
Abstract
We consider Markov decision processes (MDPs) with Büchi (liveness) objectives. We consider the problem of computing the set of almost-sure winning states from where the objective can be ensured with probability 1. Our contributions are as follows: First, we present the first subquadratic symbolic algorithm to compute the almost-sure winning set for MDPs with Büchi objectives; our algorithm takes \(O(n \cdot\sqrt{m})\) symbolic steps as compared to the previous known algorithm that takes O(n 2) symbolic steps, where n is the number of states and m is the number of edges of the MDP. In practice MDPs have constant out-degree, and then our symbolic algorithm takes \(O(n \cdot\sqrt{n})\) symbolic steps, as compared to the previous known O(n 2) symbolic steps algorithm. Second, we present a new algorithm, namely win-lose algorithm, with the following two properties: (a) the algorithm iteratively computes subsets of the almost-sure winning set and its complement, as compared to all previous algorithms that discover the almost-sure winning set upon termination; and (b) requires \(O(n \cdot\sqrt{K})\) symbolic steps, where K is the maximal number of edges of strongly connected components (scc’s) of the MDP. The win-lose algorithm requires symbolic computation of scc’s. Third, we improve the algorithm for symbolic scc computation; the previous known algorithm takes linear symbolic steps, and our new algorithm improves the constants associated with the linear number of steps. In the worst case the previous known algorithm takes 5⋅n symbolic steps, whereas our new algorithm takes 4⋅n symbolic steps.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Markov decision processes
The standard model of systems in verification of probabilistic systems is Markov decision processes (MDPs) that exhibit both probabilistic and nondeterministic behavior [13]. MDPs have been used to model and solve control problems for stochastic systems [11]: there, nondeterminism represents the freedom of the controller to choose a control action, while the probabilistic component of the behavior describes the system response to control actions. MDPs have also been adopted as models for concurrent probabilistic systems [7], probabilistic systems operating in open environments [19], and under-specified probabilistic systems [2]. A specification describes the set of desired behaviors of the system, which in the verification and control of stochastic systems is typically an ω-regular set of paths. The class of ω-regular languages extends classical regular languages to infinite strings, and provides a robust specification language to express all commonly used specifications, such as safety, liveness, fairness, etc. [24]. Parity objectives are a canonical way to define such ω-regular specifications. Thus MDPs with parity objectives provide the theoretical framework to study problems such as the verification and control of stochastic systems.
Qualitative and quantitative analysis
The analysis of MDPs with parity objectives can be classified into qualitative and quantitative analysis. Given an MDP with parity objective, the qualitative analysis asks for the computation of the set of states from where the parity objective can be ensured with probability 1 (almost-sure winning). The more general quantitative analysis asks for the computation of the maximal probability at each state with which the controller can satisfy the parity objective.
Importance of qualitative analysis
The qualitative analysis of MDPs is an important problem in verification that is of interest irrespective of the quantitative analysis problem. There are many applications where we need to know whether the correct behavior arises with probability 1. For instance, when analyzing a randomized embedded scheduler, we are interested in whether every thread progresses with probability 1 [9]. Even in settings where it suffices to satisfy certain specifications with probability p<1, the correct choice of p is a challenging problem, due to the simplifications introduced during modeling. For example, in the analysis of randomized distributed algorithms it is quite common to require correctness with probability 1 (see, e.g., [16, 17, 23]). Furthermore, in contrast to quantitative analysis, qualitative analysis is robust to numerical perturbations and modeling errors in the transition probabilities, and consequently the algorithms for qualitative analysis are combinatorial. Finally, for MDPs with parity objectives, the best known algorithms and all algorithms used in practice first perform the qualitative analysis, and then perform a quantitative analysis on the result of the qualitative analysis [6–8]. Thus qualitative analysis of MDPs with parity objectives is one of the most fundamental and core problems in verification of probabilistic systems. One of the key challenges in probabilistic verification is to obtain efficient and symbolic algorithms for qualitative analysis of MDPs with parity objectives, as symbolic algorithms allow to handle MDPs with a large state space.
Previous results
The qualitative analysis of MDPs with parity objectives is achieved by iteratively applying solutions of the qualitative analysis of MDPs with Büchi objectives [6–8]. The qualitative analysis of an MDP with a parity objective with d priorities can be achieved by O(d) calls to an algorithm for qualitative analysis of MDPs with Büchi objectives, and hence we focus on the qualitative analysis of MDPs with Büchi objectives. The classical algorithm for qualitative analysis of MDPs with Büchi objectives works in O(n⋅m) time, where n is the number of states, and m is the number of edges of the MDP [7, 8]. The classical algorithm can be implemented symbolically, and it takes at most O(n 2) symbolic steps. An improved algorithm for the problem was given in [5] that works in \(O(m \cdot\sqrt{m})\) time. The algorithm of [5] crucially depends on maintaining the same number of edges in certain forward searches. Thus the algorithm needs to explore edges of the graph explicitly and is inherently non-symbolic. A recent O(m⋅n 2/3) time algorithm for the problem was given in [4]; however the algorithm requires the dynamic-tree data structure of Sleator-Tarjan [20], and such data structures cannot be implemented symbolically. In the literature, there is no symbolic subquadratic algorithm for qualitative analysis of MDPs with Büchi objectives.
Our contribution
In this work our main contributions are as follows.
-
1.
We present a new and simpler subquadratic algorithm for qualitative analysis of MDPs with Büchi objectives that runs in \(O(m \cdot\sqrt{m})\) time, and show that the algorithm can be implemented symbolically. The symbolic algorithm takes at most \(O(n \cdot\sqrt{m})\) symbolic steps, and thus we obtain the first symbolic subquadratic algorithm. In practice, MDPs often have constant out-degree: for example, see [10] for MDPs with large state space but constant number of actions, or [11, 18] for examples from inventory management where MDPs have constant number of actions (the number of actions corresponds to the out-degree of MDPs). For MDPs with constant out-degree our new symbolic algorithm takes \(O(n \cdot\sqrt{n})\) symbolic steps, as compared to O(n 2) symbolic steps of the previous best known algorithm.
-
2.
All previous algorithms for the qualitative analysis of MDPs with Büchi objectives iteratively discover states that are guaranteed to be not almost-sure winning, and only when the algorithm terminates the almost-sure winning set is discovered. We present a new algorithm (namely win-lose algorithm) that iteratively discovers both states in the almost-sure winning set and its complement. Thus if the problem is to decide whether a given state s is almost-sure winning, and the state s is almost-sure winning, then the win-lose algorithm can stop at an intermediate iteration unlike all the previous algorithms. Our algorithm works in time \(O( \sqrt{K_{E}} \cdot m)\) time, where K E is the maximal number of edges of any scc of the MDP (in this paper we write scc for maximal strongly connected component). We also show that the win-lose algorithm can be implemented symbolically, and it takes at most \(O(\sqrt{K_{E}} \cdot n)\) symbolic steps.
-
3.
Our win-lose algorithm requires to compute the scc decomposition of a graph in O(n) symbolic steps. The scc decomposition problem is one of the most fundamental problem in the algorithmic study of graph problems. The symbolic scc decomposition problem has many other applications in verification: for example, checking emptiness of ω-automata, and bad-cycle detection problems in model checking, see [3] for other applications. An O(n⋅logn) symbolic step algorithm for scc decomposition was presented in [3], and the algorithm was improved in [12]. The algorithm of [12] is a linear symbolic step scc decomposition algorithm that requires at most min{5⋅n,5⋅D⋅N+N} symbolic steps, where D is the diameter of the graph, and N is the number of scc’s of the graph. We present an improved version of the symbolic scc decomposition algorithm. Our algorithm improves the constants of the number of the linear symbolic steps. Our algorithm requires at most min{3⋅n+N,5⋅D ∗+N} symbolic steps, where D ∗ is the sum of the diameters of the scc’s of the graph. Thus, in the worst case, the algorithm of [12] requires 5⋅n symbolic steps, whereas our algorithm requires 4⋅n symbolic steps. Moreover, the number of symbolic steps of our algorithm is always bounded by the number of symbolic steps of the algorithm of [12] (i.e. our algorithm is never worse).
Our experimental results show that our new algorithms perform better than the previous known algorithms both for qualitative analysis of MDPs with Büchi objectives and symbolic scc computation.
2 Definitions
Markov decision processes (MDPs)
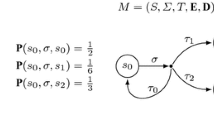
A Markov decision process (MDP) G=((S,E),(S 1,S P ),δ) consists of a directed graph (S,E), a partition (S 1,S P ) of the finite set S of states, and a probabilistic transition function \(\delta: S_{P}\rightarrow\mathcal{D}(S)\), where \(\mathcal{D}(S)\) denotes the set of probability distributions over the state space S. The states in S 1 are the player-1 states, where player 1 decides the successor state, and the states in S P are the probabilistic (or random) states, where the successor state is chosen according to the probabilistic transition function δ. We assume that for s∈S P and t∈S, we have (s,t)∈E iff δ(s)(t)>0, and we often write δ(s,t) for δ(s)(t). For a state s∈S, we write E(s) to denote the set {t∈S∣(s,t)∈E} of possible successors. For technical convenience we assume that every state in the graph (S,E) has at least one outgoing edge, i.e., E(s)≠∅ for all s∈S. We will denote by n=|S| and m=|E| the size of the state space and the number of transitions (or edges), respectively.
Plays and strategies
An infinite path, or a play, of an MDP G is an infinite sequence ω=〈s 0,s 1,s 2,…〉 of states such that (s k ,s k+1)∈E for all k∈ℕ. We write Ω for the set of all plays, and for a state s∈S, we write Ω s ⊆Ω for the set of plays that start from the state s. A strategy for player 1 is a function \(\sigma: S^{*}\cdot S_{1}\to\mathcal{D}(S)\) that chooses the probability distribution over the successor states for all finite sequences w∈S ∗⋅S 1 of states ending in a player-1 state (the sequence represents a prefix of a play). A strategy must respect the edge relation: for all w∈S ∗ and s∈S 1, if σ(w⋅s)(t)>0, then t∈E(s). A strategy is deterministic (pure) if it chooses a unique successor for all histories (rather than a probability distribution), otherwise it is randomized. Player 1 follows the strategy σ if in each player-1 move, given that the current history of the play is w∈S ∗⋅S 1, she chooses the next state according to σ(w). We denote by Σ the set of all strategies for player 1. A memoryless player-1 strategy does not depend on the history of the play but only on the current state; i.e., for all w,w′∈S ∗ and for all s∈S 1 we have σ(w⋅s)=σ(w′⋅s). A memoryless strategy can be represented as a function \(\sigma: S_{1}\to\mathcal{D}(S)\), and a pure memoryless strategy can be represented as σ:S 1→S.
Once a starting state s∈S and a strategy σ∈Σ is fixed, the outcome of the MDP is a random walk \(\omega_{s}^{\sigma}\) for which the probabilities of events are uniquely defined, where an event \(\mathcal{A}\subseteq\varOmega\) is a measurable set of plays. For a state s∈S and an event \(\mathcal{A}\subseteq\varOmega\), we write \(\mathrm{Pr}_{s}^{\sigma}(\mathcal{A})\) for the probability that a play belongs to \(\mathcal{A}\) if the game starts from the state s and player 1 follows the strategy σ.
Objectives
We specify objectives for player 1 by providing a set of winning plays Φ⊆Ω. We say that a play ω satisfies the objective Φ if ω∈Φ. We consider ω-regular objectives [24], specified as parity conditions. We also consider the special case of Büchi objectives.
-
Büchi objectives. Let T be a set of target states. For a play ω=〈s 0,s 1,…〉∈Ω, we define Inf(ω)={s∈S∣s k =s for infinitely many k} to be the set of states that occur infinitely often in ω. The Büchi objectives require that some state of T be visited infinitely often, and defines the set of winning plays Büchi(T)={ω∈Ω∣Inf(ω)∩T≠∅}.
-
Parity objectives. For c,d∈ℕ, we write [c..d]={c,c+1,…,d}. Let p:S→[0..d] be a function that assigns a priority p(s) to every state s∈S, where d∈ℕ. The parity objective is defined as Parity(p)={ω∈Ω∣min(p(Inf(ω))) is even}. In other words, the parity objective requires that the minimum priority visited infinitely often is even. In the sequel we will use Φ to denote parity objectives.
Qualitative analysis: almost-sure winning
Given a player-1 objective Φ, a strategy σ∈Σ is almost-sure winning for player 1 from the state s if \(\mathrm{Pr}_{s}^{\sigma} (\varPhi) =1\). The almost-sure winning set 〈〈1〉〉 almost (Φ) for player 1 is the set of states from which player 1 has an almost-sure winning strategy. The qualitative analysis of MDPs correspond to the computation of the almost-sure winning set for a given objective Φ. It follows from the results of [7, 8] that for all MDPs and all reachability and parity objectives, if there is an almost-sure winning strategy, then there is a pure memoryless almost-sure winning strategy. The qualitative analysis of MDPs with parity objectives is achieved by iteratively applying the solutions of qualitative analysis of MDPs with Büchi objectives [6, 8], and hence in this work we will focus on qualitative analysis for Büchi objectives.
Theorem 1
For all MDPs G, and all reachability and parity objectives Φ, there exists a pure memoryless strategy σ ∗ such that for all s∈〈〈1〉〉 almost (Φ) we have \(\mathrm{Pr}_{s}^{\sigma_{*}}(\varPhi)=1\).
Scc and bottom scc
Given a graph G=(S,E), a set C of states is a strongly connected component if for all s,t∈C there is a path from s to t going through states in C. We will denote by scc a maximal strongly connected component. An scc C is a bottom scc if for all s∈C all out-going edges are in C, i.e., E(s)⊆C.
Markov chains, closed recurrent sets
A Markov chain is a special case of MDP with S 1=∅, and hence for simplicity a Markov chain is a tuple ((S,E),δ) with a probabilistic transition function \(\delta:S \to\mathcal{D}(S)\), and (s,t)∈E iff δ(s,t)>0. A closed recurrent set C of a Markov chain is a bottom scc in the graph (S,E). Let \(\mathcal{C}= \bigcup_{C \text{ is closed recurrent}} C\). It follows from the results on Markov chains [15] that for all s∈S, the set \(\mathcal{C}\) is reached with probability 1 in finite time, and for all C such that C is closed recurrent, for all s∈C and for all t∈C, if the starting state is s, then the state t is visited infinitely often with probability 1.
Markov chain from an MDP and memoryless strategy
Given an MDP G=((S,E),(S 1,S P ),δ) and a memoryless strategy \(\sigma_{*}:S_{1}\to\mathcal{D}(S)\) we obtain a Markov chain G′=((S,E′),δ′) as follows: E′=E∩(S P ×S)∪{(s,t)∣s∈S 1,σ ∗(s)(t)>0}; and δ′(s,t)=δ(s,t) for s∈S P , and δ′(s,t)=σ(s)(t) for s∈S 1 and t∈E(s). We will denote by \(G_{\sigma_{*}}\) the Markov chain obtained from an MDP G by fixing a memoryless strategy σ ∗ in the MDP.
Symbolic encoding of an MDP
All algorithms of the paper will only depend on the graph (S,E) of the MDP and the partition (S 1,S P ), and not on the probabilistic transition function δ. Thus the symbolic encoding of an MDP is obtained as the standard encoding of a transition system (with an Obdd [22]), with one additional bit, and the bit denotes whether a state belongs to S 1 or S P . Also note that if the state bits already encode whether a state belongs to S 1 or S P , then the additional bit is not required.
Symbolic step
To define the symbolic complexity of an algorithm an important concept to clarify is the notion of one symbolic step. In this work we adopt the following convention: one symbolic step corresponds to one primitive operation, where a primitive operation is one that is supported by the standard symbolic package like CuDD [22]. For example, the one-step predecessor and successor operators, obtaining an Obdd for a cube (a path from root to a leaf node with constant 1) of an Obdd, etc. are all supported as primitive operations in CuDD [22]. If the number of state variables to encode the Obdd is ℓ, then the symbolic steps that operate on the transition relation (such as predecessor and successor operations) consider Obdds with 2⋅ℓ variables, as compared to other operations like union, intersection, obtaining cubes, etc., that operate on Obdds with ℓ variables. Thus the operations on transitions relations are quadratic as compared to other operations and we will focus on the number of symbolic steps that are on transition relations. Our algorithms will require cardinality computation of a set, and we will argue how to use primitive Obdd operations on Obdds with ℓ variables to achieve the symbolic cardinality computation.
3 Symbolic algorithms for Büchi objectives
In this section we will present a new improved algorithm for the qualitative analysis of MDPs with Büchi objectives, and then present a symbolic implementation of the algorithm. Thus we obtain the first symbolic subquadratic algorithm for the problem. We start with the notion of attractors that is crucial for our algorithm.
Random and player 1 attractor
Given an MDP G, let U⊆S be a subset of states. The random attractor Attr R (U) is defined inductively as follows: X 0=U, and for i≥0, let X i+1=X i ∪{s∈S 1∣E(s)⊆X i }∪{s∈S P ∣E(s)∩X i ≠∅}. In other words, X i+1 consists of (a) states in X i , (b) player-1 states whose all successors are in X i and (c) random states that have at least one edge to X i . Then Attr R (U)=⋃ i≥0 X i . The definition of player-1 attractor Attr 1(U) is analogous and is obtained by exchanging the role of random states and player 1 states in the above definition.
Property of attractors
Given an MDP G, and set U of states, let A=Attr R (U). Then from A player 1 cannot ensure to avoid U, in other words, for all states in A and for all player 1 strategies, the set U is reached with positive probability. For A=Attr 1(U) there is a player 1 memoryless strategy to ensure that the set U is reached with certainty. The computation of random and player 1 attractors is the computation of alternating reachability and can be achieved in O(m) time [14], and can be achieved in O(n) symbolic steps.
3.1 A new subquadratic algorithm
The classical algorithm for computing the almost-sure winning set in MDPs with Büchi objectives has O(n⋅m) running time, and the symbolic implementation of the algorithm takes at most O(n 2) symbolic steps. A subquadratic algorithm, with \(O(m \cdot\sqrt{m})\) running time, for the problem was presented in [5]. The algorithm of [5] uses a mix of backward exploration and forward exploration. Every forward exploration step consists of executing a set of DFSs (depth first searches) simultaneously for a specified number of edges, and must maintain the exploration of the same number of edges in each of the DFSs. The algorithm thus depends crucially on maintaining the number of edges traversed explicitly, and hence the algorithm has no symbolic implementation. In this section we present a new subquadratic algorithm to compute 〈〈1〉〉 almost (Büchi(T)). The algorithm is simpler as compared to the algorithm of [5] and we will show that our new algorithm can be implemented symbolically. Our new algorithm has some similar ideas as the algorithm of [5] in mixing backward and forward exploration, but the key difference is that the new algorithm never stops the forward exploration after a certain number of edges, and hence need not maintain the traversed edges explicitly. Thus the new algorithm is simpler, and our correctness and running time analysis proofs are different. We show that our new algorithm works in \(O(m \cdot\sqrt{m})\) time, and requires at most \(O(n \cdot\sqrt{m})\) symbolic steps.
Improved algorithm for almost-sure Büchi
Our algorithm iteratively removes states from the graph, until the almost-sure winning set is computed. At iteration i, we denote the remaining subgraph as (S i ,E i ), where S i is the set of remaining states, E i is the set of remaining edges, and the set of remaining target states is T i (i.e., T i =S i ∩T). The set of states removed will be denoted by Z i , i.e., S i =S∖Z i . The algorithm will ensure that (a) Z i ⊆S∖〈〈1〉〉 almost (Büchi(T)); and (b) for all s∈S i ∩S P we have E(s)∩Z i =∅. In every iteration the algorithm identifies a set Q i of states such that there is no path from Q i to the set T i . Hence clearly Q i ⊆S∖〈〈1〉〉 almost (Büchi(T)). By the random attractor property from Attr R (Q i ) the set Q i is reached with positive probability against any strategy for player 1. The algorithm maintains the set L i+1 of states that were removed from the graph since (and including) the last iteration of Case 1, and the set J i+1 of states that lost an edge to states removed from the graph since the last iteration of Case 1. Initially L 0:=J 0:=∅, Z 0:=∅, and let i:=0 and we describe the iteration i of our algorithm. We call our algorithm ImprAlgo (Improved Algorithm) and the pseudocode is given as Algorithm 1.
-
1.
Case 1. If (\((|J_{i}| > \sqrt{m})\) or i=0), then
-
(a)
Let Y i be the set of states that can reach the current target set T i (this can be computed in O(m) time by a graph reachability algorithm).
-
(b)
Let Q i :=S i ∖Y i , i.e., there is no path from Q i to T i .
-
(c)
Z i+1:=Z i ∪Attr R (Q i ). The set Attr R (Q i ) is removed from the graph.
-
(d)
The set L i+1 is the set of states removed from the graph in this iteration (i.e., L i+1:=Attr R (Q i )) and J i+1 be the set of states in the remaining graph with an edge to L i+1.
-
(e)
If Q i is empty, the algorithm stops, otherwise i:=i+1 and go to the next iteration.
-
(a)
-
2.
Case 2. Else (\(|J_{i}| \leq\sqrt{m}\) and i>0), then
-
(a)
We do a lock-step search from every state s in J i as follows: we do a DFS from s and (a) if the DFS tree reaches a state in T i , then we stop the DFS search from s; and (b) if the DFS is completed without reaching a state in T i , then we stop the entire lock-step search, and all states in the DFS tree are identified as Q i . The set Attr R (Q i ) is removed from the graph and Z i+1:=Z i ∪Attr R (Q i ). If DFS searches from all states s in J i reach the set T i , then the algorithm stops.
-
(b)
The set L i+1 is the set of states removed from the graph since the last iteration of Case 1 (i.e., L i+1:=L i ∪Attr R (Q i ), where Q i is the DFS tree that stopped without reaching T i in the previous step of this iteration) and J i+1 be the set of states in the remaining graph with an edge to L i+1, i.e., J i+1:=(J i ∖Attr R (Q i ))∪X i , where X i is the subset of states of S i with an edge to Attr R (Q i ).
-
(c)
i:=i+1 and go to the next iteration.
-
(a)

ImprAlgo
Correctness and running time analysis
We first prove the correctness of the algorithm.
Lemma 1
Algorithm ImprAlgo correctly computes the set 〈〈1〉〉 almost (Büchi(T)).
Proof
We consider an iteration i of the algorithm. Recall that in this iteration Y i is the set of states that can reach T i and Q i is the set of states with no path to T i . Thus the algorithm ensures that in every iteration i, for the set of states Q i identified by the algorithm there is no path to the set T i , and hence from Q i the set T i cannot be reached with positive probability. Clearly, from Q i the set T i cannot be reached with probability 1. Since from Attr R (Q i ) the set Q i is reached with positive probability against all strategies for player 1, it follows that from Attr R (Q i ) the set T i cannot be ensured to be reached with probability 1. Thus for the set Z i of removed states we have Z i ⊆S∖〈〈1〉〉 almost (Büchi(T)). It follows that all the states removed by the algorithm over all iterations are not part of the almost-sure winning set.
To complete the correctness argument we show that when the algorithm stops, the remaining set is 〈〈1〉〉 almost (Büchi(T)). When the algorithm stops, let S ∗ be the set of remaining states and T ∗ be the set of remaining target states. It follows from above that S∖S ∗⊆S∖〈〈1〉〉 almost (Büchi(T)) and to complete the proof we show S ∗⊆〈〈1〉〉 almost (Büchi(T)). The following assertions hold: (a) for all s∈S ∗∩S P we have E(s)⊆S ∗, and (b) for all states s∈S ∗ there is a path to the set T ∗. We prove (a) as follows: whenever the algorithm removes a set Z i , it is a random attractor, and thus if a state s∈S ∗∩S P has an edge (s,t) with t∈S∖S ∗, then s would have been included in S∖S ∗, and thus (a) follows. We prove (b) as follows: (i) If the algorithm stops in Case 1, then Q i =∅, and it follows that every state in S ∗ can reach T ∗. (ii) We now consider the case when the algorithm stops in Case 2: In this case every state in J i has a path to T i =T ∗, this is because if there is a state s in J i with no path to T i , then the DFS tree from s would have been identified as Q i in step 2 (a) and the algorithm would not have stopped. It follows that there is no bottom scc in the graph induced by S ∗ that does not intersect T ∗: because if there is a bottom scc that does not contain a state from J i and also does not contain a target state, then it would have been identified in the last iteration of Case 1. Since every state in S ∗ has an out-going edge, it follows every state in S ∗ has a path to T ∗. Hence (b) follows. Consider a shortest path (or the BFS tree) from all states in S ∗ to T ∗, and for a state s∈S ∗∩S 1, let s′ be the successor for the shortest path, and we consider the pure memoryless strategy σ ∗ that chooses the shortest path successor for all states s∈(S ∗∖T ∗)∩S 1, and in states in T ∗∩S 1 choose any successor in S ∗. Let ℓ=|S ∗| and let α be the minimum of the positive transition probability of the MDP. For all states s∈S ∗, the probability that T ∗ is reached within ℓ steps is at least α ℓ, and it follows that the probability that T ∗ is not reached within k⋅ℓ steps is at most (1−α ℓ)k, and this goes to 0 as k goes to ∞. It follows that for all s∈S ∗ the pure memoryless strategy σ ∗ ensures that T ∗ is reached with probability 1. Moreover, the strategy ensures that S ∗ is never left, and hence it follows that T ∗ is visited infinitely often with probability 1. It follows that S ∗⊆〈〈1〉〉 almost (Büchi(T ∗))⊆〈〈1〉〉 almost (Büchi(T)) and hence the correctness follows. □
We now analyze the running time of the algorithm.
Lemma 2
Given an MDP G with m edges, Algorithm ImprAlgo takes \(O(m\cdot \sqrt{m})\) time.
Proof
The total work of the algorithm, when Case 1 is executed, over all iterations is at most \(O(\sqrt{m} \cdot m)\): this follows because between two iterations of Case 1 at least \(\sqrt{m}\) edges must have been removed from the graph (since \(|J_{i}| > \sqrt{m}\) everytime Case 1 is executed other than the case when i=0), and hence Case 1 can be executed at most \(m/\sqrt{m}=\sqrt{m}\) times. Since each iteration can be achieved in O(m) time, the \(O(m\cdot \sqrt{m})\) bound for Case 1 follows. We now show that the total work of the algorithm, when Case 2 is executed, over all iterations is at most \(O(\sqrt{m} \cdot m)\). The argument is as follows: consider an iteration i such that Case 2 is executed. Then we have \(|J_{i}| \leq\sqrt{m}\). Let Q i be the DFS tree in iteration i while executing Case 2, and let \(E(Q_{i})= \bigcup_{s \in Q_{i}} E(s)\). The lock-step search ensures that the number of edges explored in this iteration is at most \(|J_{i}| \cdot|E(Q_{i})| \leq\sqrt{m} \times|E(Q_{i})|\). Since Q i is removed from the graph we charge the work of \(\sqrt{m} \cdot|E(Q_{i})|\) to edges in E(Q i ), charging work \(\sqrt{m}\) to each edge. Since there are at most m edges, the total charge of the work over all iterations when Case 2 is executed is at most \(O(m \cdot\sqrt{m})\). Note that if instead of \(\sqrt{m}\) we would have used a bound k in distinguishing Case 1 and Case 2, we would have achieved a running time bound of O(m 2/k+m⋅k), which is optimized by \(k=\sqrt{m}\). Our desired result follows. □
This gives us the following result.
Theorem 2
Given an MDP G and a set T of target states, the algorithm ImprAlgo correctly computes the set 〈〈1〉〉 almost (Büchi(T)) in time \(O(m \cdot\sqrt{m})\).
3.2 Symbolic implementation of ImprAlgo
In this subsection we will a present symbolic implementation of each of the steps of algorithm ImprAlgo. The symbolic algorithm depends on the following symbolic operations that can be easily achieved with an Obdd implementation. For a set X⊆S of states, let

In other words, Pre(X) is the predecessors of states in X; Post(X) is the successors of states in X; and CPre(X) is the set of states Y such that for every random state in Y there is a successor in X, and for every player 1 state in Y all successors are in Y. All these operations are supported as primitive operations by the CuDD package.
We now present a symbolic version of ImprAlgo. For the symbolic version the basic steps are as follows: (i) Case 1 of the algorithm is same as Case 1 of ImprAlgo, and (ii) Case 2 is similar to Case 2 of ImprAlgo, and the only change in Case 2 is instead of lock-step search exploring the same number of edges, we have lock-step search that executes the same number of symbolic steps. The details of the symbolic implementation are as follows, and we will refer to the algorithm as SymbImprAlgo.
-
1.
Case 1. In Case 1(a) we need to compute reachability to a target set T. The symbolic implementation is standard and done as follows: X 0:=T and X i+1:=X i ∪Pre(X i ) until X i+1=X i . The computation of the random attractor is also standard and is achieved as above replacing Pre by CPre. It follows that every iteration of Case 1 can be achieved in O(n) symbolic steps.
-
2.
Case 2. For analysis of Case 2 we present a symbolic implementation of the lock-step forward search. The lock-step ensures that each search executes the same number of symbolic steps. The implementation of the forward search from a state s in iteration i is achieved as follows: P 0:={s} and P j+1:=P j ∪Post(P j ) unless P j+1=P j or P j ∩T i ≠∅. If P j ∩T i ≠∅, then the forward search is stopped from s. If P j+1=P j and P j ∩T i =∅, then we have identified that there is no path from states in P j to T i .
-
3.
Symbolic computation of cardinality of sets. The other key operation required by the algorithm is determining whether the size of set J i is at least \(\sqrt{m}\) or not. Below we describe the details of this symbolic operation.
Symbolic computation of cardinality
Given a symbolic description of a set X and a number k, our goal is to determine whether |X|≤k. A naive way is to check for each state, whether it belongs to X. But this takes time proportional to the size of state space and also is not symbolic. We require a procedure that uses the structure of a BDD and directly finds the states which this BDD represents. It should also take into account that if more than k states are already found, then no more computation is required. We present the following procedure to accomplish the same. A cube of a BDD is a path from root node to leaf node where the leaf node is the constant 1 (i.e. true). Thus, each cube represents a set of states present in the BDD which are exactly the states found by doing every possible assignment of the variables not occurring in the cube. For an explicit implementation: consider a procedure that uses Cudd_ForEachCube (from CUDD package, see [22] for symbolic implementation) to iterate over the cubes of a given Obdd in the same manner the successor function works on a binary tree. If ℓ is the number of variables not occurring in a particular cube, we get 2ℓ states from that cube which are part of the Obdd. We keep on summing up all such states until they exceed k. If it does exceed, we stop and say that |X|>k. Else we terminate when we have exhausted all cubes and we get |X|≤k. Thus we require min(k,|BDD(X)|) symbolic steps, where BDD(X) is the size of the Obdd of X. We also note, that this method operates on Obdds that represent set of states, and these Obdds only use log(n) variables compared to 2⋅log(n) variables used by Obdds representing transitions (edge relation). Hence, the operations mentioned are cheaper as compared to Pre and Post computations.
Correctness and runtime analysis
The correctness of SymbImprAlgo is established following the correctness arguments for algorithm ImprAlgo. We now analyze the worst case number of symbolic steps. The total number of symbolic steps executed by Case 1 over all iterations is \(O(n \cdot\sqrt{m})\) since between two executions of Case 1 at least \(\sqrt{m}\) edges are removed, and every execution is achieved in O(n) symbolic steps. The work done for the symbolic cardinality computation is charged to the edges already removed from the graph, and hence the total number of symbolic steps over all iterations for the size computations is O(m). We now show that the total number of symbolic steps executed over all iterations of Case 2 is \(O(n \cdot\sqrt{m})\). The analysis is achieved as follows. Consider an iteration i of Case 2, and let the number of states removed in the iteration be n i . Then the number of symbolic steps executed in this iteration for each of the forward search is at most n i , and since \(|J_{i}| \leq\sqrt{m}\), it follows that the number of symbolic steps executed is at most \(n_{i} \cdot\sqrt{m}\). Since we remove n i states, we charge each state removed from the graph with \(\sqrt{m}\) symbolic steps for the total \(n_{i} \cdot\sqrt{m}\) symbolic steps. Since there are at most n states, the total charge of symbolic steps over all iterations is \(O(n \cdot\sqrt{m})\). Thus it follows that we have a symbolic algorithm to compute the almost-sure winning set for MDPs with Büchi objectives in \(O(n \cdot\sqrt{m})\) symbolic steps.
Theorem 3
Given an MDP G and a set T of target states, the symbolic algorithm SymbImprAlgo correctly computes 〈〈1〉〉 almost (Büchi(T)) in \(O(n \cdot\sqrt{m})\) symbolic steps.
Remark 1
In many practical cases, MDPs have constant out-degree and hence we obtain a symbolic algorithm that works in \(O(n \cdot\sqrt{n})\) symbolic steps, as compared to the previous known (symbolic implementation of the classical) algorithm that requires Ω(n 2) symbolic steps.
Remark 2
Note that in our algorithm we used \(\sqrt{m}\) to distinguish between Case 1 and Case 2 to obtain the optimal time complexity. However, our algorithm could also be parametrized with a parameter k to distinguish between Case 1 and Case 2, and then the number of symbolic steps required is \(O( \frac{n \cdot m}{k} + n \cdot k)\). For example, if m=O(n), by choosing k=logn, we obtain a symbolic algorithm that requires \(O(\frac{n^{2}}{\log n})\) symbolic steps as compared to the O(n 2) symbolic steps of the previous known algorithms. In other words our algorithm can be easily parametrized to provide a trade-off between the number of forward searches and speed up in the number of symbolic steps.
3.3 Optimized SymbImprAlgo
In the worst case, the SymbImprAlgo algorithm takes \(O(n \cdot\sqrt{m})\) steps. However it is easy to construct a family of MDPs with n states and O(n) edges, where the classical algorithm takes O(n) symbolic steps, whereas SymbImprAlgo requires \(\varOmega(n \cdot\sqrt{n})\) symbolic steps. One approach to obtain an algorithm that takes at most \(O(n \cdot\sqrt {n})\) symbolic steps and no more than linearly many symbolic steps of the classical algorithm is to dovetail (or run in lock-step) the classical algorithm and SymbImprAlgo, and stop when either of them stops. This approach will take time at least twice the minimum running time of the classical algorithm and SymbImprAlgo. We show that a much smarter dovetailing is possible (at the level of each iteration). We now present the smart dovetailing algorithm, and we call the algorithm SmDvSymbImprAlgo. The basic change is in Case 2 of SymbImprAlgo. We now describe the changes in Case 2:
-
At the beginning of an execution of Case 2 at iteration i such that the last execution was Case 1, we initialize a set U i to T i . Every time a post computation (Post(P j )) is done, we update U i by U i+1:=U i ∪Pre(U i ) (this is the backward exploration step of the classical algorithm and it is dovetailed with the forward exploration step in every iteration). For the forward exploration step, we continue the computation of P j unless P j+1=P j or P j ∩U i ≠∅ (i.e., SymbImprAlgo checked the emptiness of intersection with T i , whereas in SmDvSymbImprAlgo the emptiness of the intersection is checked with U i ). If U i+1=U i (i.e., a fixpoint is reached), then S i ∖U i and its random attractor is removed from the graph.
Correctness and symbolic steps analysis
We present the correctness and number of symbolic steps required analysis for the algorithm SmDvSymbImprAlgo. The correctness analysis is same as ImprAlgo and the only change is as follows (we describe iteration i): (a) if in Case 2 we obtain a set P j =P j+1 and its intersection with U i is empty, then there is no path from P j to U i and since T i ⊆U i , it follows that there is no path from P j to U i ; (b) if P j ∩U i ≠∅, then since U i is obtained as the backward exploration from T i , every state in U i has a path to T i , and it follows that there is a path from the starting state of P j to U i and hence to T i ; and (c) if U i =Pre(U i ), then U i is the set of states that can reach T i and all the other states can be removed. Thus the correctness follows similar to the arguments for ImprAlgo. The key idea of the running time analysis is as follows:
-
1.
Case 1 of the algorithm is same to Case 1 of SymbImprAlgo, and in Case 2 the algorithm also runs like SymbImprAlgo, but for every symbolic step (Post computation) of SymbImprAlgo, there is an additional (Pre) computation. Hence the total number of symbolic steps of SmDvSymbImprAlgo is at most twice the number of symbolic steps of SymbImprAlgo. However, the optimized step of maintaining the set U i which includes T i may allow to stop several of the forward exploration as they may intersect with U i earlier than intersection with T i .
-
2.
Case 1 of the algorithm is same as in Case 1 of the classical algorithm. In Case 2 of the algorithm the backward exploration step is the same as the classical algorithm, and (i) for every Pre computation, there is an additional Post computation and (ii) for every check whether U i =Pre(U i ), there is a check whether P j =P j+1 or P j ∩U i ≠∅. It follows that the total number of symbolic steps of Case 1 and Case 2 over all iterations is at most twice the number of symbolic steps of the classical algorithm. The cardinality computation takes additional O(m) symbolic steps over all iterations.
Hence we obtain the following result.
Theorem 4
Given an MDP G and a set T of target states, the symbolic algorithm SmDvSymbImprAlgo correctly computes 〈〈1〉〉 almost (Büchi(T)) and requires at most
symbolic steps, where SymbStep is the number of symbolic steps of an algorithm.
Observe that it is possible that the number of symbolic steps and running time of SmDvSymbImprAlgo is smaller than both SymbImprAlgo and Classical (in contrast to a simple dovetailing of SymbImprAlgo and Classical, where the running time and symbolic steps is twice that of the minimum). It is straightforward to construct a family of examples where SmDvSymbImprAlgo takes linear (O(n)) symbolic steps, however both Classical and SymbImprAlgo take at least \(O(n \cdot\sqrt{n})\) symbolic steps.
4 The win-lose algorithm
All the algorithms known for computing the almost-sure winning set (including the algorithms presented in the previous section) iteratively compute the set of states from where it is guaranteed that there is no almost-sure winning strategy for the player. The almost-sure winning set is discovered only when the algorithm stops. In this section, first we will present an algorithm that iteratively computes two sets W 1 and W 2, where W 1 is a subset of the almost-sure winning set, and W 2 is a subset of the complement of the almost-sure winning set. The algorithm has O(K⋅m) running time, where K is the size of the maximal strongly connected component (scc) of the graph of the MDP. We will first present the basic version of the algorithm, and then present an improved version of the algorithm, using the techniques to obtain ImprAlgo from the classical algorithm, and finally present the symbolic implementation of the new algorithm.
4.1 The basic win-lose algorithm
The basic steps of the new algorithm are as follows. The algorithm maintains W 1 and W 2, that are guaranteed to be subsets of the almost-sure winning set and its complement respectively. Initially W 1=∅ and W 2=∅. We also maintain that W 1=Attr 1(W 1) and W 2=Attr R (W 2). We denote by W the union of W 1 and W 2. We describe an iteration of the algorithm and we will refer to the algorithm as the WinLose algorithm (pseudocode is given as Algorithm 2).
-
1.
Step 1. Compute the scc decomposition of the remaining graph of the MDP, i.e., scc decomposition of the MDP graph induced by S∖W.
-
2.
Step 2. For every bottom scc C in the remaining graph: if C∩Pre(W 1)≠∅ or C∩T≠∅, then W 1=Attr 1(W 1∪C); else W 2=Attr R (W 2∪C), and the states in W 1 and W 2 are removed from the graph.
The stopping criterion is as follows: the algorithm stops when W=S. Observe that in each iteration, a set C of states is included in either W 1 or W 2, and hence W grows in each iteration. Observe that our algorithm has the flavor of iterative scc decomposition algorithm for computing maximal end-component decomposition of MDPs.

WinLose
Correctness of the algorithm
Note that in Step 2 we ensure that Attr 1(W 1)=W 1 and Attr R (W 2)=W 2, and hence in the remaining graph there is no state of player 1 with an edge to W 1 and no random state with an edge to W 2. We show by induction that after every iteration W 1⊆〈〈1〉〉 almost (Büchi(T)) and W 2⊆S∖〈〈1〉〉 almost (Büchi(T)). The base case (with W 1=W 2=∅) follows trivially. We prove the inductive case considering the following two cases.
-
1.
Consider a bottom scc C in the remaining graph such that C∩Pre(W 1)≠∅ or C∩T≠∅. Consider the randomized memoryless strategy σ for the player that plays all edges in C uniformly at random, i.e., for s∈C we have \(\sigma(s)(t)=\frac{1}{|E(s) \cap C|}\) for t∈E(s)∩C. If C∩Pre(W 1)≠∅, then the strategy ensures that W 1 is reached with probability 1, since W 1⊆〈〈1〉〉 almost (Büchi(T)) by inductive hypothesis it follows C⊆〈〈1〉〉 almost (Büchi(T)). Hence Attr 1(W 1∪C)⊆〈〈1〉〉 almost (Büchi(T)). If C∩T≠∅, then since there is no edge from random states to W 2, it follows that under the randomized memoryless strategy σ, the set C is a closed recurrent set of the resulting Markov chain, and hence every state is visited infinitely often with probability 1. Since C∩T≠∅, it follows that C⊆〈〈1〉〉 almost (Büchi(T)), and hence Attr 1(W 1∪C)⊆〈〈1〉〉 almost (Büchi(T)).
-
2.
Consider a bottom scc C in the remaining graph such that C∩Pre(W 1)=∅ and C∩T=∅. Then consider any strategy for player 1: (a) If a play starting from a state in C stays in the remaining graph, then since C is a bottom scc, it follows that the play stays in C with probability 1. Since C∩T=∅ it follows that T is never visited. (b) If a play leaves C (note that C is a bottom scc of the remaining graph and not the original graph, and hence a play may leave C), then since C∩Pre(W 1)=∅, it follows that the play reaches W 2, and by hypothesis W 2⊆S∖〈〈1〉〉 almost (Büchi(T)). In either case it follows that C⊆S∖〈〈1〉〉 almost (Büchi(T)). It follows that Attr R (W 2∪C)⊆S∖〈〈1〉〉 almost (Büchi(T)).
The correctness of the algorithm follows as when the algorithm stops we have W 1∪W 2=S.
Running time analysis
In each iteration of the algorithm at least one state is removed from the graph, and every iteration takes at most O(m) time: in every iteration, the scc decomposition of step 1 and the attractor computation in step 2 can be achieved in O(m) time. Hence the naive running of the algorithm is O(n⋅m). The desired O(K⋅m) bound is achieved by considering the standard technique of running the algorithm on the scc decomposition of the MDP. In other words, we first compute the scc of the graph of the MDP, and then proceed bottom up computing the partition W 1 and W 2 for an scc C once the partition is computed for all states below the scc. Observe that the above correctness arguments are still valid. The running time analysis is as follows: let ℓ be the number of scc’s of the graph, and let n i and m i be the number of states and edges of the i-th scc. Let K=max{n i ∣1≤i≤ℓ}. Our algorithm runs in time \(O(m) + \sum_{i=1}^{\ell}O(n_{i} \cdot m_{i}) \leq O(m) + \sum_{i=1}^{\ell}O(K \cdot m_{i}) = O(K \cdot m)\).
Theorem 5
Given an MDP with a Büchi objective, the WinLose algorithm iteratively computes the subsets of the almost-sure winning set and its complement, and in the end correctly computes the set 〈〈1〉〉 almost (Büchi(T)) and the algorithm runs in time O(K S ⋅m), where K S is the maximum number of states in an scc of the graph of the MDP.
4.2 Improved WinLose algorithm and symbolic implementation
Improved WinLose algorithm
The improved version of the WinLose algorithm performs a forward exploration to obtain a bottom scc like Case 2 of ImprAlgo. At iteration i, we denote the remaining subgraph as (S i ,E i ), where S i is the set of remaining states, and E i is the set of remaining edges. The set of states removed will be denoted by Z i , i.e., S i =S∖Z i , and Z i is the union of W 1 and W 2. In every iteration the algorithm identifies a set C i of states such that C i is a bottom scc in the remaining graph, and then it follows the steps of the WinLose algorithm. We will consider two cases. The algorithm maintains the set L i+1 of states that were removed from the graph since (and including) the last iteration of Case 1, and the set J i+1 of states that lost an edge to states removed from the graph since the last iteration of Case 1. Initially J 0:=L 0:=Z 0:=W 1:=W 2:=∅, and let i:=0, and we describe the iteration i of our algorithm. We call our algorithm ImprWinLose (pseudocode is given as Algorithm 3).
-
1.
Case 1. If (\((|J_{i}| > \sqrt{m})\) or i=0), then
-
(a)
Compute the scc decomposition of the remaining graph.
-
(b)
For each bottom scc C i , if C i ∩T≠∅ or C i ∩Pre(W 1)≠∅, then W 1:=Attr 1(W 1∪C i ), else W 2:=Attr R (W 2∪C i ).
-
(c)
Z i+1:=W 1∪W 2. The set Z i+1∖Z i is removed from the graph.
-
(d)
The set L i+1 is the set of states removed from the graph in this iteration and J i+1 be the set of states in the remaining graph with an edge to L i+1.
-
(e)
If Z i is S, the algorithm stops, otherwise i:=i+1 and go to the next iteration.
-
(a)
-
2.
Case 2. Else (\((|J_{i}| \leq\sqrt{m})\) and i>0), then
-
(a)
Consider the set J i to be the set of vertices in the graph that lost an edge to the states removed since the last iteration that executed Case 1.
-
(b)
We do a lock-step search from every state s in J i as follows: we do a DFS from s, until the DFS stops. Once the DFS stops we have identified a bottom scc C i .
-
(c)
If C i ∩T≠∅ or C i ∩Pre(W 1)≠∅, then W 1:=Attr 1(W 1∪C i ), else W 2:=Attr R (W 2∪C i ).
-
(d)
Z i+1:=W 1∪W 2. The set Z i+1∖Z i is removed from the graph.
-
(e)
The set L i+1 is the set of states removed from the graph since the last iteration of Case 1 and J i+1 be the set of states in the remaining graph with an edge to L i+1.
-
(f)
If Z i =S, the algorithm stops, otherwise i:=i+1 and go to the next iteration.
-
(a)

ImprWinLose
Correctness and running time
The correctness proof of ImprWinLose is similar as the correctness argument of WinLose algorithm. One additional care requires to be taken for Case 2: we need to show that when we terminate the lockstep DFS search in Case 2, then we obtain a bottom scc. First, we observe that in iteration i, when Case 2 is executed, each bottom scc must contain a state from J i , since it was not a bottom scc in the last execution of Case 1. Second, among all the lockstep DFSs, the first one that terminates must be a bottom scc because the DFS search from a state of J i that does not belong to a bottom scc explores states of bottom scc’s below it. Since Case 2 stops when the first DFS terminates we obtain a bottom scc. The rest of the correctness proof is identical as the proof for the WinLose algorithm. The running time analysis of the algorithm is similar to ImprAlgo algorithm, and this shows the algorithm runs in \(O(m \cdot\sqrt{m})\) time. Applying the ImprWinLose algorithm bottom up on the scc decomposition of the MDP gives us a running time of \(O(m \cdot\sqrt{K_{E}})\), where K E is the maximum number of edges of an scc of the MDP.
Theorem 6
Given an MDP with a Büchi objective, the ImprWinLose algorithm iteratively computes the subsets of the almost-sure winning set and its complement, and in the end correctly computes the set 〈〈1〉〉 almost (Büchi(T)). The algorithm ImprWinLose runs in time \(O(\sqrt{K_{E}} \cdot m)\), where K E is the maximum number of edges in an scc of the graph of the MDP.
Symbolic implementation
The symbolic implementation of ImprWinLose algorithm is obtained in a similar fashion as SymbImprAlgo was obtained from ImprAlgo. The only additional step required is the symbolic scc computation. It follows from the results of [12] that scc decomposition can be computed in O(n) symbolic steps. In the following section we will present an improved symbolic scc computation algorithm. The correctness proof of SymbImprWinLose is similar to ImprWinLose algorithm. For the correctness of the SymbImprWinLose algorithm we again need to take care that when we terminate in Case 2, then we have identified a bottom scc. Note that for symbolic step forward search we cannot guarantee that the forward search that stops first gives a bottom scc. For Case 2 of the SymbImprWinLose we do in lockstep both symbolic forward and backward searches, stop when both the searches stop and gives the same result. Thus we ensure when we terminate an iteration of Case 2 we obtain a bottom scc. The correctness then follows from the correctness arguments of WinLose and ImprWinLose. The symbolic steps required analysis is same as for SymbImprAlgo.
Corollary 1
Given an MDP with a Büchi objective, the symbolic ImprWinLose algorithm (SymbImprWinLose) iteratively computes the subsets of the almost-sure winning set and its complement, and in the end correctly computes the set 〈〈1〉〉 almost (Büchi(T)). The algorithm SymbImprWinLose requires \(O(\sqrt{K_{E}} \cdot n)\) symbolic steps, where K E is the maximum number of edges in an scc of the graph of the MDP.
Remark 3
It is clear from the complexity of the WinLose and ImprWinLose algorithms that they would perform better for MDPs where the graph has many small scc’s, rather than few large ones.
5 Improved symbolic SCC algorithm
A symbolic algorithm to compute the scc decomposition of a graph in O(n⋅logn) symbolic steps was presented in [3]. The algorithm of [3] was based on forward and backward searches. The algorithm of [12] improved the algorithm of [3] to obtain an algorithm for scc decomposition that takes at most linear number of symbolic steps. In this section we present an improved version of the algorithm of [12] that improves the constants of the number of linear symbolic steps required. In Sect. 5.1 we present the improved algorithm and correctness, and some further technical details are presented in Sect. 8.1 of Appendix.
5.1 Improved algorithm and correctness
We first describe the main ideas of the algorithm of [12] and then present our improved algorithm. The algorithm of [12] improves the algorithm of [3] by maintaining the right order for forward sets. The notion of spine-sets and skeleton of a forward set was designed for this purpose.
Spine-sets and skeleton of a forward set
Let G=(S,E) be a directed graph. Consider a finite path τ=(s 0,s 1,…,s ℓ ), such that for all 0≤i≤ℓ−1 we have (s i ,s i+1)∈E. The path is chordless if for all 0≤i<j≤ℓ such that j−i>1, there is no edge from s i to s j . Let U⊆S. The pair (U,s) is a spine-set of G iff G contains a chordless path whose set of states is U that ends in s. For a state s, let FW(s) denote the set of states that is reachable from s (i.e., reachable by a forward search from s). The set (U,t) is a skeleton of FW(s) iff t is a state in FW(s) whose distance from s is maximum and U is the set of states on a shortest path from s to t. The following lemma was shown in [12] establishing relation of skeleton of forward set and spine-set.
Lemma 3
[12]
Let G=(S,E) be a directed graph, and let FW(s) be the forward set of s∈S. The following assertions hold: (1) If (U,t) is a skeleton of the forward-set FW(s), then U⊆FW(s). (2) If (U,t) is a skeleton of FW(s), then (U,t) is a spine-set in G.
The intuitive idea of the algorithm
The algorithm of [12] is a recursive algorithm, and in every recursive call the scc of a state s is determined by computing FW(s), and then identifying the set of states in FW(s) having a path to s. The choice of the state to be processed next is guided by the implicit inverse order associated with a possible spine-set. This is achieved as follows: whenever a forward-set FW(s) is computed, a skeleton of such a forward set is also computed. The order induced by the skeleton is then used for the subsequent computations. Thus the symbolic steps performed to compute FW(s) are distributed over the scc computation of the states belonging to a skeleton of FW(s). The key to establish the linear complexity of symbolic steps is the amortized analysis. We now present the main procedure SCCFind and the main sub-procedure SkelFwd of the algorithm from [12].
Procedures SCCFind and SkelFwd
The main procedure of the algorithm is SCCFind that calls SkelFwd as a sub-procedure. The input to SCCFind is a graph (S,E) and (A,B), where either (A,B)=(∅,∅) or (A,B)=(U,{s}), where (U,s) is a spine-set. If S is ∅, then the algorithm stops. Else, (a) if (A,B) is (∅,∅), then the procedure picks an arbitrary s from S and proceeds; (b) otherwise, the sub-procedure SkelFwd is invoked to compute the forward set of s together with the skeleton (U′,s′) of such a forward set. The SCCFind procedure has the following local variables: FWSet,NewSet,NewState and SCC. The variable FWSet that maintains the forward set, whereas NewSet and NewState maintain U′ and {s′}, respectively. The variable SCC is initialized to s, and then augmented with the scc containing s. The partition of the scc’s is updated and finally the procedure is recursively called over:
-
1.
the subgraph of (S,E) is induced by S∖FWSet and the spine-set of such a subgraph obtained from (U,{t}) by subtracting SCC;
-
2.
the subgraph of (S,E) induced by FWSet∖SCC and the spine-set of such a subgraph obtained from (NewSet,NewState) by subtracting SCC.
The SkelFwd procedure takes as input a graph (S,E) and a state s, first it computes the forward set FW(s), and second it computes the skeleton of the forward set. The forward set is computed by symbolic breadth first search, and the skeleton is computed with a stack. The detailed pseudocodes are in the following subsection. We will refer to this algorithm of [12] as SymbolicScc. The following result was established in [12]: for the proof of the constant 5, refer to the appendix of [12] and the last sentence explicitly claims that every state is charged at most 5 symbolic steps.
Theorem 7
[12]
Let G=(S,E) be a directed graph. The algorithm SymbolicScc correctly computes the scc decomposition of G in min{5⋅|S|,5⋅D(G)⋅N(G)+N(G)} symbolic steps, where D(G) is the diameter of G, and N(G) is the number of scc’s in G.
Improved symbolic algorithm
We now present our improved symbolic scc algorithm and refer to the algorithm as ImprovedSymbolicScc. Our algorithm mainly modifies the sub-procedure SkelFwd. The improved version of SkelFwd procedure takes an additional input argument Q, and returns an additional output argument that is stored as a set P by the calling SCCFind procedure. The calling function passes the set U as Q. The way the output P is computed is as follows: at the end of the forward search we have the following assignment: P:=FWSet∩Q. After the forward search, the skeleton of the forward set is computed with the help of a stack. The elements of the stacks are sets of states stored in the forward search. The spine set computation is similar to SkelFwd, the difference is that when elements are popped of the stack, we check if there is a non-empty intersection with P, if so, we break the loop and return. Moreover, for the backward searches in SCCFind we initialize SCC by P rather than s. We refer to the new sub-procedure as ImprovedSkelFwd (detailed pseudocode in the following subsection).
Correctness
Since s is the last element of the spine set U, and P is the intersection of a forward search from s with U, it means that all elements of P are both reachable from s (since P is a subset of FW(s)) and can reach s (since P is a subset of U). It follows that P is a subset of the scc containing s. The part of the spine-set computation that was skipped, would have consisted of states that are reachable from s, and can reach P, and thus belong to the scc containing s. Since the scc containing s is to be removed after the call, not computing the spine-set beyond P does not change the future function calls, i.e., the value of U′, since the omitted parts of NewSet are in the scc containing s. The modification of starting the backward search from P does not change the result, since P will anyway be included in the backward search. So the ImprovedSymbolicScc algorithm gives the same result as SymbolicScc, and the correctness follows from Theorem 7.
Symbolic steps analysis
We present two upper bounds on the number of symbolic steps of the algorithm. Intuitively following are the symbolic operations that need to be accounted for: (1) when a state is included in a spine set for the first time in ImprovedSkelFwd sub-procedure which has two parts: the first part is the forward search and the second part is computing the skeleton of the forward set; (2) when a state is already in a spine set and is found in forward search of ImprovedSkelFwd and (3) the backward search for determining the scc. We now present the number of symbolic steps analysis for ImprovedSymbolicScc.
-
1.
There are two parts of ImprovedSkelFwd, (i) a forward search and (ii) a backward search for skeleton computation of the forward set. For the backward search, we show that the number of steps performed equals the size of NewSet computed. One key idea of the analysis is the proof where we show that a state becomes part of spine-set at most once, as compared to the algorithm of [12] where a state can be part of spine-set at most twice. Because, when it is already part of a spine-set, it will be included in P and we stop the computation of spine-set when an element of P gets included. We now split the analysis in two cases: (a) states that are included in spine-set, and (b) states that are not included in spine-set.
-
(a)
We charge one symbolic step for the backward search of ImprovedSkelFwd (spine-set computation) to each element when it first gets inserted in a spine-set. For the forward search, we see that the number of steps performed is the size of spine-set that would have been computed if we did not stop the skeleton computation. But by stopping it, we are only omitting states that are part of the scc. Hence we charge one symbolic step to each state getting inserted into spine-set for the first time and each state of the scc. Thus, a state getting inserted in a spine-set is charged two symbolic steps (for forward and backward search) of ImprovedSkelFwd the first time it is inserted.
-
(b)
A state not inserted in any spine-set is charged one symbolic step for backward search which determines the scc.
Along with the above symbolic steps, one step is charged to each state for the forward search in ImprovedSkelFwd at the time its scc is being detected. Hence each state gets charged at most three symbolic steps. Besides, for computing NewState, one symbolic step is required per scc found. Thus the total number of symbolic steps is bounded by 3⋅|S|+N(G), where N(G) is the number of scc’s of G.
-
(a)
-
2.
Let D ∗ be the sum of diameters of the scc’s in a G. Consider a scc with diameter d. In any scc the spine-set is a shortest path, and hence the size of the spine-set is bounded by d. Thus the three symbolic steps charged to states in spine-set contribute to at most 3⋅d symbolic steps for the scc. Moreover, the number of iterations of forward search of ImprovedSkelFwd charged to states belonging to the scc being computed are at most d. The number of iterations of the backward search to compute the scc is also at most d. Hence, the two symbolic steps charged to states not in any spine-set also contribute at most 2⋅d symbolic steps for the scc. Finally, computation of NewSet takes one symbolic step per scc. Hence we have 5⋅d+1 symbolic steps for a scc with diameter d. We thus obtain an upper bound of 5D ∗+N(G) symbolic steps.
It is straightforward to argue that the number of symbolic steps of ImprovedSCCFind is at most the number of symbolic steps of SCCFind. The detailed pseudocode and technical details of the running time analysis is presented in Appendix.
Theorem 8
Let G=(S,E) be a directed graph. The algorithm ImprovedSymbolicScc correctly computes the scc decomposition of G in min{3⋅|S|+N(G),5⋅D ∗(G)+N(G)} symbolic steps, where D ∗(G) is the sum of diameters of the scc’s of G, and N(G) is the number of scc’s in G.
Remark 4
Observe that in the worst case SCCFind takes 5⋅n symbolic steps, whereas ImprovedSCCFind takes at most 4⋅n symbolic steps. Thus our algorithm improves the constant of the number of linear symbolic steps required for symbolic scc decomposition.
6 Experimental results
In this section we present our experimental results. We first present the results for symbolic algorithms for MDPs with Büchi objectives and then for symbolic scc decomposition.
Symbolic algorithm for MDPs with Büchi objectives
We implemented all the symbolic algorithms (including the classical one) and ran the algorithms on randomly generated graphs. If we consider arbitrarily randomly generated graphs, then in most cases it gives rise to trivial MDPs. Hence we generated more structured MDP graphs. First we generated a large number of MDPs and as a first step chose the MDP graphs where all the algorithms required large number of symbolic steps, and then generated large number of MDP graphs randomly by small perturbations of the graphs chosen in the first step. Our results of average symbolic steps required are shown in Table 1 and show that the new algorithms perform significantly better than the classical algorithm. The running time comparison is given in Table 2.
Symbolic scc computation
We implemented the symbolic scc decomposition algorithm from [12] and our new symbolic algorithm. A comparative study of the algorithm of [12] and the algorithm of [3] was done in [21], and it was found that the performances were comparable. Hence we only perform the comparison of the algorithm of [12] and our new algorithm. We ran the algorithms on randomly generated graphs. Again arbitrarily randomly generated graphs in many cases gives rise to graphs that are mostly disconnected or completely connected. Hence we generated random graphs by first constructing a topologically sorted order of the scc’s and then adding edges randomly respecting the topologically sorted order. Our results of average symbolic steps are shown in Table 3 and shows that our new algorithm performs better (around 15 % improvement over the algorithm of [12]). The running time comparison is shown in Table 4.
In all cases, our implementations were the basic implementation of the algorithms, and more optimized implementations would lead to improved performance results. The source codes, sample examples for the experimental results, and other details of the implementation are available at http://www.cs.cmu.edu/~nkshah/SymbolicMDP.
Symbolic scc for academic benchmarks
We also considered the symbolic scc computation on the academic benchmark graphs: we considered the VLTS benchmarks (obtained from http://www.inrialpes.fr/vasy/cadp/resources/benchmark_bcg.html) which are also used for scc computation algorithms comparison in [1]. Our results are shown in Table 5. If the input graph has one scc, then the algorithm from [12] and our improved algorithm is the same. In the experimental results in all cases where the number of scc’s is one there is no improvement (as the algorithms coincide), and in one other degenerate case where all scc’s are self-loops there was no improvement. Other than the cases where there were no improvements, in one out of twenty-three cases there was less than 1 % improvement, in five cases between 1.5–3 % improvement, in four cases between 3–5 % improvement, in seven cases between 5–10 % improvement, and in six cases more than 10 % improvement.
7 Conclusion
In this work we considered a core problem of probabilistic verification which is to compute the set of almost-sure winning states in MDPs with Büchi objectives. We presented the first symbolic sub-quadratic algorithm for the problem, and also a new symbolic sub-quadratic algorithm (ImprWinLose algorithm). As compared to all previous algorithms which identify the almost-sure winning states upon termination, the ImprWinLose algorithm can potentially discover almost-sure winning states in intermediate steps as well. Finally we considered another core graph theoretic problem in verification which is the symbolic scc decomposition problem. We presented an improved algorithm for the problem. The previous best known algorithm for the problem required 5⋅n symbolic steps in the worst case and our new algorithm takes at most 4⋅n symbolic steps, where n is the number of states of the graph. Our basic implementation shows that our new algorithms perform favorably over the old algorithms. Optimized implementations of the new algorithms and detailed experimental studies would be an interesting direction for future work.
References
Barnat J, Chaloupka J, van de Pol J (2011) Distributed algorithms for SCC decomposition. J Log Comput 21(1):23–44
Bianco A, de Alfaro L (1995) Model checking of probabilistic and nondeterministic systems. In: FSTTCS 95. LNCS, vol 1026. Springer, Berlin, pp 499–513
Bloem R, Gabow HN, Somenzi F (2000) An algorithm for strongly connected component analysis in log symbolic steps. In: FMCAD, pp 37–54
Chatterjee K, Henzinger M (2011) Faster and dynamic algorithms for maximal end-component decomposition and related graph problems in probabilistic verification. In: SODA, pp 1318–1336
Chatterjee K, Jurdziński M, Henzinger TA (2003) Simple stochastic parity games. In: CSL’03. LNCS, vol 2803. Springer, Berlin, pp 100–113
Chatterjee K, Jurdziński M, Henzinger TA (2004) Quantitative stochastic parity games. In: SODA’04. SIAM, Philadelphia, pp 121–130
Courcoubetis C, Yannakakis M (1995) The complexity of probabilistic verification. J ACM 42(4):857–907
de Alfaro L (1997) Formal verification of probabilistic systems. PhD thesis, Stanford University
de Alfaro L, Faella M, Majumdar R, Raman V (2005) Code-aware resource management. In: EMSOFT 05. ACM, New York
de Alfaro L, Roy P (2007) Magnifying-lens abstraction for Markov decision processes. In: CAV, pp 325–338
Filar J, Vrieze K (1997) Competitive Markov decision processes. Springer, Berlin
Gentilini R, Piazza C, Policriti A (2003) Computing strongly connected components in a linear number of symbolic steps. In: SODA, pp 573–582
Howard H (1960) Dynamic programming and Markov processes. MIT Press, Cambridge
Immerman N (1981) Number of quantifiers is better than number of tape cells. J Comput Syst Sci 22:384–406
Kemeny JG, Snell JL, Knapp AW (1966) Denumerable Markov chains. Van Nostrand, Princeton
Kwiatkowska M, Norman G, Parker D (2000) Verifying randomized distributed algorithms with prism. In: Workshop on advances in verification (WAVE’00)
Pogosyants A, Segala R, Lynch N (2000) Verification of the randomized consensus algorithm of Aspnes and Herlihy: a case study. Distrib Comput 13(3):155–186
Puterman ML (1994) Markov decision processes. Wiley, New York
Segala R (1995) Modeling and verification of randomized distributed real-time systems. PhD thesis, MIT Technical Report MIT/LCS/TR-676
Sleator DD, Tarjan RE (1983) A data structure for dynamic trees. J Comput Syst Sci 26(3):362–391
Somenzi F. Personal communication
Somenzi F (1998) Colorado university decision diagram package. http://vlsi.colorado.edu/pub/
Stoelinga MIA (2002) Fun with FireWire: experiments with verifying the IEEE1394 root contention protocol. In: Formal aspects of computing
Thomas W (1997) Languages, automata, and logic. In: Rozenberg G, Salomaa A (eds) Beyond words. Handbook of formal languages, vol 3. Springer, Berlin, pp 389–455. Chap 7
Author information
Authors and Affiliations
Corresponding author
Additional information
The research was supported by Austrian Science Fund (FWF) Grant No P 23499-N23 on Modern Graph Algorithmic Techniques in Formal Verification, FWF NFN Grant No S11407-N23 (RiSE), ERC Start grant (279307: Graph Games), and Microsoft faculty fellows award.
A preliminary version of the paper appeared in Computer Aided Verification (CAV), 2011.
Appendix
Appendix
1.1 8.1 Technical details of improved symbolic scc algorithm
The pseudocode of SCCFind is formally given as Algorithm 4. The correctness analysis and the analysis of the number of symbolic steps is given in [12]. The pseudocode of ImprovedSCCFind is formally given as Algorithm 5. The main changes of ImprovedSCCFind from SCCFind are as follows: (1) instead of SkelFwd the algorithm ImprovedSCCFind calls procedure ImprovedSkelFwd that returns an additional set P and ImprovedSkelFwd is invoked with an additional argument that is U; (2) in line 4 of ImprovedSCCFind the set SCC is initialized to P instead of s. The main difference of ImprovedSkelFwd from SkelFwd is as follows: (1) the set P is computed in line 4 of ImprovedSkelFwd as FWSet∩Q, where Q is the set passed by ImprovedSCCFind as the argument; and (2) in the while loop it is checked if the element popped intersects with P and if yes, then the procedure breaks the while loop. The correctness argument from the correctness of SCCFind is already shown in Sect. 5.1.

SCCFind

ImprovedSCCFind
Symbolic steps analysis
We now present the detailed symbolic steps analysis of the algorithm. As noted in Sect. 3.2, common symbolic operations on a set of states are Pre, Post and CPre. We note that these operations involve symbolic sets of 2⋅log(n) variables, as compared to symbolic sets of log(n) variables required for operations such as union, intersection and set difference. Thus only Pre, Post and CPre are counted as symbolic steps, as done in [12]. The total number of other symbolic operations is also O(|S|). We note that only lines 5 and 10 of ImprovedSCCFind and lines 3.3 and 7.3 of ImprovedSkelFwd involve Pre and Post operations.
In the following, we charge the costs of these lines to states in order to achieve the 3⋅|S|+N(G) bound for symbolic steps. We define subspine-set as NewSet returned by ImprovedSkelFwd and show the following result.
Lemma 4
For any spine-set U and its end vertex u, T is a subspine-set iff U∖T⊆SCC(u).
Proof
Note that while constructing a subspine-set T, we stop the construction when we find any state v∈FWSet∩U from the spine set. Now clearly since v∈U, there is a path from v to u. Also, since we found this state in FW(u), there is a path from u to v. Hence, v∈SCC(u). Also, each state that we are omitting by stopping construction of T has the property that there is a path from u to that state and a path from that state to v. This implies that all the states we are omitting in construction of T are in SCC(u). □
Note that since we pass NewSet∖SCC in the subsequent call to ImprovedSCCFind, it will actually be a spine set for the reduced problem. In the following lemma we show that any state can be part of subspine-set at most once, as compared to twice in the SCCFind procedure in [12]. This lemma is one of the key points that lead to the improved analysis of symbolic steps required.
Lemma 5
Any state v can be part of subspine-set at most once.
Proof
In [12], the authors show that any state v can be included in spine sets at most twice in SkelFwd. The second time the state v is included is in line 6 of SkelFwd when the SCC(v) of the state is to be found. In contrast, ImprovedSkelFwd checks intersection of the subspine-set being constructed with the set P that contains the states of SCC(v) which are already in a subspine-set. When this happens, it stops the construction of the subspine-set. Now if v is already included in the subspine-set, then it will be part of P and would not be included in subspine-set again. Hence, v can be part of subspine-set at most once. □
Lemma 6
States added in SCC by iteration of line 5 of ImprovedSCCFind are exactly the states which are not part of any subspine-set.
Proof
We see that in line 5 of ImprovedSCCFind, we start from SCC=P and then we find the SCC by backward search. Also, P has all the states from SCC which are part of any subspine-set. Hence, the extra states that are added in SCC are states which are never included in a subspine-set. □
Charging symbolic steps to states
We now consider three cases to charge symbolic steps to states and scc’s.
-
1.
Charging states included in subspine-set. First, we see that the number of times the loop of line 3 in ImprovedSkelFwd is executed is equal to the size of the spine set that SkelFwd would have computed. Using Lemma 4, we can charge one symbolic step to each state of the subspine-set and each state of the SCC that is being computed. Now, the number of times line 7.3 of ImprovedSkelFwd is executed equals the size of subspine-set that is computed. Hence, we charge one symbolic step to each state of subspine-set for this line.
Now we summarize the symbolic steps charged to each state which is part of some subspine-set. First time when a state gets into a subspine-set, it is charged two steps, one for line 3.3 and one for line 7.3 of ImprovedSkelFwd. If its SCC is not found in the same call to ImprovedSCCFind, then it comes into action once again when its SCC is being found. By Lemma 5, it is never again included in a subspine set. Hence in this call to ImprovedSkelFwd, it is only charged one symbolic step for line 3.3 and none for line 7.3 as line 7.3 is charged to states that become part of the newly constructed subspine-set. Also because of Lemma 6, since this state is in a subspine-set, it is not charged anything for line 5 of ImprovedSCCFind. Hence, a state that occurs in any subspine-set is charged at most three symbolic steps.
-
2.
Charging states not included in subspine-set. For line 5 of ImprovedSCCFind, the number of times it is executed is the number of states that are added to SCC after initialization to SCC=P. Using Lemma 6, we charge one symbolic step to each state of this SCC that is never a part of any subspine-set. Also, we might have charged one symbolic step to such a state for line 3.3 of ImprovedSkelFwd when we called it. Hence, each such state is charged at most two symbolic steps.
-
3.
Charging SCC s. For line 10 of ImprovedSCCFind, we see that it is executed only once in a call to ImprovedSCCFind that computes a SCC. Hence, the total number of times line 10 is executed equals N(G), the number of SCCs of the graph. Hence, we charge each SCC one symbolic step for this line.
The above argument shows that the number of symbolic steps that the algorithm ImprovedSCCFind requires is at most 3⋅|S|+N(G). This completes the formal proof of Theorem 8.
We now present an example that presents a family of graphs with k⋅n states, where the SCCFind algorithm takes almost 5⋅k⋅n symbolic steps, whereas the ImprovedSCCFind algorithm takes at most 3⋅k⋅n+n symbolic steps.
Example 1
Let k,n∈ℕ. Consider a graph with k⋅n states such that the states are numbered from 1 to k⋅n. The edges are as follows: (1) for all states 1≤i≤k⋅n−1, there is an edge (i,i+1) (i.e., the states are all in a line); and (2) for all 1≤i≤n, there is an edge from state k⋅i to state (i−1)⋅k+1. We will show that the SCCFind algorithm requires roughly (5⋅k−1)⋅n symbolic steps on this graph. Note the number of scc’s in this graph is n, and hence by Theorem 8 the ImprovedSCCFind algorithm takes at most 3⋅k⋅n+n symbolic steps.
We now analyze the symbolic steps required by the SCCFind algorithm, and our analysis is in two steps.
-
1.
Step 1. In the beginning, starting from the state 1 of the graph, the algorithm performs a forward and backward search to find the spine set. This will have a cost of two symbolic steps per state (one symbolic step while going forward, and one symbolic step while going backward), except for the first vertex which gets charged only one symbolic step (it does not get charged while going backwards). This gives a cost of 2⋅k⋅n−1 symbolic steps. After this, the first scc will be found with an additional cost of only k, and the first discovered scc consists of states {1,2,…,k}. Hence the total symbolic steps required is 2⋅k⋅n−1+k.
-
2.
Step 2. After Step 1, the algorithm will start finding scc’s from the end of the spine set. So consider the set of last k states from k⋅(n−1)+1 to n⋅k. The algorithm will pick the last state n⋅k, find a spine set, consisting of the last k states (states k⋅(n−1)+1 to n⋅k). This will have a cost of 2⋅k−1 symbolic steps (k symbolic steps for the forward search, and k−1 symbolic steps for the backward search). After this, the algorithm will find the scc containing the last state n⋅k (i.e., the scc that consists of states {k⋅(n−1)+1,k⋅(n−1)+2,…,n⋅k}), and this takes k symbolic steps as there are k vertices in the scc. Now Step 2 is repeated with state k⋅(n−1), and then repeated for state k⋅(n−2) and so on. So the cost for every scc, except the very first one, is 2k−1+k=3k−1. Since there are n scc’s, the total number of symbolic steps required for Step 2 is at least (3⋅k−1)⋅(n−1).
Hence the total symbolic steps required for the algorithm is at least
Note that with k=n, SCCFind takes at least 5⋅n 2−3⋅n symbolic steps, whereas the ImprovedSCCFind takes at most 3⋅n 2+n symbolic steps.
Rights and permissions
About this article
Cite this article
Chatterjee, K., Henzinger, M., Joglekar, M. et al. Symbolic algorithms for qualitative analysis of Markov decision processes with Büchi objectives. Form Methods Syst Des 42, 301–327 (2013). https://doi.org/10.1007/s10703-012-0180-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10703-012-0180-2