
Abstract
This paper reports the application of weights-of-evidence, artificial neural networks, and fuzzy logic spatial modeling techniques to generate prospectivity maps for gold mineralization in the neighborhood of the Amapari Au mine, Brazil. The study area comprises one of the last Brazilian mineral exploration frontiers. The Amapari mine is located in the Maroni-Itaicaiúnas Province, which regionally hosts important gold, iron, manganese, chromite, diamond, bauxite, kaolinite, and cassiterite deposits. The Amapari Au mine is characterized as of the orogenic gold deposit type. The highest gold grades are associated with highly deformed rocks and are concentrated in sulfide-rich veins mainly composed of pyrrhotite. The data used for the generation of gold prospectivity models include aerogeophysical and geological maps as well as the gold content of stream sediment samples. The prospectivity maps provided by these three methods showed that the Amapari mine stands out as an area of high potential for gold mineralization. The prospectivity maps also highlight new targets for gold exploration. These new targets were validated by means of detailed maps of gold geochemical anomalies in soil and by fieldwork. The identified target areas exhibit good spatial coincidence with the main soil geochemical anomalies and prospects, thus demonstrating that the delineation of exploration targets by analysis and integration of indirect datasets in a geographic information system (GIS) is consistent with direct prospecting. Considering that work of this nature has never been developed in the Amazonian region, this is an important example of the applicability and functionality of geophysical data and prospectivity analysis in regions where geologic and metallogenetic information is scarce.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The use of geographic information systems (GISs) and expert systems (ESs) in mineral exploration makes the integration of multi-source and multi-thematic datasets possible. Airborne and ground geophysical data, remote sensing, geochemical, geologic (stratigraphic and structural), and geochronologic data are nowadays commonly integrated via procedures and spatial analysis to derive information that is useful in mineral exploration.
The methods applied for data analysis and integration in GIS-based mineral potential mapping are either knowledge-driven (conceptual) or data-driven (empirical) (e.g., Bonham-Carter 1994). Knowledge-driven methods are based on the judgment of an expert who selects and assigns weights to indirect spatial evidence of mineral potential. Data-driven methods involve quantitative analysis of spatial associations between known mineral occurrences or deposits, considered as training sites, and indirect evidence coupled with resource potential. The choice of using either data- or knowledge-driven methods depends on the level of prior exploration and the quality of data available. Several authors have used GIS methods in mineral potential assessments with different knowledge and data-driven methods and for different purposes (e.g., Carranza et al. 2008, 2009; Debba et al. 2009; Nykänen and Ojala 2007; Nykänen et al. 2007, 2008a, b; Nykänen 2008; Souza Filho et al. 2007; Raines and Mihalasky 2002; Robinson and Larkins 2007).
Most of the GIS-based mineral prospectivity models produced to date were developed in relatively easily accessible arid to semi-arid regions, where a considerable wealth of geologic and mineral resources information exists. This scenario is quite different from that found in the Amazon region, which is characterized by a lack of rocky outcrops, thick soil cover, dense forest, inaccessibility, and scarce geological information. The region is also covered with clouds all year round, which poses a problem for the use of optical remote sensing methods but opens the possibility for the successful exploitation of airborne geophysics as an alternative tool for assessing mineral resources.
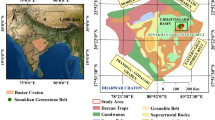
This work reports various GIS and ES spatial modeling techniques for mapping potentially favorable gold areas in the central region of the Amapá State, the northernmost part of the Brazilian Amazon (Fig. 1). This region was chosen because it represents one of the last exploration frontiers of the country. Besides, no studies focusing on spatial data modeling applied to the identification of potential areas of gold have previously been carried out in the region. The datasets used in this investigation include airborne geophysical data, stream sediments geochemical data, and lithologic structural data. The mineral prospectivity models generated using those datasets were formulated using fuzzy logic, which is a knowledge-driven method, and weights-of-evidence and neural networks, which are data-driven methods. Spatial analysis is performed using the latest version of the publicly available Arc Spatial Data Modeler (ArcSDM) software (Sawatzky et al. 2007; http://www.ige.unicamp.br/sdm). Sites indicated as being of higher potential for gold on the spatial analysis models were checked in the field and verified against detailed soil geochemical data.

The study area in the State of Amapa, Brazil, and hill shade SRTM imagery (sun azimuth angle at 45°)
2 Geological Framework
The study region is part of the Maroni-Itacaiúnas Province (MIP). The MIP is composed of deformed volcanic and sedimentary rocks metamorphosed to the greenschist to amphibolite facies, forming a greenstone belt. It also includes granulitic and gneissic-migmatitic rocks and remnants of reworked Archean crust (Fig. 2). The MIP was accreted to the Central Amazonian Province during an orogeny dated 2.2–1.95 Ga (Cordani et al. 1979). The Archean basement is composed of granulites, gneisses, amphibolites, and migmatites of the Guianense Complex, which correspond to polymetamorphosed rocks partially reworked during the Transamazonian orogenesis (Lima et al. 1974). The oldest ages recorded in this Archean nucleus of the Amapá State vary around 3.32 Ga (Klein et al. 2003). The supracrustal rocks of the Amapá central region are represented by the Vila Nova Province. It is considered a greenstone sequence inserted in NW–SE-elongated belts, metamorphosed to the greenschist to amphibolite facies and deformed in a ductile–brittle regime with the extensive development of shear zones. The age proposed for this greenstone sequence is Paleoproterozoic, around 2.26 ± 0.34 Ga (McReath and Faraco 1997), and its metamorphism occurred at around 1.97 ± 0.51 Ga (Tassinari et al. 1984). Intrusive rocks in the MIP, named Falsino granodiorite (1.75 Ga) and Mapari Alkaline rocks (1.68–1.34 Ga) (Lima et al. 1974), are related to a Proterozoic regional event, characterized by intraplate anorogenic magmatism and evidence of NE–SW faulting and reworking attributed to the Jari-Falsino Event (1.2 Ga) (Dardenne and Schobbenhaus 2003). NE–SW faulting was probably related to the reactivation of old structures, representing an important role in the concentration of gold mineralization (Dardenne and Schobbenhaus 2001).

3 Database
3.1 Geological Data
Figure 3 shows the geologic map of the study area (1:100,000 scale) that includes rocks related to the Archean basement of the Guianense Complex (granite-gneiss), Vila Nova Province (VNP) (oxide- and silicate facies BIFs, calc-silicatic rocks and skarns, schists, amphibolites, and quartzites), and associated granitoids (dioritic gneiss/diorite, granites and pegmatites, granodioritic gneiss/granodiorite, trondhjemite-tonalite-granite).

Geological map of the study area at 1:100,000 scale. Small yellow circles are the gold occurrences recorded by the Brazilian Geological Survey—CPRM (GIS 1:1,000,000)
3.2 Aerogeophysical Data
The Rio Araguari aerogeophysical (magnetometric and gamma spectrometric) project employed in this study was produced by the Brazilian Geological Survey. The data were acquired between September and October 2004 and delivered with removed IGRF and microleveled. Flight lines were N45°E-oriented and spaced 500 m apart, whereas control lines were N45°W-oriented and spaced 10,000 m apart. The flight height was 100 m above the ground (LASA 2004). The data were interpolated using two methods: minimum curvature and bidirectional algorithm for gamma-spectrometric and magnetometric data, respectively. The grid cell size was defined as 125 m (a quarter of the flight line spacing). Details of the data processing procedures and the products generated can be found in Magalhães et al. (2007). Among the aerogeophysical data products produced for this work, maps of analytic signal amplitude, magnetic lineaments interpreted from horizontal and vertical derivatives, and individual radiometric elements (K, Th, and U) were used as evidential themes in mapping the mineral potential (Figs. 4, 5).

Analytical signal map showing the magnetic lineaments

Radiometric (gamma rays) ternary map (Red: K; Green: Th; Blue: U)
3.3 Geochemical Data
Gold (Au) concentrations in ppm were obtained from 125 stream sediment samples. The Fire Assay method was used to determine Au grades in the samples, with a detection limit of 0.01 g/ton. Considering that each stream sediment sample represents materials upstream and upslope of the location it was collected, gold values should not be interpolated but represented on the basis of sub-watersheds (Carranza and Hale 1997; Nóbrega and Souza Filho 2003).
Using tools available in GIS, a digital terrain model (DTM) was used to generate a map of sub-watersheds (Jenson and Domingue 1988), according to the following steps: (1) drainage extraction and generation of a depression-free DTM, (2) generation of a matrix file with the flow direction of each cell, (3) generation of a matrix file of accumulated flow for each cell, (4) extraction of the drainage network considering an accumulated flow of 100 cells or larger, (5) conversion to a vector file, (6) delineation of the areas of the hydrographic watersheds and definition of values that corresponds to the watershed flow direction, for each drainage segment, and (7) generation of a sub-watershed map. The sub-watersheds were then classified as anomalous and non-anomalous according to gold contents >1 and ≤1 ppm, respectively (Fig. 6). The threshold of 1 ppm was defined based on personal information from local mine geologists, who consider values around 0.5 ppm already interesting from a prospective point of view. Here, we decided to use twice this value to enhance the stream sediment anomalies.

Classified sub-watershed map generated from DTM. Small yellow circles show the occurrence of gold recorded by the Brazilian Geological Survey—CPRM (GIS 1:1,000,000)
3.4 Mineral Occurrences
For the application of data-driven spatial analysis methods, the area selected for modeling must contain a satisfactory number of mineral occurrences. In this case, these occurrences must have sufficiently similar characteristics to be treated as a “descriptive mineral deposit model” that can be used as a guide when prospecting for new deposits of the same type. Such mineral occurrences function as exploration guides by means of comparisons and statistical calculations applied to the set of evidential maps, the occurrences serving as training points (Bonham-Carter 1994).
The training points used here were extracted from the 1:1,000,000 scale geologic map of Brazil (Bahia et al. 2004; Faraco et al. 2004). Sixteen gold occurrences are recorded in the study area. Four of them are associated with secondary gold concentrations (alluvium and colluvium) and were not considered in this research. The other 12 gold occurrences are related to host rocks of the Vila Nova Province and associated granitoids (Fig. 3). Two of them correspond to the Amapari gold mine, for which a metallogenic descriptive model is presented below. The other 10 gold occurrences are inserted in the same geological context of the Amapari gold deposit and, although they lack of detailed geologic records, they are assumed to fit within a similar descriptive model.
4 Metallogenic Model
The State of Amapá hosts 112 known gold occurrences. However, only 5 have been exploited economically as gold mines. The Amapari and Vicente deposits occur in the southern-central portion of Amapa, whereas the Regina, Salamangone, and Yoshidome deposits are found in the northern-central sector of the State (Bahia et al. 2004; Faraco et al. 2004) (Fig. 2).
Groves et al. (1998) summarized the main characteristics of orogenic gold deposits. They are found in deformed terranes of all ages and metamorphosed at various grades; they comprise systems of quartz-dominant veins with ≤3–5% sulfide minerals (mainly Fe-sulfides). They show a strong structural control, and they exhibit a strong lateral zonation of hydrothermal alteration phases, including chloritization, carbonatization sericitization, and sulfidization. The related ore fluids present are of a low-salinity, aqueous-carbonic nature, with near-neutral pH, and the gold is transported as a reduced sulfur complex.
Melo et al. (2003), based on these characteristics, classified the Amapari deposit as an orogenetic gold deposit type developed in a continental collision setting. Gold mineralization in this deposit was discovered in 1994 by Anglo American. Gold production was started in 2005; the mine has been operated as an open-pit mine, with total resources of 54.6 Mt @ 1.65 g/t gold, i.e., 2.9 Moz of gold to date.
The trend of the ore bodies in the Amapari deposit parallels those in the eastern margin of the Amapari granite. The ore bodies are marked by intense hydrothermal alteration, mainly silicification, sulfidation, and carbonatization. Gold is associated with sulfides, largely pyrrhotite and subordinately pyrite, chalcopyrite, pentlandite, arsenopyrite, galena, and sphalerite. In general, the sulfides occur disseminated and in thin and discontinuous quartz veins that cut across the host rocks. They also form fine lenses parallel to the bedding planes of the banded iron formation (BIF). Moreover, the BIF banding is crosscut by sulfide-bearing veinlets. Sulfides are most abundant in the schists, BIFs, and skarns. The more intensely sheared the rocks, the higher the sulfide grades, which suggest a structural control for the mineralization by N–S and NW–SE-striking shear zones (Melo et al. 2003). Despite the spatial relationship between the mineralization and the Amapari granite, available geochronologic data for the mineralization (2,118 ± 32 Ma (Pb–Pb); Tavares et al. 2005) and the granite (1,993 ± 13 Ma (Pb–Pb; Faraco et al. 2005) indicate that they are metallogenically unrelated (Melo et al. 2003).
The Vicent gold deposit is located to the south of the study area. There gold occurs in mineralized quartz veins crosscutting metasediments and metavulcanics rocks of the PVN. These veins are N10°W-trending, in agreement with the regional structural framework. Gold occurs in fractures, associated with sulfides (pyrite, chalcopyrite, pyrrhotite, arsenopyrite, and covellite) and as inclusions in quartz, pyrite, and arsenopyrite (Spier and Ferreira Filho 1999). Although a model has not yet been proposed for the formation of this deposit, considering its similar characteristics to the Amapari deposit, it is likely to be of the orogenic archetype.
5 Spatial Data Analysis and Integration
In data-driven modeling, the spatial association between known mineral occurrences (training points) and individual datasets (geophysical, geochemical, etc.) is defined computationally in order to determine weights representing the degree of favorability of each dataset. In contrast, no training points are required in knowledge-driven modeling, but expert knowledge of both the geology of the study area and the descriptive model of the mineral deposit are necessary, so that the weights can be determined, albeit subjectively (Bonham-Carter 1994).
In this work, the following methods were applied: weights-of-evidence (Agterberg et al. 1990; Assadi and Hale 2000; Bonham-Carter et al. 1989; Carranza and Hale 2000; Debba et al. 2009; Nykänen and Ojala 2007; Roy et al. 2006; Tangestani and Moore 2001), artificial neural networks (Bougrain et al. 2003; Lammoglia et al. 2007; Leite and Souza Filho 2009a, b; Nóbrega and Souza Filho 2003; Nykänen 2008; Porwal et al. 2003), and fuzzy logic (Carranza and Hale 1997; Cheng and Agterberg 1999; Lee 2007; Nykänen et al. 2008b; Quadros et al. 2006).
5.1 Data Preprocessing
The Amapari deposit is an orogenic gold deposit, and its ore comprises a wealth of pyrrhotite-rich quartz veins. Considering such specifics, the aeromagnetometric data were used in two ways. First, the deposits were considered to be associated with sites of high-intensity anomalous magnetic field. The map of analytic signal amplitude (ASA) was first transformed to 8-bit range (i.e., 0–256) in order to speed processing. Secondly, the map of linear structures interpreted from the aeromagnetic data was used to determine the proximity of the mineral occurrences to the NNW-trending linear magnetic structures. An isodistance map adopting 250-m intervals around the structures helped determine the optimum distance for this association. The original gamma-spectrometric data were multiplied by 100 to transform them into integers, because the WofE algorithm in ArcSDM requires that data be integer grids. Using 100 as multiplier prevented the original values from being shortened during the transformation.
These data were selected because they most likely contain information relevant to the metallogenic model, such as: (1) the mineralization structural control (i.e., gold in the shear zone—Melo et al. 2003), (2) mineralogical association with predominance of iron sulfides (pyrrhotite) (Melo et al. 2003), and (3) hydrothermal alteration with potassium and uranium enrichment (Faraco et al. 2003) relative to thorium (according to the geophysical maps and the WofE method analyses).
5.2 Analysis by Weights-of-Evidence (WofE)
The weights-of-evidence (WofE) technique uses statistical relationships between diverse data or information layers and known mineral occurrences in order to describe and analyze the interactions between the various spatial datasets. Predictive models of mineral potential are generated for a certain region, where the available data are sufficient to estimate the relative importance of each data or information layer to be used as evidence (Arthur et al. 2005; Bonham-Carter 1994; Raines 1999; Wang et al. 2002).
There are two ways of treating data in the WofE method. One is the categorical method of calculating weights for data or information represented as non-relational and mutually exclusive categories in a map. The other is the cumulative method of calculating weights for data or information represented as relational values (ordinal data, intervals, ratios, etc.) in a map (Boleneus et al. 2001).
For the geological map, which is a categorical dataset, the results of the calculation of weights and contrast values (C = difference between the positive and negative weights, W+ − W−) are listed in Table 1. The map of geologic units was then transformed into a binary map of favorable lithology based on values of C of each unit: favorable units with C > 1 and unfavorable units with C ≤ 1. According to Table 1, there is no relationship between BIFs and the known occurrence of gold, which contradicts the metallogenetic model proposed for the Amapari deposit that associates the highest gold grades with such rocks. This is due to the fact that the training points related to the deposit account for the mine as a whole but do not cover all the rocks found in the mine. This causes an information gap when weights are calculated.
The aerogeophysical data used in this study include an image of the analytic signal amplitude (ASA), images of potassium, thorium, and uranium individual channels, and a map of linear magnetic structures. The ASA map was treated as a cumulative descending dataset, in which higher ASA values are considered to represent areas having higher possibilities of orogenic gold type deposit occurrence. After the calculation of the weights for the ASA image, a binary evidential map was generated by using the highest contrast value (C = 1.78) as a class separator, marking the lower threshold for the favorable class. Gray levels (digital numbers, DNs) falling in the 0–254 interval were grouped in the outside class and pixels with DNs of 255 in the inside class. Secondly, the weights were calculated for the map of linear structures as a cumulative ascending evidence (CA). In other words, areas closest to the linear structures are taken as the most favorable for gold deposit occurrence. The isodistance map was then transformed into another binary evidential map by considering areas at distances within and beyond 250 m of linear structures as favorable and unfavorable, respectively, according to the highest C value of 0.7 (Table 2). The procedures to calculate W+ and W− were applied to the individual gamma-spectrometric images (Table 3) in order to generate a binary evidential map from each of them. After the individual datasets were transformed into binary evidential maps, several tests were carried out in order to find out which of them, when integrated with one another, would comply with the conditional independence requirements (Agterberg and Cheng 2002).
The input parameters used for WofE modeling were (1) prior probability = 0.00467, (2) training points = 12, and (3) unit area = 1 km2. The conditional independence ratio (CIR) test involves the ratio between the number of points used in the test (n) and the sum of all posterior probability values (T). A CIR below 1 can indicate a condition of dependence among the binary evidential maps, and for integrated models to be acceptable, they each must have a CIR higher than 0.85 (Bonham-Carter 1994; Mathew et al. 2007; Sawatzky et al. 2004). The Agterberg and Cheng conditional independence test (A&C_CIT) (Agterberg and Cheng 2002) works with the hypothesis that the difference T − n is null. The test statistics are calculated from the equation (T − n)/standard deviation of T. High values indicate that the conditional independence hypothesis is not appropriate; in other words, the lower the ratio, the better is the model. The results of the conditional tests of data independence CIR and A&C CIT are 0.90 and 62.5, respectively, suggesting some conditional dependence among the data. However, even with such a dependency, none of the tests performed here invalidated the generated models as they were within the acceptable limits of data dependency published in the literature.
The integrated WofE model that best fitted the conditional independence tests is shown in Fig. 7a. Figure 7b presents the part of the region where areas have been mapped with a posterior probability higher than 0.9. These areas are considered to be the most potentially favorable for gold occurrence and correspond to less than 1% of the study region (Fig. 8). In the graph shown in Fig. 8, cumulative frequencies of unit cells are plotted against the posterior probability and the classification thresholds of the posterior probability map (Fig. 7) defined.

a WofE model draped over the JERS-1 SAR imagery. b Detail of the area with greater possibility for gold occurrence

Curve of posterior probability versus cumulative area in the WofE model. The highlighted point means that less than 1% of the present cells have values above 0.9 for the posterior probability. The dashed lines represent the limits applied to categorize the posterior probability map into five classes (Fig. 7)
Raines (1999) recommends testing the reliability of the results by checking whether the known occurrences are located in the most favorable area, a condition assumed as ideal. The model was superimposed on the training points, but only one point (about 8% of the total number of points) coincides with the most favorable areas (values above 1.9 times the a priori probability). The area under the curve (AUC), where the relative cumulative area is plotted against the relative cumulative number of training sites, measures the precision of the final map. This yields an estimate of the efficiency of the model in correctly classifying the training points (Nykänen et al. 2008a). The AUC values were automatically calculated and transformed into percentages. The efficiency of the model is 76%.
5.3 Analysis by Fuzzy Logic
Another possibility of producing mineral prospectivity maps is the use of mathematical functions that express the degree of membership of a dataset without the necessity of training points. This method, which makes use of an expert’s knowledge to define the relationship between evidence and a mathematical function, is known as fuzzy logic (Bonham-Carter 1994; Cheng and Agterberg 1999; Karimi and Valadan Zoej 2004; Lee 2007; Luo and Dimitrakopoulos 2003; Nelson et al. 2007; Porwal et al. 2004). The degree of membership is defined on a continuous scale from 0 to 1, where 0 and 1 are the function minimum and maximum values that correspond to full non-membership and full membership, respectively. The equation below represents a linear function of the fuzzy membership:
where “μ” is a pixel value in an input map and “min” and “max” are the minimum and maximum values, respectively, in the input map. Other functions can be used to define the fuzzy membership values, and the choice of which function to use is based on the expert’s judgment about the significance of an evidential map to the type of mineral deposit considered in the analysis. This step is called “fuzzification” and is basically the simplification and standardization of data of a diverse nature into a common scale, so that they can be integrated simultaneously in a consistent and coherent manner (e.g., Nelson et al. 2007).
The fuzzy membership values are defined according to the classes of the input maps. The final map is generated by combining the input maps by means of fuzzy operators: Fuzzy-AND, Fuzzy-OR, Fuzzy-Sum, Fuzzy-Product, or Fuzzy-Gamma (Bonham-Carter 1994; Karimi and Valadan Zoej 2004; Lee 2007; Miethke et al. 2007).
Because it simple to understand and easy to implement, fuzzy logic is considered an attractive method. It also allows more flexibility in combining input maps, because, instead of combining input maps in a single operation as in WofE and artificial neural networks (ANN), the combination of input maps can be performed in a series of steps in an inference network (flow chart). This inference network is a simulation of the logical processes associated with mineralization as defined by the expert (Quadros et al. 2006).
5.3.1 Data Fuzzification
The input data for the fuzzy logic modeling were the geological and sub-watershed maps and aerogeophysical data. The aerogeophysical data included K, Th, and U channel maps, ASA and magnetic lineaments maps, which are the same as those used in the WofE modeling.
5.3.1.1 Geological Map
The geological map is a categorical dataset and, therefore, it is not possible to establish a mathematical function to make it a fuzzy set. However, based on the metallogenic model, particularly in regard to favorability of certain rock types to host the type of gold mineralization considered in this study, subjective membership values between 0 and 1 were attributed to each rock unit in the geological map (Table 4), thus enabling the fuzzification of the geological map.
5.3.1.2 Geochemistry
Similar to the geological map, the map of sub-watersheds classified according to Au content (Fig. 6) was considered a categorical dataset. The fuzzification of such data is shown in Table 5. The value 0.5 was attributed to areas where geochemical data are lacking.
5.3.1.3 Geophysics
Unlike the geological and sub-watersheds maps, the aerogeophysical data are considered continuous. Suitable fuzzy membership functions can be applied to represent the relationship between the occurrence of gold mineralization and features in the geophysical data as depicted in the metallogenic model.
Potassium and uranium channels and ASA maps
The fuzzification of the maps of K and U channels and ASA was performed using the large function (Bonham-Carter 1994):
where “μ” is a pixel value in a map; “midpoint” is the value in that map to which a fuzzy membership of 0.5 is attributed, and “spd” is a value that defines the membership spread. The spread value can vary from 0 to 10. Smaller values generate graphs with smoother curves. In this function, the highest fuzzy membership values are attributed to the highest values in the input map. This function was applied to the maps of K and U channels and ASA, because values in each of these maps probably represent geological features that are more favorable for the occurrence of a gold deposit, according to the metallogenic model.
Thorium channel and magnetic lineaments maps
The fuzzification of the maps of Th channels and the maps of distance to magnetic lineaments were performed by means of the small function (Bonham-Carter 1994):
The small function considers the smallest values to have the highest values of the membership function (i.e., it is the inverse of the large function). The fuzzification of the Th map was performed using the small function, because the data show that Th content is inversely correlated to K and U contents in the study area. The small function was also applied to the map of distance to magnetic lineaments as the Amapari deposit is structurally controlled.
5.3.2 Fuzzy Operators
After fuzzification, the evidential maps were combined by means of fuzzy operators in order to generate a prospectivity map. The operators Fuzzy-Sum, Fuzzy-Product, and Fuzzy-Gamma were used in this work. The Fuzzy-Sum operator is defined as (Bonham-Carter 1994):
where “μ” is a pixel value in the position “n.” This operator results in values that never exceed 1 but are always larger than or equal to the largest membership value for every n location in the individual input maps. For example, the Fuzzy-Sum of input values (0.2, 0.3, 0.7) at a certain location is 1 − (1 − 0.2)*(1 − 0.3)*(1 − 0.7), which equals 0.832. Similar to the results of the Fuzzy-Or operator, which are controlled by the maximum value per location in the input data, the results of the Fuzzy-Sum operator exhibit a maximizing effect.
The Fuzzy-Sum operator was used to integrate the fuzzy evidence of Au stream sediment values in sub-watersheds with the fuzzy evidence of the geological map in order to represent the contribution of the two evidential maps in the model, mainly because of the association between schists, BIFs, and skarns with the highest gold grades (Melo et al. 2003). In this way, the two evidential datasets reinforce one another to give better information than that obtained when they are used separately.
The Fuzzy-Product operator is defined (Bonham-Carter 1994) as:
where “μi” is the pixel-to-pixel fuzzy membership value of the data to be combined. The map generated contains values that are always less than or equal to the minimum value per location in the individual input maps, due to the multiplication of several numbers < 1. For example, the Fuzzy-Product of input values (0.2, 0.3, 0.7) at a certain location is (0.2)*(0.3)*(0.7), which equals 0.042. Likewise, the results of the fuzzy-and operator are controlled by the smallest value per location in the individual input maps, and the results of the Fuzzy-Product exhibit a minimizing effect. An advantage of using the Fuzzy-Sum and Fuzzy-Product operators is that the integration result carries a contribution from all input data, unlike the situation when using the Fuzzy-And and Fuzzy-Or operators. The Fuzzy-Product was employed to combine data of similar nature—gamma rays data (K, Th, and U) and magnetic data (ASA and lineaments).
The Fuzzy-Gamma operator is defined as (Bonham-Carter 1994):
where γ is a parameter that varies from 0 to 1. When gamma (γ) equals 1, the operator is the same as the Fuzzy-Sum; when γ equals 0, the operator is the same as the Fuzzy-Product. Intermediately, γ values define the importance of each operator in the final result. This is the most meaningful operator for the generation of prospectivity maps because it tends to smooth the Fuzzy-Product minimizing effect and the Fuzzy-Sum maximizing effect.
After the data were combined using the Fuzzy-Sum and Fuzzy-Product operators as described earlier, the Fuzzy-Gamma operator was applied to combine those three intermediate integration results. The following were used to develop the model: Fuzzy-Sum of the geological and sub-watersheds maps, Fuzzy-Product of the magnetic data, Fuzzy-Product of the gamma-spectrometric data and γ = 0.45.
The locations of known gold occurrences were draped over the final fuzzy model in order to visualize its ability to pinpoint areas that are of interest for future gold exploration (Fig. 9).

Fuzzy logic prospectivity map draped over the JERS-1 SAR imagery. Areas comprising important targets are delineated by boxes labeled 1–4
Four principal sectors were mapped as having higher prospectivity for gold according to the model (Fig. 9). The anomalies observed in Sector 1 and 4 are elongated according to the regional NW structural trend and are close to other known gold occurrences. Sector 2 is semicircular and associated with a magnetic high and the presence of BIFs, chemical sediments, and schists. Sector 3 comprises prospective areas related to the Amapari mine and surroundings. The remaining training points, related to gold traces, are located in the domains that are less favorable for the occurrence of gold mineralization.
5.4 Analysis by Artificial Neural Networks (ANN)
The ANN method consists of an adaptive computational system that, by means of artificial intelligence, provides pattern recognition or data classification with the objective of conducting specific tasks, such as the spatial relationship between known gold occurrences and exploration data to produce mineral potential maps (Bougrain et al. 2003; Leite and Souza Filho 2009a, b; Nóbrega and Souza Filho 2003; Porwal et al. 2003). Some properties make the neural networks a technique suitable for pattern recognition and classification of spatial data: (1) the ability to extract hidden patterns that may not be perceptible to humans or to traditional statistical techniques; (2) the capacity to analyze data without the need of previous information or a mineral deposit model; (3) the possibility of working with noisy, limited, interdependent, or non-linear data; (4) the possibility of continuous addition of new data; and (5) the capacity to analyze large datasets (Brown et al. 2000; Lammoglia et al. 2007; Nóbrega and Souza Filho 2003).
Artificial neural networks simulate the human brain in terms of organizational logic, the neurons being interconnected by weighted links that indicate the strength of each connection. The basic structure of an ANN is composed of a n-dimensional input layer (where n = evidential maps), an output layer (a mineral occurrence prospectivity map), and one or two hidden layers representing mathematical functions that establish the weights of the individual input data with respect to the output. This recognition process uses training points that offer the means to identify patterns. The recognized patterns are then stored and distributed by means of weight values (Leite and Souza Filho 2009a, b). Compared to WofE, the ANN technique does not require a large number of training points to evaluate the influence of the evidential maps in the prospectivity map. Compared to fuzzy logic, which requires expert knowledge of a metallogenic model for assigning weights to the data, the ANN does not require a well-defined metallogenic model for the type of mineral deposit under examination. Provided that the quality of the datasets is good, the ANN technique is capable of yielding relevant results for areas where records of mineralization occurrence are scarce or the metallogenic model is poorly defined. Another advantage of the method is its capability to analyze all data simultaneously (Bougrain et al. 2003).
To demonstrate the ability of ANN modeling, three data training and classification systems that are available in the ArcSDM software were used in this study: fuzzy clustering (FC), radial basis functional link network (RBFLN), and probabilistic neural network (PNN).
The FC is a very fast unsupervised classification method by neural networks. Clustering of similar classes (fuzzy clusters) is performed with no need for training points, thus characterizing it as an unsupervised technique. The number of clusters can be adjusted by the user by the elimination of small, insignificant clusters. This step corresponds to data training. From this step on, classification of the whole image is carried out automatically (Lammoglia et al. 2007; Looney and Yu 2000).
The RBFLN is a supervised method that requires training points for both known mineralized and known non-mineralized areas for the deposit type of interest. The structure of this system is composed of three layers: input, middle, and output. The input layer represents a number of evidential maps (feature vector maps), where each evidence can be defined as an index vector (feature vector). In the middle layer, radial Gaussian functions are established in order to define equal values for the vectors positioned at equal distances to the center of this base (Lammoglia et al. 2007; Looney and Yu 2000; Porwal et al. 2003). The best results occur when the number of radial basis functions is large enough to cover the whole area of the feature vector map. Therefore, a large number of training vectors (training points) is necessary because each vector is the center of the radial basis function; in other words, the more vectors, the better is the function accuracy. Despite better results being obtained with a larger number of functions, there is a risk that RBFLN may focus on a specific characteristic of a single training vector and thereby reduce its capacity to generalize the feature vector maps (Porwal et al. 2003). According to Sawatzky et al. (2004), in theory, the number of training points represents the number of radial functions. Nonetheless, this number can be modified interactively by the analyst. The classification steps come after the definition of these parameters.
The probabilistic neural network (PNN) is also a supervised classification method. Compared to RBFLN, the training points used in PNN correspond only to known mineralized areas. The structure of a PNN is also composed of three layers: input, middle, and output. The input layer consists of N nodes, one for each index vector (feature vectors). The middle layer receives information from all input nodes and is associated with a Gaussian function centered on the input vector corresponding to a certain class. The output layer receives the Gaussian function values belonging to the same class in the middle layer. Finally, these functions are summed to create the probability density function. This method involves the reduction in training vectors. This reduction is made by the analyst from the definition of a threshold between medium distances of index vectors (Sawatzky et al. 2004).
The same sets of evidential data used in the WofE analysis were combined using each of the ANNs described above in order to derive two sets of mineral potential models: (1) Model 1: geology, distance to magnetic lineaments, K, Th, U, and ASA and (2) Model 2: fuzzified geology, distance to magnetic lineaments, K, Th, U, and ASA. For simultaneous analysis by the neural nets, data from different sources must be combined, resulting in a map containing all clustered evidence (i.e., a feature vector map). The deposit points employed in the application of RBFLN and PNN were the same training points as used in the WofE technique. The non-deposit points used in the RBFLN were extracted from unfavorable sites of hosting gold deposits mapped by the WofE method, considering the characteristics of the original data. After preprocessing, the three ANN systems and the mineral prospectivity maps derived from them were tested. The best model was determined by analysis of the training parameters and classification accuracy of each system (Tables 6, 7, 8, 9, 10).
Table 6 shows that the FC model 2 (Fig. 10) is more accurate than the FC model 1 (not shown). Both the RBFLN model 1 (Fig. 11) and the PNN model 1 (Fig. 12) display better classification accuracies than their model 2 counterparts (Tables 8, 10).

Fuzzy clustering model 2 prospectivity map draped over the JERS-1 SAR imagery

RBFLN model 1 prospectivity map draped over the JERS-1 SAR imagery

PNN model 1 prospectivity map draped over the JERS-1 SAR imagery
5.5 Validation of the Models
The areas with potential for gold deposits that are identified in the models generated via WofE, fuzzy logic, PNN, and FC are also identified in the RBFLN. However, the model generated via RBFLN (Fig. 11) identifies several other areas with potential for gold occurrence that are not depicted by the other models. This means that the RBFLN model (Fig. 11) delineates more new target areas for further exploration of gold in the region, whereas the target areas defined by the other models are mostly the same as those containing the known deposit occurrences. Consequently, the gold prospectivity map derived via RBFLN was considered as a primary map to be used in the field for targeting the potential occurrence of gold that is not restricted to the known mineralized areas.
During a field trip to the Ampari mine, several deformed and strongly altered rocks consisting of pegmatites, schists, and BIFs (Fig. 13a) were observed. They show sub-vertical to vertical foliation. Sulfide mineralization is conspicuous along deformed beds of the BIFs (Fig. 13b). The locations of open pits, which follow a N–S trend in the map (TAP AB1, TAP AB2, TAP C, and Urucum pits) and a NW trend (TAP D pit) were also mapped in the field and are shown in Fig. 14. In addition, numerous areas identified by the RBFLN model 1 to be favorable for gold occurrence coincide with areas delineated by previous soil geochemical campaigns, conducted by the MPBA mining company, as geochemically anomalous for gold (Fig. 15).

Field aspects of gold mineralization in the study area. a From left to right: schists (pink and orange), pegmatites (white) and BIFs (dark gray) (pit TAP AB2—Fig. 15). b Sulfide mineralization in the BIFS

Limits of open pits of the Amapari mine: Urucum (1), TAP C (2), TAP AB2 (3), TAP AB1 (4), TAP D (5) (see text for explanation) draped over the RBFLN prospectivity map

RBFLN prospectivity map and areas recognized by the MPBA mining company to contain geochemical anomalies of Au in soil: (1) Abacate prospect, (2) Sucuriju target, (3) Gaviao/Cumaru prospect, (4) Batata target, (5) Josefa target, (6) Timbó target, (7) Urucum Leste target, (8) Urucum Oeste target, (9) Bananeira target, (10) Janaína target, (11) Taperebá Sul target, (12) Vila do Meio target, (13) Igarapé do Braço target, (14) Cupixizinho target
6 Discussion
One of the conditions necessary for the application of data-driven spatial modeling techniques is to have training points of good quality and sufficient in quantity to represent the mineral deposits of interest in a certain region. Even though only a few training points are available for this work (only two points are in fact associated with active gold mines), the results were considered plausible and interesting for regional exploration.
The model generated via WofE complied with the data independence conditions required by such a method. The prospectivity map was very restrictive; 99% of the study region has posterior probabilities less than 0.05 for the occurrence of gold. The area mapped via WofE as highly potential for gold is associated with the Amapari mine, mainly in the domains of BIFs, skarns, and calc-silicate rocks and with a N–S strike, which agrees with the descriptions of mineralized bodies verified in the area (Rosa-Costa et al. 2003). Therefore, despite the limitations of WofE for regions where data and knowledge on mineralization are scarce, the method yielded satisfactory results.
The models used in the fuzzy logic method presented the best results when the gamma operator was applied with a gamma value of 0.45. As in the WofE method, the targets are well defined, here including four significant sites. The first occurs associated within the domains of the Amapari mine, in the central portion of the area. The second and third are located in the northern portion of the area. One is semicircular, associated with a magnetic high and BIFs, chemical sediments, and schists. The other is close to two known gold occurrences; it is hosted by quartzites, chemical sediments, and schists, displays an elongated shape that agrees with the trend of the regional structure and it flanks granodiorite, granodioritic gneiss, and trondhjemite-tonalite-granite bodies to the east. The fourth site occurs in the southeastern portion of the area and it is close to a known gold occurrence. This body is also elongated according to the regional structural trend and is associated with magnetic highs and BIFs, chemical sediments, and schistose rocks.
The ANN classification method also yielded relevant results. Two models were generated, differing only by the use of a fuzzyfied geological map (model 2). Model 2 supplied the best results from the analysis of the training and classification parameters for the FC system and model 1 for the RBFLN and PNN systems. As opposed to the PNN and FC systems, the RBFLN generated the highest possibility of most favorable areas. The PNN and FC methods were more restrictive and visually similar.
The areas mapped as favorable to mineralization by the neural networks method coincide with those mapped by the WofE and fuzzy logic methods, including new targets associated with BIFs in the central-southern portion of the area (PNN and RBFLN systems) and with schists, amphibolites, and calc-silicate rocks that outline the granodiorite and granodioritic gneiss in the central portion of the area (RBFLN system). The quality of the results is associated with the input data attributes, namely a 1:100,000 scale geologic map and aerogeophysical data of high sampling density, which is one of the premises for the success of the classification methods.
The Amapa region is one of the last exploration frontiers in the Brazilian Amazon. The choice of this study area and the dataset employed in this research are suitable for demonstrating the problems faced by exploration geologists to define target areas in “green fields,” where only a few gold deposits and the occurrence of archetypal mineralization of interest are known. Due to the lack of availability of a satisfactory number and distribution of training sites, the reliabilities of the WofE and ANN models are questionable. Clearly, in these circumstances, the unsupervised (knowledge-driven) fuzzy logic method is the most appropriate modeling approach. The results based on fuzzy logic and fuzzy clustering methods, although revealing ill-defined new targets, are the ones most likely to be geologically meaningful because such methods do not require training data of locations of occurrences of the deposit type. However, it must be pointed out that a comparison between the prospectivity maps yielded by both WofE and ANN methods with the fuzzy methods shows a plausible resemblance in the overall results obtained by all models. This signifies that the training points, although small in number, describe a coherent signature for the deposit model.
Tables 11, 12, and 13 present a summary of the evidence and analysis criteria for these three modeling methods.
7 Conclusions
The use of spatial data modeling methods requires some conditions to hold for their application: (1) a large quantity of training points (WofE), (2) a database of good quality (mainly ANN), and (3) a good understanding of the metallogenetic model of the study area (fuzzy logic). Even if the first condition was not complied with here, the results were considered to be satisfactory. Previously, known areas were mapped (Amapari deposit) and other targets identified.
The gold prospectivity maps, which were generated by these three spatial modeling techniques, are included in the publicly available ArcSDM software. The methods yielded very similar results, except for the RBFLN classification system, which generated a larger quantity of exploration targets.
Field work was carried out in order to validate the models. This showed the success of using indirect methods in mineral exploration, even in a region where little is known about the geology and the information on mineral potential is scarce. The Amapari mine open pits were visited during the field work, and the superposition of these occurrences on the prospectivity map showed that the pits are located in regions with the highest potential of gold occurrence. It was also possible to observe that the most favorable areas identified in the map coincide with the soil geochemical anomalies for gold.
References
Agterberg FP, Cheng Q (2002) Conditional independence test for weights-of-evidence modelling. Nat Resour Res 11(4):249–255
Agterberg FP, Bonham-Carter GF, Wright DF (1990) Statistical pattern integration for mineral exploration. In: Gaal G, Merriam DF (eds) Computer applications in resource estimation: prediction and assessment for metals and petroleum. Pergamon Press, Oxford, pp 1–21
Arthur JD, Baker AE, Cichon JR, Wood HAR, Rudin A (2005) Florida Aquifer Vulnerability Assessment (FAVA): contamination potential of Floridas’s principal aquifer systems: report submitted to Division of Resource Assessment and Management, Florida Department of Environmental Protection, 148 p. http://suwanneeho.ifas.ufl.edu/documents/FAVA_REPORT_MASTER_DOC_3-21-05.pdf. Accessed 23 Aug 2006
Assadi HH, Hale M (2000) A predictive GIS model for mapping potential gold and base metal mineralization in Takab area, Iran. Comput Geosci 27:901–912. doi:doi:10.1016/S0098-3004(00)00130-8
Bahia RBC, Faraco MTL, Monteiro MAS, Camozzato E, Oliveira MAO (2004) Folha SA.22-Belém. In: Schobbenhaus, C, Gonçalves JH, Santos JOS, Abram MB, Leão Neto R, Matos GMM, Vidotti RM, Ramos MAB, Jesus JDA (eds) Carta Geológica do Brasil ao Milionésimo, Sistema de Informações Geográficas. Programa Geologia do Brasil. CPRM, Brasília [CD-ROM]
Boleneus DE, Raines GL, Causey JD, Bookstrom AA, Frost TP, Hyndman PC (2001) Assessment method for epithermal gold deposits in northeast Washington State using weights-of-evidence GIS modeling. Open-File Report 01-501, USGS. http://pubs.usgs.gov/of/2001/of01-501/. Accessed 16 Apr 2006
Bonham-Carter GF (1994) Geographic information systems for geoscientists—Modeling with GIS. Pergamon
Bonham-Carter GF, Agterberg FP, Wright DF (1989) Weights of evidence modelling: a new approach to mapping mineral potential. In: Agterberg FP, Bonham-Carter GF (eds) Statistical applications in the earth sciences. Geological Survey of Canada, Paper 89-9, pp 171–183
Bougrain L, Gonzalez M, Bouchot V, Cassard D, Lips ALW, Alexandre F, Stein G (2003) Knowledge recovery for continental-scale mineral exploration by neural networks. Nat Resour Res 12(3):173–181. doi:10.1023/A:1025123920475
Brown WM, Gedeon TD, Groves DI, Barnes RG (2000) Artificial neural networks: a new method for mineral prospectivity mapping. Aust J Earth Sci 47:757–770. doi:10.1046/j.1440-0952.2000.00807.x
Carranza EJM, Hale M (1997) A catchment basin approach to the analysis of reconnaissance geochemical-geological data from Albay Province, Philippines. J Geochem Explor 60:157–171. doi:doi:10.1016/S0375-6742(97)00032-0
Carranza EJM, Hale M (2000) Geologically constrained probabilistic mapping of gold potential, Baguio District, Philippines. Nat Resour Res 9(3):237–253. doi:10.1023/A:1010147818806
Carranza EJM, Wibowo H, Barritt SD, Sumintadireja P (2008) Spatial data analysis and integration for regional-scale geothermal potential mapping, West Java, Indonesia. Geothermics 37:267–299. doi:10.1016/j.geothermics.2008.03.003
Carranza EJM, Owusu EA, Hale M (2009) Mapping of prospectivity and estimation of number of undiscovered prospects for lode gold, southwestern Ashanti Belt, Ghana. Miner Deposita 44:915–938. doi:10.1007/s00126-009-0250-6
Cheng Q, Agterberg FP (1999) Fuzzy weights of evidence method and its application in mineral potential mapping. Nat Resour Res 8(1):27–35. doi:10.1023/A:1021677510649
Cordani UD, Tassinari CCG, Teixeira W, Basei MAS, Kawashita K (1979) Evolução Tectônica da Amazônia com base nos dados geocronológicos. Congresso Geológico Chileno, 2, 1979, Aricas, Actas, pp 137–148
Dardenne MA, Schobbenhaus C (2001) Metalogênese do Brasil. UnB, Brasília
Dardenne MA, Schobbenhaus C (2003) Metallogeny of the Guiana Shield. In: BRGM (eds) Géologie de la France, Geology of France and Surrounding Areas, N°2-3-4:291-319. http://geolfrance.brgm.fr/article.asp?annee=2003&revue=2&article=13. Accessed 10 March 2006
Debba F, Carranza EJM, Stein A, Van der Meer FD (2009) Deriving optimal exploration target zones on mineral prospectivity maps. Math Geosci 41:421–446. doi:10.1007/s11004-008-9181-5
Faraco MTL, Melo LV, Villas RNN, Soares JW (2003) O Campo Taperebá do Depósito Amapari, Amapá: Rochas Encaixantes e Minerografia. Simpósio de Geologia da Amazônia, 8, Manaus, Brasil, Resumos Expandidos [CD-ROM]
Faraco MTL, Marinho PAC, Costa EJS, Vale AG, Camozzato E (2004) Folha NA.22-Macapá. In: Schobbenhaus C, Gonçalves JH, Santos JOS, Abram MB, Leão Neto R, Matos GMM, Vidotti RM (eds) Carta Geológica do Brasil ao Milionésimo, Sistema de Informações Geográficas. Programa Geologia do Brasil. CPRM, Brasília [CD-ROM]
Faraco MTL, Marinho PAC, Melo LV, Villas RNN, Soares JW (2005) O Campo Taperabá do Depósito Aurífero Amapari, Amapá: Rochas Encaixantes e Minerografia. In: Horbe AMC, Souza VS (eds) Contribuições à Geologia da Amazônia. Sociedade Brasileira de Geologia—Núcleo Norte, Manaus, vol 4, pp 164–172
Groves DI, Goldfarb RJ, Gebre-Mariam M, Hagemann SG, Robert F (1998) Orogenic gold deposits: a proposed classification in the context of their crustal distribution and relationship to other gold deposit types. Ore Geol Rev 13:7–27. doi:10.1016/S0169-1368(97)00012-7
Jenson SK, Domingue JO (1988) Extracting topographic structure from digital elevation data for geographic information system analysis. Photogramm Eng Remote Sens 54(11):1593–1600
Karimi M, Valadan Zoej MJ (2004) Mineral potential mapping of copper minerals with GIS. Int Arch Photogramm Remote Sens Spatial Inf Sci 35(4):1103–1108
Klein EL, Rosa-Costa LT, Lafon JM (2003) Magmatismo Paleoarqueano (3,32 Ga) na região do Rio Cupixi, SE do Amapá, SE do Escudo das Guianas. In: Simpósio de Geologia da Amazônia, 8, Sociedade Brasileira de Geologia, Manaus, Brazil, Resumos Expandidos, CD ROM
Lammoglia T, Souza Filho CR, Almeida Filho R (2007) Caracterização de Microexsudações de Hidrocarbonetos na Bacia do Tucano Norte (BA) por Geoestatística, Classificação Hiperespectral e Redes Neurais. Rev Bras Geoc 37(4):798–811
LASA Engenharia e Prospecções S.A (2004) Projeto Aerogeofísico Rio Araguari- Relatório Final do Levantamento e Processamento dos Dados Magnetométricos e Gamaespectrométricos. Ministério de Minas e Energia, Secretaria de Geologia, Mineração e Transformação Mineral. CPRM—Serviço Geológico do Brasil. Relatório Final, 25 vol. Texto e Anexos (Mapas), Rio de Janeiro
Lee S (2007) Application and verification of fuzzy algebraic operators to landslide susceptibility mapping. Env Geol 52(4):615–623. doi:10.1007/s00254-006-0491-y
Leite EP, Souza Filho CR (2009a) Probabilistic neural networks applied to mineral potential mapping for platinum-group elements in the Serra Leste region, Carajas Mineral Province, Brazil. Comput Geosci 35:675–687. doi:doi:10.1016/j.cageo.2008.05.003
Leite EP, Souza Filho CR (2009b) Artificial neural networks applied to mineral potential mapping for copper-gold mineralizations in the Carajás Mineral Province, Brazil. Geophys Prospect 57(6):1049–1065. doi:10.1111/j.1365-2478.2008.00779.x
Lima MIC, Montalvão RMG, Issler RS, Oliveira AS, Basei MAS, Araújo JFV, Silva GC (1974) Geologia. Projeto RADAM. Folha NA/NB 22 Macapá. Rio de Janeiro, I/120p (levantamentos de recursos naturais, 6)
Looney CG, Yu H (2000) Special software development for neural network and fuzzy clustering analysis in geological information systems. Geological Survey of Canada, 34 pp. http://www.ige.unicamp.br/sdm/ArcSDM31/documentation/dataxplore.pdf. Accessed 21 March 2007
Luo X, Dimitrakopoulos R (2003) Data-driven fuzzy analysis in quantitative mineral resource assessment. Comput Geosci 29:3–13. doi:10.1016/S0098-3004(02)00078-X
Magalhães LA, Souza Filho CR, Silva AM (2007) Caracterização Geológica-Geofísica da Porcão Central do Amapá com base em Processamento e Interpretação de Dados Aerogerosfísicos. Rev Bras Geoc 37(3):464–477
Mathew J, Jha VK, Rawat GS (2007) Weights of evidence modelling for landslide hazard zonation mapping in part of Bhagirathi valley, Uttarakhand. Curr Sci 92(5):628–638
Mcreath I, Faraco MTL (1997) Sm-Nd and Rb-Sr systems in part of the Vila Nova metamorphic suite, northern Brazil. In: South American symposium on isotope geology, 1, 1997, Campos do Jordão, Extended Abstracts, pp 194–196
Melo L, Villas RNN, Soares JW, Faraco MTL (2003) Geological setting and mineralization fluids of the Amapari gold deposits, Amapá State, Brazil. In: BRGM (eds) Géologie de la France, Geology of France and Surrounding Areas, N° 2-3-4:243–255. http://geolfrance.brgm.fr/article.asp?annee=2003&revue=2&article=11. Accessed 10 March 2006
Miethke C, Souza Filho CR, Silva AM (2007) Assinatura Geofísica e Modelos Prospectivos ‘Knowledge-Driven’ e Data-Driven de Mineralizações Auríferas em Zonas de Cisalhamento Estudo de Caso no Lineamento Congonhas, Porção Sul do Cráton São Francisco, MG. Rev Bras Geoc 37(3):490–503
Nelson EP, Connors KA, Suárez SC (2007) GIS-Based Slope Stability Analysis, Chuquicamata Open Pit Copper Mine, Chile. Nat Resour Res 16(2):171–190. doi:10.1007/s11053-007-9044-7
Nóbrega RP, Souza Filho CR (2003) Análise espacial guiada pelos dados (data-driven): o uso de redes neurais para a avaliação do potencial poli-minerálico na região centro-leste da Bahia. Rev Bras Geoc 33(2-Suplemento):111–120
Nykänen VM (2008) Radial basis functional link nets used as a prospectivity mapping tool for orogenic gold deposits within the Central Lapland Greenstone Belt, Northern Fennoscandian Shield. Nat Resour Res 17(1):29–48. doi:10.1007/s11053-008-9062-0
Nykänen VM, Ojala VJ (2007) Spatial analysis techniques as successful mineral-potential mapping tools for orogenic gold deposits in the Northern Fennoscandian Shield, Finland. Nat Resour Res 16(2):85–92. doi:10.1007/s11053-007-9046-5
Nykänen VM, Ojala VJ, Sarapää O, Hulkki H, Sarala P (2007) Spatial modelling and data integration using GIS for target scale gold exploration in Finland. In: Proceedings of exploration 07: 5th decennial international conference on mineral exploration. Decennial International Mineral Conferences, Toronto, pp 911–917
Nykänen VM, Groves DI, Ojala VJ, Gardoll SJ (2008a) Combined conceptual/empirical prospectivity mapping for orogenic gold in the northern Fennoscandian Shield, Finland. Aust J Earth Sci 55:39–59. doi:10.1080/08120090701581380
Nykänen VM, Groves DI, Ojala VJ, Eilu P, Gardoll SJ (2008b) Reconnaissance-scale conceptual fuzzy-logic prospectivity modelling for iron oxide copper-gold deposits in the northern Fennoscandian Shield, Finland. Aust J Earth Sci 55:25–38. doi:10.1080/08120090701581372
Porwal A, Carranza EJM, Hale M (2003) Artificial neural networks for mineral-potential mapping: a case study from Aravalli Province, Western India. Nat Resour Res 12(3):155–171. doi:10.1023/A:1025171803637
Porwal A, Carranza EJM, Hale M (2004) A hybrid neuro-fuzzy model for mineral potential mapping. Math Geol 36(7):803–826. doi:10.1023/B:MATG.0000041180.34176.65
Quadros TFP, Koppe JC, Strieder AJ, Costa JCL (2006) Mineral-potential mapping: a comparison of weights-of-evidence and fuzzy methods. Nat Resour Res 15(1):49–65. doi:10.1007/s11053-006-9010-9
Raines GL (1999) Evaluation of weights of evidence to predict epithermal-gold deposits in the Great Basin of the United States. Nat Resour Res 8(4):257–276
Raines GL, Mihalasky MJ (2002) A reconnaissance method for delineation of tracts for regional-scale mineral resource assessment based on geologic-map data. Nat Resour Res 11(4):241–248. doi:10.1023/A:1021138910662
Robinson GR Jr, Larkins PM (2007) Probabilistic prediction models for aggregate quarry siting. Nat Resour Res 16(2):135–146. doi:10.1007/s11053-007-9039-4
Rosa-Costa LT, Ricci PSF, lafon JM, Vasquez ML, Carvalho JMA, Klein EL, Macambira EMB (2003) Geology and geochronology of Archean and Paleoproterozoic domains of southwestern Amapá and northwestern Pará, Brazil, southeastern Guiana shield. In: BRGM (eds) Géologie de la France, Geology of France and Surrounding Areas, N°2-3-4:101–120. http://geolfrance.brgm.fr/article.asp?annee=2003&revue=2&article=4. Accessed 10 March 2006
Roy R, Cassard D, Cobbold PR, Rossello EA, Billa M, Bailly L, Lips ALW (2006) Predictive mapping for cooper-gold magmatic-hydrothermal systems in NW Argentina: use of a regional-scale GIS, application of an expert-guided data-driven approach, and comparison with results from a continental-scale GIS. Ore Geol Rev 29(3–4):260–286. doi:10.1016/j.oregeorev.2005.10.002
Sawatzky DL, Raines GL, Bonham-Carter GF, Looney CG, Souza Filho CR (2004) ARCSDM3.1: ArcMAP extension for spatial data modelling using weights of evidence, logistic regression, fuzzy logic and neural network analysis. http://www.ige.unicamp.br/sdm/ArcSDM31/. Accessed 16 May 2006
Sawatzky DL, Raines GL, Bonham-Carter GF, Looney CG (2007) Spatial Data Modeller (SDM): ArcMAP 9.2 geoprocessing tools for spatial data modelling using weights of evidence, logistic regression, fuzzy logic and neural networks. http://arcscripts.esri.com/details.asp?dbid=15341. Accessed 31 Jan 2007
Souza Filho CR, Nunes AR, Leite EP, Monteiro LVS, Xavier RP (2007) Spatial analysis of airborne geophysical data applied to geological mapping and mineral prospecting in the Serra Leste Region, Carajás Mineral Province, Brazil. Surv Geophys 28(5-6):377–405. doi:10.1007/s10712-008-9031-5
Spier CA, Ferreira Filho CF (1999) Geologia estratigrafia e depósitos minerais do Projeto Vila Nova, Escudo das Guianas, Amapá. Brasil Rev Bras Geoc 29:173–178
Tangestani MH, Moore F (2001) Porphyry copper potential mapping using the weights-of-evidence model in a GIS, northern Shahr-e-Babak, Iran. Aust J Earth Sci 48:695–701. doi:10.1046/j.1440-0952.2001.485889.x
Tassinari CCG, Siga O Jr, Teixeira W (1984) Épocas metalogenéticas relacionadas a granitogênese do Cráton Amazônico. Congresso Brasileiro de Geologia, 33, Rio de Janeiro, 1984. Anais Sociedade Brasileira de Geociências 6:2963–2977
Tavares RM, Villas RNN, Soares JW (2005) Distribuição do ouro em formações ferríferas bandadas saprolitizadas do Depósito de Amapari, Amapá. In: Horbe AMC, Souza VS (eds) Contribuições à Geologia da Amazônia. Sociedade Brasileira de Geologia—Núcleo Norte, Manaus, vol 4, pp 173–179
Wang H, Cai G, Cheng Q (2002) Data integration using weights of evidence model: applications in mapping mineral resource potentials. In: Symposium on geospatial theory, processing and applications, Symposium sur la théorie, les traitements et les applicantions des données Géospatiales, Ottawa. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.126.5263&rep=rep1&type=pdf. Accessed 10 May 2006
Acknowledgments
We thank the geologists of the Mineração Pedra Branca do Amapari, particularly Alfredo Nunes and Leandro Guimarães, for providing access to proprietary data and fieldwork support. CPRM (Brazilian Geological Survey) is acknowledged for the concession of the airborne geophysical data. FAPESP (State of São Paulo Science Foundation) provided L. A. Magalhães with a research grant and financial support for the project (Proc. Nr. 03/09916-6). The authors are grateful to Dr John Carranza and an anonymous reviewer for their comments and suggestions on the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Magalhães, L.A., Souza Filho, C.R. Targeting of Gold Deposits in Amazonian Exploration Frontiers using Knowledge- and Data-Driven Spatial Modeling of Geophysical, Geochemical, and Geological Data. Surv Geophys 33, 211–241 (2012). https://doi.org/10.1007/s10712-011-9151-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10712-011-9151-1