
Abstract
Marketing and promotions of various consumer products through advertisement campaign is a well known practice to increase the sales and awareness amongst the consumers. This essentially leads to increase in profit to a manufacturing unit. Re-production of products usually depends on the various facts including consumption in the market, reviewer’s comments, ratings, etc. However, knowing consumer preference for decision making and behavior prediction for effective utilization of a product using unconscious processes is called “Neuromarketing”. This field is emerging fast due to its inherent potential. Therefore, research work in this direction is highly demanded, yet not reached a satisfactory level. In this paper, we propose a predictive modeling framework to understand consumer choice towards E-commerce products in terms of “likes” and “dislikes” by analyzing EEG signals. The EEG signals of volunteers with varying age and gender were recorded while they browsed through various consumer products. The experiments were performed on the dataset comprised of various consumer products. The accuracy of choice prediction was recorded using a user-independent testing approach with the help of Hidden Markov Model (HMM) classifier. We have observed that the prediction results are promising and the framework can be used for better business model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Consumer commodity sector spends huge amount of money on advertising the usability or success of the products. This is necessary during pretesting of various alternative advertisement campaigns before launching and also during the in-market analysis of the campaign after launching.
A number of conventional methods exist to pretest advertisements. These methods include self-reported methods such as liking, recall or purchase intent, neuromarketing, etc. “Neuromarketing” phrase is the combination of two words “neuro” and “marketing”. This can be referred to as merging of two fields, namely “neuroscience” and “marketing”. Using neuroscience, it is possible to improve the marketing of the existing products. It provides an insight to improve the design of products before actual launch in the market [24]. Therefore, neuroscience reveals information about consumer preferences on products. This is not possible using traditional methods such as questionnaire, attitude or verbal communication. Thus, neuromarketing can help the product-companies to reduce expenditure on product advertisements.
Over the past few years, researchers have developed different neurophysiological methods for analyzing the consumer behavior and advertisement phenomenon to study different aspects of marketing [7, 20]. The growth has been recorded due to the technological advancement of instruments such as Functional magnetic resonance imaging (fMRI), Magnetoencephalography (MEG), and electroencephalography (EEG) often used in neuromarketing. fMRI is a neuroimaging technique used to measure the amount of deoxygenated hemoglobin during neuronal activity. It describes brain function with spatial and temporal resolutions of one millimeter and per second change, respectively [33]. The device has been used for grading user preferences on various applications.
Berns et al. [6] have used fMRI data to predict music popularity by measuring the brain activity of 27 adolescents. The authors have shown that the positive correlation of the participant’s brain responses with the sales after three years. However, the cost associated with such experiments can be very expensive and often turns out to be in the order of several millions of dollars [35]. Moreover, additional costs such as insurance, maintenance and portability issues limit the use of fMRI in such applications. MEG is used to capture the brain activity that is caused by neuron activity. Such neuron activity creates a magnetic field that is amplified and mapped by MEG with spatio-temporal information. However, due to higher cost, technical complexities and limited access of subcortical regions for imaging, it is not preferred as a device to develop systems of neuromarketing.
To overcome some of the limitations of the above mentioned problems, we have used an inexpensive setup to examine the brain activity using EEG signals that offers a high temporal resolution and is cheaper than fMRI and incurs fewer electrodes (only 14), easy handling, wireless connectivity and lower maintenance cost. Such parameters extend the use of the device from laboratory to general practice. Generally, people do not want to fully express their feelings and preferences towards products when asked explicitly. However, neuroimaging tools (i.e. EEG) and techniques are capable in accessing the customer brain’s information during the generation of a preference or the observation towards a product. Therefore, such brain imaging techniques helps marketing researchers in decision making for further promotions of the products. Boksem and Smidts [7] reported that the brain responses captured using EEG signals while users were watching movie trailers can provide valuable inputs for predicting population-level preferences of movies. In addition to the brain imaging, other physiological aspects such as eye tracking, heart rate or respiration [21, 30] can also be measured to relate with the consumer’s experience. Motivated by the above research, we have developed an EEG enabled system that can easily replace costly setups of present day neuromarketing. Our main contributions are as follows:
-
1.
Firstly, we present a Neuromarketing framework for predicting consumer preferences while they view E-commerce products by analyzing EEG signals.
-
2.
Our second contribution is an experimental validation of the prediction using Hidden Markov Model (HMM) based sequential classifier. We also present a comparative analysis with other popular classifiers.
Rest of the paper is organized as follows. Section 2 provides an overview of the existing research. Next, we present preprocessing, feature extraction and classification methodology in Section 3. Results obtained using a custom-built dataset are presented in Section 4. In Section 5, we present the conclusion of the paper with possible future extensions.
2 Related work
In this section, we review the recent works that linked EEG signals activity in predicting the consumers behavior and emotions based on the self reported ratings. Initially, Ambler et al. [1] have exploited the relationship between the brain imaging and the consumer decision while watching a virtual video of supermarket visit. The subjects were asked to choose one of the three brands after 90 stops. The authors found improvement in predicting the product brand choice. The authors have recorded strong correlations between the brain activation in right parietal cortex with the subjects familiarity with the brand. In [19], the authors explored the brain activity of 18 subjects while making the internal decision of likes and dislikes for a set of products. Eye tracker was used to capture the user’s choice from a set of three images displayed on the computer’s screen and simultaneously the EEG signals were recorded. The authors have used Principal Component Analysis (PCA) and Fast Fourier Transformation (FFT) to analyze the changes in the main frequency bands. A significant change in the spectral activity with theta bands were recorded in the frontal, parietal and occipital areas while the participants were indicating their preference by computing mutual information between the users preference and different EEG bands. In [35], the authors predicted the choices of 10 consumer products using EEG signals recorded while the participants viewed the products on computer screen. In their second experiment, pair of the same products were shown to participants and EEG signals were recorded. They have found an increase in N200 component in the mid-frontal electrode and a correlation has also been reported between the theta band power and the preferred products.
Baldo et al. [5] have proposed a pre-market forecasting system for products using brain data. The authors have recorded EEG data of 40 participants while viewing the different shoes on the computer screen. The participants were asked either to buy the shoes or not after every presentation and also a questionnaire was given to fill with rating scale 1 to 5. The authors have shown that classification of products using EEG signals were better than the rating based classification which were reported as 80% and 60%, respectively, when 30 pairs of shoes were classified into two classes. A recommendation system for E-commerce products was proposed in [10] by combining the pre-purchase and post-purchase ratings. The EEG signals were recorded while the participants viewing virtual 3D products. The pre-purchase ratings were computed automatically using the emotional states of participants using alpha and beta bands. The authors have used adapted collaborative filtering to implement the recommendation system.
Murugappan et al. [25] have proposed an FFT based neuromarketing system for predicting the most preferred automobile brand among four categories. The brain activity of 12 subjects have been recorded while watching the brand advertisement video. Butterworth band pass and Laplacian filter were used to preprocess the EEG signals and three statistical features i.e. power spectral density (PSD), spectral energy (SE) and spectral centroid (SC) have been extracted from alpha band spectrum. The subject intention for a brand was computed using k-Nearest-Neighbor (k-NN) and Probabilistic Neural Network (PNN) classifiers where an accuracy of 96.62% was recorded using PSD feature with PNN classifier. In [7], the authors proposed a consumer choice preference modeling framework for movie trailers using EEG signals. The authors have found that high frequencies i.e. beta and gamma were significant correlated to individual preferences and population preference. Soleymani et al. [30] have proposed an approach for affective ranking of movie scenes, which is based on both user’s emotion and video content-based features. User emotions were inferred using five peripheral physiological signals and self-assessments. The authors found that the movie scenes were correlated with the user’s self-assessed arousal and valence. Moreover, the study also suggests that peripheral physiological signals can also be used to characterize and rank video contents. In [18], the authors presented the effects of color preferences on the neural mechanisms by analyzing the changes in EEG oscillations while showing two colors on the computer screen for 1 second duration to 19 users. They have found an increment in the theta amplitudes when the preferred color was presented or selected by a user. In [20], the authors have shown different choice sets to 18 users to investigate the different brain activities during decision making using EEG signals and eye tracker device. The eye tracker was used to record the frequencies of choices. In order to discover the most relevant brain regions associated with the choice task, mutual dependence between the extracted sensor features and the corresponding class label of preference was performed. They have reported high synchronization between symmetric frontal and occipital brain regions with high values for theta, alpha and beta band waves.
In [34], the authors have proposed a learning assessment methodology using EEG signals by finding a correlation between the brain waves and the learnability of a software. They have considered that the software is learnable for subjects with dominant alpha waves. Holzinger et al. [14], have developed a stroke rehabilitation system using EEG signals. The electro-cortical activity was recorded from 120 channels and applied Independent Component Analysis (ICA) for separating multivariate signals into additive subcomponents. The authors have found patterns over the sensorimotor area that have been involved in the execution and association of movements. In [15], the authors have applied Approximate Entropy (ApEn) on electrocardiogram (ECG) data from 26 participants for evaluating the human concentration. In order to acquire useful information from ECG time series, the ApEn window was kept small for intra-subject information in comparison to inter-subject. For this, the authors have proposed the term truthfulness as a complement to the statistical validity of the ApEn windows and for the stability of ApEn distribution.
The Savitzky-Golay (S-Golay) filter is widely used for signal smoothing in various fields like elastography, EEG and magnetocardiogram. In [11], the authors have investigated the use of S-Golay filter in ECG signal processing. The best choice was found to use the quadratic smoothing and differentiation filter with 17 point length for 500 Hz sampling rate ECG signal processing. A two class motor imaginary-based BCI was proposed in [9] using EEG signals. The authors have proposed Recurrent Quantum Neural Network (RQNN) architecture to filter the EEG signals using quantum mechanics and Schrodinger wave equation. In [27], the authors have proposed a real time removal of eye blink artifacts from EEG signals using S-Golay filter. They have found the correct estimation of the blink signal with high correlation to the original blink signal. Next, an adaptive noise cancellation system was adopted to remove the blink effect from the EEG signals. A summary of the related work has been shown in Table 1.
3 System setup
In our framework, the system was setup as follows. Emotiv EPOC+ device has been used for capturing the EEG signals which is a neuro-signal data acquisition, wireless device. A pictorial representation of EEG sensors layout over the scalp and the associated accessories is shown in Fig. 1. The device has 14 channels for EEG data that are located at AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8, AF4 positions as per the International 10 - 20 system as shown in Fig. 1a [20]. The electrodes that are located above the ears i.e. CMS and DRL are called reference electrodes. Internally an EPOC is sampled at a frequency of 2048 Hz that is down-sampled to 128 Hz sampling frequency per channel. The data is sent to a computer using Bluetooth connectivity by utilizing a USB dongle. Before use, felt-pads that lie on top of sensors must be moistened using a saline solution. The device battery is recharged using a USB charger. The sensor along with the USB bluetooth dongle, sensor felt-pads, saline solution and charger cable are shown in Fig. 1b.

EEG brain sensor details (a) Sensor layout on the skull (b) Emotiv EPOC+ sensor along with the associated accessories
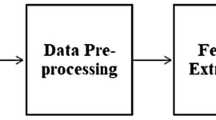
EEG sensor was mounted onto the head of participants and asked to view shopping items as shown in Fig. 2, where a user was viewing an item in computer screen. A flow diagram of the proposed approach can be seen in Fig. 3. At first during enrollment phase, EEG signals were captured simultaneously when the user was viewing an item. After viewing, the user was asked for his preference of the product in terms of two classes i.e. like or dislike. Then, the signal goes through certain signal preprocessing and feature extraction steps. For feature extraction Discrete Wavelet Transform (DWT) based features have been extracted. Next, classification models are built according to the ground truth made by user’s choice. In the testing phase, a recorded test sample is preprocessed and decomposed into frequency bands for feature extraction and tested against the trained model. The results were carried out in two classes namely, like and dislike, corresponding to a particular viewing item. The detailed description of preprocessing, wavelet decomposition and feature extraction are discussed in Section 3.1.

System setup where a user watching consumer products during experiment

Flow diagram of the proposed EEG based consumer’s choice prediction model
3.1 Preprocessing and feature extraction
In this section, we present the details of the signal smoothing technique that is used to preprocess the signal for feature extraction. Next, Discrete Wavelet Transform (DWT) based wavelet analysis has been performed to extract valuable features from the recorded signals.
3.1.1 Savitzky-Golay (S-Golay) filter
S-Golay filter has been used successfully by researchers in signal smoothing [4, 11, 17, 27]. It is a least square or polynomial based filter that smooths the noisy signal by fitting consecutive subsets of neighboring signal points using low degree polynomial and linear least squares. From a signal S j = f(t j ), (j = 1, 2 , ... , n) having length n, S-Golay filter can be computed using (1).
where, m represents the frame span, c i denotes the number of convolution coefficients and Q is smoothed signal. The frame span m is used to compute the values of c i with a polynomial. In this work, the filter has been applied to smooth EEG signals using a frame span of size 5 with a quadratic polynomial. The computed values for c i are -3, 12, 17, 12, and -3. The signal smoothing process is shown in Fig. 4, where Fig. 4a shows a raw EEG signal of a participant and Fig. 4b shows the corresponding smooth signal after applying the filter.

Example of signal preprocessing. a Raw EEG signal (b) Smoothed signal
3.1.2 Discrete wavelet transform (DWT) based features
DWT is widely used in biomedical signal processing [2] because it represents a signal in time-frequency domain. The basic idea in DWT is to convert an input signal into a series of small waves using multistage decomposition. The wavelet transformation based analysis of a signal can be performed at different frequency bands by decomposing it into approximation (A) and detail (D) coefficients. A schematic decomposition of an EEG signal is shown in Fig. 5, where the signal first passes through two digital filters i.e. Low pass filter (L) and High pass filter (H). Low-pass filter (L) removes high-frequency fluctuations from the signal and preserves slow trends. The outputs of low-pass filters provide an approximation (A) of the signal. High-pass filter (H) removes the slow trends from the signal and preserves high-frequency fluctuations. The output of the high-pass filter provides the detail (D) information about the signal that is also called wavelet coefficients. In order to get the detail coefficients at next level the approximation coefficients must be passed again to L and H filters as shown in Fig. 5 and so on. A wavelet function is defined using (2 and 3).
where a and b are the scaling and translation parameters, respectively. These parameters are having discrete values. The variables m and n are the frequency and time location that belong to Z. By choosing a 0 = 2 and b 0 = 1 provide a basis of multi-resolution analysis which decomposes a signal into approximation and details coefficients [2]. The computation of the approximation and detail coefficients are performed by using scaling and wavelet function as represented in (4) and (5), respectively.
where ϕ j, k (n) and ω j, k (n) are the scaling and wavelet functions that belongs to L and H, respectively. The variable n ∈ [0, 1, 2, ... , M − 1], M is the length of the signal, k and j takes the value from 0 to J − 1, where J = l o g 2(M). The values of A1 and D1 are obtained when the signal passed through L and H, respectively. Similarly, the values of A i and D i at the i th level are computed using (6) and (7), respectively.

Different levels of Wavelet decomposition using DB4 plotted for a single channel ‘AF4’
In this work, we have used four level of EEG signal decomposition by using the Daubechies 4 (DB4) wavelet decomposition technique as shown in Fig. 5. The DB4 decomposition results into a group of five wavelet coefficients, where each group corresponds to a frequency band that represents brain electrical activity i.e. D1, D2, D3, D4 and A4. These groups correlate with the EEG spectrum having four different frequency bands which consist of delta (1-4 Hz), theta (4-8 Hz), alpha (8-13 Hz), beta (13-22 Hz) and Gamma (32-100 Hz). A number of work have exploited the theta band power during a preference judgment tasks [18–20]. Vecchiato et al. [36] analyzed the cortical activity in the left hemisphere using theta band during the observation of TV commercials. A graphical representation of the five band waves is shown in Fig. 6b–f correspond to a smoothed EEG signal shown in Fig. 6a. The computation has been done for all 14 channels of the EEG signals that result into a 14 dimensional feature vector corresponding to each band i.e. gamma, beta, alpha, theta and delta which are denoted by F g , F b , F a , F t and F d , respectively.

Feature extraction in the form of different waves for a smoothed signal. a Smoothed signal (b) Gamma band oscillations (c) Beta band oscillations (d) Alpha band oscillations (e) Theta band oscillations (f) Delta band oscillations
3.2 HMM based consumer choice classification
Hidden Markov Model (HMM) is widely used to model the time-series data [22]. The model is successfully used by researchers in building Brain-Computer-Interface (BCI) applications using EEG signals including mental task classification [31], eye movement tracking [16] and medical applications [37]. HMM is described as λ = (π c , A c , B c ) [26], where
-
π c is the initial distribution for class c. c = 1, 2, .... , C, \({\sum }_{c=1}^{C}\lambda _{c}=1\) ,
-
A c is a S × S state transition probability, and
-
B c is the output probability matrix for the class c. The matrix contains the probability information from a state and observing a symbol belongs to observation sequence O b.
-
For each λ c , the posterior P(λ i |O b) can be estimated for observation O b likely to be assigned to one of the class C.
-
The most probable class C ∗ can be estimated as given in (8) [23].
such that,
where, P(O b) is the evidence that is calculated using (10).
The HMM models are trained separately for each feature vector i.e. using F g , F b , F a , F t and F d . Re-estimation of the initial output probabilities is done using Baum-Welch algorithm whereas the prediction of the users choice is performed using Viterbi decoding algorithm by finding the best likelihood for a given sequence.
4 Results
In this section, we present the results of the choice prediction that have been computed over the dataset collected to test the proposed framework. The results were computed in a user-independent based training approach by HMM. By user-independent, it means that predicting a user’s choice does not require his/her training data. The prediction results were carried out using leave-one-out cross validation approach. Next, a comparative analysis is performed with SVM classifier and other state of the art techniques.
4.1 Dataset description
The EEG signals using all 14 channels have been recorded from 25 participants while viewing consumer products on computer screen. All the participants are of age between 18 to 38 years who belong to Indian Institute of Technology, Roorkee, India. A collection of 14 different products have been chosen where each product has three different varieties which create 42 (14 × 3) different product images. Thus, a total of 1050 (i.e. 42 × 25) EEG signals have been recorded for all participants. The feedback response in form of like/dislike was collected from the subjects for each image in the collection. Each image was displayed for 4 seconds and EEG signals were recorded in parallel. After showing each image the choice preference of the user was recorded. During our data collection, we have instructed the users to provide their correct choices towards products. A description of the dataset along with the product name and image with their varieties are shown in Table 2. The dataset is made publicFootnote 1 for the prospective research community.
Figure 7 shows the variation in the EEG signals of three different participants for the same product as per their choices for the product. Figure 7a and b indicate the details of the products when viewed by same set of users. The first column of the figure shows the brain activity signal, column 2 shows the product image, column 3 shows the brain activity map plotted for theta band and column 4 shows the choice preference of the the participants after viewing the product. The brain activity map shows the activity in the frontal part of the brain as represented by the heat-map in figure. Similarly, the variation in the EEG signals of the same user for different products is depicted in Fig. 8.

EEG signal examples of three different users when they viewed the same product. a and (b) indicate details of two different products when viewed by same set of users. Column-wise details are as follows. (i) EEG signal response against channel ‘AF4’ (ii) Product viewed by three different users (iii) Brain activity map while watching the products (iv) The choice preference for the product

EEG signal examples for the same user (column-wise): (a) EEG signal responses against channel ‘AF4’ (b) Product type (c) Brain activity map (d) Preferred choice
4.2 Consumer choice classification
Here, we present the choice preference results using the sequential HMM classifier. The model is built by learning from the EEG samples of (N − 1) subjects and then testing the trained model using N th subject brain samples. The said policy has been applied for all the subjects in the experiments. Finally, the average performance is reported in terms of accuracy. The performance of the framework has been carried out by varying number of HMM states i.e. S t ∈ {3, 4, 5, 6, 7} and varying the number of Gaussian mixture components per state i.e. 1 to 128 with an incremental step of power of 2. The model has been trained separately for bands F g , F b , F a , F t and F d . The results are shown in Figs. 9 and 10 by varying GMM components and HMM states, respectively. A highest prediction rate of 70.33% has been recorded at 8 Gaussian mixtures components and 3 HMM states with theta band features (F t ) in comparison to other feature bands based prediction results. In this work, due to the two class problem of users choice, best accuracies are recorded with lower number of GMMs and HMMs states.

HMM based user choice classification by varying number of Gaussian mixtures

User choice classification by varying number of HMM states
In addition to this, the prediction results are also computed for each product types as shown in Fig. 11. It can be observed from the figure that the highest prediction is achieved as 95.33% for the product category ‘Shoe’ whereas lower prediction rate of 52% has been recorded for the products ‘School Bag’, ‘Belt’, ‘Sun Glass’ and ‘Sweater’. The prediction of choice preferences has also been computed individually for all 25 participants. See Fig. 12, where the maximum and minimum prediction rate of 83.09% and 60.08% are recorded for users ‘ s3’ and ‘ s2’, respectively.

An average prediction performance for each product from the dataset

User-wise prediction of preferences for all products in the dataset
Experiments are also conducted to find the dominating EEG channels corresponding to different brain lobes for consumer choice prediction. The performance has been measured according to 4 different brain lobes namely, Frontal (AF3,AF4,F3,F4,F7,F8), Parietal (P7,P8), Occipital (O1,O2) and Temporal (T7,T8). The accuracies of the different brain lobes are shown in Fig. 13. The maximum accuracy has been recorded by considering all 14-channels. In this study all experiments are performed on Core i3 CPU with 4 GB RAM on Microsoft Windows 7 operating system. It has been noted that it takes approximately 0.2 second duration to run a test sample.

User-wise prediction of preferences for different brain lobes
4.3 Error analysis
In this section, we present the product-wise prediction performance in Fig. 11. We have identified four products i.e. ‘School Bag’, ‘Belt’, ‘Sun Glass’ and ‘Sweater’ whose prediction accuracies are below the average prediction of all products. It might be due to the color combination, design and texture features of the product that did not attract the participants. Hence they created confusion while prediction. Moreover, choice preference also depends on the mental and emotional state of the participants while watching the products. This may create confusion during prediction process. Also, it has been noted that sometimes the participants started watching at different locations and got involved in other activities that also caused distortions in EEG signals and resulted into wrong predictions.
4.4 Comparative analysis
In addition, we have also evaluated the performance of the proposed framework using popular classifiers, such as, Support Vector Machine (SVM) [8], Random Forest (RF) [13] and Artificial Neural Network (ANN) [12].
SVM is a kernel based classifier proposed by [8] that can perform both linear and non-linear classification. Its main function is to map the data into feature space where a hyperplane separates the classes. The training data {x i , y i } for i = 1, ... , m and y i ∈ (−1, 1) must satisfy (11) and (12),
where w is the hyperplane parameter and b denotes the offset. SVM finds a decision boundary that maximizes the distance between two hyperplanes termed as margin. Thus, finding the decision boundary is an optimization problem to minimize ||w||2 which is solved by using Lagrange optimization framework. The general solution is represented by (13). In case of non-linear classification, the general solution is represented by (14), where k is the kernel function on behalf of which SVM provides both linear and non-linear classification functionality.
RF consists a number of trees that are grown randomly. The leaf node of each tree estimated with the posterior distribution over the like/dislike. The internal nodes of the tree contain a test that is used to split the space for the testing data. The binary test at each node is chosen either randomly or by using greedy algorithm that picks the test set to separate using information gain defined in (15)
where R is the training set of examples partitioned into two subsets R i as per the test and E(R) is the entropy computed using (16), where P j denotes the proportions of R belongs to class j. The process repeated for each internal node and stops after reaching a given depth.
If, T, C and L represent the set of trees, classes and the leaves, then estimation of the posterior probabilities (P t, l (Y(E) = c)) where c ∈ C, t ∈ T and l ∈ L. Y(E) represents the class label c for the training sample E. For testing, the test sample passed down until it reaches to the leaf node where all the posterior probabilities are averaged and the classification is done using argmax rule.
ANN classifier has been considered to be good for the classification of EEG signals by various researchers [3, 32]. The classifier has been associated with inherent properties like adaptive learning, robustness, self-organization, and generalization capability. In this work, we have implemented a feed-forward neural network with two hidden layers and one output layer. The network has been trained with error backpropagation algorithm. Sigmoid function has been considered as activation function for all units. Random small values have been used to initialized all weights followed by gradient-descent search in the network’s weight space for a minimum of a squared error function of the network’s output. The error is defined as the network’s output and the target value for each input vector.
Four statistical features, namely, Mean (M), Standard Deviation (SD), Energy (EN) and Root-Mean-Square (RMS) have been extracted using the feature vector (F t ) discussed in Section 3.1.2. The features have been computed using (17)–(20).
where x i is the i th sample of the data sequence and n denotes total number of data points.
where \(\overline {x}\) is the mean of the sample and n denotes the number of items in the sample.
where D is duration of signal, and x i is discrete samples of the signal at regular intervals (0 to n-1).
where x i is the i th item of the sequence and n is the number of items in the sequence. A new feature vector of 56 dimensions have been formed corresponding to all 14 channels. For SVM, Linear kernel has been employed to evaluate the performance by varying the regularization parameter (C). An accuracy of 62.85% has been recorded with SVM classifier with C =6. The RF classifier requires the estimation of two parameters for developing a prediction model i.e. number of classification (m) and the number of prediction variables (k) [28]. The experiment has been carried out by varying m from 1 to 100 and by keeping the value of k as constant to 7. An average accuracy of 68.41% has been recorded at m = 3. For ANN, the feed-forward network has been trained with two hidden layers and Sigmoid activation function. A comparison has been shown along with the standard deviation, average, maximum and minimum accuracies in Fig. 14, where the HMM based choice prediction model performs better than the other three. The performance has also been measured by slicing EEG signals into different time durations as shown in Fig. 15, where maximum accuracy has been recorded using the EEG signals of 4 seconds with HMM classifier.

Comparative performance analysis among four classifiers for consumer choice prediction modeling

User choice classification by varying EEG signal duration
4.5 Impact of age and gender on choice prediction
In order to show the effectiveness of the proposed framework on different genders and age groups, we have additionally collected the EEG signals of 15 female candidates along with 25 male while watching the products. Results have been computed on theta band features (F t ) with the help of HMM classifier. Gender-wise choice prediction performance is depicted in Fig. 16, where results of male candidates are better than female candidates by a margin of 4.77%. It could be due to dense hair of female subjects that cause additional noise in the incoming signals. The process also takes time to adjust the headset on female scalp.

Gender-wise user choice classification
Similarly, age-wise results have also been computed by dividing the dataset into three age categories. The details of the age categories is presented in Table 3. Choice prediction accuracies of all three categories are shown in Fig. 17, where highest results were recorded in age group ‘C’.

User choice classification in different age-groups
4.6 Scalability test
Scalability test has been performed to analyze the impact of number of users on the proposed consumer choice prediction framework. For this, we have tested the system performance by varying number of users (including both male and female) in training i.e. from 5 to 40 users. The prediction performance is depicted in Fig. 18, where the system performance becomes almost stable after 35 users.

User choice prediction performance by varying number of users in training
4.7 Comparison with existing techniques
We have compared our system by some existing user preference based state of the art research works as shown in Table 4. It can be seen from the table that the proposed method outperforms existing ones.
5 Conclusion
In this paper, we have applied neuroscience to predict the choice preference of a user for a product using EEG signals. The brain activity of 40 participants comprised of 25 male and 15 female have been recorded while viewing products. Next, the signals have been smoothed and classified using HMM classifier. The result shows the effectiveness of the proposed framework and provides a complementary solution to the traditional measures of predicting the product success in the market. The framework could be used in developing market strategies, research and predicting market success by extending the existing models. In our study we did not analyze fake answer towards product preference. Thus, approaches to deal with fake responses could be studied in future work. Moreover, a neutral choice for the products could also be employed to provide more preferences to the users. The tracking of user’s eye movement while watching products could be viewed as another parameter in predicting preferred choices. More robust features and classifier combination could be explored to improve the prediction results.
References
Ambler T, Braeutigam S, Stins J, Rose S, Swithenby S (2004) Salience and choice: neural correlates of shopping decisions. Psychol Market 21(4):247–261
Amin HU, Malik AS, Ahmad RF, Badruddin N, Kamel N, Hussain M, Chooi WT (2015) Feature extraction and classification for EEG signals using wavelet transform and machine learning techniques. Aust Phys Eng Sci Med 38(1):139–149
Anderson CW, Sijercic Z (1996) Classification of EEG signals from four subjects during five mental tasks. In: Solving engineering problems with neural networks: proceedings of the conference on engineering applications in neural networks (EANN’96), pp 407–414
Awal MA, Mostafa SS, Ahmad M (2011) Performance analysis of savitzky-golay smoothing filter using ECG signal. Int J Comput Inf Technol 1(02)
Baldo D, Parikh H, Piu Y, Müller KM (2015) Brain waves predict success of new fashion products: A practical application for the footwear retailing industry. J Creat Value 1(1):61–71
Berns G, Moore S E (2010) A neural predictor of cultural popularity. Available at SSRN 1742971
Boksem MA, Smidts A (2015) Brain responses to movie trailers predict individual preferences for movies and their population-wide commercial success. J Mark Res 52 (4):482–492
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Gandhi V, Prasad G, Coyle D, Behera L, McGinnity TM (2014) Quantum neural network-based EEG filtering for a brain–computer interface. IEEE Trans Neural Networks Learn Syst 25(2):278–288
Guo G, Elgendi M (2013) A new recommender system for 3d e-commerce: an EEG based approach. J Adv Manag Sci 1(1):61–65
Hargittai S (2005) Savitzky-golay least-squares polynomial filters in ECG signal processing. In: Computers in cardiology, pp 763–766
Hazarika N, Chen JZ, Tsoi AC, Sergejew A (1997) Classification of EEG signals using the wavelet transform. In: 13th International conference on digital signal processing proceedings, vol 1, pp 89–92
Ho TK (1995) Random decision forests. In: 3rd International conference on document analysis and recognition, pp 278–282
Holzinger A, Scherer R, Seeber M, Wagner J, Müller-Putz G (2012) Computational sensemaking on examples of knowledge discovery from neuroscience data: towards enhancing stroke rehabilitation. In: International conference on information technology in bio-and medical informatics, pp 166–168
Holzinger A, Stocker C, Bruschi M, Auinger A, Silva H, Gamboa H, Fred A (2012) On applying approximate entropy to ECG signals for knowledge discovery on the example of big sensor data. In: International conference on active media technology, pp 646–657
Hsieh CH, Chu HP, Huang YH (2014) An hmm-based eye movement detection system using EEG brain-computer interface. In: International symposium on circuits and systems, pp 662–665
Kaur B, Singh D, Roy PP A novel framework of eeg-based user identification by analyzing music-listening behavior. Multimed Tools Appl, pp 1–22
Kawasaki M, Yamaguchi Y (2012) Effects of subjective preference of colors on attention-related occipital theta oscillations. Neuroimage 59(1):808–814
Khushaba RN, Greenacre L, Kodagoda S, Louviere J, Burke S, Dissanayake G (2012) Choice modeling and the brain: a study on the electroencephalogram (EEG) of preferences. Expert Syst Appl 39(16):12,378–12,388
Khushaba R N, Wise C, Kodagoda S, Louviere J, Kahn BE, Townsend C (2013) Consumer neuroscience: assessing the brain response to marketing stimuli using electroencephalogram (EEG) and eye tracking. Expert Syst Appl 40(9):3803–3812
Kroupi E, Hanhart P, Lee JS, Rerabek M, Ebrahimi T (2014) Predicting subjective sensation of reality during multimedia consumption based on EEG and peripheral physiological signals. In: International conference on multimedia and expo, pp 1–6
Kumar P, Gauba H, Roy PP, Dogra DP (2016) Coupled hmm-based multi-sensor data fusion for sign language recognition. Pattern Recogn Lett
Kumar P, Saini R, Roy PP, Dogra DP (2016) 3d text segmentation and recognition using leap motion. Multimed Tools Appl:1–20
Morin C (2011) Neuromarketing: the new science of consumer behavior. Society 48(2):131–135
Murugappan M, Murugappan S, Gerard C, et al (2014) Wireless EEG signals based neuromarketing system using fast fourier transform (FFT). In: 10th International colloquium on signal processing & its applications, pp 25–30
Rabiner L, Juang B (1986) An introduction to hidden markov models. IEEE ASSP Mag 3(1):4–16
Rahman FA, Othman M (2015) Real time eye blink artifacts removal in electroencephalogram using savitzky-golay referenced adaptive filtering. In: International conference for innovation in biomedical engineering and life sciences, pp 68–71
Rodriguez-Galiano VF, Ghimire B, Rogan J, Chica-Olmo M, Rigol-Sanchez JP (2012) An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J Photogramm Remote Sens 67:93–104
Smith A, Bernheim BD, Camerer CF, Rangel A (2014) Neural activity reveals preferences without choices. Amer Econ J Microecon 6(2):1–36
Soleymani M, Chanel G, Kierkels JJ, Pun T (2008) Affective ranking of movie scenes using physiological signals and content analysis. In: 2nd workshop on multimedia semantics, pp 32–39
Solhjoo S, Nasrabadi AM, Golpayegani MRH (2005) Classification of chaotic signals using HMM classifiers: EEG-based mental task classification. In; 13th European signal processing conference, pp 1–4
Srinivasan V, Eswaran C, Sriraam N (2007) Approximate entropy-based epileptic EEG detection using artificial neural networks. IEEE Trans Inf Technol Biomed 11(3):288–295
Stanton SJ, Sinnott-Armstrong W, Huettel SA (2016) Neuromarketing: Ethical implications of its use and potential misuse. J Bus Ethics:1–13
Stickel C, Fink J, Holzinger A (2007) Enhancing universal access–EEG based learnability assessment. In: International conference on universal access in human-computer interaction, pp 813–822
Telpaz A, Webb R, Levy DJ (2015) Using EEG to predict consumers’ future choices. J Mark Res 52(4):511–529
Vecchiato G, Kong W, Giulio Maglione A, Wei D (2012) Understanding the impact of TV commercials. IEEE Pulse 3(3):42
Wei S, Tang J, Chai Y, Zhao W (2016) Classifying the epilepsy EEG signal by hybrid model of CSHMM on the basis of clinical features of interictal epileptiform discharges. In: Chinese intelligent systems conference, pp 377–385
Acknowledgments
The authors would like to thank the anonymous reviewers for their constructive comments and suggestions to improve the quality of the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yadava, M., Kumar, P., Saini, R. et al. Analysis of EEG signals and its application to neuromarketing. Multimed Tools Appl 76, 19087–19111 (2017). https://doi.org/10.1007/s11042-017-4580-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4580-6