
Abstract
Optical–wireless convergence is becoming popular as one of the most efficient access network designs that provides quality of service (QoS) guaranteed, uninterrupted, and ubiquitous access to end users. The integration of passive optical networks (PONs) with next-generation wireless access networks is not only a promising integration option but also a cost-effective way of backhauling the next generation wireless access networks. The QoS performance of the PON–wireless converged network can be improved by taking the advantages of the features in both network segments for bandwidth resources management. In this paper, we propose a novel resource allocation mechanism for long term evolution–Gigabit Ethernet PON (LTE–GEPON) converged networks that improves the QoS performance of the converged network. The proposed resource allocation mechanism takes the advantage of the ability to forecast near future packet arrivals in the converged networks. Moreover, it also strategically leverages the inherited features and the frame structures of both the LTE network and GEPON, to manage the available bandwidth resources more efficiently. Using extensive simulations, we show that our proposed resource allocation mechanism improves the delay and jitter performance in the converged network while guarantying the QoS for various next generation broadband services provisioned for both wireless and wired end users. Moreover, we also analyze the dependency between different parameters and the performance of our proposed resource allocations scheme.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent years, the demand for fixed as well as mobile data rates has evolved from few kbps to hundreds of Mbps with the introduction of various broadband services. Consistently, the bandwidth requirements in backhaul networks are also increased. These elevated bandwidth requirements have urged both academia and industry to uncover better access and backhauling solutions that can sustain the frequently evolving next generation (NG) broadband services. The challenge is to keep up with the ever increasing bandwidth demands in a cost-effective manner.
The passive optical networks (PONs) have been identified as one of the most cost-effective solutions for fixed broadband access. However, PON itself is incapable of catering to the mobility requirements of end users, which is becoming one of the major requirements due to the rapid popularity of smart phones and tablet computers. Moreover, deployment of PONs might not be the best option depending on different geographical considerations. To overcome these PON limitations, optical–wireless convergence is introduced to provide cost-effective, high speed ubiquitous access to end users [1, 2]. Moreover, PON is also identified as a potential backhaul solution for the NG wireless broadband access network due to its cost effectiveness and high bandwidth capacity [3]. Therefore, PON–wireless integration is receiving increased attention in recent years, both from the academic research community and from industry.
The wireless interoperability for microwave access (WiMAX/IEEE 802.16) and Wi-Fi (IEEE 802.11), are two of the most widely considered wireless broadband access network (WBAN) technologies for the PON–wireless integration in the literature [1, 2, 4, 5]. However, the long term evolution (LTE) came under the spotlight recently, and is currently being deployed by many wireless service providers worldwide. While the LTE can support higher bandwidth capacities, it is also capable of using the evolution of existing Universal Mobile Telecommunication System (UMTS) infrastructures that the most wireless service providers currently use [6]. Therefore, the LTE has become a promising solution not just because it is the state-of-the-art wireless broadband access technology, but also because of its deployment convenience.
A few studies have been reported on the LTE–PON integration recently [7, 8]. However, improving the performance of the directly integrated Gigabit Ethernet PON (GEPON)–LTE network, by using improved resource handling mechanisms, has so far received minimal attention. In this paper, we propose a resource allocation mechanism that is equipped with a novel traffic forecasting method, for GEPON–LTE converged network. The proposed mechanism improves the quality of service (QoS) performance of the guaranteed bit rate (GBR) services in the uplink of the converged network, by efficiently managing the available bandwidth resources. It takes into account the characteristics of the frame configurations of the LTE and PON, in addition to the properties of their signaling mechanisms. The proposed resource handling mechanism consists of a near-future traffic forecasting mechanism, a mechanism that allocates resources among integrated optical–wireless base stations, a mechanism that distributes the allocated resources among wired and wireless end users, and a mapping policy between the two different QoS profiles used in GEPON and LTE. Each of these components exploits the characteristics of the converged network that inherits from the LTE and GEPON networks to improve the QoS of the GBR services. We use extensive simulations to analyze the performance of our proposed mechanism. We show that our proposed resource handling mechanism improves the delay and jitter performance of the GBR services in the uplink of the converged network, without compromising the QoS performance of the non-GBR services. Moreover, we also analyze the implications of different network parameters such as GEPON cycle-length and the buffer size on the performance of the proposed scheme.
The rest of the paper is organized as follows. We briefly discuss the related work in Sect. 2. In Sect. 3, we discuss the basic operations of GEPON and LTE networks, and we introduce the integration architecture that we consider in the current paper. We propose the resource handling mechanism for LTE–GEPON converged network in Sect. 4. In Sect. 5, we discuss the simulation setup that we use for the performance evaluation and we analyze the simulation results. Finally, we conclude the paper in Sect. 6 with a short summary of our findings.
2 Related Work
Optical–wireless convergence is a broad area of research and various studies on different aspects of the optical–wireless converged networks have been reported in the literature.
On the vision of achieving a fully converged fixed-mobile network, different potential scenarios for optical–wireless convergence are discussed in [1]. In particular, authors discussed different mechanisms for integrating optical end terminals with wireless base stations. In [2], a new converged network architecture called WOBAN is presented. Authors also discussed different algorithms for the placement of optical network units (ONUs) in a WOBAN. Moreover, a techno-economic analysis on fiber–wireless convergence is presented in [9].
Many interesting works on resource handling in WiMAX–PON and WiFi–PON converged networks can be found in the literature [4, 5, 10, 11]. The resource handling mechanisms proposed for the converged network can be broadly categorized into two types: centralized and hierarchical. In the centralized mechanism, a central controller placed at the optical line terminal (OLT) governs the bandwidth allocation for the wireless subscriber stations where the bandwidth requests from the subscribers are directly sent to this central controller [5, 10]. On the other hand, in the hierarchical resource allocation mechanism, the OLT allocates the bandwidth to the integrated ONU base station and the integrated ONU base station redistributes this allocated bandwidth among its end users [4, 11]. Moreover, admission control mechanisms to guarantee the required QoS in the converged network are also investigated in the literature. In [12], a delay-based admission control mechanism to guarantee the QoS requirements of specific service bundles provisioned across the EPON–WiMAX converged network is proposed. The authors also discussed a novel bandwidth distribution approach for the uplink operation of the converged network.
In addition, bandwidth resource allocation in PON without considering the integration with wireless networks is also a well researched area. Many studies that investigate efficient bandwidth allocation techniques for EPON [13–17] and Gigabit PON (GPON) [18] can be found in the literature. In [13], an efficient bandwidth resource handling mechanism that consists of an interleaved polling mechanism with an adaptive cycle time is proposed for EPON. Moreover, a novel bandwidth allocation mechanism to efficiently handle the multiservice provisioning in EPON uplink traffic is proposed in [16]. Another interesting work that investigates an efficient resource handling mechanism to reduce the data delays and data losses in EPON is presented in [17]. This mechanism achieves those performance improvements by means of effectively predicting the traffic arrival during the waiting period and limiting the maximum resource allocation for an optical network terminal. In [14, 15], implications of different dynamic bandwidth allocation mechanisms on the performance of EPON is thoroughly investigated. In addition [18], reports an investigation on candidate architectures for the next generation access that are compatible with GPON standard. This study comparatively analyses each of these architectures from a bandwidth allocation perspective.
Recently, significant attention has been given to the integration of PON with LTE due to the rising popularity of these two technologies. Being a relatively new research area, not many studies on the LTE–PON integration can be found in the literature so far. Due to certain characteristics and requirements unique to the LTE network, improved performance from LTE–PON converged networks can be achieved by using a proper architecture for the integration and also by using an efficient resource allocation mechanism [7, 8, 19]. In [7], we present a comprehensive discussion on various feasible architectures for the integration of widely deployed tree topology based PONs with LTE networks giving special attention to facilitate the inter-communication between base stations. The integration of LTE with a native Ethernet based wavelength division multiplexing (WDM) PON that has a ring topology is studied in [8]. On the other hand, in [19], the authors present a hybrid tree/ring-based PON–LTE integration architecture that supports a distributed control plane and resilience mechanisms against nodes and fiber failures.
As most of the above mentioned studies point out, implementing an efficient resource handling mechanism is one of the crucial requirements to maintain the QoS in optical–wireless converged networks. The QoS requirements of the access networks have become tighter with the introduction of next generation applications such as e-health, e-education, and video on demand services. Therefore, special care needs to be taken when integrating a bearer-based QoS mechanism in LTE with a queue oriented QoS mechanism in PON in order to guarantee the required QoS for diverse services provisioned across the converged network and to convey the full benefits of both network segments.
While independent resource handling mechanisms can be implemented in the LTE and GEPON segments separately, the QoS performance of the converged network can be further improved by using resource handling mechanisms that exploit information from both the network segments. Moreover, it is imperative that such new mechanisms are realizable with only minimal modifications to the already standardized PON and LTE medium access control (MAC) layer protocols and structures. To this end, here we propose and analyze a novel resource handling mechanism for the PON segment of the LTE–GEPON converged network. The proposed mechanism takes the advantage of near-future traffic forecasting capability of the converged network and also exploits information from both network segments, in order to manage the bandwidth resources more efficiently. Moreover, the proposed mechanism also takes the two different QoS protocols of the LTE and PON segments into account in order to provide a seamless integration.
3 Optical–Wireless Converged Network Architecture
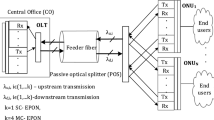
The GEPON–LTE converged network architecture considered for this study is shown in Fig. 1. In this architecture, GEPON is used as a backhaul to the LTE network. The radio access network of the LTE consists of radio base stations, which are usually referred to as evolved nodeBs (eNBs) [20]. Each eNB carries out the radio resource allocation among the end users’ equipment (UEs) that are connected to it, without the involvement of any core network elements. The LTE core network, which is also commonly known as the evolved packet core (EPC) has connection to all the eNBs in the network. The EPC consists of several core network elements: mobility management entity (MME), serving gateways (S-GW), and packet data network gateways (PDN-GW). In LTE, a mechanism called evolved-packet-system-bearer is used to facilitate the QoS for various services. The bearers specify how to treat the LTE end users’ packets when they traverse through the network. Each bearer consists of a QoS class identifier (QCI) and an allocation retention priority (ARP). While the ARP is used for admission control purposes, the QCI is used to maintain the required QoS for the services that initiated in LTE. The LTE network maintains up to nine different QCIs to provide the required QoS for diverse next-generation broadband services and applications. Each of these QCIs consists of several parameters such as a priority value, a delay threshold, and a guaranteed bit rate.

The GEPON–LTE converge network architecture
On the other hand, GEPON is recognized as an efficient solution to facilitate low-cost, fault-tolerant, and high bandwidth broadband access to the end users. GEPON consists of three major elements: an optical line terminal (OLT) located in central office, optical network units (ONUs) located at the customer premises, and a passive splitter located in the optical path between the OLT and ONUs. As opposed to the LTE, GEPON uses a queue-oriented QoS mechanism. Each ONU maintains eight different priority queues to provide proper QoS for various classes of services. Moreover, GEPON uses the multi-point control protocol (MPCP) to control the uplink transmissions of the ONUs [21]. In the MPCP, each ONU sends a REPORT message to the OLT indicating the current statuses of its queues. The OLT allocates a specific timeslot for the next cycle for each of the connected ONUs, based on the queue lengths reported by the ONUs in the current cycle. The OLT notifies these allocations to the ONUs by sending GATE messages. In contrast to the uplink transmission, in the downlink, the OLT broadcasts all the frames to all the ONUs connected to it. Each frame is tagged with the unique logical link identity (LLID) of the destination ONU, which is assigned to the ONU by the OLT at the time it is registered to the network. Consequently, each ONU filters out the frames that are not destined to it based on the destination LLID of the received frames.
The converged network architecture shown in Fig. 1 has a set of new elements called ONU–eNBs (integrated GEPON ONUs and LTE eNBs). While there can be many integration architectures for the ONU–eNB, here we only consider a direct integration architecture that is shown in Fig. 2. Each integrated ONU–eNB is capable of handling all the conventional functionalities that typical ONUs and eNBs are capable of handling. In addition, each ONU–eNB also includes a central controller that is responsible for handling common integration functionalities such as mapping of frames between the LTE QCIs and GEPON priority queues. A set of such ONU–eNBs is connected to an OLT, which in turn has connections with the LTE core network elements.

The integrated ONU–eNB architecture
4 Proposed Resource Handling Mechanisms
In this section, we introduce our proposed resource handling mechanism for the GEPON–LTE converged network that includes a QoS mapping policy, a packet arrival forecasting mechanism, a resource scheduling mechanism for the OLT, and a mechanism that allocates resources among the queues in the ONU–eNB. In each of the following subsections, we present a comprehensive discussion on each of these components, and we explain how these components can help improve the management of the available resources among both wired and wireless end users effectively.
4.1 QoS Mapping Policy
As discussed previously, LTE uses a bearer based QoS mechanism. Each node in the LTE network forwards the packets based on the bearer’s QCI [22]. On the other hand, GEPON is not compatible with such bearer based QoS mechanisms and uses a queue oriented prioritization mechanism to provide QoS for different classes of services. Therefore, a proper mapping policy between nine QCIs in LTE and eight priority queues in GEPON is important for the implementation of a united QoS model for a fully integrated network. This is particularly important due to the invisibility of the LTE bearers to the optical part of the converged network. The QoS mapping policy that we use in our proposed resource handling mechanism is shown in Fig. 3. In this mapping policy, both the GEPON queue priorities and LTE QCI’s characteristics such as the guaranteed bit rate, delay and priority are taken into account when the packets are mapped.

Mapping between LTE QCIs and GEPON priority queues
4.2 Traffic Arrival Forecasting Mechanism
The evolved-packet-system-bearers used in the LTE can be categorized into two types: GBR and non-GBR. A specific bit rate is guaranteed for the packet flows assigned to the GBR bearers by allocating dedicated transmission resources, whereas, the packet flows assigned to the non-GBR bearers are not guaranteed a specific bit rate. On the other hand in GEPON, the OLT determines the bandwidth allocation for the uplink transmission of each of the ONU–eNBs based on the bandwidth requirements reported by all the ONU–eNBs that connect to it. The OLT notifies the ONU–eNBs of these bandwidth allocations using REPORT messages, and each ONU–eNB redistributes this bandwidth granted by the OLT among its priority queues. As far as the LTE–GEPON converged network is concerned, directly using the existing GEPON resource allocation mechanisms in the converged network is less efficient, especially for allocating bandwidth for real-time GBR traffic flows instigated in the LTE network. This is because, for each of the GBR traffic flows, we need to reserve bandwidth for the entire duration of the flow. Moreover, packets from the wireless segment need to be handled more carefully as those experience additional propagation and processing delays in comparison to packets from a wired domain. Therefore, in order to provide guaranteed bit rates to meet the delay budget and to also improve the overall QoS performance of the converged network by overcoming the aforementioned difficulties, we use a novel traffic forecasting method in our proposed resource handling mechanism. This traffic forecasting method exploits the eNB’s information on resource allocation for the wireless UEs and the characteristics of the LTE uplink and downlink frame structures.
The LTE uses orthogonal frequency-division multiple access (OFDMA) for the downlink and a single carrier frequency division multiple access (SC-FDMA) technique for the uplink. Moreover, the LTE also supports both the time division duplexing (TDD) and the frequency division duplexing (FDD) modes. The control signalling, such as bandwidth allocation decisions are transmitted to the UEs on the physical downlink control channels (PDCCHs), whereas, in the uplink, the payload is transmitted in the uplink shared channel (UL-SCH). In the LTE, each eNB dynamically allocates the bandwidth resources to its connected UEs in every transmission time interval (TTI), based on the buffer statuses reported by the UEs. In contrast to early WBANs, state-of-the-art WBANs like LTE use smaller TTIs (e.g., 1 ms) in order to utilize the bandwidth resources more efficiently [6, 23]. Moreover, when a UE receives an uplink grant, it waits for a fixed period before starting the corresponding uplink transmission. This fixed time duration is equivalent to 4 subframes in the FDD mode [23], which is the mode that we consider in this study. Figure 4 shows a graphical illustration of this relationship and also the uplink operation of the converged network. As shown in Fig. 4, if an uplink grant embedded in the PDCCH is received at a wireless UE in Nth subframe, then the corresponding uplink transmission will start in the UL-SCH in (N + 4)th subframe. As a result, in any given time, each eNB is fully aware of the uplink packets that it will receive during the next four subframes. We denote this four subframe time duration for which the eNB is aware of the upcoming traffic by T aware . We take advantage of this LTE property to estimate the GBR traffic that will arrive during the upcoming GEPON cycle.

Uplink transmission timing diagram for the converged network
In addition, we also take advantage of the characteristics of the LTE frame structures to model the future packet arrival process at the ONU–eNB as follows. The LTE WBAN supports both time and frequency domain scheduling. In the LTE network, bandwidth resources are allocated to the UEs as resource blocks (RBs) [6, 23]. Each RB is a 2-dimensional virtual container equivalent to one slot duration (half a sub-frame) in the time domain and 12 sub-carriers in the frequency domain. In contrast to the downlink, in the uplink, these RBs must be contiguous in the frequency domain. Furthermore, the LTE also supports the packet fragmentation. The upper layers of the eNB see the data only when the entire data packet is received by the physical layer. That is, the data is forwarded to the upper layer for processing, only when the entire packet is received. Hence, the packets that arrive at the eNB during T aware can be represented by a step-wise function D(t) as shown in Fig. 5. In particular, the function D(t) represents the total number of bits that will be received from all the connected UEs, at the upper layer of an eNB. We use this model to estimate the packets that will arrive at the eNBs for the GBR services. For example, suppose that an ONU–eNB starts its current uplink transmission at t 1. Let t 2 be the start time of the next uplink transmission of this ONU–eNB as estimated and notified by the OLT. Then the total number of bits that will arrive at the ONU–eNB during the time interval [t 1, t 2], can be estimated as D(t 2) − D(t 1). It is understood that in order to use this estimation strategy, we need to determine the start times of the ONU–eNB’s next uplink transmission. We discuss the method we use for this purpose in the next subsection.

Packet arrival estimation
4.3 Resource Scheduling Mechanism in the OLT
The scheduler in the OLT is an important element that heavily contributes to the QoS performance of the converged network. It determines the bandwidth allocation for each of the ONU–eNBs. In our proposed resource management mechanism, we use an MPCP-based online scheduling algorithm [13, 14, 15]. However, the online scheduling algorithm that we use in our proposed mechanism is improved in such a way that it allows us to take advantage of the previously proposed traffic forecasting method.
In the online scheduling algorithm that we use in our proposed resource management scheme, each ONU–eNB sends a REPORT message to request bandwidth from the OLT at the beginning of each uplink transmission slot. The amount of bandwidth that each ONU–eNB requests from the OLT includes the amount of traffic forecasted for the next GEPON cycle, in addition to the current queue lengths. When the OLT receives a REPORT message from the ith ONU–eNB, it determines the bandwidth allocation, W i , for this ONU–eNB as
where B i is the amount of bandwidth requested by ith ONU–eNB and W max is the maximum amount of bandwidth that can be allocated for a single ONU–eNB within any given cycle.
Generally, in the online resource handling algorithms, the OLT calculates the bandwidth allocation for one of its connected ONU–eNBs and notifies it through a GATE message, while another ONU–eNB connected to the same OLT is still transmitting its uplink data. Since each of the GATE messages are transmitted while one of the other ONU–eNBs is still transmitting its uplink data, this mechanism reduces the channel idle time in the uplink, thus improving the channel utilization. In our proposed mechanism, while the OLT immediately calculates the bandwidth allocation and the transmission start time for the ith ONU–eNB when it receives the REPORT message from that ONU–eNB, the OLT does not immediately send the corresponding GATE message to that ONU–eNB. Instead, the OLT waits until time G i in order to send this GATE message to the ith ONU–eNB. The time G i is determined as follows.
Let R i denote the round trip time of ith ONU–eNB, that is, the time duration that one bit takes to complete a round trip between the OLT and the ONU–eNB. Moreover, let E n i be the estimated time of data arrival at the OLT from the ith ONU–eNB in the nth cycle. Then, the time at which the OLT transmits the GATE message to the ith ONU–eNB to notify the bandwidth allocation for the nth cycle is given by
Note that the OLT is fully aware of E n i as the bandwidth requests from all the ONU–eNBs up to the (i − 1)th ONU–eNB are received, and the corresponding transmission times are allocated at the time the OLT receives the REPORT message from the ith ONU–eNB requesting bandwidth for the uplink transmission of the nth cycle. A typical GATE message will include a start time T n i and a duration W n i for the uplink transmission of the ith ONU–eNB for the nth cycle. The GATE message used in our resource allocation mechanism also includes an estimated transmission start time \(\tilde T^{n+1}_{i}\) for the next (i.e., (n + 1)th) cycle, in addition to the T n i and the W n i . The value of \(\tilde T^{n+1}_{i}\) is calculated as follows.
Refer to Fig. 4 that was previously discussed in Sect. 4.2. In the scenario shown in this figure, the OLT receives all the REPORT messages up to the REPORT message sent by (i − 1)th ONU–eNB, before it sends out the GATE message to the ith ONU–eNB for the nth transmission cycle. As a result, the OLT can calculate the transmission start time T n+1 i-1 and the bandwidth allocation W n+1 i-1 for the (i − 1)th ONU–eNB once it receives the REPORT message from the (i − 1)th ONU–eNB in the nth cycle.
For this scenario, the transmission start time \(\tilde T^{n+1}_{i}\) of the ith ONU–eNB for the next (i.e., (n + 1)th) cycle, can be estimated as
where T Guard is the guard time between the uplink transmissions of two consecutive ONU–eNBs. This T n+1 i , which is sent as a part of the GATE message is used for the proposed traffic forecasting mechanism as described in the previous subsection.
On the other hand, it is also possible that all the REPORT messages from up to the (i − 1)th ONU–eNB that request bandwidth for the (n + 1)th cycle, might not be received by the OLT at the time the OLT transmits the GATE message to the ith ONU–eNB for the uplink transmission of the nth cycle. For example, suppose that when the OLT sends out the GATE message to the ith ONU–eNB for the uplink data transmission of the nth cycle, it has received the REPORT messages that request bandwidth for the (n + 1)th cycle only from the ONU–eNBs up to the xth ONU–eNB (where x < i − 1). In this case, the OLT uses the bandwidth allocation W n+1 x and the transmission start time T n+1 x that are calculated for the xth ONU–eNB to compute the \(\tilde T^{n+1}_{i}\). That is, T n+1 x and W n+1 x are used in Eq. (3) instead of T n+1 i-1 and W n+1 i-1 , respectively. Consequently, the actual uplink transmission of the ith ONU–eNB in the (n + 1)th cycle will occur later than the estimated \(\tilde T^{n+1}_{i}\).
Nevertheless, since this error does not lead to an overestimation of the GBR traffic arrivals, the amount of bandwidth requested by the ONU–eNBs in the nth cycle is less than their actual queue occupancies in the (n + 1)th cycle. This is because the amount of packets that will arrive at an ONU–eNB during the (n + 1)th cycle is estimated based on a time that is earlier than the actual transmission time of that ONU–eNB in the (n + 1)th cycle. In our proposed resource handling mechanism, each REPORT message sent out from an ONU–eNB includes the forecast amount of bandwidth for the next cycle, in addition to the bandwidth required by the traffic that is already queued. As a result, the aforementioned error only affects the traffic that will arrive in the next cycle but does not have any implications on the traffic that is already queued. Hence, even in the worst case, the QoS performance of the converged network will be equivalent or better than the QoS performance of the converged network when our proposed traffic forecasting mechanism is not used. Therefore, such errors do not have a significant impact on the QoS performance of the converged network as they do not overestimate the future packet arrival that causes the underutilization of allocated bandwidth.
With the help of the proposed traffic forecasting method and the proposed scheduling algorithm, the ONU–eNBs can reserve the required bandwidth for the GBR traffic flows. This is because the ONU–eNBs can pre-request bandwidth for the GBR traffic that will arrive in their future cycles. This reduces the delay experienced by the GBR packets, since those packets can be directly sent to the OLT without waiting for further bandwidth allocation in a future transmission cycle.
4.4 Resource Allocation Among Queues in the ONU–eNB
The aforementioned resource allocation mechanism is implemented at the OLT to dynamically allocate the bandwidth resources among its connected ONU–eNBs. Additionally, a proper resource handling mechanism at ONU–eNB that allocates the available bandwidth among its priority queues is also important in order to support necessary QoS and fairness to different types of traffic classes. This is particularly important for packets received from wireless users, as those packets experience large delays within the wireless network segment in comparison to packets received from wired end users. Therefore, in this section, we propose a sub-queue based resource handling mechanism for the integrated ONU–eNB.
The proposed resource allocation mechanism for the integrated ONU–eNB is as follows. Each GEPON priority queue that corresponds to each of the LTE GBR traffic classes is maintained as two sub-queues. One sub-queue is allocated for the wireless traffic, whereas the other sub-queue is reserved for the wired traffic that receives the same QoS treatment. For example, as shown in Fig. 3, the second highest priority queue in the ONU–eNB is maintained as two sub-queues: one sub-queue is for voice GBR traffic arriving from the LTE network, whereas the other is for voice traffic arriving from the wired end users. Consequently, the high priority data that arrive from both wireless and wired end users can be treated differently in order to guarantee their bit rates and other QoS requirements without degrading QoS for either type of end user. The resources are allocated among queues and sub-queues as follows.
After completing the uplink transmission in every cycle, each ONU–eNB stores the occupying lengths of its queues and sub-queues in a table. Let QL j denote the recorded queue length of jth priority queue. Once the uplink transmission starts in an allocated time slot, these queues are served according to the order of their priorities. However, each separate queue is allocated a specific bandwidth. The amount of bandwidth allocated for each queue is equivalent to their recorded queue length in the previous cycle. On the other hand, for the queues that correspond to the wireless GBR traffic, an additional amount of bandwidth equivalent to W f , which is the GBR traffic forecasted in the previous cycle (i.e., (n − 1)th), is added to their recorded queue lengths. As discussed previously in Sect. 4.2, the GBR traffic forecast for the nth cycle, W f can be calculated during the (n − 1)th cycle as \(D(\tilde T^{n}_{i})-D(T_i^{n-1})\). This prevents the under allocation of resources to the GBR traffic. Once all the queues are served up to their allocated bandwidth, the algorithm once again redistributes any leftover bandwidth to the queues in order of their priorities. The pseudo-code of this algorithm is presented in Algorithm 1. In Algorithm 1, WC j and Q j denote the consumed bandwidth and present queue length of jth queue, respectively. Moreover, P is the total number of queues and sub queues of an ONU–eNB. W ava is the bandwidth available in the ONU–eNB.

Even though the proposed resource handling mechanism is specifically designed for a LTE–PON converged network, it can be easily extended to support other converged network solutions that use a different next-generation broadband wireless access technology, e.g., WiMAX (IEEE 802.16 m). However, certain modifications may be required for the proposed resource handling mechanism depending on the wireless technology used for the integration. In particular, the traffic forecasting mechanism and the QoS mapping mechanism have to be modified based on the characteristics of the wireless technology. For example, if this proposed mechanism is to be used in a WiMAX–PON converged network, the connection oriented QoS mechanism, frame lengths, and the QoS classes, which are specific to the WiMAX should be taken into account.
5 Performance Evaluation
In this section, we analyze the performance of our proposed mechanism using simulations, and we compare it against two popular resource allocation mechanisms: online and offline bandwidth allocation mechanisms [14, 15]. For the online bandwidth allocation algorithm, the interleaved polling with adaptive cycle time (IPACT) [13], which is one of the well known online algorithms is considered. In the online resource handling mechanism, when the OLT receives a REPORT message from an ONU–eNB, the OLT immediately allocates the bandwidth to this ONU–eNB according to the Eq. (1) and notifies the ONU–eNB by sending a GATE message. On the other hand, as the offline mechanism, we consider an algorithm that dynamically allocates the bandwidth in a stop-and-wait manner [14]. In this offline resource handling mechanism, once the REPORT messages from all active ONU–eNBs are received by the OLT, the excess bandwidth available from lightly-loaded ONU–eNBs is allocated for heavy loaded ONU–eNBs in an offline manner. For brevity, we will henceforth refer to our proposed mechanism as TF-RH (traffic forecasting based resource handling), and we will refer to the online and offline resource handling mechanisms as ON-RH and OFF-RH, respectively.
5.1 Simulation Model
An event driven simulation model is developed to evaluate the performance of our proposed mechanism. The converged network architecture considered for our evaluation consists of 1 OLT and 16 ONU–eNBs. In our simulations, we generate different types of traffic for the converged network. The contributions of these different types of traffic toward the total network load are listed in Table 1. In our traffic model, while voice packets are assumed to arrive once every 20 ms with a fixed size of 160 bytes, the variable bit rate (VBR) traffic is assumed to have a Poisson arrival. The packet size of the VBR traffic is assumed to be uniformly distributed between 64 and 1,518 bytes.
The transmission time interval of the LTE is taken as 1 ms and the maximum uplink data rate supported by the LTE is considered as 50 Mbps [6]. Moreover, the line rate and the maximum cycle time of GEPON are chosen as 1 Gbps and 2 ms, respectively. The T rtt for each ONU–eNB is taken as 200 μs to account for the 20 km between the OLT and ONU–eNB. Furthermore, a scenario where both wireless UEs and wired subscribers are connected to the ONU–eNBs is considered for the sake of generality. Each ONU–eNB is assumed to have a limited buffer size of 10 Mbytes. The sum of all ONU–eNBs traffic destined to the OLT is termed as the uplink network loading. Furthermore, the traffic load as a fraction of 1 Gbps is termed as the loading. For example, the loading level of 1 represents 1 Gbps of traffic load.
5.2 Packet Delay
Packet delay is a key parameter that determines the overall QoS performance of a network. In this subsection, we analyze the packet delay of our proposed mechanism and we compare the result with the packet delay performance of ON-RH and OFF-RH. Figure 6 shows the variation of average delay in the GBR traffic originated from the wireless UEs, as a function of the uplink loading. As shown in Fig. 6, the lowest packet delays for both voice and video-high traffic classes can be achieved by our proposed mechanism followed by ON-RH and OFF-RH, respectively. Moreover, our proposed mechanism maintains the delay in both the GBR traffic classes less than 7.5 ms even when the network loading is as high as 0.95. The improvements in delay performance that can be achieved by using our proposed TF-RH mechanism in place of ON-RH, is shown in the inset of Fig. 6. As shown, the improvements in voice and video-high traffic classes increase with the network loading. In particular, when the network is heavily loaded (at 0.95 network loading), TF-RH shows approximately 14 % delay improvement in voice GBR traffic and ∼17 % improvement in video-high traffic, in comparison to ON-RH. Moreover, we have found that in comparison to OFF-RH, the TF-RH shows ∼32 and ∼24 % delay improvements in voice and video-high traffic classes, when the network loading reaches 0.95.

Delay variation experienced by wireless GBR traffic in the entire converged network
Recall that our proposed mechanism improves the QoS performance of the converged network, by improving the management of the available bandwidth resources in GEPON exploiting the information retrieved from the LTE network segment. Hence, the variation of delay experienced by wireless GBR traffic classes within the GEPON network segment is separately investigated and the outcome of this evaluation is shown in Fig. 7. Similar to the previous observations, our proposed mechanism shows the best delay performance for both the GBR traffic classes, followed by ON-RH and OFF-RH, respectively. In particular, when our proposed TF-RH is used, the delays experienced by both voice and video-high traffic within the GEPON segment are maintained below 1.1 ms, even when the network load is as high as 0.95. The inset of Fig. 7 shows the delay improvements for GBR traffic classes within the GEPON segment, that we can achieve using our proposed TF-RH in place of ON-RH. As shown, the voice traffic shows nearly constant improvement initially, when the loading level is increased from 0.6 to 0.85, whereas it shows a significant delay improvement when the loading is increased beyond 0.85. In contrast, video-high traffic shows significant delay improvements under both light loaded and heavy loaded network conditions where the improvement is increased gradually with the network loading. Overall, the delay improvements achieved by our proposed TF-RH method with respect to ON-RH are as high as ∼48 and ∼57 % for voice and video-high traffic, respectively. These results signify that our proposed mechanism successfully improves the delay performance by efficiently managing the available bandwidth resource in the GEPON segment. Moreover, it is evident that our proposed mechanism provides improved QoS for the GBR traffic. This significant improvement is due to its capability to forecast near-future GBR traffic arrivals. Consequently, the high priority packets are transmitted without long waiting times in the ONU–eNBs.

Delay variation experienced by wireless GBR traffic in GEPON segment
Next, we investigate the delay performance of the non-GBR traffic of the wireless UEs. While our proposed mechanism is aimed at improving the QoS performance for GBR traffic classes, we show the QoS performance of non-GBR traffic classes are just as good (if not better) compared to other considered resource handling mechanisms. Figure 8 shows the variation of delay of non-GBR traffic from wireless UEs, as a function of uplink loading. As shown, when the network loading increases, the delays in non-GBR traffic classes (under all the resource handling mechanisms) show linear variations until the load reaches 0.75. However, when the load increases from 0.75, delay variations show significant differences. To illustrate these variations clearly, we have included the delay variations when the load increases from 0.75 to 0.95 in the inset of Fig. 8. As shown, TF-RH shows a clear delay improvement in non-GBR traffic classes in comparison to OFF-RH. A similar variation is observed in comparison to ON-RH. Moreover, it is clear from Fig. 8, our proposed TF-RH maintains the delay for all non-GBR traffic classes below 11 ms, even if the loading level is as high as 0.95.

Delay variation in wireless non-GBR traffic classes
As shown in Figs. 6, 7, and 8, our proposed resource handling mechanism not only improves the QoS performance of the GBR traffic classes but also shows a similar or better performance in non-GBR traffic classes in comparison to the other considered resource handling mechanisms. This is because, our proposed TF-RF reduces the bandwidth starvation of non-GBR traffic classes, as it pre-allocates the bandwidth for the GBR traffic that arrives during the wait period between the bandwidth request and the bandwidth grant. Additionally, the fair resource allocation mechanism implemented in the ONU–eNB to effectively allocate bandwidth among its queues, has also contributed towards this improved QoS performance in non-GBR traffic classes.
We also analyze the delay performance of the traffic originating from the wired subscribers in order to provide a complete picture of the delay performance of the entire converged network. The delay variations of voice, video-high, video-low, and data traffic originating from the wired subscribers are shown in Fig. 9. The OFF-RH shows relatively poor delay performance compared to other considered resource handling mechanisms. Thus, we only show the delay performance of TF-RH and ON-RH in Fig. 9 for the sake of clarity. As shown in Fig. 9, when we use TF-RH in place of ON-RH, the delay of the voice traffic shows approximately 0.1 ms increase when the loading increases from 0.85 to 0.95. This is caused by the cycle length increment due to the use of forecasted traffic in our proposed mechanism. However, this difference is insignificant especially compared to the improvements that we achieve for wireless GBR traffic, which experiences more than 6 times higher average delays than the voice traffic in the wired domain. Furthermore, in comparison to ON-RH, the proposed mechanism shows similar delay performance for video-high and video-low traffic, whereas it shows significant improvements for data traffic. This improved performance of our proposed scheme is due to its ability to allocate sufficient bandwidth for future high priority traffic, which avoids the bandwidth starvation of lower priority traffic classes. These results suggest that our proposed TF-RH mechanism is capable of handling the available resource effectively, among both wireless and wired traffic, to provide improved delay performance in the converged network.

Delay variation in wired end users’ traffic
5.3 Average Jitter
In this subsection, we present an average jitter analysis for jitter sensitive traffic such as voice and video-high in the converged network. Figure 10 shows the variation of average jitter in the GBR traffic classes, as a function of uplink loading. As shown in Fig. 10, our proposed TF-RH shows the best jitter performance followed by ON-RH and OFF-RH. When the loading level increases from 0.6 to 0.85, the proposed mechanism shows a linear jitter variation in voice traffic. The ON-RH and our proposed TF-RH show similar variation for jitter in the voice traffic class when the network loading increases from 0.6 to 0.8. However, when the network loading level increases beyond 0.8, our proposed mechanism shows ∼25 % improvement in jitter for the voice traffic, in comparison to ON-RH. On the other hand, for the video-high traffic class, the proposed TF-RH mechanism shows ∼10 % improvement compared to ON-RH, until the loading level reaches 0.9. When the network loading reaches 0.95, both mechanisms show similar jitter performance. This is due to the high arrival rate in the video-high traffic class and a limited availability of resources in the congested network. It is evident from these results that our proposed resource handling mechanism improves the jitter performance, which in turn increases the overall QoS performance of the converged network.

Variation of average jitter in voice and video-high traffic classes
5.4 Implication of Cycle-Length on the QoS Performance
In the converged network, each ONU–eNB receives bandwidth allocation from the OLT on a periodic basis, i.e., one allocation in each GEPON cycle. Therefore, the length of the GEPON cycle may have implications on the QoS performance of the converged network. In this subsection, we analyze the performance of our proposed scheme under a range of GEPON cycle lengths.
It is clear from our earlier discussion that the packet delay varies with the resource allocation mechanism used, the loading level, and the type of traffic class. Hence, here we analyze the variation of packet delays in all the traffic classes as a function of cycle-length, under different network loading levels. As discussed in the previous subsection, for all traffic types, the OFF-RH mechanism shows higher delays compared to other resource handling mechanisms. Therefore, for this analysis we only consider our proposed TF-RH mechanism and the ON-RH. Figure 11 shows the variation of delay in the GBR traffic classes as a function of GEPON cycle-length, when the network loading is 0.59.

Variation of delay in GBR traffic when network loading = 0.59
As shown in Fig. 11, both the GBR traffic classes show a constant delay variation under both TF-RH and ON-RH mechanisms, regardless of the cycle-length. This is because, when the network loading is 0.59, the bandwidth allocation that each of the ONU–eNBs receives from the OLT is sufficient to send its queued data irrespective of the cycle-length. Therefore, the packet delays in both GBR traffic classes do not vary with the cycle-length.
Next, we analyze the variation of packet delay in the GBR traffic classes as a function of cycle length, when the network loading is high, i.e., when the loading level is 0.95. The results are shown in Fig. 12. It is clear from Fig. 12 that the packet delays in the GBR traffic classes increase when the GEPON cycle-length increases. This in contrast to the packet delay variation under a loading level of 0.59. In particular, when the cycle-length increases from 1 to 2 ms, notable increments in the packet delays of both GBR traffic classes can be seen for both TF-RH and ON-RH resource handling mechanisms. This is because, when the cycle-length is 1 ms, ONU–eNBs get frequent uplink transmission opportunities compared to having a cycle-length of 2 ms. Consequently, as the GBR traffic gets priority amongst other traffic classes, that traffic can be sent to the OLT more frequently. This reduces the queuing delay of the GBR traffic at the ONU–eNB. On the other hand, the transmission frequency of the GBR traffic classes decreases when the cycle-length increases with when the network operating at high loading. While the delay of the GBR traffic under both TF-RH and ON-RH increases when the cycle-length increases from 1 to 2 ms, the rate of this delay increase is low for our proposed TF-RH mechanism in comparison to the ON-RH mechanism. Moreover, as shown in Fig. 12, our proposed TF-RH mechanism shows the best delay performance in both GBR traffic classes for the entire range of the considered cycle lengths. In particular, when the cycle length is 2 ms, our proposed TF-RH shows approximately 1 and 2 ms delay improvements in comparison to ON-RH, for voice and video-high traffic classes respectively. It is clear from these results that our proposed mechanism not only improves the delay performance, but also reduces the dependency of the converged network’s QoS performance on the GEPON cycle-length.

Variation of delay in GBR traffic when network loading = 0.95
We then evaluate the implications of the GEPON cycle-length on the QoS performance of non-GBR traffic classes, when TF-RH and ON-RH are used for the bandwidth resources management. Figure 13 shows the variation of packet delays in non-GBR traffic classes, as a function of cycle-length, when the network loading is 0.59. As in the equivalent scenario for the GBR traffic classes, non-GBR traffic also exhibits a constant delay variation for all the considered cycle-lengths, for both TF-RH and ON-RH mechanisms.

Variation of delay in non-GBR traffic when network loading = 0.59
Figure 14 shows the variation of packet delays in non-GBR traffic classes when the converged network operates under a high network loading, i.e., when the loading level is 0.95. As shown in Fig. 14, when the cycle-length increases, packet delays in video-low and data show opposite behaviors. More specifically, when the cycle-length increases, the delay of the data traffic decreases, whereas the delay of the video-low traffic slightly increases. As shown in Fig. 14, when the cycle-length increases from 1 to 2 ms, the packet delay of the data traffic significantly decreases by about 3 s. This is because, when the GEPON cycle-length is 1 ms, bandwidths that are allocated for every ONU–eNB within a cycle are comparatively lower than that of the other cycle-lengths considered in this study. Therefore, when the network loading is high, the ONU–eNBs do not receive sufficient uplink bandwidth allocations to send out all the packets in their queues. This insufficient bandwidth allocation especially affects the packets in the least priority queue, i.e., to the packets in the data traffic class. Hence, the data traffic class does not get sufficient bandwidth to send out all of its packets and thus the queuing delay of the data traffic class increases. However, the packet delay of the data traffic class slightly decreases when the cycle-length increases from 2 ms. Furthermore, it is also evident from Fig. 14 that the TF-RH and the ON-RH show similar delay variation in both non-GBR traffic classes. In general, when the cycle-length increases, packet delays in the first three highest priority classes increase, whereas the packet delay in the data traffic class decreases.

Variation of delay in non-GBR traffic when network loading = 0.95
5.5 Implications of Buffer Size on the QoS Performance
The packets that are received by an ONU–eNB from both the wireless and wired end users need to be buffered until it receives a bandwidth allocation from the OLT. Consequently, buffer size is also a major parameter that contributes to the network performance. Therefore, we also analyze the ONU–eNB’s buffer occupancy under different loadings and under different resource handling mechanisms. Figure 15 shows the maximum buffer occupancy of the ONU–eNB due to the uplink traffic, as a function of the uplink loading. As shown in Fig. 15, the maximum buffer occupancy increases with the network loading, for all resource allocation mechanisms. Moreover, all the resource handling mechanisms show similar variations for the buffer occupancy with the loading level. Therefore, it is clear that even our proposed mechanism provides better QoS in the converged network, it does not require a large buffer to achieve such superior delay performance.

ONU–eNB buffer occupancy
6 Conclusion
Next-generation optical–wireless convergence is recognized as one of the most cost-effective solutions to provide high bandwidth and ubiquitous broadband access to end users. Among various integration possibilities, the convergence of GEPON and LTE is most likely to be the most prominent converged network solution because of the popularity and cost effectiveness of each of these technologies. While resource handling in both LTE and GEPON are well studied individually, carefully designed efficient resource handling mechanisms are required for the converged network since each segment of the converged network uses a different QoS mechanism. To this end, we proposed an integrated resource handling mechanism for the uplink of the GEPON–LTE converged network, which exploits a novel near-future traffic forecasting method. In our proposed traffic forecasting mechanism, information retrieved from the LTE network segment is used to forecast the arrival of GBR traffic, which in turn is used for the bandwidth resources management in the GEPON segment. Our proposed integrated resource handling mechanism also includes, a mechanism for the OLT to allocate bandwidth resources among its connected ONU–eNBs, a mechanism for ONU–eNBs to distribute bandwidth resources among its wired and wireless end users, and a mapping policy that maps the LTE QCI to the GEPON priority queues. We used simulations to analyze the performance of our proposed resource allocation mechanism. We showed that the delay and jitter performance of the converged network can be significantly improved by using our proposed resource handling mechanism. In particular, our results indicate that the proposed resource allocation mechanism takes advantage of the near future traffic forecasting functionality to provide better QoS for GBR traffic in the converged network.
References
Gangxiang, S., Tucker, R.S., Chang-Joon, C.: Fixed mobile convergence architectures for broadband access: integration of EPON and WiMAX. IEEE Commun. Mag. 45(8), 44–50 (2007)
Sarkar, S., Dixit, S., Mukherjee, B.: Hybrid wireless-optical broadband-access network (WOBAN): a review of relevant challenges. J. Lightwave Technol. 25(11), 3329–3340 (2007)
Ranaweera, C.S., Iannone, P.P., Oikonomou, K.N.,Reichmann, K.C., Sinha, R.K.: Cost optimization of fiber deployment for small cell backhaul. In: Optical Fiber Conference and National Fiber Optic Engineers Conference (OFC/NFOEC), NTH3F.2 (2013)
Kun, Y., Shumao, O., Guild, K., Hsiao-Hwa, C.: Convergence of Ethernet PON and IEEE 802.16 broadband access networks and its QoS-aware dynamic bandwidth allocation scheme. IEEE J. Sel. Areas Commun. 27(2), 101–116 (2009)
Jung, B., Choi, J., Han, Y., Kim, M., Kang, M.: Centralized scheduling mechanism for enhanced end-to-end delay and QoS support in integrated architecture of EPON and WiMAX. J. Lightwave Technol. 28(16), 2277–2288 (2010)
Sesia, S., Toufik, I., Baker, M.: LTE The UMTS Long Term Evolution: From Theory to Practice. Wiley, Hoboken, NJ (2009)
Ranaweera, C., Wong, E., Lim, C., Nirmalathas, A.: Next generation optical–wireless converged network architectures. IEEE Netw. 26(2), 22–27 (2012)
Ali, M.A., Ellinas, G., Erkan, H., Hadjiantonis, A., Dorsinville, R.: On the vision of complete fixed-mobile convergence. J. Lightwave Technol. 28(16), 2343–2357 (2010)
Ghazisaidi, N., Maier, M.: Fiber–wireless (FiWi) networks: a comparative techno-economic analysis of EPON and WiMAX. In: Global Telecommunications Conference, 2009. GLOBECOM 2009, pp. 1–6. IEEE (2009)
Luo, Y., Ansari, N., Wang, T., Cvijetic, M., Nakamura, S.: A QoS architecture of integrating GEPON and WiMAX in the access network. In: Sarnoff Symposium, 2006 IEEE, pp. 1–4 (2006)
Obele, B.O., Iftikhar, M., Manipornsut, S., Minho, K.: Analysis of the behavior of self-similar traffic in a qos-aware architecture for integrating WiMAX and GEPON. IEEE/OSA J. Opt. Commun. Netw. 1(4), 259–273 (2009)
Dhaini, A., Ho, P.H., Jiang, X.: QoS control for guaranteed service bundles over fiber–wireless (FiWi) broadband access networks. J. Lightwave Technol. 29(10), 1500–1513 (2011)
Kramer, G., Mukherjee, B., Pesavento, G.: IPACT a dynamic protocol for an Ethernet PON (EPON). IEEE Commun. Mag. 40(2), 74–80 (2002)
Ferguson, J.R., McGarry, M.P., Reisslein, M.: When are online and offline excess bandwidth distribution useful in EPONs? In: Accessnets, pp. 36–45. Springer, Berlin (2009)
McGarry, M.P., Reisslein, M., Aurzada, F., Scheutzow, M.: Impact of EPON DBA components on performance. In: Proceedings of 20th International Conference on Computer Communications and Networks (ICCCN), 2011, pp. 1–5 (2011)
Luo, Y., Ansari, N.: Bandwidth allocation for multiservice access on EPONs. IEEE Commun. Mag. 43(2), S16–S21 (2005)
Luo, Y., Ansari, N.: Limited sharing with traffic prediction for dynamic bandwidth allocation and QoS provisioning over Ethernet passive optical networks. J. Opt. Netw. 4(9), 561–572 (2005)
Zhang, J., Ansari, N., Luo, Y., Effenberger, F., Ye, F.: Next-generation PONs: a performance investigation of candidate architectures for next-generation access stage 1. IEEE Commun. Mag. 47(8), 49–57 (2009)
Madamopoulos, N., Peiris, S., Antoniades, N., Richards, D., Pathak, B., Ellinas, G., Dorsinville, R., Ali, M.: A fully distributed 10G-EPON-based converged fixed-mobile networking transport infrastructure for next generation broadband access. IEEE/OSA J. Opt. Commun. Netw. 4(5), 366–377 (2012)
3GPP TS 23.107: quality of service (QoS) concept and architecture. http://www.3gpp.org
IEEE Standard: IEEE 802.3ah Ethernet in the first mile task force
Ekstrom, H.: QoS control in the 3GPP evolved packet system. IEEE Commun. Mag. 47(2), 76–83 (2009)
Dahman, E., Parkvall, S., Skold, J., Beming, P.: 3G evolution: HSPA and LTE for mobile broadband, 2nd edn. Academic Press, Jordan Hill, Oxford and Burlington, MA (2007)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ranaweera, C., Wong, E., Lim, C. et al. An Efficient Resource Allocation Mechanism for LTE–GEPON Converged Networks. J Netw Syst Manage 22, 437–461 (2014). https://doi.org/10.1007/s10922-013-9283-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10922-013-9283-3