
Abstract
Soares, Lages, Oliveira, and Cabrera-Hernández (2019) recently showed that the mirror-letter interference effect observed for words containing reversal letters was reliable for words containing left-oriented mirror-letters as ‘d’, but not for words containing right-oriented mirror-letters as ‘b’, thus indicating that the directionality of the reversal letters cannot be disregarded when examining the cost of suppressing the mirror-generalization mechanism at the early stages of visual word recognition. Here we examined whether this bias can also be observed for left-oriented non-reversal letters such as ‘g’, ‘j’, and ‘z’, which just as ‘d’ are also prone to errors in writing in left-to-right orthographies as European Portuguese (EP). Thirty-six EP skilled readers performed a lexical decision task combined with a masked-priming paradigm in which target words containing either left-oriented (e.g., ‘g’, genial) or right-oriented (e.g., ‘c’, casual) non-reversal letters were preceded by 50 ms primes that could be the same as the target (genial–genial, casual–casual), nonword primes in which the critical letter was replaced by the mirror-image of the left- or right-oriented non-reversal letter ( enial–genial,
enial–genial,  asual–casual), or nonword primes in which the critical letter was replaced by the mirror-image of another left-oriented or right-oriented non-reversal letter as control (
asual–casual), or nonword primes in which the critical letter was replaced by the mirror-image of another left-oriented or right-oriented non-reversal letter as control ( enial-genial,
enial-genial,  asual-casual). Results showed that the amount of priming produced by identity primes and mirror-image primes was virtually the same for words with left-oriented (e.g., genial–genial =
enial–genial), but not for words with right-oriented non-reversal letters (e.g., casual–casual >
asual–casual), hence extending the right-oriented bias observed for words containing reversal letters to words containing non-reversal letters.
asual-casual). Results showed that the amount of priming produced by identity primes and mirror-image primes was virtually the same for words with left-oriented (e.g., genial–genial =
enial–genial), but not for words with right-oriented non-reversal letters (e.g., casual–casual >
asual–casual), hence extending the right-oriented bias observed for words containing reversal letters to words containing non-reversal letters.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Recent studies have shown that recognizing words that contain letters whose reverse images correspond to other letters in the Latin alphabet such as ‘b’ and ‘d’ (reversal letters) is more difficult than recognizing words that contain letters whose reverse images do not correspond to other existing letters as ‘c’ and ‘r’ (non-reversal letters), an experimental effect known as the mirror-letter interference effect. This effect has been recently explained based on the neuronal recycling hypothesis claiming that, because reading is a recent cultural invention (it has been part of the human culture for only ~ 5400 years), and we did not born naturally wired to read, the brain has to recruit ancient areas in the left occipital-temporal sulcus on the lateral border of the fusiform gyrus, originally devoted to object and face recognition (the so-called visual word form area, VWFA), at service of this “new” cognitive function (see also e.g., Cohen et al., 2000; Dehaene, 2005, 2009; Dehaene & Cohen, 2007, 2011; Dehaene, Cohen, Sigman, & Vinckier, 2005; Nakamura et al., 2012). Note, however, that the interest in studying errors with reversal letters has a long tradition on cognitive research (at least from the seminal works developed by Orton (1925) in the last century) and several other proposals have been advanced to account for the mirror-letter effects, which are still under intense debate today (see Lachmann, 2008, 2018 for recent reviews). Nevertheless, according to the neuronal recycling hypothesis, the brain transformation that occurs when learning to read has, at least, two ensuing consequences, as recently pointed out by Soares, Oliveira, and Jiménez (2020): the hardwired properties of the cortical territories that the VWFA ‘invades’ constrain reading; and the cognitive demands that reading requires reshape the previous functional organization of the visual recognition areas on which the VWFA relies on (e.g., Dehaene et al., 2010; Dehaene, Cohen, Morais, & Kolinsky, 2015; Kolinsky et al., 2011; Pegado, Nakamura, Cohen, & Dehaene, 2011; Pegado et al., 2014; see, however, Lachmann & van Leeuwen, 2007 and Lachmann, Khera, Srinivasan, & van Leeuwen, 2012 for other proposals claiming that learning to read leads to a novel synthesis of functions and not necessarily to a loss of perceptual skills; namely to a greater reliance on more analytical skills that do not seem to be originally instilled in the visual cortical areas, based preferentially on a more holistic mode of processing; see, also, Soares et al., 2020 for recent evidence on literacy effects on artificial grammar learning).
Specifically, it has been argued that, because the visual recognition system is largely insensitive to spatial orientation, due to the automatic activation of the mirror generalization mechanism, this property, that is crucial for an effective object/face recognition, has detrimental effects on visual word recognition, at least in languages with orthographic scripts containing enantiomorphs (i.e., reversal letters; see, however, Danziger & Pederson, 1998; Pederson, 2003, for evidence in languages without enantiomorphs). Thus, learning to read in languages containing reversal letters requires the visual word recognition system to develop mechanisms to suppress or inhibit the mirror generalization mechanism that is automatically activated for words’ recognition as it is for objects/faces’ recognition. Indeed, conversely to what happens with objects and faces’ recognition, the orientation of the letters is a diagnostic feature for a correct letter/word recognition, as only it allows the visual recognition system to differentiate letters that, although being symmetrical, are not the same, as ‘b’ and ‘d’. This is particularly important because letters are the building blocks of words, and a correct letter identification is critical for words’ recognition and reading, as it occurs with words such as bom [good] and dom [gift] in the European Portuguese (EP) language (see Soares et al., 2019 for details). Deficits on this mechanism are likely to result in more word recognition errors and reading problems, as observed in individuals with dyslexia relative to non-dyslexic controls (e.g., Badian, 2005; Fernandes & Leite, 2017; Orton, 1925; Terepocki, Kruk, & Willows, 2002). However, recent behavioral and neural studies showed that the mirror generalization mechanism cannot be completely “turned off” as a consequence of reading acquisition and consolidation, as evidence for letter mirror cost in visual word recognition is observed not only in developing readers but also in highly proficient skilled readers (e.g., Duñabeitia, Dimitropoulou, Estévez, & Carreiras, 2013; Duñabeitia, Molinaro, & Carreiras, 2011; Perea, Moret-Tatay, & Panadero, 2011; Soares et al., 2019).
For instance, Perea et al. (2011), using a lexical decision (go/no-go) masked priming paradigm, asked Spanish skilled readers and fourth-grade Spanish developing readers to decide, as quickly and accurately as possible, whether visually presented target words, containing either reversal letters (Experiment 1; e.g., IDEA [idea]), non-reversal letters (Experiment 2; e.g., ARENA [sand]), or both (Experiment 3; e.g., IDEA, ARENA), were real Spanish words. Critically, these target words were preceded by briefly presented (50 ms) primes that could be the same as the target (i.e., identity primes; e.g., idea–IDEA, arena–ARENA), nonword primes that were exactly the same as the identity primes except for the substitution of the critical letter in the target (reversal or non-reversal) for its mirror-image (i.e., mirror primes; e.g., ibea–IDEA, a
ena–ARENA), or nonword primes in which the target letter was replaced by an orthographic control, in Experiments 1 and 2 (e.g., ilea-IDEA, a
ena–ARENA), or by a missing character, in Experiment 3 (e.g., i ea–IDEA, a
ena–ARENA). Results showed that, for words containing reversal letters (e.g., IDEA) besides the expected advantage of the identity condition over the other conditions, participants in both reading groups were significantly faster at recognizing words preceded by primes from the control condition than by primes from the mirror condition (i.e., ilea–IDEA < ibea–IDEA). For non-reversal letters (e.g., ARENA), words preceded by primes containing the mirror-image of the non-reversal letter produced the same amount of priming as observed for targets in the identity prime condition (i.e., arena–ARENA = a
ena–ARENA).
ea–IDEA, a
ena–ARENA). Results showed that, for words containing reversal letters (e.g., IDEA) besides the expected advantage of the identity condition over the other conditions, participants in both reading groups were significantly faster at recognizing words preceded by primes from the control condition than by primes from the mirror condition (i.e., ilea–IDEA < ibea–IDEA). For non-reversal letters (e.g., ARENA), words preceded by primes containing the mirror-image of the non-reversal letter produced the same amount of priming as observed for targets in the identity prime condition (i.e., arena–ARENA = a
ena–ARENA).
The current computational models of visual word recognition (e.g., Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001; Davis, 2010; Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981; Perry, Ziegler, & Zorzi, 2007) cannot account for this mirror-letter interference effect, mostly because they were implemented with the uppercase font created by Rumelhart and Siple (1974), and not with lowercase letters, where the mirror-letter effect lies in (see footnoteFootnote 1). However, those findings led the authors to affirm that it is possible that, because at the front-end of the visual word processing the system is insensitive to letter orientation (as it is for object/face orientation), words containing reversal letters as ‘d’ or ‘b’ activate two potential attractors (i.e., the nodes corresponding to the letters ‘b’ and ‘d’), whereas non-reversal letters as ‘c’ or ‘r’ only activate one potential attractor (i.e., the letter node corresponding to ‘c’ or ‘r’), because ‘
’ and ‘
’ are inexistent as graphemes. As such, words containing reversal letters would show higher levels of competition for letter recognition through lateral inhibition connections, thereby delaying word recognition for words containing reversal letters relative to words that do not contain them (note that this inhibition is absent in the case of non-reversal letters).
Nonetheless, if lateral inhibition connections at the letter level of processing is the mechanism responsible for the mirror-letter cost observed at the early stages of visual word recognition, as Soares et al. (2019) recently highlighted, a symmetrical interference effect would be expected for reversal letters regardless of their directionality (i.e., ‘b’ would inhibit ‘d’ to the same extent as ‘d’ would inhibit ‘b’), which is not clearly the case. Indeed, in a lexical decision (go/no-go) masked priming study, mimicking the procedure adopted by Perea et al. (2011), with EP adult skilled readers (Experiment 1) and two groups of EP developing readers (third-grade children [Experiment 2] and fifth-grade children [Experiment 3]), using a highly controlled set of EP words only containing either the mirror-letter ‘b’ (b-words, as base[base]) or the mirror-letter ‘d’ (d-words, as dose[dose]), the authors showed that reliable mirror-letter interference effects (i.e., longer times/low accuracy rates to recognize words containing reversal letters preceded by its mirrored letter than by an orthographic letter control) were only observed for d-words (bose–dose > lose–dose), but not for b-words, as mirror-letter primes produced the same amount of priming as observed for control letter primes (dase–base = lase–base), hence challenging the proposal advanced by Perea et al. (2011) to account for the mirror-letter effected.
These findings were interpreted in accordance with the implicit right-orienting rule hypothesis by Fischer and colleagues (e.g., Fischer, 2011, 2017; Fischer & Koch, 2016; Fischer & Tazouti, 2012) to account for a kind of writing errors where some letters or the entire word run in the opposite direction to what would be expected so that they look normal when viewed in a mirror (e.g., ‘dase’ or ‘esad’ for ‘base’, or ‘bose’ or ‘esob’ for ‘dose’). Indeed, as in reading, mirror errors are also very common in writing particularly at the early stages of learning to read/write. Interestingly, the works conducted so far in left-to-right writing systems, as the Latin alphabet, showed that beginning readers/writers produce mirror errors not only for reversal letters, such as ‘b’ and ‘d’, but also for letters such as ‘d’, ‘g’, ‘j’, and ‘z’, that is, letters whose distinctive features are on the left side of a vertical axis that can be traced from its center (see also Fischer, 2011, 2013, 2017; Fischer & Koch, 2016; Fischer & Tazouti, 2012; Treiman, Gordon, Boada, Peterson, & Pennington, 2014; Treiman & Kessler, 2011, for evidence with uppercase letters [e.g., J, Z] and left-faced digits [e.g., 1, 3] in left and right-handed children). This pattern of results was interpreted in the context of the implicit right-orienting rule, as reflecting the fact that, during the exposure to print, children implicitly learn that most letters in the Latin alphabet are right-faced and not left-faced (e.g., Fischer, 2011, 2013, 2017, 2018; Fischer & Koch, 2016; Fischer & Tazouti, 2012; Portex, Hélin, Ponce, & Foulin, 2018; Treiman et al., 2014; Treiman & Kessler, 2011). Hence, when asked to write down single letters and/or words, the immature writing/reading system, which is insensitive to spatial orientation, as the recycling hypothesis claims (e.g., Cohen et al., 2000; Dehaene, 2005, 2009; Dehaene & Cohen, 2007, 2011; Dehaene et al., 2005, 2010, 2015; Lachmann & van Leeuwen, 2007; Nakamura et al., 2012), might over apply the implicit right-orienting rule thus making the majority of errors produced in left-to-right writings to reflect a right-asymmetry bias. In this vein, Soares et al. (2019) argued that, because left-oriented letters tend to be more reversed into right-oriented letters (d → b) than the inverse (b → d), and might have less stable orthographic representations, it is possible that the visual word recognition system has more difficulties in inhibiting or suppressing the mirror generalization mechanism when the letters conform the dominant (right) letter-orientation rule of the language than when they violate it, hence explaining why mirror-letter interference effects were observed only with words containing left-oriented reversals (d-words) when preceded by right-oriented primes.
Here we examined whether this bias can also be observed for left-oriented non-reversal letters such as ‘g’, ‘j’, and ‘z’, which just as ‘d’ are also prone to mirror-writing errors in left-to-right orthographies. Indeed, although Perea et al. (2011) have shown that words containing non-reversal letters, as ‘c’ or ‘r’, were not significantly affected by the previous presentation of nonword primes containing the mirror-image of these letters (e.g., arena-ARENA = a
ena-ARENA) as mentioned before, the truth is that the words used by the authors were not controlled attending either to the directionality of the non-reversal letters (left vs. right) or to the presence of other letters, namely reversal letters, in the stimuli, which might have confounded the results. Indeed, in the materials of Experiments 2 and 3, the authors used much more words containing right-oriented than left-oriented non-reversal letters as three out of the four targeted non-reversal letters were right-oriented (‘r’, ‘c’, ‘s’) and only one was left-oriented (‘z’), according to Treiman et al.’s (2014) work (see footnoteFootnote 2). Moreover, the targeted non-reversal letters appeared in different (non-controlled) positions, and the majority of them also presented the ‘b’, ‘p’, and ‘d’ reversal letters (e.g., barco[boat], boca[mouth], blanco[white], bosque[forest], pico[beak], perdón[forgiveness], dinero[money]), which might have confounded the results. Therefore, in the present work, we used, as Soares et al.’s (2019) work, a highly controlled set of materials to examine whether there is indeed an absence of a mirror cost in the recognition of words containing non-reversal letters, and, if there is a cost, whether this effect is modulated by the right- vs. left-oriented directionality of the non-reversal letters. If a right-asymmetry bias exists in the recognition of words containing non-reversal letters, as Soares and colleagues observed for words containing reversal letters in the abovementioned work, we expect that words containing left-oriented non-reversal letters (e.g., genial), would be recognized faster and/or with higher accuracy rates when preceded by the brief presentation of nonword primes containing the mirror-image of the non-reversal letter (
enial–genial), than when words containing right-oriented non-reversal letters (e.g., casual) were preceded by its corresponding mirror-image primes (
asual–casual), because the visual word recognition system might show decreased sensitivity to mirror reversals when the non-reversal letters conform the right-dominant rule of the language.
Method
Participants
Thirty-six undergraduate students (Mage = 21 years, SD = 4.75; 31 women) took part in the experiment in exchange for course credits. All participants had normal or corrected-to-normal vision and were native speakers of EP. None reported history of learning or reading/writing disabilities. Written informed consent was obtained from each participant and the study was conducted with the approval of the local Ethics Committee.
Materials
Two-hundred and four EP words from four- to eight-letters containing either the ‘g’, ‘j’ or ‘z’ left-oriented non-reversal letters or the ‘c’, ‘r’ or ‘f’ right-oriented non-reversal letters based on Treiman et al.’s (2014) work, were selected as targets from the Procura-PALavras (P-PAL) lexical database (see Soares et al., 2014, 2018). Note that among the letters classified as left-oriented and right-oriented in Treiman et al.’s (2014) work, we have selected the ones that were used in the EP language and that presented the highest scores in each of the Treiman’s ‘left-oriented’ and ‘right-oriented’ categories (see footnote 2).
Half of the selected words had a non-reversal left-oriented letter either in the initial (Position 1: e.g., gato[cat], 84 words) or in a medial position (Position 3: e.g., saga[saga], 18 words)—left-oriented words (LO-words from now on); while the other half had a non-reversal right-oriented letter in the same positions (Position 1: e.g., rato[mouse], 84 words, Position 3: e.g., muro[wall], 18 words) - right-oriented words (RO-words from now on), to control for letter-position as in Soares et al.’s (2019) work. Note that all the words selected only have one of the critical non-reversal letters in the abovementioned positions and that none presents any mirror-reversal letter as ‘b’, ‘d’, ‘p’, or ‘q’ in any of the remaining positions, to avoid confounds. LO- and RO-words were controlled in several psycholinguistic variables known to affect EP word processing (see Soares et al., 2015; and Soares et al., 2019 for details) as the per million word frequency (MLO-words = 24.24, MRO-words = 23.07, p = .89), word length both in number of letters (MLO-words = 5.36, MRO-words = 5.37, p = .95), phonemes (MLO-words = 5.18, MRO-words = 5.18, p = 1.0), and syllables (MLO-words = 2.44, MRO-words = 2.45, p = .91), number of orthographic (N) (MLO-words = 6.11, MRO-words = 6.20, p = .92) and phonological (PN) neighbors (MLO-words = 5.99, MRO-words = 6.32, p = .70), orthographic Levenshtein distance (OLD20) measure (MLO-words = 1.72, MRO-words = 1.63, p = .15), the summed (MLO-words = 2986.57, MRO-words = 3386.82, p = .26), and the mean log10 frequency of the bigrams within the words (MLO-words = 15.29, MRO-words = 19.31, p = .34), as obtained from the P-PAL database (Soares et al., 2014, 2018).
Four-hundred and eight nonword primes were also created for assign the targets to the two prime conditions: 204 nonwords were exactly the same as the targets except that the critical left- or right-oriented non-reversal letter was substituted by its mirror-image (e.g.,
enial–genial,
asual–casual; mirror-image condition) and 204 nonwords that shared all the letters with the targets except that the left- or right-oriented non-reversal letter was substituted by the mirror-image of another right- or left-oriented letter as a control (e.g.,
enial–genial,
asual–casual; control condition). This control was used instead of another letter as in studies with mirror-letter reversals because the correct control for the mirror-image condition should be the mirror-image of another left- or right-oriented letter and not a real letter as used by Perea et al. (2011) in Experiment 2. The complete list of targets and primes is available in “Appendix”.
Additionally, a set of 204 pseudoword targets and a set of 408 nonword primes were also created for the lexical decision task. Pseudoword targets were created by replacing one to two letters in the non-terminal positions from other EP words matched with the 204 experimental words in word length (in the number of letters and syllables) and word frequency based on the P-PAL database (Soares et al., 2014, 2018). For instance, the pseudowords ‘golhata’ and ‘fassão’ were created from the base-words galheta[cruet] and fissão[fission], respecting the ortophonotactic restrictions of EP. This procedure, adopted in many other studies (e.g., Campos, Mendes Oliveira, & Soares, 2020; Campos, Oliveira, & Soares, 2018, in press; Perea, Comesaña, & Soares, 2012; Perea, Soares, & Comesaña, 2013; Soares, Perea, & Comesaña, 2014; Soares et al., 2015; Soares, Velho, & Oliveira, 2020; Soares et al., 2019), was followed because tools supporting the generation of legal pseudowords are not available for EP. Nevertheless, extreme caution was taken to ensure that the pseudowords resembled real EP words. Another set of 408 nonword primes were also created for the pseudowords targets by using the same manipulation as for word targets (204 nonwords per prime condition). Note that, besides the mirror and the control conditions, we also used an identity-prime condition for each target word (e.g., genial–genial, casual–casual), as in Perea et al. (2011) and Soares et al.’s (2019) works, to analyze not only if the control condition differed from the identity condition but, particularly, the extent to which the identity condition differed from the mirror-image condition in each type of non-reversal words. Three lists of materials were created to counterbalance the items across the three priming conditions (i.e., each target appeared once in each list, but each time in a different priming condition). Participants were randomly assigned to each list, though ensuring the same number of participants per list (n = 12). Six additional words with the same characteristics as the experimental words (e.g., word length, word frequency) and six additional pseudowords were also selected/constructed for practice trials.
Procedure
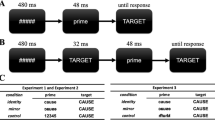
The experiment was run individually in a sound-proof booth. Presentation of the stimuli and recording of responses were controlled by DMDX software (Forster & Forster, 2003). Each trial consisted of a sequence of four visual events presented in black on a white 15″ screen with a 60 Hz refresh rate. The first event was a forward mask consisting of a row of hash marks (#) presented for 500 ms. The mask was immediately replaced by the prime presented in lowercase (14-pt Courier New font) for 50 ms and followed by another mask of hash marks (#) presented for 16.6 ms. Finally, the target, presented in lowercase letters (18-pt Courier New font), replaced the second mask and remained on the screen until participants’ response or 2500 ms had elapsed. All the stimuli were centered on the screen. As in Soares et al.’s (2019) work, we opted to present the primes and the targets in lowercase letters because the directionality of some of the non-reversal targeted letters changes when capitalized (e.g., ‘g’ → ‘G’), while others remain constant (e.g., ‘z’ → ‘Z’). The use of different font sizes in prime and target stimuli, as well as the use of a second mask, was intentionally introduced to prevent any perceptual continuity between primes and targets, as in Soares et al. (2019).
Participants were asked to press ‘sim’[yes], the ‘M’ key from the computer keyboard, if the letter string presented on the computer screen was a real EP word, and to press ‘não’[no], the ‘Z’ key from the computer keyboard, if the letter string presented on the computer screen was not a real EP word. Both speed and accuracy were stressed in the instructions. Participants were not informed of the presence of the primes. Trials order was randomized per participant. A pause was introduced after 136 trials were presented. Prior to the 408 experimental trials, each participant received 12 practice trials (six words and six pseudowords) with the same manipulation as the experimental trials to familiarize them with the task. None of the participants reported having perceived the primes when asked after the experiment. The whole session lasted approximately 15 min per participant to be completed.
Results
Reaction times (RT in ms) and accuracy (proportion of correct responses) were analyzed for word targets with linear mixed-effects (lme) models using the R software (Bates, Maechler, & Bolker, 2011; Bates, Maechler, Bolker, & Walker, 2015). The mix-model approach with crossed random effects of subjects and items is better than the classic ANOVA approach because it improves the drawbacks of the classical approach namely in what refers to the need to conduct separate by subject (F1) and by item (F2) ANOVAs, hence allowing the simultaneous generalization of the effects to the population of subjects and items and maintaining a good control of Type I and Type II errors (see Barr, Levy, Scheepers, & Tily, 2013).
Incorrect responses (8.1% of the raw data, range: 0.5–17.2% per participant; corresponding to words such as zénite[zenith], mofo[mold], faúlha[spark], and galeão[galleon], which present a very low raw frequency in EP, ranging from 0.05 to 3.40 per million words as obtained from the P-PAL database [Soares et al., 2018]), were excluded from the data. In addition, very fast correct response times (shorter than 300 ms; 6 observations) and RTs that were above 2.5 SDs of the participants’ means in each experimental condition were also removed from the latency data (2.7%). Due to the strong positive skewness observed in RT data, a scaled power transformation (box–cox transformation) was carried out to provide normality to the residuals of the linear mixed model to be estimated (Box & Cox, 1964; Fox & Weisberg, 2019). A lambda of − 0.83 was applied to the response times variable ((RTλ − 1)/λ) × 10,000 to guarantee the normality assumption of these models. Following Barr, Levy, Scheepers, and Tily (2013; see also Matuschek, Kliegl, Vasishth, Baayen, & Bates, 2017), a model with intercepts and the two repeated measurement factors (Prime type: identity|mirror|control; and Target type: LO-words|RO-words) with random slope per subject and Prime type per item (note that Target type is a between factor by item) was then conducted. Table 1 presents the matrix of variances and the correlation matrix of intercepts and slopes for items and subjects.
Concerning the dependent variable accuracy, the same full random model with a logistic link function was estimated. The result was boundary singular, a symptom of overfitting. An inspection of the random variance and covariance matrix showed perfect collinearity for Prime type conditions in items. Besides, the accuracy modeling, due to the strong variance imbalance of the random intercepts of subjects and items (4 times higher in items), could be questioned. This, together with the ceiling effect of the hits, provides very little information of interest for this study. So, accuracy modeling was finally discarded.
The RT models were fit using the lme4 and lmerTest R packages (Bates et al., 2011, 2015; Kuznetsova, Brockhoff, & Christensen, 2017). The emmeans package (Lenth, 2020) was used to contrast simple effects with differences of least squares means. For the effects that reached statistical significance, the second degree of freedom of the F statistic was approximated using the Satterthwaite’s method (see Satterthwaite, 1941; and Khuri, Mathew, & Sinha, 1998 for a review). The p values were adjusted with Hochberg’s method for all the post hoc and simple effects comparisons α ≤ .05 (see Benjamini & Hochberg, 1995, and Hochberg, 1988 for details). The means and the standard deviations of the RTs as well as the number (proportion) of correct responses for RO- and LO-words per experimental condition are presented in Table 2.
Latency analyses revealed a main effect of prime type, F(2, 45.25) = 37.75, p < .001. This effect showed that words preceded by identity primes (626.2 ms) were recognized faster than both words preceded by control primes (665.1 ms, p < .001) and words preceded by mirror-image primes (643.1 ms, p < .001), and also that words preceded by mirror-image primes were recognized faster than words preceded by control primes (p < .001), hence demonstrating facilitative priming effects for both the identity and the mirror-image prime conditions. The main effect of target type was not statistical ly significant but, crucially, the Prime type × Target type interaction effect reached statistical significance, F(2, 328.43) = 9.06., p < .001. This effect revealed that LO-words were recognized faster when preceded by identity primes than by control primes (631.1 vs. 674.8 ms, p < .001), and also faster when preceded by mirror-image primes than by control primes (634.0 vs. 674.8 ms, p < .001), hence indicating facilitative priming effects in both conditions. The difference between identity primes and mirror-image primes failed to reach statistical significance (631.1 vs. 634.0 ms, p = .27), suggesting that the amount of priming produced by identity and mirror-image primes was virtually the same (a 3 ms nonsignificant difference). For RO-words, however, the pattern of results was different. Indeed, although RO-words preceded by identity primes were recognized faster than RO-words preceded by control primes (621.5 vs. 656.1 ms, p < .001), as observed for LO-words, the difference between mirror-image primes and control primes failed to reach statistical significance (651.6 vs. 656.2 ms, p = .18). Moreover, unlike LO-words, the difference between identity primes and mirror-image primes was significant (621.5 vs. 651.6 ms, p < .001). It is also worth noting although in the mirror-image priming condition faster RTs tends to be accompanied by slightly slower accuracy rates, conversely to what occurs in all the other priming conditions, further analyses failed to show any sign of tradeoff effects, either when considering all the data as a whole or the data from each experimental condition separately. In fact, the only statistically significant correlation between RT and accuracy occurred for the LO-words in the control condition but indicating that the faster the responses the higher the accuracy rates (r = .50, p < .01). Together these findings indicate that the amount of priming produced by mirror-image primes relative both to control and identity primes were not the same for LO- and RO words, as predicted.
Finally, although analyzing the effect of the position in which the critical letters were embedded (initial vs. medial) was not the aim of this work - bear in mind that the main purpose of the current study was to analyze whether the right-asymmetry bias observed by Soares et al. (2019) for words containing reversal letters extends to words containing non-reversal letters, which lead us to control (and not to manipulate) for letter position across type of words (see materials section); we decided nevertheless to conduct ‘extra’ lme analyses considering ‘Letter position’ as an additional (third) within-subject factor as in Soares et al. (2019) work. The results failed to show any effect any significant statistical effect (main or interactions) of this factor, thus demonstrating that the right-asymmetry bias observed in our data (as in Soares et al., 2019 data) did not vary as a function of letter position.
Discussion
The current experiment aimed to examine if the right-asymmetry bias observed by Soares et al. (2019) in the mirror-letter interference effect could also be observed in the recognition of words containing non-reversal letters. Although a previous study (Perea et al., 2011) has shown that the cost of suppressing the mirror-generalization mechanism is absent in the case of words containing non-reversal letters, which was used to support the view that the mirror-letter interference effect observed in words containing reversal letters arises from the lateral inhibition connections that letters nodes established between each other at a letter level of processing, the experiments conducted in that study did not attend either to the directionality of the non-reversal letters or to the presence of other reversal letters, which might have confounded the results.
Thus, resorting to a highly controlled set of materials, the aim of this study was twofold: to examine whether there was indeed an absence of a mirror cost in the recognition of words containing non-reversal letters, as Perea et al. (2011) reported; and, if there is a cost, whether that effect was modulated by directionality (left- vs. right-orientation) of the non-reversal letters embedded in the words. Specifically, we hypothesized that if a right-asymmetry bias is observed at the early stages of recognition of words containing non-reversal letters, the mirror-image of left-oriented non-reversal letters should produce a greater amount of facilitation than the mirror-image of right-oriented non-reversal letters. This is, as in the case of reversal letters, left-oriented non-reversal letters might show less stable orthographic representations, hence making that the system can take more advantage of the mirror-image of left-oriented than right-oriented non-reversals.
The results obtained were quite straightforward and clearly demonstrate that, although nonword primes created by replacing left-oriented non-reversal letters by its mirror-image (e.g., genial →
enial), differentiated from control primes (
enial-genial <
enial-genial), but not from identity primes (
enial-genial = genial-genial), acting as nearly as the repetition of the target itself, nonword primes created by replacing right-oriented non-reversal letters by its mirror-image (e.g., casual →
asual) did not. Indeed, mirror-images primes of right-oriented non-reversal letters produced not only longer recognition times than identity primes (e.g.,
asual–casual > casual–casual) but, importantly, the same amount of priming was produced by mirror-images and control primes (
asual–casual =
asual–casual), thus failing to show any mirror facilitation effect. These findings are interesting and show that, although the visual word recognition system seems to be highly flexible at the front-end input coding schemes, as research on leet word processing (e.g., Carreiras, Duñabeitia, & Perea, 2007; García-Orza, Comesaña, Piñeiro, Soares, & Perea, 2016; Perea, Duñabeitia, & Carreiras, 2008), case mixing processing (e.g., Perea, Vergara-Martínez, & Gomez, 2015; Reingold, Yang, & Rayner, 2010), or letter case processing (e.g., Perea et al., 2012; Perea, Rosa, & Marcet, 2017; Soares et al., 2020) demonstrate, the results of the present work suggest that the level of tolerance that the visual recognition system shows on form variations seems to be modulated not only by the extent to which those forms resemble the original letters but, importantly, by its directionality. In order to rule out the possibility that these results could arise from some particularities that some of the letters integrated into each word category (i.e., LO-words vs. RO-words) could present, we conducted another lme analysis where the ‘Target type’ factor (i.e., LO-words vs. RO-words) was substituted by the within factor ‘Letter’, considering each letter individually (i.e., ‘g’, ‘j’ ‘z’, c’, ‘r’, and ‘f’). The results were quite impressive, as the pattern observed when considering each word category (the ‘Target type’ factor), and reported in the “Results” section, is basically observed in each of the letters analyzed separately. The only exception is the left-oriented letter ‘z’, where the contrasts across prime conditions did not reach statistical significance even though participants were still faster recognizing ‘z words’ as zona[zone] preceded by its mirror-image than by identity primes (
ona–zona < zona–zona), hence mimicking the pattern observed for LO-words.
Unless one assumes, as Soares et al. (2019) claim, that at the earliest stages of visual word recognition (i.e., from the perception of visual features to sub-lexical orthographic processing), there is some sort of statistical computation of the right-left regularities presented in letters of a given language, as the implicit right-orienting rule sustains (e.g., Fischer, 2011, 2017; Fischer & Koch, 2016; Fischer & Tazouti, 2012), which affects the parameters and the weights of the feedforward connections from the feature level of analysis to the letter level of processing, the feedback connections from the letter level of processing to the feature level of analysis, and/or the lateral inhibitory connections that can be established between the different nodes within the letter level of processing, one cannot account for the right-asymmetry bias observed in the visual word recognition of words containing reversal letters, now extended to the visual word recognition of words containing non-reversal letters.
Nevertheless, it is worth noting that the nature of this effect is entirely different for words containing reversal- vs. non-reversal letters. For reversal letters, the right-asymmetry bias produces an inhibitory mirror effect in the recognition of words containing left-oriented letters preceded by its mirror reversals, while for non-reversal letters the right-asymmetry bias produces a facilitative effect in the recognition of words containing left-oriented letters preceded by its mirror-image. This can be accounted for if we consider that, in both cases, left-oriented letters, regardless of the fact they can have, or not, other letters in the alphabet that corresponds to its mirror-image (i.e., they are reversal or non-reversal), might present less stable orthographic representations, thereby making the visual word recognition system to show great tolerance in the processing of those letters at the perceptual front end feature letter level of processing. However, this tolerance is a double-edged sword. In the case of reversal letters, as there is another letter in the alphabet that corresponds to its mirror-image with the added advantage of presenting the dominant right-orientation in the language, this might cause the competing right-oriented letter to receive more activation, hence producing a higher cost when the target word presents a left-oriented letter instead. In the case of non-reversal letters, as there is one letter in the alphabet that corresponds to its mirror-image and, importantly, this letter violates the dominant right-orientation in the language, this might make the reading system to show greater tolerance and to take more advantage of this kind of stimuli to speed-up recognition. As right-oriented non-reversal letters can present more stable representations, the system might be less permeable to form variations, hence justifying the absence of facilitation in these circumstances.
In conclusion, the results reported here extend previous findings on the right-asymmetry bias observed in the mirror-letter interference effect with reversal letters embedded in words to non-reversal letters embedded in words, and request further studies using other techniques more sensitive to the time course of processing namely eye-movements monitoring or event-related potentials (ERPs), to examine if this effect relies on the very earliest stages of perceptual visual letter detection and analysis, or at a later letter level of processing. Future research should also explore whether the right-asymmetry bias observed here in words containing non-reversal letters is also modulated by the visual letter features of the font used to present the stimuli, as some of the non-reversal letters used (e.g., ‘g’) are left- or right-oriented according to the type of font used (e.g., Arial, Times New Roman) or if they are rooted on a more abstract and internal letter representation that is activated regardless of the visual features of the font used to presented the stimuli (see Soares et al., 2020 for recent evidence on the impact of visual letter features in the processing of consonants vs. vowels). Another suggestion would involve examining the developmental trajectory of the right-asymmetry bias in the recognition of words containing non-reversal letters, as Soares et al. (2019) did for words containing reversal letters, and also to test if the difference between LO- and RO-words found here is still observed not only in ‘normal’ readers but also in dyslexic readers. It is possible that differences might not arise due to the difficulties of dyslexic readers to efficiently differentiate between ‘normal’ and mirrored letters regardless of its directionality, in line with previous results (e.g., Lachmann, Schumacher, & van Leeuwen, 2009). Taken together, they would provide valuable insights to the amendments that the input coding schemes of the current computational models of visual word recognition (e.g., Coltheart et al., 2001; Davis, 2010; Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981; Perry et al., 2007) should introduce in order to better account for right-asymmetry bias observed in our data. The use of other methodological options could also be considered as the results presented here rests on statistical modeling that can only handle modeled error, as Gelman, Hill, and Vehtari (2020) recently pointed out.
Notes
The uppercase letter created by Rumelhart and Siple (1974) is a highly artificial font where letters are defined by a set of 14 straight-line segments or “quanta”. Each letter is coded according to the presence (1)/absence (0) of each these segments according to its position, so that each letter is represented by a binary pattern such as 01111010100001.
To classify letters as facing right or left, Treiman et al. (2014) asked participants (college students) to decide whether each of the 52 uppercase and lowercase letters faced ‘left’, faced ‘right’, or was ‘neutral’, circling the corresponding answer on an answer sheet. The results showed that, in lowercase, the letter forms for which the most popular response was ‘left’ were (the number in parentheses indicates the proportion of ‘left’ responses): ‘a’ (.85), ‘d’ (.94), ‘g’ (1.00), ‘j’ (.97), ‘q’ (.88), ‘y’ (.91), and ‘z’ (.66); whereas the letter forms for which the most popular response was ‘right’ were: ‘b’ (.91), ‘c’ (.94), ‘e’ (.94), ‘f’ (1.00), ‘h’ (.88), ‘k’ (1.00), ‘n’ (.58), ‘p’ (.94), ‘r’ (1.00), and ‘s’ (.73). In the remaining cases, the most popular answer was that the letter form was neutral.
References
Badian, N. A. (2005). Does a visual-orthographic deficit contribute to reading disability? Annals of Dyslexia, 55, 28–52. https://doi.org/10.1007/s11881-005-0003-x.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68, 255–278. https://doi.org/10.1016/j.jml.2012.11.001.
Bates, D., Maechler, M., & Bolker, B. (2011). lme4: Linear mixed-effects models using S4 classes [Computer software]. (R package version 0.999375-42) arXiv:1406.5823
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67, 1–48. https://doi.org/10.18637/jss.v067.i01.
Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Methodological), 57, 289–300. https://doi.org/10.1111/j.2517-6161.1995.tb02031.x.
Box, G. E., & Cox, D. R. (1964). An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological), 26, 211–243. https://doi.org/10.1111/j.2517-6161.1964.tb00553.x.
Campos, A. D., Mendes Oliveira, H., & Soares, A. P. (2020). Temporal dynamics of syllable priming effects on visual word recognition: Evidence from different prime durations. Canadian Journal of Experimental Psychology, 74, 125–130. https://doi.org/10.1037/cep0000198.
Campos, A. D., Oliveira, H. M., & Soares, A. P. (2018). The role of syllables in intermediate-depth stress-timed languages: Masked priming evidence in European Portuguese. Reading and Writing: An Interdisciplinary Journal, 31, 1209–1229. https://doi.org/10.1007/s11145-018-9835-8.
Campos, A.D., Oliveira, H. M, & Soares, A. P. (in press). Syllable effects in beginning and intermediate European-Portuguese readers: Evidence from a sandwich masked go/no-go lexical decision task. Journal of Child Language.
Carreiras, M., Duñabeitia, J. A., & Perea, M. (2007). Reading words, NUMB3R5 and $YMßOL$. Trends in Cognitive Sciences, 11, 454–455. https://doi.org/10.1016/j.tics.2007.08.007.
Cohen, L., Dehaene, S., Naccache, L., Lehéricy, S., Dehaene-Lambertz, G., Hénaff, M. A., et al. (2000). The visual word form area: Spatial and temporal characterization of an initial stage of reading in normal subjects and posterior split-brain patients. Brain: A Journal of Neurology, 123, 291–307. https://doi.org/10.1093/brain/123.2.291.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204–256. https://doi.org/10.1037//0033-295X.108.1.204.
Danziger, E., & Pederson, E. (1998). Through the looking glass: Literacy, writing systems and mirror-image discrimination. Written Language & Literacy, 1, 153–169. https://doi.org/10.1075/wll.1.2.02dan.
Davis, C. J. (2010). The spatial coding model of visual word identification. Psychological Review, 117, 713–758. https://doi.org/10.1037/a0019738.
Dehaene, S. (2005). From monkey brain to human brain: A fyssen foundation symposium. Cambridge, MA: The MIT Press.
Dehaene, S. (2009). Reading in the brain: The science and evolution of a human invention. New York, NY: Penguin Group.
Dehaene, S., & Cohen, L. (2007). Cultural recycling of cortical maps. Neuron, 56, 384–398. https://doi.org/10.1016/j.neuron.2007.10.004.
Dehaene, S., & Cohen, L. (2011). The unique role of the visual word form area in reading. Trends in Cognitive Sciences, 15, 254–262. https://doi.org/10.1016/j.tics.2011.04.003.
Dehaene, S., Cohen, L., Morais, J., & Kolinsky, R. (2015). Illiterate to literate: Behavioural and cerebral changes induced by reading acquisition. Nature Reviews Neuroscience, 16, 234–244. https://doi.org/10.1038/nrn3924.
Dehaene, S., Cohen, L., Sigman, M., & Vinckier, F. (2005). The neural code for written words: A proposal. Trends in Cognitive Sciences, 9, 335–341. https://doi.org/10.1016/j.tics.2005.05.004.
Dehaene, S., Pegado, F., Braga, L. W., Ventura, P., Nunes Filho, G., Jobert, A., et al. (2010). How learning to read changes the cortical networks for vision and language. Science, 330, 1359–1364. https://doi.org/10.1126/science.1194140.
Duñabeitia, J. A., Dimitropoulou, M., Estévez, A., & Carreiras, M. (2013). The influence of reading expertise in mirror-letter perception: Evidence from beginning and expert readers. Mind, Brain, and Education, 7, 124–135. https://doi.org/10.1111/mbe.12017.
Duñabeitia, J. A., Molinaro, N., & Carreiras, M. (2011). Through the looking-glass: Mirror reading. Neuroimage, 54, 3004–3009. https://doi.org/10.1016/j.neuroimage.2010.10.079.
Fernandes, T., & Leite, I. (2017). Mirrors are hard to break: A critical review and behavioral evidence on mirror-image processing in developmental dyslexia. Journal of Experimental Child Psychology, 159, 66–82. https://doi.org/10.1016/j.jecp.2017.02.003.
Fischer, J. P. (2011). Mirror writing of digits and (capital) letters in the typically developing child. Cortex, 47, 759–762. https://doi.org/10.1016/j.cortex.2011.01.010.
Fischer, J. P. (2013). Digit reversal in children’s writing: A simple theory and its empirical validation. Journal of Experimental Child Psychology, 115, 356–370. https://doi.org/10.1016/j.jecp.2013.02.003.
Fischer, J. P. (2017). Character reversal in children: The prominent role of writing direction. Reading and Writing: An Interdisciplinary Journal, 30, 523–542. https://doi.org/10.1007/s11145-016-9688-y.
Fischer, J. P. (2018). Studies on the written characters orientation and its influence on digit reversal by children. Educational Psychology: An International Journal of Experimental Educational Psychology, 38, 556–571. https://doi.org/10.1080/01443410.2017.1359239.
Fischer, J. P., & Koch, A. M. (2016). Cognitive development mirror writing in typically developing children: A first longitudinal study. Cognitive Development, 38, 114–124. https://doi.org/10.1016/j.cogdev.2016.02.005.
Fischer, J. P., & Tazouti, Y. (2012). Unraveling the mystery of mirror writing in typically developing children. Journal of Educational Psychology, 104, 193–205. https://doi.org/10.1037/a0025735.
Forster, K. I., & Forster, J. C. (2003). DMDX: A windows display program with millisecond accuracy. Behavior Research Methods, Instruments, and Computers, 35, 116–124. https://doi.org/10.3758/BF03195503.
Fox, J., & Weisberg, S. (2019). An R companion to applied regression. California, CA: Sage Publications.
García-Orza, J., Comesaña, M., Piñeiro, A., Soares, A. P., & Perea, M. (2016). Is VIRTU4L larger than VIR7UAL? Automatic processing of number quantity and lexical representations in leet words. Journal of Experimental Psychology. Learning, Memory, and Cognition, 42, 855–865. https://doi.org/10.1037/xlm0000211.
Gelman, A., Hill, J., & Vehtari, A. (2020). Regression and other stories. Cambridge: University Press.
Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103, 518–565. https://doi.org/10.1037//0033-295X.103.3.518.
Hochberg, Y. (1988). A sharper Bonferroni procedure for multiple tests of significance. Biometrika, 75(4), 800–802. https://doi.org/10.1093/biomet/75.4.800.
Perea, M., Rosa, E., & Marcet, A. (2017). Where is the locus of the lowercase advantage during sentence reading? Acta Psychologica, 177, 30–35. https://doi.org/10.1016/j.actpsy.2017.04.007
Khuri, A. I., Mathew, T., & Sinha, B. K. (1998). Statistical tests for linear mixed models. New York, NY: Wiley.
Kolinsky, R., Verhaeghe, A., Fernandes, T., Mengarda, E. J., Grimm-Cabral, L., & Morais, J. (2011). Enantiomorphy through the looking-glass: Literacy effects on mirror-image discrimination. Journal of Experimental Psychology: General, 140, 210–238. https://doi.org/10.1037/a0022168.
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82(13), 1–26. https://doi.org/10.18637/jss.v082.i13.
Lachmann, T. (2008). Experimental approaches to specific disabilities in learning to read: The case of symmetry generalization in developmental dyslexia. In N. Srinivasan, A. K. Gupta, & J. Pandey (Eds.), Advances in cognitive science (pp. 321–342). Thousand Oaks, CA: Sage.
Lachmann, T. (2018). Reading and dyslexia: The functional coordination framework. In T. Lachmann & T. Weis (Eds.), Reading and Dyslexia (pp. 265–290). https://doi.org/10.1007/978-3-319-90805-2
Lachmann, T., Khera, G., Srinivasan, N., & van Leeuwen, C. (2012). Learning to read aligns visual analytical skills with grapheme–phoneme mapping: Evidence from illiterates. Frontiers in Evolutionary Neuroscience, 4, 8. https://doi.org/10.3389/fnevo.2012.00008.
Lachmann, T., Schumacher, B., & van Leeuwen, C. (2009). Controlled but independent: Effects of mental rotation and developmental dyslexia in dual-task settings. Perception, 38, 1019–1034. https://doi.org/10.1068/p6313.
Lachmann, T., & van Leeuwen, C. (2007). Paradoxical enhancement of letter recognition in developmental dyslexia. Developmental Neuropsychology, 31, 61–77. https://doi.org/10.1207/s15326942dn3101_4.
Lenth, R. (2020). emmeans: Estimated Marginal Means, aka Least-Squares Means. R package version 1.4.8. CRAN. https://CRAN.R-project.org/package=emmeans
Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing Type I error and power in linear mixed models. Journal of Memory and Language, 94, 305–315. https://doi.org/10.1016/j.jml.2017.01.001.
McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Part 1. An account of basic findings. Psychological Review, 88, 375–407. https://doi.org/10.1016/B978-1-4832-1446-7.50048-0.
Nakamura, K., Kuo, W. J., Pegado, F., Cohen, L., Tzeng, O. J., & Dehaene, S. (2012). Universal brain systems for recognizing word shapes and handwriting gestures during reading. Proceedings of the National Academy of Sciences of the United States of America, 109, 20762–20767. https://doi.org/10.1073/pnas.1217749109.
Orton, S. T. (1925). “Word-blindness” in school children. Archives of Neurology and Psychiatry, 14, 581–615. https://doi.org/10.1001/archneurpsyc.1925.02200170002001.
Pederson, E. (2003). Mirror-image discrimination among nonliterate, monoliterate, and biliterate Tamil subjects. Written Language & Literacy, 6, 71–91. https://doi.org/10.1075/wll.6.1.04ped.
Pegado, F., Nakamura, K., Braga, L. W., Ventura, P., Nunes Filho, G., Pallier, C., et al. (2014). Literacy breaks mirror invariance for visual stimuli: A behavioral study with adult illiterates. Journal of Experimental Psychology: General, 143, 887–894. https://doi.org/10.1037/a0033198.
Pegado, F., Nakamura, K., Cohen, L., & Dehaene, S. (2011). Breaking the symmetry: Mirror discrimination for single letters but not for pictures in the Visual Word Form Area. NeuroImage, 55, 742–749. https://doi.org/10.1016/j.neuroimage.2010.11.043.
Perea, M., Comesaña, M., & Soares, A. P. (2012). Does the advantage of the upper part of words occur at the lexical level? Memory & Cognition, 8, 1257–1265. https://doi.org/10.3758/s13421-012-0219-z.
Perea, M., Duñabeitia, J. A., & Carreiras, M. (2008). R34d1ng w0rd5 w1th numb3r5. Journal of Experimental Psychology: Human Perception and Performance, 34, 237–241. https://doi.org/10.1037/0096-1523.34.1.237.
Perea, M., Moret-Tatay, C., & Panadero, V. (2011). Suppression of mirror generalization for reversible letters: Evidence from masked priming. Journal of Memory and Language, 65, 237–246. https://doi.org/10.1016/j.jml.2011.04.005.
Perea, M., Soares, A. P., & Comesaña, M. (2013). Contextual diversity is a main determinant of word-identification times in young readers. Journal of Experimental Child Psychology, 116, 37–44. https://doi.org/10.1016/j.jecp.2012.10.014.
Perea, M., Vergara-Martínez, M., & Gomez, P. (2015). Resolving the locus of cAsE aLtErNaTiOn effects in visual word recognition: Evidence from masked priming. Cognition, 142, 39–43. https://doi.org/10.1016/j.cognition.2015.05.007.
Perry, C., Ziegler, J. C., & Zorzi, M. (2007). Nested incremental modeling in the development of computational theories: The CDP+ model of reading aloud. Psychological Review, 114, 273–315. https://doi.org/10.1037/0033-295X.114.2.273.
Portex, M., Hélin, C., Ponce, C., & Foulin, J. N. (2018). Dynamics of mirror writing compared to conventional writing in typical preliterate children. Reading and Writing: An Interdisciplinary Journal, 31, 1435–1448. https://doi.org/10.1007/s11145-018-9838-5.
Reingold, E. M., Yang, J., & Rayner, K. (2010). The time course of word frequency and case alternation effects on fixation times in reading: Evidence for lexical control of eye movements. Journal of Experimental Psychology: Human Perception and Performance, 36, 1677–1683. https://doi.org/10.1037/a0019959.
Rumelhart, D. E., & Siple, P. (1974). The process of recognizing tachistoscopically presented words. Psychological Review, 87, 99–118. https://doi.org/10.1037/h0036117.
Satterthwaite, F. E. (1941). Synthesis of variance. Psychometrika, 6, 309–316. https://doi.org/10.1007/BF02288586.
Soares, A. P., Iriarte, Á., Almeida, J. J. D., Simões, A., Costa, A., França, P., et al. (2014a). Procura-PALavras (P-PAL): Uma nova medida de frequência lexical do Português Europeu contemporâneo [Procura-PALavras (P-PAL): A new measure of word frequency for contemporary European Portuguese]. Psicologia: Reflexão e Crítica, 27, 110–123. https://doi.org/10.1590/S0102-79722014000100013.
Soares, A. P., Iriarte, Á., De Almeida, J. J., Simões, A., Costa, A., Machado, J., et al. (2018). Procura-PALavras (P-PAL): A web-based interface for a new European Portuguese lexical database. Behavior Research Methods, 50, 1461–1481. https://doi.org/10.3758/s13428-018-1058-z.
Soares, A. P., Lages, A., Oliveira, H. M., & Hernández-Cabrera, J. (2019a). The mirror reflects more for ‘d’ than for ‘b’: Right-asymmetry bias on the visual recognition of words containing reversal letters. Journal of Experimental Child Psychology, 182, 18–37. https://doi.org/10.1016/j.jecp.2019.01.008.
Soares, A. P., Lages, A., Silva, A., Comesaña, M., Sousa, I., Pinheiro, A. P., et al. (2019b). Psycholinguistics variables in the visual-word recognition and pronunciation of European Portuguese words: A megastudy approach. Language, Cognition and Neuroscience, 4, 689–719. https://doi.org/10.1080/23273798.2019.1578395.
Soares, A. P., Machado, J., Costa, A., Iriarte, Á., Simões, A., de Almeida, J. J., et al. (2015). On the advantages of frequency and contextual diversity measures extracted from measures extracted from subtitles: The case of Portuguese. Quarterly Journal of Experimental Psychology, 68, 680–696. https://doi.org/10.1080/17470218.2014.964271.
Soares, A. P., Oliveira, H. M., & Jiménez, L. (2020). Literacy effects on Artificial Grammar Learning (AGL) with letters and colors: Evidence from preschool and primary school children. Paper submitted for publication.
Soares, A. P., Perea, M., & Comesaña, M. (2014b). Tracking the emergence of the consonant bias in visual-word recognition: Evidence with developing readers. PLoS ONE, 9(2), e88580. https://doi.org/10.1371/journal.pone.0088580.
Soares, A. P., Velho, M., & Oliveira, H. M. (2020). The role of letter features on the consonant bias effect: Evidence from masked priming. Paper submitted for publication.
Terepocki, M., Kruk, R. S., & Willows, D. M. (2002). The incidence and nature of letter orientation errors in reading disability. Journal of Learning Disabilities, 35, 214–233. https://doi.org/10.1177/002221940203500304.
Treiman, R., Gordon, J., Boada, R., Peterson, R. L., & Pennington, B. F. (2014). Scientific studies of reading statistical learning, letter reversals, and reading. Scientific Studies of Reading, 18, 383–394. https://doi.org/10.1080/10888438.2013.873937.
Treiman, R., & Kessler, B. (2011). Similarities among the shapes of writing and their effects on learning. Written Language & Literacy, 14, 39–57. https://doi.org/10.1075/wll.14.1.03tre.
Acknowledgements
This study was conducted at the Psychology Research Centre (PSI/01662), University of Minho, and supported by the Grant POCI-01-0145-FEDER-028212 from the Portuguese Foundation for Science and Technology and the Portuguese Ministry of Science, Technology and Higher Education through national funds, and co-financed by FEDER through COMPETE2020 under the PT2020 Partnership Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Words and pseudowords used in the experiment
Appendix: Words and pseudowords used in the experiment





Rights and permissions
About this article

Cite this article
Soares, A.P., Lages, A., Velho, M. et al. The mirror reflects more for genial than for casual: right-asymmetry bias on the visual word recognition of words containing non-reversal letters. Read Writ 34, 1467–1489 (2021). https://doi.org/10.1007/s11145-020-10100-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-020-10100-x