
Abstract
Ecological theory predicts a positive influence of local-, landscape-, and regional-scale spatial environmental heterogeneity on local species richness. Therefore, knowing how heterogeneity measured at a variety of scales relates to local species richness has important implications for conservation of biological diversity. We took a statistical modeling approach to determine which metrics of heterogeneity measured at which scales were useful predictors of local species richness, and whether the heterogeneity-local richness relationship was always positive. Local plant species richness data came from 400-m2 vegetation plots in North and South Carolina, USA. At each of four scales from within plots to across regions, we used either GIS or field data to calculate measures of heterogeneity from abiotic environmental variables, vegetation productivity data, and land cover classifications. Among all predictors at all scales, we found that no measure of heterogeneity was a better predictor of local richness than mean pH within plots. However, at scales larger than within plots, measures of heterogeneity were correlated most strongly with local richness, and each of the three classes of variables we used had a distinct scale at which it performed better than the others. These results highlight the fact that ecological processes occurring across multiple scales influence local species richness differently. In addition, relationships between heterogeneity and richness were usually, though not always, positive, underscoring the importance of processes that occur at a variety of scales to local biodiversity conservation and management.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Worldwide, landscapes increasingly include a mix of relatively natural habitat in a mosaic of human land uses. Thus, effective biodiversity conservation of local sites requires understanding the influence of the broader context in which they occur. Ecological theory predicts that spatially varying environments promote biodiversity locally because heterogeneous environments allow more species to coexist locally than homogenous environments allow. For example, within a site, variation in resource availability can reduce the effect of competitive exclusion, allowing more species to coexist locally (Ricklefs 1977; Chesson 2000; Snyder and Chesson 2004). This predicted positive influence of local heterogeneity is the so-called spatial heterogeneity hypothesis. Testing this mechanism experimentally and empirically has become an important focus of ecological research (Reynolds et al. 2007; Lundholm 2009).
Environmental heterogeneity, however, can affect local diversity through different mechanisms acting at different scales (Shmida and Wilson 1985; Ricklefs 1987; Snyder and Chesson 2004). In addition to local variation, ecological theory predicts that heterogeneity at larger scales can also influence local species richness. Within a landscape, spatial variation in the composition or configuration of vegetation can lead to spatially-structured metapopulations, which can promote local population persistence via mechanisms such as source-sink dynamics and the rescue effect (Brown and Kodric-Brown 1977; Pulliam 1988). Regionally, greater heterogeneity increases the size of the regional species pool, or the species that are available to colonize a given local area, which can also lead to an increase in local species richness. Despite the fact that theory predicts a positive influence of environmental heterogeneity from local to regional scales on local species richness, few studies have fully investigated the relationship between local richness and heterogeneity measured across multiple scales. Our study integrates data from vegetation plots in the southeastern US with variables derived from GIS and remotely-sensed data in order to examine the relationship between local plant species richness and heterogeneity at local, landscape, and regional scales.
While a comprehensive examination of the effects of heterogeneity measured at multiple scales on local species richness is currently lacking, several studies have shown a positive relationship between heterogeneity variables measured at a single scale and species richness. Usually, these studies measure heterogeneity and species richness at the same scale, whether across local sites, landscapes, or regions. Local metrics of heterogeneity have usually come from field data within or near the sites where species richness is sampled. Most often, local heterogeneity has been measured in terms of variation in soil resource availability or vegetation structure (Gould and Walker 1997; Davies et al. 2005). Across landscapes, heterogeneity is often measured in terms of variation in land cover or vegetation productivity and is often derived from remote sensing or GIS data, although there is considerable variation among studies in the variables used (St-Louis et al. 2006; Parviainen et al. 2009). For example, St-Louis et al. (2006) show that image texture metrics describing variability in vegetation productivity across a landscape are useful predictors of bird richness in the same landscape in New Mexico. Regionally, heterogeneity has been most often characterized in terms of topographic, climate or land cover variation summarized within the boundaries of ecoregions. Studies have found a positive relationship between regional heterogeneity and regional richness of a variety of taxa, including mammals (Kerr and Packer 1997), birds (Hurlbert and Haskell 2003), insects (Kerr et al. 2001), and plants (Jimenez et al. 2009). While these previous studies have demonstrated that heterogeneity metrics can be useful predictors of species richness, there is no consensus on which heterogeneity variables, scales of measurement, or metrics of heterogeneity are most relevant for modeling species richness measured locally.
The relationship between local species richness and environmental heterogeneity at different scales is especially relevant for conservation. Assessing the relationship between local richness and heterogeneity metrics that are measured at a variety of scales will provide important information about the scales at which habitat variability is relevant for maintaining and conserving species-rich sites. In addition, measures of heterogeneity could be important for informing assessments of local biodiversity across large extents. Commonly-used approaches for mapping biodiversity, such as indirect mapping of biodiversity via habitat classification, largely ignore variability within habitats and thus may fail to capture aspects of the landscape that are important to some species (Nagendra 2001). Thus, Palmer et al. (2002) proposed the “spectral variation hypothesis”, stating that heterogeneity measures derived from remotely sensed images at a number of scales should be related to species richness and could be used as a tool for these biodiversity assessments. A comprehensive look at the relationship between heterogeneity and local species richness could inform the use of heterogeneity in biodiversity assessments.
The aim of this study was to assess how local plant species richness relates to heterogeneity at local, landscape, and regional scales. We used data from vegetation communities in North and South Carolina (NC and SC), USA, to measure local plant species richness (within 400 m2 vegetation plots). We then used mixed-effects models to relate local plant richness to measures of heterogeneity encompassing abiotic environmental variables, vegetation productivity, and land cover classes. For each of these three types of predictor variables, we computed the same suite of metrics at four scales: (1) within vegetation plots, (2) within habitat patches surrounding plots, (3) within neighborhoods spanning multiple habitat patches surrounding plots, and (4) across regions in which plots were situated. The metrics we computed for land cover were variety and Simpson’s Index of diversity (Simpson 1949), and for all other variables, we computed variance, standard deviation, range, and CV. We also computed the mean of each variable except land cover at each scale as a measure of overall resource availability and productivity for comparison with heterogeneity metrics. We made this comparison because the relationship between species richness and overall resource availability and productivity are important areas of research in ecology (Mittelbach et al. 2001; Cornwell and Grubb 2003). Recently, measures of central tendency of abiotic environmental variables and productivity at a variety of scales have been shown to be correlates of plant species richness (Davies et al. 2005; Waring et al. 2006). Therefore, comparing models with heterogeneity metrics as predictors to those with means as predictors allowed us to fully assess the utility of heterogeneity metrics.
Our goal was to analyze a broad range of heterogeneity metrics to determine which are most useful for predicting local richness. At the same time, we chose measures of heterogeneity similar to those used in previous studies to allow comparison with those studies. Furthermore, by calculating heterogeneity using widely available data, we ensured that our methods could be applied to vegetation plots spanning a large region. We asked:
-
1.
Is local plant species richness correlated with environmental heterogeneity measured at local and larger scales and is the relationship always positive as predicted by ecological theory?
-
2.
What is the best way to measure heterogeneity at each scale for predicting local plant richness?
-
3.
Is there a characteristic scale at which heterogeneity appears to have the greatest effect on local plant richness?
Based on previous studies, we hypothesized that heterogeneity would predict local plant species richness at all scales, and that the direction of the heterogeneity-richness relationship would be positive at each scale. Because the ecological processes influencing local species richness differ at each scale, we predicted that the heterogeneity measure most related to local richness would differ by scale and correspond with findings of previous studies. In particular, within plots, we expected heterogeneity of soil resource availability to be the best predictor of plant richness because several previous studies have shown those variables to be important predictors within vegetation plots (Gould and Walker 1997; Davies et al. 2005) Within habitats and across multiple-patch neighborhoods, we expected heterogeneity of vegetation productivity to be the best predictor of richness because other researchers have shown variability in productivity at those scales to be a good predictor of species richness (St-Louis et al. 2006). Because previous studies have demonstrated that regional land cover heterogeneity relates to richness (Kerr et al. 2001), we predicted that either measures of topographic or land cover heterogeneity would be the best regional predictor of local richness. Finally, because heterogeneity measured locally corresponds spatially with local measures of richness, we expected that local measures of heterogeneity would show the greatest effect on local species richness of all heterogeneity measures in our study.
Methods
Study area
The Southeast Coastal Plain of the United States provides a good context in which to study the relationship between habitat heterogeneity and plant species richness. The region is home to a rich diversity of plant species, 27% of which are endemic there (Sorrie and Weakley 2001). Many plant communities occur in the region, including longleaf pine (Pinus palustris) savannas and flatwoods, shrub wetlands (“pocosins”), bottomland hardwood forests, and tidal marshes. Vegetation is greatly influenced by soil characteristics and elevation. Species-rich longleaf pine ecosystems occur on more sandy soils, while pocosin vegetation occurs where soil organic matter content is high. Subtle differences in these soil characteristics as well as elevation and geographic location can result in large variation in local plant species richness within and among plant communities in the region (Christensen 2000; Peet 2006).
Species richness data
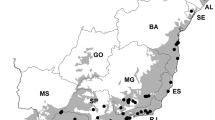
Species richness data came from 150 vegetation plots in NC and SC, in Omernik’s Level III Middle Atlantic Coastal Plain ecoregion (Environmental Protection Agency (EPA) 2004, Fig. 1). These plot data are part of the Carolina Vegetation Survey (CVS) database, and were collected between 1998 and 2007. CVS is a long-term inventory and characterization of plant composition in the natural communities of the Carolinas and has followed a consistent data collection protocol (Peet et al. 1998). Plots in the database are located throughout NC and SC, but are not uniformly distributed throughout the region (Fig. 1). Although CVS plots vary in size from 100 to 1000 m2, all the plots used for this study contain four intensively sampled 10 × 10 m2 quadrats, in which the identity of each vascular plant species has been recorded and environmental data have been collected. Our measure of plant species richness was the total number of plant species across the four intensively sampled quadrats, for an effective plot size of 400 m2.

Study area in the Middle Atlantic Coastal Plain ecoregion
Heterogeneity data
We characterized heterogeneity using three types of variables: abiotic environmental variables, variables related to vegetation productivity, and land cover classes (Table 1). Each of these variables was measured at four scales for each plot location: within each vegetation plot (hereafter, “within-plot”), within the habitat patch on which each plot was located (“within-habitat”), within circular neighborhoods surrounding each plot (“neighborhood”), and across regions (“regional”; see Table 1). Land cover heterogeneity was not measured within vegetation plots because plots were explicitly located in areas assumed to be representative of a single vegetation community type, and because the size of plots prohibited measurement of variation in land cover given the resolution of the GIS and remotely-sensed data we used for that variable.
To characterize within-plot heterogeneity, we used habitat data collected at the time of plot sampling. One soil sample was collected within each of the four intensively sampled quadrats and soil chemistry analysis was performed on the samples by Brookside Laboratories, Incorporated, New Knoxville, Ohio. Within-plot abiotic variables used were soil pH and percent organic matter content sampled within each quadrat in each plot. As a local-scale productivity measure, we used basal area of all stems greater than 2.5 cm dbh, which was measured within each quadrat. To calculate heterogeneity for the soil variables and basal area, we computed the variance, standard deviation, range, and coefficient of variation (CV) of values from the quadrats in each plot.
We used GIS to delineate extents across which within-habitat, neighborhood, and regional scale heterogeneity metrics would be calculated (Table 1; Fig. 2). For both within-habitat and neighborhood scales, we measured heterogeneity within three radius lengths from plot locations: 150, 450, and 1380 m of plot locations. To delineate neighborhoods, we employed three, progressively larger, circular buffers with those radii surrounding each plot location, resulting in areas of 7, 64, and 600 ha, respectively (Fig. 2a). We chose these sizes because they approximate the neighborhoods recommended by Riitters et al. (2000) as appropriate scales for summarizing landscape patterns. For the within-habitat scale, we used these three radii surrounding each plot, extracting only the group of contiguous pixels surrounding each plot that were mapped as a single vegetation type in the 2001 National Land Cover Database (NLCD, Homer et al. 2007, Fig. 2b, c). Thus, for each radius length, habitat patch sizes differed among plots and had mean sizes of 5, 37, and 235 ha, respectively. To delineate regions, we used single Level IV ecoregion polygons within the EPA’s Middle Atlantic Coastal Plain ecoregion. There were 17 of these regional polygons containing vegetation plots in our study area. These regions ranged from 38,000 to 705,000 ha (380–7050 km2) in size, and had a mean area of 182,100 ha (1821 km2).

An example showing how heterogeneity was calculated at neighborhood and within-habitat scales for 150, 450 and 1380-m radius lengths. a For the neighborhood scale, heterogeneity metrics were calculated across circular buffers surrounding each plot. b For the within-habitat scale, first, a habitat was defined for each radius length surrounding a plot by extracting a group of contiguous pixels mapped as a single vegetation type in the 2001 National Land Cover Database. c Next, heterogeneity metrics at the within-habitat scale were calculated across those patches. a and c show 2001 neighborhood and within-habitat scales overlaid on GAP 2001 land cover
We used three types of environmental variables to measure heterogeneity from GIS and remotely sensed data at within-habitat, neighborhood, and regional scales. First, as an abiotic factor at each of these scales, we calculated topographic heterogeneity using a 1999 digital elevation model (DEM) from the National Elevation Database (U.S. Geological Survey [USGS] 1999). Second, we used the normalized difference vegetation index (NDVI) as a measure of productivity at each of these scales. NDVI is an often-used index of greenness calculated from reflectance in the near infrared and red portions of the electromagnetic spectrum that has been shown to correlate well with aboveground net primary productivity (Pettorelli et al. 2005). It is especially useful as a proxy for productivity at larger scales across which direct measurements of productivity are not possible. For within-habitat and neighborhood scales, we used NDVI data from 14 Landsat TM images from the growing seasons of 2000–2002 that had previously been mosaicked as part of the 2001 NLCD land cover classification (Homer et al. 2004). Across ecoregions, we used NDVI from the MODIS sensor aboard the EOS AM and EOS PM satellite platforms (MOD13Q1, collection 5.0, NASA 2008). For each pixel in the MODIS data, we calculated the mean NDVI value from all images from 2001 to 2007. Therefore, our measure of productivity at the regional scale is an aggregate representing longer-term persistent patterns of productivity. We used this single mean image to extract heterogeneity metrics at this scale. Third, for land cover heterogeneity metrics, we used the 2001 Gap Analysis Program’s (GAP) land cover map (Southeast Gap Analysis Project 2008). The DEM, Landsat NDVI and GAP data have 30 m resolution. MODIS NDVI data have a resolution of 250 m.
Within the three sizes of habitat patches and circular neighborhoods, as well as region polygons, we calculated the mean, range, variance, standard deviation, and coefficient of variation of all elevation and productivity values (Table 1). We also calculated the variety of land cover classes, as well as Simpson’s Index (Simpson 1949) of land cover diversity. Simpson’s Index was used because it has been shown to be less sensitive to rare cover types, and thus to classification errors in land cover data, relative to other diversity indices (Nagendra 2002). Therefore, while land cover variety represents the richness of land cover types, Simpson’s Index emphasizes the evenness component of land cover diversity.
Analysis
To address our first question about whether plant species richness is correlated with measures of heterogeneity at local and larger scales, we used linear mixed-effects models (Zuur et al. 2009). We fit mixed-effects models using maximum likelihood estimation using region as a random effect and with random intercepts. By grouping the data into regions, these mixed-effects models incorporated similarities among vegetation communities sampled in our plot data in a more ecologically meaningful way than would incorporating a measure of simple geographic distance. In our models, the response was always within-plot species richness. For within-plot, within-habitat, neighborhood, and regional scales, we fit separate univariate models for each heterogeneity metric (Simpson’s Index or variety for land cover; variance, standard deviation, range, or CV for abiotic variables and productivity), and compared those to a univariate model incorporating the mean value of each variable at the same scale. Means were not calculated for land cover because land cover data were categorical. Within-plot, within-habitat, and neighborhood metrics were treated as level-1 predictors, while regional metrics were level-2 predictors in our mixed-effects models. We calculated correlation between pairs of predictor variables for each variable, scale, and radius.
To determine which type of distribution or transformation to use for species richness as the response, we fit linear mixed-effects models using normal distributions with both untransformed and log-transformed species richness as the response, as well as generalized linear mixed models using Poisson distributions. We compared the results of these three using AIC to determine which type was most appropriate for our species richness data. To compare these models, we scaled the AIC from the log-normal models to the raw response for comparison. We fit all linear mixed-effects models using the lme function in the nlme package (Pinheiro et al. 2009) in R (R Development Core Team 2009). To determine whether to model the relationship as linear or to use a higher-order polynomial relationship, we fit generalized additive models (GAMs) to the species richness data using a smoother for each predictor and examined the general shape of the relationship using the mgcv package (Wood 2006) in R.
We used the approach of Burnham and Anderson (2002) to compare models containing each heterogeneity metric or mean and determine the best model for each variable at each scale and radius. For models using regional variables as predictors, we computed AICc based on a sample size equal to the number of regions (level-2 groups). We used an extra sum-of-squares F-test to compare models containing each of the heterogeneity metrics for each variable type at each scale and radius to the unconditional means model, which contains no predictors but still accounts for structure in the data because data are grouped by region.
We addressed our second research question once we had established the best metric for each variable at each radius and scale. We used the Burnham and Anderson approach to determine the best predictor of plant species richness among all variables and radii at each scale. To quantify the proportion of variation in the species richness data explained in each of the univariate models, we calculated level-1 and level-2 pseudo-R 2 statistics from the variance components of the mixed-effects models (Singer and Willett 2003).
We addressed our third question about the scale at which heterogeneity has the greatest effect on local richness in two ways. First, we compared AICc values for all models to determine the best overall predictor. Second, for each variable class (abiotic, productivity and land cover) we quantified the relative effects of level-1 and level-2 heterogeneity measures on plant species richness using bivariate mixed-effects models. For each of the three classes of variables, we used the best heterogeneity metric, whether level-1 or level-2, and combined it with a corresponding metric calculated at the other level. Thus, the two predictors had the same units in each model, and the ratio of level-1 to level-2 coefficients in a given model was equivalent to the relative influence of the two predictors. We took a Bayesian approach for this part of our analysis because frequentist methods for calculating the variance of the ratio of two parameters are only approximate. In contrast, the Bayesian approach allowed us to estimate the ratio directly by capturing the uncertainty in parameter estimates and propagating that uncertainty through to the ratio (Gelman and Hill 2007). We used the arm (Gelman et al. 2009) package of R, which interfaces with WinBUGS (Lunn et al. 2000). We used Markov chain Monte Carlo (MCMC) sampling to fit mixed-effects models with random intercepts containing local and regional variables. Our models had locally uniform priors for fixed effects and non-informative priors for random effects, and we sampled for 10,000 iterations. This approach allowed us to calculate ratios of level-1 to level-2 coefficients in each model and quantify the relative effect of each predictor. Thus, for each class of variable, we determined the relative influence of the two scales of heterogeneity on richness.
Results
Correlations among predictors for a variable, scale, and radius ranged from strongly positive (1.00) to strongly negative (−0.92), and were generally strongest at smaller scales and radius lengths (Appendix 1 in Electronic Supplementary Material). Fitting GAMs to smoothed predictors suggested linear relationships between species richness and all of the metrics except mean within-plot pH. A quadratic relationship was suggested for mean pH, so we used a quadratic term in all models containing that variable. In addition, our comparison of AIC among normal, log-normal, and Poisson distributions indicated that the linear mixed-effects model with normal distribution and log-transformed species richness was most appropriate, so we present results from those models here.
Within plots, the means of each variable predicted richness better than measures of heterogeneity. At within-habitat, neighborhood, and regional scales, a heterogeneity metric was always a better predictor of species richness than the mean when the unconditional means model (the model containing no predictors but still accounting for regional structure in the data) was not selected (Table 2). Within habitats, for elevation, NDVI, and land cover, heterogeneity metrics were the best predictors and better than the unconditional means model. Across neighborhoods, for elevation, but not NDVI or land cover, heterogeneity metrics were the best predictors of plant species richness and were better than the unconditional means model. At the regional scale, for elevation and land cover, but not NDVI, measures of heterogeneity were the best predictors and were better than the unconditional means model. See Appendix 2 in Electronic Supplementary Material for full model results and all statistics for the comparison among univariate mixed-effects models.
We compared the best predictors within each scale (Table 3). Of all variables at the within-plot scale, mean pH was the best predictor of species richness. Within habitats, the standard deviation of NDVI at 450 m was the best predictor and had a negative relationship with species richness (Fig. 3a). Across neighborhoods, the variance of elevation at 150 m was the best predictor, and was positively related to species richness (Fig. 3b). Across regions, land cover variety was the best predictor of plant species richness, and the relationship was positive (Fig. 3c). A comparison of AICc from models using these four predictors showed that mean within-plot pH was the best overall predictor of plant species richness. The variance of elevation across a neighborhood with radius 150 m was the best overall heterogeneity metric.

The relationship between species richness and: a within-habitat NDVI heterogeneity, measured as the standard deviation of NDVI across habitat patches, b neighborhood elevation heterogeneity, measured as the variance in elevation across neighborhoods, c regional land cover heterogeneity, measured as the variety of land cover classes. The lines represent the fitted values for the population. In c the light dots represent all data, and dark dots represent fitted values for groups
Results from the MCMC analysis show that the same type of heterogeneity had varying effects at neighborhood or within-habitat (level-1) and regional (level-2) scales. Because the best measure of land cover heterogeneity was regional land cover variety, we used a model combining that metric with the same metric calculated in neighborhoods within 1380 m of plot locations. The posterior distribution of the ratio of the coefficients for within-habitat and regional heterogeneity in that model had a median of 0.90 and a 95% credibility interval below 1.00 (Fig. 4a). This distribution indicates that on average for land cover, a one-unit change in heterogeneity surrounding vegetation plots corresponded to the same change in species richness as a 0.90-unit change in regional heterogeneity does. Therefore, regional land cover heterogeneity had a greater correlation with species richness than local land cover heterogeneity. For the bivariate elevation model, we combined variance measured across a 150-m radius neighborhood with regional elevation variance. The posterior distribution of the ratio of level-1 to level-2 coefficients had a median of 1.04, with a lower limit of the 95% credibility interval greater than 1.00 (Fig. 4b). Therefore, a one-unit change in elevation heterogeneity in neighborhoods nearly always had a greater effect on species richness than an equivalent regional change. Finally, we combined standard deviation of NDVI in habitat patches within 450 m of vegetation plots with regional NDVI standard deviation. The posterior distribution of the ratio was highly skewed, with a median of 0.02, and a credibility interval between 1.4 × 10−5 and 5.2 × 101 (Fig. 4c). Thus, the ratio of level-1 to level-2 coefficients in this model was highly variable, likely because regional NDVI heterogeneity was not a significant univariate predictor.

Posterior distributions of the ratio of level-1 to level-2 coefficients from MCMC analysis for: a land cover heterogeneity, b elevation heterogeneity, and c NDVI heterogeneity
Discussion
Local species richness is structured by different ecological processes acting at different scales (Shmida and Wilson 1985; Levin 2000). We investigated the relationship between local plant species richness and variables measured across a variety of spatial scales in order to better understand these processes. Our results emphasize that (a) heterogeneity measured at a range of scales is correlated with local species richness, and (b) the strength and shape of the relationship depends on the heterogeneity variable used and the scale at which it is measured.
Within vegetation plots, mean pH was the best predictor, and predicted species richness better than any other variable or metric used in this study at any scale. By relating heterogeneity and richness measured within the same local sampling units, this portion of our study tested the spatial heterogeneity hypothesis, but found no support for it. Heterogeneity likely matters at this scale, and several previous studies have indeed found support for the spatial heterogeneity hypothesis (e.g., Davies et al. 2005; Jimenez et al. 2009). This result also contradicted our hypothesis that plot-level heterogeneity would be the best overall predictor. The level of environmental variation within plots may be too small to capture with the metrics and variables we used, or with the precision recorded in the CVS database. The inherent characteristics of the vegetation plots used in this analysis could account for the fact that the means of variables were better predictors than heterogeneity metrics within plots. Because Carolina Vegetation Survey plots were located to inventory sites that are characteristic of a single vegetation community and environmental setting, variation in environmental variables within plots is likely minimal and any single plot likely does not capture the heterogeneity present within communities. Sampling within transects spanning a gradient of community and abiotic characteristics, as has been done in previous studies (e.g., Gould and Walker 1997) may better facilitate examination of the effect of local heterogeneity on local species richness.
Across neighborhoods, elevation heterogeneity showed a positive relationship with local plant species richness. Neighborhood-scale elevation heterogeneity was the strongest heterogeneity predictor overall, and had a greater influence on richness than regional elevation heterogeneity. This result suggests that processes occurring across neighborhoods have a greater effect on local species richness than processes occurring within habitats or at regional scales. For example, greater variability among habitats across neighborhoods could result in increased source-sink dynamics among habitat patches, which act to maintain local population sizes via the rescue effect (Brown and Kodric-Brown 1977; Pulliam 1988). Alternatively, our results may reflect a scenario related to species pool theory, which states that there are environmental and geographic factors that act at different scales to determine local species composition and richness (Kelt et al. 1995; Belyea and Lancaster 1999). Heterogeneity measured across neighborhoods in this study may be similar to the scale at which plants disperse from neighboring habitat patches. The positive relationship we found between neighborhood heterogeneity and local richness suggests that heterogeneity at this scale could be associated with decreased constraints on dispersal.
The fact that elevation heterogeneity was the best predictor at the neighborhood scale is contrary to our hypothesis that heterogeneity of plant productivity would be the best predictor at this scale. Previous studies measuring heterogeneity at similar ecological scales have often measured heterogeneity in terms of vegetation productivity (e.g., St-Louis et al. 2006). However, elevation heterogeneity is likely an important predictor on the Southeast Coastal Plain because different vegetation communities result from subtle changes in elevation, and this variation can lead to considerable differences in plant species richness and composition (Peet 2006).
Within habitats, NDVI heterogeneity showed a negative relationship with species richness. In fact, the dominant relationship for heterogeneity variables measured within habitats was negative (Table 3). The negative relationship is contrary to our hypothesis that the heterogeneity-richness relationship would be positive at all scales. The negative relationship we found could be because habitats with more variation in productivity also have lower overall productivity. Within habitats, mean and standard deviation of NDVI are negatively correlated, although the strength of the relationship is relatively weak (Appendix 1 in Electronic Supplementary Material). This negative relationship may also be a direct result of the way in which patches were delineated in this study. We delineated patches based on areas of contiguous vegetation according to NLCD land cover data. Because relatively species poor communities in the Southeast, such as pocosin, exist within larger expanses of vegetation, patch sizes for these vegetation types are likely higher. Consequently, there is more potential for variation and heterogeneity within these larger patches. Indeed, patches surrounding plots with lower than average values of NDVI heterogeneity had a mean size of 30.4 ha, while those with higher values of NDVI heterogeneity had a mean size of 38.9 ha. In addition, Fig. 3a suggests that a few outliers could be responsible for the negative relationship between local species richness and elevation heterogeneity at the habitat scale.
Land cover heterogeneity across regions showed a positive relationship with local richness and had a stronger effect on richness than land cover heterogeneity within habitats. Heterogeneity measured across regions represents variability in the number of habitat types within an ecoregion, which are partially the result of longer-term processes, such as soil formation, that influence the total pool of species available to colonize any local area. Therefore, the positive regional heterogeneity-local richness relationship we found could be because regional heterogeneity acts to increase local species richness by increasing the number of species in the regional species pool, providing a larger group of species available before dispersal and environmental filters. The fact that land cover heterogeneity was the best predictor at the regional scale is consistent with our hypothesis and other studies (e.g., Kerr and Packer 1997).
Land use patterns in the Southeast Coastal Plain could also account for the heterogeneity-richness relationships seen here. In this analysis, the neighborhood and regional scales incorporated variability across both areas of human land use and relatively natural areas. In the region, historical conversion to agriculture and other human development occurred first in the most fertile longleaf pine communities, where highest plant richness naturally occurs (Frost 2006). Therefore, the positive correlation between richness and heterogeneity at neighborhood and regional scales could be because the richest communities are also the ones in the most fragmented landscapes.
Our results suggest that measures of heterogeneity may be generally useful in predictive models of local biodiversity. Some such models have already incorporated heterogeneity (e.g., Ewers et al. 2005); however, there is no consensus about how or at which scales to measure heterogeneity. In our study, heterogeneity measures across broad extents better predicted richness than the means of variables such as NDVI, elevation and land cover. Therefore, incorporating those heterogeneity measures could help predict richness. Specifically, by showing that at within-habitat and neighborhood scales, local richness could be predicted by variation in unclassified spatial data (elevation and NDVI), we found support Palmer et al.’s (2002) spectral variation hypothesis, as a tool that can inform surveys of species richness.
Our study examines whether heterogeneity variables are useful predictors of plant species richness. This study does not aim to develop the best multivariate models to predict richness, but rather to examine the richness-heterogeneity relationship using a range of readily available heterogeneity metrics derived from ecologically meaningful variables across a variety of scales. Indeed, other factors, most notably disturbance history, certainly have an important influence on plant species richness in the region and should be included in any comprehensive modeling effort.
Overall, this study provides a comprehensive examination of the relationship between heterogeneity and local richness. The results of this analysis are broadly consistent with, but extend the findings of other studies that have examined the relationship of heterogeneity and species richness measured at a single scale for many taxa (St-Louis et al. 2006; Jimenez et al. 2009; Lundholm 2009). Our results show that measures of heterogeneity at multiple scales are related to local species richness and the relationship is usually, though not always, positive. The strength and shape of the relationship vary by scale, highlighting the fact that local species richness is determined by different processes operating at different scales, from local to regional.
These results have important implications for how biodiversity conservation is accomplished. Because we found that heterogeneity at large scales was correlated to local richness, our study suggests that conservation of biodiversity consider processes that occur at a variety of scales surrounding those sites. The within-habitat scale, measured within contiguous vegetation at extents of less than 1 ha to 600 ha, corresponds most closely to a single forest stand or conservation preserve. The neighborhood scale measured variability across vegetation and non-vegetation surrounding plots, and might approximate the scale of a preserve plus the surrounding land uses, while the regional scale, measured at extents of 38,000–705,000 ha, is close to the scale of a large watershed. The influence of heterogeneity across these broad scales on local richness indicates that conservation efforts must consider the larger landscape, including human land uses, when aiming to conserve local sites. Indeed, these results provide support for ecosystem management, which works to achieve conservation while integrating broad-scale ecological and social factors across regional extents (Christensen et al. 1996), as an effective approach for conserving local richness. As habitat fragmentation increasingly segments the landscape, an empirical understanding of how large-scale heterogeneity contributes to small-scale species diversity will be of vital importance to future conservation.
References
Belyea LR, Lancaster J (1999) Assembly rules within a contingent ecology. Oikos 86:402–416
Brown JH, Kodric-Brown A (1977) Turnover rates in insular biogeography: effect of immigration on extinction. Ecology 58:445–449
Burnham KP, Anderson DR (2002) Model selection and multi-model inference: a practical information-theoretic approach. Springer-Verlag, New York
Chesson P (2000) General theory of competitive coexistence in spatially-varying environments. Theor Popul Biol 58:519–553
Christensen NL (2000) Vegetation of the southeastern coastal plain. In: Barbour MG, Billings WD (eds) North American terrestrial vegetation, 2nd edn. Cambridge University Press, Cambridge, pp 397–448
Christensen NL, Bartuska AM, Brown JH, Carpenter S, D’Antonio CM, Francis R, Franklin JF, MacMahon JA, Noss RF, Peterson CH, Turner MG, Woodmansee RG (1996) The report of the Ecological Society of America committee on the scientific basis for ecosystem management. Ecol Appl 6:665–691
Cornwell WK, Grubb PJ (2003) Regional and local patterns in plant species richness with respect to resource availability. Oikos 100:417–428
Davies KF, Chesson P, Harrison S, Inouye BD, Melbourne BA, Rice KJ (2005) Spatial heterogeneity explains the scale dependence of the native-exotic diversity relationship. Ecology 86:1602–1610
Environmental Protection Agency (2004) Level III and IV Ecoregions of EPA Region 4. U.S. Environmental Protection Agency, National Health and Environmental Effects Research Laboratory, Western Ecology Division, Corvallis. 1:2,000,000
Ewers RM, Didham RK, Wratten SD, Tylianakis JM (2005) Remotely sensed landscape heterogeneity as a rapid tool for assessing local biodiversity value in a highly modified New Zealand landscape. Biodiv Conserv 14:1469–1485
Frost CC (2006) History and future of the longleaf pine ecosystem. In: Jose S, Jokela E, Miller D (eds) Longleaf pine ecosystems: ecology, management, and restoration. Springer, New York, pp 9–48
Gelman A, Hill J (2007) Data analysis using regression and multilevel/hierarchical models. Cambridge University Press, Cambridge
Gelman A, Su Y, Yajima M, Hill J, Pittau MG, Kerman J, Zheng T (2009) Arm: data analysis using regression and multilevel/hierarchical models. R package version 1.2-9. http://www.stat.columbia.edu/~gelman/software/
Gould WA, Walker MD (1997) Landscape-scale patterns in plant species richness along an arctic river. Can J Bot 75:1748–1765
Homer C, Huang C, Yang L, Wylie B, Coan M (2004) Development of a 2001 national land cover database for the United States. Photogramm Eng Remote Sens 70:829–840
Homer C, Dewitz J, Fry J, Coan M, Hossain N, Larson C, Herold N, McKerrow A, VanDriel JN, Wickham J (2007) Completion of the 2001 National Land Cover Database for the conterminous United States. Photogramm Eng Remote Sens 73:337–341
Hurlbert AH, Haskell JP (2003) The effect of energy and seasonality on avian species richness and community composition. Am Nat 161:83–97
Jimenez I, Distler T, Jorgensen PM (2009) Estimated plant richness pattern across northwest South America provides similar support for the species-energy and spatial heterogeneity hypotheses. Ecography 32:433–448
Kelt DA, Taper ML, Meserve PL (1995) Assessing the impact of competition on community assembly: a case study using small mammals. Ecology 76:1283–1296
Kerr JT, Packer L (1997) Habitat heterogeneity as a determinant of mammal species richness in high-energy regions. Nature 385:252–254
Kerr JT, Southwood TRE, Cihlar J (2001) Remotely sensed habitat diversity predicts butterfly richness and community similarity in Canada. Proc Natl Acad Sci 98:11365–11370
Levin SA (2000) Multiple scales and the maintenance of biodiversity. Ecosystems 3:498–506
Lundholm JT (2009) Plant species diversity and environmental heterogeneity: spatial scale and competing hypotheses. J Veg Sci 20:377–391
Lunn DJ, Thomas A, Best N, Spiegelhalter N (2000) WinBUGS—a Bayesian modelling framework: concepts, structure, and extensibility. Stat Comput 10:325–337
Mittelbach GG, Steiner CF, Scheiner SM, Gross KL, Reynolds HL, Waide RB, Willig MR, Dodson SI, Gough L (2001) What is the observed relationship between species richness and productivity? Ecology 82:2281–2396
Nagendra H (2001) Using remote sensing to assess biodiversity. Int J Remote Sens 22:2377–2400
Nagendra H (2002) Opposite trends in response for the Shannon and Simpson indices of landscape diversity. Appl Geogr 22:175–186
NASA (2008) MODIS Vegetation Indices 16-Day L3 Global 250 m [spatial data] 5.0. https://lpdaac.usgs.gov/lpdaac/get_data/data_pool. Accessed June 2008
Palmer MW, Earls PG, Hoagland BW, White PS, Wohlgemuth T (2002) Quantitative tools for perfecting species lists. Environmetrics 13:121–137
Parviainen M, Luoto M, Heikkinen RK (2009) The role of local and landscape level measures of greenness in modelling boreal plant species richness. Ecol Model 220:2690–2701
Peet RK (2006) Ecological classification of longleaf pine woodlands. In: Jose S, Jokela E, Miller D (eds) Longleaf pine ecosystems: ecology, management, and restoration. Springer, New York, pp 51–94
Peet RK, Wentworth TR, White PS (1998) A flexible, multipurpose method for recording vegetation composition and structure. Castanea 63:262–274
Pettorelli N, Vik JO, Mysterud A, Gaillard J-M, Tucker CJ, Stenseth NC (2005) Using the satellite-derived NDVI to assess ecological responses to environmental change. Trends Ecol Evol 20:503–510
Pinheiro J, Bates D, DebRoy S, Sarkar D (2009) nlme: linear and nonlinear mixed effects models. R package version 3.1-92
Pulliam HR (1988) Sources, sinks, and population regulation. Am Nat 132:652–661
R Development Core Team (2009) R: a language and environment for statistical computing. Foundation for Statistical Computing, Vienna
Reynolds HL, Mittelbach GG, Darcy-Hall TL, Houseman GR, Gross KL (2007) No effect of varying soil resource heterogeneity on plant species richness in a low fertility grassland. J Ecol 95:723–733
Ricklefs RE (1977) Environmental heterogeneity and plant species diversity: a hypothesis. Am Nat 111:376–381
Ricklefs RE (1987) Community diversity: relative roles of local and regional processes. Science 235:167–171
Riitters KH, Wickham JD, Vogelmann JE, Jones KB (2000) National land-cover pattern data. Ecology 81:604
Shmida A, Wilson M (1985) Biological determinants of species diversity. J Biogeogr 12:1–20
Simpson EH (1949) Measurement of diversity. Nature 163:688
Singer JD, Willett JB (2003) Applied longitudinal data analysis: modeling change and event occurrence. Oxford University Press, Oxford
Snyder RE, Chesson P (2004) How the spatial scales of dispersal, competition, and environmental heterogeneity interact to affect coexistence. Am Nat 164:633–650
Sorrie BA, Weakley AS (2001) Coastal plain vascular plant endemics: phytogeographic patterns. Castanea 66:50–82
Southeast Gap Analysis Project (2008) Southeast GAP Regional Land Cover [digital data]
St-Louis V, Pidgeon AM, Radeloff VC, Hawbaker TJ, Clayton MK (2006) High-resolution image texture as a predictor of bird species richness. Remote Sens Environ 105:299–312
U.S. Geological Survey [USGS] (1999) National Elevation Dataset 7.5-Minute Elevation Data
Waring RH, Coops NC, Fan W, Nightingale JM (2006) MODIS enhanced vegetation index predicts tree species richness across forested ecoregions in the contiguous U.S.A. Remote Sens Environ 103:218–226
Wood SN (2006) Generalized additive models: an introduction with R. Chapman and Hall/CRC, Boca Raton
Zuur AF, Ieno EN, Walker N (2009) Mixed effects models and extensions in ecology with R. Springer, New York
Acknowledgments
We thank Carolina Vegetation Survey personnel, past and present, for data collection and database administration. We also thank Jack Weiss for assistance with statistical analysis. This work was supported by NASA Terrestrial Ecology and Biodiversity grant #NNG06GI70G to A.M. and R.K.P.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article
Cite this article
Costanza, J.K., Moody, A. & Peet, R.K. Multi-scale environmental heterogeneity as a predictor of plant species richness. Landscape Ecol 26, 851–864 (2011). https://doi.org/10.1007/s10980-011-9613-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10980-011-9613-3