
Abstract
We evaluated preference for and efficacy of distributed and accumulated response–reinforcer arrangements during discrete-trial teaching for unmastered tasks. During the distributed arrangement, participants received 30-s access to a reinforcer after each correct response. During accumulated arrangements, access was accrued throughout the work period and delivered in its entirety upon completion of the work requirement. Accumulated arrangements were assessed with and without the use of tokens. In Experiment 1, four of five participants preferred one of the accumulated arrangements and preference remained unchanged across mastered and unmastered tasks for all five participants. Four individuals participated in Experiment 2 and we conducted replications with new target stimuli with three of these individuals (for a total of seven analyses). Target stimuli were mastered more quickly and session durations were, on average, shorter in one of the accumulated arrangements in six of the seven analyses. Partial correspondence between preference and measures of efficacy and efficiency was obtained for two of the three individuals for whom both experiments were conducted. These results support prior research, indicating that many learners with intellectual and/or developmental disabilities prefer accumulated reinforcement and that accumulated arrangements can be as effective and as efficient as distributed arrangements in teaching new skills.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Instructional strategies commonly used to teach individuals with intellectual and/or developmental disabilities (IDD), such as discrete-trial teaching, frequently arrange for the delivery of a small amount of a consumable reinforcer immediately following a relatively small response requirement (e.g., Lerman et al. 2016; Smith 2001). This type of arrangement has been described as distributed reinforcement because reinforcer access is interspersed (or distributed) with completion of the work throughout the instructional period (DeLeon et al. 2014). A number of studies have demonstrated the efficacy of distributed reinforcement arrangements in teaching individuals with IDD (e.g., Carroll et al. 2016; Grindle and Remington 2002; Gutierrez et al. 2009; Petursdottir and Aguilar 2016). However, recent research has suggested that this may not be the most preferred arrangement (e.g., Bukala et al. 2015; DeLeon et al. 2014; Fienup et al. 2011). Specifically, a number of studies have compared preference for distributed reinforcement and accumulated reinforcement where learners bank (or accumulate) access to the reinforcer throughout the instructional period and then receive continuous, uninterrupted access to it following completion of the work requirement (e.g., Bukala et al. 2015; DeLeon et al. 2014; Fienup et al. 2011). Results have largely suggested that individuals with IDD prefer the accumulated arrangement, even when it results in a relatively lesser total magnitude of reinforcement (Ward-Horner et al. 2014).
In addition to demonstrating a strong preference for accumulated arrangements, results from this line of research have also suggested that there may be other practical advantages associated with arranging accumulated reinforcement. Specifically, educational interventions are designed, in part, to produce maximum gains with the intended behavior change (i.e., to be effective) in the shortest amount of time (i.e., to be efficient). When two interventions produce the desired behavior change, we may turn to measures of efficiency to determine which intervention produces that change in the least amount of time while also requiring the least amount of instructional resources. For example, DeLeon et al. (2014) and Bukala et al. (2015) calculated measures of efficiency associated with accumulated and distributed arrangements, such as rate of responding and task duration. Results indicated that accumulated reinforcement was associated with, on average, higher response rates (DeLeon et al. 2014) and shorter durations to complete the response requirement for activity reinforcers. These findings could have important clinical implications as preferences are often considered an index of how effective a reinforcer will be when applied contingent on some form of appropriate behavior. But efficiency is not necessarily the same as efficacy. That is, one may work rapidly but inaccurately under one set of conditions and more slowly but correctly under another. Furthermore, these prior studies included mastered tasks that facilitated amassing long durations of access to the reinforcers. Because differential reinforcement of unprompted responses is commonly recommended during acquisition (e.g., Lerman et al. 2016), the amount of reinforcement earned when learning a new skill is likely to be relatively less than the amount earned for mastered tasks. Thus, it is unclear whether individuals would continue to prefer accumulated reinforcement when arranged during acquisition of new skills. Furthermore, it is unclear whether the improved efficiency translates into more effective arrangements with individuals learning more or mastering tasks faster (not just responding faster).
In an attempt to address these matters, several researchers have recently evaluated preference for and efficacy of distributed and accumulated arrangements during acquisition of unmastered tasks (i.e., Joachim and Carroll 2017; Kocher et al. 2015). Kocher et al. (2015) compared acquisition and preference under distributed and accumulated arrangements for three individuals with autism spectrum disorder (ASD) using activity reinforcers (e.g., access to an iPod® or scooter). Joachim and Carroll (2017) included four individuals with ASD and evaluated acquisition and preference across four conditions: distributed reinforcement, accumulated reinforcement, praise, and prompts only. Joachim and Carroll included both food and activity reinforcers, and participants selected the reinforcer prior to each distributed and accumulated session. Both studies also included various measures of task efficiency, including response rate and task duration. Results indicated that the accumulated condition was more effective (i.e., resulted in mastery first) in 60% of the analyses and was more efficient (e.g., was associated with a higher rate of responding or shorter task durations) in 80% of the analyses. However, only two individuals preferred the accumulated arrangement. A third participant from Joachim and Carroll, Crystal, appeared to be indifferent between the accumulated and praise conditions and did seem to prefer both to the distributed condition.
The preference outcomes are particularly interesting in light of the consistency obtained in the prior research that has used mastered tasks. Specifically, in 12 of 13 analyses conducted by Bukala et al. (2015), DeLeon et al. (2014), Fienup et al. (2011), and Ward-Horner et al. (2014), participants preferred the accumulated arrangement. Ward-Horner et al. (2017a) conducted a narrative review of research examining response–reinforcer arrangements and described a number of variables, such as task and reinforcer type, that may affect preference for and performance under them. It is possible that differences in preference outcomes observed by Kocher et al. (2015) and Joachim and Carroll (2017) may be attributable to the use of unmastered tasks. That is, accumulated reinforcement may be more preferred when the task is mastered and the reinforcement schedule is relatively dense, allowing participants to amass long durations of reinforcer access. On the other hand, distributed arrangements may be more preferred when the task is unmastered and the reinforcement schedule is relatively lean. However, neither Kocher et al. nor Joachim and Carroll manipulated task type during their preference assessments. Thus, this matter has yet to be resolved.
As noted by Ward-Horner et al. (2017a, b), reinforcer type could also explain some of the variability in preference observed by Joachim and Carroll (2017). DeLeon et al. (2014) hypothesized that accumulated reinforcement may be more important for activity reinforcers than for food because the value of the activities may depend on or be enhanced by continuous uninterrupted access, and their results indicated that this may have been the case for at least one individual. The type of reinforcer was free to vary across selections in the study conducted by Joachim and Carroll. Shifts in preference for the type of reinforcer may also have the effect of shifting the momentary preference for accumulated and distributed arrangements.
Several procedural differences across the efficacy portions of these studies also make the results difficult to compare. Correct responses were reinforced on a fixed ratio (FR) 1 schedule during the distributed condition in the study conducted by Joachim and Carroll (2017) but on an FR 5 or FR 10 schedule in Kocher et al. (2015). The leaner reinforcement schedules used by Kocher et al. may have diminished the saliency of the response–reinforcer arrangements. In addition, Kocher et al. terminated sessions when participants earned a predetermined amount of reinforcement; thus, the number of tasks issued per session varied as a function of participant accuracy. It is possible that conditions historically associated with more work (i.e., those in which accuracy was lesser) may have been more less preferred. Joachim and Carroll, on the other hand, held the amount of work constant for each participant and permitted the overall magnitude of reinforcement to vary as a direct function of participant accuracy. This may have increased the participant’s motivation to respond correctly, particularly in the accumulated condition where the greater magnitude of reinforcement was experienced continuously.
Given the essential role of reinforcement in teaching new skills, an important goal is to identify how best to arrange work and reinforcers during instruction to maximize the effectiveness of reinforcement-based procedures. The current study attempted to answer a number of questions related to preference for and performance under distributed and accumulated reinforcement arrangements. Experiment 1 assessed whether preferences for accumulated and distributed arrangements differed according to task type (mastered or unmastered). The purpose of Experiment 2 was to determine whether performance on unmastered tasks was differentially affected by accumulated and distributed arrangements. In addition, the role of tokens was evaluated by including two accumulated reinforcement conditions, one with and one without tokens.
Method
Participants and Setting
Experiment 1 included five individuals with IDD. Sean, Tabatha, Harper, and Maisie were admitted to an inpatient hospital unit for the assessment and treatment of problem behavior. The fifth participant, Tate, was a student at an educational and treatment center serving individuals with ASD and other developmental disabilities. Experiment 2 included four individuals with IDD, three of whom participated in Experiment 1 (Harper, Maisie, and Tate) and a fourth who participated exclusively in Experiment 2 (Margo). Sean was a 14-year-old male diagnosed with ASD, moderate intellectual disability, and stereotypic movement disorder with self-injury. Tabatha was a 19-year-old female whose diagnoses included ASD, unspecified intellectual disability, stereotypic movement disorder with self-injury, unspecified disturbance of conduct, and bipolar disorder. Harper was a 21-year-old female diagnosed with ASD, unspecified intellectual disability, stereotypic movement disorder with self-injury, and unspecified mood disorder. Maisie was a 5-year-old female diagnosed with attention–deficit/hyperactivity disorder (ADHD), Tourette’s syndrome, and disruptive behavior disorder. Tate was a 13-year-old male whose diagnoses included ASD and ADHD. Margo was a 24-year-old female diagnosed with ASD, unspecified intellectual disability, and bipolar disorder. Tabatha, Maisie, and Tate spoke in complete sentences. Sean and Harper spoke using 3–4 word sentences, and Margo spoke in 1–3 word phrases. All participants followed multi-step directions.
Sessions for Sean, Tabatha, Harper, Maisie, and Margo were conducted in various areas of the inpatient hospital where they completed their daily academics (Sean, Tabatha, and Maisie) or vocational tasks (Harper and Margo). Specifically, Sean, Harper, and Margo’s sessions were conducted at a table in a bedroom located on the inpatient unit. The room measured approximately 3.5 m by 3.5 m and contained two to four beds, a small table, and several chairs. Tabatha completed her sessions at a large table in an activity area located on the inpatient unit. The activity area measured 3.2 m by 3.2 m and contained a one-way observation window, a large table placed in the center of the room, several chairs, and two small couches. Maisie’s sessions were conducted at a workstation located in a classroom in the hospital. The classroom measured approximately 6.8 m by 6.8 m and contained several small workstations (i.e., a desk and two chairs divided by a partition), a computer station, and a teacher’s desk. Tate completed his sessions in a room reserved for research purposes. The room measured 2.1 m by 2.7 m and contained a table and two chairs and a one-way observation window.
Materials
All settings also contained relevant session materials, including the reinforcer, academic or vocational tasks, tokens and token board, a timer, and condition cards. Tokens were small laminated pictures depicting the back-up reinforcer. Tokens measured approximately 3.5 cm by 5 cm and were affixed with Velcro. A laminated paper (approximately 23 cm by 29.5 cm) affixed with the corresponding pieces of Velcro was used as the token board and had the word “Tokens” printed at the top and centered. The condition cards included pieces of paper (18 cm by 27 cm) that depicted the contingencies associated with each condition. The card for the distributed condition depicted an image of the work, followed to the right by an arrow pointing to a picture of the reinforcer, followed by another image of the work and arrow pointing to the picture. This sequence was repeated five times down the left half of the card (the right half was blank). The card for the accumulated condition depicted an image of the work followed by an arrow pointing to another image of the work, which was repeated five times down the left side of the card. Following the last image of the work was a large arrow that pointed to two rows of five pictures of the reinforcer. The pictures of the reinforcer were printed on the bottom right half of the card. The card for the accumulated-token condition depicted an image of the work followed by an image of the token (which was smaller in size than the picture of the reinforcer and had colored boarder around it that matched the color of the token board to differentiate it). After the token was another image of the work and arrow pointing to the token. This sequence was repeated five times down the left half of the paper. An arrow was printed after the final token and pointed to a picture of the token board printed on the top right half of the card. Below the token board was another arrow that pointed to two rows of five pictures of the reinforcer printed on the bottom right half of the card. Finally, the card for the no-reinforcement control condition depicted an image of the work, followed by an arrow pointing to another image of the work. This sequence was repeated five times down the left side of the card, with the right side left blank.
Pre-experimental Procedures
Participants completed several assessments prior to initiating Experiment 1 or 2.
Multiple-Stimulus Without Replacement Assessment
A multiple-stimulus without replacement (MSWO; DeLeon and Iwata 1996) assessment was conducted to identify an activity for inclusion in the remainder of the study. Six (Sean, Harper, Margo, and Tate), eight (Maisie), or ten (Tabatha) items were included in the MSWO. The MSWO was conducted two (Maisie) or three (Sean, Tabatha, Harper, Margo, and Tate) times, depending on stability in preference among items in the top half of the hierarchy. That is, if the participant selected each item in the top half of the hierarchy in the same order during the second MSWO, the assessment was completed. If selection for any item in the top half differed, the experimenter conducted a third and final MSWO. Rank order was determined by averaging the order in which each item was selected across the MSWOs (e.g., an item selected first, second, and then first across three MSWOs received a rank of 1.3). The top ranked item was then included in the remainder of the study. The reinforcer for all participants included an iPad or Amazon Kindle on which they viewed and interacted with maps on Google Maps (Sean), played games (i.e., a matching puzzle game for Maisie, a bowling game for Tabatha, and a social gaming platform for Tate), or watched music videos on YouTube (i.e., Tabatha, Harper, and Margo).
Rapid Skill Assessment
A rapid skill assessment, adapted from procedures described by Lerman et al. (2004), was conducted to empirically identify mastered and unmastered tasks for both experiments. The participant’s educational coordinator or clinical team was asked to identify two tasks from the participant’s programming that the participant had yet to master: One task was hypothesized to be associated with a motivational deficit and a second task hypothesized to be associated with a skills deficit. Motivational deficit stimuli were those that the participant did not currently complete with accuracy but that the educational or clinical team believed to be in the participant’s repertoire (i.e., he or she knew how to complete the task with accuracy but chose not to). Target stimuli associated with a skills deficit, on the other hand, were those not a part of the participant’s repertoire but were within his or her level of competence (i.e., he or she did not know how to complete those particular responses with accuracy but could learn them with sufficient support and reinforcement). Table 1 includes a description of the task, including the vocal prompt provided by the experimenter and the definition of a correct participant response, and a list of the target stimuli for each condition.
The motivational deficit and skills deficit tasks were evaluated in separate sessions. Each session consisted of one guided exposure trial followed by ten test trials in which one target stimulus from the given condition (motivational deficit or skills deficit) was presented per trial. In the guided exposure trial, the experimenter delivered a verbal prompt to complete the task, then immediately physically guided the participant to emit the correct response, and implemented the contingencies associated with baseline or reinforcement (as described below). For vocal responses that could not be physically guided, the experimenter provided a vocal plus model prompt for the participant to emit the correct vocal response. During baseline, a correct response, an incorrect response, or no response within 5 s of the verbal prompt resulted in the immediate presentation of the next trial. During reinforcement, a correct response after the verbal prompt resulted in the immediate delivery of 30-s access to the reinforcer identified during the MSWO. After the 30 s elapsed, the experimenter removed the reinforcer and initiated the next trial. An incorrect or no response resulted in the immediate presentation of the next trial.
We used a multielement design imbedded within a multiple baseline design across participants to compare correct responding across skills and motivational deficit conditions. Reinforcement was conducted for a minimum of three sessions of each condition until the participant met mastery in the motivational deficit condition while lower and stable levels of responding were observed in the skills deficit condition. Mastery was defined as three consecutive sessions in which correct responding equaled or exceeded 80%.
Figure 1 depicts the percentage of correct responses after the verbal prompt for each participant during the rapid skill assessment. For all participants, correct responding was low for the skills deficit condition during baseline. Correct responding remained low to moderate following the initiation of reinforcement, and no participant met criteria for mastery with this condition. Moderate to low levels of correct responding were observed during baseline for the motivational deficit condition, with the exception of Maisie for whom we observed higher, but more variable responding. For all participants, correct responding quickly increased to mastery levels during reinforcement. The rapid skill assessment served to empirically identify mastered and unmastered tasks for inclusion in the experiment proper. As expected, participants quickly achieved mastery in the motivational deficit condition but failed to master the targets in the skills deficit condition. Thus, the rapid skill assessment effectively identified for each participant a mastered and unmastered task for use in Experiment 1 and an unmastered task for Experiment 2.

Percentage of correct responses during the rapid skill assessment. The dashed horizontal line is drawn at 80% and is used as a reference point to determine when a condition met criteria for mastery
Pretesting
Following the completion of the rapid skill assessment, pretesting was conducted to identify unmastered targets for inclusion in Experiments 1 and 2. The experimenter generated a list of 37–60 potential targets associated with the skills deficit task. The potential targets were then presented one time each across three successive sessions for a total of three presentations of each target. Pretesting was repeated with new targets for Margo and Tate prior to initiating the second baselines in Experiment 2. Pretesting was conducted under conditions identical to baseline of the rapid skill assessment for Tabatha, Maisie, and Tate. Sean, Harper, and Margo did not consistently attempt to complete either task during baseline of the rapid skill assessment. In addition, attempts to complete the tasks and correct responding to the skills deficit task increased during reinforcement for these three individuals. These data suggested that reinforcement during pretesting may be necessary to ensure that they would attempt to respond or respond correctly. Thus, pretesting was conducted under conditions identical to the reinforcement phase of the rapid skill assessment for Sean, Harper, and Margo. For all participants, the experimenter provided aperiodic praise for on-task behavior.
Targets associated with incorrect responses across all three sessions were then assigned to experimental conditions in Experiments 1, 2, or both. Margo’s task included receptive identification of community signs with a field of two, giving her a 50% chance of responding correctly on any given trial. We therefore included signs in Experiment 2 to which she responded incorrectly during at least two of the three sessions (i.e., below chance level responding). Table 2 denotes the targets assigned to each condition in Experiments 1 and 2.
Token Training
All participants used tokens during their educational or behavioral interventions; however, their individual histories varied with respect to token-production schedules (i.e., the number of responses required to earn a token), exchange-production schedules (i.e., the number of tokens required before the opportunity to exchange them became available), and token-exchange schedules (i.e., the amount of the back-up reinforcer for which each token could be exchanged). Abbreviated token training was therefore conducted using procedures similar to those described by DeLeon et al. (2014) to provide all participants with the same immediate history with each component of the token system. In addition, token training provided participants with exposure to accumulated access to the back-up reinforcer (i.e., the activity identified during the MSWO). The exchange-production schedule increased across sessions from FR 1 (i.e., one token was required in a given trial before the opportunity to exchange became available) to FR 5 (i.e., five tokens were required before the opportunity to exchange became available) and then FR 10. All participants independently traded tokens across at least 80% of trials and completed token training in three sessions.
Interobserver Agreement
Observers recorded data using paper and pencil during all pre-experimental assessments. A second observer collected data during 88.2% of MSWO sessions. Observers recorded the activity selected (or no response) in each trial of the MSWO. An agreement included both observers scoring the same selection and equaled 100% for all participants across sessions. During the rapid skill assessment and pretesting, data were collected on correct, incorrect, or no response and reinforcer delivery. A second observer collected data during a mean of 47.9% of rapid skill assessment sessions and 66.7% of pretesting sessions across participants. Agreements included both observers recording the same participant response and the presence or absence of reinforcer delivery. During the rapid skill assessment, mean agreement across participants equaled 98.8% (range, 96% to 100%) for participant responses and 99.7% (range, 98.0% to 100%) for reinforcer delivery. Mean agreement during pretesting equaled 98.9% (range, 96.6% to 100%) and 100% for participant responses and reinforcer delivery, respectively. During token training, observers collected data on compliance following the verbal or model prompts, token delivery, and the level of prompting required for token trading. A second observer independently collected data during 61.1% of these sessions. Agreements included both observers recording the same participant response, the delivery of a token, and the same level of prompting required to trade the token(s). Agreement on all data collected across participants equaled 100%.
Experiment 1: Preference for Response–Reinforcer Arrangements
The purpose of Experiment 1 was to determine whether preference for response–reinforcer arrangements used during discrete-trial teaching differed for mastered and unmastered tasks. Sean, Tabatha, Harper, Tate, and Maisie participated in Experiment 1.
Procedures
Preference for distributed, accumulated (no token), accumulated-token reinforcement conditions, and a no-reinforcement control condition was assessed in separate phases for mastered and unmastered tasks using a concurrent-chains arrangement. The initial link included a choice among the four conditions, and the terminal link included the implementation of the contingencies associated with the selected condition. Relative preference among the four conditions was determined by allocation of responding among the initial-link cards. Phase 1 for all participants included the mastered task and Phase 2 included the unmastered task.
A minimum of five choice sessions were conducted in each phase. Each session included ten trials in which the instructor delivered a prompt to complete the task and participants could earn up to 5 min of access to a reinforcer (in the three experimental conditions). What differed across the choices was the manner in which the trials and reinforcer access were arranged. During each trial, the experimenter issued a task using a three-step prompting procedure consisting of sequential verbal, model, and physical guidance prompts (for instructions requiring a vocal response that could not be physically guided, the experimenter repeated the model prompt). Correct responses following the verbal prompt were differentially reinforced in the three experimental conditions such that 30-s access to the reinforcer was provided either immediately (i.e., distributed condition) or after the completion of the ten trials (i.e., accumulated and accumulated-token conditions). Correct responses that followed the model prompt resulted in brief praise and the presentation of the next trial. The experimenter immediately delivered the next trial if physical guidance (or a repeated model prompt) was required. A phase ended when the participant selected the same condition across five consecutive sessions or at least ten sessions were conducted without a clear indication of preference.
Guided Exposure
Guided exposure was conducted with the four conditions prior to beginning each phase. During guided exposure, the experimenter placed the four cards on the table in front of the participant in a horizontal line and explained the contingencies associated with each. For the distributed condition, the experimenter explained, “If you pick this card, each time you get (task) right on the first try, you will get 30 s to play with your (activity) right away, before you do more work.” Instructions for the accumulated reinforcement condition included, “If you pick this card, each time you get (task) right on the first try, you will earn 30 s with your (activity). After you do (task) ten times, you can play with your (activity). The more you get right, the more time you will get at the end.” The instructions for accumulated-token reinforcement included, “If you pick this card, each time you get (task) right on the first try, you will earn a token that is worth 30 s with (activity). After you do (task) ten times, you can trade your tokens to play with your (activity). The more tokens you earn, the more time you get at the end.” Finally, the experimenter provided the following instructions for the control condition, “If you pick this card, you will do (task) ten times. You will not earn time to play with your (activity).” The experimenter then prompted the participant to select each card (one at a time, randomly determined) and implemented the associated terminal-link contingencies.
Discrimination Test
After completing guided exposure with each condition, the experimenter conducted a discrimination test to ensure that the participant distinguished between the contingencies depicted in each card. Discrimination was tested by prompting the participant to receptively identify each card. This represented a key step as participation in Experiment 1 depended on discrimination of the contingencies. All participants with the exception of Margo correctly identified each condition during the discrimination test. Despite several exposures to each condition, Margo appeared to display a side bias, allocating the majority of her responses to the card on the far right. Therefore, she only participated in Experiment 2.
Distributed Reinforcement
Selection of distributed reinforcement resulted in the presentation of ten trials, with reinforcer delivery interspersed. Specifically, correct completion of the task following the verbal prompt resulted in praise and 30-s access to the reinforcer. Correct responses following the model prompt resulted in praise and the delivery of the next trial. The experimenter immediately delivered the next task if physical guidance (or a repeated model prompt) was required. This sequence of events continued until the experimenter issued ten tasks.
Accumulated Reinforcement
During the accumulated reinforcement condition, the participant completed all ten trials consecutively. The participant earned 30 s of access to the reinforcer for each correct response that followed the verbal prompt, which he or she banked until the completion of the ten trials. Thus, duration of access to the reinforcer increased in a cumulative fashion throughout the work period contingent upon each correct response and was delivered in its entirety after the participant finished the tenth task. The experimenter also delivered a brief statement of praise and informed the participant of the total amount of access he or she had amassed at that point (e.g., after the fourth correctly completed task, the experimenter said, “Good job, you earned 2 min with your activity when you are done working”). As with the distributed condition, correct responding following the model prompt resulted in praise. No programmed consequences were delivered following physical guidance.
Accumulated-Token Reinforcement
The accumulated-token reinforcement condition was identical to the accumulated condition, but included the addition of a token (worth 30-s access to the reinforcer) that was delivered contingent on correct responding following the verbal prompt. Following the completion of all ten trials, the participant traded the tokens in exchange for accumulated access to the reinforcer. The participant removed the tokens one at a time, while the experimenter counted the tokens. The experimenter then delivered the reinforcer.
No-Reinforcement Control
During the control condition, the participant completed the ten trials consecutively. Correct responses following the verbal or model prompts resulted in praise. Physical guidance resulted in the immediate delivery of the next task.
Phase 1: Mastered Tasks
Phase 1 included the mastered task identified in the rapid skill assessment. The same targets were used in each session, regardless of the condition selected (see Table 2), to ensure that preference for a given condition was not affected by a preference for the specific targets with which it was associated. Ten targets, presented one time each, were included in each session for Sean, Tabatha, and Harper. Tate’s sessions included five targets presented twice each. The experimenter randomly placed the cards in a horizontal line in front of the participant and briefly explained the associated contingencies. The experimenter then prompted the participant to select a card and implemented the terminal-link procedures, as described above.
Phase 2: Unmastered Tasks
Phase 2 was identical to Phase 1 with three exceptions. First, Phase 2 included the unmastered task. Second, unmastered targets were selected from pretesting. Third, targets associated with correct responses across two consecutive sessions were replaced with new unmastered targets randomly selected from pretesting (denoted by the asterisks in Table 2). This was done to ensure that the task continued to be associated with a skills deficit, a step not taken in prior research (e.g., Kocher et al. 2015).
Experimental Design, Response Measurement, and Interobserver Agreement
As noted, Experiment 1 included a concurrent-chains arrangement in which selection in the initial link provided an index of relative preference for the experimental and control conditions. A reversal design was used if preference differed across phases.
Observers collected data using BDataPro (Bullock et al. 2017) and recorded the following participant behavior: selection of the initial-link cards (pointing to, touching, or verbally stating one of the conditions), correct responses following the verbal and model prompts (see Table 1), exchanging tokens (removing a token from the token board and placing it in the hand of the experimenter), and engagement with the reinforcer. Duration of engagement was measured and was defined on a case-by-case basis but generally included making eye contact with the screen of the iPad or Kindle, placing fingers on the screen and moving them in a manner consistent with conducting a search or operating an application, and dancing. Observers also collected data on the following experimenter behavior: delivery of verbal, model, and physical guidance (or repeated model) prompts; tokens; and the reinforcer. Observers recorded a verbal prompt when the experimenter issued the initial verbal prompt to complete the task (see Table 1). Observers recorded a model prompt when the experimenter demonstrated (physically or verbally) the correct answer. Physical guidance was recorded if the experimenter used hand-over-hand guidance to prompt the participant to complete the task. Token delivery was scored when the experimenter placed a token on the board, and reinforcer delivery was scored when the experimenter placed the reinforcer in front of the participant.
A second observer independently collected data during 42.9% of sessions across participants (range, 34.2% to 75.0%). Interobserver agreement data were calculated using the block-by-block agreement method described by Mudford et al. (2009). Mean agreement coefficients for participant behavior included 99.8% (range, 99.1% to 100.0%) for selection of the initial-link cards, 97.4% (range, 94.5% to 100.0%) for compliance following the verbal or model prompt, 99.2% (range, 98.1% to 100.0%) for token exchange, and 94.1% (range, 85.4% to 96.8%) for engagement. Mean agreement coefficients for experimenter behavior included 97.1% (range, 90.8% to 100.0%), 98.6% (range, 96.3% to 100.0%), and 95.4% (range, 88.1% to 99.1%) for prompt, token, and reinforcer delivery, respectively.
Results and Discussion
Figure 2 depicts the cumulative number of initial-link selections for each condition. Asterisks indicate when the experimenter replaced mastered targets in the skills deficit phase with new, unmastered ones to ensure that the tasks in Phase 2 remained unmastered. The top left panel of Fig. 2 depicts the data from Sean’s preference assessment and the top right panel depicts data for Tate. Sean responded almost exclusively for the accumulated-token condition in both phases, regardless of task type. In Phase 1, Tate allocated the majority of his choices to the accumulated condition. Tate continued to demonstrate a preference for the accumulated condition in Phase 2, and his response allocation became less variable.

Cumulative selections of the initial-link card. Asterisks (*) indicate when target stimuli in the unmastered condition were replaced. Mast mastered, Unmast unmastered
The middle left panel of Fig. 2 includes data from Maisie’s preference assessment. During Phase 1, Maisie alternated responses between all three reinforcement conditions across ten sessions, with no clear preference emerging. In Phase 2, Maisie selected the accumulated-token condition in the final five sessions, indicating a preference for this condition not seen in Phase 1. A series of reversals between the mastered and unmastered phases was then conducted in which Maisie continued to select the accumulated-token condition with near exclusivity.
The middle right panel of Fig. 2 depicts Harper’s data. During the first mastered task phase, Harper made several selections for both accumulated conditions before a preference for the accumulated-token condition finally emerged. During Phase 2 with the unmastered task, Harper’s responding became more variable and her selections appeared to show indifference between the two accumulated conditions. A reversal to the mastered task in Phase 3 revealed a clear and consistent preference for the accumulated condition without tokens. This pattern of apparent indifference between the two accumulated conditions and a preference for accumulated reinforcement without tokens was replicated in the final two phases. The bottom left panel depicts the data for Tabatha. Tabatha was the only participant for whom we observed a clear and consistent pattern of preference for the distributed condition, across both phases.
All participants earned a higher overall magnitude of reinforcement during the mastered phase (M = 280.3 s; range, 247.4 s to 316.1 s) than during the unmastered phase (M = 117.5 s; range 41.1 s to 186.0 s). Correct responding following the verbal prompt (i.e., accuracy) remained high in the mastered phase(s) (M = 89.5%; range, 80.0% to 98.8%) and low to moderate during the unmastered phase(s) (M = 36.5%; range, 12.1% to 58.9%).
Four participants (Sean, Maisie, Tate, and Harper) preferred the accumulated response–reinforcer arrangement (with or without tokens) when presented with mastered and unmastered tasks. The fifth participant, Tabatha, preferred the distributed arrangement with both types of tasks. These results largely support prior research showing that most learners prefer accumulated arrangements (e.g., Bukala et al. 2015; DeLeon et al. 2014). Furthermore, these results expand upon prior research by indicating that this preference for accumulated reinforcement persists in the absence of token reinforcement and also extend to tasks associated with a skills deficit.
Interestingly, preference for four participants in the current study remained identical across mastered and unmastered phases. In only one case, with Harper, did we observe consistent differences across phases. DeLeon et al. (2014) obtained a similar outcome in their comparison of preference for response–reinforcer arrangements across different types of reinforcers. The results of the current study and the study conducted by DeLeon et al. indicate that preference for a given arrangement was invariant across different types of tasks or reinforcers (respectively) for seven of nine (77.8%) participants. In addition, six of those seven individuals (87.5%) preferred an accumulated arrangement. These results further suggest that learners with IDD may have a strong and sustained preference for the arrangement of their task and reinforcers.
However, one cannot rule out the possibility that order effects drove preference in subsequent phases. We hypothesized that accumulated reinforcement may be more valuable with mastered tasks than with unmastered tasks because participants could amass a greater quantity of reinforcement when tasks were mastered. This phase was assessed first for all participants, which may have had the effect of establishing a preference for accumulated reinforcement that then carried over when the independent variable changed to unmastered tasks. Results for Maisie, Tabatha, and Harper run slightly counter to this theory. Maisie seemed indifferent to the three reinforcement conditions in the initial phase with mastered tasks. It was not until the introduction of the unmastered tasks in Phase 2 that preference for accumulated-token reinforcement was established and then maintained in subsequent reversals. Tabatha preferred the distributed, not the accumulated, arrangement across both phases. And, Harper did demonstrate a shift in preference across phases, albeit a shift from preference for accumulated without tokens to indifference between the two accumulated conditions. However, order effects could still explain the results for the majority of participants in that the preference established first carried over into the following phase(s). Future research could examine the order of presentation for the independent variable to determine whether this has an effect on subsequent preference.
It is unclear what caused the shift in Maisie’s and Harper’s preferences with the mastered tasks from Phase 1 to Phases 3 and 5. It is possible that conducting a single session with each condition in guided exposure provided insufficient experience with the contingencies to allow participants to establish a firm preference during the initial choice sessions. Exposure to the conditions in Phase 1, on the other hand, may have provided Maisie and Harper with the additional experience necessary to form a preference for the accumulated-token and accumulated conditions, respectively. This may be supported by the fact that more sessions were required in Phase 1 than in Phase 2 to establish a preference for Tabatha and Tate. Future research may consider additional guided exposure sessions to provide more experience with each condition.
Preference for the accumulated arrangement has been suggested to be a function of continuity of reinforcement (e.g., DeLeon et al. 2014). It is also possible that differences in the overall density of reinforcement earned across the conditions drove preference, independent of reinforcer continuity. For example, DeLeon et al. (2014) observed that participants earned, on average, a greater density of reinforcement in the accumulated condition of Experiment 1 relative to that earned during the distributed condition. They suggested that later preference for the accumulated condition in Experiment 2 may have been influenced by these differences in the amount of reinforcement earned. Participants in the current study experienced the preference assessment in Experiment 1 prior to being exposed to the efficacy assessment in Experiment 2. In addition, they rarely selected the distributed condition in Experiment 1. Thus, we have limited data with which to make a similar comparison. However, we did compare accuracy and overall magnitude of reinforcement earned in Phase 1 of Experiment 1 for those individuals who made at least three selections across two different conditions. For Tate, this included the distributed and accumulated-no-token conditions; for Maisie, the comparison included distributed and accumulated-token conditions; and for Harper, it included accumulated and accumulated-token conditions. In no case did either accuracy or overall reinforcer density differ appreciably.
Experiment 2: Efficacy of Response–Reinforcer Arrangements
Prior research has suggested that accumulated reinforcement may result in more rapid completion of tasks. However, these data do not indicate whether this arrangement is more effective when learning a new skill. That is, the measures of efficiency demonstrate that participants will work faster but not necessarily that participants learn faster. The purpose of Experiment 2, therefore, was to evaluate whether accumulated and distributed response–reinforcer arrangements differentially impacted accuracy and acquisition of unmastered tasks by assigning different sets of target stimuli to each condition and determining which stimuli participants mastered first.
Procedures
Experiment 2 included the task identified as unmastered in the rapid skill assessment. Three sets of targets, identified during pretesting, were assigned to three conditions: distributed, accumulated, and accumulated-token reinforcement. We attempted to equate the targets assigned to each condition on a number of dimensions. For example, Harper’s and Margo’s community signs included an equal number of syllables and/or the signs equally depicted images and written words. Maisie’s sight words included the same number words with two, three, or four letters across conditions. Tate’s vocabulary words were randomly assigned to each condition. Table 2 lists the tasks and targets included in each condition. The number of targets selected for each participant differed and was a function of multiple factors including the number of targets typically used in that individuals educational or vocational programming and clinical recommendations. For Harper and Margo, each condition included two targets, presented five times each for a total of ten trials per session. Each condition for Tate included ten targets, presented one time each for a total of ten trials. For Maisie, each condition included six targets, presented two times each for a total of 12 trials per session. The experimenter conducted a minimum of one series (i.e., one session from each condition) per day, three to 5 days per week. The order of each condition was quasi-randomized such that one session from each condition was conducted before any was repeated.
Accuracy was defined as correct completion of the task following the verbal prompt. Mastery criteria for a given condition included a minimum of 80% accuracy across three consecutive sessions. Mastered conditions were discontinued and we continued to conduct the remaining condition(s) until (a) the participant achieved mastery with that condition or (b) we conducted double the number of sessions it took to reach mastery in the initial condition. For example, if the participant met mastery with the distributed condition in six sessions, we continued to conduct both accumulated conditions until the participant met mastery in either, or until we conducted 12 sessions without achieving mastery. If a participant did not achieve mastery within double the number of sessions, a contingency change was conducted where the contingencies associated with the initially mastered condition were implemented with the targets included in the unmastered condition. This phase was conducted until mastery was achieved.
Baseline
During baseline, the experimenter presented all task trials consecutively using the same prompting procedure as in Experiment 1. Correct responses after the verbal or model prompts resulted in praise and physical guidance resulted in the presentation of the next trial.
Reinforcement
Condition cards identical to those used in Experiment 1 were included during reinforcement in Experiment 2 to facilitate discrimination between the conditions. At the start of a session, the experimenter presented the card associated with the relevant condition and briefly explained the contingencies. The experimenter then implemented those contingencies in accordance with the procedures described above in Experiment 1. That is, correct responding following the verbal prompt was differentially reinforced with 30-s access to the activity reinforcer right away (distributed) or accumulated access was delivered after the completion of the entire response requirement (accumulated and accumulated-token conditions). Correct responses after the model prompt resulted in brief praise and the presentation of the next trial. Physical guidance (or repeated model prompts) resulted in the presentation of the next trial.
Experimental Design, Response Measurement, and Interobserver Agreement
Experiment 2 included a multielement design to compare mastery across conditions. The analysis was repeated with a new set of target stimuli for Harper and Margo using a multiple baseline design across new targets to evaluate of the replicability of findings. For Tate, we repeated baseline and reinforcement with new targets in a design more akin to a reversal.
During Experiment 2, we collected data using the BDataPro program (Bullock et al. 2017). Data collection and response definitions were identical to those included in Experiment 1. The main dependent variable included the percentage of correct responses following the verbal prompt. We also determined the number of sessions until meeting the mastery criteria (i.e., three consecutive sessions with 80% correct responding following the verbal prompt). In addition, we collected data task duration as a measure of efficiency. Task duration was calculated by subtracting the time of the final task completion from that of the initial verbal prompt (while also removing reinforcer access for the distributed condition).
Interobserver agreement data were calculated for all participants using the block-by-block agreement method described by Mudford et al. (2009). A second observer independently collected data during 100% of sessions for Harper and Maisie, 36.2% of sessions for Tate, and 8.2% of sessions for Margo. Mean agreement coefficients for participant behavior included 97.7% (range, 96.5% to 100%) for compliance following the verbal or model prompt, 98.1% (range, 97.5% to 99.0%) for incorrect responses, and 97.1% (range, 96.5% to 100%) for engagement. Mean agreement coefficients for experimenter behavior included 98.6% (range, 97.1% to 100%), 98.9% (range, 98.2% to 100%), and 97.5% (range, 96.7% to 100%) for prompt, token, and reinforcer delivery, respectively.
Results and Discussion
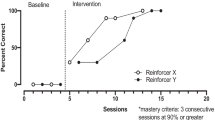
Figures 3, 4, and 5 depict the percentage of correct responses following the verbal prompt for Experiment 2. Figure 3 depicts data for Harper. Harper’s level of correct responding remained low and stable across both baseline phases (Baseline: Set 1 and Baseline: Set 2). Correct responding increased in both accumulated conditions following the introduction of reinforcement, with the largest and most immediate increases occurring in the accumulated-token condition. Harper met mastery first in accumulated-token condition with both sets of targets (nine sessions for both), followed by the accumulated condition (ten sessions with Set 1 and 15 sessions with Set 2). Responding in the distributed condition remained lower and more variable than that observed with the two accumulated conditions. Harper eventually met mastery in the distributed condition with the first set of targets (N = 14 sessions); however, a contingency change was required for Set 2. During the contingency change, the targets originally assigned to the distributed condition (i.e., fire station and school) were taught using the accumulated-token arrangement. Correct responding quickly increased and became less variable following this modification, and Harper met mastery within five sessions.

Percentage of correct responding after the verbal prompt. Conting Change contingency change, DIS distributed, ACT accumulated token. The dashed horizontal line is drawn at 80% and is used as a reference point to determine when a condition met criteria for mastery

Percentage of correct responding after the verbal prompt. Conting Change contingency change, ACC accumulated, ACT accumulated token, DIS distributed. The dashed horizontal line is drawn at 80% and is used as a reference point to determine when a condition met criteria for mastery

Percentage of correct responding after the verbal prompt. Conting Change contingency change, DIS distributed, ACT accumulated token. The dashed horizontal line is drawn at 80% and is used as a reference point to determine when a condition met criteria for mastery
Margo’s data are depicted in Fig. 4. During Baseline: Set 1 and Baseline: Set 2, Margo responded at or below chance levels (i.e., 50%) across all conditions, with the exception of a single session in Baseline: Set 2. The introduction of reinforcement in Set 1 resulted in an immediate increase in correct responding in all conditions. Margo met mastery in the accumulated-token condition within six sessions, followed by the distributed condition in nine sessions, and finally the accumulated condition in 13 sessions. These results were largely replicated with the second set in Baseline: Set 2. Margo again achieved mastery first in the accumulated-token condition (in 11 sessions), followed by the distributed condition (in 23 sessions; note that although the 23rd session in the distributed condition falls after the Contingency Change phase line, this was a result of the randomization of the order of sessions for that day and not because the contingency change was also conducted with the distributed condition). Margo’s accuracy during the accumulated (no token) condition did not increase appreciably over the course of the reinforcement phase, and she failed to meet mastery after 22 sessions. Therefore, we implemented the contingency change where we arranged accumulated-token reinforcement for the targets previously associated with the accumulated (no token) condition. Following this manipulation, Margo’s accuracy increased and became less variable. Margo met mastery with these targets in nine sessions following the contingency change.
Tate’s data are depicted in the top panel of Fig. 5. For Tate, responding during Baseline: Set 1 and Baseline: Set 2 remained low across all conditions. Responding increased with the introduction of reinforcement (Reinforcement: Set 1 and Set 2). Tate met mastery within a similar number of sessions across all three conditions during the first reinforcement phase. During the second analysis, Tate met mastery first during the accumulated condition (N = 15 sessions), followed by the distributed condition (N = 20 sessions), and then finally in the accumulated-token condition after 24 sessions.
Maisie’s data are depicted in the bottom panel of Fig. 5. Maisie engaged in a similar level of correct responses across all conditions during baseline. Accuracy did appear to be on an increasing trend; however, responding stabilized during the final four series for each condition. During reinforcement, accuracy increased in all conditions but became more variable in the distributed condition. Maisie met mastery first in the accumulated condition, in six sessions. Maisie was scheduled to be discharged from the inpatient unit the day after she mastered the targets in the accumulated condition. Because time was limited, we decided to conduct the contingency change with the distributed condition as this was the condition associated with the overall lowest and most variable levels of correct responding. During the contingency change, accumulated reinforcement was arranged for the targets previously associated with the distributed condition. We observed an immediate increase in accuracy following the contingency change, and Maisie quickly met mastery with the targets within three sessions.
We evaluated mean engagement and task duration for all four participants across the seven analyses (two each for Harper, Margo, and Tate and one for Maisie). We also calculated the total task duration to determine total time in training with each condition. These data are depicted in Table 3. Engagement was high overall for all participants with the exception of the distributed condition in Margo’s initial baseline. Mean task duration included the mean amount of time to complete the ten or 12 tasks assigned to each condition. Participants completed their respective tasks quickest in the accumulated condition in six of the seven analyses. Furthermore, the accumulated-token condition resulted in the second fastest completion and the distributed condition resulted in the slowest completion in five of the seven analyses. These results largely replicate findings from prior research (e.g., DeLeon et al. 2014).
General Discussion
We evaluated preference for and efficacy of distributed and accumulated response–reinforcer arrangements during skill acquisition using discrete-trial teaching. Results of Experiment 1 indicated that preference was invariant across mastered and unmastered tasks for four of five participants. Four participants preferred to accumulate reinforcers (with or without tokens) and one preferred the distributed arrangement. These results replicate prior research, suggesting that many learners with IDD prefer accumulated access to reinforcers. They extend prior research by suggesting that this preference for accumulated reinforcement also occurs with tasks associated with a skills deficit. Results of Experiment 2 indicated that acquisition was fastest with accumulated-token reinforcement for Harper and Margo (replicated across different sets of targets) and with accumulated reinforcement for Maisie. Results for Tate varied across sets of targets. Across all participants, at least one of the accumulated reinforcement conditions resulted in mastery in a similar number or fewer sessions than the distributed arrangement.
Harper, Tate, and Maisie participated in both Experiments 1 and 2. All three preferred accumulated reinforcement when tasks were unmastered: Harper preferred the two accumulated conditions equally, Maisie preferred the accumulated-token condition, and Tate preferred accumulated (no token). Harper’s preference data correspond nicely to the data on the efficacy of these arrangements in that both accumulated conditions were more effective than the distributed condition. Partial correspondence was observed for Tate as accumulated (no token) was mastered first with Set 2. Measures of efficiency (mean task duration and total task duration) also appear to correspond with preference across both sets of target stimuli for Harper and Tate. Although Maisie mastered the targets associated with the accumulated (no token) condition first, her preference assessment results indicated that she preferred the accumulated-token condition. In addition, she completed the task fastest in the distributed condition. These results further support the notion that preference may correspond to efficiency for some individuals. Results with regard to correspondence and efficacy remain less clear.
Practitioners and instructors face a unique challenge of balancing individuals’ preferences with treatment efficacy. We have long since recognized the right to effective treatment for individuals with IDD (e.g., Van Houten et al. 1988) and the importance of including those receiving the services in the process of determining their treatment (e.g., Hanley 2010). What is less clear is what our response as practitioners or instructors should be in the face of inconsistencies between the two. For example, the discrepancy between participants’ preference and their subsequent performance obtained in the current study and that of Kocher et al. (2015) may create a dilemma with regard to deciding how best to arrange one’s learning environment. One variable instructors may consider in the face of this dilemma is the degree of the discrepancy between efficacy and preference. For example, if the more preferred (but less effective) teaching method was only associated with marginal differences in the number of sessions to mastery, then perhaps instructors would feel less conflicted in using the more preferred strategy. On the other hand, substantial differences in these measures of efficacy may steer the instructor toward the more effective but less preferred method.
Sessions to mastery, though important, is not the only measure of efficiency when considering educational interventions. We looked at other measures of efficiency, including mean and total task duration in Experiment 2. The accumulated condition resulted in the shortest duration for six of the seven analyses. DeLeon et al. (2014) obtained similar results for activity reinforcers in Experiment 2 of their study and attributed the findings to the increased handling costs associated with the distributed condition. That is, each time the experimenter represented the task, the learner had to reorient to the materials, identify relevant stimuli, make appropriate discriminations, etc., all of which can increase duration. These handling costs have a larger impact on the distributed condition where ongoing responding is more frequently disrupted. It is possible that the outcomes with regard to faster duration with accumulated arrangements obtained in the current study could also be attributed to differences in handling costs across accumulated and distributed conditions.
The current study is not without limitation. We were unable to complete Experiments 1 and 2 with all participants as Margo failed to differentiate between the conditions after guided exposure in Experiment 1 and Tabatha was discharged from the inpatient unit before we could conduct Experiment 2. Interestingly, the three individuals who did complete both experiments all preferred one of the accumulated conditions. It is not clear whether the overall advantages in efficacy and efficiency associated with the accumulated arrangement in Experiment 2 resulted in some way from carryover from Experiment 1. However, Margo only participated in Experiment 2 and the accumulated-token arrangement was both more effective and more efficient. Furthermore, we did not complete the reinforcement phase in Experiment 2 with Maisie. Although responding increased and the variability in responding decreased immediately when the contingency change was conducted with Maisie’s distributed condition, it is unclear whether this would have happened in the absence of the contingency change, particularly because responding in the final distributed session in the reinforcement phase was quite high.
An additional limitation to the current study, and this line of research as a whole, includes the relatively homogenous sample included across studies (Ward-Horner et al. 2017a). Ward-Horner et al. (2017a) noted that all participants included in the studies reviewed up to that date included adolescents with IDD and the majority of them appeared to have relatively well development expressive and receptive language. The participants included in the current study also largely fit within this relatively homogenous group. It is unclear whether similar results would obtain with younger individuals who may exhibit greater impulsivity (e.g., Green et al. 1999). Although there are some inherent differences between evaluations of preference for accumulated and distributed arrangements as described in the current study and the typical self-control paradigm (e.g., equivalent vs. disparate magnitudes of reinforcement in the current study vs. studies on impulsivity), it is possible that there may be an association between these two lines of research. For example, selection of the distributed condition may be related to impulsive responding because distributed arrangements result in immediate access to a smaller magnitude of reinforcement while forgoing access to a larger, more continuously available magnitude of reinforcement arranged through accumulated reinforcement. Results of a recent study conducted by Ward-Horner et al. (2017b) do appear to support this notion as both of their preschool-aged participants selected the distributed condition when reinforcer quality and magnitude were held constant. However, these results are somewhat difficult to interpret because the distributed condition included features of accumulation. It is unclear whether participants would have similarly preferred the “distributed arrangement” if it were arranged in a strictly distributed fashion. It is worth noting, however, that in the current study, young participants (Maisie, 5 years of age) and participants with ADHD (Maisie and Tate) both preferred accumulated reinforcement. Interestingly, Margo had the most limited expressive language skills among the participants and was also the only participant to fail the discrimination test in Experiment 1. Across both sets of targets, she met mastery first in the accumulated-token condition and then next in the distributed condition. Although she eventually met mastery in the accumulated (no token) condition with the targets in Set 1, a contingency change was required during the second analysis with the targets in Set 2. It is possible that the immediate presentation of either the actual reinforcer or a token helped to enhance the saliency of the behavior–consequence relation in the distributed and accumulated-token conditions (respectively). The accumulated (no token) condition lacked this sort of tangible reinforcer delivery. The use of descriptive praise in that condition may have been insufficient for Margo to make the appropriate discriminations, thus slowing or preventing acquisition. It is unclear to what degree individual participant characteristics, such as language development, could influence outcomes (e.g., Ward-Horner et al. 2017a).
The results of this study suggest several areas for future research, in addition to those mentioned previously. The research assessing distributed and accumulated arrangements in skill acquisition has largely included activity reinforcers. Results from DeLeon et al. (2014) indicate that speed of completing the tasks and preference for these arrangements may differ for some individuals when food is arranged as the reinforcer. Practitioners report frequently using food as a reinforcer for individuals with IDD (e.g., Graff and Karsten 2012). Thus, it is important to understand what influence reinforcer type has on both preference and efficacy of these arrangements when used in the context of skill acquisition. Given how frequently the response–reinforcer arrangements discussed in this paper are used with individuals who engage in escape-maintained problem behavior, it is also important to understand how function of problem behavior may influence preference and efficacy outcomes. Additional research is still warranted to examine the generality of these findings across a more diverse group of participants. Finally, it is still unclear what role tokens play in preference for accumulated reinforcement. Future research should consider removing the token from the accumulated condition to determine whether preference maintains in its absence.
The right to choose is central to the autonomy of individuals with IDD. The present results add to a growing body of literature that has prompted a re-evaluation of classroom lore regarding the immediate provision of reinforcers during the acquisition of new skills. As this line of research on preference for and efficacy of response–reinforcer arrangements progresses, we may rely on this literature to formulate evidence-based practices for the promotion of skill acquisition that also closely align with the preferences of individuals with IDD.
References
Bukala, M., Hu, M. Y., Lee, R., Ward-Horner, J. C., & Fienup, D. M. (2015). The effects of work-reinforcer schedules on performance and preference in students with autism. Journal of Applied Behavior Analysis, 48, 215–220. https://doi.org/10.1002/jaba.188.
Bullock, C. E., Fisher, W. W., & Hagopian, L. P. (2017). Description and validation of a computerized behavioral data program: “BDataPro”. The Behavior Analyst, 40, 275–285. https://doi.org/10.1007/s40614-016-0079-0.
Carroll, R. A., Kodak, T., & Adolf, K. J. (2016). Effect of delayed reinforcement on skill acquisition during discrete-trial instruction: Implications for treatment-integrity errors in academic settings. Journal of Applied Behavior Analysis, 49, 176–181. https://doi.org/10.1002/jaba.268.
DeLeon, I. G., Chase, J. A., Frank-Crawford, M. A., Carreau-Webster, A. B., Triggs, M., Bullock, C. E., et al. (2014). Distributed and accumulated reinforcement arrangements: Evaluations of efficacy and preference. Journal of Applied Behavior Analysis, 47, 293–313. https://doi.org/10.1002/jaba.116.
DeLeon, I. G., & Iwata, B. A. (1996). Evaluation of a multiple-stimulus presentation format for assessing reinforcer preferences. Journal of Applied Behavior Analysis, 29, 519–533. https://doi.org/10.1901/jaba.1996.29-519.
Fienup, D. M., Ahlers, A. A., & Pace, G. (2011). Preference for fluent versus disfluent work schedules. Journal of Applied Behavior Analysis, 44, 847–858. https://doi.org/10.1901/jaba.2011.44-847.
Graff, R. B., & Karsten, A. M. (2012). Assessing preferences of individuals with developmental disabilities: A survey of current practices. Behavior Analysis in Practice, 5, 37–48. https://doi.org/10.1007/BF03391822.
Green, L., Myerson, J., & Ostaszewski, P. (1999). Discounting of delayed rewards across the life span: Age differences in individual discounting functions. Behavioural Processes, 46, 89–96. https://doi.org/10.1016/S0376-6357(99)00021-2.
Grindle, C. F., & Remington, B. (2002). Discrete-trial training for autistic children when reward is delayed: A comparison of conditioned cue value and response marking. Journal of Applied Behavior Analysis, 35, 187–190. https://doi.org/10.1901/jaba.2002.35-187.
Gutierrez, A., Hale, M. N., O’Brien, H. A., Fischer, A. J., Durocher, J. S., & Alessandri, M. (2009). Evaluating the effectiveness of two commonly used discrete trial procedures for teaching receptive discrimination to young children with autism spectrum disorders. Research in Autism Spectrum Disorders, 3, 630–638. https://doi.org/10.1016/j.rasd.2008.12.005.
Hanley, G. P. (2010). Toward effective and preferred programming: A case for the objective measurement of social validity with recipients of behavior-change programs. Behavior Analysis in Practice, 3, 13–21. https://doi.org/10.1007/BF03391754.
Joachim, B. T., & Carroll, R. A. (2017). A comparison of consequences for correct responses during discrete-trial instruction. Learning and Motivation. https://doi.org/10.1016/j.lmot.2017.01.002.
Kocher, C. P., Howard, M. R., & Fienup, D. M. (2015). The effects of work-reinforcer schedules on skill acquisition for children with autism. Behavior Modification, 39, 600–621. https://doi.org/10.1177/0145445515583246.
Lerman, D. C., Valentino, A. L., & LeBlanc, L. A. (2016). Discrete trial training. In R. Lang, T. B. Hancock, & N. N. Singh (Eds.), Early intervention for young children with autism spectrum disorder (pp. 47–83). Berlin: Springer. https://doi.org/10.1007/978-3-319-30925-5.
Lerman, D. C., Vorndran, C., Addison, L., & Kuhn, S. A. C. (2004). A rapid assessment of skills in young children with autism. Journal of Applied Behavior Analysis, 37, 11–26. https://doi.org/10.1901/jaba.2004.37-11.
Mudford, O. C., Martin, N. T., Hui, J. K. Y., & Taylor, S. A. (2009). Assessing observer accuracy in continuous recording of rate and duration: Three algorithms compared. Journal of Applied Behavior Analysis, 42, 527–539. https://doi.org/10.1901/jaba.2009.42-527.
Petursdottir, A. I., & Aguilar, G. (2016). Order of stimulus presentation influences children’s acquisition in receptive identification tasks. Journal of Applied Behavior Analysis, 49, 58–68. https://doi.org/10.1002/jaba.264.
Smith, T. (2001). Discrete trial training in the treatment of autism. Focus on Autism and Other Developmental Disabilities, 16, 86–92. https://doi.org/10.1177/108835760101600204.
Van Houten, R., Axelrod, S., Bailey, J. S., Favell, J. E., Foxx, R. M., Iwata, B. A., et al. (1988). The right to effective behavioral treatment. Journal of Applied Behavior Analysis, 21, 381–384. https://doi.org/10.1901/jaba.1988.21-381.
Ward-Horner, J. C., Cengher, M., Ross, R. K., & Fienup, D. M. (2017a). Arranging response requirements and the distribution of reinforcers: A brief review of preference and performance outcomes. Journal of Applied Behavior Analysis, 50, 181–185. https://doi.org/10.1002/jaba.350.
Ward-Horner, J. C., Muehlberger, A. O., Vedora, J., & Ross, R. K. (2017b). Effects of reinforcer magnitude and quality on preference for response-reinforcer arrangements in young children with autism. Behavior Analysis in Practice, 10, 183–188. https://doi.org/10.1007/s40617-017-0185-9.
Ward-Horner, J. C., Pittenger, A., Pace, G., & Fienup, D. M. (2014). Effects of reinforcer magnitude and distribution on preference for work schedules. Journal of Applied Behavior Analysis, 47, 623–627. https://doi.org/10.1002/jaba.133.
Acknowledgements
This research was conducted as part of the first author’s requirements for a doctoral degree in Applied Developmental Psychology at the University of Maryland, Baltimore County. We would like to thank Andrew Bonner, Anita Louie, Elizabeth Nudelman, and Rashanique Reese for their assistance with data collection and analysis.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Frank-Crawford, M.A., Borrero, J.C., Newcomb, E.T. et al. Preference for and Efficacy of Accumulated and Distributed Response–Reinforcer Arrangements During Skill Acquisition. J Behav Educ 28, 227–257 (2019). https://doi.org/10.1007/s10864-018-09312-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10864-018-09312-7