
Abstract
Facial expressions convey nonverbal cues which play an important role in interpersonal relations, and are widely used in behavior interpretation of emotions, cognitive science, and social interactions. In this paper we analyze different ways of representing geometric feature and present a fully automatic facial expression recognition (FER) system using salient geometric features. In geometric feature-based FER approach, the first important step is to initialize and track dense set of facial points as the expression evolves over time in consecutive frames. In the proposed system, facial points are initialized using elastic bunch graph matching (EBGM) algorithm and tracking is performed using Kanade-Lucas-Tomaci (KLT) tracker. We extract geometric features from point, line and triangle composed of tracking results of facial points. The most discriminative line and triangle features are extracted using feature selective multi-class AdaBoost with the help of extreme learning machine (ELM) classification. Finally the geometric features for FER are extracted from the boosted line, and triangles composed of facial points. The recognition accuracy using features from point, line and triangle are analyzed independently. The performance of the proposed FER system is evaluated on three different data sets: namely CK+, MMI and MUG facial expression data sets.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The tracking and recognition of facial activities from still images or video sequences has attracted great attention in computer vision field. Among them recognition of facial expression has been an active research topic since last decade. Facial expressions are among the most universal forms of body language. A facial expression is one or more motions, or positions of the muscles beneath the skin of the face. These movements convey the emotional state of an individual to observers. Psychological research has shown that facial expressions are the most expressive way in which human display emotions [22]. In general, researchers divided facial expressions into six basic categories: anger, disgust, fear, happiness, sadness, and surprise; which are also called primary emotions [11]. Advanced emotions include frustration and confusion, sentiments including positive, negative, and neutral, composite of two or more emotions, facial action units etc.
In the digital age, it is no secret that social relationships are changing. With all advantages that our digital devices have brought us, they are also affecting our ability to empathize with others. Recent research shows that due to excessive use of digital devices young people are losing their ability to read other people emotions or feeling [38]. Therefore it is important to recognize emotions via facial expressions accurately and in real time. On the other hand, facial emotion recognition has applications in human-computer interaction, clinical studies, advertising, action recognition for computer games, etc.
An automatic FER system generally consists of three steps [36]: (a) accurate localization of face in an image or video, (b) facial feature extraction and representation, and finally (c) recognition of facial expression using feature classification. In this paper we focus on the study of salient geometric feature extraction for recognizing the six basic prototypical facial expressions. Figure 1 shows the overall block diagram of the proposed FER system. As shown in Fig. 1, at first, face detection, feature point initialization, and tracking is performed. Viola and Jones Haar like feature based AdaBoost scheme [40] is used for face and eye detection, whereas EBGM [41] and KLT tracker [5] is used for feature point initialization and tracking in consecutive video frames, respectively. Face graph normalization scheme is proposed to bring all face graphs in standard shape before feature selection and extraction. Three different geometric features are extracted. 1) Single facial points coordinate displacements feature, 2) two points are considered at once to form line features, and 3) three facial points are considered at once to form triangle type features. Prominent line and triangle are selected using multi-class AdaBoost before feature extraction. Detail of this procedure will be discussed in section 3. Finally facial expressions are recognized using SVMs learned on points, lines, and triangles based geometric features, independently. We analyze different types of geometric feature extraction and present the recognition results in different data sets.

Architecture of the proposed facial expression recognition system
The main contributions of this paper are summarized as follows:
-
1.
We propose a fully automatic sequence based FER system using salient geometric feature representations.
-
2.
We study facial geometric feature in three different forms (point, line and triangle); their representation power for discriminating basic FER are compared, and validated using publicly available three different FER data sets.
-
3.
We show that the triangle based representation outperforms both line and point based representation, whereas line based representation outperforms point based feature representation. Therefore our study proves that, not only the facial feature movement over time but also the inter-relation between facial features movements within a face is important in discriminating facial expressions.
-
4.
We conduct extensive FER experiments on three widely used facial expression data sets to demonstrate the efficiency of our proposed method. Experimental results show that our method is superior to most state-of-the-art FER systems.
Rest of this paper is organized as follows. A brief review of the work in the field of FER is given in section 2. Face detection, facial point initialization, tracking, and normalization of face graph as well as different types of geometric feature extraction is described in section 3. Section 4 describes the analysis and selection of different geometric feature from the tracking result of dense set of facial points. The experimental setup and dataset description is given in section 5. Experimental results on different publicly available benchmark facial expression data sets are presented in section 6. Finally, conclusion of the proposed FER system is given in section 7.
2 Related work
Several researchers have presented review on FER; among them early reviews can be found in [12, 24, 30], whereas recent reviews can be found in [39, 45]. First review was made in 1994 by Samal and Iyenger [30], followed by [12, 24] in 2000 and 2003, respectively. In [45], survey of affect recognition methods including audio, visual and spontaneous expressions is made, which was published in 2009. It covers discussion of emotion perception from psychological perspective, examination of available approaches for solving problem of machine understanding of human affective behavior, discussion on collection and availability of emotion training dataset, and also outlines the scientific and engineering challenges to advancing human affect sensing technology. Recently, in 2012, meta-review of FER and analysis challenge is presented by Valster et al. [39], in which the focus is on clarifying how far the field has come, identifying new goals, and providing baseline results regarding facial emotion recognition and analysis.
The approaches reported for FER can be classified into two main categories, a) template-based and b) feature-based. The template-based methods use 2-D or 3-D facial models as templates for expression information extraction. The feature-based methods use appearance-based features or geometry-based features for expression information extraction. Geometry-based features describe the shape of the face and its components such as the mouth or the eyebrow, whereas appearance-based features describe the texture of the face caused by expression.
Among the appearance-based features, local binary pattern (LBP) is widely used recognizing facial expressions [23, 32, 46–48]. Similarly, local Gabor binary pattern [23], histogram of orientation gradient [15], Gabor wavelets representation [46], scale invariant feature transform (SIFT) [34], non-negative matrix factorization (NMF) based texture features [18, 49], linear discriminant analysis (LDA) [33], independent component analysis (ICA) [33] etc., are also widely used appearance-based feature for the recognition of facial expressions.
Most geometric feature-based approaches use the active appearance model (AAM) or its variation, to track a dense set of facial points [3, 8]. Alternatively, EBGM algorithm, KLT tracker etc., are also used for facial key point detection or tracking [14, 19]. The locations of these facial landmarks are then used in different ways to extract facial features regarding shape of the face, or movement of facial key points as the expression evolves. Kotisa et al. [19] used geometric displacement of certain selected candid nodes, defined as the differences of the node coordinates between the first and the greatest facial expression intensity frames, as geometric features for recognition of six basic facial expressions. Sung and Kim [35] introduced Stereo AAM, which improves the fitting and tracking of standard AAMs using multiple cameras to model the 3-D shape and rigid motion parameters. Active shape model (ASM) is used in [6] for modeling and tracking facial key points and the facial expressions are recognized on a low-dimensional expression manifold. Pose invariant FER based on a set of characteristic facial points extracted using AAMs is presented by Rudovic and Pantic [28]. A coupled scale Gaussian process regression (CSGPR) model is used for head-pose normalization. Ghimire and Lee [14] used tracking result of 52 facial key points modeled in the form of point and line features for the recognition of facial expressions. The key geometric features are selected based on AdaBoost and dynamic time warping (DTW) algorithm. Recently, in [20] and [29], authors also utilized geometric features for the recognition of facial expressions. In [20], facial activities are characterized by three levels. First, in the bottom level, facial feature point are tracked using ASM, in the middle level, facial action units are defined, and finally facial expressions are represented based on detected action units. Saeed et al. [29] use only eight facial key points in order to model geometric structure of face from single face image for the recognition of facial expressions.
Several classifiers have also been investigated to build recognition module for facial expressions. Therefore, FER techniques can also be categorized according to recognition modules. The most common recognition modules are support vector machines (SVMs), hidden Markov models (HMM), Gaussian mixture models (GMM), dynamic Baysian networks (DBN) etc. Among them [3, 14, 19, 23, 28, 29, 46, 47] use SVM, HMM is used in [10, 37, 43], GMM is utilized by [21, 31], whereas [9, 20] uses DBN. Recently, sparse representation classification (SRC), which is a very successful face recognition technique [42], is also used for FER [46]. In SVM, the probability is calculated using N-fold cross validation technique, in other words, there is no direct probability estimation in SVM. Therefore in order to recognize facial expressions from video, the temporal information should be embedded in feature extraction process. GMM is sensitive to noise and cannot model fast variation in the consecutive frames. HMM are mostly used to handle the sequential data when frame level features are used which has the advantage over SVM, GMM like classifiers.
3 Geometry-based facial feature extraction
Facial feature extraction attempts to find the most appropriate representation of the face image for recognition. In geometric feature-based system, the facial points in a single image or in image sequences are used in different ways to form feature vector for recognition of facial expressions. For example, the distance between feature points and the relative sizes of the major face components are computed to form a feature vector. The feature points can also form a geometric graph representation of the face. Using geometric features have their own advantage and disadvantages. The difficulty in geometric feature based approach is to initialize and track facial feature points accurately and in real time. If there is error in feature point initialization and tracking, the error gets accumulated in the geometric feature extraction process. Image resolution, head pose, eyeglass, presence of beard etc. could also affect the feature point initialization and tracking process. But once the feature points are initialized and tracked accurately, the geometric features extracted from the tracking result are robust to variation in scale, size, head orientation, texture of the face due to age variation etc.
In this section we will present the method for facial feature point initialization and tracking. Different type of geometric feature extraction technique, as well as feature selection technique to find the most discriminant geometric features for the recognition of facial expressions will be studied. The geometric features are extracted based on point, line and triangle composed of facial key points in the video sequence.
3.1 Facial feature point tracking and graph normalization
In the proposed method, the facial points are initialized and tracked automatically. The feature point initialization is performed using EBGM algorithm. The tracking in consecutive frames is performed using KLT tracker. Finally, the face graph is normalized in such a way that for each facial expression sequence, the vertex of the initial face graph starts from same position and evolves according to the movements of facial feature points as some particular facial emotion evolves over time.
We use EBGM algorithm, which was implementation by Colorado State University (CSU) as a baseline algorithm for the comparison of face recognition algorithms [4], for facial feature point initialization. Facial feature point localization in a novel imagery has two steps. First, the locations of the new feature point is estimated based on the known locations of other feature points in the image; second, the estimate is refined by comparing the Gabor jet extracted from that image in the approximate locations and the jets extracted from the same positions in the model images. In order to start the feature point localization process, the approximate locations of two eyes are detected using Haar-like feature based object detection algorithm [40].
Once the facial feature points are automatically initialized using EBGM algorithm we use pyramidal variant of well-known KLT tracker for tracking the 52 facial feature points in consecutive frames. The KLT algorithm tracks a set of feature points across the video frames. The algorithm tracks the facial feature points in the image sequence containing the formation of a dynamic human facial expression from the neutral state to the fully expressive one. KLT tracking is faster as compared to the EBG using Gabor filter based tracking algorithm used in [14]. Figure 2 shows the result of facial feature point tracking using KLT tracker.

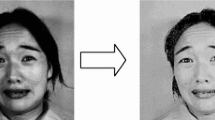
An example of facial feature point tracking in happy facial expression sequence using KLT tracker
Face graph normalization brings each face points to the uniform coordinate position in the first frame of the video shot, and as the expression evolves, the landmarks are displaced accordingly. Let us suppose (x l , y l ) k i denotes the i th feature point position in the l th frame of the k th facial expression sequence in the database. Tracking result of a single landmark is denoted by S k i , and is defined by Eq. (1).
where, N is the number of frames in an expression sequence.
An average feature point position corresponding to each feature point is computed by averaging feature points in neutral face images, i.e., first frame in the video shot. Suppose (μ x0, μ y0) i denotes the average key point position of the i th key point in the first frame of the expression sequence. Suppose (δ x0, δ y0) k i denotes the displacement of the i th key point in the first frame of the k th expression sequence, with respect to the average key point position:
Now the key point displacement described by Eq. 2 is added to the key point positions in every frame of the expression sequence. The transformed result of key point tracking is now denoted by S ′ k i and is defined as:
Figure 3 shows the result of the facial feature tracking and corresponding result after graph normalization. Note that graph is also scaled in order to make uniform size. Also, note that, the lines connecting two feature point are used just to make face like appearance.

Example of facial feature point tracking and corresponding result after normalization for two surprise facial expression sequences from MMI database
3.2 Point based geometric features
Suppose (x′, y′) is the normalized key point coordinate position in the face graph, and let us rewrite Eq. 3 in the following form:
The number of frames in different video shots of facial expression can be different. To make feature extraction and feature selection process easy, the feature point tracking result is resized to fixed length using linear interpolation. In our experiment the sequence is resampled into N = 10 frames.
The feature point displacement in each frame with respect to the first frame is calculated. Suppose (Δx ′ l , y ′ l ) k i denotes the difference between the i th landmark in the l th frame, and i th landmark in the first frame of the k th facial expression sequence in the database.
Equation (6) defines all the displacements of the i th feature point in the k th sequence.
3.3 Line based geometric features
The geometric feature extracted in the form of Eq. (6) considers only the tracking result of individual feature points. The movements of key points as the particular facial expression evolves are not independent, i.e., there is definite relationship between the movements of facial key points. In order to capture this information in the feature, pair of feature points is considered at a time, and then features are extracted as components of line. The Euclidian distance and the base angle connecting pair of facial key points within a frame are calculated as a line based geometric features.
Suppose (d l , θ l ) k i,j denotes the Euclidian distance and angle between i th and j th pair of key points in the l th frame of the k th facial expression sequence.
Let us denote the calculated sequence of distances and angle by L k i,j , and defined by Eq. (9):
Now, the obtained distance and angle between the pair of landmarks are subtracted from the corresponding distance and angle in the first frame of the video shot. Suppose (Δd l , Δθ l ) k i,j denotes the change in distance and angle between i th and j th pair of key points in the l th frame, with respect to the first frame of the k th video shot, which is defined as:
Finally, the line based geometric feature extracted from the image sequence is defined as follows:
3.4 Triangle based geometric features
Here, three facial landmarks are considered at a time and features are extracted in the form of components of triangle. The information regarding movement of facial key points and relationship between them when some facial expression evolves over time can be captured well by considering three facial key points at a time as compared to two facial key points. Triangle components in the l th frame are subtracted with the triangle components in the first frame of the video sequence as shown in Fig. 4.

Difference in components of two triangle used as features. Vertex of each triangle corresponds to the facial key point in the two frames of the video sequence
Suppose (a l , b l , α l , β l ) m i,j,k denotes the two side lengths, an included angle, and the base angle of the triangle composed of i th, j th and k th key points of the face graph in the l th frame of the m th facial expression sequence.
Now let us denote the calculated sequence of triangle components as shown in Fig. 4 by T m i,j,k , and defined as in Eq. (12).
The obtained components of triangle in the sequence are now subtracted from the corresponding components of triangle in the first frame of the video sequence. Suppose (Δa l , Δb l , Δα l , Δβ l ) m i,j,k denotes the difference between components of triangle in the l th frame of the video shot and the components of the corresponding triangle in the first frame of the video sequence, which is defined as:
Finally, triangle based geometric feature extracted from the image sequence are defined as follows:
Suppose there are N frames in the sequence, then the feature vector is composed of (N-1) × 4 components, i.e., if N = 11, feature dimension for a sequence extracted from the single triangle will be (11–1) × 4 = 40.
4 Features selection using multi-class AdaBoost with ELM
The geometric features are extracted in the form of components of lines and triangle. In total there are 52 facial key points. According to the combination principle with 52 facial points 52 C 2 = 52 !/(2 ! (52 − 2) !) = 1326 and 52 C 3 = 52 !/(3 ! (52 − 3) !) = 22100 unique lines and triangles are possible. If we use all of them in order to extract features for classification, the dimension of the feature will be large. In feature extraction process each point, line, and triangle in the face graph are represented by Eq. (6), Eq. (11), and Eq. (14), respectively. Let us call these equations as feature vector, because in this paper feature selection means selection of lines or triangles whose components represents the discriminative feature for the recognition of facial expressions. Among large number of feature vectors only the small subset will provide discriminative information for recognition of facial expressions. Our goal is to find subset of lines and triangles using some feature selection scheme. Here we use feature selective AdaBoost algorithm in combination with ELM.
4.1 Extreme learning machine
Gradient based learning algorithms are very slow and may easily converge to local minima. They also require many iterative learning steps in order to obtain better learning performance. ELM, a fast learning algorithm for single-layer feed-forward neural networks (SLFNs) proposed by Huang et al. [17], solves the gradient-based learning algorithm by analytically calculating the optimal weights of the SLFN. First, the weights between the input layer and hidden layer are randomly selected and then the optimal values for the weights between hidden layer and output layer are determined by calculating the linear matrix equations.
In summary, ELM algorithm can be written as follows:
Algorithm 1. Summary of extreme learning machine (ELM) algorithm.

Multi-class AdaBoost algorithm (Algorithm 2) is used to select the salient lines and triangles. ELM is used as a weak classifier in AdaBoost algorithm. ELM itself is not a weak classifier, but in the proposed system, in terms of feature it is treated as a weak classifier, i.e., ELM will be trained using feature extracted from single line or single triangle. The reason behind selecting ELM as a weak classifier is that it is a very fast learning algorithm, and can be trained almost in real time. In the proposed feature selection scheme we have to train 1326 ELMs for line feature selection and 22100 ELMs for triangle feature selection.
4.2 Feature selective multi-class AdaBoost
The AdaBoost learning algorithm proposed by Freud and Schapire [13], in its original form, is used to boost the classification performance of a simple learning algorithm. In our system, a variant of multi-class AdaBoost proposed by Jhu et al. [50] is used to select the lines or triangles from which features will be extracted for FER.
Algorithm 2: Multi-class AdaBoost learning algorithm. M hypothesis are constructed, each using a single feature vector. The final hypothesis is a weighted linear combination of M hypothesis.

Algorithm 2 shows the variant of multi-class AdaBoost learning algorithm proposed in [50], in which they refer their algorithm as SAMME – Stagewise Additive Modeling using a Multi-class Exponential loss function. Weak classifier T(x, f) in our system is trained ELM network using features extracted from single line or triangle. Note that we performed line and triangle selection experiment independently. But the process used for feature selection is same. The multi-class AdaBoost algorithm given in Algorithm 2 is similar to AdaBoost, with the major difference in Eq. (15). Now in order for α (m) to be positive, we only need (1 − err (m)) > 1/K, where K is the number of classes, or the accuracy of each weak classifier to be better than random guessing rather than 1/2.
The feature extraction based on the tracking result of individual landmark is simple process. It gives the maximum displacement of feature point in four directions as some expression evolves over time. But feature selection is only applied for line and triangle based feature extraction process. Before creating the feature vector for expression recognition, the feature selection process selects those line and triangle which carry most of information for discriminating six basic facial expressions. Figures 5 and 6 shows the most discriminative lines and triangle features in three different data sets. Note that line and triangle feature selection is performed independently. Mostly, the selected lines or triangles are composed of landmarks from the eyebrow, mouth and nose area. In most cases, at least one of the vertexes of the triangle is from the eyebrow or mouth or nose region.

Set of lines selected using multi-class AdaBoost with ELM in three different data sets (left to right: CK+, MMI, and MUG data sets)

First 10, 20, and 30 triangular features selected using multi-class AdaBoost with ELM. First row: CK+ data set, second row: MMI data set, and third row: MUG data set
5 Experimental setup and data sets description
In order to access the reliability of the proposed FER approach, the performance of the proposed FER system is evaluated on three different databases: extended Cohn-Kanade (CK+) facial expression dataset [26], M&M Initiative (MMI) dataset [25], and Multimedia Understanding Group (MUG) dataset [2]. These dataset consists of facial expression image sequence or videos which starts from natural frame and evolves to peak facial expression intensity.
The most common approach for testing the generalization performance of a classifier is the K-fold cross validation approach. A ten-fold cross validation was used in order to make maximum use of the available data, and produce averaged classification accuracy results. The classification accuracy is the average accuracy across all ten trials. To get better picture of the recognition accuracy of each expression type, the confusion matrices are given. The diagonal entries of the confusion matrix are the rates of facial expressions that are correctly classified, while the off-diagonal entries correspond to misclassification rates.
SVM is a well-known classifier for its generalization capability. SVM classifiers maximize the hyper plane margin between classes. In our experiment, we use a publicly available implementation of SVM, libsvm [7], in which we used radial basic function (RBF) kernel. The optimal parameter selection is performed based on the grid search strategy [16].
A brief introduction of three different data sets used in this paper is given below.
Extended Cohn-Kanade (CK+) dataset
The extended Cohn-Kanade (CK+) dataset [26] was used for FER in six basic facial expression classes (anger, disgust, fear, happiness, sadness, and surprise). This database consists of 593 sequences from 123 subjects. The image sequence varies in duration (i.e., 7 to 60 frames), and incorporates the onset (which is also the neutral face) to peak formation of the facial expression. Image sequences from neutral to target display were digitized into 640 × 480 or 640 × 490 pixel arrays. Only 327 of the 593 sequences have a given emotional class. This is because these are the only ones that fit the prototypic definition. For the evaluation of proposed FER system, 315 sequences of the dataset are selected from the database. Figure 7 (first row) shows an example of the facial expression sequence from CK+ dataset.

Example of facial expression sequence from three different data sets
M&M Initiative (MMI) dataset
The MMI face dataset [25] contains more than 1500 samples of both static images and image sequences of faces in frontal and in profile view displaying various facial expressions of emotion, single AU activation, and multiple AU activation. It not only contains posed but also contains spontaneous expressions of facial behavior. There are approximately 30 profile-view and 750 dual-view facial-expression video sequences. All video sequences have been recorded at a rate of 24 frames per second using a standard PAL camera. It includes 19 different face of students and research staff members of both sexes (44 % female), ranging in age from 19 to 62, having either a European, Asian, or South American ethnic background. Total of 203 facial expression video sequences are chosen for the evaluation of the proposed FER systems. Figure 7 (second row) shows an example of the facial expression sequence from MMI database.
Multimedia Understanding Group (MUG) dataset
Image sequences in MUG dataset [2] begin and end at neutral state and follow the onset, apex, offset temporal pattern. For each of the six basic expressions a few image sequences of various lengths are recorded. Each image sequence contains 50 to 160 images. Prior to the recordings, a short tutorial about the basic emotions was given to the subjects. The recordings of 77 subjects are available to researchers and the number of the available sequences counts up to 1462. The database includes 86 subjects with Caucasian origin and age between 20 and 35 years. There are 35 female and 51 males with or without beard. The recorded sequence consist of images saved in high quality lossy JPEG format, with a resolution of 896 × 896 pixels and a size ranging from 240 to 340 KB. Image sequences of 52 subjects and the corresponding annotation are available publically via the internet. In the proposed system 325 sequences are selected for the experiment. Figure 7 (last row) shows an example of the facial expression sequence from MUG database.
Table 1 shows the number of facial expression images/video sequences for each expression from each dataset used in this paper for the experimentation of the proposed FER system.
6 Experimental results and discussion
6.1 Facial expression recognition using point based features
In this paper basically three different types of facial geometric features are used individually for the recognition of facial expressions. As explained in section 3.2, the point based feature refers to the geometric features which are individual facial feature point displacement in four possible directions. The feature for SVM classification from i th facial key point of the k th facial expression sequence is explained as follows:
Total of 52 facial key points are tracked, therefore the dimensionality of point based feature is 52 × 4 = 208. The average recognition accuracy using point based feature with ten-fold cross validation is 96.37, 67.64, and 91.41 % in CK+, MMI, and MUG facial expression data sets, respectively. Tables 2, 3 and 4 show the corresponding confusion matrices labeled with point based feature representation along with line and triangle based features.
6.2 Facial expression recognition using boosted line based features
As explained in section 3.3, the line is created by connecting two facial key points. With 52 facial key points 1326 unique lines are possible. But the features from only a subset of those lines are sufficient to learn the basic facial expressions. Therefore AdaBoost algorithm is used to select the discriminating lines from which features for SVM classification are extracted. The magnitude of difference in length and base angle w.r.t the neutral frame are extracted from line based features from facial expression sequence represented by Eq. (11) which is given as follows:
The average recognition accuracy using line based features with ten-fold cross validation is 96.58, 74.31, and 94.13 % in CK+, MMI, and MUG dataset, respectively. There is improvement in recognition accuracy using line based features as compared to point based features. Tables 2, 3 and 4 show the corresponding confusion matrices labeled with line based feature representation along with point and triangle based features.
6.3 Facial expression recognition using boosted triangle based features
The overall procedure for extracting triangular features is explained in section 3.4. Multi-class AdaBoost with ELM is used to select the most discriminative features in the form of triangle composed of facial landmarks. A triangle in the proposed system, which is formed using facial key points, is represented by four components; two side lengths, an included angle, and a base angle of one of the triangle side with the x-axis (refer to Fig. 4).
As shown in Fig. 4, features from triangle for SVM classification are extracted by subtracting triangle components of facial landmarks. The maximum changes in magnitude of the four components of the triangle in the sequence with respect to the triangle components in the first frame are extracted. Therefore each triangle is composed of four features, but some triangles in the AdaBoost selected triangle set may share the common edge, therefore the total feature dimension is always less or equal to the number of AdaBoost selected triangles multiplied by 4. As the number of triangle in the set increases the classification accuracy also increases. Figure 8 shows the graph of the number of triangular features verses recognition accuracy in MUG facial expression dataset.

Recognition accuracy under different number of boosted triangular features in MUG dataset
Tables 2, 3 and 4 shows the confusion matrix for the FER using features extracted from 160, 84, and 98 AdaBoosted triangles in CK+, MMI, and MUG facial expression data sets respectively (labeled as triangle feature representation) along with point and line based features. The dimensionality of the feature vector using 160, 84 and 98 triangles in CK+, MMI and MUG dataset is 370, 317 and 330 respectively. The average recognition accuracies are 97.80, 77.22 and 95.50 % respectively.
We also performed the experiment by reducing the number of key points. As shows in Fig. 9, 25 and 34 key points tracking results are used to select the triangular features. The set, 25 key points, are the same set of key points used in [4] for the comparison of face recognition algorithms. Another set, 34 key points, are obtained by adding some more key points to the 25 key points set, especially in mouth and eyebrow regions. Finally, 52 key points are the set of key points used in [14], which is the extension of 34 key points set.

Three different set of facial landmarks used for the evaluation of proposed triangular feature based FER system
Figure 10 shows the comparison of FER accuracy in three different data sets using triangle based features with different number of facial key points tracking. In CK+ dataset 97.80, 97.29, and 93.37 % of recognition accuracy, in MMI dataset 77.22, 71.11, and 68.61 % of recognition accuracy and in MUG dataset 95.50, 93.92, and 93.00 % of recognition accuracy is obtained using features from tracking result of 52, 34, and 25 facial landmarks respectively. Even if the small numbers of facial landmarks are used, good recognition accuracy can be obtained using the proposed triangle based geometric features.

Comparison of FER accuracy in three different data sets with triangular feature extracted from different set of landmarks tracking results
6.4 Comparison of point, line and triangle feature based facial expression recognition
The features extracted based on the tracking result of single landmark is very simple. It gives the maximum displacement of feature point in four directions as some expression evolves over time. The second type of geometric feature is the features extracted based on line connecting two facial landmarks. Finally, third type of geometric feature is extracted in the form of components of triangles composed of facial key points.
Figure 11 shows the comparison of FER performance using three different kinds of geometric features in three data sets. The average classification accuracy using point, line and triangle features in CK+ dataset is 96.37%, 96.58%, and 97.80%, in MMI dataset is 67.64%, 74.31%, and 77.22%, and in MUG dataset is 91.41%, 94.13%, and 95.50%, respectively. The features extracted in the form of line components give better result than point based features. On the other hand, feature extracted in the form of triangle components give better result than line based features. It proves that while some facial expression evolves, the movement of facial key points is not independent, i.e., there is some definite relationship between movement of facial key points.

Comparison of point, line and triangle feature based FER in three different data sets
The performance in the MMI dataset is low as compared to CK+ and MUG dataset. This is because MMI is difficult dataset among three data sets. Even though the line based feature give better result than point based feature, and triangle based feature is superior than line based feature, the performance in CK+ and MUG dataset using point, line, and triangle feature produce comparable results. But in conclusion, the best result in all three data sets is obtained using geometric features extracted based on the triangle composed of facial landmarks.
6.5 Generalization validation across different databases
The generalization performance of the FER system can be best evaluated using cross-dataset evaluation. Most of the researchers use same dataset for both training and validation. It is obvious that higher recognition rate can be achieved when evaluated on a single dataset, because, while recording the facial expressions in lab environment, there is lot of similarity in all the recorded sequences. For example, lighting, background, way of expressing emotion, image quality, image resolutions etc. But if we take two different data sets, there will be much dissimilarity. The FER system will be a good one if it can produce better result when evaluated on a testing dataset different from the training dataset.
Table 5 shows the confusion matrix for FER using triangle based geometric feature while using CK+ dataset for training and MMI dataset for testing. The average recognition accuracy in this case is only 64.89 %. Table 6 shows the confusion matrix for FER using MUG dataset for training and CK+ dataset for testing. In this case, the average recognition accuracy is 81.74 %. Now, Table 7 shows the cross-dataset evaluation result in three different dataset in which only average recognition result are presented. From these tables it can be seen that, while MMI dataset is used either for training or testing, the recognition accuracy is low, on the other hand if CK+ and MUG dataset are used for cross dataset evaluation the recognition performance is more than 80 %. It shows that MMI dataset is the most difficult dataset among the three different dataset used in this paper. The cross-dataset evaluation is performed only for triangle based features because this feature set gives the best recognition accuracy as compared to point and line based features.
6.6 Comparison with state-of-the-art methods
Even though the experimental setup is not exactly same, the overall recognition accuracy of some recent methods of FER from the literature is compared with accuracy obtained using proposed systems. Geometric feature based FER system in which the features in the form of triangle are selected and the recognition is performed using SVM classification gives the best recognition accuracy of 97.8 % in CK+ dataset, 77.22 % in MMI dataset and 95.5 % in MUG dataset.
In the literature so far, the system in [19] has shown superior performance, and has achieved 99.7 % of recognition rate in CK+ dataset using key point displacement features. But in their method, the facial key point initialization is a manual process, and the number of key points is also larger than the number of key points used in the proposed method. On the other hand, the proposed system is fully automatic. Similarly, in [44], 97.16 % recognition rate has been achieved by extracting the most discriminative facial key points for each facial expression. Recently in CK+ dataset, [29] have achieved 83.01 % recognition accuracy in which geometric features are extracted using only 8 facial key points in the single highly expressed facial expression frame. In [32], using 96 image sequences from MMI dataset with LBP features; they achieved average recognition accuracy of 86.9 %. Recently, Albert et al. [10] achieved 71.83 % recognition accuracy in MMI dataset using attention theory based automatic sampling and optical flow as a temporal feature. In the proposed system 203 image sequences are used from MMI dataset, at which some of them are not acted facial expressions, i.e., they are naturally expressed facial expressions which adds difficulty in recognizing facial expressions with high accuracy. Rahulamathavan et al. [27] achieved 95.24 % overall recognition accuracy in MUG facial expression dataset. They performed FER in encrypted domain using local fisher discriminant analysis. Recently, in [1], 92.76 and 94.31 % recognition accuracy is obtained in MUG and CK+ dataset using leave-one-subject-out validation strategy, respectively. The manifold structure is learned using coordinates of facial key points tracking result which can be decomposed to a small number of linear subspaces of very low dimension. Table 8 shows the summary of the comparison of FER performance with different methods in the literature. One of the advantages of the proposed geometric feature based FER systems is the relatively lower dimension of feature vector compared to the feature dimension in the state of the art methods. The recognition accuracy in CK+ and MUG dataset is comparable and even better than the best recognition accuracy in the literature. In the literature in MMI dataset the best accuracy is obtained using texture feature rather than geometric features.
7 Conclusion
The aim of this paper is to present a new framework for FER in frontal image sequence based on geometric features extracted from the tracking result of facial key points. Different types of geometric feature extraction techniques from facial expression image sequence are presented. The facial expressions are recognized using most discriminative geometric feature selected using feature selective AdaBoost algorithm.
The point, line and triangle based features are presented. The point based feature can be used directly, whereas line and triangle based feature are used only after feature selection process. The performance of the proposed geometric-feature based FER system is evaluated in three different data sets: namely CK+, MMI and MUG. The line based feature gives better result than point based feature, whereas triangle based feature gives superior result than line based features. Therefore recognition accuracy using the features extracted considering more key points at a time is better than using the features extracted by considering single key point at a time. Therefore the most desirable feature is the time-varying graph itself. But we cannot use graph directly, so we need to find out efficient feature from it, which do not reduce the information in the graph.
The recognition accuracy in CK+ and MUG dataset is more than 95 %, whereas in MMI dataset the recognition accuracy is only 77.22 %. The MMI dataset is relatively difficult then CK+ and MUG dataset because it includes some spontaneous facial expressions. The generalization capability of the proposed FER system is proved using cross-dataset evaluation. More than 80 % recognition accuracy is obtained using proposed FER system while using different data sets for training and testing. While comparing the results with the state of the art methods, the performances of the proposed system is comparable and at times even better than the results reported in the literature for most cases.
References
Aifanti N, Delopoulos A (2014) Linear subspace for facial expression recognition. Signal Process Image Commun 29:177–188
Aifanti N, Papachristou A, Delpoulos A (2010) The MUG facial expression database. In Proceeding of 11th international workshop on image analysis for multimedia interactive services, pp 1–4
Asthana A, Saragih J, Wagner M, Goecke R (2009) Evaluating AAM fitting methods for facial expression recognition. In Proceeding of the international conference on affective computing and intelligent interaction, pp 1–8
Blome DS (2003) Elastic bunch graph matching. M.Sc. Thesis, Colorado State University: Fort Collins, CO, USA
Bouguet JY (1999) Pyramidal implementation of the Lucas-Kanade feature tracker. Technological Report, Intel Corporation, Microprocessor Research Lab
Chang Y, Hu C, Feris R, Turk M (2006) Manifold based analysis of facial expression. Image Vis Comput 24:605–614
Chang CC, Lin CJ (2001) LIBSVM: a library for support vector machines. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm. Accessed on 16 Jan 2015
Choi HC, Oh SY (2006) Realtime facial expression recognition using active appearance model and multilayer perceptron. In Proceeding of the international joint conference SICE-ICASE, pp 5924–5927
Cid F, Moreno J, Bustos P, Nunez P (2014) Muecas: a multi-sensor robotic head for affective human robot interaction and imitation. Sensors 14:7711–7737
Cruz AC, Bhanu B, Thakoor NS (2014) Vision and attention theory based sampling for continuous facial emotion recognition. IEEE Trans Affect Comput 5:418–431
Ekman P (1994) Strong evidence of universal in facial expressions: a reply to Russell’s mistaken critique. Psychol Bull 115:268–287
Fasel B, Luettin J (2003) Automatic facial expression analysis: a survey. Pattern Recogn 36:259–275
Freund Y, Schapire RE (1997) A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55:119–139
Ghimire D, Lee J (2013) Geometric feature-based facial expression recognition in image sequences using multi-class AdaBoost and support vector machines. Sensors 13:7714–7734
Ghimire D, Lee J (2014) Extreme learning machine ensemble using bagging for facial expression recognition. J Inf Process Syst 10:443–458
Hsu CW, Chang CC, Lin CJ (2010) A practical guide to support vector classification. Technical Report. Department of Computer Science, National Taiwan University, Taiwan
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70:489–501
Kotisa I, Buciu I, Pitas I (2008) An analysis of facial expression recognition under partial facial image occlusion. Image Vis Comput 26:1033–1046
Kotisa I, Pitas I (2007) Facial expression recognition in image sequence using geometric deformation features and support vector machines. IEEE Trans Image Process 16:172–187
Li Y, Wang S, Zhao Y, Ji Q (2013) Simultaneous facial feature tracking and facial expression recognition. IEEE Trans Image Process 22:2559–2573
Liu W, Lu J, Wang Z, Song H (2008) An expression space model for facial expression analysis. In Proceeding of IEEE congress in image and signal processing, pp 680–684
Mehrabian A (1968) Communication without words. Psychol Today 2:53–56
Moore S, Bowden R (2011) Local binary patterns for multi-view facial expression recognition. Comput Vis Image Underst 115:541–558
Pantic M, Rothkrantz L (2000) Automatic analysis of facial expressions: the state of the art. IEEE Trans Pattern Anal Mach Intell 22:1424–1445
Pantic M, Valster R, Rademaker R, Maat L (2005) Web-based database for facial expression analysis. In Proceeding of IEEE international conference multimedia and expo, pp. 317–321
Pantic M, Valster M, Rademaker R, Maat L (2010) The extended Cohn-Kanade dataset (CK+): a complete dataset for action unit and emotion-specific expression. In Proceeding of 3rd IEEE workshop on CVPR for human communication behavior analysis, pp. 94–101
Rahulmathavan Y, Phan RCW, Chambers JA, Parish DJ (2013) Facial expression recognition in the encrypted domain based on local fisher discriminant analysis. IEEE Trans Affect Comput 4:83–92
Rudovic O, Pantic M, Patras I (2012) Coupled Gaussian processes for pose-invariant facial expression recognition. IEEE Trans Pattern Anal Mach Intell 25:1357–1369
Saeed A, Al-Hamadi A, Niese R, Elzobi M (2014) Frame-based facial expression recognition using geometric features. Adv Hum Comput Interact 2014:1–13
Samal A, Iyenger PA (1994) Automatic recognition of human face and facial expressions: a survey. Pattern Recogn 25:65–77
Schels M, Schwenker F (2010) A multiple classifier system approach for facial expressions in image sequence utilizing GMM Supervectors. In Proceeding of the 2010 20th international conference on pattern recognition, pp 4251–4254
Shan C, Gong S, McOwan PW (2009) Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis Comput 27:803–816
Siddiqi MH, Lee S, Lee YK, Khan AM, Truc P (2013) Hierarchical recognition scheme for human facial expression recognition systems. Sensors 13:16682–16713
Soyel H, Demirel H (2012) Localized discriminative scale invariant feature transform based facial expression recognition. Comput Electr Eng 38:1299–1309
Sung J, Kin D (2009) Real-time facial expression recognition using STAAM and layered GDA classifiers. Image Vis Comput 27:1313–1325
Tian Y-L, Kanade T, Cohn JF (2005) Handbook of face recognition. Springer, Berlin, pp 247–275
Uddin M, Lee J, Kim T (2009) An enhanced independent component-based human facial expression recognition from video. IEEE Trans Consum Electron 55:2216–2224
Uhls YT, Michikyan M, Morris J, Garcia D, Small GW, Zgourou E, Greenfield PM (2014) Five days at outdoor education camp without screen improves pattern skills with nonverbal emotion cues. Comput Hum Behav 39:387–392
Valster MF, Mehu M, Jiang B, Pantic M, Scherer K (2012) Meta-analysis of the first facial expression recognition challenge. IEEE Trans Syst Man Cybern B Cybern 42:966–979
Viola P, Jones MJ (2004) Robust real-time face detection. Int J Comput Vis 57:137–154
Wiskott L, Fellous JM, Krüger N (1997) Face recognition by elastic bunch graph matching. IEEE Trans Pattern Anal Mach Intell 19:775–779
Wright J, Yang AY, Ganesh A, Sastry SS, Ma Y (2009) Robust face recognition via sparse representation. IEEE Trans Pattern Anal Mach Intell 31:210–227
Yeasin M, Bullot B, Sharma R (2006) Recognition of facial expressions and measurements of levels of interest from video. IEEE Trans Multimed 8:500–508
Zafeirius S, Pitas I (2008) Discriminant graph structures for facial expression recognition. IEEE Trans Multimed 10:1528–1540
Zeng Z, Pantic M, Roisman GI, Huang TS (2009) A survey of affect recognition methods: audio, visual, and spontaneous expressions. IEEE Trans Pattern Anal Mach Intell 31:39–58
Zhang S, Zhao X, Lei B (2012) Robust facial expression recognition via compressive sensing. Sensors 12:3747–3761
Zhao G, Pietikainen M (2007) Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans Pattern Anal Mach Intell 29:915–928
Zhao X, Zhang S (2011) Facial expression recognition based on local binary patterns and kernel discriminant isomap. Sensors 11:9573–9588
Zhi R, Flierl M, Ruan Q, Kleijn WB (2011) Graph-preserving sparse nonnegative matrix factorization with application to facial expression recognition. IEEE Trans Syst Man Cybern B Cybern 41:38–52
Zhu J, Zou H, Rosset S, Hastie T (2009) Multi-class AdaBoost. Stat Its Interface 2:349–360
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ghimire, D., Lee, J., Li, ZN. et al. Recognition of facial expressions based on salient geometric features and support vector machines. Multimed Tools Appl 76, 7921–7946 (2017). https://doi.org/10.1007/s11042-016-3428-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-016-3428-9