
Abstract
Confidentiality and integrity are fundamental requirements when transmitting and storing data. In order to guarantee the confidentiality and integrity of speech signal, we present a novel wateRmarking scheme for Encrypted sPeech AuthenticatIon with Recovery (REPAIR) scheme. In REPAIR, an encryption algorithm is first designed based on a hyper-chaotic method to improve the confidentiality of the original speech by encryption. Subsequently, a watermark generation and embedding algorithm is proposed to generate and embed the check bits and compression bits. Afterwards, a content authentication and tampering recovery algorithm is introduced to locate and recover the tampered speech frames. Meanwhile, a speech decryption algorithm is also presented to decrypt the encrypted speech. Analysis and experimental results demonstrate that REPAIR can detect and locate synchronization attacks and de-synchronization attacks without using the auxiliary synchronous code. Additionally, REPAIR can also recover the tampered content with high quality.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of network technology, the amount of data has been increased sharply [1]. Especially, enormous disks are needed for storing massive audio signals. Fortunately, the advent of cloud storage has provided a new storage method for digital data. However, the open and multi-tenancy storage providers are third parties which may not be completely trusted, making the number of illegal activities increased exponentially. In fact, the biggest hurdle of cloud storage is the concern about confidentiality and integrity in all areas [2, 3].
It is known that encryption technology is an effective method which can be employed to realize confidentiality by converting ordinary files into unintelligible data [4]. In addition, digital watermarking technology is a vital subdivision of steganography, which hides extra information into the cover object to authenticate integrity or protect copyright [5, 6]. Therefore, the encryption and watermarking technologies can be combined for guaranteeing the confidentiality and integrity of digital speech. Undoubtedly, the combination takes significant chances for protecting multimedia data from being revealed or tampered [7, 8].
As an essential part of multimedia, lots of speech recordings contain sensitive and important content, such as telephone banking, meeting recording, online voice orders and so on [9]. Obviously, these speech recordings need to store for preventing disputes. Once a dispute occurs, these stored speech recordings can provide strong evidence. However, the content of speech recordings may be leaked out or maliciously tampered by attackers during the transmission or storage. If these speech recordings are tampered, it is meaningless to store. Therefore, it is crucial to protect confidentiality and integrity of those vital speech recordings.
Nowadays, the encryption and watermarking technologies are used to protect confidentiality and integrity of speech respectively in most studies.
In [10], a private key speech encryption algorithm based on three-dimensional chaotic maps was introduced for protecting content confidentiality. An index-based selective audio encryption scheme was proposed to encrypt partial audio data for wireless multimedia sensor networks in [11]. In [12], chaotic characteristics of a class of the Cellular Neural Network (CNN) were used to design a chaos synchronization method, and a Lorenz system was also applied to encrypt audio signal. In [13], a novel encryption scheme based on the Cosine Number Transform (CNT) was introduced to enhance the security of the noncompressed digital audio signal. Meanwhile, by taking advantage of the underdetermined Blind Source Separation(BSS) problem, a BSS-based method was proposed for encrypting speech signals [14].
Additionally, a speech content authentication scheme based on Bessel-Fourier moments was proposed to detect insertion and deletion attacks in [15]. In [16], a content-dependent watermarking scheme had been proposed for authenticating the integrity and locating the tampered area of compressed speech. In [17], a semi-fragile speech watermarking scheme was proposed for speech authentication based on the quantization of linear prediction (LP) parameters. Apparently, digital watermarking is an effective technology to realize integrity authentication.
At present, combining the encryption and signal processing is worthy of privacy-preserving research [18,19,20]. Specially, some studies have been presented by combining encryption and steganography to realize both privacy protection and data hiding simultaneously [21,22,23]. However, the studies on speech content authentication in the encrypted domain are relatively rare. To achieve privacy protecting and content authentication of speech signal, we face the following challenges:
-
1.
How to ensure that the encryption and watermarking operations are non-interfering?
-
2.
How to detect the de-synchronization attacks without embedding extra information?
-
3.
How to recover the tampered speech content with high quality?
To solve above challenges, we present an efficient speech authentication scheme used in the encrypted domain. For the first challenge, we adopt the partial selective encryption method to encrypt partial original speech. Meantime, the residual unencrypted part is the reserved space for the embedding watermark. Obviously, the partial selective encryption and watermarking scheme chooses different area to encrypt and embed watermark that guarantees both above operations are non-interfering each other. To deal with the second challenge, the extracted check-bits and the reconstructed check-bits are compared to realize synchronization detection based on moving different lengths of sliding window. For the third challenge, motivated by existing work in [24], we attempt to produce the compressed signal of the encrypted speech and embed the watermark into the reserved space of the original speech. Once the tampering is detected, the tampered content can be recovered by the embedded compressed signal. Further, the unrecovered content can be repaired by the correlation of adjacent sampling points of the decrypted speech.
In conclusion, to solve the above problems, we present a new wateRmarking scheme for Encrypted sPeech AuthenticatIon with Recovery (REPAIR). Theoretical analysis and Experiments results show that REPAIR achieves high security and excellent inaudibility. More importantly, the tampered area caused by the synchronization attack and the de-synchronization attack can be recovered with high quality.
This paper is organized as follows: Sect. 2 illustrates the proposed REPAIR scheme. The performance analysis and experimental results are presented in Sects. 3 and 4, respectively. The conclusions are described in Sect. 5.
2 REPAIR scheme
In this section, we describe REPAIR from four aspects: the speech encryption algorithm, the watermark generation and embedding algorithm, the content authentication and tampering recovery algorithm, and the speech decryption algorithm. The flow chart of REPAIR is shown in Fig. 1. The speech encryption is first described. Then how to generate watermark and embed it into the reserved space of the original speech is presented. Subsequently, the content authentication and tampered recovery algorithm, and speech decryption algorithm are elaborated in the following.

The flow chart of the proposed REPAIR scheme
2.1 The speech encryption algorithm
For the speech owners, they do not want the content of plaintext speech to be eavesdropped during the transmission or storage. Therefore, an encryption algorithm is designed in REPAIR to convert the understandable speech into unintelligible data for protecting confidentiality. The details of the speech encryption are elaborated in the following three steps: encryption keys generation, position permutation, and amplitude encryption.
-
(1)
Encryption keys generation.
Suppose that a vector \(X_0={\left( {{x^0_1}, {x^0_2}, {x^0_3}, {x^0_4}, {x^0_5}, {x^0_6}} \right) ^T}\) is chosen as an initial key of hyper-chaotic [25]. Subsequently, a new vector can be calculated according to Eq. (1) and denoted as \(X_j={\left( {{x^j_1}, {x^j_2}, {x^j_3}, {x^j_4}, {x^j_5}, {x^j_6}} \right) ^T}\). Finally, six-dimension hyper-chaotic sequences \({\left( Y_1,Y_2,Y_3,Y_4,Y_5,Y_6\right) }\) can be obtained, and \(Y_i=(x_i^0,\ldots ,x_i^0,\ldots ,x_i^N)\) denotes the ith sequence with N elements.
$$\begin{aligned} {X_j} = A{X_{j-1}} + B, \quad j=1,2,\ldots ,j,\ldots ,N. \end{aligned}$$(1)In the above equation, matrix A and vector B are nominal matrix and nonlinear feedback controller, respectively, which are utilized to control and generate hyper-chaotic sequences. The detail of each parameter in Eq. (1) are given as follows.
$$\begin{aligned} A= & {} \left( \! {\begin{array}{cccccc} { - 0.5}&{}\quad { - 4.9}&{}\quad {5.1}&{}\quad 1&{}\quad 1&{}\quad 1\\ {4.9}&{}\quad { - 5.3}&{}\quad {0.1}&{}\quad 1&{}\quad 1&{}\quad 1\\ { - 5.1}&{}\quad {0.1}&{}\quad {4.7}&{}\quad 1&{}\quad { - 1}&{}\quad 1\\ 1&{}\quad 2&{}\quad { - 3}&{}\quad { - 0.05}&{}\quad { - 1}&{}\quad 1\\ { - 1}&{}\quad 1&{}\quad 1&{}\quad 1&{}\quad { - 0.3}&{}\quad 2\\ { - 1}&{}\quad 1&{}\quad { - 1}&{}\quad { - 1}&{}\quad { - 1}&{}\quad { - 0.1} \end{array}} \!\right) \end{aligned}$$(2)$$\begin{aligned} B= & {} \left( {\begin{array}{c} {f_1}\left( {\sigma {v_2},\varepsilon }\right) \\ 0\\ 0\\ 0\\ 0\\ 0 \end{array}} \right) \end{aligned}$$(3)Here, \(f_1\) is a uniformly bounded sinusoidal function as Eq. (4). Variable \(\varepsilon \) and variable \(\sigma \) are parameters of \(f_1\), \(\varepsilon = 5.5,~ \sigma = 20\).
$$\begin{aligned} {f_1}\left( {\sigma {v_2},\varepsilon } \right) = \varepsilon \sin \left( {\sigma {v_2}} \right) \end{aligned}$$(4)In the encryption algorithm, two keys (including the key of position permutation and the key of amplitude encryption ) are generated according to the following steps.
-
The key of position permutation.
A secure address index \(P = \left( {{p_1},{p_2}, \ldots , {p_L}} \right) \) is obtained by sorting elements of the first chaotic sequence \(Y_1\) in ascending order. Hence, the address index P represents the key of position permutation.
-
The key of amplitude encryption.
Firstly, \( K =(K_1,K_2,K_3,K_4,K_5)\) is produced by the hyper-chaotic sequences \((Y_2,Y_3,Y_4,Y_5,Y_6)\) as Eq. (5), and each vector is denoted as \(K_i=(\kappa _i^0,\kappa _i^1,\ldots ,\kappa _i^j,\ldots ,\kappa _i^N)\) with N elements.
$$\begin{aligned} {K _i} = \bmod ((| Y_{i+1}| - \left\lfloor |Y_{i+1}| \right\rfloor ) \times 10^{15},2^\lambda ) \end{aligned}$$(5)Subsequently, a selecting sequence \(\overline{K}=(\overline{\kappa }_1, \ldots , \overline{\kappa }_j, \ldots ,\overline{\kappa }_N)\) can be obtained by using the following Eq. (6).
$$\begin{aligned} \overline{K}= \bmod \left( \sum \limits _{i = 1}^5 {{K_i}} ,5\right) \end{aligned}$$(6)Finally, the key of amplitude encryption of the jth group can be determined as shown in Table 1 and denoted as \(k^j=(k^j_0,k^j_1,k^j_2,k^j_3,k^j_4)\) according to Eqs. (5) and (6).
-
-
(2)
Position permutation
For the reason that the values of adjacent sampling points are approximate, attackers can get some useful information according to the correlation of adjacent sampling points. Therefore, we adopt the generated key P to permutate the position of adjacent sampling points and eliminate the correlation of adjacent sampling points according to the following Eq. (7). Suppose that an original speech signal is denoted as \(S=\{s_1,\ldots ,s_l,\ldots ,s_L\}\) with the length of L. The permutated speech is denoted as \(S'\), \(S'=\{s'_1,\ldots ,s'_l,\ldots ,s'_L\}\).
$$\begin{aligned} s'_l=s_{p_l} \end{aligned}$$(7) -
(3)
Amplitude encryption
It is known that the distribution of speech sampling values is regular, attackers can get the statistical property by analyzing its sampling values. Therefore, to eliminate the statistical characteristic of original speech, the amplitude of the scrambled speech \(S'\) is encrypted in the following way.
-
(a)
Firstly, the \(\lambda _2\) LSBs of each sampling point of that scrambled speech are initialized as zero, which is the reserved space for embedding watermark. The processed speech is divided into I frame with four sampling points according to the generated key \(k^i\). The \(i^{th}\) frame is denoted as \(S^*_i=\{s_{1}^{i*},s_{2}^{i*},s_{3}^{i*},s_{4}^{i*}\}\).
-
(b)
According to Table 1, each speech frame \(S'_i\) can be encrypted by the following equation to obtain the encrypted speech frame \(E_i~(E_i=\{e_{1}^i,e_{2}^i,e_{3}^i,e_{4}^i\})\).
$$\begin{aligned} \begin{array}{l} {e_{1}^i} = s_{1}^{i*} \oplus k^i_1 \oplus k^i_0\\ {e_{2}^i} = s_{2}^{i*} \oplus k^i_2 \oplus {e_{1}^i}\\ {e_{3}^i} = s_{3}^{i*} \oplus k^i_3 \oplus {e_{2}^i}\\ {e_{4}^i} = s_{4}^{i*} \oplus k^i_4 \oplus {e_{3}^i} \end{array} \end{aligned}$$(8)Here, \(k^i=(k^i_0,k^i_1,k^i_2,k^i_3,k^i_4)\) is the ith group key of amplitude encryption. \(S^*_i\) and \(E_i\) are the ith scrambled speech frame and final encrypted speech frame, respectively.
-
(c)
All encrypted speech frames are connected in turn to achieve the final encrypted speech E, which is denoted as \(E=\{E_1,E_2,\ldots , E_i,\ldots ,E_I\}\).
-
(a)
2.2 Watermark generation and embedding algorithm
In the watermark generation and embedding algorithm, we adopt a clustering algorithm and a compression algorithm to generate the self-embedding watermark. The watermark generation and embedding algorithm includes three steps: speech division, watermark generation, and watermark embedding. The details are described as follows.
-
1.
Speech division.
Assume that the encrypted speech \(E=\{e_1,e_2,\ldots ,e_l,\ldots ,e_L\}\) is quantified by \(\lambda \) bits. Firstly, the encrypted signal E is divided into I frames with length \(J(I=\lfloor L/J\rfloor )\). Each frame is denoted as \({E_i} = \left( {e_{1}^i, \ldots ,e_{j}^i, \ldots ,e_{J}^i} \right) \).
-
2.
Watermark generation.
The watermark generation process includes four parts: compressed bits generation, check bits generation, frame number bits generation and watermark generation.
(1) Compressed bits generation.
In this step, the compressed bits will be used to recover the tampered content, which is generated by reference sharing mechanism [24] and the generation process is given in the follows detailedly.
-
(a)
For each frame signal \({E_i}\), all sampling points are converted into \(\lambda \) bits. Among them, the Most Significant Bits (MSBs) with the length of \(\lambda _1\) are applied to generate watermark and the Least Significant Bits (LSB) with the length of \(\lambda _2 (\lambda _2=\lambda -\lambda _1)\) are reserved space to embed watermark.
-
(b)
For the ith speech frame, the \(\lambda _1\) MSBs of each sample are connected to produce a data vector \(B_i\) with the length of \(\lambda _1\times J\) as Eq. (9). An example is illustrated in Fig. 2 (here, \(\lambda _1=14\) and \(\lambda _2=2\)).
$$\begin{aligned} B_i = (b_i^{1,1}, \ldots , b_i^{1,\lambda _1}, \ldots ,b_i^{J,1}, \ldots , b_i^{J,\lambda _1})^T \end{aligned}$$(9) -
(c)
The I groups of data vectors are connected to obtain a data sequence and denoted as \(B=\{ B_1, \ldots , B_{i}, \ldots , B_I\}\) containing \((\lambda _1 \times J)\times I \) bits.
-
(d)
According to a secret key \(k_1\), the sequence B is permuted and re-divided into I groups. \(B'_i= (b'_{i,1},\ldots ,b'_{i,2},\ldots ,b'_{i,\lambda _1\times J})^T\) represents the ith new group.
-
(e)
A pseudo-random binary matrix M is used for compressing each group \(B'_i\) to obtain the compressed bits \(R_i\) as Eq. (10).
$$\begin{aligned} R_i= \begin{bmatrix} r_{i,1} \\ r_{i,2} \\ \vdots \\ r_{i,\lambda _r} \end{bmatrix}=mod( M \cdot \begin{bmatrix} b'_{i,1} \\ b'_{i,2} \\ \vdots \\ b'_{i,\lambda _1\times J} \end{bmatrix},2)\quad \end{aligned}$$(10)Here, M has \(\lambda _r\) rows and \((\lambda _1\times J)\) columns. The symbol \( \cdot \) denotes dot-product of two vectors, and \(mod(\cdot )\) is a modulo function. \(R_i\) is the generated compressed bits of the ith group. Here, \(\lambda _r<(\lambda _1\times J)\).
-
(f)
All generated compressed bits are connected together and scrambled by a secure key \(k_2\). Then, the scrambled compressed bits are redivided into I groups. The bits of the ith group are represented as a set and denoted as \(\omega ^1_i= \{\omega ^1_{i,1},\omega ^1_{i,2},\ldots ,\omega ^1_{i,\lambda _r} \}\).
(2) Check-bits generation.
To verify the integrity of each speech frame, the self content of speech frame is adopted to produce the check-bits by the following steps:
-
(a)
For each frame \({E_i}\), the \(\lambda _2\) LSBs of each sampling point are initialized as zero. Meanwhile, a distance matrix can be obtained by calculating the distance of each element in frame signal \({E_i}\) as Eq. (11).
$$\begin{aligned} M^d_{m,n} = |e_{m}-e_n| \end{aligned}$$(11)Here, \(e_m\) and \(e_n\) are the mth sampling point and the nth sampling point in speech frame \(E_i\).
-
(b)
According to the clustering algorithm proposed in [26], the elements of each frame can be classified into several categories on the basis of the obtained distance matrix \(M^d\). Suppose that all elements of each frame are divided into X categories, where the xth category is denoted as \(C_x\).
-
(c)
The probability distribution of each category \(C_x\) can be calculated as Eq. (12) and denoted as \(p_x\). Here, \(N_x\) is the element number of xth category. J is the total element number of speech frame.
$$\begin{aligned} p_x= \frac{N_x}{J} \end{aligned}$$(12) -
(d)
According to the above probability, the entropy of ith frame can be calculated by the following equation.
$$\begin{aligned} H_i = -\sum _{x=1}^{X}(p_x\times log_2(p_x)) \end{aligned}$$(13) -
(e)
The check-bits of ith speech frame are produced by the calculated entropy \(H_i\) as Eq. (14) and denoted as \(\omega ^2_i=\{\omega ^2_{i,1},\omega ^2_{i,2},\ldots ,\omega ^2_{i,y},\ldots ,\omega ^2_{i,\lambda _c}\}\) with the length of \(\lambda _c\).
$$\begin{aligned} \omega ^2_{i,y}=\left( \frac{H_i}{2^y}\right) \%2,\quad y=1,2,\ldots ,\lambda _c \end{aligned}$$(14)
(3) Frame number bits generation
Each frame number i is converted into binary bits to produce the frame number bits \(\omega ^3_i\) with the length of \(\lambda _f\). Here, \(\omega _i^3=\{\omega ^3_{i,1},\omega ^3_{i,y},\ldots ,\omega ^3_{i,\lambda _f}\}\).
$$\begin{aligned} \omega ^3_{i,y}=\left( \frac{i}{2^y}\right) \%2, \quad y=1,2,\ldots ,\lambda _f \end{aligned}$$(15)(4) Watermark generation
The compressed bits \( \omega _i^1\), check-bits \( \omega _i^2\) and frame number bits \(\omega _i^3\) are connected as the final watermark of the ith speech frame and denoted as \({W_i}\).
$$\begin{aligned} W_i=\{\omega ^1_{i,1},\ldots ,\omega ^1_{i,\lambda _r},\ldots ,\omega ^2_{i,1},\ldots ,\omega ^2_{i,\lambda _c},\ldots ,\omega ^3_1,\ldots ,\omega ^3_{\lambda _f}\} \end{aligned}$$(16) -
(a)
-
3.
Watermark embedding.
For the ith speech frame \({E_i}\), the \(\lambda _2\) LSBs of each sampling points are substituted by the generated watermark \({W_i}\). Then, the ith watermarked speech frame can be obtained and denoted as \(C_i\). After that, each speech frame is watermarked and connected in turn until the end of all speech frames watermarked. The encrypted-watermarked speech is denoted as \(C=(C_1,C_2,\ldots ,C_i,\ldots ,C_I)\).

An example of how to generate the data vector
2.3 Content authentication and tampering recovery algorithm
In REPAIR, the content authentication and tampering recovery algorithm includes the following steps: speech frame selection, watermark extraction, check bits reconstruction, tampering location and tampering recovery. The steps of how to authenticate the integrity of speech are illustrated as follows:
-
1.
Speech frame selection.
Suppose that \(C=\{c_1,\ldots ,c_l,\ldots ,c_L\}\) is a received encrypted-watermarked speech signal. A speech frame signal of the received speech C can be selected by a sliding window and denote as f.
-
2.
Watermark extraction.
The embedding watermark can be extracted from the \(\lambda _2\) LSBs of the selected frame signal f. Hence, the compressed bits \(w^1\) (with the length of \(\lambda _r\)), the check bits \(w^2\) (with the length of \(\lambda _c\)) and frame number bits \(w^3\) (with the length of \(\lambda _f\))can be obtained.
-
3.
Check-bits reconstruction.
On the basis of step 2 in Sect. 2.2, the check-bits can be reconstructed by the same operations of the selected frame signal f and denoted as \(w^{2*}\).
-
4.
Tampered detection and tampered localization.
Synchronization is a vital issue in speech authentication. In REPAIR, synchronization can be realized by comparing the extracted check-bits and reconstructed check-bits without using extra information. Firstly, the extracted check-bits \(w^{2}\) and the reconstruct check-bits \(w^{2*}\) are compared. There are two corresponding cases listed as following.
-
(a)
If both groups of check-bits \(w^{2}\) and \(w^{2*}\) are identical, it indicates that the selected frame is intact. Therefore, the correct frame number can be obtained as Eq. (17) by the extracted frame number bits \(w^3\).
$$\begin{aligned} n=w^3_1\times 2^{\lambda _f-1} + w^3_2\times 2^{\lambda _f-2}+\cdots + w^3_{\lambda _f}\times 2^0 \end{aligned}$$(17)Besides, the correct compressed bits \(w^1\) and frame signal f of the nth frame are retained and denoted as \(w^1_n\) and \(f_n\) respectively.
Subsequently, the sliding window moves J sampling points (one frame, as shown in Fig. 3,1) and the next speech frame will be chosen to verify its integrity.
-
(b)
If both groups of check-bits \(w^{2}\) and \(w^{2*}\) are not identical, the selected speech frame will be considered as not intact. Obviously, if the detected speech is attacked by de-synchronization, the deleted sampling points or the inserted sampling points will destroy the correct grouping. Therefore, the sliding window moves only one sampling point (as shown in Fig. 3,2–5) and the next speech frame will be chosen to verify its integrity. This step will repeat until the correct speech frame is found (shown in Fig. 3, 6).
Fig. 3 
An example of synchronous detection
After all speech frames are detected and the correct speech frames are found, the indexes of missing frames can be obtained according to the continuity of these correct frame numbers. Therefore, the missing frame signals and corresponding compressed bits are marked as special values. For instance, the correct frame numbers are 1, 2, 3, 5, 6, and the missing frame number 4 can be determined based on the continuity of these numbers.
-
(a)
-
5.
Tampered recovery.
In REPAIR, the tampered sampling points are converted into binary bits and diffused into different groups of data sequence. Obviously, a group of data sequence contains a small number of tampered binary bits. Therefore, those tampered binary bits can be recovered by solving Eq. (19). The detailed steps of tampering recovery is described as follows.
-
(a)
The binary sequence \(B'=\{B'_1,\ldots ,B'_i,\ldots , B'_I\}\) is produced by converting the detected speech frames into binary bits, which contains special bits of tampered frames. Similarly, all extracted compressed bits of each frame containing special values are connected as \(W^1=\{w^1_1, \ldots , \)\(w^1_i, \ldots , w^1_I\}.\)
-
(b)
Using the secure key \(k_1\), the scrambling operation is performed on \(B'\). Subsequently, the scrambled data sequence is redivided into I groups. Each group is denoted as \(B^*_i= (b^*_{i,1}, \ldots , b^*_{i,\lambda _1\times J})^T\). Therefore, those special values of data sequence are diffused into different groups.
-
(c)
Using the secure key \(k_2\), the inverse scrambling and division are performed on the obtained compressed bits \(W^1\) to diffuse those special compressed bits into different groups. Each redivided group of compressed bits is denoted as \(R'_i = (r'_{i,1},r'_{i,2},\ldots ,r'_{i,\lambda _r})^T.\)
-
(d)
For each group, the corresponding data vector \(B^*_i\) and partial compressed bits \(R^*_i\) (\(R^*_i\) contains the extracted reliable compressed bits of \(R'_i\)(\(\lambda _3\le \lambda _r\))) are used to obtain the following equation:
$$\begin{aligned} R^*_i= \begin{bmatrix} r^{*}_{i,1} \\ r^{*}_{i,2} \\ \vdots \\ r^{*}_{i,\lambda _3} \end{bmatrix}=M^E \cdot \begin{bmatrix} b^*_{i,1} \\ b^*_{i,2} \\ \vdots \\ b^*_{i,\lambda _1\times J} \end{bmatrix} \end{aligned}$$(18)Here, the matrix \(M^E\) (sized \(\lambda _3\times \lambda _1\times J\)) is constituted of some rows in matrix M whose row number is corresponding to those rows of correct compressed bits.
-
(e)
Eq. (18) can be reformulated as Eq. (19).
$$\begin{aligned} M_i^{E2}\cdot B^2_i = R^*_i - M_i^{E1}\cdot B^1_i \end{aligned}$$(19)In this equation, the data sequence \(B^*_i\) is split into two parts \(B^1_i\) and \(B^2_i\). \(B^1_i\) contains correct bits selected from those intact frames. \(B^2_i\) contains special bits selected from those tampered frames which need to be recovered. Matrix \(M^{E1}\) consists of the columns in \(M^E\) corresponding to the rows of data bits \(B^1_i\). Matrix \(M^{E2}\) consists of the columns in \(M^E\) corresponding to the rows of data bits \(B^2_i\). Obviously, all parameters are known except \(B^2_i\) in this equation.
If Eq. (19) has a unique solution, all unknown data bits of \(B^2_i\) can be calculated. However, if the number of unknown bits is too large or too many linearly dependent equations exist in Eq. (19), the solution may not be unique. In this case, the calculated \(B^2_i\) may be erroneous, Hence, those error data bits are also marked as a special value which will be recovered by their adjacent sampling points.
-
(f)
Step 5d to Step 5e will be repeated until all missing data bits are recovered. Those recovered data bits are used to retrieve the tampered sample values of the encrypted watermarked speech. Then, the final recovery watermarked speech is denoted as E. Moreover, if some error data bits cannot be recovered, the corresponding sampling points are marked as a special value which will be recovered by adjacent sampling points after decryption.
-
(a)

2.4 Speech decryption algorithm
In order to decrypt the encrypted speech and obtain the original speech, the downloader needs to use the same key (formed by the initial key v) to decrypt the recovered speech E. The detailed steps are described as follows.
-
1.
Key generation.
The same operations are performed to obtain the key of position permutation P and the key of amplitude encryption k as paragraph (1) in Sect. 2.1.
-
2.
Amplitude decryption.
Firstly, the recovered encrypted speech E is divided into I frame, the frame length is consistent with the encryption algorithm. Then, According to the ith group of the selected key \((k^i_0,k^i_1,k^i_2,k^i_3,k^i_4)\), each frame speech is decrypted by the following Eq. (20), where the final decrypted speech is denoted as S.
$$\begin{aligned} \begin{array}{l} {s_{1}^{i}} = e_{1}^{i} \oplus k^i_1 \oplus k^i_0\\ {s_{2}^{i}} = e_{2}^{i} \oplus k^i_2 \oplus {s_{1}^{i}}\\ {s_{3}^{i}} = e_{3}^{i} \oplus k^i_3 \oplus {s_{2}^{i}}\\ {s_{4}^{i}} = e_{4}^{i} \oplus k^i_4 \oplus {s_{3}^{i}} \end{array} \end{aligned}$$(20)In this equation, \(S_i=\{s_{1}^{i},s_{2}^{i},s_{3}^{i},s_{4}^{i}\}\) and \(E_i=\{e_{1}^{i},e_{2}^{i},e_{3}^{i},e_{4}^{i}\}\) are the ith recovered speech frame and decrypted speech frame, respectively.
-
3.
Position inverse permutation.
The calculated key of position permutation P is used to inversely permutate the decrypted speech \(S^*\) so as to obtain the final decrypted speech.
-
4.
Recovering the unrecovered sampling points.
Obviously, the tampered and unrecovered sampling points are diffused to the entire speech after decryption. As the adjacent sampling points have a strong correlation in plaintext speech, those special tampered sampling points can be recovered by the mean values of their adjacent sampling points. After that, the final decrypted and recovered speech signal can be obtained.
3 Security analysis
Confidentiality is one of important indicator for data security. In REPAIR, the encryption technology is used to protect the confidentiality of speech content. Therefore, key space analysis and statistical analysis are used to evaluate the security performance of the proposed encryption algorithm.
3.1 Keyspace analysis
Keyspace is a set of possible keys that can be used to decrypt data in a cryptosystem. In a strong encryption algorithm, the keyspace should be large enough to resist brute-force attack. Undoubtedly, higher security will be achieved with increased keyspace.
The keys of the proposed speech encryption algorithm are generated by using Shen’s hyper-chaotic, which is controlled by six initial values (\(v_1\), \(v_2\), \(v_3\), \(v_4\), \(v_5\), and \(v_6 \)). IEEE floating-point standard has mentioned that the computational precision of a 64-bit double-precision number is about \(10^{15}\) [27, 28]. Therefore, the keyspace of the proposed encryption algorithm is approximately \((10^{15})^6=10^{90} \), which is large enough to resist brute-force attack.
3.2 Statistical analysis
Admittedly, the distribution of speech sampling points is regular. Thus, attackers can possibly get useful information by the statistical features of a speech signal. For resisting statistical analysis, the diffusion operation and confusion operation are combined to conceal plaintext statistical features. In this section, the statistical analysis of the proposed encryption algorithm has been done via histogram and correlation analysis.
-
1.
Histogram analysis
Histogram can be used to measure the distribution of sampling points. From Fig. 4a, it shows that the distribution of the original speech is regular obviously. However, the sampling values of original speech are encrypted and the value range is expanded to \([-2^{\lambda -1}+1,2^{\lambda -1}]\)(\(\lambda \) is the quantization bits of original speech). It can be seen that the sampling values of encrypted speech have a more uniform distribution as shown in Fig. 4b. Therefore, statistical features of original speech can be concealed by encryption.
-
2.
Correlation analysis
Correlation is another parameter used to evaluate the encryption quality in a cryptosystem. In this section, partial sampling points of the plaintext and ciphered speech are randomly selected to describe the correlations between adjacent sampling points. Figure 5a shows that adjacent sampling points of the original speech have a strong correlation. Conversely, the distribution of encrypted speech is fluctuant as shown in Fig. 5b. Additionally, correlation coefficient is a useful measure to assess the encryption quality between original speech and cipher speech, which is calculated as Eq. (21).
$$\begin{aligned} r_{xy}=\frac{C(x,y)}{\sqrt{V(x)}\sqrt{V(y)}} \end{aligned}$$(21)In this equation, V(x) and V(y) are the variances of the speech signals x and y. C(x, y) is the covariance between the original speech x and the encrypted speech y as Eq. (22). \(N_s\) is the number of speech sampling points.
$$\begin{aligned} C(x,y)=\frac{1}{N_s}\sum _{i=1}^{N_s}(x(i)-E(x))(y(i)-E(y)) \end{aligned}$$(22)The calculated correlation coefficient of original speech is 0.9629. It means that the adjacent sampling points of original speech were strongly correlated. In contrast, the calculated correlation coefficient of the encrypted speech is -0.0018, which indicates that the adjacent sampling points of encrypted have low correlation. In conclusion, the proposed encryption algorithm has a strong ability to eliminate the correlation between adjacent sampling points.

Histograms of original speech and its encrypted speech; a Histogram of the original speech; b Histogram of the encrypted speech

Correlations of two adjacent sampling points: a Correlation of original speech; b Correlation of encrypted speech
3.3 Analysis of tampered detection
In transmission or storage, speech signals may subject to forgery attack which is usually undetectable. Therefore, locating the tampered speech frames is the most important issue for speech content authentication.
Suppose that all bits of the extracted check-bits \(w^2\) and the reconstructed check-bits \(w^{2*}\) are independent. For REPAIR, if one speech frame is maliciously tampered, partial bits of the reconstructed check-bits will be different from the corresponding extracted check-bits. Furthermore, the probability that each bit of the reconstructed check-bits is equal to the corresponding bit in the extracted check bits, which is 50%. If all extracted check-bits match the reconstructed check-bits, the authentication client will declare that the detected frame is intact. Thus, the probability of false detection is computed theoretically as Eq. (23). In that equation, \(\lambda _c\) is the length of check-bits.
In other words, the attacked frame can be detected correctly with the probability \(P_c\) as Eq. (24).
If \(\lambda _c\) is large enough, the values of \(P_f\) and \(P_c\) will be close to 0 and 1 respectively, in other words, REPAIR can precisely detect the tampered frames of attacked speech.
4 Experimental results
In this section, the speech database of ITU-T test signals for telecommunication systems [29] is selected to evaluate the performance of REPAIR. This database includes twenty languages and each language has eight female speech recordings and eight male speech recordings (320 speech recordings in all). Every speech recording is a 16-bits monaural file in WAVE format. In addition, important variables are set as Table 2.
4.1 Encryption and decryption
To quantify the performance of the proposed encryption algorithm, the signal-to-noise ratio (SNR) is used for evaluating the differences between each original speech and its encrypted/decrypted speech. SNR values are calculated as Eq. (25). The calculated results are shown in Table 3 (the SNR values of twenty speech recordings are listed in this table). According to the encryption algorithm, the sampling values of encrypted speech are changed, it indicates that amplitudes of original speech signals have been well concealed. Therefore, the SNR values between the original speeches and encrypted speeches are negative. Meanwhile, the original speech can be recovered by the decryption algorithm without any loss. Therefore, the calculated SNR values between original speeches and decrypted speeches are infinity.
Additionally, the waveforms of one original speech, its corresponding encrypted speech and decrypted speech are shown in Fig. 6. From this figure, it can be seen that original speech and encrypted speech are totally different. This means that the designed encryption has favorable ability to conceal characteristics of the original speech. Meanwhile, the decrypted speech is visually indistinguishable from the original speech.

Waveforms of original speech, encrypted speech and decrypted speech
4.2 Inaudibility
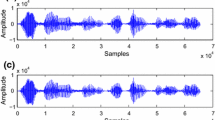
Inaudibility reflects the change degree between two speech signals. In order to evaluate the inaudibility of REPAIR, the waveforms of the original speech and the decrypted-watermarked speech are shown in Fig. 7. We observe that there is no obvious difference between the original speech and the decrypted-watermarked speech. This means that the embedded watermark cannot be found in the decrypted-watermarked speech by vision.

Waveforms of original speech and decrypted-watermarked speech
Meanwhile, SNR is also employed to measure the quality of the decrypted-watermarked speech. According to the International Federation of the Photographic Industry(IFPI), the SNR values should be more than 20 dB. Figure 8 shows the SNR values of REPAIR and the compared methods in [30,31,32]. From this figure, it is clear that the SNR values between the original speech and the decrypted-watermarked speech of REPAIR are greater than 50 dB which satisfy the IFPI standard. This means that the decrypted watermarked speech is similar to the original speech. Comparing with other methods, the SNR values of REPAIR are obviously bigger. Hence, we can conclude that REPAIR has an excellent inaudibility without affecting the decryption.

SNR (dB) values of different algorithms
4.3 Tampered localization and recovery
In this section, one speech signal is selected to obtain the encrypted-watermarked speech. Then, the encrypted-watermarked speech will be attacked as follows to test the performance of tampering localization and recovery of REPAIR: (1) unattacked speech; (2) the speech of substitution attack; (3) the speech of insertion attack; (4) the speech of deletion attack.
4.3.1 Tampered localization and decryption without attack
To compare the performance of the attack speech, the tampered localization and decryption of unattack speech is executed. Figure 9a shows the waveform of the encrypted-watermark speech without attack. In the subgraph(b), if the values of tampered localization result are set to one, it means that the corresponding speech frames are maliciously tampered. Otherwise, the corresponding speech frames are intact. Visibly, the values of tampering localization result are equal to zero in Fig. 9b. Consequently, it is confirmed that all speech frames are intact. Moreover, the decrypted and watermarked speech is shown in Fig. 9c. It is obvious that the decrypted watermarked has no visual difference with the original speech which is shown in Fig. 6a. Meantime, the SNR value between the decrypted-watermarked speech and the original speech is 53.33 dB.

The tamper localization result and recovery speech of without attack
4.3.2 Tampered localization and recovery of substitution attack
Substitution attack represents randomly replacing partial samples of the encrypted watermarked speech. The waveforms of the attacked speech, the tampered localization result and the decrypted-recovered speech are shown in Fig. 10a–c, respectively. For the attacked speech, the attacked area (from the 14101st to the 16100th samples, a total of 2000 sampling points) is indicated by a rectangle. According to the tampered localization result, we can find that the speech frames from the 110th to the 126th are tampered. Besides, there is no visual difference between Figs. 9c and 10c and . In addition, the SNR value between the recovered-decrypted speech and the original speech is 53.33 dB. Overview, it is believed that REPAIR has precise locating ability and favorable recovering ability for substitution attack.

The tampered localization result and recovery speech of substitution attack
4.3.3 Tampered localization and recovery of insertion attack
In this experiment, some random values are inserted into the encrypted watermarked speech signal. In Fig. 11a, it shows that sampling points from 70001st to 75000th (a total of 5000 sampling points) are inserted. Meanwhile, the tampered localization result in Fig. 11b shows that only the 547th frame is tampered. The reason is that the inserted sampling points destroyed only one frame. In light of the recovery algorithm in REPAIR, sampling points of that tampered frame can be recovered. Distinctly, the decrypted-recovered waveform shown in Fig. 11c has no visual difference with the waveform of decrypted-watermarked in Fig. 9c. Moreover, the SNR value between the recovered-decrypted speech and the original speech is 53.33 dB, which is equal to the SNR value of the decrypted-watermarked speech without attack. In conclusion, REPAIR has accurate locating ability and excellent recovering ability for insertion attack.

The tampered localization result and recovery speech of insertion attack
4.3.4 Tampered localization and recovery of deletion attack
In this experiment, partial sampling points (from the 43,201st to the 44,200th, a total of 1000 sampling points) of the encrypted-watermarked speech are deleted. The waveform of the tampered speech is shown in Fig. 12a. Meanwhile, the tampered localization result in Fig. 12b shows that the speech frames from the 336th to the 346th are considered as tampered speech frames. Figure 12c gives the waveform of the recovered-decrypted speech, which is similar to the decrypted-watermarked speech shown in Fig. 9c. Further, the calculated SNR value between the recovered-decrypted speech and the original speech is 53.33 dB. Therefore, it is proved that the speech subjected by deletion attack can effectively recover in REPAIR.

The tampered localization result and recovery speech of deletion attack
From the above experiment, we can see that the REPAIR has a strong ability to detect various malicious attacks and locate the tampered speech frames accurately. In the authentication process, the extracted check-bits and the reconstructed check-bits are compared to realize frame synchronization and tampered detection simultaneously. Additionally, the embedded compressed bits can be used to recover those tampered speech frames with high quality. Consequently, we can obtain a smooth waveform of that recovered-decrypted speech signal and a high SNR value between the recovery-decrypted speech and the original speech.
Further, the SNR and objective Difference Grade(ODG) [33] are calculated to measure the quality of recovered speech under different length substitution attacks objectively. ODG represents the expected perceptual quality of the degraded signal, which is calculated by perceptual evaluation of audio quality (PEAQ). The score of ODG has a range of [\(-4\), 0] and the meaning of each score is listed in Table 4.
The numbers of substituted samples are 500, 1000, 1500, 2000, 3000, 5000, 8000 and 10,000 respectively. From Table 5, it can be seen that REPAIR has excellent recovery quality than the methods of [30, 32]. In [31], there is no recovery mechanism to recover those tampered speech frames. Hence, the recovery quality in [31] is not mentioned in this table. Moreover, the calculated SNR and the ODG values of methods in [30, 32] decrease obviously due to the fact that the recovered speech frames loss more detailed information after compression. In contrast, in REPAIR, the calculated SNR and ODG values of recovered speeches are close to the corresponding values of decrypted-watermarked speeches by the recovery algorithm. Therefore, the tampered speech frames can be recovered with high quality in REPAIR.
4.4 Complexity
In this section, we use the computational complexity and runtime to evaluate the complexity of the REPAIR. In REPAIR, there are four modules including encryption, watermark generation and embedding, authentication and recovery, and decryption. In each process, speeches are divided into frames to perform corresponding operations. Suppose that a speech contains N frames, each frame will be executed corresponding operations one time and the runtime of the algorithm will increase with the increase of N. Thus, its computational complexity is O(N). However, there are many differences of details between each process. There are only key generation operation and exclusive or operation in encryption and decryption processes. Meanwhile, there are more operations in other process, the matrix multiplication are employed in watermark generation which will cost more times. Moreover, if the watermarked speech subjects malicious tampering, solving the equations of multiple variables will cost more time. The runtime of each process is shown in the Table 6, it is clear that the runtime increases with the increase of duration of speech.
4.5 Comparison with other methods
For comparing REPAIR with other methods more intuitively, further comparison results are given as Table 7. In this table, the keyspace and correlation coefficient are selected to evaluate the confidentiality, while the SNR and ODG values are chosen to describe the quality of watermarked speeches and recovered speeches. Additionally, ability of detecting the typical attack types is also listed in that table. According to this table, it can be found that only REPAIR and [8] can realize confidentiality and integrity simultaneously while REPAIR has a larger keyspace. In addition, the given SNR values and ODG values indicate that the imperceptibility of the REPAIR is better than other schemes. Meanwhile, the schemes in [8, 30, 32] and REPAIR have ability to recover the tampered speech content. For instance, the watermarked speeches were subjected to substitution attack in those schemes. The recovery quality manifests that the REPAIR has more favorable imperceptibility. Furthermore, the more sampling points subject to attack, the more distortions will be introduced when utilizing the algorithms of [8, 30, 32]. From Table 7, it shows that most schemes can resist the de-synchronization attacks such as insertion attack and deletion attack except the schemes in [30, 34]. However, the scheme in [9] can only detect the de-synchronization attacks on entire frames. Similar to the scheme [8, 31, 32], we use the self-generated watermark in REPAIR. Thus, the de-synchronization without using other extra synchronous code is realized. In conclusion, it is believed that REPAIR provides a preferable performance for confidentiality and authentication.
5 Conclusions
To realize the confidentiality and integrity, a speech authentication scheme (namely REPAIR) used in the encrypted domain was proposed in this paper. In REPAIR, an encryption algorithm was designed to conceal speech features. After that, the self-embedded watermark was generated and embedded in the reserved space of encrypted speech. In the content authentication and recovery process, the embedded check-bits and frame number bits can be extracted to verify the integrity of speech content. Meanwhile, the embedded compressed bits and adjacent sampling points were used to recover those tampered frames. Experiments show that REPAIR can achieve high security with an excellent inaudibility of the decrypted-watermarked speech. More importantly, the tampered area can be recovered with high quality.
References
Jiang, D., Wang, Y., Lv, Z., et al. (2019). Big data analysis-based network behavior insight of cellular networks for industry 4.0 applications. IEEE Transactions on Industrial Informatics,. https://doi.org/10.1109/TII.2019.2930226.
Kamara, S., & Lauter, K. (2010). Cryptographic cloud storage. In Sion, R. et al. (eds) Financial Cryptography and Data Security. FC 2010, pp. 136–149.
Wang, F., Jiang, D., Wen, H., et al. (2019). Adaboost-based security level classification of mobile intelligent terminals. The Journal of Supercomputing,. https://doi.org/10.1007/s11227-019-02954-y.
Li, P., & Lo, K. (2018). A content-adaptive joint image compression and encryption scheme. IEEE Transactions on Multimedia, 20(8), 1960–1972.
Zamani, M., & Manaf, A. B. A. (2015). Genetic algorithm for fragile audio watermarking. Telecommunication Systems, 59(3), 291–304.
Saadi, S., Merrad, A., & Benziane, A. (2019). Novel secured scheme for blind audio/speech norm-space watermarking by Arnold algorithm. Signal Processing, 154, 74–86.
Xiong, L., Xu, Z., & Shi, Y. Q. (2018). An integer wavelet transform based scheme for reversible data hiding in encrypted images. Multidimensional Systems and Signal Processing, 29(3), 1191–1202.
Qian, Q., Wang, H., Sun, X., et al. (2018). Speech authentication and content recovery scheme for security communication and storage. Telecommun Systems, 67(4), 635–649.
Qian, Q., Wang, H. X., Hu, Y., Zhou, L. N., & Li, J. F. (2016). A dual fragile watermarking scheme for speech authentication. Multimedia Tools and Applications, 75(21), 13431–13450.
Farsana, F. J., & Gopakumar, K. (2018). Private key encryption of speech signal based on three dimensional chaotic map. In 2017 International Conference on Communication and Signal Processing (ICCSP), pp. 2197–2201. IEEE Press, Chennai, 2018.
Wang, H., Hempel, M., Peng, D., Wang, W., Sharif, H., & Chen, H. H. (2010). Index-based selective audio encryption for wireless multimedia sensor networks. IEEE Transactions on Multimedia, 12(3), 215–223.
Li, G., Pu, Y., Yang, B., & Zhao, J. (2018). Synchronization between different hyper chaotic systems and dimensions of cellular neural network and its design in audio encryption. Cluster Computing,. https://doi.org/10.1007/s10586-018-1700-7.
Lima, J. B., & da Silva Neto, E. F. (2016). Audio encryption based on the cosine number transform. Multimedia Tools and Applications, 75(15), 8403–8418.
Lin, Q. H., Yin, F. L., Mei, T. M., & Liang, H. L. (2006). A blind source separation based method for speech encryption. IEEE Transactions on Circuits and Systems I: Regular Papers, 53(6), 1320–1328.
Liu, Z., & Wang, H. (2014). A novel speech content authentication algorithm based on Bessel–Fourier moments. Digital Signal Processing, 24, 197–208.
Chen, O. T., & Liu, C. H. (2007). Content-dependent watermarking scheme in compressed speech with identifying manner and location of attacks. IEEE Transactions on Audio, Speech, and Language Processing., 15(5), 1605–1616.
Yan, B., & Guo, Y. J. (2013). Speech authentication by semi-fragile speech watermarking utilizing analysis by synthesis and spectral distortion optimization. Multimedia Tools and Applications, 67(2), 383–405.
Xia, Z., Wang, X., et al. (2016). A privacy-preserving and copydeterrence content-based image retrieval scheme in cloud computing. IEEE Transactions on Information Forensics and Security, 11(11), 2594–2608.
Fu, Z., Wu, X., Guan, C., et al. (2016). Toward efficient multikeyword fuzzy search over encrypted outsourced data with accuracy improvement. IEEE Transactions on Information Forensics and Security, 11(12), 2706–2716.
Wu, T. Y., Chen, C. M., Wang, K. H., Meng, C. C., & Wang, E. K. (2019). A provably secure certificateless public key encryption with keyword searchA provably secure certificateless public key encryption with keyword search. Journal of the Chinese Institute of Engineers, 42(1), 20–28.
Zhang, W., Ma, K., & Yu, N. (2014). Reversibility improved data hiding in encrypted images. Signal Processing, 94, 118–127.
Qian, Z., Zhang, X., & Wang, S. (2014). Reversible data hiding in encrypted JPEG bitstream. IEEE Transactions on Multimedia, 16(5), 1486–1491.
Karim, M. S. A., & Wong, K. (2014). Universal data embedding in encrypted domain. Signal Processing, 94, 174–182.
Zhang, X., Wang, S., Qian, Z., & Feng, G. (2011). Reference sharing mechanism for watermark self-embedding. IEEE Transactions on Image Processing, 20(2), 485–495.
Shen, C., Yu, S., Lu, J., & Chen, G. (2014). A systematic methodology for constructing hyperchaotic systems with multiple positive Lyapunov exponents and circuit implementation. IEEE Transactions on Circuits and Systems I: Regular Papers, 61(3), 854–864.
Rodriguez, A., & Laio, A. (2014). Clustering by fast search and find of density peaks. Science, 344(6191), 1492–1496.
Kahan, W. (1985). IEEE standard 754 for binary floating-point arithmetic. ANSI/IEEE Std, 754–1985, 94720–1776.
Cowlishaw, M. F. (2003). Decimal floating-point: algorism for computers. In Proceedings of 16th IEEE Symposium on Computer Arithmetic. IEEE Press, pp. 104–111.
ITU-T Test Signals for Telecommunication Systems (2015). Test Vectors Associated to Rec. ITU-T P.501. http://www.itu.int/net/itu-t/sigdb/genaudio/AudioForm-g.aspx?val=10000501. (2015).
Chen, F., He, H., & Wang, H. (2008). A fragile watermarking scheme for audio detection and recovery. In Proceeding of international congress on image and signal processing, IEEE Press, pp. 135–138.
Wang, J., & He, J. (2017). A speech content authentication algorithm based on a novel watermarking method. Multimedia Tools and Applications, 76(13), 14799–14814.
Liu, Z., Zhang, F., Wang, J., Wang, H., & Huang, J. (2016). Authentication and recovery algorithm for speech signal based on digital watermarking. Signal Processing, 123, 157–166.
Thiede, T., Treurniet, W. C., Bitto, R., Schmidmer, C., Sporer, T., Beerends, J. G., et al. (2000). PEAQ-The ITU standard for objective measurement of perceived audio quality. Journal of the Audio Engineering Society, 48(1/2), 3–29.
Ballesteros, M., & CamiloLemus, L. (2018). Authenticity verification of audio signals based on fragile watermarking for audio forensics. Expert Systems with Applications, 91, 211–222.
Acknowledgements
This work is supported by the National Natural Science Foundation of China (NSFC) under the Grant No. 61902085 and the Guizhou Provincial Science and Technology Plan ([2020]1Y267, [2017]1051).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Qian, Q., Cui, Y., Wang, H. et al. REPAIR: fragile watermarking for encrypted speech authentication with recovery ability. Telecommun Syst 75, 273–289 (2020). https://doi.org/10.1007/s11235-020-00684-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11235-020-00684-8