
Abstract
Hindi graphs, called akshara, are difficult to learn because of their visual complexity and large set of graphs. Akshara containing multiple consonants (complex akshara) are particularly difficult. In Hindi, complex akshara are formed by fusing individual consonantal graphs. Some complex akshara look similar to their component parts (transparent), whereas others do not (opaque). We taught 35 English-speaking adults a semi-artificial orthography that was modeled on the Devanagari script used for Hindi and other Indic languages. Participants were taught 80 complex akshara using 4 different methods: (1) choosing the components (from several choices) given the graph (2) choosing the correct graph (from several choices) given its components, (3) copying a graph while the graph and its components are displayed, and (4) writing a graph from memory given its components. Methods 1 and 2 compare emphasis on part-whole versus whole-part relationships, methods 1 & 2 and 3 & 4 compare motor effects, and methods 3 and 4 compare testing effects. We found that transparent graphs were better learned than opaque graphs. Testing on the akshara typically did not improve learning and there were few effects of emphasis on part-whole versus whole-part relationships. There was evidence for motor effects; copying & writing the akshara improved pure orthographic knowledge and people’s ability to produce the phonological form of a given akshara. These results corroborate other studies showing that copying and writing graphs helps beginning learners of English, Chinese, and Arabic build orthographic knowledge. Copying was more time efficient than writing, suggesting that having beginning learners copy akshara is an important pedagogical tool to use in classrooms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
A critical precursor to reading is the ability to recognize graphs. Although graph recognition is relatively easy in the English orthography, which has 26 letters, it can be more difficult in extensive orthographies. Hindi has an alphasyllabic writing system (also known as Abugida; Share & Daniels, 2016), in which each graph represents a syllable. Because languages have more syllables than phonemes, most alphasyllabaries have between 250 and 500 graphs (Nag & Snowling, 2010).
In Hindi, phonemes combine in a non-linear manner to form open syllabic graphs called akshara. The number of phonemes the different akshara represent varies greatly. Simple akshara represent either a vowel phoneme or a consonantal phoneme with an inherent schwa vowel. Consonant–vowel (CV) akshara have consonant and vowel subcomponents. Complex akshara contain two or more consonants and may also have a vowel subcomponent (see Table 1). The large inventory of graphs and the visual complexity and non-linear nature of the graphs in alphasyllabaries slows the pace of orthographic learning.
Complex akshara are used to represent consonantal blends and adjacent consonants across a syllabic boundary. For example, in the Hindi word /gram/ (village), the /gr/ sound is a consonantal blend and is expressed with a complex akshara. Blends can occur in word initial positions (/gram/), word medial positions (/pə.ri.ʃrəm/), and word final positions (/nəʃʈ/). Complex akshara can also be used across syllabic breaks. For example, in the Hindi word /əg.ni/ (fire), there is a syllabic break between the /g/ and the /n/ sounds. However, the /g/ and the /n/ sounds are written together as one complex akshara. All blends are expressed as complex akshara, but only some consonantal syllabic breaks occur within complex akshara. For example, the phonological sequence /r.t̪a/ in which there is a syllabic break between the two consonants, can either be expressed as a complex akshara combining the r and t̪ sounds ( ; in the Marathi word
; in the Marathi word  /hər.t̪a/ [remover]) or as two separate akshara (
/hər.t̪a/ [remover]) or as two separate akshara ( ; in the Marathi word
; in the Marathi word  /hər.t̪aɭ/ [a strike]). In the latter case, when the syllabic break is expressed as two akshara, there is an inherent vowel between the two consonants which is understood by native speakers to be deleted.
/hər.t̪aɭ/ [a strike]). In the latter case, when the syllabic break is expressed as two akshara, there is an inherent vowel between the two consonants which is understood by native speakers to be deleted.
Complex akshara are particularly difficult to learn, a result demonstrated in many alphasyllabaries (Telugu: Vasanta, 2004; Bengali: Nag & Sircar, 2008; Malayalam: Tiwari, 2011; Kannada: Nag, 2007; Nag, Treiman, & Snowling, 2010; Joshi, 2013). For example, Nag (2007) tested first to fourth graders learning Kannada on their knowledge of 20 akshara: eight simple consonantal akshara, one simple vowel akshara, five CV akshara, and six complex akshara. First grade children named 71.8% of simple consonantal akshara correctly, but were near zero on the other akshara types. By second grade, children were nearly perfect at naming consonantal simple akshara, but continued to struggle with the other akshara types. Fourth grade children named only 80% of akshara correctly overall. More specifically, although they were nearly perfect at naming consonantal simple akshara, they were on average only 72.5% correct at naming CV akshara, and 55.2% correct at naming complex akshara. Similarly, Tiwari (2011) studied third grade children learning Malayalam and found that though they had a strong grasp on simple akshara, they found CV akshara more difficult, and complex akshara extremely difficult. Out of the six complex akshara they were tested on, children in the 25th percentile got all of them wrong, the median score was three, and children in the 75th percentile got only 4.75 correct. Not only is akshara recognition difficult, but so is production. Both good and poor spellers in Grades 4–5 learning Kannada had more difficulty spelling words containing complex akshara than words containing CV akshara, which in turn were more difficult than words with only simple akshara. Furthermore, the difference between the good and poor spellers was largest on words containing CV and complex akshara (Nag, Treiman, & Snowling, 2010).
Complex akshara may be difficult to learn because, although complex akshara as a type is common, an individual complex akshara is rare. For example, Patel, Bapi, and Nag (2013) identified 702 different akshara in texts for children in Grades 1–5. Although 285 of those akshara were complex akshara (40%), only 60 of those complex akshara occurred more than 10 times. Of the 50 most common akshara, only three were complex akshara (Nag, 2014). Therefore, although complex akshara recognition is very important for text comprehension, texts may not provide enough examples of a given complex akshara for a child to be able to easily recognize it. Furthermore, many instructors report that a very small percentage of complex akshara are explicitly taught (Nag, 2014; Nag & Sircar, 2008; Patel, 2004). Thus, instruction that explicitly teaches complex akshara may be beneficial.
Because recognizing complex akshara is both difficult and necessary for fluent reading, it is important to identify effective methods for teaching complex akshara. In this study, we compared four methods for teaching complex akshara. The four methods tested three specific hypotheses: (1) Does emphasis on part-whole versus whole-part relationships matter? (i.e., learning to build up simple akshara to form complex akshara as opposed to decomposing complex akshara); (2) Does motor encoding benefit learning?; and (3) Does testing benefit learning? We predicted that motor encoding and testing would benefit learning, but the emphasis on part-whole versus whole-part relationships would not matter. Finally, in Hindi, some complex akshara are transparent (i.e., the subcomponents are easily visible) whereas others are opaque (i.e., the subcomponents are not easily visible). We also tested whether the efficacy of the learning method varied by transparency.
Transparency
In Hindi, some complex akshara look very similar to their components; here we refer to them as transparent. Others look very different from their components; here we refer to them as opaque.Footnote 1 Transparent complex akshara are akshara in which both consonants are easily visible. The most common way to concatenate consonants is to drop the right-most portion of the first consonant and to physically attach it to the second consonant (e.g.,  ). These complex akshara are the most transparent. For some of the rounded consonants, the consonants are vertically joined (e.g.,
). These complex akshara are the most transparent. For some of the rounded consonants, the consonants are vertically joined (e.g.,  ). These are highly transparent to read, but when writing them one must remember that they are not horizontally joined, which is the most common way of concatenating consonants. When
). These are highly transparent to read, but when writing them one must remember that they are not horizontally joined, which is the most common way of concatenating consonants. When  is the first consonant, the second consonant is often attached to round part of (e.g.,
is the first consonant, the second consonant is often attached to round part of (e.g.,  ). Again, when writing them, one must remember that they are not horizontally joined, which is most common. Furthermore, although the components are easily visible, they can be difficult to read because they are non-linear in nature; although is pronounced first, it is on the right-hand side. Complex akshara involving
). Again, when writing them, one must remember that they are not horizontally joined, which is most common. Furthermore, although the components are easily visible, they can be difficult to read because they are non-linear in nature; although is pronounced first, it is on the right-hand side. Complex akshara involving  (/r/) are moderately opaque. The is not easily visible, but its shape change follows a consistent rule. When the is the first consonant, it is always written as a curved line above the second consonant (e.g.,
(/r/) are moderately opaque. The is not easily visible, but its shape change follows a consistent rule. When the is the first consonant, it is always written as a curved line above the second consonant (e.g.,  ). When the is the second consonant, it is written as one diagonal line when attaching to a vertical line and two diagonal lines when attaching to a curve (e.g.,
). When the is the second consonant, it is written as one diagonal line when attaching to a vertical line and two diagonal lines when attaching to a curve (e.g.,  ). Finally, some complex akshara are highly opaque; they do not look like either of their components and must be memorized (e.g.,
). Finally, some complex akshara are highly opaque; they do not look like either of their components and must be memorized (e.g.,  ) (see Table 2 for larger versions of the akshara).
) (see Table 2 for larger versions of the akshara).
It is reasonable to expect that opaque complex akshara are more difficult to learn than transparent complex akshara because they must be memorized and cannot be derived using rules. It is also possible that learning strategies that build orthographic knowledge, such as copying and writing, are more important for opaque complex akshara. Therefore, in this study, we varied the opacity of the graphs in a semi-artificialFootnote 2 orthography. Transparent graphs were all formed using the most common rule in Devanagari-based orthographies: drop the right portion of the first graph and physically connect it to the second graph (e.g.,  ). Opaque graphs did not contain one or both of their component graphs (e.g., complex graph that does not contain one component graph:
). Opaque graphs did not contain one or both of their component graphs (e.g., complex graph that does not contain one component graph:  complex graph that does not contain both component graphs:
complex graph that does not contain both component graphs:  ).Footnote 3
).Footnote 3
Benefit of motor encoding
Physically copying and writing graphs/words has been shown to be more helpful for building orthographic knowledge than viewing, tracing, typing, mentally recalling, and manipulating tiles (here copying is defined as writing while viewing a model, writing is defined as writing from memory). Furthermore, the benefit of copying and writing has been demonstrated with children and adults learning English letters, Chinese characters, Bengali and Gujarati akshara, Arabic graphs, and pseudoletters/characters (Cunningham & Stanovich, 1990; Guan, Liu, Chan, Ye, & Perfetti, 2011; Longcamp et al., 2008; Longcamp, Zerbato-Poudou, & Velay, 2005; Naka, 1998; Naka & Naoi, 1995; Ouellette, 2010; Wollscheid, Sjaastad, & Tømte, 2016; Xu, Chang, & Perfetti, 2014; see Tables 3, 4). For example, Cunningham and Stanovich (1990) taught English-speaking first graders to spell several English words in three conditions: copying, typing, and physically re-ordering letter tiles. Students learned best in the copying condition and this result held whether the post-test required them to spell via writing, typing, or manipulating tiles. Similarly, Longcamp et al. (2008) had English-speaking adults learn the orthographic forms of Bengali and Gujarati akshara; the akshara were simple akshara and were not paired with their phonological forms. The participants practiced one set of akshara via copying and the other via typing. Participants were better at determining whether an akshara was in its correct orientation or was a mirror-image when they learned via copying than via typing, and participants remembered handwritten akshara for a longer period of time.
However, the benefit of motor encoding is not seen consistently. The discrepant results could reflect the fact that studies vary in terms of the experience levels of the participants, the assessments used, and the conditions motor encoding is compared to. For example, Naka (1998) found that, for Japanese children learning Chinese-pseudocharacters (with which they have some experience), the benefit of copying was most apparent in the youngest age group.
In addition to experience, the assessments used also affect whether or not a benefit of motor encoding is seen (Guan et al., 2011; Naka & Naoi, 1995; Xu, Chang, Zhang, & Perfetti, 2013). For example, Xu et al. (2013) found that participants performed better on lexical decision and character production tasks if they learned by writing than via viewing, whereas participants performed better on a pinyin production task if they learned by viewing.
Finally, it is important to consider which learning methods are compared with copying and writing. For example, both Ouellette (2010) and Ouellette and Tims (2014) worked with English-speaking second graders learning English non-words and used spelling as one of the assessments. However, Ouellette (2010) demonstrated a benefit of writing but Ouellette and Tims (2014) did not. The discrepant results could reflect the fact that Ouellette (2010) compared writing to viewing whereas Ouellette and Tims (2014) compared writing to typing.
Although there are some discrepant results, copying and writing typically benefit orthographic learning. Why are they beneficial? Motor experience with objects may alter neural activation patterns; the motor system is active when viewing objects that we have had motor experiences with. Therefore, it is possible that the physical action of copying and writing helps engage the motor system when viewing graphs (James, 2010). Multiple neuroimaging studies have demonstrated that learning graphs via copying and writing changes the neural response to the graphs (Cao et al., 2013; James, 2010; James & Atwood, 2009; Longcamp et al., 2008). For example, two studies have demonstrated that motor encoding is associated with increased activity in left fusiform (James, 2010; James & Atwood, 2009). This is significant because the left fusiform is where the visual word form area is located, an area that is particularly important for orthographic recognition. Furthermore, another study (Longcamp et al., 2008) demonstrated that writing leads to better akshara learning than does typing and also found neural differences between the two learning conditions. Writing was associated with more brain activation in several areas: the cerebellum which is critical for motor memory consolidation, the posterior part of the middle temporal gyrus which is important for learning associations between visual stimuli and motor responses, and the somatosensory cortex which is associated with motor execution and imagery.
Furthermore, there is some evidence to suggest that, in addition to the motor movement, momentarily holding the orthographic form in memory and seeing the physical form you produce is also important. Naka (1998) examined first, third, and fifth grade Japanese students learning Chinese pseudocharacters. The children learned the characters better when they copied them rather than just viewed them. However, the benefit of copying decreased when children traced the characters or copied them with the other side of their pen (thus producing no physical mark).
In light of previous evidence, the present study examines if motor encoding benefits complex akshara learning for novice participants. In contrast to previous studies, which used either copying or writing, the present study uses both, enabling a direct comparison. Copying and writing are compared to multiple choice learning methods. Finally, the present study employs a variety of assessments to see if the benefit of motor encoding varies by assessment.
Benefit of testing
As stated in the prior section, one goal of the present study was to directly compare copying and writing. Writing may be more beneficial than mere copying because of writing’s greater demands on memory for the graphic form. There is some limited evidence to support that hypothesis. For example, Naka (1998) argued that the need to momentarily hold the orthographic form in memory was why copying was more beneficial than tracing. Because writing requires participants to hold the orthographic form in memory to a greater extent than copying does, we predicted that writing would be more beneficial than copying. However direct comparisons of writing and copying are lacking. Some studies have tested writing (Cao et al., 2013; Chang, Xu, Perfetti, Zhang, & Chen, 2014; Guan et al., 2011; Ouellette & Tims, 2014; Vaughn, Schumm, & Gordon, 1993; Xu et al., 2013; see Table 4) whereas others have tested copying (Cunningham & Stanovich, 1990; James, 2010; James & Gauthier, 2006; Longcamp et al., 2005; Naka, 1998; Vaughn et al., 1992; see Table 3). Here we make a direct comparison between writing and copying.
To more clearly differentiate the writing and copying conditions, we instantiated the writing condition slightly differently from previous studies (Cao et al., 2013; Chang et al., 2014; Guan et al., 2011; Ouellette & Tims, 2014; Vaughn et al., 1993; Xu et al., 2013). In those studies, the character/word was shown, removed from the sight, and then participants had to write it down. In the present study, we showed participants the two simple akshara and asked them to produce the complex akshara they comprise from memory (e.g., participants shown  participants need to write
participants need to write  ). Therefore, rather than briefly holding the visual form in working memory, participants had to retrieve the visual form from long-term memory. Thus, the writing condition was similar to the testing effect: the phenomenon that retrieving information from memory strengthens the memory for that information (Roediger & Karpicke, 2006). Retrieval practice is a domain-general learning mechanism that has been demonstrated in many educational contexts, including spelling (Rieth et al., 1974). Observing a writing effect here could be construed as a special case of a testing effect.
). Therefore, rather than briefly holding the visual form in working memory, participants had to retrieve the visual form from long-term memory. Thus, the writing condition was similar to the testing effect: the phenomenon that retrieving information from memory strengthens the memory for that information (Roediger & Karpicke, 2006). Retrieval practice is a domain-general learning mechanism that has been demonstrated in many educational contexts, including spelling (Rieth et al., 1974). Observing a writing effect here could be construed as a special case of a testing effect.
Study overview and hypotheses
To increase our experimental control, we used a semi-artificial orthography strongly modeled on Devanagari and novice participants. Although this approach lacks the authenticity of real literacy contexts, there are two specific benefits of the semi-artificial orthography. First, in Devanagari, there are significantly more transparent complex akshara than opaque complex akshara. Therefore, it can be difficult to test the effect of opacity because the small number of opaque graphs would reduce statistical power. By using a semi-artificial orthography, we can create mappings such that half the complex akshara are opaque. Second, learning a new language entails learning both a new phonological system and a new orthographic system. Because we were interested in orthographic learning, we paired our simple graphs with English phonemes and our complex graphs with English consonantal clusters. Using the English phonological system eliminated the need for participants to learn a new phonological system and allowed us to isolate orthographic learning. We chose to work with novice learners rather than HindiFootnote 4 students because Hindi students may vary significantly in their akshara exposure and knowledge of ligaturing rules; working with novice learners minimized the confound of previous knowledge.
This study compared four learning methods. The first two methods were multiple-choice (MC) methods that do not benefit from motor encoding. In the first method, decompose complex akshara MC, the complex akshara was provided and participants had to choose the corresponding simple akshara from a set of choices. In the second method, compose complex akshara MC, the simple akshara were provided and the participants had to choose the corresponding complex akshara from a set of choices. Comparing these two methods allowed us to test if emphasis on part-whole versus whole-part relationships matters. The third and fourth methods involved copying and writing, respectively.
This study also used a variety of outcome measures of specific skills. Some measures (orthographic legality and writing tests) required high-quality orthographic representations whereas others required a connection between orthography and phonology (hear and choose, reading, and writing tests). Finally, this study used both transparent and opaque graphs.
We hypothesized that participants would perform better on transparent graphs than opaque graphs on tests that require a connection between orthography and phonology. Furthermore, because of the benefit of testing, participants would perform better when they learn via writing than via copying on tests that require a connection between orthography and phonology, especially on opaque graphs. Because of the benefit of motor encoding, participants would perform better when they learn via copying & writing than via MC on tests that require high quality orthographic representations. We did not predict any differences between the two MC conditions because we did not expect emphasis on part-whole versus whole-part relationships to have an effect.
Methods
Participants
Participants were 47 undergraduate students at the University of Pittsburgh. Six participants did not finish all three sessions and were thus excluded. The remaining 41 participants were aged 18–28 years (average age = 19.75 years, SD = 1.78 years) and there were 26 males. All participants were from the subject pool and received course credit for participating. Participants were also given a $10 bonus for attending all three sessions and “performing well” (the bonus was not contingent on performance, but participants were told it was to encourage them to try their best). All participants were native English speakers and had no experience with any languages that use orthographies other than linear, alphabetic orthographies (i.e., no experience with Ethiopian, Hebrew, Arabic, Cree, Eritrean, and Asian languages including Hindi, Chinese, and Korean). The participants may have known other linear, alphabetic orthographies such as Cyrillic.
Materials
Graphs Materials included 15 simple akshara (all consonants) and 80 complex akshara that were formed using pairs of simple akshara. Half of the complex akshara were transparent (i.e., they looked like a combination of their components, e.g.,  ) and half were opaque (i.e., they did not look like a combination of their components, although for some, one of the components was visible, e.g.,
) and half were opaque (i.e., they did not look like a combination of their components, although for some, one of the components was visible, e.g.,  ).Footnote 5 All of the akshara were real Devanagari akshara, but some were paired with different sounds so that non-native phonology would not confuse the participants. For example,
).Footnote 5 All of the akshara were real Devanagari akshara, but some were paired with different sounds so that non-native phonology would not confuse the participants. For example,  is pronounced as /ɳ/ in Hindi. Because that phoneme is not present in English, it would have been difficult for participants to pronounce. Therefore, we paired it with the phoneme /m/. Furthermore, the mappings between some of the pairs of simple akshara and their corresponding complex akshara were invented. For example, in Hindi,
is pronounced as /ɳ/ in Hindi. Because that phoneme is not present in English, it would have been difficult for participants to pronounce. Therefore, we paired it with the phoneme /m/. Furthermore, the mappings between some of the pairs of simple akshara and their corresponding complex akshara were invented. For example, in Hindi,  , but our participants learned
, but our participants learned  . This was done to ensure that half of the pairing were transparent and the other half were opaque. See Table 5 for all of the graphs used in the study.
. This was done to ensure that half of the pairing were transparent and the other half were opaque. See Table 5 for all of the graphs used in the study.
Complex akshara can represent either consonantal blends or consonantal syllabic breaks. This study focused on teaching akshara in isolation, not embedded within words. Because it is very difficult to pronounce isolated consonantal syllabic breaks, but not to pronounce isolated consonantal blends, we only used consonantal blends in this study. To ease pronunciation, most of the consonantal blends used can be found in English words.
Learning methods Participants learned the complex akshara using one of four learning methods: decompose complex akshara MC, compose complex akshara MC, copy, or write. The goal of all four learning methods was to promote intra-akshara awareness by drawing attention to the component akshara. Importantly, phonology was not included in any of the learning methods. Instead, the learning methods focused on teaching participants about the component akshara, which were already associated with their pronunciations. If participants can identify the component akshara and if they know the pronunciation of the component akshara, they can pronounce the complex akshara.
Decompose complex akshara MC In this learning method, participants were shown a complex akshara. They had to choose the two simple akshara that comprise the complex akshara, from among four choices, in the correct order. They could not move on to the next akshara until they got the answer correct.
Compose complex akshara MC In this learning method, participants were shown two simple akshara and had to choose the correct complex akshara from among four choices. They could not move on to the next akshara until they got the answer correct.
Copy In this learning method, participants were shown the two simple akshara and the complex akshara they comprise. They had to write the complex akshara on a sheet of paper. There was no demonstration of how to write the akshara in this condition to more closely mirror the multiple choice conditions.
Write In this learning method, participants were shown the two simple akshara. They had to write the corresponding complex akshara onto a sheet of paper from memory, as best they could. They were then shown a static image of the correct complex akshara so they could check their answer. If they got the answer incorrect, they were asked to write the correct answer down. There was no demonstration of how to write the akshara in this condition to more closely mirror the multiple choice conditions.
Comparing the decompose complex akshara MC and compose complex akshara MC learning methods allowed us to determine if emphasis on part-whole versus whole-part relationships matters. Comparing the copy and write learning methods allowed us to determine if testing benefits learning. Comparing the decompose complex akshara MC & compose complex akshara MC and copy & write learning methods allows us to determine if motor encoding benefits learning.
It is important to note that, although all three learning methods provide feedback, they provide feedback in slightly different ways. The two multiple choice methods do not let participants move on until they select the correct answer, the copying method provides the correct answer as a model, and the writing method provides the correct answer after participants have selected an answer. However, all three methods do provide the correct answer in some manner, so all three methods do provide specific, highly informative feedback.
Tests Participants were tested on the complex akshara using four tests: hear and choose, orthographic legality, reading, and writing. The hear and choose test was administered on Day 2 (tested on all complex akshara) and Day 3 (tested on ¼ of the complex akshara). The other three tests were administered only on Day 3 and tested ¼ of the akshara each.
Hear and choose Participants heard a pronunciation and then saw two akshara. Participants had to quickly choose the akshara that matches the pronunciation via button press. The foils were other learned akshara and were chosen randomly. This test requires a connection between orthography and phonology. Participants responded via a button box to allow for precise collection of both accuracy and reaction time data.
Orthographic legality Participants saw two versions of the same akshara, one correct and one with an orthographic error (see Fig. 1). Participants had to quickly choose the correct akshara via button press. This test requires high quality orthographic representations. Participants responded via a button box to allow for precise collection of both accuracy and reaction time data.

Examples from the orthographic legality test. Participants have to choose the orthographically legal akshara (in this case, always the one on the left). The examples illustrate some of the different types of orthographic problems present in the test (from top to bottom mirror images, incorrect components, incorrectly positioned components)
Reading Participants had to say the pronunciation of the complex akshara aloud. The answers were recorded to check for scoring accuracy. This test requires a connection between orthography and phonology.
Writing Participants heard the pronunciation of an akshara and had to write the corresponding akshara on a piece of paper. This test requires a connection between orthography and phonology and high quality orthographic representations.
Procedure
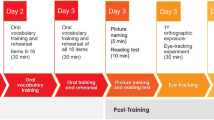
The experiment took place over three consecutive days. One hour was allotted on the first and third days and two hours on the second day. Participants typically took most/all of the allotted time on the first two days but finished early on the third day (see Table 6 for an overview of the three day procedure).
Day 1 On the first day, participants first learned the 15 simple akshara. They were shown each akshara on the screen and heard its pronunciation. They then repeated the pronunciation aloud and copied the akshara onto a sheet of paper. They went through all of the akshara twice in a random order. The first time through, the experimenter demonstrated how the akshara was written before the participant copied the akshara.
After the learning phase, participants were tested on the akshara. The first test was a reading test; they were shown the simple akshara and had to say its corresponding pronunciation aloud. The answers were recorded to check for scoring accuracy. If they got at least 80% (12/15) correct, they were then given the writing test. If not, they went through the learning phase again (but only saw each akshara once) and then re-took the reading test. This cycle continued until they passed the reading test or took the reading test three times, whichever came first. The second test was a writing test; they heard an akshara’s pronunciation and had to write the akshara. If they did not get at least 80% correct, they re-did the learning phase and then took the test again. This cycle continued until they passed the writing test or took the writing test three times, whichever came first. For both tests, the correct answers were provided after the participants gave their answers.
Next, participants were introduced to the complex akshara. First, they saw a complex akshara and heard its pronunciation. Then, they saw the complex akshara’s composition in equation form (i.e., simple akshara + simple akshara = complex akshara) and heard the pronunciations of all three akshara. They then repeated the pronunciation of only the complex akshara aloud. The akshara were presented in a randomized order.
Day 2 Participants began the second day by re-taking the simple reading and writing tests to refresh their memories. After that, the participants were introduced to the complex akshara one more time. Then, the participants began to learn the complex akshara. Participants learned a quarter of the akshara using each learning method (decompose complex akshara MC, compose complex akshara MC, copy, write). First, they went through all four learning methods once, with the akshara associated with the learning method presented twice. Then, they went through the four learning methods one more time, with the akshara associated with that learning method presented once. Which akshara were paired with which learning method and the order of the learning methods were counterbalanced across participants. Half of the graphs associated with each learning method were opaque and half were transparent. After that, the participants completed the hear and choose test using all of the graphs.
Day 3 On the third day, the participants cycled through each learning method one more time and practiced each akshara associated with that learning method one time. Then they completed the hear and choose, orthographic legality, reading, and writing tests. Each test covered ¼ of the graphs. The graphs on each test were evenly distributed among the four learning methods and the opaque/transparent distinction. Therefore, there were 20 akshara tested on each test, five from each learning method. Two to three of those were opaque and two to three were transparent (see Table 7 for distribution of stimuli across learning conditions and tests).
Note that there are only two to three items in each test from each learning condition/transparency combination. This would not be sufficient if our statistical tests were done with a typical by-participants ANOVA, in which we average across all items in a given condition for each participant. However, we used linear mixed effects modeling, in which the unit of observation is the individual trial rather than an average for each participant. Therefore, linear mixed effects models yield more power than do traditional ANOVAs.
Results
Simple graph learning
On the first day, 14 participants did not pass the reading test after three attempts. Of the participants that did pass, they took an average of 2.52 attempts to pass. One participant did not pass the writing test after three attempts. Of the participants that did pass, they took an average of 1.56 attempts to pass.
On the second day, participants re-took the simple reading and writing tests. Any participant who got less than 11/15 correct on either test was excluded from analysis because the complex akshara learning methods are predicated on knowing the simple akshara well. If a participant knows the pronunciations of the simple akshara, and knows which simple akshara comprise a complex akshara, he/she can deduce the pronunciation of the complex akshara. If a participant does not know the pronunciations of the simple akshara, the methods of learning the complex akshara will not be useful. Based on this exclusion criterion, we excluded six participants. Of these six participants, four had failed to pass the reading test and one had failed to pass both the reading and writing tests on the first day. This left us with a final sample of 35 participants (age range 18–28 years; average age = 19.64 years, SD = 1.83 years; 23 males). Of the remaining participants, average accuracy on the Day 2 reading and writing tests was high, 90.3 and 90.9% respectively. Scores on the Day 2 simple reading and writing tests were significantly correlated, r = .365, p = .029.
Data analysis for tests of complex graph learning
The hear and choose, orthographic legality, and reading data were analyzed using the same model, described here. The writing data were analyzed using a different model, described in the relevant section. The accuracy data were analyzed using logit linear mixed effects models and the reaction time data were analyzed using general linear mixed effects models. The data were analyzed using the lme4 package in R (Bates, Maechler, Bolker, & Walker, 2015). The models included the main effects of and an interaction between learning method and transparency. Learning method was tested using three orthogonal contrasts: the comparison between composing complex akshara & decomposing complex akshara and copying & writing (motor effects), the comparison between copying and writing (testing effects), and the comparison between composing complex akshara and decomposing complex akshara (emphasis on part-whole vs. whole-part relationships). Transparency was compared using effects coding. Performance on the Day 2 simple reading and writing tests were included when possible. Random effects that significantly contributed to the models as indicated by likelihood ratio test were included: a random intercept for participant, a random intercept for items, and the effect of transparency was allowed to vary by participant.
For the reaction time data, only reaction times to correct answers were considered. Any reaction times more than three standard deviations from the participants’ mean were removed. Six, one, and four RTs were trimmed from the Day 2 hear and choose, Day 3 hear and choose, and Day 3 orthographic legality tasks respectively (all <0.75%).
For all analyses, all significant and marginal effects. See Table 8 for mean performance on the tasks and Table 9 for a summary of the hypotheses and results.
Day 2 hear and choose
In these models, performance on the Day 2 simple reading and writing tests were included as main effects.
Accuracy Participants were more accurate on transparent graphs than on opaque graphs, z = 7.882, p < .001. Better performance on the Day 2 simple reading test was associated with marginally better performance, z = 1.829, p = .067. Participants were marginally more accurate when they learned via decomposing complex akshara than via composing complex akshara, z = −1.673, p = .094. There was a marginal interaction between method (copy & write/decompose complex akshara & compose complex akshara) and transparency, z = −1.776, p = .078. There was no difference between the two learning conditions for transparent graphs, but motor encoding was associated with better performance for opaque graphs, z = 2.084, p = .037. There was also a marginal interaction between method (copy/write) and transparency, z = −1.765, p = .078, but none of the post-hocs separating by transparency were significant. Thus, the interaction may have been a spurious result.Footnote 6
Reaction time Participants were faster on transparent graphs than on opaque graphs, t(61) = −3.211, p = .002. Participants were marginally faster when they learned via copying & writing than via composing complex akshara & decomposing complex akshara, t(1904.30) = −1.672, p = .095.
Day 3 hear and choose
Accuracy For this model, performance on the Day 2 simple tests could not be included because the model did not converge when they were included. However, preliminary analyses suggest that these variables did not explain significant variance.
Participants were more accurate on transparent graphs than on opaque graphs, z = 4.892, p < .001. The comparison between composing complex akshara & decomposing complex akshara and copying & writing interacted with transparency at a trend level, z = 1.670, p = .095. Copying & writing were marginally better than the two multiple choice methods for transparent graphs, z = 1.692, p = .091, but not for opaque graphs, z = −0.083, p = .934.Footnote 7
Reaction time For this model, performance on the Day 2 simple reading and writing tests were included as main effects. There were no significant main effects nor interactions.
Day 3 orthographic legality
Accuracy For this model, performance on the Day 2 simple tests could not be included because the model did not converge when they were included. However, preliminary analyses suggest that these variables did not explain significant variance.
Participants were more accurate when they learned via copying & writing than via composing complex akshara & decomposing complex akshara, z = 2.947, p = .003. The odds of answering correctly were 1.941 times higher if people learned via copying & writing than via composing complex akshara & decomposing complex akshara.Footnote 8 There was also a trend-level interaction between the composing complex akshara/decomposing complex akshara comparison and transparency, z = 1.788, p = .074. The two learning methods were equivalent for opaque graphs, z = −0.493, p = .622, but composing complex akshara outperformed decomposing complex akshara for transparent graphs, z = 1.961, p = .050.Footnote 9
Reaction time For this model, performance on the Day 2 simple reading and writing tests were included as main effects.
Participants were approximately 110.82 ms faster if they learned via copying & writing than via composing complex akshara & decomposing complex akshara, t(469.70) = −2.063, p = .040.
Day 3 reading accuracy
For this model, performance on the Day 2 simple tests could not be included because the model did not converge when they were included. However, preliminary analyses suggest that these variables did not explain significant variance.
Participants were more accurate on transparent graphs than on opaque graphs, z = 8.262, p < .001. Participants were also more accurate if they learned via writing than via copying, z = 2.301, p = .021. The odds of answering correctly were 1.950 times higher if people learned via writing than via copying.Footnote 10
Day 3 writing accuracy
The writing analyses required a slightly different model. Because accuracy on opaque graphs was very low (7.4%), transparency could not be included as a fixed effect although it was retained as a random slope. Furthermore, the random slope that allowed learning method (copy/write) to vary across items explained a large portion of the variance so that was included as well. Although transparency could not be included as a fixed effect, participants were more accurate on transparent graphs (54.3%) than opaque graphs (7.4%). Performance on the Day 2 simple tests could not be included because the model did not converge when they were included. However, preliminary analyses suggest that these variables did not explain significant variance.
Participants were more accurate when they learned via copying & writing than via composing complex akshara & decomposing complex akshara, z = 5.048, p < .001. The odds of answering correctly were 3.096 times higher if people learned via copying & writing than via composing complex akshara & decomposing complex akshara.Footnote 11
Time on task
We did not control for time on task; we allowed for natural variation as would happen in an educational setting. However, because we recorded the start time of each task, we could estimate time on task using the intervals between consecutive tasks. We used the second time through each learning condition to estimate time on task; because participants did not need instructions the second time through, the estimates were more accurate. The average amounts of time spent on the compose complex akshara MC, decompose complex akshara MC, copying, and writing conditions were 4 m 40 s, 4 m 58 s, 5 m 22 s, and 8 m 44 s, respectively. Paired t tests showed that the two MC conditions did not vary from each other, t(34) = 1.052, p = .300. Participants took longer to copy than to compose complex akshara MC, t(34) = 3.205, p = .003, but copy and decompose complex akshara MC did not vary from each other, t(34) = 0.965, p = .341. Writing took longer than the other three conditions, all ts > 8.996 and all ps < .001.
Discussion
Transparency
We predicted that participants would perform better on transparent graphs than opaque graphs, especially on tasks that require a strong connection between orthography and phonology. This hypothesis was strongly supported; on the hear and choose task participants were more accurate (Days 2 and 3) and faster (Day 2) on transparent graphs. For the reading and writing tasks, participants were more accurate on transparent graphs. The only task that did not show an effect of transparency was the orthographic legality task, which was expected because the task does not require phonological knowledge.
We expected that the type of learning method would matter more for opaque graphs, which are harder to learn. Although we did see an interaction to that effect in the Day 2 hear and choose data, for the Day 3 orthographic legality and hear and choose tests, learning method mattered more for transparent graphs. We especially expected to see an interaction on the writing assessment because knowing that a complex graph is transparent and what its two components are allows easy derivation of the orthographic form. In contrast, the opaque graphs have to be individually memorized, which is very difficult. It is possible that we did not find the expected interactions because half of the graphs were transparent and half were opaque. So, although it was easy to derive the orthographic form of transparent graphs, it was difficult to remember which graphs were transparent and which were opaque. Devanagari has more transparent akshara than opaque akshara. It is possible that we would see the expected interaction between learning method and transparency with a more natural stimulus set.
Benefit of motor encoding
We predicted that the copying & writing conditions would perform better than the MC conditions on tasks that require high-quality orthographic representations because motor encoding has been shown to increase orthographic knowledge. This effect was particularly robust. On the orthographic legality test, participants were significantly more accurate and faster if they learned via copying & writing than via MC. Similarly, on the writing test, participants were more accurate if they learned via copying & writing. Copying & writing were even beneficial on the hear and choose task, a task on which we were not expecting to see effects. The only task that did not show a benefit of copying & writing was reading. This finding was expected because reading does not require high-quality orthographic representations; it is possible to read words you cannot spell (Martin-Chang, Ouellette, & Madden, 2014).
Overall, the data support prior research (Cunningham & Stanovich, 1990; Guan et al., 2011; Longcamp et al., 2005, 2008; Naka, 1998; Ouellette, 2010; Xu et al., 2013) that suggests that motor encoding is valuable for strengthening orthographic representations. Most importantly, the data suggest that copying & writing is beneficial when one is given a phonological form and needs to produce/recognize the orthographic form (i.e., writing and hear and choose) or when one needs pure orthographic knowledge (i.e., orthographic legality) but not when one is given the orthographic form and needs to produce the phonological form (i.e., reading).
Benefit of testing
We predicted that the writing condition would perform better than the copying condition on tasks that require a strong connection between orthography and phonology because testing benefits memory. This hypothesis was largely not supported, although the expected effect was seen on the reading test. It is surprising that writing did not outperform copying because participants spent significantly more time on the writing condition than on the copying condition.
A large body of work has shown that testing improves memory performance for a variety of materials, including orthographic information (Rieth et al., 1974). We did not see the same effect. One possible reason could be that the previous study did not control for exposure, whereas our study did.
Furthermore, there are some exceptions to the testing effect. For example, if participants get an answer incorrect during an initial test, it can strengthen the incorrect response and lead to more incorrect responses on a final test (see Roediger & Karpicke, 2006 for review). Butler, Marsh, Goode, and Roediger (2006) found that when the initial test was easy and participants got most of the answers correct, testing benefitted learning. In contrast, when the initial test was difficult and participants got many incorrect answers, testing produced additional costs. In this case, the initial test was quite difficult and accuracy was low. Therefore, testing could have strengthened incorrect responses, thus negating the benefits of testing.
We did not expect testing to strengthen the incorrect response in this study for two reasons: (1) immediate feedback was given and (2) the task involved orthographic learning. Previous research has shown that incorrect responses are not problematic when immediate feedback is given (Butler & Roediger, 2006), as was the case in this study. Furthermore, much of the research on the negative effects of testing has used word lists and texts as the to-be-learned material. Studies that focus on orthographic learning often fail to demonstrate the same effect. For example, Ehri, Gibbs, and Underwood (1988) had experimental participants generate spellings for difficult-to-spell pseudowords (thus generating many misspellings) while control participants rested or performed an alternate task. Then, all the participants studied the correct spellings. Generating the misspellings did not interfere with experimental participants’ ability to remember the correct spellings.
Although we did not expect poor performance on the initial test to strengthen the incorrect response in this study, post hoc analyses suggest that this may have occurred. We did a median split of the participants based on how many questions they got correct during the writing learning condition to see whether it interacted with the copying/writing contrast. We saw a significant interaction on the writing test, in that writing accuracy during learning interacted with the copying/writing contrast, z = 2.033, p = .042. People who got many answers correct during the writing learning condition found writing marginally more beneficial than copying, z = 1.859, p = .063, whereas people who got many answers incorrect found copying slightly more beneficial than writing. Thus, this study suggests that even with immediate feedback and orthographic information as the to-be-learned material, poor performance on an immediate test can strengthen incorrect responses. Future studies should do more initial learning so that the writing condition elicits fewer incorrect responses and see if the benefits of testing are apparent in those conditions.
Time on task
We did not control for time on task; we allowed it to vary naturally as it would in an educational setting. However, we did obtain estimates of time on task so we could test if time on task was driving our results. Overall, composing complex akshara, decomposing complex akshara, and copying took approximately the same amount of time (although copying took more time than composing complex akshara, decomposing complex akshara did not significantly vary from the two other learning methods). However, writing took significantly more time than the three other learning methods. Time on task did not predict post-test outcomes. Although copying took approximately the same amount of time as the two MC conditions, it resulted in better post-test outcomes. Furthermore, although writing took significantly more time than copying, both of those learning conditions resulted in similar post-test outcomes. Therefore, our results were not an artifact of time on task. Furthermore, the time on task data suggests that copying is a particularly beneficial pedagogical tool for beginning learners; it is time efficient and leads to comparably high levels of learning.
Discrepancies in the prior literature
The results from this study can help resolve some of the discrepancies in the prior literature. Specifically, the results suggest that copying is helpful for novice learners who need to perform tasks that require pure orthographic knowledge or the production of an orthographic form when given a phonological form. Writing is beneficial for experienced learners performing those same tasks.
Copying was beneficial in the present study because the participants were novice learners. The benefit was most apparent on tasks that required pure orthographic knowledge (orthographic legality) and tasks that required producing an orthographic form when given a phonological form (hear and choose, writing). Copying was also beneficial in Cunningham and Stanovich’s (1990) study in which relatively novice learners (first graders) performed a task which required producing an orthographic form given a phonological form (spelling). Similarly, copying was beneficial in Longcamp et al.’s (2005) study in which novice learners (4 years olds) performed a task which required pure orthographic knowledge (orthographic legality). Longcamp et al. (2008) also used an orthographic legality test and novice learners (English-speakers learning akshara) and found copying to be beneficial. Finally, Naka (1998) and Naka and Naoi (1995) found that copying was beneficial when Japanese-speaking adults and children learned Arabic graphs (which were completely novel to them). The task, a free recall of the graphs, required pure orthographic knowledge. Additionally, Naka (1998) demonstrated that copying was very beneficial for first graders learning pseudo-Chinese characters (with which they had some experience). Similarly, Naka and Naoi (1995) found that copying benefited the learning of novel graphic patterns. Together, these studies suggest that copying is beneficial on tasks that require pure orthographic knowledge or the production of an orthographic form when given a phonological form. Copying is beneficial for novice learners, either those learning a new script or very beginning learners of their first language script (4 year olds—first graders).
The studies that have not found a benefit of copying either used advanced learners or tasks that required the production of a phonological form given an orthographic form. For example, Naka (1998) did not find a large copying benefit for Japanese-speaking children in Grades 3–5 learning pseudo-Chinese characters (with which they had some experience). Similarly, Vaughn et al. (1992) did not find a copying benefit for second to third grade children. Furthermore, Naka and Naoi (1995) did not find a copying benefit when Japanese–English adult bilinguals learned Japanese and English words, nor when English-speaking adults learned English words. Furthermore, no copying benefit was found when the Japanese–English bilinguals needed to recall the pronunciations of novel Arabic letters. In fact, on this task, viewing was a more beneficial learning method than was copying.
In contrast to copying, writing appears to be beneficial for advanced learners. Ouellette (2010) found that writing was beneficial for second graders when the post-test was a spelling task. Similarly, Guan et al. (2011) found that writing was beneficial for English learners of Chinese who were enrolled in Elementary Chinese II. This benefit was apparent on tasks that required pure orthographic knowledge, lexical decision and partial cue-based character recognition. Xu et al. (2013) studied a similar population (students were enrolled in their 2nd semester of a Chinese course) and found that the writing was beneficial on a task that required pure orthographic knowledge (lexical decision) and on a task that required participants to write the character given a pinyin prompt.
Writing is not beneficial for novice participants or for tasks that require participants to produce a phonological form from an orthographic form. Chang et al. (2014) found that writing was not beneficial for English speakers enrolled in their first semester of Chinese classes (they had 8 weeks of prior instruction). Thus, it seems that at least some Chinese instruction is necessary before writing becomes beneficial. Furthermore, Guan et al. (2011) and Xu et al. (2013) did not find a benefit of writing on tasks that required participants to produce a phonological form from an orthographic form. In the Guan et al. (2011) study, participants were required to produce the pinyin for the learned characters. In the Xu et al. (2013) study, participants were shown a character and then saw a pinyin representation combined with a voice pronouncing the syllable. Participants had to decide whether the character matched the pronunciation. Because the character was shown first, this task primarily relied on producing a phonological form for the character.
Although the framework we proposed explains most of the discrepancies in the literature, it does not explain all of them. Notably, both Ouellette and Tims (2014) and Vaughn et al. (1993) used writing practice with relatively advanced learners (second–fourth graders learning their first language, English). The tasks involved either pure orthographic knowledge (orthographic legality) or producing an orthographic form from a phonological form (spelling). Nevertheless, a writing benefit was not found. It is unclear why this is the case. Two of the studies that demonstrated a writing benefit did so for participants learning individual Chinese characters (Guan et al., 2011; Xu et al., 2013). Ouellette (2010) found that writing was more beneficial than viewing for second graders learning English pseudowords. In contrast, Ouellette and Tims (2014) compared writing to typing and Vaughn et al. (1993) compared writing to both tracing and typing. Thus, it is possible that writing is very beneficial for advanced learners learning visually complex isolated graphs (such as Chinese characters). However, for advanced learners learning words composed of a relatively small set of visually simple graphs (such as English letters), writing is more beneficial than viewing but as effective as typing and tracing. This hypothesis may be especially true for participants who are proficient in typing (Ouellette & Tims, 2014). Thus, more research comparing writing to various other encoding methods in a variety of orthographies with participants varying in proficiency is necessary to identify the conditions in which writing is beneficial.
Our framework implies that it is the participants’ experience with the graphs they are learning, rather than their age or language background, that affects whether copying or writing would be most beneficial to them. Therefore, we would expect the similar results if the present study was to be replicated with participants with a different language background (e.g., Chinese) or with a different age (e.g., children).
This pattern of results can be easily explained through the lens of desirable difficulties. Effortful retrieval makes encoding more difficult. Whether or not that difficulty is desirable depends on properties of the subjects, materials, and criterial tasks (McDaniel & Butler, 2011). For subjects who find retrieval relatively easy (in this experiment, participants who performed well during the writing learning condition; in other experiments participants who were more experienced), the additional difficulty leads to more robust learning. However, for subjects who find retrieval extremely difficult (in this experiment, participants who performed poorly during the writing learning condition; in other experiments participants who were novices), the additional difficulty is not beneficial.
Use of artificial orthographies
This experiment was conducted with an semi-artificial orthography and novel participants. These conditions allowed us to fully control the distribution of transparent and opaque graphs, the phonological difficulty of the graphs, and the background knowledge of participants. However, we do acknowledge some shortcomings to this approach. First, we chose to have equal numbers of transparent and opaque complex graphs to ease comparisons between the two. However, the proportion of transparent and opaque complex graphs may affect learning. Therefore, it is necessary to replicate this study with a more natural stimulus set.
Second, we chose to use novice participants to better control for prior knowledge. Our results and previously published data suggest that the benefit of copying may decrease with experience whereas the benefit of writing may increase with experience. Thus, studies with more experienced students are needed to determine if writing is more beneficial than copying for those students.
The focus of the current study was on learning orthography–phonology connections for single akshara. Because Hindi has a highly (although not completely) consistent orthography, learning the orthography–phonology connections is a critical first step in learning to read Hindi. Once a person can pronounce singleton akshara, it is relatively easy to pronounce whole words and to access the semantic referents of the words. Because our focus was on pronouncing isolated akshara, we did not embed the akshara in words and we did not teach semantics. However, we acknowledge that, although pronouncing single akshara is a critical precursor to reading development, word-level effects also play a role in reading. First, an understanding of word-level prosody and semantic support is important for correct pronunciation of the schwa vowel, which is not expressed in the orthography (Bhide, Gadgil, Zelinsky, & Perfetti, 2014; Nag, 2014; Pandey, 2014). Second, it is difficult to pronounce single complex akshara that cross syllable boundaries, but those complex akshara do occur in words. Studies of word reading have shown that blends are easier to learn than syllabic breaks (Nag, 2014). Therefore, it is important to do similar research with words rather than singleton akshara so that consonantal syllabic breaks can be included and the effects of word-level prosody and semantic support can be studied.
Educational implications
This study suggests that motor encoding is very important for early learning, especially for building pure orthographic knowledge and the ability to produce an orthographic form given a phonological form. Traditional educational methods in India involve extensive copying (Nag, 2012) and these results suggest that these traditional methods are likely beneficial for the students during early learning and should be continued. For example, worksheets that involve repeatedly copying akshara (see Fig. 2) are likely helpful and should be used in classrooms. Recently, different methods for practicing akshara are being introduced. For example, Aksharit, a game similar to scrabble in which students spell words by manipulating tiles containing akshara, is currently being used by 3000 schools throughout India (“Aksharit,” n.d.). Although the game aspect of it may be engaging and increase motivation, the fact that it only involves manipulating tiles may decrease its educational effectiveness. We do not think such instructional materials should never be used in classrooms, but teachers should be sure to supplement them with some copying practice.

This is a worksheet in which students have to trace and copy /ʊ/ repeatedly. /ʊ/ is simple akshara. The results of this study suggest that similar worksheets should be used for complex akshara as well. This image was taken from http://www.hindicity.com/vowels-worksheets/ and was labeled for reuse
Conclusion
To conclude, this study suggested that transparent graphs are easier to learn that opaque graphs. Testing is not important for orthographic learning, although future studies need to elucidate whether this finding generalizes to other instances, or is only applicable during initial learning when accuracy is low. Furthermore, this study has identified the specific instances in which motor encoding is helpful for learning. Specifically, we propose that motor encoding is helpful for tasks that require pure orthographic knowledge or the ability to produce an orthographic form given a phonological form. Motor encoding is less helpful when a person is given the orthographic form and asked to produce the phonological form. Copying and writing are equally beneficial during early learning, but copying is more time efficient. We recommend that teachers use copying practice when teaching complex akshara to beginning learners.
Notes
Note that transparent and opaque have very different meanings when describing single graphs than when describing an orthography. When describing single graphs, transparency refers to how easily visible the components are. When describing an orthography, transparency refers to the consistency between orthographic and phonological codes.
We refer to the orthography as semi-artificial because portions of the orthography are authentic whereas portions are invented. Specifically, the orthography is authentic in that: (1) Some of the phonology-graph mappings are the same in the semi-artificial orthography and Devanagari; (2) All of the graphs are real Devanagari graphs; and (3) Some of the simple akshara pair-complex akshara mappings are the same in the semi-artificial orthography and Devanagari.
Note that these are not the mappings between simple and complex akshara in Hindi; they are the mappings used in the semi-artificial orthography developed for the present experiment.
We refer to the language Hindi because it is the most well-known language that uses the Devanagari script. However, there are other languages that use the Devanagari script (e.g., Marathi, Sanskrit, Nepali languages) (Sinha & Mahabala, 1979). In fact, we use one akshara (
 ) which is used in Marathi but not in Hindi (Rathod, Dhore, & Dhore, 2013). Because the stimuli are modeled on Devanagari, but there is nothing specific to Hindi per se, the results of this study are equally applicable to all languages that use Devanagari.
) which is used in Marathi but not in Hindi (Rathod, Dhore, & Dhore, 2013). Because the stimuli are modeled on Devanagari, but there is nothing specific to Hindi per se, the results of this study are equally applicable to all languages that use Devanagari.Note that these are not the mappings between simple and complex akshara in Hindi; they are the mappings used in the semi-artificial orthography developed for the present experiment.
Although the model did not converge, the relative gradient was equal to .001.
Although the model did not converge, the relative gradient was equal to .001.
The model parameter estimates are in log odds. The odds are obtained by back-transforming the parameter estimates from the model.
Although the model did not converge, the relative gradient was less than .001.
Although the model did not converge, the relative gradient was less than .001.
Although the model did not converge, the relative gradient was less than .001.
 ) which is used in Marathi but not in Hindi (Rathod, Dhore, & Dhore,
) which is used in Marathi but not in Hindi (Rathod, Dhore, & Dhore, References
Aksharit. (n.d.). Retrieved from http://www.revolvy.com/main/index.php?s=Aksharit.
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. doi:10.18637/jss.v067.i01.
Bhide, A., Gadgil, S., Zelinsky, C. M., & Perfetti, C. A. (2014). Does reading in an alphasyllabary affect phonemic awareness? Inherent schwa effects in Marathi–English bilinguals. Writing Systems Research, 6(1), 73–93. doi:10.1080/17586801.2013.855619.
Butler, A. C., Marsh, E. J., Goode, M. K., & Roediger, H. L. (2006). When additional multiple-choice lures aid versus hinder later memory. Applied Cognitive Psychology, 20(7), 941–956. doi:10.1002/acp.1239.
Butler, A. C., & Roediger, H. L. (2006, May). Feedback neutralizes the detrimental effects of multiple-choice testing. Poster presented at the 18th annual convention for the association for psychological science, New York, NY.
Cao, F., Vu, M., Chan, D. H. L., Lawrence, J. M., Harris, L. N., Guan, Q., et al. (2013). Writing affects the brain network of reading in Chinese: a functional magnetic resonance imaging study. Human Brain Mapping, 34(7), 1670–1684. doi:10.1002/hbm.22017.
Chang, L.-Y., Xu, Y., Perfetti, C. A., Zhang, J., & Chen, H.-C. (2014). Supporting orthographic learning at the beginning stage of learning to read Chinese as a second language. International Journal of Disability, Development and Education, 61(3), 288–305. doi:10.1080/1034912X.2014.934016.
Cunningham, A. E., & Stanovich, K. E. (1990). Early spelling acquisition: Writing beats the computer. Journal of Educational Psychology, 82(1), 159–162. doi:10.1037/0022-0663.82.1.159.
Ehri, L. C., Gibbs, A. L., & Underwood, T. L. (1988). Influence of errors on learning the spellings of English words. Contemporary Educational Psychology, 13(3), 236–253. doi:10.1016/0361-476X(88)90024-0.
Guan, C. Q., Liu, Y., Chan, D. H. L., Ye, F., & Perfetti, C. A. (2011). Writing strengthens orthography and alphabetic-coding strengthens phonology in learning to read Chinese. Journal of Educational Psychology, 103(3), 509–522. doi:10.1037/a0023730.
James, K. H. (2010). Sensori-motor experience leads to changes in visual processing in the developing brain. Developmental Science, 13(2), 279–288. doi:10.1111/j.1467-7687.2009.00883.x.
James, K. H., & Atwood, T. P. (2009). The role of sensorimotor learning in the perception of letter-like forms: Tracking the causes of neural specialization for letters. Cognitive Neuropsychology, 26(1), 91–110. doi:10.1080/02643290802425914.
James, K. H., & Gauthier, I. (2006). Letter processing automatically recruits a sensory-motor brain network. Neuropsychologia, 44(14), 2937–2949. doi:10.1016/j.neuropsychologia.2006.06.026.
Joshi, R. M. (2013). Literacy in Kannada, an alphasyllabic orthography. In H. Winskel & P. Padakannaya (Eds.), South and Southeast Asian psycholinguistics (pp. 184–191). New York, NY: Cambridge University Press.
Longcamp, M., Boucard, C., Gilhodes, J.-C., Anton, J.-L., Roth, M., Nazarian, B., et al. (2008). Learning through hand- or typewriting influences visual recognition of new graphic shapes: Behavioral and functional imaging evidence. Journal of Cognitive Neuroscience, 20(5), 802–815. doi:10.1162/jocn.2008.20504.
Longcamp, M., Zerbato-Poudou, M.-T., & Velay, J.-L. (2005). The influence of writing practice on letter recognition in preschool children: A comparison between handwriting and typing. Acta Psychologica, 119(1), 67–79. doi:10.1016/j.actpsy.2004.10.019.
Martin-Chang, S., Ouellette, G., & Madden, M. (2014). Does poor spelling equate to slow reading? The relationship between reading, spelling, and orthographic quality. Reading and Writing: An Interdisciplinary Journal, 27(8), 1485–1505. doi:10.1007/s11145-014-9502-7.
McDaniel, M. A., & Butler, A. C. (2011). A contextual framework for understanding when difficulties are desirable. In A. S. Benjamin (Ed.), Successful remembering and successful forgetting: A festschrift in honor of Robert A Bjork (pp. 175–198)., New York, NY: Psychology Press.
Nag, S. (2007). Early reading in Kannada: The pace of acquisition of orthographic knowledge and phonemic awareness. Journal of Research in Reading, 30(1), 7–22. doi:10.1111/j.1467-9817.2006.00329.x.
Nag, S. (2012). Multiple pathways to literacy: Findings from two longitudinal studies. In: International symposium on language, literacy and cognitive development. Bangalore: The Promise Foundation and University of York.
Nag, S. (2014). Akshara-phonology mappings: The common yet uncommon case of the consonant cluster. Writing Systems Research, 6(1), 105–119. doi:10.1080/17586801.2013.855621.
Nag, S., & Sircar, S. (2008). Learning to read in Bengali: Report of a survey in five Kolkata primary schools. Bangalore, India: The Promise Foundation.
Nag, S., & Snowling, M. J. (2010). Cognitive profiles of poor readers of Kannada. Reading and Writing, 24(6), 657–676. doi:10.1007/s11145-010-9258-7.
Nag, S., Treiman, R., & Snowling, M. J. (2010). Learning to spell in an alphasyllabary: The case of Kannada. Writing Systems Research, 2(1), 41–52. doi:10.1093/wsr/wsq001.
Naka, M. (1998). Repeated writing facilitates children’s memory for pseudocharacters and foreign letters. Memory and Cognition, 26(4), 804–809. doi:10.3758/BF03211399.
Naka, M., & Naoi, H. (1995). The effect of repeated writing on memory. Memory and Cognition, 23(1), 201–212.
Ouellette, G. (2010). Orthographic learning in learning to spell: The roles of semantics and type of practice. Journal of Experimental Child Psychology, 107(1), 50–58. doi:10.1016/j.jecp.2010.04.009.
Ouellette, G., & Tims, T. (2014). The write way to spell: Printing vs. typing effects on orthographic learning. Frontiers in Psychology, 5, 1–11. doi:10.3389/fpsyg.2014.00117.
Pandey, P. (2014). Akshara-to-sound rules for Hindi. Writing Systems Research, 6(1), 54–72. doi:10.1080/17586801.2013.855622.
Patel, P. G. (2004). Reading acquisition in India: Models of learning and dyslexia. New Delhi: Sage.
Patel, J., Bapi, R. S., & Nag, S. (2013). Akshara counts in child directed print: A pilot study with 101 texts. (Manuscript in Preparation).
Rathod, P. H., Dhore, M. L., & Dhore, R. M. (2013). Hindi and Marathi to English machine transliteration using SVM. International Journal on Natural Language Computing, 2(4), 55–71.
Rieth, H., Axelrod, S., Anderson, R., Hathaway, F., Wood, K., & Fitzgerald, C. (1974). Influence of distributed practice and daily testing on weekly spelling tests. The Journal of Educational Research, 68(2), 73–77. doi:10.1080/00220671.1974.10884711.
Roediger, H. L., & Karpicke, J. D. (2006). The power of testing memory: Basic research and implications for educational practice. Perspectives on Psychological Science, 1(3), 181–210.
Share, D. L., & Daniels, P. T. (2016). Aksharas, alphasyllabaries, abugidas, alphabets and orthographic depth: Reflections on Rimzhim, Katz and Fowler (2014). Writing Systems Research, 8(1), 17–31. doi:10.1080/17586801.2015.1016395.
Sinha, R. M. K., & Mahabala, H. N. (1979). Machine recognition of Devanagari script. IEEE Transactions on Systems, Man, and Cybernetics, 9(8), 435–441.
Tiwari, S. (2011). A preliminary investigation of akshara knowledge in the Malayalam alphasyllabary: Extension of Nag’s (2007) study. Writing Systems Research, 3(2), 145–151. doi:10.1093/wsr/wsr013.
Vasanta, D. (2004). Processing phonological information in a semi-syllabic script: Developmental data from Telugu. Reading and Writing: An Interdisciplinary Journal, 17(1), 59–78. doi:10.1023/B:READ.0000013830.55257.3a.
Vaughn, S., Schumm, J. S., & Gordon, J. (1992). Early spelling acquisition: Does writing really beat the computer? Learning Disability Quarterly, 15(3), 223–228.
Vaughn, S., Schumm, J. S., & Gordon, J. (1993). Which motoric condition is most effective for teaching spelling to students with and without learning disabilities? Journal of Learning Disabilities, 26(3), 191–198.
Wollscheid, S., Sjaastad, J., & Tømte, C. (2016). The impact of digital devices vs. Pen(cil) and paper on primary school students’ writing skills---A research review. Computers & Education, 95, 19–35. doi:10.1016/j.compedu.2015.12.001.
Xu, Y., Chang, L. Y., & Perfetti, C. A. (2014). The effect of radical-based grouping in character learning in Chinese as a foreign language. Modern Language Journal, 98(3), 773–793. doi:10.1111/j.1540-4781.2014.12122.x.
Xu, Y., Chang, L.-Y., Zhang, J., & Perfetti, C. A. (2013). Reading, writing, and animation in character learning in Chinese as a foreign language. Foreign Language Annals, 46(3), 423–444. doi:10.1111/flan.12040.
Acknowledgements
This research partially fulfills the dissertation requirements for AB. I would like to thank my advisor, Charles Perfetti, for input on experimental design and feedback on manuscript drafts. I would also like to thank my committee members, Natasha Tokowicz, Julie Fiez, and Marta Ortega-Llebaria for help with experimental design and useful comments. Furthermore, I would like to thank Scott Fraundorf for his assistance with the statistical analyses. Moreover, I would like to thank my lab manager, Kimberly Muth, for assistance with IRB protocols and participant payment. Finally, I would like to thank Austin Marcus for help with data collection and entry. This research was supported by NSF PSLC [grant SBE08-36012] and the Andrew Mellon Predoctoral Fellowship awarded to AB.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bhide, A. Copying helps novice learners build orthographic knowledge: methods for teaching Devanagari akshara. Read Writ 31, 1–33 (2018). https://doi.org/10.1007/s11145-017-9767-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-017-9767-8