
Abstract
Reconfigurable manufacturing system (RMS) is designed around part family providing exact production function and capacity in cost-effective way when needed. Besides the grouping accuracy of part family impacting the responsiveness of RMS, the efficiency problem of RMS resulting from the difference of process time and capacity demand should be solved. Therefore, a similarity coefficient method for RMS part family grouping considering process time and capacity demand is proposed. First, the longest common subsequence (LCS) among different part process routes is extracted and the shortest composite supersequence (SCS) of parts is constructed. Idle machine (IM) and bypass move (BPM) are analyzed based on SCS. Then, the process time (T) and capacity demand (D) are used as characteristic value of operation. And characteristic value sequences of process route, LCS, SCS, IM and BPM are gained, that is, TDP, TDLCS, TDSCS, TDIM and TDBPM respectively. By analyzing the relationships between TDLCS and TDSCS, the characteristic value sequences of TDLCS, TDIM and TDBPM are used to calculate the similarity between parts. Based on the similarity matrix, the netting clustering algorithm is used for clustering to complete the part family grouping. Finally, a case study is presented to implement the proposed method and validate the effectiveness.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
As the economy develops, customer demands become more diverse, leading to ever-increasing product types and large fluctuations in market demand. The shortcomings of currently existing manufacturing systems have been gradually revealed, and a new type of manufacturing system that pursues rapid responsiveness at cost-effective way is needed. Reconfigurable manufacturing system (RMS) is a promising paradigm to handle suddenly irregular changes, which can rapidly adjust its capacity and function within a part family (Koren et al. 1999). On the basis of maximum utilization of currently available resources and through rapid reconfiguration, the manufacturing system is converted economically in response to specific new demands (Luo et al. 2000; Liang and Ning 2003; ElMaraghy 2005).
The design goal of a RMS is to meet the capacity and function requirements of a part family. That is, the system design of RMS is centered on a specific part family (Goyal et al. 2013b; Koren 2013), which remedies the overcapacity of the dedicated manufacturing system (DMS) and the functional redundancy issue of the flexible manufacturing system (FMS). Every part family corresponds to a specific RMS configuration (Zhao et al. 2000), and the configuration has the capability to produce all parts within the part family. Thus, the grouping of part family directly determines the RMS configuration, and the grouping effect of part family determines the efficiency of RMS when production.
The part family grouping technology was studied before the proposed of RMS and RMS adopted it as an enabling technology to provide customized flexibility. In the early phase, researchers focused on analyzing the characteristics of part operation (Choobineh 1988; Vakharia and Wemmerlov 1990, etc.), the problem scale (Balakrishnan and Jog 1995), clustering algorithm (Tam 1990), etc. Lozano et al. (2001) analyzed the weakness of a binary parts-machine correlation matrix and proposed a process route similarity based neural network algorithm. Yin and Yasuda (2005) summarized and compared Jaccard similarity coefficient-based similarity coefficient. After the proposed of RMS, the part family grouping research went into a new era. Galan et al. (2007) concerned the production efficiency of RMS when grouping part family. Abdi (2012) selected part family for reconfigurability. Ma et al. (2011) and Ashraf and Hasan (2015) tried to study the part family formation considering characteristics of RMS (modularization, reusability, etc.). Excepting the RMS characteristics, the influence of production factors on the efficiency of manufacturing system aroused the interest of some researchers. Seifoddini and Djassemi (1995) firstly studied the impact of production volume on the similarity between parts. Abdi (2012) considered manufacturing requirement, market requirement, cost, etc. Goyal et al. (2013a) and Wang et al. (2016) investigated the idle machine situation when grouping part into family. The most current literatures with concentrate on part family grouping are summarized in Table 1. In conclusion, existing literature rarely considered process time (production factors) and capacity demand (RMS characteristics). The difference of process time on common operations of parts will lead to an imbalance of production line, which decreases the efficiency of manufacturing system. The difference of capacity demands among part requires re-planning of scalability increasing reconfiguration efforts of RMS, which will magnify the impact of process time difference as well. It is necessary to recognize the parts with abnormal process time on common operations and capacity demand and eliminate during part family grouping to keep efficiency of manufacturing system. Seifoddini and Djassemi (1995) showed the flexibility of the similarity coefficient method when combined with production factors, which can be extended to characteristics of RMS. Therefore, a similarity coefficient method for RMS part family grouping with consideration of process time and capacity demand is proposed in this paper.
The remaining part of this paper is structured as follows: Firstly, a literature review of related works is given. Section 3 defines the necessary concept and analyzes the problem. Section 4 shows the part family grouping method including the design of similarity coefficient and the selection of cluster algorithm. Section 5 provides a case study of the proposed method. Section 6 concludes this paper.
2 Literature review
RMS considers production capacity and function adjustment through rapid alterations of system structure at its initial design stage (Koren 2013) giving it excellent market potential. A lot of researchers from all over the world paid passion to it. Mehrabi et al. (2000, 2002) compared RMS with flexible manufacturing systems (FMS), predicted the prospects of RMS, discussed the enabling technology, and believed that RMS is the key to future manufacturing technologies. Spicer et al. (2002) discussed the design principle of RMS and comparatively analyzed the performance indices of balancing, equipment investment, and capacity scalability of production lines of different configurations. Abdi and Labib (2003) selected an optimal plan among feasible plans by applying the networking analysis method and considering the manufacturing system response. Yamada et al. (2003) proposed a production cell optimization method and a transportation robot local optimization method within RMS. Keeling et al. (2007) measured the grouping efficiency of machine-part cell formation. Hasan et al. (2014) used the service level index as an RMS performance assessment index; these indices are conducive for obtaining better part families at the initial configuration stage.
Part family grouping is a group technology proposed before the concept of RMS. Choobineh (1988) proposed a process route similarity-based similarity coefficient derived from the Jaccard similarity coefficient. Vakharia and Wemmerlov (1990) used the process route similarity coefficient to group part family and production cells during the design of cellular manufacturing systems, and they considered machine order and load, making research a step closer to reality. Tam (1990) proposed a part family grouping method that combines a clustering algorithm with process similarity-based similarity coefficients. Ho et al. (1993) proposed the concept of a compatibility index and applied it to process route similarity. Balakrishnan and Jog (1995) tackled the shortcomings of most methods that are not able to solve large-scale problems. Seifoddini and Djassemi (1995) reported that the combination of similarity coefficient and production volume makes the method more flexible. Askin and Zhou (1998) proposed a LCS-based manufacturing line cell design method, which considers machine order in the similarity coefficient.
As the RMS became popular, the research of part family grouping began to combine with RMS factors. Galan et al. (2007) showed that the grouping efficiency and accuracy of the part family is the key in improving RMS efficiency. They grouped a part family by combining AHP with consideration of the factors of modularization, versatility, compatibility, and reusability. Zhang and Qiu (2008) proposed a part family grouping method that considered similarity assessment indices such as part modularization, universality and compatibility. Ma et al. (2011) also used part modularization, universality, compatibility, and reusability as similarity assessment indices to construct a similarity matrix for each index and grouped the part family through an improved AHP method. Gupta et al. (2012) proposed a three-stage part family grouping method. The first stage is to construct a process similarity coefficient matrix for the parts. The second stage is to use principal component analysis to calculate characteristic values and eigenvectors of the similarity coefficient matrix, use scatterplots to identify the most correlated parts, and form the initial part family. The third stage is to use the agglomerative hierarchical K-means clustering algorithm to optimize the results of the second stage. Abdi (2012) comprehensively considered manufacturing factors such as part processing, part type, production volume, production cost, process demand, modularization, and reusability and used the network analysis method to group and optimize part families. Goyal et al. (2013a) based their analysis on the similarity coefficient method, considered idle machine and part bypass move factors, and used a hierarchical clustering algorithm to group part families. Kashkoush and ElMaraghy (2014) proposed a part family formation method for reconfigurable assembly systems. A novel consensus tree-based method is applied to find the best aggregation for the three different hierarchical clustering trees. Ashraf and Hasan (2015) put forward a part family grouping method considering multiple production similarities, such as modularity, reusability and so on. Wang et al. (2016) improved the similarity coefficient of Goyal et al. (2013a) resulting in a higher discrimination. Khanna and Kumar (2017) used bond energy algorithm to recognize the operation groups of parts. Table 1 is a summary of existing method and the production factors considered.
3 Concept definition and problem analysis
3.1 LCS/SCS construction and IM/BPM analysis
LCS refers to the longest process route subsequence among the process routes that have the same process function and process order. SCS is constructed by adding non-LCS elements to the LCS in order. The construction of LCS and SCS have been done in the authors’ previous work (Wang et al. 2016), as shown in Fig. 1. Idle machine (IM) means that a machine is not activated during machining process, bypass move (BPM) means that a part need bypass an idle machine during machining process. The analysis of IM and BPM have been done in the authors’ previous work (Wang et al. 2016) as well, as shown in Fig. 2. IM and BPM are generated from the dissimilarity between parts, and the purpose of part family formation is grouping the similar parts together. So, it’s very important to avoid the happenings of IM and BPM when grouping parts into families.

Reproduced with permission from Wang et al. (2016)
Construction of LCS and SCS.

IM and BPM of part 1 and part 2
3.2 Impact analysis of process time and capacity demand
In the process of part machining, each process operation corresponds to a specific process time (including setup time) to complete a specific number of the same part (capacity demand). Assuming that the similarity of the process route between two parts is very high, however, there is a difference in capacity demand, or the process times of these two parts are different at certain process operations. In this case, if these parts are placed into the same part family mistakenly, the system layout and operational efficiency of RMS will be greatly impacted.
System balancing is one of the most critical issues in operating efficiently any manufacturing system (Battaïa and Dolgui 2013). RMS is built aiming at increasing the production efficiently, however, the difference of process time in common operations (LCS element) will cause the unbalancing problem of RMS and rebalancing works needed increases reconfiguration efforts. For example, we have part 3 and part 4 with same capacity demand, which the process routes are {1, 2, 3, 4} and {1, 2, 3, 5} respectively and the corresponding process time sequences are {1, 2, 1, 1} and {1, 2, 2, 1} respectively. There are three common operations between part 3 and part 4, and the last common operation (operation 3) of part 3 and part 4 have different process time. When producing these two parts successively, rebalancing works of RMS is needed to maintain the efficiency of RMS, as shown in Fig. 3. Obviously, when changeover from part 3 to part 4, a new machine with the function of operation 3 is added to rebalance the configuration of part 4, and when changeover from part 4 to part 3, one of the operation 3 machines is deleted to rebalance the configuration of part 3. Different process times reduce the similarity between part 3 and part 4. Additionally, the process time difference of non-common operation is neglected here, because they are already different and more analysis about them are meaningless.

Rebalancing process of part 3 and part 4
Duo to RMS is capable of providing exact capacity and function when producing a part within the part family, the difference of capacity demand will cause re-planning of scalability of RMS. The idea of scalability planning in Koren et al. (2017) study was adding as less as possible new machines to meet the new capacity demand with the task shift among stages. However, in the part family grouping period, it is impossible to decide how less new machine can meet the new capacity demand when the task shift situation is unclear. To simplify, we choose to add/delete a production line to scale the capacity in the analysis of the changeable capacity demand. Similar example part 3 and part 4 with same process time, the capacity demand of part 3 is 1 and the capacity demand of part 4 is 2. The configuration of part 3 and part 4 according to the specific process operation and capacity demands is shown in Fig. 4. Obviously, the difference in capacity demands reduce the similarity between parts.

Re-planning scalability of part 3 and part 4
Besides, if there are different process time and capacity demand in the same time between part 3 and part 4, that is, process time sequences are {1, 2, 1, 1} and {1, 2, 2, 1} respectively and capacity demands are 1 and 2 respectively. Seen from Fig. 5, a conclusion can be drawn that the difference in capacity demands magnifies the difference in process time compared with Fig. 4, and vice versa. Above all, the part family grouping results will be affected by the differences in process time and capacity demand. It is necessary to recognize these differences when grouping parts into family.

Changeover when process time and capacity demand are different at the same time
4 Part family grouping method
4.1 Construction double sequences of LCS/SCS and IM/BPM
The analysis in Sect. 3 noted the definitions and impact of idle machines, part bypass moves, process time and capacity demand on the part family grouping. In existing literature, researchers usually used figure “1” or “0” to express whether a machine is needed or nor when processing. This approach simplifies the relation description between part and machine and makes it possible to calculate the similarity between parts. However, as analyzed above, this idea only considers process functionality (machine) and process order (process routes), which overlooks the impact of process time and capacity demands. In order to remedy this drawback, the product of process time and capacity demand (process time × capacity demand) is used as the characteristic value (TD, where T means process time and D means capacity demand) of process operation. Similarly, the corresponding characteristic value sequence of LCS, SCS, IM, and BPM can be expressed as TDLCS, TDSCS, TDIM, and TDBPM respectively.
Using the same parts in Sect. 3 (part 1 and part 2) as the example, assuming the process time sequence of part 1 is T1 = {1, 1, 1, 1, 1, 2, 1, 1}, its capacity demand is D1 = 1, the process time sequence of part 2 is T2 = {1, 1, 1, 1, 1, 1, 1}, and its capacity demand is D2 = 2, as shown in Table 2. Therefore, the characteristic value sequence of part 1 is TD1 = T1 × D1 = {1, 1, 1, 1, 1, 2, 1, 1} × 1 = {1, 1, 1, 1, 1, 2, 1, 1}; the characteristic value sequence of part 2 is TD2 = T2 × D2 = {1, 1, 1, 1, 1, 1, 1} × 2 = {2, 2, 2, 2, 2, 2, 2}. According to Sect. 2.2, the SCS and LCS of parts 1 and 2 is LCS12 = {3, 10, 6}, SCS12 = {1, 11, 8, 3, 4, 9, 10, 11, 6, 2, 5, 7}, respectively. Thus, the corresponding characteristic value sequences of LCS and SCS are TDLCS1 = {1, 1, 1}, TDLCS2 = {2, 2, 2}, TDSCS1 = {1, 1, 2, 1, 1, 1, 2, 2, 1, 1, 2, 2} and TDSCS2 = {1, 1, 2, 2, 1, 1, 2, 2, 2, 1, 2, 2}, and the construction procedure is shown in Fig. 6.

Construction procedure of TDLCS/TDSCS
The idle machines of part 1 are machine 8, 11, 5 and 7, that is IM1 = {8, 11, 5, 7}, and the corresponding characteristic value sequence is TDIM1 = {2, 2, 2, 2}. The bypass moves of part 1 are machine 8 and 11, that is BPM1 = {8, 11}, and the corresponding characteristic value sequence is TQBPM1 = {2, 2}. The idle machines of part 2 are machine 1, 11, 4, 9 and 2, that is IM2 = {1, 11, 4, 9, 2}, and the corresponding characteristic value sequence is TDIM2 = {1, 1, 1, 1, 1}. The bypass moves of part 2 are machine 4, 9 and 2, that is BPM2 = {4, 9, 2}, and the corresponding characteristic value sequence is TDBPM2 = {1, 1, 1}. And the construction procedure is shown in the Fig. 7.

Construction process of TDIM/TDBPM
Based on above analysis, the process time and capacity demand of part are merged into process routes as characteristic value smoothly, which tell more detail information about part machining affecting the relationship between parts. The calculation of TDLCS, TDIM and TDBPM between any two parts (part x and part y) is shown in following formulas, that is (1), (2), (3), (4), (5), (6).
where Nx is the length of process route of part x, Ny is the length of process route of part y, NSCSxy is the length of SCSxy.
4.2 Similarity coefficient
The analysis of LCS, SCS, IM and BPM with characteristic value shows the relationship between parts from process function, process order, process time and capacity demand. The grouping of part family is a process of choosing the parts with high similarity to constitute a part family. The concept of IM and BPM are proposed to eliminate the part from a part family with a high difference of process function and process order. In the same way, the characteristic value is added in the process of part family grouping to eliminate the part with a high difference of process time and capacity demand, which will affect production efficiency of corresponding RMS analyzing in Sect. 2. Therefore, the proposed idea of part family grouping is closer to the realistic manufacturing conditions of RMS, and the result of part family grouping is more reasonable with high efficiency.
LCS consists of all the same elements from process routes of two parts considering process order, which implies the similarity between parts. The longer LCS between two parts is, the more similarity the parts are. SCS consists of all the elements from process routes of two parts and the duplicated elements (that is LCS) consider only once. Actually, the SCS is consist of LCS and IM, and BPM is part of IM. If the length of LCS is equal, the shorter SCS means less IM and BPM elements and higher similarity between corresponding parts. That is, the shorter SCS between two parts is, the more similarity the parts are. Here, a similarity coefficient of RMS part family grouping is established considering the impacts of process function, process order, process time and capacity demand from LCS/SCS perspective, that is TDLCS, TDIM and TDBPM calculating from formula (1)–(6), as shown in formula (7).
where, TDSxy represents the similarity coefficient between parts x and y, 0 ≤ TDSxy ≤ 1; (TDLCSx + TDLCSy) denotes the degree of similarity between parts x and y; (|TDLCSx − TDLCSy|) denotes the dissimilarity between part x and part y resulting from the differences of process time and capacity demand, the symbol “| |” means calculating the absolute value; (TDLCSx + TDLCSy -|TDLCSx − TDLCSy|) implies that the similarity of part x and part y will decrease if there is any difference of part x and part y in process time and capacity demand; (TDIMx + TDIMy) and (TDBPMx + TDBPMy) denote the impacts of IM and BPM from the perspective of characteristic value, respectively. The essence of the proposed method is the ratio of LCS and SCS considering the impact of process time and capacity demand.
4.3 Clustering algorithm
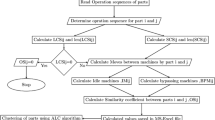
Based on the similarity coefficient in Sect. 4.2, the similarity matrix among parts could be solved. And then, a clustering algorithm is needed to complete the part family grouping. The proposed part family grouping method is based on the similarity matrix, so it is suitable to use the similarity relations-based direct clustering algorithm, including the maximum tree algorithm and netting algorithm. Another popular clustering algorithm in the literatures is average linkage clustering (ALC) algorithm (Goyal et al. 2013a; Wang et al. 2016, etc.). Because the netting algorithm is more intuitive than the maximum tree algorithm and requires less computation than ALC, this paper employs the netting algorithm for clustering. The main steps of the netting algorithm are as follows.
-
(1)
Matrix transformation. Transforming the similarity matrix into the lower triangular matrix Rα, where α is the similarity value between part families and α is determined by the experienced decision maker according to the facility condition. Rα is shown in Eq. (8).
$$R_{\alpha } = \left[ {\begin{array}{*{20}c} 1 & {} & {} & {} & {} \\ {TQS_{21} } & 1 & {} & {} & {} \\ {TQS_{31} } & {TQS_{32} } & \ddots & {} & {} \\ \vdots & \vdots & {} & 1 & {} \\ {TQS_{n1} } & {TQS_{n2} } & \ldots & {TQS_{n(n - 1)} } & 1 \\ \end{array} } \right]$$(8) -
(2)
Replacing the ‘1’ in the main diagonal by the part number i (1, 2, …, n), as shown in Eq. (9).
$$R_{\alpha } = \left[ {\begin{array}{*{20}c} 1 & {} & {} & {} & {} \\ {TQS_{21} } & 2 & {} & {} & {} \\ {TQS_{31} } & {TQS_{32} } & \ddots & {} & {} \\ \vdots & \vdots & {} & {n - 1} & {} \\ {TQS_{n1} } & {TQS_{n2} } & \ldots & {TQS_{n(n - 1)} } & n \\ \end{array} } \right]$$(9) -
(3)
Determining the specific value of α and replace similarity matrix Rα elements greater than α with ‘*’. For example, if TQS21 > a, using “*” to replace TQS21 of Rα, as shown in Eq. (10).
$$R_{\alpha } = \left[ {\begin{array}{*{20}c} 1 & {} & {} & {} & {} \\ {\mathop *\limits^{{}} } & 2 & {} & {} & {} \\ {TQS_{31} } & {TQS_{32} } & \ddots & {} & {} \\ \vdots & \vdots & {} & {n - 1} & {} \\ {TQS_{n1} } & {TQS_{n2} } & \ldots & {TQS_{n(n - 1)} } & n \\ \end{array} } \right]$$(10) -
(4)
Using vertical and horizontal lines to connect the part numbers on the diagonal with ‘*’ symbol (netting) and the connected subjects are clustered as one type. In this case, part 1 and part 2 can be clustered as one family, as shown in Eq. (11).
$$R_{\alpha } = \left[ {\begin{array}{*{20}c} 1 & {} & {} & {} & {} & {} \\ | & {} & {} & {} & {} & {} \\ * & - & 2 & {} & {} & {} \\ {TQS_{31} } & {} & {TQS_{32} } & \ddots & {} & {} \\ \vdots & {} & \vdots & {} & {n - 1} & {} \\ {TQS_{n1} } & {} & {TQS_{n2} } & \ldots & {TQS_{n(n - 1)} } & n \\ \end{array} } \right]$$(11)
5 Case study
Based on the authors’ previous work (Wang et al. 2016) considering idle machine and bypass move, this paper further takes into account one production factor—process time in common operations and one characteristics of RMS—capacity demand of parts. And the netting algorithm is used to complete the grouping process for intuitive clustering and less computation. A case is studied in this section to show the implementation of proposed part family grouping method and validate the effectiveness. In this case, because RMS is able to process every part of the family, parts are processed in first-come-first-processed principle. And the capacity demand of each part should be processed in a continuous processing.
5.1 Implementation of the proposed method
The example parts of the authors’ previous work (Wang et al. 2016) is adopted to show the implementation of the proposed method, that is part 1 and 2 presenting in Sect. 3.1 according to Table 2, the process time sequences of part 1 and part 2 are T1 = {1, 1, 1, 1, 1, 2, 1, 1} and T2 = {1, 1, 1, 1, 1, 1, 1}, respectively. The capacity demands of part 1 and part 2 are D1 = 1 and D2 = 2, respectively. Here, we get the characteristics value sequences of part 1 and part 2, that is, TD1 = {1, 1, 1, 1, 1, 2, 1, 1} and TD2 = {2, 2, 2, 2, 2, 2, 2}, respectively. After the analysis of idle machine and bypass move based on LCS and SCS, the TDLCS1, TDLCS2, TDIM1, TDIM2, TDBPM1 and TDBPM2 can be calculated according to formula (1)–(6) (TDLCS1 = 4, TDLCS2 = 6, TDIM1 = 8, TDIM2 = 5, TDBPM1 = 4 and TDBPM2 = 3). And then, the similarity of part 1 and part can be calculated according to formula (7) as shown in the following equation:
And the similarity matrix is obtained as shown in the following:
Finally, the grouping decision can be made according to the predetermined netting algorithm parameter α by executing Eqs. (9)–(11). Assuming that the parameter α is set as 0.2, due to 0.286 > 0.2, that is TDS12 > α, part 1 and part 2 are grouped into a same part family according to netting algorithm principle, part family 1 = {1, 2} as shown in the following:
The implementation process is shown in Fig. 8.

Implementation of the proposed method
5.2 Validation of proposed method
Comparing to the similarity of part 1 and part 2 in Wang et al. (2016), TDS12 = 0.267 < 0.30, which results from the differences of process time and capacity demand of part 1 and part 2. This result shows that proposed method can reflect the differences of process time and capacity demand among parts, which is necessary to a similarity method considering process time and capacity demand. Moreover, if similarity parameter α between part families is set as 0.290, the similarity of proposed method is smaller than α, that is, the part family grouping result is two part families (part family 1 = {1}, part family 2 = {2}). However, the result of Wang et al. (2016)’s method still groups part 1 and part 2 into a same part family, because their method has not the ability to recognize the differences between part 1 and part 2 in process time and capacity demand. Besides, let’s see the real situation when processing these two part. Seen from Fig. 9, excepting the different operations between part 1 and part 2, the differences of process time and capacity demand leads to one machine 3 and one machine 6 (LCS elements) added/deleted when changeover between part 1 and part 2. Two machines added/deleted during reconfiguration is not small reconfigurable efforts. It is not an indispensable situation can be overlooked. And, it is the meaning of proposed method.

The configurations of part 1 and part 2
The above analysis concerns about the differences of process time in common operation. Here, another case is studied to investigate the impact of non-LCS operations with the differences of process time. Reset the process time sequences of part 1 and part 2 as \({\text{T}}_{1}^{\prime }\) = {1, 1, 1, 1, 3, 2, 1, 1} and \({\text{T}}_{2}^{\prime }\) = {1, 1, 1, 1, 1, 1, 1}, respectively. And remain the capacity demands of part 1 and part 2 unchanged (D1 = 1, D2 = 2). Calculate the similarity of part 1 and part with new process time sequences, \(TDS_{12}^{\prime }\) = 0.235 < TDS12 = 0.267. There is more difference of process time between part 1 and part 2. So, the result (\(TDS_{12}^{\prime } < TDS_{12}\)) is correct and in line with the actual situation. The result shows that the proposed similarity coefficient is very sensitive to any change of process time, which only one operation’s process time has been changed in this case. Also, the configuration of part 1 is different, as shown in Fig. 10. There are two more machine 9 needed to re-balance the manufacturing system when the process time of operation 9 increases from 1 to 3, which increases reconfigurable efforts.

The new configurations of part 1
As to capacity demand, resetting the capacity demand of part 1 and part 2 as \(D_{1}^{\prime }\) = 1 and \(D_{2}^{\prime }\) = 1 and remaining the process time sequences unchanged (T1 = {1, 1, 1, 1, 1, 2, 1, 1} and T2 = {1, 1, 1, 1, 1, 1, 1}). Calculating the similarity of part 1 and part with new capacity demand values, \(TDS_{12}^{\prime \prime }\) = 0.286 > TDS12 = 0.267, but \(TDS_{12}^{\prime \prime }\) < 0.30 (the similarity of part 1 and part 2 in of Wang et al. (2016)’s method). There is less difference of capacity demand (their capacity demands are equal) between part 1 and part 2. But, there is still difference in process time (the process times of operation 10 (LCS element) are different). So, the result (\(TDS_{12}^{\prime \prime }\) > TDS12 and \(TDS_{12}^{\prime \prime }\) < 0.30) is correct as well. Also, the proposed similarity coefficient is very sensitive to any change of capacity demand. The new configuration of part 2 is different too, as shown in Fig. 11. Compared with the configuration of part 1 in Fig. 9, there is only one common machine (machine 10) needed to add/delete when reconfiguring between part 1 and part 2 with new capacity demand. Thus, the result is in line with the actual situation. Moreover, less reconfigurable efforts are needed reconfiguring between part 1 and part 2 when the capacity demand of part 2 decreases from 2 to 1.

The new configurations of part 2
5.3 Computation comparation
In this part, the computation comparation between netting algorithm and ALC is conducted to show the advantage of netting algorithm in computation. The ALC has been adopted in many literatures (Goyal et al. 2013a, b; Wang et al. 2016, etc.), the process routes test case in these literatures is used to start the comparation, as show in Table 3. In the authors’ previous work (Wang et al. 2016), based on the similarity matrix of test parts, the part family grouping result using ALC is obtained, that is, a tree diagram of clustering process covering all the possibilities of part families and a similarity among part families (similar to the α in netting algorithm) is chosen to select a specific part family group, as show in Fig. 12. In fact, the specific part family group including one or more part families is the basis of RMS construction. So, one clustering result is needed when constructing RMS. But, the results of the ALC include all possible clustering results, which wastes a lot of computation energy. Unlike ALC, the netting algorithm decides the α before clustering and only one computation is executed to obtain the specific part family group. Based on the test case in Table 3, the process time and capacity demand are generated by random function, and the similarity matrix of the proposed similarity method is presented in Table 4. And then, the clustering process of the netting algorithm is executed according to the predetermined α = 0.5 and the result is shown in Fig. 13. The specific part family group is {1 3 4 7 8 9}, {2 10}, {5 6}, {11 18}, {12 13 17 19}, {14} and {15 16}. Above all, the netting algorithm has more computational efficiency than the ALC by getting rid of most unnecessary computation.

The tree diagram and part family group selection

Clustering results of the proposed method (α = 0.5)
6 Conclusions
RMS can rapidly respond to market fluctuations by adjusting software and hardware within a part family. Therefore, the part family grouping is important in the implementation of RMS. This paper analyzes the impact of process time and capacity demand on the efficiency of RMS, and then a part family grouping method is proposed considering process time and capacity demand. The product of process time and capacity demand (process time × capacity demand) is used as characteristic value of part operation, based on which the characteristic value sequences of process route, LCS, SCS, IM and BPM can be obtained, that is TDP, TDLCS, TDSCS, TDIM and TDBPM, respectively. The computational formulas of TDLCS, TDIM and TDBPM are presented. And the similarity coefficient is designed by combining TDLCS, TDIM and TDBPM together. Finally, the netting algorithm is used to group part into families based on the similarity matrix. The case study shows how to implement the proposed part family grouping method and validates the effectiveness of the proposed method, which the proposed similarity coefficient is sensitive to the changes of process time and capacity and is capable of grouping the parts with less difference on process time and capacity demand into the same part family. And the advantage of the netting algorithm is also given in the case study. However, the weights of idle machine, bypass move, process time and capacity are not discussed in this paper, which will be done in the future work.
References
Abdi MR (2012) Product family grouping and selection for reconfigurability using analytical network process. Int J Prod Res 50(17):4908–4921. https://doi.org/10.1080/00207543.2012.657976
Abdi MR, Labib AW (2003) A design strategy for reconfigurable manufacturing systems (RMSs) using analytical hierarchical process (AHP): a case study. Int J Prod Res 41(10):2273–2299. https://doi.org/10.1080/0020754031000077266
Ashraf M, Hasan F (2015) Product family grouping based on multiple product similarities for a reconfigurable manufacturing system. Int J Model Oper Manag 5(3–4):247–265. https://doi.org/10.1504/IJMOM.2015.075800
Askin RG, Zhou M (1998) Grouping of independent flow-line cells based on operation requirements and machine capabilities. IIE Trans 30(4):319–329. https://doi.org/10.1080/07408179808966472
Balakrishnan J, Jog PD (1995) Manufacturing cell grouping using similarity coefficients and a parallel genetic TSP algorithm: formulation and comparison. Math Comput Model 21(12):61–73. https://doi.org/10.1016/0895-7177(95)00092-G
Battaïa O, Dolgui A (2013) A taxonomy of line balancing problems and their solution approaches. Int J Prod Econ 142(2):259–277. https://doi.org/10.1016/j.ijpe.2012.10.020
Choobineh F (1988) A framework for the design of cellular manufacturing systems. Int J Prod Res 26(7):1161–1172. https://doi.org/10.1080/00207548808947932
ElMaraghy HA (2005) Flexible and reconfigurable manufacturing systems paradigms. Int J Flex Manuf Syst 17(4):261–276
Galan R, Racero J, Eguia I, Garcia JM (2007) A systematic approach for product families grouping in reconfigurable manufacturing systems. Robot Comput Integr Manuf 23(5):489–502. https://doi.org/10.1016/j.rcim.2006.06.001
Goyal KK, Jain PK, Jain M (2013a) A comprehensive approach to operation sequence similarity based part family grouping in the reconfigurable manufacturing system. Int J Prod Res 51(6):1762–1776. https://doi.org/10.1080/00207543.2012.701771
Goyal KK, Jain PK, Jain M (2013b) A novel methodology to measure the responsiveness of RMTs in reconfigurable manufacturing system. J Manuf Syst 32(4):724–730. https://doi.org/10.1016/j.jmsy.2013.05.002
Gupta A, Jain PK, Kumar D (2012) Grouping of part family in reconfigurable manufacturing system using principle component analysis and K-means algorithm. Paper presented at the annals of DAAAM for 2012 and proceedings of the 23rd international DAAAM symposium
Hasan F, Jain PK, Kumar D (2014) 24th Daaam international symposium on intelligent manufacturing and automation, 2013 service level as performance index for reconfigurable manufacturing system involving multiple part families. Procedia Eng 69:814–821. https://doi.org/10.1016/j.proeng.2014.03.058
Ho YC, Lee CC, Moodie CL (1993) Two sequence-pattern, matching-based, flow analysis methods for multi-flowlines layout design. Int J Prod Res 31(7):1557–1578. https://doi.org/10.1080/00207549308956809
Kashkoush M, ElMaraghy H (2014) Product family formation for reconfigurable assembly systems. Procedia CIRP 17:302–307. https://doi.org/10.1016/j.procir.2014.01.131
Keeling KB, Brown EC, James TL (2007) Grouping efficiency measures and their impact on factory measures for the machine-part cell formation problem: a simulation study. Eng Appl Artif Intell 20(1):63–78. https://doi.org/10.1016/j.engappai.2006.04.001
Khanna K, Kumar R (2017) Part family and operations group formation for RMS using bond energy algorithm. Int J Eng Technol 9(2):1365–1373. https://doi.org/10.21817/ijet/2017/v9i2/170902273
Koren Y (2013) The rapid responsiveness of RMS. Int J Prod Res 51(23–24):6817–6827. https://doi.org/10.1080/00207543.2013.856528
Koren Y, Heisel U, Jovane F, Moriwaki T, Pritschow G, Ulsoy G, Van Brussel H (1999) Reconfigurable manufacturing systems. CIRP Ann Manuf Technol 48(2):527–540. https://doi.org/10.1016/S0007-8506(07)63232-6
Koren Y, Wang WC, Gu X (2017) Value creation through design for scalability of reconfigurable manufacturing systems. Int J Prod Res 55(5):1227–1242. https://doi.org/10.1080/00207543.2016.1145821
Liang FJ, Ning RX (2003) Theoretical research of reconfigurable manufacturing system. Chin J Mech Eng 39(6):36–43. https://doi.org/10.3901/JME.2003.06.036
Lozano S, Canca D, Guerrero F, García JM (2001) Machine grouping using sequence-based similarity coefficients and neural networks. Robot Comput Integr Manuf 17(5):399–404. https://doi.org/10.1016/S0736-5845(01)00015-1
Luo Z, Sheng H, Zhao B, Zhao X, Liu R, Jiang J (2000) Rapidly reconfigurable manufacturing systems. China Mech Eng 11(3):300–303
Ma LM, Li JY, Liu JP (2011) Product family partition of reconfigurable manufacturing systems (RMS) based on improved hierarchical clustering algorithm. Mach Des Manuf 8:78–80
Mehrabi MG, Ulsoy AG, Koren Y (2000) Reconfigurable manufacturing systems: key to future manufacturing. J Intell Manuf 11(4):403–419. https://doi.org/10.1023/a:1008930403506
Mehrabi MG, Ulsoy AG, Koren Y, Heytler P (2002) Trends and perspectives in flexible and reconfigurable manufacturing systems. J Intell Manuf 13(2):135–146. https://doi.org/10.1023/a:1014536330551
Seifoddini H, Djassemi M (1995) Merits of the production volume based similarity coefficient in machine cell grouping. J Manuf Syst 14(1):35–44. https://doi.org/10.1016/0278-6125(95)98899-H
Spicer P, Koren Y, Shpitalni M, Yip-Hoi D (2002) Design principles for machining system configurations. CIRP Ann Manuf Technol 51(1):275–280. https://doi.org/10.1016/S0007-8506(07)61516-9
Tam KY (1990) An operation sequence based similarity coefficient for part families groupings. J Manuf Syst 9(1):55–68. https://doi.org/10.1016/0278-6125(90)90069-T
Vakharia AJ, Wemmerlov U (1990) Designing a cellular manufacturing system: a materials flow approach based on operation sequences. IIE Trans 22(1):84–97. https://doi.org/10.1080/07408179008964161
Wang GX, Huang SH, Shang XW, Yan Y, Du JJ (2016) Formation of part family for reconfigurable manufacturing systems considering bypassing moves and idle machines. J Manuf Syst 41:120–129. https://doi.org/10.1016/j.jmsy.2016.08.009
Yamada Y, Ookoudo K, Komura Y (2003) Layout optimization of manufacturing cells and allocation optimization of transport robots in reconfigurable manufacturing systems using particle swarm optimization. Paper presented at the intelligent robots and systems, 2003 (IROS 2003). https://doi.org/10.1109/iros.2003.1248968
Yin Y, Yasuda K (2005) Similarity coefficient methods applied to the cell grouping problem: a comparative investigation. Comput Ind Eng 48(3):471–489. https://doi.org/10.1016/j.cie.2003.01.001
Zhang XH, Qiu M (2008) Problem of classification of product family for reconfigurable manufacturing systems. Machinery 35(7):47–51
Zhao X, Wang J, Luo Z (2000) A stochastic model of a reconfigurable manufacturing system part 1: a framework. Int J Prod Res 38(10):2273–2285. https://doi.org/10.1080/00207540050028098
Acknowledgements
The authors are grateful to the anonymous reviewers for their comments, which have helped to improve this paper. All authors have approved to submit to your journal, and there is no conflict of interest regarding the publication of this manuscript. The authors acknowledge the supporting funds, the National Natural Science Foundation, China (No. 51375049) and Graduate technological innovation project of Beijing institute of technology (Project No. 2017CX10040).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Huang, S., Yan, Y. Part family grouping method for reconfigurable manufacturing system considering process time and capacity demand. Flex Serv Manuf J 31, 424–445 (2019). https://doi.org/10.1007/s10696-018-9322-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10696-018-9322-1