
Abstract
This paper proposes a novel high capacity robust audio watermarking algorithm by using the high frequency band of the wavelet decomposition at which the human auditory system (HAS) is not very sensitive to alteration. The main idea is to divide the high frequency band into frames and, for embedding, to change the wavelet samples depending on the average of relevant frame’s samples. The experimental results show that the method has a very high capacity (about 11,000 bps), without significant perceptual distortion (ODG in [−1 ,0] and SNR about 30dB), and provides robustness against common audio signal processing such as additive noise, filtering, echo and MPEG compression (MP3).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Digital watermarking is one of the most popular approaches for providing copyright protection of digital contents. This technique is based on direct embedding of additional information data into the digital contents. The watermarking process should not introduce any perceptible artifacts into the original contents (e.g. an audio signal). Ideally, there must be no perceptible difference between the watermarked and the original digital contents. I.e. the watermark data should be embedded imperceptibly into the audio media. Using the properties of the human auditory system (HAS) is a usual approach to design imperceptible and robust algorithms. Apart from imperceptibility, capacity and robustness are two fundamental properties of audio watermarking schemes. The watermark should be extractable after various intentional and unintentional attacks. These attacks may include additive noise, re-sampling, MP3 compression, low-pass filtering, re-quantization, and any other attack which removes the watermark or confuse the watermark extraction system. Considering a trade-off between capacity, transparency and robustness is the main challenge for audio watermarking applications.
Many audio watermarking schemes take advantage of the properties of the human auditory system (HAS) and different transforms, resulting in various techniques such as embedding algorithms based on low-bit coding, echo, patchwork [6], rational dither modulation [5], Fourier transform [3, 4], quantization [1, 2, 18] and the wavelet transform [12, 15].
Considering the embedding domain, audio watermarking techniques can be classified into time domain and frequency domain methods. Time domain watermarking schemes are relatively easy to implement and require less computing resources compared to transform domain watermarking methods. On the other hand, time domain watermarking systems are usually weaker against signal-processing attacks compared to the transform domain counterparts. Phase modulation [8] and echo hiding [7] are well known methods in the time domain.
In frequency domain watermarking, after taking one of the usual transforms such as the Discrete/Fast Fourier Transform (DFT/FFT) [3, 4], the Modified Discrete Cosine Transform (MDCT) or the Wavelet Transform (WT) [12, 15–17] from the signal, the hidden bits are embedded into the resulting transform coefficients. For example, [17] takes advantage of the mean of absolute values to design a scheme which has capacity equal to 40 bits (which are embedded in a 20-second audio signal in the experiments given in the paper), and robustness against common attacks. In [3, 4] the FFT domain is selected to embed watermarks for making use of the translation-invariant property of the FFT coefficients to resist small distortions in the time domain. In particular, [3, 4, 12, 15–17] show that the frequency domain provides excellent robustness against attacks. In fact, using methods based on transforms provides a better perception quality and robustness against common attacks at the price of increasing the computational complexity.
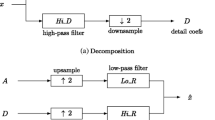
Among the existing transforms, the wavelet transform has several advantages in audio signal processing. Its inherent frequency multi-resolution and logarithmic decomposition of the frequency bands resemble the human perception of frequencies, since it provides the decomposition to mimic the critical band structure of the HAS.
In the proposed scheme, the last high frequency band of the second level wavelet decomposition (DD), for which the HAS is not very sensitive to alteration, is used for embedding. In the embedding process, the samples are changed based on the corresponding secret bit. The main idea is to select a part of the samples in each frame and change them based on average of a relevant frame. E.g. if we want embed “1” into a sample with value equal to 1, the value may be changed to 0.5, but if we want embed “1” in a sample with value 10, then it may be modified to 5. If we used 0.5 for embedding “1” at all samples, then the scheme would be very fragile to attacks. On the other hand, if we changed the values to 5 always, then we would be enforcing a large distortion in the marked audio signal. Thus, it is advisable to change the samples based on their values. To design a blind scheme and, also, to achieve good robustness and transparency results, the high frequency band (DD) is divided into small frames and the average of each frame is used as a reference value to change the value of the samples. These reference values are the same in the coder/decoder or sender/receiver. When the elements of a set are divided by their average, the new values of the elements will be near one. In this algorithm, we divide each element by the average of the corresponding frame and then we use all values in the interval [−k, k] for embedding, where k is the embedding interval value. If the secret bit is “0”, the corresponding sample in the interval is changed to -m i , whereas for embedding a “1” the sample is altered to + m i (where m i is the mean of the i-th frame).
The experimental results show that high capacity, remarkable transparency and robustness against most of common attacks are achieved.
The rest of the paper is organized as follows. In Section 2, the proposed method is presented. In Section 3, a discussion on the transparency and robustness of the suggested scheme is provided, and the experimental results are shown. Finally, Section 4 summarizes the most relevant conclusions of this research.
2 Proposed scheme
A wide work has been performed over the years in understanding the characteristics of the HAS and applying this knowledge to audio compression and audio watermarking. Figure 1 shows a typical absolute threshold curve, where the horizontal axis is the frequency measured in hertz (Hz) and the vertical axis is the absolute threshold in decibels (dB). As it can be seen, human beings tend to be more sensitive towards frequencies in the range from 1 to 4 kHz, while the threshold increases rapidly at very high and very low frequencies. Based on the HAS, the human ear sensitivity in higher frequencies is lower than in middle frequencies. It is thus clear that, by embedding data in the high frequency band, which is used in the proposed scheme, the distortion will be mostly inaudible and thus more transparency can be achieved.

Typical absolute threshold curve of the human auditory response
2.1 Embedding
The embedding steps are described below.
-
1.
Compute the second level wavelet transform of the original signal.
-
2.
Divide the cDD samples into frames of a given length and, based on average of the absolute values of each frame’s samples, compute the average m i for each frame by using Eq. 1.
$$ {m_i} = \frac{1}{s}\sum\limits_{j = \left( {i - 1} \right)s + 1}^{is} {\left| {{c_j}} \right|} $$(1)Where {c j } are the wavelet coefficients of the high-frequency sub-band (DD), s is the frame size and m i is the average of the i-th frame.
-
3.
The marked wavelet coefficients \( \left\{ {c_j^\prime } \right\} \) are obtained by using Eq. 2.
$$ c_j^\prime = \left\{ \begin{array}{lll} {{m_i}} \hfill & {\left| {{c_j}/{m_i}} \right| < k,{w_l} = 1} \hfill \\{ - {m_i}} \hfill & {\left| {{c_j}/{m_i}} \right| < k,{w_l} = 0} \hfill \\{{c_j}} \hfill & {\left| {{c_j}/{m_i}} \right| \geq k} \end{array}\right. $$(2)Where \( i = \left\lfloor {j/s} \right\rfloor + 1 \), m i stands for the frame average, w l is the l-th bit of the secret stream, k is the embedding interval (k > 2) and \( \left\lfloor \cdot \right\rfloor \) denotes the floor function. I.e. if c j in [-km i , km i ] then, depending on the secret bit, it is changed to-m i or + m i . Each secret bit is embedded into a suitable sample and thus, after embedding the bit, the index l is incremented and the next secret bit is embedded into the next suitable wavelet sample.
-
4.
Finally, the inverse DWT is applied to the modified wavelet coefficients to get the marked audio signal.
The modified area of DWT coefficients for each frame is [-km i , km i ] which is determined by the absolute mean value of each frame and the embedding interval, k. By increasing k, the interval is extended in such a way that the number of modified coefficients which satisfy the condition \( \left| {{c_j}/{m_i}} \right| < k \) is increased and, thus, capacity and distortion also become greater. To manage robustness and transparency, we use a scale factor, α, which defines strength of watermark (0.5 < α < k). In fact, in Eq. 2, instead of changing \( c_j^\prime \) to m i , we can change it to αm i .
Figure 2 illustrates the effect of the embedding steps in the wavelet samples. Figure 2 (a) shows the high frequency wavelet decomposition (cDD) of a RIFF WAVE file of a second, c j . Figure 2 (b) shows the modified samples c j /m i and Fig. 2 (c) illustrates the marked samples, \( c_j^\prime \). This figure shows that, by dividing samples by the average of each frame, all of them will be in the same range. It also illustrates that, after embedding, the marked samples are very similar to the original ones.

Wavelet samples in embedding steps
Figure 3 shows the flowchart for the selection of the embedding parameters. In the flowchart, the required capacity is denoted by Cap, N k is the number of samples in selected embedding interval, ODG min is the threshold of acceptable distortion, BER max is maximum tolerable of BER and REP is the number of times the loop is repeated to reach to the demanded properties. In the tuning steps, first a suitable embedding interval, k, is fixed based on Cap. If there are not enough samples in the interval which is defined by k, the interval should be extended. I.e. by increasing k, the interval is extended and capacity is increased. Then ODG and BER are regulated by scale factor, α, and the frame size, s. As mentioned above, increasing α and s increases robustness and distortion. Thus, to obtain suitable transparency and robustness, these parameters can be changed. Considering the trade-off between the properties (capacity, robustness and transparency) of watermarking techniques, in some cases alteration in the requested properties is necessary. E.g. obtaining parameters to achieve Cap = 11,000 bps, BER max = 0 and ODG min = 0.0 is difficult or maybe impossible. However, finding tuning parameters to obtain BER max = 1 and ODG min = −0.5 should not be difficult.

Flowchart for tuning the embedding parameters
2.2 Extracting
In the receiver, \( m_i^\prime \), which stands for the marked frame average, is calculated by using Eq. 3 and an interval is defined such that, if \( c_j^\prime \) is in the interval, a secret bit can be extracted. The secret bit stream is achieved by using Eq. 4.
Where \( c_j^\prime \) is the sample of the high frequency band of the second level wavelet decomposition (cDD) of the marked signal, α is the strength of watermark and \( w_l^\prime \) is the l-th bit of the extracted secret stream. E.g. if k = 2 and α = 1 then, if \( c_j^\prime \) in \( \left[ {0,1.5m_i^\prime } \right] \) the secret bit is “1” and, if in \( \left[ { - 1.5m_i^\prime,} \right.\left. 0 \right) \), the secret bit is “0”.
Since, in the coder, the DWT samples in the interval [-km i , km i ] are changed to αm i or-αm i . It is thus clear that the average of the absolute values is equal to αm i in the receiver. If the signal is distorted by attacks, the absolute mean of the coefficients \( m_i^\prime \) is slightly modified. However, the experimental results show that this change does not affect the extraction process since an interval, not a constant number, is used for extracting. E.g. under the MP3-128 compression attack, the variation is about 5% which is acceptable for extraction.
In a real application, the cover signal would be divided into several blocks of a few seconds and it is essential that the detector can determine the position (the beginning sample) of each of these blocks. One of the most practical solutions to solve this problem is to use synchronization marks such that the detector can determine the beginning of each block. [15] is used with the method described here in order to produce a practical self-synchronizing solution. Note that the synchronization method described in [15] is already shown to be robust against different types of manipulations and, more precisely, against attacks which lead to de-synchronization, such as re-sampling, re-quantization and random cropping. Because of this reason, de-synchronization attacks will not be examined in the experimental results of this paper, since they are already analyzed in [15].
To increase security, pseudo-random number generators (PRNG) can be used to change the secret bit stream by a stream which makes more difficult for an attacker to extract the secret information. For example, the embedded bitstream can be constructed as the XOR sum of the real watermark and a pseudo-random bit stream. The seed of the PRNG would be required as a secret key both at the embedder and the detector [9].
3 Discussion and experimental results
To show the performance of the proposed scheme and to consider the applicability of the scheme in a real scenario, five songs (RIFF WAVE files) included in the album Rust by No, Really [10] have been selected. All audio clips are sampled at 44.1 kHz with 16 bits per sample and two channels. The two-level wavelet decomposition is implemented using the 8-coefficient Daubechies wavelet (db8) filter. The experiments have been performed for each channel of the audio signals separately. We provide imperceptibility results both as SNR and Objective Difference Grade (ODG), where ODG = 0 means no degradation and ODG = −4 means a very annoying distortion. SNR is provided only for comparison with other works, but ODG is a more appropriate measurement of audio distortions, since it is assumed to provide an accurate model of the subjective difference grade (SDG) results which may be obtained by a group of human listeners. The SNR results are computed using the whole (original and marked) files, whereas the ODG results are provided using the advanced ITU-R BS.1387 standard [14] as implemented in the Opera software [11] (which computes the average ODG of measurements taken in frames of 1024 samples).
In order to reduce computation time and memory usage, each song is divided into clips of 10 s, and the synchronization [15] and embedding algorithm is applied for each clip separately. We embed 16 synchronization bits, “1 0 1 1 0 0 1 1 1 1 0 0 0 0 1 0” with a quantization factor equal to 0.125, in the first 80 samples of each clip, then the information watermark is embedded and, finally, all these clips are joined together to generate the marked signal.
3.1 Discussion on transparency and robustness
This section provides a discussion of the robustness and transparency of the suggested scheme. These results are not purely theoretical, but the reasons why both transparency and robustness are achieved are outlined. These results have been obtained for k = 6, α = 2 and the frame size equal to 10, but they can be easily extended to other values of the tuning parameters. As transparency is concerned, Fig. 4 shows the spectrum of the original, the marked signals and the difference between them. To make the comparison between the original and the marked signals easier, the scale difference of the difference has been magnified 10 times. Note that most changes occur around the 10 kHz region, where the human auditory response is not as sensitive (the auditory threshold is about 20 dB) as it is in lower frequencies ranges, such as [200, 5000] Hz. These plots do not prove that the distortion introduced around 10 kHz is below the audible threshold (20 dB), since the final power of the final audio signal depends on different factors such as the physical device used to generate it, including different parameters such as volume and equalizers. However, the experimental results given in Section 3.2, in terms of both ODG and SNR, show that the imperceptibility of the suggested scheme is very remarkable (imperceptible or not annoying).

Spectrum of the original, marked and difference between marked and original signals for two audio files of [10]
With respect to robustness, considering general attacks and their effect on the marked signal in a theoretical manner is a complex process, since the effect depends on both the embedding scheme and the attack. For example, in an embedding method using the LSB of the signal, it is evident that attacks like LSBZero, re-quantization and Amplify will remove the secret information.
In our case, the proposed scheme takes advantage of the wavelet transform, which is a time-frequency function, and thus to consider the theoretical reasons why some attacks are survived needs complex equations and conditions which can be different for different types of audio signals.
However, note that this scheme is robust against all attacks which produce a scaling change in the DD wavelet coefficients. If the cDD wavelet samples are scaled, the mean of these samples is scaled accordingly, and the extracting process is still successful. Such a scaling change in the DD area occurs in several attacks. A simple attack which produces scaling is Amplify, which changes the amplitudes of the (time domain) samples.
Another attack which is relevant for this particular scheme is RC low-pass filtering, since the high frequency area is used for embedding in this scheme, what would seem to imply that the suggested scheme is fragile against this kind of attack. However, the suggested method is able to overcome these attacks, as shown in Fig. 5. Figure 5 (a) shows the original cDD, Fig. 5 (b) illustrates the cDD of the signal attacked using an RC low-pass filter with cut-off frequency equal to 5 kHz and Fig. 5 (c) shows the cDD of the signal attacked using an RC low-pass filter with a cut-off frequency equal to 2 kHz. It can be noticed that these RC low-pass filters do not destroy the cDD samples, but their amplitudes are scaled down by some factor (lower than 1). However, as mentioned above, this change in the scale does not affect the extracting process, since we use the ratio between the wavelet sample and the average of its frame. Hence, if the cDD samples are scaled then the average of the samples is scaled as well, the ratio is not changed by scaling and the extraction procedure is successful. In case of using other kind of filters with attenuation higher than that of RC low-pass filters, the watermark might be erased, but the perceptual quality of the attacked file would also be seriously damaged (since all frequencies beyond the cut-off frequency would be practically suppressed).

cDD a original b after RC_lowpass with cut-off frequency 5 kHz c after RC_lowpass with cut-off frequency 2 kHz
To consider the effect of MP3 compression and RC low-pass filter on the high frequency band of the wavelet decomposition, a part of “Beginning of the End” audio file is used as a sample and the attacks are performed on it. Figure 6 (a) shows the last high frequency band of the two-level wavelet decomposition with the 8-coefficient Daubechies wavelet, cDD of 15 s of “Beginning of the End”. As Fig. 6 (b) illustrates, the cDD, samples after coding and decoding by MP3-128, are similar to the original cDD samples. Furthermore, Fig. 6 (c) shows that the difference between the original and coded-decoded cDD samples is too small to affect the extracting process, as the experimental results presented in the next section show.

cDD a original b coded-decoded c difference between original and coded-decoded
3.2 Experimental results and comparative analysis
Table 1 shows the perceptual distortion and the payload obtained for the five songs with BER equal to zero (or near zero) under the attacks detailed in Table 2, for k = 6, α = 2 and the frame size equal to 10. In fact, by selecting k = 6, almost all wavelet samples are used for embedding. The following conditions can be assumed to obtain different capacity and transparency:
-
1.
No robustness. In this case, very good capacity and transparency can be achieved.
-
2.
Robustness against MP3 is demanded. In this case, more distortion should be accepted, compared with Condition 1.
-
3.
Robustness against the attacks in Table 2 is demanded. This is more complicated than the previous conditions since we need robustness against most common attacks. Thus, according to the trade-off between capacity, transparency and robustness, a sacrifice in capacity and transparency is required.
The results shown below try to provide robustness against common attacks. We have used several random bits for embedding, leading to different transparency results which are shown in the ODG column. Note that all the results have an ODG between 0 (not perceptible) and −1 (not annoying), the average SNR is 30 dB and capacity is around 11,000 bps for all the experiments. The proposed method is thus able to provide large capacity whilst keeping imperceptibility in the admitted range (−1 to 0).
Table 2 illustrates the effect of various attacks provided in the Stirmark Benchmark for Audio v1.0 [13] on ODG and the BER for the five audio signals of Table 1. The synchronization [15] which is robust against common attacks and the embedding method described in Section 2 have been used and, then the SMBA software has been applied to attack the whole marked files. Finally, the attacked file is scanned in time domain to find the synchronization codes then the secret information of each clip is extracted. The ODG in Table 2 is calculated between the marked and the attacked-marked files.
The parameters of the attacks are defined based on SMBA web site [13] for the proposed scheme. Other schemes may use different parameters. For example, in AddBrumm, 1–5 k shows the strength and 1–6 k shows the frequency. This row illustrates that any value in the range 1–5 k for the strength and 1–6 k for the frequency could be used with slight changes in BER. In fact, this table shows the ranges (the worst and best) of ODG and BER for the five test signals. When the BER is (slightly) greater than zero, it can be made zero by using Error Correction Codes at the price of reducing the capacity. The BER column for proposed scheme shows the total BER after embedding synchronization mark and watermark. E.g. the BER of the BassBoost attack changes from 0 to 2 without considering the synchronization however BER is increased to 6 to 14 after using synchronization.
Only a few attacks such as Pitchscale and TimeStretch in Table 2 remove the hidden data (BER > 15%). Note, however, that the ODG of these attacks are extremely low (about −3.5). This means that these attacks do not only remove the hidden data, but also destroy the perceptual quality of the host signal.
As already remarked, this scheme uses the high frequency band of the wavelet coefficients for embedding. Hence, it may seem that it would be fragile against attacks which manipulate or suppress the high frequency data. In Table 3, The MP3 and RC low-pass filter attacks are analyzed in depth with different types of audio clips. This table shows that the BER is increased by decreasing the MP3 rate also by decreasing cut-off frequency of the low-pass filter. In spite of that, the suggested method is still robust (BER < 15%) against these attacks for a wide range of the attack parameters.
In Table 4, we compare the performance of recent audio watermarking strategies, which are robust against common attacks, with the proposed method. [5] measures distortion using the mean opinion score (MOS), which is a subjective measurement, and achieves transparency between imperceptible and perceptible but not annoying (MOS = 4.7). [1, 16] propose low capacity schemes, but they are robust against most common attacks. In particular, [16] is robust against most common signal processing and attacks, such as Gaussian noise, re-sampling, re-quantization, and MP3 compression. Although the chosen schemes from the literature use different audio signals and attack parameters, the properties of each algorithm in capacity of embedding secret information and transparency are summarized in Table 4, and robustness against attacks is shown in Table 2. The comparison shows that the compared schemes are robust against common attacks and transparency is in an acceptable range, about 30 dB. However, the capacity of these schemes is just a few hundred bps (except for the method suggested in [3]). This comparison shows that the capacity of the proposed scheme is very remarkable, whilst keeping the transparency and BER in their acceptable ranges.
Using frames of wavelet samples results in an increased robustness against attacks, since the average of the samples is more robust than the value of each sample. Thus, by increasing the frame size, better robustness can be achieved. However, by increasing the frame size, we enforce the same value for a greater number of samples, which decreases the audio quality and transparency. In our experiments, the frame size equal to 10 has provided excellent transparency and acceptable robustness, but, depending on the specific application, this value might be adjusted.
It may seem that using high frequencies for embedding the secret bits would lead to a fragile scheme against low-pass filtering. Indeed, the experimental results show that the secret stream is damaged by low-pass filters with a cut-off frequency lower than 2 kHz, but these filters damage the cover signal as well. Figure 7 shows that, under the RC low-pass/high-pass filter attacks, the secret bit stream is extractable (BER < 5%) even when the ODG between the marked and the attacked file is about −3. I.e. this kind of filtering removes the secret information only if the quality of the attacked file is far from acceptable (in the “very annoying” ODG scale). As mentioned above, depending on the specific application, the embedding interval and the scale factor could be changed. E.g. if k = 6 and α = 1 for the clip “Beginning of the End”, ODG = −0.4 and BER under the attack MP3-128 is 0.07, but for k = 6 and α = 2, ODG = −0.6 and BER = 0.01. This example shows how the parameter α can be used to tune the trade-off between transparency and robustness. The embedding interval, k, and the scale factor, α, play a relevant role in adjusting the properties of the scheme. In fact, these parameters adjust the trade-off between capacity, transparency, and robustness. Figure 8 (a) shows that increasing the embedding interval increases the number of modified samples in the interval, which defines the capacity of the scheme. Similarly, Fig. 8 (b) illustrates the effect of the scale factor, (watermark strength) on transparency (ODG between original and marked signal) and robustness against Gaussian Noise (BER). It is obvious that with a small scale factor better transparency is achieved and increasing α leads to better robustness (decreasing BER) and more distortion. It is worth pointing out that, in the experimental results shown in this figure, α is chosen in the interval [0.5, 3].

Transparency versus BER under a low pass filtering attack b high pass filtering attack

a Capacity versus embedding interval b BER under Gaussian Noise versus ODG for various scale factors, α
4 Conclusion
Using the high frequency band of the wavelet decomposition, for which the human auditory system (HAS) is not very sensitive to alteration, leads to a robust high-capacity watermarking algorithm for digital audio. The proposed scheme divides the high frequency band into frames and uses the frames’ average (which is the same in the sender and receiver for each frame) as a key value, resulting in a blind scheme which provides robustness against common audio signal processing attacks. The experimental results show that this scheme has an excellent capacity (about 11 kbps) without significant perceptual distortion (ODG in the range [−1, 0] and SNR about 30 dB) and provides robustness against common signal processing attacks such as additive noise, echo, filtering or MPEG compression (MP3). A comparison with other schemes in the audio watermarking literature is also provided, showing that the suggested scheme outperforms the capacity of other approaches whilst keeping robustness and transparency in their acceptable ranges.
References
Akhaee MA, Saberian MJ, Feizi S, Marvasti F (2009) Robust audio data hiding using correlated quantization with histogram-based detector. IEEE TRANS ON Multimedia 11:1–9
Chen B, Wornell G (2001) Quantization index modulation: a class of provably good methods for digital watermarking and information embedding. IEEE Trans Inf Theory 47(4):1423–1443
Fallahpour M, Megías D (2009) High capacity audio watermarking using FFT amplitude interpolation. IEICE Electron Express 6(14):1057–1063
Fallahpour M, Megías D (2009) High capacity method for real-time audio data hiding using the FFT transform, Advances in Information Security and Its Application, Springer-Verlag. pp. 91–97
Garcia-Hernandez JJ, Nakano-Miyatake M, Perez-Meana H (2008) Data hiding in audio signal using Rational Dither Modulation. IEICE Electron Express 5(7):217–222
Kang H, Yamaguchi K, Kurkoski B, Yamaguchi K, Kobayashi K (2008) Full-index-embedding patchwork algorithm for audio watermarking. IEICE TRANS on Information and Systems E91-D(11):2731–2734
Kim HJ, Choi YH (2003) A novel echo hiding scheme with backward and forward kernels. IEEE Trans. Circuit and Systems, pp. 885–-889
Lie N, Chang LC (2005) Multiple watermarks for stereo audio signals using phase-modulation techniques. IEEE Trans Signal Processing 53(2):806–815
Megías D, Herrera-Joancomartí J, Minguillón J (2005) Total disclosure of the embedding and detection algorithms for a secure digital watermarking scheme for audio. Proceedings of the Seventh International Conference on Information and Communication Security, pp. 427–440, Beijing, China
No, really, “rust”. http://www.jamendo.com/en/album/7365
OPTICOM OPERA software site. http://www.opticom.de/products/opera.html
Pooyan M, Delforouzi A (2007) Adaptive and robust audio watermarking in wavelet domain. Third International Conference on International Information Hiding and Multimedia Signal Processing 2:287–290
Stirmark Benchmark for Audio. http://wwwiti.cs.uni-magdeburg.de/∼alang/smba.php
Thiede T, Treurniet WC, Bitto R, Schmidmer C, Sporer T, Beerens JG, Colomes C, Keyhl M, Stoll G, Brandenburg K, Feiten B (2000) PEAQ—The ITU standard for objective measurement of perceived audio quality. Journal of the AES 48((1/2)):3–29
Wang X-Y, Zhao H (2006) A novel synchronization invariant audio watermarking scheme based on DWT and DCT. IEEE Trans on Signal Processing 54(12):4835–4840
Wu S, Huang J, Huang D, Shi Y (2005) Efficiently self-synchronized audio watermarking for assured audio data transmission. IEEE Trans Broadcasting 51(1):69–76
Xiang S, Kim HJ, Huang J (2008) Audio watermarking robust against time-scale modification and MP3 compression. Signal Processing 88:2372–2387
Xu Z, Wang K, Qiao XH (2006) Digital audio watermarking algorithm based on quantizing coefficients. IEEE Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing 0-7695-2745-0/06
Acknowledgements
This work is partially supported by the Spanish Ministry of Science and Innovation and the FEDER funds under the grants TSI2007-65406-C03-03 E-AEGIS and CONSOLIDERINGENIO 2010 CSD2007-00004 ARES.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Fallahpour, M., Megías, D. High capacity audio watermarking using the high frequency band of the wavelet domain. Multimed Tools Appl 52, 485–498 (2011). https://doi.org/10.1007/s11042-010-0495-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-010-0495-1