
Abstract
In this paper we present an experimental framework for Arabic isolated digits speech recognition named ARADIGITS-2. This framework provides a performance evaluation of Modern Standard Arabic devoted to a Distributed Speech Recognition system, under noisy environments at various Signal-to-Noise Ratio (SNR) levels. The data preparation and the evaluation scripts are designed by deploying a similar methodology to that followed in AURORA-2 database. The original speech data contains a total of 2704 clean utterances, spoken by 112 (56 male and 56 female) Algerian native speakers, down-sampled at 8 kHz. The feature vectors, which consist of a set of Mel Frequency Cepstral Coefficients and log energy, are extracted from speech samples using ETSI Advanced Front-End (ETSI-AFE) standard; whereas, the Hidden Markov Models (HMMs) Toolkit is used for building the speech recognition engine. The recognition task is conducted in speaker-independent mode by considering both word and syllable as acoustic units. Therefore, an optimal fitting of HMM parameters, as well as the temporal derivatives window, is carried out through a series of experiments performed on the two training modes: clean and multi-condition. Better results are obtained by exploiting the polysyllabic nature of Arabic digits. These results show the effectiveness of syllable-like unit in building Arabic digits recognition system, which exceeds word-like unit by an overall Word Accuracy Rate of 0.44 and 0.58% for clean and multi-condition training modes, respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The recent progress in wireless applications such as speech recognition over mobile devices has led to the development of client–server recognition systems, also known as Distributed Speech Recognition (DSR) (Pearce 2000). In DSR architecture, the front-end client is located in the terminal device and it is connected over a protected data channel to a remote back-end recognition server. Although many technological developments have been made, the existing speech recognition performance still needs improvement, particularly when the speech utterances are exposed to high noise environments.
With regard to developing evaluation databases for DSR systems in multiple languages, there have been the activities of AURORA working group (Hirsch and Pearce 2000; Pearce 2001; AURORA 2006). Their evaluation scenarios have had a considerable impact on noisy speech recognition research; this includes AURORA-2, AURORA-3, AURORA-4, and AURORA-5 databases. AURORA-2 is a small vocabulary evaluation of noisy connected digits for American English talkers; the task performs speaker-independent recognition of isolated and connected digits, with and without adding background noise. AURORA-3 consists of a noisy small vocabulary speech recorded inside cars, and it serves to test the frond-end from different languages, namely Finnish (Nokia 2000), Danish (Lindberg 2001), Spanish (Macho 2000), German (Netsch 2001), and Italian (Knoblich 2000). AURORA-4 provides a large vocabulary continuous speech recognition tasks, which aims to compare the effectiveness of different DSR front-end algorithms. In addition to its similarity to AURORA-2, AURORA-5 covers the distortion effects caused by the hands-free speech input inside a room. Furthermore, the AURORA tasks have been distributed with the HMMs Toolkit (HTK) scripts, which allow attaining easily the baseline performance for further speech recognition research.
Numerous evaluation methodologies and frameworks for AURORA-2 were developed by the working group of the information processing society for Japanese noisy speech recognition, namely CENSREC-1/AURORA-2J, CENSREC-2, CENSREC-3, and CENSREC-4 (Nakamura et al. 2005; Fujimoto et al. 2006; Nishiura et al. 2008). The first developed version, AURORA-2J, contains Japanese noisy connected digit utterances and their associated HTK evaluation scripts. CENSREC-2 is another database for evaluation of noisy continuous digits recognition whose data were recorded in real car driving environments. CENSREC-3 database contains speech utterances, of isolated words, recorded in similar environments to those considered in CENSREC-2. The last developed database, CENSREC-4, is an evaluation framework of distant-talking connected digit utterances in various reverberation conditions.
Arabic is one of the most widely spoken languages in the world. Nowadays, it is considered as the fifth widely used language, the native language of more than 350 million of people (World Bank 2016) as well as the liturgical language for over a billion Muslims around the world. In the Arab world today, there are two forms of Arabic, The Modern Standard Arabic (MSA) and the Modern Colloquial Arabic (MCA). MSA, commonly known as the modern form of classical Arabic (or Quranic Arabic), is considered as the official language in academic institutions, written and broadcasted Arabic media, and civil services. The vernacular or colloquial form is the most used when people speak about everyday life topics. Moreover, there exists a variety of MCA forms from different Arabic regions (e.g. Middle East, North Africa, and Egypt).
Lack of Arabic language resources is one of major issues confronted by the Arabic speech research community. Among the most relevant developed corpora one can cite the Orientel project (Siemund et al. 2002). This project covers an important package of data collection, on both MSA and MCA ranging from Mediterranean to Middle East countries, including Turkey and Cyprus, as well as applications for mobile and multi-modal platforms. Abushariah et al. (2012) have developed a large vocabulary speech database for MSA native speakers from 11 Arab countries, in which a total of 415 sentences are recorded by 40 speakers (20 male and 20 female). This database takes into account the speaker variability such as gender, age, country, and region, with the motivation of making it suitable for the design and development of Arabic continuous speech recognition systems.
Moreover, there exist data centers that provide relevant speech databases for both MSA and MCA. For example, the European Language Resources Association (ELRA), where the most popular project was NEMLAR broadcast news speech Arabic corpus. This project is composed of about 40 h of MSA recorded from four different radio stations (ELRA 2005). Also, the Linguistic Data Consortium (LDC) has developed recently a new database that contains 590 h of recorded Arabic speech from 269 male and female speakers. The LDC recordings are conducted by the speech group at King Saud University in different noise environments for read and spontaneous speech (LDC 2014). However, with such diversity and richness of Arabic language, there is a difficult process to generate from the existing databases a proper dataset for the problem at hand, as well as for testing the industrialized speech platforms.
Automatic recognition of spoken digits is essential in many DSR application areas for different languages. Compared to other commonly used languages, a limited number of recent efforts on building Arabic digit recognizers have been conducted. Among the previous researches, using either Artificial Neural Networks (ANNs) or Hidden Markov Models (HMMs) as recognition engine, the works presented in (Alotaibi et al. 2003; Alotaibi 2005, 2008; Hyassat and Abu Zitar 2006; Amrouche et al. 2010; Ma & Zeng 2012; Hajj and Awad 2013). However, there is a lack of common Arabic digits database for evaluation and results comparison of the systems proposed. This is principally due to the differences in the types of features and noises used, and differences in the testing methodologies.
The main objective of this work is to investigate Arabic spoken digits from the speech recognition point of view. We introduce an Arabic noisy speech speaker-independent isolated digits database and its evaluation scripts, named ARADIGITS-2. This database is particularly conceived to evaluate the recognition performance of MSA digits in a DSR system. The data preparation (i.e. speech files, used noises, and text transcriptions) and the HTK evaluation scripts are designed by drawing inspiration from AURORA-2 database (Hirsch and Pearce 2000). The spoken digit utterances are 112 Algerian MSA native speakers (56 male and 56 female) corrupted by additive noises at different Signal-to-Noise Ratio (SNR) levels. The European Telecommunications Standards Institute Advanced Front-End (ETSI-AFE) standard (ETSI 2007) is used for Mel Frequency Cepstral Coefficients (MFCCs) feature vectors extraction and compression. Whereas, the recognition task is performed using the two training modes: clean (that is, models are trained with clean data and the test is performed with noisy data) and multi-condition (that is, training is performed with clean and noisy data).
For small vocabulary tasks such as digits recognition, word acoustic unit is used more commonly. In this work, a syllable-based recognition system is also designed. The application of syllable unit is motivated by the polysyllabic nature of Arabic digits that has many differences in terms of syllable types and numbers (Naveh-Benjamin and Ayres 1986; Ryding 2005). When compared to other languages such as English, Arabic digits have about twice as many syllables per digit as those in English. For example, in Naveh-Benjamin & Ayres (1986) for the chosen four languages, English, Spanish, Hebrew, and Arabic, the mean number of syllables per word for the digits (0–6, 8, 9) is 1, 1.625, 1.875, and 2.25, respectively.
The motivation for building DSR system using Algerian MSA rather than Algerian MCA is two-fold: (i) As the case of different Arabic countries, the divergence among several Algerians MCA makes very complex the task of collecting data and designing a common recognition system. It is therefore similar to the case of MCA digits recognition where the digits are pronounced quietly different from place to place and town to town and (ii) In some DSR services where the front-end spoken digit numbers are highly important, such as bank account, credit card and insurance identification, the use of a recognition system based on MSA may guarantee more accurate performance.
The remainder of this paper is structured as follows: In Sect. 2, we present a general overview of ETSI DSR standards, AURORA-2 database, and HTK speech recognition toolkit. A detailed description of the ARADIGITS-2 data preparation and HTK parameterization is the object of Sect. 3. The recognition system performance obtained by empirically fine-tuning the suitable recognition parameters, for both word and syllable-like acoustic models, is presented in Sect. 4. Finally, we summarize the conclusion of the presented work in Sect. 5, as well as further work that needs to be completed.
2 DSR standards and AURORA-2 database
2.1 DSR standards
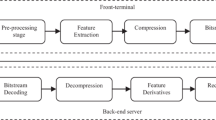
As depicted in Fig. 1, the main idea of DSR consists of using a local front-end terminal from which the MFCC vectors are extracted and transmitted, through an error protected data channel, to a remote back-end recognition server. Compared to the traditional network-based automatic speech recognition, a DSR system provides specific benefits for mobile services, such as (i) acoustic noise compensation at the client side, (ii) low bit-rate transmission over data channel, and (iii) improved recognition performance.

DSR system architecture
In the basic DSR standard ETSI Front-End (ETSI-FE) (ETSI 2003a), the speech features (i.e. MFCC components) are derived from the extracted speech frames, in the front-end part, at frame length of 25 ms with frame shift of 10 ms, using Hamming windowing. A Fourier transform is then performed and followed by a Mel filter bank with 23 bands in the frequency range from 64 up to 4 kHz. The extracted features are the first 12 MFCCs (C 1-C 12) and the energy coefficients, such as (C 0) and the log energy (log E) in each extracted frame.
The different blocks of the ETSI front-end MFCC extraction algorithm are illustrated in Fig. 2.

Block diagram of feature extraction algorithm (ETSI 2003a)
The abbreviation of each block is listed as bellow:
-
ADC: Analog to Digital Converter
-
Offcom: Offset Compensation
-
Framing: Frame length is 25 ms, with frame shift is 10 ms
-
PE: Pre-emphasis Filter, with a factor of 0.97
-
Log E: Log Energy Computation
-
W: Hamming Windowing
-
FFT: Fast Fourier Transform (only magnitude components are considered)
-
MF: Mel filter bank with 23 frequency bands
-
LOG: Nonlinear Transformation
-
DCT: Discrete Cosine Transform
In the compression task (i.e. source coding), the 14-dimentional feature vector [C 1, C 2, ..., C 12, C 0, log E] is split into seven sub-vectors, and each of them is quantized with its own 2-dimensional vector quantizer. The resulting compression bit-rate is 4400 bps and 4800 bps when the overhead and error protection bits are included (i.e. channel coding). In the back-end side delta and delta–delta coefficients, or time derivatives, are estimated and appended to the 13 static features [C 1, C 2, ..., C 12, C 0 or log E], to obtain a total of 39 elements for each feature vector.
In some DSR applications, for example, in human assisted dictation, the machine and the human recognition are mixed in the same application, so it may be necessary to reconstruct the speech signal at the back-end. The ETSI Extended Front-End (ETSI-EFE) standard (ETSI 2003b) provides additional parameters such as voicing class and fundamental frequency, which are extracted at the front-end. These parameters allow reconstructing the speech signal at the back-end side. Therefore, the transmission of these additional components will increase relatively the compression bit-rate.
An advanced front-end feature extraction and compression algorithms (ETSI-AFE) (ETSI 2007) have been published by ETSI for robust speech recognition. The standardized AFE provides considerable improvements in recognition performance in the presence of background noise. In the feature extraction part of the ETSI-AFE standard, noise reduction is performed first, which is based on Wiener filtering theory. Then, MFCCs coefficients and log energy are computed from the de-noised signal and blind equalization is applied to cepstral features. Voice activity detection (VAD) for the non-speech frame dropping is also implemented in the front-end feature extractor. The VAD flag is used for excluding the non-speech frames from the recognition task.
On the server side, unlike the conventional ETSI-FE standard, where the cepstral derivatives are computed through the HTK recognition engine using centered finite difference approximation (Young et al. 2006), ETSI-AFE includes additional scripts that compute these coefficients based on polynomial approximation (more details are provided in Sect. 3.2). Also, in ETSI-AFE back-end side, the energy coefficients C 0 and log E are both used in the recognition task by employing the following combination:
where \(\alpha\) and \(\beta\) are set to 0.6/23 and 0.4, respectively (ETSI 2007).
2.2 AURORA-2 database and HTK toolkit
The original high quality TIDigits database (Leonard 1984) is the source speech of AURORA-2 database that consists of isolated and connected digits task. It provides speech samples and scripts to perform speaker-independent speech recognition experiments in clean and noisy conditions. This database has been prepared by down-sampling from the original 20 kHz sampling frequency to 8 kHz with an ideal low pass filter. An additional filtering is applied with the two standard frequency characteristics: G.712 (ITU-T 1996) and Modified Intermediate Reference System (MIRS) (ITU-T 1992).
AURORA-2 contains eight types of realistic additive noises with stationary and non-stationary segments (suburban train (subway), babble, car, exhibition hall, restaurant, street, airport, and train station) at different SNR levels (clean, 20, 15, 10, 5, 0, and −5 dB). This database contains two training sets of 8440 utterances for each one (clean and multi-condition sets), and three test sets (set A, set B, and set C).
The clean training set is filtered with the G.712 characteristic without any noise added. In multi-condition training set, the same utterances are equally split into 20 subsets, after filtering with the G.712 characteristic. These subsets are corrupted by four noises (subway, babble, car, and exhibition hall) at five different SNR levels (clean, 20, 15, 10, and 5 dB).
The first test set called test set A, consists of 28,028 utterances filtered with the G.712 characteristic using four different noises, namely subway, babble, car, and exhibition hall. In total, this test set consists of 28 subsets where the noises are added at seven different SNR levels (clean, 20, 15, 10, 5, 0, and −5 dB). Test set A contains the same noises to those used in the multi-condition training set; this leads to a high match between training and test data. The second test set called test set B, which is created by the same way as test set A (i.e. same clean utterances filtered with the G.712) but by using four different noises, restaurant, street, airport, and train station. The third test set called test set C contains 14,014 utterances distributed into 14 subsets, where two different types of noises are considered, subway and street. In test set C, speech and noises are first filtered with the MIRS (i.e. in order to simulate the frequency characteristics received from the terminal device), and then these noises are added at different SNR levels (clean, 20, 15, 10, 5, 0, and −5 dB). Furthermore, a full description of AURORA-2 database is given in Hirsch & Pearce (2000).
The HTK toolkit is principally designed for building HMM-based speech processing tools, in particular recognizers. It consists of a set of library modules and tools in C source code available from http://htk.eng.cam.ac.uk/. The tools provide sophisticated facilities for speech analysis, HMM training, testing, and results analysis. There are two major processing stages involved. Firstly, the HTK training tools are used to estimate the parameters of a set of HMMs using training utterances and their associated transcriptions. Secondly, unknown utterances are transcribed using the HTK engine.
In AURORA-2 task, the model set contains 11 whole word HMM models (digits 0 to 9 and “oh”) which are linear left-to-right with no skips over states, also known as Bakis topology (Bakis 1976). Two silence models are defined, i.e. “sil” (silence) and “sp” (short pause). The “sil” model has three emitting states and each state has six mixtures, while the “sp” model has only a single state. Each word model has 16 states with three Gaussian mixtures per state (in HTK structure, two dummy states are added at the beginning and at the end of the given set of states). Each Gaussian component is defined by the global means and variances of acoustic coefficients.
The overall Word Accuracy Rate (WAR) of recognition experiments, conducted on AURORA-2 task, using ETSI-AFE standard are summarized in Tables 1 and 2 (Hirsch and Pearce 2006). These experiments are performed on different training modes, with and without (i.e. baseline) MFCCs compression, and without including the optional VAD parameter.
3 ARADIGITS-2 data description and system parameterization
As outlined in the previous section, the aim of the present work is to develop an Arabic small vocabulary isolated digits database for DSR applications. The used spoken words in ARADIGITS-2 database are the Arabic digits zero through nine, which are polysyllabic (except for the monosyllabic digit “zero”). Arabic digits include almost all types of MSA syllables, which are limited to the following combinations of consonants /C/ and vowels /V/ (Ryding 2005):
-
Full form pronunciation syllables: consists of (i) short or weak syllables /CV/ (consonant–short vowel) and (ii) long or strong syllables /CVV/ (consonant–long vowel) or /CVC/ (consonant–short vowel–consonant).
-
Additional pause form pronunciation syllables: consists of super-strong syllables /CVVC/ (consonant–long vowel–consonant) or /CVCC/ (consonant–short vowel–consonant–consonant).
The corresponding pronunciations of the MSA ten digits, as well as the number and types of used syllables, are given in Table 3.
3.1 Data preparation
The speech utterances used in ARADIGITS-2 are gathered from the original ARADIGITS spoken Arabic isolated digits database. This database was initially used in the recognition system evaluation proposed by Amrouche et al. (2010). ARADIGITS is a set of Arabic digit utterances pronounced in MSA (from 0 to 9) collected from 120 Algerian native speakers, by considering speaker variability such as gender and age (from 18 to 50) and speaking style. The speech utterances were recorded in a large and a very quiet auditory room (with a capacity of up to 1800 people), using a high quality microphone. At the time of the recording, the room was largely empty with an overall environmental Sound Pressure Level (SPL) less than 35 dB. A total of 3600 speech utterances were originally recorded at 22.050 kHz sampling frequency and was then down-sampled into 16 kHz.
From the original 3600 utterances of ARADIGITS we selected and manually verified the transcriptions of a total of 2704 utterances spoken by 112 speakers, 56 males and 56 females. Some utterances are discarded due to bad quality of recordings and mispronunciations. The wave speech files are down-sampled from 16 to 8 kHz and then represented as a 16-bit little-endian byte order. These tasks can be performed thanks to the Praat script (Boersma and Weenink 2015). The selection of training and test sets is made in such a way to equilibrate between speaker and gender (equally distributed). In the training set, a total of 1840 utterances (4052 syllables), produced by 34 males and 34 females, are used. In the test set, 864 utterances (1906 syllables), pronounced by the rest of speakers (i.e. 22 males and 22 females), are used. The occurrence frequency of each digit is shown in Table 4, indicating that the occurrences are balanced to have approximately the same number of utterances of each digit.
By following the same way as AURORA-2 database, ARADIGITS-2 consists of two training sets (for clean and multi-condition training modes), and three test sets, test set A, test set B, and test set C, where each set is split into four sub-sets. The speech signals are filtered with the two standard frequency characteristics G712 and/or MIRS (ITU-T 1992; ITU-T 1996), and then they are corrupted by eight different noises at different SNR levels (20, 15, 10, 5, 0, and −5 dB). The noises used, for considering the variability of environmental conditions, are issued from AURORA-2 database, such as suburban train, babble, car, exhibition hall, restaurant, street, airport, and train-station. The open-source Filtering and Noise Adding Tool (FaNT) (Hirsch 2005) is used to filter speech signals with the appropriate filter characteristic as defined by the International Telecommunication Union (ITU) standards. This tool allows adding a noise signal to clean speech at a desired SNR level, which can be expressed as:
where E S and E N represent the total energy of the speech signal and the total energy of noise signal, respectively. The speech energy is estimated by using the ITU-T P.56 voltmeter function from the ITU-T Software Tool Library (Neto 1999).
In total, each ARADIGITS-2 test set consists of 6048 utterances, and 1840 utterances for each training set. Figures 3 and 4 show a detailed block scheme which describes how the training set is divided between different noises and noise levels and how each of the test sets are divided between noise and noise levels. However, unlike AURORA-2, in test set C of ARADIGITS-2 we add two additional sub-sets with two noise environments which contain non-stationary segments, namely babble, and restaurant.

Training dataset in ARADIGITS-2 (clean and multi-condition modes)

Test dataset in ARADIGITS-2 (test set A, B, and C)
3.2 Time derivatives estimation
In speech recognition systems there are, generally, two ways to approximate the time derivatives or dynamic features. Firstly, by exploring the discrete time representation of cepstral coefficients, a finite difference approximation is performed by simply using a first or second-order finite difference (e.g. the case of HTK). However, this approximation is intrinsically noisy and the cepstral sequence usually cannot be expressed in a suitable form for differentiation (Soong 1988; Rabiner 1993). The second way, which is the more appropriate one, approximates the derivatives by the use of an orthogonal polynomial of each cepstral coefficient trajectory over a finite length window (Furui 1981, 1986; Rabiner 1993).
As defined in the ETSI-AFE standard, the first and second derivative coefficients, ΔĈ i and ΔΔĈ i, respectively, for each feature component C i (i.e. C 1- C 12 and C comb ) are computed on a 9-frame window (i.e. derivative window or the interval over which the derivatives are estimated) using the following weighted sums (ETSI 2007):
where t is the frame time index. The respective weighting coefficients are set as follows:
According to the weighting coefficient values and from (3) and (4), one may deduce that the first and second derivatives are calculated by fitting the cepstral trajectory with a second order polynomial over a window of 2M + 1 frame length with M = 4. For a given M the weighting coefficients Δw t and ΔΔw t , at time t, are estimated by the following formulas (Rabiner 1993):
where
However, in ETSI-AFE, the weights are normalized by the maximum weight, such that the largest weight is equal to 1. Thus, the normalized weights at time t, Δŵ t and ΔΔŵ t , can be expressed as:
3.3 HTK parameterization
MFCC coefficients are extracted for each speech utterance based on the client front-end ETSI-AFE extraction algorithm. The final feature vector consists of the first 12 MFCC coefficients (C 1-C 12) and the combination of C 0 and log E (C comb ). Our choice of ETSI-AFE, for MFCCs extraction, is motivated by its specifications which allow reducing considerably the effect of background noise. Also, it is expected that ETSI-AFE will give improved recognition performance compared to the conventional ETSI-FE for all languages (Pearce 2001).
The HTK speech recognizer engine with software version 3.4 (Young et al. 2006) is used to evaluate the recognition performance of ARADIGITS-2. The digits are modelled as: (i) whole word model, i.e. the recognition unit should comprise the whole word and (ii) syllable model where each word is mapped onto its syllable representation. The number of units is the 10 Arabic digits for word model and 19 syllables for syllable model (from Table 3, the 19 syllables are obtained by eliminating the redundant ones).
The silence model is considered as the same case as AURORA-2; it consists of three states with a transition structure, and six Gaussian mixtures for each state (see Fig. 5); however, the inter-word short pause “sp” model is not considered, as the database contains only isolated digits. The MFCC extraction is followed by the global means and the global variances computation. Then, HMM for each unit initialized with global means and variances is created. The embedded Baum-Welch for HMM parameter re-estimation scheme is used in the training process. In the testing process, the forward/backward algorithm is performed, where the most probable pronunciation is assigned to each word from the transcription file.

Three states silence model architecture (with two dummy states)
The ARADIGITS-2 data analysis and HTK parameters are given in Table 5; except to the derivatives window length, the number of emitting states of each digit model, as well as the number of Gaussian mixtures per state. The optimal configuration of these parameters will be the objective of the next section.
4 System testing and evaluation
Recognition experiments are conducted in speaker-independent mode; it means that the data in the test set does not cross with those in the training set. The baseline system uses a feature vectors, which consists of 39-component including the 13 extracted static coefficients (C 1-C 12, C comb ) and the corresponding first and second derivative parameters (that is, the used HTK parameter type is MFCC_E_D_A). The recognition performance is measured in terms of WAR given by the following formula:
where N is the total number of words in the test set, S is the number of substitution errors, D is the number of deletion errors, and I is the number of insertion errors (Young et al. 2006). We should point out that the ARADIGITS-2 results are presented with respect to the convention used in AURORA-2 database, where the overall WAR is calculated by considering the performance for SNRs from 20dB down to 0dB.
Initially, we conducted an experiment on ARADIGITS-2 with similar AURORA-2 model parameters, such as 16 states and three Gaussian mixtures for each recognition unit (i.e. syllable or word). The derivatives are computed on a 9-frame window using formulas (3) and (4). We should highlight that in case of considering syllables as acoustic models; they can be concatenated to form word models according to a syllable pronunciation dictionary (this dictionary is generated from pronunciations in Table 3). Table 6 shows the overall baseline performance for both cases word and syllable-based recognition with both clean and multi-condition training modes.
In the following subsections, a series of experiments will be focused on studying the effects related to the derivative window lengths, the number of states, as well as the number of Gaussian mixtures per state. Also, these parameters are fine-tuned on ARADIGIT-2. This optimization will be performed with respect to the best recognition performance obtained for each parameter variation.
4.1 Effects of derivative window length
The first and second derivative window length is initially chosen from the results of the recognition experiments, with the two training modes, summarized in Figs. 6 and 7. Here the derivative window length is varied from 5 to 21 frames, where the same AURORA-2 HMM parameters are considered. We note that the two derivative windows have the same lengths.

WAR (%) versus derivative window length for ARADIGITS-2 (word model)

WAR (%) versus derivative window length for ARADIGITS-2 (syllable model)
Comparison of recognition results indicates that generally the maximum accuracy rates are obtained when an 11-frame window is used to calculate the derivatives. However, it can be observed that for the case of syllable-based models trained with clean speech, the maximum performance is achieved at 17-frame window, with a degraded recognition rate comparing to the case of word level unit. This may be due to the fact that the chosen model parameters are inappropriate. Furthermore, studies on effects of derivative window, e.g. in Applebaum and Hanson (1991) and Lee et al. (1996), expect that the derivative features estimated over long intervals may help most when the mismatch of training and test is greatest.
The same experiment is carried out on AURORA-2 database; this can show how Arabic compares to English in digits recognition. Results in Figs. 6 and 8 (i.e. when using the same acoustic unit) indicate that the maximum accuracy rates, for English digits, are obtained when a 9-frame window is used. However, comparing to English digits, more number of frames may be needed to accurately represent the transitional information from one phoneme to another in Arabic digits. Furthermore, as mentioned in Furui (1986), one of the possible causes of variation in the optimal window length might be caused by the difference of languages; however, this still remains to be investigated.

WAR (%) versus derivative window length for AURORA-2 (word model)
4.2 Effects of number of states and Gaussian mixtures per state
We will now study the effects related to the number of states and mixtures in Arabic digits. We first adopt an 11-frame derivative window for both HMM models (word or syllable) and training conditions. After finding the optimal number of states and number of mixtures, another fine-tuning of the derivatives window length will be performed. The overall WAR using 11-frame is shown in Table 7.
The issue of the number of states to use in each unit model and the number of mixture densities per state is highly dependent on both the amount of training data and the vocabulary words (Rabiner et al. 1989). In this work, the number of states is globally optimized, where each acoustic model is allowed to have the same number of states. This implies that the models will work best when they represent units with the same number of phonemes (Rabiner 1989). The optimization procedure is principally based on varying the number of states for each model (4, 8, 12, 16), and the number of Gaussian mixtures for each state (3, 6, 9, …, 27). However, other optimal combinations may be found by further increasing the number of states or mixtures, but with relatively more computational complexity.
During the training process, the mixture densities are gradually increased as follows. We start by a single Gaussian density per state for all acoustic models. We collect statistics from the training data and estimate the model parameters by applying three re-estimation iterations. Then, the mixture densities are increased and the parameters are re-estimated by applying three further iterations. This process is repeated until the number of desired mixtures is obtained. Finally, further seven re-estimation iterations are performed (Hirsch and Pearce 2000).
To illustrate the effects of varying the number of states and the number of mixtures, Figs. 9, 10, 11, and 12 show the overall WAR in clean and multi-condition training modes. It can be seen that the overall best accuracies are achieved at 16 states and the number of Gaussian mixtures can take the two values 3 or 6. However, the reached maximum accuracy of syllable model remains degraded, in clean training mode. We will show later how the accuracy of syllable model is improved through a number of investigations.

WAR (%) versus number of mixtures and states in clean training (word model)

WAR (%) versus number of mixtures and states in multi-condition training (word model)

WAR (%) versus number of mixtures and states in clean training (syllable model)

WAR (%) versus number of mixtures and states in multi-condition training (syllable model)
4.3 Fitting of models parameters
Previously, various tests are conducted in order to show the effects of derivative window length and HMM topology parameters (i.e. the number of states and the number of Gaussian mixtures). The optimal combination of initial estimates is to adopt an 11-frame derivative window, 16 states and three or six Gaussian mixtures per state. However, further investigations are needed to further optimize the parameters, as well as to provide more reliable assessment of syllable and word based recognition systems.
Table 8 shows more details of results of Table 7 in which an analysis of WAR versus SNR levels is conducted with clean training. The accuracies are analyzed for high SNRs which stand for (10–20) dB and low SNRs which stand for (0–5) dB. We can see that the use of syllable like unit may lead to performance that is prone to low recognition rates for low SNRs. This is due to its weak robustness to high noise levels. However, the results using both acoustic units are somewhat similar, in case of low noises (i.e. high SNRs).
More precisely, to assess the effects of noise on recognition performance, results in Tables 9, 10, 11 and 12 display detailed information about confusion among digits in different training modes for a set of high noisy utterances extracted from test set A. Confusion matrices reveal the “zero” model as the cause for most confusions, in clean training mode. However, the confusion effect of “zero” model in word-based system is relatively less important with respect to syllable-based system. From results obtained with multi-condition training, we expect that the digit “zero” is more susceptible to noisy environments than the other digits.
Furthermore, in case of considering word unit, although “zero” segments are masked by noise; this digit can be easily discriminated as it is the only monosyllabic one with the shortest duration; however, when the syllable model is adopted, the recognition of class “zero” will be more difficult as the models are all monosyllabic, so the discrimination by segment duration may be less. In other word, the use of an acoustic unit with a longer duration facilitates exploitation of simultaneously temporal and spectral variations (Gish and Ng 1996; Ganapathiraju et al. 2001).
4.3.1 Fixing the “zero” model
In Arabic language, the word “zero”, pronounced as “sěfr”, is a monosyllable word with type /CVCC/. This type of syllable is less frequent and it occurs only at the word-final position or in monosyllabic words (Al-Zabibi 1990). The digit “sěfr” consists of mainly unvoiced phonemes and it is usually the shortest among all the other digits. It starts with the relatively long consonant /s/ (unvoiced fricative) followed by the short vowel /i/ and then it ends with two consonants, namely /f/ (unvoiced fricative) and /r/ (voiced lateral) (Alotaibi 2005).
The digit “zero” is mainly dominated by unvoiced phonemes. Generally, this part of speech can be masked more easily by the background noise, because it is often acoustically noise-like and its energy is usually much weaker than that of voiced speech (Hu and Wang 2008). Therefore, we expect that more number of mixture densities will be needed to capture the large amount of variations in the feature space of this digit. The solution of increasing acoustic resolution using sub-word modeling has demonstrated its effectiveness in improving the recognition performance, in previous research studies, e.g. (Lee et al. 1990).
Various experiments have been conducted in order to assess the effects of only increasing the number of mixtures of the digit “zero” (3, 6,…, and 36 mixtures). As shown in Figs. 13 and 14, the degraded performance due to high noise level is compensated by increasing the “zero” model densities. The optimal numbers of mixtures in which the best overall accuracies are achieved, when the rest of the models are trained either by three or six mixtures, are illustrated in Table 13.

WAR (%) by varying number of mixtures of “zero” model in clean training

WAR (%) by varying number of mixtures of “zero” model in multi-condition training
We conducted a second experiment with the new optimized mixtures by considering the same previous test utterances for low SNRs, in order to see the effects of the confusion among digits. Tables 14, 15, 16 and 17 show that using the optimal densities of digit “zero” increases the number of correctly predicted elements from the confusion matrix diagonal. It can also be noticed that the overall system accuracy using syllable as acoustic unit outperforms word unit.
Furthermore, it can be observed from previous results (see Fig. 11) that there is no improvement in system performance if mixtures of all syllables are increased together. This could explain the effects on performance by increasing only the mixtures of “zero” model.
4.3.2 Optimizing the derivative window length
We performed another experiment to determine the optimal derivative window length, based on the maximum achieved performance. In this experiment, the recognition systems use the obtained optimal mixtures for both acoustic units (refer to Table 13). Comparing results in Figs. 15 and 16 with the previous results in Figs. 6 and 7, it can be seen that the optimal derivative window is changed only when using syllable model in clean training. The new window length for syllable model is reduced from 17-frame to 13-frame. Other results in Table 18 show that better overall recognition performance is obtained when using syllable model in both training conditions, with the new optimized configuration.

WAR (%) versus derivative window length after fixing “zero” model (word-based recognition)

WAR (%) versus derivative window length after fixing “zero” model (syllable-based recognition)
4.4 Detailed experimental results using syllable unit
A series of tests have been conducted in order to find an optimal configuration for the ARADIGIT-2 task, where we demonstrated that using syllable unit with the appropriate parameters leads to best performance. Tables 19, 20, 21 and 22, summarize a detailed ARADIGITS-2 recognition performance, for different noise types and various SNR levels. The HMM models are trained by considering the following optimized parameters: (i) Each syllable model has 16 states, with three mixtures per state; except to the “zero” model which has 27 and 12 mixtures per state, for clean and multi-condition, respectively (refer to Table 13) and (ii) 13-frame and 11-frame sizes are used to estimate the derivatives for clean and multi-condition, respectively (refer to Fig. 16). Similar to AURORA-2 database, the silence model has three states and each state has six mixtures. The recognition performance is evaluated for the case of uncompressed MFCCs (baseline) and for the case of compressed MFCCs using ETSI-AFE encoder at 4400 bps.
From Tables 19 and 20, it can be observed an expected overall improvement in performance of test set A compared to test set B in multi-condition training mode. This can be justified by the fact that test set A contains the same noises as used in multi-condition training mode. Also, the results show degraded recognition performance for test set C. This degradation is due to the effect of MIRS filtering (i.e. handling convolutional distortion). Comparing to clean training mode, we notice a graceful degradation on the performance of test clean utterances in multi-condition training mode. This can be interpreted by the improvement on noisy speech at the cost of scarifying the recognition performance of the clean one (Cui and Gong 2007). It can be seen that the noises which contain the non-stationary segments such as babble, restaurant, airport, and train-station (Hirsch and Pearce 2000) do not reduce considerably the performance with respect to the rest of noises.
Results in Tables 21 and 22 show a graceful degradation in the recognition performance, using the quantization codebooks of ETSI-AFE encoder with multi-condition training (with 0.21% of relative degradation rate). However, the recognition performance could be further improved if the quantization codebooks are re-estimated by the use of new MFCC vectors extracted from Arabic corpus. We should point out that the results correspond to the case where the HMM models are trained on uncompressed features; this means that there is a mismatch between training and test data.
5 Conclusion
In this paper we presented ARADIGIT-2, an HMM-based speaker-independent Arabic digits speech recognition database. Designed within an experimental framework, ARADIGIT-2 provides a performance evaluation of MSA isolated digits under noisy environments at various SNR levels. Generally, we followed the same methodology as AURORA-2 database, which is widely used for noise robust DSR systems evaluation. ARADIGITS-2 is aimed to make available a corpus of Arabic speech data, in order to allow researchers and developers to perform evaluation of their developed algorithms, as well as for building DSR applications which need Arabic digits as input data.
Although the word unit is the frequently used in building digits recognition engines, we have also adopted the syllable unit in building ARADIGIT-2. The use of syllable unit is motivated by the polysyllabic nature of Arabic digits comparing to other languages such as English. To improve the recognizer performance, a series of experiments have been conducted in order to find the optimal combination of parameters of acoustic units, especially for the monosyllabic Arabic digit “zero”. The parameters of interest are: the number of states per model, the number of Gaussian mixtures per state, and the derivative window length. We found that syllable-like unit fits better comparing to word like-unit. The recognition performance using syllable unit exceeds word unit by an overall WAR of 0.44 and 0.58% for clean and multi-condition training modes, respectively. However, finding more effective configuration remains to be established.
The final obtained results, using syllable unit, are promising. These results correspond to the cases of both uncompressed and compressed features of ETSI-AFE DSR standard, with an overall recognition performance on both clean and multi-condition modes of (88.08, 95.94%), and (88.29, 95.73%), for uncompressed and compressed MFCCs, respectively.
In addition, since the ETSI-AFE standard has been tested on a range of languages, the elaborated ARADIGITS-2 made the possibility of testing this standard in Arabic language. However, our future work will focus on extending the DSR ARADIGITS-2 to a large vocabulary Arabic continuous speech recognition database, by constructing a mixture of word, syllable, and phoneme-based acoustic units.
References
Abushariah, M. A., Ainon, R. N., Zainuddin, R., Elshafei, M., & Khalifa, O. O. (2012). Phonetically rich and balanced text and speech corpora for Arabic language. Language Resources and Evaluation, 46(4), 601–634.
Alotaibi, Y. A. (2003). High performance Arabic digits recognizer using neural networks. In Proceedings of the international joint conference on neural networks, IJCNN, (pp. 670–674).
Alotaibi, Y. A. (2005). Investigating spoken Arabic digits in speech recognition setting. Information Sciences, 173(1), 115–139.
Alotaibi, Y. A. (2008). Comparative study of ANN and HMM to Arabic digits recognition systems. Journal of King Abdulaziz Universitys, 19(1), 43–59.
Al-Zabibi, M. (1990). An acoustic-phonetic approach in automatic Arabic speech recognition (Doctoral dissertation, The British Library in Association with UMI,1990).
Amrouche, A., Debyeche, M., Taleb-Ahmed, A., Rouvaen, J. M., & Yagoub, M. C. E. (2010). An efficient speech recognition system in adverse conditions using the nonparametric regression. Engineering Applications of Artificial Intelligence, 23(1), 85–94.
Applebaum, T. H., & Hanson, B. (1991). Regression features for recognition of speech in quiet and in noise. In Proceedings of the international conference on acoustics, speech, and signal processing, ICASSP, (pp. 985–988).
AURORA project. (2006). AURORA speech recognition experimental framework. Retrieved September 15, 2016, from http://AURORA.hsnr.de/index.html
Bakis, R. (1976). Continuous speech recognition via centisecond acoustic states. The Journal of the Acoustical Society of America, 59(S1), S97.
Boersma, P., & Weenink, D. (2015). Praat: Doing phonetics by computer. Version 5.4.08. Retrieved September 15, 2016, from http://www.praat.org/
Cui, X., & Gong, Y. (2007). A study of variable-parameter Gaussian mixture hidden Markov modeling for noisy speech recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 15(4), 1366–1376.
ELRA. (2005). NEMLAR broadcast news speech corpus. ELRA catalogue, ELRA-S0219. Retrieved September 15, 2016, from http://catalog.elra.info/product_info.php?products id = 874
ETSI document ES 201 108. (2003a). Speech processing, transmission, and quality aspects (stq): Distributed speech recognition; front-end feature extraction algorithm; compression algorithms. Version 1.1.3.
ETSI document ES 202 211. (2003b). Speech processing, transmission, and quality aspects (STQ): Distributed speech recognition; extended front-end feature extraction algorithm; compression algorithms; back-end speech reconstruction algorithm. Version 1.1.1.
ETSI document ES 202 050. (2007). Speech processing, transmission, and quality aspects (STQ): Distributed speech recognition; advanced front-end feature extraction algorithm; compression algorithms. Version 1.1.5.
Fujimoto, M., Takeda, K., & Nakamura, S. (2006). CENSREC-3: An evaluation framework for Japanese speech recognition in real car-driving environments. IEICE Transactions on Information and Systems, 89(11), 2783–2793.
Furui, S. (1981). Cepstral analysis technique for automatic speaker verification. Acoustics, IEEE Transactions on Acoustics, Speech, and Signal Processing, 29(2), 254–272.
Furui, S. (1986). Speaker-independent isolated word recognition using dynamic features of speech spectrum. IEEE Transactions on Acoustics, Speech, and Signal Processing, 34(1), 52–59.
Ganapathiraju, A., Hamaker, J., Picone, J., Ordowski, M., & Doddington, G. R. (2001). Syllable-based large vocabulary continuous speech recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 9(4), 358–366.
Gish, H., & Ng, K. (1996). Parametric trajectory models for speech recognition. In Proceedings of the international conference on spoken language processing, ICSLP, (pp. 466–469).
Hajj, N., & Awad, M. (2013). Weighted entropy cortical algorithms for isolated Arabic speech recognition. In Proceedings of the International Joint Conference on Neural Networks, IJCNN, (pp. 1–7).
Hirsch, H.-G., & Pearce, D. (2000). The AURORA experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In Proceedings of ISCA tutorial and research workshop, (pp. 181–188).
Hirsch, H-G. (2005). FaNT, filtering and noise adding tool. Retrieved September 15, 2016, from http://dnt.kr.hsnr.de/
Hirsch, H-G., & Pearce, D. (2006). Applying the advanced ETSI frontend to the AURORA-2 task. technical report, Version 1.1.
Hu, G., & Wang, D. (2008). Segregation of unvoiced speech from nonspeech interference. The Journal of the Acoustical Society of America, 124(2), 1306–1319.
Hyassat, H., & Abu Zitar, R. (2006). Arabic speech recognition using SPHINX engine. International Journal of Speech Technology, 9(3), 133–150.
ITU-T, Recommendation P.830. (1992). Subjective performance assessment of telephone-band and wideband digital codecs. Geneva, Switzerland.
ITU-T, Recommendation G.712. (1996). Transmission performance characteristics for pulse code modulation channels, Geneva, Switzerland.
Knoblich, U. (2000). Description and baseline results for the subset of the Speechdat-Car Italian database used for ETSI STQ Aurora WI008 advanced DSR front-end evaluation. Alcatel. AU/237/00.
Lee, C. H., Rabiner, L., Pieraccini, R., & Wilpon, J. (1990). Acoustic modeling of subword units for speech recognition. In Proceedings of the international conference on acoustics, speech, and signal processing, ICASSP, (pp. 721–724).
Lee, C. H., Soong, F. K., & Paliwal, K. K. (1996). Automatic speech and speaker recognition: advanced topics (Vol. 355). London: Springer Science & Business Media.
Leonard, R. (1984). A database for speaker-independent digit recognition. In Proceedings of the international conference on acoustics, speech, and signal processing, ICASSP, (pp. 328–331).
Lindberg, B. (2001). Danish Speechdat-Car Digits database for ETSI STQ AURORA advanced DSR. CPK, Aalborg University. AU/378/01.
Ma, D., & ZENG, X. (2012). An improved VQ based algorithm for recognizing speaker-independent isolated words. In Proceedings of the international conference on machine learning and cybernetics, ICMLC, (pp. 792–796).
Macho, D. (2000). Spanish SDC-AURORA database used for ETSI STQ AURORA WI008 advanced DSR front-end evaluation, description and baseline results. Barcelona: Universitat Politecnica de Catalunya (UPC). AU/271/00.
Nakamura, S., Takeda, K., Yamamoto, K., Yamada, T., Kuroiwa, S., Kitaoka, N., Nishiura, T., Sasou, A., Mizumachi, M., Miyajima, C., Fujimoto, M., & Endo, T. (2005). AURORA-2J: An evaluation framework for Japanese noisy speech recognition. IEICE Transaction on Information and Systems, 88(3), 535–544.
Naveh-Benjamin, M., & Ayres, T. J. (1986). Digit span, reading rate, and linguistic relativity. The Quarterly Journal of Experimental Psychology, 38(4), 739–751.
Neto, S.F.D.C. (1999). The ITU-T software tool library. International Journal of Speech Technology, 2(4), 259–272.
Netsch, L. (2001). Description and baseline results for the subset of the Speechdat-Car German database used for ETSI STQ AURORA WI008 advanced DSR front-end evaluation. Texas Instruments. AU/273/00.
Nishiura, T., Nakayama, M., Denda, Y., Kitaoka, N., Yamamoto, K., Yamada, T., et al. (2008). Evaluation framework for distant-talking speech recognition under reverberant: Newest part of the CENSREC Series. In Proceedings of the language resources and evaluation conference, LREC, (pp. 1828–1834).
Nokia. (2000). Baseline results for subset of Speechdat-Car Finnish database used for ETSI STQ WI008 advanced front-end evaluation. AU/225/00.
Pearce, D. (2000). Enabling new speech driven services for mobile devices: An overview of the ETSI standards activities for distributed speech recognition. In Proceedings of the voice input/output applied society conference, AVIOS (pp. 83–86). San Jose: AVIOS
Pearce, D. (2001). Developing the ETSI AURORA advanced distributed speech recognition front-end & what next?. In Proceedings of the workshop on automatic speech recognition and understanding, ASRU, (pp. 131–134).
Rabiner, L. R. (1989). A tutorial on Hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), 257–286.
Rabiner, L. R., & Juang, B. H. (1993). Fundamentals of speech recognition (Vol. 14). Englewood Cliffs: PTR Prentice Hall.
Rabiner, L. R., Wilpon, J. G., & Soong, F. K. (1989). High performance connected digit recognition using hidden Markov models. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(8), 1214–1225.
Ryding, K. C. (2005). A reference grammar of modern standard Arabic. Cambridge: Cambridge University Press.
Siemund, R., Heuft, B., Choukri, K., Emam, O., Maragoudakis, E., Tropf, H., et al. (2002). OrienTel: Arabic speech resources for the IT market. In Proceedings of the language resources and evaluation conference, LREC.
Soong, F. K., & Rosenberg, A. E. (1988). On the use of instantaneous and transitional spectral information in speaker recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 36(6), 871–879.
The Linguistic Data Consortium. (2014). King Saud University database. Retrieved September 15, 2016, from https://catalog.ldc.upenn.edu/ldc2014s02
World Bank (2016). Retrieved September 15, 2016, from http://data.worldbank.org/region/ARB
Young, S., Evermann, G., Gales, M., Hain, T., Kershaw, D., Liu, X., Moore, G., Odell, J., Ollason, D., Povey, D., Valtchev, V., & Woodland, P. (2006). The HTK Book. Version 3.4. Cambridge: Cambridge University, Engineering Department.
Acknowledgements
This work has been supported in part by the LCPTS laboratory project. We would like to thank Dr Abderrahmane Amrouche for making many suggestions which have been exceptionally helpful in carrying out this research work. We also would like to thank Dr. Amr Ibrahim El-Desoky Mousa for providing support in interpreting results.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Touazi, A., Debyeche, M. An experimental framework for Arabic digits speech recognition in noisy environments. Int J Speech Technol 20, 205–224 (2017). https://doi.org/10.1007/s10772-017-9400-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-017-9400-x