
Abstract
Coverage is a significant performance indicator of wireless sensor networks. Data redundancy in k-coverage raises a set of issues including network congestion, coverage reduction, energy inefficiency, among others. To address these issues, this paper proposes a novel algorithm called complex alliance strategy with multi-objective optimization of coverage (CASMOC) which could improve node coverage effectively. This paper also gives the proportional relationship of the energy conversion function between the working node and its neighbors, and applies this relationship in scheduling low energy mobile nodes, thus achieving energy balance of the whole network, and optimizing network resources. The extensive simulation results demonstrate that CASMOC could not only improve the quality of network coverage, but also mitigate rapid node energy consumption effectively, thereby extending the life cycle of the network significantly.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
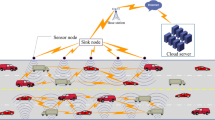
In wireless sensor networks (WSNs) [1–4], each sensor node has a set of capabilities, such as perception, computing, communication and storage [5–8]. Two important indicators of the performance of WSNs are network coverage quality and energy consumption. Coverage affects the quality of the merits of regional nodes deployed to monitor a given area [9–12]. The amount of available energy has a direct effect on the performance, functionality and lifetime of WSN [13]. Energy consumption affects the entire length of the life cycle of network and quality of service. A typical requirement is that every point of the whole monitored area can be covered by at least k sensors at any time, so called k-coverage. In general, nodes are randomly deployed because of the topography and environmental constraints. It is inevitable that the presence of randomness generates coverage blind spots in the monitored area. In order to achieve effective coverage of blind points, the only way is to add more nodes. However, existing methods have some drawbacks [14–17]. Firstly, due to the existence of the k-degree coverage, the data collection and calculation in the communication link would have a transfusion which results in significant uncertainty. Secondly, the essence of coverage is to cover one or several specific targets, rather than enshrouding the whole monitoring circumstances. A large number of nodes consuming more energy increases the probability of collapse of the entire network [18–20]. Finally, the existence of randomness inevitably leads to the excessive density of nodes in one particular monitoring area that results in bottleneck effects, eventually producing information redundancy, channel interference and reducing the network scalability.
To overcome the above drawbacks, we propose a novel energy policy with a valid node alliance covering algorithm called complex alliance strategy multi-objective optimization coverage (CASMOC). Clustering groups a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters). Alliance is defined as a pact, coalition or friendship between two or more parties, made in order to advance common goals and to secure common interests. Therefore, in this paper, the concept of alliance, rather than clustering, is used to highlight the common goal of optimizing coverage (rather than similarity highlighted by clustering) through the use of administrator nodes featured by high node energy, strong computing power and communication capabilities.
The contributions made by this paper could be summarized as follows:
-
This paper proposes to calculate the expectation value and proportional of coverage by fan-shaped area which is formed by the coverage of the target node when it is moving through the monitoring area.
-
With respect to energy, the paper presents a transmission solution process. For working sensor nodes, when the mobile node moves through the k target coverage area, under the premise of meeting a necessary coverage ratio, the adaptive conversion mechanism calls its node into a dormant state when the node energy is within the range of the threshold value or higher than the threshold. For other sensor nodes, the energy scheduling mechanism is used to complete the sensor node energy conversion process for the improvement of the network lifetime. In this paper, the time span from when the network system starts to when the first node “dies” is defined as the network life time. When a node “dies”, this will not affect the entire network life time significantly if the node is in multiple coverage (k> = 2).
The rest of the paper is organized as follows. Section 2 reviews various coverage algorithms. Section 3 introduces the network model and provides necessary definitions, theorems, corollaries and corresponding proofs. Section 4 presents the details of the proposed CASMOC algorithm. Performance evaluation results are presented in Sect. 5. Section 6 concludes this paper.
2 Related work
Coverage control is a fundamental problem in the field of WSNs because the extent of coverage quality directly affects the lifetime of the network. In recent years tremendous progress has been made in this area. Paper [21] aims to maximize two objectives by placing sensors and adjusting their sensing radius: (1) the coverage (formulated as the ratio of the covered positions by the total number of positions) and (2) the lifetime in the WSN while minimizing the number of sensors. In this paper, we introduce a new formulation of this problem, considering the evolution of the coverage under time, even if one or more sensors stops working. In addition to giving connectivity coverage agreement constitution methods and the proportional relationship between the quality of network coverage and network connectivity, Paper [22] presents a scheduling control algorithm (SCA) in order to meet the minimum number of nodes to ensure the connectivity of the entire network. Paper [23] introduces a solution which combines swarm algorithm from artificial intelligence and particle algorithms to realize the entire network monitoring. Local parameter α is introduced in paper [24] to achieve global optimization by multiple uses of local optimization. These algorithms achieve the effective coverage of the monitored area under certain circumstances, but there exist some deficiencies such as high complexity, intesive computation and poor extensibility. Paper [25] introduces a generic multi-objective optimization problem relating to wireless sensor network which consists of input variables, required output, objectives and constraints. A list of constraints is also presented to give an overview of different constraints which are considered while formulating the optimization problems in WSNs. Paper [26] proposes a maintained-Connection Coverage algorithm, which maintains network connectivity and coverage when the sensor nodes are in movement by using relative adjacency graph and the their own deployment features. The algorithm can maintain the network connectivity of any topology which is formed by the sensor node when moving in any direction, whereas the coverage characteristics of moving target node mainly depends on the constraints of network connectivity. Although to some extent, the algorithm can keep the network Connected Coverage, the effective coverage region is mainly local. Globally, when the number of the target nodes increases to a certain threshold, their coverage decreases. This reveals that this algorithm has some limitations.
Centralized cluster k cover configuration protocol is proposed in Paper [27], which analyzes the coverage protocol by using a constructed network model, and proposed four types of k degree overage configuration protocol, which are Centralized Randomized Connected k-Coverage (CERA_Ck); T-Clustered Randomized Connected k-Coverage (T-CRACCk); D-Clustered Randomized Connected k-Coverage (D-CRACCk) and Distributed Randomized Connected k-Coverage (DIRACCk). This paper proves that in the network model, when k ≥ 3 and the length of side of the reuleaux triangle formed is the perception radius r after coverage, at least k sensor nodes are needed. This paper also gives the comparison between the communication radius and the perception radius when k degree coverage is finished. In addition, this paper presents the process to calculate the minimum sensor nodes number to complete cover monitoring area, and the formula to calculate the density of needed sensor nodes. Though the research result has achieved the goal of effectively covering the target nodes in monitoring area, it has quite high algorithm complexity and heavy calculation burden, as well as harsh requirements deploying sensor nodes. Paper [28] proposes a maximized network life cycle k degree discrete barrier coverage algorithm. Its theoretical significance lies in analyzing the condition of upper and lower limitation of coverage of network model with concrete barrier, and complete effective covering moving target node. In terms of network energy consumption, a sensor node scheduling algorithm is proposed, which introduces greedy algorithm to redeploy the sensor nodes, completing state transition between sensor nodes using scheduling mechanism, thereby maximizing network life cycle. When covering the moving target node, the algorithm needs to guarantee that the distributed sensor nodes in the monitoring area are always connected or intersected. Once the moving target node appears on the “blind area” of coverage, the moving target node is not able to be effectively covered, which indicate that the network model is too idealistic. Paper [29] approaches the coverage problem from different perspectives and describes the evaluation metrics of coverage control algorithms. This paper also analyzes the relationship between coverage and connectivity, compares typical simulation tools, and discusses research challenges and existing problems in this area.
Paper [30] proposes a multi-objective coverage algorithm, based on the linear energy efficiency, which uses the cluster architecture. The optimal coverage of multiple target nodes can be obtained linearly through the calculation of coverage ability and the residual energy. Paper [31] proposes a coverage algorithm based on an event-driven mechanism which uses a probabilistic model to obtain results of node coverage and expectations and then optimize these results. Although these two algorithms could achieve optimal network coverage and extend the lifetime of networks, there are two major drawbacks: high complexity and harsh requirements of coverage. Paper [32] presents a maintained agreement that includes a redundancy computational model of sensor node’s radius which follows the normal distribution without geographic information. The coverage of the monitored area and the network lifetime could be improved by scheduling the sensor nodes through this computational model. This algorithm can solve the coverage problem and inhibit the energy consumption at the same time by scheduling the sensor nodes. However, high complexity and large computation still plague this algorithm. Paper [33] gives a distributed algorithm for autonomous mobile scheduling plan. Optimal coverage of the target node is done by a set of autonomous mobile sensor nodes. When a moving target node enters an autonomous group, the sensor node that has completed the first round coverage will pass configuration protocol to the next one. Through this process, it can archive the coverage of the whole autonomous set. Although the algorithm can cover a moving target, the model is too idealistic, therefore the process is difficult to implement in reality. Paper [34] proposes a coverage algorithm which utilizes the characteristics of exponential distribution to calculate the coverage quality, but the algorithm has quite high computation complexity. Paper [35] describes a maximum coverage node deployment method, based on genetic algorithm, which leverages Monte Carlo characteristics to achieve balanced coverage. This method accelerates the process of coverage and satisfies certain coverage requirements, yet it does not take the node energy consumption factors into account. The algorithms proposed in [36, 37] are based on the location information of sensor nodes as a prerequisite to calculate the coverage, but the location information of sensor nodes requires external positioning equipment, such as GPRS, which will introduce signal interference which will affect coverage accuracy and incur high cost. Paper [38] introduces an adaptive hierarchical WSN data collection framework that analyzes and forecasts the data by head node of cluster. The prediction model is also given in this framework, but it does not consider the energy consumption problem. Papers [39, 40] develop a node energy conversion model which can effectively suppress the consumption of the node based on the research of effective coverage problem [41, 42]. Although this model is good at the inhibition of the node energy consumption, the coverage effect on the concerned target node decreases. Wu [43] presents a distributed localization protocol which uses static nodes to implement the continuous coverage of the target, but the efficiency is lower than using dynamic nodes.
Traditionally, all the nodes distributed in the interconnected network are clustered according to the functional relationship between the sensor radius and the communication radius. When a moving target node passes through the cluster, the cluster head node turns on all the nodes within the cluster by sending information to the neighboring member nodes in its cluster. Whereas in this paper, the moving target node is covered by the fan-shaped areas formed by each part of the cluster members. In this way, a large amount of network energy is saved and thus the network life time is prolonged. In coverage, we only focus on the target node concerned, and improve their coverage.
On the premise of certain coverage [44–46], how to use least nodes to complete effective coverage of monitoring area, and how to use some kind of strategy to rationally configure between nodes, as well as by which kind of algorithm to reduce the unnecessary connectivity between the nodes to extend the network life cycle are the focuses in WSN research. Therefore, coverage is in a certain sense an important measurement of network service. To this end, this paper analyzes and investigates coverage from the following four aspects:
-
(1)
Conduct a comprehensive literature review, identify the advantages and disadvantages of all kinds of coverage of monitoring area, and then propose the main idea of the algorithm in this paper.
-
(2)
A WSN coverage model is constructed in this paper. For the network model, the proportion relationship between the coverage and the coverage expectation is proved, furthermore, least number of needed sensor nodes to cover the monitoring area is calculated; In the process of calculation, the proof process of coverage expectation value and variance in two level monitoring area is also given; when more than one target node become target nodes, the computation method is also proposed when covering multiple targets.
-
(3)
In terms of suppressing the energy consumption of nodes, this paper introduces the node control scheduling strategy to optimize the communication path between nodes by reducing unnecessary connectivity to prolong the network life cycle; for monitoring area, we prove the meaning of existence of the node energy attenuation limitation.
-
(4)
At last, with simulation experiment, this paper gives the coverage and the network life cycle curves using different parameters, as well as compares the algorithm proposed in this paper with other algorithms in the literature, which verifies the effectiveness of the algorithm of this paper.
This paper investigates the coverage problem of randomly deployed sensor nodes in monitoring area. By calculating network system performance index and proof, we give the process of resolving coverage expectation value and variance, we also give the proof process of the first mathematical expectation when the first round coverage is completed. Simulation experiments are carried out comparing the algorithm CASMOC of this paper and the other four kinds of algorithms. On the premise of the same coverage, by dynamic adjustment of the parameters, the algorithm of this paper eventually reached the goal that the number of nodes needed using this algorithm is less than the number of nodes needed using the other two algorithms, which verifies that less number of sensor nodes are needed to achieve effective coverage of monitoring area in this algorithm, thereby realizing the suppression of fast consumption of node energy and prolonging the network life time.
3 Network model and coverage quality
The development of the proposed CASMOC algorithm is based on the following assumptions:
-
(1)
Sensor nodes are isomorphic, and the sensing radius and communication radius is a circle.
-
(2)
The position information of sensor nodes could be obtained by GPS.
-
(3)
All sensor nodes have the same initial energy, sensing radius, and clock synchronization.
-
(4)
Sensor nodes are randomly deployed in the monitoring square l 2, and the sensing radius of nodes is far less than the length of l so that the boundary effect could be neglected.
3.1 Basic definitions
Definition 1
(Complete coverage) In the monitoring area, each target node is covered by at least one sensor node. The coverage for which Euclidean distance between the sensor node and the target node is less than the sensor node sensing radius, d (i,t) ≤ R s, called the complete coverage; set which is composed of the nodes that meet conditions, called the coverage set.
Definition 2
(k-coverage) In the monitoring region, that any target node is covered by at least k sensor nodes is called K-coverage. The monitoring area is called the k-coverage area.
Definition 3
(Coverage quality) Coverage quality is the ratio of the sum of all sensors node’s sensing area to the entire monitoring area. To some extent, it reflects the degree of target node coverage.
Definition 4
(Multi-level coverage ) Assuming p represents the probability value of any target node covered by at least one sensor node. Then the probability value when the target node is covered by multiple sensor nodes is:
In this formula, P n is multi-level coverage and n denotes the number of sensor nodes.
3.2 Network model
When some mobile target nodes enter the monitoring area and become the focus of the target node, it is required that the focus is on the mobile target node with k degree coverage. In order to save energy, when the moving target nodes move in/out of the region formed by the sensor nodes, the points of entry and exit, and sense center form a fan-shaped region. The fan region formed by four different angles of the four sensor nodes is shown in Fig. 1, where L is the side length of the square of the monitoring area. The target node tanks and soldiers are in the k = 4 degree coverage. We assume that the sensor node sensing radius is R s, then the fan area could be calculated as:
Let θ be α 1 + α 2 + α 3 + α 4, thus
The target node is always in a sensor node coverage area, so the whole network coverage rate is

k-Degree coverage network model
Theorem 1
For multi-level coverage, let k ≥ 3, if the edge length of any arcuate region and adjacent arcuate region are r s and r i respectively, then among the double arc area which is formed by these two regions, there exist k sensor nodes in the active state. We can say that this area is covered by k degree. r i is the side length of equilateral triangle which is formed by centers of sensor nodes.
Proof
Assume the monitoring area of network is a bow shaped grid region which is made of several arcuate regions. For any arcuate area in this region, there exists an adjacent arcuate neighbor. There are k active sensor nodes in the double arc area that is shaped by these two arcuate regions. Each arcuate region has the side length of r i. The maximum distance between any nodes in the double arc area and the triangle that is shaped by the two arcuate regions does not exceed r i, then these nodes should be covered by at least k nodes. Similarly this conclusion could be extended to any other arcuate region, then the entire monitoring area is k-coverage area. Thus this theorem has been proved. □
Theorem 2
In the monitoring area, the probability value that a target node is covered by a sensor node can be calculated as:
Proof
Let us suppose that R s is the sensing radius of sensor nodes which are randomly deployed among an l square area. The fan region whose angle is θ is a valid coverage area. Due to the fact that the sensing radius R s obeys the rule of normal distribution N(l,σ 2), for squared monitored area, the expectation of coverage is:
Let:
therefore
Substituting formula (4) and (8) into formula (6), then
Corollary 1
Under the condition of sufficient coverage, when we use the minimum number of sensor nodes to cover the monitoring area with multi-level coverage, the corresponding expectation value is:
Proof
The positions of all sensor nodes within the monitoring area are independent. According to Theorem 1, within the monitoring area, the expectation of any target node that is covered by at least one working node which belongs to coverage set is:
If there exist multiple working nodes N in the coverage set, the expectation of any target node which is covered by multi-level coverage could be obtained as
In a certain quality of coverage, there must be a very small number ε that satisfies the limitation as follows:
And then,
The expectation values of multi-level coverage are less than ε.
When the coverage of the monitoring area is complete, the expectation of the minimum number of sensor nodes to cover is obtained as given in Eq. (14).
Theorem 1 and Corollary 1 show the process of how to calculate coverage expectations and multi-level expectations. In general, a trajectory of a mobile target node is a fan area when it is covered by senor nodes in the monitoring area. The coverage expectation is calculated through probability and mathematical geometric theory. However, how to get the first coverage expectation is one challenge we must address when a mobile target node firstly enters the monitoring area. This is why Theorem 3 is introduced in this paper.
Theorem 3
When a mobile target node first enters the monitoring area, the expectation of initial coverage on a mobile node is E(X) = [1 − (1 − p) N ]p −1 , where N is the largest number of mobile target node transfers, p is the coverage rate of the sensor nodes.
Proof
According to the probability theory, let X be the number of mobile target node transfer, then the range of X is X∈[1,2,3…N].
When X is equal to m and 1 ≤ m ≤ N − 1, the distribution density function of X is
According to the expectation formula of coverage, then
Let q = 1 − p,\(S = \sum\limits_{k = 1}^{N - 1} {k\left( {1 - p} \right)^{k - 1} }\), thus
Multiply p in both sides of this equation, it is transformed to \(qS = \sum\limits_{k = 1}^{N - 1} {kq^{k} }\). so
Substitute Eq. (14) into (13), then
3.3 Energy conversion
In the square monitoring area, there must be some energy consumption of working sensor nodes when time elapses [47–49]. In order to reduce the energy consumption of sensor nodes and extend the network life cycle, this paper adopts the energy node model to analyze energy consumption by multilateral and unilateral transmission of sensor nodes, at the same time ignoring the consumption of data processing, storage and control by the sensor nodes. The energy consumption model of sending process is
and receiving process model is
where l denotes the number of transmission bits, d denotes the Euclidean distance between sensor node and its neighbors, d 0 denotes the threshold of distance communication between nodes. When the communication distance between nodes is less than d 0, the energy attenuation index is 2, otherwise the attenuation index will be 4 if its distance is beyond d 0. E elec denotes the energy consumption of the receiving and sending module of the communication nodes.
Definition 5
(Optimal Subset) Let us suppose a wireless sensor node that belongs to a set of G, in unit time, there exists a subset of sensor nodes G 1 ⊂ G making the sensor nodes belonging to G 1 completely cover the entire target set T, then G 1 is defined as an optimal subset of G.
Definition 6
(Energy attributes) W = {w 1,w 2,w 3…w n } is the initial energy set of sensor nodes, in which w i denotes the initial energy of the sensor node s i,. W obeys the normal distribution W~N(μ,σ 2).
Definition 7
(Maximum distortion) Under the premise of meeting certain coverage, the maximum distortion is:
where s 1(x,y) denotes the estimated value of Euclidean distance between the sensor node and the target node, s(x,y) denotes the average measurement value of Euclidean distance between the sensor node and the target node.
Theorem 4
The distance between the communicating nodes is less than or equal to half the deference between variance and the distortion.
Proof
Let us suppose that the target node t(x,y) is at the measured value s(x,y). The data information includes the measurement data, when multiple target nodes have been measured, the mean value of measurements is subject to normal distribution. The energy collection of sensor nodes is W = {w 1,w 2,w 3…w n }. Euclidean distance between communication nodes is:
Let H be a sensor node collection of measured data and H 1 be its complement. The signal data in H 1 can be estimated by a measurement value of a sensor node from H 1 which is nearest to the target node. Therefore, the estimated value s 1(x 0,y 0) at the target node (x,y) is:
From Eq. (14) and (15) we know:
Including Eq. (22) into (25), then
Theorem 5
In an initial state, the transmission data is l bit, the energy consumption of the multilateral transmission is less than the energy consumed by unilateral transmission.
Proof
Let the collection of neighbors of working nodes S i be Z. Any node that belongs to collection Z is S z . For the purpose of convenience, we firstly assume that there are four nodes in the neighbor collection. When n → ∞, this theorem can be proven by the mathematical induction method.
For example, in Fig. 2, let us suppose that A is a source node, D is the sink node, B and C are neighbor nodes, and O is the center of sensor nodes. There are two cases for the communication path. One is unilateral direct transmission mode, i.e. A- > D. The other is multilateral multi-hop mode, i.e. A- > B- > C- > D. Let us suppose that the size of any stored data sequence is I bits, data is transmitted from node A to node D. Here we discuss the two cases described above to verify the effectiveness.

Multilateral and unilateral node connectivity diagram
Case 1
The information is transmitted directly from A to D. According to formula (16), the energy consumption in sending from node A is:
Case 2
The information is propagated to D through the node B. When k = 3, the node energy consumption model for A transmission module is:
The energy consumption in receiving module of B is
From node B to node D, the energy consumption of sending module of B is
So far, the total energy consumption of the nodes by the path from A through B to D is
Since all nodes are independent, they have the same energy. From the basic properties of triangles, we know
Thus, the above equation is true, i.e., the energy consumption of the multilateral transmission is less than the energy consumed by unilateral transmission when k = 3.
This conclusion can also be extended to the situation when n → ∞. ∠α > ∠ACD = π/2 which implies ∠α is an obtuse angle. By the cosine theorem, cos∠α < 0 that is BC2 + CD2 < BD2. For an obtuse triangle that is formed by the combination of each neighboring node, the square of side length which is corresponding to the acute angle is smaller than the one correspond with the obtuse angle. After n-2 times of superposition, the results are still BC2 + CD2 < BD2, that is
In practical applications, due to the limited communication radius of nodes, obstructions and environmental factors, it is often difficult to achieve a direct transmission from the source node to the destination node. And the energy consumption of the multilateral transmission is less than the energy consumed by unilateral transmission in a WSN.
4 Proposed CASMOC algorithm
This section presents the details of the CASMOC algorithm proposed in this paper.
Initially, all the nodes have equal energy, the administrator node is randomly selected from the nodes in the same alliance. Then the administrator node is taken on as the center, the single hop or multiple hop being the routing protocols of the transmission. Assuming that the management node is deployed in advance, with unlimited energy and can communicate directly with member nodes, whereas the member nodes need one or more hops to get to the administrator node. This is the least-cost routing problem from the source node to the destination node. Because the energy consumption model is set: communication energy calculation model, the calculation model of data processing power, and the environment energy calculation model. Each time a message is received, the administrator node keeps track of the energy changes of the nodes the message has passed by using energy computation model according to the message length and the volume of data. In each round, the nodes in an alliance is divided into four status in this protocol, which are perception, forwarding, start and sleep. Perception nodes are only responsible for monitoring the environment and collecting data; Forwarding nodes are only responsible for forwarding data; Perception and forwarding nodes have both functionalities; Inactive nodes enter sleep state. The administrator node determines the state of each node according to the energy, topology relationship and network mission. After generating the routing, the administrator node broadcasts the state of the nodes and routing information to every node. Due to situations such as packet loss or data processing or delay, there may be deviation in energy computation model, so that it is necessary for the member nodes to periodically send energy update messages to the administrator node, directly reporting its current energy. Then the administrator node generates the optimal routing information and informs the member nodes in the same alliance.
4.1 Ideology of the CASMOC algorithm
The CASMOC algorithm uses neighboring nodes within the sensing radius of a sensing node to form an alliance. All nodes are divided into several alliances. An alliance consists of one administrator node which has the characteristics of high node energy, strong computing power and communication capabilities, and other nodes which are member nodes of the alliance. In the network initialization phase, due to the same node attributes, the administrator node is selected arbitrarily. Member node first sends a “Coverage” message to the administrator node, administrator node according to its own characteristics opens up a certain amount of storage space, and the collected information is stored in the chain (CL) among open space. “Coverage” message mainly contains the information of sending node’s own property and current state, such as sending node energy changes, identity (ID) information and target node coverage and so on. After a few rounds, the administrator node collects all the sending information of nodes in the alliance. The various information that had been collected by the administrator nodes, all member nodes are sorted by the value of residual energy and coverage expectations which are calculated using the formula given in Step 1 of CASMOC algorithm. This order needs to be stored in CL list. Each node is given a certain weight, and the high rank nodes have larger weights than the back nodes. Administrator node bases the target node coverage on searching qualified members of the nodes from the list in order, and marking the qualified members, at the same time the “Notice” message is sent to the qualified members to schedule the member nodes to complete the corresponding task of coverage.
4.2 Description of the CASMOC algorithm
The CASMOC algorithm consists of seven steps:
-
Step 1: First calculate the coverage expectations of all member nodes in each alliance structure as E(X) = ∪{(s i,L)|s i N(l,σ 2)/l 2}.
-
Step 2: The administrator node stores all the collected information of its member nodes in a CL, “Coverage” message includes information of ID, energy and coverage expectation of sending nodes.
-
Step 3: After several rounds, all member nodes are sorted in terms of the value of residual energy and coverage expectations. Meanwhile, put a higher weight value to the top-ranking member nodes.
-
Step 4: The administrator node searches the entire list to find a member node that could cover the target node, and marks the corresponding node.
-
Step 5: The administrator node searches the list to check the residual energy of each node. When the residual energy is higher than the threshold E thr , it will send a “Notice” message to this node in order to turn on its sensing module for covering the target area.
-
Step 6: If there exists a target node which is simultaneously covered by k member nodes, the administrator node will search the whole list again to shut down the corresponding member nodes that cover the target node.
-
Step 7: When the administrator node finishes searching the list, the self-adaptive scheduling mechanism would select the best node which is responsible for the task of covering the monitoring area, otherwise go step 2.
4.3 Algorithm code and protocol operation
The procedure of implementing the CASMOC algorithm is as follows:
-
Step 1: according to theorem 2, we calculate the coverage expectations of all the sensor nodes.
-
Step 2: the calculated results are stored in the list of CL, which also includes properties between nodes.
-
Step 3: after one or more rounds, the administrator node reorders the nodes according to the amount of energy and the coverage expectation, then sets the node with the highest amount of energy to the head of the list.
-
Step 4: the administrator node marks the node which meets certain coverage requirement in the next cycle.
-
Step 5: in the next coverage cycle, if the residual energy of a member node is greater than the predefined threshold, the administrator node sends a “Notice” message and start the member node moving target effectively.
-
Step 6: according to the theorem 5, if a target node has several sensor nodes, the administrator will unilaterally closed sample data members of the node according to the data communication mode, so as to save the whole network energy consumption.
-
Step 7: when the administrator node has completed traversing the list, it searches the optimal node with self-adaptive scheduling mechanism, and effectively covers the monitoring area by making full use of the nodes. If unable to find the optimal node, the administrator returns to the second step to calculate any sensor node set within the coverage expectation alliance.
At the initial time, because all the nodes have equal energy, one node is randomly selected as a member of the administrator nodes. After one or several rounds of work, each node consumes certain energy. According to the algorithm presented in this paper, the node with the highest energy is chosen as the administrator of the next round. At the same time, all nodes in the list are re-ordered. In the establishment stage of alliance, each node selects a random number between 0 and 1. If the number is less than a certain threshold, the node becomes the administrator node. Then the administrator node broadcasts the news of himself as an administrator node to all nodes. Each node determines which alliance to join according to the signal strength of received radio, and responds to the administrator member in the same alliance. In data transmission phase, all nodes in the alliance send data to the administrator member in accordance with the TDMA (Time Division Multiplexing) time slot. After the data are fused, the administrator member sends the results to base station. After working for a period of time, the network re-enters the start stage, and selects the administrator for the next round and build new alliances.
The pseudo code of the CASMOC algorithm is given below and the corresponding flow chat is given in Fig. 3. Lines 1–4 implement Step 1; Lines 5–10 implement Steps 2 and 3; Lines 11–17 implements Step 4; Lines 18–25 implement Steps 5, 6 and 7. 

CASMOC algorithm flow chart
4.4 Explanation of message exchange
This section describes the message exchange involved in the CASMOC algorithm.
The CASMOC algorithm divides the network into several clusters with the help of available clustering technologies. Each cluster has an administrator node and many member nodes, and all member nodes are managed by the administrator node. In the network initialization phase, the coverage expectations for the member nodes are calculated by formulas (5) to (7). At first, the member node with higher coverage expectation sends a “Coverage” message to its administrator node, and the administrator node stores the received message in a linked list CL. The “Coverage” message contains information about some attributes and the state of a sender node, such as the ID, sensory ability, residual energy, and other relevant information of a member node. After one or several unit cycles, the administrator node receives the messages from all member nodes, and sorts the linked list according to the residual energy and sensory ability of the member nodes in descending order. The nodes locating in the front of the linked list are with higher priority to cover. The administrator node searches its stored linked list from up to down according to the situation of the moving target node covered by the member nodes, and marks the eligible member nodes. Finally, the administrator node sends a “Notice” message to all eligible member nodes which have been marked, in order to adjust the sensory unit of the corresponding neighbor nodes to cover the moving target.
High density of sensor nodes deployment could leads to a larger amount of energy cost [50]. However, on the other hand, it is also the basis of design the energy saving protocol. A widely used strategy is to schedule the node states with heuristic scheduling algorithm by turning off the nodes in turn on the premise of satisfying the coverage requirement using the node redundancy, thus reducing the energy consumption. This is also the basic idea of multi-coverage. Most energy saving strategy of multi-coverage saves energy by rotating the active node, the key is to maximize the number of rotation nodes under certain network coverage requirement. Considering there is no precise geographic information, to avoid the existence of blind area caused by the difficulties in measuring the coverage relationship in the monitoring area, a mathematical model is used to make it possible that as long as the ratio of the monitoring range to the perception radius of the node is settled, the number of nodes to reach certain QOS (Quality Of Services) expectation can be calculated. Because the model does not depend on the position information of nodes, it can greatly cut the hardware cost, as well as reduce the number of nodes to decrease the overhead of obtaining and maintaining the location information. Therefore it is applicable to the randomly deployed WSN network [51]. The network life time can be effectively prolonged by using the rotation active and sleep NSS (Node Self-scheduling) coverage control protocol. The protocol uses a mechanism of node rotation cycle. Each cycle consists of a self- scheduling stage and a working stage. In self—scheduling stage: each node broadcasts notification messages to the neighbor nodes in its perception radius, including its node ID and location information. The node checks whether its sensing tasks can be performed by its neighboring node, if it is true then the alternative node returns a status notification message before it enters sleep state, the node which need to continue to work executes the perception task. In judging whether the node can sleep, if an adjacent nodes inspects that its own perception task can be finished by the other one, it enters sleep state.
4.5 Analysis of the algorithm complexity
In the analysis of CASMOC algorithm, n denotes the number of sensor nodes, m denotes the number of edges connected between any two sensor nodes. P min and P max are the minimum and maximum coverage values of the monitoring area, respectively. Δp denotes the increment of coverage after each covered process. Let P min = c, P max = bn, where c and b are constant coefficient. Let us assume that at the initial moment, the coverage percentage of a sensor node is p(0) = b/n, at time t, the transition probability of a sensor node is greater than c/2bn which also means the minimum probability of sensor node’s coverage P min = c/2bn. Set R = (1 − e)p(t−1) at time t + 1, the coverage of a sensor node is:
When \(L = \frac{b}{{\left( {1 - e} \right)\left( {c + ce + R} \right)}}\), the time complexity of CASMOC algorithm is given by
Since \(\sum\limits_{m = 1}^{n - 1} {\frac{1}{m}}\) is the sum of harmonic series of first n − 1 terms, let \(H_{n - 1} = \sum\limits_{m = 1}^{n - 1} {\frac{1}{m}}\), then \(\sum\limits_{x = 1}^{n - 1} {\frac{1}{x} - 1 < \int_{1}^{n - 1} {\frac{1}{x}} } dx < \sum\limits_{x = 1}^{n - 1} {\frac{1}{x}}\) that is:
The above analysis process of the CASMOC algorithm is for the maximum and minimum of coverage rate. We can always find a function, i.e. p min = c, p max = bn, where b and c are constant coefficient. At the initial time t = 0, the coverage rate of a sensor node is p(0) = b/n, where n is the number of sensor nodes. When the CASMOC algorithm runs at time t, if the coverage rate of any sensor node is larger than c/2bn, we think that the minimum coverage rate of some node is c/2bn, i.e. p min = c/2bn. According to formulas (30) and (31) and the relationship between the number of all sensor nodes and edges, the algorithm complexity E(T) can be solved using the basic definitions of harmonic series. So, finally we utilize the basic theorems of harmonic series to solve the complexity of the CASMOC algorithm, i.e. O(lnn).
5 Performance evaluation
In order to verify the validity and stability of the CASMOC algorithm, we compared the performance of the algorithm with four existing algorithms, including Energy- Efficient Target Coverage Algorithm (ETCA) in paper [30], and Linear programming maximum lifetime coverage with energy harvesting (LP_MLCEH) in paper [9], Event Probability Driven Mechanism (EPDM) in paper [31] and Optimization Strategy Coverage Control (OSCC) in Paper [3]. MATLAB is selected as the simulation platform and the experimental environment works in the following conditions: WINXP OS, a PC with RAM 2G, CPU dual core 1.7 GHz. Simulation parameters are given in Table 1. We developed a set of MATLAB programs to conduct six experiments, as described as follows.
Experiment 1 In this experiment, we obtain the relationship between the number of sensor nodes and coverage rate when k value varies.
Figure 4 shows the curve diagram of different k values corresponding to the sensor nodes and the coverage rate of changing in the 300 × 300 monitoring region. As can be seen in Fig. 4, coverage rate increases along with the number of sensor nodes under a certain monitoring area. When k = 2, coverage probability (CP) is positively correlated with working sensor node. When CP reaches the value of 99.9 %, it could be considered that the full coverage of the WSN is achieved. At this time, the number of sensor nodes is 280. When k increases to 3, the number of sensor nodes to achieve the full coverage is 231. Under the condition of k = 4, the number of sensor nodes decreases to 183. When coverage rate among the value of 85–99.9 %, the rising tendency of coverage rate boosts obviously and broader monitoring area need to be covered.

Chart of changing K-coverage
Experiment 2 In this experiment, we compare the CASMOC algorithm with the ETCA algorithm and the LP_MLCEH algorithm in terms of the lifetime of the network. Experimental results are given in Figs. 5, 6 and 7, when the monitoring region varies.

Graph of the network lifetime changing (100 × 100)

Graph of the network lifetime changing (200 × 200)

Graph of the network lifetime changing (300 × 300)
This experiment is a comparative investigation on the lifetime of network for the CASMOC algorithm, the ETCA algorithm and the LP_MLCEH algorithm. k takes various values in this experiment and the network scale is controlled by changing the number of sensor nodes distributed randomly in the monitoring area. For the smaller monitoring area, as shown in Fig. 5, the initial number of sensors node deployed randomly is 20 and this number increases gradually with step size of 20. We could see that, with the increase in the number of sensor nodes, the lifetime of the WSN would also extend linearly. This phenomenon was due to the fact that the member nodes which belong to the alliance collection are scheduled alternately to cover the target node. In the same network environment, the mean lifetime of the CASMOC algorithm had 13.7 and 12.1 % longer lifetime than the lifetime of the ETCA algorithm and the LP_MLCEH algorithm, respectively. For larger scale network monitoring area, as shown in Fig. 7, we use 50 as initial number of randomly deployed sensor node and increase gradually with step size of 50. The curve of the network lifetime also shows the rising trend with the increase in the number of working sensor nodes. The magnitude of the rising trend is more notable in the larger monitoring area than the trend in the smaller one. The average of lifetime in the CASMOC algorithm had 15.13 and 14.71 % longer than the ETCA algorithm and the LP_MLCEH algorithm, respectively.
Experiment 3 In this experiment, we compare the CASMOC algorithm, the EPDM algorithm and OSCC algorithm proposed by [3] in terms of coverage for the case of 200 × 200 by running 200 simulations. The experiment results are given in Figs. 8 and 9.

200 × 200 chart of network coverage rate

200 × 200 chart of network running time
In Fig. 8, with the increase in the number of sensor nodes, the coverage rate also increases gradually. In the case of k = 2, the sensor node number is 171 at the 99.9 % coverage rate. When k = 3, the number of sensor nodes is 155. When k = 4, the number of sensor nodes drops to 107. And in the k = 4 case, the EPDM algorithm and the OSCC algorithm fail to reach 100 % coverage rate. This indicates that the CASMOC algorithm has higher coverage degree than that of EPDM algorithm and the OSCC algorithm, which verifies the effectiveness of this proposed algorithm. In Fig. 8, three algorithms have the same coverage rate during the initial state of running time. With the elapse of time, the coverage rate of both algorithms shows the downward trend. The main reason is that the EPDM algorithm utilizes uninterrupted coverage method of sensor nodes in the network operation time, in which the target node in the monitoring area is continuously covered until the completion of node energy consumption.
At time t = 150, all the three algorithms show sharp downward trends. The details of the experimental results are as follow: when k = 2 CP = 40.24 %; when k = 3 CP = 64.05 %; when k = 4 CP = 82.19 %; the coverage possibility (CP) of the EPDM algorithm and the OSCC algorithm are 75.13 and 79.55 %, respectively. As can be seen throughout the entire network lifetime, the mean coverage rate of the CASMOC algorithm is higher than the mean one of the EPDM algorithm and the OSCC algorithm at k = 4. So the conclusion could be drawn: under the condition of the same amount of sensor nodes, the CASMOC algorithm coverage rate is significantly higher than the rate of the EPDM algorithm and the OSCC algorithm. This verifies the effectiveness of the CASMOC algorithm.
Experiment 4 In this experiment, we obtain the number of working sensor nodes needed to meet different coverage fraction when the number of sensor nodes varies for 300 × 300 m2 monitoring area and the same k. The experimental results are given in Figs. 10, 11, 12 and 13.

When k = 1, the variation curves of the sensor node number and the working node number

When k = 2, the variation curves of the sensor node number and the working node number

When k = 3, the variation curves of the sensor node number and the working node number

When k = 4, the variation curves of the sensor node number and the working node number
Figures 10, 11, 12 and 13 present the change curves of the number of the working nodes to the number of the whole sensors node for four different CP in the case of the same k. The change process of CP value from 85 to 100 % when k is equal to 1 is presented in Fig. 10. Taking CP = 100 % for example, when CP is equal to 100 %, the number of working nodes maintains 290, which is mainly because that, for the same k, the higher CP is, the more the working nodes needed are, so when CP is equal to 100 %, its slope value is higher. The principle of the other 3 figures is similar to the above processes. Four figures in the experiment 4 can be divided into two groups: the first one is Figs. 10 and 11, the other one is Figs. 12 and 13. As we can see, by comparing Figs. 11 with 12, the number of working nodes in Fig. 12 is less thanthe working nodes in Fig. 12 is less than that in Fig. 13 along the lengthwise axis, mainly because the parameter in Fig. 12 is higher than that in Fig. 11. There is a linear relationship between the average and the standard deviation of the perceived radius of nodes, so the slope value in Fig. 12 is lower than that in Fig. 11, and the number of the working nodes in Fig. 12 is less than that in Fig. 11. In the analysis of the change of the number of working nodes in Figs. 12 and 13, we can find that the change curves of Figs. 12 and 13 are horizontal, mainly because when parameter k is equal to 2 or 3, they all reach their respective coverage standards. It is seen from the vertical axis, the number of the working nodes needed in Fig. 13 is lower than that of Fig. 12. The reason is similar to Figs. 11 and 12. We can see that the number of working nodes needed in Fig. 12 is smaller than that of Fig. 10 in the same way. In Figs. 10 and 11, at original time, the total number of sensor nodes is 200–250; fast-rising speed of four curves is mainly due to the small k value. It needs more working sensor nodes and the CP does not reach 99.9 % at the moment. When the total sensor node number is greater than 300, four curves level off; in the case of same k, higher CP needs more working nodes, so curves of higher CP are on the upper side, and curves of lower CP are at the bottom; in Figs. 12 and 13, four curves basically level off, it is mainly due to the higher k value relative to two above-mentioned cases. For the curve of lower CP, working nodes number is mostly kept between 250 and 270; for the curve of higher CP, the number of working nodes is kept between 280 and 300, which illustrates the extensibility of the CASMOC algorithm in the paper. Generally, based on different parameters and the same CP, the number of working nodes needed in Figs. 10 and 11 decrease, achieving an enhanced coverage progress. The coverage speed of Figs. 12 and 13 is higher than that of Figs. 10 and 11. For the same CP, the number of the working nodes in Figs. 12 and 13 is smaller than that in Figs. 10 and 11, which verifies the validity of the CASMOC algorithm in the paper.
Experiment 5 Randomly deploying nodes in diverse monitoring area, then optimizing the communication paths using sensor node scheduling strategy to reduce the sensor node energy consumption, see Figs. 14, 15, 16, 17, 18 and 19:

100 × 100 m2, ETCA sensor nodes deployment diagram

100 × 100 m2, sensor nodes optimization diagram using CASMOC algorithm

200 × 200 m2, ETCA sensor nodes deployment diagram

200 × 200 m2, sensor nodes optimization diagram using CASMOC algorithm

300 × 300 m2, ETCA sensor nodes deployment diagram

300 × 300 m2, sensor nodes optimization diagram using CASMOC algorithm
Figures 14, 15, 16, 17, 18 and 19 show the distribution of the initial state of the sensor nodes in different monitoring area and the state diagram after optimizing the sensor nodes communication path. As can be seen from Fig. 19, in the case of 300 × 300 m2, at the initial moment, 1100 sensor nodes are randomly distributed, and they constitute a large number of communication path. Because of the existence of the large number of communication paths, the sensor node energy is consumed too fast. In unit time, if the sensor node energy is greater than or equal to the energy threshold ε, from the CASMOC algorithm in this article, if the coverage a sensor node has obtained by itself is less than P, the sensor node enters wait state. Otherwise, if the coverage the sensor node has obtained itself is greater than or equal to P, the node will transforms to the competition state. Once succeed,the node becomes a start node, and enters the working state. When a sensor node perceives some target node, it wakes up its neighbor nodes, and then determine whether the aroused node elects itself to be a working node with a probability of P. If the obtained probability is greater than or equal to P, then it enters working state after competition state, otherwise, it transforms into wait state after the judge state. After some cycles of unit time, the randomly deployed node are energy-balanced. At this time, the number of working sensor nodes is 373, which is the 33.91 % of the total number. If the sensor node energy is less than the threshold energy ε, it means that the node is in a state of “death”, and will not transform to any scheduling state. The purpose is to suppress too rapid energy consumption of a large number of sensor nodes, thereby not only improves the network life cycle, but also ensures unblocked communication links between any sensor nodes.
Experiment 6 When verifying the network protocol and properties including the data performance, comparing experiments are carried out among the Stationary, Random and the DCSR protocols of this article. In the four protocols, passive submission mode is adopted by DCSR and CASMOC algorithm in which the data is stored in the node locally when collected, and is not sent to the Sink node until the node receives the notice. Whereas the Random and Stationary adopt active submission mode, in which any data are send to sink node actively, therefore the routing protocol is used. The simulation experiment is mainly related to the amount of data collected, the throughput, and the success rate of sending packets. Let us suppose the moving speed is 5 and 10 m/s, and the monitoring area is 200 × 200 m2.
The contrast of the volume of data collected in the four protocols is shown in Figs. 20 and 21. In them, the sink in Fig. 20 moves at a speed of 5 m/s, the sink in Fig. 21 moves at a speed of 10 m/s, while Stationary sink nodes are static, the same below. It can be observed from the figures that, with the increase in the number of nodes and acceleration in moving speed, the network conflict increases, so that the volume of data collected in all the schemes are fluctuated. Because the CASMOC algorithm does not need its node to forward data, it consumes less energy, therefore it has relatively longer working time and can collect the most amount of data; Whereas the other three protocols have more complicated routes, which results in such situation as premature death of part of the nodes and are inaccessible to some nodes, therefore they collect relatively less amount of data. Due to network interruption in Stationary, it collects least amount of data. In terms of the rate of successful packet forwarding, the comparison of the data collection efficiency of the four protocols is as shown in Figs. 22 and 23. Due to the fact that CASMOC algorithm needs less network routing expenditure and the nodes need not to forward data, it has relatively higher collection efficiency. The comparison of the network throughput (unit: packet number/s) of the four protocols is as shown in Figs. 24 and 25. Network throughput is one of the important indexes to measure the performance of network. It can be seen from the chart that passive submission networks have higher throughput than active submission networks. This is because that the node does not have the burden to forward data, so that it can keep working instead of dying prematurely. Whereas in an active submission network, a large number of nodes die quite early, and data of some individual node is not easy to collect for sink node, therefore the network throughput is relatively low. Because CASMOC algorithm and DCSR protocol have more reasonable route than Random and Stationary, their data collections are more stable with higher throughput.

5 m/s data acquisition contrast chart

10 m/s data acquisition contrast chart

5 m/s the rate of successful packet sending in the network

10 m/s the rate of successful packet sending in the network

5 m/s network throughput

10 m/s network throughput
6 Conclusion
Based on the characteristic analysis of the WSN coverage, this paper proposes a novel algorithm called complex alliance strategy multi-objective optimization coverage (CASMOC). In this paper we present a calculation method of coverage expectations which uses a fan sector as the covering area, and based on this, we give the solution procedure for calculating the expectation of using the minimal sensor nodes to complete the coverage of monitoring area. Also the specific steps and detailed description of algorithm that is used to suppress the energy consumption of sensor node is also given in this paper. In addition, this paper proves that the energy consumed by multi-level transportation of data is less than the energy consumption of data transferred by single level. This paper verifies the validity and stability of the CASMOC algorithm through various simulation experiments which compare with the ETCA algorithm and the EPDM algorithm in terms of lifetime and coverage rate of WSNs. In the future, we will focus on how to realize the effective coverage of nonlinear rule nodes of multiple targets and how to improve the effective coverage of the monitoring region boundary. How to use the less energy and computation to finish the encryption of data and identity authentication and finish the running tasks reliably under the Damaged or disturbed environment.
References
Wei, W., Yang, X., Shen, P., & Zhou, B. (2012). Holes detection in anisotropic sensornets: Topological methods. International Journal of Distributed Sensor Networks, 2012, 1–9.
Xing, X., Wang, G., & Li, J. (2014). Collaborative target tracking in wireless sensor networks. Ad Hoc & Sensor Wireless Networks, 23(8), 117–135.
Sun, Z., Weiguo, W., Wang, H., Chen, H., & Wei, W. (2014). An optimization strategy coverage control algorithm for WSN. International Journal of Distributed Sensor Networks, 2014, 1–17.
Liao, Z., Wang, J., Zhang, S., & Zhang, X. (2013). A deterministic sensor placement scheme for full coverage and connectivity without boundary effect in wireless sensor networks. Ad Hoc & Sensor Wireless Networks, 19(3–4), 327–351.
Dong, M., Ota, K., Laurence, T. Y., Chang, S., Zhu, H., & Zhou, Z. (2014). Mobile agent-based energy-aware and user-centric data collection in wireless sensor networks. Computer Networks, 74(3), 58–70.
Tseng, Y., Chen, P., & Chen, W. (2012). k-Angle object coverage problem in a wireless sensor network. IEEE Sensors Journal, 12(12), 3408–3416.
Ghaderi, R., Esnaashari, M., & Meybodi, M. (2014). A cellular learning automata-based algorithm for solving the coverage and connectivity problem in wireless sensor networks. Ad hoc & Sensor Wireless Networks, Ad hoc & Sensor Wireless Networks, 22(4), 171–203.
Yanling, H., Dong, M., Ota, K., Liu, A., & Guo, M. (2014). Mobile target detection in wireless sensor networks with adjustable sensing frequency. IEEE Systems, 8(3), 1–12.
Yang, C., & Chin, K. (2014). Novel algorithm for complete targets coverage in energy harvesting wireless sensor networks. IEEE Communications Letters, 18(1), 118–121.
Wei, W., & Qi, Y. (2011). Information potential fields navigation in wireless ad-hoc sensor network. Sensor, 2011, 4794–4807.
Long, J., Dong, M., Ota, K., Liu, A., & Hai, S. (2015). Reliability guaranteed efficient data gathering in wireless sensor networks. IEEE Access, 3(2), 430–444.
Wang, Y., & Tseng, Y. (2008). Distributed deployment schemes for mobile wireless sensor networks to ensure multi-level coverage. IEEE Trans. Parallel and Distributed Systems, 19(9), 1280–1294.
Akhtar, F., & Rehmani, M. H. (2015). Energy replenishment using renewable and traditional energy resources for sustainable wireless sensor networks: A review. Elsevier Renewable and Sustainable Energy Reviews, 45(5), 769–784.
Yen, L., Changwu, Yu., & Cheng, Y. (2006). Expected k-coverage in wireless sensor networks. Ad Hoc Networks, 5(4), 636–650.
Kong, L., Zhao, M., Liu, X., Jialiang, L., Liu, Y., Minyou, W., & Shu, W. (2014). Surface coverage in sensor network. IEEE Transactions on Parallel and Distributed Systems, 25(1), 234–243.
Sendra, S., Fernandez, P., Turro, C., & Lloret, J. (2010). IEEE 802.11a/b/g/n indoor coverage and performance comparison. The Sixth International Conference on Wireless and Mobile Communications (ICWMC 2010), Valencia (Spain), September 20–24, 2010.
Garcia, M., Tomás, J., Boronat, F., & Lloret, J. (2009). The development of two systems for indoor wireless sensors self-location. Ad Hoc & Sensor Wireless Networks, 8(3), 235–258.
Sendra, S., Lloret, J., Turro, C., & Agriar, J. M. (2014). IEEE 802.11a/b/g/n short scale indoor wireless sensor placement. International Journal of Ad Hoc and Ubiquitous Computing, 15(2), 68–82.
Mohamed, L., Herve, G., & Mohammed, F. (2010). Cluster-based energy-efficient k-coverage for wireless sensor networks. Network Protocols and Algorithms, 2(2), 89–106.
Suárez, A., Santana, J. A., Maciaslopez, E. M., Mena, V. E., Canino, J. M., & Marrero, D. (2014). RSSI prediction in WiFi considering realistic heterogeneous restrictions. Network Protocols and Algorithms, 4(6), 19–40.
Matthieu, L., Faicel, H., & Hichem, S. (2011). Multi-objective optimization in wireless sensors networks, 2011 Internation Conference on Microelectronics (ICM 2011), Hammamet, Tunisia, pp. 1–4, 19–22 Dec. 2011.
Meng, F., Wang, H., & He, H. (2011). Connected coverage protocol using cooperative sensing model for wireless sensor network. Acta Elecronica Sinca, 9(4), 772–779.
Mini, S., Udqata, S. K., & Sabat, S. L. (2014). Sensor deployment and scheduling for target coverage problem in wireless sensor networks. IEEE Sensros Journal, 14(3), 636–644.
Li, Y., Chinh, V., Ai, C., Chen, G., & Zhao, Y. (2011). Transforming complete coverage algorithms to partial coverage algorithm for wireless sensor networks. IEEE Transactions on Parallel and Distributed Systems, 22(4), 695–703.
Iqbal, M., Naeem, M., Anpalagan, A., Ahmed, A., & Azam, M. (2015). Wireless sensor network optimization: multi-objective paradigm. Sensors, 7, 17572–17620.
Razafindralambo, T., & Simplotryl, D. (2011). Connectivity preservation and coverage schemes for wireless sensor networks. IEEE Transactions on Automatic Control, 56(10), 2418–2428.
Ammari, H. M., & Das, S. K. (2012). Centralized and clustered k-coverage protocols for wireless sensor networks. IEEE Transactions on Computers, 61(1), 118–133.
Junzhao, D., Wang, K., Liu, H., & Guo, D. (2013). Maximizing the lifetime of k-discrete barrier coverage using mobile sensors. IEEE Sensors Journal, 13(12), 4690–4701.
Zhu, C., Zheng, C., Shu, L., & Han, G. (2012). A survey on coverage and connectivity issues in wireless sensor networks. Journal of Network and Computer Applications, 35(2), 619–632.
Xing, X., Wang, G., & Li, J. (2014). Polytype target coverage scheme for heterogeneous wireless sensor networks using linear programming. Wireless Communications and Mobile Computing., 14(8), 1397–1408.
Sun, Z., Weiguo, W., Wang, H., Chen, H., & Xing, X. (2014). A novel coverage algorithm based on event-probability-driven mechanism in wireless sensor network. EURSIP Journal on Wireless Communications and Networking, 2014(1), 1–17.
Wang, H., Meng, F., & Li, Z. (2010). Energy efficient coverage conserving protocol for wireless sensor networks. Journal of Software, 21(12), 3124–3137.
Cheng, T. M., & Savkin, A. V. (2009). A distributed self -deployment algorithm for the coverage of mobile wireless sensor networks. IEEE Communications Letters., 13(11), 877–879.
Abrar, H., Chakrabarti, S., & Biswas, P. K. (2012). Impact of sensing model on wireless sensor network coverage. IET Wireless Sensor Systems, 2(3), 272–281.
Yoon, Y., & Kim, Y. (2013). An efficient genetic algorithm for maximum coverage deployment in wireless sensor network. IEEE Transactions on Cybernetics., 45(5), 1473–1483.
Sundhar Ram, S., Manjunath, D., & Lyer, S. K. (2007). On the path coverage properties of random sensor networks. IEEE Transactions on Mobile Computing, 6(5), 1–13.
Cardei, M., & Jie, W. (2005). Energy-efficient coverage problems in wireless ad-hoc sensor networks. Computer Communications, 29(4), 413–420.
Zhao, Q., & Mohan, G. (2008). Lifetime maximization for connected target coverage in wireless sensor networks. IEEE/ACM Transactions on Networking, 16(6), 1378–1391.
Jiang, H., Jin, S., & Wang, C. (2011). Prediction or not? An energy-efficient framework for clustering-based data collection in wireless sensor network. IEEE Transactions on Parallel and Distributed Systems, 22(6), 1064–1071.
Zhu, J., & Xiaodong, H. (2008). Improved algorithm for minimum data aggregation time problem in wireless sensor networks. Journal of System Science & Complexity, 21(4), 626–636.
Xiaohua, X., Li, X., & Mao, X. (2011). A delay-efficient algorithm for data aggregation in multihop wireless sensor networks. IEEE Transaction on Parallel and Distributed Systems, 22(1), 163–175.
Lei, L., Lin, C., Cai, J., & Shen, X. (2009). Rerformance analysis of wireless opportunistic schedulers using stochastic petri nets. IEEE Transactions on Wireless Communications, 8(4), 2076–2087.
Yanwei, W., Li, X., & Liu, Y. (2010). Energy-efficient wake-up scheduling for data collection and aggregation. IEEE Transactions on Parallel and Distributed Systems, 21(2), 275–287.
Jie, W., Fei, D., & Ming, G. (2002). On calculating power-aware connected dominating sets for efficient routing in ad hoc wireless network. Journal of Communications and Networks, 4(1), 1–12.
Oliveira, T., Raju, M., & Agrawal, D. P. (2012). Accurate distance estimation using fuzzy based combined RSSI/LQI values in an indoor scenario: Experimental verification. Network Protocols and Algorithms, 4(4), 174–199.
Elbes, M., Jordan, A., Fuqaha, A. A., & Anan, M. (2013). A precise indoor localization approach based on particle filter and dynamic exclusion techniques. Network Protocols and Algorithms, 5(2), 50–71.
Lloret, J., Tomas, J., Garcia, M., & Canovas, A. (2009). Hybrid stochastic approach for self-location of wireless sensors in indoor environments. Sensors, 9(5), 3695–3712.
Sendra, S., Lloret, J., García, M., & Toledo, J. F. (2011). Power saving and energy optimization techniques for wireless sensor networks. Journal of Communications, 6(6), 439–459.
Wei, W., Qin, X., Wang, L., Hei, X., Shen, P., Shi, W., & Shan, L. (2014). GI/Geom/1 queue based on communication model for mesh networks. International Journal of Communication Systems, 27(11), 3013–3029.
Jameii, S. M., Faez, K., & Dehghan, M. (2015). Multiobjective optimization for topology and coverage control in wireless sensor networks. International Journal of Distributed Sensor Networks, 1, 1–11.
Wei, W., Yang, X., Zhou, B., Feng, J., & Shen, P. (2012). Combined energy minimization for image reconstruction from few views. Mathematical Problems in Engineering., 2012, 1–15.
Acknowledgments
Projects (61170245, U1304603) supported by the National Natural Science Foundation of China; Projects (2014B520099, 2014A510009) supported by Henan Province Education Department Natural Science Foundation; Projects (142102210471, 142102210063, 142102210568) supported by Natural Science and Technology Research of Foundation Project of Henan Province Department of Science; Project (1401037A) supported by Natural Science and Technology Research of Foundation Project of Luoyang Department; Project (2014M562153) supported by Postdoctoral Science Foundation of China; Project (2012GGJS-191) supported by the funding scheme for youth teacher of Henan Province; Project (1201430560) supported by Guangzhou Education Bureau Science Foundation. This paper was also supported by China Postdoctoral Science Foundation (Nos. 2013M542370, 2014M562153) and the Specialized Research Fund for the Doctoral Program of Higher Education of China (Grant No. 20136118120010).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, Z., Zhang, Y., Nie, Y. et al. CASMOC: a novel complex alliance strategy with multi-objective optimization of coverage in wireless sensor networks. Wireless Netw 23, 1201–1222 (2017). https://doi.org/10.1007/s11276-016-1213-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-016-1213-3