
Abstract
Information fusion is a very important technology which can use multisensor network data to get a better performance than single one; therefore, it is widely used in the filed of target recognition, target tracking, automatic control, decision making and so on. However, because of noise and interference, sometimes the sensors may obtain erroneous, inaccurate or heterogeneous data, which will produce the conflict information among different sensors and get the wrong result after information fusion. In this paper, based on the Dempster–Shafer (D–S) theory, we introduce how to set up the model of multisensor network information fusion. And then, we discuss the problem of conflict information fusion in the framework of evidence and several improved methods are introduced. Finally, based on Mahalanobis distance, an improved solution method is presented. The numerical simulation results prove that this new improved method can get the same result as traditional methods, beyond which it can make a reasonable decision with high conflict information. Therefore, this new improved method can be used in the filed of high noise and interference.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
As it is well known, by combining multiple homogeneous or heterogeneous sensor information, multisensor information fusion techniques can get better performance than single sensor [1]. The aim of multisensor information fusion is to improve the quality of decisions by increasing the amount of global information while decreasing its uncertainty, using the information redundancy and complementariness between information sources. Therefore, the technology of multisensor information fusion [2] is widely used in monitoring of manufacturing processes, target recognition and tracking, remote sensing, intelligent transportation system, condition-based maintenance of complex machinery, medical diagnosis, and so on.
As one of the most important techniques in multisensor information fusion, the Dempster–Shafer theory (D–S theory) [3] is a generalization of the Bayesian theory of probability. A significant advantage of the D–S theory over the traditional probability is that it allows for the allocation of a probability mass to sets or intervals and can handle both stochastic and subjective uncertainty. In addition, it has a better fusion result via simple reasoning process without knowing the prior probability. Therefore, the D–S theory is a powerful and flexible mathematical tool for handling uncertain, imprecise, and incomplete information.
In D–S theory, trust updating can be achieved by fusion rule, which is one of core cornerstones of the theory and very easy for computer implementation. However, the normalization procedure in the fusion rule may involve counter-intuitive behaviors or absurdities when evidences conflict. For example, there are three sensors to detect the real-time temperature of a running embedded system, the temperature of first sensor is 66 F, the second one is 82 F, and the third one is 71 F. Supposing, when the temperature of sensor is higher than 75 F, the system is in a bad working condition. Now, according to the detection result, what decision should we make? Is this system in the bad situation? The answer is not sure, because when we use the detection result separately, some important information of the system state may be lose; therefore, different decision can be gotten.
Since the fuse paradox was presented by Zadeh [4], the fuse of conflicted evidences has become one of the important research fields for the D–S theory. Many researchers have presented different methods for conflict assignment and provided corresponding rules for evidence fuse. Dempster firstly combines different evidences by orthogonal sum, and uses normalized factor to adjust fusion results, which can avoid assigning non-zero probability to the empty set. Yager [5] assigns the conflicted evidence to the unknown domain. Smets [6] introduces the TBM (transferable belief model) to the fusion of evidence, which makes the results from the non-exhaustively of the frame of discernment. Dubois and Prade [7] suggest assigning the conflicted evidence to the union of focal elements. Murphy [8] averaged the evidences to produce a new evidence model combined afterwards by Dempster rule. However, it is merely a simple averaging method which does not involve the importance of different evidences, so its fusion results are not good. Sun [9] supposed that even if it exists the conflict between evidences, the evidences are also partly available. Therefore, by calculating the mean value of the conflict between every two pieces of evidences, they defined the valid coefficients of evidences, and then allocated total evidential conflict K to propositions according to a certain proportion. Li [10] indicated that Sun’s method has some physical meanings and subjective factors of their formulas, but they are not obvious. Therefore, they presented a model to allocate evidential conflict in accordance with the weighted averaging support of each proposition. This method still supposes all the evidences equally important, but the precision and the convergence rate of its fusion results have made much greater improvements. Liang [11] further improved Li’s method and got a better result using the reliability of evidences through which original evidence models can be corrected. But, they still adopted the allocation strategy as before which cannot make full use of such information as reliability. Deng [12] introduced distance to measure evidence weights by which each original evidence is corrected to be with equal importance, so did Liu [13]. So far, it is one of the most effective and simple methods, characterized by clear definition and operation, moderate computation, and fast convergence. But, like Dempster rule, it has some instability at times, such as much smaller mass value of non-targets, which might also cause an abnormal fusion result. In addition, there are many other improved methods, because of the space limitation, we do not discuss all of them in this paper.
In this paper, we systematically study the recent achievements concerning fusion rules of D–S theory, and present a new fusion method based on Mahalanobis distance. The numerical simulation results prove that this new improved method can get the same result as traditional methods, beyond which it can make a reasonable decision with high conflict information. Therefore, this new improved method can be used in the filed of high noise and interference.
This paper is organized as follows. In Sect. 1, we introduce the background of this paper, and discuss the recent achievements concerning fusion rules of D–S theory. In Sect. 2, we introduce the D–S theory in detail. In Sect. 3, we explain the shortcomings of D–S fusion method. In Sect. 4, we introduce some improved D–S fusion method in detail. In Sect. 5, based on Mahalanobis distance, a new fusion method for multisensor conflicting information is presented. In Sect. 6, several numerical simulation experiments are used to prove the effectiveness, accuracy and superiority of this new improved method. In Sect. 7, a summary of this paper is given.
2 The description of D–S theory
D–S theory is an uncertain reasoning theory, which is first proposed by Dempster [14] in 1967 and later developed by Shafer [15]. Using belief function, D–S theory can distinguish uncertainty information and generate a better fusion result by simple reasoning form without knowing prior probabilities. It has an effective method for expressing and combining uncertain information. D–S theory has already been widely used in the fields of target recognition, fault diagnosis, expert system and so on. In this section, we will describe the basic concept of D–S theory. The frame of discernment, basic probability assignment and belief function are defined as follows:
Firstly, D–S theory defines a hypotheses set of \(\Theta \), which is called as the framework of discernment, which can be defined as follows [16].
It is composed of N exclusive and exhaustive hypotheses. According to the framework of discernment \(\Theta \), we can define the power set \(2^{\Theta }\), which contains all the subsets of \(\Theta \), and the number of elements in \(2^{\Theta }\) is \(2^{N}\). Therefore, \(2^{\Theta }\) is shown as follows.
Here, \(\varnothing \) is an empty set, which means nothing happening. Those subsets which have only one element are defined as singletons.
For example, if the target recognition system has two target \(H_1\) and \(H_2\), then the frame of discernment can be described as \(\Theta =\{H_1 ,H_2 \}\), and its coordinated power set \(2^{\Theta }=\{\varnothing ,\{H_1 \},\{H_2 \},\Theta \}\), which contains 4 elements. In the \(2^{\Theta }\), the singleton \(\{H_1\}\) shows that the target is \(H_1\), while the singleton \(\{H_2\}\) shows the target is \(H_2\). Besides, \(\varnothing \) means there is nothing happens, and the composite hypotheses \(\{H_1,H_2\}\) means either target \(H_1\) or target \(H_2\) happens, in other words, we still cannot make final decision.
When the framework of discernment is determined, the mass function m is defined as a mapping of the power set to a number between 0 and 1.
The mass function is very similar to a probability distribution, but it should be distributed among the power set of \(2^{\Theta }\), which includes the singletons and composite hypotheses. In addition, the mass function m should meet the following requirements:
The mass function m is also called as a basic probability assignment function(BPAF) on the power set of \(2^{\Theta }\), which represents the degree of supporting a particular subset of \(2^{\Theta }\) from a certain evidence source. If \(m(A)>0\), this subset A is defined as focal element.
The belief function Bel is defined as:
The plausibility function Pl is defined as:
Meantime, they satisfy the following properties:
The belief function and plausibility function can be used to describe the uncertainty of the information, and the belief function shows the minimum uncertainty for the hypothesis, while plausibility shows the maximum certainty for the hypothesis. Therefore, \([\mathrm{{Bel}}(A),\mathrm{{Pl}}(A)]\) is the belief interval of hypothesis A.
Suppose that, in the same framework of discernment, there are two different sensor sources, which are described as A and B, accordingly, the evidences are described as \(E_1\) and \(E_2\), the mass functions are described as \(m_{1}\) and \(m_2\), and the focal elements are described as \(A_i\) and \(B_j\), which are shown in Figs. 1 and 2.

The basic probability assignment of each focal element in evidence \(E_{1}\)

The basic probability assignment of each focal element in evidence \(E_{2}\)
Figure 3 shows the principle of D–S fusion method. In this figure, the horizontal axis represents the basic probability assignment function \(m_1 \) which is assigned to the focal elements of \(E_{1}\), and the vertical axis represents the basic probability assignment function \(m_2 \) which is assigned to the focal elements of \(E_{2}\). The intersection rectangle of the horizontal and the vertical axis represents the belief value which is assigned to \(C=A_i \cap B_j \), it is \(\sum \nolimits _{A_i \cap B_j =C} {m_1 (A_i )\cdot m_2 (B_j )} \). To avoid assigning non-zero probability to the empty set, each belief value should be multiplied by a normalized coefficient \([ {1-\sum \nolimits _{A_i \cap B_j =\varnothing } {m_1 (A_i )\cdot m_2 (B_j )} } ]^{-1}\). The conflicted coefficient is defined as follows:

The principle of D–S fusion method
The Dempster fusion method is defined in formula (9), which is an orthogonal sum.
For multisensor evidences \(m_1,m_2,\ldots ,m_n\), the focal elements are \(A_1,A_2,\ldots ,A_N\), the fusion method is defined as
Here, \(K=\sum \nolimits _{\cap A_i =C} {\prod \nolimits _{1\le i\le N} {m_k (A_i )} } \), \(1\le k\le n\), \(1\le i\le N\).
3 The disadvantages of D–S fusion method
In the classical evidence fusion rules, the value of K shows the conflicted degree among different sensors. For each focal element \(A_1 \) and \(A_2 \), \(m(A_{1})\) and \(m(A_{2})\) assign the belief degree to both incompatible propositions, respectively, when \(A_1 \cap A_2 =\varphi \). If \(A_{1}\) and \(A_{2}\) are conflicted, \(m(A_1)\oplus m(A_2)\) will be dropped. Therefore, K is regarded as the whole dropped conflict mass during the fusion. The large value of K is, the higher conflicts are among different sensors. If \(K=1\), all sensors are conflicting. More detailed discussion is given in the following example.
Example one, supposed,
The Conflicted coefficient is \(K=1\), the fusion result is \(m(A)=0\), \(m(B)=1,m(C)=0\). It shows that the belief of target B is 1, which means target B is absolutely happened from the fusion view. However, it does not agree with the actual data obviously.
Example two, supposed,
The Conflicted coefficient is \(K=0.99\), The fusion result of D–S is \(m(A)=0,\) \(m(B)=0.01\) \(m(C)=0.99\). It shows that the belief of target C is 1. However, the third evidence is defined as follows:
The Conflicted coefficient is \(K=0.9999\); however, the fusion result is also \(m(A)=0\), \(m(B)=0.01\), \(m(C)=0.99\), which is same as above. It is easy to get the conclusion that no matter how higher belief value of evidence is assigned to A, the fusion result of A is always 0. Obviously, it does not meet our common sense.
As discussed above, in the Dempster fusion rules, they could get a better fusion result when combining non-conflict evidences; however, during the process of combining highly conflicted evidences, Dempster fusion rule only normalizes the results and ignores the conflicted mass. Therefore, it has a bad fusion result with highly conflicted evidences. Furthermore, Dempster fusion rule also has the “Veto by one vote” problem and bad robustness.
To solve these problems, it is necessary to modify the mathematical model or modify the fusion rule. Currently, most researchers are focusing on data preprocessing before combining. The following section will introduce some traditional methods and present a new improved fusion rule.
4 The improved fusion rule of D–S theory
4.1 Jousselme principled distance
In Ref. [17], it introduces Jousselme Principled distance between two basic probability assignments or two bodies of evidence based on a quantification of the similarity between evidences. Now, we will describe the concept of Jousselme Principled distance.
A metric distance defined on the set \(\Theta \) is shown as follows:
It satisfies the following properties for any subset A and B of \(\Theta \):
-
(a)
Non-negativity: \(d(A,B)\ge 0\).
-
(b)
Non-degeneracy: \(d(A,B)=0\Leftrightarrow A=B\).
-
(c)
Symmetry: \(d(A,B)=d(B,A)\).
-
(d)
Triangle inequality: \(d(A,B)\le d(A,C)+d(C,B),\forall C\in \Theta \).
Let \(m_1\) and \(m_2\) be two BPAF on the same framework of discernment \(\Theta \). The distance between \(m_1\) and \(m_2\) is defined as follows:
\(\mathbf{D}\) is a \(2^{N}\times 2^{N}\) matrix whose elements are shown as follows.
4.2 The similarity degree between evidences
In Ref. [18], supposed, \(E_1\) and \(E_2\) are two evidence bodies from two different sensor sources in the same framework of discernment \(\Theta \), and the corresponding mass functions are \(m_1\) and \(m_2\), the focal elements are \(A_i\) and \(B_j\), the similarity degree [11] between \(E_1\) and \(E_2\) is defined as follows.
Here \(C_k =A_i \cap B_j\). The \(d_{12}\) represents the similarity degree between \(E_1\) and \(E_2\).
Supposed, the fusion system has n different evidence sources, according to the formula (16), we can calculate the similarity degree of every two different evidences, which can be described with a similarity matrix:
The sum of each row in similarity matrix represents the support of other evidences to \(m_i \), which is shown as follows.
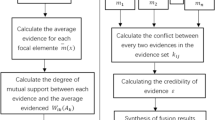
Sup\((m_i)\) represents the support of other evidences to \(m_i \). If the value of sup(\(m_{i}\)) is greater, other evidences should give greater support to \(m_{i}\). On the other hand, if the value of sup(\(m_i\)) is smaller, other evidences should give smaller support to \(m_i\). Through normalization method, we can calculate the reliability degree of \(m_i \), which is defined as follows.
The Crd\((m_i)\) represents the credibility degree of evidence \(m_i\). Generally speaking, the higher level of evidence is supported by other evidences, the greater credibility degree of the evidence is shown, on the other hand, if one evidence is not supported by other evidences, it has a low credibility degree.
4.3 Improved K-L distance
In Ref. [19], based on evidence distance, a novel fusion method of conflict evidence is proposed. The distance between evidences is calculated by an improved K-L distance, and is further changed to the weights of evidence, which will reflect the importance of evidence. According to these weights, the basic probability assignment will be reallocated, and then they are used to get the final fusion result by the improved method.
K-L distance is also named as the relative information entropy, which is a distance measure of two probability distributions P and Q, the K-L distance of P relative to Q is defined as follows:
K-L distance can be used to measure the information distance, and it has an asymmetric nature. However, when it is used in practical applications, there are also some problems, such as \(q_i\) cannot be 0. Meantime, when \(p_i\) is 0, the K-L distance is also 0, which is an invalid result. Therefore, the author improves the K-L distance, which is defined as follows:
Here, \(m_1\) and \(m_2\) are two mass functions, \(\alpha \) is a very small fixed value and it tends to 0.
The distance between evidence \(E_1\) and \(E_2\) is defined as follows:
In multisensor fusion system, the conflict of mass function \(m_i\) with other mass functions is defined as follows:
Here, \(\delta (m_i)\) is the question degree of \(E_i \), the credibility degree of the evidence can be define as follows:
5 The improved method based on Mahalanobis distance
5.1 Mahalanobis distance
Mahalanobis distance [20–23] is proposed by Indian statistician P. C. Mahalanobis, it is a method to calculate the distance between two points using covariance. It can calculate the shortest distance between a sample and the “center of gravity” of the sample set, or calculate the similarity degree of two unknown sample sets. Mahalanobis distance is much more powerful than Euclidean distance which is only a special case of the Mahalanobis distance. Mahalanobis distance is shown Fig. 4. There are two normal distributions, and their mean values are a and b, however their variances are different; the question is point A belongs to which population, a or b? Obviously, A more likely belongs to the left population a. And it is the subjective meaning of Mahalanobis distance.

The Intuitive sense of the Mahalanobis distance
Mahalanobis distance can be defined as follows: suppose X and Y are two sample sets obtaining from population G, with the same mean vector \(\mu \) and covariance matrix \(\Sigma \); therefore, the Mahalanobis distance between X and Y is defined as follows:
And the Mahalanobis distance between X and population G is defined as follows:
According to the definition of Mahalanobis distance, we can obtain some features, which are shown as follows:
-
(a)
Mahalanobis distance has nothing to do with the measurement, and the inverse covariance matrix can get rid of the scale effects on distance. It is a very important feature in the application of multisensor information fusion, because these sensors provide different properties of the targets, and have different unit; therefore, we need to remove the dimension before combining. However, different preprocess method of evidence will get different results, even some preprocess method of evidence will make the fusion results affected by the fusion sequence.
-
(b)
The preprocess method of evidence of standardized and centralization data (the difference between the original data and the mean value) has the same Mahalanobis distance, it is similar to the first point; therefore, Mahalanobis distance has nothing to do with preprocess.
-
(c)
Mahalanobis distance can get rid of correlation jamming among variables.
-
(d)
Mahalanobis distance satisfies four axioms of distance: symmetry, non-negativity, non-degeneracy and triangle inequality, this point guarantees the availability and rationality of Mahalanobis distance.
5.2 The reliability degree of the evidence based on Mahalanobis distance
The previous section introduces some advantages of Mahalanobis distance. In this section, it is used to calculate the distance between the evidences, and then the credibility degree of evidences is calculated.
Supposed, \(E_1\) and \(E_2\) are two evidence bodies, and the corresponding mass functions are \(m_1\) and \(m_2\), the focal elements are \(A_i\) and \(B_j\), the total number of targets is n, and the Mahalanobis distance between \(E_1\) and \(E_2\) is defined as follows:
Here, \(\Sigma \) is the covariance matrix of evidence vector M:
Because Mahalanobis distance has nothing to do with unit, therefore, it is no need to preprocess. As it is well known, if one evidence is far away from other evidences, then the evidence has a low support by other evidences, and its reliability is lower than other evidences. On the contrary, the evidence has a high degree of support, and its reliability is higher than other evidences.
To calculate the reliability of every evidence, firstly, we should calculate the distance among evidences, the distance matrix is defined as follows:
And then, we can calculate the average distance of each evidence to other evidences
Here
Because the sum of all basic probability assignment function is 1, therefore, through normalizing the average distance, we can calculate the weight of every evidence:
The weight matrix is defined as follows:
And then, we can further correct the basic probability assignment function,
5.3 The new improved fusion method of D–S theory
After correcting the basic probability assignment function, D–S fusion method is used to get the final result. In this paper, according to the fusion method in Ref. [24], we propose a new fusion method.
Conflicted coefficient reflects the conflict degree of sensor evidence, conversely, the basic probability assignment of every focal element will affect conflicted coefficient. Supposed, the framework of discernment is \(\Theta =\{A_1 ,A_2 ,\ldots ,A_n \}\), and there are K evidence sources, the weighting factor of \(A_i \) is defined as follows:
The above formula represents the weight of every focal element, so the conflicted coefficient assigned to \(A_i \) is defined as follows:
In this way, the fusion method is defined as follows:
As it can be seen from the above statement, because there will have conflict information between the sensor evidence, therefore, the basic probability assignment function should be reallocated. While after reallocating the basic probability assignment function by Conflicted coefficient, the assignment of unknown items will be excluded. Therefore, this new improved method can make full use of conflict information and get a better final fusion result.
6 The analysis of numeric simulation
In this section, two numeric simulation examples are presented to prove the effectiveness and priority of the improved method, the first one is consistent information which is used to prove the effectiveness of the method, and the second one is conflict information, which is used to prove the priority of improved method.
6.1 The numeric simulation result with consistent information
The consistent information is described in Table 1.
Fusion results with different methods are shown in Table 2.
According to Table 2, D–S fusion method [3] has a very obvious phenomenon of casting vote, the fusion result of target b is always 0, which is not reasonable. Yager fusion method [18] postulates that the framework of discernment is exhaustive, and the conflict mass function has been distributed to all subsets. In addition, the conflict mass function \(m(\varnothing )\) is assigned to the whole set \({\varvec{\Theta }} \), which will assign a large number to the unknown result and cannot get the right fusion result. Although fusion method [26] can get an ideal fusion result, however, this method uses the simple statistical average, which cannot be widely used in the practical application. In addition, K-L distance [12] and Jousselme distance fusion method [9] and the improved fusion method can be used to calculate distance between different evidences, and obtain the credibility degree of all evidences, which can be used to correct the evidence, therefore, the reasonable fusion results can be gotten. According to Table 2, the new improved method can get the same fusion result as the other methods; therefore, it is an effective fusion method.
6.2 The numeric simulation result with conflict information
The conflict information is described in Table 3.
Fusion results with different methods are shown in Table 4
According to Table 4, D–S fusion method [3] assigns number one to target c, which is not reasonable result. Yager fusion method [18] assigns a large number to \(m({\varvec{\Theta }})\), it means the fusion result is still fuzzy and uncertain; therefore, it cannot be used to get a reasonable result with high conflict information. Murphy fusion method [26] has an ideal fusion result in the numeric simulation, but this fusion method uses a simple statistical average to correct the evidence sources; therefore, in some practical applications, it cannot get a reasonable result. K-L [12], Jousselme [9] distance fusion method and the improved fusion method can get an effective and correct result. However, the K-L and Jousselme distance fusion method do not take the overall statistical characteristics of the evidences into account. Therefore, the improved fusion result is more obvious fusion result than the K-L and Jousselme distance fusion method. For example, the correct fusion result m(a) is larger, and the uncertain fusion result \(m({\varvec{\Theta }})\) is smaller, which will make the final decision much easier.
7 Conclusion
Due to the rapid development and wide application of multisensor network, multisensor information fusion technology has been widely used. However, the uncertainty, incomplete and contradictory of multisensor information will lead to confliction, which will make wrong fusion results. In this paper, based on D–S theory, we talk about the fusion of conflict information. Firstly, we study the conflict problem, the classic D–S fusion method and its limitations are discussed in detail. Furthermore, several improved fusion methods have been analyzed, such as Yager fusion method and Murphy fusion method. And then, based on different distance between evidences and the credibility degree of evidence, the method of the weight of evidence is analyzed, such as K-L and Jousselme distance method. Finally, according to the discussion above, based on the Mahalanobis distance, a new fusion method is presented. According to the theory analysis and numeric simulation, the improved fusion method takes the overall statistical characteristics of the evidences into account, and correct the evidence sources; therefore, it can get better fusion result with high conflict information and make the final decision easier.
References
Fang Z, Liyan H (2006) A survey of multisensor information fusion technology. J Telem Track command 27(3):1–7
Llinas J, Hall DL (1998) An introduction to multisensor data fusion. IEEE, pp I537–I540
Shafer G (1976) A mathematical theory of evidence. Princeton Univ. Press, Princeton
Zadeh LA (1984) Review of books: a mathematical theory of evidence. AI Mag 10(2):235–247
Yager RR (1987) On the Dempster–Shafer framework and new combination rules. Inf Sci 41:93–137
Smets P (1990) The combination of evidence in the transferable belief model. IEEE Pattern Anal Mach Intell 12(5):447–458
Dubois D, Prade H (1988) Default reasoning and possibility theory. Artif Intell 35(z):243–257
Murphy CK (2000) Combining belief functions when evidence conflicts. Decis Support Syst 29:1–9
Sun Q, Ye XQ, Gu WK (2000) A new combination rules of evidence theory. Acta Electron Sin 28(8):117–119
Li BC, Wang B, Wei J, Qian ZB, Huang YQ (2002) An efficient combination rule of evidence theory. J Data Acquis Process 17(1):33–36
Liang XR, Yao PY, Liang DL (2008) Improved combination rule of evidence theory and its application in fused target recognition. Electron Optics Control 15(12):37–41
Deng Y, Shi WK, Zhu ZF, Liu Q (2004) Combining belief functions based on distance of evidence. Decis Support Syst 38(3):489–493
Liu HY, Zhao ZG, Liu X (2008) Combination of conflict evidences in D–S theory. J Univ Electron Sci Technol China 37(5):701–704
Dempster A (1967) Upper and lower probabilities induced by multivalued mapping. Annu Math Stat 38(2):325–339
Shafer G (1976) A mathematical theory of evidence. Princeton University Press, New Jersey
Xu P, Deng Y, Su X, Mahadevan S (2013) A new method to determine basic probability assignment from training data. Knowl Based Syst 46:69–80
Jousselme AL, Grenier D, Bosse E (2001) A new distance between two bodies of evidence. Inf fusion 2(1):91–101
Wang X-X, Yang F-B (2007) A kind of evidence combination method in conflict. Danjian Yu Zhidao Xuebapo 27(8):255–257
Yong-Chao Wei (2011) An improved D–S evidence combination method based on K-L distance. Telecommun Eng 51(1):191–201
McLachlan GF (1999) Mahalanobis Distance. General articlewei, pp 20–26
Mitchell AFS, Krzanowski WJ (1985) The Mahalanobis distance and elliptic distributions. Biometrika 72(2):464–467
De Maesschalck R, Jouan-Rimbaud D, Massart DL (2000) The Mahalanobis distance[J]. Chemometrics and Intelligent Laboratory Systems, pp 1–18
Xiang S, Nie F, Zhang C (2008) Learning a Mahalanobis distance metric for data clustering and classification[J]. Pattern Recognit 41:3600–3612
Lefevre E, Colot O, Vannoorenberghe P, de Brucq D (1998) A generic framework for resolving the conflict in the combination of belief structures. In: The 3rd International Conference on Information Fusion Paris. France, pp 182–188
Yager RR (1996) On the aggregation of prioritized belief structures. IEEE Trans Syst Man Cybern Part A Syst Hum 26(6):708–717
Zhang Y, Fang K (1999) Introduction to multivariate statistical analysis. Science Press, Beijing
Acknowledgments
This work was supported by the Key Development Program of Basic Research of China (JCKY2013604B001), the Nation Nature Science Foundation of China (No. 61301095 and No. 61201237), Nature Science Foundation of Heilongjiang Province of China (No. QC2012C069, F201408 and F201407) and the Fundamental Research Funds for the Central Universities (No. HEUCF1508).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Meantime, all the authors declare that there is no conflict of interests regarding the publication of this article.
Rights and permissions
About this article

Cite this article
Lin, Y., Wang, C., Ma, C. et al. A new combination method for multisensor conflict information. J Supercomput 72, 2874–2890 (2016). https://doi.org/10.1007/s11227-016-1681-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-016-1681-3