
Abstract
Coupled simulation-optimization models are useful tools for solving optimum water allocation and crop planning problems. In this study, the optimum crops pattern in the Arayez plain in the Karkheh river basin in Iran is determined by integration of a network flow programming (NFP) based simulation model and the shuffle frog leaping optimization algorithm (SFLA) in the form of a simulation-optimization approach. MODSIM applies NFP for finding water allocations which by use of its customization ability, the benefit of water supply for the agricultural crops is calculated based on the agronomic equations. The objective function is to maximize the total net benefit gained from crops production where the decision variables which are the irrigation depths and the cultivation areas are optimized by SFLA. Results show that by use of the coupled SFLA-NFP model, the net benefit increases 12% comparing the present situation in the plain. Also, the sensitivity analyses on effective parameters indicate that the potential maximum yield and the net price of the crops yield in the market have a direct impact on the crops optimum cultivation area.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Increasing water demands are inevitable due to growth of population and industrial or agricultural development in many countries. Scarcity of water resources in arid and semi-arid regions like Iran and the necessity of sustainable management make it impossible to fully supply all growing water needs. So, optimum water allocation is an urgent subject for water managers and decision makers in such a situation. Agricultural water consumption possesses a share of 90% of the annual water uses in Iran, while there is a huge amount of water losses in the farms due to low irrigation efficiency and inappropriate crop patterns in the agricultural plains (Hipel et al. 2015). As a result, optimum irrigation and crop pattern planning would cause to save a huge amount of water in the present critical situation of water scarcity in the country.
Application of mathematical models for optimizing the crops pattern has a reputation of about 50 years in the literature. Common objective of the problem is to maximize the net benefit gained from the system which occurs in a trade-off between maximization of the value of the crops production and minimization of the amount of the water consumption. In another words, the optimum crop pattern is a plan which yields maximum economic benefit while consumes the least water as possible. In order to find this pattern, application of the robust mathematical models which are able to simulate crop yield equations to a desirable accuracy and to optimize the crops irrigation and cultivation area is known essential in up-to-date studies.
During the recent years, a large number of simulation and optimization models have been used for the proper planning and management of water use in irrigated agriculture (Shourian et al. 2008; Singh 2014). An integrated soil-water balance algorithm was developed and coupled to a nonlinear optimization model by Montazar et al. (2010) in order to carry out water allocation planning in complex deficit agricultural water resources systems based on an economic efficiency criterion. The model was applied to a command area in Iran to evolve an optimal allocation plan of surface water and groundwater for irrigation of multiple crops, and to enhance the overall benefits from cropping activities. An LP-based economic engineering optimization model was used by Khare et al. (2007) to investigate the scope of the conjunctive use of surface water and groundwater for a link canal command in Andhra Pradesh, India. Md. Azamathulla et al. (2008), Karamouz et al. (2008), and Yang et al. (2009) used a similar approach for the management of water resources for sustainable irrigated agriculture. An inexact rough-interval fuzzy linear programming for agricultural irrigation systems was developed by Lu et al. (2011) to generate conjunctive water allocation strategies. Li et al. (2011) developed and used a robust multistage interval stochastic programming method for the planning of regional water management systems. Recently, Condon and Maxwell (2013) and Singh and Panda (2013) utilized LP-based models for solving the optimization problems of land and water allocation and management.
In the present study, a novel simulation-optimization approach is used for optimum crops’ land and irrigation management. This aim is achieved by taking the advantage of MODSIM water planning simulation model custom coding feature where makes it possible to couple its network flow programming (NFP) solver with an out-layer optimization procedure. In this coupled routine, the simulation model finds the irrigation water amounts for the crops in each time step while the optimization algorithm searches for the optimum values of monthly irrigation depths and the cultivation area for the crops. The benefits of water allocation to the crops are calculated based on the agronomic relations in the custom coding environment of MODSIM. The mechanism of the model’s structure is described in the following sections.
2 Network Flow Programming Based Water Allocation Model
MODSIM (Labadie 2006), as a generalized river basin simulation model, has been used to simulate operations of river systems throughout the world. It employs network flow programming (NFP) for simultaneously assuring that water is allocated according to physical, hydrological and institutional aspects of river basin management. Within the confines of mass balance throughout the network, model sequentially solves the following linear optimization problem over the planning period of record through an efficient minimum cost network flow program:
Subject to:
where A is the set of all arcs or links in the network; N is the set of all nodes; O i is the set of all links originating at node i (i.e., outflow links); I i is the set of all links terminating at node i (i.e., inflow links); q l is the integer valued flow rate, l l is the lower bound and u l is the upper bound on flow in link l; c l is the cost (i.e. negative benefits in the minimization form), weighting factors or priorities per unit of flow rate in link l;. The data base for the network optimization problem is completely defined by the link parameters for each link l: [l l , u l , c l ], as well as the sets O i , I i , N and A.
A feature of MODSIM (version 8.1 or higher) is its customization ability by which access to all key variables and object classes in the model is provided. By coding the shuffled frog leaping algorithm in the custom coding environment and coupling it to the NFP solver, value of c l for the crop’s link could be set equal to the economic benefit gained from the yield production and therefore, NFP would obtain q l for the crops according to maximization of the agricultural production. Values of c l are calculated based on agronomic equations.
3 Shuffled Frog Leaping Algorithm
Shuffled frog leaping algorithm (SFLA) is a population based random search algorithm inspired by nature memetics (Samuel and Rajan 2014). In SFLA, a population of possible solution defined by a group of frogs that is partitioned into several communities referred to as memeplexes. Each frog in the memeplexes is performing a local search. Within each memeplex, the individual frog’s behavior can be influenced by behaviors of other frogs, and it will evolve through a process of memetic evolution. After a certain number of memetics evolution steps, the memeplexes are forced to mix together and new memeplexes are formed through a shuffling process. The local search and the shuffling processes continue until convergence criteria are satisfied. The steps are as follows:
-
(1)
The shuffled frog leaping algorithm involves a population of possible solution, defined by a group of virtual frogs (n).
-
(2)
Frogs are sorted in descending order according to their fitness and then partitioned into subsets called as memeplexes (m).
-
(3)
Frog i is expressed as X i = (X i1 , X i2 , …, X iS ) where S represents number of variables.
-
(4)
Within each memeplex, the frogs with worst and best fitness are identified as X w and X b .
-
(5)
Frog with the global best fitness among all memeplexes is identified as X g .
-
(6)
The frog with worst fitness is improved according to the following equations:
where rand is a random number in the range of [0,1]; D i is the frog leaping step size of frog i and D max is the maximum allowed change in a frog’s position. If the fitness value of X w.new is better than the current one, X w.new will be accepted. If it is not improved, then Eqs. (4) and (5) are repeated with X b replaced by X g . If no improvement becomes possible in the case, a new X w will be generated randomly. The update operation is repeated for a specific number of iterations. After a predefined number of memetic evolutionary steps within each memeplex, the solutions of evolved memeplexes are replaced into new population. This is called the shuffling process. The shuffling process promotes a global information exchange among the frogs. Then, the population is sorted in order of decreasing performance value and updates the population best frog’s position, repartition the frog group into memeplexes and progress the evolution within each memeplex until the convergence criterion is satisfied.
4 Integration of NFP-Based Simulation Model and SFLA for Optimum Crop Area and Irrigation Planning
By taking the advantage of customization in MODSIM, SFLA code is written in VB.NET language and coupled with the NFP routine. In the NFP algorithm default, the benefit coefficients (c l ) for water allocation are calculated based on the priority defined by user for the demand node located at the end of each link. It is possible to update automatically these coefficients to the desired values. Therefore, in the links leading to the agricultural crops nodes, agronomic equations are used instead of priority-based coefficients. The point that needs to be paid attention is that the agricultural profit coefficients calculated and embedded in the NFP routine must have the same order of the factors of the other demand nodes priorities consisting of the potable and industrial sites in the system in order to prevent scaling error occurrence. The other side of this statement is that if a comprehensive economic database is provided, the benefit coefficients for all demand nodes in the system could be input based on the economic benefit of unit water allocation to each node. In this study, c l ’s for potable and industrial demand nodes are calculated based on the pre-defined priority of water allocation while the coefficients for the agricultural crops nodes are obtained base on the production benefit of the crops. In the following, the agronomic equations for calculation of c l for the crops nodes are described.
The objective function of the problem is to maximize the benefit gained by crops production which equals the sum of the product of the crop’s actual yield per unit area to the crop’s cultivation area to the unit price of each product as shown in Eq. (6):
where, c is the index for the crops, Nc is the number of crops, YA is the weight of crop actual grain yield per unit cultivation area, CA is the cultivation area for each crop and price is the net benefit gained from the unit weight of crop actual grain yield. This function has a nonlinear form where YA and CA for each crop are unknown depending on the amount of irrigation water and price is an input data. CA(c) and YA(c) could be calculated based on agronomic equations at the end of the agronomic period.
In order to optimize crops irrigation and cultivation area in an agricultural plain by the SFLA-MODSIM model, a flow link should be assigned for water allocation to each crop for c l and water allocation calculations. Therefore, it is needed to define a demand node for each crop cultivated in the agricultural plain. The schematic of a sample network and the used parameters for defining crops pattern in an agricultural plain is shown in Fig. 1.

Schematic network of an agricultural plain for crops planning by SFLA-MODSIM
In Fig. 1, Q(t) is the water allocated to the agricultural plain in time step t equal to sum of q(c,t) which is the allocated water to crop c in time step t. If the required water for growth of crop c in time step t per unit cultivation area is known by RW(c,t), then q(c,t) is equal to:
Values of q(c,t) are obtained by the NFP algorithm calculations where the model maximizes total benefit of water allocation according to the benefit coefficient of transferring water to each node. Therefore, it is logical to equate the NFP benefit of water allocation to each crop node in each time step with the economic benefit of the crops production:
In Eq. (8), c l (c,t) is the benefit coefficient of water allocation to crop c in time step t. By replacing Eq. (7) in (8) we have:
Therefore, if the water allocation benefit coefficients for the crops (c l ) in the NFP algorithm are replaced by the values obtained by Eq. (9), NFP would allocate water to the crops with the objective of maximizing the net agricultural benefit. From here onwards, the agronomic model equations are presented for calculation of RW(c,t) and YA(c,t). Equation of hydrologic balance in the root zone of each crop is as following (Cai et al. 2003):
where, RZD: depth of the root zone (water retention capacity), z: amount of soil moisture in the root zone of the crop as a percentage of the root depth which depends on amount of irrigation water, e IR : irrigation efficiency, e D : water transmission and distribution efficiency, ER: effective rainfall, ETA: actual evapotranspiration of the crop and RF: runoff outflow from the root zone. In Eq. (10), values of z in percentage are unknown and must be optimized as the irrigation planning variables which z(c, t + 1) = z(c, 1) when t = T (number of irrigation planning time steps equal to 12 here). RZD, e IR , e D and ER are known as input data. Values of ETA and RF depend on z and could be calculated by obtaining its value. ETA is estimated according to the crop characteristics and soil moisture (Cai et al. 2003):
where, ET ref : reference evapotranspiration, kat: component of soil water stress on transpiration, kap: component of soil water stress on evaporation from the soil, kc: component of the crop evapotranspiration and kct: component of the crop transpiration. ET ref and kc are input data. Component of soil water stress on transpiration is proposed as follows (Cai et al. 2003):
where, z w : soil moisture as a percentage of root depth at the plant welting point and z s : soil moisture as a percentage of root depth at the field capacity point which both are input data. Also, component of soil water stress on evaporation from soil is estimated according to following (Cai et al. 2003):
Plant transpiration component is expressed as follows (Cai et al. 2003):
Crop emergence period is the duration between planting and budding of the plant. By substituting Eqs. (12)–(14) in Eq. (11), actual evapotranspiration of the crop is calculated. Runoff from root zone includes all flows that exit vertically or horizontally from the plant root zone and consists of two main components. The first component is surface runoff and the second component consists of total subsurface runoff and percolation. RF is calculated as follows (Cai et al. 2003):
where, k s : soil hydraulic conductivity and LAI: leaf area index which both are as input data. Relations between deficit irrigation and crop yield and actual evapotranspiration also must be determined. Below equations which represent the relationship between relative evapotranspiration and crop yield are used as follows:
In the above equations, YA: actual crop yield per unit cultivation area, YR: relative crop yield, YM: maximum possible yield per unit cultivation area, ky and ky season : FAO equation coefficients, CETA: cumulative actual evapotranspiration, CETM: cumulative potential evapotranspiration and ETM: maximum (potential) evapotranspiration. YM, ky, ky season , kc and ET ref are input data. In order to share YA(c) in agronomic model monthly time steps, a linear relation is assumed and therefore YA(c,t) = YA(c) / T is used in Eq. (9) which T is the number of agronomic model time steps that is equal to 12 here. The same process is also used for computation of price(c,t) from price(c).
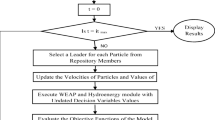
For optimizing the crops irrigation and cultivation area by the defined agronomic model, by taking the advantage of MODSIM’s customization ability, it is enough to search and produce the values of z(c,t) by SFLA. According to Eq. (9), values of c l (c,t) coefficients are calculated using agronomic relations. Then the NFP solver is executed and the values of q l (c,t) are obtained in the links of the network. By use of Eq. (7), average values of CA(c) are obtained. This procedure is repeated in every iteration of SFLA run until the algorithm converges to the optimum values for the decision variables. In Fig. 2, flowchart of the simulation-optimization procedure applied in the SFLA-MODSIM model is shown.

Flowchart of coupled SFLA-NFP simulation-optimization procedure
Through a more precise look at the procedure applied in SFLA-NFP, it is seen that a nested optimization is performed in every iteration of SFLA. Decision variables of the problem which are z(c,t) (by which c l (c,t) is generated) and q l (c,t) make the form of the optimization problem a non-linear one, therefore it cannot be solved by NFP alone. By integration of SFLA and NFP, SFLA searches for optimum values of z(c,t) and by calculating and entering the values of c l (c,t) to NFP in every iteration and changing the form of the problem to a linear one, NFP as a fast and efficient program, is able to obtain the optimum values of numerous q l (c,t) in the links of the river basin network and therefore CA(c) is resulted. This procedure is continued until the SFLA stopping criteria, which is reaching to the maximum number of iterations (500 in this study) or repeating of the best objective function value in a pre-defined number of successive iterations (20 in this study) after iteration number 100, each one occurs sooner is met. The above described procedure, named SFLA-NFP, is a useful and robust method for solving real large-scale water resources planning problems. In the following, application of the method for finding optimum crops irrigation and cultivation area in a real case study is presented.
5 Simulation of the Arayez Plain and Formulation of the Problem
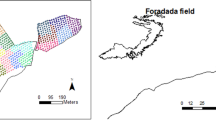
Karkheh river basin is one of the populated basins in Iran which contains the grand Karkheh river and its tributaries. The basin with the area of 51,000 km2 is located between eastern longitudes of 46° 57′ 00″ and 49° 10′ 00″ and northern latitudes of 31° 48′ 00″ and 34° 58′ 00″. Arayez plain is one the sub-basins in the Karkheh river basin where the most area of the plain is under cultivation for agricultural purposes. In Fig. 3, location of the Arayez plain in the Karkheh river basin is shown.

Location of the Arayez plain in the Karkheh river basin, Iran
Four major crops of wheat, barley, maize and rice are the main cultivated crops in the Arayez plain which are numbered 1 to 4 respectively. Local limitations of arable area for the crops, based on the regional data, are given in Table 1. Main agricultural and soil characteristics of the Arayez plain are also given in Table 2. All the data used in the study are extracted from the governmental approved reports (National Water Master Plan 2013).
Characteristics of the crops, based on the regional data are reported in Tables 3, 4, and 5. Time series of the historical inflow to the Arayez plain for the simulation period which is the 10 years period of 2000–2009 is shown in Fig. 4.

Time series of 10 year historical inflow to the Arayez plain
The Arayez plain is simulated in MODSIM (version 8.1) and values of the input parameters are entered to the model. The objective function defined for the SFLA-NFP model is to maximize the benefit of total water supply for the river basin demand sites and the crops yield in the agricultural plain. Accordingly, mathematical formulation of the problem of optimizing crops irrigation and cultivation area in the Arayez plain is presented as follows:
Subject to:
In Eq. (19), b 1 : benefit coefficient for average annual water supply for non-agricultural demands in the Arayez plain considered equal to 1000 and TWSup: average annual water supply for the non-agricultural demand sites. Other parameters are as defined before. A detailed economic analysis is needed for evaluation of the benefit of water allocation to non-agricultural demands in the basin like municipal and industrial demands. As there is not such a study available for the Arayez plain, based on a trial and error approach a constant benefit coefficient of 1000 is considered for water supply to these demand nodes in the model noting that less than 10% of the total water allocation belongs to these demands. The value of this coefficient must not be so small that the model ignores water allocation to non-agricultural demands and also must not be so big that the model prefers not to supply water for the agricultural demands.
To solve an optimization problem by a meta-heuristic algorithm like SFLA, a possible way for consideration of the constraints is to define the relations as a penalty term in the objective function. Constraints of the arable area for the crops are entered as the penalty terms in case of violation in the objective function. Accordingly, the mathematical equation of the objective function to optimize the crops irrigation and cultivation area in the Arayez plain is presented as the following:
where, p 1 to p 7 : penalty coefficients which are respectively equal to 10, 500, 500, 50, 50, 50 and 50 in case of violation of the arable area limitations and equal to zero, otherwise. These values for the penalty coefficients are obtained by trial and errors and are the values which cause the objective function to be sensitive to violation of the constraints. The above objective function is defined for the SFLA algorithm and the optimization code is written in the MODSIM’s custom coding environment and linked to the simulation model. Decision variables of the problem are crops irrigation depths (z(c,t)) and water allocations (q l ) in all links of the network by which cultivation area (CA) are obtained.
6 Results and Discussion
The SFLA-NFP model is executed 10 times for assuring of the model’s results consistency. In Table 6, average results for the optimum total water supply, benefit of agricultural yield and crops cultivation area are compared with the existing situation values in the Arayez plain. Also in Table 7, optimum values of the soil moisture contents (z(c,t)) defining irrigation depths are reported. In Fig. 5, present and optimum cultivation areas for the crops are compared.

Crops cultivation area in the present and optimum situations
It is seen that total optimum cultivation area in the Arayez plain is obtained 8805 ha by the model while the maximum possible area is 30,000 ha. This result is because of water deficit which does not allow further crop planting in the optimum situation. About 64% of the total cultivation area is dedicated to Crop 4 (rice) because of having the highest benefit among the others. The agricultural yield benefit and total water supply are increased 12 and 3.2% respectively in the optimum situation comparing the present condition.
7 Sensitivity Analysis and Results Assessment
In order to evaluate the impact of parameters values on the model’s results, sensitivity analysis is a useful tool. To do so, the effect of the parameter variation on the results is assessed. In this study, the sensitivity analysis is performed on two effective parameters of crops net price and crops maximum yield. In one scenario, the net price of Crop 3 (maize) which was the lowest among the others is increased to become the highest price. Also, in another scenario it is supposed that the maximum yield of Crop 2 (barley) which was the lowest one is increased to become the highest among the other crops. In Table 8, values of the input parameters (maximum grain yield and the net price) in two Scenarios 1 and 2 accompanying the existing condition (Scenario 0) are reported.
SFLA-NFP is executed with new values of parameters in Scenarios 1 and 2. In Table 9, results obtained by the model in Scenarios 0, 1 and 2 are reported.
Table 9 shows that in Scenario 1, cultivation area of Crop 3 which has the highest net price is obtained more comparing Scenario 0. Also, in Scenario 2 where the maximum yield of Crop 2 has raised up, the cultivation area of Crop 2 is also increased. In general, it could be stated that by increase of the crop’s net price or maximum yield, the model tries to increase the crop’s cultivation area for gaining more production profit. In Fig. 6, the crops’ optimum cultivation area obtained in the sensitivity analysis scenarios are depicted.

Crops optimum cultivation area in the sensitivity analysis scenarios
8 Conclusion
In this study, the problem of optimum water allocation considering optimum crop patterning is solved by use of a novel simulation-optimization approach. To do so, instead of considering a constant amount of water requirement for the agricultural node, through a demand management approach the crops optimum cultivation area are obtained by use of the agronomic equations in the custom coding environment of MODSIM and coupling it with the Shuffled Frog Leaping Algorithm. By searching for the irrigation depth variables by SFLA, the remaining problem finds a linear format and therefore could be solved by the Network Flow Programming algorithm embedded in MODSIM. Actually, a nested optimization procedure is used where in the outer layer, SFLA searches for the independent decision variables of irrigation depths and in the inner layer, NFP finds the optimum values for the dependent variables of water allocations in the network links. The SFLA-NFP model is utilized for optimum crop irrigation and planning in the Arayez plain in Iran.
Results obtained by the model indicate that this hybrid simulation-optimization approach has an appropriate ability for solving optimum water allocation planning problems. Although the maximum total arable area in the plain is 30,000 ha, but the model results show that the optimum pattern is to cultivate 8805 ha of the arable lands because of available water limitation. The optimum pattern is to plant the wheat, barley, maize and rice crops in 1686, 703, 718 and 5698 ha respectively with an irrigation planning as reported in Table 7. About 64% of the total cultivation area is dedicated to rice because of having the highest benefit among the others. According to the results, the total agricultural net benefit in the Arayez plain is increased 12% in the optimum situation comparing the present condition. Also, the sensitivity analyses on the crops net price and maximum yield state that these parameters have a direct impact on the results of the model which by increase of their value for a crop, the model has tried to allocate more cultivation area to that plant.
References
Cai X, McKinney DC, Lasdon LS (2003) Integrated hydrologic-agronomic-economic model for river basin management. J Water Res Plan Manag 129(1):4–17
Condon LE, Maxwell RM (2013) Implementation of a linear optimization water allocation algorithm into a fully integrated physical hydrology model. Adv Water Resour 60:135–147
Hipel KW, Fang L, Cullmann J, Bristow M (2015) Conflict resolution in water resources and environmental management. Springer, Heidelberg, 291 pages
Karamouz M, Zahraie B, Kerachian R, Eslami A (2008) Crop pattern and conjunctive use management: A case study. Irrig Drain 59(2):161–173
Khare D, Jat MK, Sunder JD (2007) Assessment of water resources allocation options: Conjunctive use planning in a link canal command. Resour Conserv Recycl 51(2):487–506
Labadie J (2006) MODSIM: decision support system for integrated river basin management. Diss. International environmental modeling and software society
Li YP, Huang GH, Nie SL, Chen X (2011) A robust modeling approach for regional water management under multiple uncertainties. Agric Water Manag 98(10):1577–1588
Lu H, Huang G, He L (2011) An inexact rough-interval fuzzy linear programming method for generating conjunctive water-allocation strategies to agricultural irrigation systems. Appl Math Model 35(9):4330–4340
Md. Azamathulla H, Wu FC, Ghani AA, Narulkar SM, Zakaria NA, Chang CK (2008) Comparison between genetic algorithm and linear programming approach for real time operation. J Hydroenviron Res 2(3):172–181
Montazar A, Riazi H, Behbahani SM (2010) Conjunctive water use planning in an irrigation command area. Water Resour Manag 24(3):577–596
National Water Master Plan (2013) Karkheh Basin reports. Ministry of Energy, Tehran In Persian
Samuel G, Rajan CCA (2014) A modified shuffled frog leaping algorithm for long-term generation maintenance scheduling. In: Pant M et al (eds) Proceedings of the third international conference on soft computing for problem solving. Springer, India, pp 11–24
Shourian M, Mousavi SJ, Tahershamsi A (2008) Basin-wide water resources planning by integrating PSO algorithm and MODSIM. Water Resour Manag 22(10):1347–1366
Singh A (2014) Optimizing the use of land and water resources for maximizing farm income by mitigating the hydrological imbalances. J Hydrol Eng 19(7):1447–1451
Singh A, Panda SN (2013) Optimization and simulation modelling for managing the problems of water resources. Water Resour Manag 27(9):3421–3431
Yang CC, Chang LC, Chen CS, Yeh MS (2009) Multiobjective planning for conjunctive use of surface and subsurface water using genetic algorithm and dynamics programming. Water Resour Manag 23(3):417–437
Acknowledgements
The second author would like to thank and acknowledge Professor S. Jamshid Mousavi from Amirkabir University of Technology, Tehran, Iran, for supervising his PhD research where a primary version of the present study was proposed and discussed.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Fazlali, A., Shourian, M. A Demand Management Based Crop and Irrigation Planning Using the Simulation-Optimization Approach. Water Resour Manage 32, 67–81 (2018). https://doi.org/10.1007/s11269-017-1791-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-017-1791-6