
Abstract
Flash flood is an uncertain and most catastrophic disaster worldwide that causes socio-economic problems, devastation and loss of infrastructure. One of the major triggering factors of flash floods is the extreme events like cloudburst that causes flooding of area within a short span of time. Therefore, this study aims to understand the variations in hydro-meteorological variables during the devastating Kedarnath cloudburst in the Uttarakhand, India. The hydro-meteorological variables were collected from the global satellites such as Moderate Resolution Imaging Spectroradiometer, Tropical Rainfall Measuring Mission, modelled datasets from Decision Support System for Agrotechnology Transfer and National Center for Environmental Prediction (NCEP). For the validation of satellite meteorological data, the NCEP Global analysis data were downscaled using Weather Research and Forecasting model over the study area to achieve the meteorological variables’ information. The meteorological factors such as atmospheric pressure, atmospheric temperature, rainfall, cloud water content, cloud fraction, cloud particle radius, cloud mixing ratio, total cloud cover, wind speed, wind direction and relative humidity were studied during the cloudburst, before as well as after the event. The outcomes of this study indicate that the variability in hydro-meteorological variables over the Kedarnath had played a significant role in triggering the cloudburst in the area. The results showed that during the cloudburst, the relative humidity was at the maximum level, the temperature was very low, the wind speed was slow and the total cloud cover was found at the maximum level. It is expected that because of this situation a high amount of clouds may get condensed at a very rapid rate and resulted in a cloudburst over the Kedarnath region.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Cloudburst, a natural hazard, results in immediate extreme precipitation and causes flash flood in a region. This flash flood results in an overflow of the huge amount of water from the source to another terrain responsible for the devastation, infrastructural and socio-economic property losses. From the last several years, the extreme precipitation events such as cloudburst have been observed worldwide. Over the 100 years, many countries are facing a higher percentage of precipitation in 1-day event (Burton 1993). Developing countries are still having a lack of knowledge to evaluate, recognize, predict and forecast flash flood (as a result of cloudburst) to perform flood risk and disaster management. The rate of cloudburst events which creates flash flood is increasing rapidly due to climate change and unexpected weather variability. In India, a maximum number of cloudburst events have been happened between the elevation ranges from 1000 to 2500 m (Dimri et al. 2017). According to The Global Flash Flood Guidance (GFFG) report 14 Feb 2009, of WMO (World Meteorological Organization), an average of 5000 people per year killed due to flash flood worldwide while more than 500 million people per year are extremely affected by such floods. After Bangladesh, India is the second most flood-affected country in the world (Bapalu and Sinha 2005). In India, more than 40 million hectares land areas are vulnerable to flood. The developing country like India has severe losses from the flash flood because of lack of proper disaster management. From the statistics, the flash flood fatality rate of Uttarakhand is the highest in India (Pande 2010).
In this direction, satellite remote sensing can provide rainfall observations, which will enhance our knowledge and understanding of the flash flood events. The advancement in the field of remote sensing, the high-resolution satellite datasets, could be used to understand the weather parameters responsible for the extreme events like cloudburst. The datasets can help in the mapping and monitoring of disastrous natural events. It will also help us to develop proper mitigation strategies for flood disaster management. Some satellites like the Tropical Rainfall Measuring Mission (TRMM) and Global Precipitation Mission (GPM) satellites were launched and provide precise global tropical precipitation imaginary data (Su et al. 2008). For flood events analysis, GPM/TRMM daily database 3B42 Version 7 datasets have been used to estimate real-time precipitation (Gupta et al. 2013; Islam et al. 2012, 2015). The TRMM, with the help of microwave imager and precipitation radar, provides rainfall observations, which can be applied for flood risk analysis over the large area (Maurya et al. 2016). The MODIS Terra sensor is functional since 2000, which provides imagery data with a pixel size varying between 250 m and 1 km. MODIS satellite imagery datasets may be used for flood inundation mapping because of its accuracy with high frequency, spectral and spatial resolution at the regional scale (Chen et al. 2013). Some studies have also used Numerical Weather Prediction model for flood assessment and modelling such as by using Weather Research and Forecasting (WRF) model, etc. (Hong and Lee 2009; Srivastava et al. 2014).
Very few research articles are available, which have discussed the relation of meteorological variables in relation to the cloudburst. Further, due to the disastrous nature of the cloudburst, there is a need to understand the variation in meteorological variables that cause cloudburst. Therefore, this study could be considered as a first-time comprehensive appraisal of the meteorological variables for deducing its roles in the cloudburst. For cross-verification of the results obtained using the satellite meteorological data analysis, we have performed downscaling using the Weather Research and Forecasting (WRF) model to assess the cloudburst occurred over the Kedarnath, Uttarakhand. In the purview of the above-mentioned problem, this study focuses on the following objectives: (1) assessment of satellite meteorological datasets during the cloudburst events, (2) variability analysis of meteorological variables before the cloudburst, during the cloudburst and after the cloudburst, and (3) estimating the prominent factors responsible for the cloudburst. Following Introduction, this manuscript is divided into following sections: Sect. 2 covers the materials and methodology, which includes a study area, datasets and statistical analysis, Sect. 3 covers result and discussion, Sect. 4 includes the appraisal of temporal variability in meteorological factors using the WRF model, and the conclusions of the study are provided in Sect. 5.
2 Materials and methodology
2.1 Study area
The natural extreme event of cloudburst was occurred over the Uttarakhand region; therefore, we have selected this region as our case study area. The Uttarakhand (latitude 28.68 to 31.49° N and longitude 77.51 to 81.09° E) is situated at the foothills of Western Himalayas in the northern part of India (Fig. 1). This region covers 53,485 km2 geographical areas with 100.86 lakh population. Elevation of the Uttarakhand ranges from 210 to 7817 m above mean sea level. The average rainfall of this state is 1000–2500 mm per year (Kala 2014), and most of the rainfall occured during the south-west monsoon. On 16 to 17 June 2013, a cloudburst causes a flash flood in five districts of Uttarakhand that are Uttarkashi, Rudraprayag, Chamoli, Pithoragarh and Tehri. The average annual temperature of the Uttarakhand region stays maximum 30 °C (summer) and minimum 2 °C (winter), while the relative humidity varies from 77 to 92% throughout the year. The accumulated rainfalls and the snowmelt over the hilly regions of Uttarakhand generally result in frequent flooding and landslides in the region.

Geographical location of study area
2.2 Synoptic character allied with the cloudburst
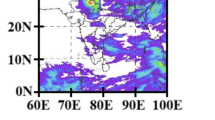
Some major synoptic characters allied with the cloudburst (during 16 to 18 June 2013) have also observed by IMD. The IMD mean surface pressure chart valid at 00 UTC 15 and 16 June 2013, respectively (Fig. 2a, b), clearly shows that the presence of well-marked monsoon low-pressure system moved northwest ward during the period and merged with monsoon trough. It further intensified the monsoon low-level westerlies along with the presence of an off shore trough over the Arabian Sea. The monsoon low-pressure system and western disturbance lead to the extension of easterly Bay of Bengal current from Eastern India to the Western Himalayas.

The analysis suggests that the two-day rainstorm (16–17 June 2013 over the Uttarakhand state) was caused by the disturbed large-scale atmospheric conditions. These conditions were generated because of the interface amid the westward stirring monsoon low and the eastward affecting deep trough (low barometric pressure area) in the mid-latitude westerly. During the period, the axis of monsoon trough has been monitored passing to Bikaner–Gwalior–Gaya, and Imphal and across the Gangetic region of West Bengal (Fig. 2a, b). A low-pressure area was formed (13 June 2013) over the Bay of Bengal and moved north-westward till 18 June 2013. The presence of the low-pressure zone over Rajasthan (east) and its adjacent areas results in significant moisture influx over entire northwest India on 16 June 2013 (Fig. 2b). The low-level vorticity, convergence and abundance of moisture in the atmosphere, when superposed by the upper-level divergence in the mid- and upper tropospheric westerlies, made the environment conducive for large-scale convection, hence causing the extreme monsoon rains over entire northwest India on 16 June 2013, about a month earlier than its normal date of 15th July.
The nine districts of Uttarakhand state received heavy rainfall resulting in flash flood and landslides over different locations of the Uttarakhand. The Kedarnath Temple that is one of the famous temples of Lord Shiva (part of the Char Dham yatra) in India was damaged, and media has reported around 1000 people death while 5700 people have presumed dead. The Uttarakhand cloudburst was one of the extreme disastrous flash floods in Indian history. Due to the massive flow of floodwater, most of the residential parts of Kedarnath town were washed away while landslides cause large debris over that area.
2.3 Datasets
2.3.1 MODIS datasets
The Moderate Resolution Imaging Spectroradiometer (MODIS) is the instrument that consists of the AQUA (EOS PM-1) and TERRA (EOS AM-1) satellites. MODIS helps in the collection of remotely sensed data which can be used for the monitoring, assessing and modelling the impacts of natural and anthropogenic processes on the earth’s surface. MODIS instrument is widely utilized for thermal infrared measurements aboard NASA’s TERRA satellite. In this study, the MODIS Terra level 2 daily data are used (0.1°; 3600 × 1800) to calculate cloud fraction (CF), cloud water content (CWC) and cloud particle radius (CPR). TERRA having 705-km circular orbital path is a sun-synchronous satellite near polar (Horváth and Davies 2001). MODIS TERRA satellites orbit the earth across the equator in the morning time from north to south and named as EOS AM-1. TERRA MODIS with a swath width of 2330 km views orbits the entire earth’s surface in 24–48 h named as the EOS PM-1. TERRA satellites record data between 0.405 and 14.385 μm in 36 spectral bands with the spatial resolutions of 250 m, 500 m and 1000 m, respectively (http://modis.gsfc.nasa.gov/data/). MODIS is a suitable optical satellite for data collection because of its daily temporal resolution and frees near real-time data availability (Guleria et al. 2012). The MODIS datasets were analysed by using the software Environment for Visualizing Images (ENVI) version 5.2, and the statistical analysis has been made to find the factor responsible for the cloudburst over the Uttarakhand area as follows:
2.3.1.1 Cloud fraction (CF)
Cloud fraction is the determination that how much amount of cloud covered the earth atmosphere (http://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_CLD_FR). Cloud fraction is the amount of sky covered by a specific type of cloud (maybe contrail, cirrus, cumulus, cirrostratus), cloud particle phase (maybe water, ice, liquid), cloud height (may vary with low, mid- and high level) or all cloud types (total cloud fraction) (Ackerman et al. 1998). Approximately 0.7–2.2 km is the altitudes where cloud cover exists (Whiteman and Melfi 1999a). From the lowest altitude cloud to the highest altitude cloud, the liquid water mixing ratio increases with an increase in altitudes (Whiteman and Melfi 1999a). Cloud fraction is derived from the 1-km pixel resolution cloud mask product made from radiance and reflectance measurements of earth collected by the MODIS aboard NASA’s Aqua and Terra satellites (http://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_CLD_FR). Scientists intended to perform accurate prediction of the future state of weather that how CF, clouds property or cloud cover regulates and affects the earth’s climate system. Information about the CF is collected in pixel or gridded boxes (1 km2) by the MODIS TERRA satellite, and the portion of each gridded pixel, which is covered by clouds, is called as CF (http://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_CLD_FR).
2.3.1.2 Cloud water content (CWC)
The CWC is a measurement that measures how much total water exists in a cloud within a vertical column of atmosphere. CWC can also be explained as the amount of water (in grams) that is present in per square metre. From cloud to cloud, this CWC varies greatly (Radke et al. 1989). The measurement of the CWC of any cloud depends on the type of clouds present at a given location, at different atmospheric layers (Sassen et al. 2008). For instance, cirrus clouds have low density, while cumulonimbus has higher density and is very wet. The unit of CWC is water per volume of air g/m3 or per mass of air g/kg. With reference to the density of water, the CWC unit can also be represented as the depth of water in a column (mm). CWC can be derived from measurements of clouds optical thickness and cloud particle radius collected by the MODIS satellite sensors. MODIS sensors measure the CWC in grams of water contained in a given 1-m square column of cloud. MODIS measures the shortwave (0.66-micron) and near-infrared (2.1-micron) light reflected up through the higher altitude of the atmosphere.
2.3.1.3 Cloud drop/particle radius (CDR/CPR)
The CPR also named as cloud effective radius is a weighted mean of cloud droplet size distribution. Hansen and Travis (1974) coined the term CPR. In the daytime, the cloud optical thickness (COT) and CPR reflect the multi-wavelength solar radiation and emit thermal radiation, which can be used for the measurements of CPR by using satellite datasets. Retrieving the COT and CPR depends on two parameters that are visible spectral bands of 0.645 microns and near-infrared spectral bands of 1.64, 2.13 and 3.75 microns. MODIS thermal spectral bands are used for cloud cover with cloud top properties. CDR is the area-weighted radius of cloud drops. The CPR shows different radius values for different clouds. Normally the CDR is around 14 μm, whereas for ice it is around 25 μm. In clouds, the non-precipitating liquid water droplets are a sphere in shape (Pruppacher and Klett 1997). While the radii range from 0.5 to 50 µm ranging from the type of cloud, the average radius of the droplets of the cloud water increases with the increase in liquid water (Whiteman and Melfi 1999b) content of clouds.
2.3.1.4 TRMM precipitation datasets
TRMM 3B42 Version 7 datasets were used to estimate real-time precipitation. The datasets were obtained from http://mirador.gsfc.nasa.gov and have been used for assessment of weather and climate system. Satellite is composed of passive and active sensors, the TRMM microwave imager (TMI) as passive and precipitation radar (PR) as an active sensor to collect precipitation information. The TRMM includes 5 instruments, 3-sensors rainfall suite PR, TMI and a visible/infrared scanner (VIRS) and 2 related instruments (LIS and CERES). The TMI is used to calculate the emission intensity at five-frequency channel: 10.7 GHz, 19.4 GHz, 21.3 GHz, 37 GHz and 85 GHz. The PR is used as scanning radar, at a frequency of 13.8 GHz. The PR helps in the measurement of 3D precipitation with the depth layer of the precipitation. The TRMM precipitation radar data are retrieved by the standard algorithm of level 2 that is designated as 2A25. TRMM datasets integrate high quality or infrared precipitation and root mean square (RMS) precipitation error which is produced by the 3B42 algorithm (Huffman et al. 2013). In the following study MODIS Terra, the level 2 data (TRMM-3B42) are used that are a daily 0.25° (with resolution 1440 × 720) imagery product having multi-satellite precipitation-based analysis with a grid over latitude band 50 N–S (Gupta et al. 2014). TRMM 3B42 (daily, 0.25°) precipitation data are processed by a 4-stage process which includes: (1) calibration of microwave precipitation estimates, (2) the estimation of microwave precipitation (calibrated) is used to create infrared (IR) precipitation estimates, (3) by using stage-1 and stage-2 products the microwave precipitation and IR estimates are integrated and (4) rescaling of data to month-wise is applied using the indirect use of precipitation data. TRMM datasets were used to determine the real-time precipitation, which can be used for the future weather and climate prediction and to perform research to develop our understanding to weather and climate for flood monitoring and future weather forecasting.
2.3.1.5 DSSAT datasets
Decision Support System for Agrotechnology Transfer (DSSAT) was used for retrieving relative humidity (RH) and atmospheric temperature (Atm_temp) data. DSSAT is a NASA-POWER (Prediction Of Worldwide Energy Resources) database that provides the global modelled meteorological dataset, in International Consortium for Agricultural Systems Applications (ICASA) standards format with global coverage (White et al. 2011). The datasets in NASA-POWER are available over a global grid scale having a spatial resolution of 0.5° latitude and 0.5° longitude. In the NASA-POWER archives, the RH is calculated by using the pressure (kPa), air temperature (°C) and mixing ratio (for example specific humidity (kg/kg) at height 2 m above the local ground surface (Stackhouse Jr et al. 2018)). The RH data are available from MERRA-2 and averaged over a grid of 0.5° latitude and 0.5° longitude (Stackhouse Jr et al. 2018). Daily mean temperature values in the NASA-POWER archives are also available from the MERRA-2 (Stackhouse Jr et al. 2018) with a spatial resolution of 0.5° latitude and 0.5° longitude. DSSAT database measures daily atmospheric parameters based on satellite observations and assimilation models. DSSAT (NASA/POWER) database is mainly based on elevations (mean) over 1° grid cells and the Cooperative Observer Program (COOP) data which are equivalent to the elevation of specific stations. Meteorological parameters RH and atmospheric temperature data were downloaded from http://power.larc.nasa.gov/cgi-in/cgiwrap/solar/agro.cgi?email=agroclim@larc.nasa.gov.
2.3.1.6 Weather Research and Forecasting (WRF) model
The WRF model can be used in a broad range of applications across scales ranging from metres to thousands of kilometres (Schwartz et al. 2009; Srivastava et al. 2015a, b). The downscaling of meteorological variables is performed using the WRF model with domain fixed over the Indian region, and the meteorological information of the Uttarakhand region is retrieved using the software Grid Analysis and Display System (GrADS). The WRF modelling system is fully compressible, non-hydrostatic Euler equations following the philosophy of Ooyama (1990), cast in flux conservation form, using mass (hydrostatic pressure) vertical coordinate and state-of-the-art atmospheric simulation system that is portable and efficient on available parallel computing platforms. The WRF model is useful in both operational forecasting and atmospheric research. The working framework of WRF model includes the preprocessing of meteorological data under WRF Preprocessing System (WPS), the output of WPS as an input to the forecast model (WRF-ARW). The schematic of the WRF modelling system is provided in Fig. 3. The detailed description of model governing equations, physics and dynamics are presented in Skamarock et al. (2005).

Framework of the WRF model (Dudhia 2014)
The National Centers for Environmental Prediction (NCEP) 6 hourly 1 degree by 1 degree is downscale over the Uttarakhand region. To achieve the better performance of the WRF model, we have selected WRF single-moment (WSM) 6-class and Kain–Fritsch microphysics scheme for cumulus parameterization. We have chosen these schemes because of its good performance with the WRF model (Hong and Lim 2006). The radiative transfer (RRTM scheme) model is used to achieve the best performance of the model under the clear sky with upward and downward cloud radiation fluxes (Mlawer et al. 1997). Under shortwave radiation, Dudhia scheme is showing the best performance (Chen and Dudhia 2001). For boundary layer fluxes, the YSU scheme is selected for parameterization of surface weather operation (Kim and Wang 2011).
2.4 Statistical analysis
Descriptive statistical analysis of meteorological variables is performed with the help of box and whisker plot. The box and whisker plot or box plot is similar to histogram used as a standardized way of displaying the data (Hoaglin et al. 2011). Distribution of datasets in a box plot is based on the five parameters which are minimum (lower extremes), quartile first, median, quartile third and maximum (upper extremes).
Seriation analysis is a statistical unidimensional scaling method used for sequencing and arrangement of all the data variables in a set of linear sequences for cluster analysis (Srivastava et al. 2016). The recognition of graphical data matrix including its hierarchical clustering has been depending on the attentiveness of the seriation analysis (Singh et al. 2012). A similar cluster of the similar groups is displayed in uninterrupted order where dark square has little dissimilarity showing on the diagonal plot. Hidden structural information in the datasets can be explained by using the cluster plot. For seriation analysis of the datasets, the unidimensional scaling least-squares criterion (Caraux and Pinloche 2005) has been used in this study. Seriation analysis helps in reorganizing rows and columns by simultaneous synchronized permutation that reflects the similar feature between pairs of elements in the hydro-meteorological datasets (Singh et al. 2013). Seriation analysis shows different meteorological parameters are used as the variables in the datasets, while the rows represent the meteorological parameters in the heat map. In the following study, the whole linkage rule for both row and column is utilized, while for tree seriation analysis unidimensional scaling rule is used (Singh et al. 2012). Seriation analysis measures the effectiveness between component ‘d’ and the distance δ by using the relation (Singh et al. 2012):
where δ (i, j) refers to the distance between j and i and can be represented using:
Principal component analysis (PCA) is a statistical procedure intended to reduce the data redundancy and put as much information from the image bands into the fewest number of components (http://statistics.ats.ucla.edu/stat/spss/output/principal_components.htm). PCA determines a group of orthogonal vectors termed as the principal components (PCs). These PCs are defined by the linear amalgamation of the original variables and regimented by the sum of variances explained. Coefficients of variables to determine PCs are stored in the loading matrix. PCA describes the information of significant parameters that describe an entire dataset without the loss of the original information (Santo 2012).
3 Results and discussion
3.1 Evaluation of meteorological variables
The meteorological dataset of June 2013 over the Uttarakhand is used that includes atmospheric pressure (Atm_press), atmospheric temperature (Atm_temp), rainfall (RF), CWC, CF, CPR and RH. The value of Atm_press was found 1.003 Bar and 1.002 Bar on 16 and 17 of June, respectively. The value of (Atm_temp) was estimated at 14 °C on the 16th of June while it lowered down by 3 °C on the 17th of June. Evaluation of the meteorological datasets was carried out by using the box and whisker plots (Fig. 4). In box plots, the central rectangle area from the first quartile to the third quartile is represented as the interquartile range (IQR). IQR can be measured by subtracting the third quartile (Q3) with quartile (Q1). The value of the median is represented between the horizontal lines between the Q1 and Q3. In the 3rd week of June 2013, plots of (Atm_temp) data showed an increment because most of the values are concentrated below the higher values and median is closer to the lower or bottom quartile while the (Atm_press) data also showed an increment in the 3rd week of June 2013. RH and CF on the 3rd week of June 2013 showed a decrement plot because the distribution of median value is towards the lower or bottom quartile. On the 3rd week of June 2013, box–whisker analysis of CPR, CWC and rainfall showed an increase in the values (Fig. 4). DSSAT provides modelled meteorological data, which showed that on 16th June and 17th June the temperature was dropped from 14.33 to 13.38 °C while the relative humidity was found as 95.22% and 95.27%, respectively, on the dates. TRMM RF was measured around 102.28 mm on 16th June, while on 17th June RF was found as 119.23 mm. On 16th June and 17th June, the CWC was found as 82.87 g/m2 and 87.95 g/m2, respectively. The value of CF was observed as 128.42 and 133.33 on 16th and 17th June, respectively, which was higher than the normal days (Fig. 4). The value of CPR was observed as 94.03 µm on 16th June while the value of CPR was 885.06 µm on 17th June.

Box–whisker plot of the third week of June 2013 showing variations among the meteorological variables CF, CPR, Rainfall, CWC, RH, Atm_temp, Atm_press
On the day when the cloudburst event happened, the value of RH was observed higher than the other days of June month which was > 95% on both 16th June and 17th June. The comparative analysis of meteorological data represents that the value of temperature was low on 16 and 17 June 2013 in comparison with normal days and RH was very high on both 16th and 17th June of 2013. Temperature and RH are inversely dependent on each other also reported by another researcher (Manabe and Wetherald 1967). O’Gorman and Schneider (2009) reported the relation of rainfall with RH and showed that when the RH of the atmosphere increases, it leads to rain in most of the cases (Trenberth 1998).
3.2 Interrelationship between the meteorological datasets
Variability in weather and climate system has been influenced by the variation in meteorological variables like Atm_press, Atm_temp, relative humidity, precipitation. Air temperature and atmospheric pressure are important meteorological variables for variation in weather/climatic conditions and for a stable environment over a region. To understand the relationship between the meteorological variables Pearson’s and Spearman’s correlations are calculated as shown in Fig. 5. This study has also aimed to understand how these meteorological parameters correlated with each other when the cloudburst occurred over the Uttarakhand. The correlation analysis showed that the RH of the atmosphere depends on the current temperature of the atmosphere. The results suggested that when the temperature is low, there is possibility of high RH. Both the temperature and the RH are inversely proportional to each other; the correlation analysis of this study is also showing the same. The increase in RH may increase the chances of rainfall. The correlation analysis of the study also represents the positive relationship between temperature and RH. The increase in RH acts as an indicator or precursor to the occurrence of precipitation (Umoh et al. 2013). RH and CF also show the positive correlation that means when the RH is high, the CF will be high. Further, CF and rainfall are showing a positive correlation, which means increasing CF will lead to rainfall. Correlation analysis between RH and CWC showed a negative relationship with each other while atmospheric pressure and CWC indicated a positive correlation. In Fig. 5, CF_mean is the mean value for the cloud fraction. Further, between RH and CPR, an inversely proportional relationship has been observed.

Correlation matrix plots between CF, CPR, Rainfall, CWC, RH, temperature and pressure
The timeseries (TS) analysis shows that increase in CPR may favour high rainfall (Fig. 6a). The TS analysis shows that Atm_press and Atm_temp are showing a decreasing trend on 16th to 17th June (Fig. 6b). The analysis also showed that CWC and CPR are dependent on each other (Fig. 6c); therefore, the increase in CWC leads to increase in CPR value. Graphical representation also showed that when the atmospheric temperature is low, the RH is high (Fig. 6d). The analysis has further showed that the RH and RF are interdependent on each other (Fig. 6e). The analysis shows that before and after the day of cloudburst event the values of RH were low, but on 16 and 17 June 2013, the values of RH were at the maximum level (> 95%). On the day, when cloudburst occurred over the Uttarakhand region, the graphical data analysis showed that the values of CWC, TRMM rainfall and RH on 16 June 2013 were 82.87 (g/m2), 102.28 mm and 95.22%, respectively. On 17th June, the values of the CWC, TRMM rainfall and RH were found as 87.95 (g/m2), 119.23 mm and 95.27%, respectively, while on 18 June 2013 the values of TRMM rainfall and RH were dropped to 114.81 mm and 94.22%, respectively. Evaluation of graphical data showed that the TRMM rainfall and RH were very high when the cloudburst was occurred in the Uttarakhand region (Fig. 6e).

Graphs showing the relationship between the variables CF_mean and Rainfall (a), Atm_press and Avg_temp (b), CPR_mean and CWC_mean (c), RH and Avg_temp (d), and Rainfall and RH (e)
3.3 Linkages between cloudburst and variables under investigation
3.3.1 Seriation analysis
Seriation analysis refers to the sequencing or arrangement of variables in a group of linear orders for performing cluster analysis, variable selection and other structural information analysis (Buchta et al. 2008). The seriation analysis also refers to the classification of variables into groups having similar characteristics. For seriation analysis, hierarchical clustering is used in this study to perform k-means clustering to identify groups with similar property. Seriation analysis is used to enumerate and rearrange rows or columns of datasets in a suitable order (Buchta et al. 2008). Seriation analysis represents a matrix plot of meteorological variables as shown in Fig. 7. The seriation plot explains the relationships between the elements that are used in the analysis and reorder the variables into a sequence with similar property. The objective function (R) value for the row was obtained as 0.550 while for the column it is obtained as 0.472. The sum of all pairwise distances of the neighbouring rows [path length (S)] was obtained for both row and column as 968.280 and 5981.256, respectively. Seriation matrix plot is showing black colour for the lowest value (or no value) while the bright red colour shows the maximum value. The column matrix plot is separated into three groups: The first group (G1) contains the average temperature while the third group (G3) contains atmospheric pressure that shows the maximum value and behaves as a runt. On the other hand, CF, CPR, RH and RF are clustered in the second group (G2), which indicates that they share similar properties and influence each other in a stronger way. The seriation analysis plot was divided into eight cluster plots, where the first cluster (C1) includes the data values of 11th June, 10th June, 14th June, 28th June, 13th June, 27th June and 30th June; these clusters are showing similar characteristics. The (C2) did not show any relation with other variables and behave as a runt. Third cluster (C3) contains the groups with 17 June, 18 June, 26 June, 16 June, 25 June and 24 June with values of similar characteristics. The fourth cluster (C4) shows the cluster of 1 June, 4 June, 17 June and 26 June that are the cluster of a similar pattern. The fifth cluster (C5) grouped with 2 June, 1 June, 9 June and 23 June. The sixth cluster (C6) shows clustering with 7 June and 4 June. The seventh cluster (C7) makes a cluster with 19 June, 8 June, 3 June, 6 June and 29 June. The eighth cluster (C8) includes data from 20 June, 22 June, 5 June and 21 June. It can be seen from the analysis that during the cloud burst days, a different set of association is found between the variables at a finer level within the dendrogram.

Seriation plot between CF, CPR, Rainfall, CWC, RH, temperature and pressure
3.3.2 Principal component analysis (PCA)
PCA helps to evaluate the constituent arrangements between the meteorological variables. An eigenvalue represents the significance of the components. The component having the eigenvalues of 1.0 or greater is considered significant (Srivastava et al. 2012). The PCA evaluates the patterns of composition between the examined variables and identifies the factors that influence each other. The principal component explains the communalities, which represent the proportions of the variance of every variable (Table 1). Communalities values are the sum of squared factor loadings. In communalities, PCA represents the initial value 1 for all the selected meteorological parameters. Extraction values represent the percentage of difference of each variable which can be represented by the principal components (PCs). Communality table shows the value of the major components which are RH, CWC and CPR with a higher proportion, which is 0.857, 0.842 and 0.840, respectively (Table 1). Table 2 shows the total variance analysed by the PCA, while the variances in the PCs are represented through the initial eigenvalues.
In the table of total variance explained, the total column showed the eigenvalues of the first component having a value of 3.330 (Table 2). The next component accounts for as much of the leftover variance with value of 1.491 and so on. Hence, each successive component in the total column accounts for the less and less variance. In % of variance column, the first component represents the 47.568% of the variance, whereas the second component and third components represent the total 21.99 and 12.862% of the variance for the corresponding variables, respectively. In Table 2, column of cumulative % contains the cumulative fraction of the variances, which indicates that the first and second components together count for the 68.867% of the total variances.
The scree plot is used to represents the eigenvalues of the component number (Fig. 8). PCs having eigenvalues equal to or more than 1 are considered significant or vice versa (Wold et al. 1987). The correlations among the variables and the components are explained in Table 3. Component loadings are correlations in which possible values vary between − 1 and + 1. Three PCs have been extracted with eigenvalues (PC1) 0.825 for CF, PC2, i.e. RH with value of 0.794 and RF of 0.753. The PCA applied to meteorological datasets showed that the above 3 factors were the major component responsible for the heavy rainfall over the Uttarakhand. These factors were CF_mean, RH and rainfall with values of 0.825, 0.794 and 0.753, respectively.

Scree plots of between CF, CPR, Rainfall, CWC, RH, Atm_temp and Atm_press
4 Appraisal of temporal variability in meteorological factors using the WRF model
In this study, along with the satellite datasets, the WRF model was used to determine the state of meteorological variables at the time of cloudburst held over the Kedarnath, Uttarakhand, India. In the following study, we have followed the classification of rainfall characterized by the IMD (Table 4). Rainfall assessment over the Kedarnath region shows very light rain on 16 June 2013 (0.8–1 mm/day) while on 17 June 2013 this region received light rain between 2.4 and 2.7 mm/day (Fig. 9). On 16 June 2013 and 17 June 2013, total cloud cover (TCC) over the Uttarakhand was found between 90 and 100%. TCC refers to all the visible clouds. WRF assessment on temperature (average) over the Kedarnath region represents that on 16 June 2013 and 17 June 2013 the temperature was recorded 0–5 °C and 3–6 °C, respectively.

WRF downscaled hydro-meteorological variables of the dates 15–18 June 2013
Relative humidity is one of the significant variables in triggering the meteorological variable. On 16 June 2013 and 17 June 2013, the relative humidity was found between 95 and 100% over the Kedarnath and its adjoining areas. Wind speed was found 5–6 m/s (18–21.6 km/h) on 16 June 2013 while on 17 June 2013 it was 10–12 m/s (36–43 km/h) (Fig. 9). During the days when Kedarnath faces the cloudburst event, the directions of wind over this region were from the south-east and south direction on 16 June 2013 while on 17 June 2013 this region receives wind from the eastern and south-south-east direction. During this event, the wind direction has been observed from south-east to moving towards the east-south-east direction over the Kedarnath region. The assessment of above meteorological variables suggests that the condition of low temperature, maximum RH, maximum TCC, light rainfall and slow wind speed creates the appropriate situation for triggering flash flood in the Uttarakhand.
5 Conclusions
Satellite remote sensing techniques and advancement in mesoscale modelling are emerged as successful tool for various aspects of flood risk management, flood monitoring and forecasting. This study is a first-time comprehensive evaluation of satellite and modelled datasets for understanding the cloudburst phenomenon. In this study, attempts have been made to understand the relationship between the hydro-meteorological parameters obtained from satellite and models such as TRMM, MODIS, WRF and DSSAT. Several parameters were used such as atmospheric pressure, atmospheric temperature, rainfall, cloud water content, cloud fraction, cloud particle radius, cloud mixing ratio, total cloud cover, wind speed, wind direction, relative humidity to evaluate the relationship with the cloudburst. Seriation analysis was used to understand the interrelationship between the parameters. The cross-verification of this study is also carried out with the WRF downscaling of hydro-meteorological variables. Both satellite and WRF simulated results indicated that the relative humidity was very high during the cloudburst days. Furthermore, it is also evident from the results that a low temperature, maximum RH, maximum TCC, light rainfall and slow wind speed occurred on the day of cloudburst in the Uttarakhand region. However, before going to an all-encompassing conclusion, more studies are needed in this direction by the research community to model the cloud burst phenomenon. Some improvement in the hydro-meteorological parameters can be carried out by using the data assimilation schemes in WRF, parameterization and bias correction at a different scale and hence will be attempted in future work.
References
Ackerman SA, Strabala KI, Menzel WP, Frey RA, Moeller CC, Gumley LE (1998) Discriminating clear sky from clouds with MODIS. J Geophys Res 103:32141–132157
Bapalu GV, Sinha R (2005) GIS in flood hazard mapping: a case study of Kosi River Basin, India. GIS Dev Wkly 1:1–3
Buchta C, Hornik K, Hahsler M (2008) Getting things in order: an introduction to the R package seriation. J Stat Softw 25:1–34
Burton I (1993) The environment as hazard. Guilford Press, London
Caraux G, Pinloche S (2005) PermutMatrix: a graphical environment to arrange gene expression profiles in optimal linear order. Bioinformatics 21:1280–1281
Chen F, Dudhia J (2001) Coupling an advanced land surface–hydrology model with the Penn State–NCAR MM5 modeling system. Part I: model implementation and sensitivity. Mon Weather Rev 129:569–585
Chen Y, Huang C, Ticehurst C, Merrin L, Thew P (2013) An evaluation of MODIS daily and 8-day composite products for floodplain and wetland inundation mapping. Wetlands 33:823–835
Dimri A et al (2017) Cloudbursts in Indian Himalayas: a review. Earth Sci Rev 168:1–23
Dudhia J (2014) WRF modeling system overview. www.2.mmmucaredu/wrf/users/tutorial/201201/WRF_Overview_Dudhia ppt.pdf
Guleria RP et al (2012) Validation of MODIS retrieval aerosol optical depth and an investigation of aerosol transport over Mohal in North Western Indian Himalaya. Int J Remote Sens 33:5379–5401
Gupta M, Srivastava PK, Islam T, Ishak AMB (2013) Evaluation of TRMM rainfall for soil moisture prediction in a subtropical climate. Environ Earth Sci. https://doi.org/10.1007/s12665-013-2837-6
Gupta M, Srivastava PK, Islam T, Ishak AMB (2014) Evaluation of TRMM rainfall for soil moisture prediction in a subtropical climate. Environ Earth Sci 71:4421–4431
Hoaglin DC, Mosteller F, Tukey JW (2011) Exploring data tables, trends, and shapes, vol 101. Wiley, Hoboken
Hong S-Y, Lee J-W (2009) Assessment of the WRF model in reproducing a flash-flood heavy rainfall event over Korea. Atmos Res 93:818–831
Hong S-Y, Lim J-OJ (2006) The WRF single-moment 6-class microphysics scheme (WSM6). J Korean Meteorol Soc 42:129–151
Horváth Á, Davies R (2001) Feasibility and error analysis of cloud motion wind extraction from near-simultaneous multiangle MISR measurements. J Atmos Ocean Technol 18:591–608
Huffman GJ, Bolvin DT, Braithwaite D, Hsu K, Joyce R, Xie P, Yoo S-H (2013) NASA Global Precipitation Measurement (GPM) Integrated Multi-satellite retrievals for GPM (IMERG). In: Algorithm theoretical basis document, version 4.1. NASA, IMD Terminologies and Glossary
Islam T, Rico-Ramirez MA, Han D, Srivastava PK, Ishak AM (2012) Performance evaluation of the TRMM precipitation estimation using ground-based radars from the GPM validation network. J Atmos Solar Terr Phys 77:194–208
Islam T, Srivastava PK, Dai Q, Gupta M, Jaafar WZW (2015) Stratiform/convective rain delineation for TRMM microwave imager. J Atmos Solar Terr Phys 133:25–35
Kala CP (2014) Deluge, disaster and development in Uttarakhand Himalayan region of India: challenges and lessons for disaster management. Int J Disaster Risk Reduct 8:143–152
Kim H-J, Wang B (2011) Sensitivity of the WRF model simulation of the East Asian summer monsoon in 1993 to shortwave radiation schemes and ozone absorption. Asia Pac J Atmos Sci 47:167–180
Manabe S, Wetherald RT (1967) Thermal equilibrium of the atmosphere with a given distribution of relative humidity. J Atmos Sci 24(3):241–259
Maurya S, Srivastava PK, Gupta M, Islam T, Han D (2016) Integrating soil hydraulic parameter and microwave precipitation with morphometric analysis for watershed prioritization. Water Resour Manag 30:5385–5405. https://doi.org/10.1007/s11269-016-1494-4
Mlawer EJ, Taubman SJ, Brown PD, Iacono MJ, Clough SA (1997) Radiative transfer for inhomogeneous atmospheres: RRTM, a validated correlated-k model for the longwave. J Geophys Res Atmos 102:16663–16682
O’Gorman PA, Schneider T (2009) The physical basis for increases in precipitation extremes in simulations of 21st-century climate change. Proc Natl Acad Sci 106:14773–14777
Ooyama KV (1990) A thermodynamic foundation for modeling the moist atmosphere. J Atmos Sci 47:2580–2593
Pai DS, Bhan SC (2013) Monsoon Report 2013 IMD Met Monograph: ESSO/IMD/SYNOPTIC MET/01-2014/15
Pande RK (2010) Flash flood disasters in Uttarakhand. Disaster Prev Manag Int J 19:565–570. https://doi.org/10.1108/09653561011091896
Pruppacher H, Klett J (1997) Microphysics of clouds and precipitation: with an introduction to cloud chemistry and cloud electricity. Kluwer, Norwell
Radke LF, Coakley JA, King MD (1989) Direct and remote sensing observations of the effects of ships on clouds. Science 246:1146–1149
Santo RdE (2012) Principal component analysis applied to digital image compression. Einstein (São Paulo) 10:135–139
Sassen K, Wang Z, Liu D (2008) Global distribution of cirrus clouds from CloudSat/Cloud-Aerosol lidar and infrared pathfinder satellite observations (CALIPSO) measurements. J Geophys Res Atmos. https://doi.org/10.1029/2008JD009972
Schwartz CS et al (2009) Next-day convection-allowing WRF model guidance: a second look at 2-km versus 4-km grid spacing. Mon Weather Rev 137:3351–3372
Shekhar M, Pattanayak S, Mohanty U, Paul S, Kumar MS (2015) A study on the heavy rainfall event around Kedarnath area (Uttarakhand) on 16 June 2013. J Earth Syst Sci 124:1531–1544
Singh S, Srivastava PK, Gupta M, Mukherjee S (2012) Modeling mineral phase change chemistry of groundwater in a rural–urban fringe. Water Sci Technol 66:1502
Singh SK, Srivastava PK, Pandey AC, Gautam SK (2013) Integrated assessment of groundwater influenced by a confluence river system: concurrence with remote sensing and geochemical modelling. Water Resour Manag 27:4291–4313
Skamarock WC, Klemp JB, Dudhia J, Gill DO, Barker DM, Wang W, Powers JG (2005) A description of the advanced research WRF version 2. National Center for Atmospheric Research, Boulder, CO, Mesoscale and Microscale Meteorology Div
Srivastava PK, Han D, Gupta M, Mukherjee S (2012) Integrated framework for monitoring groundwater pollution using a geographical information system and multivariate analysis. Hydrol Sci J 57:1453–1472
Srivastava PK, Han D, Rico-Ramirez MA, Islam T (2014) Sensitivity and uncertainty analysis of mesoscale model downscaled hydro-meteorological variables for discharge prediction. Hydrol Process 28:4419–4432
Srivastava PK, Han D, Rico-Ramirez MA, O’Neill P, Islam T, Gupta M, Dai Q (2015a) Performance evaluation of WRF-Noah land surface model estimated soil moisture for hydrological application: synergistic evaluation using SMOS retrieved soil moisture. J Hydrol 529:200–212
Srivastava PK, Islam T, Gupta M, Petropoulos G, Dai Q (2015b) WRF dynamical downscaling and bias correction schemes for NCEP estimated hydro-meteorological variables. Water Resour Manag 29:2267–2284
Srivastava PK, Islam T, Singh SK, Petropoulos GP, Gupta M, Dai Q (2016) Forecasting Arabian Sea level rise using exponential smoothing state space models and ARIMA from TOPEX and Jason satellite radar altimeter data. Meteorol Appl 23:633–639
Stackhouse Jr PW et al (2018) POWER Release 8.0. 1 (with GIS Applications) Methodology (Data Parameters, Sources, & Validation) Documentation Date December 12, 2018 (All previous versions are obsolete) (Data Version 8.0. 1; Web Site Version 1.1. 0)
Su F, Hong Y, Lettenmaier DP (2008) Evaluation of TRMM Multisatellite Precipitation Analysis (TMPA) and its utility in hydrologic prediction in the La Plata Basin. J Hydrometeorol 9:622–640
Trenberth KE (1998) Atmospheric moisture residence times and cycling: implications for rainfall rates and climate change. Clim Change 39:667–694
Umoh AA, Akpan AO, Jacob BB (2013) Rainfall and relative humidity occurrence patterns in Uyo Metropolis, Akwa Ibom State, South-South Nigeria. IOSRJEN 3:27–31
White JW, Hoogenboom G, Wilkens PW, Stackhouse PW, Hoel JM (2011) Evaluation of satellite-based, modeled-derived daily solar radiation data for the continental United States. Agron J 103:1242–1251
Whiteman D, Melfi S (1999a) Cloud liquid water and particle size detection using a Raman lidar. Ratio 2:27
Whiteman DN, Melfi SH (1999b) Cloud liquid water, mean droplet radius, and number density measurements using a Raman lidar. J Geophys Res Atmos 104:31411–31419
Wold S, Esbensen K, Geladi P (1987) Principal component analysis. Chemom Intell Lab Syst 2:37–52
Acknowledgements
The authors would like to thank the University Grants Commission, Government of India, for providing necessary support and funding for this research. The authors also would like to acknowledge Banaras Hindu University for providing the seed grant. Author is also thankful to University Corporation for Atmospheric Research (UCAR) for providing NCEP-FNL data to perform this study.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Pratap, S., Srivastava, P.K., Routray, A. et al. Appraisal of hydro-meteorological factors during extreme precipitation event: case study of Kedarnath cloudburst, Uttarakhand, India. Nat Hazards 100, 635–654 (2020). https://doi.org/10.1007/s11069-019-03829-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-019-03829-4