
Abstract
Fearful faces both capture our attention and hold it. However, little is known about the time-course for the capture and hold of spatial attention by fearful, and other emotional, faces. In three dot-probe studies we examined this time-course. Experiments 1 and 2 used fearful and neutral faces. In Experiment 1, dot-probe targets occurred 133, 266, and 532 ms post-face onset and in Experiment 2, dot-probe targets occurred 84, 168, 336, and 672 ms post-face onset. In Experiment 1, for both 133 and 266 ms conditions, reaction times were fastest for congruent trials and slowest for incongruent trials with reaction times for baseline trials falling between the two. The same pattern was found for the 84 and 168 ms conditions in Experiment 2. For the later time-points in both experiments there were no significant differences between conditions. To examine whether this time-course is unique to fearful faces, a third dot-probe experiment using time-points identical to Experiment 2 was conducted with happy and neutral faces. The results from Experiment 3 suggest that happy faces captured and held attention in the 168 and 336 ms conditions. Together, the results indicate that attention is captured and held by fearful faces at times earlier than approximately 300 ms, while happy faces also captured and held attention, but on a slightly different time-course from 168 to 336 ms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Fearful facial expressions are important social signals of potential environmental threat, which automatically capture observers’ attention. This capture of visuospatial attention by fearful faces occurs both when awareness of these faces is unrestricted (Carlson and Mujica-Parodi 2015; Pourtois et al. 2004), as well as when awareness is restricted by backward masking (Carlson and Reinke 2008; Fox 2002). The attentional response is theorized to occur in three stages: (1) the initial capture or orienting of attention, (2) the hold or engagement of attention, and (3) the disengagement or release of attention from a stimulus (Posner 1980; Posner et al. 1987). Past research suggests that fearful faces both facilitate the orienting of attention toward their location, as well as delay the disengagement of attention from their location (Carlson and Mujica-Parodi 2015; Carlson and Reinke 2010; Carlson et al. 2011). It is adaptive for an individual to both rapidly orient their attention to others’ expressions of fear and hold their attention to this location until the threat has subsided or additional information about the potential threat has been gained (e.g., eye gaze indicating the direction of threat). Once the location of the threat responsible for eliciting the fear expression is known, attention is redirected towards its location. Thus, fearful faces capture and hold attention, but only for a finite period of time. The purpose of this study was to investigate the time-course for the capture and hold of visuospatial attention by fearful faces.
The dot-probe task is a commonly used method for measuring affective attentional biases (MacLeod and Mathews 1988; Macleod et al. 1986). Typically, two stimuli of different emotional content (e.g., fearful vs. neutral face) are presented simultaneously; one on each side of a computer screen. After the stimuli disappear, a dot appears on either side of the screen. At this point, the participant is asked to indicate which side of the screen the dot is located. The idea is that because participants’ attention is automatically drawn to the emotional stimulus, reaction times will be faster for dots occurring at spatially congruent, compared to incongruent, locations. Thus, the difference in reaction times between congruent and incongruent trials represents a measure of attentional bias. It should be noted that the dot-probe task overcomes an interpretation problem that arises when only a single affective or neutral stimulus is presented (e.g., emotional Stroop and emotional cueing tasks). Reaction time differences between singular presentations of affective and neutral stimuli can theoretically occur from a differential allocation of attention between the stimuli or behavioral freezing (i.e., the presence of any threatening stimulus could induce a freezing affect) resulting in a slowing of reaction times (Clarke et al. 2013; Macleod et al. 1986; Mogg et al. 2008). Given that congruent and incongruent trials each contain an emotional and neutral stimulus, behavioral freezing cannot account for reaction time differences and therefore the dot-probe task represents a relatively pure measure of attentional bias.
Dot-probe studies have found (congruent vs. incongruent) attentional bias effects for a variety of visual threats including fearful and angry faces, threatening words, weapons, as well as poisonous and predatory animals (Armony and Dolan 2002; Beaver et al. 2005; Carlson et al. 2009; Cooper and Langton 2006; Fox 2002; Fox et al. 2001; Koster et al. 2004; MacLeod and Mathews 1988; Macleod et al. 1986; Mogg and Bradley 2002; Pourtois et al. 2004; Salemink et al. 2007). Past research examining the time-course of the overall congruent versus incongruent attention effect in the dot-probe task has found greater attention for threatening words at time-points ranging from 100 to 1500 ms in high trait anxious individuals (Mogg et al. 1997). Additional research in highly anxious individuals using visual images of threat has found attention effects that are restricted to relatively shorter time points (≤500 ms; Koster et al. 2005; Mogg and Bradley 2006). A bias towards angry faces and other visual threat images has been reported in general samples at 100 ms, but not 500 ms (Cooper and Langton 2006; Koster et al. 2005). Thus, for a variety of visual threat stimuli, attention appears to be captured early (i.e., 100 ms), but not universally at later stages (i.e., 500 ms). Yet, it remains unclear at precisely what point within this (100–500 ms) range attention is no longer captured.
The addition of baseline (or undirected attention) conditions to the dot-probe task allows for determining the relative contributions of orienting and disengagement to the overall (congruent vs. incongruent) attention effect (Carlson and Reinke 2008; Koster et al. 2004). Baseline trials contain two stimuli of the same type. Typically, two neutral stimuli are used, but similar results are found when two fearful stimuli are used (Carlson and Reinke 2008, 2010; Carlson et al. 2011). The rationale is that if reaction times are faster on congruent compared to baseline trials, this indicates a facilitated orienting effect; whereas slower responses on incongruent compared to baseline trials indicates a delay in the disengagement of attention. Research using baseline conditions has found that fearful facial expressions (Carlson and Mujica-Parodi 2015; Carlson and Reinke 2010; Carlson et al. 2011) and fearful facial features (i.e., the eyes Carlson and Reinke 2014; Carlson et al. 2016) both facilitate orienting and delay disengagement. However, this research only assessed attention at early (≈100 ms) time points. Prior research exploring the time-course for the overall capture of attention in the dot-probe task to other threat signals indicates attention is sustained until some point between 100 and 500 ms post-stimulus onset (Cooper and Langton 2006; Koster et al. 2005; Mogg and Bradley 2006). However, little is known about the time-course for orienting and disengagement processes associated with fearful face elicited attention. As mentioned above, fearful faces are important social indicators of potential threat, yet without accompanying information (e.g., eye gaze or turned head), provide little information about the location of this potential threat. Thus, due to this uncertainty, attentional orienting and disengagement to fearful facial expressions may follow a unique time-course when compared to threat signals where the source/location of the threat is known (e.g., angry faces, weapons, poisonous and predatory animals).
To address this knowledge gap we ran three dot-probe studies in which we systematically varied the time-point in which attention was sampled. We focused our sampling at time points approximately ≤500 ms with greater focus on earlier and intermediate time points where attention is thought to be captured and released, respectively. Experiments 1 and 2 used fearful and neutral facial expressions. In Experiment 1, we used three different SOAs (133, 266, and 532 ms) and in Experiment 2 we used four different SOAs (84, 168, 336, and 672 ms). Based on the research reviewed above, we hypothesized for both experiments that attention would be captured at earlier compared to later time-points and that orienting (i.e., faster RT for congruent vs. baseline trials) and disengagement (i.e., faster RT for baseline vs. incongruent trials) effects would be present. To assess the extent to which results from Experiments 1 and 2 generalize to other facial expressions, and in particular positive emotion, Experiment 3 used happy and neutral faces while sampling attention at the same time-points used in Experiment 2.
Experiment 1
Method
Participants
Forty-eight college students (28 females) ages between 18 and 32 (M = 20.57, SD = 2.90) participated in Experiment 1. Forty-four reported being right handed. The Northern Michigan University Institutional Review Board approved this study. Based on our previous work we expected the overall attention (i.e., congruency; partial η2 = 0.55), orienting (d = 0.51), and disengagement (d = 0.49) effects (see “Dot-Probe Task” section below for more details on these effects) to have medium to large effect sizes (Carlson and Mujica-Parodi 2015). Using G*Power 3.1.9.2 with d = 0.49 (smallest effect size), α = 0.05, and power = 0.80 it was determined that an N ≥ 28 would be needed to detect these effects. All sample sizes (and subsamples) for Experiments 1-3 have an N ≥ 28. The participants received extra credit in their psychology course for their participation.
Dot-Probe Task
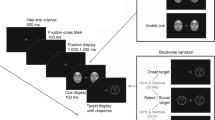
The dot-probe task was programmed using E-Prime2 software (Psychology Software Tools, Pittsburg, PA). A 60 Hz 16″ LCD computer monitor was used to display the task. Four fearful and four neutral (half female) grayscale faces were used as the stimuli. The faces were retrieved from a well-studied database (Gur et al. 2002). As displayed in Fig. 1, each trial started with a white fixation cue (+) in the center of the black background for 1000 ms. Then two faces were simultaneously presented to the left and the right of the fixation cue for 133 ms.Footnote 1 The faces subtended 5° × 7° of the visual angle and were separated by 14° of the visual angle. The target dot appeared either 0, 133, or 399 ms after the faces appeared. This resulted in three SOAs of 133, 266, and 532 ms. Each SOA doubled the length of time of the previous SOA. This allowed us to look at a relatively long time-course while prioritizing the temporal resolution of earlier time-points, which have previously been shown to more consistently capture attention by other types of threatening stimuli (Cooper and Langton 2006; Koster et al. 2005). Participants indicated the location of the dot using an E-Prime serial response box. They were instructed to focus on the fixation cue throughout the experiment and to indicate left sided target dots on the first left most button using their right index finger and to indicate right sided target dot, they used their middle finger on the second button.

Experiments 1 and 2 included fearful and neutral faces, whereas experiment 3 used happy and neutral faces. Each trial started with a white fixation cue (+) in the center of the screen. Then two faces were simultaneously presented to the left and the right of the fixation cue. The task contained incongruent (top), neutral–neutral baseline (middle), and congruent (bottom) trials. The amount of time between face offset and target onset varied: Experiment 1 had a delay of 0, 133, or 399 ms, Experiment 2 and 3 had a delay of 33, 117, 285, and 621 ms. Participants were instructed to locate the dot as quickly as possible
For each SOA, there were congruent trials (dot was on the same side as fearful face), incongruent trials (dot was on the same side as the neutral face), and baseline trials (two neutral faces were presented). Faster responses on congruent compared to incongruent trials was considered to represent an attentional bias to threat. Since baseline trials had two neutral faces, attention should not be allocated to either side. To assess the orienting and disengagement of attention, congruent and incongruent trials were compared to baseline trials (Carlson and Reinke 2008; Koster et al. 2004). The task was divided into six blocks and each block contained 30 congruent, 30 incongruent, and 30 baseline, with equal amounts of the three SOA conditions. Thus, the experiment contained a total of 540 trials.
Data Analyses
We first examined the time-course for the overall attention effect (i.e., congruent vs. incongruent difference). To meet this end, we ran a two-way repeated measures Analysis of Variance (ANOVA) to assess the effects of congruency and time-point on reaction times. Subsequent analyses were restricted to time-points where attention was captured and aimed to isolate the relative contribution of orienting and disengagement processes to this capture of attention. Additionally, for these analyses we excluded individuals showing an attentional avoidance of fearful faces (congruent RTs > incongruent RTs) at a particular time-point. That is, in order to break down this overall attentional bias into orienting and disengagement components, there must first be an attentional bias to break down. Accordingly, we first identified at a group-level where attentional bias effects were occurring and then excluded individuals showing attentional avoidance. Single-tailed paired-samples t tests were used to test for facilitated orienting (congruent RTs < baseline RTs) and delayed disengagement (incongruent RTs > baseline RTs).Footnote 2 The Bonferroni correction was applied to all post hoc analyses.
Results
Only correct responses that were between 150 and 750 ms after target presentation (96.37% of all data) were used in the following analyses (Carlson and Reinke 2008). A 3 × 2 repeated measured ANOVA was conducted comparing the effects of SOA (133, 266, and 532 ms) and trial type (congruent vs. incongruent trials) on participants’ RT in the dot-probe task. There was a significant effect of SOA, F(2, 94) = 270.201, p < .001, \(\eta_{p}^{2}\) = .852. RTs were slowest during the 133 ms SOA condition. There was also a significant effect of trial type, F(1, 47) = 35.042, p < .0001, \(\eta_{p}^{2}\) = .427. RTs were faster for congruent (M = 386.65 ms) compared to incongruent (M = 393.14 ms, SE diff = 1.09 ms) trials. Both of these main effects were better explained by an interaction between SOA and trial type, F(2, 94) = 13.06, p < .0001, \(\eta_{p}^{2}\) = .217. As can been seen in Fig. 2, post hoc comparisons indicated that in the 133 ms SOA there was a significant difference between congruent (M = 421.57 ms) and incongruent (M = 425.82 ms, SE diff = 1.88 ms, p < .05, d = 0.33) trials. There was also a difference between the 266 ms SOA’s congruent (M = 366.99 ms) and incongruent (M = 380.70 ms, SE diff = 1.75 ms, p < .0001, d = 1.13) trials. In the 532 ms SOA condition, there was no difference between congruent trials (M = 371.41) and incongruent trials (M = 372.90, SE diff = 1.82, p = .42, d = 0.12). The difference between congruent and incongruent trials was greater in the 266 ms condition compared to the 133 ms (SE diff = 2.67, p = 0.003, d = 0.51) and 532 ms conditions (SE diff = 2.38, p < 0.001, d = 0.79), but did not differ between the 133 and 532 ms conditions (SE diff = 2.60, p > 0.05, d = 0.15).

In Experiment 1, reaction times on fear-congruent trials were significantly faster than incongruent trials for SOA 1 (133 ms) and SOA 2 (266 ms), but not SOA 3 (532 ms). Similarly, in Experiment 2, reaction times on fear-congruent trials were significantly faster than incongruent trials for SOA 1 (84 ms) and SOA 2 (168 ms), but not for SOA 3 (336 ms) or SOA 4 (672 ms). In experiment 3, reaction times on happy-congruent trials were significantly faster than incongruent trials for SOA 2 (168 ms) and SOA 3 (336 ms), but not SOA 1 (84 ms) or SOA 4 (672 ms). Error bars represent the 95% confidence interval of the mean difference
Paired samples t tests were used to compare the differences between trial types within the SOA conditions. After exclusion of participants showing an attentional avoidance of threat (congruent > incongruent) sample sizes included N = 33 for the 133 ms and N = 46 for the 266 ms SOA conditions. In the 133 ms SOA condition, RTs for congruent (M = 409.9) were significantly faster than baseline trials (M = 415.78 ms, SE diff = 1.68 ms), t(31) = −3.49, p = .003, d = 0.62, see Fig. 3. Incongruent (M = 420.66 ms) were significantly slower than baseline trials, SE diff = 1.79, t(31) = 2.72, p = .01, d = 0.48. In the 266 ms SOA condition, congruent (M = 366.75 ms) were significantly faster than baseline trials, M = 376.59 ms, SE diff = 1.52 ms, t(44) = −6.49, p < .001, d = 0.97. Incongruent (M = 381.48 ms) were significantly slower than baseline trials, SE diff = 1.95, t(44) = 2.50, p = .016, d = 0.37, see Fig. 2.

In Experiment 1 and 2, when attention was captured, attentional bias to fearful faces was associated with facilitated orienting (congruent RTs < baseline RTs) and delayed disengagement (incongruent RTs > baseline RTs). Error bars represent the 95% confidence interval of the mean difference
Discussion
In Experiment 1, we found that for SOAs of 133 and 266 ms fearful faces capture attention through facilitated orienting and delayed disengagement. In Experiment 2, we sampled attention at time-points (SOAs of 84, 168, 336, and 672 ms) which allowed us to look at time-points intermediate as well as those earlier and later than those assessed in Experiment 1. As in Experiment 1, each SOA doubled the length of time of the previous SOA. We found a main effect of SOA in Experiment 1, which suggested that RT was slowest during the shortest SOA (133 ms) in relation to the other two SOAs. This effect reflects the know problem of the shortest SOA resulting in the longest RTs when multiple SOAs are used in a random order—the “fore-period” (Naatanen 1970). In Experiment 2, we included only one SOA per block in a randomized order in an attempt to minimize the “fore-period” effect (Naatanen 1970).
Experiment 2
Method
Fifty-eight participants (39 female) were used in the second experiment, ages ranged from 18 to 38 (M = 19.98, SD = 3.55). Forty-seven reported being right handed. The Northern Michigan University Institutional Review Board approved this study. The participants received extra credit in their psychology course for their participation.
The dot-probe task used the same software and computer system as in Experiment 1; however, this experiment used four different SOAs instead of three. Also, the faces were presented for 51 ms and the time between the face and the dot varied: 33, 117, 285, and 621 ms. Therefore, the four different SOAs were 84, 168, 336, and 672 ms (as in Experiment 1, each SOA doubled the length of time of the previous SOA). There were four blocks, one for each SOA (presented in a randomized order across participants). We used 30 congruent, 30 incongruent, and 30 baseline trials for each SOA condition. The experiment contained 360 total trials.
Results
Again, only correct responses between 150 and 750 ms after target presentation were used for statistical analyses (97.97% of the data). A 4 × 2 repeated measures ANOVA was conducted comparing the effects of SOA (84, 168, 336, and 672 ms) and trial type (congruent vs. incongruent trials) on participants’ RT in the dot-probe task. There was a significant effect of SOA, F(3, 171) = 18.84, p < .001, \(\eta_{p}^{2}\) = .248. RTs were again slowest for the shortest (84 ms) SOA condition. The effect of trial type was again significant, F(1, 57) = 21.30, p < .001, \(\eta_{p}^{2}\) = .270. RTs were faster for congruent (M = 369.97 ms) than incongruent trials (M = 374. 98 ms, SE diff = 1.09 ms). As in Experiment 1, there was an interaction between SOA and trial type, F(3, 171) = 3.12, p = .01, \(\eta_{p}^{2}\) = .052. As can been seen in Fig. 2, the post hoc analysis revealed that in the 84 ms SOA condition, congruent trials (M = 384.49 ms) were significantly faster than incongruent trials (M = 389.59 ms, SE diff = 2.04 ms, p = .03, d = 0.33). In the 168 ms SOA condition, congruent (M = 357.35 ms) were faster than incongruent (M = 367.52 ms, SE diff = 2.03 ms, p < .001, d = 0.66) trials. There was no significant differences between congruent (M = 362.96 ms & M = 375.10 ms) and incongruent (M = 365.67 ms & M = 377.15 ms) trial types in the 336 ms SOA (SE diff = 2.20, p > 0.2, d = 0.16) or 672 ms SOA (SE diff = 2.05, p > 0.2, d = 0.12) conditions. The difference between congruent and incongruent trials was greater in the 168 ms condition compared to the 336 ms (SE diff = 2.71 p < 0.05, d = 0.36) and 672 ms conditions (SE diff = 2.60, p < 0.05, d = 0.41), but did not differ between any other SOA conditions.
Paired samples t tests were used to compare between trial types within the SOA conditions. Using the same process described in Experiment 1, individuals that displayed an attentional avoidance of threat (congruent > incongruent) were excluded from this analysis (resulting samples: 84 ms SOA N = 38; 168 ms SOA N = 43). As can be seen in Fig. 3, in the 84 ms SOA condition, congruent trials (M = 370.98 ms) were moderately faster than baseline trials (M = 374.63, SE diff = 2.10 ms, t(37) = −1.73, p = .09, d = 0.28) and incongruent trials (M = 384.66 ms,) were significantly slower than baseline trials (SE diff = 1.74 ms, t(37) = 5.77, p < .001, d = 0.93). In the 168 ms SOA condition, congruent trials (M = 352.68 ms) were significantly faster than baseline trials, M = 360.36 ms, SE diff = 1.71 ms, t(42) = −4.49, p < .001, d = 0.69. Incongruent trials (M = 369.11 ms,) were significantly slower than baseline, SE diff = 1.83 ms, t(42) = 4.79, p < .001, d = 0.73, see Fig. 2.
Discussion
In Experiment 2, we found that for SOAs of 84 ms and 168 ms, fearful faces capture attention through facilitated orienting and delayed disengagement. Across Experiment 1 and Experiment 2, fearful faces captured and held attention for time-points less than 300 ms. To determine if this attentional time-course is unique to fearful faces or present for other facial expressions, a third dot-probe experiment was conducted with happy and neutral faces. In Experiment 3, we sampled attention at the same time-points used in Experiment 2 and again only included one SOA per block in a randomized order.
Experiment 3
Method
Forty-eight individuals (30 female) participated in the third experiment, ages ranged from 18 to 25 (M = 19.40, SD = 1.62). Forty-eight reported being right handed. The Northern Michigan University Institutional Review Board approved this study. The participants received course credit or extra credit for their participation.
The dot-probe task used the same software and computer system as in Experiments 1 and 2. However, in Experiment 3 an E-Prime Chronos response box was used (opposed to the E-Prime serial response box used in Experiments 1 and 2). As in Experiment 2, faces were presented for 51 ms and the time between the face and the dot varied: 33 ms, 117 ms, 285 ms, and 621 ms. Therefore, the four different SOAs were 84 ms, 168 ms, 336 ms, and 672 ms (as in Experiments 1 and 2, each SOA doubled the length of time of the previous SOA). There were four blocks, one for each SOA (presented in a randomized order across participants). We used 30 congruent, 30 incongruent, and 30 baseline trials for each SOA condition. The experiment contained 360 total trials.
Results
Again, only correct responses between 150 and 750 ms after target presentation were used for statistical analyses (97.8% of the data). A 4 × 2 repeated measures ANOVA was conducted comparing the effects of SOA (84, 168, 336, and 672 ms) and trial type (congruent vs. incongruent trials) on participants’ RT in the dot-probe task. There was a significant effect of SOA, F(3, 141) = 8.88, p < .001, \(\eta_{p}^{2}\) = .16. RTs were slowest for the 84 and 672 ms conditions. As was the case in the first two experiments, there was a significant effect of trial type, F(1, 47) = 18.86, p < .001, \(\eta_{p}^{2}\) = .29. RTs were faster for congruent (M = 313.72 ms) than incongruent trial types (M = 318.59 ms, SE diff = 1.12 ms). The interaction between SOA and trial type was nonsignificant, F(3, 141) = 0.81, p = .49, \(\eta_{p}^{2}\) = .02. However, given that the primary objective of Experiment 3 was to provide a comparison time-course for Experiments 1 and 2 based on happy facial expressions, we ran planned comparisons to test for differences in trial type across the four SOAs. These planned comparisons revealed that in the 168 ms SOA condition, congruent trials (M = 305.83 ms) were significantly faster than incongruent trials (M = 311.94 ms, SE diff = 2.21 ms, p = .008, d = 0.40) and in the 336 ms SOA condition congruent trials (M = 307.21 ms) were faster than incongruent trials (M = 314.41 ms, SE diff = 2.63 ms, p < .001, d = 0.40, Fig. 2). There was no significant differences between congruent (M = 321.55, 320.31 ms) and incongruent (M = 325.08, 322.91 ms) trial types with the 84 ms SOA (SE diff = 2.18 ms, p > 0.1, d = 0.23) and 672 ms SOA (SE diff = 2.40, p > 0.2, ms d = 0.16) conditions.
Paired samples t tests were used to compare between trial types within the SOA conditions. Using the same process described in Experiment 1 and 2, only individuals that displayed an attention effect (congruent < incongruent) were used in this analysis (168 ms SOA N = 28; 336 ms SOA N = 32). As displayed in Fig. 3, in the 168 ms SOA condition, congruent trials (M = 299.80 ms) were significantly faster than baseline trials (M = 305.08, SE diff = 2.04 ms, t(27) = −2.58, p = .016, d = 0.49) and incongruent trials (M = 316.31 ms, SE diff = 2.49 ms) were significantly slower than baseline trials, t(27) = 4.51, p < .001, d = 0.85. In the 336 ms SOA condition, congruent trials (M = 301.56 ms) were significantly faster than baseline trials (M = 311.96 ms, SE diff = 2.61 ms, t(42) = −3.98, p < .001, d = 0.70) and incongruent trials (M = 318.79 ms, SE diff = 2.81 ms) were significantly slower than baseline, t(42) = 2.43, p < .05, d = 0.43, see Fig. 4.

In Experiment 3, when attention was captured, attentional bias to happy faces was associated with facilitated orienting (congruent RTs < baseline RTs) and delayed disengagement (incongruent RTs > baseline RTs). Error bars represent the 95% confidence interval of the mean difference
Discussion
The results from Experiments 1 and 2 suggest that there was an attentional bias toward fearful facial expressions when the lag between face offset and target dot onset was relatively short (≤266 ms). In the shorter SOA conditions for both experiments, the RTs for congruent trials were faster than baseline trials, which were faster than incongruent trials. The inclusion of these baseline trials allowed us to break down the overall attention effect into orienting (congruent < baseline) and disengagement (baseline < incongruent) components. In Experiment 3, we found that happy (relative to neutral) faces also capture attention, but appear to do so on a slightly delayed time-course. The results demonstrate that at all time-points where attention was captured by fearful or happy facial expressions, both facilitated orienting and delayed disengagement contributed to this effect.
Our results add to previous work demonstrating that fearful faces, and other threat-relevant stimuli such as weapons and harmful animals, automatically capture our attention (Armony and Dolan 2002; Beaver et al. 2005; Blanchette 2006; Carlson et al. 2009; Cooper and Langton 2006; Fox 2002; Fox et al. 2001; Koster et al. 2004; MacLeod and Mathews 1988; Macleod et al. 1986; Mogg and Bradley 2002; Ohman et al. 2001; Pourtois et al. 2004; Salemink et al. 2007). Previous dot-probe studies examining the time-course of attentional bias in low trait anxious or unselected populations, have observed overall (congruent vs. incongruent) attention effects for emotionally salient visual images and angry faces in conditions with relatively short SOAs (100 ms; Cooper and Langton 2006; Koster et al. 2005). Additional research examining the time-course for attentional bias in individuals selected for high trait anxiety, has similarly found an early attentional bias to threatening images, which appears to be maintained to somewhat longer SOAs (≥500 ms; Koster et al. 2005; Mogg and Bradley 2006). Our results extend this previous work using angry faces and negatively valenced images (i.e., IAPS), by providing evidence that fearful facial expressions follow a similar time-course of an early attentional capture, which later subsides (<300 ms). Thus, the capture of attention by fearful facial expressions is rapid and fleeting. From an evolutionary perspective, we might expect our attentional bias to fearful faces to be sustained past 300 ms. In both experiments, faces were presented very briefly (≤133 ms) and then disappeared. In the absence of a prolonged threat cue, simultaneous multiple threat cues, or dynamically updating threat cues, it may be advantageous for an individual to limit the allocation of their attentional resources to fleeting threat information. In real world situations, fearful facial expression are often accompanied by additional information (e.g., auditory distress signals). Future research should assess the time-course for the attentional capture of fearful facial expressions that are accompanied by additional threat cues such as screams and other non-verbal auditory distress signals, verbal warnings, or changes in expression. Multiple or dynamic fear cues may elicit a longer capture of attention, in so far as the additional cue does not indicate the location of threat. Conversely, if the fearful face had directed eye gaze, it would be expected that attention would rapidly reorient to the location of the gaze (Carlson 2016; Fichtenholtz et al. 2007; Kuhn and Tipples 2011; Pecchinenda et al. 2008; Putman et al. 2006). Nevertheless, our results indicate that although fleeting, fearful facial expressions robustly capture and hold spatial attention.
Based on the results of Experiment 3, it appears that the time-course for fearful faces is similar to, but distinct from, happy faces. Relative to fearful faces (Experiments 1 and 2) happy faces resulted in a longer time-course (336 ms). Both happy and fearful faces are salient stimuli in our environments (Adams and Kleck 2005) and have been shown to capture attention in young children through a genetically mediated mechanism (Elam et al. 2010). This bias towards socially relevant safety signals appears to extend beyond humans and has recently been observed in bonobos (Kreta et al. 2016), which may indicate a cross-species bias to attend to affiliative safety signals from other members of an organism’s species. Although attending to positive emotional expressions is adaptive, we anticipated seeing a longer time-course for trials using fearful faces due to an evolutionarily-driven priority to attend to and avoid threats in the environment. One possible explanation for the unique capture of attention by happy faces at later time-points is the shared signal hypothesis (Adams and Kleck 2005), which states that fearful faces signal the existence of threat in the environment, but attention is directed away from the face in order to identify the location of the threat via eye gaze (Carlson 2016; Fichtenholtz et al. 2007; Kuhn and Tipples 2011; Pecchinenda et al. 2008; Putman et al. 2006); whereas, happy faces may not capture attention with the purpose of redirecting attention (Milders et al. 2011). Although our study did not examine gaze direction, the shared signal hypothesis may explain the time-course for fearful, compared to happy faces, in our results. That is, fearful faces captured attention quickly and held it for a short amount of time (84–266 ms), which would be advantageous for locating the actual source of threat (signal avoidance). On the other hand, happy faces had a delayed, but longer, capture of attention (168–336 ms), which may indicate an approach bias. Similar differential (early vs. late, respectively) time-courses have been observed in fear conditioning studies assessing attentional biases in visual saccades to conditioned signals of threat and safety (Schmidta et al. 2016).
If the overall capture of attention in the dot-probe task reflects both orienting and disengagement components, is there an added benefit of including baseline trials in future dot-probe studies? We think that there are two primary reasons for including baseline trials: (1) establishing that RTs for baseline trials fall between congruent and incongruent RTs could serve as an easy manipulation check. (2) Although at the group-level, the overall capture of attention in the dot-probe task can be evenly split into orienting and disengagement effects, prior work using between subject variables has found that individual differences are uniquely related to specific orienting or disengagement subcomponents. For example, attentional bias has been linked to an early genetic influence (Elam et al. 2010) and in particular has been linked to the serotonin transporter polymorphism (i.e., 5-HTTLPR; Beevers et al. 2007; Carlson et al. 2012; Fox et al. 2009; Osinsky et al. 2008; Perez-Edgar et al. 2010). Short allele carriers, compared to homozygous long individuals, display a rapid orienting of attention to fearful faces, but do not display delayed disengagement (Carlson et al. 2012). On the other hand, individual differences in cognitive reappraisal (Arndt and Fujiwara 2012) and trait anxiety (Fox et al. 2001; Koster et al. 2006; Salemink et al. 2007; Yiend and Mathews 2001) are linked to delayed disengagement, but not facilitated orienting. However, more recent evidence suggests that anxiety is associated both with facilitated orienting and delayed disengagement (Rudaizky et al. 2014). Due to the theoretical importance of attentional bias as a causal factor in the development of anxiety (Mathews and Mackintosh 1998; Mathews and MacLeod 2002), further research into the attentional components underlying anxious symptoms is of particular importance. Furthermore, individual differences in trait anger (van Honk et al. 2001), depression (Mogg et al. 1995), post-traumatic stress disorder (Bryant and Harvey 1997), substance abuse and other addictions (Bradley et al. 2004; Field et al. 2004) as well as a number of other traits are related to attentional bias. Establishing the contribution of the orienting and disengagement components to attentional bias in these examples and others will play an important role in understanding the underlying behavioral mechanisms contributing to attentional bias in these populations. Identifying whether attentional bias in a particular group (or individual) is attributed to facilitated orienting, delayed disengagement, or a combination of these factors may lead to personalized treatments including attention bias modification (Hakamata et al. 2010; Kuckertz and Amir 2015).
The current study excluded individuals showing an attentional avoidance of threat (incongruent RTs < congruent RTs) in order to reduce noise in our estimates of orienting and disengagement. Although effective in meeting this end, one limitation of this strategy is the removal of a relatively large number of participants. As mentioned above, a number of individual differences in personality traits and genetics are related to differences in attentional bias and may account for the attentional avoidance of threat observed in these individuals (e.g., 5-HTTLPR long–long allele individuals have been found to have an attentional avoidance of threat, Carlson et al. 2012). More research is needed to understand the factors related to attentional avoidance. Yet, for individuals displaying an attentional bias to fearful or happy faces, our results show a clear pattern suggesting that when attention is captured, both orienting and disengagement effects are present.
In conclusion, we report results from two dot-probe studies indicating that fearful faces capture attention through facilitated orienting and delayed disengagement for time-points occurring earlier than approximately 300 ms. In a third experiment we provide additional evidence that happy facial expressions also capture attention through facilitated orienting and delayed disengagement from approximately 150-350 ms post face onset. Thus, fearful and happy facial expressions capture and hold attention, but do so on slightly different time-courses. Although it is common for dot-probe studies to use SOAs of 500 ms or more, the current findings suggest that SOAs <300 ms would be optimal. It appears that in the absence of additional information, or sustained presentation, the capture and hold of attention by emotional faces is fleeting.
Notes
Faces were presented for the same duration (i.e., 133 ms) in all SOA conditions in order to hold the amount of face processing constant across conditions.
Although this may at first glance appear to be a case of circular analysis, it is not circular. A circular analysis is one in which data are reduced based on meeting a particular criterion and then this criterion is tested in the reduced dataset. Here, data are being reduced based on the difference between two conditions (A and B; i.e., congruent and incongruent trials) and are then used in independent comparisons to a third condition (C; baseline trials) and not each other. The difference between A and B (e.g., if A = 350 and B = 400, A < B) has no bearing on whether or not C is different from A or B (e.g., if C = 325, C < A & B; if C = 375, C > A, but < B; or C = 425, C > A & B).
References
Adams, R. B., Jr., & Kleck, R. E. (2005). Effects of direct and averted gaze on the perception of facially communicated emotion. Emotion, 5(1), 3–11. doi:10.1037/1528-3542.5.1.3.
Armony, J. L., & Dolan, R. J. (2002). Modulation of spatial attention by fear-conditioned stimuli: An event-related fMRI study. Neuropsychologia, 40(7), 817–826.
Arndt, J. E., & Fujiwara, E. (2012). Attentional bias towards angry faces in trait-reappraisal. Personality and Individual Differences, 52(1), 61–66. doi:10.1016/J.Paid.2011.08.030.
Beaver, J. D., Mogg, K., & Bradley, B. P. (2005). Emotional conditioning to masked stimuli and modulation of visuospatial attention. Emotion, 5(1), 67–79.
Beevers, C. G., Gibb, B. E., McGeary, J. E., & Miller, I. W. (2007). Serotonin transporter genetic variation and biased attention for emotional word stimuli among psychiatric inpatients. Journal of Abnormal Psychology, 116(1), 208–212. doi:10.1037/0021-843X.116.1.208.
Blanchette, I. (2006). Snakes, spiders, guns, and syringes: How specific are evolutionary constraints on the detection of threatening stimuli? Quarterly Journal of Experimental Psychology (Colchester), 59(8), 1484–1504.
Bradley, B., Field, M., Mogg, K., & De Houwer, J. (2004). Attentional and evaluative biases for smoking cues in nicotine dependence: Component processes of biases in visual orienting. Behavioral Pharmacology, 15(1), 29–36.
Bryant, R. A., & Harvey, A. G. (1997). Attentional bias in posttraumatic stress disorder. Journal of Traumatic Stress, 10(4), 635–644.
Carlson, J. M. (2016). Facilitated orienting underlies fearful face-enhanced gaze cueing of spatial location. Cogent Psychology, 3(1), 1147120. doi:10.1080/23311908.2016.1147120.
Carlson, J. M., Fee, A. L., & Reinke, K. S. (2009). Backward masked snakes and guns modulate spatial attention. Evolutionary Psychology, 7(4), 527–537.
Carlson, J. M., & Mujica-Parodi, L. R. (2015). Facilitated attentional orienting and delayed disengagement to conscious and nonconscious fearful faces. Journal of Nonverbal Behavior, 39(1), 69–77. doi:10.1007/s10919-014-0185-1.
Carlson, J. M., Mujica-Parodi, L. R., Harmon-Jones, E., & Hajcak, G. (2012). The orienting of spatial attention to backward masked fearful faces is associated with variation in the serotonin transporter gene. Emotion, 12(2), 203–207.
Carlson, J. M., & Reinke, K. S. (2008). Masked fearful faces modulate the orienting of covert spatial attention. Emotion, 8(4), 522–529. doi:10.1037/a0012653.
Carlson, J. M., & Reinke, K. S. (2010). Spatial attention-related modulation of the N170 by backward masked fearful faces. Brain Cognition, 73(1), 20–27. doi:10.1016/j.bandc.2010.01.007.
Carlson, J. M., & Reinke, K. S. (2014). Attending to the fear in your eyes: Facilitated orienting and delayed disengagement. Cognition and Emotion, 28(8), 1398–1406. doi:10.1080/02699931.2014.885410.
Carlson, J. M., Reinke, K. S., LaMontagne, P. J., & Habib, R. (2011). Backward masked fearful faces enhance contralateral occipital cortical activity for visual targets within the spotlight of attention. Social Cognitive and Affective Neuroscience, 6(5), 639–645. doi:10.1093/Scan/Nsq076.
Carlson, J. M., Torrence, R. D., & Vander Hyde, M. R. (2016). Beware the eyes behind the mask: The capture and hold of selective attention by backward masked fearful eyes. Motivation and Emotion, 40(3), 498–505. doi:10.1007/s11031-016-9542-1.
Clarke, P. J., Macleod, C., & Guastella, A. J. (2013). Assessing the role of spatial engagement and disengagement of attention in anxiety-linked attentional bias: A critique of current paradigms and suggestions for future research directions. Anxiety Stress Coping, 26(1), 1–19. doi:10.1080/10615806.2011.638054.
Cooper, R. M., & Langton, S. R. (2006). Attentional bias to angry faces using the dot-probe task? It depends when you look for it. Behaviour Research and Therapy, 44(9), 1321–1329.
Elam, K. K., Carlson, J. M., DiLalla, L. F., & Reinke, K. S. (2010). Emotional faces capture spatial attention in 5-year-old children. Evolutionary Psychology, 8(4), 754–767.
Fichtenholtz, H. M., Hopfinger, J. B., Graham, R., Detwiler, J. M., & LaBar, K. S. (2007). Happy and fearful emotion in cues and targets modulate event-related potential indices of gaze-directed attentional orienting. Social Cognitive and Affective Neuroscience, 2(4), 323–333. doi:10.1093/scan/nsm026.
Field, M., Mogg, K., Zetteler, J., & Bradley, B. P. (2004). Attentional biases for alcohol cues in heavy and light social drinkers: The roles of initial orienting and maintained attention. Psychopharmacology (Berl), 176(1), 88–93. doi:10.1007/s00213-004-1855-1.
Fox, E. (2002). Processing emotional facial expressions: the role of anxiety and awareness. Cognitive, Affective, and Behavioral Neuroscience, 2(1), 52–63.
Fox, E., Ridgewell, A., & Ashwin, C. (2009). Looking on the bright side: Biased attention and the human serotonin transporter gene. Proceedings of the Royal Society B: Biological Science, 276(1663), 1747–1751. doi:10.1098/rspb.2008.1788.
Fox, E., Russo, R., Bowles, R., & Dutton, K. (2001). Do threatening stimuli draw or hold visual attention in subclinical anxiety? Journal of Experimental Psychology: General, 130(4), 681–700.
Gur, R. C., Sara, R., Hagendoorn, M., Marom, O., Hughett, P., Macy, L., et al. (2002). A method for obtaining 3-dimensional facial expressions and its standardization for use in neurocognitive studies. Journal of Neuroscience Methods, 115(2), 137–143.
Hakamata, Y., Lissek, S., Bar-Haim, Y., Britton, J. C., Fox, N. A., Leibenluft, E., et al. (2010). Attention bias modification treatment: A meta-analysis toward the establishment of novel treatment for anxiety. Biological Psychiatry, 68(11), 982–990. doi:10.1016/J.Biopsych.2010.07.021.
Koster, E. H., Crombez, G., Verschuere, B., & De Houwer, J. (2004). Selective attention to threat in the dot probe paradigm: Differentiating vigilance and difficulty to disengage. Behavioural Research and Therapy, 42(10), 1183–1192.
Koster, E. H., Crombez, G., Verschuere, B., Van Damme, S., & Wiersema, J. R. (2006). Components of attentional bias to threat in high trait anxiety: Facilitated engagement, impaired disengagement, and attentional avoidance. Behavioural Research and Therapy, 44(12), 1757–1771.
Koster, E. H., Verschuere, B., Crombez, G., & Van Damme, S. (2005). Time-course of attention for threatening pictures in high and low trait anxiety. Behavioural Research and Therapy, 43(8), 1087–1098. doi:10.1016/j.brat.2004.08.004.
Kreta, M. E., Jaasmab, L., Biondac, T., & Wijnend, J. G. (2016). Bonobos (Pan paniscus) show an attentional bias toward conspecifics’ emotions. Proceedings of the National Academy of Sciences of the United States of America. doi:10.1073/pnas.1522060113.
Kuckertz, J. M., & Amir, N. (2015). Attention bias modification for anxiety and phobias: Current status and future directions. Current Psychiatry Reports, 17(2), 9. doi:10.1007/s11920-014-0545-x.
Kuhn, G., & Tipples, J. (2011). Increased gaze following for fearful faces. It depends on what you’re looking for! Psychonomic Bulletin & Review, 18(1), 89–95. doi:10.3758/s13423-010-0033-1.
MacLeod, C., & Mathews, A. (1988). Anxiety and the allocation of attention to threat. Quarterly Journal of Experimental Psychology A, 40(4), 653–670.
Macleod, C., Mathews, A., & Tata, P. (1986). Attentional bias in emotional disorders. Journal of Abnormal Psychology, 95(1), 15–20.
Mathews, A., & Mackintosh, B. (1998). A cognitive model of selective processing in anxiety. Cognitive Therapy and Research, 22(6), 539–560.
Mathews, A., & MacLeod, C. (2002). Induced processing biases have causal effects on anxiety. Cognition and Emotion, 16(3), 331–354.
Milders, M., Hietanen, J. K., Leppanen, J. M., & Braun, M. (2011). Detection of emotional faces is modulated by the direction of eye gaze. Emotion, 11(6), 1456–1461. doi:10.1037/a0022901.
Mogg, K., & Bradley, B. P. (2002). Selective orienting of attention to masked threat faces in social anxiety. Behavioural Research and Therapy, 40(12), 1403–1414.
Mogg, K., & Bradley, B. P. (2006). Time course of attentional bias for fear-relevant pictures in spider-fearful individuals. Behavioural Research and Therapy, 44(9), 1241–1250. doi:10.1016/j.brat.2006.05.003.
Mogg, K., Bradley, B. P., de Bono, J., & Painter, M. (1997). Time course of attentional bias for threat information in non-clinical anxiety. Behavioural Research and Therapy, 35(4), 297–303.
Mogg, K., Bradley, B. P., & Williams, R. (1995). Attentional bias in anxiety and depression: The role of awareness. British Journal of Clinical Psychology, 34(Pt 1), 17–36.
Mogg, K., Holmes, A., Garner, M., & Bradley, B. P. (2008). Effects of threat cues on attentional shifting, disengagement and response slowing in anxious individuals. Behavioural Research and Therapy, 46(5), 656–667. doi:10.1016/j.brat.2008.02.011.
Naatanen, R. (1970). The diminishing time-uncertainty with the lapse of time after the warning signal in reaction-time experiments with varying fore-periods. Acta Psychologica (Amst), 34(4), 399–419.
Ohman, A., Flykt, A., & Esteves, F. (2001). Emotion drives attention: Detecting the snake in the grass. Journal of Experimental Psychology: General, 130(3), 466–478.
Osinsky, R., Reuter, M., Kupper, Y., Schmitz, A., Kozyra, E., Alexander, N., et al. (2008). Variation in the serotonin transporter gene modulates selective attention to threat. Emotion, 8(4), 584–588. doi:10.1037/a0012826.
Pecchinenda, A., Pes, M., Ferlazzo, F., & Zoccolotti, P. (2008). The combined effect of gaze direction and facial expression on cueing spatial attention. Emotion, 8(5), 628–634. doi:10.1037/a0013437.
Perez-Edgar, K., Bar-Haim, Y., McDermott, J. M., Gorodetsky, E., Hodgkinson, C. A., Goldman, D., et al. (2010). Variations in the serotonin-transporter gene are associated with attention bias patterns to positive and negative emotion faces. Biological Psychology, 83(3), 269–271. doi:10.1016/j.biopsycho.2009.08.009.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32(1), 3–25.
Posner, M. I., Inhoff, A. W., Friedrich, F. J., & Cohen, A. (1987). Isolating attentional systems—A cognitive-anatomical analysis. Psychobiology, 15(2), 107–121.
Pourtois, G., Grandjean, D., Sander, D., & Vuilleumier, P. (2004). Electrophysiological correlates of rapid spatial orienting towards fearful faces. Cerebral Cortex, 14(6), 619–633.
Putman, P., Hermans, E., & van Honk, J. (2006). Anxiety meets fear in perception of dynamic expressive gaze. Emotion, 6(1), 94–102. doi:10.1037/1528-3542.6.1.94.
Rudaizky, D., Basanovic, J., & MacLeod, C. (2014). Biased attentional engagement with, and disengagement from, negative information: Independent cognitive pathways to anxiety vulnerability? Cognition and Emotion, 28(2), 245–259. doi:10.1080/02699931.2013.815154.
Salemink, E., van den Hout, M. A., & Kindt, M. (2007). Selective attention and threat: Quick orienting versus slow disengagement and two versions of the dot probe task. Behavioural Research and Therapy, 45(3), 607–615.
Schmidta, L. J., Belopolskya, A. V., & Theeuwesa, J. (2016). The time course of attentional bias to cues of threat and safety. Cognition and Emotion. doi:10.1080/02699931.2016.1169998.
van Honk, J., Tuiten, A., de Haan, E., van den Hout, M., & Stam, H. (2001). Attentional biases for angry faces: Relationships to trait anger and anxiety. Cognition and Emotion, 15(3), 279–297.
Yiend, J., & Mathews, A. (2001). Anxiety and attention to threatening pictures. Quarterly Journal of Experimental Psychology Section A: Human Experimental Psychology, 54(3), 665–681.
Acknowledgements
We would like to thank the students in the Cognitive × Affective Behavior and Integrative Neuroscience (CABIN) lab at Northern Michigan University for assisting in the collection of this data.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Torrence, R.D., Wylie, E. & Carlson, J.M. The Time-Course for the Capture and Hold of Visuospatial Attention by Fearful and Happy Faces. J Nonverbal Behav 41, 139–153 (2017). https://doi.org/10.1007/s10919-016-0247-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10919-016-0247-7