
Abstract
The replica strategies in traditional cloud computing often result in excessive resource consumption and long response time. In the edge cloud environment, if the replica node cannot be managed efficiently, it will cause problems such as low user’s access speed and low system fault tolerance. Therefore, this paper proposed replica creation and selection strategy based on the edge cloud architecture. The dynamic replica creation algorithm based on access heat (DRC-AH) and replica selection algorithms based on node service capability (DRS-NSC) were proposed. The DRC-AH uses data block as replication granularity and Grey Markov chain to dynamically adjust the number of replicas. After the replica is created, when client receives the user’s request, the DRS-NSC selects the best replica node to respond to the user. The experiments show that the proposed algorithms have significant advantages in prediction accuracy, user’s request response time, resource utilization, etc., and improve the performance of the system to a certain extent.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Under the traditional cloud computing system, cloud computing services have a strong dependence on network bandwidth and delay, and the current network performance cannot meet the needs of services, which will lead to excessive network load [1]. In view of the above shortcomings, this paper proposed the edge cloud computing architecture [2,3,4]. The edge cloud computing architecture, which is composed of “edge cloud” and “central cloud”, reduces the network load of edge cloud through the monitoring and management of each edge cloud node by the core cloud. Users use related services in local “edge cloud”, which effectively reduces the dependence of cloud computing system on network. Each edge cloud is managed and coordinated by the central cloud, which solve the problems of limited resource capacity and difficult collaboration of a single system in the traditional cloud computing system. Secondly, replica technology is one of the most commonly used and efficient data management methods [5], which means to store multiple replicas of a data item on multiple nodes in a distributed system. A good replica strategy can improve system efficiency.
Furthermore, replica technology is a key technology in cloud storage system, which can greatly reduce transmission delay and improve data access and processing efficiency. This paper focuses on replica creation and replica selection techniques. How to dynamically adjust the number of replicas in the edge cloud environment and select the most appropriate replica to respond to users is a question worth studying. The traditional static replica creation strategy uses files as replication granularity, but sometimes the users only need to pay attention to some data blocks in the file. The number of replicas cannot be adjusted efficiently and accurately, thus affecting the selection process of replicas. How to select the best data replica based on the actual data access request? Traditional replica selection strategies often fail to quickly select the most appropriate replica to respond to user needs. For example, some replica selection strategies simply select the replica in the node that is physically closest to the client; this causes large network delay and unbalanced node load. Therefore, the key of replica selection is to compare the advantages and disadvantages of multiple candidate nodes by considering many factors such as node load, response time and network bandwidth, so as to select an optimal replica for users. The purpose is to ensure the high reliable storage of files, reduce the access delay of files, improve the ability of files to provide data services, and optimize the overall performance of the system. The random replica placement strategy refers to the random placement of replicas without considering the real-time load of nodes, which is likely to lead to unbalanced load of the cluster system and excessively large network distance for storing replicas, affecting the data transmission performance of the system.
In order to solve the above problems, dynamic replica creation and replica selection strategies in edge cloud environment are proposed. In this paper, a dynamic replica creation (DRC-AH) algorithm based on access heat is proposed. The Grey Markov model has the advantages of high accuracy, reflecting long-term trend and better processing of stochastic dynamic process, which improves the accuracy of prediction results. This model can ensure the dynamic adjustment process of the replica more quickly and accurately. Replica selection technology mainly considers bandwidth, node load, network delay, access time and other factors to select the best replica response from all replica nodes for the user. In this paper, a replica selection algorithm (DRS-NSC) based on the service capability of the node is proposed. In the selection of the replica, the service capability of the node is considered, that is, the load capacity of the replica node itself and the network distance between the replica node and the user node are considered comprehensively. The data are transmitted between the client and the node through the network, and the network bandwidth has a great influence on the reading speed of the client, so this strategy takes the bandwidth as the main influencing factor. The system needs to select the most appropriate node from all nodes that have a replica of the data file as the target node to respond to the user. The algorithm reduces the user’s request delay and balances the node load. The dynamic replica creation and replica selection strategy proposed in this paper can maintain the load balance of the whole system. Ensure the high availability of data and optimize the overall performance of the system.
This paper aims at settling above problems, and the main contributions are summarized as follows.
- (1)
DRC-AH is proposed. Markov describes a class of stochastic processes, which can predict the future development trend of the system according to the relationship between state transition probabilities. However, the Grey theory model is suitable for forecasting problems of short time, small data and small fluctuation, etc., with high accuracy, but it cannot deal with some wave data sequences. The Grey Markov model combines the advantages of the two models. In this paper, the Gray Markov model is used to predict the size of data blocks, and the state transition matrix for the prediction of data blocks is established according to the Markov model, which makes the process of dynamically adjusting the replica more accurate.
- (2)
DRS-NSC is proposed. Firstly, the service capability of the node is calculated based on the load and transmission time of the replica node. Secondly, the service capability of all nodes containing the replica of the user request is sorted, and finally the optimal node is returned to the user. The algorithm considers the storage capacity of the replica node and the distance between the replica node and the user node. The most serviceable replica nodes are selected to reduce latency of user requests and load balancing between nodes.
- (3)
Based on edge cloud experimental environment, the replica creation and replica selection algorithm is tested by the experiments and comparative analysis is given. Experimental results show that DRC-AH is better than other algorithms in balancing node load and reducing network delay. The DRS-NSC improves the access time, job completion time, effective network bandwidth utilization and memory space utilization.
The rest of this article is organized as follows: Sect. 2 reviews the work, and Sect. 3 describes the dynamic replica creation model based on access heat and the dynamic replica selection model based on node service capability. Section 4 describes the implementation of the corresponding algorithm. Section 5 analyzes and verifies the advantages of the proposed replica strategy. Finally, Sect. 6 gives the conclusion and the future work.
2 Related work
In recent years, people have done a lot of research on the creation and selection of replicas. In this section, we will give a brief introduction to these works.
2.1 The architecture of edge cloud
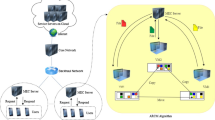
The edge cloud computing architecture is composed of “edge cloud” and “core cloud”. Figure 1 shows the architecture for an edge cloud. The edge cloud applications include automotive navigation, smart home, industrial manufacturing, media applications, agricultural environmental monitoring, etc. By monitoring and managing each edge cloud, the network load of the edge cloud is reduced, and the difficulty of service collaboration in distributed cloud computing architecture is solved.

The architecture of the edge cloud
Some researchers have studied the strategy of the edge cloud. Satyanarayanan et al. [6] proposed that edge computing, an emerging technology, could provide responsive cloud services for mobile computing, provide scalability and privacy strategy enforcement for the Internet of things, and be able to block temporary cloud outages. Shi et al. [7] proposed that the success of the Internet of things and the abundance of cloud services help create the need for edge computing, which addresses issues such as latency, limited battery life on mobile devices, bandwidth costs, security and privacy. Pan et al. [8] investigated key principles that benefit from the edge cloud, state-of-the-art efforts, key enabling technologies and research topics, and typical IOT applications. The objective is to have a comprehensive understanding of the ongoing research work and possible future research directions. Munish et al. [9] proposed a comprehensive framework for analyzing the national integrity of defense personnel based on IOT. An automatic decision tree based on probability decision tree is proposed to help defense officials analyze the activities of defense personnel so as to evaluate their integrity. Munish et al. [10] proposed an intelligent medical framework based on Internet of things technology. The intelligence of this framework lies in its ability to analyze health status in real time during training and predict the probability and vulnerability of health status. Munish et al. [11] proposed a fog-based computing paradigm to generate time perception results, and together with cloud storage proposed a comprehensive cloud computing paradigm to provide novel cloud architecture for efficient medical services in intelligent offices.
2.2 Replica creation in distributed file system
Replica creation is usually divided into two perspectives. One is the static replica creation strategy, and the other one is the dynamic replica creation strategy. Although the dynamic replica creation strategy is more complex than the static, it is the most practical application for the existing system.
In recent years, scholars have studied replica creation from different perspectives. It is shown in Table 1. Zhao et al. [12] proposed an improved dynamic replica creation strategy based on file heat and node load. Combined with node load, the number of replicas is adjusted using average heat and average load. Li et al. [13] proposed an efficient data reliability management mechanism PRCR based on generalized data reliability model. By using the active replica checking approach, PRCR ensures the reliability of large amounts of cloud data with minimal number of replicas, which can also serve as a cost–benefit benchmark for a replica-based approach. Madi et al. [5] proposed a dynamic replication mechanism, called the replication number mechanism (RNM), is proposed to determine the optimal number of replicates to create or delete to minimize overall resource usage (network bandwidth and storage usage). Qu et al. [14] describes a dynamic replica strategy for distributed file systems based on an improved Markov model (DRS). DRS can dynamically increase or decrease the number of replicas as the data changes in heat and cold, and the smooth probability distribution of the system is calculated. Nivetha et al. [15] proposed that data management is an important strategy to be considered in large-scale cloud environment. The creation of replicas may depend on the maximum availability/accessibility of data in the cloud data center. Ouyang et al. [16] proposed an algorithm to dynamically calculate the threshold value, which takes into account such key parameters as job QOS timing constraint, task execution characteristics and optimal system resource utilization rate, so as to identify task switchers. Mansouri et al. [17] proposed the DHR algorithm. The DHR algorithm is a dynamic replica creation method based on analytic hierarchy process (AHP), which needs to set the upper and lower thresholds of dynamic adjustment for data replicas. The similarity between the DHR algorithm and the DRC-AH is that they all avoid unnecessary replication operations and thus improve storage efficiency. The difference is that DHR algorithm needs to set the upper and lower thresholds for the number of replicas, which effectively reduce the access time of files, while the DRC-AH dynamically adjusted the number of replicas using the Markov model and considered the comprehensive effects of the size of the data blocks and the access heat of the data blocks, which reduce the response time of jobs. Aral et al. [18] proposed a distributed data distribution method, which relies on continuous monitoring of data requests from the underlying network edge nodes to dynamically create/replace/delete replicas.
The replica creation literature mentioned above has, respectively, considered the node load, the network bandwidth, the resource consumption, the node heat and other factors, but did not comprehensively consider these factors. Therefore, this paper proposed a dynamic replica creation model based on edge cloud, which takes into account factors such as average job response time, average bandwidth delay and network utilization to improve the efficiency of replica creation. Compared with the previous research work, the method proposed in this paper has the following advantages.
- (1)
Data blocks are adopted as replication granularity. In fact, in most cases, the users only need a part of the file, which can better handle users’ unexpected access.
- (2)
The Gray Markov Chain is used to predict the access frequency of data blocks and modify the access frequency, which makes the predicted value more accurate and more efficient to dynamically adjust the number of replicas.
- (3)
Dynamic and static factors that affect replica creation are considered. The dynamic factor in this paper refers to the access heat of data block, which changes with the change of time and environment. The static factor refers to the size of the block, which does not change with the change of time and environment. This paper considers the interaction of dynamic and static factors.
In the literature [12, 14], the histories of the file access and node load are considered. They can effectively improve the average response time, but without considering the cloud storage costs, resource utilization, etc. In the literature [15], the frequency of data block access is considered. The availability of cloud data center is improved, but the factors such as node load and resource utilization were not considered. In the literature [5, 13, 16, 18], total resource utilization rate and cloud storage cost are considered, response time and resource utilization rate are improved, but the factors such as node load are not considered.
2.3 Replica selection in distributed file system
For distributed storage systems with multi-replica technology, the replica selection refers to selecting the optimal data replica to provide services for the upper layer when users submit data access requests, and the replica selection strategy needs to improve data access performance.
Some researchers have studied the strategy of the replica selection. Rajalakshmi et al. [19] proposed a dynamic data replication method in the cloud environment. Design an algorithm for selecting and placing appropriate optimal replicas to improve data availability in the cloud. Zhang et al. [20] proposed a PGSA (Plant Growth Simulation Algorithm)-based replica selection scheme for cloud storage data, which comprehensively considered network state, storage node load and historical information of replica selection to improve the average access time and replica utilization. Jiang et al. [21] summarized the existing replica selection algorithms. According to the information requirements of the replica selection algorithm, the replica selection algorithm is divided into three categories: the replica selection algorithm with unknown information, the independent replica selection algorithm of the client and the feedback replica selection algorithm. Hamrouni et al. [22] are particularly concerned with how extracted knowledge enhances data replication and replica selection strategies. You can effectively discover relevant knowledge such as file access patterns, file dependencies, user or job access behavior, and predictions of future behavior or network performance. These findings are then used to enhance data replication and replica selection strategies. Navimipour et al. [23] proposed a new replica selection method based on ant colony optimization to improve the average access time. Xue et al. [24] proposed a dynamic intelligent replica selection algorithm (2PhaseEnhencing algorithm), which can reduce the file request time in two stages. The algorithm uses a local file to record each user’s history file request and selects the best site with the highest score based on the user’s QOS and the network context of the second stage, thus reducing the directory search time of the first stage. Yi et al. [25] proposed to apply NetRS framework to solve the basic factors affecting the effectiveness of the replica selection algorithm, and to support the selection of network replicas for key value storage. NetRS supports multiple replica selection algorithms, effectively reducing response latency. Bo et al. [26] proposed the default dynamic replica selection algorithm (DRS). The similarity between the DRS and the DRS-NSC is that they all considered the network bandwidth and access latency to select the best replica node and response to the user. The difference is that the DRS selects a replica of the node that is physically closest to the user’s node for access, which reduced user’s access latency, while the DRS-NSC selects the replica of the node with the strongest service capability for access, which shortens the user’s response time and balances the load on the nodes. Altiparmak et al. [27] proposed the multi-threaded and integrated optimal replica selection algorithm based on maximum traffic for processing heterogeneous storage architecture. The proposed algorithm and the existing algorithm are evaluated using various isomorphic and heterogeneous multi-disk storage architectures.
These related studies consider how to optimize the replica selection strategy from multiple aspects, but all of these strategies not emphasized the response time of user requests, which is easy to cause a large number of user requests to queue. Therefore, this paper proposed a dynamic replica selection model based on the service capability of the node, which reduces the user’s request response time. The purpose of this study is to calculate the response time, save storage resources and improve the efficiency of the whole system’s replica management. Compared with the previous research work, the method proposed in this paper has the following advantages.
- (1)
The service capability of the node is a criterion for the data node to better respond to the user request. The better the service capability of a node, the more responsive the replica of that node will be to user requests.
- (2)
The node workload and the network status are evaluated, effectively avoiding the impact of network congestion.
- (3)
The transmitted file size and the bandwidth between nodes jointly determine the transmission time, which can better cope with changes in the environment.
3 Replica creation based on the access heat and replica selection based on node service capability
In this section, we describe the replica creation model based on the access heat and the replica selection model based on node service capability. Figure 2 shows the replica creation and selection in edge cloud.

Replica creation and selection in edge cloud
Edge cloud platform consists of client, edge cloud node and cloud service center. Among them, the client is the user who uses the edge cloud platform to complete relevant work, the edge cloud node of each network region is responsible for receiving and processing the task request of the user in the network segment, and the cloud service center is responsible for managing and monitoring all edge cloud nodes. In the replica creation strategy, the cloud service center calculates the number of replicas of nodes and dynamically adjusts the number of copies of edge cloud nodes based on the prediction of the frequency of node access by the heat of node access. In the replica selection strategy, the cloud service center reasonably selects the best replica for users based on the load and other information of each edge node.
In cloud computing environment, data sources exist multiple replicas. If the contents of one replica are changed, the resulting data content should be an updated structure when the user accesses data or any replicas of the corresponding data. In order to achieve this kind of demand, all replicas of the data source need to be consistent. If the replica is not for consistency maintenance, the reliability and correctness of the data read by the user will be directly affected.
The dynamically adjusted number of replicas in the replica creation module will be used to place the appropriate number of replicas in the replica placement module and place replicas on reasonable nodes according to the replica placement module [28].
3.1 DRC-AH model
This section focuses on creating a replica model based on the access heat. The decision on the number of replicas in a replica strategy is closely related to the frequency with which files are accessed. The replica creation strategy based on access heat is concerned with hot data, which can ensure that the number of replicas of the current hot data in the next cycle meets the demand, and the satisfaction of most users is taken into consideration. In distributed file systems with large data volume, there are some hot files with high demand for access. These hot files have the following characteristics:
- (1)
Dynamic: Hot files are not specific files, but refer to different files according to the change of file access requirements.
- (2)
Predictability: The change of file access demand has continuity, so the change trend can be known from its historical access demand, and then the future access demand of the file can be predicted to some extent. Corresponding to the hot file, there is a very small demand for access to the file, also has the above two characteristics.
In this paper, data block is used as replication granularity and data block access frequency is used as the evaluation index of data block access heat. By analyzing the access frequency of data blocks within a given time, and then predicting the future access frequency of data blocks according to the historical access frequency, the number of replicas is calculated and the number of replicas is adjusted dynamically to ensure that sudden access to data blocks can be processed.
Figure 3 shows the dynamic replica creation process. The user makes a request to the edge cloud node and the resource manager receives and distributes the request. The application manager is responsible for predicting the access frequency of the file data blocks based on the file history access heat and calculating the number of replicas to be created. The node manager is responsible for monitoring the node state and returning the collected data to the resource manager. Firstly, you can detect whether a block of data is accessed at random. Adjust the initial data sequence to match GM (1, 1). Then, according to the access heat, a Grey Markov chain model is established to accurately predict the access frequency of data blocks. Finally, the number of dynamic replicas can be calculated based on the popularity of the data block to ensure that the number of replicas can be adjusted to handle unexpected access blocks.

Replica creation model based on the access heat
- A.
The access frequency prediction model of data block based on GM (1,1)
GM (1, 1) [29] is the basis of the Grey Markov chain model and is used to predict the access frequency. The process of the access frequency prediction model is shown as follows.
- (1)
The access frequency history data sequence \(x^{(0)} = (x^{0} (1),x^{0} (2),x^{0} (3), \ldots ,x^{0} (n))\) can be obtained. The access frequency of data blocks in the i-th time period can be denoted by \(x^{0} (i)\).
- (2)
In order to improve the accuracy of the data block access frequency prediction, we check if the data block can be accessed randomly by calculating the data block access frequency ratio \(\lambda (k)\), which can be obtained as follows.
$$\lambda (k) = x^{(0)} (k - 1)/x^{(0)} (k),\quad k = 2,3, \ldots ,n$$(1)If the access frequency ratios \(\lambda (k)\) of all data block are within the tolerance coverage \((e^{ - 2/(n + 1)} ,e^{2/(n + 2)} )\), the model GM (1, 1) can be used for Gray prediction with the input data \(x^{0}\). Otherwise, the data access sequence \(x^{0}\) needs to be adapted by taking a constant \(C\) for translation transformation.
- (3)
The Gray differential equation of the data block access frequency can be obtained as \(x^{(0)} (k) + az^{(1)} (k) = b\), where \(z^{(1)} (k) = 0.5x^{(1)} (k) + 0.5x^{(1)} (k - 1),\quad k = 2,3, \ldots ,n\) is the near-average generating sequence of
$$x^{(1)} (k) = \sum\nolimits_{i = 1}^{k} {X^{(0)} (i)} ,\quad k = 1,2, \ldots ,n$$(2)a and b are the traditional Grey parameters.
- (4)
The generalized whitening differential equation of GM (1, 1) is shown as
$$\frac{{{\text{d}}x^{(1)} }}{{{\text{d}}t}} + ax^{(1)} = b ,$$(3)where \(a\) and \(b\) can be obtained by the least squares method.
- (5)
In order to learn the hidden regular pattern in the initial data series of the access frequency of data blocks, we define the Accumulated Generating Operation (AGO) below:
$$x^{(1)} = (x^{1} (1),x^{1} (2),x^{1} (3), \ldots ,x^{1} (n)) ,$$(4)where \(x^{(1)} (k) = \sum x^{(0)} (i)\,(k = 1,2, \ldots ,n)\).
Furthermore,\(z^{(1)} = \left( {z^{(1)} (2),z^{(1)} (3), \ldots,z^{(1)} (n)} \right),\) where \(z^{(1)} (k) = 0.5x^{(1)} (k) + 0.5x^{(1)} (k - 1),\quad k = 2,3, \ldots ,n\). According to \(x^{(1)}\) and \(z^{(1)}\), we can calculate that
$$\hat{u} = (a,b)^{T} = (B^{T} B)^{ - 1} B^{T} Y ,$$(5)where \(Y = (x^{(0)} (2),x^{(0)} (3), \ldots ,x^{(0)} (n))^{T}\), \(B = \left[ {\begin{array}{*{20}l} { - z^{(1)} (2)} \hfill & { - z^{(1)} (3){\kern 1pt} } \hfill & \ldots \hfill & { - z^{(1)} (n)} \hfill \\ 1 \hfill & 1 \hfill & \ldots \hfill & 1 \hfill \\ \end{array} } \right]\)
We employ the method of model construction and solution in [30]. Therefore, we can calculate the prediction model equation of GM (1, 1) as
where \(\hat{x}^{(0)} (k + 1)\) denotes the preliminary forecast values of access frequency of data blocks during interval \(K + 1\).
- B.
The access frequency correction model of data block based on Grey Markov Chain
The Grey Markov chain model corrects the preliminary prediction value of GM (1, 1) by calculating the residual value of the access frequency prediction, and constructing the transition probability matrix of the access frequency state interval. The process of access frequency correction model is shown as follows.
- (1)
The residual value can be denoted by \(\delta (k) = x^{(0)} (k) - \hat{x}^{(0)} (k)\).\(\varepsilon (k) = (x^{(0)} (k) - \hat{x}^{(0)} (k))/x^{(0)} (k)\) denotes the residual relative value. \(\varepsilon (k) < 0.2\) indicates that the accuracy of the access frequency prediction meets the basic requirements.
- (2)
The residual state interval can be divided into 5 intervals represented by \(E = (E_{1} ,E_{2} ,E_{3} ,E_{4} ,E_{5} )\). The ranges of \(\varepsilon (k)\) in \(E_{1} ,E_{2} ,E_{3} ,E_{4} ,E_{5}\) are \(( -\,0.2, -\,1.0],( -\,0.2, -\,0.1],( -\,0.1,0.1],(0.1,0.2],(0.2,1.0]\), respectively.
- (3)
The k-step state transition probability indicates the possibility that the state of the residual value is transferred to another state through the k-step during the change process of the data block. The residual value state transition probability matrix for data block prediction can be denoted by \(P = (P_{ij} )_{5 \times 5}\), where \(P_{ij} = P(E_{i} \mathop{\longrightarrow}\limits{k}E_{j} ) = n_{ij}^{(k)} /N_{i}\, (i,j = 1,2, \ldots ,5)\). \(n_{ij}^{(k)}\) and \(N_{i}\) denote the number of times and transitions, respectively.
- (4)
The final value of access frequency can be expressed as follows.
$$\hat{x}^{(0)} (k + 1) = \hat{x}^{(0)} (k)/(1 - \hat{\varepsilon }(k))$$(7) - (C)
The dynamic replicas number calculation model based on data block popularity
In the replica creation process, we consider the dynamic and static impact factors to calculate the number of dynamic replicas for data blocks. The dynamic factor that affects the dynamic replica creation is the access popularity of data blocks, and the static factor is the data block size.
The predicted popularity of data block \(i\) in the next time period \(j\) can be denoted by \(h_{ij} = {{\alpha \times \hat{x}^{(0)} (j)}/{ {{{\alpha \times \hat{x}^{(0)} (j)} {(S_{i} + 1)}}} \kern-0pt} {(S_{i} + 1)}}\), where \(\alpha\) is a constant which is used to unify the popularity of data block. \(S_{i}\) indicates the impact of data block \(i\) on the access popularity. If \(S_{i} \% S_{0} = 0\), there is \(S_{i} = \left\lceil {F_{k} /S_{0} } \right\rceil\). Otherwise, there is \(S_{i} = \left\lceil {F_{k} /S_{0} } \right\rceil + 1\). \(F_{k}\) denotes the size of file k, and \(S_{0}\) denotes the fragment size of the HDFS system. Besides, we use the size of data blocks as the static impact factor which can be expressed by \(q_{i} = \beta /S_{i}\), where \(\beta\) is a constant which is used to unify the static impact factor. Therefore, considering the interaction of dynamic and static influence factors, the number of dynamic replicas \(D_{ij}\) can be calculated as follows.
3.2 DRS-NSC model
This section discusses dynamic replication selection of data blocks. This paper proposed a replica selection model based on node service capability, which is determined by transmission time and node load. This strategy is able to select the most appropriate replica from all replica nodes to return to the user.
Figure 4 shows that when the user makes an access request to the data file, it first queries the information of the target data file through the sub-domain meta-data server of the sub-network where the user is located. If there is a replica of the target data file in the user’s sub-network, the replica is accessed directly. If there is no replica of the target data file in the user's sub-net, center cloud server will be queried. The central cloud data server calls the replica selection module, first finds all nodes containing replicas of the target data files, calculates the service capability of these nodes, sorts the nodes according to the service capability, and finally returns the target node, so as to respond to the user’s request. However, when a large number of users are accessing concurrently, the central cloud server does not provide a good choice of replicas. Instead, it takes a do-it-yourself approach and randomly selects replicas to respond. This is far from meeting the requirements of user access response time, especially in concurrent access, it is necessary to select the node with strong service capability. Considering the service capability of nodes, the probability of selecting low-load nodes can be increased, the waiting time of request queuing can be reduced, and the cluster workload can be balanced. The effect of network congestion is avoided by considering node load and network state evaluation.

Replica selection model based on node service capability
In the process of replica selection, the replica node with the strongest service capability is selected according to the service capability of the replica node to respond to the user’s request. There are two factors that affect the service capability of the replica node: the load condition of the replica node and the transmission time between the sub-network where the replica node is located and the sub-network where the user is located.
During the replica selection process based on service capability, the following conventions are made for the convenience of calculation:
- (1)
\(SC_{i}\) is used to represent the service capability of the \(i\) replica node
- (2)
\(LOAD_{i}\) is used to represent the load condition of the \(i\) replica node
- (3)
\(TT_{ij}\) is used to represent the time required to transfer data files between sub-network \(i\) and sub-network \(j\).The value of \(SC\) is inversely proportional to the replica node load \(LOAD\), and inversely proportional to the transmission time \(TT\) between the sub-networks.\(SC_{i}\) can be expressed by formula (9):
$$SC_{i} = \frac{1}{{LOAD_{i} \times TT_{ij} }}$$(9)
Firstly, load \(LOAD\) on the replica node is discussed. There are many factors affecting the load of replica nodes. For the convenience of calculation, this paper mainly considers two factors: the number of cells in the replica node and the number of user requests currently processed by the replica node. Make the following provisions:
- (1)
\(Cnum{}_{i}\) is used to represent the number of cells in the \(i\) replica node;
- (2)
\(AccessNum_{i}\) is used to represent the number of user requests that the \(i\) replica node is currently processing
- (3)
Based on the above conventions, the load condition of the \(i\) replica node \(LOAD_{i} {\kern 1pt}\) can be calculated by formula (10):
$$LOAD_{i} {\kern 1pt} = \frac{{Cnum{}_{i}}}{{AccessNum_{i} }}$$(10)
According to the principle of nearby access, the closer the distance between the target node and the user node, the lower the response time of the user request; on the contrary, the farther distance between the target node and the user node, the higher the response time of the user request. Therefore, replica selection also takes into account the transmission time between the sub-network in which the replica is located and the sub-network in which the user is located. The transmission time \(TT_{ij}\) between sub-network \(i\) and sub-network \(j\) can be expressed by formula (11):
According to the principle of nearby access, the closer the distance between the target node and the user node, the lower the response time of the user request. \(S_{\text{file}}\) represents the size of the data file, \(NetBW_{ij}\) represents the network bandwidth between the sub-network \(i\) and the sub-network \(j\), formula (10) and formula (11) are substituted into formula (12), formula (12) can be obtained:
During the replica selection process based on service capability, the value of service capability SC of each replica node is calculated according to formula (12) and the replica node with the largest value of SC is selected as the target replica node to respond to the user’s request.
4 Algorithms of creating and placing replica dynamically
4.1 DRC-AH algorithm
In this section, three algorithms are proposed to realize dynamic replica creation based on access heat. One is the block access frequency prediction algorithm based on GM (1, 1); the other is the block access frequency correction algorithm based on Markov; the third is the dynamic replica creation algorithm based on Gray Markov chain model. Firstly, according to the historical access frequency of the data block, the access frequency of the data block in the next period is predicted through the calculation of Algorithm 1. Secondly, the probability matrix of the relative error of the initial access frequency is constructed through Algorithm 2, and the initial value is corrected. Finally, the dynamic replica number is calculated by Algorithm 3, and the dynamic replica number is adjusted.
(1) Algorithm 1 depicts the pseudo-code for the prediction algorithm of access frequency of data blocks based on GM (1, 1). Firstly, check and adjust the initial data series to GM(1,1) model (Algorithm 1 Line 4); Secondly, perform an accumulation operation on the data series that satisfies the premise of the GM(1,1) prediction model (Algorithm 1 Line 6); Finally, establish a differential equation of the preliminary forecast values of access frequency of data blocks and solve it (Algorithm 1 Line 7–8).

The overall complexity of the proposed prediction algorithm of access frequency of data blocks based on GM (1, 1) in this paper is \(O(n*T)\).
(2) Algorithm 2 depicts the pseudo-code for the correction algorithm of access frequency of data blocks based on Markov chain model. Firstly, calculate the relative error between the actual value and the preliminary forecast value according to ormula (5) (Algorithm 2 Line 3). Secondly, classify model accuracy level according to Table 1 (Algorithm 2 Line 4). Third, obtain kth-transition probability matrix P of relative error of the preliminary forecast values of access frequency according to formula (6) (Algorithm 2 Line 5). At last, correct the preliminary forecast values of access frequency according to formula (7) (Algorithm 2 Line 6).

The time complexity of the correction algorithm of access frequency of data blocks based on Grey Markov chain model is \(O(n*T^{2} )\).
(3) Algorithm 3 describes the pseudo-code of the dynamic replication creation algorithm based on access heat. The algorithm is divided into four steps. First, examine the initial data sequence and adjust it to the GM (1, 1) model. The second step (line 4–5 of Algorithm 3) is to predict the access frequency of the data block in the next interval according to GM (1, 1) (line 6 of Algorithm 3). Refer to Algorithm 1 for the specific algorithm. The third step is to modify the initial prediction of access frequency according to the Markov chain model (lines 7–10 of Algorithm 3).The specific algorithm refers to Algorithm 2. The fourth step is to calculate the number of dynamic copies. Finally (lines 11–12 of Algorithm 1), copy or delete the replica according to the transformation table (lines 13–19 of Algorithm 1).

Therefore, the overall complexity of the dynamic replica creation algorithm is \(O(n*T^{2} )\). DRC-AH algorithm flow chart is shown in Fig. 5.

The flowchart of DRC-AH algorithm
The example diagram of this algorithm is shown in Fig. 6. The HDFS information is counted, and the data block access frequency is preliminarily predicted according to the historical access frequency. The Markov chain correction mainly constructs the Kth-transition probability matrix \((P_{ij} )_{5 \times 5}\) of relative error of the preliminary forecast values of access frequency and corrects the preliminary forecast values. The dynamic replica calculation block calculates the dynamic replica number and updates the replica number.

The instance diagram of DRC-AH algorithm
4.2 DRS-NSC algorithm
Based on the above idea of replica selection, the service capability of a node is used to evaluate whether a node can be selected as an access node, and a specific algorithm description is given for the replica selection strategy:
- (1)
The client user sends a request to the name node for access to the file;
- (2)
The data node where the name node queries the replica of the file;
- (3)
Calculate the service capability \(SC\) of the data node according to the formula, and select the node with the strongest service capability as the target node \(dest\_replica\_node\)
- (4)
Target node \(dest\_replica\_node\) transmits data to the client.


The pseudo-code of the replica selection algorithm based on node service capability is shown in the algorithm. Define a function to calculate the service capabilities of all replica nodes (lines 4 through 11 of Algorithm 4). Sort the replica nodes by service capability (Algorithm 4, lines 13 through 21). The algorithm returns the best replica node based on service capability. The time complexity of this algorithm is \(O\left( {{\text{n}}^{2} } \right)\), and the space complexity is \(O\left( {\text{n}} \right)\). DRS-NSC flow chart is shown in Fig. 7.

The flowchart of DRS-NSC
5 Evaluation
In this paper, the experiment is divided into three parts. The first part is to verify the experiment of replica creation algorithm, verify the prediction precision of the file access frequency and verify the dynamic adjustment strategy of replicas of data blocks. The second part is the dynamic replication algorithm based on access to heat (DRC-AH) with the default static replication algorithm in HDFS (SRC) and DHR to create comparative experiment of the algorithm. Experiments show that DRC-AH is suitable for high-volatility data and has good response time performance when facing a large number of users. The third part is the comparison experiment between the node-based service capability algorithm (DRS-NSC) and the default dynamic replication algorithm of HDFS (DRS). It can be seen that the DRS-NSC has significant advantages in job execution time, system availability, load balancing, resource utilization and other aspects.
5.1 Experimental environment
The edge cloud and the center cloud are connected via a VPN. The experimental environment configuration parameters are listed in the table below. Tables 2 and 3, respectively, show in the experimental environment hardware configuration parameters of the edge cloud and the central cloud.
The HDFS log file system provides all the log information (JobHistory), including the start time of the task, execution time, access block ID, and various Counter information, as shown in Fig. 8.

Log data type graph
The log file in HDFS provides all log information including the start and execution time of the task, the accessed block ID, and various counter information. At the same time, it also provides a customized interface for the log which facilitates the acquisition of experimental data. In this paper, we get all log information about data block operations with a custom TestGetBlock file.
The performance metrics used in this paper are the average response time [29] in the verification experiment of DRC-AH, the job response time in the dynamic replica creation comparison experiment. The average network delay, the average access time, the location time, the job completion time, the replica load standard deviation, the average response time, effective network saved, the replica read response time, the rate of storage space utilization, the rate of memory utilization and the rate of CPU utilization in the dynamic replica selection comparison experiment. Here, the replica load standard deviation is denoted as follow:
where the total number of data nodes is \(n\), \(\overline{\text{load}}\) is the average number of times each data node is accessed, \({\text{load}}_{i}\) is the number of times the data node \(i\) is accessed.
The relevant benchmark algorithms in this experiment are as follows:
For the purpose of verifying the effectiveness of the DRC-AH and the DRS-NSC, the experiments are conducted in two steps. Firstly, in order to evaluate the DRC-AH, the proposed algorithm is compared with two benchmark algorithms which are the SRC and the DHR algorithm [31]. The DHR algorithm sets the threshold value for the data replica by set the weight of specific parameters for the AHP. The DHR algorithm and the DRC-AH all considered access latency and storage resource utilization, which improved storage efficiency and reduce the job response time. Secondly, in order to evaluate the DRS-NSC, the DRS-NSC is compared with the DRS [26]. The DRS takes minimizing the global network bandwidth consumption and access delay as the target to selects a replica of the node that is physically closest to the user node for access. The DRS and the DRS-NSC all considered the bandwidth and access delay, which reduce user’s response time and improve job execution time.
5.2 Experiment result and analysis
5.2.1 Verification of DRC-GM
-
(1)
Analysis of the impact of file access frequency on system performance
The replica creation of data blocks directly affects the job response time. In order to verify the impact of access frequency on the job response time, experiment uses JMeter [17] to simulate the user access situation of the application and count the job response time of files 1–5 with different sizes (32 MB, 64 MB, 128 MB, 256 MB, 312 MB). The repeated experiment for each file is 30 times, and the average response time (MJT) of the job is calculated. The statistical result is shown in Fig. 1. From Fig. 8, the larger file size, the longer the average response time. As the simulated access frequency of files increases, the average response time also rises. When access frequency is higher than a specific value (e.g., file 4, file 5 is 70 times per minute), the average response time suddenly rises so that user access request is not responded. Besides, when access frequency of file 5 and file 4 reaches 80, the average response time is increased by 120% and 112.5%, respectively. Analysis shows that the above phenomenon is mainly caused by users preempting data block and network bandwidth resources.
- (2)
Verification of the access frequency prediction accuracy
In order to fully demonstrate the accuracy of prediction results, the actual data coming from the Baidu Statistical Traffic Research Institute [32] is used to verify the accuracy of the prediction algorithm based on the Grey Markov chain model (G-Markov). The statistical time is from September 1, 2017 to November 30, 2017. The access entry selection is shown in Fig. 9.

The impact of file access fluctuations on average response time
In the experiment, we perform 30 predictions for each set of data and obtain the average values for 30 times. As for three types of traffic entry methods including direct access, other links and search engine, the prediction results of the G-Markov algorithm and the GM (1, 1) algorithm are shown in Tables 4, 5 and 6, respectively. The Mean Absolute Error and the Mean Absolute Error Percentage of the Grey Markov chain prediction are smaller than that of GM (1, 1). As for the Grey Markov chain prediction, the residual and relative residual fluctuation ranges are around 0.5% and 0.01%, respectively. The results show that the average absolute error value of the Gray Markov chain is 0.093 lower than that of GM (1, 1), and the average relative error value of the Gray Markov chain is 0.897 lower than that of GM (1, 1). Therefore, the prediction accuracy based on the Grey Markov chain prediction model is better than the traditional GM (1, 1) prediction mode.
- (3)
Verification of the dynamic adjustment strategy of replicas of data blocks
In order to verify that the system can dynamically adjust the number of replicas according to the access frequency of data blocks, we first configure the environment as follows. The size of slice is 64 M. The initial replica number of data blocks is 1. The replicas number created is calculated every 1 h and recorded. There are 9 intervals and the simulated access frequency (e.g., times per minute) of data blocks is constantly changing in each interval, which is shown in Table 7.
The JMeter was used to simulate the changes of access frequency according to Table 7, and observe the replica creation of a single data block over continuous intervals. The dynamic change of replicas is shown in Fig. 11. According to Fig. 10, the proposed replica creation algorithm based on Gray Markov chain model can respond to the situation of burst-access data blocks by creating multiple replicas and dynamically adjust the number of replicas according to the access frequency of data blocks by the SaaS application user.

The proportion of page-views brought by different access entries

The dynamic change of replicas
5.2.2 Performance comparison between DRC-AH and the existing replica creation algorithms
The file access frequency will affect the efficiency of the proposed dynamic replica creation algorithm. In order to evaluate the effect of the file access frequency on the average response time and the increase/decrease ratio with different data block sizes, we set three different data block sizes with 64 MB, 128 MB and 320 MB, respectively. The file access frequency ranges from 0 to 90 times per minute.
As shown in Fig. 12, when the file access frequency is between 10 and 60 times per minute, the average response time of the DRC-AH, the SRC and DHR algorithm is basically the same. When the file access frequency is 70 times per minute, the job response time shows a significant turning point. The reason for the above phenomenon is that as the file access frequency increases, the replica creation phase transitions to the replica placement phase, and the cluster resources including CPU resources and IO resources are occupied. When the replica creation phase is not completed, the proposed algorithm has little effect on the performance of the entire cluster system compared to the SRC and DHR algorithm. After the data block replica creation phase is completed, the newly added data block replicas and the original data provide the data storage service to the user, which obviously improves the overall system performance, especially in the case of multi-user access. Therefore, the performance of the proposed algorithm is better than the SRC and DHR algorithm in the average response time.

The effect of the file access frequency on the average response time
5.2.3 Performance comparison between DRS-NSC and the existing replica selection algorithms
In the experiment in this section, the size of replica files was evenly distributed within the range of 300 MB ~ 1 GB, and the number of replica files varied within the range of [10, 80].
When the number of replicas varies from 10 to 50, the network latency comparison is shown in Fig. 13a. The network latency of the DRS-NSC is smaller than the DRS. When the number of replicas is small, there is little difference in network latency between the two strategies. However, with the increasing number of replicas, the advantages of the DRS-NSC are reflected. The average access time comparison is shown in Fig. 13b. It is obvious from the figure that the average access time of the DRS-NSC is smaller than the DRS. Due to the small number of replicas in the cloud storage at the beginning, the average access time of the two algorithms has little difference. However, as the number of replicas in cloud storage increases, the DRS-NSC gradually shows its advantages. The experimental results also confirm the theoretical analysis in this paper that the DRS-NSC has the best performance, because it effectively achieves the load balance of the nodes where the replicas are located, thus reducing the average access time of the replicas.

The effect of replica number on average network latency and average access time
When the number of replicas varies from 10 to 50, the replica location time is shown in Fig. 14a. The job completion time is shown in Fig. 14b. In a relatively stable period of time, the number and location of data replicas are stable, and it is an optimization problem to select the optimal replica to meet the needs of user jobs in a relatively stable period of time. While access to a file, the DRS-NSC to locate replica of the file time than the DRS positioning time is long, However, since the DRS-NSC is based on the node load balancing and the minimum transmission time, it greatly reduces the running time and improves the overall performance of the system.

The effect of replica number on replica location time and job completion time
When the number of jobs between 10 and 100. The average job execution time is shown in Fig. 15a. Compared to the DRS, the DRS-NSC does reduce the average job execution time, but the effect is not obvious when the number of jobs is small. With the increase in the number of homework, this advantage began to gradually increase, and the more the number of homework, the more obvious. As shown in Fig. 15b, it can be seen that the load standard deviation mean of the DRS is larger than that of the DRS-NSC, and the volatility is very high as the number of jobs increases. The mean standard deviation of the load of the DRS-NSC is small and the fluctuation is small. It can be seen that the DRS-NSC has a significant advantage in replica balancing. As shown in Fig. 15c, the effective network bandwidth utilization of the DRS-NSC is significantly better than the DRS. Based on the DRS-NSC, the overall trend is that the effective bandwidth utilization decreases with the increase in the number of operations, but the decrease is not obvious. But the DRS is on an overall downward trend. It shows that the DRS-NSC can effectively control the use of network resources and select the replica with high service capacity of nodes for use as far as possible, thus avoiding severe consumption of network bandwidth resources. While the DRS is far lower than the DRS-NSC when the number of jobs increases significantly, the DRS-NSC has better applicability. Because of this, the access efficiency of end users can be improved, and the overall performance of the system meets the expectations.

The impact of changes in the number of jobs
The operating time of the system varies between 0 and 4000 s. The rate of network bandwidth utilization changes is shown in Fig. 16a. The rate of storage resource utilization is shown in Fig. 16b. The rate of memory utilization is shown in Fig. 16c. The rate of CPU utilization is shown in Fig. 16d.

The impact of running time on bandwidth, memory, storage resources, and CPU utilization
- (1)
As shown in Fig. 16a, with the increase in running time the concurrent visits of users gradually increase, resulting in the increase in the data transmitted on the network, which directly leads to an upward trend of bandwidth utilization. When the concurrent visits fluctuate, the bandwidth utilization also shows a trend of first rising and then falling. Compared to the DRS, the DRS-NSC achieved lower bandwidth utilization, or better network performance, throughout the process. Thus it can be seen that the DRS-NSC has better performance in terms of transmission speed.
- (2)
As shown in Fig. 16b, with the increase in concurrent visits by users, the frequency of access to replicas increases, this directly leads to the increase in resource utilization. As the number of tasks decreases, storage resource utilization tends to decrease gradually. Among them, the DRS-NSC can achieve the highest resource utilization in the whole execution phase of the current batch of tasks. The storage resource utilization of the DRS is much lower than that of the DRS-NSC. Especially when the number of tasks decreases, the advantage of DRS-NSC in storage resource utilization is more obvious.
- (3)
As shown in Fig. 16c, with the gradual increase in the number of tasks, the memory utilization under the DRS-NSC first shows a trend of gradual increase, then tends to be stable for a period of time, and finally with the decrease in the number of tasks, the memory utilization shows a trend of decline, until all tasks are completed. The memory utilization of the DRS is much lower than that of the DRS-NSC.
- (4)
As shown in Fig. 16d, with the increase in user visits and the increase in task number, the CPU utilization under the DRS-NSC firstly shows a trend of gradual increase, and then fluctuates by 10% within a certain period of time. Finally, as the task is gradually processed and completed, the number of tasks decreases and the CPU utilization shows an obvious trend of decline. The CPU utilization of the DRS is lower than that of the DRS-NSC. The DRS-NSC can achieve low CPU utilization, memory utilization, storage resource utilization and relatively moderate bandwidth utilization in the process of processing tasks. It can be seen that this algorithm balances the load condition of the system to a certain extent and obtains a more balanced overall performance of the system.
Files vary from 300 M to 1G. The change in replica access time is shown in Fig. 17. In this experiment, the number of replicas of each file is set to be 15. It is clear from Fig. 17 that the DRS-NSC takes less time to read a file of the same size than the DRS. The DRS-NSC improves the speed at which clients can read data, thus reducing the time it takes clients to read data from a distributed file system and optimizing system performance. As the number of experimental tests changes. As can be seen from Fig. 18, in the first few reads, the response time of the DRS was slightly shorter than that of the DRS-NSC, but the response time of the DRS was longer and longer as the number of requests increased, while the latter was basically stable. Therefore, it can be concluded that the algorithm based on node service capability has advantages over the DRS in terms of system availability.

The effect of file size on replica access time

The influence of the number of experimental tests on the response time of replica reading
5.3 Experiment summary
Firstly, in the verification experiment of the creation algorithm based on access heat, the prediction accuracy of file access frequency is verified by combining with the Gray Markov model, and the experiment proves that the algorithm can dynamically adjust the number of replicas. DRC-AH is compared with the SRC and DHR algorithm. Experiments show that DRC-AH is suitable for high-volatility data and has good job response time performance when facing a large number of users.
Secondly, in the verification experiment base the node-based service capability, it can be seen that DRS-NSC has significant advantages in job execution time, system availability, load balance, resource utilization and other aspects. For different user needs, each replica algorithm dynamically selects the required replicas according to the corresponding indicators, so as to make better use of the resources of the cloud platform. While ensuring data reliability, each scheme has obvious advantages in its own optimization objectives.
6 Conclusion and future work
Aiming at the problems existing in the management of data block replica in traditional cloud computing storage applications, a dynamic replica creation and selection algorithm based on edge cloud structure is proposed. Firstly, based on block access heat, a dynamic replica creation based on access heat model is proposed by using Markov chain. Secondly, according to the node load and the transmission time between the node and the user, a dynamic replica selection algorithm based on the node service capability is proposed. At last, DRC-AH and DRS-NSC are evaluated through lots of experiments. Experimental results show that DRC-AH has certain advantages in predicting data block access frequency and average response time.
In the future, we will test and verify the proposed dynamic replica creation and selection algorithm in more datasets. At the same time, we will consider the impact of other factors on replica creation and replica selection, such as user permissions, which will be given priority to users with high permissions. In addition, other issues of replica management will be considered.
References
Yang C, Huang Q, Li Z, Kai L, Fei H (2017) Big data and cloud computing: innovation opportunities and challenges. Int J Digit Earth 10(1):13–41
Xu C, Lei J, Li W, Fu X (2016) Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE ACM Trans Netw 24(5):2795–2808
Jonathan A, Ryden M, Oh K, Chandra A, Weissman J (2017) Nebula: distributed edge cloud for data intensive computing. IEEE Trans. Parallel Distrib Syst 28(11):3229–3242
Mostafa N, Ridhawi I, Hamza A (2015) An intelligent dynamic replica selection model within grid systems. In: GCC Conference & Exhibition, Muscat, Oman. IEEE Computer Society, USA, pp 1–6
Madi MK, Tahir HM, Yusof Y, Hassan S (2015) A novel dynamic replica creation mechanism for data grids. In: Game Physics & Mechanics International Conference, Langkawi, Malaysia. IEEE Computer Society, USA, pp 1–5
Satyanarayanan M (2017) The Emergence of Edge Computing. Computer 50(1):30–39
Shi W, Dustdar S (2016) The promise of edge computing. Computer 49(5):78–81
Pan J, Mcelhannon J (2017) Future edge cloud and edge computing for internet of things applications. IEEE Intel Things 5(1):439–449
Bhatia M, Sood SK (2018) Internet of things based activity surveillance of defence personnel. J Ambient Intel Hum Comput 9(6):2061–2076
Bhatia M, Sood SK (2017) A comprehensive health assessment framework to facilitate iot-assisted smart workouts: a predictive healthcare perspective. Comput Ind 92–93:50–66
Bhatia M, Sood SK (2018) Exploring temporal analytics in fog-cloud architecture for smart office healthcare. In: Mobile Networks and Applications, pp 1–19
Zhao YH, Li CL, Li LY, Zhang P (2017) Dynamic replica creation algorithm based on file heat and node load in hybrid cloud. In: 2017 19th International Conference on Advanced Communication Technology (ICACT), Pyongyang, South Korea. IEEE Computer Society, USA, pp 213–220
Li W, Yang Y, Yuan D (2016) Ensuring cloud data reliability with minimum replication by proactive replica checking. IEEE Trans Comput 65(5):1494–1506
Qu K, Meng L, Yang Y (2016) A dynamic replica algorithm based on Markov model for hadoop distributed file system (HDFS).In: International Conference on Cloud Computing & Intelligence System, Beijing, China. IEEE, New York, pp 337–342
Nivetha NK, Vijayakumar D (2016) Modeling fuzzy based replication algorithm to improve data availability in cloud datacenter. In: International Conference on Computing Technologies & Intelligent Data Engineering, Kovilpatti, India. IEEE Computer Society, USA, pp 225–230
Ouyang X, Garraghan P, Mckee D, Townend P, Xu J (2016) Straggler detection in parallel computing systems through dynamic threshold calculation. In: 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland. IEEE, New York, pp 213–220
Apache JMeter (2018) http://jmeter.apache.org/. Accessed 18 Oct 2018
Aral A, Ovatman T (2018) A decentralized replica placement algorithm for edge computing. IEEE Trans Netw Serv Manag 15(2):516–529
Rajalakshmi A, Vijayakumar D, Srinivasagan KG (2014) An improved dynamic data replica selection and placement in cloud. In: International Conference on Recent Trends in Information Technology, Chennai, India. IEEE, New York, USA
Zhang B, Wang XW, Huang M (2014) A PGSA based data replica selection scheme for accessing cloud storage system. Advanced Computer Architecture. Springer, Berlin, pp 140–151
Jiang W, Xie H, Zhou X, Fang L, Wang J (2017) Performance analysis and improvement of replica selection algorithms for key-value stores. In: 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, CA, USA. IEEE Computer Society, USA, pp 786–789
Hamrouni T, Slimani S, Charrada FB (2016) A survey of dynamic replication and replica selection strategies based on data mining techniques in data grids. Eng Appl Artif Intel 48:140–158
Navimipour NJ, Milani BA (2016) Replica selection in the cloud environments using an ant colony algorithm. In: Third International Conference on Digital Information Processing, Moscow, Russia. IEEE, New York, pp 105–110
Xue M, Shen J, Guo X (2016) Two phase enhancing replica selection in cloud storage system. In: Control Conference, Chengdu, China. IEEE, New York, pp 5255–5260
Su Y, Feng D, Hua Y, Shi Z, Zhu T (2018) NetRS: cutting response latency in distributed key-value stores with in-network replica selection. In: IEEE International Conference on Distributed Computing Systems, Vienna, Austria. IEEE Computer Society, USA, pp 143–153
Chunlin Li, Tang Jianhang, Hengliang Tang, Luo Youlong (2019) Collaborative cache allocation and task scheduling for data-intensive applications in edge computing. Future Gener Comput Syst 95:249–264
Altiparmak N, Tosun A (2016) Multithreaded maximum flow based optimal replica selection algorithm for heterogeneous storage architectures. IEEE Trans Comput 65(5):1543–1557
Zeng L, Xu S, Wang Y, Kent KB, Bremner D, Xu C (2017) Toward cost-effective replica placements in cloud storage systems with QoS-awareness. Softw Pract Exp 47(6):813–829
Nguyen PH, Sheu TW, Nguyen PT (2014) Using the combination of gm(1,1) and taylor approximation method to predict the academic achievement of student. SOP Trans Appl Math 1(2):55–69
Yanling Shao, Chunlin Li, Hengliang Tang (2019) A data replica placement algorithm for IoT workflows in collaborative edge and cloud environments. Comput Netw 148:46–59
Mansouri N, Dastghaibyfard GH (2012) A dynamic replica management algorithm in data grid. J Netw Comput Appl 35(4):1297–1303
Wu X, Guan H (2016) Data set replica placement algorithm based on fuzzy evaluation in the cloud. J Intell Fuzzy Syst 31(6):2859–2868
Acknowledgements
The work was supported by the National Natural Science Foundation (NSF) under Grants (Nos. 61672397, 61873341), Application Foundation Frontier Project of Wuhan (No. 2018010401011290), Fund Project of Shaanxi Key Laboratory of Land Consolidation (No. 2019-ZD01). Any opinions, findings, and conclusions are those of the authors and do not necessarily reflect the views of the above agencies.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, C., Tang, J. & Luo, Y. Scalable replica selection based on node service capability for improving data access performance in edge computing environment. J Supercomput 75, 7209–7243 (2019). https://doi.org/10.1007/s11227-019-02930-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02930-6