
Abstract
In contrast to traditional job-shop scheduling problems, various complex constraints must be considered in distributed manufacturing environments; therefore, developing a novel scheduling solution is necessary. This paper proposes a hybrid genetic algorithm (HGA) for solving the distributed and flexible job-shop scheduling problem (DFJSP). Compared with previous studies on HGAs, the HGA approach proposed in this study uses the Taguchi method to optimize the parameters of a genetic algorithm (GA). Furthermore, a novel encoding mechanism is proposed to solve invalid job assignments, where a GA is employed to solve complex flexible job-shop scheduling problems (FJSPs). In addition, various crossover and mutation operators are adopted for increasing the probability of finding the optimal solution and diversity of chromosomes and for refining a makespan solution. To evaluate the performance of the proposed approach, three classic DFJSP benchmarks and three virtual DFJSPs were adapted from classical FJSP benchmarks. The experimental results indicate that the proposed approach is considerably robust, outperforming previous algorithms after 50 runs.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Because of the evolution and widespread diffusion of advanced production environment, previous studies have discussed and investigated various job-shop scheduling problems involving the complex constraint conditions of production. Over the previous two decades, the superior search and evolution capability of genetic algorithms (GAs) has led to the refinement of numerous GA approaches for flexible job-shop scheduling problems (FJSPs) for searching optimal makespan (Goldberg 1989; Gong et al. 2014; Ho et al. 2007; Jia et al. 2003; Kawanaka et al. 2001; Kim et al. 2002; Mesghouni et al. 1997; Toksarı et al. 2014; Yilmaz Eroglu and Ozmutlu 2014; Zhang et al. 2014, 2011; Cheng et al. 1996; Kacem et al. 2002a; Tay and Wibowo 2004). Jian-Bo (2001) proposed a GA-based discrete dynamic programming approach for scheduling problems in a flexible manufacturing environment. Kacem et al. (2002b) presented two novel approaches for solving job assignment and complete or partial FJSPs. First, a localisation approach was used to build an ideal assignment schema. Second, advanced genetic manipulations were used to enhance the solution quality. Gen et al. (2009) proposed a multistage-based GA with a bottleneck-shifting function to solve FJSPs. In addition, phenotype-based crossover and mutation operators were applied to the special chromosome structures and to the characteristics of the problem. Watanabe et al. (2005) proposed an adaptive GA approach for solving job-shop scheduling problems (JSPs) where parameter adjustment is unnecessary. Pezzella et al. (2008) developed a GA with various initial population strategies to improve the solution of FJSPs. Ho et al. (2007) proposed the LEGA approach, which effectively integrated evolution and learning into a random search process, extracting knowledge from previous generations through a schemata learning module. Gao et al. (2014) proposed an effective discrete harmony search (DHS) algorithm to solve FJSP which aimed at minimization of makespan and tardiness. Three approaches were adopted for solving FJSP; the first, some exiting heuristics were employed for initialization machine assignment and operations sequence; secondly, authors develop a new rule for producing a new harmony for FJSP; thirdly, several local search methods were embedded to enhance the local exploitation ability of algorithm. Nouiri et al. (2015) and Delice et al. (2014) proposed an modified particle swarm optimization (PSO) algorithm for FJSP, various benchmark data taken from literature are tested. İnkaya and Akansel (2015) develop a GA based heuristics for solving the optimal transfer lot size in the supply chain based on authors’ mathematical model. Hao et al. (2015) proposed an effective multiobjective estimation of distribution algorithm which solves minimizes the expected average makespan and the expected total tardiness within a reasonable amunt of computational time. AitZai et al. (2014) proposed a PSO algorithm for no-wait job shop scheduling problem.
In recent years, the distributed and flexible job-shop (DFJSP) has attracted increasing attention because of the emergence of globalized operations. To respond to market demands quickly and maintain competitiveness, factories have shifted from a centralized to a more decentralized structure (Behnamian and Fatemi Ghomi 2014). Hence, scheduling problems have also become increasingly complex.
Many studies have considered JSPs and FJSPs have been considered as a nondeterministic polynomial-time hard problem in many studies, DFJSP can be considered an extension of the FJS problem, which is a complex optimization problem for addressing production scheduling in a distributed manufacturing environment by assigning jobs to suitable flexible manufacturing units (FMUs) and determining FMU scheduling problems Giovanni and Pezzella (2010). Because the scheduling problem of each manufacturer has its own unique characteristic, and because DFJSPs are a novel concept, literature reviews in this field are scant. Some scholars have contributed to this area by using a refined GA to solve DFJSPs. Jia et al. (2003) presented a refined GA for distributed scheduling problems. In that study, a two-step encoding method was adopted to encode the factory candidates and to assign jobs and operations, and the proposed method yielded satisfactory results when tested on several classic scheduling benchmarks. Chan et al. (2005) proposed a dominant gene crossover method to enhance the capability of genetic searches in multifactory environments. Chan et al. (2006) presented multifactor scheduling optimisation problems with a refined GA solution, without accounting for transport time, and proposed a dominated gene operator in the crossover step of the GA for solving the problem of multi-factory scheduling optimization. Empirical results show that the performance of the model has substantially improved based on a simple case. Considering the transport time and various constraints, Giovanni and Pezzella (2010) proposed combining a local search and GA for solving the multi-factory scheduling problem, which integrates two types of crossover operator and four types of mutation operator, to minimize the global makespan of the FMUs.
In addition, hybridisation can facilitate compensation for the shortcomings of tuning the solutions toward an optimal value; therefore, hybrid genetic algorithms (HGAs) have attracted considerable attention in recent years. Cheng et al. (1999) indicated that HGAs can be categorized into the following three types: (1) Adapted genetic operators. Nonbit string encoding is adopted and integrated with repairing procedures in a crossover step to avoid illegal or unfeasible solutions; (2) Heuristic-featured genetic operators. A traditional search algorithm is integrated into a mutation step; and (3) HGAs. A localisation technique is incorporated into the main GA loop of recombination and selection. Two design concepts were identified in the literature: The first aims to prevent changes when crossing over to ensure that the features of the parents are inherited as much as possible, whereas the second is designed to generate changes when crossing over, thereby enhancing the search capability. For example, Zhang et al. (2011) integrated local and global selection methods for generating a high-quality initial population during initialisation, and the empirical results of that study indicated that their approach can efficiently solve FJSPs. Gao et al. (2008) proposed a variable neighbourhood descent (VND) method for solving FJSPs, in which the proposed method can identify assignable time intervals. Giovanni and Pezzella (2010) integrated several crossover and mutation operators as well as a localisation method for solving DFJSPs.
However, the following three considerations are crucial when using GAs to handle JSPs, FJSPs, and DFJSPs: (1) how to encode the problem solutions into a chromosome without creating infeasible or illegal solutions; (2) how to enhance the performance of the genetic search by incorporating a traditional heuristic method; and (3) how to obtain the optimal solutions (Herrera and Lozano 1996). A review of the literature revealed a core issue involved in using GAs to solve various scheduling problems: a common concern is that invalid jobs assignments are typically encountered when using GAs to solve traditional DFJSPs, where a job operation is assigned to an unfeasible machine following a crossover or mutation; consequently, the chromosome genes must be repaired.
In summary, incorporating encoding solutions into a chromosome, increasing the diversity of chromosomes, or retaining the features of elite parents by combining crossover or mutation operators can increase the probability of identifying an optimal solution and avoiding incorrect job assignments. Therefore, this study adopted the probability-based encoding mechanism proposed by Tung-Kuan et al. (2014) and hybrid evolution operators to develop an HGA. This novel encoding mechanism is used either to avoid infeasible solutions or to find diverse solutions. The proposed HGA is aims for minimizing the makespan.
Evaluating the proposed algorithm yielded satisfactory results, based on three classic DFJSP benchmarks. This outcome contrasts those of previous studies (Chan et al. 2006; Giovanni and Pezzella 2010). The optimal solution obtained in this study was nine time units (Instance 1) and 37 (Instances 2 and 3) time units, whereas the previously reported optimal solution was 11 time units and 37 time units. These results demonstrated the feasibility of the proposed approach, which is capable of effectively solving problems and quickly discovering the optimal makespan solution.
Defining a hypothesis for solving distributed and flexible job-shop scheduling problem
The DFJSP can be organized as jobs \(J_{i}=\{j_{1},\, j_{2},\ldots ,j_{i}\}\), operations \(O_{i,j}=\{O_{i,1},\, O_{i,2},\ldots ,O_{i,j}\}\), flexible manufacturing units \(F_{m}=\{F_{1},\,F_{2},\ldots ,F_{m}\}\), machine selection \(M_{m,k}=\{M_{m,1},\,M_{m,2},\ldots ,M_{m,k}\}\), processing time \(P_{i,j,m,k}\), and delivery time \(d_{i,n}\). Each job \(J_{i}\) involves a set of operations \(O_{i,j}\), each operation can be assigned only to one flexible manufacturing unit \(F_{m}\) for processing, every flexible manufacturing unit is equipped with a set of machines \(M_{m,k}\), and each machine exhibits a different level of performance, meaning different processing times.
Some classical hypotheses are as follows:
-
1.
Operations must be processed one after another; the insert action is not permitted.
-
2.
Based on cost considerations, operations belonging to the same job should be completed at the same factory.
-
3.
All flexible manufacturing units, jobs, and machines are available at time zero.
-
4.
One operation at most can be processed in a machine at a time.
-
5.
Each machine can process a set of predefined operations.
-
6.
Diverse FMUs may define a different sequence of operations to finish the same job, because of the different manufacturing techniques used.
The DFJSP seems to be a complex problem; however, this problem can be divided into three core topics: FMU selection, machine selection, and operation assignment.
Framework of the proposed algorithm
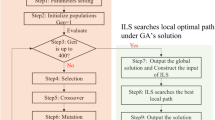
GA, being optimization methods, can produce offspring with improved adaptability, using genetic rules; thus, GA has been widely used for scheduling optimization. Herrera and Lozano (1996) proposed an adaptive GA using a fuzzy logic set, and adopted two crossover operators to enhance the depth and width of searching. In the present study, this concept was adopted and extended to increase the diversity of chromosomes. A hybrid GA is thus proposed, which combines several crossover and mutation operators into an evolutionary process named “HGA”. The flowchart of the HGA is shown in Fig. 1. In contrast to traditional GA, the parent chromosome is copied into seven candidate chromosomes, and performs various crossover and mutation operations simultaneously (not in sequence). This design increases the diversity of chromosomes, and promotes searching for the optimal global solution. The framework is detailed as follows.

Flow chart of HGA approach proposed in this article
Objective function: fitness
In many studies, the makespan (minimum total operations completed in a given time) has been adopted as an objective function of the DFJSP to minimise the maximal completion time. The major difference in the traditional FJSP is the time of completion of the previous operation of a job and the inclusion of the transportation time. The formula is expressed as follows: (3.1).
where \(C_{\max }\) represents the maximum total orders completed in a given time (makespan), \(T_{i,j,k}\) is the start time of operation \(j\) of job \(i\) in machine \(k\) of \({\textit{FMU}}_{m}\), and \(P_{i,j,m,k}\) represents the processing time of operation \(j\) of job \(i\) in machine \(k\) of \({\textit{FMU}}_{m}\).
Initial population of chromosomes
The initial population is crucial for GAs because it directly influences the convergence rate of the fitness values and the ultimate quality of the optimal solutions.
The first step is to determine the number of jobs and number of job operations based on the data. A DFJSP proposed by Giovanni and Pezzella (2010) is detailed in Table 1. Job 1 \((J_{1})\) involves three operations, represented by three genes 1(111) in the chromosome, Job 2 \((J_{2})\) involves two operations, represented by two genes 2(22) in the chromosome, etc. All of the genes are combined into one chromosome (e.g., 11122333455), and then randomly dispersed; the dispersed gene order is used to determine the processing order of operations. The third gene of the chromosome is 2.22, meaning the first operation of Job 2; the eighth gene in the chromosome is 2.48, indicating the second operation of Job 2, etc. The order of genes represents a processing sequence.
After performing these steps, the job is assigned to feasible factories and machines. In Table 2, the code of the final gene is “1.36,” the integer part “1” represents the job number (in this case, Job 1), and the decimal value “0.36” of the final gene represents the probability of being selected for a feasible factory and machine, as determined using the roulette wheel method. In considering Job 1 \(O_{1,3}\) for example, six machines could be chosen: \(M_{1,1},\,M_{1,2},\,M_{1,3},\,M_{2,1},\, M_{2,2}\), and \(M_{3,2}\). The probability of being selected for each feasible machine is equal to 1/6 (16.6 %). Once a feasible machine is identified, the FMU is also selected. For example, the decimal value of gene \(O_{1,3}\) is 0.36, which is located in the range of [0.33, 0.5). Machine \(M_{1,3}\), which belongs to FMU 1, is selected; thus, the operation \(O_{1,3}\) of Job 1 is assigned to the machine \(M_{1,3}\) of FMU 1 for processing (Fig. 2).

FMU selection for operation 3 of job 1
In this study, half of the initial populations were generated using the global selection method, and the remainder were randomly generated. This differs from the procedure of the traditional GA, in which the offspring is generated by multiplying a parent chromosome into seven chromosomes at a time, using four of the seven chromosomes for performing a crossover operation, with the three remaining for performing a mutation operation. The crossover and mutation operations were performed simultaneously, and were then evaluated.
Global selection
-
Step 1 The sequential order of operations for individual jobs is randomly determined, and the integer parts of all chromosomes are generated if the restrictions mentioned in “Defining a hypothesis for solving distributed and flexible job-shop scheduling problem” section are met.
-
Step 2 The matrix that shows the processing times on all machines is established with an initial value of 0.
-
Step 3 Genes in the chromosome are read sequentially.
-
Step 4 The processing times on available machines for the corresponding operations of the genes, as well as the current times on the corresponding machines shown in the matrix established in Step 2, are added to generate the tentative matrix Temp.
-
Step 5 Times on individual available machines in Temp are compared, and the Machine k with the shortest length of time is selected. When the times are identical, one of the machines is randomly chosen.
-
Step 6 The decimal value of the operation is set to correspond to the Machine k selected in the previous step.
-
Step 7 The processing time on the Machine k selected in the previous step is renewed and added to the matrix in Step 2.
-
Step 8 The next gene in the chromosome is read. Steps 3–7 are repeated. As soon as all of the genes in the chromosome are read, go to Step 9.
-
Step 9 Return to Step 2 to read the next chromosome until all of the chromosomes are read.
Random generation
-
Step 1 The sequential order of operations for individual jobs is randomly determined if the restrictions mentioned in “Defining a hypothesis for solving distributed and flexible job-shop scheduling problem” section are met.
-
Step 2 Each operation is added to the randomly generated decimal.
Selection
The preferred selection is intended to generate high-quality offspring. Thus, the chromosomes of newly generated parents are reselected. Previous selection methods have involved the roulette approach and tournament approach. The tournament approach was adopted in this study to select preferred chromosomes. All of the chromosomes were collected after the GA was performed, and were collectively combined with the chromosomes of the original parents. Subsequently, the chromosomes were sequenced according to their fitness values. Chromosomes with preferred fitness values were selected. A rule of thumb in the selection is that chromosomes with the same fitness values are not repeatedly selected. When the selection is completed and the quantity of chromosomes still falls short of the predefined requirement, a chromosome is randomly selected from those eliminated, and a repeated selection is allowed.
Crossover
Two common tactics are used be adopted in GA algorithm for enhancing the quality of the crossover result: one is the elitist policy and the other is increasing the diversity of chromosomes to increase the probability of finding a near-optimal or optimal solution. In this study, the two-point crossover, precedence-preserving order-based crossover (POX), and uniform crossover methods were used to perform the crossover operation; these methods can either prevent reparations or increase the diversity of chromosomes. In this section, the two-point crossover and uniform crossover methods are used for machine selection; the POX and two-point crossover methods are used in operation assignments.
Mutations
Mutations are intended to increase the diversity of chromosomes. Genes in parent chromosomes that meet the mutation criteria are modified to become new chromosomes, and are then added to the population. In this study, mutation was divided into two parts: machine and operation.
Machine selection
The mutation approach is applied to a machine for changing specific genes in the chromosome. Two machine mutation methods were used in this study. The following are detailed descriptions of how these two methods were performed:
-
1.
Selection of the machine with the shortest processing time for the operation.
-
Step 1 Genes are read sequentially from all parent chromosomes, and random numbers [0,1) are generated. If the corresponding random number of a gene is lower than the preset mutation rate, then Step 2 is performed. Otherwise, skip Step 2 and go directly to Step 3.
-
Step 2 The machine with the shortest processing time among those available for the corresponding operation of the gene is selected, and the selected machine is restored to the decimal range that the machine falls in.
-
Step 3 After all genes in all parent chromosomes are read, the process is completed. Otherwise, return to Step 1 and continue with the next gene.
-
-
2.
Repeated random selection of a machine
-
Step 1 Genes are read sequentially from all parent chromosomes, and random numbers [0,1) are generated. If the corresponding random number of a gene is lower than the preset mutation rate, then Step 2 is performed. Otherwise, skip Step 2 and go directly to Step 3.
-
Step 2 The integer part of the gene is conserved, and a random number [0, 1) is again generated for the decimal.
-
Step 3 After all genes in all parent chromosomes are read, the process is completed. Otherwise, return to Step 1 and continue with the next gene.
-
Operation assignment
-
1.
Repeated random operation assignment
-
Step 1 Genes are read sequentially from all parent chromosomes, and random numbers [0,1) are generated. If the corresponding random number of a gene is lower than the preset mutation rate, then Step 2 is performed. Otherwise, skip Step 2 and go directly to Step 3.
-
Step 2 Other genes in the same chromosome as the current gene are randomly selected and exchanged with their integer positions.
-
Step 3 After all genes in all parent chromosomes are read, the process is completed. Otherwise, return to Step 1 and continue with the next gene.
-
Experimental results and evaluation
Introduction of the DFJSP instance
Based on a review of the literature, research on DFJSPs is scant. Therefore, the performance of the HGA was tested using three classic and three virtual DFJSP benchmarks that were based on traditional FJSP benchmarks (i.e., MK1, MK2 and MK3) that were adapted from Brandimarte (1993). In this study, the jobs were randomly assigned to two FMUs, and a randomly generated delivery time was added in Table 6.
Regarding to selection DFJSPs, the first DFJSP benchmark was formulated by Giovanni and Pezzella (2010), with a size of three FMUs, five jobs, and eight machines. For identification, this instance was named “DFJSP 1.” The second DFJSP instance had a size of two FMUs and six jobs with four operations each; this instance was proposed by Chan et al. (2006), and it was named in the current study as instance “DFJSP 2.” The final instance was also proposed by Chan et al. (2006), and had a size of two FMUs and 10 jobs with four operations each; this instance was named “DFJSP 3.”
Regarding to selection of virtual DFJSPs, three problems were generated based on traditional FJSP benchmarks formulated by Brandimarte (1993): MK1 and MK2 involved two FMUs, 20 jobs, 12 machines, and 5–6 operations per job. MK3 involved two FMUs and 16 machines, and 10 operations per job. Table 3 lists the information of the three classic and virtual DFJSPs benchmarks.
Parameters
In this study, the Taguchi method was adopted to optimise the GA parameters; three control factors (parameters) of GA are the generation, the population and mutation rate. Each parameter has three levels (the control factors are listed in Table 4); thus, the experiments were designed on the basis of the \(L_{9}(3^{4})\) orthogonal array technique, thereby reducing the number of experiments from 27 to 9, which shortened the experimental times considerably and conserved resources. The formulation of S/N ratio is shown in (4.1).
The optimal parameter values were determined according to the level with the higher S/N ratio. The optimal parameters of the GA for DFJSP 2 are A2 (1000 generations), B2 (100 population) and C2 (mutation rate\(\,=\,\)0.3). The optimal GA parameters for DFJSP 3 are A2 (1000 generation), B2 (100 population) and C2 (mutation rate\(\,=\,\)0.3).
Comparison with previous studies
The experiments conducted in this study were implemented using a personal computer (3.3-GHz Intel Xeon E3-1230 V2 CPU, 32 GB RAM) with 64-bit Windows Server 2008 R2. Matlab was used as a system development tool.
The results are summarised in Table 5 when using the proposed HGA approach to solve the three DFJSP instances. The minimum makespan obtained during the 50 runs, average makespan (Av.), and percent standard deviation (Dev.%) are listed.
Table 5 shows a comparison with previous algorithms. When the proposed HGA was used, the makespan for all five jobs and 11 operations in the instance DFJSP 1 was nine time units (6 time units \(+\) 3 time units of transportation time\(\,=\,\)9 time units). A substantial improvement was thus obtained, outperforming the results reported by Giovanni and Pezzella (2010) in 11 time units. The optimal scheduling result of Giovanni and Pezzella (2010) is shown in Fig. 3a, and those obtained using the proposed HGA are presented in Fig. 3b. All of the factories finished their manufacturing operations in six time units, indicating that the workloads in all of the factories were adequately balanced, thus improving equipment utilization and production capacity. Regarding the minimum makespan of the proposed HGA approach, the instance DFJSP 2 was 37 time units, which was the same value obtained by Giovanni and Pezzella (2010), and was superior to that of Chan et al. (2006). Regarding the average makespan, the proposed approach was 37.6 time units, outperforming those of the other two studies (38.6 and 43.1 time units). The Gantt chart and convergence results are displayed in Fig. 4a, b, respectively. The workloads of the two factories were adequately balanced. The transportation time reported by Giovanni and Pezzella (2010) was adopted in this study, and was considered one time unit in Instances 2 and 3. The makespan of the instance DFJSP 3 was 37 time units, being the same as that of Giovanni and Pezzella, and superior to that of Chan et al. (2006). The average makespan of the proposed approach was 37.48 time units, outperforming the other two studies (38.3 and 51 time units). A Gantt chart and the convergence results for DFJSP 3 are shown in Fig. 5a, b, respectively. The workloads of the two factories were adequately balanced, and the machine loads were approximately balanced. The makespan of MK1 was 51 time units, and the average makespan of the proposed approach was 51.8 time units. A Gantt chart and the convergence results of MK1 are shown in Fig. 6a, b, respectively. The workloads of the two factories were adequately balanced, and the machine loads were approximately balanced. The makespan of MK2 was 39 time units, and the average makespan of the proposed approach was 41.9 time units. A Gantt chart and the convergence results of MK2 are displayed in Fig. 7a, b. The workloads of the two factories were adequately balanced, and the machine loads were approximately balanced. The makespan of MK3 was 210 time units, and the average makespan of the proposed approach was 217.8 time units. A Gantt chart and the convergence results of MK3 are shown in Fig. 8a, b. The workloads of the two factories were adequately balanced, and the machine loads were approximately balanced.

a The optimal scheduling results of Giovanni and Pezzella (2010). b The optimal scheduling results obtained in the proposed HGA algorithm. c The convergence of instance DFJSP 1

a The Gantt chart of instance DFJSP 2. b The convergence of instance DFJSP 2

a The Gantt chart of instance DFJSP 3. b The convergence of instance DFJSP 3

a The Gantt chart of instance MK1. b The convergence of instance MK1

a The Gantt chart of instance MK2. b The convergence of instance MK2

a The Gantt chart of instance MK3. b The convergence of instance MK3
Table 5 shows the computation time for the six benchmarks. The performance of the proposed approaches is clearly worse than that of previous studies because the Taguchi method required a considerable length of time to optimise the GA parameters.
Conclusion
This article proposes a HGA for solving the DFJSP. The roulette method was adopted for encoding FMUs and selecting a machine to be incorporated into the initial chromosomes, thereby successfully overcoming the drawback of traditional GAs. Furthermore, the GA parameters were optimised using the Taguchi method. In addition, the HGA approach was effectively applied to six DFJSP benchmarks, and the empirical results demonstrate that this approach can produce a satisfactory scheduling outcome.
However, many factors that influence the results of scheduling, such as rescheduling caused by disruptions and uncertain problems, have yet to be investigated, and thus require further research.
References
AitZai, A., Benmedjdoub, B., & Boudhar, M. (2014). Branch-and-bound and PSO algorithms for no-wait job shop scheduling. Journal of Intelligent Manufacturing. doi:10.1007/s10845-014-0906-7
Behnamian, J., & Fatemi Ghomi, S. M. T. (2014). A survey of multi-factory scheduling. Journal of Intelligent Manufacturing. doi:10.1007/s10845-014-0890-y
Brandimarte, P. (1993). Routing and scheduling in a flexible job shop by tabu search. Annals of Operations Research, 41(3), 157–183. doi:10.1007/BF02023073.
Chan, F. T. S., Chung, S. H., & Chan, P. L. Y. (2005). An adaptive genetic algorithm with dominated genes for distributed scheduling problems. Expert Systems with Applications, 29(2), 364–371. doi:10.1016/j.eswa.2005.04.009.
Chan, F. T. S., Chung, S. H., Chan, L. Y., Finke, G., & Tiwari, M. K. (2006). Solving distributed FMS scheduling problems subject to maintenance: Genetic algorithms approach. Robotics and Computer-Integrated Manufacturing, 22(5–6), 493–504. doi:10.1016/j.rcim.2005.11.005.
Cheng, R., Gen, M., & Tsujimura, Y. (1996). A tutorial survey of job-shop scheduling problems using genetic algorithms—I. Representation. Computers & Industrial Engineering, 30(4), 983–997. doi:10.1016/0360-8352(96)00047-2.
Cheng, R., Gen, M., & Tsujimura, Y. (1999). A tutorial survey of job-shop scheduling problems using genetic algorithms, part II: Hybrid genetic search strategies. Computers & Industrial Engineering, 36(2), 343–364. doi:10.1016/S0360-8352(99)00136-9.
De Giovanni, L., & Pezzella, F. (2010). An improved genetic algorithm for the distributed and flexible job-shop scheduling problem. European Journal of Operational Research, 200(2), 395–408. doi:10.1016/j.ejor.2009.01.008.
Delice, Y., Kızılkaya Aydoğan, E., Özcan, U., & İlkay, M. (2014). A modified particle swarm optimization algorithm to mixed-model two-sided assembly line balancing. Journal of Intelligent Manufacturing. doi:10.1007/s10845-014-0959-7
Gao, K. Z., Suganthan, P. N., Pan, Q. K., Chua, T. J., Cai, T. X., & Chong, C. S. (2014). Discrete harmony search algorithm for flexible job shop scheduling problem with multiple objectives. Journal of Intelligent Manufacturing. doi:10.1007/s10845-014-0869-8
Gao, J., Sun, L., & Gen, M. (2008). A hybrid genetic and variable neighborhood descent algorithm for flexible job shop scheduling problems. Computers & Operations Research, 35(9), 2892–2907. doi:10.1016/j.cor.2007.01.001.
Gen, M., Gao, J., & Lin, L. (2009). Multistage-based genetic algorithm for flexible job-shop scheduling problem. In M. Gen, D. Green, O. Katai, B. McKay, A. Namatame, R. Sarker, et al. (Eds.), Intelligent and evolutionary systems (Vol. 187, pp. 183–196). Berlin, Heidelberg: Springer. (Studies in Computational Intelligence).
Goldberg, D. E. (1989). Genetic algorithms in search, optimization and machine learning. Boston: Addison-Wesley Longman.
Gong, H., Chen, D., & Xu, K. (2014). Parallel-batch scheduling and transportation coordination with waiting time constraint. The Scientific World Journal. doi:10.1155/2014/356364
Hao, X., Gen, M., Lin, L., & Suer, G. (2015). Effective multiobjective EDA for bi-criteria stochastic job-shop scheduling problem. Journal of Intelligent Manufacturing. doi:10.1007/s10845-014-1026-0
Herrera, F., & Lozano, M. (1996). Adaptation of genetic algorithm parameters based on fuzzy logic controllers. Genetic Algorithms and Soft Computing, 8, 95–125.
Ho, N. B., Tay, J. C., & Lai, E. M. K. (2007). An effective architecture for learning and evolving flexible job-shop schedules. European Journal of Operational Research, 179(2), 316–333. doi:10.1016/j.ejor.2006.04.007.
İnkaya, T., & Akansel, M. (2015). Coordinated scheduling of the transfer lots in an assembly-type supply chain: a genetic algorithm approach. Journal of Intelligent Manufacturing. doi:10.1007/s10845-015-1041-9
Jia, H. Z., Nee, A. Y. C., Fuh, J. Y. H., & Zhang, Y. F. (2003). A modified genetic algorithm for distributed scheduling problems. Journal of Intelligent Manufacturing, 14(3–4), 351–362. doi:10.1023/A:1024653810491.
Jian-Bo, Y. (2001). GA-based discrete dynamic programming approach for scheduling in FMS environments. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 31(5), 824–835. doi:10.1109/3477.956045.
Kacem, I., Hammadi, S., & Borne, P. (2002a). Approach by localization and multiobjective evolutionary optimization for flexible job-shop scheduling problems. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 32(1), 1–13. doi:10.1109/TSMCC.2002.1009117.
Kacem, I., Hammadi, S., & Borne, P. (2002b). Pareto-optimality approach for flexible job-shop scheduling problems: Hybridization of evolutionary algorithms and fuzzy logic. Mathematics and Computers in Simulation, 60(3–5), 245–276. doi:10.1016/S0378-4754(02)00019-8.
Kawanaka, H., Yamamoto, K., Yoshikawa, T., Shinogi, T., & Tsuruoka, S. (2001). Genetic algorithm with the constraints for nurse scheduling problem. In Evolutionary Computation, 2001. Proceedings of the 2001 congress on, 2001 (Vol. 2, pp. 1123–1130, vol. 1122). doi:10.1109/CEC.2001.934317
Kim, D.-W., Kim, K.-H., Jang, W., & Frank Chen, F. (2002). Unrelated parallel machine scheduling with setup times using simulated annealing. Robotics and Computer-Integrated Manufacturing, 18(3–4), 223–231. doi:10.1016/S0736-5845(02)00013-3.
Mesghouni, K., Hammadi, S., & Borne, P. (1997). Evolution programs for job-shop scheduling. In Systems, man, and cybernetics, 1997. Computational cybernetics and simulation., 1997 IEEE International conference on, 12–15 Oct 1997 (Vol. 1, pp. 720–725, vol. 721). doi:10.1109/ICSMC.1997.625839
Nouiri, M., Bekrar, A., Jemai, A., Niar, S., & Ammari, A. (2015). An effective and distributed particle swarm optimization algorithm for flexible job-shop scheduling problem. Journal of Intelligent Manufacturing. doi:10.1007/s10845-015-1039-3
Pezzella, F., Morganti, G., & Ciaschetti, G. (2008). A genetic algorithm for the flexible job-shop scheduling problem. Computers & Operations Research, 35(10), 3202–3212. doi:10.1016/j.cor.2007.02.014.
Tay, J., & Wibowo, D. (2004). An effective chromosome representation for evolving flexible job shop schedules. In K. Deb (Ed.), Genetic and evolutionary computation—GECCO 2004, Lecture Notes in Computer Science (Vol. 3103, pp. 210–221). Berlin, Heidelberg: Springer.
Toksarı, M. D., Oron, D., & Aydoğan, E. K. (2014). New developments in scheduling applications. The Scientific World Journal. doi:10.1155/2014/268941
Tung-Kuan, L., Yeh-Peng, C., & Jyh-Horng, C. (2014). Developing a multiobjective optimization scheduling system for a screw manufacturer: A refined genetic algorithm approach. IEEE Access, 2, 356–364. doi:10.1109/ACCESS.2014.2319351.
Watanabe, M., Ida, K., & Gen, M. (2005). A genetic algorithm with modified crossover operator and search area adaptation for the job-shop scheduling problem. Computers & Industrial Engineering, 48(4), 743–752. doi:10.1016/j.cie.2004.12.008.
Yilmaz Eroglu, D., & Ozmutlu, H. C. (2014). MIP models and hybrid algorithms for simultaneous job splitting and scheduling on unrelated parallel machines. The Scientific World Journal. doi:10.1155/2014/519520
Zhang, G., Gao, L., & Shi, Y. (2011). An effective genetic algorithm for the flexible job-shop scheduling problem. Expert Systems with Applications, 38(4), 3563–3573. doi:10.1016/j.eswa.2010.08.145.
Zhang, G.-Q., Wang, J.-J., & Liu, Y.-J. (2014). Scheduling jobs with variable job processing times on unrelated parallel machines. The Scientific World Journal. doi:10.1155/2014/242107
Acknowledgments
This work was partially supported by the Ministry of Science and Technology, Taiwan (R.O.C.), under Grant No. 103-2221-E-327-031-, and by the Bureau of Energy, Ministry of Economic Affairs, Taiwan (R.O.C.), under Grant No. 102-D0629.
Conflict of interest
The authors declare no conflicts of interest regarding the publication of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Chang, HC., Liu, TK. Optimisation of distributed manufacturing flexible job shop scheduling by using hybrid genetic algorithms. J Intell Manuf 28, 1973–1986 (2017). https://doi.org/10.1007/s10845-015-1084-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-015-1084-y