
Abstract
Videos are amongst the most popular online media for Internet users nowadays. Thus, it is of utmost importance that the videos transmitted through the internet or other transmission media to have a minimal data loss and acceptable visual quality. Video quality assessment (VQA) is a useful tool to determine the quality of a video without human intervention. A new VQA method, termed as Error and Temporal Structural Similarity (EaTSS), is proposed in this paper. EaTSS is based on a combination of error signals, weighted Structural Similarity Index (SSIM) and difference of temporal information. The error signals are used to weight the computed SSIM map and subsequently to compute the quality score. This is a better alternative to the usual SSIM index, in which the quality score is computed as the average of the SSIM map. For the temporal information, the second-order time-differential information are used for quality score computation. From the experiments, EaTSS is found to have competitive performance and faster computational speed compared to other existing VQA algorithms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many multimedia applications deal with visual assets nowadays. This is more evident in mobile devices such as smartphones, tablets, smart watches, and smart glasses. These devices use microprocessors or microcontrollers with high processing ability. This processing ability enables them to process data on their own without relying on external processing devices. According to the research done by Ooyala [18], mobile video views increased from 6.3% of the overall mobile traffic data in 2012 to 45.1% in Q3 2015. This shows the importance of videos in multimedia equipment. Assessment of the video qualities of these products is crucial as a quality feedback tool for device manufacturers and content service providers.
Since humans are ultimate users of these visual related devices, their quality ratings of images and videos are the most accurate. The quality assessment which involves humans as evaluators is known as subjective quality assessment. In spite of its accuracy, subjective quality assessment cannot be performed to all assessment tasks as it is costly and time-consuming. Thus, automatic quality assessment methods without human involvement are highly desirable. This requirement motivates the development of objective quality assessment method. Instead of obtaining quality scores from humans, algorithms are used to rate images and videos automatically. An objective method is more cost and time effective, especially for real-time tasks. However, the problem of inaccuracy in terms of human perception is still a concern for objective methods. The accuracy or the performance of objective methods is measured through the correlation of objective scores and subjective scores (ground truth results). In recent decades, hard works are devoted by researchers to improve the accuracy of objective quality assessment methods. The proposed method in this paper also aims to predict video quality with high correlation to subjective scores.
A video composed of a series of images. The changes of images or frames over time create an additional temporal dimension. Temporal information is extremely useful for interpreting motion on which many applications are based on. One typical example of these applications is activity recognition [15, 16]. In terms of quality, temporal information can affect the perceived quality of a video. Different types of temporal distortion are found on videos, such as compensation mismatch, jitter, and mosquito noise. A short review of various types of temporal distortions and their causes can be found in [23]. On the other hand, the motion from temporal effects can mask distortions too. This phenomenon is known as motion silencing. Motion silencing is gaining attention and interest from researchers recently. A popular illusion of motion silencing is demonstrated in Suchow and Alvarez’s work [30]. Hence, temporal information should be considered during video quality assessment for its adverse and advantageous effects.
In this paper, a new video quality assessment (VQA) algorithm is proposed. It is dubbed as Error and Temporal Structural Similarity (EaTSS). EaTSS is derived from the authors’ previous work [17] in which only compressed videos are dealt with. There are several highlights of EaTSS. Firstly, EaTSS is used to assess videos of all types of distortions. This property is highly desirable. There are image quality assessment (IQA) and VQA metrics which only deal with specific distortion. The no reference IQA metric in [3] is one of them. This metric only assesses qualities of Gaussian blur distorted images. These types of metrics have limited applications. Besides that, localized error based weight is incorporated in EaTSS. Structural Similarity Index (SSIM) [40] map is weighted by this weight for spatial quality evaluations. This weighting is very different from other weightings used in the variants of SSIM such as the works in [12, 39]. For the temporal part, EaTSS involves second-order time-differential information of a video. To the best of our knowledge, no research on VQA to date employed second-order time-differential information. There are only VQA methods that make use of first order time-differential information [4, 7, 36]. Lastly, EaTSS also has low complexity and good efficiency as shown in Section 4.4.
The remainder of this paper is organized as follows. Section 2 presents a brief review of the related previous works by other researchers and the authors [40]. EaTSS is elaborated in Section 3. In Section 4, correlation results of EaTSS are presented and discussed. Computational time and complexity are also shown in this section. In Section 5, a general conclusion is presented.
2 Previous work
VQA methods can be categorized into full reference (FR), reduced reference (RR), and no reference (NR) methods [34]. FR methods conduct the assessment task with all information of pristine videos available. Instead, part or no information from ground truth data is accessible for RR and NR methods respectively. This paper concentrates on FR methods so some state-of-the-art FR VQA methods are briefly discussed in this section. They are classified into IQA based and non-IQA based methods. A previous work by the authors [17] upon which the proposed method is built is also detailed in this section.
2.1 Previous work by other researchers
Some researchers had proposed VQA metrics which are based on IQA metrics. Existing IQA metrics can assess video quality too. However, they disregard temporal distortions and effects in a video. This is the main reason for inaccuracy and inappropriateness of IQA metrics for VQA tasks. Some popular IQA metrics that are commonly utilized and modified in VQA metrics are Mean Squared Error (MSE) or Peak Signal to Noise Ratio (PSNR) [38], SSIM [40], Multiscale SSIM (MSSIM) [42], Most Apparent Differences (MAD) [10], and Visual Information Fidelity (VIF) [27]. Some of their extensions are briefly discussed here.
By extending MSE, Rimac-Drlje et al. proposed Foveated Mean Squared Error (FMSE) [22]. FMSE makes use of center bias and eccentricity of the human visual system (HVS) for spatial quality assessment. To consider temporal effects, foveation-based contrast sensitivity of the method in [11] is applied for scenes with movement. Wang et al. adapted SSIM for VQA in Video Structural Similarity (VSSIM) index [41]. VSSIM further incorporates chrominance components while the luminance component is given more weight. The spatial quality score of each frame is weighted by global motion to generate an overall video quality score. Vu and Deshpande had proposed ViMSSIM [36] which builds upon MSSIM. Spatial quality scores are obtained by a modified exponential moving average procedure for MSSIM indices of every frame. For the temporal part, MSSIM indices for the reference and distorted frame difference information are computed. Recently, Vu and Chandler derived ViS3 [35] from MAD. Firstly, motion magnitudes from optical flow are combined with the MAD indices to obtain the first score. The second score is the resulting dissimilarities of reference and distorted spatiotemporal slices (STS) frames. Then, two scores are integrated into an overall video quality. Another method based on VIF is put forward by Sheikh and Bovik [26]. This method incorporates source model, distortion model, and information fidelity criterion. The mutual information from wavelet subband coefficients of reference and distorted videos is employed for measuring spatial quality. For temporal quality scores, temporal distortions are measured by the information loss due to motion. The loss is computed by deviations in spatiotemporal derivatives of a video.
Nevertheless, there are VQA metrics that are not based on any IQA approach. VQM [20], proposed by Pinson and Wolf, is perhaps the first non-IQA based VQA metric. Reference and distorted videos are sampled and calibrated first. This is followed by the extraction of perception based features [44], computation of video quality parameters, and calculation of VQM models. Watson et al. had proposed Digital Video Quality (DVQ) [43] which embodies just noticeable difference (JND). In DVQ, discrete cosine transform (DCT) coefficients of a video are first filtered by contrast sensitivity function (CSF). Later, a JND threshold is applied to the filtered coefficients to generate a quality score. Another well-known VQA method that is non-IQA based is motion-based video integrity evaluation (MOVIE) [23]. MOVIE is based on statistics of natural videos. Spatial impairments are calculated from the combination of contrast masking and 3D Gabor filtered videos. 3D Gabor filtered videos also interact with motion information from the optical flow to account for temporal distortions. The overall video quality is the geometric mean of spatial and temporal scores. Pinson et al. [21] had extended VQM to VQM variable frame delay (VQM-VFD) in 2014. VQM-VFD further embodies two additional perception based parameters for measuring frame delay. A neural network is trained to integrate all parameters into a quality score. More recently, Choi and Bovik [5] had improved the MOVIE framework by injecting the flicker sensitive index. They prove that the temporal masking of flicker impairments improves VQA performances.
From the works mentioned above, it is obvious that temporal effect plays an important role in VQA. This is evident from VQM-VFD and the method by Choi and Bovik (dubbed C-B method hereafter). They supplement their previous methods with additional temporal effect consideration. Their performance improvements motivate us to improve the temporal part of our previous work. Furthermore, the spatial part of the previous work is also improved in this paper. This is motivated by the high performances of the VQA methods that implicate Gabor filters. However, for the sake of complexity, only the localization nature of Gabor filters [22] is incorporated in the proposed method. Thus, weighting based on the local errors is implemented. Before introducing the proposed method, our previous work is elaborated concisely in the next section.
2.2 Previous work by the authors
EaTSS extends the previous method by the authors. This previous method is known as MSE Difference SSIM (MD-SSIM) [17]. There are two main parts in MD-SSIM, i.e. local and global. The overall video quality is the arithmetic mean of local and global quality scores. Local quality scores are derived from spatial and temporal quality scores. For spatial quality scores, they are computed by weighting SSIM map with the MSE map. This is shown as [17]:
where MDSSIM(spatial) refers to spatial quality scores of the local part of MD-SSIM, E(x, y) is the error map from MSE, and S(x, y) is the SSIM map from SSIM.
Temporal quality scores are the differences between the spatial quality score of every successive frame. Then, local quality scores are defined as the weighting of spatial quality scores by temporal scores. This is shown as [17]:
In (2), MDSSIM(local) is the local quality score of MD-SSIM, Wf is the temporal quality score at frame f, and F is the total number of frames. For the global part, the quality score is the average of SSIM indices on a frame-by-frame basis. It is defined as [17]:
where SSIM(f) is the SSIM quality score of frame f. The overall MD-SSIM score of a video is the arithmetic mean of local and global quality scores [17]:
Based on the results in [17], the average of the SSIM map in usual SSIM metric is insufficient to capture distortions perceived by HVS in videos. MSE weighting of the SSIM map is an alternative to compute the SSIM index from SSIM map. This method is proven [17] to correlate better with subjective scores for compressed videos. Based on MD-SSIM, EaTSS extends to evaluate qualities of videos suffered from various distortions, other than compressed videos only. Next, EaTSS is deliberated.
3 Error and temporal structural similarity - EaTSS
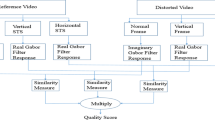
In this section, EaTSS is discussed in detail. Similar to most of the existing metrics, EaTSS composes of spatial and temporal components. The spatial component is extended from MD-SSIM [17] while the temporal component is inspired by the works of Vu and Deshpande [36], Cardoso et al. [4], and Ítalio et al. [7]. The overall video quality score is the arithmetic mean of spatial and temporal scores. Spatial part, temporal part, and their combination are discussed sequentially in the following subsections. The overall workflow of EaTSS is shown in Fig. 1.

Workflow of EaTSS
3.1 Spatial part of EaTSS
The weighting method from [17] is extended for the spatial part of EaTSS. In [17], MSE of reference and distorted frames are used as the weight. According to Akramullah [1], MSE is inaccurate because a particular pixel in a frame is visually affected by its surrounding pixels. The work by Akramullah is supported by Limb’s experiment [14]. This experiment shows that image quality ratings by humans are the average of errors in local areas with the highest error values. In other words, the image quality is proportional to the level of distortion in distorted regions. This result is extended to videos for EaTSS. Each frame in a video is exposed to HVS for a very short instant of time. Thus, we assume that HVS is not able to focus on every local part of the whole frame. Instead, HVS concentrates on local salient components in a frame. In EaTSS, distortions are deemed as the salient components. Thus, we compute the weighting in accordance with the degree of local errors to model localization. There is a distinction between this method and the result in [14]. Global effect is considered in our weighting method. Yet, more weight is given to distorted local regions. This corresponds to the characteristic of HVS that acts as a bandpass filter [6] when it searches for salient regions. This characteristic is modeled as MSE of the error of a pixel to errors of its surrounding pixels. Also, as stated in Section 2, the incorporation of localization characteristic is motivated by high performances of VQA methods which involve Gabor filter. Since high localization is the main property of Gabor filter, it is modeled and incorporated in EaTSS.
Dissimilar to MD-SSIM [17], error maps from the MSE of reference and distorted frames are not used for weighting. Instead, the differences from the subtraction of the two frames are used. This aims to include direction factors in the weighting. Direction factors indicate whether errors are causing the original luminance values to become brighter (positive direction) or darker (negative direction). Errors in different directions are considered the same in MSE maps due to the squaring of errors. By direct subtraction of frames, directions of the errors are used for the later computation of localization model. The computation of the new error map is shown as:
In (5), E(x, y) is the error map while R(x, y) and D(x, y) are the frames of reference and distorted videos respectively.
Next, the localization model is applied to the error map. MSE of the error in a pixel with the errors of its surrounding pixels is calculated. This is shown as:
In (6), W(x, y) is the weighting function, parameters i and j are the pixel positions around the target pixel, and s is the number of pixels surrounding the target pixel. The squaring of the numerator in (6) is to prevent negative values. This process does not conflict with the aforementioned statement of direction factors. This is because the subtraction in the numerator in (6) has already taken into consideration of the direction factor. The goal of squaring is to prevent inaccurate normalization in the computation of spatial score later. The clarification of localization is shown in Fig. 2. Figure 2a and b show the first frame of the reference and distorted videos from the LIVE video database [24, 25]. Figure 2c shows the error map of both frames. The illustrated error map is the result of inverting and modulus of results from (5). Figure 2d is the weight function calculated using (6). The illustrated weight function is inverted and normalized for illustration purpose. The regions where distortions are more severe have been emphasized in Fig. 2d. Moreover, regions with less significant errors have less weight according to the weight function.

After that, SSIM maps can be computed. It is shown in the equation below [40]:
where SSIM(x, y) is the SSIM map, x and y refer to a particular frame from reference and distorted videos respectively, μ is the mean intensity, σ is the standard deviations of the intensities, and σxy is the cross correlation of intensities from the reference and distorted videos. Parameters C1 and C2 are constants added into (7) to prevent instability. The main reason for using SSIM instead of other IQA metrics is that it has good performance with low complexity. Although MSE and PSNR are simple and fast to compute, their performances are unsatisfactory. On the other hand, other good performing IQA metrics like MSSIM and MAD have a much higher complexity than SSIM. In order to strike a balance between performance and complexity, SSIM is chosen in our method.
Then, W(x, y) from (6) is used to weight SSIM maps from (7) to obtain a spatial quality score. This is done by the weighted summation of W(x, y) and SSIM(x, y). The weighted summation is also referred as local distortion-based pooling in [39]. Although the pooling method proposed in [39] can definitely improve the performance of SSIM maps, the aspects that we are considering here is different from the work in [39]. EaTSS focuses more on distortions while the work in [39] focuses more on the content in relation to HVS. The authors in [39] also compared their works with local distortion-based pooling. However, the weight used is totally different. Moreover, EaTSS focuses more on local distortions. The weighted summation is shown as:
where M and N are the width and height of the frames of the video. This weighting causes the resulting spatial score to focus more on severely distorted regions in a frame.
3.2 Temporal part of EaTSS
Temporal information is very useful in order to consider temporal impairments and effects in a video. This is evident from the previous works by other researchers [5, 11, 20,21,22,23, 26, 35, 36, 41, 43, 44]. The most direct method to obtain temporal information of particular frames is through frame subtraction. This method is the generalization of the equation in [8] which measures temporal information of a video:
where TI is the temporal information, maxf is the maximum over time dimension and stdx, y is the standard deviation over space dimension. Parameter Af(x, y) is the current frame of a video while Af − 1(x, y) is the previous frame of the same video. Thus, the temporal information in terms of pixels can be measured by frame subtraction disregarding maxf and stdx, y. To capture temporal distortions and effects better, Vu and Deshpande had proposed an alternative in [36]. Two types of temporal information are computed for comparison; reference and distorted temporal information. Reference temporal information, TIR, is computed by generalizing (9). This is shown as:
Distorted temporal information is obtained from two frames. One of them is the current time frame from the distorted video, Df(x, y). The other frame is the previous time frame from reference video, Rf − 1(x, y). It is shown as:
where TID is distorted temporal information. Both TIR andTID are actually time-differential or frame differenced information. By utilizing frames from reference and distorted videos, TID further incorporates spatial information that is affected by temporal transitions. This corresponds to HVS functions whereby temporal and spatial sensitivities affect each other [37]. According to these functions, HVS’s temporal sensitivity depends on spatial information while temporal information changes human spatial contrast sensitivity functions [37].
The alternative by Vu and Deshpande has high correlations to subjective scores. This is shown in the results in [36]. A recent RR VQA method, spatiotemporal reduced reference entropic differences (STRRED) [29], also utilized frame differences. Wavelet coefficients from frame differences are used to capture spatial and temporal information distinction of reference and distorted videos. Authors in [29] called the frame differences as time-differential information. The excellent performances of these two VQA metrics motivate us to further extend time-differential information in a different fashion to [29, 36]. We choose to extend the method by Vu and Deshpande in this paper. This method does not involve domain transformation and has lower computational cost. Most VQA methods obtain temporal information in terms of motion from optical flow or other types of motion estimation techniques. These estimation techniques are known to be complex and need long computational time. For instance, the work in [19] states that MOVIE spends more than 55% of its computation time in computing optical flow. As shown in (10) and (11), there is no multiplication or division needed for time-differential information. Thus, this method has a very low complexity that is desirable for real-time applications.
To extend time-differential information, second-order time-differential information or the differences of temporal information are computed. To date, research in the second-order time-differential information for quality assessment is still lacking. This choice is enlightened by the good performances in object recognition [13] and categorization [2] by utilizing second-order features. Thus, an assumption that second-order information is useful in predicting the video quality is made. Second-order time-differential information is defined as:
where VTID(x, y) and VTIR(x, y) represent second-order of distorted and reference temporal information respectively. The first part of the right hand side of (12) and (13) correspond to temporal information at the current time frame. Meanwhile, the second part of both equations refers to temporal information of the previous time frame.
In [36], MSSIM index is adopted for temporal information comparison. Meanwhile, STRRED incorporated Gaussian scale mixture model of wavelet coefficients of frame differences [29]. In this paper, a new variant of SSIM is used. The rationale for this choice is to reduce computational complexity. MSSIM is well known for its high computational complexity, although with good performance. Similarly, wavelet transformations also involve complex computations. Direct difference and MSE are not utilized to prevent dissimilar range to that of the spatial quality scores. A simpler variant of SSIM is utilized to maintain the performance while reducing computational complexity. SSIM index is simplified instead of utilizing it directly as in the spatial part. This is because resulting maps after computing second-order temporal information are similar to whitened images. No luminance component left in VTID and VTID after subtractions in (12) and (13). They are similar to whitened images in which luminance information is absent. In the original SSIM index, there are luminance, contrast, and structure comparisons of two frames. Consequently, the luminance comparison function can be discarded. The mean is set to zero in parameters σxy, σx, and σy. Standard deviation is defined as the correlation of pixels to their mean value. Instead of mean, the correlation of pixels second-order time-differential information to a static scene is more desirable in this case. This is to reflect characteristics of temporal information better. For a static scene, there is no temporal information. So, every pixel in a static scene will have zero values. In consequence, the mean value is replaced by zero. In the case of the cross correlation, similar reason holds. Cross correlation is defined as the correlation of standard deviations of reference and distorted temporal information. In each standard deviation, temporal information is compared to a static scene. Therefore, the mean value in the original equation can be replaced by zero. In overall, the new variant is simplified from (7) as:
where SSIM_no_lc is the variant of SSIM map with no luminance comparison. Parameters x and y in (14) correspond to distorted and reference second-order time-differential information at a particular pixel location. The resulting map function, map(x, y), that compares VTID(x, y) and VTIR(x, y), is shown by the equation below:
Similar to the spatial part of EaTSS, the localized weighting function is utilized to weight map(x, y). The reason for this weighting is similar to the spatial part. Due to the short instant of frames changes, HVS can only focus on certain regions of the video. The more distorted regions in terms of temporal information are considered as the salient regions that HVS will concentrate on. The weighting function is shown as:
where e(x, y) is the error map of VTID(x, y) and VTIR(x, y), w(x, y) is the weighting function for map(x, y), and the parameters i, j and s are the same as in (6). The temporal quality score of EaTSS is defined as:
where the definition of M and N are the same as in (8). The weighting function w(x, y) has the similar function to W(x, y). It enables the temporal quality score to focus more on the distorted region. It also weights local salient temporal information more than of global temporal information.
3.3 Overall video quality
The overall video quality score of EaTSS is the combination of spatial and temporal quality scores. The same importance is given to both quality scores. As stated in Section 3.2, they can affect each other. Since both spatial and temporal quality scores are normalized to the same range, the geometric mean is unnecessary. Thus, the arithmetic mean of the spatial and temporal quality scores is used. The overall video quality score is defined as:
4 Results and discussion
The performance of EaTSS is evaluated by comparing its correlation results with existing VQA metrics. The results are based on two benchmark video databases, the LIVE video database [24, 25] and the CSIQ video database [35].
4.1 Details of the databases
The LIVE video database was released by the University of Texas, Austin with all video files having planar YUV 4:2:0 format and do not contain any headers. The spatial resolution of all videos is 768 × 432 pixels. The types of distortions and their respective numbers of videos and frames are listed in Table 1. There are four levels of severity for each type of distortion except for the IP distortion with only three levels of severity. There are 10 reference videos in the database with 15 distorted videos for each reference video. Overall, there are 150 videos that consist of 48,255 frames that need to be tested.
Second benchmark database, the CSIQ video database, was released by the 318 Advanced Technology Research Center from Oklahoma State University. All videos are in the YUV 4:2:0 format with the resolution of 832 × 480. All videos have 10 s duration. There are 12 reference videos and 216 distorted videos. Each reference video is distorted by six types of distortions as listed in Table 2. For each type of distortion, there are three levels of severity. Altogether, there are 82,260 frames to be tested. All distortions in both benchmark video databases are common types of errors found in video transmission and display.
4.2 Evaluation metrics
In order to measure the performance of EaTSS and compare to existing VQA methods, correlations of VQA methods quality scores and human-rated subjective scores from the benchmark databases are computed. As recommended in [33], two types of correlation coefficients are utilized. They are Spearman rank-order correlation coefficient (SC) and Pearson linear correlation coefficient (PC). SC computes prediction monotonicity. Its values reflect the degree of objective and subjective scores can fit a monotonic function. On the other hand, PC measures prediction accuracy to indicate linearity between objective and subjective scores. So as to avoid inaccuracies due to the nonlinearity of objective scores and subjective scores, objective scores need to be transformed. This is the standard procedure recommended by [33]. This procedure is also being used by other VQA methods for performance comparison such as in [5, 21, 23, 29, 35]. Before computing PC, objective quality scores are fitted to subjective scores by using a four-parameter logistic function which is defined as [33]:
where τ1, τ2, τ3, and τ4 are regression parameters to be fitted. In this paper, these parameters are fitted using nonlinear least squares optimization based on the subjective scores from the two databases utilized in this paper. This fitting complies with the ITU guidelines [33] and is also implemented by most objective assessments [5, 21,22,23, 26, 35, 41, 43]. Parameter x is the objective scores and f(x) are fitted scores.
F-test is utilized in this paper to test the statistical significance of VQA methods. It tests the ratio of variances of two sets of scores at 95% significant level. The null hypothesis considers two set of scores are indistinguishable. During the testing, larger variances are put in the numerator. The procedures follow descriptions in [24, 34]. Interested readers can refer to [24, 34] for detailed explanations. First of all, differences of objective scores after the nonlinear transformation and subjective score, D, are computed. This is shown as [24, 34]:
where f(x) is the transformed objective scores from (20), Sub is the subjective score from databases, and K is the total number of videos to be tested. These differences are assumed to follow normal distributions. As utilized by [28], the kurtosis-based criterion is used to test Gaussianity. If the kurtosis lies between 2 and 4, the dataset is Gaussian.
EaTSS is compared with some popular IQA (applied in frame-by-frame basis) and VQA metrics. The IQA metrics to be compared are MSE/PSNR, SSIM, and MSSIM. VQA metrics involved include MOVIE [23] in addition to recently proposed VQA metrics. They are ViS3 [35], STRRED [29], VQM-VFD [21] and C-B method [5]. The RR VQA method is included as it can be applied in FR manner. Moreover, it involves time-differential information which is similar to second-order time-differential information used in EaTSS. The previously proposed metric, MD-SSIM [17], is also being compared to show improvements of EaTSS. It is implemented to videos of all distortions types. All VQA metrics are applied in their default implementations. For VQM-VFD, only results for the LIVE video database are computed. This is because the platform for testing is of insufficient memory while computing results from the CSIQ database. Since C-B method coding is not publicly available, its results for the LIVE video database are directly quoted from [5]. Therefore, VQM-VFD and C-B method are not being compared in the CSIQ database. Spatial and temporal quality scores of EaTSS are also compared in both databases. This is to show relative contributions of spatial and temporal parts of EaTSS to EaTSS. Spatial and temporal parts of EaTSS are denoted as EaTSS (Spatial) and EaTSS (Temporal) respectively.
4.3 Performance evaluation
Tables 3, 4, 5, 6 and 7 show SC and PC of all metrics for the LIVE and CSIQ video databases. Figure 3 shows scatter plots of EaTSS against human-rated subjective scores for the LIVE and CSIQ video database.

Scatter plots: a EaTSS scores against subjective scores for the LIVE video database and b EaTSS scores against subjective scores for the CSIQ video database
The best two VQA metrics for each distortion are highlighted in Tables 3, 4, 5, 6 and 7. The values that are in italic form are the best performing metrics for the comparison of EaTSS to IQA metrics only. In terms of SC in the LIVE video database, EaTSS has better performance than all IQA metrics (MSE/PSNR, SSIM, and MSSIM) as shown in Table 3. Compare with existing VQA metrics (MOVIE, ViS3, MD-SSIM, ST-MAD, STRRED, VQM-VFD, and C-B method), EaTSS achieves the best results for IP distorted videos. For MPEG-2 distorted videos, EaTSS has a very close performance to the best performing metric, i.e. MOVIE. EaTSS performs better than VQM-VFD and MD-SSIM for wireless distorted videos. Yet, it falls behinds MOVIE and ViS3. Meanwhile, it achieves the third best results in H.264 compressed videos. Overall, in terms of SC, EaTSS and MOVIE are the best performing metrics. They both attain the best two results in half of the total distortion types. While comparing spatial and temporal parts of EaTSS, it is obvious that EaTSS outperforms the implementation of solely spatial or temporal part. The improvement is particularly significant for MPEG-2 compressed videos. Both spatial and temporal parts of EaTSS perform poorly, but EaTSS attain the second best result. The possible reason is that EaTSS (Spatial) and EaTSS (Temporal) consider complementary aspects of the distortions. Thus, their combination is more effective.
Table 4 tabulates PC for all distortions in the LIVE video database. Similar to SC, EaTSS outperforms all IQA metrics. Compared to existing VQA metrics, EaTSS is still among the best two for IP and MEPG-2 distortions. However, there are some differences in relation to results of SC. EaTSS has better performance than MOVIE for MPEG-2 distorted videos. MOVIE’s performance is rather insignificant vis-à-vis SC. On the contrary, C-B method performs better. Similar to EaTSS, it has good correlations in two types of distortions. Again in terms of PC, EaTSS has the competitive performance. For spatial and temporal parts of EaTSS, the overall results are similar to SC. The improvement of EaTSS for IP and MPEG-2 distorted videos are more significant. In terms of the LIVE video database, EaTSS performs the best. It is amongst the best two methods for both SC and PC. Comparing to MOVIE and C-B Method, they attain good results for either SC or PC only. This shows that EaTSS is more consistent and correlates better to HVS.
EaTSS also demonstrates good performances in the CSIQ database. We reclaim that VQM-VFD and C-B method are excluded in this comparison. This is due to the incompetence of hardware and unavailability of codes as well as results. The results in terms of SC and PC are shown in Tables 5 and 6 respectively. EaTSS outperforms all IQA metrics for all distortions except for H.264 compressed videos. Similar condition holds for other VQA metrics. MSSIM has the best SC and PC for H.264/AVC. This attributes to the variable block-size motion compensation (multiscale operation) for segmenting movement regions [9] in H.264/AVC. MSSIM also performs the best for MJPEG compressed videos. The underlying rationale is that MJPEG only involves intra-frame compressions [32]. Thus, IQA metrics perform better than VQA metrics for MJPEG compressed videos. When only the spatial part of EaTSS is tested, it achieves 0.9367 and 0.9417 for SC and PC respectively. The results are significantly better than MSSIM and other IQA metrics. This proves that metrics without temporal consideration can perform better in MJPEG compressed videos. MSSIM also achieves the best PC for wavelet compressed videos. Since HEVC utilizes multiscale transform units in the inverse transform [31], MSSIM can perform better in HEVC compressed videos.
For VQA metrics excluding spatial and temporal parts of EaTSS, EaTSS achieves top two performances in three out of six distortion categories for both SC and PC. In overall, EaTSS only achieve lower correlations for two distortion types, i.e. H.264/AVC and wavelet. Yet, EaTSS still perform as good as MOVIE for these two distortions. Apparently, EaTSS (Spatial) performs better than the EaTSS (Temporal) and the EaTSS. The probable cause of this condition is the imbalance of spatial and temporal distortions in videos of the CSIQ database. This is evidenced by results that in most distortion types, IQA metrics perform better than VQA metrics. This intimates that spatial distortions are dominant for most videos. Therefore, EaTSS (Spatial) performs better. To conclude, EaTSS has the best performance in the CSIQ database. It has the most top two rankings among all VQA metrics for all distortion types. Similar to the LIVE video database, the performance of EaTSS is more consistent than existing methods in the CSIQ video database. EaTSS achieves the best two results for the same distortion types for SC and PC. This is not the case for existing methods. Most of them perform well in either case only. The best performing existing method is STRRED which attains good results for two same distortion types for PC and SC.
Compare to existing VQA metrics, EaTSS has good performance for each distortion. The overall performances of all VQA metrics for each and all databases are tabulated in Table 7. For the LIVE video database with four distortion categories, ViS3 exceeds EaTSS in terms of PC. At the same time, they have similar performances in terms of SC. Conversely, EaTSS defeats C-B method in SC but performs slightly poorer than C-B method in PC. ViS3, C-B method, and EaTSS has very close PC. For EaTSS (Spatial) and EaTSS (Temporal), both perform equally with MD-SSIM. Yet, their combination gives a competitive result. Thus, spatial and temporal parts of EaTSS capture spatial and temporal distortions complementarily in the LIVE video database.
For CSIQ video database with six distortion types, EaTSS has the best performance in terms of PC. For SC, its result is only 0.01 lower than ViS3. Consequently, EaTSS has similar performance to ViS3 in the CSIQ database. The good performances of EaTSS in the CSIQ database are mainly due to the spatial part of EaTSS. This is evident as EaTSS (Spatial) performs much better than EaTSS (Temporal). However, there are still improvements when combing the two parts, although it is minor.
In Table 7, the weighted average of SC and PC, as in [39, 45], over the two databases are also shown. The weight for each database is computed according to the number of videos respectively. From the weighted average, EaTSS achieves the best performance for both SC and PC. This shows that EaTSS has better generalizations to distortion types and videos. ViS3 achieves the second best result. Although EaTSS perform as well as ViS3 with respect to each database, weighted average indicates that ViS3 has lower generalizations to different distortion types and videos. EaTSS (Spatial) also has better generalities than EaTSS (Spatial). Still, their combination performs much better than their sole implementations. From the results in Tables 3, 4, 5, 6 and 7, EaTSS is among the best performing metrics as compared with existing metrics independent to databases.
4.4 Statistical evaluation
Statistical significance of the correlations of all VQA methods is also verified. This is done by using F-test as demonstrated by the works in [24, 34]. The Gausiannity results through the kurtosis based criterion stated in Section 4.2 are shown in Tables 8 and 9 for the LIVE and CSIQ databases respectively. For each database, there is only one category that fails the kurtosis based criterion. Thus, F-test is appropriate to be tested on these two databases. The F-test results are shown in Tables 10 and 11. Three symbols are used to indicate the result. Symbols “-“, “1″, and “0″ indicates the statistical performance of VQA method placed in the row are indistinguishable, superior, and inferior to that of the method in the column respectively. In order to make the tables more compact, we use M1 to M8 to represent the VQA methods being compared. M1 to M8 indicates MOVIE, ViS3, MDSSIM, STRRED, VQM-VFD, EaTSS (Spatial), EaTSS (Temporal), and EaTSS respectively.
The first four symbols for every entry in Table 10 refers to the F-test of wireless, IP, H.264, and MPEG-2 distortions respectively. The fifth symbol is the results for all distortion types. For all videos in the LIVE video database, all VQA methods perform equally with an exception that ViS3 is statically superior to EaTSS (temporal). For wireless distorted videos, all VQA methods perform better than STRRED. Similar condition holds for MOVIE in IP and MPEG-2 distorted videos. For MPEG-2 compressed videos, VQM-VFD is statically superior to EaTSS (temporal). All of the VQA methods have identical performance for H.264 compressed videos.
For the CSIQ database, there are seven symbols for each entry. The first six symbols represent the distortions list in the first column of Table 2 sequentially. Meanwhile, the last symbol is the overall performance of all videos. To summarize the results, all VQA methods are superior to EaTSS (Temporal) for H.264/AVC, wavelet, and HEVC compressed videos. STRRED is superior to all methods except EaTSS (Spatial) for H.264/AVC compressed videos. For plr distortion, EaTSS (Spatial) outruns STRRED while the others perform equally. In terms of MJPEG compressed videos, EaTSS (Spatial) is superior to all methods except MOVIE. MOVIE further superiors to ViS3, STRRED, and EaTSS (Temporal). All methods surpass MOVIE and MDSSIM except EaTSS (Temporal) for white noise impaired videos. For HEVC compressed videos, EaTSS (Spatial) outperforms MOVIE, ViS3, and STRRED. In terms of all distortion types, ViS3, EaTSS (Spatial), and EATSS are superior to EaTSS (Temporal). EATSS further defeat MOVIE and MDSSIM. EaTSS (Spatial) is also superior to MDSSIM.
In terms of F-test, ViS3, MDSSIM, VQM-VFD, EaTSS (Spatial), and EaTSS are the best performing metrics for LIVE video database. On the other hand, EaTSS (Spatial) exceeds all VQA methods for CSIQ video database. This is followed by EaTSS. Thus, EaTSS is regarded as statically superior to other VQA methods excluding EaTSS (Spatial) and EaTSS (Temporal).
4.5 Computational complexity
Other than correlations, computational complexity of VQA metrics is also measured. The computational cost of each metric is measured in terms of the processing time. Table 12 shows the processing time for VQA metrics excluding C-B method. The test is done for a video (bs2_25fps.yuv) from the LIVE video database. The video is assessed by different VQA algorithms repeatedly for ten times, and the average processing time is calculated. MD-SSIM has the shortest processing time of 9.53 s. EaTSS only requires 17.79 s. The time is much less than the processing times of ViS3 and MOVIE which are 314.32 s and 2,923,261.93 s respectively. Thus, EaTSS has low processing time and a lower computational cost than existing VQA methods other than the previous work by the authors.
The complexity of EaTSS is also analyzed theoretically. The total number of additions or subtractions and multiplications or divisions of each step in EaTSS is shown in Table 13. Parameter n refers to the total number of pixels in a frame and m is the total number of pixels in the patches used for SSIM and SSIM_no_lc in (7) and (14) respectively. In total, there are 8nm + 46n + 1 additions and subtractions as well as 8nm + 39n + 3 multiplications and divisions. So, EaTSS is a O(nm) operation. If it is expressed in terms of frame height, M, frame width, N, and patch size, p × p, then EaTSS is a O(MNp2) operation. This shows that EaTSS has low computational complexity and high efficiency.
Other than computational time and theoretical analysis, the complexity of VQA methods is also compared in terms of efficiency. We follow procedures in [34] for this test. Computational Level (CL) is first computed for each method. CL is defined as the ratio of the computational time of VQA methods to the computational time of PSNR. Then, the graph of CL and PC are plotted. The results of CL and PC of every VQA methods are shown in Table 14. The graph of CL versus PC is illustrated in Fig. 4. For VQA methods with good efficiency, their points should be located as near as possible to the lower right of the plot. Meanwhile, the points of methods with poor efficiencies are located near to the upper left of the plot. From the figure, EaTSS and ViS3 have very similar efficiency. Since the y-axis is in log scale, EaTSS has better efficiency as compared to ViS3. MOVIE, on the other hand, has the worst efficiency due to the long computational time. In overall, EaTSS has the best efficiency among all VQA methods being tested.

CL versus PC plot
5 Conclusion
A VQA method, EaTSS, is proposed in this paper based on error signals, locally weighted SSIM, and second-order time-differential information. The experiment results show that it performs very well in both benchmark databases. For the LIVE video database, it has similar performance to ViS3 and the C-B method. It outperforms most of the recently proposed VQA metrics, i.e. STRRED, VQM-VFD, and MOVIE. EaTSS also has very good performance in the CSIQ video database where it achieves competitive performance with ViS3. In overall, EaTSS assess the distortions in these two databases well. Weighted PC and SC show that EaTSS has good generalization to videos suffered from different types of distortions that are database independent. Furthermore, EaTSS has low computational time and cost. Besides that, it has the highest efficiency compared with existing VQA metrics.
References
Akramullah S (2014) Digital video concepts, methods, and metrics. New York, USA
Banno H, Saiki J (2015) The use of higher-order statistics in rapid object categorization in natural scenes. J Vis 15(2):1–20. https://doi.org/10.1167/15.2.4
Bong DBL, Khoo BE (2015) Objective blur assessment based on contraction errors of local contrast maps. Multimed Tools Appl 74(17):7355–7378. https://doi.org/10.1007/s11042-014-1983-5
Cardoso JVM, Alencar MS, Regis CDM, Oliveira IP (2014) Temporal analysis and perceptual weighting for objective video quality measurement. IEEE southwest symposium on image analysis and interpretation (SSIAI). IEEE, 2014, pp 57–60. https://doi.org/10.1109/SSIAI.2014.6806028
Choi LK, Bovik AC (2016) Flicker sensitive motion tuned video quality assessment. 2016 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI). IEEE, 2016, pp 29–32. https://doi.org/10.1109/SSIAI.2016.7459167
Hall CF, Hall EL (1977) A nonlinear model for the spatial characteristics of the human visual system. IEEE Trans Syst Man Cybern 7(3):274–283. https://doi.org/10.1109/TSMC.1977.4309680
Ítalio PO, José VMC, Carlos DMR, Marcelo SA (2013) Spatial and temporal analysis considering relevant regions applied to video quality assessment. XXXI Brazilian Telecommunications Symposium (SBrT), 2013, pp 1–5
ITU-T (1999) ITU-T recommendation P. 910: subjective video quality assessment methods for multimedia applications. ITU-T
ITU-T (2016) ITU-T recommendation H.264: advanced video coding for generic audiovisual services. ITU-T
Larson EC, Chandler DM (2010) Most apparent distortion: full-reference image quality assessment and the role of strategy. J Electron Imaging 19(1):011006–011006. https://doi.org/10.1117/1.3267105
Lee S, Pattichis MS, Bovik AC (2002) Foveated video quality assessment. IEEE Trans Multimedia 4(1):129–132. https://doi.org/10.1109/6046.985561
Li C, Bovik AC (2009) Three-component weighted structural similarity index. Proceding SPIE 7242, image quality and system performance VI, 72420Q. SPIE, 2009, pp 1–9
Li P, Xie J, Wang Q, Zuo W (2017) Is second-order information helpful for large-scale visual recognition?. IEEE international conference on computer vision (ICCV). IEEE, 2017, pp 2070–2078
Limb JO (1979) Distortion criteria of the human viewer. IEEE Trans Syst Man Cybern 9(12):778–793. https://doi.org/10.1109/TSMC.1979.4310129
Liu Y, Nie L, Han L, Zhang L, Rosenblum DS (2015) Action2Activity: recognizing complex activities from sensor data. Proceedings of the 24th international conference on artificial intelligence. IJCAI, 2015, pp 1617–1623
Liu L, Cheng L, Liu Y, Jia Y, Rosenblum DS (2016) Recognizing complex activities by a probabilistic interval-based model. Proceedings of the thirtieth AAAI conference on artificial intelligence. AAAI, 2016, pp 1266–1272
Loh WT, Bong DBL (2015) Video quality assessment method: MD-SSIM. IEEE international conference on consumer electronics - Taiwan (ICCE-TW). IEEE, 2015, pp 290–291. https://doi.org/10.1109/ICCE-TW.2015.7216904
Ooyala (2016) Ooyala global video index q3 2015. Ooyala. http://go.ooyala.com/rs/OOYALA/images/Ooyala-Global-Video-Index-Q3-2015.pdf. Accessed 14 Apr 2016
Peng P, Cannons K, Li ZN (2013) Efficient video quality assessment based on spacetime texture representation. In: Proceedings of the 21st ACM international conference on multimedia. ACM, 2013, pp 641–644. https://doi.org/10.1145/2502081.2502168
Pinson MH, Wolf S (2004) A new standardized method for objectively measuring video quality. IEEE Trans Broadcast 50(3):312–322. https://doi.org/10.1109/TBC.2004.834028
Pinson MH, Choi LK, Bovik AC (2014) Temporal video quality model accounting for variable frame delay distortions. IEEE Trans Broadcast 60(4):637–649. https://doi.org/10.1109/TBC.2014.2365260
Rimac-Drlje S, Vranješ M, Žagar D (2010) Foveated mean squared error - a novel video quality metric. Multimed Tools Appl 49(3):425–445. https://doi.org/10.1007/s11042-009-0442-1
Seshadrinathan K, Bovik AC (2010) Motion tuned spatio-temporal quality assessment of natural videos. IEEE Trans Image Process 19(2):335–350. https://doi.org/10.1109/TIP.2009.2034992
Seshadrinathan K, Soundararajan R, Bovik AC, Cormack LK (2010) Study of subjective and objective quality assessment of video. IEEE Trans Image Process 19(6):1427–1441. https://doi.org/10.1109/TIP.2010.2042111
Seshadrinathan K, Soundararajan R, Bovik AC, Cormack LK (2010) A subjective study to evaluate video quality assessment algorithms. IS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, 2010, pp 75270H-75270H-10. https://doi.org/10.1117/12.845382
Sheikh HR, Bovik AC (2005) A visual information fidelity approach to video quality assessment. First international workshop on video processing and quality metrics for consumer electronics. Springer, 2005, pp 23–25
Sheikh HR, Bovik AC, de Veciana G (2005) An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans Image Process 14(12):2117–2128. https://doi.org/10.1109/TIP.2005.859389
Sheikh HR, Sabir MF, Bovik AC (2006) A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans Image Process 15(11):3440–3451. https://doi.org/10.1109/TIP.2006.881959
Soundararajan R, Bovik AC (2013) Video quality assessment by reduced reference Spatio-temporal entropic differencing. IEEE Trans Circuits Syst Video Technol 23(4):684–694. https://doi.org/10.1109/TCSVT.2012.2214933
Suchow JW, Alvarez GA (2011) Motion silences awareness of visual change. Curr Biol 21(2):140–143. https://doi.org/10.1016/j.cub.2010.12.019
Sullivan GJ, Ohm JR, Han WJ, Wiegand T (2012) Overview of the high efficiency video coding (HEVC) standard. IEEE Trans Circuits Syst Video Technol 22(12):1649–1668. https://doi.org/10.1109/TCSVT.2012.2221191
Vo DT, Nguyen TQ (2008) Quality enhancement for motion JPEG using temporal redundancies. IEEE Trans Circuits Syst Video Technol 18(5):609–619. https://doi.org/10.1109/TCSVT.2008.918807
VQEG (2003) Final report from the video quality experts group on the validation of objective models of video quality assessment. VQEG
Vranješ M, Rimac-Drlje S, Grgić K (2013) Review of objective video quality metrics and performance comparison using different databases. Signal Process Image Commun 28(1):1–19. https://doi.org/10.1016/j.image.2012.10.003
Vu PV, Chandler DM (2014) ViS3: an algorithm for video quality assessment via analysis of spatial and spatiotemporal slices. J Electron Imaging 23(1):013016–013016. https://doi.org/10.1117/1.JEI.23.1.013016
Vu C, Deshpande S (2012) ViMSSIM: from image to video quality assessment. Proc of the 4th workshop on mobile video. ACM, 2012, pp 1–6. https://doi.org/10.1145/2151677.2151679
Wandell BA (1995) Foundations of vision. Sinauer Associates, Sunderland
Wang Z, Bovik AC (2009) Mean squared error: love it or leave it? A new look at signal fidelity measures. IEEE Signal Process Mag 26(1):98–117. https://doi.org/10.1109/MSP.2008.930649
Wang Z, Li Q (2011) Information content weighting for perceptual image quality assessment. IEEE Trans Image Process 20(5):1185–1198. https://doi.org/10.1109/TIP.2010.2092435
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 3(4):600–612. https://doi.org/10.1109/TIP.2003.819861
Wang Z, Lu L, Bovik AC (2004) Video quality assessment based on structural distortion measurement. Signal Process Image Commun 19(2):121–132. https://doi.org/10.1016/S0923-5965(03)00076-6
Wang Z, Simoncelli EP, Bovik AC (2003) Multiscale structural similarity for image quality assessment. Conference record of the thirty-seventh Asilomar Conf on signals, systems and computers. IEEE, 2003, pp 1398–1402. https://doi.org/10.1109/ACSSC.2003.1292216
Watson AB, Hu J, McGowan JF (2001) Digital video quality metric based on human vision. J Electron Imaging 10(1):20–29. https://doi.org/10.1117/1.1329896
Wolf S, Pinson M (1998) In-service performance metrics for MPEG-2 video systems. Proc made to measure 98-measurement techniques of the digital age technical seminar. IAB, 1998, pp 12–13
Xue W, Mou X, Zhang L, Bovik AC, Feng X (2014) Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans Image Process 23(11):4850–4862
Acknowledgments
This work was supported by Ministry of Higher Education Malaysia through the provision of research grant: F02/FRGS/1492/2016.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Loh, WT., Bong, D.B.L. An error-based video quality assessment method with temporal information. Multimed Tools Appl 77, 30791–30814 (2018). https://doi.org/10.1007/s11042-018-6107-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6107-1