Rajagopalan, R., & Varshney, P. K. (2006). Data-aggregation techniques in sensor networks: A survey. IEEE Communication Surveys and Tutorials, 8(4), 48–63.
Silberstein, A., Braynard, R., & Yang, J. (2006). Constraint chaining: On energy-effcient continuous monitoring in sensor networks. In Proceedings of the ACM SIGMOD international conference on management of data (SIGMOD ’06) (pp. 157–168).
Thangaraj, M., & Punitha Ponmalar, P. (2011). A survey on data aggregation techniques in wireless sensor networks. International Journal of Research and Reviews in Wireless Sensor Networks (IJRRWSN), 1(3), ISSN 2047–0037.
The RED queing discipline, http://opalsoft.net/qos/DS-26.htm.
Tulone, D., & Madden, S. (2006). An energy efficient querying framework in sensor networks for detecting node similarities. In Proceedings of the 9th ACM international symposium on modeling analysis and simulation of wireless and mobile systems (MSWiM ’06) (pp. 191–300).
Vinoth Selvin, S., Manoj Kumar, S. (2012) Tree based energy efficient and high accuracy data aggregation for wireless sensor networks. In Proceedings of international conference on modelling optimization and computing (Vol. 38, pp. 3833–3839).
Wang, C., Ma, H., He, Y., & Xiong, S. (2012). Adaptive approximate data collection for wireless sensor networks. IEEE Transactions on Parallel and Distributed Systems, 23(6), 1004–1016.
Xu, H., Huang, L., Zhang, Y., Huang, He, Jiang, S., & Liu, G. (2010). Energy-efficient cooperative data aggregation for wireless sensor networks. Elsevier Parallel Distributed Computing, 70(9), 953–961.
Zhu, Y., Vedantham, R., Park, S.-J., & Sivakumar, R. (2008). A scalable correlation aware aggregation strategy for wireless sensor networks. Information Fusion, 9(3), 354–369.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Manoj Kumar, S., Rajkumar, N. SCT Based Adaptive Data Aggregation for Wireless Sensor Networks. Wireless Pers Commun 75, 2121–2133 (2014). https://doi.org/10.1007/s11277-013-1457-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-013-1457-5