
Abstract
Scientific collaboration is getting tremendous attention from scholars and becoming the most common way of producing research works from different disciplines, enabling them to solve complex problems. Nevertheless, when the number of collaborators increases in research work, it becomes challenging to single out and recognize one scholar who contributes the most to the collaboration team of multiauthored publications. Hence, determining an influential author either from multiauthored papers or co-authorship networks is an interesting research problem. To address these problems, we develop a citation and similarity-based author ranking method, namely CLARA, that captures the influential author in multiauthored publications. The method considers attributes of publications such as citing papers and co-cited papers and similarity between publications. Firstly, the method computes the contribution of the co-authors in a given paper by employing fractional counting metrics. Secondly, it computes the contextual similarity between the given paper and its co-cited papers. Finally, the method ranks each co-author using the mathematically defined metric, called KeyScore, and discovers the “key” author among the co-authors of the given paper. We validate our method by extracting the papers of the “Chinese Outstanding Youth” winning researchers from the Microsoft Academic Graph dataset. The experimental results show that the CLARA method performs well in identifying key authors accurately and effectively, despite the position of the authors in the author list of their corresponding papers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Scientific research has become complicated and challenging for solo authors to produce high-quality research output. Dong et al. (2017) found that between the 1990s through 2000s, the productivity of solo authors declined by 50% in terms of the average number of publications they provided. In addition, solo-authored publications received fewer citations in contrast to those with two or more co-authors. Hence, scientific collaboration, where two or more authors collaborate on a research publication, is getting tremendous attention from scholars and becoming the most common and crucial mechanism connecting dispersed knowledge and expertise to new ideas and venues (Li et al., 2022; Yu et al., 2021). Scientific collaboration embraces the capability of tackling large and complex research problems (DeHart, 2017; Xia et al., 2017). Moreover, it increases the impact of scientific outcomes due to its cross-disciplinary characteristics (Turner & Baker, 2020). Fortunato et al. (2018) discussed the advantages of team-based research works, indicating that a collaboration of scientists from different disciplines increases novelty, visibility of the research work amongst separate connections of each collaborator, as well as knowledge production. However, when establishing scientific collaboration in a cross-disciplinary research approach, one has to deal with several issues such as the overall structure of the collaboration (Guan et al., 2016), the evolution of collaboration (Coccia & Wang, 2016), its impact on knowledge production as well as the quality of the research works (Wu et al., 2019), the ranking and identifying of suitable collaborators (Alshareef et al., 2019; Kong et al., 2016; Xia et al., 2019), and how long researchers maintain their collaborations (Kong et al., 2019; Yu et al., 2019).
As scientific collaboration trends are emerging, the average number of co-authors in a paper is increasing. As a result, assigning credits to each author in multiauthored articles becomes a challenging task that needs further investigation (Bai et al., 2020; Zhang et al., 2020). Furthermore, determining an influential author either from multiauthored papers or co-authorship networks is equally an interesting research problem (Ren et al., 2019; Xia et al., 2020). One of the ways to capture a scientific collaboration is in the form of a co-authorship network (Saberi et al., 2022). A co-authorship network (—an author-to-author relationship that contains a combination of nodes and edges) is beneficial for analyzing the processes that form the scientific collaboration community (Sachmpazidi et al., 2021; Yu et al., 2017). In a co-authorship network, nodes and edges indicate researchers and their joint publications, respectively. Researchers form a connection if they have one or more research works together. Besides, citation networks can also be considered the primary evaluation measurement of scientific productivity as well as authors’ academic status in a scientific community (Cai et al., 2019). A citation network is a directed network that comprises a collection of publications that are connected by citation relationships (i.e., paper-to-paper connections). For instance, when a paper \(a_i\) cites a paper \(a_j\), they can form a citation network by putting an arrow from \(a_i\) to \(a_j\). From a citation network, data related to the citation information of authors, citing papers, and co-cited papers can be extracted. For example, how many citation counts an author has in each of his/her papers, how a paper is contextually related to its citing (—papers that have cited a given paper) and co-cited papers (—papers that have been cited by citing papers (see “Methods” section for details).
Several methods have been proposed to tackle credit allocation and influential author identification problems by considering different scenarios. There exist some simple but popular methods that are used to identify central nodes from different types of networks, such as PageRank, CiteRank (Walker et al., 2007), HITS (Han et al., 2011), the classical centrality measures proposed by Freeman (Knoke & Yang, 2019), and “h-index” (Schubert, 2011). Nonetheless, these methods come up with limitations when adopting them solitary for ranking and identifying influential authors. For example, in the case of degree centrality measure, some authors could have a large number of collaborators (i.e., degree) but a smaller citation counts due to the quality of their papers. Another example is citation counts, some senior researchers might have larger citation counts, but they might not be active in academia anymore. So, for such and similar scenarios, individually adopting these well-known methods is not optimal. There are many works proposed to alleviate this problem. For example, Zhang et al. (2016) proposed ScholarRank, which takes into account citation counts of scholars, mutual impact amongst co-authors, and communal reinforcement process that occurs between varieties of nodes in a heterogeneous academic network. Shen and Barabási (2014) proposed a method that assigns credit to each co-author in a multiauthored paper. The method by Shen and Barabási considers the citation details of a given paper. It also analyzes the contributions of co-authors by adopting fractional counting metrics to allocate credit for each author in a paper.
Ranking authors or assessing the contribution of authors to a scientific community or a particular research activity provides the potential to easily identify influential researchers who have a higher reputation in the community (Kong et al., 2020; Xia et al., 2019). On top of that, designing influential authors identification models benefit researchers to choose as well as recommend collaborators in accordance with their requirements. Henceforth, this paper specifically focuses on author ranking issues, the discovery of an influential author, and the allocation of credit to co-authors based on their contribution to particular research work.
Most of the existing methods focus on the connection strength of the authors. However, they did not consider the importance of citations and similarity scores between the citing and co-cited papers of a given paper to rank authors. Therefore, a Citation and simiLarity bAsed authoR rAnking called CLARA, which identifies the most influential author from a subnetwork, is proposed. The subnetwork will be extracted from a given co-authorship network, a collaboration formed among co-authors of a single paper. The influential author in scientific collaboration is named the “most influential” or “key” author; thus, the terms are used interchangeably throughout this paper.
Unlike many existing methods, the proposed algorithm simultaneously considers citation information and similarity scores between two papers as important parameters for ranking and identifying key authors. The proposed method first uses a citation network to address the issue of the author ranking problem. Citation attributes such as citation counts, number of citing papers, and number of co-cited papers of a given paper play significant roles in identifying an influential author (Liu et al., 2019b). As citing or referencing others’ work indicates the importance of the cited paper (Chang et al., 2019), it is crucial to analyze citation-related attributes for the author ranking problem. Besides, the citation network illustrates how the authors of each cited article have influenced the contributions of the citing authors (Kataria et al., 2011; Tu et al., 2010).
The second method is computing the contextual similarity between the given and the co-cited papers. The intuition of computing similarity is that if the two papers have maximum similarity scores, it is an indication that the authors in the paper are influential. In other words, the authors are experts in that particular area of research. For instance, given a research article by the well-known researcher Mark NewmanFootnote 1 on the topic “Community structure”, Mark Newman has plenty of papers on this research topic but with different research objectives. The similarity between his papers on this topic would be high; hence the researcher is considered as an expert and influential author in that particular research topic. In this work, it is assumed that the similarity between papers does not indicate the duplication of research works; instead, it tends to indicate the authors’ specialties.
In order to validate the effectiveness of the proposed approach, the authors designed an evaluation strategy that incorporates the Microsoft Academic Graph (MAG)Footnote 2 (Wang et al., 2019b) dataset. The dataset contains some crucial parameters such as a list of co-authors, a list of papers, citation counts, citing papers, co-cited papers, and the “h-index” of each author in the network.
The contributions of this paper are summarized as follows:
-
Proposed a citation and similarity-based author ranking approach called CLARA.
-
Constructed a matrix for author contribution by adopting the authors’ credit allocation metric called fractional counting.
-
Computed the level of contextual similarity between papers.
-
Designed a metric called KeyScore that enables to rank authors in a multiauthored paper.
The remaining parts of this paper are organized as follows. The “Related works” section describes existing methods in author ranking, credit allocations, and similarity-based methods. The “Materials and methods” section gives a detailed explanation about the proposed method (i.e., CLARA) and details of the experimental settings. Analysis of the results is discussed in the “Results and discussion” section. Finally, the “Conclusion” section presents the conclusion of the proposed approach and indicates possible future directions.
Related works
This section discusses three different concepts relevant to the proposed approach. These are
-
(i)
authors ranking methods,
-
(ii)
author credit allocation approaches, and
-
(iii)
topic modeling approaches that hold the potential to check similarity between two documents (e.g., research articles).
Author ranking methods
At the current time of scientific development, we are witnessing that quantifying the influences of scientists along with their research works has gained substantial enhancements (Liu et al., 2019a; Sarli & Carpenter, 2014). Quantifying the number of publications is one of the metrics used to measure the degree of influence of scholars or authors. Nevertheless, this may not give fair recognition to authors who have fewer but influential research works. Several researchers have proposed methods by integrating numerous relationships between authors and papers, like assessing authors’ influences and ranking them through co-citation relationships between papers as well as authors. Also, author ranking can be materialized by employing different approaches using different features as weights. As discussed extensively in Amjad et al. (2018), most ranking methods are a combination of different methods. For instance, Zhao et al. (2019) proposed a random-walk-based ranking approach named Author-PageRank (APR), which is implemented on a heterogeneous network that combines author and paper citation networks. In this work, they only considered papers that have cited older papers (e.g., papers published five, ten, or more years before the citing paper); and they attempted to overcome the problem of an acyclic network by forming connections between authors and papers.
Farooq et al. (2017) proposed a method which is an extension of the g-index (Egghe, 2006), namely DS-Index. DS-Index takes citation patterns of the publications of authors into consideration for distinctively ranking authors. In another work, Zhang et al. (2019) integrated a weighted bibliometric network and propagation algorithm and presented a ranking method called W-Rank. W-Rank allots weight to the connections of authorship and citation networks by assessing the relevance of citations and contributions of the authors. Unlike other ranking methods, Zhang et al. (2019) employed network-based and semantic-based approaches to quantify the citation relevance.
Usmani and Daud (2017) proposed an iterative ranking algorithm by taking into account in-links and out-links (—a paper gets in-links when it is cited by other papers and gets out-links when it cites other papers) of publication along with the venue where the article is get published. They argued that whenever an author cites another’s work, then s/he should get a credit; moreover, as there is a direct relationship between publications and venues, an author who publishes his/her work in a reputed venue should get higher credit. Recently, Ren et al. (2019) proposed a dynamic scholar ranking method that quantifies the academic potential of scholars, namely Academic Potential Index (API). API can be applied to identify and rank potential scholars who have made a significant contribution in their corresponding research area of interest at their earlier academic phase.
Credit allocation methods
As the number of collaborators in each publication grows, assigning the authorship credit to each collaborator turns out to be the most challenging task. Several approaches have been proposed to tackle such a challenge. In some cases, citation counts are considered a means to equally give each author distributed credits in a multiauthored paper, which is called full counting (Waltman, 2016). However, the sole use of citation counts should not be directly considered as a measure to allocate credits to authors. Citation count will not help us identify influential authors as it will assign the same value to all co-authors of a single paper. Preferably, it can be considered essential to rank the impact of a given publication in the scientific community (Wang et al., 2019c).
Some other methods have been proposed aiming to give appropriate credits to authors in a multiauthored paper. Among them, fractional counting (Waltman, 2016) is a quite popular quantification, which gives a publication value of 1 and equally distributes this value among the N co-authors of the publication that is equal to 1/N. In essence, all the contributors get equal shares. The other well-known measure is “harmonic counting” (Hagen, 2008), which takes into consideration the order of the author list in the paper. Thus, in this case, the more number of co-authors participate in a paper, the lesser their credit would be.
With the same perspectives, Kim and Diesner (2014) proposed “a network-based approach to co-authorship credit allocation.” In this method, each co-author in a paper shares a part of their credit equally with authors in the same paper whose names come prior to them, i.e., an author whose order is at the \((i+1){\hbox {th}}\) share his credit with the author at the \(i{\hbox {th}}\) position. In addition, Kim and Diesner introduced three mathematical formulas to calculate the credit share for the first author, the middle author(s), and the last author. Besides, the method takes a distribution factor d as an input with a range between 0 and 1. Hence, the same author in the same paper can obtain different credit values according to the distribution factor taken.
Similarly, Jung and Yoon (2019) proposed a metric that gives total credit of 3 to a given paper, from which the first and corresponding authors get 1 credit each. The remaining 1 point will be distributed to the rest of the authors in accordance with their order in the author list of the given paper. Nevertheless, this metric may not be applicable in some cases, as there are rare publications that mention the actual contributions of co-authors in a multiauthored paper. Moreover, it is believed that authors tend to be listed in most cases depending on the contribution they have made to particular research work. Due to this reason, the first author receives high credit than the second and the like. As a result, the methods that rank authors based on their position in the author list cannot be applicable in disciplines where the authors of papers are listed in alphabetical order (Waltman, 2012).
There are several credit allocation approaches that do not rely on the position of authors in the author list of a multiauthored paper. One of the methods is proposed by Tol (2011), in which the method allocates weights to each author of a multiauthored paper by considering the citation characteristics between a given paper and the author’s previously published papers. In another work, Shen and Barabási (2014) proposed a topic-oriented method that collectively allocates credit to co-authors in a multiauthored paper by taking co-citation relationships between papers and the prior work of each author in a particular scientific community into consideration. Motivated by the work of Shen and Barabási (2014), Bao and Zhai (2017) proposed a dynamic credit allocation algorithm (DCAA) that considered three main elements simultaneously. These elements are briefly explained as follows.
-
I.
Reinforcement mechanism typically, highly-cited papers tend to be cited more often than papers with a smaller number of citations. This indicates that highly-cited papers are comparatively influential. As a result, co-authors of the influential authors would get more credit.
-
II.
Temporal relaxation function researcher improves their previous work or other’s work by integrating new ideas into their work; as a consequence, the originality of existing works and total credit declines through time.
-
III.
Co-citation strength the contribution of co-authors in a multiauthored paper is captured by taking the perception of a particular scientific community into account. The contribution value of an author increases depending on the relevance and acceptability of his/her paper in the scientific community.
Wang et al. (2019a) proposed an author ranking method aiming to overcome the limitation of DCAA, which is the idea that each citing paper contributes equally. The improved method is a combination of PageRank and DCAA, namely IDCA (—which stands for Improved Dynamic Credit Allocation). IDCA mainly considered the temporal relaxation aspect of DCAA for allocating credit to co-authors in a multiauthored paper. The methods (Bao & Zhai, 2017; Shen & Barabási, 2014; Wang et al., 2019a) were validated on Nobel Prize-winning papers. They also investigated and analyzed the opinions of fellow scholars about the acceptability of authors in a given corresponding scientific community. Despite the different assumptions each literature considers, the experimental results of all three methods are promising. As a result, the present work has borrowed and adopted their mutual features in the proposed approach.
In addition, basing the work of Shen and Barabási (2014) and Xing et al. (2021) designed a method for distributing credit that is according to a co-citing network that relies on references instead of citations, arguing that the connections of references can efficiently identify similar subject areas between articles. This is due to the main ideas of each article being spontaneously categorized by the main content of consequent citing papers. The method of Xing et al. (2021) assigns more credit to authors whose work is more directly related to the target article. Recently, Ding et al. (2021) offered a new mechanism to distribute the co-author credit in a multiauthored paper based on fourteen positions of “contributor roles taxonomy (CRediT)”. With this approach, the contribution of each co-author to an article is determined by looking at how many of the fourteen contributor duties are covered by a particular co-author. However, this method cannot be applied to articles where the contribution of each author is not mentioned specifically. Li et al. (2022) use a dynamic credit allocation algorithm based on path similarity to evaluate the contribution of each co-author to collaborative work. Xu et al. (2022) use correlation with imputed contributions to the specific paper and science as a whole to explore the relationship between team structure and the knowledge characteristics they generate. Yang et al. (2022) proposed a context-based author credit model to allocate personal credit to coauthors in multi-author papers. Wu et al. (2022) grouped metrics and theories according to three basic attributes of science: thermal and cold science, soft and hard science, fast science, and slow science to help understand and model the mechanisms of science that contribute to the effective development and application of metrics.
Similarity-based methods
One of the challenging processes in a machine learning approach is a numerical representation of textual documents, i.e., changing words, sentences, paragraphs, or full documents into a vector. Such a representation can be used for various reasons, such as information retrieval, document similarity, searching, and other text-related tasks on the web. Nevertheless, there have not many promising approaches that could somehow ease the overall process of document representation. To do this task, in most cases, researchers adopt well-known approaches, including bag-of-words (bow), Latent Dirichlet Allocation (LDA), word2vec, and an extension of word2vec called doc2vec. Bag-Of-Words (Li et al., 2010) is the simplest method yet does not give satisfying results as it misses multiple distinctive representations; for instance, it fails to consider the arrangement of the words. LDA (Blei et al., 2003) is a commonly used method to retrieve keywords or topics from texts, but it is challenging to adjust and evaluate the outputs. Word2vec (Mikolov et al., 2013) generates vectors from words, i.e., it outputs numerical representation in terms of vectors for each word. Doc2vec (Le & Mikolov, 2014) aims to give numerical representations of documents despite the length of the document.
One of the author ranking methods that took topic similarity into consideration is the work proposed by Amjad and Daud (2017). Amjad and Daud (2017) proposed a method called Domain Specific Index (DSI) that considers the author’s specific research interest. The proposed method first extracts the latent topics by using the Latent Dirichlet Allocation LDA. Then, the method gives scoring for authors by taking into consideration the author’s research interest. Finally, the method calculates topic-based citations to give a score, that is, how much the author contributes in some specific area of interest. The one who participated more in the area will get a higher score. Similarly, another work by Amjad et al. (2016) introduced a topic-based method that allocates topic-sensitive weighted citations to authors related to their topic. The method gives a higher score to co-authors if their research topic is similar to the focus of the main author (i.e., the first author).
Materials and methods
Methods
The main problem addressed in this paper is to identify an influential author in a multiauthored paper. Given a huge set of authors from academic networks, the main goals of our research are to
-
(1)
identify which author is more influential amongst the co-authors of the given paper in a particular research area that the given paper focuses on, and
-
(2)
implicitly determine the most influential authors from automatically identified citation networks.
This paper proposed the citation and similarity-based author ranking approach (CLARA), which considers citation attributes and text similarity scores to identify the influential authors automatically. In this paper, an influential author is specifically defined as an author who is supposed to have comparatively high experience in a specific research area. In essence that the author may have relatively more number of publications in a specific area of interest, that makes him a key author, highly cited publications, and productive in academia in terms of actively participating in scientific collaborations in their corresponding scientific communities. How the CLARA approach is implemented is briefly described below.
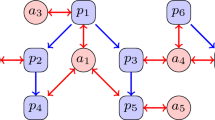
As depicted in Fig. 1, an article \(p_0\) is assumed to have n co-authors. In order to determine the shared value of each author’s contribution score, the method first identifies all papers that have cited \(p_0\) as \(cp=\{{{C}_1,{C}_2,{C}_3,\ldots ,{C}_n}\}\). Secondly, it identifies all co-cited papers (ccp) that are referenced by the papers in cp as \(ccp=\{{p_1,p_2,\ldots ,p_j}\}\). Each co-cited paper \(p_j\) is associated with \(p_0\) by a joint weight, that is a citation frequency (\(citfreq_{ij}\)). The citation frequency, \(citfreq_{0j}\), is the number of times \(p_0\) and \(p_j\) cited together by the papers in cp (see Fig. 1). The fractional value (\(fracval_{ij}\)) is also computed, where each author in the paper is given equal contribution value (i.e., 1/N) (see Table 1 for the description of each notation used in this paper).
Finally, similarity scores between the given and the co-cited papers are used to rank influential authors. To compute the similarity scores, a doc2vec representation of each paper by considering abstracts as documents is produced. Then compute the similarity between the given paper and each co-cited paper in terms of a research topic.
It is assumed that a given paper \(p_0\) is also regarded as its own co-cited paper; therefore, its citation frequency is equivalent to the number of citations it gets.

A given paper (\(p_0\)), citing papers (\({{C}_1,{C}_2,{C}_3,{C}_4,{C}_5}\)), and co-cited papers (\(p_1, p_2\), and \(p_3\)) are depicted in this figure. \(p_0\) has two authors, colored in red and blue. \(fracval_{a_{ij}}\) represents the fractional credit, which is the contribution of the authors of the given paper in every co-cited paper (1/n, n depicts the number of co-authors in the given paper). The author in red has contributed to the given paper and one co-cited paper (i.e., \(p_3\)), so that the author gets a fracval of (1/2, 0, 0, 1/4). Similarly, the author in blue has contributed to the given paper as well as to two co-cited papers (i.e., \(p_2\) and \(p_3\)), so that, the author gets a fracval of (1/2, 0, 0, 1/4). “\(citfreq_{0j}\)” shows the citation frequency of \(p_0\) along with each co-cited paper \(p_j\). \(p_0\) has been cited together with the co-cited papers (\(p_1\), \(p_2\), and \(p_3\)) 2, 1, and 3 times, respectively. (Color figure online)
Important concepts that are used in identifying an influential author are defined below.
Author ranking
To order co-authors of a multiauthored paper based on their degree of influence in a particular research area.
Citing papers
Papers that have cited a given paper are referred to as “citing papers”. The Microsoft Academic Graph (MAG) dataset (see the “Dataset and preprocessing” section) is used to extract citing papers for each given paper.
Co-cited papers
The papers that are cited by the given paper and the citing papers at the same time are referred to as “co-cited papers”. The Microsoft Academic Graph (MAG) dataset (see the “Dataset and preprocessing” section) is used to extract co-cited papers for a given paper.
Citation frequency
“Citation frequency” is a vector obtained by counting the number of times the given paper is cited together with each co-cited paper.
Fractional value (Perianes-Rodriguez et al., 2016)
To assess each author’s contribution value in a given paper. A value is given to authors in \(p_0\) depending on their contribution to the co-cited papers by using Eq. 7.
Similarity value
To determine the relevance and similarity level of the given paper with each co-cited paper, a “similarity value” is computed using an approach that computes the similarity amongst documents.
KeyScore
When ranking authors, there needs to have a specific value to order the authors. KeyScore is a value computed using the CLARA approach to rank authors in a multiauthored paper.
Description of The CLARA approach
Herein, a detailed description of the process of CLARA is given. First, describe how the author contribution matrix (ACM) is computed. Then, describe how the author contribution value (ACV) is obtained. Finally, present a detailed algorithm of CLARA (Algorithm 1). Figure 2 illustrates the overall framework of the CLARA method.

The overall framework of the CLARA method. The orange-filled cylindrical shapes represent the MAG dataset ( ).
The rounded rectangle shapes (
).
The rounded rectangle shapes ( )
indicate the starting and end of the whole process. The unfilled rectangular shapes (
)
indicate the starting and end of the whole process. The unfilled rectangular shapes ( )
represent processes that take place while implementing the method. The blue-filled shapes (
)
represent processes that take place while implementing the method. The blue-filled shapes ( )
represent the retrieved documents from the filtered dataset. The green-filled shapes (
)
represent the retrieved documents from the filtered dataset. The green-filled shapes ( )
depict input parameters for the consecutive processes. (Color figure online)
)
depict input parameters for the consecutive processes. (Color figure online)
Author contribution matrix (ACM)
An author contribution matrix \(ACM_{ij}\) is defined as shown in Eq. 1, which computes the contribution value of each author of the given paper. The value is computed from each co-cited paper \(p_j\).
This work evaluated the accuracy percentage of different conventional credit counting metrics, such as fractional, harmonic, arithmetic, and geometric, and found that fractional counting has better accuracy (see “Accuracy” section). Hence, for the CLARA approach, the ACM is computed according to a fractional counting metric. The fractional value of the co-authors are distributed equally, that is, each co-author is assumed to have an equal contribution to a particular research article. Besides, fractional credit share for the authors of the given paper is computed by taking into account the co-cited papers. For instance, if author \(a_i\) contributed in a paper \(p_j\) among other 3 co-authors, then the \(fracval_{a_{ij}}\) becomes 1/4, whereas if author \(a_i\) of a given paper did not contribute to the co-cited paper \(p_j\), then the \(fracval_{a_{ij}}\) becomes 0. The author contribution matrix is written as:
where \(fracval_{a_{ij}}\) represents the fractional value of an author \(a_i\) of the given paper in the co-cited paper \(p_j\). \(i=\{1,\ldots ,N\}\) and \(j=\{0,\ldots ,M\}\) in which N and M indicate the total number of authors in the given paper and the total number of co-cited papers, respectively.
Author contribution value (ACV)
The author contribution value (ACV) is computed for each co-author in a multi-authored paper by considering the citation attributes and the paper similarity scores. Citation attributes such as citing papers of the given paper and co-cited papers.
One of the fundamental objectives of this paper is to discover influential authors in specific areas of interest. Hence, quantifying similarities between papers (i.e., between a given paper with other co-cited papers) is vital to identify co-authors’ areas of expertise as well as to recognize the influential author in specific research areas. On top of that, researchers who participate in different research areas will probably have more works in some areas in which they are highly experienced. However, the proposed method does not consider each co-author’s discipline; instead, it considers the works they have done on that particular topic related to the given paper. Hence, our method does not discriminate between researchers who work on various research topics with scholars in different disciplines and those who work on the same research topics for a long time. In order to compute the similarity scores between papers, the doc2vec approach, which represents a given document in terms of a vector, is employed. In this work, the doc2vec representation is computed from the abstracts of the papers. doc2vec is computed using the well-known gensim Python libraryFootnote 3, an open-source python library that provides a tool for discovering the semantic structure of documents. The basic process is that gensim reads a paragraph of the corpus, namely the abstract of the given paper, and outputs a vector to represent the papers in the vector space. Then, the cosine similarity method in gensim is used to compute the similarity score of a given paper against each co-cited paper.
The similarity score of a given paper with all the co-cited papers is formulated as:
where \(p_0\) is the given paper, M is the total number of co-cited papers, and \(simvalp_j\) is the similarity of \(p_0\) and \(p_j\) in which \(j=\{0,1,\ldots ,M\}\).
The higher the similarities between a given paper and a co-cited paper, the more related they are. \(ACV_{ij}\) is the product of fractional credit share of the authors of a given paper \(ACM_{a_{ij}}\) and similarity value \(simval_{p_{j}}\). Thus, the contribution value of author \(a_i\) in the paper \(p_j\) is mathematically formulated as in Eq. 3.
where \(ACM_{a_{ij}}\) is the fractional credit share of an author in a paper \(p_{j}\), and \(simval_{p_{j}}\) is the similarity value of the co-cited paper \(p_{j}\) with the given paper \(p_{0}\) (Eq. 2).
Authors KeyScore computation
Based on the author contribution value (ACV) and the citation frequency, the present work proposes a metric to rank co-authors in a multi-authored paper called KeyScore. KeyScore is used to identify the “key” or “influential” author from a multiauthored paper. It is assumed that the higher KeyScore indicates the degree of influence of the respective author in a particular research area. Thus, an author who has a higher KeyScore is considered to be “influential” as per the context of the aforementioned definition (see “Materials and methods” section). The mathematical formula of author ranking KeyScore metric is defined as:
where \(KeyScore_{a_{ij}}\) represents the KeyScore of an author \(a_i\) in a paper \(p_j\), which is a sum where the contribution value (\(ACV_{ij}\)) of each co-author is multiplied by the citation frequency (\(citfreq_{0j}\)). \(citfreq_{0j}\) is the number of times the given paper \(p_0\) cited together with each co-cited paper \(p_j\).

Experiment materials
Dataset and preprocessing
The experiment is conducted using the 2018 version of the Microsoft academic dataset (Wang et al., 2019b) (—Microsoft Academic Graph (MAG))Footnote 4. MAG contains millions of publications from 1800–2018, along with their information, including authors, affiliations, venues, journals, and citation counts. The dataset initially contained 12,923,247 publications, specifically from the computer science field of study. This paper uses computer science publications as a base for our experiments to verify our experimental findings based on our knowledge about the respective scientific community. Consequently, 1,515,662 publications were selected which are related to the research topics of the outstanding youth winners and prepared to be applicable for the experiment. Besides, publications with incomplete citations and abstract information were filtered out as well as solo-authored publications were discarded. Finally, after preprocessing, the dataset’s size was reduced to 1,140,996 publications, which is used to conduct the experiments.
Dataset preparation
To calculate the author’s ranking score, we need to extract different datasets for the citation relationship, the similarity between papers, and the author’s contribution value in each paper. As a result, we have generated three different datasets from MAG: these are a citation network, a paper-abstract data table, and a paper-author network. We constructed a directed citation network in which papers and citations are considered as nodes and edges, respectively. A paper directly connected to another paper, if one cites the other one. Subsequently, we constructed a paper-abstract table that contains a list of papers and their corresponding abstracts. We used the paper-abstract data to analyze the contextual similarity between a given paper and co-cited papers. As mentioned previously, co-cited papers are references cited by papers that cited the given paper. Besides, we have constructed a paper-author network to analyze the relationship between papers and authors. An author is directly connected to a paper if s/he is the co-author of that particular paper.
Dataset for validation
We have adopted the data repository of the“Chinese Outstanding Youth” winning authors for the validation experiment. This repository has a collection of young and middle-aged researchers with great potential and competitiveness, representing the future of scientific research. The national science foundation for outstanding young people is a special fund approved by the state council in 1994 and administered by the national natural science foundation of China. The fund supports outstanding young scholars under the age of 45 to conduct innovative research in their own choice of research direction. The aims are to promote the growth of young scientific and technological talents, attract overseas talents, and train a group of outstanding academic leaders at the forefront of science and technology in the world. Recipients of the national science foundation for outstanding young people are often referred to as “Outstanding Youth”. We sampled researchers who won the “Outstanding Youth” title between 1994 and 2014. Consequently, we have extracted 3057 publications from the MAG dataset that belong to the selected 67 “Outstanding Youth” winners. Due to the roughness of a unique name identifier in the MAG dataset, we collected the sampled authors’ publications after processing the identifiers. Hence, we were able to assign a publication to its corresponding author accurately. To do this process, we used a python library called disambyFootnote 5. The selected publications were written before the authors got the award. This helps in analyzing the researchers’ ability in terms of continuously producing good research works and the quality of their previous works. In other words, researchers who have frequently provided publications on a specific research topic will be among the influential authors. In comparison, researchers, who have been inactive or unproductive after getting the award, will get a lower score.
Evaluation metrics
This section discusses some selected evaluation metrics to compare with the results found using our proposed method.
Datasets with ground-truth
We employed the “Outstanding Youth” dataset to evaluate the performance of our ranking approach. “Outstanding Youth” is awarded to young Chinese people who have made outstanding achievements in research or made significant contributions to science and technology advancement. Herein, the assumption is that if the CLARA approach gives scores that match the real-data, i.e., if a winner gets a higher KeyScore, we may declare that it generates valid results.
h-index
The majority of the scientific communities accepted “h-index” as one of the most commonly used metrics. The “h-index” was first introduced in 2005 by Hirsch (2005). It is a standard metric that quantifies the productivity level and citation impact of a researcher. The “h-index” considers the researcher’s list of publications as well as citation counts that consist of important information (Hirsch, 2005). This information includes the number of publications (\(N_p\)) over certain years, citation counts of each publication, the publisher, and more. Hirsch defined “h-index” as “a scientist has index h if h of his or her \(N_p\) papers have at least h citations each and the other \((N_{p}-h)\) papers have \(\le h\) citations each.” In this paper, we adopted the “h-index” to evaluate the effectiveness of our proposed method, considering the future of influential authors identified by CLARA.
Citation counts
Similar to the “h-index”, citation counts have become the widely accepted metric for measuring the quality of scientific works as well as assessing how prestigious an author is in terms of the number of citations s/he has accumulated. Senior researchers are most likely to have many papers with high citations than new researchers such as graduate students and Ph.D. candidates. This indicator gives the best result when it is applied to compare researchers within the same research area. However, it is not recommended to use citation counts as a metric to compare seniors against junior researchers since it affects the latter negatively. Moreover, it allows us to determine if a researcher is more active at the current time than in the preceding years.
Results and discussion
In this section, we give detailed explanations of the experimental results.
Evaluation of CLARA
We have evaluated our system in terms of accuracy and performance. In the following subsections, we discuss the experimental results.
Validation
Table 2 depicts the KeyScore values for some selected papers written by the “Outstanding Youth” winners. In five of the six papers, we found out that the winners have the highest KeyScore values, regardless of their order in the papers. Whether they are the first author (e.g., Hongkai Xiong in Table 3) or the last author (e.g., Jianhua Tao) or they preserve the medium position in the author list (e.g., Jianmin Wang and Xilin Chen), the winners get relatively high contribution score. For instance, the 2013 winner Jianmin Wang achieves the highest score, and the remaining co-authors have equivalent KeyScore values except one of them. Applying the CLARA method to some selected papers of the winners, for example, paper “https://doi.org/10.1109/ICME.2006.262865”, we have got: \(KeyScore=[7.983, 6.798, 6.798, 7.983, 8.316]\). After then, we gave the highest score to the corresponding author, that is, the “Outstanding Youth” winner “Jianhua Tao” in 2014. This indicates that our method accurately identifies influential authors considering their contribution to the scientific community. Moreover, we have applied our method to more than 1.5 M papers, and the obtained results depicted the accuracy of the CLARA in identifying key authors. Besides, we found that the authors with higher KeyScore correspond to 79% of the “Outstanding Youth” winners. Similarly, we have applied the baseline methods on the “Outstanding Youth” dataset. The findings show that approximately 64% and 71% of the winners have higher scores in the case of Shen and Barabási (2014) and DDCA (Bao & Zhai, 2017) baseline methods, respectively.
Table 3 shows the characteristics of the KeyScore values distributed to co-authors. In some cases, KeyScore is evenly distributed to all co-authors in a paper. On the other hand, three out of 4 to 6 authors get equivalent KeyScore values. According to the results, we noticed that they probably get equal KeyScore value when authors collaborate more often. Furthermore, as we have mentioned earlier, the author’s position in the author list does not have much impact in identifying influential authors in a multiauthored paper.
Table 4 illustrates the “Outstanding Youth” winners in different years with their average number of papers they have authored before getting the “Outstanding Youth” title along with their average KeyScore compared with their corresponding co-authors. From Table 4, we can see that each author has an average of 4 co-authors in each of his/her papers. One interesting finding is that our method enables us to compare authors in the same discipline even if they do not co-author a paper. For example, instead of a paper, we will take a particular research area such as Big Data, then we extract authors who work on this domain. Once their papers are collected, we apply our method to get each author’s KeyScore value. Then, consider taking a cumulative KeyScore in a scenario where an author has more than one paper on that specific research area. As the collected papers are in the same area of interest, it is possible but computationally inefficient to compare the authors based on their contributions in each of their papers.
Performance
To evaluate the performance of the CLARA method, we have selected 565 papers, which are written by 47 “Outstanding Youth” winners. First, we rank the authors in each paper based on the KeyScore obtained using the CLARA method. Then, we compute the precision at the n (Precision@n) value of each author. The precision@n evaluation metric is one of the ranking metrics, which indicates how precise the system is in predicting the correct order at the given position (n).
In recommender and information retrieval systems, Precision@n is used to compute the performance of the system on the correctness of answers, considering the top n responses out of all possible results. In general, the Precision@n is computed as follows:
where n is the ranking of the “Outstanding Youth” winners based on their KeyScore and #relevant is the number of relevant responses until position n.
Here, the assumption is that the “Outstanding Youth” winners should be ranked first or second position in the list. Hence, when the authors are ranked by their KeyScore value, the Precision@n of the “Outstanding Youth” winners will be 100% if it is in the first position, 50% if it is in the second position, and so on. For the Precision@1, the value will be 0 unless the “Outstanding Youth” winners are in the first position.
Our evaluation result shows that our method attains 67.26% and \(82.48\%\) Precision@1 and 2 values, respectively. In the case of the baseline methods ( Shen and Barabási (2014) and DDCA Bao and Zhai (2017)), the winning authors attained top ranks by approximately 61.42% and 64.42% Precision@1, respectively. Although the three methods show closely related performance, the CLARA method can be considered a better option to rank authors and identify influential ones as it explicitly assesses each author’s specialty in terms of contextual similarity approach.
Accuracy
To further investigate the accuracy of our proposed method, we analyzed three more preceding metrics to construct ACM. Each of the preceding metrics manifests discrete premises about the contribution of authors in a multiauthored paper. These metrics (see the “Comparison of the CLARA with prior author credit allocation metrics” section) are fractional counting, harmonic counting, arithmetic counting, and geometric counting. We have applied the metrics with the CLARA and two other state-of-the-art credit allocation methods proposed in Shen and Barabási (2014) and Bao and Zhai (2017), respectively.
Herein, we have tested the accuracy of the three methods on the 67 “Outstanding Youth” winning authors. We have defined accuracy (accuracy) as the proportion of the number of authors (—that have obtained higher ranking scores using each of the three approaches) to the total number of “Outstanding Youth” winning authors. The accuracy is mathematically written as:
where \(auth_{key}\) represents the number of “Outstanding Youth” winning authors that are identified as key authors using the CLARA method and \(tot_{auth}\) represents the total number of “Outstanding Youth” winning authors, i.e., 67.
Table 5 depicts the computational findings of the CLARA and baseline algorithms corresponding to each preceding metric. The findings show that fractional counting, which neglects the order of the authors in a multiauthored paper, provides relatively higher accuracy and a better result when adopting it in our method and the baseline methods (Bao & Zhai, 2017; Shen & Barabási, 2014) for assigning author’s contribution value. Moreover, the CLARA and the two baselines show closely related accuracy values. However, when we compare CLARA with the baselines (Bao & Zhai, 2017; Shen & Barabási, 2014), it generates more accurate and promising results in terms of identifying the most influential authors in a specific area of research interest as CLARA specifically computes the contextual similarity between papers, unlike the two baseline methods.
Effectiveness of CLARA
To further validate the effectiveness of the proposed method, in terms of its capability to identify key authors who would be future rising stars, we analyzed the citation counts and “h-index” distributions of the “Outstanding Youth” winners and non-winning authors. Hence, to conduct the validation process, we have extracted authors who have collaborated in the 565 papers of the “Outstanding Youth” winners and then formed subnetworks. To create a subnetwork, we first consider the “Outstanding Youth” winners as leading or central nodes. Then, for each “Outstanding Youth” winner, we identify their co-authors and form subnetworks. By combining the subnetworks, we have constructed an edge-weighted collaboration network. The collaboration network consists of nodes, edges, and edge-weights. The nodes and edges represent authors and the connection amongst authors, respectively. The edge-weight is equal to the number of times two authors collaborated with each other. Subsequently, we have performed edge-weight based ranking and selected non-winning authors whose edges with any winning authors have a higher weight. Figure 3 depicts the citation counts of “Outstanding Youth” title winners (—the influential authors in our case) against non-winning authors. From Fig. 3, we can see the increment of the citation counts of the winning authors each year. Whereas, the non-winning authors have a lower impact than the winning authors. The citation counts of non-winning authors show little to no progress over time. For instance, the citation counts author Mingyou Yu obtained from 2012–2019 is 111 each year.

The citation counts distribution of “Outstanding Youth” winning authors after receiving the winning award until 2019 and their frequent non-winning co-authors (i.e., Ya Li, Mingyu You, and Qianchuan Zhao). The KeyScore value of each author is given in bracket. (Color figure online)
Figure 4A shows the “h-index” versus the average KeyScore distribution of “Outstanding Youth” winners. Figure 4B is analysed by taking into account each sampled winning author’s KeyScore value for each paper. We have found that authors with high “h-index” but fewer papers have relatively lower KeyScore values. In Fig. 4B, the red dots illustrate the distribution of the h-index versus the KeyScore rank of the sampled winning authors, the green dots depict the distribution of the number of papers of each winning author versus their KeyScore rank in each paper, and the blue dots indicate the distribution h-index versus the number of papers. This indicates that our proposed method effectively identifies authors who are not only active in academics but also productive in terms of incessantly providing scientific research works. In essence, authors with higher h-index values are considered to have worth-cited research publications on particular areas of interest. The other interesting finding is that the citation counts and the “h-index” of the non-winning authors have almost static patterns, which do not show noticeable progress, i.e., no increment or increase slowly over time.

A The h-index distribution of the “Outstanding Youth” winners. B The h-index vs number of papers distribution graph with respect to KeyScore rank of the “Outstanding Youth” winning authors
Comparison of the CLARA with prior author credit allocation metrics
We have compared the performance of our method against four previously proposed author credit allocating metrics, including fractional, harmonic, arithmetic, and geometric metrics. The metrics are explained as follows.
Fractional counting (Perianes-Rodriguez et al., 2016)
An author who collaborated on a paper with an N number of co-authors will get a credit of 1/N, which is defined as a “fractional value” of an author. Whether the author is the first, second, or last author in the paper, s/he will get 1/N value.
The fractional counting is calculated as:
Harmonic counting (Hagen, 2008)
The credits of authors decrements as per their order in the author list of a given paper, i.e., the \(i{\hbox {th}}\) author will get higher credit than the \((i+1){\hbox {th}}\) author, apparently the last author will get the least credit value.
The harmonic counting is computed as:
Arithmetic counting (Trueba & Guerrero, 2004)
The first author receives a credit twice the second author if there are only two authors in a paper. As the number of co-authors increases, the credit of the last author decreases. This metric has no static ratio of credit assignment when N increases.
Arithmetic counting is computed as:
Geometric counting (Zarezadeh et al., 2018)
This metric assigns credit to the \(i{\hbox {th}}\) author twice the \((i+1){\hbox {th}}\) author, which indicates that the allocated credit swiftly approaches asymptotic values as the co-authors grow in number. As a result, the first few co-authors receive comparatively high credit while insignificant credit is assigned to the remaining authors in a given multiauthored paper.
Geometric counting is computed as:
In these equations (Eqs. 7–10), N and i represent the number of co-authors in a given paper and the order of an author in the author list (\(i={1,\ldots ,N}\)), respectively.
Table 6 illustrates the distribution of contribution values given to each co-author in the given paper, computed by applying the Eqs. 7–10 of the four baseline credit allocation metrics, respectively.
From Table 6, we can tell that our method obtained accurate value as far as the real-data is concerned. The “Outstanding Youth” winner Jian Ying has obtained a higher KeyScore value and higher “h-index”. Hence, the “h-index” value of each author supports the accuracy and effectiveness of our method. In essence, the higher “h-index” values of the winners indicate that our method can effectively recognize authors who are active in academia as well as authors who provide quality research works where their accessibility continues. Except for the fractional metric, all the other three baseline metrics give credit by highly depending on the position of co-authors in the given paper. The finding shows that these four baseline metrics are not applicable to identify influential authors as they do not consider the previous works of the authors.
Limitations of the CLARA method
Although our approach performs well in discovering influential authors, it still has limitations that need further investigation. We have listed them as follows:
-
credit assignment metric, i.e., in our method, the fractional counting metric, which gives equal credits to every co-author of a multiauthored paper, is used;
-
not considering the scientific impact of the citing papers while assessing the co-citation relations;
-
high demand for data, we need more information than others.
-
not considering the publication years;
-
not excluding self-citations from the citation counts;
-
the inefficiency and time consumption while applying the CLARA method to rank authors in the same discipline rather than in a single multiauthored paper;
-
not checking the method on different datasets of different disciplines.
Considering the above-mentioned limitations, as future work, we are interested in expanding the CLARA method to make it more effective and improve its robustness when applying it to multidisciplinary and big academic networks.
Conclusion
Research for solo authors is getting challenging to produce quality results. In this regard, scientific collaboration is considered as an important pillar to produce quality results. However, identifying reliable collaborators is challenging. One of the approaches is to quantify the contribution of authors considering different dimensions. In this regard, our study focuses on identifying influential authors in a particular scientific domain.
In this study, we proposed a citation and similarity-based author ranking approach (CLARA) to identify influential authors as well as quantify the contribution of co-authors of a multiauthored paper. The method is based on citation attributes such as citing and co-cited papers and contextual similarity between a given paper and each co-cited paper. In CLARA, we have adopted an author credit allocation metric called fractional counting to assign credit to each author of the given paper according to their contribution to the co-cited papers. In addition, to compute the similarity between two papers, we have employed a doc2vec topic modeling approach that converts the abstracts of each paper into a vector. By taking the contribution value of the authors in the given paper, the similarity score between the given paper and each co-cited paper, and citation frequency in which the given paper is cited together with each co-cited paper into consideration, we have identified the “influential” or “key” author from a multiauthored paper using the newly formulated metric, called KeyScore.
We applied our method to the MAG dataset by constructing two networks and one data table, i.e., a citation network, paper-author network, and paper-abstract data table. Our experimental results reveal that authors with high KeyScore, produced by the CLARA method, have proven influential when validated on the gold standard “Outstanding Youth” winning authors. We also confirmed that those authors have relatively high “h-index” and citation counts compared to the non-winning authors. Moreover, we found out that our approach produces higher accuracy when compared with the state-of-the-art approaches. Furthermore, it can effectively identify influential scholars who are currently active in academia. Our method surpasses the existing baseline credit allocation metrics in generating promising results from the analysed sampled datasets. As a further improvement, the proposed method will be expanded to identify influential authors from a big academic network and check robustness by employing different datasets of distinct disciplines.
References
Alshareef, A. M., Alhamid, M. F., & El Saddik, A. (2019). Academic venue recommendations based on similarity learning of an extended nearby citation network. IEEE Access, 7, 38813–38825. https://doi.org/10.1109/ACCESS.2019.2906106
Amjad, T., Bibi, S., Shaikh, M., & Daud, A. (2016). Author productivity indexing via topic sensitive weighted citations. Science International, 28(4), 4135–4139.
Amjad, T., & Daud, A. (2017). Indexing of authors according to their domain of expertise. Malaysian Journal of Library & Information Science, 22(1), 69–82. https://doi.org/10.22452/mjlis.vol22no1.6
Amjad, T., Daud, A., & Aljohani, N. R. (2018). Ranking authors in academic social networks: A survey. Library Hi Tech, 36(1), 97–128. https://doi.org/10.1108/LHT-05-2017-0090
Bai, X., Pan, H., Hou, J., Guo, T., Lee, I., & Xia, F. (2020). Quantifying success in science: An overview. IEEE Access, 8, 123200–123214.
Bao, P., & Zhai, C. (2017). Dynamic credit allocation in scientific literature. Scientometrics, 112(1), 595–606. https://doi.org/10.1007/s11192-017-2335-9
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022.
Cai, L., Tian, J., Liu, J., Bai, X., Lee, I., Kong, X., & Xia, F. (2019). Scholarly impact assessment: A survey of citation weighting solutions. Scientometrics, 118(2), 453–478.
Chang, L. L. H., Phoa, F. K. H., & Nakano, J. (2019). A new metric for the analysis of the scientific article citation network. IEEE Access, 7, 132027–132032. https://doi.org/10.1109/ACCESS.2019.2937220
Coccia, M., & Wang, L. (2016). Evolution and convergence of the patterns of international scientific collaboration. Proceedings of the National Academy of Sciences, 113(8), 2057–2061. https://doi.org/10.1073/pnas.1510820113
DeHart, D. (2017). Team science: A qualitative study of benefits, challenges, and lessons learned. The Social Science Journal, 54(4), 458–467. https://doi.org/10.1016/j.soscij.2017.07.009
Ding, J., Liu, C., Zheng, Q., & Cai, W. (2021). A new method of co-author credit allocation based on contributor roles taxonomy: Proof of concept and evaluation using papers published in plos one. Scientometrics, 126(9), 7561–7581.
Dong, Y., Ma, H., Shen, Z., & Wang, K. (2017). A century of science: Globalization of scientific collaborations, citations, and innovations. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, New York, NY, USA (pp. 1437–1446). https://doi.org/10.1145/3097983.3098016
Egghe, L. (2006). Theory and practise of the g-index. Scientometrics, 69(1), 131–152. https://doi.org/10.1007/s11192-006-0144-7
Farooq, M., Khan, H. U., Iqbal, S., Munir, E. U., & Shahzad, A. (2017). Ds-index: Ranking authors distinctively in an academic network. IEEE Access, 5, 19588–19596. https://doi.org/10.1109/ACCESS.2017.2744798
Fortunato, S., Bergstrom, C. T., Börner, K., Evans, J. A., Helbing, D., Milojević, S., Petersen, A. M., Radicchi, F., Sinatra, R., Uzzi, B., Vespignani, A., Waltman, L., Wang, D., & Barabási, A. L. (2018). Science of science. Science. https://doi.org/10.1126/science.aao0185.
Guan, J., Zuo, K., Chen, K., & Yam, R. C. (2016). Does country-level R & D efficiency benefit from the collaboration network structure? Research Policy, 45(4), 770–784. https://doi.org/10.1016/j.respol.2016.01.003
Hagen, N. T. (2008). Harmonic allocation of authorship credit: Source-level correction of bibliometric bias assures accurate publication and citation analysis. PLoS ONE, 3(12), 4021. https://doi.org/10.1371/journal.pone.0004021
Han, J., Pei, J., & Kamber, M. (2011). Data mining: Concepts and techniques. Berlin: Elsevier Science.
Hirsch, J. E. (2005). An index to quantify an individual’s scientific research output. Proceedings of the National Academy of Sciences of the United States of America, 102(46), 16569. https://doi.org/10.1073/pnas.0507655102
Jung, S., & Yoon, W. C. (2019). Citation-based author contribution measure for byline-independency. In 2019 IEEE International Conference on Big Data (Big Data), IEEE, Los Angeles, CA, United States (pp 6086–6088). https://doi.org/10.1109/BigData47090.2019.9006230
Kataria, S., Mitra, P., Caragea, C., & Giles, C. L. (2011). Context sensitive topic models for author influence in document networks. In Twenty-Second International Joint Conference on Artificial Intelligence, IJCAI, Barcelona, Spain.
Kim, J., & Diesner, J. (2014). A network-based approach to coauthorship credit allocation. Scientometrics, 101(1), 587–602. https://doi.org/10.1007/s11192-014-1253-3
Knoke, D., & Yang, S. (2019). Social network analysis (Vol. 154). Berlin: SAGE Publications.
Kong, X., Jiang, H., Yang, Z., Xu, Z., & Xia, F., & Tolba, A. (2016). Exploiting publication contents and collaboration networks for collaborator recommendation. PLoS ONE, 11(2), 0148492. https://doi.org/10.1371/journal.pone.0148492
Kong, X., Mao, M., Jiang, H., Yu, S., & Wan, L. (2019). How does collaboration affect researchers’ positions in co-authorship networks? Journal of Informetrics, 13(3), 887–900. https://doi.org/10.1016/j.joi.2019.07.005
Kong, X., Zhang, J., Zhang, D., Bu, Y., Ding, Y., & Xia, F. (2020). The gene of scientific success. ACM Transactions on Knowledge Discovery from Data, 14(4), 1–19.
Le, Q., & Mikolov, T. (2014). Distributed representations of sentences and documents. In International Conference on Machine Learning (pp. 1188–1196). JMLR.
Li, T., Mei, T., Kweon, I. S., & Hua, X. S. (2010). Contextual bag-of-words for visual categorization. IEEE Transactions on Circuits and Systems for Video Technology, 21(4), 381–392. https://doi.org/10.1109/TCSVT.2010.2041828
Li, X., Verginer, L., Riccaboni, M., & Panzarasa, P. (2022). A network approach to expertise retrieval based on path similarity and credit allocation. Journal of Economic Interaction and Coordination, 17(2), 501–533.
Liu, J., Kong, X., Zhou, X., Wang, L., Zhang, D., Lee, I., Xu, B., & Xia, F. (2019). Data mining and information retrieval in the 21st century: A bibliographic review. Computer, 34, 100193.
Liu, J., Tian, J., Kong, X., Lee, I., & Xia, F. (2019). Two decades of information systems: A bibliometric review. Scientometrics, 118(2), 617–643.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, neural information processing systems (pp. 3111–3119).
Perianes-Rodriguez, A., Waltman, L., & Van Eck, N. J. (2016). Constructing bibliometric networks: A comparison between full and fractional counting. Journal of Informetrics, 10(4), 1178–1195. https://doi.org/10.1016/j.joi.2016.10.006
Ren, J., Wang, L., Wang, K., Yu, S., Hou, M., Lee, I., Kong, X., & Xia, F. (2019). Api: An index for quantifying a scholar’s academic potential. IEEE Access, 7, 178675–178684. https://doi.org/10.1109/ACCESS.2019.2958649
Saberi, M. K., Mokhtari, H., Mirezati, S. Z., Ansari, N., & Mohammadian, S. (2022). Co-authorship networks of Iranian researchers’ publications on the field of management during a half-century (1969–2018). International Journal of Information Science and Management (IJISM), 20(1), 1.
Sachmpazidi, D., Olmstead, A., Thompson, A. N., Henderson, C., & Beach, A. (2021). Team-based instructional change in undergraduate stem: Characterizing effective faculty collaboration. International Journal of STEM Education, 8(1), 1–23.
Sarli, C. C., & Carpenter, C. R. (2014). Measuring academic productivity and changing definitions of scientific impact. Missouri Medicine, 111(5), 399.
Schubert, A. (2011). A hirsch-type index of co-author partnership ability. Scientometrics, 91(1), 303–308. https://doi.org/10.1007/s11192-011-0559-7
Shen, H.W., & Barabási, A.L. (2014). Collective credit allocation in science. Proceedings of the National Academy of Sciences, 111(34), 12325–12330.
Tol, R. S. (2011). Credit where credit’s due: Accounting for co-authorship in citation counts. Scientometrics, 89(1), 291. https://doi.org/10.1007/s11192-011-0451-5
Trueba, F. J., & Guerrero, H. (2004). A robust formula to credit authors for their publications. Scientometrics, 60(2), 181–204. https://doi.org/10.1023/b:scie.0000027792.09362.3f
Tu, Y., Johri, N., Roth, D., & Hockenmaier, J. (2010). Citation author topic model in expert search. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Association for Computational Linguistics, Stroudsburg, PA, USA (pp. 1265–1273).
Turner, J. R., & Baker, R. (2020). Collaborative research: Techniques for conducting collaborative research from the science of team science (scits). Advances in Developing Human Resources. https://doi.org/10.1177/1523422319886300
Usmani, A., & Daud, A. (2017). Unified author ranking based on integrated publication and venue rank. International Arab Journal of Information Technology, 14(1), 5. https://doi.org/10.1016/j.joi.2018.11.005
Walker, D., Xie, H., Yan, K. K., & Maslov, S. (2007). Ranking scientific publications using a model of network traffic. Journal of Statistical Mechanics: Theory and Experiment, 2007(06), P06010. https://doi.org/10.1088/1742-5468/2007/06/P06010
Waltman, L. (2012). An empirical analysis of the use of alphabetical authorship in scientific publishing. Journal of Informetrics, 6(4), 700–711. https://doi.org/10.1016/j.joi.2012.07.008
Waltman, L. (2016). A review of the literature on citation impact indicators. Journal of Informetrics, 10(2), 365–391. https://doi.org/10.1016/j.joi.2016.02.007
Wang, J. P., Guo, Q., Zhou, L., & Liu, J. G. (2019). Dynamic credit allocation for researchers. Physica A: Statistical Mechanics and its Applications, 520, 208–216. https://doi.org/10.1016/j.physa.2019.01.011
Wang, K., Shen, Z., Huang, C. Y., Wu, C. H., Eide, D., Dong, Y., Qian, J., Kanakia, A., Chen, A., & Rogahn, R. (2019). A review of microsoft academic services for science of science studies. Frontiers in Big Data, 2, 45. https://doi.org/10.3389/fdata.2019.00045
Wang, M., Ren, J., Li, S., & Chen, G. (2019). Quantifying a paper’s academic impact by distinguishing the unequal intensities and contributions of citations. IEEE Access, 7, 96198–96214. https://doi.org/10.1109/ACCESS.2019.2927016
Wu, L., Kittur, A., Youn, H., Milojević, S., Leahey, E., Fiore, S. M., & Ahn, Y. Y. (2022). Metrics and mechanisms: Measuring the unmeasurable in the science of science. Journal of Informetrics, 16(2), 101290.
Wu, L., Wang, D., & Evans, J. A. (2019). Large teams develop and small teams disrupt science and technology. Nature, 566(7744), 378–382. https://doi.org/10.1038/s41586-019-0941-9
Xia, F., Liu, J., Nie, H., Fu, Y., Wan, L., & Kong, X. (2019). Random walks: A review of algorithms and applications. IEEE Transactions on Emerging Topics in Computational Intelligence, 4(2), 95–107.
Xia, F., Liu, J., Ren, J., Wang, W., & Kong, X. (2020). Turing number: How far are you to am turing award? In ACM SIGWEB Newsletter (Autumn) (pp. 1–8).
Xia, F., Wang, W., Bekele, T. M., & Liu, H. (2017). Big scholarly data: A survey. IEEE Transactions on Big Data, 3(1), 18–35. https://doi.org/10.1109/TBDATA.2016.2641460
Xing, Y., Wang, F., Zeng, A., & Ying, F. (2021). Solving the cold-start problem in scientific credit allocation. Journal of Informetrics, 15(3), 101157.
Xu, F., Wu, L., & Evans, J. (2022). Flat teams drive scientific innovation. Proceedings of the National Academy of Sciences, 119(23), e2200927119.
Yang, S., Xiao, A., Nie, Y., & Dong, J. (2022). Measuring coauthors’ credit in medicine field-based on author contribution statement and citation context analysis. Information Processing & Management, 59(3), 102924.
Yu, S., Bedru, H. D., Lee, I., & Xia, F. (2019). Science of scientific team science: A survey. Computer Science Review, 31, 72–83. https://doi.org/10.1016/j.cosrev.2018.12.001
Yu, S., Xia, F., Zhang, C., Wei, H., & Keogh, K., & Chen, H. (2021). Familiarity-based collaborative team recognition in academic social networks. IEEE Transactions on Computational Social Systems, 9, 5.
Yu, S., Xia, F., Zhang, K., Ning, Z., Zhong, J., & Liu, C. (2017). Team recognition in big scholarly data: Exploring collaboration intensity. In 2017 IEEE 15th Intl Conf on Dependable, Autonomic and Secure Computing, 15th Intl Conf on Pervasive Intelligence and Computing, 3rd Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), IEEE, Orlando, FL, USA (pp. 925–932). https://doi.org/10.1109/DASC-PICom-DataCom-CyberSciTec.2017.155
Zarezadeh, S., & Ashrafi, S., & Asadi, M. (2018). Network reliability modeling based on a geometric counting process. Mathematics, 6(10), 0197. https://doi.org/10.3390/math6100197
Zhang, J., Ning, Z., Bai, X., Wang, W., Yu, S., & Xia, F. (2016). Who are the rising stars in academia? In 2016 IEEE/ACM Joint Conference on Digital Libraries (JCDL), IEEE (pp. 211–212).
Zhang, J., Wang, W., Xia, F., Lin, Y. R., & Tong, H. (2020). Data-driven computational social science: A survey. Big Data Research, 21, 100145.
Zhang, Y., Wang, M., Gottwalt, F., Saberi, M., & Chang, E. (2019). Ranking scientific articles based on bibliometric networks with a weighting scheme. Journal of Informetrics, 13(2), 616–634. https://doi.org/10.1016/j.joi.2019.03.013
Zhao, F., Zhang, Y., Lu, J., & Shai, O. (2019). Measuring academic influence using heterogeneous author-citation networks. Scientometrics, 118(3), 1119–1140. https://doi.org/10.1007/s11192-019-03010-5
Acknowledgements
This work is partially supported by the Fundamental Research Funds for the Central Universities under Grant No. DUT22RC(3)060.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bedru, H.D., Zhang, C., Xie, F. et al. CLARA: citation and similarity-based author ranking. Scientometrics 128, 1091–1117 (2023). https://doi.org/10.1007/s11192-022-04590-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-022-04590-5