
Abstract
Individuals with Autism Spectrum Disorders (ASD) succeed at a range of musical tasks. The ability to recognize musical emotion as belonging to one of four categories (happy, sad, scared or peaceful) was assessed in high-functioning adolescents with ASD (N = 26) and adolescents with typical development (TD, N = 26) with comparable performance IQ, auditory working memory, and musical training and experience. When verbal IQ was controlled for, there was no significant effect of diagnostic group. Adolescents with ASD rated the intensity of the emotions similarly to adolescents with TD and reported greater confidence in their responses when they had correctly (vs. incorrectly) recognized the emotions. These findings are reviewed within the context of the amygdala theory of autism.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In Kanner’s (1943) description of 11 children with inborn autistic disturbances of affective contact, 6 showed an interest for music, and since that time, musical abilities have been considered as a relative strength in individuals with autism spectrum disorders (ASD), in comparison to their global profile (Applebaum et al. 1979; Rimland 1964). Above-average auditory processing abilities, including enhanced pitch discrimination (Bonnel et al. 2003; Heaton et al. 1999b) and increased sensitivity to alterations of single pitches in a melody (Heaton et al. 1999b; Mottron et al. 2000) have been observed in children and adolescents with ASD. Children with autism can identify single pitches more accurately and possess better long-term memory for pitches than typically developing children (Heaton et al. 1998, 2008b; Heaton 2003). Music and music therapy have also been shown to have a powerful and lasting effect on a variety of outcome measures among individuals with ASD, facilitating social interaction and general behavioral improvements (Kaplan and Steele 2005; Kim et al. 2008; Whipple 2004).
The communication of emotion is generally regarded to be a primary purpose, intent or effect of music (Juslin and Sloboda 2001; Meyer 1956). Hence, the evidence of preserved musical ability in ASD is intriguing because impairments in processing emotional information are characteristic of autism (Buitelaar et al. 1999; see Hobson 2005 for a review). The relationship between autism and emotions has been studied extensively (Hobson 2005), but few studies have focused on how individuals with ASD perceive emotions conveyed by music.
Children with autism were shown to identify melodies in a major mode as happy and melodies in a minor mode as sad (Heaton et al. 1999a), a distinction that typically developing children can normally accomplish by 3 or 6 years of age depending on study design (Dalla Bella et al. 2001; Kastner and Crowder 1990). Children with ASD are more accurate than children with Down syndrome when asked to associate musical excerpts with visual representations of feelings: anger, fear, love, triumph, and contemplation (Heaton et al. 2008a). However, in that particular study, the effect of diagnosis failed to reach statistical significance when verbal mental age was accounted for. Thus, the authors suggest that emotional deficits present in ASD do not generalize to music and that understanding of music is limited by cognitive function, specifically verbal ability. A detailed comparison of groups for each one of the five emotions included in the study would have been interesting. However, data were only presented for all five emotions collapsed together.
Parents report that affect elicited by music in their children with ASD remains for prolonged periods of time in comparison to what is reported by parents of controls (Levitin et al. 2004). Compared to controls, children and adolescents with ASD are equally distracted by music when it accompanies moving visual images (Bhatara et al. 2009). Adults with ASD respond to and appreciate music in a fashion similar to the typical listener, as indicated by a semi-structured interview (Allen et al. 2009). However, adults with ASD tend to describe the effects of music in terms of arousal or internally focused language (e.g. calm, tense) rather than emotional language (e.g. happy, sad).
Thus far, investigating emotion perception via tasks of identification, recognition or categorization through music in ASD has yielded interesting results and warrants further exploration. In addition, employing musical stimuli addresses methodological concerns encountered in more traditional studies of emotion recognition. For one, it reduces reliance on verbal material. This is important because it has been suggested that individuals with ASD who have higher levels of cognitive functioning (indicated by higher verbal or nonverbal mental age or IQ) can adopt cognitive strategies enabling them to solve emotion recognition tasks successfully (Hobson 1986; Ozonoff et al. 1990; Teunisse and de Gelder 2001). Emotion research could also benefit from alternatives to the photographs and line drawings of faces or parts of faces often used as experimental stimuli. Behavioral and imaging data suggests that children and adults with ASD do not process facial cues, specifically the eyes, in the same way as typically developing individuals (Gross 2004; Pelphrey et al. 2002; Schultz et al. 2000; Spezio et al. 2007). This may cause differences in emotion recognition in ASD that are specific to faces but do not appear across other domains.
Studies in the auditory domain suggest that children with autism recognize basic emotions such as happiness, sadness, and anger in nonverbal vocalizations (Ozonoff et al. 1990) and adults with Asperger syndrome can recognize these same emotions in the voice (O’Connor 2007). However, adults with high-functioning autism or Asperger syndrome are impaired at recognizing complex emotions or mental states portrayed by the voice such as being hopeful, concerned, nervous, or embarrassed (Golan et al. 2007; Rutherford et al. 2002). Individuals with ASD have difficulty matching nonverbal vocalizations (Hobson 1986) and speech to videos (Loveland et al. 1995) or pictures (O’Connor 2007) of people displaying basic emotions. In addition, level of functioning (low vs. high), but not diagnosis (autism vs. control), can distinguish among children, adolescents, and young adults in their ability to recognize basic emotions conveyed in videos where verbal and/or nonverbal emotional cues are emphasized to varying degrees (Loveland et al. 1997).
Although most studies have found that, when verbal ability is considered, children with autism (Castelli 2005; Ozonoff et al. 1990) and adults with high-functioning autism (Baron-Cohen et al. 1997; Neumann et al. 2006) can recognize facial expressions of basic emotions, some studies report deficits in similar tasks (Baron-Cohen et al. 1993; Celani et al. 1999) that have been attributed to impaired recognition of one emotion in particular: fear (Pelphrey et al. 2002). For example, Teunisse and de Gelder (2001) presented faces which were morphed along a continuum from one emotion to another. They found that young adults with high-functioning autism and typically developing young adults discriminate happy versus sad similarly, but that they discriminate angry versus sad and angry versus afraid differently.
The amygdala is known to play a role in the processing of complex mental states including social emotions (Adolphs et al. 2002; Baron-Cohen et al. 1999) and the recognition of fear in both facial expressions (Adolphs et al. 1994, 1995) and auditory stimuli (Scott et al. 1997). Adults with unilateral amygdala resection have difficulty recognizing scary and peaceful music (Gosselin et al. 2005; peaceful can be thought of as an antonym of scary, hence its use). Higher functioning adolescents and adults with ASD, like patients with amygdala damage, show difficulty identifying eye-gaze direction and facial expressions of fear (Howard et al. 2000) and trustworthiness (Adolphs et al. 2001). They also show an atypical pattern of fear acquisition (Gaigg and Bowler 2007). Although they exhibit appropriate electrodermal response to distress cues, they show hyporesponsiveness to threatening stimuli (Blair 1999). Findings from event-related potential (ERP) studies demonstrate that 3–4 year olds with ASD do not exhibit the typical N300 and negative slow wave responses to fearful versus neutral faces (Dawson et al. 2004). Thus, Baron-Cohen et al. (2000) proposed the “amygdala theory of autism,” which posits that reduced functioning of the amygdala (hypoamygdalism) or circuits including it contribute to social and emotional deficits and may explain abnormal responses to fear in autism. However, animal models (Amaral et al. 2003) and psychological assessments of a patient (S.M.) with bilateral amygdala damage (Tranel et al. 2006) suggest that amygdala damage does not impair social behavior nor the range of affects and emotions, although it alters reactions to or sense of fear, danger, and distrust. Specifically, S.M.’s recognition of scary music is impaired (Gosselin et al. 2007). Thus, Amaral et al. (2003) suggest that atypical amygdala functioning accounts primarily for increased anxieties in ASD rather than social deficits per se.
As noted by Baron-Cohen et al. (2000), research on emotional responsiveness including fear represents an indirect way to confirm the amygdala theory of autism in ASD (the direct way requiring imaging techniques). This has fuelled many studies focusing on fear recognition in ASD, most of which have been conducted in the visual domain. The experimental task presented here seeks to assess emotion recognition in a different modality: music. To the authors’ knowledge, only one study to date (Heaton et al. 2008a) has included scary music in tasks of emotion recognition in ASD but data for all the emotions presented were analyzed together, i.e. no separate analysis was carried out on results for recognition of scary music specifically.
Based on the experiments conducted by Gosselin et al. (2005, 2007), the present study explores the ability of individuals with ASD to recognize or categorize different emotions in music using a forced-choice experimental procedure and explores perception of emotional intensity in music. Happy, sad, scary, and peaceful music are employed to compare results with those obtained in previous studies (Gosselin et al. 2005, 2007; Heaton et al. 1999a). It is hypothesized that children and adolescents with ASD will be able to recognize happy and sad music (per Heaton et al. 1999a). However, the amygdala theory of autism (Baron-Cohen et al. 2000) and studies including patients with damage to the amygdala (see Gosselin et al. 2005), suggest that individuals with ASD will exhibit difficulties recognizing scary and peaceful music, and will provide lower ratings of emotional intensity in comparison to controls. In addition, self-awareness of emotion perception will be assessed through confidence ratings given by participants. This has not been studied extensively, therefore, confidence ratings are being used here as exploratory measures. This will allow for a test of Hill et al.’s (2004) argument that, although individuals with ASD show some degree of insight, there seems to be a dissociation between what they think, feel or experience and their descriptions of their thoughts, feelings, and experiences.
Method
Participants
Two groups (typically developing; ASD) composed of 26 participants each (52 participants in total) were included in the final sample retained for the analyses (see Table 1). Given the mean age of the participants (years: months; ASD: M = 13:7, SD = 1:1, range of 10:10 to 19:4; TD: M = 13:6, SD = 2:2, range of 9:11 to 17:9) and for brevity, we will refer to the participants collectively as adolescents rather than children and adolescents from this point on.
Seventy-nine participants were initially recruited (46 typically developing adolescents, TD, and 33 high-functioning adolescents with ASD). Participants with ASD were then group-matched to participants with TD so that performance and full scale IQ scores (PIQ and FSIQ) obtained with the Wechsler Abbreviated Scale of Intelligence (WASI: Wechsler 1999) differed by less than one standard deviation between groups (see Table 1). However, a statistical difference remained between groups on verbal IQ, and consequently ANCOVAs and stepwise linear regression analyses were used in the main analyses reported below to fully account for the impact of verbal ability on task performance. The final ASD group comprised 3 adolescents with Autism, 13 with Asperger, and 10 with PDD-NOS. Independent samples t-tests confirmed no significant difference between groups on the following: (a) chronological age, (b) sequential auditory processing and auditory working memory, and (c) number of years of musical training and number of instruments played. Auditory processing and working memory (b above) were assessed using the Digit Span and Letter-Number Sequencing subtests of the Wechsler Intelligence Scale for Children, 4th edition (WISC-IV: Wechsler 2003) because the experimental task requires use of temporal auditory memory. Musical training and experience (c above) was assessed by combining information from the Salk and McGill Musical Inventory (SAMMI, Levitin et al. 2004) completed by parents and a semi-structured interview conducted with the participants (Queen’s University Music Questionnaire—Revised, based on Cuddy et al. 2005).
Participants with TD were recruited through word of mouth, and advertisements placed at the university and posted in four schools in Montreal (two elementary schools and two high schools). Participants with ASD were recruited through a specialized clinic for ASD at the Montreal Children’s Hospital (25 participants) and a Montreal school offering special education for children with ASD (8 participants). All participants with ASD had received a diagnosis by a specialized medical team (child psychiatrist, developmental psychologist, etc.) based on DSM-IV criteria.
Parents filled out the Social Responsiveness Scale (SRS; Constantino et al. 2003) and the Social Communication Questionnaire (SCQ; Rutter et al. 2003). This provided descriptive information (and converging evidence of the diagnosis) in the case of adolescents with ASD. It also confirmed that participants with TD did not show signs of ASD. Before proceeding to group-matching, 3 adolescents originally classified as TD had been excluded because they presented a neurodevelopmental or psychiatric disorder that interfered with testing, ADHD for example. None of the profiles for the remaining adolescents with TD indicated the possibility of ASD or other disorders. Two participants with ASD included in the 26 participants retained for analyses did not meet the cut-off for ASD on the SCQ, a raw score of 15, but they scored in the ASD range on the SRS. Therefore, they were retained in the analyses.
Stimulus Creation and Experimental Procedure
A musical task was created by the present authors to assess recognition or categorization of emotions combining the methodologies described by Gosselin et al. (2005, 2007) and Rapport et al. (2002). This task was validated with 20 participants (19–39 years old; 7 men and 13 women) recruited through word of mouth and advertisements placed at the university in order to evaluate how normal healthy adults respond to the task and to infer probable reactions in adolescents with typical development and ASD. The validation study included 28 music clips that had previously been used in the last author’s laboratory to target happiness, sadness, scariness, and peacefulness. Of those, the 20 music clipsFootnote 1 (five for each target emotion) for which the highest agreement was obtained were retained for the experiment (see “Appendix 1”).
Before testing, participants with TD and ASD were asked to identify the emotions depicted by 4 faces (without labels) and positive feedback or correction was given. The 4 faces were then presented with the appropriate label (happy, sad, scared, and peaceful). During testing, a “judgment screen” appeared on the computer 7 s after the beginning of exposure to the music clip. Participants chose which of the 4 faces coupled with the appropriate label best described the music clip. There was only one “judgment screen”; the same 4 faces and labels were presented for each musical stimulus (see “Appendix 2”). These 4 emotions were employed in order to present the same emotions that Gosselin et al. (2005, 2007) had focused on for patients with damage to the amygdala. A forced-choice procedure was used per previous research (Juslin and Sloboda 2001) and thus the experimental task will be referred to from this point on as a task of emotion recognition.
To avoid possible stimulus or participant biases due to factors such as age, gender and ethnicity, line drawings of faces were used instead of pictures (visual stimuli adapted from Hess et al. 2004, 2005). Line drawings have also been successfully employed in the past in experiments with individuals with ASD (Heaton et al. 1999a). The order of presentation of the music clips was randomized for each participant. Responses were considered to be “correct” (and assigned a score of 1) if the emotion selected by the participant corresponded to the “intended emotion”.Footnote 2 Responses were considered “incorrect” (and assigned a score of 0) if the selection did not match the “intended emotion.” The maximum possible score was 20 for the total score and 5 for the score for each emotion. Participants also rated how intensely the music clip conveyed the selected emotion by using the computer mouse to move a slider along a continuous scale of 32 cm where ratings ranged from slightly intense (0) to very intense (1). With an identical slider scale, participants rated how confident they were that they had correctly recognized the emotion from not at all confident (0) to very confident (1). Response times were also obtained for the time to select an emotion. The response times reported do not include the 7 s listening period.
Participants heard the music clips through stereo loudspeakers (Advent Powered Partners 570, Audiovox Electronics Corporation, New York, 2004) connected to a laptop computer (Powerbook G4 15’’, Apple Computer Inc., 2006). The task was programmed in PsiExp (for the graphics, Smith 1995) and MaxMSPRunTime (for the sounds, Cycling 74/IRCAM, 2005). The music clips’ durations were between 30 and 50 s. Equal subjective loudness was obtained by collecting loudness matching judgments from 5 trained listeners in a separate validation study, a method more reliable than using acoustical or electrical measurements for time-varying stimuli such as music (Caclin et al. 2005; Marozeau et al. 2003). Each musical clip had a sound pressure level varying between 50 and 70 dB A-weighted at the position of the participants’ ears as measured with a Brüel and Kjær 2203 sound level meter fitted with a Brüel and Kjær 4144 omnidirectional microphone (Brüel and Kjær, Naerum, Denmark).
Participants were tested individually in a soundproof room. The emotion recognition task lasted between 10 and 20 min and was included as part of a larger experimental protocol that lasted approximately 3 h. Informed consent was obtained from parents and participants. Participants and parents were debriefed at the end of each session. Participants received a $20 gift certificate for a local music store as compensation and parking was also paid for. The research received ethical approval from both McGill University and McGill University Health Center Research Ethics Boards.
Statistical Analyses
Repeated measures ANOVA and ANCOVAs were performed to assess performance on the emotion recognition task. The role of VIQ on task performance was accounted for by ANCOVAs. Linear regressions and ANOVAs assessed various predictors of task performance including VIQ and gender. These analyses were repeated to assess recognition of each emotion with a specific interest in recognition of scary and peaceful music given the amygdala theory of autism. This led to an analysis of patterns of confusions, i.e. which emotion was selected instead of the “intended emotion” when “incorrect” responses were given, with inter-rater agreement and Chi-Square test. Patterns of confusions were compared between groups with intraclass correlations. Next, correlations were performed on ratings of intensity and confidence and response times. MANOVA and ANOVAs were performed on these measures with a specific interest for group differences in terms of intensity ratings given the amygdala theory of autism. Confidence ratings were compared within the ASD group to explore self-awareness of emotion recognition in ASD in line with Hill et al.s’ (2004) work. Finally, the impact of musical training and experience on task performance was evaluated by creating groups based on these factors and ANOVAs and ANCOVAs were performed.
Results
Emotion Recognition
Performance of each group on emotion recognition is reported in Table 2. Visual examination of Table 2 reveals that, at least in terms of raw scores on the task, the mean performances of the ASD group are slightly below those of the TD group. Repeated measures ANOVA and ANCOVAs (Table 3) were conducted with “intended emotion” as a within-subject factor with four levels (happy, sad, scared, peaceful), diagnostic group (ASD and TD) as the between-subject factor, and VIQ as a covariate for the ANCOVA. Significant main effects were found for both diagnostic group and “intended emotion” (ANOVA in Table 3); the participants with ASD were less accurate than participants with TD, but the effects failed to reach significance when VIQ was considered as a covariate (First ANCOVA in Table 3). The diagnostic group’s effect size decreased form a medium-large to a medium-small effect when VIQ was considered as a covariate. A significant main effect was found for the VIQ covariate with a medium to large effect size. There was no significant interaction between “intended emotion” and diagnostic group, indicating that some emotions were recognized with greater accuracy than others and that this pattern was similar for both groups. A follow-up repeated measures ANCOVA (Second ANCOVA in Table 3) showed a significant interaction between VIQ and diagnostic group, indicating that the effect of VIQ on task performance was not the same for each diagnostic group.
Given the significant interaction effect between VIQ and diagnostic group, stepwise regressions were performed for each diagnostic group and for both groups combined. The outcome variable to be predicted by the regression models was the total score on the emotion recognition task (max = 20), which differed between groups (Table 2). The following predictors were entered: chronological age, VIQ, PIQ, Social Responsiveness Scale (t-score), Social Communication Questionnaire (raw score), total digit span (scaled score), letter-number sequencing (scaled score), number of years of musical training and number of instruments played. VIQ was retained as a significant predictor for both groups combined, R 2VIQ = .15, B = .06, SE B = .02, p < .01, as well as for the ASD group, R 2VIQ = .17, B = .07, SE B = .03, p = .04; the other predictors were not retained. For the TD group, none of the predictors were significant. Regression slopes for the total score on the emotion recognition task and VIQ are presented for both groups in Fig. 1. Thus, VIQ was related to task performance for the ASD group but not for the TD group (confirming the Diagnostic group × VIQ effect previously found). The effect of gender on task performance was explored through ANOVA instead of a linear regression (because gender is a categorical variable). That ANOVA revealed that the effect of gender on task performance was not significant for both groups combined nor for the groups considered separately.

Regression slopes for recognition of musical “intended emotion” (total score) and VIQ
Specific Emotions
Analyses were conducted to assess specific a priori hypotheses regarding separate recognition of each of the four emotions in ASD. Bonferroni adjusted one-tailed t-tests, with an adjusted alpha level of .013, failed to show significant differences between the ASD and TD groups for recognizing music as happy, sad, and scared (Table 2). An ANCOVA revealed a significant effect of VIQ for recognition of music as scared but there were no differences between groups whether or not VIQ was considered as a covariate for this emotion. A significant diagnostic group difference was found for recognizing peacefulness, with the participants with ASD being less accurate than participants with TD, but the group effect did not remain significant when the effect of VIQ was controlled for.
Given that the diagnostic group effect on the score for recognizing peaceful music did not remain significant when VIQ was controlled for and that the effect of VIQ was not significant, a stepwise regression was performed to assess if any of the other potential predictors previously considered for the total score (see Table 1) predicted the score for recognizing peaceful music. Number of instruments played was retained as the only significant predictor, R 2Instruments = .09, B = .33, SE B = .15, p = .04, and VIQ was not retained. An ANOVA revealed that the effect of gender for recognizing peaceful music was not significant for both groups combined or for the groups considered separately.
Analyses of Confusion Matrices
Additional analyses were conducted to further investigate the participants’ responses. Measures of inter-rater agreement (Cohen 1960) performed on the data presented in Table 4 revealed that the majority of responses fell along the diagonal, ASD: κ = .63; 95% CI: .58–.68 and TD: κ = .73; 95% CI: .68–.78, indicating consistent agreement between the “intended emotion” and the emotion selected. Follow-up analyses were performed to assess the possibility that the three remaining (incorrect) emotions were equally confusable. Taking the diagonal entries as fixed values, Chi-Square tests conducted on the off-diagonal cells (incorrect responses) revealed that the three remaining emotions were not selected equally often (Table 4); seven comparisons showed significance and one showed a trend. Visual inspection of Table 4 suggests that peacefulness tended to be confused with happiness or sadness for both diagnostic groups. The pattern of confusions made by both groups was not significantly different; that is, if an emotion was confused with another one, this was the case equally for both groups as demonstrated by the intraclass correlation coefficients (Shrout and Fleiss 1979) obtained for each “intended emotion”, Happy: .99, Sad: .98, Scared: .99, Peaceful: .95.
Intensity and Confidence Ratings and Response Times
Accuracy (correct vs. incorrect emotion recognition) was significantly positively correlated to ratings of intensity, Kendall’s tau (τ) = .14, p ≤ .01, and to ratings of confidence, Kendall’s tau (τ) = .16, p ≤ .01. In turn, intensity and confidence ratings were correlated to each other, Pearson r = .63, p ≤ .01, as revealed by two-tailed Pearson correlations. These correlations remained significant when groups were analyzed separately. In addition, response times were significantly negatively correlated with confidence ratings for participants with TD, Pearson r = −.23, p ≤ .01, indicating that shorter response times were associated with higher confidence ratings, but this failed to reach significance for participants with ASD, Pearson r = −.04, ns.
A MANOVA was performed with the intensity ratings, confidence ratings, and response times as dependent variables. MANOVA was selected to take into account the associations among the dependent variables. Diagnostic group (ASD, TD) and response accuracy (correct or incorrect emotion recognition) were considered as independent variables.
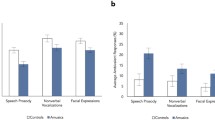
The difference between diagnostic groups in terms of intensity ratings was nonsignificant, F(1,1040) = 2.13, p = .15. Correct responses were associated with higher intensity ratings than incorrect responses, F(1,1040) = 31.14, p < .01. The interaction between diagnostic group and accuracy was nonsignificant, F(1,1040) = .77, p = .38 (Fig. 2).

Means and standard errors for intensity ratings
Although the TD group generally gave higher confidence ratings, F(1,1040) = 21.10, p < .01, confidence ratings were lower for both the TD and the ASD group when their responses were incorrect, F(1,1040) = 37.68, p < .01. This pattern of response did not differ between groups, F(1,1040) = 2.76, p = .10 (Fig. 3). An additional ANOVA assessing confidence ratings given by participants with ASD only confirmed they gave higher confidence ratings when they had correctly (vs. incorrectly) selected the “intended emotion”, F(1, 520) = 27.64, p < .01.

Means and standard errors for confidence ratings
For response times considered as dependent variables, the difference between groups was marginally significant, F(1,1040) = 3.27, p = .07, with participants with TD responding slightly faster than participants with ASD; the difference between correct and incorrect responses was not significant, F(1,1040) = 2.46, p = .12, nor was the interaction between diagnostic group and accuracy, F(1,1040) = .12, p = .73.
Musical Training and Experience
Although groups were matched for musical training and experience, additional analyses were performed to further investigate the impact of musical training and experience. Two groups were created based on the data collected with the Salk and McGill Musical Inventory (SAMMI) and the Queen’s University Music Questionnaire—Revised (see “Methods”). Participants were included in the first group if they played at least one musical instrument and if they had received at least 2 years of musical training. Ten adolescents with TD and 18 with ASD were included in this “musicians” group (N = 28). The remaining participants, 16 with TD and 8 with ASD, were included in the second “non-musicians” group (N = 24). A repeated measures ANOVA was performed with “intended emotion” as a within-subject factor and musical training and experience as the between-subject factor (Table 5). Significant main effects of “intended emotion” and musical training and experience were found. The analysis was repeated as an ANCOVA with VIQ as the covariate. The effect of VIQ was significant, while the effects of both “intended emotion” and musical training and experience failed to reach significance. Two repeated measures ANCOVAs were then performed separately for the participants with TD and ASD. For participants with TD, no significant effects were found. For participants with ASD, the effect of VIQ was significant, while the effects of both “intended emotion” and musical training and experience failed to reach significance.
Discussion
The current study was conducted to complement the existing, albeit scarce, literature on emotion perception in music in ASD and to discover whether the deficits in emotion recognition and categorization reported in the visual domain for individuals with ASD might also exist in the musical domain. Stimuli included happy, sad, scary, and peaceful music to compare results with those previously reported for patients with damage to the amygdala (Gosselin et al. 2005, 2007). Thus, the experimental task allowed for a test of the amygdala theory of autism at the perceptual level in the musical domain. Ratings of emotional intensity were also collected to assess the amygdala theory of autism. Self-awareness of emotional recognition in music by adolescents with ASD was also explored via confidence ratings.
Emotion Recognition
The group means for raw scores revealed that adolescents with ASD were not as accurate as adolescents with TD at recognizing or categorizing emotions (happy, sad, scared, peaceful) represented in musical excerpts, but when verbal ability was accounted for as a covariate, the two groups did not differ statistically. The lack of a significant interaction between “intended emotion” and diagnostic group reveals that both groups exhibited a similar pattern of performance in the task, meaning that emotions recognized with greater accuracy by participants with TD were also recognized with greater accuracy by participants with ASD. In other words, some emotions are easier to recognize in music, whether or not an adolescent has ASD, and verbal ability is related to the ability to make such judgments accurately. This was also supported by high intraclass correlation coefficients found when analyzing patterns of confusions.
Burack et al. (2004) emphasize the importance of interpreting findings of studies on ASD within a developmental context while taking into account the role of cognitive functioning on task performance and, consequently, on group differences in performance. In the present study, the effects of diagnostic group on task performance were not significant once VIQ was controlled for. This is paralleled by a lower effect size associated to diagnostic group in the ANCOVA with VIQ than in the ANOVA (without VIQ). Task performance for the group of participants with TD was not predicted by any of the factors entered in a regression model including chronological age, VIQ, PIQ, measures of auditory memory, and musical training and experience, while VIQ was retained as the only significant predictor of total task performance for participants with ASD (Fig. 1). These results may be because the groups included in this study were matched more closely on PIQ than VIQ or that the variability and range in VIQ and on the emotion recognition task were greater for the ASD group. To the authors’ knowledge, only one study to date has reported results on a task of emotion recognition in music wherein a group of participants with autism were matched to two different control groups according to verbal or nonverbal IQ (Heaton et al. 1999a). There, the two matching procedures did not yield different results, i.e. both types of matching showed that children with ASD could distinguish happy and sad music as accurately as both controls groups. Given this lack of difference and given that participants with ASD in the present study were high-functioning, the fact that groups were matched more closely on PIQ than VIQ does not invalidate the results, although it can limit interpretations. It would be instructive to conduct this study with lower-functioning children with ASD and with younger participants to discover whether the findings can be replicated, and thus, further understand the contribution of verbal ability to emotion recognition in music. Findings reported here are not unexpected given the existing evidence that, in ASD, performance on emotion recognition tasks can be mediated by cognitive function and, more specifically, by verbal ability (Heaton et al. 2008a; Hobson 1986; Ozonoff et al. 1990; Teunisse and de Gelder 2001). Findings also support the two-threshold model proposed by Happé (1995), which states that a higher level of verbal ability is required for children with ASD to succeed on mentalizing tasks in comparison to controls who can succeed while exhibiting lower levels of verbal ability. In line with this, VIQ predicted task performance for participants with ASD (see Fig. 1) in the present study while performance of participants with TD seemed to be unrelated to VIQ.
In addition to controlling for VIQ, the impact of gender on task performance was controlled for statistically because an uneven number of girls and boys with ASD participated in the study, and an uneven number of men and women participated in the validation study. This could represent a limitation to the study; however, there was no effect of gender on task performance for participants with TD (similar number of TD boys and girls participated in the study) and participants with ASD, and for both groups combined. Although this suggests that gender does not have a crucial impact on emotion recognition in music in high-functioning adolescents with ASD, more research is needed to address this issue. For instance, gender may have a greater impact on emotion recognition in music in younger children with ASD or in lower functioning individuals with ASD. In typical development, emotion recognition in music develops at least until the age of 8 (Heaton et al. 2008b).
Specific Emotions
When “intended emotions” were considered separately, performance of participants with ASD and TD could not be distinguished when asked to recognize music as happy, sad, or scared, although participants with ASD were slightly less accurate than participants with TD (but not statistically so). Thus, recognition of basic emotions in music is comparable in ASD and TD, as is the case for recognition of basic emotions in nonverbal vocalizations (Ozonoff et al. 1990), the voice (O’Connor 2007) and facial expressions (Baron-Cohen et al. 1997; Castelli 2005; Neumann, et al. 2006; Ozonoff et al. 1990). In addition, the present results replicate findings by Heaton et al. (1999a) that children with ASD can distinguish happy and sad music.
Scary and Peaceful Music and the Amygdala Theory of Autism
Notably, it had not been predicted that adolescents with ASD would be able to recognize scary and peaceful music (for peaceful music, the group effect was not significant when the effect of VIQ was controlled for) as accurately as adolescents with TD. These results fail to replicate those of Gosselin et al. (2005, 2007) for patients with damage to the amygdala. Thus, emotion recognition in music among individuals with ASD differs from that in patients with damage to the amygdala, in the sense that individuals with ASD can recognize some musical emotions that patients with damage to the amygdala cannot recognize such as scary and peaceful music. This observation, combined with the lack of group difference for ratings of emotional intensity, cannot be reconciled with the amygdala theory of autism at the perceptual level. Emotion perception in music in ASD does not seem out of norms. Data from psychophysiological measures such as electrodermal response, heart rate, and imaging techniques could potentially inform this issue, but for now, the behavioral results presented in the current study indicate that this may well be the case. Imaging techniques could be considered in future research to assess amygdala activation associated to musical emotion recognition in comparison to activation of other brain areas thought to be atypically developed in ASD such as the frontal cortex (see Hill 2004, for a review) while considering possible atypical neural connectivity in ASD (Belmonte et al. 2004; Just et al. 2004). Exploring recognition of musical emotions in ASD with the help of recent imaging techniques, such as diffusion tensor imaging, seems promising, as well as comparing emotion recognition in many modalities (visual: still images, videos; auditory: voice, non-voice). In addition to amygdala activation, it will also be important to consider other areas implicated in emotional processing of music such as the temporal poles (Koelsch et al. 2006) and areas involved in pitch processing such as Heschl’s gyrus in the auditory cortex (Patterson et al. 2002).
The Case of Peaceful Music
When many potential predictors of task performance were considered, the number of instruments played—which averaged near 1 for both diagnostic groups—was retained as a predictor for recognizing peaceful music while VIQ was not. When peaceful music was not correctly recognized, it tended to be confused with happy or sad, which was the case for both diagnostic groups. Interestingly, typically developing adults who participated in a validation study for stimulus selection were also less accurate at recognizing peaceful music than the other three emotions (see “Appendix 1”), which suggests that peaceful music is generally the most difficult of the four emotions to recognize. A possible explanation for this is that a state of peacefulness can be thought of as a complex emotion or mental state whereas the other three emotions included in the experimental task are basic emotions (as per Golan et al. 2007; Rutherford et al. 2002). Findings reported here are thus coherent with previous findings, which suggest that individuals with ASD have difficulty recognizing complex emotions and mental states in the voice (Golan et al. 2007; Rutherford et al. 2002).
Perhaps, difficulties presented by both groups can be attributed to the nature of the peaceful stimuli used, which may represent a limitation of this study. However, it seems more likely that the difficulty in recognizing peaceful music may be attributable to a quality inherent to peaceful music itself; boundaries or conventions for what is considered to be peaceful music may be ambiguous. This could partly explain why group differences were nonsignificant when verbal ability was controlled for. Teunisse and de Gelder (2001) showed that, although individuals with ASD can assign emotions to categories, the way they classify representation of emotions falling between category boundaries is different from typically developing individuals. Thus, the inaccurate recognition of music meant to be peaceful (an ambiguous category), by participants with ASD, can be seen as consistent with work from Teunisse and de Gelder. To explore this question, future studies of emotion recognition in music could examine classification of emotions along a continuum instead or in addition to using a forced-choice method. Allowing participants to recognize more than one emotion per stimulus could also be informative.
Intensity and Confidence Ratings and Response Times
Emotion recognition accuracy was found to be associated to ratings of emotional intensity, confidence in task performance, and response times. Participants rated music as more emotionally intense when they correctly recognized the “intended emotion” and this was the case for both groups. Like participants with TD, participants with ASD reported being more confident of their responses when they correctly (vs. incorrectly) recognized the “intended emotion.” Thus, one can argue that high-functioning adolescents with ASD can perceive and relate to the emotional quality of music similarly to the typical listener. In addition, confidence ratings made by participants with ASD suggest awareness of their response accuracy, which supports the claim made by Hill et al. (2004) that individuals with ASD show some degree of insight into their own thought processes. Whether or not there is a dissociation between what adolescents with ASD think, feel or experience while listening to music and their descriptions of their thoughts, feelings, and experiences remains to be addressed. Future work using psychophysiological measures (electrodermal response, heart rate, etc.) could inform this issue. In addition, different questions can be asked of participants in future studies such as how music makes them feel, how it makes someone else feel, which music they prefer, etc. Interviews on experiences with music performed by Allen et al. (2009) with adults with ASD could be adapted to adolescents in pursuit of these questions.
Implications for ASD
Results from the current study suggest that high-functioning adolescents with ASD can recognize basic emotions in music. Specifically, this is the case for happy, sad, and scary music. These findings underscore the need to vary the types of stimuli used to test emotion recognition in ASD and, moreover, not to limit stimuli to the visual domain. Studies of emotion recognition, so far, are more consistent in the musical domain than the visual domain, and it may be due to the nature of music. Although music is initially a social product created by a composer, a listener does not have to enter into a direct interpersonal interaction with the composer in order to appreciate the music. This may explain why the participants with ASD were able to interpret the music’s meaning in a similar way as participants with TD. These findings therefore suggest that emotion processing deficits in ASD are domain specific, arising in response to social stimuli and situations specified in the DSM-IV criteria for pervasive developmental disorders and may not generalize to other domains such as music.
Music seems to be a channel through which emotions can be communicated to individuals with ASD. Whether individuals with ASD feel emotions from music or process them similarly to the typical listener at the neural level remains to be verified by additional behavioral, physiological, and imaging measures. Further research comparing emotion recognition in many modalities and including other basic emotions is needed.
In closing, this study’s findings can be applied in the context of music therapy or other intervention programs to target social, communicative, and emotional skills. Although findings do not suggest music therapy to be a panacea, they do not contradict use of music therapy in ASD. Music perception seems to be a relative strength for individuals with ASD, in the context of a profile characterized by strengths and weaknesses (Happé and Frith 1994; Happé 1999). Music therapy has yielded positive increases in verbal and nonverbal communication in ASD (Gold et al. 2006). Musical soundtracks influence emotional interpretation of stories in typically developing children (Ziv and Goshen 2006). Music may help individuals with ASD understand basic emotions and/or social situations in everyday life. Verbal instruction techniques meant to teach children with ASD to perceive and express emotions have been shown to be more efficient with the addition of background music targeting the emotions to be learned (Katagiri 2009). Given the accessibility of music, children with ASD and their parents could create lists of songs associated to basic emotions or social situations that they refer to or play to demonstrate which emotion a family member is feeling or felt. Unfortunately, these efforts will be limited by the reality that not all emotions, to say nothing of complex mental states, can be reliably expressed through music. Future studies could also examine if music can be used efficiently for a variety of purposes such as helping individuals with ASD regulate their mood, reduce anxiety or increase concentration.
Notes
Recordings of the stimuli can be found at: http://www.psych.mcgill.ca/labs/levitin//MusicalEmotionRecognition_Quintin_et_al_2010.htm
Here, “intended emotion” does not mean to imply that this was necessarily the emotion intended by the composer; rather, it is the emotion most often identified by participants in validation studies, and thus, is the emotion that the experimenters “intended” the participant to recognize., i.e. select in the recognition task.
References
Adolphs, R., Baron-Cohen, S., & Tranel, D. (2002). Impaired recognition of social emotions following amygdala damage. Journal of Cognitive Neuroscience, 14(8), 1264–1274. doi:10.1162/089892902760807258.
Adolphs, R., Sears, L., & Piven, J. (2001). Abnormal processing of social information from faces in autism. Journal of Cognitive Neuroscience, 13(2), 232–240. doi:10.1162/089892901564289.
Adolphs, R., Tranel, D., Damasio, H., & Damasio, A. (1994). Impaired recognition of emotion in facial expressions following bilateral damage to the amygdala. Nature, 372, 669–672. doi:10.1038/372669a0.
Adolphs, R., Tranel, D., Damasio, H., & Damasio, A. (1995). Fear and the human amygdala. Journal of Neuroscience, 15(9), 5879–5891.
Allen, R., Hill, E., & Heaton, P. (2009). ‘Hath charms to soothe…’: An exploratory study of how high-functioning adults with ASD experience music. Autism, 13(1), 21–41. doi:10.1177/1362361307098511.
Amaral, D. G., Baumann, M. D., & Schuman, C. M. (2003). The amgdala and autism: implications from non-human primate studies. Genes, Brain and Behavior, 2(5), 295–302. doi:10.1034/j.1601-183X.2003.00043.x.
Applebaum, E., Egel, A. L., Koegel, R. L., & Imhoff, B. (1979). Measuring musical abilities of autistic children. Journal of Autism and Developmental Disorders, 9, 279–285. doi:10.1007/BF01531742.
Baron-Cohen, S., Ring, H. A., Bullmore, E. T., Wheelwright, S., Ashwin, C., & Williams, S. C. R. (2000). The amygdala theory of autism. Neuroscience and Biobehavioral Reviews, 24(3), 355–364. doi:10.1016/S0149-7634(00)00011-7.
Baron-Cohen, S., Ring, H., Wheelwright, S., Bullmore, E., Brammer, M., Simmons, A., et al. (1999). Social intelligence in the normal and autistic brain: an fMRI study. European Journal of Neuroscience, 11, 1891–1898. doi:10.1046/j.1460-9568.1999.00621.x.
Baron-Cohen, S., Spitz, A., & Cross, P. (1993). Do children with autism recognise surprise? A research note. Cognition and Emotion, 7(6), 507–516. doi:10.1080/02699939308409202.
Baron-Cohen, S., Wheelwright, S., & Joliffe, T. (1997). Is there a “Language of the eyes”? Evidence from normal adults and adults with autism or Asperger syndrome. Visual Cognition, 4(3), 311–331. doi:10.1080/713756761.
Belmonte, M. K., Cook, E. H., Anderson, G. M., Rubenstein, J. L. R., Greenough, W. T., Beckel-Mithchener, A., et al. (2004). Autism as a disorder of neural information processing: Directions for research and targets for therapy. Molecular Psychiatry, 9, 646–663.
Bhatara, A. K., Quintin, E. M., Heaton, P., Fombonne, E., & Levitin, D. J. (2009). The effect of music on social attribution in adolescents with autism spectrum disorders. Child Neuropsychology, 15, 375–396. doi:10.1080/09297040802603653.
Blair, R. J. R. (1999). Psychophysiological responsiveness to the distress of others in children with autism. Personality and Individual Differences, 26, 477–485. doi:10.1016/S0191-8869(98)00154-8.
Bonnel, A., Mottron, L., Peretz, I., Trudel, M., Gallun, E., & Bonnel, A.-M. (2003). Enhanced pitch sensitivity in individuals with autism: A signal detection analysis. Journal of Cognitive Neuroscience, 15(2), 226–235. doi:10.1162/089892903321208169.
Buitelaar, J. K., van der Wees, M., Swaab-Barneveld, H., & van der Gaag, R. J. (1999). Verbal memory and performance IQ predict theory of mind and emotion recognition ability in children with autistic spectrum disorders and in psychiatric control children. Journal of Child Psychology and Psychiatry, 46(6), 869–881. doi:10.1111/1469-7610.00505.
Burack, J. A., Iarocci, G., Flanagan, T. D., & Bowler, D. M. (2004). On mosaics and melting pots: Conceptual considerations of comparison and matching strategies. Journal of Autism and Developmental Disorders, 34(1), 65–73. doi:10.1023/B:JADD.0000018076.90715.00.
Caclin, A., McAdams, S., Smith, B. K., & Winsberg, S. (2005). Acoustic correlates of timbre space dimensions: A confirmatory study using synthetic tones. Journal of the Acoustical Society of America, 118(1), 471–482. doi:10.1121/1.1929229.
Castelli, F. (2005). Understanding emotions from standardized facial expressions in autism and normal development. Autism, 9(4), 428–449. doi:10.1177/1362361305056082.
Celani, G., Battacchi, M. W., & Arcidiacono, L. (1999). The understanding of the emotional meaning of facial expressions in people with autism. Journal of Autism and Developmental Disorders, 29(1), 57–66. doi:10.1023/A:1025970600181.
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20, 213–220. doi:10.1177/001316446002000104.
Cohen, J. (1992). A power primer. Psychological Bulletin, 112, 155–159. doi:10.1037/0033-2909.112.1.155.
Constantino, J. N., Davis, S., Todd, R., Schindler, M., Gross, M., Brophy, S., et al. (2003). Validation of a brief quantitative measure of autistic traits: Comparison of the Social Responsiveness Scale with the autism diagnostic interview-revised. Journal of Autism and Developmental Disorders, 33, 427–433. doi:10.1023/A:1025014929212.
Cuddy, L. L., Balkwill, L.-L., Peretz, I., & Holden, R. R. (2005). Musical difficulties are rare: A study of “tone deafness” among university students. Annals of the New York Academy of Sciences, 1060, 311–324. doi:10.1196/annals.1360.026.
Dalla Bella, S., Peretz, I., Rousseau, L., & Gosselin, N. (2001). A developmental study of the affective value of tempo and mode in music. Cognition, 80, B1–10. doi:10.1016/S0010-0277(00)00136-0.
Dawson, G., Webb, S. J., Carver, L., Panagiotides, H., & McPartland, J. (2004). Young children with autism show atypical brain responses to fearful versus neutral facial expressions of emotion. Developmental Science, 7(3), 340–359. doi:10.1111/j.1467-7687.2004.00352.x.
Gaigg, S. B., & Bowler, D. M. (2007). Differential fear conditioning in Asperger’s syndrome: Implications for an amygdala theory of autism. Neuropsychologia, 45, 2125–2134. doi:10.1016/j.neuropsychologia.2007.01.012.
Golan, O., Baron-Cohen, S., Hill, J. J., & Rutherford, M. (2007). The ‘reading the mind in the voice’ test-revised: A study of complex emotion recognition in adults with and without autism spectrum conditions. Journal of Autism and Developmental Disorders, 37(6), 1096–1106. doi:10.1007/s10803-006-0252-5.
Gold, C., Wigram, T., & Elefant, C. (2006). Music therapy for autism spectrum disorders. Cochrane Database for Systematic Reviews, Issue, 2, 1–8.
Gosselin, N., Peretz, I., Johensen, E., & Adoplhs, R. (2007). Amygdala damage impairs emotion recognition from music. Neuropsychologia, 45, 236–244. doi:10.1016/j.neuropsychologia.2006.07.012.
Gosselin, N., Peretz, I., Noulhiane, M., Hasboun, D., Beckett, C., Baulac, M., et al. (2005). Impaired recognition of scary music following unilateral temporal lobe excision. Brain: A Journal of Neurology, 128(3), 628–640.
Gross, T. F. (2004). The perception of four basic emotions in human and nonhuman faces by children with autism and other developmental disabilities. Journal of Abnormal Child Psychology, 32(5), 469–480. doi:10.1023/B:JACP.0000037777.17698.01.
Happé, F. (1995). The role of age and verbal ability in the theory of mind task performance of subjects with autism. Child Development, 66, 843–855. doi:10.2307/1131954.
Happé, F. (1999). Autism: Cognitive deficit or cognitive style? Trends in Cognitive Sciences, 3(6), 216–222. doi:10.1016/S1364-6613(99)01318-2.
Happé, F., & Frith, U. (1994). Autism: Beyond “theory of mind”. Cognition, 50, 115–132. doi:10.1016/0010-0277(94)90024-8.
Heaton, P. (2003). Pitch memory, labelling and disembedding in autism. Journal of Child Psychology and Psychiatry, 44(4), 543–551. doi:10.1111/1469-7610.00143.
Heaton, P., Allen, R., Williams, K., Cummins, O., & Happé, F. (2008a). Do social and cognitive deficits curtail musical understanding? Evidence from autism and Down syndrome. British Journal of Developmental Psychology, 26, 171–182. doi:10.1348/026151007X206776.
Heaton, P., Hermelin, B., & Pring, L. (1998). Autism and pitch processing: A precursor for savant musical ability. Music Perception, 15(3), 291–305.
Heaton, P., Hermelin, B., & Pring, L. (1999a). Can children with autistic spectrum disorders perceive affect in music? An experimental investigation. Psychological Medicine, 29, 1405–1410. doi:10.1017/S0033291799001221.
Heaton, P., Pring, L., & Hermelin, B. (1999b). A pseudo-savant: A case of exceptional musical splinter skills. Neurocase, 5(6), 503–509. doi:10.1080/13554799908402745.
Heaton, P., Williams, K., Cummins, O., & Happé, F. (2008b). Autism and pitch processing splinter skills: A group and subgroup analysis. Autism, 12(2), 203–219. doi:10.1177/1362361307085270.
Hess, U., Adams, R. B., & Kleck, R. E. (2004). Facial appearance, gender, and emotion expression. Emotion, 4(2), 378–388. doi:10.1037/1528-3542.4.4.378.
Hess, U., Adams, R. B., & Kleck, R. E. (2005). Who may frown and who should smile? Dominance, affiliation, and the display of happiness and anger. Cognition and Emotion, 19(4), 515–536. doi:10.1080/02699930441000364.
Hill, E. (2004). Evaluating the theory of executive dysfunction in autism. Developmental Review, 24, 189–233. doi:10.1016/j.dr.2004.01.001.
Hill, E., Berthoz, S., & Frith, U. (2004). Brief report: Cognitive processing of own emotions in individuals with autistic spectrum disorder and in their relatives. Journal of Autism and Developmental Disorders, 34(2), 229–235. doi:10.1023/B:JADD.0000022613.41399.14.
Hobson, R. P. (1986). The autistic child’s appraisal of expressions of emotion. Journal of Child Psychology and Psychiatry, 27(3), 321–342. doi:10.1111/j.1469-7610.1986.tb01836.x.
Hobson, P. (2005). Autism and emotion. In F. R. Volmar, R. Paul, A. Klin, & D. Cohen (Eds.), Handbook of autism and pervasive developmental disorders (Vol. 1, pp. 406–422). Hoboken: Wiley.
Howard, M. A., Cowell, P. E., Boucher, J., Broks, P., Mayes, A., Farrant, A., et al. (2000). Convergent neuroanatomical and behavioural evidence of an amygdala hypothesis of autism. NeuroReport, 11(13), 2931–2935. doi:10.1097/00001756-200009110-00020.
Juslin, P. N., & Sloboda, J. A. (2001). Communicating emotion in music performance: A review and theoretical framework. In P. N. Juslin (Ed.), Music and emotion: Theory and research (pp. 307–331). New York: Oxford University Press.
Just, M. A., Cherkassky, V. L., Keller, T. A., & Minshew, N. J. (2004). Cortical activation and synchronization during sentence comprehension in high-functioning autism: Evidence of underconnectivity. Brain, 127, 1811–1821. doi:10.1093/brain/awh199.
Kanner, L. (1943). Autistic disturbances of affective contact. Nervous Child, 2, 217–250.
Kaplan, R. S., & Steele, A. L. (2005). An analysis of music therapy program and outcomes for clients with diagnoses on the autism spectrum. Journal of Music Therapy, 42(1), 2–19.
Kastner, M. P., & Crowder, R. G. (1990). Perception of the major/minor distinction: IV. Emotional connotations in young children. Music Perception, 8(2), 189–202.
Katagiri, J. (2009). The effect of background music and song texts on the emotional understanding of children with autism. Journal of Music Therapy, 46(1), 15–31.
Kim, J., Wigram, T., & Gold, C. (2008). The effects of improvisation music therapy on joint attention behaviors in autistic children: A randomized controlled study. Journal of Autism and Developmental Disorders, 38(9), 1758–1766. doi:10.1007/s10803-008-0566-6.
Koelsch, S., Fritz, T., Carmon, D. Y.v., Müller, K., & Friederici, A. D. (2006). Investigating emotion with music. Human Brain Mapping, 27, 239–250. doi:10.1002/hbm.20180.
Levitin, D. J., Cole, K., Chiles, M., Lai, Z., Lincoln, A., & Bellugi, U. (2004). Characterizing the musical phenotype in individuals with Williams syndrome. Child Neuropsychology, 10(4), 223–247. doi:10.1080/09297040490909288.
Loveland, K. A., Tunali-Kotoski, B., Chen, R., Brelsford, K. A., Ortegon, J., & Pearson, D. A. (1995). Intermodal perception of affect in persons with autism or Down syndrome. Development and Psychopathology, 7(3), 409–418. doi:10.1017/S095457940000660X.
Loveland, K. A., Tunali-Kotoski, B., Chen, Y. R., Ortegon, J., Pearson, D. A., Brelsford, K. A., et al. (1997). Emotion recognition in autism: Verbal and nonverbal information. Development and Psychopathology, 9(3), 579–593. doi:10.1017/S0954579497001351.
Marozeau, J., de Cheveigné, A., McAdams, S., & Winsberg, S. (2003). The dependency of timbre on fundamental frequency. Journal of the Acoustic Society of America, 114(5), 2946–2957. doi:10.1121/1.1618239.
Meyer, L. B. (1956). Emotion and meaning in music. Chicago, IL: University of Chicago Press.
Mottron, L., Peretz, I., & Ménard, E. (2000). Local and global processing of music in high-functioning persons with autism: Beyond central coherence? Journal of Child Psychology and Psychiatry, 41(8), 1057–1065. doi:10.1111/1469-7610.00693.
Neumann, D., Spezio, M. L., Piven, J., & Adolphs, R. (2006). Looking you in the mouth: Abnormal gaze in autism resulting from impaired top-down modulation of visual attention. Social Cognitive and Affective Neuroscience, 1(3), 194–202. doi:10.1093/scan/nsl030.
O’Connor, K. (2007). Brief report: Impaired identification of discrepancies between expressive faces and voices in adults with Asperger’s syndrome. Journal of Autism and Developmental Disorders, 37, 2008–2013. doi:10.1007/s10803-006-0345-1.
Ozonoff, S., Pennington, B. F., & Rogers, S. J. (1990). Are there emotion perception deficits in young autistic children? Journal of Child Psychology and Psychiatry, 31(3), 343–361. doi:10.1111/j.1469-7610.1990.tb01574.x.
Patterson, R. D., Uppenkamp, S., Johnsrude, I. S., & Griffiths, T. D. (2002). The processing of temporal pitch and melody information in auditory cortex. Neuron, 36, 767–776. doi:10.1016/S0896-6273(02)01060-7.
Pelphrey, K. A., Sasson, N. J., Reznick, J. S., Paul, G., Goldman, B. D., & Piven, J. (2002). Visual scanning of faces in autism. Journal of Autism and Developmental Disorders, 32(4), 249–261. doi:10.1023/A:1016374617369.
Rapport, L. J., Friedman, S. L., Tzelepis, A., & Van Voorhis, A. (2002). Experienced emotion and affect recognition in adult attention-deficit hyperactivity disorder. Neuropsychology, 16(1), 102–110. doi:10.1037/0894-4105.16.1.102.
Rimland, B. (1964). Infantile autism. New York: Appleton-Century-Crofts.
Rutherford, M. D., Baron-Cohen, S., & Wheelwright, S. (2002). Reading the mind in the voice: A study with normal adults and adults with Asperger syndrome and high-functioning autism. Journal of Autism and Developmental Disorders, 32(3), 189–194. doi:10.1023/A:1015497629971.
Rutter, M., Bailey, A., & Lord, C. (2003). SCQ: Social Communication Questionnaire. Los Angeles, CA: Western Psychological Services.
Schultz, R. T., Gauthier, I., Klin, A., Fulbright, R. K., Anderson, A. W., Volkmar, F., et al. (2000). Abnormal ventral temporal cortical activity during face discrimination among individuals with autism and Asperger syndrome. Archives of General Psychiatry, 57(4), 331–340. doi:10.1001/archpsyc.57.4.331.
Scott, S. K., Young, A. W., Calder, A. J., Hellawell, D. J., Aggleton, J. P., & Johnson, M. (1997). Impaired auditory recognition of fear and anger following bilateral amygdala lesions. Nature, 385(6613), 254–257. doi:10.1038/385254a0.
Shrout, P. E., & Fleiss, J. L. (1979). Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86(2), 420–428. doi:10.1037/0033-2909.86.2.420.
Smith, B. (1995). Psiexp: An environment for psychoacoustic experimentation using the IRCAM musical workstation. Paper presented at the Society for Music Perception and Cognition Conference, University of California, Berkeley.
Spezio, M. L., Adolphs, R., Hurley, R. S. E., & Piven, J. (2007). Analysis of face gaze in autism using “Bubbles”. Neuropsychologia, 45(1), 144–151. doi:10.1016/j.neuropsychologia.2006.04.027.
Teunisse, J.-P., & de Gelder, B. (2001). Impaired categorical perception of facial expressions in high-functioning adolescents with autism. Child Neuropsychology, 7(1), 1–14. doi:10.1076/chin.7.1.1.3150.
Tranel, D., Gullickson, G., Koch, M., & Adolphs, R. (2006). Altered experience of emotion following bilateral amygdala damage. Cognitive Neuropsychiatry, 11(3), 219–232. doi:10.1080/13546800444000281.
Wechsler, D. (1999). Wechsler abbreviated scale of intelligence. San Antonio, TX: Harcourt Assessment, Inc.
Wechsler, D. (2003). Wechsler scale of intelligence for children (4th Canadian ed.). Toronto, ON: Harcourt Assessment, Inc.
Whipple, J. (2004). Music in intervention for children and adolescents with autism: A meta-analysis. Journal of Music Therapy, 41(2), 90–105.
Ziv, N., & Goshen, M. (2006). The effect of ‘sad’ and ‘happy’ background music on the interpretation of a story in 5 to 6-year-old children. British Journal of Music Education, 23(3), 303–314. doi:10.1017/S0265051706007078.
Acknowledgments
This paper is submitted in partial fulfillment of the requirements for the doctoral degree (Ph.D.) in Psychology at Université du Québec à Montréal by the first author. The research was supported in part by doctoral grants to EMQ by FQRSC and the Canadian Autism Research Training Program, and by research grants to DJL from NAAR/Autism Speaks (#1066), NSERC (#221875-10), and the John and Ethelene Gareau Foundation. We would like to thank the participants and their families; the English Montreal Schoolboard, Summit School, Montreal Children’s Hospital; Pamela Heaton for guidance and advice; Annie Coulter, Many Black, Shirley Elliott, and Bianca Levy for help with testing and recruiting participants; Bennett Smith and Karle-Philip Zamor for technical assistance.
Author information
Authors and Affiliations
Corresponding author

Rights and permissions
About this article
Cite this article
Quintin, EM., Bhatara, A., Poissant, H. et al. Emotion Perception in Music in High-Functioning Adolescents With Autism Spectrum Disorders. J Autism Dev Disord 41, 1240–1255 (2011). https://doi.org/10.1007/s10803-010-1146-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10803-010-1146-0