
Abstract
This paper develops an empirical methodology for the construction of a synthetic multi-dimensional cross-country comparison of the performance of governments around the world in improving the livelihood of their younger population. The devised ‘Youth Welfare Index’ is based on the nonparametric Data Envelopment Analysis (DEA) methodology and allows for cross-country benchmarking and comparison over time. The value added of the youth index is to produce country-specific rankings and trace performance evolution with respect to indicators solely centered on youth, unlike other development indicators like the Human Development Index (HDI) which bundles many social and development indicators.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The use of social indicators in the world, like the UN’s Human Development Index (HDI) or the EU’s Social Inclusion indicators has been evolving rapidly in recent years, and they are coming to play an increasingly important role in monitoring and comparing international and national performance and progress towards shared development goals.Footnote 1 Recently issues related to youth development have taken center stage around the world, as many developing countries are currently faced with their largest youth cohort in modern history. Young men and women in these countries are facing increased social exclusion and marginalization, with rising unemployment rates, higher exposure to health risks and a precarious educational system. The development of a Youth Welfare Index is therefore timely and necessary, given the state of exclusion young women and men are facing in the world. Yet the construction of such an index is a difficult task which requires clear and agreed upon methodological principles, and the compilation of data specialized in Youth development in a regular manner.
This paper presents a methodology for the construction of a ‘Youth Welfare’ composite index; a methodology for cross-country benchmarking and also comparison over time. This methodology is inspired by new developments in the field of robust rankings of multi-dimensional performance (Zaim et al. 2001; Atkinson 2003; Cherchye and Kuosmanen 2004); which was recently applied to social inclusion performance in the EU in Cherchye et al. (2004). These new developments were largely initiated after dissatisfaction with the way many social development indicators, especially the United Nations’ Human Development Index (HDI), rank countries relative to their performance. In effect, the HDI takes several dimensions—income, school enrollment and literacy rate, longevity—and combines them into a single figure that measures the degree of development of a given country. However, there is disagreement about (i) how to normalize the scores for the different criteria to make them comparable and (ii) how to aggregate the (normalized) scores over the different criteria. Obviously, changes in normalization and/or aggregation will affect the country rankings. There was a need therefore for robust rankings, i.e., rankings which hold for a wide set of normalization and/or aggregation procedures.
Zaim et al. (2001) provide a useful alternative to the HDI with desirable axiomatic properties. Also, they propose an improvement index, which alleviates difficulties associated with comparisons of HDI overtime (the HDI is by construction designed to measure performance at a point of time rather than being a measure of over-time comparisons). The approach is known as the economic approach to index number theory and relies on the assumptions of optimizing behavior. While deriving the achievement index, the authors heavily rely on the theory of quantity indexes whose axiomatic properties are well established. The roots of their improvement index on the other hand are well grounded in the productivity growth literature. The proposed indexes in Zaim et al. (2001) improve upon the empirical literature on social indicators in two aspects. First, unlike the previous studies which typically produce a synthetic indicator which aggregates over its constituents using artificially assigned weights, their approach implicitly recognizes the underlying production process which transforms inputs into private and social goods. The success of country “i” in the provision of social goods with respect to another country “j” is evaluated by measuring the distance of both countries with respect to a common benchmark, i.e., a best practice technology in the provision of social and private goods. The best practice technology is constructed over the observations on inputs, social goods and private goods, using the now widely known technique of Data Envelopment Analysis (DEA). Thus, while providing an economic content to social indicators, the authors exploit the aggregator characteristics of distance function that aggregate over the components with optimally chosen weights determined by the data. Second, the approach that is based on axiomatic production theory allows constructing an improvement index, which measures the success of a particular country in expanding its social goods from 1 year to another.
2 Empirical Methodology for the Static ‘Youth Welfare Index’
A satisfactory Youth Welfare Index would allow having a synthetic multi-dimensional cross-country comparison of the performance of governments around the world in improving the livelihood of their younger population. Yet at least two constraints make this endeavor difficult: first, data availability on youth-related fields in countries around the world is a major issue. If one were to estimate the cost of youth exclusion, he/she would have to gather a vast array of variables; and if one of them is missing then the country has to be dropped out of the full analysis. Second some researchers or policymakers might argue that one field is more important than the other, and therefore might require an extra weight assigned to it. Assigning random weights to each field of youth exclusion is not accurate, and one would therefore want a methodology that unequally weights the different youth inclusion objectives, with the weight of each objective being determined by the priority that is given to it. Data Envelopment Analysis (DEA) appears particularly well suited to obtain such an outcome. It allows for a full comparison among countries on the basis of their relative performance. The empirical methodology to construct the Youth Welfare Index builds on recent innovative uses of DEA in Cherchye and Kuosmanen (2004) to estimate the aggregate costs of youth exclusion, and compute estimates across Middle East countries.
Data Envelopment Analysis (DEA) uses piecewise linear programming to calculate the best-practice frontier for a sample of decision-making units (DMUs). This technology frontier also envelopes the less efficient units, with the distance between these units’ positions and the calculated frontier providing an indicator of their relative inefficiency. DEA models can be input or output oriented. Input-oriented models typically seek to answer the following question: “By how much can input usage be proportionally reduced without changing the output quantities produced?” On the other hand, output-oriented models deal with the question: “By how much can output levels be proportionally expanded without modifying the input quantities used?” DEA has been mainly used to evaluate the relative efficiency of productive firms, yet recently its use has been expanded to cover the measurement of efficiency in hospitals, universities, political campaigns and human development.
In the context of cross-country comparison of the costs of youth exclusion, we model countries as decision-making units producing a set of ‘outputs’ linked to youth exclusion by using a set of ‘inputs’ linked to investments in human capital.
The theoretical model underlying the estimation procedure, which is based on the axiomatic approach to modeling the production technology, is shortly discussed below. More details on this methodology can be found in Färe et al. (1994). Let \( x \in \Re_{ + }^{N} \) denote a vector of inputs and \( y \in \Re_{ + }^{M} \) the resulting output vector. Assume that there are \( k = 1, \ldots ,\;K \) countries so that the data is given by \( (x^{k} ,\;y^{k} ),\;k = 1, \ldots ,\;K \). There are, among others, two equivalent ways to express the type of reference technology to be evaluated: the Input Requirement Set L(y), which shows all the combinations of inputs that can be used to produce the output vector y; and the Output Possibility Set P(x), which shows all the combinations of outputs that can be produced by the input vector x. Only P(x) is considered in this present exposition.
The Farrell Output-Oriented Measure of Technical Efficiency is formally defined by: \( F_{0} (x,\;y) = \max \left\{ {\theta :\theta y \in P(x)} \right\} \) where P(x) is the output possibility set. Inefficient countries have output efficiency scores greater than one, and efficient countries have scores equal to one. Therefore, a country is technically output efficient if: \( F_{0} (x,\;y) = 1 \). Otherwise, the country is technically output inefficient. For example, a country with a score of 1.40 could increase its output by 40% if it were operating on the best practice frontier.
In the context of youth welfare and exclusion, we seek to model the ‘production’ of human capital by countries using a set of inputs. The question we seek to answer is: “If a country is using a given set of resources, by how much can it reduce youth exclusion compared to the ‘best practice’ technology in reducing youth exclusion?” The DEA programming model helps to construct such a frontier, and assign a score for each country indicating how far it lies from this hypothetical benchmark. Since youth exclusion carries a set of undesirable outcomes, the output and input sets have to be modified in a way to capture the optimization problem of minimizing a set of undesirable outputs given a set of inputs. This is done by inverting the maximization problem into an input-oriented DEA model, by simply substituting undesirable outputs for inputs to minimize and writing fixed inputs as outputs (the mirror procedure of the one exposed above).
The individual country scores obtained under this methodology would allow situating this country relative to the best-practice frontier in reducing youth exclusion. Yet a central issue remains in the choice and number of youth exclusion variables to include in the construction of this score (since inputs can be more or less constant). The idea here is that we can include many variables, even if they are in different units or measure different things. The advantage of the non-parametric DEA approach is that it is very flexible with regards to multi-output and multi-input treatments. Data availability will be therefore the main constraint researchers will face when constructing a broad index, as the more variables are included the less likely all countries will be represented in the sample.
3 Empirical Methodology for the Dynamic ‘Youth Welfare Improvement Index’
The dynamic ‘Youth Welfare Improvement Index’ is an extension of the static Youth Index, by using the widely known technique of the Malmquist index. This index is based on the same concept of distance functions, and is also computed with DEA. In this section we present the Malmquist productivity index between periods t and t + 1. Let x t represent the input vector, \( x^{t} = \left( {x_{1}^{t} , \ldots ,\;x_{m}^{t} } \right), \) and y t represent the output vector \( y^{t} = \left( {y_{1}^{t} , \ldots ,\;y_{n}^{t} } \right), \) in time period \( t = 1,2, \ldots ,\;T. \) The Malmquist productivity index between periods t and (t + 1) can be defined as
where D represents the inverse of the distance function introduced by Caves et al. (1982), computed with Data Envelopment Analysis.
M is the geometric mean of two ratios of input inverse distance functions. The first ratio represents the period t Malmquist index; it gives a measure of productivity change from period t to period (t + 1) using period t technology as a benchmark. The second ratio is the period (t + 1) Malmquist index and gives a measure of productivity change from period t to period (t + 1) using period (t + 1) technology as a benchmark. M > 1 means that period (t + 1) productivity is greater than period t productivity, whilst M < 1 means productivity decline and M = 1 corresponds to stagnation.
M is a local index; its value can vary across observations and between different adjacent time periods. Thus, some countries may exhibit an increase and others may exhibit a decrease in technical efficiency relative to reducing youth exclusion, and this can change over time. This feature allows considerable flexibility in explaining the observed pattern of productivity change, both across countries and over time.
The estimation of the dynamic ‘Youth Welfare Improvement Index’ is closely linked to having a comprehensive set of ‘output’ and ‘input’ variables to model the reduction in youth exclusion technology; however the necessity to have several time periods imposes a balanced data condition on the sample to be used.
4 Empirical Estimation with Selected Indicators
In this section a simulation is undertaken for the two indicators developed above. Comprehensive cross-country data linked to youth exclusion is available only for three fields: youth unemployment, school dropouts and adolescent fertility rates. We consider these three fields as the (negative) outputs that countries which to minimize. For inputs, we use gross cumulative fixed capital formation as a share of GDP as a proxy for a country’s overall economic investment level; the youth labor force participation rate as a proxy for a country’s youth labor input; and public education and health total expenditures as a share of GDP as proxies for public investment in human capital. We seek to capture through these inputs the macroeconomic factors that closely affect youth exclusion, as we don’t have specific data by country on investments in youth-linked initiatives. Moreover, to estimate the evolution of the cross-country costs of youth exclusion over time, we need data on all of these variables to be available for most countries in several time periods. Data from the World Development Indicators, the IMF’s Global Financial Statistics and the Penn World Tables allowed to recover a homogeneous sample of 59 countries grouped in two time periods each spanning 2 years: 2000–2002 and 2003–2005. The ON FRONT® software designed by Färe and Grosskopf (2000) is used to obtain the non-parametric results derived in this section.
Table 1 below shows the empirical results for both time periods, indicating for each country its rank relative to the best practice frontier in reducing youth exclusion, the change in its rank from period to the next, and the Youth Welfare Improvement Index (YWII) value for each country. For example, Saudi Arabia was ranked 39 in the first period, and dropped to rank 57 in the second time period among 59 countries, thus loosing 18 places. Its YWII dropped by −5% during the same time period.
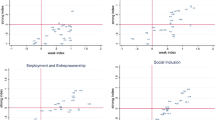
Figure 1 below shows the correlation between the devised Youth Index (YI) for the countries included in the sample and the Human Development Indicator (HDI), by correlating the ranking of countries in the two indices. Countries on the 45° line have the same rank under both indices. The correlation shows that both indices are generally related, i.e. they tend to rank countries in a consistent manner. This is due to the fact that the HDI contains many elements of the YI. Yet some countries may perform better under the HDI than the YI, or the reverse. Notice in Fig. 1 that Saudi Arabia achieves a better rank under the HDI than the YI, while Iran has a lower rank under the HDI than the YI. Countries can therefore be performing better in their overall economic, social and environmental development; yet be in a situation where youth development is still problematic.

Correlation between rankings under the youth index (YI) and the human development indicator (HDI) in 2005
5 Conclusion
The value added of the youth index presented in this paper is to produce country-specific rankings and trace performance evolution with respect to indicators solely centered on youth, unlike other development indicators like the HDI which bundles many social and development indicators together. This paper has shown that the production of a youth exclusion index should be done using a nonparametric methodology, which allows for the compilation of various exclusion variables into the index through statistical rather than subjective weights. This paper has also shown that Data Envelopment Analysis (DEA), by constructing a nonparametric benchmark frontier using ‘output’ and ‘inputs’ of youth exclusion ‘technology’, can be used to obtain a timely and informative youth exclusion index, by offering the following advantages: (1) DEA provides an indication of the required efforts a country should make to reach the ‘best-practice frontier’ for reducing youth exclusion; (2) DEA provides ranking for countries in a given period and evolution from period to period; (3) the method is easy to implement. Yet the DEA methodology also imposes several constraints which should be highlighted: (1) Heavy data requirements: the index requires matching ‘outputs’ with ‘inputs’ for a balanced sample of countries, this sample remaining stable throughout the time periods; (2) Data limitations mean that the index cannot be constructed on a yearly basis; (3) Matching ‘outputs’ with ‘inputs’ would potentially exclude variables from this index (like perception-based variables).
As a comparison with the HDI, the youth index eventually will contain some sub-components of the HDI, and therefore rankings for a given year are close for the two indices. However policies affecting these two indices differ greatly, and therefore the evolution of rankings might differ over time. It is equally likely that some countries which score better in youth-related policies fail in other development indicators, and the opposite also applies.
Notes
See Atkinson et al. (2004) for an extensive discussion of the EU’s social inclusion indicators.
References
Atkinson, A. B. (2003). Multidimensional deprivation: Contrasting social welfare and counting approaches. The Journal of Economic Inequality, 1, 51–65. doi:10.1023/A:1023903525276.
Atkinson, A. B., Marlier, E., & Nolan, B. (2004). Indicators and targets for social inclusion in the EU. Journal of Common Market Studies, 42(1), 47–75. doi:10.1111/j.0021-9886.2004.00476.x.
Caves, D. W., Christensen, L. R., & Diewert, W. (1982). The economic theory of index numbers and the measurement of input. Output and productivity. Econometrica, 50, 1393–1414. doi:10.2307/1913388.
Cherchye, L., & Kuosmanen, T. (2004). Benchmarking sustainable development: A synthetic meta-index approach. In M. McGillivray (Ed.), Perspectives on inequality, poverty and human well-being. Tokyo: United Nations University Press.
Cherchye, L., Moesen, W., & Van Puyenbroeck, T. (2004). Legitimately diverse, yet comparable: Synthesizing social inclusion performance in the EU. Journal of Common Market Studies, 42(5), 919–955. doi:10.1111/j.0021-9886.2004.00535.x.
Färe, R., & Grosskopf, S. (2000). Reference guide to On Front, EMQ. www.emq.com.
Färe, R., Grosskopf, S., & Lovell, C. K. (1994). Production frontiers. Cambridge: Cambridge University Press.
Zaim, O., Fare, R., & Grosskopf, S. (2001). An economic approach to achievement and improvement indexes. Social Indicators Research, 56, 91–118. doi:10.1023/A:1011837827659.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Chaaban, J.M. Measuring Youth Development: A Nonparametric Cross-Country ‘Youth Welfare Index’. Soc Indic Res 93, 351–358 (2009). https://doi.org/10.1007/s11205-008-9328-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-008-9328-2