
Abstract
Police practice of double-blind sequential lineups prompts a question about the efficacy of repeated viewings (laps) of the sequential lineup. Two laboratory experiments confirmed the presence of a sequential lap effect: an increase in witness lineup picks from first to second lap, when the culprit was a stranger. The second lap produced more errors than correct identifications. In Experiment 2, lineup diagnosticity was significantly higher for sequential lineup procedures that employed a single versus double laps. Witnesses who elected to view a second lap made significantly more errors than witnesses who chose to stop after one lap or those who were required to view two laps. Witnesses with prior exposure to the culprit did not exhibit a sequential lap effect.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Laboratory research has generated recommendations for police practice to improve the veracity of eyewitness evidence (Wells et al., 1998; Technical Working Group for Eyewitness Accuracy, 1999). Among the reforms advised by scientists are the use of double-blind lineup administration and a sequential presentation format for identification procedures, the double-blind sequential lineup (Wells et al., 2000). Over the past decade, this protocol has been introduced into practice in a number of jurisdictions (see e.g., Gaertner & Harrington, 2009; Klobuchar, Steblay, and Caligiuri, 2006).
The application of eyewitness research findings to law enforcement practice and public policy prompts questions that compel further laboratory examination, questions that may center on practical concerns but often hold implications for broader theoretical issues as well. For example, when recommended police lineup procedure is adjusted to meet convenience or operational needs of a local jurisdiction, a relevant question is whether (and why) the change will compromise or enhance eyewitness accuracy. The laboratory’s randomized controlled trials and knowledge of ground-truth identification accuracy offer an objective means to address such questions.
The recommended sequential (one photo at a time) lineup protocol calls for only one viewing of the lineup per witness. The witness is required to make a decision for each photo before moving to the next, photos are never compared side-by-side, and the witness does not know how many photos will be shown (Lindsay & Wells, 1985). However, in jurisdictions that have implemented the double-blind sequential lineup, common practice is that the sequential protocol allows the witness, once the end of the lineup photos is reached, to view the sequential array again (see e.g., Klobuchar et al., 2006). Upon witness request, what has come to be called a second lap or even multiple laps may be taken through the lineup. In 2006, Klobuchar et al. published the first field data on double-blind sequential lineups and evaluated the “lapped” sequential procedure. Results revealed that the frequency of known errors (filler picks) increased with more lineup laps. In the field, the true status of the suspect as guilty or innocent is unknown, and therefore the Klobuchar et al. study could not assess the impact of sequential laps on correct identifications. As the field data were collected, however, a laboratory analogue was constructed to determine the impact of sequential lineup laps on identification accuracy. This report details the lab investigation, one that began with a practical question from the field: What is the impact on identification accuracy of allowing eyewitnesses a second viewing of a sequential lineup?
The lapped sequential lineup may be viewed as an expedient remedy for the concern of law enforcement that some good identifications will be lost if overly cautious eyewitnesses get only one chance to view the suspect in a sequential array. Laboratory research provides possible justification for law enforcement concern. Experimental comparisons of sequential versus simultaneous lineup formats indicate that the sequential lineup produces a lower frequency of witness picks from the lineup than does the simultaneous array (Steblay, Dysart, Fulero, & Lindsay, 2001). In effect the sequential lineup is a more conservative procedure, a seemingly more challenging task for the eyewitness with a weak memory. The research also shows that a lower witness choosing rate is of benefit when the culprit is absent from the lineup in that errors are reduced, but when the culprit is present in the lineup less choosing can lower the number of correct identifications. The underlying reason for lower witness picks under a sequential lineup format has been explained with the concepts of relative and absolute judgment (Wells, 1984; Wells, Memon, and Penrod, 2006). Briefly stated, a witness may compare simultaneously displayed lineup members to one another to determine which is closest to memory—a use of relative judgment in decision-making that can increase the tendency to pick a member of the lineup. This decision strategy may help the witness find the offender in the lineup, but may also place an innocent suspect at risk when the true culprit is absent (Wells, 1993). The sequential lineup was developed in order to reduce the tendency for relative judgment and to move the witness toward greater reliance on absolute judgment—an independent decision for each lineup member about the match between memory and that lineup member’s face (Lindsay & Wells, 1985).
The procedural change to allow witnesses a second view of a sequential lineup is a practical revision aimed at securing a greater number of accurate positive identifications, presumably by capturing the correct memories of witnesses who are hesitant in their first assessment of the lineup photos but who can be accurate in their identifications with a second viewing. However, one could alternatively surmise that a second lap through the sequential lineup may approximate a de facto simultaneous array and move the witness’s experience in the direction of a simultaneous presentation. Although the witness is still not allowed a side-by-side comparison of photos in the second lap, the witness now knows how many photos are in the array and views each photo more than once. The repeated viewing of the lineup may undermine the purpose of the sequential lineup: witnesses may begin to mentally compare photos and thereby lapse into relative judgment, a change that will increase choosing rate but not necessarily improve accuracy. Lindsay, Lea, and Fulford (1991) found no significant change in identification errors when they required witnesses to view a second lap for an “extremely biased” culprit-absent sequential lineup (p. 743). However, a deterioration of witness performance in sequential lineup laps was evident in a study by MacLin & Phelan (2007) who also required their witnesses to take a second sequential lap. MacLin and Phelen found that a sequential format advantage was eliminated with the second lap (although witness accuracy with the sequential lineup remained better than with a simultaneous lineup). The current Experiment 1 focuses on a sequential second lap that is elected by the witness, a procedure that more closely approximates field practice—and that may reduce second-guessing that may be incurred when witnesses are required to view a second lap. Experiment 2 takes an additional step toward understanding sequential laps, directly addressing the question of why a sequential lap effect occurs by comparing witness performance when a second lap is required versus elected.
This pair of studies will ascertain levels of correct and erroneous identifications in sequential double-lap versus single-lap lineups. An extra lap may simply allow witnesses to confirm a previous decision (no change from first to second lap). A witness who recognizes the culprit but hesitates at first lap may use the second lap to make a correct identification, a positive outcome. One can also speculate, however, that a witness with a poor memory of the culprit who reaches the end of the lineup without a pick may be tempted by a second chance at the lineup. This witness may be induced (perhaps with the aid of relative judgment) to make a lineup pick in the second lap, driving up the number of misidentifications. The hypothesis of Experiment 1 is that a second sequential lap will prompt choosing, particularly by witnesses who have not yet made a lineup pick, and it is anticipated that the second lap will yield disproportionately more errors than correct decisions thereby reducing the diagnosticity (Wells & Turtle, 1986; Wells & Olson, 2002) of the lapped sequential lineup. This outcome is predicted for witnesses who attempt to identify a stranger-perpetrator, the typical task for eyewitness studies. It is possible that a lap effect is closely tied to memory strength. Therefore, an additional component of Experiment 1 is examination of witnesses who have had prior exposure to the culprit. The stronger encoded memory created by prior exposure is expected to eliminate witnesses’ need for a repeat viewing of the lineup; therefore, no sequential lap effect is expected for this group of witnesses.
Experiment 1
Method
The study design was a 2 × 2 factorial with independent variables of lineup format (simultaneous or sequential), and offender presence in the lineup (culprit-present or absent). The primary variable of interest—number of lineup laps—was an ex post facto (non-manipulated) variable, in that each witness made a decision as to whether to repeat the lineup viewing. A second ex post facto variable was the witness’s prior exposure to the perpetrator. The actor who played the perpetrator in the video was a recent graduate of the college at which the study was conducted, a fact that allowed assessment of familiarity between witness and offender. Participants were asked after the lineup if they were familiar with any of the actors prior to the experiment. Key dependent measures were witness choosing, identification accuracy, and confidence assessed on a 1–6 scale at the completion of the lineup.
Participants
Witness-participants were 372 male (37.9%) and female (62.1%) undergraduate students and community members ages 18–65 (M = 21.04 years, Mdn = 20, SD = 4.53). Eighty-eight percent of participants identified themselves as Caucasian. Participants were provided the choice of course credit or five dollars.
Stimulus Materials
The experiment was delivered via laptop computer. A video of a short (30-s) purse-snatching incident served as the stimulus crime incident. The event was filmed in color with audio and shot from the victim’s perspective. The face of the male Caucasian perpetrator, age 21, was visible at close range for 10 s.
A six-person photo lineup of Caucasian males, ages 18–23, was constructed to capture moderate physical similarity between lineup members and the perpetrator, using a match-to-description method. Each photo was a head-and-shoulders view with a gray background. All lineup members including the offender wore street clothes for the lineup, none matching the clothing worn by the perpetrator at the time of the crime. Functional size of the lineup was 4.29 (Wells, Leippe, & Ostrom, 1979) and effective size (Tredoux, 1998), E′, was 4.79 (95% CI [4.14, 5.67]). The culprit’s photo was chosen by 23% of the test witnesses, not significantly above the rate of chance. Each lineup member was picked by at least 5% of the participants.
For each participant, the computer program generated a six-person lineup of sequential or simultaneous format, culprit-absent or culprit-present. Across subjects, the six fillers rotated in and out of the culprit-present lineup. The position of fillers in all lineups and the position of the perpetrator in the culprit-present lineup were counterbalanced with the exception that the offender never appeared in position one. The witness controlled the temporal presentation of the lineup, taking as much time as desired for each photo in the sequential display. The witness did not know prior to the end of the lineup that the lineup could be repeated. Response options were dichotomous; witnesses were allowed to either select a photo or indicate no to each photo (sequential) or to the lineup (simultaneous). After the final photo of the sequential lineup, the computer program questioned the witness as to whether he or she would like to see the lineup again. If the witness opted to repeat the lineup, all photos were shown again in the same order.Footnote 1
Procedure
Each participant was run individually during a 15-min laboratory session. The experimenter maintained a “computer-blinded” status by keeping the laptop computer facing toward the participant and away from the experimenter. After a brief introduction, participants worked through the computer application, which requested demographic information and showed the crime video. The experimenter was out of the room during this time. At the conclusion of the crime video, the experimenter re-entered the room and verbally provided instructions for all participants, emphasizing a cautionary instruction (“the lineup may or may not include the perpetrator you saw in the film”) and an appearance change instruction (“Sometimes the appearance of the offender will change between the event and the lineup. Please keep this in mind.”). A minor deception was employed to establish the experimenter’s blind status for witnesses by informing them that the specific perpetrator in the witness’s film was one of many employed in multiple versions of the film, thus not knowable to the experimenter.
Results and Discussion
Eyewitness decisions for the subset of participants (68%) for whom the offender was a stranger (n = 253) and the subset of participants for whom the offender was familiar (n = 119) are detailed in Tables 1 and 2, respectively.Footnote 2 Only five witnesses opted for a third viewing (lap) of the sequential lineup, therefore the analyses combine second and third laps and simply refer to first versus second (final) laps. The analyses address witness decisions at two points. All witnesses (simultaneous and sequential) made a decision about the lineup, referred to below as “first” decision. Only sequential lineup witnesses were offered a second lap, and “final” decisions include the decision changes of these witnesses who opted for a second sequential lap as well as decisions of simultaneous and one-lap witnesses which are, of course, the same as their first decision. Alpha was set at .05, and all confidence intervals are reported at the 95% level.
Choosing Rates
Logistic regression analysis was used to examine the impact of lineup format (simultaneous/sequential), culprit presence in the lineup (present/absent), and witness’s prior exposure to the culprit (familiar/stranger) on eyewitness picks of any lineup member. Only culprit presence produced a significant effect on choosing rate at first decision, with a higher level of choosing when the culprit was present (44%) than when he was absent from the lineup (26%), Wald’s χ2 (1, N = 372) = 12.01, p < .001, Expβ = .462, h = .38.
At final decision, lineup format, culprit presence, and prior exposure each were significant predictors of choosing rate, Wald’s χ2 (1, N = 372) = 11.71, Expβ = 2.19, χ2 = 20.91, Expβ = 28.53, and χ2 = 28.65, Expβ = 82.84, respectively, all ps < .001. Simultaneous lineups produced lower choosing rates than sequential lineups (34.7 vs. 51.5%, h = .35). A significant interaction moderated the relationship between prior exposure and culprit presence in the lineup: the highest choosing rate (71%) was from witnesses who had prior exposure to the perpetrator and viewed a culprit-present lineup, and the lowest choosing rate was from witnesses with prior exposure who viewed a culprit-absent lineup (10.5%), Wald’s χ2 (1, N = 372) = 30.99, p < .0001, Expβ = .04, h = 1.33.Footnote 3
Culprit and Filler Identifications from Culprit-Present Lineups
At both first and final decision, witness familiarity with the culprit had a significant impact on correct identifications and on filler picks. Wald’s χ2 values (1, N = 190; Expβ in parentheses) for correct identifications in first and final laps and filler picks in first and final laps were, respectively: χ2 = 45.63 (15.74), χ2 = 44.87 (12.77), χ2 = 7.59 (.216) and χ2 = 11.43 (.178), all ps < .01. Witnesses who had prior exposure to the perpetrator were more likely to identify him from the lineup than were witnesses for whom the perpetrator was a stranger, at first decision (59.7 vs. 8.6%, h = 1.16) and at final decision (62.9 vs. 11.7%, h = 1.13). Witnesses with prior exposure were also less likely to make a filler pick, at first (6.5 vs. 24.2%, h = .49) and final decision (8.1 vs. 31.2%, h = .61). Lineup format had a significant impact only on filler picks at final decision, with sequential lineups producing higher levels of filler picks than simultaneous lineups, 29.7 vs. 16.9%, Wald’s χ2 (1, N = 190) = 5.23, p = .02, Expβ = 2.34, h = .31.
False Alarm Rates from Culprit-Absent Lineups
When the culprit was absent from the lineup, prior exposure again had a significant impact, Wald’s χ2 (1, N = 182) = 9.58, Expβ = .23 and χ2 = 18.78, Expβ = .129, ps < .001, first and final decisions, respectively, with fewer errors generated when the culprit was familiar. Filler picks did not change from first to final decision for those witnesses who were familiar with the perpetrator, but witnesses for whom the perpetrator was a stranger increased their errors from first to final decision 33.6 to 46.4%, h = .25. At final decision, this increase in errors produced a significant effect for lineup format, with errors now more frequent in sequential than simultaneous lineups (41.6 vs. 27.2%), Wald’s χ2 (1, N = 182) = 4.78, p = .01, Expβ = 2.12, h = .32.
In sum, regression analyses indicated that witness choosing rate was affected significantly by the status of witness memory for the perpetrator. Not surprisingly, witnesses who had prior exposure to the offender (having seen him on campus, interacted with him, or knowing him personally) were significantly more likely to choose him from the lineup when he was present and significantly less likely to pick a photo from a culprit-absent lineup. Important to the issue of sequential laps is the fact that very few witnesses who were familiar with the perpetrator opted for a second lap (4.5%), none in the culprit-absent lineup condition. If prior exposure to the culprit can be equated with better witness memory (that is, experience provides a basis for recognition), this result speaks to the conditions under which a witness may choose a second lap through the lineup: a good memory will preclude the need for a second look at the lineup.
Witness Performance (Stranger-Perpetrator)
The analyses below examine witness performance in sequential lineup laps when the perpetrator was a stranger, witness memory based solely on the 10-s video view of the culprit. Table 1 reveals that for both simultaneous and sequential lineups, witness performance was poor. Correct identification rate in culprit-present lineups (8.6%) compared to average identification error rate in culprit-absent lineups (5.6%), indicated no significant difference, Z (N = 93) = 1.00, p = .16. Rejections of the lineup were not more common from a culprit-absent lineup (66.4%) than from a culprit-present lineup (67.2%). In short, witnesses responded to the stranger-perpetrator’s photo at no better than chance levels (the rate of guessing). It appears that either the short exposure time was quite challenging for memory encoding (the witnesses had only a weak memory), the lineup task particularly difficult for memory retrieval, witnesses very cautious, or all of the above.
Choosing: Sequential Lineup Laps (Stranger-Perpetrator)
As predicted, witness choosing rate increased significantly from first to final lap for both culprit-present (up 19.6%) and culprit-absent lineup conditions (up 23.2%), McNemar Test (Binomial), N = 66, p < .0001, h = .41, and McNemar’s Test (Binomial), N = 69, p < .0001 h = .47, respectively (see Table 1).Footnote 4
Correct Identifications: Culprit-Present Sequential Lineup Laps (Stranger-Perpetrator)
Witness decisions for the entire group of 66 sequential lineup witnesses were significantly different from one lap to the next, McNemar–Bowker Test χ2 (2, N = 66) = 14.00, p = .002. Correct identifications increased by 6%, McNemar Test (Binomial), N = 66, p = .06, h = .19. Filler picks grew by 13.6%, McNemar Test (Binomial), N = 66, p < .001, h = .28. The 39 witnesses who opted for a second lap produced a 10.2% increase in correct identifications, McNemar Test (Binomial), N = 39, p = .06, h = .39 and a 23.1% increase in filler picks, McNemar Test (Binomial), N = 39, p < .001, h = .51.
The decisions of individual witnesses who elected to repeat the culprit-present lineup can be tracked from first to final lap. For most (64%) of these two-lap witnesses, lineup decision remained the same from first to final lap; the remaining 36% changed their answers. The decision change in a second lap improved performance for 29% of witnesses (4 of 14); for 2½ times as many (10 of 14, 71%), the decision change produced an error (see Table 6).
Identification Errors: Culprit-Absent Sequential Lineup Laps (Stranger-Perpetrators)
As reported above, witness choosing (and therefore error) for culprit-absent lineups increased significantly from first to final lap. For the 44 witnesses who opted for a repeat of the lineup, 64% maintained their initial answer; the remainder moved from a correct rejection to a filler selection, a significant change, McNemar’s Test (Binomial), N = 69, p < .0001, h = .80.
Accuracy of Single-Lap Witnesses
At the end of one lap, the decisions of witnesses who did not opt for a second lap were significantly different than two-lap witnesses, χ2 (4, N = 66) = 15.29, p = .002, culprit-present condition, and χ2 (2, N = 69) = 10.99, p = .002, culprit-absent conditions, respectively (Table 1), with more correct identifications but also more misidentifications. The final decisions of two-lap witnesses did not differ significantly from one-lap witnesses.
Diagnosticity
An index of diagnosticity estimates the probative value of eyewitness identification evidence: how much more likely it is that the suspect, if identified, is the culprit rather than an innocent person (Wells & Lindsay, 1980). Our calculation of diagnosticity is a ratio of the percentage of correct identifications in the culprit-present lineup to the average identification rate (filler picks/6) for the culprit-absent lineup.Footnote 5 Diagnosticity between lineup conditions was compared using an interaction test for proportions (Wells & Olson, 2002). There were no significant differences in diagnosticity between simultaneous and sequential lineups (at first or final lap), or between sequential first and final laps within the group of witnesses who viewed a familiar perpetrator or within the group of witnesses who viewed a stranger-perpetrator. Not surprisingly, diagnosticity was significantly higher for any lineup viewed by a witness who was familiar with the culprit compared to any lineup viewed by a witness who was unfamiliar with the offender (a stranger-perpetrator) (ps < .0001).
Confidence
ANOVA was used to examine the impact of lineup format, culprit presence in the lineup, and prior exposure to the culprit on witness confidence. Simultaneous lineups produced a marginally significant higher level of confidence (M = 4.83, SE = .08, CI [4.68, 4.99]) than did sequential lineups (M = 4.63, SE = .07, CI [4.49, 4.77]), F (1,364) = 3.59, p = .06, two-tailed. Witnesses who had prior exposure expressed significantly higher confidence (M = 5.36, SE = .09, CI [5.19, 5.54]) than witnesses for whom the culprit was a stranger (M = 4.10, SE = .06, CI [3.98, 4.22]), F (1, 364) = 138.68, p < .0001. Among witnesses who viewed a sequential culprit-present lineup looking for a stranger-perpetrator, confidence was higher for those who ended at one lap, M = 4.44, SD = .94, CI [4.24, 4.64], compared to those who went on to a second lap, M = 3.73, SD = 1.17, CI [3.36, 4.10], t (124) = 3.58, p < .0001. When the culprit was absent, confidence was again higher for those who ended at one versus two laps, t (120) = 3.70, p < .0001, M = 4.19, SD = .87, CI [4.0, 4.38], one-lap; M = 3.54, SD = 1.00, CI [3.23, 3.85], two-laps. Finally, for witnesses who continued to a second lap, confidence increased significantly from first lap, M = 3.72, SD = 1.19, CI [3.35, 4.09] to second lap, M = 4.15, SD = 1.01, CI [3.84, 4.46] with the culprit-present lineup, t (38) = 2.04, p = .02. For the culprit-absent lineup, confidence also increased significantly from first lap, M = .3.52, SD = 1.02, CI [3.22, 3.82], to second lap, M = 4.05, SD = .78, CI [3.82, 4.28], t (43) = 3.12, p = .002.
Summary
The hypothesis of the study was supported in that repeated viewing of a sequential lineup significantly increased witness choosing rates, thereby elevating both correct and erroneous identification decisions when the witness and culprit were strangers. As predicted, the significant increase in false alarms for repeated culprit-absent lineups (23.2%) was disproportionately larger than the (non-significant) 6% increase in correct identifications achieved with repeated culprit-present lineups. Within the culprit-present lineup condition, filler picks also increased significantly, 13.6% from first to final lap. The tracking of individual witness decisions revealed that a majority of witnesses in both culprit-present and absent conditions held to their first answer as they moved from first to second lap. Witnesses who changed their responses were significantly at risk for error: Twenty-six of 30 (87%) moved from no-choice to a false alarm. It is possible that a second sequential lineup lap is only damaging under the extreme circumstance of witness guessing that occurred in this study. Experiment 2 probes this possibility as part of an exploration of the underlying dynamics of the sequential second lap.
Experiment 2
The configuration of lineup laps as an ex post facto variable in Experiment 1 was intentional, a means to capture greater ecological validity. Witnesses were allowed to decide whether they would see a second lap or not. However, the study failed to address an intriguing question: Is the negative impact of the second lap due to the lap itself, to some characteristic of the witness who opts for a second lap, or both? Experiment 2 incorporates the second lap as a true independent variable, with random assignment of participants to conditions that either required or allowed a second viewing of the lineup by the witness. As in Experiment 1, the expectation is that eyewitnesses who view a second lap of the sequential lineup will produce higher choosing rates, increased correct identifications, and increased false alarms. Experiment 1 revealed that witnesses who had not made a decision by the end of the first lap were at risk for picking a filler in the second lap. One can speculate that, compared to witnesses who are required to see a second lap, a greater proportion of witnesses who elect a second lap will end the first lap without a pick. Therefore, the risk of second-lap errors should be greater for these witnesses. It is predicted that witnesses who elect a second lap will have the highest rates of choosing and errors.
Method
Pilot Studies
Low suspect identification rates in Experiment 1 suggested that the perpetrator’s appearance in his lineup photo presented a very difficult recognition task for witnesses. Therefore, Experiment 2 employed a new perpetrator photo that more closely resembled his appearance in the crime video. The salient feature change from old to new photo was hairstyle, a significant feature for witness identification (Shapiro & Penrod, 1986; Pozzulo & Warren, 2003; Pozzulo & Balfour, 2006); however, it must be acknowledged that other unknown aspects of the new photo may also cue the memory of witnesses.
Prior to Experiment 2, two brief studies tested the new lineup configuration, specifically to determine whether the new perpetrator photo would increase correct identifications in the culprit-present condition above the level of chance. If so, this would inspire confidence that the crime video produced witness memory that could serve reasonably well for the lineup recognition task. Ninety-three participants all of whom were unfamiliar with the culprit (stranger identifications) took part in a 2 × 2 design study (sequential/simultaneous lineup format; culprit-present/absent), using the same procedure and materials as Experiment 1 but with the replacement of the old with new perpetrator photo. Collapsed across simultaneous and sequential lineups, correct identification rate in culprit-present lineups (60.9%) was compared to average identification error rate in culprit-absent lineups (7.45%), a significant difference, Z (N = 93) = 5.51, p < .001. Rejections of the lineup were significantly more common from a culprit-absent lineup (55.3%) than from a culprit-present lineup (28.3%), Z (N = 93) = 2.70, p = .004. In short, witnesses responded to the perpetrator’s photo at significantly better than chance levels (see Table 3), in a pattern expected from the lineup literature (Charman and Wells, 2006).
With a second group of 60 participants, lineup quality was reassessed. Functional size was determined to be 4.0, effective size (Tredoux’s E′) equal to 4.81 (95% CI [4.01, 6.00]. The culprit’s photo was chosen by 25% of the test witnesses, a non-significant difference from the expected value of 16.7%. Each lineup member was selected by at least 7% of the witnesses.
With the new lineup, we proceeded to Experiment 2, in which the impact of a sequential lineup lap was directly tested through a 2 × 3 factorial design. Participants were randomly assigned to view either a culprit-present or culprit-absent sequential lineup and to one of three lap conditions: a single lap, a required second lap, or the option of a second sequential lap. Extra participants were assigned to the third condition, in anticipation of the fact that not all witnesses would elect to see the second lap; some number would stop at the end of the first viewing of the lineup (an ex post facto configuration within the third lap condition).
Participants
One hundred thirty participants were recruited from college classes, the community, and an urban business corporation. The sample was 52.5% male and 48.5% female, with ages from 18 to 70 (M = 28.13, Mdn = 23.00, SD = 10.85). No participant reported familiarity with the perpetrator.
Materials
The same video as in the previous study was used. However, the lineup was delivered with paper photos rather than via computer. (We were unable to adjust the computer software to effectively deliver the lineups as needed for the new lapped conditions.) To counterbalance photo position across subjects, the perpetrator’s photo was rotated between positions two and five (switching positions with the filler); all other lineup photos were in fixed position. To mimic this process in the culprit-absent lineup, two fillers alternated between positions two and five. Suspect photo position is included in the regression analyses reported below as a methodological check for a position effect; no position effect is expected. The sequential lineup was delivered in a three-ring binder, back-loaded to disguise the number of photos. The witness’s answer sheet included spaces to rate 12 photos (although only six were actually shown in the binder). Each binder page included one photo equal in size to that of the computer display in Experiment 1, and the photos were numbered 1–6.
As in Experiment 1, the experimenter left the room while the participant watched the crime video and received instruction via computer for the subsequent lineup. When the experimenter returned to the room for the lineup procedure, a verbal instruction was provided, with cautionary and blind instructions as in the prior experiment. The ACI instruction was slightly modified for this experiment: “Keep in mind that things like hairstyles, beards, and mustaches can change between the crime event and the lineup, and that complexion colors may look slightly different in photographs.”
Specific instructions were provided for the sequential lineup: “In this book is a series of photos, displayed one at a time. The photos are in no particular order. For each photo, indicate whether that photo is or is not the perpetrator in the film. Please look at each of them, one at a time, without going back to previous photos. Take as much time as you need. Record your answer for each photo on this sheet. Even if you identify someone during the procedure, continue to look at the rest of the photos in the full series. Again, do not go back to earlier photos. You’ll see a page that says ‘stop’ at the end of the lineup.”
The experimenter left the cubicle, but remained in a position so as to monitor the progression of the sequential lineup (to make certain that the witness did not look backward in the lineup book; no witness did so). At the completion of the lineup (Lap 1), the experimenter initiated the manipulation. The experimenter re-entered the witness’s cubicle, collected the witness’s response sheet face-down without looking at it, and immediately placed it face-down on her clipboard (this was done in direct view of the witness in order to avoid any suggestion that the witness’s first responses were known or questioned by the experimenter). The experimenter then issued one of the following four statements.
-
Condition 1: (Required 1 Lap): Thank you. This completes the lineup procedure.
-
Condition 2: (Required 2 Laps): Now I would like you to view the lineup once again. The photos are in the same order. Here is another answer sheet for you. Please record your response to each photo.
-
Condition 3: (Witness’s Choice): Would you like to see the lineup again?
-
If “yes” (Elected 2 Laps): Here is the lineup once again. The photos are in the same order. Here is another answer sheet for you. Please record your response to each photo.
-
If “no” (Elected 1 Lap): Thank you. This completes the lineup procedure.
Results and Discussion
Choosing and Decision Accuracy from Lap 1 (SeqLap1) to Lap 2 (SeqFinal) (Table 4)
As in Experiment 1, choosing increased significantly from first to second lap in both the culprit-present lineup (an increase of 13.8%) and culprit-absent lineup (an increase of 15.3%), McNemar’s Tests (Binomial), N = 65, p = .002, h = .30, and N = 65, p = .003, h = .32, respectively. Correct identifications increased by 9.2%, McNemar’s (Binomial), N = 65, p = .01, h = .18. The sequential lap effect was replicated, now with a photo of the perpetrator that more closely resembled his appearance at the time of the crime.Footnote 6
Choosing and Identification Accuracy in 1-Lap Versus 2-Lap Witnesses
Logistic regression analysis was used to examine the impact on eyewitness decisions of culprit presence (present/absent), number of laps viewed (one/two) and suspect position in the lineup (2/5). The number of laps viewed significantly affected choosing: witnesses who viewed two laps picked from the lineup at higher rates (72.4%) than witnesses who viewed one lineup (60.9%), Wald’s χ2 (1, N = 130) = 3.10, p = .04, Expβ = 1.96, h = .23. A significant interaction between culprit presence and number of laps was revealed for witness accuracy, Wald’s χ2 (1, N = 130) = 14.02, p < .001, Expβ = .51. One-lap witnesses were more accurate than two-lap witnesses in both culprit-present and culprit-absent lineups, but the difference between these groups of witnesses was larger when the culprit was absent from the lineup. Otherwise stated, the gap in decision accuracy between groups was three times greater (22.1 vs. 7.1%) for culprit-absent versus culprit-present lineups. As predicted, the impact of a second lap was disproportionately greater when the culprit was not in the lineup.
Choosing and Identification Accuracy in Required Versus Elected Second Laps (Table 5)
The analysis now moves to the 30 witnesses who viewed a second lap of the lineup. The primary research question of this study is whether the sequential lap effect occurs when the second lap is required (Required 2 Laps), when it is optional (Elected 2 Laps), or under both circumstances, and the most direct test of this question is the comparison of witnesses who were required to take a second lap and those who elected to take a second lap. A logistic regression analysis examined the impact of lap condition (required/elected), culprit presence (present/absent), and suspect position in the lineup (2/5) on final decision. Lap condition was the only significant predictor of choosing, with witnesses who elected a second lap more likely to pick from the lineup (87.1%) compared to those who were required to view the lineup a second time (62.9%), Wald’s χ2 (1, N = 66) = 5.67, p = .01, Expβ = 5.32, h = .57. A significant interaction between lap condition and culprit presence for identification accuracy was also obtained, Wald’s χ2 = 5.01, p = .01, Expβ = .62. The difference in witness performance—between those for whom a second lap was required and those for whom the second lap was elected—was larger for culprit-absent lineups: When the culprit was present in the lineup, witnesses who elected to see a second lap were more likely to correctly identify him (50.0%) than witnesses who were required to view the second lap (37.5%); when the culprit was not in the lineup, witnesses who elected a second lap were more likely to choose a filler (88.2%) than witnesses who were required to view the second lap (68.4%). As can be seen on Table 5, witnesses who elected a second lineup also generated almost twice the number of filler picks than witnesses who were required to see a second lineup even when the culprit was in the lineup (35.7 vs. 18.8%). In sum, participants who elected a second lineup demonstrated significantly higher rates of choosing compared to witnesses who were required to view the lineup a second time. With the increased choosing came both more correct identifications and significantly more false alarms.
Choosing and Accuracy Within Required and Within Elected 2-Lap Conditions
As in Experiment 1, the individual responses of lineup members can be examined to determine the pattern of decision changes from first to final lap (Table 6). Overall, 68% of witnesses held to their initial decision when they examined the lineup in a second lap, 80% of witnesses who were required to see another lineup lap and 51% of witnesses who had elected a second lap.
A required second lineup lap increased witness choosing in the culprit-present condition by 12.5%, and all of the new choices in Lap 2 were of the culprit, McNemar’s Test (Binomial), N = 16, p = .25, h = .28 (Table 5). When the culprit was absent from the lineup, identification errors increased by 21%, McNemar’s Test (Binomial), N = 19, p = .07, h = 43. Table 5 also details the rise in choosing rate for witnesses who elected a second lap, which more than doubled from first to second lap, to 85.7%, when the culprit was present in the lineup, McNemar’s Test (Binomial), N = 14, p = .008, h = 1.09, and to 88.2% (errors) when the culprit was absent, McNemar’s Test (Binomial), N = 17, p = .03, h = .80. For those who changed their decision, the second lap was somewhat productive if the culprit was present in the lineup, with an increase in correct identifications (28.6%) McNemar’s Test (Binomial), N = 36, p = .07, h = .62. However, filler picks in the culprit-present lineup also rose (21.4%), McNemar’s Test (Binomial), N = 14, p = .13, h = .52 along with the significant increase in identification errors when the culprit was absent from the lineup. Statistically significant differences between first and final lap occurred only in the elected-lap condition.
Diagnosticity
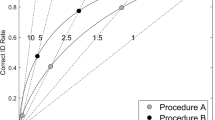
Diagnosticity of the lineup procedure was significantly higher when witnesses elected a single lap (10.27) compared to lineups in which witnesses either elected or were required to see a second lap, Zs > 1.65, ps < .05. A single required lap (8.97) did not significantly decrease diagnosticity compared to the elected single-lap lineup, although the slight reduction in correct identifications in this condition resulted in only marginally significant differences between the required one-lap and the two-lap witnesses, Zs = 1.0 and 1.33, ps = .16 and .09 for elected two-lap and required two-lap lineups, respectively.Footnote 7
Summary and Concluding Discussion
A sequential lap effect can be defined as an increase in witness lineup picks from first to second lineup lap. In each of two experiments in which witnesses attempted to identify a stranger-perpetrator, the increase in choosing rate was similar between culprit-present and culprit-absent lineups, as evidenced by comparable effect sizes in the two (culprit-present and absent) lineup conditions. More witness choosing resulted in increased correct identifications and false alarms from culprit-present lineups and identification errors from culprit-absent lineups. As predicted, hits were significantly less frequent than misses. When the additional lap prompted a decision change from a previous no-choice response to a lineup pick, more often than not this change was an error.
In Experiment 1, the accuracy of participants’ first lineup decisions did not exceed chance, and the second lap exacerbated this problem of guessing: errors grew significantly without an off-setting increase in correct identifications; yet confidence increased significantly from first to second lap. It is difficult to imagine how an extra lap could improve eyewitness performance or lineup diagnosticity if witnesses are essentially guessing and the lineup is unbiased. Experiment 2 demonstrated that the negative impact of a second sequential lap is not exclusive to conditions under which witnesses are merely guessing. Even when 49% of witnesses could identify the culprit in the first lap (an identification level well above chance), a second sequential lap was corrosive to witness performance: correct identifications increased significantly in the second lap, but again not enough to compensate for the errors incurred. A second sequential lap did not improve witness performance over single-lap witnesses in either experiment; in Experiment 2, one-lap witnesses were significantly more accurate than two-lap witnesses in both culprit-present and culprit-absent lineups, with a pronounced superiority when the culprit was absent from the lineup.
What is the role of witness cautiousness across sequential laps? This question addresses the premise that careful but potentially accurate eyewitnesses may simply decline to make a lineup pick during a first sequential lap. Otherwise stated, the conservative sequential procedure may suppress witness picks even in the face of witness recognition of the culprit; this cautious witness may then benefit from another lap. Diagnosticity figures for first and final laps offer information on this point. Eyewitnesses who elected to repeat the lineup had low choosing rates at the first lap of culprit-present lineups in both experiments, suggestive of caution. Correct identifications at final lap increased, significantly exceeding the rate of guessing in Experiment 2, an indication of identification accuracy. However, errors grew dramatically from first to final lap in both experiments—e.g., witnesses who elected a second viewing of a culprit-absent lineup pushed identification errors to an alarming 88% in Experiment 2. It appears that the final identification decisions of witnesses who opted for a second lap were influenced not so much by sharp memory of the culprit as by an increased willingness to pick someone from the lineup at the second lap. If these witnesses were initially cautious, that cautiousness was lost at the second viewing; confidence grew even as substantial memory errors were generated. These findings do not support the notion that a second lap will capture an increased number of good memories from otherwise cautious witnesses.
The memory strength that prompts absolute judgment and reliable identification evidence requires a combination of favorable encoding conditions, limited memory interference (e.g., short delay) and a reasonable likeness of the offender within the lineup—conditions of ecphoric similarity (Charman & Wells, 2007). Indeed, witnesses with prior exposure to the culprit produced relatively strong eyewitness performance (albeit not perfect) that did not rely on a second lap even with a lineup photo that was not a clear likeness of the known offender. Conversely, a combination of limited encoded memory of a stranger (from a 10-s view) and the difficult lineup photo prompted witnesses to guess, and the sequential second lap became a dangerous vehicle for identification errors. Witness performance in recognizing a stranger-perpetrator was aided by a seemingly easier-to-recognize lineup photo in Experiment 2 (suggesting even the 10-s view provided some useful memory of the offender), but again a damaging impact of sequential lineup laps occurred. The common feature of the two studies—limited memory for strangers—nudged some witnesses toward a second lap. However, a second lap certainly cannot enhance encoding nor decrease memory interference. One could argue that a second lap allows the witness to confirm a first impression formed during the initial lineup lap, perhaps after more carefully examining a lineup photo. To some extent this appears to be true, as the majority of second-lap witnesses did not change from initial to final response (whether accurate or inaccurate). However, can a second lap help the witness discern a match to memory? The current data indicate that the second sequential lap did not aid or capitalize on existing memory strength.
The sequential lap effect is primarily a function of the witness who makes the decision to review the lineup, with the lap procedure itself fueling the effect. The invitation to an additional lap may be tempting when the sequential lineup ends with the witness having not made a decision. Witnesses for whom a second lap was required, it must be remembered, were forced to take another lap. That is, a witness in the required-lap group, if given the option, may have either stopped at one lineup or preferred a second lap. Extrapolation from elected-lap conditions predicts that only 50% of required-lap witnesses in the culprit-present lineup condition and 59% in the culprit-absent condition would have opted for a second lap if given the chance, and nine would have changed their decisions (six actually did so in the required-lap condition). Accordingly, it is not surprising that 80% of required-lap witnesses held to their original decision, a level that fell between that of the elected one-lap (100%) and elected two-lap (51%) conditions. Fewer witnesses in the required-lap condition second-guessed their initial decisions than did witnesses who elected a second lap, and subsequent effect sizes for the required-lap condition are roughly half as large as those for the elected two-lap condition.
The sequential lap effect produced the type of overall impact on eyewitness accuracy that has been demonstrated in simultaneous lineups when compared to sequential single-lap lineups: increases in witness choosing rates that elevate correct identifications but even more so increase filler picks (Steblay et al., 2001). However, the performance of two-lap witnesses in Experiment 1 was not equivalent to witnesses who viewed simultaneous lineups, suggesting that a lapped sequential lineup is not simply a simultaneous display at least under this difficult lineup condition. Relative judgment may increase with the second lap, particularly as less confident witnesses struggle to find the offender in the lineup. However, relative judgment is not easily engaged without side-by-side comparison. Number of sequential lineup laps offers a broad-brush indicator of the witness’s desire to compare lineup members, but the process through which the witness evaluates a sequential lineup at second lap may be somewhat different from that of a simultaneous lineup, perhaps reflective of an unproductive lowering of decision criterion at the second lap as well as a relative judgment process. A fascinating aspect of the lapped procedure is that witnesses who had already decided no for each of the six sequential photos then returned to the lineup and reversed a decision—apparently lowering their criterion for identification (Meissner, Tredoux, Parker, & MacLin 2005).
Not surprisingly, sequential and simultaneous lineup formats produced no significant difference in identification accuracy for witnesses who had prior exposure to the perpetrator; a known offender allows relatively easy recognition. At the other extreme of difficulty—a stranger-offender seen for only 10 s—simultaneous and sequential (first lap) lineups also produced no significant witness performance differences, a surprising outcome particularly in the case of culprit-absent lineups wherein errors are typically substantially higher for simultaneous lineups (Steblay et al., 2001). The reason for the anomaly in the current experiment is unknown. Clark, Howell, & Davey (2008) have suggested that increased lineup fairness may diminish the sequential lineup advantage (perhaps a factor in the current study) and Gronlund, Carlson, Dailey, & Goodsell (2009) recently claimed that position effects reduce the sequential advantage (however, photo position was not a significant factor in our study). Whatever the reason, the continuing interest in sequential lineup field performance underscores the need to conduct additional studies of sequential laps that move beyond the single stimulus of one research project—and that capture the impact of sequential laps across a range of witnesses, crime stimuli, and lineup circumstances. It should be noted that MacLin and Phelan (2007), with witnesses who had a 3-min view of the culprit, found a sequential lap effect under conditions in which the typical sequential superiority occurred for first-lap lineups; a second lap erased the sequential lineup performance advantage.
Implications for Practice
The current studies indicate that a sequential format with witnesses held to one lap is preferable to a lapped sequential protocol. An intriguing finding is that witnesses who decline the offer of a second viewing of the lineup generated the highest diagnosticity ratios. However, this finding occurred only when the perpetrator’s photo approximated his crime-scene appearance. Future research will determine the reliability of this finding and its implication for trustworthiness of eyewitness decisions.
The field version of sequential lineup laps has been documented by Klobuchar et al. (2006), who concur with these lab findings that there is a danger of error when a witness ends a first lineup lap with no pick but then asks for a second viewing. Two important aspects of the field experience not captured in these laboratory studies should be noted. First, field witnesses are allowed to make tentative identifications at the first lap which can then be confirmed with a final lap; these second laps in the field may represent less dramatic decision changes (a movement from maybe to yes). Additionally, witnesses in the field typically are allowed a sequential lap only upon request, whereas the lab protocol included a direct question to witnesses as to whether they wanted a second lineup lap. Witness responses to the invitation of a second lap may vary, as the lab results demonstrate, depending on such factors as the presence/absence of the offender in the lineup, prior familiarity with the offender, and the quality of the offender’s photo. The sequential lap effect in the field may have less potential for error because witnesses are not invited to review the lineup. An exception to this point is in England and Wales, where video identification parades are performed in sequential format, but the witness is required to see the lineup twice before making a decision (Valentine, Darling, & Memon, 2007).
Data from both field and lab indicate that a witness who has not made at least a tentative identification at the end of the first lineup viewing presents a subsequent risk for identification error. This leads to a recommendation that repeated laps be employed only with careful recording of witness responses across laps. Future research will determine the comparability of the current lab results to field processes. Nevertheless, the current studies have provided initial laboratory evidence consistent with the proposition that sequential lineup laps can harm eyewitness performance.
Notes
Two pilot tests of the computer program and lineups produced correct identifications at 20–25%, suggesting a somewhat difficult lineup task and/or somewhat cautious witnesses (choosing rate of 40%).
Of the witnesses who reported to know the perpetrator, 25% reported they knew him personally, 25% had talked with him on at least one occasion, 25% had seen him a few times on campus, and 25% stated that he simply “looked familiar” from campus.
Thirty-three cross-race stranger identifications were attempted, with overall accuracy rates not significantly different from same-race stranger identification attempts, 39 versus 37%, respectively. There was also no difference in accuracy between same and cross-race identification attempts for simultaneous versus sequential formats.
Effect size h for is the arcsine transformation for difference between proportions. The effect size h is approximately twice the size of r for small effect sizes.
Diagnosticity calculations require an estimate of the risk to an innocent suspect. There was no a priori specification of an innocent suspect in the target-absent lineup, so the average rate of picks per lineup member in the culprit-absent lineup (percent of identification errors/6) was used. One could also employ effective size of the lineup as the denominator; we chose to use the consistent value (6) across the two studies.
Across conditions, only four witnesses opted for a third viewing (lap): as in Experiment 1, analyses combine second and third laps as the final lap.
Unfortunately, most witnesses failed to complete a confidence measure after the second lap, therefore confidence was not analyzed for this study.
References
Charman, S. D., & Wells, G. L. (2006). Applied lineup theory. In R. C. L. Lindsay, D. F. Ross, J. D. Read, & M. P. Toglia (Eds.), Handbook of eyewitness psychology: Memory for people (pp. 219–254). Mahwah, NJ: Lawrence Erlbaum Associates.
Charman, S. D., & Wells, G. L. (2007). Eyewitness lineups: Is the appearance change instruction a good idea? Law and Human Behavior, 31, 3–22. doi:10.1007/s10979-006-9006-3.
Clark, S. E., Howell, R. T., & Davey, S. L. (2008). Regularities in eyewitness identification. Law and Human Behavior, 32, 187–218. doi:10.1007/s10979-006-9082-4.
Gaertner, S., & Harrington, J. (2009, April). Successful eyewitness identification reform: Ramsey County’s blind sequential lineup protocol. The Police Chief, 76(4), 130–141.
Gronlund, S. D., Carlson, C. A., Dailey, S. B., & Goodsell, C. A. (2009). Robustness of the sequential lineup advantage. Journal of Experimental Psychology: Applied, 15, 140–152. doi:10.1037/a0015082.
Klobuchar, A., Steblay, N. K. M., & Caligiuri, H. L. (2006). Improving eyewitness identifications: Hennepin County’s blind sequential lineup pilot project. Cardozo Public Law, Policy and Ethics Journal, 2, 381–414.
Lindsay, R. C. L., Lea, J. A., & Fulford, J. A. (1991). Sequential lineup presentation: Technique matters. Journal of Applied Psychology, 76, 741–745.
Lindsay, R. C. L., & Wells, G. L. (1985). Improving eyewitness identifications from lineups: Simultaneous versus sequential presentation. Journal of Applied Psychology, 70, 556–561.
MacLin, O. H., & Phelan, C. M. (2007). PC_Eyewitness: Evaluating the New Jersey method. Behavior Research Methods, 39, 242–247.
Meissner, C. A., Tredoux, C. G., Parker, J. F., & MacLin, O. H. (2005). Eyewitness decisions in simultaneous and sequential lineups: A dual-process signal detection theory analysis. Memory and Cognition, 33, 783–792.
Pozzulo, J. D., & Balfour, J. (2006). Children and adults’ eyewitness identification accuracy when a culprit changes his appearance: Comparing simultaneous and elimination lineup procedures. Legal and Criminological Psychology, 11, 25–34.
Pozzulo, J. D., & Warren, K. L. (2003). Descriptions and identifications of strangers by youth and adult eyewitnesses. Journal of Applied Psychology, 84, 167–176.
Shapiro, P. N., & Penrod, S. (1986). Meta-analysis of facial identification studies. Psychological Bulletin, 100, 139–156.
Steblay, N., Dysart, J., Fulero, S., & Lindsay, R. C. L. (2001). Eyewitness accuracy rates in sequential and simultaneous lineup presentations: A meta-analytic comparison. Law and Human Behavior, 25, 459–473. Retrieved from: http://www.jstor.org/stable/1394515.
Technical Working Group for Eyewitness Accuracy. (1999). Eyewitness evidence: A guide for law enforcement. Washington, DC: U.S. Department of Justice. Research Report.
Tredoux, C. G. (1998). Statistical inference on measures of lineup fairness. Law and Human Behavior, 22, 217–237. Retrieved from: http://www.jstor.org/stable/1394144.
Valentine, T., Darling, S., & Memon, A. (2007). Do strict rules and moving images increase the reliability of the sequential identification procedures? Applied Cognitive Psychology, 21, 933–949. doi:10.1002/acp.1306.
Wells, G. L. (1984). The psychology of lineup identifications. Journal of Applied Social Psychology, 36, 1546–1557.
Wells, G. L. (1993). What do we know about eyewitness identification? American Psychologist, 48, 553–571.
Wells, G. L., Leippe, M. R., & Ostrom, T. M. (1979). Guidelines for empirically assessing the fairness of a lineup. Law and Human Behavior, 3, 285–293.
Wells, G. L., & Lindsay, R. C. L. (1980). On estimating the diagnosticity of eyewitness nonidentifications. Psychological Bulletin, 88, 776–784.
Wells, G. L., Malpass, R. S., Lindsay, R. C. L., Fisher, R. P., Turtle, J. W., & Fulero, S. M. (2000). From the lab to the police station: A successful application of eyewitness research. American Psychologist, 55, 581–598. doi:10.1037//0003-066X.55.6.581.10.
Wells, G. L., Memon, A., & Penrod, S. D. (2006). Eyewitness evidence: Improving its probative value. Psychological Science in the Public Interest, 7(2), 45–75. doi:10.1111/j.1529-1006.2006.00027.x.
Wells, G. L., & Olson, E. A. (2002). Eyewitness identification: Information gain from incriminating and exonerating behaviors. Journal of Experimental Psychology: Applied, 8, 155–167. doi:10.1037//1076-898X.8.3.155.
Wells, G. L., Small, M., Penrod, S., Malpass, R. S., Fulero, S. M., & Brimacombe, C. A. E. (1998). Eyewitness identification procedures: Recommendations for lineups and photospreads. Law and Human Behavior, 22, 603–647. Retrieved from: http://www.jstor.org/stable/1394446.
Wells, G. L., & Turtle, J. (1986). Eyewitness identification: The importance of lineup models. Psychological Bulletin, 99, 320–329.
Acknowledgment
This project was supported by Award No. 2004-IJ-CX-0044 awarded by the National Institute of Justice, Office of Justice Programs, U.S. Department of Justice. The opinions, findings, and conclusions or recommendations expressed in this publication are those of the authors and do not necessarily reflect those of the Department of Justice.
Author information
Authors and Affiliations
Corresponding author
Additional information
Preliminary results of this project were reported at the American Psychology-Law Society Conference, St. Petersburg, Florida, 2006.
Co-authors were affiliated with Augsburg College as students at the time of the research.
About this article
Cite this article
Steblay, N.K., Dietrich, H.L., Ryan, S.L. et al. Sequential Lineup Laps and Eyewitness Accuracy. Law Hum Behav 35, 262–274 (2011). https://doi.org/10.1007/s10979-010-9236-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10979-010-9236-2