
Abstract
A geoinformation technology for creating spatially distributed greenhouse gas inventories based on a methodology provided by the Intergovernmental Panel on Climate Change and special software linking input data, inventory models, and a means for visualization are proposed. This technology opens up new possibilities for qualitative and quantitative spatially distributed presentations of inventory uncertainty at the regional level. Problems concerning uncertainty and verification of the distributed inventory are discussed. A Monte Carlo analysis of uncertainties in the energy sector at the regional level is performed, and a number of simulations concerning the effectiveness of uncertainty reduction in some regions are carried out. Uncertainties in activity data have a considerable influence on overall inventory uncertainty, for example, the inventory uncertainty in the energy sector declines from 3.2 to 2.0% when the uncertainty of energy-related statistical data on fuels combusted in the energy industries declines from 10 to 5%. Within the energy sector, the ‘energy industries’ subsector has the greatest impact on inventory uncertainty. The relative uncertainty in the energy sector inventory can be reduced from 2.19 to 1.47% if the uncertainty of specific statistical data on fuel consumption decreases from 10 to 5%. The ‘energy industries’ subsector has the greatest influence in the Donetsk oblast. Reducing the uncertainty of statistical data on electricity generation in just three regions – the Donetsk, Dnipropetrovsk, and Luhansk oblasts – from 7.5 to 4.0% results in a decline from 2.6 to 1.6% in the uncertainty in the national energy sector inventory.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Kyoto Protocol to the United Nations Framework Convention on Climate Change (UNFCCC) defines obligations for its parties to reduce their greenhouse gas (GHG) emissions compared with those of a base year. According to the Protocol, each party must develop a national system for estimating anthropogenic emissions and sinks of GHGs. The Intergovernmental Panel on Climate Change (IPCC) has developed a general methodology for estimating GHG emissions and sinks, which has been published in the Revised 1996 IPCC Guidelines (IPCC, 1997a) and corresponding software (IPCC, 1997b). A positive feature of the IPCC methodology is its universality, which allows it to be used by experts in many countries, notwithstanding these countries’ different locations around the world and their different levels of economic development. This is one reason why the IPCC Guidelines have been so important during the formation of the Kyoto Protocol mechanisms.
In the future, however, this universality could slightly decrease the efficiency of GHG inventories and thus limit the use of the Kyoto mechanisms. Because of its universality, the IPCC methodology cannot consider regional disparities within countries, which could thus increase inventory uncertainty. Moreover, in most large countries, the various GHG sources and sinks are distributed nonuniformly across the territory. This is the case with Ukraine, for instance, which has an area of 603,000 square kilometers and comprises 25 administrative units (oblasts). The IPCC GHG inventory methodology gives results for entire countries and thus cannot be an effective tool for those making strategic economic and political decisions on regional development within a country.
Integrated information on the actual spatial distribution of GHG sources and sinks would aid in making well-considered economic and environmental decisions. Neighboring countries are interested in real information on ecological conditions near their borders. Geographically explicit data are needed for modeling GHG fluxes. Moreover, spatially distributed analysis of GHGs and their uncertainties can help to identify cost-effective ways of reducing uncertainty.
GHG inventories for regions within a country and the use of geographical information systems (GIS) to increase inventory quality and usability are becoming more widespread. In Portugal, for example, the national GHG inventory was carried out by region and the emissions were spatially analyzed for emission-reduction purposes (Seixas et al., 2002). There have also been efforts to disaggregate GHG emissions on a spatial grid and to produce the georeferenced maps necessary for modeling. For example, the project CARBOEUROPE-GHG (Synthesis of the European Greenhouse Gas Budget; see http://gaia.agraria.unitus.it/ceuroghg/projghg.html) disaggregates GHG emissions to a 50 × 50 km grid. The project currently concentrates on the 15 original European Union (EU) member countries; however, the plan is to ultimately study the new EU countries as well, and to obtain disaggregated GHG emissions for Ukraine and Russia for full coverage of the continent. Another project is aimed at spatial disaggregation of the 1990 emissions inventory data to a 20 × 20 km grid for Africa south of the equator (Fleming & van der Merwe, 2000).
This article discusses bottom-up inventory analysis. We examine carbon dioxide (CO2) emissions and their uncertainties in two dimensions – energy subsectors and spatial distribution – and determine which dimension is the most influential. A similar analysis has been performed for the Netherlands by Vreuls (2004), who considers more GHG gases and sources but omits spatial analysis. We agree with Gillenwater, Sussman, and Cohen (2007) that the uncertainty inherent in the uncertainty estimates is rather large. Nevertheless, we think that the uncertainty estimates should be used to aid policy making. Examples of practical ways of coping with the uncertainties in GHG emissions estimates when trading or comparing national GHG emissions are listed in the conclusions by Monni, Syri, Pipatti, and Savolainen (2007); valuable theoretical work is also offered by Nahorski, Horabik, and Jonas (2007).
The basic approach to carrying out a multilevel, spatially distributed inventory is considered in Section 2 of this chapter, and the geoinformation technology developed to carry out such an inventory is discussed in Section 3. Sections 4 and 5 illustrate the application of the technology for the analysis of GHG emissions in the energy sector at the regional and plot levels, respectively, while Section 6 is devoted to simulations and analysis of the uncertainties and uncertainty reduction measures. Conclusions are presented in the final section.
2 Basic Approach
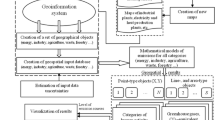
The IPCC methodology (IPCC, 1997a) covers a number of human activities associated with GHG emissions and sinks – in particular, fossil fuel combustion, industry and agriculture, land-use change, and deforestation. On the basis of this methodology, we have developed a geoinformation technology that presents GHG inventories at three levels: the national level, the regional (oblast) level, and the plot level (Bun, 2004). Such a multilevel inventory model reflects the disparities among GHG emissions and sinks, and can be helpful for making policy decisions at the national and regional levels (Fig. 1). Information at lower inventory levels can prove extremely valuable for decision makers.

Three-level structure of the inventory process
2.1 National Level
At the highest inventory level, the national level, the GHG inventory is carried out for a country as a ‘point in space.’ In this case, GHG inventory methods commonly used for an entire country can be utilized, following the formula
where Y and y s are the inventory results for the entire country and for the sth sector, respectively; S is the number of human activity sectors according to the IPCC (1997a); a sm and x sm are the emissions factor and data on the mth human activity in the sth sector, respectively; and M s is the total number of human activities in the sth sector. Input data used for the inventory are taken from statistical yearbooks, research results, etc. Provided that all the necessary data are available for a country, the Revised 1996 IPCC Guidelines permit the calculation of GHG emissions and sinks (the output data of the model). In this case, the methodology described in the Revised 1996 IPCC Guidelines and presented by expression (1) can be regarded as a mathematical model of inventory at the highest level. We have mathematical expressions mapping input data to output data, which are necessary for making an inventory for the whole country. At the highest inventory level, the input data and inventory results are ‘lumped,’ that is, a single value is generated for the entire country. The uncertainties are considered for the economic sectors and the country as a whole.
2.2 Regional Level
At the middle inventory level, the regional level, the inventory is carried out for each administrative region of a country. As in the previous case, the parameters of the mathematical models are lumped. Ukraine, for example, has 25 administrative regions (oblasts), some of which are the size of small countries. In principle, a methodology based on the Revised 1996 IPCC Guidelines can be applied to each region as described above, using an inventory model of the following form:
where Y r and y rs are the inventory results for the rth region and its sth sector, respectively, based on the IPCC methodology (IPCC, 1997a); a rsm and x rsm are the emissions factor and data on the mth activity in the sth sector for the rth region, respectively; and R is the total number of regions.
Model (2) reflects regional characteristics of GHG emissions and sinks quite well, although the model parameters are lumped. Like the mathematical model for the highest level, this model has input and output data. Input data are obtained from statistical yearbooks (because most of the statistical information is published for administrative regions) and from the results of scientific research representing regional characteristics of some of the parameters used in the IPCC Guidelines. In situations where a parameter is known for the country but not for individual regions, some assumptions and additional information can be used to obtain the algorithm for determining the necessary parameters for the regions. In this case, the uncertainties are considered by economic sector and region. We introduce additional information into the inventory (e.g., region-specific emissions factors and activity data) that decreases the overall uncertainty of the inventory at the national level; however, some regional uncertainties can be quite large.
2.3 Plot Level
At the lowest inventory level, the plot level, both input and output data are stored in a georeferenced database. This inventory level is used for plots (say, 10 × 10 km) covering the entire country (in the case of Ukraine, about 60,300 plots in total). For each plot, a GHG inventory is performed following the IPCC methodology (IPCC, 1997a) using a mathematical model defined according to the IPCC Guidelines.
Data on human activity in the nth plot are denoted by Δx nsm , with corresponding indices. Inventory results in total and by sector for a given plot are denoted by ΔY n and Δy ns , respectively. In this case, the inventory model can be written in the following form:
where a nsm is the emissions factor for the mth activity of the sth sector in the nth plot, and N is the total number of plots. Unlike in the previous cases, in model (3), input and output data relate to individual plots; that is, they are not lumped. Some model parameters can be obtained (e.g., using a digital map and additional algorithms), and other model parameters are estimated following algorithms developed under certain assumptions.
Concerning this distributed model, in some cases the GHG emissions and sinks within a particular plot can be calculated directly using the IPCC Guidelines with corresponding emissions factors – for example, emissions from power plants, cement production plants, chemical plants, fertilized fields, etc. However, in some cases it is more efficient to distribute results obtained for a region using data on the spatial distribution of activities – for example, GHG emissions from gas flaring used for heating buildings and cooking. The GHG emissions distribution in this case correlates with population density, which is obtained from spatial analysis of a digital map (Kujii & Oleksiv, 2003; Tsybrivskyy & Klym, 2003). In the worst case, if one cannot derive detailed data on GHG emissions caused by specific human activities within a region, the total emissions quantity for all plots within the region can be distributed uniformly. GHG inventories at the plot level include more information than those at the national and regional levels (e.g., location of stationary emissions sources, spatial distribution of sources and sinks, usage of plant-specific emissions factors and activity data, etc.) and thus decrease the overall uncertainty.
In summary, in the modeling approach presented here the distributed inventory is carried out for a selected class of objects (regions, districts, or plots). Information obtained from layers of a digital map and statistical data for regions and districts are used as input data. From this distributed inventory, new layers of a digital map are formed corresponding to the economic sectors of the IPCC methodology. Summing inventory results for all plots within Ukraine produces a general inventory for the entire country (Bun et al., 2002, 2003).
The technology used is based on a GIS, the IPCC methodology, and special software. The use of digital maps and the geoinformation approaches makes possible a distributed inventory of the territory, while the use of the IPCC methodology and software means the inventory results are compatible and comparable with those of traditional approaches. Moreover, the use of region-specific emissions factors and activity data increases the quality of the GHG inventory (Bun, 2004).
3 A Geoinformation Technology for Distributed GHG Inventories
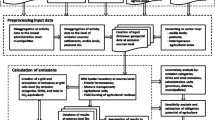
The geoinformation technology presented in the previous section, which combines georeferenced databases, geoinformation systems, and the IPCC methodology, is illustrated in more detail in Fig. 2, which shows the corresponding layers of a digital map. Here, information from these layers together with statistical data and data from scientific research serve as input data. The databases (i.e., the new layers of the digital map) corresponding to the economic sectors of the IPCC methodology (energy, industrial processes, etc.) are created using this input information.

Geoinformation approach to GHG inventory
We perform the inventory using the IPCC methodology for all plots within a given country. In this way, we form the new layers of a digital map corresponding to the results of the GHG inventory of emissions of carbon dioxide (CO2), methane (CH4), etc. Finally, we obtain the layer of the digital map corresponding to the total GHG emissions in CO2 equivalent terms. Thus, in the proposed approach to creating a distributed inventory, the results are produced in the form of layers of a digital map of Ukraine. Lower-level inventory results include information about specific levels of GHG emissions and sinks per unit area within the country.
The digital map of Ukraine produced by Intelligence Systems GEO Ltd. (ISGEO: http://www.isgeo.kiev.ua) was chosen for use in the proposed geoinformation technology. The map is a spatial database at a 1:500,000 scale. The database is organized in the form of separate tables containing cartographic objects and classifiers, and is realized in the MapInfo system format. The following segments were used to create an inventory of GHG emissions: settlements (inhabited localities and their population), forested lands, hydrology, oblast boundaries, vegetation, and soil.
Statistical data published by the State Committee of Statistics of Ukraine in a number of statistical collections (e.g., Ukrstat, 2001) are another major source of input information for the GHG inventory. The statistical data are issued for many economic sectors, and the information is aggregated for oblasts. Regional statistical collections also exist. Thus it is an easy step from GHG inventories at the national level to those at the oblast level. On the basis of the statistical collections, one can obtain the input data necessary to complete the input worksheets of the IPCC methodology by economic sector.
The proposed geoinformation system consists of two basic modules: GHGinvent and GHGmap (Bun & Oleksiv, 2003). GHGinvent is a programming module that performs a GHG inventory according to a user-defined inventory model (i.e., at the selected level). The main function of GHGinvent is to input data into the corresponding Excel tables in the IPCC methodology (IPCC, 1997b). This module forms initial GHG inventory tables using the results of the IPCC methodology according to the model used.
The basic functions of the GHGmap module are to organize queries into inventory tables and to form new geoinformation layers with the inventory results, which are then reflected in the digital map of Ukraine. The inventory tables organized by GHGinvent, together with the topographical information of the digital map of Ukraine, serve as input data for GHGmap. The proposed geoinformation technology is quite complex with respect to software implementation because a number of different kinds of software components have to interact correctly if the entire information system is to perform as it should. The software includes databases of input information filled in by the operator (Bun & Oleksiv, 2003); Excel tables of the IPCC methodology filled in by the program according to the inventory model used; and database tables that are compatible with MapInfo for inventory results reflected in the digital map of Ukraine. Below, a number of results of GHG inventories at the regional and plot levels as well as a spatial uncertainty analysis are presented to illustrate possible ways of using the technology.
4 Inventory at the Regional Level: Energy Sector
Let us consider GHG inventories at the regional level, using as an example the energy sector, which accounts for about 95% of total GHG emissions in Ukraine. The primary sources of GHGs in the energy sector are fuel production, fuel transportation, and fuel combustion (Kujii, 2003). The Revised 1996 IPCC Guidelines (IPCC, 1997a) for the energy sector cover six GHGs: NO2, CH4, nitrous oxide (N2O), carbon monoxide (CO), nitrogen oxides (NO x ), non-methane volatile organic compounds (NMVOCs), and sulfur dioxide (SO2). CO2, CH4, and NO x emissions are the largest. Below we consider a sectoral approach; that is, we account for the carbon in fuels supplied to the economic sectors (IPCC, 1997a).
CO2 emissions resulting from fuels combusted in the energy industries (i.e., fuel-extraction or energy-producing industries; for details, see IPCC, 1997a, Vol. 1) determine the sector emissions (Kujii, 2003). With integrated statistical data on production, export, import, and consumption of fuel and energy resources, one can use the IPCC Guidelines (IPCC, 1997a) to estimate the carbon mass (in gigagrams [Gg]) in the utilized fuel:
where m is the mass of combusted fuel (in Gg), T is the fuel calorific value (in terajoules [TJ] per Gg), and k c is the carbon emissions factor (in tons of carbon per TJ). The fraction of nonoxidized carbon (f c) should also be accounted for.
Models that create an inventory of GHG emissions from fuel combustion by economic sector (energy industries; manufacturing industries and construction; international marine and air transport; the commercial/institutional and residential sectors; agriculture/forestry, etc.) provide more useful information than more aggregated models, since different coefficients – T, k c, and f c – are applied to different economic sectors.
In many countries, natural, historical, and other factors have led to the nonuniform distribution of GHG emissions from the energy sector. This is true of Ukraine, which has developed industrial regions with high consumption of fuel and energy resources, as well as of regions without heavy industry. The technology for creating spatially distributed inventories is useful for presenting these differences in GHG emissions at the regional level. Results of an inventory of CO2 emissions caused by fuels combusted in the energy industries at the regional level are presented in Fig. 3. The data relate to the economic activity of the regions of Ukraine in 2000. The emissions are very irregularly distributed; thus, for convenient presentation of the results, a square root function of the data is used (the column height is proportional to the square root of the emissions value).

Variation of GHG emissions resulting from fuels combusted in the energy industries among the regions of Ukraine
The Donetsk oblast has the highest CO2 emissions in Ukraine (26.89% of total CO2 emissions). Half the total emissions (51.84%) are contributed by three oblasts: Donetsk, Luhansk, and Dnipropetrovsk. Most of the CO2 emissions occur in the processes of the energy industries. The difference between the results of CO2 emissions obtained using the reference (accounting for the carbon in fuels supplied to the entire economy) and sectoral approaches does not exceed 10%. The discrepancy between the emissions estimates using the two different approaches can be explained by the fact that statistical data for sectors are set equal to zero in cases where their values are below the lowest-order number in the corresponding statistical table. This phenomenon occurs where fuel-energy resources are presented by oblast or economic activity. Therefore, total emissions do not always equal the sum of the individual components. The small discrepancy between the calculated emissions values in the oblasts allows the user to draw conclusions as to the consistency of the statistical data on fuels combusted in the energy industries of Ukraine (Bun, 2004).
In 2000, for all GHGs, the highest emissions were observed in the Donetsk (109,669 Gg of CO2 equivalent), Dnipropetrovsk (56,607 Gg of CO2 equivalent), and Luhansk (41,964 Gg of CO2 equivalent) oblasts. CO2 sink values exceeded emissions values in a number of oblasts, particularly in the Volynska (2,348 Gg of CO2 equivalent), Zakarpatska (Uzhgorod) (4,821 Gg of CO2 equivalent), Rivne (1,828 Gg of CO2 equivalent), Chernivtsi (92 Gg of CO2 equivalent), and Chernihiv (1,897 Gg of CO2 equivalent) oblasts. The emissions levels are determined mainly by the energy sector; absorption levels, by the land use change and forestry sector (Bun, 2004).
Within the energy sector, the lowest CO2 emissions are from natural gas combustion, as it has the lowest emissions factor (approximately half that of coal) (IPCC, 1997a). Thus, the shift from coal to natural gas and black oil in combined heat and power (CHP) plants could solve the GHG problem for Ukraine’s energy sector. Taking into account the significant contribution of CHP plants to the total GHG budget of Ukraine, plans for the development of domestic sources of electricity and heat supply must be revised. Increasing the efficiency of power equipment will help solve this problem (Bun, 2004).
5 Spatial Analysis of GHG Emissions
In carrying out the distributed inventory, each plot of Ukrainian territory is analyzed in turn. If the border between two or more administrative units lies within a plot, the emissions and sinks are assigned in proportion to each unit’s contribution.
CO2 emissions resulting from the combustion of coal in the public sector at the plot level (10 × 10 km plots, distributed inventory results) are shown in Fig. 4. The figure only gives qualitative information on the territorial distribution of the emissions; however, the digital layer comprises the data in each plot that can be used for analysis. This type of digital layer can be made for each GHG and for each kind of human activity considered in the IPCC methodology (IPCC, 1997a).

Presentation of CO2 emissions resulting from combustion of coal in the public sector at the plot level (distributed inventory); darker areas indicate higher emissions levels
Moreover, the geoinformation technology allows the user to make projections of GHG emissions and sinks following different scenarios of economic development. In the most favorable scenario, the GHG emissions reach their 1990 level in 2011–2012 (Bun, 2004). Emissions reach this level in 2013–2014 in the favorable scenario and in 2020 in the unfavorable scenario. As the unfavorable scenario corresponds to slow changes in the economy, it is the most likely scenario.
The territorial approach to constructing CO2 inventories takes into account regional differences in economic activities within Ukraine. The multilevel inventory is aimed at obtaining quantitative estimates for separate regions of the country. Estimates of distributed GHG emissions (on a territorial basis) from the energy sector can help to accelerate the implementation of actions to reduce emissions – for example, means for GHG utilization, the capture of CO2 from exhaust, the creation of favorable conditions for carbon absorption by forests, etc.
6 Results of Spatial Inventory and Uncertainty Reduction
In carrying out national inventories and in trading emissions permits, one must be sure that inventory results are of ‘good quality’ (i.e., that the uncertainties are small). All data used in the inventory (emissions factors, calorific values, statistical activity data, etc.) have some uncertainty that can significantly slow the process of implementing the Kyoto Protocol mechanisms.
Uncertainty in GHG inventories is the value indicating the lack of certainty in the cadastre components resulting from such arbitrary random factors as uncertainty of emissions sources, lack of transparency in the inventory process, etc. (IPCC, 2000). Most often, relative uncertainty is characterized as a 95% confidence interval, meaning that the probability that the value of a real parameter falls within the interval is 95%. Relative uncertainty is ‘measured’ in percent as the ratio of the confidence interval value to the mean parameter value. If every value used in the GHG inventory has some uncertainty, then the inventory process according to the IPCC methodology (IPCC, 1997a), which utilizes multiplication and summing, leads to an ‘uncertainty combination’ in compliance with the following formulas (IPCC, 2000):
for the uncertainty of the sum of values \( x_{1} + x_{2} + \ldots + x_{k} \), and
for the uncertainty of the product of the values. The resulting uncertainty is given as a percentage; x i and U i are the uncertain value and its relative uncertainty, respectively (in percent).
The formulas presented above for the uncertainty combination relate to the case of a normal distribution of random uncorrelated values. The Monte Carlo method is more general and consists of choosing random values of emissions factors and activity data from their individual probability distributions and calculating corresponding emissions (IPCC, 2000). This procedure is repeated many times, and the results of all iterations form the probability distribution of emissions. A Monte Carlo analysis can be conducted for every emissions source for economic sectors, national regions, or the entire cadastre. The Monte Carlo method allows the user to work with probability distributions of any form and to account for correlations. The experiment results presented below were obtained using this method.
The geoinformation technology developed for creating a multilevel inventory allows the user to carry out experiments on the uncertainties in national GHG inventories in, for example, the energy sector and to determine the dependence of the uncertainties on inventory components. Using this feature highlights ways of reducing the uncertainties. A number of such experiments are discussed below.
Experiment 1
A report by the IPCC (2000) provides uncertainty intervals for statistical data for countries such as Ukraine. For data on fuels combusted in the energy industries (which largely determines GHG emissions in Ukraine), the interval provided by the IPCC is 5–10% – a more exact uncertainty value should be found by national experts. Using these recommended uncertainty intervals, we carried out an experiment on the influence of activity data uncertainty on the uncertainty of the national inventory in the energy sector. Figure 5 shows the results based on economic activity in the regions of Ukraine in 2000 for three uncertainty values from the uncertainty interval recommended by the IPCC (energy industries) – the lowest (5.0%), middle (7.5%), and highest (10.0%) interval values. In all experiments reported here, the uncertainties in other sectors were assumed to be the mean of the intervals recommended by the IPCC (2000) (see specifications in Experiment 2).

Influence of activity data uncertainty on the uncertainty of national inventory in the energy sector
It was assumed that the statistical data on economic activity in the energy sector were of a normal probability distribution and that their uncertainty, characterized by a 95% confidence interval, was similar in all regions. Data on the calorific value of the fuel were assumed to have a normal probability distribution and 5% uncertainty for the 95% confidence interval. The other data used in the inventory were assumed to be known exactly. The calculations of national emissions in the energy sector were carried out many times for different randomly chosen inventory parameters for the regions of Ukraine. The probability distribution of the parameters for the national inventory in the energy sector is determined from the calculated results. The results show that decreasing the uncertainties in national statistics is valuable for implementing the Kyoto Protocol mechanisms. The uncertainty of national energy sector inventory data decreases from 3.2% (for higher uncertainty of statistical data – the 10% interval value) to 2.0% (for lower uncertainty of statistical data – the 5% interval value). This leads to a change in the confidence interval of 8.4 Gg of CO2.
Experiment 2
Calculation results demonstrating the dependence of national energy sector inventory uncertainty (in percent) on the uncertainty in each subsector are shown in Fig. 6. The estimation is carried out using data on economic activity in Ukraine in 2000 for minimum and maximum uncertainties of the statistical data for each subsector as follows: (1) fuels combusted for energy production (5–10%); (2) manufacturing industries and construction (5–10%); (3) transport (5–10%); (4) commercial/institutional, and residential sectors (15–20%); (5) agriculture/forestry (5–10%); and (6) other (15–20%). The minimum and maximum uncertainties are taken from the uncertainty intervals recommended by the IPCC (2000). When the simulation was carried out for one of the subsectors, the uncertainties for the other subsectors were chosen to be the mean of the recommended intervals. The other parameters are defined as in Experiment 1.

Influence of uncertainty in each subsector on total inventory uncertainty in the energy sector: (from left) 1 = energy industries; 2 = manufacturing industries and construction; 3 = transport; 4 = commercial/institutional and residential sectors; 5 = agriculture/forestry; 6 = other
The results demonstrate that considerable emissions result from fuels combusted in the energy industries and that decreasing the uncertainty in this subsector is an urgent problem. Specifically, the relative uncertainty in the national inventory in the energy sector can be reduced from 2.19 to 1.47% (when absolute uncertainty equals 2.5 Gg of CO2).
Experiment 3
Continuing from Experiment 2, an analysis was carried out on how energy sector inventory uncertainty in each region contributes to the total inventory uncertainty (in absolute values). The results are presented in Table 1. The greatest influence appears in the ‘energy industries’ subsector in the Donetsk oblast, where the absolute uncertainty is 5,081 Gg of CO2 (2.23% uncertainty relative to the total CO2 emissions in this subsector; that is, 227,819.40 Gg of CO2), followed by the Dnipropetrovsk and Luhansk oblasts, with uncertainties in these subsectors equaling 2,066 Gg of CO2 (0.91%) and 1,262 Gg of CO2 (0.55%), respectively.
Experiment 4
The improvement of statistics (i.e., decreasing the uncertainty in statistical data) requires considerable investments, such as the installation of additional equipment, the implementation of organizational and administrative measures for a more accurate and complete record of all economic spheres, and additional research for a better understanding of emissions processes. Thus, those administrative regions that have the most influence on energy sector emissions should be identified, and investments for decreasing the uncertainty in statistical data should be increased only in these regions. As these regions have the most influence on emissions, decreasing uncertainty here will lead to a decrease of uncertainty in the national inventory.
As shown in Fig. 3, the CO2 emissions resulting from fuels combusted in the energy industries are the highest in the Donetsk, Dnipropetrovsk, and Luhansk oblasts. According to the IPCC recommendations (IPCC, 2000), uncertainty in ‘better-developed’ statistics is within a 3–5% interval. Thus, the influence of investments was studied only with respect to improving statistics relative to CO2 emissions from fuels combusted in the energy industries and only in those regions where decreased inventory uncertainty would reduce the national energy sector GHG inventory uncertainty (Fig. 7).

An example of uncertainty decrease in inventory results
The uncertainty values shown in Fig. 7 relate to economic activity in Ukraine in 2000. Column 1 illustrates the initial uncertainty of the national inventory in the energy sector if the statistical data in all regions have a mean uncertainty from the IPCC (2000) interval for ‘poorly developed’ statistical systems (7.5% for CO2 emissions from fuels combusted in the energy industries; other parameters are defined as in Experiment 1). Column 2 corresponds to the case where the uncertainties of all data in all regions remain unchanged, except for the uncertainties of statistical data in the Donetsk oblast, which decrease to 4%, the mean value from the uncertainty interval recommended for countries with a ‘well-developed’ statistical system (IPCC, 2000). Column 3 corresponds to the case where the uncertainty is decreased to 4% in two regions: the Donetsk and Dnipropetrovsk oblasts. Column 4 relates to the case where the uncertainty is decreased in the third region (Luhansk oblast) as well. The decline of uncertainty in the national inventory from 2.6 to 1.9% (a considerable decrease of uncertainty in absolute values presented in Fig. 7 is achieved just by decreasing uncertainty in only one activity type in three regions.
7 Conclusions
The IPCC methodology (IPCC, 1997a) provides inventory methods for entire countries. From the international viewpoint, such inventories make sense. However, every government should also have tools for exploring the real situation at the regional level. The proposed geoinformation technology for creating a multilevel distributed inventory allows GHG emissions cadastres to be created at both the regional and the plot level (covering the entire country). Integrated information on the actual spatial distribution of GHG sources and sinks would be quite useful for decision makers. Such information and corresponding visualization tools could serve as an effective instrument in economic and environmental decision making. Features of the proposed geoinformation technology include the following:
-
The technology reflects the real state of GHG emissions and sinks at the regional level.
-
It is based on the use of digital maps and the IPCC methodology, combining inventory transparency and ease of documentation.
-
It allows the effective utilization of remote-sensing data, neural network technologies, and approaches to estimating and projecting a number of parameters of distributed models of processes of GHG emissions and sinks at the regional level.
-
It is effective for large countries with nonuniformly distributed GHG sources and sinks, and thus is a good instrument for regional management decision making and for carrying out projections in accordance with development strategies, including sustainable development strategies.
The decrease of uncertainties in national statistics has a considerable influence on inventory uncertainty. For example, the inventory uncertainty in the energy sector declines from 3.2 to 2.0% when the uncertainty of energy-related statistical data on fuels combusted in the energy industries declines from 10 to 5%.
Within the energy sector, the ‘energy industries’ subsector has the greatest impact on inventory uncertainty. The relative uncertainty in the national inventory in the energy sector could be decreased from 2.19 to 1.47% if the specific statistical data uncertainty on combusted fuels were to decrease from 10 to 5%.
This subsector has the largest influence in the Donetsk oblast, where the absolute uncertainty is 5,081 Gg of CO2 (2.23% uncertainty relative to the total CO2 emissions in this subsector). Second and third are the Dnipropetrovsk and Luhansk oblasts, with uncertainties in this subsector of 2,066 Gg of CO2 (0.91%) and 1,262 Gg of CO2 (0.55%), respectively.
Improving the statistical system, especially for the ‘energy industries’ subsector in three regions of Ukraine (Donetsk, Dnipropetrovsk, and Luhansk oblasts) in order to decrease the uncertainty of the statistical data from 7.5% (for a ‘poorly developed’ statistical system) to 4% (for a ‘better-developed’ statistical system) will result in a decline in the uncertainty in the national energy sector inventory from 2.6 to 1.6%.
The geoinformation technology for creating distributed inventories proposed here enables the most essential sources of uncertainty to be defined (kinds of activity and regional locations) and makes possible the more effective utilization of investments to reduce uncertainty in these locales and in these kinds of activity. Certainly, for the geoinformation technology for spatially distributed inventories, some new problems arise concerning uncertainty and verification, but this technology allows for qualitative and quantitative ‘distributed’ presentation of the uncertainty problem at the regional level.
References
Bun, R. (Ed.) (2004). Information technologies for greenhouse gas inventory and prognosis of carbon budget of Ukraine. Lviv, Ukraine: UAP.
Bun, R., Gusti, M., Dachuk, V., Oleksiv, B., & Tsybrivskyy, Y. (2003). Specialized computer system for multilevel inventory of greenhouse gases. Herald of Technological University of Podillia, 3, 77–81.
Bun, R., & Oleksiv, B. (2003). Specialized database for information technologies of greenhouse gases inventory. Information Technologies and Systems, 1–2, 195–201.
Bun, R., Oleksiv, B., Klym, Z., Kujii, L., & Tsybrivskyy, Y. (2002). Geoinformation systems as a tool for carbon cycle monitoring and greenhouse gas inventory in the Western Region of Ukraine. In Proceedings of the International Conference ‘Mountains and People,’ Vol. 2, ‘In the Context of Sustainable Development, Rakhiv, Ukraine, October 2002, pp. 21–25.
Fleming, G., & van der Merwe, M. (2000). Spatial disaggregation of greenhouse gas emission inventory data for Africa South of the equator. CSIR, Pretoria, South Africa. Available at http://gis.esri.com/library/userconf/proc00/professional/papers/PAP896/p896.htm.
Gillenwater, M., Sussman, F., & Cohen, J. (2007). Practical policy applications of uncertainty analysis for national greenhouse gas inventories. Water, Air, & Soil Pollution: Focus (in press). doi:10.1007/s11267-006-9118-2
IPCC (1997a). Revised 1996 IPCC Guidelines for National Greenhouse Gas Inventories: Reporting Instructions, the Workbook, Reference Manual, Vol. 1–3, IPCC/OECD/IEA, Intergovernmental Panel on Climate Change (IPCC) Working Group I (WG I) Technical Support Unit, Bracknell, UK. Available at http://www.ipcc-nggip.iges.or.jp/public/gl/invs4.htm.
IPCC (1997b). IPCC Greenhouse Gas Inventory Software for the Workbook, IPCC. Intergovernmental Panel on Climate Change (IPCC), Geneva, Switzerland. Available at http://www.ipcc-nggip.iges.or.jp/public/gl/software.htm.
IPCC (2000). Good Practice Guidance and Uncertainty Management in National Greenhouse Gas Inventories, Intergovernmental Panel on Climate Change (IPCC) National Inventories Programmes, Technical Support Unit, Institute for Global Environmental Strategies, Hayama, Kanagawa, Japan. Available at http://www.ipcc-nggip.iges.or.jp/public/gp/english/.
Kujii, L. (2003). Models for greenhouse gas inventories in the energy sector of Ukraine. Information Technologies and Systems, 1–2, 202–210.
Kujii, L., & Oleksiv, B. (2003). Methods and means for realization of geoinformation system of greenhouse gases inventory. Scientific Papers of the Institute for Modelling Problems in Energetics, 19, 182–192.
Monni, S., Syri, S., Pipatti, R., & Savolainen, I. (2007). Extension of EU emissions trading scheme to other sectors and gases: Consequences for uncertainty of total tradable amount. Water, Air, & Soil Pollution: Focus (in press). doi:10.1007/s11267-006-9111-9
Nahorski, Z., Horabik, J., & Jonas, M. (2007). Compliance and emissions trading under the Kyoto Protocol: Rules for uncertain inventories. Water, Air, & Soil Pollution: Focus (in press). doi:10.1007/s11267-006-9112-8
Seixas, J., Martinho, S., Gois, V., Ferreira, F., Moura, F., Furtado, C., et al. (2002). ‘Greenhouse Gases in Portugal: Emissions/Economics and Reduction Measures,’ 11th International Emission Inventory Conference: ‘Emission Inventories – Partnering for the Future,’ held in Atlanta, GA, USA.
Tsybrivskyy, Y., & Klym, Z. (2003). Information technologies for greenhouse gas inventories: Pilot analysis of emission sources in industry and agriculture of Ukraine. Information Technologies and Systems, 1–2, 183–194.
Ukrstat (2001). Statistical Yearbook of Ukraine for 2000, State Committee of Statistics of Ukraine (Ukrstat), Tehnika, Kyiv, Ukraine.
Vreuls, H. (2004). Uncertainty analysis of Dutch greenhouse gas emission data, a first qualitative and quantitative (TIER 2) analysis. In Proceedings of the International Workshop on Uncertainty in Greenhouse Gas Inventories: Verification, Compliance and Trading, held 24–25 September in Warsaw, Poland, pp. 34–44. Available at http://www.ibspan. waw.pl/GHGUncert2004/papers.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Bun, R., Gusti, M., Kujii, L. et al. Spatial GHG Inventory: Analysis of Uncertainty Sources. A Case Study for Ukraine. Water Air Soil Pollut: Focus 7, 483–494 (2007). https://doi.org/10.1007/s11267-006-9116-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11267-006-9116-4