
Abstract
This paper examines health care expenditure (HCE) disparities between the European Union countries over the period 1995–2010. By means of using a continuous version of the distribution dynamics approach, the key conclusions are that the reduction in disparities is very weak and, therefore, persistence is the main characteristic of the HCE distribution. In view of these findings, a preliminary attempt is made to add some insights into potentially main factors behind the HCE distribution. The results indicate that whereas per capita income is by far the main determinant, the dependency ratio and female labour participation do not play any role in explaining the HCE distribution; as for the rest of the factors studied (life expectancy, infant mortality, R&D expenditure and public HCE expenditure share), we find that their role falls somewhat in between.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Health care expenditure (hereafter HCE) has been sharply on the rise for at least the last two/three decades in most European Union (EU) economies. As indicated by Breyer et al. (2010) and Pammolli et al. (2012), advancement of medical technology, higher income levels, population ageing and female labour participation have contributed significantly to what might be termed as “explosion” of health costs.Footnote 1 In the current context of severe global economic and financial crisis, this issue has become a major concern for European politicians as they are under heavy pressure for achieving fiscal consolidation. In this vein, it seems mandatory to closely follow the HCE distributionFootnote 2 across the EU countries to, among other things, get insights about the evolution of cross-country disparities in HCE, as well as about potential factors that could explain it and promote HCE convergence among them.
The so-called convergence debate came to the fore throughout the 1990s or so, basically with reference to per capita income or productivity. This debate has been particularly intense and has served to provide different interpretations of convergence and, related to it, different methodologies applied to test for its existence.Footnote 3 Surprisingly enough, it has not been until the last few years that researchers have begun to examine the issue of HCE convergence/divergence. There are, however, at least three closely related reasons for the interest on this topic in the EU. First, it is the fact that, as economic integration fosters income convergence and HCE tends to be closely related to income (Newhouse 1977), it seems that HCE should also follow a rather similar convergence path (Wang 2009). Additionally, different aspects and mechanisms of the European policies “tend to generate forces for convergence at the level of public health” (Nixon 2000, p. 1). Finally, as economic integration promotes “the mobility in the labour market and reduces the transaction costs of cross-border shopping within the health care system ... convergence in HCF reduces the incentive and benefit to follow the outside option” (Leiter and Theurl 2012, p. 7).
Despite the aforementioned reasons, there is a relatively scant literature on the topic of HCE convergence and, consequently, there still exist important gaps that must be covered. Illustrative of this is the fact that, as far as we know, an important methodological approach, the so-called distribution dynamics approach, which offers critical information about what happens within the distribution, has not been employed in the analysis of HCE convergence yet.
This is precisely the gap we intend to fill in this paper. Its main contribution, therefore, lies on the application of a distribution dynamics approach to the study of HCE convergence. The key advantage of this approach is that it enables us to uncover important features of the dynamics of the HCE distribution that might characterise the convergence process and that other approaches fail to do so. Traditional regression techniques analyse the behaviour of a representative unit, so they do not reveal the dynamics of the entire cross-sectional distribution; in other words, they do not provide information on how one country behaves with respect to another. On the contrary, the distribution dynamics approach captures the evolution of the entire cross-sectional distribution.Footnote 4 Additionally, and bearing in mind that the results obtained by this new approach show a rather slow HCE convergence process, the paper also offers a first and provisional attempt to unveil some important factors underlying HCE disparities.
As mentioned, considering the severe budgetary and financial restrictions that most European countries are currently experiencing, this paper takes the EU as a sort of laboratory and analyses per capita HCE (HCEpc) over the period 1995–2010. HCE data are extracted from the National Health Accounts database of the World Health Organisation (WHO), which provides information on total health expenditure and its composition, public and private.Footnote 5 Specifically, HCE includes final (public and private) consumption on health goods and services plus (public and private) capital investment in health care infrastructures. Depending on the issue at hand, HCE data are expressed either in constant (2005) per capita purchasing power parity (PPP) currency unitsFootnote 6 or as percentages. Additionally, when it comes to examining the factors that are behind the HCEpc distribution, Eurostat is employed for obtaining per capita income, dependency ratio, female labour participation, life expectancy, infant mortality, and R&D spending data, whereas the WHO database is used for public HCE share.
The rest of the paper is organised as follows. Next section briefly reviews the most relevant contributions to the literature on HCE convergence. Afterwards, we concisely document the key stylised facts on HCE in the EU. In the fourth section the distribution dynamics approach is introduced and employed to analyse the existence, or not, of a process of convergence across EU countries in HCEpc. Subsequently, section fifth examines the role played by different factors in explaining the main characteristics of the HCEpc distribution in the EU. As usual, the final section offers some concluding remarks.
Health care expenditure convergence: a brief literature review
As mentioned in the Introduction, studies about HCE convergence are rather scant.Footnote 7 In this regard, most contributions have been oriented to examine the issue in the context of the OECD countries. Concerning them, the study by Barros (1998), in the same vein than that by Hitiris and Nixon (2001) for the EU, analyses a sample of twenty-four countries for the period 1960–1992. They observe clear and strong evidence of the existence of \(\upbeta \)-convergence in HCE. Methodologically, the paper by Okunade et al. (2004) gives a step forward as it addresses several of the econometric problems found when testing the validity of the convergence hypothesis in HCE to small samples. Paying attention to the determinants of per capita HCE growth in a sample of OECD countries between 1968 and 1997, the paper basically reveals that countries with lower (higher) initial per capita HCE saw their levels to grow at faster (slower) rates, a result that is fully consistent with the definition of conditional \(\upbeta \)-convergence.
With reference to five selected OECD countries, Narayan (2007) investigates the fulfilment of the catch-up hypothesis for HCE between them and the USA over the period 1960–2000. Making use of the stochastic definition of convergence this study shows that, depending on the specific unit-root test employed, the results differ: there is no convergence (catch-up) when the univariate ADF test is used; however, when the LM univariate test is employed, the convergence hypothesis is fulfilled. Additionally, Narayan (2007) considers the same five countries as a panel and, once again, finds that the conclusion about convergence depends on the type of unit-root test used: there is no evidence of convergence when applying classical unit-root tests but there is strong evidence of convergence when structural changes are included.
More recently, Panopolou and Pantelidis (2012) have applied a new methodology to a sample of nineteen OECD countries over the period 1972–2006. The main trait of this methodology is that, apart from being robust to the stationarity properties of the series under scrutiny, it provides a simple algorithm to identify groups of economies that converge to different equilibria. By using this approach, they offer support for the existence of a convergence process for seventeen of the nineteen countries in the sample.
Leiter and Theurl (2012), and focusing on the role played by the public sector in health care financing, carry out a conventional \(\sigma \) and \(\upbeta \) convergence analysis for twenty-two OECD countries between 1970 and 2005. They conclude that, whatever the specification of the dependent variable and the different approaches used to test for convergence, as well as the different assignments of countries to subsamples, a process of convergence took place.
As for the EU, the contributions to this topic have been even less abundant. Among them, Hitiris (1997) seminal paper, working with a panel of ten EU countries over the period 1960–1991, finds no sign of HCE convergence. Hitiris and Nixon (2001) paper, employing a standard \(\upbeta \)-convergence approach to a sample of fifteen EU member states for the period 1980–1995, reveals that a process of convergence developed over this period. Finally, Kerem et al. (2008), by using cross-sectional data for three different samples of EU countries over the period 1992–2004, conclude that, irrespective of its definition, a process of convergence did exist for the three samples.
Apart from the studies devoted to the OECD and EU countries there have also been some attempts to extend this analysis to a single, decentralised economy. Among them Wang’s (2009) paper for the United States stands out because, as it is well-known, HCE in this country is higher than in any other developed country. By applying cross-section and time-series techniques to the fifty states over the period 1980–2004 the results suggest that: (a) convergence occurred across the states; (b) the rate of convergence was relatively slow; and (c) states converged to a number of groups (clusters) with different characteristics.Footnote 8
This brief and selected review of the literature on HCE convergence seems to suggest that, at least for developed countries, there has been a process of convergence. This being so, it is also true that the speed and strength of convergence depends on the country and time samples considered, the definition of convergence employed, and the econometric methodology applied.
Although illuminating, the literature on HCE convergence has paid no attention to the so-called distribution dynamics approach yet. This is quite striking because of, as shown in convergence studies on per capita income and/or productivity, this technique not only adds new interesting insights to the conclusions obtained by the standard convergence approaches but also addresses some of their limitations.
Health care expenditure in the European Union: some stylised facts
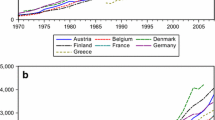
Two main stylised facts can be discerned when it comes to the study of HCEpc for the EU (see Fig. 1). First, HCEpc has more than doubled in real terms between 1995 and 2010,Footnote 9 this fact raising concerns about its sustainability in the future (Fig. 1a). Second, HCEpc has increased following a continuous and rather stable path (Fig. 1b). It is only in 2010, and probably because of the very urgent need to control public expenditure in most EU countries, that HCEpc has seen notably reduced its rate of growth.

HCE evolution a Normalised levels (1995 = 100), b Growth rates
Although similar results are obtained when the variable under consideration is HCE relative to GDP, there are two important differences worth to be highlighted. On the one hand, that the average growth of this ratio (1.4 %) has been much slower than that of the HCEpc (5.4 %), so that over the sample period HCE/GDP has increased less than 25 % (see again Fig. 1a). On the other hand, that the upward trend has not been as stable (Fig. 1b). In addition, it is interesting to stress that the HCE/GDP ratio has increased over time, which seems to imply that (a very rough measure of) the income elasticity of HCE is greater than one; put it another way, this means that health care can be considered as a luxurious good.Footnote 10

HCE dispersion (1995 = 100). Dispersion is measured by the coefficient of variation
From a country’s perspective, dispersion in HCEpc, as measured by the coefficient of variation, has exhibited a downward trend (Fig. 2). As for HCE as a percentage of GDP, the overall result is also one of declining but in a less intense way and with two sub-periods clearly differentiated. Accordingly, it seems that, at this stage of the analysis, the preliminary conclusion is that, albeit weak, there has been a process of HCE convergence across the European countries.
Finally, it is worth mentioning that the growth in HCE, either in per capita terms or as a percentage of GDP, is the result of the increase in both the public and private HCE components. Now, even though the growth of private HCE has been faster than that of public HCE, the contribution of the public sector to HCE has been much greater than that of the private sector. This is simply because its share on HCE is much larger (Table 1).
Health care expenditure convergence in the European Union: a distribution dynamics approach
As previously mentioned, the literature analysing the evolution of HCE disparities across economies has usually resorted to econometric techniques with no regard to some important characteristics of the distribution. In particular, conventional regression techniques (cross-section, panel and, partially, time-series approaches), albeit illustrative, fail to capture two potentially interesting features of the distribution: its shape and its internal changes over time (Quah 1996a, b). These two drawbacks are conveniently addressed by the distribution dynamics approach.
To do that, for the sake of simplicity and due to the fact that the correlation between HCEpc and HCE as a percentage of GDP is in all cases quite high—on average is 0.96–, hereafter we will be just paying attention to the HCEpc. Regarding the shape of the distribution, we propose to depict it by estimating univariate density functions. These are estimated non-parametrically by the kernel method. In formal terms, the kernel density estimate of a series \(X\) at a point \(x\) is given by the expression:
where \(n\) is the number of observations, \(K\) is the kernel function, \(h\) the smoothing parameter, \(X_{i}\) the values of the variable of interest, and \(x\) the value of this same variable for which one seeks an estimate. There are, thus, two relevant factors in the computation of stochastic kernels: the kernel function and the bandwidth.
As regards the kernel function (a weighting function giving the weights of the nearby data points in making the estimate) we use the Gaussian kernel given by:
As for the bandwidth, its purpose being to put less weight on observations that are further from the point being evaluated,Footnote 11 we have chosen, as it is common practice in the literature, the Silverman’s (1986) bandwidth selector \(h=1.06sn^{-0.2}\), where \(s\) denotes the standard deviation of the data.

Density functions (EU = 100). The plots are densities calculated non-parametrically using a Gaussian kernel with bandwidth chosen as suggested in Silverman (1986)
Then, after normalising HCEpc (EU average equal to 100) and applying Eq. (1) to our data for some selected years (1995, 2000, 2005 and 2010), two main conclusions can be obtained (Fig. 3). On the one hand, the range of the distribution has slightly diminished over time. On the other hand, the probability mass concentrating around the average is a little higher in 2010 than in any other year.Footnote 12 Therefore, these conclusions corroborate what was previously said about the existence of convergence: it exists but at a very slow pace. Finally, a second mode began to develop around the year 2000 at HCE levels above 200 % of the average and it persists over time; this is evidence of the existence of a small group (club) of countries devoting twice as much of resources to health care than the European average.
The previous analysis, albeit informative and useful, fails to clarify whether changes in the external shape of the distribution were accompanied by changes in the relative position of countries within the distribution (intra-distribution dynamics). In order to gain some insight into this question the well-known Markov chain approach could be employed. The main problem with this approach, however, is that its conclusions about the mobility degree (and the existence or not of convergence) might critically depend on the number and length of the states chosen for the analysis. To overcome this drawback, a continuous approach involving the calculation of stochastic kernels is commonly developed (see Quah 1997; Durlauf and Quah 1999). This approach, based on the estimation of the conditional density of a variable Y (in our case, HCEpc in the final year) given a variable X (HCEpc in the initial year), can be interpreted as a transition matrix with infinite rows and columns. Following this approach, Hyndman et al. (1996) developed a novel technique, the so-called highest conditional density region (HCDR) approach, which offers, apart from better statistical properties, additional, interesting insights with respect to the former: a much powerful visualisation tool which allows an easier and direct interpretation of the results.Footnote 13 A key innovation of this paper lies in the application of this relatively novel technique to the analysis of HCE.Footnote 14
The estimator proposed by Hyndman et al. (1996) is given by the expression:
where \(Y_i^*(x)=e_i +\hat{{r}}(x)-\hat{{l}}(x)\), being \(\hat{{r}}(x)\) the estimator of the conditional mean function \(r(x)=E\left[ {Y\left| {X=x} \right. } \right] \), \(e_i =y_i -\hat{{r}}(x_i )\), and \(\hat{{l}}(x)\) the mean of the estimated conditional density of \(e\left| {X=x} \right. \). It can be proved that when \(\hat{{r}}(x)=\hat{{m}}(x)=\sum \nolimits _{i=1}^n {w_i (x)Y_i } \), then \(\hat{{f}}_\tau ^*\left( y\left| x \right. \right) =\hat{{f}}_\tau \left( y\left| x \right. \right) \), but the mean function \(\hat{{f}}_\tau ^*\left( y\left| x \right. \right) \) has better bias properties than the traditional kernel estimator, as well as a smaller integrated mean square error.
Once again, a crucial decision in the estimation of Eq. (3) refers to the method employed to select the bandwidth. Specifically, we use optimal bandwidths in the two directions \(x \)and \(y\) following Bashtannyk and Hyndman’s (2001) rules.Footnote 15 Regarding the kernel function, the Gaussian kernel given by equation (2) is again used.
Apart from this new estimator, Hyndman et al. (1996) also proposed, as it was mentioned before, new ways to visualize the conditional density: the stacked conditional density (SCD) plot and HCDR plot. The SCD plot shows a number of densities plotted side by side in a perspective graph; because of that, it highlights the conditioning inside the distribution. The HCDR plot represents, on the other hand, the so-called highest density regions; without entering into details, the highest density region is defined ‘as the smallest region of the sample space containing a given probability’ (Hyndman et al. 1996, p. 327).

Stacked conditional density plot (EU = 100). Conditional densities of transitions between 1995 and 2010. Estimates are based on a Gaussian product kernel density estimator with bandwidth selection based on the rule suggested by Bashtannyk and Hyndman (2001). The SCD plot was estimated at 50 points

Highest conditional density region plot (EU = 100). From dark to light, the shadings represent 25, 50, 75 and 90 % of the total probability. Bullets indicate the mode. Estimates are based on a Gaussian product kernel density estimator with bandwidth selection based on the rule suggested by Bashtannyk and Hyndman (2001). The highest density region plot was estimated at 50 points
The results of applying this new approach to our sample are displayed in Figs. 4 and 5. First, the SCD plot displays one conditional probability density in 2010 for each value of the relative HCEpc in 1995. The interpretation of this plot (Fig. 4) is straightforward: peaks of density functions following the diagonal would imply high persistence (low mobility). Overall, the results seem to show that the probability mass and most of the peaks tend to be clustered along the main diagonal, a clear sign of high persistence. This tentative conclusion, however, will be qualified further down.
A much more informative and precise way to represent the changes within a distribution is based on the HCDR plot which, as mentioned, displays the highest density regions. Each vertical strip in Fig. 5 represents the highest-density portion of the probability distribution for a given HCEpc level in the initial year (1995). In particular, this figure shows the highest density regions for a probability of 25, 50, 75 and 90 % (as it passes from a darker to a less dark area). In addition, it illustrates, as a bullet \(({\bullet })\), the mode (value of relative HCEpc in the final year (2010) where the density function takes its maximum value) for each value in the initial year. To interpret this graph it should be noted that when the main diagonal crosses the 25 % HDRs (or the bullets are close to it) there is evidence of persistence in relative HCEpc levels; this means that it would be quite unlikely for a country to dramatically change its relative position within the distribution during the course of 5 years. By contrast, when the main diagonal does not touch the 25 % HDRs (or the bullets are quite far from the diagonal) we can say that mobility is the prevailing characteristic of the distribution and that this is the greater the further the 25 % HDRs from the diagonal.
The results depicted in Fig. 5 indicate that, as mentioned before, high persistence is the main characteristic of the distribution. Nevertheless, Fig. 5 also shows some signs of mobility (the main diagonal does not cross the 25 % HDRs) that, according to their direction, have undoubtedly contributed to fuel HCEpc convergence: namely, countries with an HCEpc below 25 % and between 75 and 90 % of the EU average have improved their relative position in the distribution; on the contrary, countries with a very high HCEpc (above 140 %) have worsened them.

Ergodic distribution. Hypothetical long-term equilibrium distribution if current trends in intra-distribution dynamics remain unchanged in future
To conclude this analysis, we compute the ergodic (i.e. the long-run equilibrium) distribution by iterating the stochastic kernel under the assumption that current trends will persist in the future. The results obtained –which obviously should be taken with caution given the short time-span of the sample - reveal that the ergodic distribution has just one mode located around a HCEpc close to 110 (Fig. 6). Additionally, it is also worth adding that, according to the shape of the ergodic distribution, disparities in HCEpc levels are expected to remain very high in the near future. This could be possibly linked to the fact that “national health policy is a unique political expression of the underlying social values and norms” (Spitzer et al. 2006) and, as it is well known, these differ across the EU countries.
Factors underlying health care expenditure distribution in the European Union: a preliminary analysis
The previous analysis has revealed clear but weak signs of convergence in HCE and some mobility in the distribution. In view of these findings we are interested in knowing which factors could be behind such traits of the distribution. To this end, and using once again the methodology proposed by Hyndman et al. (1996), we proceed to compare, for the whole sample period,Footnote 16 the original HCEpc distribution with conditioned distributions obtained by making use of factors conventionally regarded by the literature on health economics as explanatory of disparities in HCEpc.
Although we are conscious that the selection of explanatory factors is somewhat arbitrary, considering the literature on the issue and data availability we specifically assess the role played by seven factors. First, per capita GDP, because it is generally considered the main factor behind HCEpc.Footnote 17 Second, the dependency ratio (defined as the percentage of population under 15 and over 65 years old to the population aged 15–64), as it seems also a good indicator of health care needs and expenditures. Third, the share of public HCE on total HCE, because evidence somewhat supports the existence of a direct link between this share and HCEpc.Footnote 18 Fourth, female labour participation since it presumably has a direct impact on HCE (Pammolli et al. 2012). Finally, life expectancy, infant mortality and total R&D expenditures (as a percentage of GDP),Footnote 19 as some authors (Okunade and Murthy 2002; Dreger and Reimers 2005; Xu et al. 2011) suggest these factors as proxies for technological progress.
The procedure for building our seven conditioned distributions is always the same. It consists of two steps (Maza et al. 2009). To begin with, and for each one of the seven conditioning factors, we arrange countries in four groups defined by quartiles. Then, we normalise the HCEpc of each country by the average HCEpc of the countries remaining in the same quartile.
After having obtained the seven conditioned distributions, we compare them (one by one) with the original one (HCEpc of each country normalised by the average HCEpc in the EU). Regarding the graphics, some comments are mandatory as their interpretation somewhat differs from that in the previous section. In this case, when the modes are close to the positive diagonal—in other words, the 25 % HDRs touch the diagonal–, it can be inferred that the conditioning factor does not contribute to explaining HCEpc distribution. This is so because the distribution does not significantly change when countries are grouped based on the conditioning factor. In contrast, when the modes follow the horizontal line at 100, it can be reckoned that the conditioning factor is a crucial element behind the HCEpc distribution. This is because the HCEpc of any country is now much more similar to the HCEpc of the countries in the same quartile than to the average HCEpc in the EU.



Factors explaining HCEpc distribution (1995–2010). a Per capita GDP, b Life expectancy, c Infant mortality rate, d R&D expenditures (% GDP), e Public HCE share, f Dependency ratio, g Female labour participation. From dark to light, the shadings represent 25, 50, 75 and 90 % of the total probability. Bullets indicate the mode. Estimates are based on a Gaussian product kernel density estimator with bandwidth selection based on the rule suggested by Bashtannyk and Hyndman (2001). The highest density region plot was estimated at 50 points
The results obtained are displayed in Fig. 7, in which, for reasons of simplicity, we only show the HCDR plots. In summary, the estimations clearly reveal that per capita GDP is, apart from the upper tail of the distribution (above 200 of the HCEpc average), a key factor underlying HCEpc (Fig. 7a), which is in accordance with the literature (e.g. the seminal work by Newhouse (1977) and, more recently, Hitiris 1997; Okunade and Murthy 2002; Okunade 2005; and Xu et al. 2011). The same seems to occur, although to a lesser extent, with life expectancy and infant mortality rate (Fig. 7b, c). If we continue ranking the factors according to their explanatory power of the HCEpc distribution, the following factors would be R&D expenditures (Fig. 7d) and the share of public on total HCE (Fig. 7e); these factors seem to have a certain influence on the distribution, especially for values between 75 and 150 of the average HCEpc. Additionally, Fig. 7f indicates that the dependency rate does not play any key role in explaining the HCEpc distribution, as it happens that the probability mass is mostly concentrated around the diagonal. Although seemingly against what conventional analysis predicts, this is quite a common conclusion in the empirical literature, which often obtains mixed results about the explanatory power of this factor (Hitiris 1997; Barros 1998; Okunade 2005; Xu et al. 2011; Leiter and Theurl 2012). Something similar occurs with female labour market participation, which role seems to be almost negligible.
Concluding remarks
In the last few years the huge and continuous increase in HCE in the EU has come to the forefront of political attention for different reasons; among these, the need for securing fiscal consolidation is, no doubt, one of the most relevant. In this context, unveiling the main characteristics of the HCE distribution, among which those related to the evolution of disparities and intra-distribution dynamics, seems to be of paramount importance, if only to indirectly test the robustness of the link between income convergence and HCE convergence.
Although some serious efforts have been done, the literature on this topic is still very scant, this explaining some of its gaps. In particular, this paper attempts to fill one of these gaps by means of using the so-called distribution dynamics approach. This approach, in contrast with the traditional techniques employed so far in the literature on HCE convergence, focuses on examining the external shape of the distribution and the main changes occurred in the relative position of countries within it.
As a starting point, and to position the paper in the existing research, a brief review of the literature on HCE convergence is carried out. Next, the paper provides a preliminary analysis of the HCEpc in the EU between 1995 and 2010, revealing the existence of a relatively weak process of convergence across countries. Afterwards, a distribution dynamics approach is applied, from which some important insights can be gained.
First, the shape of the distribution has no changed significantly over time. However, the distribution is less spread and the probability mass concentrating around the average is slightly higher in 2010 than in 1995, which supports the existence of a convergence process, although rather slow. This result, in line with that of Wang (2009) for the US states, seems to support the idea that European policies have generated, to a certain extent, forces for convergence on HCEpc and/or that simultaneously there has been a reduction of the incentive to cross-border shopping in Europe in terms of health.
Second, we should nonetheless highlight that, being true that high persistence is the main feature of the distribution, there are also some signs of mobility that have clearly contributed to convergence. Overall, countries with initially the lowest (highest) levels of HCEpc have improved (deteriorated) their relative position in the distribution over the time span.
Finally, the ergodic distribution reveals that, assuming current mobility patterns persist in the long-term, the distribution would exhibit two modes: the main one would group countries with HCEpc values around the average, whilst the second would be made up of a much smaller group of countries with HCEpc values of approximately twice the average. In addition, the ergodic distribution also reveals that disparities across countries are expected to persist in the near future.
Additionally, and in view of the conclusions about convergence and mobility in the HCEpc distribution in the EU, the analysis ends up examining—according to the literature and data availability—the role played by a set of factors in explaining the distribution. The results point to per capita GDP as the key explanatory factor; as it happens that a process of weak income convergence took place during the sample period, it seems that income convergence is somewhat behind HCEpc convergence. Additionally, the paper also shows that life expectancy, infant mortality and, to a lesser extent, R&D expenditure and the share of public HCE on total HCE expenditure have some explanatory power. In contrast, and somewhat against conventional wisdom, the dependency ratio and female labour participation are found to play no role in explaining the HCEpc distribution.
While appealing, our results should be considered as furnishing only a broad picture of a much more complex phenomenon that requires further investigation. In particular, a clear avenue for future research would be to evaluate the robustness of these results by taking alternative estimation strategies. By doing this, for example through semiparametric estimation techniques, we could address the potential problem of endogeneity in the explanation of the covariates of HCEpc. Another possible extension of the paper would consist on grouping countries according to some of their specific characteristics, as the results could differ if, for instance, transformation countries were studied separately. Finally, we could also focus our analysis on the current period of economic crisis, attempting to uncover the differences that undoubtedly exist between it and the previous ones.
Notes
In the same line, the empirical literature on the determinants of HCE, pioneered by Newhouse (1977), mainly considers four groups of determinants: income, demographic, heterogeneity of health care systems, and technological progress related variables.
Although in a different context, Meijer et al. (2013) also stress the fact that, with reference to health care expenditure, we need not only to account for its growth “but also explain changes in its distribution” (p. 88).
Quantile regressions, sometimes used to study convergence/divergence, are somewhat better suited than conventional regresssion methods to use the information for the whole distribution. However, they do it to a much lesser extent than the distribution dynamics approach.
Although we are well aware that OECD Health Data is the largest available source of statistics to compare OECD health care systems, here we have opted for the National Health Accounts database of the WHO because the OECD database does not provide information for some EU countries (Bulgaria, Cyprus, Latvia, Lithuania, Malta and Romania).
The PPPs are given in national currency units (NCU) per US dollar.
Another important and recent paper on this issue, devoted to Indian States, is Apergis and Padhi (2013). Other papers have also studied the issue of convergence/divergence across regions/states of a country but from the point of view of health outcomes. Montero-Granados and Dios Jimenez (2007), for the Spanish case, and Gächter and Theurl (2011), for the Austrian one, are among the most relevant.
As stressed by Hartwig (2008), “the share of current health expenditure (HCE) in the gross domestic product (GDP) rises rapidly in virtually all developed nations” (p. 603).
The bandwidth election gives a trade-off between bias and variance. Small bandwidths produce small bias and large variance, while large bandwidths yield large bias and small variance.
The “plateau” between around 30 and 130 % of the average is “taller” in 2010 than in the other selected years.
We refer the reader to Maza et al. (2010) for technical details regarding the main differences between the traditional and Hyndman continuous approaches.
These authors proposed a three-steps strategy for bandwidth selection: first, bandwidth selection with the traditional rule suggested by Silverman (1986); second, a bootstrap bandwidth selection approach for estimating conditional distribution functions (Hall et al. 1999); third, a regression-based bandwidth selector (Fan et al. 1996).
Then, we have 16 years \(\times \) 27 countries = 432 observations.
Although Wilson (1999) has argued for the need to count with “a formal theory to explain or predict the per capita medical care expenditure of a nation” (p. 160) and Hartwig (2008) has intended to meet this demand by revisiting Baumol’s model of unbalanced growth, it happens that, as stated by Hoffmeyer and McCarthy (1994) “there is just one, very clear, very well-established statistical fact relating to health expenditure care: its correlation with GDP. No other robust and stable correlation has yet been found” (p. 67).
However, it is necessary to stress that there is no consensus on this point in health economics literature. As rightly pointed out by an anonymous referee, there are doubts about whether a link exists, the signs of the coefficients, and even the direction the link runs.
We use total R&D data because there are no homogeneous data on health R&D spending for all the countries included in our sample.
References
Apergis, N., & Padhi, P. (2013). Health expenses and economic growth: Convergence dynamics across the Indian States. International Journal of Health Care Finance and Economics, 13(3–4), 261–277.
Barros, P. P. (1998). The black box of health care expenditure growth determinants. Health Economics, 7(6), 533–544.
Bashtannyk, D., & Hyndman, R. (2001). Bandwidth selection for kernel conditional estimation. Computational Statistics and Data Analysis, 36, 279–298.
Breyer, F., Costa-Font, J., & Felder, S. (2010). Ageing, health and health care. Oxford Review of Economic Policy, 26(4), 674–690.
Clark, R. (2011). World health inequality: Convergence, divergence, and development. Social Science and Medicine, 72, 617–624.
De Meijer, C., O’Donnell, O., Koopmanschap, M., & Van Doorslaer, E. (2013). Health expenditure growth: Looking beyond the average through the composition of the full distribution. Journal of Health Economics, 32, 88–105.
Dormont, B., Martins, J.O., Pelgrin, F. & Suhcke, M. (2007). Health expenditure, longevity and growth. Paper presented in the IX European Conference of the Fondazione Rodolfo Debenedetti on “Health, Longevity and Productivity”.
Dreger, C. & Reimers, H.E. (2005). Health care expenditures in OECD countries: A panel unit root and cointegration analysis. IZA DP \(\text{ N }^{\rm o}\) 1469.
Durlauf, S. N., & Quah, D. (1999). The new empirics for economic growth. In J. Taylor & M. Woodford (Eds.), Handbook of macroeconomics (Vol. I, pp. 235–308). Amsterdam: North-Holland.
Fan, J., Yao, Q., & Tong, H. (1996). Estimation of conditional densities and sensitivity measures in nonlinear dynamical systems. Biometrika, 83(1), 189–206.
Farag, M., NandaKumar, A., Wallackm, S., Hodgkin, D., Gaumer, G., & Erbil, C. (2012). The income elasticity of health care spending in developing and developed countries. International Journal of Health Care Finance and Economics, 12(2), 145–162.
Fischer, M. M., & Stumpner, P. (2008). Income distribution dynamics and cross-region convergence in Europe. Spatial filtering and novel stochastic kernel representations. Journal of Geographical Systems, 10(2), 109–140.
Gächter, M., & Theurl, E. (2011). Health status convergence at the local level: Empirical evidence from Austria. International Journal for Equity in Health, 10, 34.
Getzen, T. E. (2000). Health care is an individual necessity and a national luxury: Applying multilevel decision models to the analysis of health care expenditure. Journal of Health Economics, 19, 259–270.
Goli, S., & Arokiasamy, P. (2013). Trends in health and health inequalities among major states of India: Assessing progress through convergence models. Health Economics, Policy and Law, doi:10.1017/S1744133113000042.
Hall, P., Wolff, R. C., & Yao, Q. (1999). Methods for estimating a conditional density distribution. Journal of the American Statistical Association, 94(455), 154–163.
Hartwig, J. (2008). What drives health care expenditure?—Baumol’s model of “unbalanced growth” revisited. Journal of Health Economics, 27, 603–623.
Hitiris, T. (1997). Health care expenditure and integration in ten countries of the European Union. Applied Economics, 29, 1–6.
Hitiris, T., & Nixon, J. (2001). Convergence on health care expenditure in the EU countries. Applied Economics Letters, 8, 223–228.
Hoffmeyer, U. K., & McCarthy, T. R. (Eds.). (1994). Financing health care (Vol. 1). Dordrecht: Kluwer Academic Publishers.
Hyndman, R. J., Bashtannyk, D. M., & Grunwald, G. K. (1996). Estimating and visualizing conditional densities. Journal of Computational and Graphical Statistics, 5(4), 315–336.
Islam, N. (2003). What have we learnt from the convergence debate? Journal of Economic Surveys, 17, 309–362.
Kerem, K., Püss, T., Viies, M., & Maldre, R. (2008). Health and convergence of health care expenditure in EU. International Business and Economics Research Journal, 7, 29–44.
Laurini, M. P., & Valls, P. L. (2009). Conditional stochastic kernel estimation by nonparametric methods. Economics Letters, 105(3), 234–238.
Leiter, A. M., & Theurl, E. (2012). The convergence of health care financing structures: empirical evidence from OECD-countries. European Journal of Health Economics, 13, 7–18.
Maza, A., Hierro, M., & Villaverde, J. (2010). Measuring intra-distribution dynamics: An application of different approaches to the European regions. Annals of Regional Science, 45(2), 313–329.
Maza, A., Villaverde, J., & Hierro, M. (2009). Regional productivity distribution in the EU: Which are the influencing factors? European Planning Studies, 17(1), 149–159.
Montero-Granados, R., & De Dios Jimenez, J. (2007). Decentralisation and convergence in health among provinces of Spain. Social Science and Medicine, 64, 1253–1264.
Narayan, P. K. (2007). Do health expenditures ‘catch-up’? Evidence from OECD countries. Health Economics, 16, 993–1008.
Newhouse, J. P. (1977). Medical-care expenditure: A cross-national survey. The Journal of Human Resources, 12(1), 115–125.
Nixon, J. (2000). Convergence of health care spending and health outcomes in the European Union, 1960–95. Centre for Health Economics, Discussion Paper : The University of York. 183.
Okunade, A. (2005). Analysis and implications of the determinants of heathcare management expenditure in African countries. Health Care Management Science, 8, 267–276.
Okunade, A., & Murthy, V. (2002). Technology as a ’major driver’of health care costs: A cointegration analysis of the Newhouse conjecture. Journal of Health Economics, 21, 147–159.
Okunade, A., Karakus, M., & Okeke, C. (2004). Determinants of health expenditure growth of the OECD countries: Jackknife resamplin plan estimates. Health Care Managament Science, 7, 173–183.
Pammolli, F., Riccaboni, M., & Magazzini, L. (2012). The sustainability of European health care systems: Beyond income and aging. European Journal of Health Economics, 13, 623–634.
Panopolou, E., & Pantelidis, T. (2012). Convergence in per capita health expenditures and health outcomes in the OECD countries. Applied Economics, 44(30), 3909–3920.
Quah, D. (1996a). Twin peaks: Growth and convergence in models of distribution dynamics. Economic Journal, 106, 1045–1055.
Quah, D. (1996b). Empirics for economic growth and convergence. European Economic Review, 40, 1353–1375.
Quah, D. (1997). Empirics for growth and distribution: Stratification, polarization, and convergence clubs. Journal of Economic Growth, 2, 27–59.
Silverman, B. W. (1986). Density estimation for statistics and data analysis. London: Chapman and Hall.
Spitzer, A., Camus, D., Desaulles, C., & Kuhne, N. (2006). The changing context of Western European healthcare systems: Convergence versus divergence in nursing problematics. Social Sciences and Medicine, 63, 1796–1810.
Villaverde, J., & Maza, A. (2011). Measurement of regional economic convergence. In P. de Lombaerde, R. Flores, R. Lapadre, & M. Schulz (Eds.), The regional integration manual. Quantitative and qualitative methods (pp. 147–178). London: Routledge.
Wang, Z. (2009). The convergence of health care expenditure in the United States. Health Economics, 18, 55–70.
Wilson, R. M. (1999). Medical care expenditures and GDP growth in OECD nations. American Association of Behavioral and Social Sciences Journal, 2, 159–171.
Xu, K., Saksena, P. & Holly, A. (2011). The determinants of health expenditure. A country-level panel data analysis. WHO Working Paper, December.
Acknowledgments
We gratefully acknowledge an anonymous referee and the Editor (P. P. Barros) for comments and suggestions on an earlier version of the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Villaverde, J., Maza, A. & Hierro, M. Health care expenditure disparities in the European Union and underlying factors: a distribution dynamics approach. Int J Health Care Finance Econ 14, 251–268 (2014). https://doi.org/10.1007/s10754-014-9147-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10754-014-9147-8