
Abstract
This paper investigates the role of economic variables in predicting regional disparities in reported life satisfaction of European Union (EU) citizens. European subnational units (regions) are defined according to the first-level EU nomenclature of territorial units. We use multilevel modeling to explicitly account for the hierarchical nature of our data, respondents within regions and countries, and for understanding patterns of variation within and between regions. Main findings are that personal income matters more in poor regions than in rich regions, a pattern that still holds for regions within the same country. Being unemployed is negatively associated with life satisfaction even after controlled for income variation. Living in high unemployment regions does not alleviate the unhappiness of being out of work. After controlling for individual characteristics and modeling interactions, regional differences in life satisfaction still remain, confirming that regional dimension is relevant for life satisfaction.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since Easterlin (1974), a blooming socio-economic literature on happiness has developed ways of measuring happiness of individuals induced by life events, economic performances and other “external” factors related to the area where people live (Frey and Stutzer 2002). In this stream of literature, several studies have focused on the effects of socio-demographics (such as marital status, age and education) on individual well-being, while others have focused on personal economic characteristics, mainly the level of income and the role of being unemployed (Diener et al. 1993; Clark and Oswald 1994; Oswald 1997; Winkelmann and Winkelmann 1998).
A somewhat different perspective is the evaluation of the effects of macro-variables that reflect the socio-economic environment where individuals live. Di Tella et al. (2003) provide evidence that, after controlling for a wide set of individual characteristics, the subjective well-being of Europeans is largely affected by levels and changes of country-level macroeconomic variables, such as inflation, per capita GDP, unemployment rate and social welfare state indicators. Alesina et al. (2004) and Graham and Felton (2006) address the question of how income inequality affects individual well-being, finding different results between developed and developing countries and also between United States and Europe. Political arrangements also matter. The degree of trust and freedom of democratic institutions (Layard 2005), as well as the degree of participating in direct democracy (Frey and Stutzer 2000) seem to positively influence individual reported well-being.
Most of the analyses in the European Union (EU) have focused on the effects on individual well-being of national economic indicators.Footnote 1 On the other hand, it can be argued that local rather than national macro-variables may influence the individual well-being to a larger extent. The EU has devoted particular attention to subnational disparities that are still wide both economically and socially. Their reduction is a target that has been made explicit in the Treaty on EU and an increasing volume of the EU budget has been devolved toward this objective (European Commission 2008).
Our paper focuses on the role of economic variables, both at individual and aggregate level, in explaining observed subnational (regional) differences in life satisfaction of Europeans.
Our understanding of the relation between economic variables and subjective well-being is based on a strategy that refers to different levels of analysis. At the level of individuals, we study to what extent personal characteristics make European citizens more satisfied. Specifically, we concentrate on the role of personal income and employment status. We want to determine to what extent personal income and employment status may predict life satisfaction differently across European subnational units (“regions,” defined according to the first-level EU nomenclature of territorial units).
At aggregate level, we want to find out if the role of regional per capita GDP and unemployment rate goes beyond the simple aggregation of individual effects, that is, for example, do richer regions and poor regions may help predicting the individual well-being in a different way?
Multilevel models provide a natural and suitable framework for accounting for these different levels of variation, allowing us to understand the relation between income, unemployment status and life satisfaction among individuals and regions simultaneously.
The paper is articulated as follows. In the next section we present the relevant characteristics of the reported life satisfaction in our dataset in European countries and regions. This section also sketches multilevel modeling and gives some details on the varying-intercept and varying-slope model, which is our central fitted model. Section 3 reports the empirical results of the fitted models. Throughout, we emphasize graphical summaries of the results. Consistent with many other studies, we find that personal income is positively associated to individual well-being and unemployment strongly deteriorates the subjective life satisfaction, even controlling for the indirect effect of income loss.
Our main finding is that, on average, personal income matters more in poor regions than in rich regions. Living in high unemployment regions does not alleviate the unhappiness of being out of work. Finally, after controlling for individual characteristics and modeling interactions, regional differences in life satisfaction still remain, confirming that regional dimension is relevant for life satisfaction. Some concluding remarks are given in Sect. 4.
2 Data and Model Design
2.1 Measurement in the Eurobarometer Surveys
Research programs aimed to evaluate correlates and determinants of subjective well-being rely, for the most part, on data collected from large surveys in which people are asked to self-report their overall level of happiness and life satisfaction on a numerical scale. A skeptical view on its use in economic and policy literature is expressed by Bertrand and Mullainathan (2001) and Wilkinson (2007). This sort of survey is considered a fairly weak technique for probing into people’s feelings, and more fine-grained self-reported techniques, such as experience sampling or daily reconstruction, have been proposed as more accurate tools to evaluate emotional recall (Kahneman and Krueger 2006).
Another concern is that cross-personal comparison is not possible: different people may understand the concept of life satisfaction or happiness in different ways. In international surveys, moreover, the terms “happiness” and “life satisfaction” have no precise equivalent in some languages, reflecting cultural heterogeneity.
Beyond these measurement issues, life satisfaction is not the same as happiness: both are broadly consistent measures of subjective well-being, but have to be considered separately. When asked how happy they are, people tend to consider the more volatile concept of current emotional state, while life satisfaction is closer to the concept of an overall and more stable living flourishing and actualizing the best potential within oneself. A person’s subjective well-being includes both these emotive and cognitive judgments, and different people weigh them differently. This explains how several nations, like Nigeria, report low life satisfaction in the World Values Survey and at the same time high levels of happiness.
Even though questions on overall life satisfaction or happiness suffer from several limitations, their use is widely recognized. A review of some of the arguments made in the economic literature in favor of using survey “happiness data” is reported in Di Tella et al. (2001) and Alesina et al. (2004). An evaluation of the reliability of the global judgment of life satisfaction or happiness has been recently given by Krueger and Schkade (2007). Apart from the fact that large surveys allow comparisons across many different groups of people in terms of socio-economic characteristics, one argument is that responses to life satisfaction questions have been found to be highly correlated with a variety of relevant physical relations that can be thought of as describing true, internal happiness, as objective physiological and medical criteria (e.g., electrical readings in the brain) or individual’s emotional states (e.g., smiling frequency, sleep quality) or ratings made by friends. Furthermore, when using representative population samples, idiosyncratic effects of recent events that may affect the answers are likely to average out. Kahneman and Krueger (2006) also note that respondents are not reluctant to answer life satisfaction or happiness questions. Overall, we acknowledge that available happiness data are flawed, perhaps more than most economic data in several respects, but at any rate self-reported measurements tell us a lot about the conditions under which different kinds of people are inclined to say that they are satisfied or unsatisfied with life.
Data of our analysis are drawn from a series of repeated cross-sectional sample surveys, the Eurobarometer surveys, collected and harmonized by ICPSR (Inter-university Consortium for Political and Social Research) in the Mannheim Eurobarometer Trend File, 1970–2002 (Schmitt and Scholz 2005). The Eurobarometer surveys have been conducted on behalf of the European Commission since the early seventies at least two times a year in all member states on a representative sample of people aged 15 and over residing in the EU. The Eurobarometer surveys include European countries only after their entrance to the EU. The Eurobarometer series is designed to provide regular monitoring of the social and political attitudes in the EU publics through specific trend questions. The Mannheim Eurobarometer Trend File, a collaborative effort between the Mannheimer Zentrum fur Europaische Sozialforschung and the Zentrum fur Umfragen, Methoden und Analysen, combined the most important trend questions of the Eurobarometer surveys conducted between 1970 and 2002. The file consisted of questions asked at least five times in standard Eurobarometer surveys. Over 1.1 million respondents from a total of 15 EU member nations were interviewed in these surveys.
Respondents were also asked for their overall satisfaction with life, as measured on a four-point scale. The question usually asked is: “On the whole, are you very satisfied, fairly satisfied, not very satisfied or not at all satisfied with the life you lead?.” Life satisfaction questions were not asked in the 1996 surveys. The surveys also include a similar question on the level of happiness, on a three-point scale, but this question was not included in the most recent years. Demographic and other background information collected include the respondents’ age, gender, and marital status, the number of people residing in the household, the number of children under 15 in the household, respondent’s age at completion of education, left-right political self-placement, occupation, religion, income and region of residence.
2.2 Life Satisfaction in the European Regions
We first present an overall descriptive analysis of life satisfaction in Europe at national and regional level. The Eurobarometer surveys have a code for the regions where individuals live. We reclassify the Eurobarometer codes according to the most recent nomenclature of territorial units for statistics (NUTS). We focus on the first level of the classification (NUTS1) that divides the 15 European countries analyzed into a total of 70 subnational units.Footnote 2 This choice seems a reasonable compromise between the goal of investigating regional influences, regional data availability and sample size. Previous empirical results of happiness equations that make use of the Eurobarometer Surveys did cover the period from mid seventies to, at the most, the year 1992 (Blanchflower and Oswald 2004; Di Tella et al. 2003). We analyze the period 1992–2002, which is the last decade available in the Mannheim File.
In order to present a comprehensive picture, we treat the reported level of life satisfaction as an ordinal measure from 1 for “not at all satisfied” to 4 for “very satisfied.”
Figure 1 reports life satisfaction scores of the countries, classified as Northern (Denmark, Sweden, Finland, UK and Ireland), Central (Netherlands, Luxemburg, Belgium, France, Germany and Austria) and Southern (Spain, Portugal, Italy and Greece) over the period 1992–2002.

Pattern of life satisfaction in European countries: Northern countries (left panel), Central countries (middle panel) and Southern countries (right panel); 1992–2002
Northern countries were consistently more satisfied than the rest of Europe and were also more stable over time. Denmark was by far the happiest country in the EU and its level of life satisfaction was stable over time. Ireland seems to have had the most irregular pattern, with a remarkable increase in 1997 followed by two evident declines, one in 1998 and the other in 2002. Regarding Central countries, Netherlands and Luxembourg reported the highest levels of life satisfaction, while France reached the level of Germany after the mid-1990. Southern countries showed the lowest levels of life satisfaction, but there was a sizeable increase after 1998, especially Spain.
Figure 2 reports the time-average levels of life satisfaction of the regions within each country, ranking the countries from the highest satisfied level to the lowest. The rank of the countries is similar to the one obtained from the World Values Survey during the period 1995–2005 (Veenhoven 2007), which is based on combined happiness and life satisfaction scores.

Average life satisfaction in European regions on the period 1992–2002. The circles represent the European NUTS1 subnational regions. Countries are ordered from the most to the least satisfied with life
There is also variability within countries. This was more evident in Belgium, Germany, Spain, Italy and Portugal. A table with the codes, the names of the subnational regions along with their average life satisfaction levels and their decile ranking is reported in Appendix Table 1. To get a sense of the dispersion across regions, we look at the decile ranking that indicates where each region falls in the distribution of life satisfaction. Decile rankings range from 1 to 10, with 1 meaning that regions are in the top 10% of the distribution. The Flemish region Vlaams Gewest had a life satisfaction of 3.2 and it was located in the third decile ranking of the distribution, while the Belgian region Wallonne had a value of 2.9 and it was positioned in the seventh decile. In Germany the happiest region was the northern region of Schleswig–Holstein, placed in the third decile of the distribution, while there were two ex East Germany regions (Thüringen and Mecklenburg-Vorpommern) in the bottom decile. The bottom decile also comprised the Greek regions and the Continental region of Portugal. Spain had one region in the 5th decile (Centro, that includes Castilla y León, Castilla-La Mancha and Extremadura), while the Communidad de Madrid was in the ninth decile. Big disparities were also present in Italy, where residents in southern regions and islands (Sud and Isole, both in the ninth decile) were less satisfied than residents in the north (Nord Est and Nord Ovest, both in the sixth decile).Footnote 3 More homogeneous were the Netherlands (all the four NUTS1 regions were located in the top decile, with similar values), Greece (all the four in the bottom decile) and, to a lesser extent, Austria and Portugal. French citizens were, on average, more satisfied in the Ouest, which includes Pays de la Loire, Bretagne and Poitou-Charantes, positioned in the sixth decile, and less satisfied in the Mèditerranèe region, positioned in the ninth decile ranking. UK regions were distributed between the second and the fifth decile: Northern Ireland displayed the highest level of life satisfaction (3.3, very similar to Ireland), with Scotland the lowest (3.1, similar to the northern English regions, North East and North West). Regions where the capital city is located usually reported levels of happiness among the lowest within their country. This was the case for London, Berlin, Paris, Madrid, Vienna and Athens.
The observed variability across European regions motivates our choice to account for both individual-and regional-level variation in a multilevel framework.
2.3 Multilevel Modeling
Multilevel modeling can be thought as linear or generalized linear regression in which the parameters, the varying group coefficients, are given a probability model. Classical regression can incorporate varying groups coefficients by including dummy variables, but the main difference between multilevel and classical regression is in the modeling of the variation between groups. The crucial multilevel modeling step is that the group coefficients are themselves modelled (most simply a common distribution for the group coefficients or, more generally, a regression model that includes group-level predictors). Multilevel models can include group indicators (dummies) along with group-level predictors. As special cases of multilevel models are the classical regression models. When the variation between groups tend to zero, multilevel models collapse to complete-pooling models, while when the variation between groups goes to infinity they reduce to the no-pooling model. Given multilevel data, we can estimate the variation between groups. Therefore, there is no reason (except for convenience) to accept estimates that arbitrarily set this parameter to one of these two extreme values (Gelman and Hill 2007).
When the number of groups is large, there is typically enough information to accurately estimate group-level variation from the data alone and, as a result, multilevel models gain much beyond classical varying-coefficient models, that suffer from reduction in degrees of freedom. Multilevel models, in this setting, estimate more accurately heterogeneous groups in small samples, avoiding the problem of large standard error related to the smallness of sample size in small area estimation procedures (Longford 2007).
There are two compelling reasons for using multilevel models to study the effects of socio-economic conditions of Europeans on their level of life satisfaction.
First, multilevel models allows us to explicitly account for the hierarchical nature of our data. We use, in fact, as predictors of life satisfaction variables both at individual and at regional level coming, respectively, from survey data on individuals (Eurobarometer) and national accounting data for regions and countries (Eurostat). Second, multilevel models also let us estimate patterns of variation within and between regions simultaneously, by allowing their intercepts, and eventually slopes, to vary (see Snijders and Bosker 1999, for a general overview of multilevel models, and Gelman and Hill 2007, for the notation used here).
Since reported life satisfaction is intrinsically ordinal, the natural way to treat it in an econometric model should be by ordered logit or probit equations. As discussed in Ferrer-i-Carbonell and Frijters (2004) and Frey and Stutzer (2002), ordinality or cardinality of life satisfaction scores makes little difference, so the use of ordered logit models or linear models is not expected to change the substantive findings. To give grounds to this hypothesis, we implement the ordered logit, and the easier to interpret linear regression for modeling the determinants of satisfaction in life.
Whatever the choice of the selected functional form, our central model is a multilevel varying-intercept and varying-slope model that estimates life satisfaction on individual socio-demographic characteristics and regional variables. Considering for sake of simplicity only one individual predictor, life satisfaction of individual i resident in region j can be written as:Footnote 4
where y is the life satisfaction level, x is an individual-level predictor, as income, \(\sigma_{y}^{2}\) is the unexplained within-region variation and j[i] indexes the region j where person i resides.
The second step of the model, what makes it “multilevel,” is the simultaneous modeling of the region-level intercepts α j and slopes β j as:
where μ α and μ β are the means of the region intercepts and slopes respectively, σ α and σ β their standard deviations and ρ the between-region correlation parameter.
A further step of the model is to add group-level predictors to improve inference for the group coefficients α j and the varying slopes β j :
where U is a matrix of region-level predictors, γ α the vector of coefficients for the region-level regression (2) and γ β the vector of coefficients for the region-level regression (3).
Group-level predictors not only are themselves of interest, but play a special role in the multilevel context, since they may reduce the unexplained group-level variation, that are the standard deviation σ α and σ β . Reduction of unexplained group-level variation can be therefore interpreted as a measure of the importance of the predictor.
Since our model focuses on the effects of economic variables, we let the coefficients of personal income and unemployment status vary by group (region). To control for demographic characteristics, we also consider additional variables whose coefficients are unmodelled, as sex, age, marital status, education.
When we have multiple predictors, it is convenient to move to matrix notation in which there are J groups, K individual-level predictors whose coefficients vary by group (including the constant term), R individual-level predictors whose coefficients do not vary by group and L predictors in the group-level regression (including the constant term):
where X 0 is the n × R matrix of individual predictors and β 0 the vector of their unmodelled regression coefficients; X is the n × K matrix of individual predictors (the first column is a column of 1s) that have coefficients varying by groups and B is the J × K matrix of their regression coefficients. Therefore, B j[i] is the jth row of B, that is the vector representing the intercept and the slope for the group that includes unit i. M B is a vector representing the mean of the distribution of the varying-intercepts and varying-slopes and \(\Upsigma_B\) is the covariance matrix.
We can extend model (4) to include group-level predictors:
where B is the J × K matrix of individual-level coefficients, U is the J × L matrix of group-level predictors (including the constant term), and G is the L × K matrix of coefficients for the group-level regression.
2.4 Regional Macroeconomic Variables as Group Predictors
The group-level predictors we include in our more structured model are macroeconomic variables at the subnational level. The subnational variables are from Regio, the Eurostat’s harmonized regional statistical database. Regio covers the main aspects of economic and social life in the EU, classified up to the first three levels of the nomenclature of territorial units (NUTS). National accounts aggregates at NUTS level are based on data from the European System of Accounts ESA 1995, using an harmonized methodology, and were calculated by Eurostat from 1995. On the other hand, as previously mentioned, life satisfaction data are not available for 1996. Therefore, due to data availability in the Eurobarometer surveys and in the European regional data set, we confine our modeling to the 1997–2002 period. The groups (the second level of the model) we refer to are 70 regions of 15 European countries at NUTS1, the first category of the nomenclature of territorial units.
The group-level predictors are regional per capita GDP and regional unemployment rate. These two economic variables, along with the rate of inflation, have been most thoroughly investigated and recognized as the most influential. On the first variable, Frey and Stutzer (2002) report studies showing that life satisfaction and income are uncorrelated over time within countries. Across countries, instead, they observe weak correlation once a certain stage of income has been reached. They also document that higher levels of unemployment reduce the average satisfaction with life, even after controlling for individual unemployment status. The GDP per capita, instead, matters among European countries, as shown in Di Tella et al. (2003), giving us a motivation to investigate these relationships across European regions in further details.
Regional per capita income is the GDP per inhabitant at market prices converted to national purchasing power standard to make a correction for different cost of living. Unfortunately, Eurostat does not possess comparable regional price levels which would have been enabled us to handle for regional differences in price levels within same countries. Adjusting GDP per capita to national purchasing power has effects on data dispersion since low incomes in poor regions tend to be partially counterbalanced by lower costs of living (Pittau and Zelli 2006). Unemployment rates represent unemployed persons as a percentage of the civilian labor force in each region.
3 Empirical Results
3.1 Influence of Individual Characteristics
We start fitting models that allow personal characteristics to predict life satisfaction within each region, letting the intercepts α j vary across regions but keeping unmodeled the slopes β’s, that is a special case of model (4) in which X is simply a vector of 1s. The inclusion of a varying intercept captures region-to region variation that remains unexplained after controlling for individual characteristics.
We estimate the model considering the linear and ordered logit specification.Footnote 5 In the linear model, life satisfaction outcome is treated as a continuous variable ranging from 1 to 4, while in the ordered logistic regression life satisfaction is considered as a four categorical outcome.
Individual characteristics used as first-level predictors are: income level, employment status, age, marital status, gender and education level.Footnote 6 For other interesting characteristics, like religion, number of children and political self-placement, we have too many missing observations to include them in the equation since for several years these variables have not been collected. The Mannheim Trend File uses twelve income categories, making this variable comparable across countries and over time. Income classes are expressed in absolute values. Educational categories refer to the age when interviewers finished their full-time education and are codified as: up to 15 years old, between 16 and 19 years old, over 20. We exclude interviewers who responded “don’t know” or did not respond.
Figures 3 and 4 report the estimated coefficients for the individual characteristics in the two different model specifications.Footnote 7 Time indicator variables are included in the models. The zeros correspond to the baseline categories for each categorical variable.

Estimated coefficients with relative ±2 standard errors of individual characteristics in the basic fitted multilevel linear model with respondents nested within regions and countries (1997–2002)

Estimated coefficients with relative ±2 standard errors of individual characteristics in the basic fitted ordered logistic model with respondents nested within regions and countries (1997–2002). The estimated cutpoints and their standard errors are: c 1|2 = −3.52 (0.11), c 2|3 = −1.57 (0.10), c 3|4 = 1.62 (0.10)
The influence of economic individual characteristics on life satisfaction are in accordance to the main findings of Di Tella et al. (2003) on the Eurobarometer surveys in previous years. The effects of income and unemployment status are substantial in both specifications. In the linear models there are no significant differences with respect to first income class until income level 4. But, for example, moving from the bottom class to the upper income class (level 11) increases, ceteris paribus, the life satisfaction score by 0.11. Interpreting the coefficients of the ordered logistic regression is not straightforward. Given the estimated cutpoints, the baseline individual (who is a man of average age, with income level 1, self-employed, single, who left school before 15 years old and interviewed in the year 1997) has a probability of being “very satisfied” approximately equal to 2%, of being “fairly satisfied” equal to 62%, of being “not very satisfied” equal to 37% and being “not at all satisfied” equal to 1%. If this man increases his income level until class 11 the estimated probabilities change as follow: “very satisfied” to 3%, “fairly satisfied” to 88%, “not very satisfied” 9% and “not at all satisfied” to 0%. Regarding the employment status, being unemployed has a negative and highly significant effect even though we are controlling for income. Being unemployed with respect to being self-employed reduces by 0.05 life satisfaction level in the linear specification without accounting the eventual income loss. Again, the interpretation of the ordered logistic model has to be done referring to a specific respondent. As an example, the probability of the baseline individual of being “very satisfied” if he becomes unemployed decreases from 2% to 0%, the probability of being “fairly satisfied” goes down from 62% to 40%, while the probability of being “not very satisfied” increases by 18 percentage points. His probability of being “not at all satisfied” goes up from 1% to 5%.
Also for social and demographic characteristics our results confirm evidence of previous literature. Life satisfaction increases with years of education. Women are, ceteris paribus, more satisfied than men. Marital status appears to have a positive association on life satisfaction for those who are in some form of relationship (married or as married) while it has the most negative association for those who are separated or divorced. There is U-shape pattern of happiness with age: happiness starts off relatively high in early adulthood, then falls, reaching its minimum in middle age, and then rises after that age into old age, in line with results obtained by Blanchflower and Oswald (2004).
Overall our findings confirm that associations with individual characteristics analyzed in micro-econometric “happiness” regressions display similar structure across time and, whatever the model specification, the fitted regressions display similar patterns. For a more straightforward interpretation of the coefficients from now on we concentrate on the linear specification.
3.2 Do Personal Income and Unemployment Status have a Common Effect across Regions?
We now present the results of fitting a varying-intercept and varying-slope model (4) letting the coefficients of income and employment status vary by region.Footnote 8 From this new model, we find substantial variation across regions in the association of personal income with individual life satisfaction. Figure 5 shows the estimated income slopes for the European regions plotted versus a measure of the richness of a region, its GDP per capita. To give a visual impression of the relationships between the coefficients and the economic variables, we added in the graphs a nonparametric regression line.Footnote 9
Figure 5 reveals that, on average, personal income matters more in poor regions than in rich regions. The steeper slopes tell us that, controlling for basic socio-demographic characteristics, an individual living in a poor context is more likely to relate his subjective well-being to his own income. In other words, personal income is a better predictor for subjective life satisfaction in poorer regions than in rich regions. This evidence does not necessarily implies that a poor individual in a rich region feels less frustrated than a poor individual in a poor region, but this evidence can be related to the perspective of Inglehart (1990) and other scholars of postmaterialism, with life satisfaction in rich societies more related to non-materialistic issues.Footnote 10

Estimated regional income slopes β j in the varying-intercept varying-slope regression model plotted versus regional log of GDP per capita, purchasing power adjusted, 2001. The regional income slopes measure the association of individual income with life satisfaction within each region. The horizontal line represents the European average of the slopes. The curve shows lowess fits (Cleveland 1979)
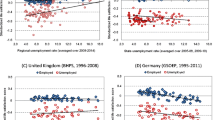
This pattern holds for almost all the countries for which we have enough regions, confirming the variability between regions within the same country. From the multilevel regression with varying intercepts and slopes, we display in Fig. 6, for a selection of countries, life satisfaction as a function of individual income. In each graph, the three (or four) lines represent the predicted values of life satisfaction as a function of income categories for three or four representative regions within the country: a rich region (in terms of per capita GDP), one or two middle income region and a (relatively) poor region. For each region in the plot, the circles show the relative proportion of individuals in each income category. Within the same country, we generally find a systematic pattern of the within-region slopes, with the steepest slope in the poorest region and the shallowest slope in the richest region: income is always positively correlated with life satisfaction, but it is a weaker predictor in rich regions and a strong predictor in poor regions. This is true for France, Italy and Spain. In United Kingdom, Northern Ireland is the only exception since its slope is flatter than expected. Germany and Greece do not display such a clear pattern since middle-income regions (Hessen for Germany and Kentriki Ellada for Greece) display the shallowest slope while the richest regions (Hamburg and Attiki) have the same slope as the poorest regions (Thuringen and Voreia Ellada).

Expected life satisfaction as a function of income categories, for a selection of European countries. For each country, the lines are based on the fitted varying-intercept and varying-slope linear model and refer to a rich region, middle income regions and a poor region. The circles show the relative proportion of individuals in each income category in each region. The richest regions in terms of per capita GDP are: London (UK), Comunidad de Madrid (Spain), Hamburg (Germany), Nord Est (Italy), Ile de France (France), Attiki (Greece). Middle income regions are: Scotland and Northern Ireland (UK), Este (Spain), Hessen (Germany), Centro (Italy), Est (France), Kentriki Ellada (Greece). The poorest regions are: Wales (UK), Sur (Spain), Thuringen (Germany), Sud (Italy), Nord-Pas-de-Calais (France), Voreia Ellada (Greece)
Figure 7 shows the estimated coefficients of model (4) associated with unemployment status plotted versus the unemployment rate of the regions. The negative effect on life satisfaction of being unemployed is strong in all regions (on average −0.22), with an estimated variability of 0.11. These estimated values indicate that the self-proclaimed well-being of an unemployment individual is much lower than the level of an employed individual with similar characteristics in each region. Since we are controlling for all the individual attributes, including individual income, these negative coefficients might be interpreted as “pure” effects of being unemployed: unemployed people suffer from high non-pecuniary costs beyond the expected drop in their income level.

Estimated regional coefficients β j for individual unemployment status in the varying-intercept varying-slope regression model plotted versus regional unemployment rate, 2001. The regional coefficients for individual unemployment status measure the association of being unemployed with life satisfaction within each region. The horizontal line represents the European average of the slopes. The curve shows lowess fits (Cleveland 1979)
According to a large body of economic literature of happiness (see, e.g., Frey and Stutzer 2002; Clark 2003), an environment with a large portion of people out of work should alleviate the unhappiness of being unemployed. When the reference group is the European subnational region, this thesis is not supported by our data. As reported in Fig. 7, unemployed regional coefficients do not reduce as regional unemployment rates increase. This evidence does not necessarily mean that there is no social psychological effect of being unemployed in an environment where the others are also unemployed, but our results are not in line with this hypothesis when the reference group is the region.
To go beyond the visual impression of Figs. 5 and 7, we verify the detected relationship by introducing GDP per capita and unemployment rate as contextual variables in the second level of the multilevel model (5). We model income coefficients and unemployment coefficients as a function of per capita GDP and unemployment rates, respectively, as exemplified in Eq. 3.
Starting with the equation of the income coefficients, in the upper panel of Fig. 8, we plot over time the estimated γ β of regional GDP.Footnote 11 From this model, we indeed find a systematic negative relation between the β j , the coefficients of personal income on life satisfaction, and the richness of the region measured by its per capita GDP, confirming that personal income matters more in poor regions than in rich regions.

Estimated γ β coefficients (±2 standard errors) for varying intercepts and slopes model (5) with per capita GDP and unemployment rate as regional predictors, fitted separately from 1997 to 2002
Considering the equation of the unemployment coefficients, we show in the lower panel of Fig. 8 the estimated γ β of regional unemployment rates. The estimated γ β’s are too close to zero to make any statement about the relation between being out of work and living in a region with high unemployment rate.
3.3 Do We Still Observe Differences across Regions?
The group-level equation in the multilevel model 4 shows that the regional intercepts, α j ’s have a substantial variability, with an estimated mean of 3.2 and standard deviation of 0.2. Each estimated intercept can be viewed as an indicator of regional residual attitude for life satisfaction, representing the variation across European regions that still remains even after controlling for individual observable characteristics. Starting from the assumption of normality for the α j ’s, moving from μ α −σ α to μ α +σ α increases the regional attitude to be satisfied with life by 0.42 points, an increment of 14%. This persistent variability remaining after controlling for personal socio-economic characteristics, indicates that life satisfaction disparities across European regions are still wide and need to be further investigated. A potential reason for the unexplained geographical differences is related to economic disparities across European regions. From this perspective we use the per capita GDP and the unemployment rate of each region as macroeconomic variables in (5) for modeling this unexplained regional-level variability of estimated life satisfaction.
To explore the association between the α j ’s and the macroeconomic context, we first plot the estimated regional intercepts against per capita GDP and unemployment rate at regional level. Figure 9 displays the estimated regional intercepts against regional (log) GDP per inhabitant at market prices in PPS. A positive relationship is clearly detected until a certain level, while the relationship seems to become almost irrelevant after a threshold. Note that richer areas are generally those with the largest cities that report low levels of life satisfaction. A conjecture is that, in those areas, other factors that go along with urban agglomeration, like mobility and commuting problems, unsafe environment and perception of unsafeness are negatively associated with the level of well-being. Overall, subjective well-being differences between rich and poor regions cannot be simply attributed to the aggregation of the effects of individual incomes. A different picture is detected by looking at the estimated regional intercept versus regional unemployment rates (Fig. 10). The clear negative correlation tells us that, even controlling for personal characteristics including unemployment status, individuals in higher unemployment areas tend to be less satisfied. People living in areas with high level of unemployment may fell unhappy, even if they are employed, since they worry about the possibility of becoming unemployed themselves in the near future and feel unsafe because of the potential increase of social tensions. Again, the low levels of life satisfaction in regions with high unemployment are not due to simple aggregation of unhappiness of the unemployed individuals.

Estimated regional intercepts α j in the varying-intercept varying-slope regression model plotted versus regional log of GDP per capita, purchasing power adjusted, 2001. The horizontal line represents the European average of the intercepts. The curve shows lowess fits (Cleveland 1979)

Estimated regional intercepts α j in the varying-intercept varying-slope regression model plotted versus regional unemployment rate, 2001. The horizontal line represents the European average of the intercepts. The curve shows lowess fits (Cleveland 1979)
A formal way to include regional macroeconomic variables as group-level predictors is to extend the varying intercepts and slopes model by explicitly modeling the α j , as formalized in model (5) and exemplified in Eq. 2. The estimated coefficients γ α of model (5) over time are plotted in Fig. 11. We add two more predictors that measure the disparity between the regional variable and its corresponding country value. The first variable is calculated as the ratio of the per capita GDP of region j and the per capita GDP of the country k where region j[k] belongs to. Analogously, unemployment disparity is the ratio of the regional unemployment rate and the respective country rate. The inclusion of these additional predictors help exploring the possibility of having also a country effect by measuring the discrepancies in GDP per capita (“GDP disparities”) and unemployment (“unemployment disparities”) that eventually turn out between regional and national levels. On average, the reduction of unexplained variability of the estimated α j ’s is slightly more than 10%.

Estimated γ α coefficients (±2 standard errors) for varying intercepts and slopes model (5) with per capita GDP, GDP disparities, unemployment rate and unemployment disparities as regional predictors, fitted separately from 1997 to 2002
The effect of per capita GDP is large and it remains fairly stable over time, confirming that this variable, when observed cross-sectionally, matters. Also the unemployment rate has a significant and sizeable effect, with the expected negative sign. Conversely, the coefficient of unemployment disparities is not statistically significant, indicating that what really matters is the regional unemployment rate rather than the corresponding national one. The coefficients of the GDP disparities, instead, are statistically significant but small in size. Their negative signs may imply that there is aversion to economic disparities within countries, that is people who live in richer areas of the country are aware of poor areas in their own country. When we study these macroeconomic variables with a time lag, the substantive conclusions remain the same.
4 Concluding Remarks
Our analysis on reported life satisfaction in Europe drawn from the Eurobarometer surveys has emphasized the relevance of regional disparities, between and within countries.
In accordance with the most important findings in the happiness literature, we have found that personal income is positively associated with the reported level of life satisfaction of individuals, controlling for observable socio-demographic personal characteristics. Personally experiencing unemployment, instead, markedly reduces life satisfaction, beside the indirect effect of income loss. These findings are robust to alternative specifications of the models and show a stable structure over time.
Our main findings are that personal income matters, generally, more in poor regions than in rich regions and this pattern still holds for regions within the same country. This evidence is in line with the theory of Post-materialism, being life satisfaction in rich societies more related to non-materialistic issues. From this perspective, it makes sense that life satisfaction is more about economics in poor regions and more about “culture” in rich regions. And it also makes sense that, among low-income individuals, reported level of well-being are not much different in rich and poor societies, whereas the cultural differences between rich and poor societies become larger for the upper-middle class.
We also have found no evidence that dissatisfaction of being unemployed is lower in regions where jobs are scarse and the opportunities of being re-employed are less. This evidence does not support the hypothesis that individual unhappiness of being out of work is influenced by local social standards (Warr and Jackson 1987), that is personal impact of unemployment is alleviated in areas where unemployment is a typical condition.
Even after controlling for individual characteristics and different effects of income and employment status across regions, we have found that the unexplained regional-level variability of the estimated life satisfaction is still high, indicating that geography still matters considerably.
The introduction in the model of regional per capita GDP and unemployment rate reduces this variability by around 10% steadily over time and their effects are large and stable. This evidence shows that these macroeconomic variables may help explaining differences in reported subjective well-being across regions, but also other factors may be equally or more influent. Since we have controlled for the personal level of income and employment status and possible interactions, the effects of per capita GDP and unemployment rate go beyond the simple aggregation of individual incomes and individual unemployment status. Unemployment reduces life satisfaction also in individuals who are not out of work. This may be due to the perception of an increasing risk of loosing a job or of being trapped in the job one has, but also to aversion to social inequality. Regional per capita GDP, at least cross-sectionally, also matters. Per capita GDP is positively correlated with several others factors that could affect life satisfaction. It is well documented that in Europe GDP per capita is highly correlated with levels and quality of basic facilities and services, such as transportation and communications systems, and with levels and quality of public institutions like schools and hospitals, as well as with low levels of crime and corruption (Tanzi and Davoodi 2000). These factors might explain the size of the effect of regional GDP on happiness.
To account for country effects, we have also included indicators of disparity between the regional and the corresponding national per capita GDP and unemployment rate. It turns out that the effects of these macroeconomic regional variables largely sweep off the effects that the corresponding country variables have on reported life satisfaction. Factors affecting the subjective well-being are essentially local. An interesting progression of this research would be to further disaggregate the territorial units, moving from the first level of NUTS to the second or third level, also including the new EU members.
The technique of multilevel models has given us a natural framework for understanding these patterns and for modeling hierarchical data, individual characteristics within European regions. With respect to traditional alternatives, multilevel modeling has allowed us to estimate differences between large number of groups (in terms of variation between groups) and to analyze data coming from different sources inside the same model.
Notes
A notable exception is the recent analysis of regional well-being in Europe by using European Social Survey data of Aslam and Corrado (2007).
Because of data deficiencies, Sweden and Finland are considered as whole countries and the French Départements D’Outre-Mer are excluded.
These findings are in accordance to the ones obtained by Scoppa and Ponzo (2008) who used data on Italians subjective well-being from the Bank of Italy Survey of Household Income and Wealth.
Estimates of the models are obtained by the lmer function in R (R Development Core Team 2006) and are based on the restricted maximum likelihood procedure (REML). The REML procedure corrects the downwards bias of the maximum likelihood estimator of variance components related to the lost of degrees of freedom in estimating the fixed effects. The name lmer stands for linear mixed effects in R but the function works also for generalized linear models. However some technical challenges exist in fitting multinomial models in a multilevel framework. Therefore, for the ordered logit model we use the classical no-pooling regression. The term “mixed effects” refers to random effects (coefficients that vary by group) and fixed effects (coefficient that do not vary) (Gelman and Hill 2007).
As pointed out by, e.g., Di Tella et al. (2003) and Frey and Stutzer (2006), estimated effects should be treated with caution since some personal characteristics can be considered endogenous. Moreover if unobserved personal traits influence reported life satisfaction, results suffer from potential bias.
Due to data availability in the European regional data set we use in models with more complex multilevel structure, we report for coherence the results of the fitting for the period 1997–2002. However, we did not find any significant difference when we use the Eurobarometer data expanding the period backward to 1992. Detailed results of the fitted models are available upon request from the authors.
Income is treated as a continuous variable and centered to reduce the correlation between group-level intercepts and slopes. We allow the coefficients of each employment category to vary. In line with our goal, results are focused only on the unemployment status.
We implemented the weighted local polynomial regression (LOWESS, LOcally WEighted Scatterplot Smoother), as proposed by Cleveland (1979). As Cleveland discusses, rather than calculating one regression line for an entire dataset, one calculates regression estimates for overlapping sets of x values. To find smoothed values, the procedure fits n polynomial regressions to the data, one for each observation j, including the points with x-values that are near x j . We implemented this model in R by choosing an appropriate smoothing span that gives the proportion of points in the plot which influence the amount of smoothing at each value. The choice of the LOWESS procedure among other possible approaches of “smoothing” relies on its robustness to the presence of outliers.
Adding per capita GDP in the model for the whole period (1997–2002) is problematic as a potentially non stationary predictor (the GDP) is introduced to explain an outcome that is naturally stationary (the life satisfaction rated on a four-point scale). Therefore, the estimated coefficients may be “unpersuasive” due to the inapplicability of conventional statistical procedures (Di Tella et al. 2003). The (stochastic) trend of the non stationary variable will in fact dominate all other variations. To overcome this problem we prefer to model the time-series structure of our dataset repeating the model year-by-year. The method of repeated modeling, followed by time-series plots of estimates is rarely used as a data analytic tool but it can be very informative and easy to understand.
References
Alesina, A., Di Tella, R., & MacCulloch, R. (2004). Inequality and happiness: Are Europeans and Americans different. Journal of Public Economics, 88, 2009–2042.
Aslam, A., & Corrado, L. (2007). No man is an island: The inter-personal determinants of regional well-being and life satisfaction in Europe. Cambridge Working Paper in Economics, CWPE 0717.
Bertrand, M., & Mullainathan, S. (2001). Do people mean what they say? Implications for subjective survey data. American Economic Review, 91, 67–72.
Blanchflower, D. G., & Oswald, A. J. (2004). Well-being over time in Britain and the USA. Journal of Public Economics, 88, 1359–1386.
Clark, A. (2003). Unemployment as a social norm: Psychological evidence from panel data. Journal of Labor Economic, 21(2), 323–351.
Clark, A., & Oswald, A. J. (1994). Unhappiness and unemployment. Economic Journal, 104, 648–659.
Cleveland, W. S. (1979). Robust locally weighted regression and smoothing scatter plots. Journal of American Statistical Association, 74, 829–836.
Diener, E. Sandvik, E., Seidlitz, L., & Diener, M. (1993). The relationship between income and subjective well-being: Relative or absolute? Social Indicators Research, 28, 195– 223.
Di Tella, R., MacCulloch, R., & Oswald, A. J. (2001). Preferences over inflation and unemployment: Evidence from happiness surveys. American Economic Review, 91(1), 335–42.
Di Tella, R., MacCulloch, R., & Oswald, A. J. (2003). The macroeconomics of happiness. Review of Economics and Statistics, 85, 809–827.
Easterlin, R. A. (1974). Does economic growth improve the human lot? Some empirical evidence. In P. David & M. Reder (Eds.), Nations and households in economic growth. New York: Academic Press.
European Commission. (2008). A new partnership for cohesion convergence competitiveness cooperation. Third report on economic and social cohesion.
Ferrer-i-Carbonell, A., & Frijters, P. (2004). How important is methodology for the estimates of the determinants of happiness? Economic Journal, 114, 641–659.
Frey, B. S., & Stutzer, A. (2000). Happiness, economy and institutions. Economic Journal, 110, 918–938.
Frey, B. S., & Stutzer, A. (2002). Happiness and economics: How the economy and institutions affect human well-being. Princeton: Princeton University Press.
Frey, B. S., & Stutzer, A. (2006). Does marriage make people happy, or do happy people get married. Journal of Socio-Economics, 35(2), 326–347.
Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge: Cambridge University Press.
Gelman, A., Park, D. K., Shor, B., Bafumi J., & Cortina G. (2008b). Red state, blue state, rich state, poor state: Why Americans vote the way they do. Princeton: Princeton University Press.
Gelman, A., Shor, B., Bafumi, J., & Park, D. (2008a). Rich state, poor state, red state, blue state: What’s the matter with Connecticut? Quarterly Journal of Political Science, 2, 345–367.
Graham, C., & Felton, A. (2006). Inequality and happiness: Insights from Latin America. Journal of Economic Inequality, 4(1), 1569–1721.
Inglehart, R. (1990). Culture shift in advanced industrial society. Princeton: Princeton University Press.
Kahneman, D., & Krueger, A. B. (2006). Developments in the measurement of subjective well-being. Journal of Economic Perspectives, 20(1), 3–24.
Krueger, A. B., & Schkade, D. A. (2007). The reliability of subjective well-being measures. NBER Workin Paper No. 13027.
Layard, R. (2005). Happiness: Lessons from a new science. New York: Penguin Press.
Longford, N. T. (2007). Missing data and small-area estimation. New York, NY: Springer-Verlag.
Oswald, A. J.(1997). Happiness and economic performance. Economic Journal, 107, 1815– 1831.
Pittau, M. G., & Zelli, R. (2006). Empirical evidence of income dynamics across EU regions. Journal of Applied Econometrics, 21, 605–628.
R Development Core Team. (2006). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
Schmitt, H., & Scholz, E. (2005). The Mannheim Eurobarometer Trend File, 1970–2002 [Computer file]. Prepared by Zentralarchiv fur Empirische Sozialforschung. ICPSR04357-v1. Mannheim, Germany: Mannheimer Zentrum fur Europaische Sozialforschung and Zentrum fur Umfragen, Methoden und Analysen [producers]. Cologne, Germany: Zentralarchiv fur Empirische Sozialforschung/Ann Arbor, MI: Inter-university Consortium for Political and Social Research [distributors].
Scoppa, V., & Ponzo, M. (2008). An empirical study of happiness in Italy. B. E. Journal of Economic Analysis and Policy, 8(1) (Contributions), article 15.
Snijders, T. A. B., & Bosker, R. J. (1999). Multilevel analysis. London: Sage.
Tanzi, V., & Davoodi, H. R. (2000). Corruption, growth and public finances. IMF Working Paper No. 182.
Veenhoven, R. (2007). World database of happiness, distributional findings in nations. Rotterdam: Erasmus University.
Warr, P. B., & Jackson, P. (1987). Adopting to the unemployed role; a longitudal investigation. Social Science Medicine, 25, 1219–1224.
Wilkinson, W. (2007). In pursuit of happiness research. Is it reliable? What does it imply for policy? Policy Analysis, 590, 1–41.
Winkelmann, L., & Winkelmann, R. (1998). Why are the unemployed so unhappy? Economica, 65(257), 1–15.
Acknowledgments
The authors thank the Columbia University, Applied Statistics Center, and the National Science Foundation and National Institutes of Health for financial support. They also acknowledge Sapienza, University of Rome, for financial assistance under grant number C26F07R754. They would like to thank an anonymous reviewer and participants of the XXX IARIW conference, Portoroz, Slovenia, August 2008, for their precious comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
About this article
Cite this article
Pittau, M.G., Zelli, R. & Gelman, A. Economic Disparities and Life Satisfaction in European Regions. Soc Indic Res 96, 339–361 (2010). https://doi.org/10.1007/s11205-009-9481-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-009-9481-2