
Abstract
This paper introduces IFUC, which is an Improved Fuzzy Unequal Clustering scheme for large scale wireless sensor networks (WSNs).It aims to balance the energy consumption and prolong the network lifetime. Our approach focuses on energy efficient clustering scheme and inter-cluster routing protocol. On the one hand, considering each node’s local information such as energy level, distance to base station and local density, we use fuzzy logic system to determine each node’s chance of becoming cluster head and estimate the cluster head competence radius. On the other hand, we use Ant Colony Optimization (ACO) method to construct the energy-aware routing between cluster heads and base station. It reduces and balances the energy consumption of cluster heads and solves the hot spots problem that occurs in multi-hop WSN routing protocol to a large extent. The validation experiment results have indicated that the proposed clustering scheme performs much better than many other methods such as LEACH, CHEF and EEUC.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Wireless Sensor Network (WSN) [1] is an emerging information acquisition technology. It has got a great scientific research development recent years, and it has been used widely in many fields, such as military affairs, circumstance observation, smart home and so on. However, WSN is confronted with many difficulties [2], such as limited communication ability, limited resources and mobile network, etc., so the design work of WSN protocols is very important. At present, it has been widely recognized that energy consumption is the primary consideration when designing WSNs, since it is non-rechargeable once the sensor nodes are deployed. Under this circumstance, we focus on the research of the network organization and data transmission technologies for large scale WSN in this paper.
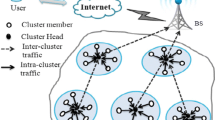
WSN routing technology is one of the most important technologies. According to the network architecture, WSN routing technologies can be divided into planar and hierarchical, and hierarchical network is also referred to cluster-based. Many experiments have provided evidence that cluster-based routing protocols work better in network topology management, energy minimization, data aggregation and so on than planar ones [3]. In large scale networks, nodes are usually partitioned into a number of small groups, called clusters, for aggregating data through efficient network organization. In cluster-based networks, cluster head nodes collect data packets from cluster members and transmit data to base station (BS) in either single hop or multi-hop mode by means of wireless communication.
In general, there have been substantial amount of researches on clustering protocol for WSN, and some development has been got in this study [4–6]. Summarily, one of the developing trends of WSN routing protocol is to improve the clustering scheme and optimize the paths from the cluster heads to the BS.
The clustering methods of WSN can be classified into centralized ones and distributed ones. The centralized methods often require all the nodes in the network send data packets to the BS directly and frequently. For example, in BCDCP, a centralized clustering method proposed by article [7], BS determines clusters and cluster heads according to node energy, node location and other information that reported by all the sensor nodes in the network. In the distributed methods such as LEACH [8] and HEED [9], clustering is performed by the interaction among proximity nodes in a distributed autonomous fashion, randomly or taking into account node energy, node density, etc. By contrast, the distributed self-clustering method based on local information is more effective in large scale WSNs. However, in many cases, the election of cluster heads is random or energy factor taken into consideration only. Therefore, limitations do exist.
In cluster-based network, cluster heads send data to BS in single hop or multi hop mode. Many studies have proved that, compared to single hop communication, multi hop communication mode is much more energy efficient especially in large scale networks. However, with multi hop communication the cluster heads that are closer to the BS are more likely to die earlier. Because they are under heavy traffic so that they deplete energy more rapidly, and that is called hot spots problem. EECS [10] and EEUC [11] are two typical unequal clustering routing protocols, and they have given new solutions on mitigating the hot spots problem occurred in that circumstance. In EECS, a distance-based cluster formation method is proposed to produce clusters of unequal size in single hop networks. A weight function is introduced to let cluster farther away from the BS have larger sizes, thus some energy could be preserved for long-distance data transmission to the BS. EEUC wisely organizes the network via unequal clustering and multi hop routing. It is a distributed competitive algorithm, where cluster heads are elected by localized competition, and the node’s competition range decreases as its distance to the BS decreasing. In the proposed multi hop routing protocol of EEUC for inter-cluster communication, a cluster head chooses a relay node from its adjacent cluster heads according to the node’s residual energy and its distance to the BS. However, most of the current unequal clustering schemes adopt the method of making the size of clusters closer to the BS smaller than those farther from the BS, so that more energy can be preserved for inter-cluster data transmission. Besides, the cluster size is determined by the distance from cluster head to BS only and the experiment condition adopted by them is also too idealistic. In fact the quantity values of some parameter indexes have fuzzy characteristics and usually they are difficult to be confirmed accurately. In order to handle the fuzzy characteristics, an improved fuzzy unequal clustering routing (IFUC) algorithm is proposed in this paper, the aim of which is to balance the energy consumption in the network and make a further improvement in prolonging the lifetime of WSN.
In the first phase, fuzzy logic module is adopted to handle the uncertainties in electing cluster heads and determining the cluster size. Fuzzy logic has great potential for dealing with conflicting situations and imprecision in data using heuristic human reasoning without needing complex mathematical modeling. The potential of fuzzy logic has been fully explored in the fields of signal processing, speech recognition, aerospace, robotics, embedded controllers, networking, business and marketing [12, 13]. Article [14] presents an extensive survey of fuzzy logic applications to various problems in WSNs from various research areas and publication venues. The authors also give a brief summary on the application of fuzzy logic to energy aware routing problem in WSN. A fuzzy logic approach for cluster head election based on energy, concentration and centrality is proposed for cluster head election in [15]. Experiments result indicates that this fuzzy method brings a great improvement to the network energy efficiency. However, the cluster heads in this method are elected at the BS and the defects of this centralized method are unavoidable. CHEF [16] is another fuzzy logic based clustering approach, which takes nodes’ energy and local distance into consideration in the process of clustering. Local distance in CHEF is the sum of distances between the tentative cluster head and other nodes within a constant distance. Moreover, it performs clustering in localized method, but it does not consider the inter-cluster data transmission. In our paper, the process of fuzzy logic based unequal clustering method is self-organized and distributed. The main idea of this clustering scheme is to utilize the sensor nodes’ local information including remaining energy, distance to BS and node density to determine the tentative cluster heads’ chance to be cluster heads and their competence radius.
In the second phase, we introduce Ant Colony Optimization (ACO) to our inter-cluster routing method. ACO was first put forward by Colorni et al. in 1991, which was originally presented under the inspiration of the collective behavior study results on real ant system and it has been applied extensively to many complicated combinatorial optimization problems. Nowadays, ACO has been used popularly by researchers to address the issue of energy aware routing, and it performs a significant potential to improve the performance of WSNs. Article [17, 18] present introductions to ant inspired algorithms and brief overviews of ant-based routing methods in WSNs. However, almost all of these applications are about planar routing in WSNs. In this paper, in order to achieve the goal of load balance, we adopt ACO to find the optimal paths from cluster heads to the BS by taking the characteristic of inter-cluster traffic into consideration.
The remainder of the paper is organized as follows: Section 2 introduces the basic model of IFUC algorithm. Subsequently, our IFUC algorithm is described in detail in Section 3, which is divided into two sub-sections, including the self-clustering module based on fuzzy logic and the inter-cluster routing based on ACO. Then, in Section 4 several simulation experiments are conducted and the simulation results are presented. Conclusion and future work are summarized in the last section.
2 System model
2.1 Network model
In this paper, we consider a sensor network consisting of N sensor nodes randomly deployed over a vast field to continuously monitor the environment. We make some assumptions about the sensor nodes and the underlying network model:
-
Sensors and the BS located from the sensing field are all stationary after deployment.
-
Sensors are homogeneous and have the same capabilities. All sensor nodes have the same amount of energy when they are initially deployed. Each node is assigned a unique identifier (ID).
-
Sensors can use power control to vary the amount of transmission power according to the distance to the desired recipient.
-
Links are symmetric. A node can compute the approximate distance to another node based on the received signal strength, if the transmitting power is known.
2.2 Energy consumption model
The communication energy dissipation model shown in [8] is adopted by this paper. We consider both the free space (d 2 power loss) and the multi-path fading (d 4 power loss) channel models. The energy spent for transmission of an l-bit packet over distance d depends on the distance between the transmitter and receiver, which is shown in Eq. 1.
And the energy spent to receive this message is shown in Eq. 2:
The item E elec in the equation above represents the energy consumption of radio dissipation, whiles ε friss−amp and ε two−ray−amp represent the energy consumption for amplifying radio, which are used depending on the transmission distance. And d 0 is a threshold value, \( {d_0} = \sqrt {{{\varepsilon_{{friss - amp}}}/{\varepsilon_{{two - ray - amp}}}}} . \)
It is assumed that the sensed information is highly correlated, whereas the correlation degree of sensed data from different clusters is comparatively low, thus the cluster head also play the role of aggregating the data gathered from its members into a single length-fixed packet, and the operation of 1 bit data aggregation consumes the energy as E DA .
3 The proposed mechanism
3.1 Fuzzy logic based unequal self-clustering scheme
The BS broadcasts an initial message to all the sensor nodes at the network deployment stage. The initial message contains the initial energy of the sensor nodes in the network, the farthest distance between the sensor nodes and the BS, the maximum nodes density designed for the network and the largest competence radius set for this network, which are useful in the process of clustering. Besides, each sensor node in the network can compute the approximate distance to the BS based on the received signal strength. In this paper the operation of the proposed clustering scheme is divided into rounds like many other clustering algorithms and the characteristic of this algorithm is the application of fuzzy logic. Fuzzy logic imitates the logic of human thought, which is much less rigid than the calculations computers generally perform, and it offers several unique features that make it a particularly good alternative for many control problems [19, 20]. The main structure of this clustering scheme is shown in Fig. 1. As is shown in Fig. 1, the process of the clustering algorithm is performed in the following five steps, and next we will explain this in more detail.

Structure of fuzzy logic based unequal self-clustering scheme
Local information gathering
Several tentative cluster heads are first elected randomly to compete for final cluster heads at the beginning of each round. The percentage of the desired tentative cluster heads is T, which is a predefined threshold. Every sensor node generates a random number that between 0 and 1. If the number is under the threshold, the node will become the tentative cluster head and it will receive the HELLO_MSG broadcasted by other nodes that not become tentative cluster heads. According to the signal strength, the approximate distance between the receiver and transmitter will be calculated and the transmitters will be added to the receiver’s neighbor nodes set. At last, the following three parameters are collected by each tentative cluster head.
-
Remaining Energy(represented by ENERGY), which is the remaining battery power of the tentative cluster head.
-
Distance to BS(represented by DISTANCE), which is a value has been got at the network deployment stage.
-
Local Density (represented by DENSITY), which is the number of nodes in a tentative cluster head’s neighbor nodes set.
Fuzzification
Fuzzification is the first phase of the clustering process. It maps each crisp input value to the corresponding fuzzy sets and thus assigns it a truth value or degree of membership. It is done by giving values (ENERGY, DISTANCE and DENSITY) to each of a set of membership functions. The fuzzy sets for the input variables are given in Table 1, and the membership functions for the input variables are shown in Figs. 2, 3 and 4, respectively.

Membership function for ENERGY

Membership function for DISTANCE

Membership function for DENSITY
Fuzzy decision blocks
For this step, the fuzzified values got from fuzzification step will be further processed by the inference engine. A rule base and various methods for inferring the rules are involved in the inference engine. The rule base usually contains a series of IF-THEN rules that relate the input fuzzy variables with the output fuzzy variables using linguistic variables, each of which is described by a fuzzy set, and fuzzy implication operators AND, OR etc. In this paper, we denote the three fuzzy input variables (ENERGY, DISTANCE and DENSITY) by x 1, x 2 and x 3, respectively. And we use CHANCE and RADIUS to represent a tentative cluster head’s chance to be final cluster head and its competence radius, which are two fuzzy output variables in our system. For simplicity, we denote them by y 1 and y 2.
We describe the basic form of the rules in our rule base as followed, and 27 such rules are contained in our rule base:
-
Rule(i) IF x 1 is \( A_1^i \) AND x 2 is \( A_2^i \) AND x 3 is \( A_3^i \) THEN y 1 is \( B_1^i \) AND y 2 is \( B_2^i \)
Where, i means the i-th rule in the fuzzy rule base. A 1…A 3 is the fuzzy set of x 1…x 3, B 1and B 2is the fuzzy set of y 1 and y 2 respectively.
Table 2 shows a few rules of fuzzy rule base. The rules can be formulated according to the criteria described above. All the rules in the rule-base are processed in a parallel manner by the fuzzy inference engine. An output is produced for each rule and the outputs of all rules are aggregated at last. For simplicity, the method we use here is the most commonly used fuzzy inference method called Mamdani Method.
Defuzzification
Defuzzification is a process turning the output generated and aggregated by the fuzzy logic rules into a crisp output variable. There are a number of ways of doing this, and we use the Center of Area (COA) method here, which is one of the simplest and most widely used methods. It works as like this:
Where Z COA is the crisp output value, and μ(z) is the membership function after the outputs of all rules are aggregated.
Table 3 gives the corresponding fuzzy sets of output variables. Figures 5 and 6 show the shape of each membership function of the output variables.

Membership function for CHANCE

Membership function for RADIUS
Cluster construction
Through the above four steps, each tentative cluster head can get its chance to be cluster head and competence radius, and then cluster head competition begins. Each tentative cluster head broadcasts a COMPETE_CH_MSG which contains node ID and chance to be cluster head within its competence radius. Once the tentative cluster head finds that there is another tentative cluster head with a greater chance to be cluster head, it will give up competition by advertising a QUIT_COMPETE_MSG within its competence radius. Otherwise, it will become the cluster head in the end. And at last the tentative cluster head with the greatest chance to be cluster head within its competence radius will become cluster head. After cluster head election phase is completed, each cluster head broadcasts an advertisement message indicating its role through the network. Receiving these messages, ordinary sensor nodes in the network make a choice and join to the closest cluster, and the cluster construction is completed.
3.2 Inter-cluster routing based on ant colony optimization
ACO has been applied to optimization problems in a variety of fields successfully [21, 22] as a promising algorithm, and it has obvious advantage in adaptive routing in communication networks. We propose the inter-cluster routing based on ACO in this paper, and it will be introduced as following steps.
-
Step 1:
The main point of the inter-cluster routing is how to find a proper relay node for a cluster head. This is the first priority for a cluster head after gathering and aggregating the data of its own member nodes. Therefore, we first construct a neighbor set which the relay cluster head node could be chosen from.
At first, all the cluster head nodes broadcast a NEIGHBOR_DISCOVERY_MSG with a certain power, which contains the cluster head’s Node ID, Residual Energy and Distance To BS. We consider a cluster head receives such messages from several cluster heads around within a radius of R. The receiver is denoted by S i , and the transmitters can be denoted by S j1, S j2, S j3···. And according to the received signal strength, the distance between the receiver and transmitter can also be calculated. Any transmitter node S j that meets the following requirement can be placed into the neighbor node set of S i .
$$ {d_{{({S_j},{\text{\,BS}})}}} < {d_{{({S_i},\,{\text{BS}})}}} $$(4)The purpose of the above equation is to ensure that the inter-cluster data be transmitted in the right direction to the BS. Where \( {d_{{({S_j},{\text{BS}})}}} \) is the distance between S j and BS, and \( {d_{{({S_i},{\text{BS}})}}} \) is the distance between S i and BS.
-
Step 2:
Next, an ant is placed at each cluster head at regular intervals to find a path to the BS. And the ant determines the next hop node according to the following equation.
$$ p_{{ij}}^k = \frac{{{{[{\tau_{{ij}}}(t)]}^{\alpha }}{{[{\eta_{{ij}}}]}^{\beta }}}}{{\sum\nolimits_{{s \in {N_i}}} {{{\left[ {{\tau_{{is}}}(t)} \right]}^{\alpha }}{{\left[ {{\eta_{{is}}}} \right]}^{\beta }}} }} $$(5)$$ {\eta_{{ij}}} = \frac{{{E_j}}}{{\sum\nolimits_{{s \in {N_i}}} {{E_s}} }} \cdot \frac{1}{{{d^2}_{{({S_i},{\,S_j})}} + {d^2}_{{({S_j},\,{\text{BS}})}}}} $$(6)\( p_{{ij}}^k \) in Eq. 5 is the probability with which ant k chooses to move from node S i to node S j , and we make it a trade-off between visibility (which says that nodes with more energy and less transmission cost should be chosen with high probability) and actual trail intensity (that says that if on connection (S i , S j ) there have been a lot of ants passing by then it is highly desirable to use that connection). τ ij (t) is the pheromone trail value of edge (S i , S j ) and η ij is the visibility function from cluster head S i to S j , which is denoted by Eq. 6. α and β are the parameters that control the relative importance of trial versus visibility. N i is the neighbor set of S i , from which the next hop cluster head can be chosen by the k-th ant.
-
Step 3:
The path information is collected by the ants that pass by, and the BS begins to analyze data after the k-th ant’s arrival. And the information collected by the k-th ant is described as \( \{ ({S_0},{d_{{({S_0},{S_1})}}}),\;({S_1},{d_{{({S_1},{S_2})}}}),\;({S_2},{d_{{({S_2},{S_3})}}}),...\;({S_{{l - 1}}},{d_{{({S_{{l - 1}}},{S_l})}}})\} \). Where S 0 is the source cluster head node and S l is the destination BS. And the sequence of distinct nodes {S 0, S 1, S 2…S l } constitutes the path. Meanwhile, we define a function F to evaluate the path mentioned above, and the equation is given below.
$$ F = \frac{Q}{{Cost \cdot Balance}} $$(7)Where Q is a constant, Cost is a value indicating the communication cost of the path and Balance is a variance value indicating the balance degree of energy consumption among the edges in the path. The energy consumption in edge (S i–1, S i ) is denoted by C i . Considering the energy consumption is proportional to the square of transmission distance and in multi hop transmission mode the data traffic increases with the decreasement of the distance to BS, we define Cost as Eq. 8 and Balance as Eq. 9.
$$ Cost = \sum\limits_{{i = 1}}^l {{C_i} = } \sum\limits_{{i = 1}}^l {i{d^2}_{{({S_{{i - 1}}},{S_i})}}} $$(8)$$ Balance = \frac{1}{l} \cdot \sum\limits_{{i = 1}}^l {{{({C_i} - \frac{1}{l} \cdot \sum\limits_{{i = 1}}^l {{C_i}} )}^2}} $$(9)According to the evaluation function, the best path among all the ants in one iteration will be got by the BS. Then, the BS broadcasts a message to inform the nodes in the best path to update the pheromone according the following equations:
$$ {\tau_{{ij}}}(t + n) = (1 - \rho ){\tau_{{ij}}}(t) + \Delta {\tau_{{ij}}} $$(10)$$ \Delta {\tau_{{ij}}} = {F_{{best}}} $$(11)The symbol ρ in Eq. 10 is a evaporation coefficient such that (1–ρ) represents the reservation of pheromone concentration since the last time updated. F best is the evaluation function value of the best path found in one iteration.
By performing step 2 and step 3 several iterations, each cluster head node will be able to find the best next hop cluster head node to send a packet, and then data transmission will begin.
4 Simulation and Results
In this part, we conduct a series of simulation experiments to investigate the feasibility and effectiveness of the unequal clustering routing scheme IFUC proposed in this paper. These simulation experiments are all implemented in Matlab programming environment. The emphasis of our work is to construct a model that can simulate the energy consumption in the network with various protocols. We consider a scenario like this: sensed data is produced from every sensor node at regular intervals, and then turned into data packets. Cluster heads collect data packets from cluster members, aggregate the data, and then transmit the data to BS. The control messages during the process of clustering and data transmission can be seen as the overheads in various protocols, the energy consumption brought by which is also taken into consideration in our work. Similar to EEUC, an ideal MAC layer and error-free communication links are assumed and we calculate each node’s energy consumption from data transmission and aggregation per round.
According to the network model and energy consumption model mentioned in Section 2, we evaluate the performance of our algorithm and compare it with several protocols like LEACH, EEUC, CHEF and IFUC-M. The IFUC-M we mentioned above is a protocol named first in our paper. It combines the fuzzy unequal clustering mechanism of IFUC and the multihop data transmission method of EEUC, and the purpose of IFUC-M is to clearly verify the effectiveness of fuzzy logic based unequal clustering and ACO based inter-cluster routing separately.
In our simulation, we deploy 400 nodes in the area of 200 × 200meters randomly, and the BS is located at (100,250)m. Each sensor node is assigned 0.5 J energy initially and the length of data packet in our simulation is 4000bits, control packet size is 100bits. The other parameters that are relevant to radio model is the same as [8], in which \( {E_{{DA}}} = {\text{5nJ}},\;{E_{{elec}}} = {5}0{\text{nJ}}/{\text{bit}}/{\text{m}},\;{\varepsilon_{{friss - amp}}} = {1}0{\text{pJ}}/{\text{bit}}/{{\text{m}}^{{2}}},\;{\varepsilon_{{two - ray - amp}}} = 0.00{\text{13pJ}}/{\text{bit}}/{{\text{m}}^{{4}}} \). The initial parameters that are relevant to ACO are: \( \alpha = {1},\;\beta = {5},\;\rho = 0.{2},\;Q = {6} \times {1}{0^{{9}}} \), iteration times = 20,the number of ants = 15.
In order to check the energy efficiency of the five algorithms, we examine the network lifetime first. Figure 7 illustrates the distribution of the dead sensor nodes with respect to the number of rounds for each algorithm, from which we can see that the number of dead nodes in IFUC changes over time more slowly overall, next IFUC-M, then EEUC, CHEF and LEACH in order. The metrics First Node Died (FND) and Half of the Nodes Died (HND) are used in this paper as the indicator of WSN lifetime. The bar chart in Fig. 8 gives a comparison of the five algorithms graphically considering FND and HND metrics.

Number of dead nodes over time

Values of FND and HND metrics for each algorithm
As seen in Fig. 8, if FND metric is considered, the performance of IFUC and IFUC-M are almost the same, and they are better than the other three algorithms. And if we consider the HND metric, IFUC runs the best among the five algorithms. The lifetime of network with IFUC is longer than that with IFUC-M, EEUC, CHEF and LEACH about 23%, 46%, 77% and 84% respectively. In our simulation work, we choose 20 rounds randomly and calculate the amount of the cluster heads energy consumption during each round in the five algorithms, the result of which is shown clearly in Fig. 9. As we can see, the energy consumed by cluster heads in IFUC, IFUC-M and EEUC per round is much lower than in LEACH and CHEF significantly. Furthermore, the cluster heads energy consumption of IFUC-M is a little lower than EEUC and IFUC consumes less energy than IFUC-M.

The amount of energy consumed by cluster heads per round
We also calculate the variance of amount of energy spent by cluster heads in each of the 20 randomly selected rounds, and the result is shown in Fig. 10, which indicates the balance degree of the energy consumption among cluster heads per round in the five algorithms. As is shown in Fig. 10, the variance of IFUC, IFUC-M and EEUC is also much lower and steadier than LEACH, CHEF and EEUC evidently. And the performance of IFUC is also the best in this respect.

The variance of energy consumed by cluster heads per round
Next, we will draw some conclusions from the above results and give corresponding explanations. The performance of LEACH is the poorest, because the election of cluster heads is random, neither residual energy nor other factors are taken into consideration during clustering. And the data transmission between cluster heads and BS is another important factor, because the single hop model adopted by LEACH results in a great waste of energy. CHEF also use the single hop inter-cluster data transmission method, so although it takes energy and local distance factors into consideration to elect cluster heads by using fuzzy logic system, the improvement of its performance is just in a limited range. In contrast, EEUC, IFUC-M and IFUC perform much better. Because of the application of unequal clustering and inter-cluster data forwarding, EEUC achieves an obvious improvement on the network lifetime and a significant reduction in the energy consumption of cluster heads. Furthermore, the amount of energy consumed by cluster heads per round becomes far more stable. The difference between EEUC and IFUC-M is that the latter adopts unequal clustering scheme based on fuzzy logic, and in the process of cluster head election and competence radius calculation, node’s energy level, distance to base station and local density are considered. So we can see from the simulation results that IFUC-M performs better than EEUC. The clustering method of IFUC is the same as IFUC-M. Besides, IFUC introduces ACO into the inter-cluster routing. The experiment results indicate that the election of cluster heads and the decision of cluster size are more reasonable due to the use of fuzzy logic. And the inter-cluster routing based on ACO balances the energy consumption and makes the hot spot problem alleviated effectively. Therefore, IFUC makes a further improvement in prolonging the network lifetime, and the energy consumption of cluster heads per round decreases further with the most steady. Generally speaking, IFUC performs the best among the five algorithms.
5 Conclusions and future work
We have proposed a new unequal clustering scheme based on fuzzy logic in this paper to improve the energy efficiency and achieve the network load balance. Local information of tentative cluster heads including residual energy, distance to BS and local density were used as the three input of the fuzzy logic system, by which we got the tentative cluster heads’ chance to be final cluster heads and their competence radius as the important criteria for cluster construction. Besides, considering the inter-cluster communication cost and the balance degree of energy consumption along the path, we used ACO to find the optimal path between cluster head and BS. The simulation experiments we have done show that both the unequal clustering method and inter-cluster scheme of IFUC have excellent performance. It balances the energy consumption in the network and extends the network lifetime to a great extent, so it’s a suitable algorithm for large scale WSNs.
In the future, we will study more factors that affect the performance of WSNs in the process of clustering. As for the membership function of the fuzzy logic system, we will seek more reasonable fashion, and adaptive adjustment may offer a good solution. And there is still room for the improvement of inter-cluster routing based on ACO. We will study the parameter settings of ACO in the future, and look for optimal parameters combination through more simulation works.
References
Akyildiz I, Su W, Sankarasubramaniam Y, Cayirci E (2002) A survey on sensor networks. IEEE Comm Mag 40(8):102–114
Wang F, Liu J (2011) Networked wireless sensor data collection: issues, challenges, and approaches. IEEE Commun Surv Tutor 13(4):673–687
Belding-Royer E (2002) Hierachical routing in ad hoc mobile networks. Wirel Commun Mob Comput 2(5):515–532
Deosarkar BP, Yadav NS, Yadav RP (2008) Cluster head selection in clustering algorithm for wireless sensor networks: A survey, International Conference on Computing, Communication and Networking, 2008. ICCCN, pp;1–8
Younis O, Krunz M, Ramasubramanian S (2006) Node clustering in wireless sensor networks: recent developments and deployment challenges. IEEE Netw 20(3):20–25
Abbasi AA, Younis M (2007) A survey on clustering algorithms for wireless sensor networks. Comput Commun 30(14–15):2826–2841
Muruganathan SD, Ma DCF, Bhasin RI, Fapojuwo AO (2005) A centralized energy-efficient routing protocol for wireless sensor networks. IEEE Comm Mag 43(3):S8–13
Heizelman W, Chandrakasan A, Balakrishnan H (2002) An application-specific protocol architecture for wireless MicroSensor networks. IEEE Trans Wirel Commun 1(4):660–670
Younis O, Fahmy S (2004) HEED: a hybrid, energy-efficient, distributed clustering approach for Ah Hoc Sensor networks. IEEE Trans Mob Comput 3(4):660–669
Ye M, Li CF, Chen GH, Wu J(2005) EECS: An Energy Efficient Clustering Scheme in Wireless Sensor Networks, 24th IEEE International Performance, Computing, and Communication Conference, 2005. IPCCC , pp. 535–540
Li CF, Ye M, Chen GH, Wu J(2005) An energy-efficient unequal clustering mechanism for Wireless sensor network. IEEE International Conference on Mobile Adhoc and Sensor Systems Conference, 2005. pp. 596–640
Ghosh S, Razouqi Q, Schumacher H, Celmins A (1998) A survey of recent advances in fuzzy logic in telecommunications networks and new challenges. IEEE Trans Fuzzy Syst 6(3):443–447
Zadeh LA (2008) Is there a need for fuzzy logic? Annual Meeting of the North American on Fuzzy Information Processing Society, May 19-22, 2008, NAFIPS, pp. 1–3
Kulkarni RV, Forster A, Venayagamoorthy GK (2011) Computational intelligence in wireless sensor networks: a survey. IEEE Commun Surv Tutor 13(1):68–96
Gupta I, Riordan D, Sampalli S (2005) Cluster-head election using fuzzy logic for wireless sensor networks. In Proceedings of the 3rd Annual Communication Networks and Services Research Conference, pp. 255–260
Kim J, Park S, Han Y et al (2008) CHEF: cluster head election mechanism using fuzzy logic in wireless sensor networks. Proceedings of the ICACT, Feb. 17–20, 2008. 654–659
Iyengar SS, Wu HC, Balakrishnan N et al (2007) Biologically inspired cooperative routing for wireless sensor networks. IEEE Syst J 1(1):29–37
Sim KM, Sun WH (2003) Ant colony optimization for routing and load-balancing: Survey and new directions. IEEE Trans Syst Man Cybern 33(5):560–572
Zadeh LA (1996) Fuzzy logic = computing with words. IEEE Trans Fuzzy Syst 4(2):103–111
Minhas MR, Gopalakrishnan S, LeungV (2008) Fuzzy Algorithm for Maxmum Lifetime Routing in Wireless Sensor Networks. In Proceedings of the IEEE Global Telecommunications Conference (Globecom), pp. 1–7
Dorigo M, Gambardella LM (1997) Ant colony system: a cooperative learing approach to the travelling salesman. IEEE Trans Evol Comput 1(1):53–66
Kim Y-M, Lee E-J, Park H-S (2011) Ant colony optimization based energy saving routing for energy-efficient networks. IEEE Comm Lett 15(7):779–781
Acknowledgments
This work was supported by National Science and Technology Major Project of the Ministry of Science and Technology of China (Grant No.2009ZX03006-006, No. 2009ZX03006-009)and National Natural Science Foundation of China(Grant No. 60902046, No. 60972079),and this research was partly supported by the The Ministry of Knowledge Economy, Korea, under the ITRC support program supervised by the NIPA (NIPA-2011-C1090-1111-0007).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Mao, S., Zhao, C., Zhou, Z. et al. An Improved Fuzzy Unequal Clustering Algorithm for Wireless Sensor Network. Mobile Netw Appl 18, 206–214 (2013). https://doi.org/10.1007/s11036-012-0356-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11036-012-0356-4