
Abstract
Managers of water quality and water monitoring programs are often faced with constraints in terms of budget, time, and laboratory capacity for sample analysis. In such situation, the ideal solution is to reduce the number of sampling sites and/or monitored variables. In this case, selecting appropriate monitoring sites is a challenge. To overcome this problem, this study was conducted to statistically assess and identify the appropriate sampling stations of monitoring network under the monitored parameters. To achieve this goal, two sets of water quality data acquired from two different monitoring networks were used. The hierarchical agglomerative cluster analysis (HACA) were used to group stations with similar characteristics in the networks, the time series analysis was then performed to observe the temporal variation of water quality within the station clusters, and the geo-statistical analysis associated Kendall’s coefficient of concordance were finally applied to identify the most appropriate and least appropriate sampling stations. Based on the overall result, five stations were identified in the networks that contribute the most to the knowledge of water quality status of the entire river. In addition, five stations deemed less important were identified and could therefore be considered as redundant in the network. This result demonstrated that geo-statistical technique coupled with Kendall’s coefficient of concordance can be a reliable method for water resource managers to identify appropriate sampling sites in a river monitoring network.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Water quality is a complex topic and water quality monitoring networks have been developed to address a variety of water management issues. Effective monitoring of water quality in large rivers provides adequate information on the impacts of activities within the catchment throughout a river basin as a whole. Traditional monitoring of water quality implemented by individual agencies usually relates to specific objectives, such as meeting quality standards for pollution discharges, and does not provide sufficient information on basin-scale impacts, particularly in large river basins (Chapman et al. 2016). Therefore, the greater the number of monitoring sites throughout the water body, the higher the probability that they accurately represent its current status (Chapman et al. 2016). However, there are concerns about resource when a larger number of monitoring sites is required, hence a balance is needed to meet both resource and scientific requirements (Earle 2008). In this case, reducing the number of monitoring sites to the extent possible, in order to minimize the operational monitoring cost, is ideally the aim of the current tendency (Chapman et al. 2016).
Monitoring networks are not static and therefore they need to be evaluated and modified periodically. Also, the water management objectives should be re-evaluated and the data to be reviewed to determine if they capture the spatial and temporal variability of resource management correctly (IISD 2015). In this regard, existing monitoring networks are evaluated to confirm whether the objectives for which the network was designed are achieved or not. The result of this evaluation may include a redefinition of the extent and scope of the network, which may lead to the removal (due to the redundancy or uselessness of the information provided) or the inclusion of additional monitoring points at the places where the monitored variable cannot be sufficiently determined from existing stations (SEGURA 2012).
In general, the same methods used to design monitoring networks are used for their evaluation. Many approaches have been used to evaluate monitoring networks and monitoring programs, as well as to assess the similarity influence between monitoring stations and the provided data. The widely used methods and techniques for assessing and designing monitoring networks are summarized by Xu et al. (2017) as: (i) statistically based, (ii) spatial interpolation, (iii) information theory-based, and (iv) hybrid approach. These methods are more consistent and specific with regards to meeting the expectations of monitoring objectives.
Jimênez et al. (2005) elaborated a methodology for designing quasi-optimal monitoring networks for lakes and reservoirs. The main elements of their methodology were a numerical model, used due to lack of field data; a kriging-based technique for spatial interpolation and obtaining estimates from available monitoring networks; and an optimization model based on a genetic algorithm to generate the set of non-dominated optimal (costs vs accuracy) monitoring networks. Beveridge et al.( 2012) applied a geo-statistical technique to identify the optimal water quality monitoring stations of Great Lake Winnipeg by clustering the lake monitoring stations and omitting those with redundant information. They used Kriging method, which indicated the redundant stations among all the existing stations and Local Moran’s I values, which suggested the redundant stations in each group. In addition, Ou et al. (2012) applied a complex approach for an integrated assessment of sampling locations of water quality monitoring networks in Lake Winnipeg. Their techniques include geo-statistical methods coupled with principal component analysis and fuzzy optimal model.
Unlike the previous studies, the present study applied an integrated approach combining multivariate statistics, such as cluster analysis and geo-statistical and Kendall’s W non-parametric test to spatiotemporal assessment of water quality and water monitoring networks of Selangor River in Malaysia, for adequate planning and management of the river’s water resources.
Methodology
Study area
The Selangor River basin is situated in the state of Selangor, Malaysia. The catchment area is about 2200 km2, almost a quarter of the total area of Selangor State (Chowdhury et al. 2018). The basin is found in the north of the city of Kuala Lumpur, bounded to the south by the Klang Basin and to the north to the Bernam Basin.
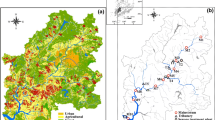
Selangor River flows southwest and travels a total distance of about 110 km before flowing into the channel of Malacca. The river is recognized as the largest source of water in the states of Selangor and Kuala Lumpur. Sungai Batang Kali, Sungai Buloh, Sungai Serendah, Sungai Kerling, Sungai Kundang, Sungai Sembah, and Sungai Rawang are among the main tributaries. The map of Selangor River basin is shown in Fig. 1.

Location of the study area along with the sampling stations
Data sources and analyses
Two sets of data were obtained from two different monitoring networks. The first dataset, provided by the DOE network, was generated from the nine monitoring stations of the Department of Environment (DOE) in Malaysia. Since 2000, the DOE regularly (every 2 months) monitors the stream water quality of these stations across the Selangor River system. The monitoring data between 2005 and 2015 which include dissolved oxygen (DO), chemical oxygen demand (COD), biochemical oxygen demand (BOD), suspended solids (SS), ammonia nitrogen (NH3-N), and pH are the first dataset used in this study. This dataset included 603 data points derived from 6 measurements on 66 samples. However, the second dataset was collected in 2016 during drought and rainy reasons from 12 sampling sites proposed by Lembaga Urus Air Selangor (LUAS). All the measurements for these parameters were made using the standard water quality testing procedure, while the laboratory analyses for water samples were conducted based on the standard method of wastewater analysis procedure (APHA 1998).
The data were summarized and the water quality index WQI for each station was calculated and presented in Table 1. The local WQI mainly used in Malaysia was emanated from an opinion polling formula of a panel of experts consulted on the choice of parameters and the weighting of each parameter (Gazzaz et al. 2012). The six parameters chosen for the WQI are DO, COD, BOD, SS, pH, and NH3-N. The calculations are done on the sub-indices rather than the parameters themselves. From the computed WQI, a river can be categorized into a number of classes, each indicating the valuable uses to which that river can be used. This classification is based on allowable limits of designated pollution parameters. For this reason, the DOE has defined the values of the water quality variables (WQVs) and WQI indicators that determine each water quality class (DOE 2007). Details on the WQI calculation procedures are provided in the supplementary materials of this study. In addition, Microsoft Excel, ArcGIS 10.3, and SPSS software were used for WQI computing, cluster and time series analyses, and geo-statistical analysis and Kendall’s W procedure, respectively. In this study, a log transformation and first or second order trend removal were applied to the variables that exhibited no normal distribution and/or significant trends.
Cluster analysis
Cluster analysis (CA) is a method of multivariate grouping that involves the use of analysis of variance to measure the distance between the observation clusters to reduce the sum of squares of every two clusters that is shaped at each step (Wang et al. 2014). Water quality variables with similar characteristics are grouped together. Ward’s method is widely used for CA. The Ward minimum criterion of variance reduces the total variance within a cluster. To apply this method, at each step, look for a pair of cluster which causes an increase in the total variance in the cluster after the merge (de Amorim 2015). This increase is the weighted squared distance separating cluster centers. In the early phase, all clusters comprise a distinct point. To implement an iterative algorithm under this target function, the primary distance between objects must be relative to Euclidean squared distance (de Amorim 2015). In this study, hierarchical agglomerative cluster analysis (HACA) was achieved with Euclidean distances to examine the similarity among the stations and Ward’s method for linking the clusters to one another (Al-Mutairi et al. 2015).
Geostatistical analysis
Kriging is a geostatistical estimation method that estimates unknown values using measured values at sampled points and calculates estimation errors as estimation variances. The ordinary kriging used in this study is the simplest type of kriging expressed as follows (Karamouz et al. 2005):
in which, \( {Z}_v^{\ast } \) is the kriging estimation at prediction location, λi is the unknown weight for measured value at ith location, \( {Z}_{v_i} \)is the quantity or measured value at ith location, and n is the number of measured values (or samples).
Analysis of variogram is the first step in Kriging analysis, therefore the empirical variance or semi-variance demonstrates the extent of dependence of the samples and the value of the semivariance of a group of points is dependently influenced by the distance that separates them (Karamouz et al. 2005). The following equation is commonly used to calculate the semivariogram:
in which, his the value of semivariogram at a distance equal to h, Z(xi)is the variable values at xi point, Z(xi + h)is the variable values at xi + h point, and n is total number of points measured.
To perform the Kriging analysis, the empirical variogram must be replaced by a theoretical variogram model such as the spherical, the Gaussian, the exponential, the power, or the hole effect (Kitanidis and Peter 1997) with minimal possible errors (Table 2). In general, a variogram consists of three main parameters, which are as follows:
- a)
Nugget effect (C0)
- b)
Sill (C)
- c)
Range (R)
An example of empirical and theoretical variograms and the definition of the parameters are shown in Fig. 2 (Karamouz et al. 2005).

A pair of empirical and theoretical variograms
The change in kriging variance (also known as residual) was calculated from the equation below (Ou et al. 2012):
Where KVari is the difference, at the location i, between the value of variance before (Var1) and after the removal of station (Var0). A large KVar indicates that the removed station is an important location in the network. On the contrary, a small KVar indicates that there is a significant redundancy between the removed station and its neighborhood (Beveridge et al. 2012). Therefore, a station with a small KVar may not provide additional information within the context of the existing network (Ou et al. 2012).
Kendall’s W
Proposed by Kendall & Smith (1939), the Kendall’s W (also called Kendall’s coefficient of concordance) is a non-parametric technique that measures the agreement between several variables which are evaluating a set of n objects being observed. Kendall’s coefficient of concordance can be calculated from the equations below (Legendre 2005), assuming that station i has given the ri, j by parameter number j, where there are in total n stations and m parameters. The total rank that is given to station is: \( {R}_i=\sum \limits_{j=1}^m\ {r}_{i,j} \);The total of ranks mean value is: \( {R}_i=\frac{1}{n}\sum \limits_{j=1}^m\ {R}_i \);S is the sum of squared deviation defined as: \( S=\sum \limits_{j=1}^n{\left({R}_i-\overline{R}\right)}^2 \); andKendall’s W is then determined as: \( W=\frac{12S}{m^2\left({n}^3-n\right)} \).
Results and discussion
Cluster analysis
Water quality variables and monitoring stations were analyzed using a multivariate statistical technique to determine their temporal trends. Cluster analysis yielded a dendrogram (Fig. 3a) in which the nine DOE sampling stations were grouped into three major clusters. The first cluster consisted of six stations, 1SR03, 1SR06, 1SR07, 1SR08, 1SR04, and 1SR05. These monitoring stations are located downstream of the watershed and are classified in class II by the Malaysian water quality index (WQI), which means that their status in terms of water quality is generally good (Table 1). However, the second cluster concerned only one 1SR01 station located in the upstream part of the river with a moderate water quality class. The third cluster consisted of two stations, 1SR09 and 1SR10. These stations are in the midstream of the river system and 1SR09 has the same water quality status (moderate) with 1SR01 (Table 1).

Dendrogram views of cluster analysis for DOE (a) and LUAS (b) monitoring stations
Figure 3b shows the result of cluster analysis of the data collected in the fieldwork network at the sampling sites proposed by LUAS. As indicated in the dendrogram, the 12 sampling stations were classified into three clusters. The first cluster includes the LUAS9, LUALUAS3, LUALUAS1, LUALUAS2, LUAS5, LUAS7, LUAS6, and LUAS8 located upstream of the watershed. Therefore, all stations in this group are either in good water quality (class II) or in very good water quality (class I), as shown in Table 1. However, the second group comprises two sampling sites, LUAS1 and LUAS2, located downstream, these stations are in good water quality as well. And the third group also contains two sites, LUAS3 and LUAS4, located in the midstream of the river with good and moderate water quality levels, respectively. These clustering results are supportive to the finding of Othman et al. (2018) in clustering the sampling stations for risk assessment and identification of heavy metals sources in Selangor River. However, this study does not support the results of the study conducted by Al-Mutairi (2015) in the Kuwait Bay. In general, the results of this study showed that the monitoring sites were insignificantly polluted and could be utilized as a source of usable water. This is consistent with the findings of Santhi & Mustafa (2013) on assessing the impact of fertilizers to the Selangor River basin.
Time series analysis
The results of the time series analysis of water quality parameters for each cluster over a 10-year period are presented in Fig. 4. Based on DO results, no significant trend is observed in clusters 2 and 3, which indicate that the stations at these sites recorded the lowest values of DO (mg/L) from 2006 to 2010. Unlike cluster 1, the stations in clusters 2 and 3 are below the annual mean level. For BOD, cluster 2 showed a significant upward trend, followed by cluster 3: these two clusters contain monitoring sites that recorded BOD values above the mean annual level during this monitoring period. As BOD, for COD, the cluster 2 equally showed a significant change in trend during this monitoring period, then comes cluster 3, which is also relatively above the annual mean level. The same remark can be made for SS where cluster 2 indicated the changing trend while clusters 3 and 1 showed no significant change. Unlike the preceding parameters, the results of the pH analysis showed that clusters 2 and 3 were below the annual mean level. These clusters include the stations that recorded a pH value lower than that of cluster 1. In the case of NH3-N, the stations in cluster 3 recorded relatively high values of NH3-N over the monitoring years. This is followed by cluster 2, and only cluster 1 is below the annual mean level. For temperature (°C), the evolution of the trend among clusters is relatively insignificant, with clusters 2 and 3 being above the annual mean level. Moreover, for DO, the trend change between clusters is relatively low as compared with BOD, COD, and SS, where the peak concentrations are observed in cluster 2 in the years 2014 and 2011. In addition, the annual average water quality showed a decreasing trend for most variables throughout this investigation period, with the highest decrease in SS. This could be due to the water quality management efforts of the local authorities that envisaged to effectively handle the pollution sources of the river (Kusin et al. 2016).

Annual series of water quality parameters in the station clusters during 10 years
However, from 2014, the annual mean of water quality trend showed an upward shift for BOD, pH, NH3-N, and Temp., which interpellates the local water authority to take more measures to ensure future supply of clean water from the basin. Many factors may contribute to the increasing trend in the Selangor River as the river receives pollutant loads from poultry farms, municipal wastewaters, and industrial wastewaters (Fulazzaky et al. 2010). Agricultural fertilizers from farms in the area and effluents from treatment plants probably also contribute to the deterioration of water quality of the Selangor River (Santhi & Mustafa 2013; Camara et al. 2019) and urban runoff that flow into the river, resulting in wide variations in the water quality. Strict monitoring of industrial discharges and sewages in the river should be done to control untreated discharges, as the sources are located in different states. This requires efforts to address both the sources of pollution and the pollution processes (Camara et al. 2019).
Kriging analysis
In order to assess the performance of the stations in the networks, a kriging analysis was carried out. The six water quality parameters, COD, DO, NH3-N, SS, BOD, pH, and the WQI were used as variables to interpolate. Table 3 shows the results of Kriging variance (KVar) for each station for all the variables, which were achieved by the cross-validation (known as leaving-one-out) procedures. The ranges of KVar of the parameters were relatively different from one another. A low KVar indicates that the particular station does not provide additional information and could possibly be considered redundant. The ranks of the parameters are also presented in Table 3 in ascending order of KVar and most of the ranks of the stations are different among the parameters.
For COD, the KVar range for the stations was from − 3.67 to 6.07 (Table 3). From this result, it can be seen that the KVar of LUAS1, LUAS5, ISR05, LUAS7, and LUAS2 were ranked 21, 20, 19, 18, and 17 respectively. These stations could be considered the five least informative for COD monitoring. On the other hand, ISR06, ISR10, ISR03, ISR01, and ISR08 were ranked 1, 2, 3, 4, and 5 respectively. These stations could therefore be regarded as the five most informative for providing knowledge on the variations of COD within the river (see Fig. 5a). In addition, Table 3 shows that the KVar of DO for the stations ranged from − 1.20 to 0.90. From the table, the KVar of LUAS9, LUAS8, LUAS4, LUAS12, and LUAS6 were ranked 21, 20, 19, 18, and 17 respectively. These stations could be considered the five least informative for DO parameter. However, ISR10, ISR03, ISR04, ISR09, and ISR06 were ranked 1, 2, 3, 4, and 5 respectively. These stations could therefore be considered as the five most informative to provide knowledge of the variation of the DO in the river (see Fig. 5b). However, the KVar of NH3-N for the stations ranged from − 0.18 to 0.41 (Table 3). This indicates that the KVar of LUAS3, LUAS1, LUAS9, ISR07, and LUAS2 were ranked 21, 20, 19, 18, and 17 respectively. These stations could therefore be considered as the five least informative to provide information on the variation of NH3-N in the monitoring network (see Fig. 5c). The five most informative stations for this parameter were ISR09, LUAS4, ISR01, ISR10, and ISR03, ranked 1, 2, 3, 4, and 5 respectively. Moreover, the KVar of SS for the stations ranged from − 40.34 to 59.94 (Table 3) and the KVar of LUAS1, ISR10, LUAS5, LUAS2, and LUAS11 were ranked 21, 20, 19, 18, and 17 respectively. These stations are considered the five least informative for SS monitoring. In contrast, ISR01, ISR09, LUAS4, LUAS3, and ISR03 were ranked 1, 2, 3, 4, and 5 respectively. These stations could be considered as the five most informative to provide knowledge on the variations of SS within the river (see Fig. 5d). For BOD, the KVar range for the stations was from − 0.49 to 2.63 (Table 3). This result indicates that the KVar of LUAS8, LUAS2, LUAS4, LUAS7, and LUAS9 were ranked 21, 20, 19, 18, and 17 respectively. These stations are considered the five least informative for BOD monitoring. On the other hand, ISR01, ISR09, ISR10, ISR03, and ISR04 were ranked 1, 2, 3, 4, and 5 respectively. These stations could be considered as the five most informative for monitoring BOD within the river (see Fig. 5e).


Spatial variation of water quality within the monitoring networks
Table 3 shows that the KVar range of pH for the stations was from − 0.63 to 0.35. From the table, the KVar of LUAS7, LUAS10, LUAS1, LUAS4, and LUAS2 were ranked 21, 20, 19, 18, and 17 respectively. These stations could be considered the five least informative for DO monitoring. However, ISR06, ISR10, ISR04, ISR07, and ISR09 were ranked 1, 2, 3, 4, and 5 respectively. These stations could therefore be considered as the five most informative for monitoring the variation of pH (see Fig. 5f).
In addition, for WQI, the KVar for the stations ranged from − 4.80 to 3.45 (Table 3). This indicates that KVar of LUAS4, ISR09, ISR03, ISR01, and ISR06 were ranked respectively as 21, 20, 19, 18, and 17. These stations are considered as the five least informative for the monitoring of WQI. In contrast, LUAS3, SLUAS7, LUAS11, LUAS5, and LUAS1 were ranked 1, 2, 3, 4, and 5 respectively. These stations could be considered as the five most informative to provide information on WQI variations in the river (see Fig. 5g).
Assessment of agreement between the parameters’ ranking of the stations
In this study, unlike previous studies (e.g., Ou et al. 2012) , the Kendall’s coefficient of concordance was used to measure the agreement among the parameters (raters), namely COD, DO, NH3-N , SS, BOD, pH, and WQI which were used to assess the individual performance of the stations in the monitoring network. Proposed by Kendall & Smith (1939), the Kendall’s W is a non-parametric technique in which the null hypothesis (H0) indicates that the distributions of the stations are identical (raters’ agreement is due to chance). On the other hand, the alternative hypothesis (H1) indicates that the distributions are not identical (raters’ agreement is not due to chance). As such, the null hypothesis (H0) was rejected in this study because the P value is 0.002, which is below the significance level (0.05) (Table 4). This could mean that the parameter’s rating of the stations is not the result of a random assessment. Thus, the ranking order resulting from Kendall’s W is reliable, and it can be seen from the results that ISR10, ISR09, ISR03, ISR06, and ISR04, ranked respectively 1, 2, 3, 4, and 5 are the five most important stations in the network that contribute more to the knowledge of water quality status of the entire river system. These stations are located within the main tributaries of the river in Fig. 6. However, the results indicate that LUAS1, LUAS2, LUAS9, LUAS8, and LUAS4, ranked respectively 21, 20, 19, 18, and 17 are deemed less important and could therefore be considered redundant in the network. The location of these stations is also shown in Fig.6.

Spatial distribution of monitoring stations of Kendall W's rank order
Conclusion
To spatiotemporally assess water quality and water monitoring networks in Selangor River we applied various techniques. First, we used HACA to group stations with similar characteristics in the networks (Fig. 3). The results indicated consistency between the station clusters. For example, in both networks, the first clusters are all located downstream, the second clusters, upstream, and the third, in the middle of the basin. The similar results were obtained by Othman et al. (2018) in clustering the sampling stations for risk assessment and identification of heavy metals sources in Selangor River. Secondly, we observed the temporal variation of each water quality variable in different station clusters using time series analysis (Fig. 4). The overall results showed that trends in water quality parameters vary from one cluster to another depending on the observed variable. Thirdly, to identify the redundant stations in the networks, we used an ordinary kriging analysis. The stations were then ranked according to their performance under each water quality parameter using KVar (Table 3). The results indicated that the ranking of stations differs from one parameter to another. To resolve this ranking disagreement, we used the Kendall’s coefficient of concordance to measure the agreement among the parameters. The result indicated that the ranking of stations under the parameters was not the result of a random assessment (P value = 0.002 < 0.05) (Table 4). Thus, the ranking order resulting from Kendall’s W procedure was reliable (Table 4 and Fig. 6). This study demonstrated that geo-statistical technique coupled with Kendall’s coefficient of concordance can be a reliable method for water resource managers to identify appropriate sampling sites in a river monitoring network. This proposed approach for evaluating the number of sampling stations provides the decision maker with optimal combinations of variables to be used to discontinue a sampling location from a statistical point of view. However, it is necessary to integrate various qualitative and management criteria to decide which stations to abandon and which stations to monitor permanently. Since the assessment of water quality monitoring networks is primarily based on the monitoring objectives, it is recommended that they be reviewed and accurately defined for the Selangor River monitoring system.
References
Al-Mutairi, N., AbaHussain, A., & El-Battay, A. (2015). Spatial assessment of monitoring network in coastal waters: a case study of Kuwait Bay. Environmental Monitoring and Assessment, 187(10), 621. https://doi.org/10.1007/s10661-015-4841-7.
American Public Health Association. (1998). Standard methods for the examination of water and wastewater (20th edition.). American Public Health Association, Washington, DC.
de Amorim, R. C. (2015). Feature rRelevance in Ward’s Hhierarchical Cclustering Uusing the L p nNorm. Journal of Classification, 32(1), 46–62. https://doi.org/10.1007/s00357-015-9167-1.
Beveridge, D., St-Hilaire, A., Ouarda, T. B. M. J., Khalil, B., Conly, F. M., & Ritson-Bennett, E. (2012). A geostatistical approach to optimize water quality monitoring networks in large lakes: Application application to Lake Winnipeg. Journal of Great Lakes Research, 38, 174–182. https://doi.org/10.1016/J.JGLR.2012.01.004.
Camara, M., Jamil, N. R., Abdullah, A., & Bin, F. (2019). Impact of land uses on water quality in Malaysia: a review. Ecological Processes, 8(1), 10. https://doi.org/10.1186/s13717-019-0164-x.
Chapman, D. V., Bradley, C., Gettel, G. M., Hatvani, I. G., Hein, T., & Kovács, J. (2016). Developments in water quality monitoring and management in large river catchments using the Danube River as an example. Environmental Science and Policy, 64, 141–154. https://doi.org/10.1016/j.envsci.2016.06.015.
Chowdhury, S., Othman, F., Jaafar, W. Z. W., Mood, N. C., & Adham, I. (2018). Assessment of pollution and improvement measure of water quality parameters using scenarios modeling for Sungai Selangor Basin. Sains Malaysiana, 47(3), 457–469. https://doi.org/10.17576/jsm-2018-4703-05.
Department of Environment. (2007). Malaysia Environmental Quality Report, 2006 https://environment.com.my/wp-content/uploads/2016/05/River.pdf. .
Earle, R. (2008). Presented at the 10 th IWA International Specialized Conference on diffuse pollution and sustainable basin management. Blacklocke / Desalination, 226, 134–142. https://doi.org/10.1016/j.desal.2007.02.103.
Fulazzaky, M. A., Seong, T. W., & Masirin, M. I. M. (2010). Assessment of water quality status for the Selangor River in Malaysia. Water, Air, and Soil Pollution, 205(1–4), 63–77. https://doi.org/10.1007/s11270-009-0056-2.
Gazzaz, N. M., Yusoff, M. K., Aris, A. Z., Juahir, H., & Ramli, M. F. (2012). Artificial neural network modeling of the water quality index for Kinta River (Malaysia) using water quality variables as predictors. Marine Pollution Bulletin, 64(11), 2409–2420. https://doi.org/10.1016/j.marpolbul.2012.08.005.
International Institute for Sustainable Development. (2015). Water quality monitoring system design. www.iisd.org.
Jimênez, N., Toro, F. M., Vélez, J. I., & Aguirre, N. (2005). A methodology for the design of quasi-optimal monitoring networks for lakes and reservoirs. Journal of Hydroinformatics, 7(2). https://doi.org/10.2166/hydro.2005.0010.
Karamouz, M., Hafez, B., & Kerachian, R. (2005). Water quality monitoring network for river systems: application of ordinary kriging. In Impacts of Global Climate Change (pp. 1–12). Reston, VA: American Society of Civil Engineers. https://doi.org/10.1061/40792(173)91.
Kendall, M. G., & Smith, B. B. (1939). The problem of m rankings. The Annals of Mathematical Statistics, 10(3), 275–287. https://doi.org/10.1214/aoms/1177732186.
Kitanidis, P. K. & Peter K. . (1997). Introduction to geostatistics : applications to hydrogeology. Cambridge University Press. https://search.proquest.com/docview/232632534?pq-origsite = gscholar.
Kusin, F. M., Muhammad, S. N., Zahar, M. S. M., & Madzin, Z. (2016). Integrated river basin management: incorporating the use of abandoned mining pool and implication on water quality status. Desalination and Water Treatment, 57(60), 29126–29136. https://doi.org/10.1080/19443994.2016.1168132.
Legendre, P. (2005). Species associations: the Kendall coefficient of concordance revisited. Journal of Agricultural, Biological, and Environmental Statistics, 10(2), 226–245. https://doi.org/10.1198/108571105X46642.
Othman, F., Chowdhury, M. S., Wan Jaafar, W. Z., Faresh, E. M. M., & Shirazi, S. M. (2018). Assessing risk and sources of heavy metals in a tropical river basin: a case study of the Selangor River, Malaysia. Polish Journal of Environmental Studies, 27(4), 1659–1671. https://doi.org/10.15244/pjoes/76309.
Ou, C., St-Hilaire, A., Ouarda, T. B. M. J., Conly, F. M., Armstrong, N., Khalil, B., & Proulx-McInnis, S. (2012). Coupling geostatistical approaches with PCA and fuzzy optimal model (FOM) for the integrated assessment of sampling locations of water quality monitoring networks (WQMNs). Journal of Environmental Monitoring, 14(12), 3118. https://doi.org/10.1039/c2em30372h.
Santhi, V. A., & Mustafa, A. M. (2013). Assessment of organochlorine pesticides and plasticisers in the Selangor River basin and possible pollution sources. Environmental Monitoring and Assessment, 185(2), 1541–1554. https://doi.org/10.1007/s10661-012-2649-2.
Segura, J. L. A. (2012). Optimisation of monitoring networks for water systems. CRC PRESS Retrieved from https://www.routledge.com/Optimisation-of-Monitoring-Networks-for-Water-Systems-UNESCO-IHE-PhD-Thesis/Segura/p/book/9781138424319.
Wang, Y.-B., Liu, C.-W., Liao, P.-Y., & Lee, J.-J. (2014). Spatial pattern assessment of river water quality: implications of reducing the number of monitoring stations and chemical parameters. Environmental Monitoring and Assessment, 186(3), 1781–1792. https://doi.org/10.1007/s10661-013-3492-9.
Xu, P., Wang, D., Singh, V. P., Wang, Y., Wu, J., Wang, L., Zou, X., Liu, J., Zou, Y., & H. R. (2017). A kriging and entropy-based approach to raingauge network design. Environmental Research, 161, 61–75. https://doi.org/10.1016/J.ENVRES.2017.10.038.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(DOCX 50 kb)
Rights and permissions
About this article

Cite this article
Camara, M., Jamil, N.R., Abdullah, A.F.B. et al. Spatiotemporal assessment of water quality monitoring network in a tropical river. Environ Monit Assess 191, 729 (2019). https://doi.org/10.1007/s10661-019-7906-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-019-7906-1