
Abstract
Recommender Systems learn users’ preferences and tastes in different domains to suggest potentially interesting items to users. Group Recommender Systems generate recommendations that intend to satisfy a group of users as a whole, instead of individual users. In this article, we present a social based approach for recommender systems in the tourism domain, which builds a group profile by analyzing not only users’ preferences, but also the social relationships between members of a group. This aspect is a hot research topic in the recommender systems area. In addition, to generate the individual and group recommendations our approach uses a hybrid technique that combines three well-known filtering techniques: collaborative, content-based and demographic filtering. In this way, the disadvantages of one technique are overcome by the others. Our approach was materialized in a recommender system named Hermes, which suggests tourist attractions to both individuals and groups of users. We have obtained promising results when comparing our approach with classic approaches to generate recommendations to individual users and groups. These results suggest that considering the type of users’ relationship to provide recommendations to groups leads to more accurate recommendations in the tourism domain. These findings can be helpful for recommender systems developers and for researchers in this area.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recommender systems aim at analyzing the preferences, tastes and characteristics of a user to generate potentially interesting suggestions for this user. These systems have been applied in a wide range of application domains, such as movies (O’Connor et al. 2001), news (Billsus and Pazzani 2000) and music (Crossen et al. 2002). Recommender systems can use different types of information to determine the user profile, such as demographic information, user ratings, user navigation preferences, among others. The field of individual recommender systems has yielded a wide variety of techniques such as collaborative filtering (Resnick et al. 1994), content-based filtering (Pazzani and Billsus 2007) and demographic profiles (Krulwich 1997), aimed at exploring and exploiting users’ profiles in order to fine-tune suggestions so as to replicate personalized strategies. Some recommender systems even combined these methods resulting in hybrid techniques (Burke 2002; Schiaffino and Amandi 2009).
In the last years, a new set of recommender systems arised to cope with services or products that users consume collectively. Domains such as movies or restaurants (McCarthy 2002) tend to be used more frequently by groups formed by individual users with particular preferences. In the same way that individual recommender systems attempt to replicate the relationship between a customer and a sales-representative, social group recommender systems attempt to replicate the process of negotiation necessary in any collective activity. Generating recommendations to groups of users opens new challenges in the Recommender Systems research area (Jameson and Smyth 2007), since the idea of generating a set of recommendations that satisfies a group of users with possible competing interests is a significant challenge.
Group recommender systems can be classified in two main categories: (1) those that perform an aggregation of individuals’ preferences (or ratings) to obtain a group prediction for each candidate item; and (2) those that perform an aggregation of individuals’ models into a single group model and generate suggestions based on this model. Some of the techniques applied to aggregate individuals’ ratings are multiplication, maximizing average satisfaction and minimizing misery, among others. To create a group model reflecting the preferences of the majority of the group, a common solution is to aggregate group members’ prior preferences. Then, suggestions are generated for the “virtual user”representing the group profile, by applying a classic recommendation technique for individual users.
Analyzing how groups are composed, we can observe that they may vary from formally established, long-term groups to ad-hoc collections of individuals who use a system together on a particular occasion (Jameson and Smyth 2007). Thus the difficulty of the group recommendation problem is mainly represented by the dynamics and diversity of the groups, and the ability to generate a model to describe them. Most of the well-known techniques to satisfy groups of users are focused on the individual preferences, by analyzing the users’ evaluations and/or the content of the candidates items. Group recommendation techniques traditionally assume that users are independent individuals, ignoring the effects of social interaction and relationships among users. However, in a real group decision making process, users tend to observe not only their own preferences, but also the opinions given by other close members. The problem of how to make recommendations for a group considering the social influence and relations among group members rather than viewing each individual’s preferences separately is an issue that has begun to be considered in the last years but it is still in early research stages (Shang et al. 2011; Cantador and Castells 2012; Quijano-Sanchez et al. 2013).
In this context, we present an approach to generate suggestions to both individuals and groups of users, which combines three well-known recommendation strategies: collaborative, content-based and demographic filtering. Thus, the disadvantages of one technique are overcome by the others. Moreover, to generate group recommendations the approach analyzes not only the three types of individual members’ profiles but also the social influence derived from the members’ relationships. This is based on the hypothesis that depending on the relationship between each pair of members, users could be influenced and even change their own opinions (Masthoff 2010). Our approach has been materialized in Hermes, a recommender system for the tourism domain. The results obtained thus far provide some clues about how relationships bewteen users can affect recomendations in the tourism domain. These findings could be helpful for group recommender systems developers both at research and commercial levels.
The rest of the article is organized as follows. Section 2 presents some basic concepts and analyzes related works. Section 3 presents an overview of the proposed approach. Section 4 details the proposed hybrid approach to build profiles and generate suggestions for individuals and groups of users. Then, Section 5 presents the experimental results obtained thus far. Finally, in Section 6 we present our conclusions.
2 Background and related work
Generating recommendations to customize and satisfy the interests of individual users has been an active research area since the mid-1990s. A variety of approaches have been used to make recommendations (Bobadilla et al. 2013). The content-based approach is based on the intuition that each user exhibits a particular behavior under a given set of circumstances, and that this behavior is repeated under similar situations. A content-based recommender learns a model of the user interests based on the features present in items the user rated as interesting either by implicit or explicit feedback. Thus, a user profile contains those features that characterize a user interests, enabling agents to categorize items for recommendation based on the features they exhibit (Pazzani and Billsus 2007). The user profiles derived by content-based recommenders depend on the learning methods employed.
In contrast to the content-based approach, in which the behavior of users is predicted from their past behavior, collaborative filtering (CF) is based on the idea that people within a particular group tend to behave alike under similar circumstances. In the collaborative filtering approach the behavior of a user is predicted from the behavior of other like-minded people. A user profile in this approach comprises a vector of item ratings, with the ratings being binary or real-valued. The aim of collaborative filtering for the active user u is to predict the score for an item i, which has not been rated yet by u, in order to recommend this item. By comparing the ratings of the active user to those of other users using some similarity measure, the system determines users who are most similar to the active one, and makes predictions or recommendations based on items that similar users have previously rated highly (Linden et al. 2003).
Demographic recommenders aim at categorizing users based on their personal attributes as belonging to stereotypical classes. In this case, a user profile is a list of demographic features that represent a class of users. This representation of demographic information in a user profile can vary greatly.
Finally, in knowledge-based approaches recommendation is based on inferences about a user’s needs and preferences, which are performed using some functional knowledge, that is, there is knowledge about how a particular item meets a particular user need and one can therefore reason about the relationship between a need and a possible recommendation. The user profiles in knowledge-based recommenders can also take different forms, since they can consist in any knowledge structure that supports inference (Kaminskas et al. 2014). Ontology-based user profiling is an example of knowledge-based recommendation.
In view of the exponential growth of the available information generated by social networks, researchers in the area of recommendation have begun to analyse this context to exploit the users’ information to generate more accurate recommendations. These systems are known as social recommender systems and their study has recently begun (Schall 2015).
The issue of generating recommendations to groups is a relatively new research field (Boratto and Carta 2011) although it has produced a number of techniques aimed at meeting the needs of groups in a variety of domains such as music, movies (Christensen and Schiaffino 2011), and TV shows (Yu et al. 2006). One of the most successful techniques to combine individual preferences into a group preference is by using an aggregation function. There are many alternative aggregation functions that can be used to obtain a final group satisfaction. Each function has a different priority goal, such as total satisfaction or equity. Four of the most used aggregation functions are described below (Masthoff 2010):
-
Multiplicative: This function computes the aggregate rating R i by multiplying the individual ratings of the group members. A disadvantage of this strategy is that certain members might always be disconformed if their opinions happen to be a minority.
-
Maximizing average satisfaction: This function computes the average rating of the groups members.
-
Minimizing misery: The goal of this function is to minimize dissatisfaction, by computing the aggregate rating as the minimum rating given by all the members of the group.
-
Ensuring some degree of fairness: This functions returns the average ratings of all the members of the group, discounting the standard deviation weighted by some fixed factor. This way, the average rating is penalized with the amount of variation among the individual ratings.
Cantador and Castells (2012) revised the state of the art in group recommender systems and present open research problems to be considered in this research area, especially related to the social web and social dynamics, among others. However, there are only a few works that include proposals that analyze social factors to anticipate the social influence exerted among group members in the decision-making process in the group recommendation context. For example Gartrell et al. (2010) proposed the use of three descriptors of the group members to generate recommendations: a social descriptor, which gives a weight of importance to relationships between members, depending on frequency of daily contact; a descriptor of experience, which determines the experience or knowledge of the members in the domain; and a dissimilarity descriptor, which describes the degree of disagreement between any pair of group members. Social influence has been studied by various authors in an attempt to identify interpersonal factors that could be understood as indicators of opinion changes (Friedkin and Johnsen 2011; Crandall et al. 2008). For instance Young and Srivastava (2007) describe an overview of the impact of social influence on e-commerce and explain that central nodes in a social network could represent influential consumers, while trust could be used to increase the accuracy of suggestions. Additionally Bonhard et al. (2006) demonstrate users’ interests, not only users’ ratings, are important to decision-makers when choosing items. Other authors focused on achieving consensus in the recommendation to a group of users. For instance, Ioannidis et al. (2013) propose a model that allows users to asynchronously vote, add and comment on alternatives. This model captures how a user is influenced by decisions made by other users. Finally, the decision of the item for the group depends on the number of positive votes (the average strategy is used to determine the group preference for an item). In this article, we take a different approach for considering social influence. We define different possible relationships among members, based on the four types of relationships proposed by Masthoff (2010), and associate different weights to each relationship, as described in Section 4.2. Castro et al. (2015) also focused on improving recommendations to groups by applying techniques taken from group decision making and concensus reaching. However, this approach does not consider the social influence among members of the group.
As regards tourism recommender systems, different approaches have been applied to deliver personalized services as described in an analysis of the state of the art in this area in Borras et al. (2014). Example recomemnder systems in the tourism domain for individual users are PTA (PersonalTravel Assistant) (Coyle and Cunningham 2004) and PTS (Personalization Travel Support) (Srivihok and Sukonmanee 2005). PTA uses case-based reasoning to reserve and sell flights. PTS applies reinforcement learning to analyze, learn customer behaviors and recommend products to meet customer interests. Finally, Noguera et al. (2012) focused on improving the user experience by integrating a location-sensitive hybrid recommender engine with a custom-made 3D GIS architecture capable of running interactively on modern mobile devices. The proposed recommender system adapts the recommendations according to the user’s physical location, offering a rich and detailed virtual representation of the place where the turist is currently located.
As regards recommendations for group or users in the tourism domain, INTRIGUE (Ardissono et al. 2003) recommends attractions and tourist services to groups of users in a personalized way, by building homogeneous groups from the information provided in registration forms. The work in Garcia et al. (2009) introduces a method for giving recommendations of tourist activities to a group of users, which makes recommendations based on the group tastes, their demographic classification and the places visited by the users in former trips. The group recommendation is computed from individual personal recommendations through the use of techniques such as aggregation, intersection or incremental intersection. In Sebastia et al. (2011) the authors present a Multi Agent System aimed to support a user or a group of users on the planning of different leisure and tourist activities in a city. The system integrates agents that cooperate to dynamically capture the users profiles and to obtain a list of suitable and satisfactory activities for the user or for the group, by using the experience acquired through the interaction of the users and similar users with the system. Our work, as stated in Borras et al. (2014), is on the new trend of recommender systems that consider social aspects to provide recommendations. There are not many works in this direction in the tourism domain. One work we can cite is CATS (Collaborative Advisory Travel system) (McCarthy et al. 2006). CATS takes an approach to cooperative group recommendation that uses a variety of social interaction features to communicate group, as well as individual, preferences and activity, and constructs a reliable group-preference model by combing critique histories in order to generate recommendations on a proactive and reactive basis.
3 Overview of our proposed approach
In this work we propose a hybrid approach that analyzes individual and group preferences in order to recommend items that satisfy these preferences. The recommendations (for both individuals and groups) are generated by combining three filtering techniques: collaborative, which considers the user community’s preferences, content-based, which considers the preferences given to items attributes, and demographic, which considers the personal demographical information of the individuals users. Therefore, for each individual user the approach creates an individual hybrid profile, which is utilized to estimate unknown ratings. Hence, these hybrid individual profiles combine three different profiles: collaborative profile, content-based profile, and demographic profile.
3.1 Users’ and items’ data considered for profile building
Considering the tourism domain, the collaborative profile contains the ratings given to different tours, previously taken by users, in a range from 1 to 5 stars. One of the main issues to consider in any recommender system is the cold start problem, that is what to recommend to users that are new in the system. For these kind of users, the system does not have ratings about tours, and therefore, a colaborative-based approach is not feasible. To face this problem, our approach includes the creation of a demographic profile and a content-based profile.
The demographic profile consists in information regarding users that do not depend on tours and that can be used to provide some initial recommendations. Our approach considers users’ personal demographic information to generate both individual and group recommendations. The information analyzed for each individual user is presented in Table 1. The demographic profile is used in combination with the collaborative and content-based profiles but also as a single resource to deal with the cold start problem, i.e. when a new user requires a recommendation, for which no preference is known, the approach obtains the users’ personal data and compares it with tours’ attributes in order to generate suggestions. In Section 4.1.1, we describe how this information is used to compute similarities among users. Additionally, for users that have not given any information about themselves, the proposed approach considers to recommend the most popular tours (that are the tours with the higher average rating in the system).
On the other hand, the content-based profile contains ratings given to different tour attributes. The information stored about tours is presented in Table 2. For each tour, we store its name, departing and arriving cities, number of accommodation nights, accomodation, a set of associated activites, mean of transport, season, final price and a free text description. An accomodations has a name, the city in which it is located, the category (number of stars), the type and services offered (see Table 3 for details). A city is described by a name, the country to which it belongs, the main climate and a set of landforms that can be found in the region (see Table 3 for details). The description of the activities that can be part of the tours include a limitations element that consist of possible phisical limitations of a person might have that prevent taking the activity. Furthermore, the cardinality attribute allow to distinguish between individual and groupal activities, the context (whether the activity is performed indoors or outdoors) and the type that group the activities in 7 different categories (see Table 3 for details).
The proposed approach considers that users express their preferences regarding the city, activities and accommodations that they want to include in the tours. These attributes for which users are asked about their preferences are considered as a starting point to generate recommendations by filtering those tours that do not satisfy these initial requirements. Table 3 presents all the attributes and their possible values considered in this work. For each of these values, the user is asked to indicate “like”, “don’t like” and “indiferent”. This step is optional and users can start using the proposed system without expressing any preference regarding these attributes.
Attributes and their values presented in Table 3 were selected by analyzing different desktop and Web systems, and by interviewing travel agents. However, the system is easily adaptable to include other featuers and values.
3.2 Individual and group profiling
To generate the individual recommendations, our proposed approach combines three types profiles, namely content-based, collaborative and demographic, in order to estimate unknown ratings of the candidate items. This process is explained in detail in the Section 4.1. To generate group recommendations, our approach builds a group profile by analyzing all the individual hybrid profiles and other information related to the group. The group profile contains information about the members, their relationships, the initial group preferences, and the estimated group preferences. Our approach considers that the group can propose a set of initial preferences, such as a particular weather, country, city, landforms, and accommodation, among others. With this information, an initial search of the tours is performed in order to reduce the dimension of the items to evaluate. These group preferences have a higher priority level than individual preferences: if the group aims to go to the beach and a member has a negative preference about this type of landform, his/her individual evaluation decreases the group evaluation depending on the types of relationships with other group members. The degree of influence that an individual may have on another may be established by analyzing some social factors. In this paper we focus on the relationships explicitly indicated by group members. We consider nine type of relationships among users, grouped in four categories: (1) Close relationship, in which the users can change their opinions due to the influence exerted by others’ opinions (for example, couples); (2) Hierarchical relationship, in which the users can change their opinions due to the influence exerted by those who have a higher hierarchical position (for example, a parent-child or employee-employer relationship) (3) Acquaintances, in which consensus is achieved from a position of equality, averaging the individual values (for example, friendship), and (4) Unknown, this relationship generates different reactions on individuals: a direct competition or a complete indifference. More details about the relationships among group members is given in Section 4.2.
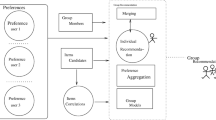
Figure 1 shows the general flow of the proposed approach. For each user, a hybrid profile is built, considering the demographic information about the user, the ratings of the community regarding the tours and the similarities among tours. Details of the Individual Recommendercomponent in Fig. 1 is given in Fig. 2. The individual recommender first checks whether the user has already provided a rating for the target tour. If the rating of the target tour is unknown, different information is used to compute the rating, according to somespecified thresholds. If the target tour has not been previously rated by a minimum number of users yet, the collaborative filtering profile would not be precise enough to estimate the rating. A similar situation arises if we are not able to find a minimum number of users similar to the target user. On the other hand, the content-based estimation is useful only if we are able to find a minumum number of tours (similar enough to the target tour) for which the target user has already provided feedback. Finally, the demographic profile can be always considered for estimating new ratings, even for new users for which we do not have ratings on existent tours.

General flow to generate recommendations in Hermes

Individual Recommender based on the user’s hybrid profile
Regarding groups, the system analyzes each individual hybrid profile, the users’ community and the tours features. The candidate tours are initially filtered according to a set of preferences explicitly given by the group. The filtered candidates and the group members’ relationships are considered to obtain a group evaluation for each candidate. Moreover, each individual preference is updated by considering the interests of those people that are related in the social network (in the figure the thickness of the arrows indicates the strenght of the relationships). Finally, the approach obtains the group evaluation by implementing an aggregation technique, which combines the individual preferences.
4 Proposed profile building approach
In this section we present how the different profiles used in our approach are built. We start describing the hybrid individual profile in Section 4.1, giving details of the different components for rating estimation: demographic, collaborative and content-based. Finally, in Section 4.2, we describe how the group profile is built and used to estimate the rating of different tours in which the group might be interested in.
4.1 Individual profiles
In order to estimate unknown ratings (or preferences) the approach uses the hybrid individual profiles as shown in Fig. 3. Given the target user’s demographic information, his/her explicit ratings on tours features and the ratings of the comunity (R i,j ), we determine three different ratings, one for each type of profile: demographic rating, content-based rating and collaborative rating. In the following subsections, we give details about how these ratings are computed.

Estimating preferences with the hybrid approach
4.1.1 Demographic rating estimation
To estimate the demographic rating for a tour our proposed approach matches the users’ personal information with the tours’ features. For this comparison, we consider three factors: (1) Price, (2) Limitations, and (3) Activities, as shown in (1). The first factor is based on the price of the tour and the user revenues, i.e. if the price of the tour is out of the range of user revenues the evaluation is minimized. The second factor refers to the users’ limitations to perform an activity in a tour, which can be a motor disability, a visual disability or a hearing impairment. For this reason, we define a general set of physical limitations for both users and tours; the comparison between them calculates a tour’s rating for that user. Moreover, the activities of a tour are compared with respect to four main aspects: age, education, gender and income. For each activity we define a set of characteristics, which describe the appropriate type of person to perform it. These characteristics indicate a suggested value for the activity according the four aforementioned aspects. For example, the activity “Nightclubs” has a suggested age range between 18 and 30 years old. Finally, these three factors are linearly combined in order to obtain a single tour evaluation for the user.
4.1.2 Collaborative filtering rating estimation
On the other hand, to estimate the collaborative rating for a tour, our approach uses a classical collaborative technique, which considers not only the users’ preferences but also the demographic information to determine the users’ similarities. Each user profile is composed of a rating vector with values in the range of 1–5. Therefore, the system stores a rating matrix in which the columns are tours and the rows are users and the intersection between row i and column j is the rating given by user u i to tour t j . In this work, we use the classical K-NN technique that compares the active user’s profile with the profiles of the users in the community and obtains the K users most similar to the active user for which the evaluation for the target item is known. The evaluations of these K users are then combined with a weighted average by considering the users’ similarity value. This value is obtained with the combination of a collaborative similarity (s i m c (u i ,u j )) and a demographic similarity (s i m D (u i ,u j )) (see (1)Footnote 1). The collaborative similarity is obtained with the classical Pearson correlation, which is normalized to the range [0–1]. The demographic similarity between two users is obtained by comparing the information described in the demographic profile gathered in four groups: (1) age, (2) familiar status, (3) socioeconomic status and, (4) gender.
Equation (3) shows the formula used to compute demographic similarity:
The similarity of the age factor is based on the users’ age and physical limitations, which are combined using a disjunctive operation (see (4)), so that if one of the internal comparisons is not met the similarity is null. Each term in the Equation outcomes a binary value: 1 if it is met or 0 otherwise. The terms involved for family relationship (5), socio-economic comparison (6) and gender (7) operate in the same way as the age.
sameAge(u1;u2) evaluates if the users belong to the same age range. sameLim(u1;u2) analyzes if the two users have similar physical limitations. sameMaritalStatus(u1;u2) indicates if both users exhibit the same marital status. sameNumberKids(u1;u2) and sameIncome(u1;u2) analyzes if the two users have selected the same range in these aspects when registering into the system. sameArea(u1;u2)indicates whether the users live in the same residential area. sameEducation(u1;u2) indicates whether the users considered share the same education level. Finally, s i m P r e f(u1;u2) in (3), behaves a bit different. The idea is to add a certain value, defined by PrefFactor, only in cases in which both users share at least an amount of preferences equal to thresholdPref.
4.1.3 Content-based rating estimation
Content-based rating estimation is based on computing similarities between pairs of tours, aiming at finding tours that are silimar to tours that the target user previously liked. One of the main advantages of using the information about tours is that tours that did not received any ratings can be recommended.
The calculation process of a user’s rating for a tour begins with the selection of those tours similar to the target tour that have been already rated by the user. Tours are considered similar if their similarity value with the target tour is greater than or equal to an itemSimilarityThreshold, set by default in 0.5. Once similar tours are identified, our approach estimates the tour’s rating, by computing the weighted average of the ratings provided by the user for similar tours. This follows the hypothesis that not all tours affect the rating in the same degree: the more similar the item, the greater weight will have its assessment on the estimate.
To compute similarity among tours, each tour is compared with respect to the destination, the accommodations offered, the activities offered, the price and/or duration per season and transport. The calculation performed by the proposed approach deliveries similarity values in the [0 .. 1] range. The formula used is shown in (8).
The values of α B C , β B C , γ B C , δ B C and 𝜖 B C enable to weigh them differently if necessary. Our system sets these values in 0.2 by default. The first term in (9) compares destination cities, based on their climate and landforms. s i m C i t y(t1;t2) in (8) is defined as:
where
Equation (10) computes the similarity between two climates. Our approach associates a numerical value to each climate, so that they can be ordered according to the temperature. Considering that a city can have more than one associated landforms, the geographical similarity is computed as the number of matches between the landforms of both places, as shown in (11). The comparison of accomodation is done according to (12).
s i m L o d g i n g(t 1;t 2) in (8) is defined as:
where
Similarly to climates, different accomodation types are ordered according to a numerical value reflecting their value (beeing camping the lowest and All-inclusive resorts the highest). The similarity between facilities offered is done in a way similar to the city landforms, as shown in (14).
With respect to the price, we compare whether both tours have been taken in the same season, since in this case the prices should be alike. In order to make prices comparable among different seasons, we use a equivalence table (see Table 4). By using this table we compute the equivalent price for a high season for each pair of tours. If the difference is lower than 10 % we consider the tours price equivalent.
Finally, for the means of transport, we look for an exact match for both tours.
4.2 Group profile
A group is a set of interdependent people, with relationships among them and able to interact with each other. To model a group in a computer system it is necessary to take these relationships into account. A group profile is defined by its members and their preferences, the relations between them, and the target or goal of the group. Our approach allows the definition of relationships between users in a way similar to known social networking systems. Once the user is logged into the system, he/she can contact other members through a user interface by means of a notification. When a user receives a notification, he/she can accept it or reject it.
As regards, users’ relationships and their influence, Masthoff (2010) considers four types of relationships that might be present in a group: communal sharing (somebody you share everything with, e.g. a best friend), authority ranking (somebody you respect highly), equality matching (somebody you are on equal footing with), and market pricing (somebody you do deals with/compete with). It has been demonstrated that one is more likely to be contaged and influences by somebody he/she loves (like a best friend) or respect (like his/her mother or boss) than by somebody one is on equal footing with or are in competition with. Based on this work, in our approach, we define nine types of social relationships among members of a group (see Table 5). Each relationship has an associated weight that is inverse proportional to the influence that the other member of the group can have on the target member’s opinion.
Recommendations can be generated from the moment a group is created, by using the group preferences, the profiles of each group member and the relationships among members described in the previous paragraph. The group preferences are used to make an initial filtering of the tours to be considered for recommendations. Recommendations are generated in two stages, as shown in Fig. 4. First, we compute the ratings for each member and each pre-selected tour. For users that have not explicitly rated a given tour, the rating is computed as shown in Section 3.2. Then, with this information, for each user u in group G and each tour T i , we compute the influenced individual rating, i i r u (T i ). This rating considers not only the individual rating of the user, but also the satisfaction of the remaining members of the group regarding this rating, weighted by the existent social relationships.

Prediction of group ratings
In this formula, R u (T i ) represents the rating given or estimated for user u to tour T i , R v (T i )−R u (T i ) represents the difference in satisfaction between users v and u regarding the tour T i , and w u,v represents the relationship weight between u and v (the greater the weight, the lower the influence). For values of i i r u >5 and i i r u <1 we set the value to 5 and 1 respectively. For example, consider we have three users in a group, named U 1, U 2 and U 3 and three tours T 1, T 2 and T 3 with the relationships and ratings shown in Fig. 5. The individual rating for user U 1 to tour T 1 is 3, while the influenced individual rating, according to (15) is computed as \(iir_{U_{1}}(T_{1})=3+(4-3)/2+(1-3)/1.5=2.16\). In this example, users U 1 and U 3 are a couple (with a relationship weight of 1.5) and U 2 is their son/daughter (relationship weight equals to 2)

Group recommendation example
Each influenced individual rating for a group is then combined using an aggregation function to obtain a final group satisfaction measure for each tour. The satisfaction value is used to sort the candidate tours and the top N tours are recommended to the group. In Section 2 we mentioned some of the most used aggregation functions for combining individual ratings into a group rating. For our experiments, we use the multiplicative function.
5 Experimental results
In this section we describe the results we obtained when evaluating our proposed approach both for individual and group recommendations in the tourism domain. In Section 5.1 we briefly describe the system developed to evaluate our approach, the datasets utilized and the experimental setting. In Section 5.2 we described the methodology used to validate our approach and in Section 5.3 we present the metrics used in our experiments. Finally, in Sections 5.4 and 5.5 we present the results for the different experiments we conducted, analyze the results and discuss our findings.
5.1 Hermes
Our approach was materialized into a recommender system in the tourism domain named Hermes, which makes recommendations of tours both to individual users and to groups of users. A snapshot of the system is shown in Fig. 6. In this Figure, we can see different functionalities of the system: the recommendations for the individual user, named Juan Perez (at the left side of the screenshot); the recommendations for one of the groups the user belongs to (at the top of the screenshot); general recommendations (at the bottom of the screenshot); information about a certain tour (at the center of the figure); and feedback provided by the user about tours (shown at the right of the screenshot). Also, the application provides other functionalities such as building groups by connecting to other users, tours search, asking for recommendations, among others. When a user creates a group, the system presents the user’s contacts and requests a set of initial optional preferences, such as a particular weather, country, city, landform, accommodation, among others. If a user belongs to a group, then the system allows the use of the bookmarks section, which is shared by all group members. Group members may highlight an specific tour in which they are interested, so that it is easily accessible to the rest of the group.

Visualization of the recommendations in Hermes
5.2 Methodology
We conducted a set of experiments using the Hermes systems with an artificial dataset, which consists of 1300 tours and 800 users, following a simulation evaluation method, as described in Hevner et al. (2004). Tours could take place in 80 cities in 60 different countries. The cities in the dataset contain 10 types of geographical landscapes and 5 different climates. The dataset contains 300 accomodations (hostels, campings, etc.), based on 9 types of accommodations and 12 types of services. Each tour contains up to 5 different activities. Refer to Section 3.1 for more information about the tours information and their features.
Different parameters were experimentally determined before running the experiments. Some of them are described as follows. As regards the collaborative filtering technique, the minimum threshold value for user similarity was set to 0.4. The minimum number of similar users was set to 3. The minimun threshold value for item similarity was set to 0.4. For content-based similarity, the minimum number of similar items was set to 3.
To evaluate the performance of our approach, we conducted experiments comparing the results obtained when applying traditional techniques against the ones proposed in this work. First, we tested the algorithm for individual recommendations (Section 4.1). Then, the algorithm for group recommendation was compared against widely known aggregation techniques (Section 4.2).
For evaluating the efficiency of the hybrid profile to generate good individual recommendations, we followed the following steps;
-
1.
We selected two of the most popular tours in the dataset (namely Rio de Janeiro Jet High Season and Cairo Jet High Season).
-
2.
We selected 20 users that have highly rated each of these tours (rating of 5).
-
3.
We estimated the rating for each of the tours selected for each of the 40 users with our technique, and with two traditional techniques such as collaborative filtering and content-based filtering.
For evaluating group recommendation we conducted three different experiments, each one involving different types of group regarding social relationships. The goal was to analyze the effects of the different types of relationships in group recommendation. In experiment 1, the types of groups involved considered at least two couples with friendship relations between members of the different couples (see example in Fig. 7). In experiment 2. the groups involved were families (see example in Fig. 8). Finally, in experiment 3 the groups involved were groups of friends (see example in Fig. 9). The size of groups considered were small, from 3 to 5 members.

Example of group for Experiment 1

Example of group for Experiment 2

Example of group for Experiment 3
5.3 Metrics
Recommender systems research has used several types of measures for evaluating the quality of a recommender system. Statistical accuracy metrics evaluate the accuracy of a system by comparing the numerical recommendation scores against the actual user ratings for the user-item pairs in the test dataset. Mean Absolute Error (MAE) between ratings and predictions is a widely used metric. MAE is a measure of the deviation of recommendations from their true user-specified values. For each ratings-prediction pair < r k , p k > this metric treats the absolute error between them i.e., |p k - r k | equally. The MAE is computed by first summing these absolute errors of the N corresponding ratings-prediction pairs and then computing the average (16). The lower the MAE, the more accurately the recommendation engine predicts user ratings.
where p k is the predicted rating, r k is the actual rating, and N is the number of items.
Precision is another commonly used metric for evaluating the performance of recommender systems. We consider precision as the complement of the normalized MAE (Avazpour et al. 2014), which takes into account the rating range to obtain a scaled version of the metric (17).
where p k is the predicted rating, r k is the actual rating, N is the number of items, Rmin is the minimum rating (in our case 1) and Rmax is the maximum rating (in our case 5).
5.4 Results obtained
As described in Section 5.2, we evaluated Hermes regarding both individual recommendations and group recommendation by comparing the proposed hybrid approach with regards to a pure collaborative filtering technique and a pure content based technique. The results obtained are shown in Table 6. As we can see, the average mean absolute error for the pure content-based technique was 10 % lower than the pure collaborative filtering technique. On the other hand, our proposed hybrid approach, achieve a mean absolute error even 5 % lower than the content-based profile, demonstrating that for the selected case study combining both kinds of techniques achieve a better performance than the pure techniques. All results are significantly different at p < 0.05.
Regarding recommendation to groups, we first modeled a scenario in which the target group included two couples, in which one member of each couple is a friend of a member of the other couple, and is an acquintance of the other member of the other couple, as depicted in Fig. 7. The table presented in Fig. 7 represents the social influence weights among members of the group, computed as described in Section 4.2.
We compared the mean absolute error obtained by our apprach with other two commonly used strategies for group recommendation: Minimizing Misery and Average Satisfaction. Results are shown in Table 7. We can see that our approach reduced the mean absolute error to half of that obtained by the minimizing misery strategy, while the average satisfaction strategy resulted in between.
The second experiment involved groups conformed by families with two children. Figure 8 depicts this situation and Table 8 shows the results obtained for this scenario. We can see that, similarly to the first scenario, our approach presents a better performance reducing the mean absolute error to almost 50 % with respect to the average satisfaction strategy and 43.66 % with respect to minimizing misery strategy.
Finally, the third scenario, depicted in Fig. 9 represents groups conformed by friends in which we assumed an equal influence weight among members. As demonstrated by results presented in Table 9, in this scenario the three strategies performed almost equally, which demonstrates that the consideration of different weights associated to the social influence among members of a group let us improve the performance of a group recommender system.
5.5 Analysis
As we can observe in Table 6, our hybrid approach obtained better performance than two of the traditional techniques considered separatedly. This result is consistent with other previous studies (Schiaffino and Amandi 2009), since one technique can overcome the disadvantages of the other techniques in the combination chosen.
As regards group profiling, the proposed social based approach perfomed better than two of the traditional aggregation techniques for the different types of groups involved in most cases. The best results were obtained for groups that consider hierarchical relationships, i.e. families. On the other hand, for experiment 3 in which groups of friends were involeved, our approach achieves results comparable to minimizing misery. This finding suggests that in groups with no hierarchical relationships, members tend to cede their own preferences to avoid misery in the whole group.
6 Conclusions
In this article we presented a hybrid approach for generating recommendations to groups of users that considers not only individual and group preferences regarding items but also the social relationships among members of the group. Individual profiles are built using the demographic information of users, the ratings of the community (collaborative filtering) and the content-specific information about the items to be recommended (content-based). All this information is combined in a hybrid profile that is used to estimate individual ratings to unknown items.
Following the idea that, when participating in groups, the individual preferences are influenced by the preferences of other members of the group, the individual ratings obtained by using the hybrid profile are then weighted according to the social relationships among members of the group. Thus, the individual ratings are updated to obtain an influenced individual rating. The influenced individual ratings of all members of a group are then combined to estimate a group rating for different items.
We evaluated our approach in a recommender system named Hermes, which suggests tourist attractions to both individuals and groups of users. The results obtained thus far are promising and provide evidence that considering the type of relationship between users leads to more accurate group recommendations. These findings coincide with related research in other application domains, and are useful for recommender systems developers both at commercial and at research levels. As a future work we intend to evaluate the approach in a real setting with real users. We are also planning to extend/adapt and apply the proposed approach to other domains, such as recommending restaurants to groups of users. Finally, we will consider other social factors and social network analysis to determine the influence among users in a group.
Notes
α=0.8 and β=0.2, since we consider tour similarity more relevant than demographic similarity.
References
Ardissono, L., Goy, A., Petrone, G., Segnan, G., & Torasso, G. (2003). Intrigue personalized recommendation of tourist attractions for desktop and handset devices. In Applied artificial intelligence (pp. 687–714). Taylor and Francis.
Avazpour, I., Pitakrat, T., Grunske, L., & Grundy, J. (2014). Recommendation systems in software engineering. In Dimensions and metrics for evaluating recommendation systems (pp. 245–273). Berlin: Springer.
Billsus, D., & Pazzani, M.J. (2000). User modeling for adaptive news access. User Modeling and User-Adapted Interaction, 10, 147–180.
Bobadilla, J., Ortega, F., Hernando, A., & Gutiérrez, A. (2013). Recommender systems survey. Knowledge-Based Systems, 46, 109–132.
Bonhard, P., Harries, C., McCarthy, J., & Sasse, M. (2006). Accounting for taste: using profile similarity to improve recommender systems. In Proceedings of the SIGCHI conference on human factors in computing systems (pp. 1057–1066). ACM Press.
Boratto, L., & Carta, S. (2011). State-of-the-art in group recommendation and new approaches for automatic identification of groups. In Soro, A., Vargiu, E., Armano, G., & Paddeu, G. (Eds.) Information retrieval and mining in distributed environments, volume 324 of studies in computational intelligence (pp. 1–20). Berlin: Springer.
Borras, J., Moreno, A., & Valls, A. (2014). Intelligent tourism recommender systems: a survey. Expert Systems with Applications, 41(16), 7370–7389.
Burke, R. (2002). Hybrid recommender systems: Survey and experiments. User Modeling and User-Adapted Interaction, 12(4), 331–370.
Cantador, I., & Castells, P. (2012). Group recommender systems: New perspectives in the social web Vol. 32: Springer, Intelligent Systems Reference Library.
Castro, J., Quesada, F.J., Palomares, I., & Martínez, L. (2015). A consensus-driven group recommender system. International Journal of Intelligent Systems, 30(8), 887–906.
Christensen, I.A., & Schiaffino, S. (2011). Entertainment recommender systems for group of users. Expert Systems with Applications, 38(11), 14127–14135.
Coyle, L., & Cunningham, P. (2004). Advances in case-based reasoning. In 7th European conference, ECCBR 2004, proceedings, volume 3155 of LNCS, chapter improving recommendation ranking by learning personal feature weights (pp. 560–572). Springer.
Crandall, D., Cosley, D., Huttenlocher, D., Kleinberg, J., & Suri, S. (2008). Feedback effects between similarity and social influence in online communities. In Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 160–168).
Crossen, A., Budzik, J., & Hammond, K.J. (2002). Flytrap: intelligent group music recommendation. In IUI ’02: Proceedings Of the 7th international conference on intelligent user interfaces (pp. 184–185). New York: ACM.
Friedkin, N., & Johnsen, E. (2011). Social influence network theory: a sociological examination of small group dynamics. Cambridge University Press.
Garcia, I., Sebastia, L., Onaindia, E., & Guzman, C. (2009). A group recommender system for tourist activities. In Proceedings of the 10th international conference on e-commerce and web technologies, EC-web 2009 (pp. 26–37). Berlin: Springer.
Gartrell, M., Xing, X., Lv, Q., Beach, A., Han, R., Mishra, S., & Seada, K. (2010). Enhancing group recommendation by incorporating social relationship interactions. In Proceedings of the 16th ACM international conference on supporting group work, GROUP ’10 (pp. 97–106). New York: ACM.
Hevner, A.R., March, S.T., Park, J., & Ram, S. (2004). Design science in information systems research. MIS Quarterly, 28(1), 75–105.
Ioannidis, S., Muthukrishnan, S., & Yan, J. (2013). A consensus-focused group recommender system. arXiv:1312.7076.
Jameson, A., & Smyth, B. (2007). Recommendation to groups. In The adaptive web: Methods and strategies of web personalization, chapter 20 (pp. 596–627).
Kaminskas, M., Fernández-tobías, I., Ricci, F., & Cantador, I. (2014). Knowledge-based identification of music suited for places of interest. Information Technology & Tourism, 14(1), 73–95.
Krulwich, B. (1997). Lifestyle finder: Intelligent user profiling using large-scale demographic data. AI Magazine, 18(2), 37–45.
Linden, G., Smith, B., & York, J. (2003). Amazon.com recommendations - item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76–80.
Masthoff, J. (2010). Recommender systems handbook. In Group recommender systems: Combining individual models (pp. 677–702). Springer.
McCarthy, J.F. (2002). Pocket restaurantfinder a situated recommender system for groups. In Proceedings of the workshop on mobile ad-hoc communication at the 2002 ACM conference on human factors in computer systems. Minneapolis: ACM.
McCarthy, K., McGinty, L., Smyth, B., & Salamó, M. (2006). The needs of the many: a case-based group recommender system. In Proceedings of the 8th european conference on advances in case-based reasoning, ECCBR’06 (pp. 196–210). Berlin: Springer.
Noguera, J.M., Barranco, M.J., Segura, R.J., & Martínez, L. (2012). A mobile 3d-gis hybrid recommender system for tourism. Information Sciences, 215, 37–52.
O’Connor, M., Cosley, D., Konstan, J.A., & Riedl, J. (2001). Polylens a recommender system for groups of users. In ECSCW’01: Proceedings of the seventh conference on european conference on computer supported cooperative work (pp. 199–218). Norwell: Kluwer Academic Publishers.
Pazzani, M., & Billsus, D. (2007). Content-based recommendation systems. In Brusilovsky, P., Kobsa, A., & Nejdl, W. (Eds.) The adaptive web, volume 4321 of lecture notes in computer science, chapter 10 (pp. 325–341). Berlin: Springer.
Quijano-Sanchez, L., Recio-Garcia, J., Diaz-Agudo, B., & Jimenez-Diaz, G. (2013). Social factors in group recommender systems. ACM Transactions on Intelligent Systems and Technology, 4(1), 8:1–8:30.
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., & Riedl, J. (1994). Grouplens: an open architecture for collaborative filtering of netnews. In Proceedings of ACM 1994 conference on computer supported cooperative work (pp. 175–186). ACM Press.
Schall, D. (2015). Social network-based recommender systems. Springer.
Schiaffino, S., & Amandi, A. (2009). Building an expert travel agent as a software agent. Expert Systems with Applications, 36(2, Part 1), 1291–1299.
Sebastia, L., Giret, A., & Garcia, I. (2011). A multi agent architecture for single user and group recommendation in the tourism domain. International Journal of Artificial Intelligence, 6(11), 161–182.
Shang, S., Hui, P., Kulkarni, S., & Cuff, P. (2011). Wisdom of the crowd: Incorporating social influence in recommendation models. In IEEE 17th international conference on parallel and distributed systems (ICPADS), 2011 (pp. 835–840).
Srivihok, A., & Sukonmanee, P. (2005). E-commerce intelligent agent: personalization travel support agent using q learning. In Proceedings of the 7th international conference on electronic commerce. ICEC 2005 (pp. 287–292). ACM Press.
Young, K., & Srivastava, J. (2007). Modeling information diffusion in implicit networks. In Proceedings of the 9th international conference on electronic commerce (pp. 293–302). ACM Press.
Yu, Z., Zhou, X., Hao, Y., & Gu, J. (2006). Tv program recommendation for multiple viewers based on user profile merging. User Modeling and User-Adapted Interaction, 16(1), 63–82.
Acknowledgments
We would like to thank Soledad Diez González and Matias Urrutia who developed the Hermes system.
This work has been partially funded by ANPCyT through project PICT 2011-0366.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Christensen, I., Schiaffino, S. & Armentano, M. Social group recommendation in the tourism domain. J Intell Inf Syst 47, 209–231 (2016). https://doi.org/10.1007/s10844-016-0400-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-016-0400-0