
Abstract
TTEthernet is a deterministic, synchronized and congestion-free network protocol based on the Ethernet standard and compliant with the ARINC 664p7 standard network. It supports safety-critical real-time applications by offering different traffic classes: static time-triggered (TT) traffic, rate-constrained (RC) traffic with bounded end-to-end latencies and best-effort traffic, for which no guarantees are provided. TTEthernet uses three integration policies for sharing the network among the traffic classes: shuffling, preemption and timely block. In this paper, we propose an analysis based on network calculus (NC) to determine the worst-case end-to-end delays of RC traffic in TTEthernet. The main contribution of this paper is capturing the effects of all the integration policies on the latency bounds of RC traffic using NC, and the consideration of relative frame offsets of TT traffic to reduce the pessimism of the RC analysis. The proposed analysis is evaluated on several test cases, including realistic applications (e.g., Orion Crew Exploration Vehicle), and compared to related works.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Ethernet (IEEE 802.3 2012), although it is low cost and has high speeds (e.g., up to 10 Gbps), is known to be unsuitable for real-time and safety-critical real-time applications (Decotignie 2005; Lee et al. 2005). For example, in half-duplex implementations, frame collision is unavoidable, leading to unbounded transmission times. Decotignie (2005) presents the requirements for a real-time network and how Ethernet can be improved to comply with these requirements. Several real-time communication solutions based on Ethernet have been proposed, such as FTT-Ethernet (Pedreiras et al. 2005), ARINC 664 Specification Part 7 (ARINC 664p7, for short) (ARINC 2009), TTEthernet (SAE 2011), EtherCAT (ETG 2013) and IEEE Audio Video Bridging (AVB) (IEEE 802.1BA 2011). Schneele and Geyer (2012), Cummings et al. (2012) and Danielis et al. (2014) describe and compare several of the proposed Ethernet-based real-time communication protocols. FTT-Ethernet is a flexible time-triggered protocol integrating event-triggered (ET) and time-triggered (TT) traffic. The main advantage of FTT-Ethernet is that it provides dynamic quality-of-service (QoS) management at some time with guaranteed timeline for the TT traffic. Its disadvantage is that it is an academic protocol, not yet available on the market. ARINC 664p7 extends Ethernet for the avionics area providing timing guarantees for ET traffic and enforcing the separation of mixed-criticality flows through the concept of virtual links. However it does not support TT traffic. EtherCAT is specialized for industrial automation based on a master/slave approach. It provides high-performance for real-time applications, however, its scalability is limited due to the logical ring topology. AVB does not support TT traffic with strict timing requirements but it is intended to provide QoS guarantees for lower latency communication, especially for multimedia flows. In this paper, we are interested in the TTEthernet protocol (SAE 2011).
TTEthernet (SAE 2011; Kopetz and Grunsteidl 2005) is a deterministic, synchronized and collision-free network protocol based on the IEEE 802.3 Ethernet standard and compliant with ARINC 664p7. TTEthernet is suitable for several safety-critical application areas, including automotive (Steinbach et al. 2012), avionics (Suen et al. 2013), space (Fletcher 2009) and industrial (Steiner and Dutertre 2010). Although current work on Time Sensitive Networking (TSN) (IEEE P802.1Qbv 2015) is intended to extend Ethernet for use in several application areas, existing Ethernet variants will still remain in certain niche areas. TTEthernet will continue to be used, for example, in the aerospace market since it provides fault-tolerance services not available in TSN, which are very relevant for avionics applications (Steiner 2016). ARINC 664p7 (ARINC 2009) is a full-duplex Ethernet network, which provides predictable event-triggered communication through the concept of rate-constrained (RC) traffic. In addition to the functionality offered by Ethernet (best-effort or BE traffic) and ARINC 664p7 (with RC traffic), TTEthernet supports time-triggered (TT) communication, especially suitable for applications with highest criticality requirements.
Thus, TTEthernet classifies flows into the three traffic classes (Steiner et al. 2009): time-triggered (TT) traffic, rate-constrained (RC) traffic and best-effort (BE) traffic. TT traffic uses time-triggered communication implemented using static schedules relying on a synchronized time base by arranging TT frames in predetermined time slots along the transmission path. RC traffic has a lower priority than TT, uses event-triggered communication and has bounded end-to-end latencies. Both TT and RC traffic can be used for hard real-time applications with strict timing constraints, and the choice depends on the particularities of the application, legacy constraints and the experience of the system engineer (Gavrilut et al. 2015). BE traffic has the lowest priority and it is used for applications that do not require any timing guarantees.
The schedulability of the TT traffic is determined by the TT schedules, which have to be synthesized such that all frames meet their deadlines. For the RC traffic, which is event-triggered, a RC flow is schedulable if its worst-case end-to-end delay (WCD) is smaller than its deadline. Although latency analysis methods have been successfully applied to RC traffic in ARINC 664p7 networks (Frances et al. 2006; Bauer et al. 2010; Li et al. 2010; Scharbarg et al. 2009; Adnan et al. 2010; Mauclair and Durrieu 2013), they cannot be directly applied for the timing analysis of RC traffic in TTEthernet due to the static TT schedules. The earliest analysis approach for RC traffic (Steiner 2011) in TTEthernet assumes pessimistically that all RC frames in an outgoing port of a switch will delay the current frame under analysis, and considers that the TT schedules contain periodically alternating phases for TT traffic and for RC traffic. However, realistic schedules do not necessarily contain such periodic phases. Later, we (Zhao et al. 2014) proposed a network calculus (NC)-based analysis to compute the WCD of RC frames by considering a variable size of TT frames and focusing on the shuffling integration policy. But the protocol uses fixed size frames and also has preemption and timely block integration policies, which we have not considered. A recent analysis for RC flows in TTEthernet has been proposed in Tamas-Selicean et al. (2015b). The authors use a response-time analysis based on the concept of “busy period” and show that they are able to significantly reduce the pessimism compared to previous approaches. However, their analysis computes the latencies for each time instance in the TT schedule, which is time-consuming. As we will see in the experimental results (Sect. 8), their method does not scale for large problem sites. In addition, another potential drawback of the work in Tamas-Selicean et al. (2015b) is that it is based on a response-time analysis instead of network calculus (Cruz 1991). This is a drawback because there has been a strong investment by the industry in NC, which is a well-established theory, supported by academic and industrial tools (Le Boudec and Thiran 2001; Mabille et al. 2013; Wanderler and Thiele 2006). For example, NC has been used for ARINC 667p7 for the design and certification of the Airbus A380 (Frances et al. 2006; Boyer and Fraboul 2008). No such tools and certification approaches exist for the type of analysis employed in Tamas-Selicean et al. (2015b).
The contribution of this paper is the modeling of TT traffic flows in NC to reduce the pessimism of the RC analysis. By capturing the effects of different integration policies on the latency bounds of RC flows, we extend the existing NC approaches to analyze the RC traffic for all the three integration policies of TTEthernet. In addition, this paper evaluates the proposed method on several test cases, including large realistic applications (e.g., Orion Crew Exploration Vehicle) and compares the latency upper bounds and runtimes with the results from the previous work, Zhao et al. (2014), Steiner (2011) and Tamas-Selicean et al. (2015b). In this paper, we do not address the BE traffic since it has no timing requirements.
The reminder of this paper is organized as follows. Section 2 presents the architecture and application models. Section 3 introduces the TTEthernet protocol in detail. Section 4 briefly describes the network calculus theory. Section 5 presents the problem formulation and overall analysis strategy. Section 6 describes the worst-case latency analysis of RC traffic in the shuffling integration policy. In Sect. 7, the influence of timely block integration on RC traffic is given. Section 8 evaluates the proposed analysis and Sect. 9 concludes this paper.
2 System model
2.1 Architecture model
A TTEthernet network is composed of a set of clusters. Each cluster consists of end systems (ESes) interconnected by links and switches (SWs). Each ES has a buffer for the output port and is connected to exactly one input port of SW. Each SW has no input buffers on input ports and a buffer for each output port. The output port of SW is connected to one ES or another switch input port. The links are full duplex, allowing thus communication in both directions, and the networks can be multi-hop. An example cluster is presented in Fig. 1, where we have 4 ESes, \(ES_{1}\) to \(ES_{4}\), and 3 SWs, \(SW_{1}\) to \(SW_{3}\). In the following we use “node” to represent an ES or a SW, and use “node output port” to represent an output port of an ES or a SW.

TTEthernet cluster example
We model a TTEthernet cluster as an undirected graph \({{{\textsf {\textit{G}}}}}({{{\textsf {\textit{V}}}}},{{{\textsf {\textit{E}}}}}\,)\), where \({{{\textsf {\textit{V}}}}}={{{\textsf {\textit{ES}}}}}\cup {{{{\textsf {\textit{SW}}}}}}\) is the set of end systems (ES) and switches (SW), and \({{{\textsf {\textit{E}}}}}\) is the set of physical links. For Fig. 1, \({{{\textsf {\textit{V}}}}}={{{\textsf {\textit{ES}}}}}\cup {{{{\textsf {\textit{SW}}}}}}=\{ES_{1}, ES_{2}, ES_{3}, ES_{4}\}\cup \{SW_{1},SW_{2},SW_{3}\}\), and the physical links \({{{\textsf {\textit{E}}}}}\) are depicted with thick, black, double arrows.
A dataflow link \(dl_{i}=\left[ v_{j},v_{k}\right] \in {{{{\textsf {\textit{L}}}}}}\), where \({{{\textsf {\textit{L}}}}}\) is the set of dataflow links in a cluster, is a directed communication connection from \(v_{j}\) to \(v_{k}\), where \(v_{j}\) and \(v_{k}\in {{{{\textsf {\textit{V}}}}}}\) can be ESes or SWs. A dataflow path \(dp_{i}\in {{{{\textsf {\textit{DP}}}}}}\) is an ordered sequence of dataflow links connecting one sender to one receiver. For example, in Fig. 1, \(dp_{1}\) connects the source end system \(ES_{1}\) to the destination end system \(ES_{3}\), while \(dp_{2}\) connects \(ES_{1}\) to \(ES_{4}\) (the dataflow paths are depicted with green arrows). Moreover, \(dp_{1}\) in Fig. 1 can be denoted as \(\left[ \left[ ES_{1},SW_{1}\right] ,\left[ SW_{1},SW_{2}\right] ,\left[ SW_{2},ES_{3}\right] \right] \).
The space partitioning between messages of different criticality transmitted over physical links and network switches is achieved through the concept of virtual link. Virtual links are defined by ARINC 664p7 (ARINC 2009), which is implemented by the TTEthernet protocol, as a “logical unidirectional connection from one source end system to one or more destination end systems”. We denote the set of virtual links in a cluster with \({{{\textsf {\textit{VL}}}}}\). A virtual link \(vl_{i}\in {{{{\textsf {\textit{VL}}}}}}\) is a directed tree, with the sender as the root and receivers as leafs. For example, \(vl_{1}\), depicted in Fig. 1 using dot-dash red arrows, is a tree with the root \(ES_{1}\) and leafs \(ES_{3}\) and \(ES_{4}\). Each virtual link is composed of a set of dataflow paths, one such dataflow path for each root-leaf connection. More formally, we denote with \({{{\textsf {\textit{R}}}}}_{VL}(vl_{i})=\{\forall dp_{j}\in {{{{\textsf {\textit{DP}}}}}}\,\big |dp_{i}\in vl_{i}\}\) the routing of virtual link \(vl_{i}\). For example, in Fig. 1, \({{{\textsf {\textit{R}}}}}_{VL}(vl_{1})=\{dp_{1},dp_{2}\}\).
Let us assume that in Fig. 1 we have two applications, \({{{\textsf {\textit{A}}}}}_{1}\) and \({{{\textsf {\textit{A}}}}}_{2}\). \({{{\textsf {\textit{A}}}}}_{1}\) is a high criticality application consisting of tasks \(\phi _{a}\) to \(\phi _{c}\) mapped on \(ES_{1}\), \(ES_{3}\) and \(ES_{4}\), respectively. \({{{\textsf {\textit{A}}}}}_{2}\) is a non-critical application, with tasks \(\phi _{d}\) and \(\phi _{e}\) mapped on \(ES_{2}\) and \(ES_{3}\), respectively. \(\phi _{a}\) sends message \(m_{1}\) to \(\phi _{b}\) and \(\phi _{c}\). Task \(\phi _{d}\) sends message \(m_{2}\) to \(\phi _{e}\). With TTEthernet, a message has a single sender and may have multiple receivers. The flow of these messages will intersect in the physical links and switches. Virtual links are used to separate the highly critical message \(m_{1}\) from the non-critical message \(m_{2}\). Thus, \(m_{1}\) is transmitted over virtual link \(vl_{1}\), which is isolated from virtual link \(vl_{2}\), on which \(m_{2}\) is sent, through protocol-level temporal and spatial mechanisms, which are presented in detail in Tamas-Selicean et al. (2012b).
2.2 Application model
TTEthernet transmits data using flows (in this paper we use the term “flow” to denote a “frame” in the TTEthernet protocol). The TTEthernet frame format fully complies with the ARINC 664p7 (ARINC 2009). Messages are transmitted in the payload of frames.
The size \(m_{i}.size\) for each message \(m_{i}\in {\omega }\) is given, where \(\omega \) is the set of all messages. As mentioned, TTEthernet supports three traffic classes: TT, RC and BE. We assume that the designer has decided the traffic classes for each message. We define the sets \(\omega _{TT}\), \(\omega _{RC}\) and \(\omega _{BE}\), respectively, with \(\omega =\omega _{TT}\cup \omega _{RC}\cup \omega _{BE}\). Similarly, we define \(\tau _{TT}\), \(\tau _{RC}\) and \(\tau _{BE}\), with \(\tau =\tau _{TT}\cup \tau _{RC}\cup \tau _{BE}\) is the set of all the flows in cluster. Knowing the size \(m_{i}.size\) for each message \(m_{i}\), we can compute the frame size \(l_{i}\) of the flow \(\tau _{i}\) packing \(m_{i}\). In addition, for the TT and RC flows we know their periods/rate and deadlines, \(p_{TT{i}}\) and \(r_{RC_{i}}\), and \(\tau _{i}.deadline\), respectively. The routing of virtual links and the assignment of flows to virtual links are given.
TT flows \(\tau _{TT}\) are transmitted according to offline computed schedules. Note that due to the implementation of TTEthernet schedules, the sending time offset of a TT flow \(\tau _{TT_{i}}\) is identical in all periods. The complete set of local schedules in a cluster are denoted by \({{{\textsf {\textit{S}}}}}\), and the TT schedule for a dataflow link \(dl_{j}\) is denoted by \({{{\textsf {\textit{S}}}}}_{j}\in {{{{\textsf {\textit{S}}}}}}\). Several approaches (Steiner 2010a; Steiner and Dutertre 2010; Steiner 2011; Tamas-Selicean et al. 2012b; Tamas-Selicean et al. 2015a) to the synthesis of schedules \({{{\textsf {\textit{S}}}}}\) for a cluster have been proposed.
RC flows \(\tau _{RC}\) are not necessarily periodic, but have a minimum inter-arrival time. For each virtual link \(vl_{i}\) carrying a RC flow \(\tau _{RC_{i}}\) the designer decides the Bandwidth Allocation Gap (BAG). A \(BAG_{RC_{i}}\) is minimum time interval between two consecutive frames of a RC flow \(\tau _{RC_{i}}\) and may take fixed values of \(2^{i}\) ms, \(i=0, \ldots , 7\). The BAG is set in such a way to guarantee that there is enough bandwidth allocated for the transmission of a flow on a virtual link, with \(BAG_{RC{i}}\le {1}/r_{RC_{i}}\). The BAG is enforced by the sending ES. Thus, an ES will ensure that each \(BAG_{RC{i}}\) interval will contain at most one frame of \(\tau _{RC_{i}}\). The maximum bandwidth used by a virtual link \(vl_{i}\) transmitting a RC flow \(\tau _{RC_{i}}\) is \(\rho _{RC_{i}}=l_{RC_{i}}/BAG_{RC_{i}}\), where \(l_{RC_{i}}\) is the frame size of \(\tau _{RC_{i}}\). The BAG for each RC flow is computed offline, based on the requirements of the messages it packs.
3 TTEthernet protocol
3.1 Time triggered transmission
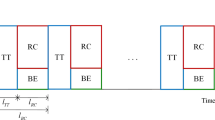
In this section we present how TT flows are transmitted by TTEthernet, using the example in Fig. 2, where the TT message \(m_2\) is sent from task \(\phi _2\) on \(ES_1\), to task \(\phi _4\) on \(ES_2\). We mark each step of the TT transmission in Fig. 2 with a letter from (a) to (n) on a blue background.

TT and RC traffic transmission example
Thus, in the first step denoted with (a), task \(\phi _2\) packs \(m_2\) into flow \(\tau _{TT_{2}}\) and in the second step (b), \(\tau _{TT_{2}}\) is placed into buffer \(B_{1,Tx}\) for transmission. Conceptually, there is one such buffer for every TT frame sent from \(ES_1\). As mentioned, the TT communication is done according to static communication schedules determined offline and stored into the ESes and SWs. Thus, the sending schedule \(S_S\) contains the sending times for all the TT flows transmitted during an application cycle \(T_{cycle}\). A periodic flow \(\tau _{TT_{i}}\) may contain several frames within \(T_{cycle}\). We denote the xth frame of \(\tau _{TT_{i}}\) with \(f_{TT_{i}}^{x}\). In step (d), the TT scheduler task \(TT_S\) will send \(\tau _{TT_{2}}\) to \(SW_1\) at the time specified in the sending schedule \(S_S\) stored in \(ES_1\) (c). Often, TT tasks are used in conjunction with TT frames, and the task and TT schedules are synchronized such that the task is scheduled to finish before the frame is scheduled for transmission (Obermaisser 2011). Moreover, the TT scheduler task \(TT_S\) provides the separation mechanisms implemented by TTEthernet to isolate mixed-criticality flows (such as \(\tau _{RC_{1}}\) and \(\tau _{TT_{2}}\) in our example) and implements fault-tolerance services to protect the network e.g., by only transmitting frames as specified in the schedule table \(S_S\), even if a task such as \(\phi _2\) becomes faulty and sends more frames than scheduled.
Next, \(\tau _{TT_{2}}\) is sent on a dataflow link to \(SW_1\) (e). The Filtering Unit (FU) task is invoked every time a frame is received by an SW to check the integrity and validity of the flow, e.g., for \(\tau _{TT_{2}}\) see step (f). After \(\tau _{TT_{2}}\) is checked (f), it is forwarded to the TT receiver task \(TT_R\) (h). \(TT_R\) relies on a receiving schedule \(S_R\) (g) stored in the switch to check if a TT flow has arrived within a specified receiving window and drop the faulty frames arriving outside the receiving window. This window is determined based on the sending times in the sending schedules (schedule \(S_S\) on \(ES_1\) for the case of flow \(\tau _{TT_{2}}\)), the precision of the clock synchronization mechanism and the integration policy used for integrating the TT traffic with the RC and BE traffic (see next subsection for details). Then, the switching fabric forwards (i) the TT flow \(\tau _{TT_{2}}\) into the sending buffer \(B_{1,Tx}\) for later transmission (j). Next, \(\tau _{TT_{2}}\) is sent by the TT scheduler task \(TT_S\) in \(SW_1\) to \(ES_2\) at the time specified in the TT sending schedule \(S_S\) in \(SW_1\).
When \(\tau _{TT_{2}}\) arrives at \(ES_2\) (l), the FU task will store the frame into a dedicated receive buffer \(B_{2,Rx}\) (m). Finally, when task \(\phi _4\) is activated, it will read \(\tau _{TT_{2}}\) from the buffer (n).
3.2 Rate constrained transmission
This section presents how RC traffic is transmitted using the example of flow \(\tau _{RC_{1}}\) in Fig. 2 sent from \(\phi _1\) on \(ES_1\) to \(\phi _3\) on \(ES_2\). Similarly to the discussion of TT traffic, we mark each step in Fig. 2 using numbers from (1) to (14), on a green background.
Thus, \(\phi _1\) packs message \(m_1\) into flow \(\tau _{RC_{1}}\) (1) and inserts it into a queue \(Q_{1,Tx}\) (2). Conceptually, there is one such queue for each RC virtual link. RC traffic consists of event-triggered messages. The separation of RC traffic is enforced through BAG, which is the minimum time interval between two consecutive frames of a RC flow \(\tau _{RC_{i}}\). The BAG is enforced by the traffic regulator (TR) task. For example, \(TR_1\) in \(ES_1\) in Fig. 2 will ensure that each \(BAG_1\) interval will contain at most one frame of \(\tau _1\) (3). Therefore, even if a flow is sent in bursts by a task, it will leave the TR task within a specified BAG.
Several flows will be sent from an ES. Let us first discuss how RC flows are multiplexed, and then we will discuss the integration with the TT traffic. In an ES, the RC scheduler task \(RC_S\) (such as the one in \(ES_1\)) will multiplex several RC flows (4) coming from the traffic regulator tasks, \(TR_i\), such as \(TR_1\) and \(TR_2\) in \(ES_1\). Figure 3 depicts how this multiplexing is performed for the flow \(\tau _{RC_{x}}\) and \(\tau _{RC_{y}}\) with the sizes and BAGs in a output port h as specified in Fig. 3a and b, respectively. Figure 3c shows one of the possible output scenarios, in the case two flows attempt to transmit frames at the same time. How they will be sent on the outgoing dataflow link \([ES_1,SW_1]\) is non-deterministic and selected by the \(RC_S\) task. The jitter for the frame \(f_{RC_{y}}^{h,0}\) equals to the transmission duration of \(\tau _{RC_{x}}\). RC traffic also has to be integrated with TT traffic, which has higher priority. Thus, RC flows are transmitted only when there is no TT traffic on the dataflow link. Hence, for our example on \(ES_1\), the \(TT_S\) task on \(ES_1\) will transmit flow \(\tau _{RC_{1}}\) (5) to \(NS_1\) on the dataflow link \([ES_1,SW_1]\) only when there is no TT traffic (6). There are three integration policies in TTEthernet (Steiner et al. 2009; SAE 2011): (i) shuffling, (ii) preemption and (iii) timely block, as shown in Fig. 4. (i) With shuffling, the higher priority TT frame is delayed until the RC frame finishes the transmission. In the case (ii) of preemption, the RC frame is preempted, and its transmission is restarted from the beginning after the TT frame finished transmitting. In the case (iii) of timely block, the RC frame is blocked (postponed) from transmission on a dataflow link if a TT frame is scheduled to be sent before the RC frame would complete its transmission. The timely block integration policy is used when the TT frames have very strict timing requirements, and no delays can be accepted compared to the scheduled transmission times. However, this comes at the expense of wasted bandwidth (no other frames can be transmitted in the blocked interval) and increased delays for RC frames. In case TT frames can tolerate slight variations in their transmission times, the shuffling is a good option since it is able to make use of the previously blocked intervals, which increases bandwidth usage and reduces RC delays.

Multiplexing two RC flows

Integration policies of TT and RC traffic
When the RC flow \(\tau _{RC_{1}}\) arrives at \(NS_1\), the filtering unit (FU) task (7) will check its validity and integrity. Fault-containment at the level of RC virtual links is provided by the traffic policing (TP) task, see \(NS_1\) in Fig. 2. TP implements an algorithm known as leaky bucket (ARINC 2009; SAE 2011), which checks the time interval between two consecutive frames on the same virtual link. After passing the checks of the TP task (8), \(\tau _{RC_{1}}\) is forwarded by the switching fabric to the outgoing queue \(Q_{Tx}\) (9). In this paper we assume that all the RC flows have the same priority, thus the \(TT_S\) (11) will send RC frames in \(Q_{Tx}\) in a FIFO order, but only when there is no scheduled TT traffic. At the receiving ES, after passing the FU (12) checks, \(\tau _{RC_{1}}\) is copied in the receiving \(Q_{2,Rx}\) queue (13). Finally, when \(\phi _3\) is activated, it will take \(\tau _{RC_{1}}\) (14) from this queue.
4 Network calculus background
Network calculus (Cruz 1991; Le Boudec and Thiran 2001; Chang 2000) is a mature theory proposed for deterministic performance analysis, such as the computation of the worst-case latency of a flow transmitted over a network. The approach in network calculus is to construct appropriate arrival and service curve models for the investigated flows and network nodes, such as an ES or a SW. The arrival and service curves are defined by means of the min-plus convolution (Le Boudec and Thiran 2001).
An arrival curve \(\alpha (t)\) is a model constraining the arrival process R(t) of a flow, in which R(t) represents the input cumulative function counting the total data bits of the flow that has arrived in the network node up to time t. We say that R(t) is constrained by \(\alpha (t)\) if
where \(\mathop {inf}\) means infimum (greatest lower bound) and \(\otimes \) is the notation of min-plus convolution. A typical example of an arrival curve is the “leaky bucket” (Cruz 1991) model and given by,
where \(\sigma \) represents the maximum burst tolerance of the flow and \(\rho \) is the upper bound of the long-term average rate of the flow.
A service curve \(\beta (t)\) models the processing capability of the available resource. Assume that \(R^{*}(t)\) is the departure process, which is the output cumulative function that counts the total data bits of the flow departure from the network node up to time t. We say that the network node offers the service curve \(\beta (t)\) for the flow if
A typical example of the service curve is the rate-latency service curve and given by,
where R represents the service rate, T represents the service latency and the notation \([x]^{+}\) is equal to x if \(x\ge 0\) and 0 otherwise.

A simple analysis example by using network calculus

Analysis model of a node output port
Let us assume that the flow constrained by the arrival curve \(\alpha (t)\) traverses the network node offering the service curve \(\beta (t)\). Then, the latency experienced by the flow in the network node is bounded by the maximum horizontal deviation between the graphs of two curves \(\alpha (t)\) and \(\beta (t)\),
where sup means supremum (least upper bound). Consider a flow constrained by the leaky bucket \(\alpha _{\sigma ,\rho }(t)\) and served in a node with the rate-latency service curve \(\beta _{R,T}(t)\). The worst-case latency is shown using the green line labelled \(h(\alpha ,\beta )\) in Fig. 5. With these definitions, the worst-case end-to-end delay of the flow is the sum of latency bounds in network nodes along its virtual link.
5 Problem formulation and overall analysis strategy
In this paper we are interested in determining the worst-case end-to-end latency \(D_{RC_{i}}\) of RC flow \(\tau _{RC_{i}}\) along each path of the virtual link in a TTEthernet cluster, considering all three traffic integration policies, (i) shuffling, (ii) preemption and (iii) timely block.
Considering a RC flow, the source of delays are as follows: (1) queueing latency in the output ports of each node (both ESes and SWs) along its path from its source to its destinations, (2) the technological latency due to switches and (3) the transmission latencies on the physical links.
As in previous work, we assume an upper bound \(d_{tech}\) on the technological latency (2), which captures the latencies due to the FU and TP tasks and the switching fabric in a SW, see Sect. 3. The transmission latency (3) is determined by the frames size \(l_{RC_{i}}\) and the physical link rate C. The focus of the paper is on using network calculus to determine (1) the worst-case latencies at the output port h of a node. To compute the worst-case latency in a node port h, it is necessary to obtain the aggregate arrival curve \(\alpha _{RC}^{h}(t)\) and remaining service curve \(\beta _{RC}^{h}(t)\) of the intersecting RC flows. Figure 6 shows an overview of the network calculus model used to determine the worst-case latencies at the output port h, for two cases. Figure 6a for the shuffling traffic integration policy, and Fig. 6b for timely block. From the definition of integration policies in Sect. 3, we can see that the worst-case latency with the preemption is the same with the timely block. This is because in the current TTEthernet protocol implementation, a RC frame that is preempted will restart its transmission from the beginning, and for the timely block all the intersecting RC flows are in FIFO order thus the service during blocked time cannot be used for other RC flows. These two cases of shuffling and timely block are presented separately in Sects. 6 and 7, respectively.

An example of a TT schedule in a node port
For the aggregate arrival curve \(\alpha _{RC}^{h}(t)\) of the RC traffic, we use the model from the related work on ARINC 664p7 (Frances et al. 2006). This will be briefly described in Sect. 6.3. However, for the remaining service curve \(\beta _{RC}^{h}(t)\) of RC traffic, we cannot use the related work on strict priority policy, since the TT traffic with higher priority is scheduled in fixed time slots, which is particular to TTEthernet. Therefore, with our approach, the remaining service curve for RC traffic is calculated by removing the service required by all TT flows going through h. The definition for \(\beta _{RC}^{h}(t)\) is presented in Sect. 6.2 for the shuffling integration policy, \(\beta _{RC\_S}^{h}(t)\), and in Sect. 7.2 for the timely block integration policy, \(\beta _{RC\_T}^{h}(t)\).
Hence, we first have to capture the aggregate arrival curve \(\alpha _{TT}^{h}(t)\) of intersecting TT flows going through an output port h. First, we model the arrival curve \(\alpha _{TT_{i}}^{h}(t)\) for the single TT flow \(\tau _{{TT}_{i}}\). Then we put these together into an the aggregate arrival curve \(\alpha _{TT}^{h}(t)\) for all intersecting TT flows in h by considering the relative offsets, based on its sending schedule \(S_S\) for the output port h. The re-ordering capability of the TTEthernet switches will not effect the worst-case timing analysis for RC traffic since the TT frames are re-ordered according to sending schedules. We present our approach to determine \(\alpha _{TT}^{h}(t)\) for shuffling in Sect. 6.1. Section 7.1 presents how we consider the effect of additional waiting time (named as timely block curve \(\gamma _{TT}^{h}(t)\)) during which the node does not forward a RC frame when a TT frame is scheduled to be sent before the RC frame would complete its transmission, where we also need determine \(\alpha _{TT}^{h}(t)\) (Sect. 6.1) for timely block.
6 Worst-case latency analysis of RC traffic with shuffling integration policy
6.1 Impact of TT traffic on RC traffic (\(\alpha _{TT}^{h}(t)\))
In this section we discuss the aggregate arrival curve of TT traffic flows multiplexing in a node output port h to show its impact on the service of RC traffic. Recall that TT flows are transmitted according to sending static schedules \(S_S\), determined offline as discussed in Sect. 3.1. For example, in Fig. 7a, there are three TT traffic flows on an output port h, \(\tau _{TT_{1}}\), \(\tau _{TT_{2}}\) and \(\tau _{TT_{3}}\). They are respectively with periods \(p_{TT_{1}}=2\;ms\), \(p_{TT_{2}}=4\;ms\) and \(p_{TT_{3}}=8\;ms\). In our analysis, the sending times in the \(S_S\) schedule for a given output port h are captured using the concept of “relative offsets”, see the later discussion in this section. For example, considering \(\tau _{TT_{1}}\) as a reference, the sending time of \(\tau _{TT_{2}}\) is captured by \(o_{2,1(0)}^{h}\).
First, we discuss the arrival curve for a single TT flow \(\tau _{TT_{i}}\). Its arrival process on each node along its virtual link can be described as periodic transmission with the period \(p_{TT_{i}}\), see Fig. 8 for an example.
Theorem 1
The arrival curve of the single TT flow \(\tau _{TT_{i}}\) in an node port h along its transmission is given by the staircase function
where \(l_{TT_{i}}\) is the size of the TT frame from \(\tau _{TT_{i}}\) and \(p_{TT_{i}}\) is its period, see Fig. 8, for an illustration.

Arrival curve of a single TT flow
Proof
For an arbitrary interval \((s,t\rceil \), there are at most \(n_{TT_{i}}^{h}(s,t)\) frames of \(\tau _{TT_{i}}\) traversing an arbitrary node port h along its transmission path,
Assume that \(R_{TT_{i}}^{h}(t)\) be the arrival process of the TT flow \(\tau _{TT_{i}}\) in the node port h, we have
Thus, the arrival curve for a single TT flow \(\tau _{TT_{i}}\) in the node port h is given by \(\alpha _{TT_{i}}^{h}(t)=l_{TT_{i}}\cdot \left\lceil \dfrac{t}{p_{TT_{i}}}\right\rceil \) for \(t>0\) and 0 otherwise. \(\square \)
Figure 9 depicts the arrival curves of each single TT flow \(\tau _{TT_{1}}\), \(\tau _{TT_{2}}\) and \(\tau _{TT_{3}}\) for the example in Fig. 7a.

Example of single arrival curves of three TT flows
However, there may be more than one TT flow, i.e., \(\tau _{TT_{i}}=\{\tau _{TT_{1}},\tau _{TT_{2}},\ldots ,\tau _{TT_{n}}\}\), traversing the same output port h of a node. And, different from flows in asynchronous networks, these intersecting TT flows cannot arrive at the same time. Their arrival times are determined by the schedule tables, which are created such that there is no contention between TT flows. Hence, it would be very pessimistic to simply sum arrival curves of each single TT flow \(\tau _{TT_{i}}\), (\(i=1, \ldots , n\)) intersecting. In the following, we propose how to construct the aggregate arrival curve \(\alpha _{TT}^{h}(t)\) of these intersecting TT flows passing through h.
Even though the transmission of a single TT flow satisfies the property of strict periodicity, several TT flows passing through the same node port h, will not satisfy such a periodicity property. Since the schedule of the TT traffic is known a priori, we will know the schedule of the TT frames in an interval (s,t] relative to a given TT frame as reference. Conversely, any interval (s, t] can be traversed if we consider all TT frames as a reference. This will lead to different possible aggregate arrival curves of intersecting TT flows in the node port h. Moreover, the number of benchmark frames is limited by \(N_{TT}^{h}\), which is given by the following Eq. (8). Now, let us define the LCM cycle \(p_{TT}^{h}\) as the least common multiple (LCM) of periods of the intersecting TT flows sharing the output port h of a node,
Then, we can then say that the arrangement of intersecting TT flows passing through the node port h is repeated in \(p_{TT}^{h}\). In an interval \([0,p_{TT}^{h})\) of LCM cycle length, there are
TT frames from these intersecting TT flows, where \(N_{TT_{i}}^{h}\) is the number of frames of \(\tau _{TT_{i}}\) in such LCM cycle. By considering one of the TT frames as a reference, there will be \(N_{TT}^{h}\) possible aggregate arrival curves. Here, let us define such a reference TT frame as the “benchmark frame” \(bf_{TT_{i}}^{h,k}\), in which the subscript \(TT_{i}\) represents the TT flow that such benchmark frame belongs to and the superscript k (\(k=0, \ldots , N_{TT_{i}}^{h}-1=p_{TT}^{h}\big /{p_{TT_{i}}-1}\)) is an index of frames of \(\tau _{TT_{i}}\) in the LCM cycle traversing through the node port h. In addition, we define \(f_{TT_{j},i(k)}^{h,g}\) as the frame g (\(g=0,1, \cdots , N_{TT_{j}}^{h}\)) of \(\tau _{TT_{j}}\) arriving after the benchmark frame \(bf_{TT_{i}}^{h,k}\), and g is the relative index with respect to k. This means that specifically \(f_{TT_{j},i(k)}^{h,0}\) represents the benchmark frame \(bf_{TT_{i}}^{h,k}\) if \(j=i\). Moreover, we use the concept of “relative offset” \(o_{j,i(k)}^{h}\) to define the arrival interval between the benchmark frame \(bf_{TT_{i}}^{h,k}\) of \(\tau _{TT_{i}}\) and the first frames \(f_{TT_{j},i(k)}^{h,0}\) of TT flows \(\tau _{TT_{j}}\) (\(j\in [1,n]\)) coming after \(bf_{TT_{i}}^{h,k}\). Note that \(o_{j,i(k)}^{h}\) equals to 0 if \(j=i\).
For example, when the frame \(bf_{TT_{1}}^{h,0}\) of \(\tau _{TT_{1}}\) is considered as the benchmark frame in Fig. 7a, the relative offset \(o_{2,1(0)}^{h}\) (resp. \(o_{3,1(0)}^{h}\)) is as shown in Fig. 7a. However, if \(bf_{TT_{2}}^{h,0}\) is considered as the benchmark frame as depicted in Fig. 7b, then the relative offset \(o_{1,2(0)}^{h}\) (resp. \(o_{3,2(0)}^{h}\)) is the interval between \(bf_{TT_{2}}^{h,0}\) and \(f_{TT_{1},2(0)}^{h,0}\) (resp. \(f_{TT_{3},2(0)}^{h,0}\)) arrived immediately after \(bf_{TT_{2}}^{h,0}\).
Theorem 2
The possible aggregate arrival curve of intersecting TT flows \(\{\tau _{TT_{1}}, \ldots , \tau _{TT_{n}}\}\) in an arbitrary node port h considering the benchmark frame \(bf_{TT_{i}}^{h,k}\) is given by
where \(\alpha _{TT_{j}}^{h}(t)\) is the arrival curve of the single TT flow \(\tau _{TT_{j}}\) and \(o_{j,i(k)}^{h}\) is the relative offset between the benchmark frame \(bf_{TT_{i}}^{h,k}\) and the adjacent frame \(f_{TT_{j},i(k)}^{h,0}\) of \(\tau _{TT_{j}}\). Note that \(o_{i,i(k)}^{h}=0\).
Proof
Since \(bf_{TT_{i}}^{h,k}\) is considered as the benchmark frame, for any conditional arbitrary interval (s, t] that \(bf_{TT_{i}}^{h,k}\) is the first encountered frame, there are at most \(n_{TT_{j},i(k)}^{h}(s,t)\) frames of \(\tau _{TT_{j}}\) (\(j=1, \ldots , n\)) arriving in node port h,
Let \(R_{TT,i(k)}^{h}(t)\) be the arrival process of intersecting TT flows in the node port h, then we have
Thus, the possible aggregate arrival curve based on \(bf_{TT_{i}}^{h,k}\) is given by \(\alpha _{TT,i(k)}^{h}(t)=\sum \limits _{j=1}^{n}\alpha _{TT_{j}}^{h} \left( t-o_{j,i(k)}^{h}\right) \). \(\square \)
Considering the TT flows from Figs. 7a and 10a shows one possible aggregate arrival curve if we consider \(bf_{TT_{1}}^{h,0}\) of \(\tau _{TT_{1}}\) as the benchmark frame. The red dotted line represents the arrival curve of single flow \(\tau _{TT_{1}}\), and yellow and blue dotted lines, respectively, represent the arrival curves of single flow \(\tau _{TT_{2}}\) and \(\tau _{TT_{3}}\) shifted to the right by relative offsets \(o_{2,1(0)}^{h}\) and \(o_{3,1(0)}^{h}\) according to the schedule considered in Fig. 7a. Similarly, Fig. 10b is another possible aggregate arrival curve considering \(bf_{TT_{2}}^{h,0}\) of \(\tau _{TT_{2}}\) as the benchmark frame. For our example, there are at most \(\sum _{i=1}^{3}N_{TT_{i}}^{h}=7\) possible aggregate arrival curves in Fig. 11.

Example of possible overall arrival curves of TT flows

Example of the overall arrival curve of TT flows
Then the worst-case aggregate arrival curve \(\alpha _{TT}^{h}(t)\) for the intersecting TT flows is the supremum or upper envelope of all these possible aggregate arrival curves, given by
where \(\alpha _{TT,i(k)}^{h}(t)\) is given by Theorem 2. An example is shown in Fig. 11 in the red staircase curve. As mentioned, the number of possible aggregate arrival curves is limited by \(N_{TT}^{h}\), thus it is feasible to enumerate.
6.2 Service curve \(\beta _{RC\_S}^{h}(t)\) for aggregate RC flows with shuffling integration policy
With the shuffling integration, since a RC frame is non-preemptive, the service for the aggregate RC frames in a node port h is affected only by the time slots occupied by TT frames.
Theorem 3
Assume that \(\alpha _{TT}^{h}(t)\) is the aggregate arrival curve of TT flows, as determined in Sect. 6.1, in the node port h. Then, the service curve \(\beta _{RC\_S}^{h}(t)\) for the aggregate RC flows in h with shuffling is given by
where C is the physical link rate for the node output port h.
Proof
Assume that \(R_{TT}^{h}(t)\) and \(R_{TT}^{h*}(t)\) (resp. \(R_{RC}(t)\) and \(R_{RC}^{h*}(t)\)) are the arrival and departure process of n TT flows \(\tau _{TT_{1}}\), ..., \(\tau _{TT_{n}}\) (resp. m RC flows \(\tau _{RC_{1}}\), ..., \(\tau _{RC_{m}}\)) crossing through the node port h. Let s be the start of the busy periodFootnote 1 for TT traffic (Steven and Minet 2006). The amount of service for RC flows is lower bounded by the total output service minus the service for TT frames during [s, t) in h,
Since s is the beginning of the busy period, we have \(R_{TT}^{h*}(s)=R_{TT}^{h}(s)\) and \(R_{RC}^{h*}(s)=R_{RC}^{h}(s)\). Then
and obviously due to \(R_{TT}^{h*}(t)\le R_{TT}^{h}(t)\),
where \(\alpha _{TT}^{h}(t)\) represents the arrival constraint of aggregate TT flow up to time t in the node port h. Since \(R_{RC}^{h*}(t)\) is a wide-sense increasing function, we have
\(\square \)
Considering the aggregate arrival curve of TT flows from Fig. 11, the remaining service curve for RC flows is given by the blue solid line labeled \(\beta _{RC\_S}^{h}(t)\) in Fig. 12. In addition, the dotted line represents the function \(C\cdot t-\alpha _{TT}^{h}(t)\).
6.3 Worst-case end-to-end latency of RC flows with shuffling
Since RC traffic is compatible with ARINC 664p7, the arrival curve of each \(\tau _{RC_{i}}\) in the source ES node port is constrained by the leaky bucket (Bauer et al. 2010),
where \(h_{0}\) represents the output port of the first node (source ES) along the path, \(\sigma _{RC_{i}}^{h_{0}}=l_{RC_{i}}\) and \(\rho _{RC_{i}}^{h_{0}}=l_{RC_{i}}\big /BAG_{RC_{i}}\). In addition, since RC flows are asynchronous, they may simultaneously arrive and queue up in a node port. The aggregate arrival curve of competing RC flows is the sum of their respective arrival curves,
where \(\alpha _{RC_{i}}^{h}(t)\) is the input arrival curve (Le Boudec and Thiran 2001) of \(\tau _{RC_{i}}\) in the node port h. If \(h\ne {h_{0}}\), \(\alpha _{RC_{i}}^{h}(t)\) is given by
where \(h'\) is the previous node port along the virtual link of \(\tau _{RC_{i}}\), and \(D_{RC_{i}}^{h'}\) is the worst-case queuing latency of \(\tau _{RC_{i}}\) in the node port \(h'\), which is given by Eq. (21).

Example of the service curve for RC flows in the shuffling integration policy
According to the network calculus theory, the upper bound latency of a RC flow \(\tau _{RC_{i}}\) in the node port h is given by the maximum horizontal deviation between the arrival curve \(\alpha _{RC}^{h}(t)\) and the service curve \(\beta _{RC\_S}^{h}(t)\) of the RC flows intersecting the node port h,
An example of such horizontal deciation is shown in Fig. 13.
By disseminating the computation of latency bounds along a path \(dp_{i}\) of the virtual link \(vl_{i}\) of the flow \(\tau _{RC_{i}}\), the worst-case end-to-end latency with the shuffling integration policy is obtained by the sum of delays from its source ES to its destination ES,
where \(h\in dp_{i}\) and \(d_{tech}\) is the technological latency in a switch.

Upper bound latency of RC flows in a node port in the shuffling integration
7 Worst-case latency analysis of RC traffic with timely block integration policy
7.1 Impact of timely block integration on RC traffic (\(\gamma _{TT}^{h}(t)\))
For the timely block integration policy (see Sect. 3.2 for the definition of timely block), we should not only consider the arrival impact of TT traffic on RC traffic as we have done in Sect. 6.1, but also the impact of the waiting time before each TT frames. We define the blocking interval \(BI_{TT}^{h}\) to represent the worst-case waiting time before a TT frame due to the timely block integration. It is related to the maximum frame size \(l_{RCmax}^{h}=\max \limits _{1\le i\le m}\{l_{RC_{i}}\}\) of RC flows traversing the output port h and the interval \(I_{TT}^{h}\) which is the distance between such TT frame and its previous adjacent TT frame. If \(I_{TT}^{h}\) is larger than or equal to the maximum transmission time of RC frames, i.e., \(I_{TT}^{h}\ge l_{RCmax}^{h}\big /C\), the blocking interval \(BI_{TT}^{h}\) equals to \(l_{RCmax}^{h}\big /C\), otherwise \(I_{TT}^{h}\). Let us consider the example in Fig. 14, where for simplicity, we assume that traversing RC flows and TT flows have the same frame size. Since the schedule table is repeated with the LCM cycle \(p_{TT}^{h}\), the adjacent frame before \(f_{TT_{1}}^{h,0}\) is \(f_{TT_{1}}^{h,3}\). Then the interval \(I_{TT_{1}}^{h,0}\) between the first TT frame \(f_{TT_{1}}^{h,0}\) of \(\tau _{TT_{1}}\) and its previous adjacent frame \(f_{TT_{1}}^{h,3}\) is larger than the transmission time of a RC frame \(f_{RC}^{h}\), and the worst-case blocking interval before \(f_{TT_{1}}^{h,0}\) is \(BI_{TT_{1}}^{h,0}=l_{RCmax}^{h}\big /C\). However, the worst-case blocking interval before the second TT frame \(f_{TT_{1}}^{h,1}\) of \(\tau _{TT_{1}}\) equals to \(BI_{TT_{1}}^{h,1}=I_{TT_{1}}^{h,1}\) since \(I_{TT_{1}}^{h,1}<l_{RCmax}^{h}\big /C\).
Different from the discussion of arrival curve of a single TT flow in Sect. 6.1, the impact of a timely block before each TT frame of a single TT flow is not periodic in a LCM period, due to the fact that the blocking intervals \(BI_{TT}^{h}\) may not equal to the same length (as mentioned in Fig. 14). Therefore, in order to traverse all the situations and easily discuss, we will consider different TT frames, the number of which is bounded in a LCM cycle, as a benchmark frame \(bf_{TT_{i}}^{h,k}\) in the following. Now, we will give two Lemmas first.

Time interval between two adjacent TT frames
Lemma 1
The interval \(I_{TT_{j},i(k)}^{h,g}\) between any TT frame \(f_{TT_{j},i(k)}^{h,g}\) \((g=0, \ldots , N_{TT_{j}}^{h}-1\), \(j=1, \ldots , n)\) and its previous adjacent TT frame by considering \(bf_{TT_{i}}^{h,k}\) \((k=0, \ldots , N_{TT_{i}}^{h}-1\), \(i=1, \ldots , n)\) as the benchmark frame in the node port h is,
Proof
Without loss of generality, let us assume that benchmark frame \(bf_{TT_{i}}^{h,k}\) arrives at time zero. Therefore, the first frame of \(\tau _{TT_{j}}\) arrives at \(o_{j,i(k)}^{h}\) after the benchmark frame. Then, the gth frame of \(\tau _{TT_{j}}\) arrives at \(o_{j,i(k)}^{h}+g\cdot p_{TT_{j}}\).
The adjacent TT frame arriving before \(f_{TT_{j},i(k)}^{h,g}\) may be from any TT flows \(\tau _{TT_{m}}\) (\(m=1, \ldots , n\)) traversing the node port h. In order to ensure that there exists at least one frame from \(\tau _{TT_{m}}\) before \(f_{TT_{j},i(k)}^{h,g}\) after the time zero, we consider that the frame of \(\tau _{TT_{j}}\) arrives at \(o_{j,i(k)}^{h}+g\cdot p_{TT_{j}}+p_{TT}^{h}\). And this is the same with the frame \(f_{TT_{j},i(k)}^{h,g}\) arrives at \(o_{j,i(k)}^{h}+g\cdot p_{TT_{j}}\) since the TT schedule for the node port h is repeated by the LCM cycle \(p_{TT}^{h}\). Then, there will be \(N_{TT_{m},i(k)}^{h,j(g)}=\left\lceil {\left( g\cdot p_{TT_{j}}+p_{TT}^{h}+o_{j,i(k)}^{h}-o_{m,i(k)}^{h}\right) }\big /{p_{TT_{m}}} \right\rceil \) TT frames of \(\tau _{TT_{m}}\) before \(f_{TT_{j},i(k)}^{h,g}\). Thus, the nearest TT frame of \(\tau _{TT_{m}}\) finishes its transmission at \(\left( N_{TT_{m},i(k)}^{h,j(g)}-1\right) \cdot p_{TT_{m}}+o_{m,i(k)}^{h}+l_{TT_{m}}\). By considering all the nearest TT frames from different TT flows, the adjacent TT frame before \(f_{TT_{j},i(k)}^{h,g}\) finishes transmission at \(\max \limits _{1\le m\le n}\left\{ \left( N_{TT_{m},i(k)}^{h,j(g)}-1\right) \cdot p_{TT_{m}}+o_{m,i(k)}^{h}+l_{TT_{m}}\right\} \). \(\square \)
Lemma 2
The worst-case blocking interval \(BI_{TT_{j},i(k)}^{h,g}\) before a TT frame \(f_{TT_{j},i(k)}^{h,g}\) \((g=0, \ldots , N_{TT_{j}}^{h}-1)\) of the TT flow \(\tau _{TT_{j}}\) \((j=1, \ldots , n)\) by considering \(bf_{TT_{i}}^{h,k}\) as the benchmark frame in the node port h is
where \(l_{RCmax}\) is the maximum frame size of RC flows sharing the output port h and \(I_{TT_{j},i(k)}^{h,g}\) is given by Lemma 1.
Theorem 4
The possible overall timely block curve of all TT flows \(\{\tau _{TT_{1}}, \ldots , \tau _{TT_{n}}\}\) in a node port h by considering the benchmark frame \(bf_{TT_{i}}^{h,k}\) is
where

Example of blocking intervals based on \(bf_{TT_{i}}^{h,k}\)

Example of a possible overall timely block curve based on \(bf_{TT_{1}}^{h,0}\)
Proof
For any conditional arbitrary interval (s, t] that taking \(bf_{TT_{i}}^{h,k}\) as the benchmark frame, the worst-case effect of timely block is related to the encountered TT frames during (s, t]. As mentioned before, since the blocking intervals before frames \(f_{TT_{j},i(k)}^{h,g}\) (\(g=0, \ldots , N_{TT_{j}}^{h}-1\)) belonging to the same TT flow \(\tau _{TT_{j}}\) may different within a LCM cycle, as shown in Fig. 15, we will discuss each of them separately. In the worst-case, there are at most \(n^{h,g}_{TB_{j},i(k)}(s,t)=\left\lceil (t-s-o_{j,i(k)}^{h}-g\cdot p_{TT{j}}+BI_{TT_{j},i(k)}^{h,g})\big /{p_{TT}^{h}}\right\rceil \) blocking intervals with the maximum interval length \(BI_{TT_{j},i(k)}^{h,g}\) before \(f_{TT_{j},i(k)}^{h,g}\) in the node port h if \(t-s>\max \{0,o_{j,i(k)}^{h}+g\cdot p_{TT{j}}-BI_{TT_{j},i(k)}^{h,g}\}\), and 0 otherwise. Let \(R_{TB,i(k)}^{h}(t)\) be the blocked process due to intersecting TT flows in the node port h, by considering the maximum number of blocking intervals within (s, t] from each TT frame of \(\tau _{TT_{j}}\) and all the intersecting TT flows, we have
Thus, the possible overall timely block curve based on \(bf_{TT_{i}}^{h,k}\) is given by
\(\square \)
The grey staircase curve in Fig. 16 shows a possible timely block curve \(\gamma _{TT,1(0)}^{h}(t)\) for the benchmark frame \(bf_{TT_{1}}^{h,0}\) from Fig. 7.
The worst-case overall timely block curve \(\gamma _{TT}^{h}(t)\) in the node port h is the upper envelope of all the possible timely block curves \(\gamma _{TT,i(k)}^{h}(t)\), an example is shown in Fig. 17 with a solid line,
7.2 Worst-case end-to-end latency of RC flows with timely block
Theorem 7 gives the service curve \(\beta _{RC\_T}^{h}(t)\) of aggregate RC flows in a node port h with the timely block integration policy.
Theorem 7
The service curve \(\beta _{RC\_T}^{h}(t)\) for the aggregate RC flows in h in the timely block integration policy is
where \(\alpha _{TT}^{h}(t)\) is the aggregate arrival curve of TT flows and \(\gamma _{TT}^{h}(t)\) is the timely block curve in the node port h. An example of the remaining service curve for RC flows is given by the blue solid line in Fig. 18, by considering the aggregate arrival curve of TT flows from Fig. 11 and the timely block curve from Fig. 17. Moreover, the dotted line represents the function \(C\cdot t-\alpha _{TT}^{h}(t)-\gamma _{TT}^{h}(t)\).

Example of the overall timely block curve

Example of the service curve for RC flows in the timely block integration
Similarly, the worst-case latency of a RC flow \(\tau _{RC_{i}}\) in a node port h is given as shown in Fig. 19 by

Upper bound latency of RC flows in a node port
8 Experimental evaluation
In this section, for the evaluation of our approach, we used three synthetic test cases, TC1 to TC3, and one realistic test case, Orion Crew Exploration Vehicle (CEV), named here TC4 adapted from Tamas-Selicean (2014a), Paulitsch et al. (2011). Our proposed analysis was implemented in C++ combined with the dynamic link library of RTC toolbox (Wanderler and Thiele 2006), running on a computer with Intel Core i7-3520M CPU at 2.90 GHz and 4 GB of RAM.
The comparison of configurations of four test cases is given by Table 1. As we can see, TC1 is from Tamas-Selicean et al. (2015b) and has a topology of 12 ESes, 4 SWs, 19 VLs and 36 dataflow paths (due to VL multicast reason), connected by dataflow link transmitting at 100 Mbps, running 20 TT flows and 26 RC flows. The details of the TT and RC flows are presented in Table 2. We use the same schedule tables from Tamas-Selicean’s work (2015b) which were generated using the method from Tamas-Selicean et al. (2015a). In Table 3 we compare our method using network calculus for TTEthernet (called NC/TTE) with three other methods from related work. For each RC flow in TC1, Table 3 shows the WCDs obtained with each method, considering the timely block integration policy. The most recent WCD analysis method for RC traffic is the trajectory approach from Tamas-Selicean et al. (2015b), which we denote with Tam15. The method from Steiner (2011) is denoted with Ste11. None of these methods use network calculus. As we have argued in the introduction, using NC has the advantage of a well-established theory supported by certified tools used in the safety-critical area. Without using our NC method NC/TTE, the only option with NC is to model the TT flows as high-priority periodic RC traffic that inherit their periods from TT schedule tables. We call such a method NC with strict priority, or NC/SP, and we have implemented NC/SP by using the NC approach for RC from Frances et al. (2006) extended to consider TT flows as high priority RC traffic using the method from Schmitt et al. (2003). Such a NC/SP method is the best that can be achieved with NC without considering the particularities of TTEthernet, as we do in this paper. In addition, in order to compare clearly, we also show the results of four methods in Fig. 20. We use NC/TTE as the baseline (the red “+” symbols forming a vertical line), i.e., the values on the x-axis show the percentage deviation of WCDs from the WCD obtained with our method NC/TTE, which is normalized to 100. The upper bounds calculated by NC/SP, Tam15 and Ste11 are normalized by
where x represents one of the other methods, NC/SP, Tam15 and Ste11.

Comparison of upper bounds by NC/TTE, NC/SP and Tam15

Comparison of upper bounds by NC/TTE, NC/SP and Tam15
As we can see from Table 3 and Fig. 20, Ste11 obtains the largest WCDs, which is expected, since it pessimistically assumes that all RC frames in an output port will delay the RC frame under analysis. Tam15 obtains the best results, and it can improve the WCDs obtained by our NC/TTE method with 19% on average for TC1 (36% maximum). However, this improvement costs computation time: Tam15 needs 6 minutes for TC1 whereas our NC/TTE method completes in 7.94 s. As we will see for the larger test cases, Tam15 does not scale well, and is unable to obtain results for the largest test case we have used. This is because the time necessary of Tam15 to compute the WCDs depends on both the number of RC flows and on the size of the TT schedules. Also, Tam15 is not based on NC, which makes it impossible to integrate into the existing certified tool-chains. The results obtained with NC without using our method, i.e., NC/SP, are more pessimistic (larger WCDs) than our results. As we can see, our proposed analysis reduces the pessimism compared to NC/SP and Ste11 on average by 68 and 86%, respectively (78 and 94% maximum). The computation time of TC1 for NC/SP is 1.98 s. Note that in Table 3 we have considered timely block in order to perform a fair comparison, since this is the only integration policy handled by Ste11 and Tam15.
To show the scalability of our method, we apply it to larger test cases TC2 and TC3, which are having increasing complexity, as shown in Table 1. The compared worst-case end-to-end delays computed by NC/TTE, NC/SP and Tam15 on these two test cases are respectively presented in Fig. 21a and b. In Table 3 we have presented the WCD values for the different methods. Since these test cases are larger, and due to a lack of space, we present the WCDs visually in the figures. On the y-axis we have the RC flows, from RC1 to RC51 in Fig. 21a and from RC1 to RC81 in Fig. 21b. Each data-point in the figure corresponds to a WCD value. The results from Fig. 21 (TC2 and TC3) confirm the results from TC1. We can see that our network calculus approach NC/TTE, significantly reduces the pessimism compared with NC/SP. Our approach takes 17.26 and 31.62 s on TC2 and TC3, respectively, compared to Tam15 and NC/SP, which need 164 minutes and 446 minutes, and 2.02 s and 2.58 s, respectively.

Network topology of the Orion CEV, derived from Paulitsch et al. (2011)

Comparison of upper bounds of shuffling and timely block by NC/TTE
In the last experiment, we use the real-life case study Orion CEV (TC4), derived from Tamas-Selicean (2014a), Paulitsch et al. (2011). The topology for the case study is shown in Fig. 22. The Orion CEV case has 31 ESes, 15 SWs, 100 VLs and 190 dataflow paths, connected by dataflow link transmitting at 100 Mbps, and running 100 TT flows and 87 RC flows, with parameters presented in Paulitsch et al. (2011). In the last set of experiments, we were interested to determine how our method handles the two traffic integration policies, namely, shuffling and timely block. We have run NC/TTE on TC4 and obtained WCDs for both cases. The compared results are shown in Fig. 23, where the upper bounds with timely block integration are normalized to 100. Our analysis has successfully computed on this large test case, for all traffic integration policies. We were unable to run Tam15 on TC4, since it reported that it runs out of memory, which, together with the large runtimes on TC1 and TC3, shows that their method is not scalable. As expected, the latency bounds with the shuffling integration are lower than the bounds with timely block integration, since for the timely block integration, a RC frame will not be forwarded until there is an enough idle time interval for such the whole RC frame, and for the shuffling integration the higher priority TT frame is delayed until the RC frame finishes the transmission. On average, timely block leads to 40% larger WCDs for TC4. This number is related to the “porosity” of TT schedules. The porosity concept is introduced by Steiner (2011) and is related to the density (intensive or sparse) of TT scheduling slots. If TT frames are scheduled back-to-back without any intervals (pores) in-between, the RC frames will experience large delays. These delays can be reduced by introducing more porosity in the schedules.
9 Conclusions
This paper has proposed a network calculus approach for the TTEthernet to analyze the worst-case end-to-end latency of RC traffic. TTEthernet is suitable for mixed-critical systems as it offers three types of traffic classes, time-triggered, rate-constrained and best-effort.
The contribution of this paper is capturing the effects of all the integration policies, shuffling, preemption and timely block, on the latency bounds of RC traffic using network calculus, and the consideration of relative frame offsets of TT traffic to reduce the pessimism of the RC analysis. We construct the aggregate arrival curve for intersecting TT flows by considering the fixed offsets among TT flows, and the overall timely block curve due to the blocking interval before each TT frame. The experimental results and the comparison to the previously proposed analysis methods show that the network calculus approach is a viable approach for the analysis of TTEthernet, with the extensions proposed in the paper. Our NC/TTE method is scalable and can handle large problem sites, without a significant increase in pessimism compared to Tam15. In addition, our NC/TTE method reduces the pessimism of worst-case delay calculated by the traditional network calculus approach NC/SP for strict priority without a significant increase in computation time.
Notes
A busy period for level L is defined by an interval [s, t) such that s and t are both idle times for level L and there is no idle time for level L in (s, t). An idle time s for level L is a time such that all frames with a priority greater than or equal to L generated before s have been processed at time s.
References
Adnan M, Scharbarg JL, Ermont J, Fraboul C (2010) Model for worst case delay analysis of an AFDX network using timed automata. In: IEEE conference on emerging technologies and factory automation, Bilbao, pp 1–4
ARINC (2009) ARINC 664P7: Aircraft data network, Part 7. Avionics full-duplex switched Ethernet network
Bauer H, Scharbarg JL, Fraboul C (2010) Improving the worst-case delay analysis of an AFDX network using an optimized trajectory approach. IEEE Trans Ind Inform 6(4):521–533
Boyer M, Fraboul C (2008) Tightening end to end delay upper bound for AFDX network calculus with rate latency FIFO servers using network calculus. In: IEEE international workshop on factory communication systems, Dresden, pp 11–20
Chang CS (2000) Performance guarantees in communication networks, 1st edn. Springer, London
Cruz C (1991) A calculus for network delay, part I, network elements in isolation. IEEE Trans Inform Theory 37(1):114–131
Cummings R, Richter K, Ernst R, Diemer J, Ghosal A (2012) Exploring use of Ethernet for in-vehicle control applications: AFDX, TTEthernet, EtherCAT, and AVB. SAE Int J Passeng Cars Electron Electr Syst 5(1):72–88
Danielis P, Skodzik J, Altmann V et al (2014) Survey on real-time communication via Ethernet in industrial automation environments. In: Proceedings of the 2014 IEEE emerging technology and factory automation (ETFA), IEEE, pp 1–8
Decotignie JD (2005) Ethernet-based real-time and industrial communications. Proc IEEE 93(6):1102–1117
ETG (2013) ETG.1000.1 EtherCAT Specification. EtherCAT Technology Group
Frances F, Fraboul C, Grieu J (2006) Using network calculus to optimize the AFDX network. In: Proceedings of 3rd European congress embedded real-time software, Toulouse, France
Fletcher M (2009) Progression of an open architecture: from Orion to Altair and LSS. White paper S65-5000-20-0, Honeywell, International
Gavrilut VM, Tamas-Selicean D, Pop P (2015) Fault-tolerant topology selection for TTEthernet networks. In: Safety and reliability of complex engineered systems: proceedings of the 25th European safety and reliability conference. CRC Press, London, pp 4001–4010
Grieu J (2005) Analyse et valuation de techniques de com-mutation Ethernet pour l’interconnexion des systmes avioniques. Ph.D. dissertation, Laboratory Space and Aeronautical Telecommunications, Toulouse, France
IEEE (2011) IEEE 802.1BA—IEEE standard for local and metropolitan area networks—audio video bridging (AVB) systems. The Institute of Electrical and Electronics Engineers, Inc
IEEE (2012) IEEE 802.3—IEEE standard for Ethernet. The Institute of Electrical and Electronics Engineers, Inc
IEEE (2015) IEEE P802.1Qbv (Draft 3.1)—enhancements for scheduled traffic, IEEE Time-Sensitive Networking Task Group. http://www.ieee802.org/1/pages/802.1bv.html
Kopetz H (1991) Event-triggered versus time-triggered real-time systems. In: Karshmer A, Nehmer J (eds) Operating systems of the 90s and beyond. Lecture notes in computer science, vol 563. Springer, Berlin, pp 86–101
Kopetz H, Grunsteidl G (2005) The time-triggered Ethernet (TTE) design. In: 8th IEEE international symposium on object-oriented real-time distributed computing, Washington DC, pp 22–33
Kopetz H (2011) Real-time systems: design principles for distributed embedded applications. Springer, Berlin
Le Boudec JY, Thiran P (2001) Network calculus: a theory of deterministic queuing systems for the internet. In: Lecture notes on computer science, 5th edn. Springer, New York
Lee YH, Rachlin E, Scandura PA (2005) Safety and certification approaches for Ethernet-Based Aviation Databuses. Technical report DOT/FAA/AR-05/52, Federal Aviation Administration
Li XT, Scharbarg J, Fraboul C (2010) Improving end-to-end delay upper bounds on an AFDX network by integrating offsets in worst-case analysis. In: IEEE conference on emerging technologies and factory automation, Bilbao, pp 1–8
Mabille E, Boyer M, Fejoz L et al (2013) Towards certifying network calculus. Interactive theorem proving. Springer, Berlin
Mauclair C, Durrieu G (2013) Analysis of real-time networks with monte carlo methods. EUCASS Proc Ser 6:501–514
Obermaisser R (2011) Time-triggered communication. CRC Press, London
Paulitsch M, Schmidt E, Gstottenbauer B, Scherrer C, Kantz H (2011) Time-triggered communication (industrial applications). In: Time-triggered communication. CRC Press, London, pp 121–152
Pedreiras P, Almeida L, Buttazzo G (2005) FTT-Ethernet: a flexible real-time communication protocol that supports dynamic QoS management on Ethernet-based systems. IEEE Trans Ind Inform 1(3):162–172
SAE (2011) AS6802: Time-triggered Ethernet. SAE International
Scharbarg JL, Ridouard F, Fraboul C (2009) A probabilistic analysis of end-to-end delays on an AFDX avionic net-work. IEEE Trans Ind Inform 5(1):28–49
Schmitt J, Hurley P, Hollick M et al (2003) Per-flow guarantees under class-based priority queueing. In: IEEE global telecommunications conference, pp 4169–4174
Schneele S, Geyer F (2012) Comparison of IEEE AVB and AFDX. In: Proceedings of the digital avionics systems conference, pp 7A1C1–7A1C9
Steinbach T, Lim HT, Korf F, Schmidt TC, Herrscher D, Wolisz A (2012) Tomorrows in-car interconnect? A competitive evaluation of IEEE 802.1 AVB and time-triggered Ethernet (AS6802). In: IEEE vehicular technology conference. IEEE Press, New York, pp 1C5
Steiner W, Bauer G, Hall B, Paulitsch M, Varadarajan S (2009) TTEthernet dataflow concept. In: 8th IEEE international symposium on network computing and applications, Cambridge, MA, pp 319–322
Steiner W (2010a) An evaluation of SMT-based schedule synthesis for time-triggered multi-hop networks. In: IEEE 31st real-time systems symposium (RTSS), San Diego, CA, pp 375–384
Steiner W, Dutertre B (2010b) SMT-Based formal verification of a TTEthernet synchronization function. Formal methods for industrial critical systems. Springer, Berlin
Steiner W (2011) Synthesis of static communication schedules for mixed-criticality systems. In: 14th IEEE international symposium on object/component/service-oriented real-time distributed computing work-shops, Newport Beach, CA, pp 11–18
Steiner W (2016) Deterministic Ethernet for real-time and critical applications. In: 12th IEEE world conference on factory communication systems, Aveiro, Portugal
Steven M, Minet P (2006) Schedulability analysis of flows scheduled with FIFO: application to the expedited forwarding class. In: 20th international parallel and distributed processing symposium
Suen J, Kegley R, Preston J (2013) Affordable avionic networks with Gigabit Ethernet assessing the suitability of commercial components for airborne use. In: Proceedings of SoutheastCon, pp 1C6
Tamas-Selicean D, Marinescu SO, Pop P (2012a) Analysis and optimization of mixed-criticality applications on partitioned distributed architectures. In: 7th IET international conference on system safety, incorporating the cyber security conference, Edinburgh, pp 21–26
Tamas-Selicean D, Pop P, Steiner W (2012b) Synthesis of communication schedules for TTEthernet-based mixed-criticality systems. In: Proceedings of the eighth IEEE/ACM/IFIP international conference on hardware/software codesign and system synthesis, New York, pp 473–482
Tamas-Selicean D (2014a) Design of mixed-criticality applications on distributed real-time systems. PhD Thesis, Technical University of Denmark
Tamas-Selicean D, Pop P, Steiner W (2015a) Design optimization of TTEthernet-based distributed real-time systems. Real-Time Syst 51(1):1–35
Tamas-Selicean D, Pop P, Steiner W (2015b) Timing analysis of rate constrained traffic for the TTEthernet communication protocol. In: International symposium on real-time computing (ISORC)
Wanderler E, Thiele L (2006) Real-time calculus (RTC) toolbox. http://www.mpa.ethz.ch/Rtctoolbox
Zafirov A (2013) Modeling and simulation of the TTEthernet communication protocol. Masters thesis, Technical University of Denmark
Zhao LX, Xiong HG, Zheng Z, Li Q (2014) Improving worst case latency analysis for rate-constrained traffic in the Time-Triggered Ethernet Network. IEEE Commun Lett 18(11):1927–1930
Acknowledgements
This study is co-supported by the National Natural Science Foundation of China (61073012 and 61301086) and the Fundamental Research Funds for the Central Universities of China (YWF-14-DZXY-023 and YWF-15-GJSYS-055).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhao, L., Pop, P., Li, Q. et al. Timing analysis of rate-constrained traffic in TTEthernet using network calculus. Real-Time Syst 53, 254–287 (2017). https://doi.org/10.1007/s11241-016-9265-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11241-016-9265-0