
Abstract
There are various face recognition techniques in literature, which are faced with challenges such as occlusion, pose variation, illumination, and facial expressions. Existing methods often perform well when their database is small, or multiple samples per person exist. However, face recognition methods with just one reference sample per person may not work well, especially on a large database. To address this problem, this paper proposes a scheme to extract features from facial images. Using Non-negative Matrix Factorization (NMF), basic features are extracted from the face structure. The matrix of images is decomposed into basis matrix (W) and weight matrix (H). The basis matrix contains several versions of mouths, noses and other facial parts, where the various versions are in different locations or forms. Hence, to recognize a facial image in the database, searching is done on the weight matrices feature set. In this research, to more precisely form the structural elements, a separate basis matrix is constructed for the upper and lower parts of the facial images from the database. Also the images are enhanced using pre-processing techniques including histogram equalization, image intensity, and contrast limited adaptive histogram. The FERET database with 990 single images per person was used to evaluate the proposed method. Experimental results show that the proposed method can achieve a recognition rate close to 93%.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Face recognition (FR) is used in a variety of applications such as security maintenance, image processing, video surveillance, and criminal identification. Single Sample per Person (SSPP), especially in a large database such as one used for passport identification, is one of the most important challenges in FR [31]. When only one sample per person is available for training, FR becomes more difficult [30]. Although several studies have been done on this topic, it is still an active challenge [7, 10].
As mentioned, one of the active subjects in face recognition is SSPP [7], and some SSPP face recognition methods were proposed in the literature. These methods can be divided into five categories: direct methods, generic learning methods, patch-based methods, expanding sample methods, and deep learning methods [35].
Direct methods perform based on SSPP by applying an algorithm directly on the facial images [35]. Generic learning methods use an auxiliary dataset to make multiple samples for each person to extract discriminative information [9, 33]. Patch-based methods divide images into several local patches, then extract features from each patch [35]. The expanding sample methods are with some special means such as perturbation-based methods [19, 36], photometric transforms, and geometric distortion [28] to increase the number of samples per person [35]. Thus processing is performed on these samples. The deep learning method, as the name implies, uses deep learning models [35].
Here, our proposed method is included in the first category. We propose a method that extracts a feature vector with an evident distance between individuals. It increases the accuracy of the method in face recognition, and is applicable on large databases. Hence, to extract the basic features of the face structure, Non-negative Matrix Factorization (NMF) is used. This method is inspired by the human vision system and is based on parts. Using NMF, the matrix of images is decomposed into basis and weight matrices. Then using a suitable similarity criterion, the similarity between the test image and the database images are measured on the associated weight matrices. Experimental results on the widely used face datasets demonstrate that our method outperforms state-of-the-art face recognition methods.
The remaining parts of the paper are structured as follows. Section 2 reviews related works. In Section 3 the proposed method will be described. Experiments and results are provided in Section 4.
2 Related works
Recently, several SSPP face recognition methods were proposed in literature. Gao et al. [4] made Fisher Linear Discriminant Analysis (FLDA) able to be used in the SSPP case to estimate the intra-class variance. Using transformation [28], SVD decomposition [36], small perturbation [38], or sub-images generated by dividing each image into small patches [3], virtual samples are generated. Then the intra-class variance between original and virtual samples was calculated.
Lu et al. [18] proposed a patch-based face recognition method, namely Discriminative Multi-Manifold Analysis (DMMA). The training samples were segmented to obtain patches. Then, they were used to learn discriminative features. Pan et al. [25] proposed a Locality Preserving Projection (LPP) feature transfer. To reach the selective sample source the transfer sources were screened using the whitened cosine similarity metric. The vectors of source faces and target faces were projected into feature sub-space using LPP. Then the feature transfer matrix was calculated to approximate the mapping relationship. The feature transfer matrix was applied on training samples and finally, the nearest neighbour classifier was used for face recognition.
Liu et al. [17] proposed a fast face recognition method based on DMMA using a rectified K-means to cluster two groups of people. The face images were partitioned into several non-overlapping patches, then DMMA was applied to them. The fast DMMA was obtained by repeating the two former steps.
In [8] the single sample and its transpose were decomposed into two sets of basis images by the lower-upper (LU) decomposition algorithm. The two approximation images were reconstructed from the two basis image sets by the experimental estimation method. The FLDA was used to evaluate the optimal projection space using the new training set consisting of the single sample and its two approximation images for each person.
Xin et al. [22] proposed the Local Gabor Binary Pattern (LGBP) for feature extraction and the Locality Preserving Discriminant Analysis (LPDA) for dimension reduction. Image enhancement and geometric transformation were applied to the images. Then the original images along with the transformed images were considered as the training set. The LGBP and then LPDA were used for feature extraction and feature reduction, respectively. The Euclidean distance-Nearest Neighbor was used for classification.
Zeng et al. [35] proposed a scheme which combined traditional and deep learning (TDL) methods. An expanding sample method based on the traditional approach was used to generate samples. Then transfer learning was used and a well-trained deep convolutional neural network (DCNN) model was applied.
Min et al. [21] used transfer learning by training a deep convolutional neural network on a face dataset. Then the well-trained model was applied to a target dataset. A sample expansion was presented that called K Class Feature Transfer (KCFT) to enrich intra-class variation information for a single-sample face feature. Then the expanded sampled was used to train a classifier.
As briefly discussed above, most of the existing face recognition methods lean on a feature reduction method due to the large size of the extracted features. In addition, some of them, although considered as an SSPP method, generate different samples per person to consider appearance changes. Most importantly, these methods can be used to identify a limited number of faces. Once the number of faces in the database increases, the intra-class distance is reduced, which drops accuracy of the method. Hence, in this research, we intend to extract valuable features with a considerable intra-class distance between individuals to increase the performance of the system in terms of both the accuracy and the number of identifiable people.
3 Proposed method
The proposed method has two stages: preprocessing, and feature extraction. The images are enhanced in the preprocessing stage to improve their pictorial information. Humans can differentiate between various facial images considering the structure of facial elements. We use the NMF for decomposing facial images into their constituent parts. In the feature extraction stage, the NMF is employed to indicate the significance of various basis elements in the composition of the facial image, which is denoted as the feature vector. Finally, for recognizing a facial image the feature vector of the image is compared with those from the database images using a similarity measure to look for the most similar image.
3.1 Image enhancement
In the proposed face recognition method, images are initially enhanced to extract more accurate information in the feature extraction step. This preprocessing stage can improve the performance of face recognition systems [24, 29]. Image enhancement techniques such as Histogram Equalization (HE) [39], Contrast Limited Adaptive Histogram Equalization (CLAHE) [6], and Image Intensity are used to improve image appearance in this research.
HE is a technique that enhances an image’s contrast by adjusting its intensity [39]. This technique uses an ascending function to change the pixel values of the image, so that histogram of the image becomes approximately smooth. Histogram equalization is applied according to a cumulative density function:
where pixel value qk in image q is changed to pixel value pk in image p, dq(qi) is the ith normalized histogram of q, ni represents the number of pixels with gray level i, N indicates a total number of image pixels, L is grayscale maximum and k is the gray in the interval [0, L-1]. Finally, the values in p (i. e. pk) must be rounded to the correct values in the interval [0, L-1]. See Fig. 1(b). This technique equally improves all of the image’s pixels, hence noise may be made more obvious in the image [2]. It may also wash out some parts of the image [34]. To solve these problems, the CLAHE technique is employed to locally improve the contrast.

(a) Original image; (b) Histogram equalized image, (c) CLAHE image, (d) Intensity image, (e) Applying all three techniques on the original image
The CLAHE technique is applied to the regions of the image, whereas the HE improves the whole image to a certain extent. First, the image is divided into tiled areas, then each region (tile) is enhanced independently. The bilinear interpolation is then used to combine neighboring tiles for preventing artifacts [16]. In this technique, less improvement is achieved in smooth areas, thus preventing the washing out of images and the amplification of noise (see Fig. 1(c)).
Image intensity maps the intensity values in the grayscale image I to new values in A:
where min and max represent the minimum and maximum values of pixels in image I. In most cases, if the image intensity is not enhanced, the image will be different from the real mode.
Applying all of the three preprocessing techniques mentioned above will eventually improve the accuracy of face recognition.
It should be noted that characteristics of facial elements that can help in differentiating between different people should be considered in face recognition. For example, skin texture or hair style are not suitable features for face recognition. As seen in Fig. 1(e), the structure of the eyebrows, lips, nose volume and so on is well shown in the enhanced image. Hence, the enhanced characteristics of these elements can improve the accuracy of face recognition.
3.2 Feature extraction
Raw data is usually expected to be high dimensional, often leading to an often increase in computational cost and reduced system performance for data analysis. Therefore, it seems necessary to use a method that maps data to an alternate lower dimensional space but with a more valuable information load.
Humans recognize facial images by considering the structure of the face and facial elements. One of the simplest principles in human perception is to understand the structure of objects based on their components, and human vision has the ability to easily detect the presence or absence of an object. Thus, it is better to develop a method that is inspired by the assumption that humans recognize objects based on their detail. The NMF technique can be used for data decomposition. It has a part-based representation [14], and a wide range of applications in the field of image processing [15, 23].
The NMF method is an algorithm in linear algebra which decomposes a matrix into two factor matrices, under the condition that the matrix contains non-negative values only. Hence this constraint leads to more interpretable results. NMF is a low-rank approximation technique for unsupervised data decomposition [13]. As mentioned, this method learns a part-based representation.
The image database is regarded as an n × m matrix V, each column of which contains n non-negative pixel values from one of the m facial images. Then this method constructs approximate factorization of the form V ≈ WH or
The r columns of W in (3) are called basis images. Since the elements of W are non-negative; the basis columns can be visualized [32]. Each column of H is called an encoding, and includes the coefficients which represent a face with a linear combination of basis images. Also, an encoding is in one-to-one correspondence with a facial image in V [13]. The dimensions of the matrix factors W and H are n × r and r × m respectively; such that these matrices minimize the following criterion:
where r is a positive integer that determines the rank of the NMF, and F is the Frobenius norm. The rank r of the factorization is generally chosen so that (n + m)r < nm, and the product WH can be regarded as a compressed form of the data in V [13].
As seen in Fig. 2, the basis images have several versions of noses, mouths and other facial components, with different versions in different locations or shapes. By combining these pieces from one face, variations of that face can be generated. However, each face does not use all the existing pieces [13]. One of the advantages of the NMF in comparison with other factorization methods such as PCA [20], SVD [37] and ICA [1] is the reduction of the storage space, because it makes the W and H matrices sparse [12].

Decompression of a face image using the NMF method
The objective function (4) does not converge with two matrix factors W and H synchronously. Therefore, the global minimum cannot be found. At best, only the achievement of the local minimum is expected [14]. Therefore, the convergence is one of the objectives of the NMF method. Recently several algorithms have been proposed to solve this problem.
Kim et al. [11] introduced the Alternating Non-negative Least Squares (ANLS) with the Block Principal Pivoting (BPP) method. Also in their research, ANLS with BPP is used for the objective function. This algorithm performs better than others in terms of recognition rates and recovery times.
4 Experiments and results
4.1 Dataset
Color FERET database contains 11,338 color facial images of 990 individuals. FERET consists of following subsets: frontal images (fa, fb), quarter left (ql), quarter right (qr), profile left (pl), profile right (pr), half left (hl), half right (hr) and rotated images (ra, rb, rc) [26]. The images contain variations in lighting, facial expressions, pose angle, etc. In this work, only frontal faces are considered. The fa set is used as a gallery set, contains frontal images of 990 people, and the fb set (990 images) is used as a probe set. See Fig. 3. The fb set was taken a few seconds after the corresponding fa.

From FERET database, samples from fa in the first row, and samples from fb in the second row
4.2 Face recognition
Pre-processing is applied on all images from the database as stated earlier. Then each image is divided into two areas, containing the upper and lower parts of the face, and NMF is applied on each area to obtain the feature vector. Dividing the image into two areas can assist NMF to more appropriately extract the facial elements with more accurate features. Note that each column of H is regarded as a feature vector for a face. Then, a similarity measure is needed to compare the feature vectors associated with the matching images. In this paper, several similarity measures have been experimented on the database, of which their results are shown in Table 1. According to the results, the correlation coefficient was selected.
The correlation coefficient between the feature vector of the upper part of the test image and the upper part of all images in the dataset is calculated. The same is exactly done for the lower part. The correlation coefficient c is computed as below:
where A is the upper (lower) part of the test image and B is the upper (lower) part of the image in the dataset. Also, \( \overline{A} \) and \( \overline{B} \) are the mean of A and B, respectively. The correlation coefficients of the two areas corresponding with one image are then considered for decision making. Finally the coefficients of the test image are compared with those from all images in the database.
To use NMF, it is important to consider the rank (r) and size of images. They play a significant role in accuracy- the number of correctly recognized image with respect to the total number of images. If the rank is not set properly, it may identify two different faces alike. As mentioned above, the equation (n + m)r < nm is used to select the order value.
Hence, different ranks (r) and sizes are applied to calculate the accuracy. As shown in Fig. 4, the highest recognition rate is obtained when the size of the images is 20 × 20 and r = 56. Figure 4 represents the accuracy without applying the pre-processing stage which was about 89%. The achieved image size indicates that the structure of face and the form of facial elements are more important than the image details for the proposed face recognition method.

Results of experiments for appropriately choosing the image size and matrix rank (r) for the proposed face recognition method, without applying the pre-processing stage
If a facial image is given to the NMF in full, the recognition accuracy could go up to 83%. However, if the image is divided into upper and lower areas and the NMF is applied on each area, this leads to an extraction of more precise elements. So it can be an effective factor in improving the accuracy. The results provided in Fig.4 are through sub-dividing the facial images of the database into the lower and upper areas.
It is important to keep a face’s significant information in divisions. Hence in an empirical manner the images were horizontally divided into two parts from different rows to find more appropriate division. Our investigations show that horizontally dividing the facial images from the middle, i.e. the area between the eyes and nose is more appropriate. Then the correlation coefficient between the upper and lower parts of the test image and those from the database images are computed (See Fig. 5.).

Two different images from the same person in the database. Comparing feature vectors of the upper and lower parts of the images
Since the significance of the two parts of the image may not be the same in face recognition, we use the following equation for decision making:
Two images are considered similar if the correlation coefficient reached the highest value among all the images in the database. The optimal values of α and β are obtained using a validation data set. The best result is obtained with α = 0.8 and β = 0.2 , indicating that the upper part of the face is more important than the lower part in face recognition.
In Fig. 6, a sample of the correlation coefficient between the feature vector of the test image and the feature vectors of all images from the database are shown. Regarding the obtained values, the largest correlation coefficient belongs to image #310 of the database. This means that the closest facial image to the test image is image #310.

Correlation coefficients between the feature vector of a test image and those from the database. The maximum value (x = 310) represents the high match
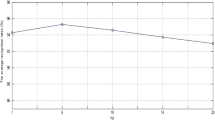
We tested the proposed method with a different number of images in the database on a PC with Intel corei7, 3.3 GHz CPU and 64 GB RAM. Results in Fig. 7(a) indicate that the computational complexity of the proposed method is approximately in order of N, i.e. O(N), in which N represents the number of images in the database. This figure shows that it takes about 64 milliseconds in average to recognize (to retrieve) an image from the database of 990 faces. The results in Fig. 7(b) show the competency of the proposed method in recognizing faces from a large database as the recognition rate is moderately reduced with respect to an increase in the number of database images.

(a) Running time in seconds, and (b) recognition rate of the proposed method with respect to the number of images in database
Table 2 shows the performance of the proposed method in comparison with other existing methods as reported in the related references. The bold numbers in this table denote the highest recognition rate. Comparing with other methods in the table, the proposed method achieves the best recognition performance.
5 Conclusions
In this study, a feature extraction algorithm based on Non-negative Matrix Factorization (NMF) was presented for face recognition with a single sample per person in the database. The images are initially pre-processed to enhance them for acquiring more discriminant features in the feature extraction step. The NMF is used to decompose the images from the database into their constituent parts such as nose, lip, eyebrow, and chin; then a small feature set is used to discriminate individuals. In the proposed method, only one sample per person is enough to construct the constituent elements of the faces from the database. Several experiments were performed on the proposed method, using the FERET database, to evaluate its accuracy in face recognition. The results indicate superiority of the proposed method compared to other existing face recognition methods in terms of recognition accuracy. In addition, the accuracy of the proposed method is slightly reduced by increasing the number of faces in the database, which indicates its competency in recognizing a face from a large database.
References
Bartlett MS, Movellan JR, Sejnowski TJ (2002) Face recognition by independent component analysis. IEEE Trans Neural Netw Publ IEEE Neural Netw Council 13(6):1450
Chang DC, Wu WR (1998) Image contrast enhancement based on a histogram transformation of local standard deviation. IEEE Trans Model Imaging 17(4):518–531
Chen S, Liu J, Zhou Z-H (2004) Making FLDA applicable to face recognition with one sample per person. Pattern Recogn 37(7):1553–1555
Gao QX, Zhang L, Zhang D (2008) Face recognition using FLDA with single training image per person. Appl Math Comput 205(2):726–734
George KK, Kumar CS, Ramachandran KI, Panda A (2015) Cosine distance features for improved speaker verification. Electron Lett 51(12):939–941
Grag R, Mittal B, Grag Sh (2011) Histogram Equalization Techniques For Image Enhancement. Int J Electron Commun Technol (IJECT) 2(1)
Guo Y, Jiao L, Wang S, Wang S, Liu F (2018) Fuzzy sparse autoencoder framework for single image per person face recognition. IEEE Trans Cybernet 48(8):2402–2415
Hu C and Lu X (2015) Single sample face recognition via lower-upper decomposition. Control Conf (ASCC), 10th Asian. IEEE. 1–6
Ji H-K, Sun Q-S, Ji Z-X, Yuan Y-H, Zhang G-Q (2017) Collaborative probabilistic labels for face recognition from single sample per person. Pattern Recogn 62:125–134
Kan M, Shan S, Su Y, Xu D, Chen X (2013) Adaptive discriminant learning for face recognition. Pattern Recogn 46(9):2497–2509
Kim J, Park H (2011) Fast nonnegative matrix factorization: an active-set-like method and comparisons. SIAM J Sci Comput 33(6):3261–3281
Langville AN, Meyer CD, Albright R, Cox J, Duling D (2014) Algorithms, initializations, and convergence for the nonnegative matrix factorization. arXiv preprint arXiv:1407.7299
Lee D, Seung HS (1999) Learning the parts of objects by non-negative matrix factorization. Nature 401(6755):788
Lee DD, Seung HS (2000) Algorithms for non-negative matrix factorization. Adv Neural Inf Proces Syst 13:556–562
Li S, Hou X, Zhang H, Cheng Q (2001) Learning spatially localized, parts- ased representation. In IEEE Computer Vision and Pattern Recognition, Martigny, Switzerland. 207–212
Li W, Chen Y, Sun W, Brown M, Zhang X, Wang S, Miao L (2019) A gingivitis identification method based on contrast-limited adaptive histogram equalization, gray-level co-occurrence matrix, and extreme learning machine. Int J Imaging Syst Technol 29(1):77–82
Liu H, Hsu S, and Huang C (2015) Single-sample-per-person based face recognition using fast discriminative multi-manifold analysis. Proc Asia-Pac Sign Inform Proc Assoc 1–9.Hong Kong, China
Lu J, Tan Y, Wang G (2013) Discriminative multi manifold analysis for face recognition from a single training sample per person. IEEE Trans Pattern Anal Mach Intell 35(1):39–51
Martinez AM (2002) Recognizing imprecisely localized, partially occluded, and expression variant faces from a single sample per class. IEEE Trans Pattern Anal Mach Intell 24(6):748–763
Martínez AM, Kak AC (2001) Pca versus lda. IEEE Trans Patt Anal Mach Intel 2:228–233
Min R, Xu S, Cui Z (2019) Single-sample face recognition based on feature expansion. IEEE Access 7:45219–45229
Minghai Xin YZ, Yan J (2015) Single sample face recognition using LGBP and locality preserving discriminant analysis. Int J Appl Math Inform Sci 9(1):353–360
Nikolaus R (2007) Learning the parts of objects using non-negative matrix factorization. MMer Team
Oloyede MO, Hancke GP (2016) Unimodal and multimodal biometric sensing systems: a review. IEEE Access 4:7532–7555
Pan J, Wang XS, Cheng YH (2016) Single-sample face recognition based on LPP feature transfer. IEEE Access 4:2873–2884
Phillips PJ, Moon H, Rauss P, Rizvi SA (1997) The FERET evaluation methodology for face-recognition algorithms. Proc IEEE Comput Soc Conf Comput Vis Patt Recog. IEEE. 137–143
Ragnemalm I (1993) The Euclidean distance transform in arbitrary dimensions. Pattern Recogn Lett 14(11):883–888
Shan S, Cao B, Gao W, Zhao D (2002) Extended Fisherface for face recognition from a single example image per person. Proc IEEE Int Sympos Circ Syst 2:II-81–II-84, Seoul, Korea
Shi Z, Zhu MM, Guo B, Zhao M, Zhang C (2018) Nighttime low illumination image enhancement with single image using bright/dark channel prior. EURASIP J Image Video Proc 2018(1):13
Swets DL, Weng JJ (1996) Using discriminant eigenfeatures for image retrieval. IEEE Trans Patt Anal Mach Intel 8:831–836
Tan X, Chen S, Zhou ZH, Zhang F (2006) Face recognition from a single image per person: A survey. Pattern Recogn 39(9):1725–1745
Wild S, Curry J, Dougherty A (2004) Improving nonnegative matrix factorizations through structured initialization. IEEE Trans Patt Recog 37(11):2217–2232
Yang M, Cool LV, Zhang L (2013) Sparse variation dictionary learning for face recognition with a single training sample per person. Proc IEEE Int Conf Comput Vis 689–696
Yoon H, Han Y, Hahn H (2009) Image Contrast Enhancement based Sub-histogram Equalization Technique without Over-equalization Noise. World Acad Sci Eng Technol 3:132–138
Zeng, J., Zhao, X., Gan, J., Mai, C., Zhai, Y. and Wang, F., 2018. Deep Convolutional Neural Network Used in Single Sample per Person Face Recognition. Comput Intel Neurosci
Zhang D, Chen S, Zhou Z (2005) A new face recognition method based on SVD perturbation for single example image per person. Appl Math Comput 163(2):895–907
Zhang G, Zou W, Zhang X, Hu X, Zhao Y (2017) Singular value decomposition based sample diversity and adaptive weighted fusion for face recognition. Dig Sign Proc 62:150–156
Zhao H, Yuen PC, Yang J (2005) Optimal subspace analysis for face recognition. Int J Pattern Recognit Artif Intell 19(03):375–393
Zhou S, Chen J, Wen Q (2019) A weight-based optimization algorithm of histogram equalization. In 9th International Symposium on Advanced Optical Manufacturing and Testing Technologies: Optoelectronic Materials and Devices for Sensing and Imaging (Vol. 10843, p. 108430T). International society for optics and photonics
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nikan, F., Hassanpour, H. Face recognition using non-negative matrix factorization with a single sample per person in a large database. Multimed Tools Appl 79, 28265–28276 (2020). https://doi.org/10.1007/s11042-020-09394-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-09394-4