
Abstract
Context
Field inventory plots which usually have small sizes of around 0.25–1 ha can only represent a sample of the much larger surrounding forest landscape. Based on airborne laser scanning (LiDAR) it has been shown for tropical forests that the bias in the selection of small field plots may hamper the extrapolation of structural forest attributes to larger spatial scales.
Objectives
We conducted a LiDAR study on tropical montane forest and evaluated the representativeness of chosen inventory plots with respect to key structural attributes.
Methods
We used six forest inventory and their surrounding landscape plots on Mount Kilimanjaro in Tanzania and analyzed the similarities for mean top-of-canopy height (TCH), aboveground biomass (AGB), gap fraction, and leaf-area index (LAI). We also analyzed the similarity in gap-size frequencies for the landscape plots.
Results
Mean biases between inventory and landscape plots were large reaching as much as 77% for gap fraction, 22% for LAI or 15% for AGB. Despite spatial heterogeneity of the landscape, gap-size frequency distributions were remarkably similar between the landscape plots.
Conclusions
The study indicates that biases in field studies of forest structure may be strong. Even when mean values were similar between inventory and landscape plots, the mostly non-normally distributed probability densities of the forest variable indicated a considerable sampling error of the small field plot to approximate the forest variable in the surrounding landscape. This poses difficulties for the spatial extrapolation of forest structural attributes and for assessing biomass or carbon fluxes at larger regional scales.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The structure of forest landscapes is often spatially heterogeneous at various scales due to topographical, ecological, and biogeochemical effects, man-made land use or natural disturbances (Hewitt et al. 2007; Gossner et al. 2013). Especially in tropical montane forests with steep slopes and regular disturbances such as landslides or fire, spatial heterogeneity of forest structure may be quite pronounced (Dislich and Huth 2012; Brown et al. 2013; Punchi-Manage et al. 2013). Such spatial variation in habitat structure can have cascading feedback effects where plant demographics interact with spatial structure, leading to changes in tree-size distributions and overall intensified successional forests dynamics (Hewitt et al. 2007; Getzin et al. 2008). Consequently, spatial heterogeneity within forest landscapes does strongly affect the distribution of canopy openings, aboveground biomass and carbon stocks, important ecophysiological attributes such as the leaf-area index, but also animal movement patterns, biodiversity or ecosystem services (Asner et al. 2013a; Detto et al. 2015; Bustamante et al. 2016; McLean et al. 2016).
The monitoring of forest structure is often based on terrestrial data obtained from field inventory plots but such plots have usually only small sizes of around 0.25–1 ha (Getzin et al. 2006; Mascaro et al. 2011; Asner and Mascaro 2014; Rutten et al. 2015). Their limited size is attributed to the high efforts being associated with plot establishment and monitoring (Fischer et al. 2010; Bustamante et al. 2016). Also, the size and the particular location of field inventory plots may depend on accessibility of remote forest areas and on topographical constraints such as surrounding deep valleys, riverbeds or swamps. Additionally, the selected forest plots shall usually represent undisturbed stands with trees and relatively closed canopy but not areas which may have much larger proportions of disturbance-driven openings. Therefore, especially in montane tropical forests with undulating or steep-sloping terrain, the choice of setting up inventory plots can hardly account for the spatial variability being inherent to the forest structure of the host landscape surrounding the small field plots. Consequently, biases in local plot selection may cause undesired effects when the goal is to extrapolate terrestrial information on vegetation structure to larger spatial scales. This difficulty hampers also the appropriate estimation and simulation of carbon stocks and fluxes with forest models for various scenarios of climate change (Fischer et al. 2015). In order to assess and quantify the actual bias in the selection of small field inventory plots, it is necessary to integrate technologies such as remote sensing for scaling up results in ecology and conservation (Marvin et al. 2016).
One important tool for acquiring large-scale information on forests is light detection and ranging (LiDAR). Airborne 3D-laser scanning or LiDAR is capable of accurate monitoring of forest structure in remote areas which would be otherwise inaccessible for terrestrial surveys (Asner et al. 2010, 2013a; Boyd et al. 2013). Hence, LiDAR-based surveys can gather information at a scale exceeding tens, hundreds or thousands of times the size of field inventory plots (Asner and Mascaro 2014). 3D-information from airborne laser scanning allows nowadays precise estimates of key structural attributes such as gap fraction and gap-size distribution (Asner et al. 2013b; Boyd et al. 2013; Bonnet et al. 2015), top-of-canopy height (TCH), aboveground biomass (AGB) or carbon density (Asner et al. 2013a; Asner and Mascaro 2014). Furthermore, the information from multiple returns of LiDAR echos can be used to calculate the leaf-area index (LAI) for a given vertical foliage profile contained in a volumetric pixel or also called voxel (Harding et al. 2001; Detto et al. 2015). Similar to AGB, the LAI is a key variable for regional and global models of biosphere–atmosphere exchanges of energy, carbon dioxide or water vapor (Asner et al. 2003).
Once these different structural attributes and ecophysiological variables have been determined with LiDAR for a forest region, their mean values and frequency distributions can be compared to the mean values obtained from the small field inventory plots located within the surrounding host landscape. Due to the presence of spatial heterogeneity, such comparisons may reveal strong biases in the selection of local field plots, as has been recently shown in a study from Peruvian Amazonia. In this research, Marvin et al. (2014) found that mean biases in forest canopy structure and aboveground biomass in both lowland Amazonian and montane Andean landscapes may reach as much as 9–98%. The study thus demonstrated that there was a considerable sampling error of the location and size of field inventory plots to approximate their surrounding host landscape.
Here, we undertook a related study in wet montane tropical forest of northern Tanzania to investigate whether comparable biases do also prevail in equatorial East Africa. For this reason, we selected the UNESCO World Heritage Site, Mount Kilimanjaro, because this ancient volcano comprises of considerable slopes, steep gorges and valleys. Furthermore, the six chosen inventory plots and surrounding host landscape plots between 1800 and 2560 m altitude are partly affected by past disturbance and land use (Ensslin et al. 2015), making them ideal to explore the effects of spatial heterogeneity on forest structure. The primary goal of this study is to assess the spatial heterogeneity with respect to selected field plots and forest variables such as TCH, AGB, gap fraction or LAI.
Besides spatial heterogeneity and structural dissimilarity, we also explored the similarities between the six different host landscapes with respect to canopy openings. It is assumed that forests are organized by allometric scaling relationships that explain how trees use resources and pack their crowns to fill space (Enquist et al. 2009; Taubert et al. 2015). Thus, a set of very general scaling rules may explain why, for example, tropical tree size distributions can be remarkably consistent despite differences and spatial heterogeneity in the environments that support them (Farrior et al. 2016). Nowadays, high-resolution data based on drone images or LiDAR also enables the accurate detection of very small gap sizes including openings of just 1 m2 (Boyd et al. 2013; Getzin et al. 2014). This allows, in particular, detailed analyses of the poorly understood gap-size frequency distributions in tropical forests and thus novel insights into gap dynamics. One of the key questions we are asking in this context is whether gap-size frequencies are similarly power-law distributed and consistent across different forest landscapes as is known from Amazonia (Asner et al. 2013b; Espírito-Santo et al. 2014; Marvin and Asner 2016). Our study will therefore compare recent results from South American tropical forests not only with respect to spatial heterogeneity of forest structure but also in the light of scaling rules that may potentially govern the distribution of canopy openings equally across the otherwise heterogeneous landscape. The following are the main questions of this study: (1) are the biases between inventory and landscape plots in montane tropical forest of East Africa similar to findings from tropical Amazonia, (2) are the forest variables on Mount Kilimanjaro also primarily non-normally distributed as in Amazonia, and (3) are the gap-size frequencies power-law distributed in different stands with various degrees of spatial heterogeneity?
Methods
Study sites and inventory plots
The study sites were located at the southern and south-eastern slopes of Mount Kilimanjaro in Tanzania. Our six chosen inventory plots (IP) named Flm1, Flm2, Flm6, FOc1, FOd4, and FOd5 (Ensslin et al. 2015) were located in the lower and middle montane forests which are characterized by Ocotea-Agauria or -Syzygium associations and Ocotea-Podocarpus, respectively. The climate there is wet tropical with mean annual precipitation reaching ≈2700 mm and mean annual temperature ≈15.6 °C at 2200 m altitude (Hemp 2006). The IPs Flm1, Flm2, and Flm6 belong to the natural lower montane forests at 1800–2040 m altitude, FOc1 is a natural middle montane forest at 2120 m altitude, and FOd4 and FOd5 are anthropogenically affected montane forests at 2370–2560 m elevation (Ensslin et al. 2015). Except for the inventory plot FOc1 which has a size of 60 × 43 m2, all other IPs have a size of 50 × 50 m2.
Mapping landscape with airborne LiDAR
Full waveform airborne laser scanning data were obtained in 2015 with a Riegl LMS Q780. The scanner has a rotating polygon mirror and scans in parallel lines. The scan field of view is 60° and the wavelength of the scanner is near infrared (1064 nm). The waveform signal of the laser scanner has been automatically decomposed by the RIEGL software tool RiANALYZE into components of echos to produce discrete-return data. With the supplied LASer (LAS) file format, up to seven returns per pulse were generated to enable the accurate mapping of all vegetation layers deep into the understory and to the ground.
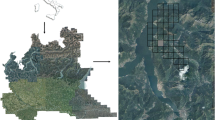
The aircraft was an Airbus helicopter (Model: AS 350B3) which flew in separate narrow lines over the inventory plots on the slopes of Mount Kilimanjaro (Fig. 1a). As a result, the airborne LiDAR data of the surrounding host landscape around each IP represents a stripe-like landscape plot (LP). The shapefiles of the individual flight paths were analyzed with QGIS 2.12-software (www.qgis.org) and overlayed with the borders of the inventory plots. Visual interpretation based on satellite imagery available in Google Earth was employed to select the final borders of the surrounding landscape plots so as to have a representative host landscape that generally matches the individual location of the IP (see Fig. 1b, c for an example). Notably, this was an estimation based on canopy structure and the possibility to identify even individual tree crowns using these high resolution images from 2014 to 2016. With this visual approach we were able to apriorily exclude strongly biasing effects and abrupt changes in bordering forest structure that may typically occur on Mount Kilimanjaro resulting from past disturbances (e.g. fire or logging) or from sudden changes in terrain structure such as neighboring steep gorges. Hence, the goal was to select surrounding host landscapes that were as much as possible representative for the small inventory plots because we excluded very obvious changes in forest structure based on information from satellite imagery (Fig. 1c). The Kilimanjaro landscape is in itself relatively heterogeneous at scales that would be otherwise more homogeneous, for example, in areas of Amazonia. But the objective of this study was to select uniform subsets of host landscapes and then to assess the representativeness of the chosen inventory plots based on LiDAR analysis that enables a statistical comparison of forest structure and bias far more precisely and standardized than a mere visual interpretation of satellite images. The exclusion of unrepresentative areas from the LiDAR flight paths resulted in host landscapes of varying sizes (Table S1). The mean size of all six LPs was 31 ha and thus more than 120 times larger than the 0.25 ha IPs.

Mount Kilimanjaro features extensive montane tropical forests on its slopes (a). A LiDAR-based point cloud of the forest inventory plot Flm1 is shown (b). The same plot is indicated as a 50 × 50 m2 square within the surrounding 28 hectare landscape plot (c). The landscape plot was gridded to 25 × 25 m2 cells and forest structural attributes such as mean top-of-canopy height within each cell was calculated (d)
Calculating different metrics from LiDAR
The LiDAR raw data were processed with a combination of R-software (R Development Core Team 2016) and LAStools-software (Isenburg, http://lastools.org). At first, we used LASnoise to remove outlier points and then LASground to determine ground points and the digital terrain model (DTM). LASheight was used to height normalize the data points where all returns represent the true Z-coordinate of aboveground vegetation, irrespective of the underlying topography. These un-thinned data sets containing all the points were later employed to calculate the leaf-area index (see below) but for all other metrics, the point clouds were thinned out to generate a canopy-height model (CHM). Initially, the CHM was obtained with LASgrid via a smoothing kernel and selecting the highest point within a 0.25 × 0.25 m2 grid cell. However, the point density was finally reduced to the highest LiDAR return within a 1 × 1 m2 grid cell.
Mean top-of-canopy height (TCH) was calculated at a resolution of 25 × 25 m2 grid cells (Fig. 1d), a scale which was e.g. similarly used for this purpose by Asner et al. (2016). Hence, mean TCH is the average of all 625 height values within each grid cell, obtained from the CHM at 1 m2 resolution. For the 50 × 50 m2 inventory plots, we then calculated from that the overall mean value in the IP. The same was also done for the much larger landscape area but additionally we calculated from all 25 × 25 m2 grid cells in the LP the coefficient of variation (CV), which is a measure for the spatial heterogeneity of the forest variable (Marvin et al. 2014). In order to analyze the bias (%Δ) in the mean TCH for the inventory plot as compared to the landscape plot, we calculated the difference between both estimates as a percentage of the landscape plot (i.e. [meanIP − meanLP]/meanLP×100). Finally, we tested whether the frequency distributions from mean TCH (and see below, also AGB, gap fraction, and LAI) were normally distributed using the Shapiro–Wilk normality test at α = 0.05 significance level (Table 1).
Aboveground biomass (AGB) was derived from mean TCH for each 25 × 25 m2 grid cell. The goal here was to get a standardized estimate of the spatial heterogeneity of standing biomass in the forest landscape. For this purpose, we applied the formula provided by Asner and Mascaro (2014, cf. their Table 2) which is based on plot-aggregate allometry equations across five tropical countries. Note that we used here a universal equation rather than a locally parameterized form, hence our biomass values are primarily useful for comparative purposes. The results of this formula AGB = 6.85 × TCH0.952 were divided by 0.48 to get biomass and not carbon because standing biomass consists of approximately 48% carbon (Martin and Thomas 2011). Again as done for TCH, the overall mean estimates were compared between IPs and LPs, the bias was calculated and normality tests were undertaken.
Gap fraction was calculated for each 25 × 25 m2 grid cell by considering all 1 m2 cells with a vegetation of less than 10 m height as a gap. Hence, gap fraction is the number of 1 m2 cells with tree height Z < 10 m, divided by the area of a 25 × 25 m2 grid cell (625 m2). As done above, the mean gap-fraction values were then compared between IPs and LPs.
Leaf-area index (LAI) was also estimated based on 25 × 25 m2 grid cells for IPs and LPs but the un-thinned CHM raw data with a mean point density of 47/m2 were used for this purpose because the LAI is a measure which strongly depends on all returns from the top of the canopy, down to the bottom and the ground. We followed the approach of Harding et al. (2001) using a 1 m height interval. This gives at first a vertical profile of the LiDAR point cloud by returning a point count per height class. Then, the vertical foliage profile is derived by determining a height threshold, hence a value below every LiDAR point is regarded as ground return, and by specifying the light extinction coefficient k. For this threshold we used a value of 5 m. The value of the light extinction coefficient k was derived by relating it to the parameters G, the projection coefficient used to adjust the apparent foliage profile, and C, which is the clumping index that adjusts the linear relationship between effective LAI and true LAI. In this, we followed Tang et al. (2012) and assumed a random foliage distribution within the canopy and thus a value of G = 0.5 and a clumping index of C = 1.58. The light extinction coefficient corresponds then to the formula k = G/C and thus k = 0.3. The LAI for a given 25 × 25 m2 grid cell is finally the sum of values contained in the vertical foliage profile. We verified that our LiDAR-derived LAI values showed sufficient agreement with the field measured LAI for the inventory plots (Rutten et al. 2015). As done for the other forest structural attributes, the mean LAI values were compared between IPs and LPs.
Gap-size frequency distributions were derived from the classification of 1 m2 cells into gap pixels and non-gap pixels. As for calculating gap fraction above, we used here primarily a canopy height threshold of Z < 10 m for the gap definition. However, to supplement this analysis we also add some information on data results from gap definitions using a more restricted height threshold of Z < 5 m where canopy openings were considered as gaps only if the vegetation height was below 5 m. Gap-size distributions were derived from classifying individual gaps based on neighborhood properties. This was done using the “raster package” in R-software and the clump() function which detects and aggregates patches of connected cells in either four (Rook’s case) or eight (Queen’s case) directions. We identified adjacent gap cells at the 1 m grid resolution in four but not eight directions in order to not overestimate the size of larger gaps because the primarily used height threshold of Z < 10 m in this study is already in benefit of detecting larger gap sizes (Lobo and Dalling 2014). We plotted the gap distributions as a linear relationship between frequency and size on a log–log scale and fitted the discrete Pareto distribution (also called Zeta distribution) to the data, which is a power-law distribution that is described by its scaling exponent lambda (λ). Large values of λ indicate fewer large gaps because the size-frequency distributions are steeper. We used the approach of Asner et al. (2013b) to estimate the parameter lambda based on maximum likelihood methods.
Results
Mean top-of-canopy height (TCH)
The mean top-of-canopy height in the six IPs ranged from 17.9 to 26.8 m (Table 1). Differences to the mean values for the surrounding host landscape plots were considerable with biases reaching as much as 32.4 and 27.3% in Flm2 and FOd5, respectively. Also the spatial heterogeneity of mean TCH in the LPs, expressed as coefficient of variation, was large ranging from 14.2 to 33.5%. Mean TCH was not normally distributed in the LPs Flm2, Flm6, FOc1 and FOd5, indicating one reason for the large coefficients of variation (Fig. 2). However, even when the null hypothesis of the normal distribution could not be rejected, such as for FOd4, the difference in the mean values between IP and LP indicates a considerable sampling bias of almost 10%.

Probability density distributions are shown for the structural attribute mean top-of-canopy height in the 25 × 25 m2 cells of the landscape plots. Red vertical lines indicate the mean height value within the 50 × 50 m2 inventory plot. Except for FOd4, the variable was not normally distributed in the landscape plots
Aboveground biomass (AGB)
LiDAR-derived AGB in the inventory plots based on the general formula provided by Asner and Mascaro (2014) had an average value of 265 t/ha which sufficiently well approximated the average value of 302 t/ha for field-measured AGB (Ensslin et al. 2015).
Since aboveground biomass was directly derived from mean TCH, the biases between mean values in IPs and LPs were very similar (Table 1). The lowest bias was found for AGB in the landscape plot Flm1, indicating that the IP was relatively representative for AGB in the surrounding LP (Fig. 3a). AGB was not normally distributed in the LPs Flm2, Flm6, FOc1 and FOd5 (Fig. S1).

Exemplary for the landscape plot Flm1, the spatial variation of LiDAR-derived aboveground biomass (a), gap fraction (b), and leaf-area index (c) is shown
Gap fraction
The percentage gap fraction was the structural variable that showed the highest spatial heterogeneity and biases (Fig. 3b). The coefficient of variation ranged between 84.4% in FOc1 to even 206.1% in Flm1 and average biases between all IPs and LPs reached 77.1% (Table 1). All biases were negative which means that the inventory plots were selected in favor of representing forest samples with rather closed canopies but not gaps. Gap fraction was not normally distributed in all the six landscape plots (Fig. S2).
Leaf-area index (LAI)
Our LiDAR-derived LAI values showed sufficient agreement with the field-measured LAI for the inventory plots (Rutten et al. 2015). For the six chosen IPs Flm1, Flm2, Flm6, FOc1, FOd4, FOd5 we found that LiDAR-derived mean LAI values were 6.1, 6.2, 5.4, 5.3, 9.4, 8.8 (Table 1) and field-measured LAI values were 6.1, 6.2, 5.8, 6.9, 7.3, 7.1, respectively. Our LiDAR-derived LAI values showed also a generally good agreement with other known values from tropical forests where maximal LAI values may reach 9–12 (Asner et al. 2003). For the plot Flm1, there was only a small bias in LAI of 3.4% between IP and LP and thus, the IP represented the mean in the host landscape relatively well (Table 1; Fig. 3c). However, this was an exception and the average bias of the variable was with 22.1% for all investigated plots higher than for the other two variables mean TCH and AGB. LAI was not normally distributed in all the six landscape plots (Fig. S3).
Gap-size frequency distributions
On average, circa 50% of all gap sizes consisted of the 1 m2 size class. The smallest gap sizes of one and 2 m2 dominated the frequency distributions and made up circa 63% of all gaps (Table 2). Together with the size class of up to 5 m2, these small gaps constituted 75.9%. Large gaps with >100 m2 made up only 3.4% on average. These size frequencies showed remarkably similar power-law distributions across all six landscape plots despite the presence of considerable spatial heterogeneity and large differences in the number of gaps (Fig. 4). The number of gaps with a height definition of Z < 10 m ranged between 711 and 1854 but the lambda values of the scaling exponent varied only slightly and ranged between 1.61 and 1.70. However, when the canopy height criterion used to identify gaps was more strict and Z was defined as <5 m in an additional analysis (data not shown), then the lambda values increased and showed more variation, ranging from 1.69 to 2.04 (Table 2).

Gap-size frequency distributions based on a canopy height cut-off of Z < 10 m for the gap definition are shown for the six landscape plots, together with the scaling exponent λ of the fitted discrete Pareto distributions
Discussion
Biases in field studies of forest structure
The majority of LiDAR-based studies of tropical forests have so far been undertaken in Central and South America with a focus on, for example, Panama (Asner et al. 2013a; Lobo and Dalling 2014; Detto et al. 2015), Costa Rica (Kellner et al. 2009), Ecuador (Molina et al. 2016) or Peruvian Amazonia (Asner et al. 2010, 2013b; Boyd et al. 2013). In comparison, forest structure has been much less investigated with airborne laser scanning on the African continent (but see Kent et al. 2015 or Vaglio Laurin et al. 2016 for a few examples). Here, we aim to provide some comparisons between these results from neotropical America and equatorial Africa. Our research on montane tropical forest in East Africa was inspired by Marvin et al. (2014) who found for Peruvian Amazonia that the use of single, small field inventory plots results in biases when trying to extrapolate the local results to the surrounding landscape scale with its substantial spatial heterogeneity. They found that particularly in the montane Andean landscapes biases may reach as much as 98%.
Our study from Mount Kilimanjaro in Tanzania shows generally strong agreement with these findings from South America. For the key variable mean top-of-canopy height, there was only the Flm1 inventory plot that had a bias of less than 5% at the scale of 50 × 50 m2 but even in its surrounding host landscape, mean TCH was not normally distributed (Fig. 2a). Biases in our six plots ranged from –3 to 32% with an overall average of 16%, which strongly agrees with the range of −5 to 26% and an average of around 14% found by Marvin et al. (2014) for mean TCH in Amazonian montane forests. These results translate directly to the bias for aboveground biomass which was calculated based on a general formula provided for tropical forests by Asner and Mascaro (2014). Consequently, our landscape plots showed also for AGB, and hence carbon stocks, a strong spatial heterogeneity as manifested in a coefficient of variation as high as 32% for AGB in the plot Flm2. It needs to be stressed that it is not only the inherent presence of spatial heterogeneity in the landscape plot that may cause a sampling error by use of small inventory plots but it is also the non-normal spatial distribution of the forest structural attribute itself that occurred in the study sites. This can be well illustrated based on the natural forest plot FOc1 where mean TCH was not normally distributed (Fig. 2d; Table 1), despite that biases in the mean values of mean TCH or AGB were only around 6%. Thus, even when a mean value of a structural attribute is relatively similar between an inventory and landscape plot, a non-normally distributed probability density of the forest variable indicates a considerable sampling error of the small field plot to approximate the forest attribute in the surrounding host landscape (Marvin et al. 2014). We suggest that such a bias could not be compensated for simply by enlarging the field plot or by randomly sampling several 0.25 ha plots within the host landscape but only the larger-scale mapping with methods such as airborne LiDAR can capture this variability of forest structural attributes (Mascaro et al. 2011; Marvin et al. 2016).
One reason for the considerable bias observed for mean TCH, AGB but also for leaf-area index can be explained with our results on gap fraction. The biases on gap fraction were for all six plots very large with an average of 77%, ranging from around −10 to −95%. More importantly, the fact that all biases were negative indicates that the forest inventory plots have been locally chosen so as to represent quite dense forest stands with preferably closed canopy cover. This is justifiable since the overall study project seeks to investigate mature forest at this elevation on Mount Kilimanjaro (Hemp 2006; Ensslin et al. 2015). However, except for the plot FOc1, the true gap fraction in the surrounding host landscapes was about 10 to almost 20 times larger than within the inventory plots. Also in this case of mapping canopy gap fraction, a large-scale sampling based on airborne LiDAR is advantageous over field measurements. Interestingly, this sampling bias was surprisingly similar for montane forests in Amazonia were Marvin et al. (2014) found also only negative biases for gap density with an average of 64%, ranging from around −17 to −100%. In our case, spatial heterogeneity and biases of sampling gap fraction were similar across the landscape, irrespective of whether the plots represented anthropogenically disturbed (FOd4 and FOd5) or natural forest. It is likely that, despite a preference for selecting a rather closed forest stand, accessibility partly played a role in setting up the inventory plots because e.g. the IP Flm2 borders to the east on a more open area.
The bias in the gap fraction did also translate into leaf-area and thus the vertical foliage properties. LAI mean values for inventory plots were in five out of six cases higher than in the host landscape and the average bias was 22%. The large spatial heterogeneity of LAI ranging between 15 and 41% indicates that localized LAI measurements in field plots can hardly account for the spatial variability in the landscape. The use of airborne LiDAR in assessing LAI has thus two advantages. It not only enables the mapping of LAI at spatial scales that would be non-feasible based on local ground measurements but it prevents also the underestimation of leaf area in the upper canopy that usually goes along with ground-level measurements (Detto et al. 2015). Especially for spatially heterogeneous montane forests where disturbances on slopes and topographic roughness may cause high gap fractions, an airborne mapping approach is key for better understanding the large-scale variation of LAI and for up-scaling ecosystem functions from leaf to stand levels at the landscape scale. Generally, our results agree with similar LiDAR-based measurements from lowland tropical forest in Central America, where spatial variation of LAI was almost as equally high (Detto et al. 2015).
Gap-size frequency distributions
Gap definitions for forests are highly diverse and depend on the specific question being under investigation (Asner et al. 2013b; Espírito-Santo et al. 2014). For example, when the maximum canopy height threshold used to identify gaps is relaxed from 2 to 10 m, the scaling exponent λ of the power-law distribution decreases linearly (Lobo and Dalling 2014). However, this did not affect this study because we were primarily interested in asking whether gap-size distributions show similarities between the landscape plots, despite their different elevations and land-use histories. In this respect, we made two distinct observations.
Firstly, gap-size frequency distributions were dominated by small gaps, rather than by medium-sized or large gaps. In the montane forests of Mount Kilimanjaro, circa 50% of all gap sizes consisted of the 1 m2 size class and together with the 2 m2 size class they made up circa 63% of all gaps. Our results strongly agree with similar findings for Amazonia (Boyd et al. 2013; Marvin and Asner 2016) and we emphasize the importance of identifying gaps as small as 1 m2 with modern remote sensing approaches such as airborne LiDAR or unmanned aerial vehicles (Getzin et al. 2014). The small gap openings may result from repeated gap formation induced by small-scale disturbance (Torimaru et al. 2012). These smallest gaps are also important determinants of regeneration, since light heterogeneity in the understory may induce light-gradient partitioning and affect recruitment processes (Montgomery and Chazdon 2002).
Secondly, we found a remarkable similarity in gap-size frequency distributions that may be related to allometric scaling relationships which describe how trees use resources and pack their crowns to fill space (Enquist et al. 2009; Taubert et al. 2015). Despite the large structural dissimilarity between the six landscape plots with gap numbers ranging from 711 to 1854, there was a striking similarity with all plots having nearly identically around 50% of the gaps in the 1 m2 size class and around 13% in the 2 m2 size class (Table 2). Also the scaling exponent λ of the fitted power-law distributions was very consistent across all six plots and ranged between 1.61 and 1.70 (threshold Z < 10 m). Only when the canopy height criterion used to identify gaps was relaxed to Z < 5 m, then the lambda values increased and showed more variation. Generally, a height threshold of Z < 10 m enables the inclusion of more gaps and larger gaps (Boyd et al. 2013). Obviously, this more relaxed height definition does also homogenize the lambda values because it is less sensitive to plot-level variation in spatial heterogeneity and past disturbance regimes. Also, a threshold of Z < 10 m accounts more reasonably for disturbance dynamics in the canopy layer and thus for typical gap-phase transitions because only few disturbance events are causing openings that extent down to the ground surface (Kellner et al. 2009; Boyd et al. 2013). Such a gap definition is then also more appropriate for forest modeling approaches where the individual-based dynamics of forest succession can be investigated in “virtual laboratories” (Dislich and Huth 2012; Fischer et al. 2015; Taubert et al. 2015).
Conclusion
Overall, our results on the gap-size frequency distributions agree with very general scaling rules that may explain why, for example, tropical tree size distributions can be remarkably consistent despite differences in the environments where they grow. Farrior et al. (2016) recently suggested that after a disturbance, new individuals in the forest gap grow quickly and overtop each other and that the 2D-space filling of the growing crowns of the tallest individuals relegates a group of weaker individuals to the understory. Those weak individuals left in the understory would then be forced to follow a power-law size distribution where the scaling rule depends only on the crown area–to–diameter allometry exponent. Such scaling rules suggest also that competition for light does not play a direct role in shaping tree diameter distributions (Taubert et al. 2015). The above mentioned principles are indeed supported by empirical findings from tropical forest in Africa which show that it is not the competition within height classes that regulates the 2D-tree spacing but it is the size dominance of superior individuals that overtop their weaker neighbors once they have exceeded a critical height threshold (Getzin et al. 2011).
However, before we can model and theoretically back up such scaling rules with empirical data, we need to ensure that the model is well parameterized and calibrated to the plot-level data. We have demonstrated in this study that there is strong need to bridge the gap between available data based on local forest inventories and the necessity for up-scaling such empirical data to the larger landscape scale in order to, for example, simulate forest succession, energy fluxes or the large-scale distribution of biomass and carbon (Fischer et al. 2015). As was shown here, the spatial extrapolation of forest structural attributes may be hampered by strong biases and by non-normally distributed forest variables because both factors manifest a considerable sampling error of the small field plot with respect to the surrounding host landscape. We conclude that these problems can be overcome with modern remote-sensing tools such as airborne LiDAR or unmanned aerial vehicles (Marvin et al. 2016), both of which are able to account for the full spatial heterogeneity being inherent to forest structure at the landscape scale.
References
Asner GP, Scurlock JMO, Hicke JA (2003) Global synthesis of leaf area index observations: implications for ecological and remote sensing studies. Global Ecol Biogeogr 12(3):191–205
Asner GP, Powell GVN, Mascaro J, Knapp DE, Clark JK, Jacobson J, Kennedy-Bowdoin T, Balaji A, Paez-Acosta G, Victoria E, Secada L (2010) High-resolution forest carbon stocks and emissions in the Amazon. Proc Natl Acad Sci USA 107(38):16738–16742
Asner GP, Kellner JR, Kennedy-Bowdoin T, Knapp DE, Anderson C, Martin RE (2013a) Forest canopy gap distributions in the Southern Peruvian Amazon. PLoS ONE 8(4):e60875
Asner GP, Mascaro J, Anderson C, Knapp DE, Martin RE, Kennedy-Bowdoin T, van Breugel M, Davies S, Hall JS, Muller-Landau HC, Potvin C (2013b) High-fidelity national carbon mapping for resource management and REDD+. Carbon Balance Manag 8(7):1–14
Asner GP, Mascaro J (2014) Mapping tropical forest carbon: calibrating plot estimates to a simple LiDAR metric. Remote Sens Environ 140:614–624
Asner GP, Sousan S, Knapp DE, Selmants PC, Martin RE, Hughes RF, Giardina CP (2016) Rapid forest carbon assessments of oceanic islands: a case study of the Hawaiian archipelago. Carbon Balance Manag 11(1):1–13
Bonnet S, Gaulton R, Lehaire F, Lejeune P (2015) Canopy gap mapping from airborne laser scanning: an assessment of the positional and geometrical accuracy. Remote Sens-Basel 7(9):11267
Boyd DS, Hill RA, Hopkinson C, Baker TR (2013) Landscape-scale forest disturbance regimes in southern Peruvian Amazonia. Ecol Appl 23(7):1588–1602
Brown C, Burslem DF, Illian JB, Bao L, Brockelman W, Cao M, Chang LW, Dattaraja HS, Davies S, Gunatilleke CV, Gunatilleke IA (2013) Multispecies coexistence of trees in tropical forests: spatial signals of topographic niche differentiation increase with environmental heterogeneity. Proc R Soc Lond B Biol Sci 280(1764):20130502
Bustamante M, Roitman I, Aide TM, Alencar A, Anderson LO, Aragão L, Asner GP, Barlow J, Berenguer E, Chambers J, Costa MH (2016) Toward an integrated monitoring framework to assess the effects of tropical forest degradation and recovery on carbon stocks and biodiversity. Glob Change Biol 22(1):92–109
Detto M, Asner GP, Muller-Landau HC, Sonnentag O (2015) Spatial variability in tropical forest leaf area density from multireturn lidar and modeling. J Geophys Res 120(2):294–309
Dislich C, Huth A (2012) Modelling the impact of shallow landslides on forest structure in tropical montane forests. Ecol Model 239:40–53
Enquist BJ, West GB, Brown JH (2009) Extensions and evaluations of a general quantitative theory of forest structure and dynamics. Proc Natl Acad Sci USA 106(17):7046–7051
Ensslin A, Rutten G, Pommer U, Zimmermann R, Hemp A, Fischer M (2015) Effects of elevation and land use on the biomass of trees, shrubs and herbs at Mount Kilimanjaro. Ecosphere 6(3):1–15
Espírito-Santo FD, Gloor M, Keller M, Malhi Y, Saatchi S, Nelson B, Junior RC, Pereira C, Lloyd J, Frolking S, Palace M (2014) Size and frequency of natural forest disturbances and the Amazon forest carbon balance. Nat Commun 5:3434
Farrior CE, Bohlman SA, Hubbell S, Pacala SW (2016) Dominance of the suppressed: power-law size structure in tropical forests. Science 351(6269):155–157
Fischer M, Bossdorf O, Gockel S, Hänsel F, Hemp A, Hessenmöller D, Korte G, Nieschulze J, Pfeiffer S, Prati D, Renner S (2010) Implementing large-scale and long-term functional biodiversity research: the biodiversity exploratories. Basic Appl Ecol 11(6):473–485
Fischer R, Ensslin A, Rutten G, Fischer M, Costa DS, Kleyer M, Hemp A, Paulick S, Huth A (2015) Simulating carbon stocks and fluxes of an African Tropical Montane forest with an individual-based forest model. Plos ONE 10(4):e0123300
Getzin S, Dean C, He FL, Trofymow JA, Wiegand K, Wiegand T (2006) Spatial patterns and competition of tree species in a Douglas-fir chronosequence on Vancouver Island. Ecography 29(5):671–682
Getzin S, Wiegand T, Wiegand K, He F (2008) Heterogeneity influences spatial patterns and demographics in forest stands. J Ecol 96(4):807–820
Getzin S, Worbes M, Wiegand T, Wiegand K (2011) Size dominance regulates tree spacing more than competition within height classes in tropical Cameroon. J Trop Ecol 27(1):93–102
Getzin S, Nuske RS, Wiegand K (2014) Using unmanned aerial vehicles (uav) to quantify spatial gap patterns in forests. Remote Sens-Basel 6(8):6988–7004
Gossner MM, Getzin S, Lange M, Pašalić E, Türke M, Wiegand K, Weisser WW (2013) The importance of heterogeneity revisited from a multiscale and multitaxa approach. Biol Conserv 166:212–220
Harding DJ, Lefsky MA, Parker GG, Blair JB (2001) Laser altimeter canopy height profiles—methods and validation for closed-canopy, broadleaf forests. Remote Sens Environ 76(3):283–297
Hemp A (2006) Continuum or zonation? Altitudinal gradients in the forest vegetation of Mt. Kilimanjaro. Plant Ecol 184(1):27–42
Hewitt JE, Thrush SF, Dayton PK, Bonsdorff E (2007) The effect of spatial and temporal heterogeneity on the design and analysis of empirical studies of scale-dependent systems. Am Nat 169(3):398–408
Kellner JR, Clark DB, Hubbell SP (2009) Pervasive canopy dynamics produce short-term stability in a tropical rain forest landscape. Ecol Lett 12(2):155–164
Kent R, Lindsell JA, Laurin GV, Valentini R, Coomes DA (2015) Airborne LiDAR detects selectively logged Tropical forest even in an advanced stage of recovery. Remote Sens-Basel 7(7):8348–8367
Lobo E, Dalling JW (2014) Spatial scale and sampling resolution affect measures of gap disturbance in a lowland tropical forest: implications for understanding forest regeneration and carbon storage. Proc R Soc Lond B Biol Sci 281(1778):20133218
Martin AR, Thomas SC (2011) A reassessment of carbon content in tropical trees. PLoS ONE 6(8):e23533
Marvin DC, Asner GP (2016) Branchfall dominates annual carbon flux across lowland Amazonian forests. Environ Res Lett 11(9):1–11
Marvin DC, Asner GP, Knapp DE, Anderson CB, Martin RE, Sinca F, Tupayachi R (2014) Amazonian landscapes and the bias in field studies of forest structure and biomass. Proc Natl Acad Sci USA 111(48):E5224–E5232
Marvin DC, Koh LP, Lynam AJ, Wich S, Davies AB, Krishnamurthy R, Stokes E, Starkey R, Asner GP (2016) Integrating technologies for scalable ecology and conservation. Glob Ecol Conserv 7:262–275
Mascaro J, Detto M, Asner GP, Muller-Landau HC (2011) Evaluating uncertainty in mapping forest carbon with airborne LiDAR. Remote Sens Environ 115(12):3770–3774
McLean KA, Trainor AM, Asner GP, Crofoot MC, Hopkins ME, Campbell CJ, Martin RE, Knapp DE, Jansen PA (2016) Movement patterns of three arboreal primates in a Neotropical moist forest explained by LiDAR-estimated canopy structure. Landscape Ecol 31(8):1849–1862
Molina PX, Asner GP, Abadia MF, Manrique JCO, Diez LAS, Valencia R (2016) Spatially-explicit testing of a general aboveground carbon density estimation model in a Western Amazonian forest using Airborne LiDAR. Remote Sens-Basel 8(1):9
Montgomery R, Chazdon R (2002) Light gradient partitioning by tropical tree seedlings in the absence of canopy gaps. Oecologia 131(2):165–174
Punchi-Manage R, Getzin S, Wiegand T, Kanagaraj R, Savitri Gunatilleke CV, Nimal Gunatilleke IA, Wiegand K, Huth A (2013) Effects of topography on structuring local species assemblages in a Sri Lankan mixed dipterocarp forest. J Ecol 101(1):149–160
Rutten G, Ensslin A, Hemp A, Fischer M (2015) Vertical and horizontal vegetation structure across natural and modified habitat types at Mount Kilimanjaro. PLoS ONE 10(9):e0138822
Tang H, Dubayah R, Swatantran A, Hofton M, Sheldon S, Clark DB, Blair B (2012) Retrieval of vertical LAI profiles over tropical rain forests using waveform lidar at La Selva, Costa Rica. Remote Sens Environ 124:242–250
Taubert F, Jahn MW, Dobner HJ, Wiegand T, Huth A (2015) The structure of tropical forests and sphere packings. Proc Natl Acad Sci USA 112(49):15125–15129
Team RDC (2016) R: a language and environment for statistical computing. Austria, Vienna
Torimaru T, Itaya A, Yamamoto S-I (2012) Quantification of repeated gap formation events and their spatial patterns in three types of old-growth forests: analysis of long-term canopy dynamics using aerial photographs and digital surface models. For Ecol Manag 284:1–11
Vaglio Laurin G, Puletti N, Chen Q, Corona P, Papale D, Valentini R (2016) Above ground biomass and tree species richness estimation with airborne lidar in tropical Ghana forests. Int J Appl Earth Obs Geoinf 52:371–379
Acknowledgements
We are grateful to T. Nauss from the University of Marburg for providing the LiDAR data. The study was funded by the German Research Foundation (DFG) and is part of the DFG research unit FOR1246 “Kilimanjaro ecosystems under global change: linking biodiversity, biotic interactions and biogeochemical ecosystem processes”. AH and RF were supported by the Helmholtz-Alliance Remote Sensing and Earth System Dynamics. NK was funded by the German Federal Ministry for Economic Affairs and Energy (BMWi) under the funding reference 50EE1416. We thank two reviewers for their constructive comments on our paper.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Getzin, S., Fischer, R., Knapp, N. et al. Using airborne LiDAR to assess spatial heterogeneity in forest structure on Mount Kilimanjaro. Landscape Ecol 32, 1881–1894 (2017). https://doi.org/10.1007/s10980-017-0550-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10980-017-0550-7