
Abstract
Recover accurate images from larger database with an efficient way is nearly essential in CBIR. Create a new method to improve the accuracy in CBIR with the combination MTH (Multi Texton Histogram) and MSD (Micro Structure Descriptor). It is called Composite Micro Structure Descriptor (CMSD). The planned CBIR algorithm is developed based on different image feature characteristic and structure, also emulating the procedure of graphical substantial transmission and representation in upper-level sympathetic, with the aid of the future graphic improvement for property union. We have used four different kind of data sets to evaluate the performances of new method. Out new designed method outperforms compared with other CBIR methods such as MTH and MSD.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Texture is an essential characteristic in image retrieval and analysis, and has lured more researches in this area in few decades. Texture analysis and classification is a hot research topic in image processing (Luo and Crandall 2006). Now days, requirement high efficiency and high accuracy Image Retrieval systems are incresed. Previous period of time, Information Retrieval methods had used the text based methods, later on the scope of using such methods was come down due to the existence of CBIR Systems, because contents based retrieving methods give accurate results visually. From Quellec et al. (2012) and Umamaheswaran et al. (2015) literature, CBIR methods discover more subjectively and in effect than text based methods.
Image Retrieval systems primary intention are efficient, more accuracy in searching, reading and retrieving from bear-sized data sets either online or offline. Few newly distinctive image retrieval applications are processed for face recognition, detect and retrieve the human body actions from stored databases (Jones and Shao 2013; Zarchi et al. 2014; Singh et al. 2012; Zhang et al. 2012; Low 2004). Image retrieval system accuracy depends on appropriate representation of image property descriptors. An Image Retrieval system are capable to bring familiarized indiscriminately select images. Currently, image retrieval systems have used more number of methods are semantic based, because it deals with the CBIR problems (Low 2004; Haralick and Shangmugam 1973; Tamura et al. 1978). Cross and Jain (1983), Manjunathi and Ma (1996) and Ojala et al. (2002) stated that using feedback algorithms may help to identify the semantic properties and help to extract the results closely related to human perception in CBIR.
The computed statistical parameter from Gray Level Co-occurrence parameters for sequential, random window has been estimated by Wang et al. (2011). This work has applied image preprocessing over the texture and wcount is found out by splitting the texture size with the window size. When a statistical window method is followed, the variables i, j and count are initialized to 1. The window is read from the preprocessed image and GLCM features are calculated in 0˚, 45˚, 90˚ and 135˚ from the window. If the count is greater than wcount, then the results are applied to the retrieval system. This process stops when the count is greater than wcount. In the same way, random window is also considered. This work concludes that retrieval done after preprocessing shows better results than other leading methods (Liu and Zhang 2010; Luo and Crandall 2006; Liu and Yang 2013; Su and Jure 2012).
2 Related works
More researche have been performed in the area of CBIR using varied number of features. In this section, we discussed about some of recent works in the CBIR based on texture features. Image can not split or sub-grouped as multiple regions in Global feature based method. Chen et al. (2010) utilized color content alone to describe the image features. Existing method was extracted and preserved the third moment of the color distribution and output are finer than other properties of color, only color features have to be considered. The low level primary attribute like texture, color and shape are utilized effectively to be the global image by Wang et al. (2011). The Wang proposed method have used pseudo-Zernike moments and decomposition steerable filter to acquire dominant group of color information which is needed for construction their descriptor. The above mention method not considered structure of local neighbours to encode connection between the neighbouring pixels. Lot of Researchers have integrated the spatial location to build the feature description in Region based method. Hsiao et al. (2010) designed a method, it split the images as five different regions based on its fixed absolute locations and same for semantic retrieval also, these methods also required user interference in-between process of image retrieval. Beside, these method used local neighbor pixel value to boost local power. The developed a method by Lin et al. (2011), used three feature descriptors to represent the spatial and color properties of the images. These method used one of the unsupervised algorithm for split and convert the image into variety clusters based on image pixel intensity. This method has given keen outcome with the cost of high computation then sizable multidimensional descriptions.
Liu and Yang (2008) designed a method based on co-occurrence matrix with combination of histogram features and based on these features they developed a new feature descriptor for CBIR like a Multi-texton Histogram (MTH). Liu et al. (2011) had presented Micro Structure Descriptors (MSD), this descriptor combined all three low level features and image spatial properties for efficient image retrieval. Xingyuan and Zongyu (2013) designed a good descriptor as SEH (Structure Element Histogram) by using combined color, texture features. The SEH based methods given auspicious results in CBIR, but their performance was slow down in scaling and rotation operations. Reduce the complexities of Classification of Images and CBIR problems by using a single feature of low level features, therefore, many of the methods preferred to club features for not exceeding spatial properties values from limit. Wang et al. (2013) designed a method used two (color and texture) low level basic features. These method acquired color attribute value based on Zemike chromaticity distribution from the opposite chromaticity space. Bella and Vasuki (2019) proposed a method based on Fused Information Feature to retrieve Image. Zhang et al. (2019) proposed new algorithm for image retrieval based on a shadowed set. The proposed algorithm used the theory of shadowed set for extract the salient regions, shadowed regions and non- salient regions from image and combined the two extracted features i.e. the salient region and shadowed regions and used in retrieval process. Shamna et al. (2019) had introduced a new automated image retrieval system using Topics and Location model, to get Topic information used Guided Latent Dirchlet Allocation and along with the spatial information of visual words. They used new metric Position weighted Precision to evaluate the system.
Overcome from drawbacks prevailed in above mentioned descriptors, a novel composite micro structure descriptor is presented for the Image retrieval system. The present approach assumes and treat full image content as a one region and build new descriptor. The CMSD is unify color cues and textural cues of the image by a good way. The work is organized in paper as following order: third section have discussed about proposed technique. The elaborated results analysis a are given in fourth section, then conclusion part and future enhancement in the fifth section.
3 Feature extraction process
Extraction of feature is defined as a form of spatial property reduction that transforms the input data into a diminished representation. The pull out feature from image is predicted to give the characteristics as an input to the classifier by pickings into record form of the suitable attributes of image into a dimension location. The core objective of feature extraction from images is, original data set to be reduced using attribute measurement (Oliva and Torralba 2001).
It provides the image’s different characteristics, that characteristics are considered in image retrieval system. The proposed CBIR system use three different feature vectors such as:
- 1.
F(V1) of original image.
- 2.
F(V2) of Oriented Gabor filters image.
- 3.
F(V3) using Micro structure descriptor.
3.1 Calculation of feature vector F(V1) using original image
In general, divides the image into a number of little size images is called Gridding. The present method use 4 grids, 18 grids, and 24 grids to divide the original image. The value for block count is computed using pixel intensity, its range from 1 to 255. The subsequent F(V1) is calculated from the primary gridding image.
3.2 Calculation of F(V2) using gabor transform
A complex sinusoid value is used to modulate the Gabor function. The Gaussian envelope is specified by the sinusoid frequency ω and the SD \(\sigma_{x} \,and\,\sigma_{y}\).
The structure of Gabor filter is built based on result of Gabor filter for Image I, and is presented by
After Gabor orientation process of original image, then the gridding process is applied, then value of block count is computed using Gabor orientation image’s pixel intensity value.The consequential F(V2) is received from the Gabor transform gridding image.
3.3 Calculation of histogram vector F(V3)
The histogram vector computing process lie in two point:
- i.
Image formation for Texton Structure.
- ii.
Every intensity value are used to calculate value to block count for texton structure image.
3.4 Texton image structure creation process
In texture analysis, Texton is highly used and essential feature. Julesz (1981) Texton is type of pattern and its common property shared by all over the image. First, frame the template of texton using on four variety of texton and use these texton templates to extract the texton structure map from images, at last, form texton structure image by combining all texton structure map.
The extraction of texton structure map is consists four stage process as represented the original image f (a, b) splits as 3 × 3 blocks as below
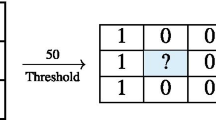
Create a block size with 3 × 3 to move into original image f(a,b) such as vertically and horizontally, then move towards right from left and up to down from origin i.e.(0,0) with a fixed length of three pixels. Texton structure map is created as T1(a,b), where 0 ≤ a ≤ M − 1, 0 ≤ b ≤ N − 1.
Step (ii) are repeated from the beginning of (0,1),(1,0) and (1,1) and create texton structure maps T2(a,b) where 0 ≤ a ≤ M − 1,0 ≤ b ≤ N − 1, T3(a,b), where 0 ≤ a ≤ M − 1,0 ≤ b ≤ N − 1, and T4(a,b), where 0 ≤ a ≤ M − 1, 0 ≤ b ≤ N − 1, respectively.
The final T(a,b) texton structure map is created using the Eq. (3.3):
The texton structure map T1(a,b) extraction process is shown in Fig. 1.

Texton structure map T1(a,b) extraction process
The final texton structure T(a,b) is arranged using union of texton structure map T1(a,b), T2(a,b), T3(a,b) and T4(a,b) is shown in Fig. 2.

Organization of final Texton structure T(a,b) using by texton structure maps T1(a,b), T2(a,b), T3(a,b) and T4(a,b)
The final texton structure mask is applied to the original image. The mask are set to empty if pixels do not match. Based on modified MSD, final texton structure image is created, it is displayed in Fig. 3.

Texton structure Image extraction process
3.5 Calculation of blocks count value
A Texton image T(a,b) value is expressed as T(a, b) = w, w = {0,1,2,3…..N − 1}. All 3 × 3 block of T(a,b), P0 = (a0, b0) denotes position of centre and let T(P0) = w0, Pi = (ai, bi) denotes the eight neighbour pixel values to P0 and let \(T(P_{i} ) = w_{i} ,\,\,i = 1,2,3, \ldots 8\). Let N stand for co-occurring number of two values w0,wi, then \(\bar{N}\) stand for number of values in w0. Create a block in the size of 3 × 3, moves the block from bottom to top direction and from right to left direction in structure of image. Then, create image texton structure using Eq. (3.4), Liu et al. (2011):
And then, used image pixel intensity value to measure the block count numerical value. Finally, resulting vector F(V4) is got from image texton structure.
3.6 Derived the final feature vector (F(V))
Thus, proposed CMSD uses \(F(V) = F(V_{1} ) + F(V_{2} ) + F(V_{3} )\) multidimensional vector as the last image property for image retrieval.
4 Result analysis
This section have discussed more about HIDs based available methods for CBIR, then discusses in details about the image data sets, the result analysis and comparison with existing methods and optimization strategy of the model parameters.
4.1 Retrieval metrics
The accuracy and recollectt are major metrics in area of Image and Information Retrieval. The above said two metrics are combined as the subjective harmonics indicates, that is, F-measure, and it is helped to analysis systems performance Liu and Zhang (2010).
The metrics are defined as:
4.2 Similarity metrics
The system accuracy is just not based on storing attribute content. It can achieved through the efficient way of calculating similarity feature vector. Corresponding, feature vector of query image Q is described as \(f_{Q} = f_{Q1} + f_{Q2} + \cdots f_{{Q_{\lg } }}\) got after the attribute removal. Similarly, calculate feature vector for images in the DB and it has described with feature vector \(f_{{DB_{j} }} = (f_{{DB_{j1} }} + f_{{DB_{j2} }} + \cdots f_{{DB_{{jL_{g} }} }} );\,\,j = 1,2, \ldots \left| {DB} \right|\). In this work, Canberra distance are used and shown below:
4.2.1 Canberra (L1)
where \(f_{{DB_{ji} }}\) is the ith feature of jth image in the record.
We have compared our proposed with other image retrieval method against various descriptor such as CHD, CCM, MSD and MTH. The result analysis are described by using two evaluation methods (i.e.precision and Recall). Results are displayed in Table 1.
From performance graphs, the proposed system is given better results than previously available methods. The precision and recall performance graphs are given in Figs. 4 and 5.

Precision measure result comparison with Corel 1000 for each category

Recall measure result comparison with Corel 1000 for each category
Proposed method CHSDs-based experiments are conducted on Corel-1000 dataset and other four different data sets comparing and with MTH, CHD, CCM and MSD. The average experimental results of different methods with four data sets is given in Table 2.
5 Conclusion and feature work
The designed proposed method, a novel composite micro structure descriptor is shown better performances than other CBIR systems, which integrates the advantages of both muti texton histogram and micro-structure descriptor. Proposed method, CMSD is designed such way that internal correlations are explored and multi-scale feature is analyse. Beside, Gabor filters are integrated into bar-shaped structure to stimulate orientation-selective mechanism and to represent image. Then block value is measured for each pixel intensity values 1–255 for original and transform image. New proposed approach has proved its performance (81.44% / 9.75.% in Corel 1000 data set, for average precision/average recall) better than other methods by comparing with other descriptor such as CCM, CHD, MTH and MSD through experimental results. A similar comparison shows better performance in terms of average precision and average recall on other datasets (Oliva, New Caltech and Corel 10000).
References
Bella, M., & Vasuki, A. (2019). An efficient image retrieval framework using fused information feature. Journal of Computers & Electrical Engineering,75, 46–60.
Chen, W. T., Liu, W. C., Chen, M. S., et al. (2010). Adaptive color feature extraction based on image color distributions. IEEE Transactions on Image Processing,19(8), 2005–2016.
Cross, G., & Jain, A. (1983). Markov random field texture models. IEEE Transactions on Pattern Analysis and Machine Intelligence,5(1), 25–39.
Haralick, R. M., & Shangmugam, D. (1973). Textural feature for image classification. IEEE Transactions on Systems Man, and Cybernetics,3(6), 610–621.
Hsiao, M. J., Huang, Y. P., Tsai, T., Chiang, T. W., et al. (2010). An efficient and flexible matching strategy for content-based image retrieval. Journal of Life Science,7(1), 99–106.
Jones, S., & Shao, L. (2013). Content-based retrieval of human actions from realistic video databases. Information Science,236, 56–65.
Julesz, B. (1981). Textons, the elements of texture perception and their interactions. Nature,290, 91–97.
Lin, C. H., Huang, D. C., Chan, Y. K., Chen, K. H., Chang, Y. J., et al. (2011). Fast color-spatial feature based image retrieval methods. Journal of Expert System Application,38(9), 11412–11420.
Liu, G. H., Li, Z. Y., Zhang, L., Xu, Y., et al. (2011). Image retrieval based on micro-structure descriptor. Journal of Pattern Recognition,44(9), 2123–2133.
Liu, G. H., & Yang, J. Y. (2008). Image retrieval based on the texton co-occurrence matrix. International Journal of Pattern Recognition,41(12), 3521–3527.
Liu, G. H., & Yang, J. Y. (2013). Content-based image retrieval using color deference histogram. International Journal of Pattern Recognition,46(1), 188–198.
Liu, G. H., & Zhang, L. (2010). Image retrieval based on multi-texton histogram. International Journal of Pattern Recognition,43(7), 2380–2389.
Low, D. G. (2004). Distinctive image features from scale-invariant key points. International Journal of Computer Vision,60(2), 91–110.
Luo, J., & Crandall, D. (2006). Color object detection using spatial-color joint probability functions. IEEE Transactions on Image Processing,15(6), 1443–1453.
Manjunathi, B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. IEEE Transactions on Pattern Analysis and Machine Intelligence,18(8), 837–842.
Ojala, T., Pietikanen, M., Maenpaa, T., et al. (2002). Multi-resolution gray-scale and rotation minvariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence,24(7), 971–987.
Oliva, A., & Torralba, A. (2001). Modeling the shape of the scene: a holistic representation of the spatial envelope. International Journal of Computer Vision,42(3), 145–175.
Quellec, G., Lamard, M., Cazuguel, G., Cochener, B., Roux, C., et al. (2012). Fast wavelet-based image characterization for highly adaptive image retrieval. IEEE Transactions on Image Processing,21(4), 1613–1623.
Shamna, P., Govindan, V. K., Abdul Nazeer, K. A., et al. (2019). Content based medical image retrieval using topic and location. Journal of Biomedical Informatics,91, 103112.
Singh, N., Dubey, S. R., Dixit, P., & Gupta, J. P. (2012). Semantic image retrieval by combining color, texture and shape features. In International conference on computing sciences (pp. 116–20).
Su, Y., & Jure, F. (2012). Improving image classification using semantic attributes. International Journal of Computer Vision,100(1), 59–77.
Tamura, H., Mori, S., Yamawaki, T., et al. (1978). Texture features corresponding to visual perception. IEEE Transactions on Systems, Man, and Cybernetics,8(6), 460–473.
Umamaheswaran, S., Suresh kumar, N., Ganesh, K., Rajendra Sethupathi, P. V., Anbuudayasankar, S. P., et al. (2015). Variants, meta-heuristic solution approaches and applications for image retrieval in business-comprehensive review and framework. International Journal of Business Information systems,18(2), 160–197.
Wang, X. Y., Yang, H. Y., Li, D. M., et al. (2013). A new content-based image retrieval technique using color and texture information. Journal of Computer Electrical Engineering,39(3), 746–761.
Wang, X. Y., Yu, Y. J., Yang, H. Y., et al. (2011). An effective image retrieval scheme using color, texture & shape features. Journal of Computer Stand Interfaces,33(1), 59–68.
Xingyuan, W., & Zongyu, W. (2013). A novel method for image retrieval based on structure elements descriptor. Journal of Visual Communication and Image Representation,24(1), 63–74.
Zarchi, M. S., Monadjemi, A., Jamshidi, K. A., et al. (2014). Semantic model for general purpose content-based image retrieval systems. Journal of Computer and Electrical Engineering,40(7), 2062–2071.
Zhang, D. S., Islam, M. M., Lu, G. J., et al. (2012). A review on automatic image annotation techniques. Journal of Pattern Recognition,45(1), 346–362.
Zhang, H., Zhang, T., Pedrycz, W., Zhao, C., Miao, D., et al. (2019). Improved adaptive image retrieval with the use of shadowed sets. Pattern Recognition,90, 390–403.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Umamaheswaran, S., Lakshmanan, R., Vinothkumar, V. et al. New and robust composite micro structure descriptor (CMSD) for CBIR. Int J Speech Technol 23, 243–249 (2020). https://doi.org/10.1007/s10772-019-09663-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-019-09663-0