
Abstract
Urban reservoir is one of the important urban drinking water sources, and it is of important significance to ensuring the safety of urban water supply. The water quality of the reservoir is an important factor affecting the safety of water supply. Timely and accurate water quality prediction is very important for the formulation of a scientific and reasonable reservoir water supply plan. Considering the problem of high requirement of basic data in constructing water quality hydrodynamic physical model, this paper established a new data-driven model of water quality prediction in urban reservoir based on the Long and Short-Term Memory (LSTM) model, and the water quality data’s decomposition is implemented through the Complete Ensemble Empirical Modal Decomposition with Adaptive Noise (CEEMDAN) method. This model can not only realize the water quality prediction during different foreseen periods, but also solve the problem of low prediction accuracy caused by the randomness and large volatility of the measured data. Taking Xili Reservoir in Shenzhen of China as an example, the prediction of water concentration including total nitrogen, ammonia nitrogen, total phosphorus and PH value of Xili reservoir was realized based on historical monitoring data. Through simulation calculation, the prediction results of total nitrogen, ammonia nitrogen, total phosphorus and PH value in the water quality prediction model are highly consistent with the measured results, it is found that the simulation effect is good, and this model can well simulate the reservoir’s water quality concentration change process. For the total nitrogen and ammonia nitrogen, the relative prediction error of the model can be controlled below 10%, which shows the rationality of the built model. The research of this paper can provide an important theoretical and technical support for the water quality prediction and operation plan formulation of Xili Reservoir.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of social economy, the city scale is increasing, and the demand for water resources is increasing. At the same time, because the rapid development of the economy is often at the cost of the environment, the problem of water pollution in many large cities has become more and more serious in recent years, which further aggravates the tension of urban water supply. Although various countries and governments have also invested a lot of manpower and financial resources to carry out water pollution prevention and control, and have also achieved certain results, with the increase of urban population, the shortage of water resources has not been substantially alleviated.
There are many types and functions of reservoirs, one of which is generally called the water source of urban reservoirs, and they are mainly located inside the city or around the city, which is mainly used to store fresh water and ensure the supply of the drinking water in the city. The economic development will inevitably bring about certain pollution problems, so it is of great significance to maintain the urban reservoir water source and to ensure the safety of urban water supply. One of the most important work is to track and monitor the water quality of the water source, and find pollution problems in real-time to ensure the safety of water supply.
There are many methods for reservoir water quality prediction, which can be divided into physical driven and data driven (Sunna 2019). Data driven is generally based on a long series of historical monitoring data, and uses neural network and other methods to predict the water quality in future periods. Its basic principles and processes are simple and widely used.
The prediction method of water quality data based on mathematical physical model is called physical driven. The common models of physical drive include Streeter-Phelps model, WASP6 model and MIKE model, etc. The physical driven method according to the terrain data to predict region, water quality monitoring sites of cross section data, water quality, hydrological data structure such as the local hydrodynamic model to simulate the change of water quality in the region and to make predictions, such method fully considers the factors that influence the water quality of prediction effect is good, but this kind of model construction process complex, extremely high requirement to the terrain data, therefore, it is difficult to build successfully with insufficient data. Thus, the advantages of data-driven models emerge in the presence of a long series of historical monitoring data (Kratzert et al. 2019). Common data-driven prediction methods include Artificial Neural Network (ANN) model, support vector machine, time series model, etc. Among them, the neural network model is the most widely used (Hu et al. 2019; Wang et al. 2017; Huang and Kuo 2018; Dogan et al. 2009), including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Long and Short-Term Memory network (LSTM) (Taieb et al. 2011), etc. LSTM is an excellent model of RNN, it inherits most of the RNN model features, while solving the Vanishing Gradient problem of the gradient inversion process due to gradual reduction, and it is well suited for handling problems highly correlated to time series (Xiang et al. 2020). However, the performance of a single LSTM network model is limited, so it cannot be predicted quickly and accurately. In order to improve the performance of LSTM model and improve the generalization ability and prediction accuracy of water quality prediction model, many scholars have carried out research on this. For example, Barzegar et al. (2020) proposed a CNN-LSTM water quality prediction model, Zou et al. (2021) proposed a LSTM-GRU water quality prediction model, in summary, LSTM has a great space for development in the research of water quality prediction. In addition, considering the randomness and volatility of measured water quality data, the prediction results obtained by the measured water quality data input into the LSTM model will have a large error. In order to improve the accuracy and generalization of the water quality prediction model, it is necessary to conduct proper decomposition processing before prediction to improve the prediction accuracy of the model.
At the same time, we found that Xili Reservoir, as a water supply reservoir of Shenzhen city, has some real-time water quality monitoring points, but its water quality prediction system is not perfect. In order to better control the water quality of Xili Reservoir in a certain period in the future. In order to ensure the safety of drinking water in Shenzhen, this paper based on the use of adaptive noise the complete set of empirical mode decomposition (CEEMDAN) method, the decomposition on the basis of building the reservoir water quality prediction model based on LSTM model(CEEMDAN-LSTM), is applied to the Shenzhen Xili reservoir water quality prediction, so as to formulate scientific and rational urban type reservoir of the reservoir scheduling program operation, to ensure the security of urban water supply. The results show that the coupled model has better predictive performance than LSTM.
2 Methodology
2.1 LSTM Model
LSTM (Long and Short-Term Memory) (Wei and Xu 2019; LIU et al. 2019) is a special kind of RNN (Yin et al. 2021). It solves the problem of gradient disappearance and explosion in RNN training (Hochreiter and Schmidhuber 1997). A normal RNN uses a set of state vectors (the previous output value of the layer) to deliver information before the point in time. The state is generated directly from the output of the last time point and is a message transfer of "short-term states". The characteristic of LSTM is that it uses a long-term and effective short-term memory to transfer the state on the time axis (called cell state). The state is not only transmitted to the next time node, but also can be effective for a long time in the following period of time, so it is more effective for multi-period prediction of time series. The structure of the LSTM is shown in Fig. 1a. In the figure, there are three LSTM inputs at time t: 1) the input value Xt of the current time network. 2) Hidden value St-1 at the previous moment. 3) Unit state Ct-1 at the previous moment. There are two output at the t time: 1) the hidden value St of the current moment. 2) Unit status Ct at the current moment. The LSTM performs special processing within the node by adding three "gates" for the purpose of receiving the information generated by an earlier time node. The three "doors" are "forgetting gate", "input gate", and "output gate". The internal structure of the LSTM unit is shown in Fig. 1b below.

The LSTM model principle
The status transfer logic of the LSTM is as follows.
Step 1: Multiply the hidden value St-1 at the previous moment and the input Xt at that moment with the weight matrix Wf of this layer, plus the bias coefficient bf. Map the results to the nonlinear space to obtain ft, then multiply ft with Ct-1, and finally achieve the effect of "forgetting".
Step 2: In the “input Door”, multiply hidden unit ht-1 at the last moment and the input Xt at the previous moment with weight matrix Wi of this layer, plus the bias value bi, map the results to the nonlinear space to get it.
Step 3: In the same way as the previous step, the activation function is changed from Sigmoid to tanh to obtain a new candidate value vector \({\tilde{C }}_{t}\).
Step 4: multiply the value obtained from step 2 and step 3. Add it up with the results of the first step. New cell state \({C}_{t}\) is obtained.
Step 5: Calculate the output value and the implied layer at time t. Multiply ht-1 and xt with weight matrix Wo of output layer, plus the bias value bo of output layer, get the output results Ot at that time after the activation function processing. The resulting new cell state was treated by tanh, mapped to -1 with 1, and multiplying it and the result of O to obtain the updated hidden layer state St.
Step 6: Multiply updated the hidden layer status St with the weight matrix Wd plus a bias value bd to get the final output Yt at the current moment.
In the state transfer logic of LSTM, the first step is completed in “Forgetting Gate”, steps 2, 3 and 4 are completed in “Input Gate”, and steps 5 and 6 are completed in Output Layer.
2.2 CEEMDAN Algorithm
Due to the water quality data fluctuating too much, it is difficult to train good results when directly entering the established LSTM model, and the appropriate decomposition processing before the prediction is needed to improve the model prediction accuracy. Complete set of empirical mode decomposition of adaptive noise (Complete Ensemble Empirical Mode Decomposition with Adaptive Noise, CEEMDAN) is an algorithm made for certain improvement based on the Empirical Mode Decomposition (EMD) as well as the Ensemble Empirical Mode Decomposition (EEMD) (Torres et al. 2011). Although EEMD algorithm can alleviate the modal stacking problem by adding Gaussian white noise, there is a noise signal of a certain amplitude in the decomposition component. Although the amount of noise can be reduced by increasing the average number of sets, the number of mean envelope screening will also increase, and the program running time is too long, which lacks the advantage in real-time for some fields of engineering application. And the average number of sets is too few can lead to an excessive amount of noise residue in the decomposed components. The CEEMDAN algorithm make the noise in the components offset each other through the positive or negative equal-amplitude adaptive noise pairs, eliminates the partial noise amplitude in the component, effectively handles the problem of excessive average number of Ensemble Empirical Mode Decomposition (EEMD) algorithm, and improves the decomposition efficiency of the algorithm (Wu and Huang 2004; Torres et al. 2011). Assuming the original signal \(x(\mathrm{t})\), representing the noise signal with \(\delta (\mathrm{t})\) and the n-order component of the EMD decomposition with \({E}_{n}(\cdot)\), the operation steps of the CEEMDAN algorithm are as follows.
Step1: Add the noise signal \(\delta (\mathrm{t})\) to the original signal \(x(\mathrm{t})\) to get add the noise signal \(s\left(\mathrm{t}\right)\).
In formula, j = 1, 2, …, J represents the number of noise pairs added.
The first intrinsic mode component \({imf}_{1}\) is obtained for performing the EMD decomposition to \(\mathrm{s}(\mathrm{t})\), \({r}_{1}\) is the residual signal of the first stage.
Set averaging of the components yields the first component \(\overline{{imf }_{1}}\) and the remainder \({R}_{1}\).
Step2: subtract \({imf}_{1}\) with \(s\left(\mathrm{t}\right)\) to get the remaining signal, and add an adaptive decomposition noise component \({E}_{1}(\delta \left(t\right))\) to the remaining signal to get a new signal. Conduct EMD decomposition to this signal, and stop decomposition in one layer, and get the second component \(\overline{{imf }_{2}}\) and remaining term \({R}_{2}\).
Step3: Repeat Step2 for the remaining signal \({R}_{2}\) to get a series of IMF components and residual R, as follows.
Among these, n = 1, 2, …, N represents the number of IMF components. The raw signal can be represented by a series of IMF components and remainder term R, as follows.
The sum of the IMF component and remain term R is approximated to the original signal x(t), and there is partial noise in the IMF component of each order. The EEMD decomposition and CEEMDAN decomposition errors are indicated as follows.
It can be found that the error of EEMD decomposition mainly comes from the added white noise, mainly reduce the interference with poor partial decomposition effect by means of averaging through multiple integration. The CEEMDAN algorithm is decomposed by adding pairs of positive and negative noise, so that the noise in the components can cancel each other. In addition, the CEEMDAN adds the noise component of EMD decomposition, and the noise amplitude is small. EEMD is treated with a complete EMD decomposition after each adding noise, while CEEMDAN adopts a single layer of EMD decomposition, which improves the decomposition speed of the algorithm.
2.3 CEEMDAN-LSTM Model
A single LSTM model cannot meet the current demand for water quality prediction. In order to improve the accuracy and generalization performance of the prediction model, a variational mode decomposition method (CEEMDAN) is introduced based on LSTM. This method can decompose the data into many IMF components well, and the decomposed data has more data features. The CEEMDAN-LSTM coupling model can be built on the basis of fully mining the potential information of data and improving the accuracy of water quality prediction. The structure of CEEMDAN-LSTM coupling model is shown as Fig. 2 follows.

CEEMDAN-LSTM model
2.4 Evaluation Indicators of Model Forecast Results
After obtaining the prediction value by using the established prediction model, it is necessary to evaluate the prediction effect, and analyze the accuracy and practicability of the prediction results. The prediction accuracy evaluation mainly includes the following accuracy indicators.
-
1.
Mean absolute error (MAE)
The mean absolute error represents the absolute gap between the prediction result and the real result, the smaller the value, the better the prediction result, formula as follow:
$$MAE=\frac{1}{n}{\sum }_{i=1}^{n}\left|{y}_{i}-\widehat{{y}_{i}}\right|$$(15)In formula, n represents the number of predicted results, \({y}_{i}\) represents the real results and \(\widehat{{y}_{i}}\) represents the predicted results.
-
2.
Average relative error (MRE)
The mean relative error represents the relative gap between the prediction and the real results, the smaller the values the better the prediction, formula as follow.
$$MRE=\frac{1}{n}{\sum }_{i=1}^{n}\frac{\left|{y}_{i}-\widehat{{y}_{i}}\right|}{{y}_{i}}$$(16) -
3.
Root of mean square error (RMSE)
The root mean square error represents the degree of deviation between the prediction result and the real result, and the smaller the values, the better the prediction results, formula as follow.
$$RMSE=\sqrt{\frac{1}{n}{{\sum }_{i=1}^{n}({y}_{i}-\widehat{{y}_{i}})}^{2}}$$(17) -
4.
Deterministic coefficient (R2)
The deterministic coefficient reflects the fit of the prediction results to the real outcome trend, and the closer the value is to 1, the better the prediction results, with the following formula.
$${R}^{2}=1-\frac{{\sum }_{i=1}^{n}({y}_{i}-\widehat{y}{)}^{2}}{{\sum }_{i=1}^{n}({y}_{i}-\overline{y}{)}^{2}}$$(18)In formula, \(\overline{y }\) represents mean of actual results.
-
5.
Percent of pass
When the error of one forecast is less than the license error (30% of the measured variation), it is the qualified forecast. The percentage of the number of qualified forecasts and the total forecast times is the qualified rate, which indicates the overall accuracy level of multiple forecasts, and the qualified rate is calculated according to the formula.
$$\mathrm{QR}=\frac{n}{m}*100\mathrm{\%}$$(19)In formula, QR —qualified rate, %. n —the number of qualified forecasts. m —the total number of forecasts.
Water quality forecast accuracy, according to the relevant provisions of the hydrology information forecast specification error, should be 30% of the measured values for permission to prepare solution using the qualified as evaluation standard, according to the regulation: if QR≧70%, it can forecast as homework, if 60%≦QR < 70%, model can be used for reference and prediction, and if QR < 60%, it do not be used in job forecast.
2.5 Model Implementation Process
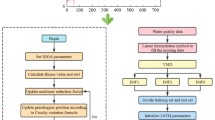
This paper established a new model of water quality prediction in Xili reservoir based on the Long and Short-Term Memory (LSTM) model and the water quality data decomposition is implemented through the Complete Ensemble Empirical Modal Decomposition with Adaptive Noise (CEEMDAN) method. The model implementation process is shown in Fig. 3 below.

Model implementation Process
3 Case Study
3.1 Xili Reservoir Overview
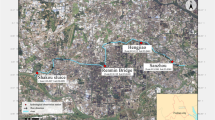
Xili Reservoir is located in Nanshan District, Shenzhen, built in 1960 with a rainwater collection area of 29km2. The reservoir area is 2.78 km2, the total storage capacity is 32,388,100 m3. The original design is mainly farmland irrigation and takes the comprehensive utilization of flood control and power generation into account. With the rapid development of Shenzhen's economy and the continuous growth of water demand, Xili Reservoir has been transformed into a medium-sized reservoir with both urban water supply, raw water transfer and storage and urban flood control functions. In 2002, Xili Reservoir, as the water crossing point of the Dongjiang Water Source Project, became an important regulating reservoir in the water supply system of Shenzhen. Nowadays, the water supply and flood control of Xili Reservoir are basically guaranteed, but due to the complex terrain and boundary conditions of Xili Reservoir, the water pollution and bad water environment of the reservoir have become the difficulties in the reservoir management. As one of the important drinking water sources in Shenzhen, there are many water plants around the reservoir that draw water from the reservoir. The water quality of the reservoir affects the dispatching plan of the water supply plant. Therefore, the water quality prediction of Xili Reservoir is related to the water supply safety around the reservoir and even the whole city, which is very important to ensure the production and life of Shenzhen people (Fig. 4).

Location diagram of Xili Reservoir
3.2 Model Input Data and Model Parameters
In the construction of water quality prediction model of Xili Reservoir, considering that there are three water quality monitoring stations in Xili Reservoir, i.e., Dachong water quality monitoring station, Dongjiang water come inlet water quality monitoring station, and Xitiezha water quality monitoring station, the location distribution is shown in Fig. 5 below. Among them, the data of Dachong water quality monitoring station is relatively sufficient. Therefore, this paper is based on the historical data of the Dachong water quality monitoring point in Xili Reservoir, established a single sequence input water quality prediction model based on LSTM, to model and predict the total phosphorus, total nitrogen and ammonia nitrogen in Xili Reservoir.

Location Distribution Information of the Water Quality Monitoring Station in Xili Reservoir
The water quality indexes to be predicted in this paper are total phosphorus, total nitrogen, ammonia nitrogen and PH value. The water quality data set used in this paper is the daily data of Xili Dachong water quality monitoring station of Xili Reservoir from 2019/1/1 to 2021/7/31. The data are provided by Shenzhen Water Bureau, with a total of 943 records, each of which includes the data of nine indicators including total phosphorus, total nitrogen, ammonia nitrogen, PH value, dissolved oxygen, conductivity, turbidity, temperature and COD. However, based on the Environmental Quality Standard for Surface Water and project requirements, the water quality indexes to be predicted this time are 3772 data of total nitrogen, total phosphorus, ammonia nitrogen and PH value.
In this paper, Pearson's correlation coefficient is used to analyze the relationship between data. Pearson's correlation coefficient is an index proposed by Karl Pearson to measure the correlation between two variables. Pearson's correlation coefficient between two variables is defined as the quotient of covariance and standard deviation between two variables, and Pearson's correlation coefficient is formulated as follows.
\(\frac{{X}_{i}-\overline{X}}{{\sigma }_{X}}\), \(\overline{X }\) and \({\sigma }_{X}\) are the standard score, sample mean, and sample standard deviation of the \({X}_{i}\) sample respectively.
The size of the Pearson’s coefficient between –1 ~ 1, when \(0 \leqq |\mathrm{ r }| < 0.2\), which indicates that the two variables are very weak relevant or irrelevant, when \(0.2 \leqq |\mathrm{ r }| < 0.4\), which indicates that two variables are weak relevant, when \(0.4 \leqq |\mathrm{ r }| < 0.6\), shows that the two variables are moderately correlated, when \(0.6 \leqq |\mathrm{ r }| < 0.8\), which indicates that two variables are strongly related, when \(0.8 \leqq |\mathrm{ r }| < 1\), shows that two variables are highly relevant.
Table 1 shows the correlation analysis results of various water quality parameters.
According to the size of the above-mentioned Pearson’s correlation coefficient and the classification of Pearson’s correlation coefficient, the selected as input characteristic of Pearson’s coefficient absolute value is greater than 0.2. As can be seen from the above table, when predicting PH value, the selected relevant input feature is the concentration of dissolved oxygen, when predicting total nitrogen, the selected input characteristics are COD, turbidity, dissolved oxygen and total phosphorus, when forecasting the total phosphorus, the selected input characteristics are ammonia nitrogen, total nitrogen, turbidity and COD, while the selected input characteristics for ammonia nitrogen prediction are temperature, total phosphorus, electrical conductivity and COD.
The step length of the water quality historical data of Xili Reservoir is 1d, and output the future water quality data of 1 steps, and the training period, validation period and test period were divided in a ratio of 3:1:1.
In this paper, the Adam optimization algorithm trains the LSTM neural network model described above, which is commonly used to solve the optimization problem of large data volume and high characteristic latitude in machine learning. It combines two popular algorithms "Adagrad" (for sparse gradients) and "RMSPro" (for unsteady data), and consumes less memory. Other hyperparameters were adjusted during validation period, epoch and batch_size were selected first. The initial value of epoch was 50, and that of batch_size was 16. The epoch chose on a range of [10, 50, 100, 200], and the batch_size chose on a range of [8, 16, 32, 64, 128]. The following Table 2 shows the results of the validation set (the five average values are selected). Due to too much data, only ten data are shown.
From the above table, it can be seen that the model performs best when epoch is 200 and batch_size is 32. At that time, R2 is 0.936, RMSE is 0.039, and MAE is 0.02.
After the epoch and batch_size are determined, and then the input step size should be determined. The input step size is selected from 1 to 15, as shown in the following Table 3.
It can be seen from the table that when the input step size is 3, the model performance is the best. At that time, R2 = 0.965, RMSE = 0.028, MAE = 0.015.
After determining the step size, epoch and batch_size, it is time to determine the number of neurons. The number of neurons is set to 50, 100, 150, 200 and 250. Their performance in the model is as Table 4 follows.
It can be seen from the table that when the number of neurons is 250, the model performance is the best. At that time, R2 = 0.971, RMSE = 0.026, MAE = 0.016。
In summary, after the hyperparameter screening during the validation period, the optimal parameter settings for this model are as Table 5 follows.
Before the prediction, the water quality data is CEEMDAN decomposed, and then the decomposed data is predicted through the neural network model, and finally add the predicted decomposition data together to predict the water quality.
3.3 Results Analysis and Discussion
3.3.1 Water Quality Data Decomposition Based on CEEMDAN
The sequence change process of the Xili Reservoir total nitrogen data, the ammonia nitrogen data sequence change process, and the total phosphorus data sequence change process are shown in Fig. 6. It can be seen that the fluctuation of the total nitrogen, ammonia nitrogen and the total phosphorus measured data are relatively large, especially the total phosphorus. At this time, if the LSTM model is to be directly input for prediction, the model can’t well grasp the change law of the curve process, and the prediction effect is not good. Therefore, the data needs to decompose the data to a certain extent before the prediction.

Measured data of each water quality index
According to the above total nitrogen, ammonia nitrogen and total phosphorus data, CEEMDAN decomposition was performed, and the resulting decomposition data are shown in Fig. 7 below.

Sequence of each water quality indicator after the CEEMDAN decomposition
Figure 7 shows that the total nitrogen data, total phosphorus data and PH data are decomposed by CEEMDAN and are decomposed into 10 sequences with different frequencies. The ammonia nitrogen data was decomposed by CEEMDAN and decomposed into 11 sequences with different frequencies. It can be seen that the sequence regularity of the decomposition is significantly enhanced, which can greatly improve the prediction accuracy of the prediction model.
3.3.2 Prediction Results Before Water Quality Decomposition
After training on the training set and selecting hyperparameters for the validation set, the model performs best with the hyperparameters shown in the following Table 6.
The test set results obtained by feeding the data into the model optimized on the validation set are as Fig. 8 follows.

prediction of water quality indicators during the test period of the LSTM model
As shown in Table 7, it is the water quality evaluation index in the test period obtained in the LSTM model.
It can be seen from Table 7 that, taking the pass rate as an example, the pass rate of total nitrogen, ammonia nitrogen and PH value can basically be controlled at more than 90%, which is far higher than the operation forecast standard required for water quality forecast, and the accuracy is high. The effect of total phosphorus is relatively poor, only 66.8%, but it can also meet the reference forecast standard for water quality forecast.
3.3.3 Prediction Results After Water Quality Decomposition
After the optimization of the hyperparameters of the CEEMDAN-LATM model in Sect. 3.2, the prediction results of the total nitrogen, total phosphorus, ammonia nitrogen and PH value in the test period obtained by the model prediction are shown in Fig. 9.

prediction of water quality indicators during the test period of the CEEMDAN-LSTM model
As shown in Table 8, it is the water quality evaluation index in the test period obtained in the CEEMDAN-LSTM model.
It can be seen that after CEEMDAN decomposition, the results of the water quality prediction model have been comprehensively and largely improved in various statistical indicators such as MAE, RMSE, R2, MRE, and pass rate(QR). Taking QR as an example, all water quality indicators have been greatly improved, and the pass rate of ammonia nitrogen and PH value is as high as 100%. For total phosphorus, it has increased from 66.8% to 93.6%.
In general, from the comparison process between the predicted results of total nitrogen, ammonia nitrogen, total phosphorus and PH value and the measured results, the model prediction effect is also good, and the process of predicting water quality is very good to track and simulate the measured process.
3.3.4 Comparative Analysis of the Results Before and After the Water Quality Decomposition
In order to compare and analyze the difference in the effect of CEEMDAN before and after the decomposition treatment, the evaluation indicators of total phosphorus, total nitrogen, ammonia nitrogen and PH value were compared, as shown in Table 9. It can be clearly seen that each index has been significantly optimized after decomposition. Take total nitrogen as an example, after decomposition, R2 is increased by 5%, RMSE is decreased by 51%, MAE is decreased by 57.4%, MRE is decreased by 57.6% and QR is increased by 6.4% compared with before decomposition. After the decomposition of CEEMDAN, the relative prediction error, mean absolute error and root mean square error of total nitrogen, ammonia nitrogen, total phosphorus and PH value have been reduced to varying degrees, and the pass rate and coefficient of certainty have been improved to varying degrees (see Fig. 10). This shows that it is feasible and effective to decompose the CEEMDAN data sequence before forecasting.

Comparison of water quality model evaluation indicators before and after CEEMDAN decomposition (test period)
4 Conclusion
Based on the CEEMDAN decomposition method and Long and Short-Term Memory neural network model, this paper constructed the water quality model of Xili reservoir, which can realize the water quality prediction in the next periods. It was found by calculating the simulations, on the one hand the model simulation works well, the simulation results show that the prediction results of total nitrogen, ammonia nitrogen, total phosphorus and PH value in the water quality prediction model have a high agreement with the measured results, and can track the simulated actual measurement process well. As for the total nitrogen, ammonia nitrogen and PH value, the relative prediction error can be controlled below 10% for both the training period and the test period, so it shows the rationality of the built model. On the other hand, given the small amount of data, there is room for the further prediction effect, especially for the total phosphorus prediction model, this is also the subsequent research direction of this study. In general, the model in this study can greatly improve the prediction accuracy of the LSTM model, and can provide important model and technical support for the water quality prediction of Xili Reservoir, which is of great significance for ensuring the safety of water supply in Shenzhen. The improvement of water quality prediction accuracy is not only of great significance in the regulation of reservoirs, but also plays an important role in the prevention and control of water pollution. At the same time, the model has a wide range of applicability. Although there are significant differences in the flow field morphology of different sites, the model it can be adapted to other regions through parameter calibration, so that it can be used in water quality prediction in other regions.
Availability of Data and Materials
Some or all data, models, or code that support the findings of this study are available from the corresponding author upon reasonable request.
References
Barzegar R, Aalami MT, Adamowski J (2020) Short-term water quality variable prediction using a hybrid CNN-LSTM deep learning model. Stoch Environ Res Risk Assess 1–19
Dogan E, Sengorur B, Koklu R (2009) Modeling biological oxygen demand of the Melen River in Turkey using an artificial neural network technique. J Environ Manage 90:1229–1235
Hochreiter S, Schmidhuber J (1997) LSTM can solve hard long time lag problems. Neural Info Process Syst 473–479
Hu ZH, Zhang YR, Zhao YC et al (2019) A water quality prediction method based on the deep LSTM network considering correlation in smart mariculture. Sensors 19:1420
Huang CJ, Kuo PH (2018) A deep CNN-LSTM model for particulate matter (PM2.5) forecasting in smart cities. Sensors18:2220
Kratzert F, Klotz D, Shalev G et al (2019) Towards learning universal, regional, and local hydrological behaviors via machine-learning applied to large-sample datasets. Hydrol Earth Syst Sci 23:5089–5110
Liu S, Peng Y, Shao YM et al (2019) Expressway travel time prediction based on gated recurrent unit neural networks. Appl Math Mech 40:1289–1298
Sunna (2019) The application of Sunna Machine Learning Theory in runoff intelligent prediction. Huazhong University of Science and Technology
Taieb SB, Bontempi G, Atiya AF et al (2011) A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst Appl 39:7067–7083
Torres ME, Colominas MA, Schlotthuer G et al (2011) A complete ensemble empirical mode decomposition with adaptive noise. Brain Res Bull 125:4144–4147
Wang YY, Zhou J, Chen KJ et al (2017) Water quality prediction method based on LSTM neural network, Nanjing, China: 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), pp 1–5
Wei YZ, Xu XN (2019) ULTRA-short-term wind speed prediction model using LSTM networks. J Electron Measure Instrument 33:64–71
Wu ZH, Huang NE (2004) A study of the characteristics of white noise using the empirical model decomposition method. Proc R Soc Lond 460:1597–1611
Xiang Z, Yan J, Demir I (2020) A rainfall‐runoff model with LSTM‐based sequence‐to-sequence learning. Water Resour Res 56
Yin H, Zhang X, Wang F et al (2021) Rainfall-runoff modeling using LSTM-based multi- state- vector sequence- to- sequence model. J Hydrol 598:126378
Zou K, Li Z, Mu X et al (2021) Study on sewage quality prediction model based on LSTM-GRU. Chin Energy Environ Protect 43(12):59–63
Funding
This study was financially supported by the Natural Science Foundation of China (52179016, 51809098), Natural Science Foundation of Hubei Province (2021CFB597), Natural Science Fund of Anhui Province (grant no. 2008085ME158).
Author information
Authors and Affiliations
Contributions
Z.L.: data curation, formal analysis, writing – original draft; J.Z.Q.: conceptualization, funding acquisition, methodology, supervision; H.S.S.: validation, software; D.J.F: investigation, visualization; W.P.F.: writing – original draft, writing – review & editing; Z.T.: funding acquisition, methodology.
Corresponding author
Ethics declarations
Ethics Approval
Not applicable.
Consent to Participate
Not applicable.
Consent to Publish
All authors agree to publish.
Competing Interests
The authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, L., Jiang, Z., He, S. et al. Study on Water Quality Prediction of Urban Reservoir by Coupled CEEMDAN Decomposition and LSTM Neural Network Model. Water Resour Manage 36, 3715–3735 (2022). https://doi.org/10.1007/s11269-022-03224-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-022-03224-y