
Abstract
In the frame of a process aiming at harmonizing National Forest Inventory (NFI) and ICP Forests Level I Forest Condition Monitoring (FCM) in Italy, we investigated (a) the long-term consistency between FCM sample points (a subsample of the first NFI, 1985, NFI_1) and recent forest area estimates (after the second NFI, 2005, NFI_2) and (b) the effect of tree selection method (tree-based or plot-based) on sample composition and defoliation statistics. The two investigations were carried out on 261 and 252 FCM sites, respectively. Results show that some individual forest categories (larch and stone pine, Norway spruce, other coniferous, beech, temperate oaks and cork oak forests) are over-represented and others (hornbeam and hophornbeam, other deciduous broadleaved and holm oak forests) are under-represented in the FCM sample. This is probably due to a change in forest cover, which has increased by 1,559,200 ha from 1985 to 2005. In case of shift from a tree-based to a plot-based selection method, 3,130 (46.7 %) of the original 6,703 sample trees will be abandoned, and 1,473 new trees will be selected. The balance between exclusion of former sample trees and inclusion of new ones will be particularly unfavourable for conifers (with only 16.4 % of excluded trees replaced by new ones) and less for deciduous broadleaves (with 63.5 % of excluded trees replaced). The total number of tree species surveyed will not be impacted, while the number of trees per species will, and the resulting (plot-based) sample composition will have a much larger frequency of deciduous broadleaved trees. The newly selected trees have—in general—smaller diameter at breast height (DBH) and defoliation scores. Given the larger rate of turnover, the deciduous broadleaved part of the sample will be more impacted. Our results suggest that both a revision of FCM network to account for forest area change and a plot-based approach to permit statistical inference and avoid bias in the tree sample composition in terms of DBH (and likely age and structure) are desirable in Italy. As the adoption of a plot-based approach will keep a large share of the trees formerly selected, direct tree-by-tree comparison will remain possible, thus limiting the impact on the time series comparability. In addition, the plot-based design will favour the integration with NFI_2.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Forest resources in European countries are being monitored at the large scale by two main categories of survey, the National Forest Inventories (NFIs) (Tomppo et al. 2010) and the Level I Forest Condition Monitoring (FCM) originally installed under the auspices of the UN-ECE International Co-operative Programme on the Assessment and Monitoring of Air Pollution Effects on Forests (ICP Forests) (Fischer and Lorenz 2011).
NFIs have a long history in providing basic information on forest resources in a given country (e.g. Frayer and Furnival 1999): NFIs based on statistical sampling have been installed in Europe since the 1920s in Nordic countries and now cover all European countries (e.g. Thorell and Ostlin 1931; Tomppo et al. 2010). Traditionally, NFIs were concerned with the estimation of forest areas, growing stock and marketable forest products, and only recently their objectives have been widened to include also non-forest products and attributes related to forest condition, diversity and sustainability and represent a valuable source of environmental data (Gasparini et al. 2009). Because NFIs are typically developed at national level, target populations (e.g. definitions of forest), sampling designs, attributes and mensuration methods may differ considerably among countries (Tomppo et al. 2010). Recently, a process has been promoted by a network of European NFIs (ENFIN, http://enfin.info/) to harmonize NFIs in Europe.
FCM Level I networks were installed in Europe in the 1980s in response to the concern about a possible deterioration of forest health in relation to air pollution (e.g. Lorenz 1995; Innes 1993) and now cover ca. 35 European countries. FCM is mostly concerned with a visual estimate of tree condition, with defoliation being the most important attribute to be assessed (Ferretti 1997). It is worth noting that—unlike NFIs—FCM was installed under an international perspective following harmonized methodologies and supported by international conventions (UN-ECE Convention on Long-Range Transboundary Air Pollution), regulations and funds (e.g. EC Reg. 3528/86). Despite this background, the international Level I network appears as a composite of country-based FCM networks (Cozzi et al. 2002) where differences similar to those reported for NFIs (Tomppo et al 2010) exist.
Due to country-specific approaches in implementing NFIs and FCM, different relations exist between the two systems in the various countries: In some countries, FCM was installed on NFI plots (e.g. Austria, Switzerland); in others (e.g. Spain), the two networks were designed and implemented separately; and in some other countries (e.g. Finland, Italy), although initially on the same network, FCM and NFI were subsequently separated (Chirici et al. 2010).
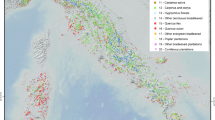
In Italy, the first NFI (hereafter referred to as NFI_1) was carried out in 1985 and was based on a systematic 3 × 3-km grid resulting in approximately 9,000 forest sampling units (Table 1) (MAF-ISAFA 1985). A subsample of these units, selected on a 15 × 18-km grid to obtain a density of 1 U/256 km2 (consistent with the ICP Forests-recommended 16 × 16 km grid), was adopted for FCM (Fig. 1). Since then, annual observations have been conducted on a number of trees selected on these units according to a spiral track (Fig. 2). In 2002, a new NFI (hereafter referred to as NFI_2) was undertaken according to a different definition of forest and a more sophisticated and efficient design (Gasparini et al 2010), with a three-phase sampling based on tessellation stratified sampling (Cordy and Thompson 1995; Stevens 1994; Fattorini et al. 2006). The original NFI_1 network was then abandoned for inventory purposes, while the subsample selected for FCM was kept. The consequence is that nowadays NFI and FCM are on two different networks and address two different target populations. Besides this, FCM and NFI_2 still adopt different methods for tree selection (Table 1). This point does matter: On one side, NFI_2 adopts fixed area plots with a variable number of trees (hereafter referred to as plot-based); on the other side, FCM keeps selecting a fixed number of trees (min. 10, max. 30, Bussotti et al. 1999; hereafter referred to as tree-based) according to a spiral track (Fig. 2) starting from the sampling point, and sample trees are permanently numbered. It is worth noting that such a selection of a fixed number of trees precludes the estimation of population parameters (at least from a design-based perspective), owing to the difficulties in determining the inclusion probabilities of trees (Kleinn and Vilĉko 2006). In this line, the recently revised ICP Forests manual for FCM emphasizes that “it is important that plots are designed on a fixed area basis, a condition necessary for estimation purposes and to allow a better integration with NFIs” (Ferretti et al. 2010). The plot-based approach has been recently suggested as a unifying framework for FCM in Europe (Travaglini et al. 2012).

Distribution of FCM Level I sampling points

Impact of the sample trees selection method. a Tree-based selection: Sample trees (DBH ≥ 12 cm, dominant or co-dominant) are selected moving clockwise on a spiral track. b Plot-based selection: Sample trees (dominant or co-dominant) are selected within circular sample plots (r = 12 m for tress with DBH ≥ 10 cm and r = 18 m for trees with DBH ≥ 40 cm). The two samples shares six trees (n. 1, 2, 3, 4, 6 and 7). Moving from tree-based to plot-based selection, four trees are excluded (tree n. 5 DBH < 40 cm; trees 8, 9 and 10 too far from the plot centre); two trees are included (entrances) (trees A and B fulfil the dimensional and dominance requirements but are not along the spiral)
The disadvantages of having two different monitoring systems are obvious: Costs, possible inconsistency of information and—in case of separation of NFI and FCM—potential loss of representativeness in relation to change in the target population. This latter problem may occur also because—as customary in Europe—FCM plots were installed only on forested land and therefore cannot reflect the conversion of non-forest land to forest uses. As similar situations of separated networks are frequent in Europe (Chirici et al. 2010), there is a generalized interest to develop concepts and methods to favour some form of harmonization or integration between NFIs and FCM (e.g. Wulff et al. 2011). According to Ferretti (2010), possible perspectives towards the harmonization/integration between NFIs and FCM include (a) simple harmonization of mensurational methods, leading to comparable datasets (common attributes and measurement protocols); (b) functional integration, i.e. as (a) plus the adoption of the NFI plot design on FCM, thus favouring estimation process; and (c) full integration, e.g. the complete shift of one network to the other. In all cases, an important issue to be considered is the “integrity of long-term datasets when adjusting a pre-existing monitoring program”, and any harmonization/integration process should consider not to waste existing data series (Lindenmayer et al. 2011). This is particularly relevant for the case in hand, as defoliation data (at country and European level) often spans a 20-year period.
With this background, a harmonization/integration process was started in Italy in 2009, and a step-wise test phase was launched in the frame of the Life+ FutMon project (www.futmon.org). This test phase consists—among other—of several FCM and NFI_2 measurements to be carried out on both networks, FCM and (on a subsample of) NFI_2 (Table 2). This paper concentrates on the results obtained after the first steps of the test phase and focuses on two questions, which are of relevance for the future forest monitoring in Italy. Firstly, we evaluate at what extent FCM sampling points selected in 1985 are still consistent with the composition of today’s Italian forests. It is worth noting that the original definition of the target statistical populations is different between the two NFIs. In addition, the FCM sample was selected after NFI_1 in 1985, thus reflecting the structure, composition and distribution of forests at that time. Further, due to the fact that the locations of the FCM plots were obvious due to the trees having been clearly labelled in the field, the execution of management practices may have been impacted on those plots. Secondly, we evaluate the effect of different tree selection criteria (tree-based and plot-based) on sample DBH, dimension and defoliation statistics.
Methods
Tree sample selection and data collection
The Italian FCM is based on the NFI_1 and represents the ICP Forests large-scale network in Italy. It consists of 261 sampling points systematically distributed on forest area according to a 15 × 18-km grid (Fig. 1). At each point, the sample trees were selected moving clockwise on a spiral track (Fig. 2a). Only co-dominant to dominant trees with diameter at breast height (DBH) >12 cm were eligible as sample trees. According to the former ICP Forests Manual (UN-ECE 1998), a minimum of ten trees per sampling point was mandatory. Dead and removed trees are replaced by new sample trees, selected according to the same procedure as above.
The original NFI_2 plot design consists of two circular, concentric plots, with radius 4 and 13 m. The 4-m radius plot is used for measuring trees with DBH < 10 cm, and so it is not relevant for crown condition survey. For the purposes of this test phase, the NFI_2 plot design was slightly modified and since 2010 adopted also on the FCM sampling points. Sample trees were selected within two concentric circular plots, a 13-m radius plot for trees with DBH ≥ 10 cm, like in the NFI_2, and a 18-m radius plot for trees with DBH larger than 39 cm (Fig. 2b). The minimum DBH for crown condition sample trees was moved from 12 to 10 cm, to be consistent with the DBH threshold used in the NFI_2.
In 2010, the tree condition assessment on the FCM network was therefore carried out on two partly overlapping samples of trees: the original tree-based sample and the plot-based sample. Since the centre of the newly established plots corresponds with the starting point of the tree-based selection, the sample trees may be classified into three sets: one common between the two selection procedures (tree-based and plot-based), one exclusive of the tree-based sample (which will be abandoned in case of shift to the plot-based selection procedure) and one exclusive of the plot-based sample (which would enter the sample in case of shift to the plot-based selection procedure).
All 261 FCM Level I plots were classified according to the forest type classification adopted by the NFI_2 (INFC 2003), while measurements were carried out on 252 of them because nine plots were not reachable for different practical reasons. On the 252 plots, all sample trees were callipered and FCM attributes assessed according to Bussotti et al. (1999). Tree height was measured on a sub-sample of the trees within the plot following the NFI_2 protocol (INFC 2006).
Quality assurance
A total of 60 field crews coming from all across Italy were involved in the field survey, and—at each plot—the same crew performed both the tree-based and the plot-based measurements and assessment. Standard Quality Assurance procedures were adopted (e.g. Ferretti et al. 1999). Field crews were subject to training according to the procedure described by Bussotti et al. (2009) and Gasparini et al. (2009). After theoretical lessons and guided exercises, field crews were asked to score independently various sets of trees of the most frequent species as reported in the FCM Level I database: Norway spruce (Picea abies Karst.), Scots pine (Pinus sylvestris L.), beech (Fagus sylvatica L.), Turkey oak (Quercus cerris L.) and European chestnut (Castanea sativa Mill.). A total of 102 trees were assessed. Results show a general good agreement between the reference team and the field crews, although large differences may occur for certain crews at the level of individual trees.
Data processing and analysis
Sample statistics were calculated for the tree-based and the plot-based samples and for the trees exclusive of tree- and plot-based samples. As far as the sample composition and characteristics, total number of trees per species, mean number of trees per species and sampling plot/point, mean DBH per species and number of sampling plots/points where the species was present were calculated. As far as defoliation was concerned, frequency of trees per defoliation class was calculated. We considered 5 % defoliation classes as well as the traditional uneven defoliation classes used in national/international reporting (Fischer and Lorenz 2011): class 0 (defoliation 0–10 %), 1 (>10–25 %), 2 (>25–60 %), 3 (>60–99 %) and 4 (100 %, dead trees). Consistency of the FCM network in relation to the forest area estimated by NFI_2 was tested by the chi-square goodness of fit between the frequency of the expected distribution of sampling units per forest category (number of units per forest category proportional to the area of the category itself) and the actual frequency distribution of the 261 FCM sampling points.
We tested a number of null hypothesis. As some common trees exist between the two plot designs, we are in between the assumptions for unpaired and paired tests; for this reason, we used both types of tests but reported only the results of the most conservative one. The equal number of species and trees per sampling unit between the two designs was tested by comparing the median values with the Mann–Whitney U test. The non-parametric test was necessary because both variables do not approximate the normal distribution (Kolmogorov–Smirnov D test for normality, D = 0.18; P < 0.0001 for the number of species and D = 0.215; P < 0.0001, for the number of trees in the tree-based sample) and transformation did not succeed in normalizing distributions. The mean DBHs obtained from the two designs were compared both by the unpaired samples t test and the Student's paired t test on data transformed for normalizing their distribution. Distributions of trees into defoliation classes were compared by the chi-square goodness of fit test. Lastly, the relation between crown defoliation percentage and DBH was investigated.
Results
Question 1: consistency of FCM network in relation to NFI_2 forest areas estimates
Table 3 reports the number of FCM sampling points by forest category, groups of categories and elevation class. Deciduous broadleaved forests are the largest group, especially below 1,000 m a.s.l., with beech, temperate and Mediterranean oaks forests being the most frequent categories. Coniferous forests are the largest group at high elevation (>1,500 m a.s.l.), with Norway spruce forests being the most frequent. Evergreen broadleaved forests are much less frequent, with cork oak forests being the most common.
Figure 3 reports the proportion of FCM sampling points (sub-sample of NFI_1 in 1985) together with the percent area of the forest categories as estimated by NFI_2 in 2005. Despite an apparent general consistency between the pattern of number of FCM sampling units and NFI_2 area estimates, the chi-square test showed that significant differences exist between the two distribution (chi-square = 52.8, P < 0.001, df 16). From Fig. 3, this seems particularly due to some individual categories, with larch and stone pine, Norway spruce, other coniferous, beech, temperate oaks and cork oak proportionally over-represented and hornbeam and hophornbeam, other deciduous broadleaved and holm oak proportionally under-represented.

Frequency (in percent) of FCM Level I sampling units per NFI forest category (light grey) and percentage of forest area by NFI forest category as estimated by NFI_2 (dark grey). Forest categories are listed in Table 1
Question 2: comparison of tree-based and plot-based selection methods
Sample size at network and plot level
Table 4 reports the number of species, the number of trees and the mean DBH for both the samples originated by the tree-based and the plot-based selection method. The total number of trees is smaller (−24.7 %) for the latter selection method, and this is mainly due to the reduction of the number of trees per sampling units (Table 4). The statistical test showed that the medians of the number of trees per sampling unit (28 and 19, respectively) differ significantly (Mann–Whitney U test = 48,193; P < 0.0001). A further consequence of the plot-based selection is a larger variability of the number of trees per plot, as indicated by the greater value of the standard deviation (from 6.09 to 10.80).
Species composition and distribution
The total number of species surveyed (63) is not affected by the tree selection method (Table 4), and the median of the number of species per sampling unit does not differ significantly between the tree-based and the plot-based samples (medians = 2 and 3, respectively—Mann–Whitney U = 31,147; P > 0.05). Table 5 provides sample statistics for individual tree species. All species with fewer than ten trees in the tree-based sample were grouped in the categories of “broadleaved-10” (evergreen and deciduous species undistinguished) or “conifer-10”, thus shortening the original list of species from 63 to 38. In Table 5, species are listed in decreasing order of total number of trees observed according to the tree-based sample. The rank of the species is rarely the same in the two samples, but differences are generally of minor importance, especially for the most frequent species. For example, the 15 most frequent species (accounting for 87.0 and 87.8 % of the trees in tree-based and plot-based sample, respectively) are the same in both samples. Moving from the tree-based to the plot-based sample, the number of trees by species decreases, exception being Ostrya carpinifolia Scop., broadleaved-10, Fraxinus ornus L., Pinus strobus L., conifers-10 and Acer platanoides L.. The increase is particularly relevant for Ostrya and Fraxinus (plus 25.4 and 38.2 %, respectively).
The reduction of the total number of trees per species when moving from the tree- to the plot-based sampling is generalized and caused by two main factors: the reduction of the number of trees per plot and the reduction of the number of plots where a given species is observed (Fig. 4). The two factors are probably related to a likely reduction of the area explored by the plot-based method. For some species (C. sativa Mill, P. sylvestris L., Larix decidua Mill., Quercus pubescens Willd.), both the reductions are considerable. For some others (F. sylvatica L., Q. cerris L.), the reduction of the number of plots is more important, with almost no change in the number of trees per plot. For other species (Pinus nigra Arn., Pinus cembra L., Pinus pinea L., P. abies Karst., Cupressus sempervirens L., Alnus cordata Loisel., Alnus incana Moench.), the opposite is true.

Differences in the number of plots (x-axis) and the number of trees per plot (y-axis) when moving from the tree-based to the plot-based sample. Data points belonging to important species showing considerable differences are identified
Some species show a reduction of the mean number of trees per plot, but an increase in the number of plots where they were found. This is particularly relevant for Norway spruce that loses 330 trees in total (i.e. seven trees per plot, on average), but was found on two new plots. Only a few species show both an increase of tree number per plot and of number of plots on which they were found; however, also a large increase of the number of plots does not lead to a relevant increase of trees (e.g. “broadleaved-10” with +19 plots and +0.1 trees per plot).
The bottom part of Table 5 summarizes the changes occurred for the three groups of species. The reduction of the total number of trees is evident and particularly large, especially for conifers. However, it is due only to the reduction of the number of trees per plot, since the number of plots on which the species groups were found does not change noticeably.
Table 6 reports the same statistics as in Table 5 for the trees that would “leave” and “enter” the sample in case of a shift from a tree-based to a plot-based selection method. Among the most important species, conifers (namely larch, Norway spruce, black pine, Silver fir, Scot pine) are the most impacted, with a replacement rate between 11 and 21 % with respect to their tree-based sample. Conifers would be therefore comparatively lost at greater rate per plot and on more plots than broadleaves.
All in all, moving from the tree-based to the plot-based approach would result in a shift in the composition of the tree sample. This is especially true for conifer trees, whose number is reduced to 58 % with respect to the original tree-based sample. Differences are less pronounced for deciduous (83 %) and evergreen broadleaved trees (74 %). Consequently, the tree sample would shift towards an even more deciduous broadleaved–dominated sample.
DBH
The average DBH of the sample trees (Table 4) is slightly, but significantly smaller in the plot-based sample than in the tree-based one (t = 2.0; P < 0.05). The plot-based sample shows also a larger variability of DBH (wider range and standard deviation slightly greater). When considering the data at the level of individual species and groups (Table 5), this pattern appears very common, especially within deciduous and evergreen broadleaves (Table 5, bottom part). The mean DBH is smaller in plot-based sample in 76 % of cases, although the difference is slight, 1.6 cm in average (min −7.5 cm, Prunus avium L.; max +4.7 cm, Alnus glutinosa Gaertner.). The DBH of conifers seems less influenced by the tree selection method.
Table 6 explains the reason behind this slight, general decrease of mean DBHs. The mean DBH of those trees that leave the sample when the plot-based approach is adopted is much larger in comparison to the mean DBH of the trees that enter. For example, 1,930 broadleaved trees with an average DBH of 25.2 ± 9.27 cm are replaced by 1,225 new trees with DBH 15.8 ± 6.23 cm. Note that this is similar between species and groups of species (bottom part of Table 6). However, the effect is compensated/exacerbated by the number of trees that leave/enter the sample, which varies with the species. Note that this balance is particularly unfavourable for conifers that lose 1,022 trees with mean DBH = 37.8 cm and get only 168 trees with mean DBH = 28.9, so the compensation effect of these entries is limited. The selection of smaller trees is partly due to the smaller DBH threshold adopted, but also—and perhaps at larger extent—to the inclusion of young trees that were not selected when the FCM network was installed in 1985. In the end, the plot-based approach leads to a sample with slightly but significantly smaller DBH and probably younger trees than the tree-based one.
Defoliation
Cumulative frequencies for 5 % defoliation classes are shown in Fig. 5 for the main groups of species and in total. Distribution for conifers and evergreen broadleaves is nearly identical between the tree-based and plot-based samples. Differences occur in deciduous broadleaves, for which the frequency distribution suggests greater defoliation for the tree-based sample.

Cumulative frequency (in percent) of trees by defoliation class in 2010 according to the tree-based (left) and the plot-based (right) selection method for the main groups of species and total
Table 7 reports the sample statistics in terms of frequency of trees by the traditional uneven defoliation categories adopted in the forest condition reporting (e.g. Fischer and Lorenz 2011) and for the main groups of species. Although the distribution of trees in the defoliation categories is quite similar between the two samples (tree-based and plot-based) in conifers (chi-square = 4.3; P > 0.05) and evergreen broadleaves (chi-square = 2.3; P > 0.05), significant differences occur for deciduous broadleaves (chi-square = 105.4; P < 0.0001). The overall (all species) distributions of trees by defoliation category showed significant differences between the two samples (chi-square = 39.5; P < 0.0001), with larger differences for the classes 0–10 % and >25–60 %.
Figure 6 reports the median defoliation of the trees exclusive of tree-based (x-axis) and plot-based (y-axis) samples for all species and for the most important ones. In general, this figure suggests that, while conifers and evergreen broadleaves are randomly distributed around the bisector, the deciduous broadleaves exclusive of the tree-based sample are more defoliated than those exclusive of the plot-based sample. For example, from our database, it emerged that moderately defoliated deciduous broadleaved trees are replaced by less defoliated (−5.6 % on average) trees. When considering the median defoliation of the ten most important species, the 1,532 trees of five deciduous broadleaved species are replaced by 946 slightly less (5 %) defoliated trees; the 832 trees of the four conifer species are replaced by much less trees (116), which are equally or slightly more defoliated. The only exception is black pine, which shows a distinct increase in defoliation. The 107 Quercus ilex L. trees are replaced by 70 equally defoliated trees.

Median defoliation per species, considering for each species the trees exclusive of the plot-based sample plotted against those exclusive of the tree-based sample. Left all species; right most frequent species; the dotted line is the 1:1 line
The reason why newly selected trees are—in general—slightly less defoliated that the former ones is not clear. A possible explanatory hypothesis might consider the potential smaller defoliation of smaller/younger trees when compared to bigger/older ones, at least in broadleaves. Figure 7 reports the relation between DBH and defoliation for the main groups of species and for the main species of each group. There is clearly a weak relation, and no clear pattern can be detected. If any, an opposite pattern seems true: Conifers show greater defoliation values for trees with DBH < 40 cm; deciduous broadleaves have greater defoliation for DBH < 30 cm; evergreen broadleaves have greater defoliation values for DBH < 20 cm.

Plot-based sample trees: defoliation of individual trees plotted against DBH for the three groups of species (left) and for the correspondent most important species (right)
Discussion
The comparison between the distribution of FCM sampling points by forest categories and the (NFI_2) forest area distribution shows an overall significant difference. This is probably due to the reported changes in the forest cover in Italy, which amounts to 1,559,200 ha over the period between the two NFIs (Mariano et al 2010), and to the different sampling schemes.
When moving from the tree-based to the plot-based sample, the Level I FCM network in Italy is going to be constituted of fewer trees (n = 5,045 vs. 6,702), with a significant decrease of the mean number of trees per sampling unit. This is the result of both the abandonment of 3,130 former trees (46.7 % of the tree-based sample) and the inclusion of 1,473 new trees (29.2 % of the new, plot-based sample). In other words, approximately 50 % of the original sample would be abandoned in case of shift from the tree-based to the plot-based selection method. Despite this, the number of species is not affected by the tree selection method, neither at network nor at plot level. On the other hand, the abundance of trees per species is impacted, and the combination of the two processes (exclusion and inclusion) results in a new sample composition with a larger proportion of deciduous broadleaves. The main tree species, however, hold their rank in terms of abundance, and differences concentrated on infrequent species that on the whole make about 13 % of the entire sample of trees.
The reduction of the number of trees is clearly due to the fact that the former ICP Forests Manual requirement of having a minimum number of trees per plot is no longer applicable under a plot-based sampling perspective. In addition, as no clear indication was formerly provided in terms of maximum distance between the sampling point and the farthermost sample tree, the area explored for tree selection according to the tree-based approach can be much wider than that of the plot-based one. This is probably the reason for the reduction of the number of plots where a given species is encountered when moving from the tree-based to the plot-based method.
The impact of the plot-based tree selection method on the DBH of the resulting new sample is slight, but significant on the average, and much more pronounced on deciduous broadleaves. This is mostly due to smaller DBH threshold adopted and to the replacement rates, high in deciduous broadleaves, low in conifers.
Overall defoliation (all species, all trees) statistics are slightly, but significantly impacted by the tree selection method. When considering 5 % defoliation classes for the main groups of species, plot-based sampling showed almost no changes for conifers and evergreen broadleaves and a slight decrease for deciduous broadleaves. This seems again due to the substantial replacement of the former deciduous broadleaved trees with less defoliated ones. These changes seem, however, larger for species with low number of trees (e.g. other broadleaves) rather than for the most important species, with few exceptions (e.g. black pine).
Differences in defoliation statistics are significant when considering uneven defoliation categories traditionally used for forest health reports and especially when considering broadleaves for the 0–10 and >25–60 % defoliation classes. It is not clear, however, whether this is an effect of the inherent limitation of these classes (e.g. Bussotti et al. 2003).
The reason why the newly selected trees are less defoliated than the former ones is not obvious. An age effect on defoliation was often reported, and it is often argued that observing year after year, the same trees risk monitoring just the age effect on defoliation (e.g. Strand 1995). Assuming DBH as a proxy for age, however, no clear pattern was detected within our datasets.
In summary, differences in defoliation statistics may be expected at individual species level and especially for the species with low number of trees. Difference seems less important for conifers and evergreen broadleaves, while they are significant for deciduous broadleaves and for the entire sample of trees.
Conclusions
Based on concerns about the actual representativeness and ability of FCM networks to provide reliable statistics on forest condition, the recently revised ICP Forests manual suggests that steps should be undertaken to favour integration between Level I and NFIs. In this line, a change of tree selection criteria at the sampling points from the former tree-based (with a minimum number of trees required) to a plot-based was suggested (Ferretti et al. 2010; Travaglini et al. 2012). However, questions arise about the impact of such changes on the comparability and time consistency of forest condition statistics. A comprehensive test phase has been therefore undertaken in Italy, to test the current consistency of the FCM Level I network (installed in 1985) in relation to the forest area distribution by forest category and to compare the results obtained from tree-based and plot-based selection methods.
Our results confirm that, although considerable care is necessary to not disrupt data series, harmonization/integration between FCM and NFI is desirable and feasible. Changes in forest cover occurred in Italy over 20 years seem to be the cause for the inconsistency between the distribution of Level I plots and the extent of some forest categories estimated by NFI_2. In addition, since changes may concern specific forest categories (e.g. reforestation of abandoned agricultural areas by new, young forests), there is a risk that the sample will be biased also in terms of age, DBH and structure (e.g. Brassel and Brändli 1999). These concerns have been substantiated in the present investigation. With the tree-based selection method, the monitoring might observe a sample that deviates more and more from the real age structure of the country’s forest (e.g. Ferretti et al. 2001). Lastly, the tree-based selection method does not allow a probabilistic approach to statistical inference. These factors thus result in a progressive loss of representativeness of the Level I network which is also unfit for quantitative estimates of population parameters. For these reasons, further steps have been already undertaken in Italy, with a parallel FCM carried out on a subsample of NFI_2 plots. This will provide data to compare and integrate statistics and estimates originating from the current Level I and NFI_2 networks.
The feasibility of the harmonization/integration process in terms of adoption of similar methods, crews and plot design was also demonstrated. When moving from the tree-based to the plot-based design, we reported significant changes in the size and composition of the sample, a slighter, still significant change in its dimensional characteristics and significant changes in the frequency distribution within the defoliation classes. This is an important issue to be considered. At species level, defoliation of the main species seem—in general—not impacted, and the significant decrease in defoliation recorded for the deciduous broadleaved after the plot-based sampling is due at a large extent to less frequent species. However, the overall results support the idea that country-scale time series of defoliation statistics can be impacted when the tree-based selection method is replaced by the plot-based one. In this respect, a solution exists because a tree-by-tree direct comparison based on the share of former sample trees that will remain in the plot-based design (in Italy 3,572 individuals, ca. 50 % of the original tree-based sample in 2010) will permit to keep a consistent data series. It is worth noting, however, that, unlike the tree-based sample, the plot-based sample would allow not only sample statistics but also quantitative estimates of defoliation parameters and change estimation.
References
Brassel, P., & Brändli, U.-B. (Eds.). (1999). Schweizerisches Landesforstinventar. Ergebnisse der Zweitaufnahme 1993–1995 (p. 442). Birmensdorf: Eidg. Forschungsanstalt für Wald, Schnee und Landschaft. Bern, Bundesamt für Umwelt, Wald und Landschaft.
Bussotti, F., Gerosa, G., Cenni, E., Cozzi, A., Ferretti, M., Bettini, D., et al. (2003). Crown condition surveys in Italian forests: issues in reporting findings. Environmental Monitoring and Assessment, 85, 221–238.
Bussotti, F., Ferretti, M., Cozzi, A., & Cenni, E. (1999). Condizione delle chiome degli alberi. Valutazione nelle aree permanenti di livello 2—Manuale di Campagna. Rome: Ministero per le Politiche Agricole.
Bussotti, F., Cozzi, A., Cenni, E., Bettini, D., Sarti, C., & Ferretti, M. (2009). Measurement errors in monitoring tree crown conditions: entity, control, evolution and implications for results. Journal of Environmental Monitoring, 11, 769–773.
Cozzi, A., Ferretti, M., & Lorenz, M. (2002). Quality assurance for crown condition assessment in Europe. Geneva: UN/ECE.
Chirici, G., Corona, P., Ferretti, M., Travaglino, D., Fattorini, L., Barbati, A., & Bottalico, F. (2010). The Futmon large-scale forest monitoring grid. Final report of Action C1-harmonLS of the project FutMon (LIFE07 ENV/D/000218). http://www.futmon.org/futmon-results. Accessed 28 Mar 2012.
Cordy, C. B., & Thompson, C. M. (1995). An application of deterministic variogram to design-based variance estimation. Mathematical Geology, 27, 173–205.
Stevens, D. (1994). Implementation of a national monitoring program’. Journal of Environmental Management, 42, 1–29.
Fattorini, L., Marcheselli, M., & Pisani, C. (2006). A three-phase sampling strategy for large-scale multiresource forest inventories. Journal of Agricultural, Biological, and Environmental Statistics, 11, 296–316.
Ferretti, M. (1997). Forest health assessment and monitoring. Issues for consideration. Environmental Monitoring and Assessment, 48, 45–72.
Ferretti, M., Bussotti, F., Cenni, E., & Cozzi, A. (1999). Implementation of quality assurance procedures in the Italian Programs of Forest Condition Monitoring. Water, Air, and Soil Pollution, 116, 371–376.
Ferretti, M., Cherubini, P., Dobbertin, M., Nimis, P. L., & Parr, T.W. (2001). La questione del campionamento nelle reti di monitoraggio degli effetti dell’inquinamento ambientale e dei cambiamenti climatici sulle risorse naturali in Europa—Tra vecchi problemi e nuove necessità. In ISAFA (Ed.), Comunicazioni di Ricerca 2001/2 (pp. 51–72). Trento.
Ferretti, M. (2010). Harmonizing forest inventories and forest condition monitoring—the rise or the fall of harmonized forest condition monitoring in Europe? iForest. doi:10.3832/ifor0518-003.
Ferretti, M., Fischer, R., Mues, V., Granke, O., & Lorenz, M. (2010). Basic design principles for the ICP Forests Monitoring Networks. In Manual (part II) on methods and criteria for harmonized sampling, assessment, monitoring and analysis of the effects of air pollution on forests. Hamburg: UNECE ICP Forests Programme Co-ordinating Centre. ISBN: 978-3-926301-03-1. http://www.icp-forests.org/Manual.htm. Accessed 28 Mar 2012.
Fischer, R., & Lorenz, M. (Eds.). (2011). Forest condition in Europe, 2011 technical report of ICP forests and FutMon. Work report of the institute for world forestry 2011/1. Hamburg: ICP Forests.
Frayer, W. E., & Furnival, G. M. (1999). Forest survey sampling designs: a history. Journal of Forestry, 97(12), 4–8.
Gasparini, P., Bertani, R., De Natale, F., Di Cosmo, L., & Pompei, E. (2009). Quality control procedures in the Italian national forest inventory. Journal of Environmental Monitoring, 11, 761.
Gasparini, P., Tosi, V., & Di Cosmo, L. (2010). Development of the Italian National Forest Inventory. In E. Tomppo, T. Gschwantner, M. Lawrence, & R. E. McRoberts (Eds.), National forest inventories—pathways for common reporting (pp. 311–331). New York: Springer.
INFC (2003). Guida alla classificazione della vegetazione forestale. Trento: CRA-MPF. http://mpf.entecra.it/?q=it/node/1322. Accessed 28 Mar 2012.
INFC (2006). Procedure di posizionamento e di rilievo degli attributi di terza fase (con istruzioni per l’impiego degli applicativi NAV3 e RAS3). Trento: CRA-MPF. http://mpf.entecra.it/?q=it/node/686. Accessed 28 Mar 2012.
Innes, J. L. (1993). Forest health: Its assessment and status. Wallingford: CAB International.
Kleinn, C., & Vilĉko, F. (2006). Design-unbiased estimation for point-to-tree distance sampling. Canadian Journal of Forest Research, 36, 1407–1414.
Lindenmayer, D. B., Likens, G. E., Haywood, A., & Miezis, L. (2011). Adaptive monitoring in the real world: proof of concept. Trends in Ecology & Evolution, 26(12), 641–646.
Lorenz, M. (1995). International co-operative programme on assessment and monitoring of air pollution effects on forests-ICP Forests. Water, Air, and Soil Pollution, 85, 1221–1226.
MAF-ISAFA (1985). IFN-Inventario Forestale Nazionale. Sintesi metodologica e risultati. Altomonte: Ministero dell’Agricoltura e delle Foreste.
Strand, G.-H. (1995). Estimation of the difference in crown vigour for 2280 coniferous trees in Norway from 1989 to 1994, adjusted for the effects of ageing. Environmental Monitoring and Assessment, 36, 61–74.
Mariano, A., Gasparini, P., De Natale, F., Colletti, L., De Macrì, A., Pompei, E., Romano, R., Sambucini, V., Visentin, R., & Vitullo, M. (2010). Global Forest Resources Assessment 2010. Country report, Italy, FRA2010/202. http://www.fao.org/docrep/013/al537E/al537E.pdf. Accessed 28 Mar 2012.
Tomppo, E., Gschwantner Th., Lawrence, M., & McRoberts, R.E. (Eds.) (2010). National Forest Inventories—pathways for common reporting. New York: Springer.
Thorell, K. E., & Ostlin, E. O. (1931). The national forest survey of Sweden. Journal of Forestry, 4, 585–591.
Travaglini, D., Fattorini, L., Barbati, A., Bottalico, F., Corona, P., Ferretti, M., et al. (2012). Towards a sampling strategy for the assessment of forest condition at European level: combining country estimates. Environmental Monitoring and Assessment. doi:10.1007/s10661-012-2788-5. Online First™, 3 August 2012. With kind permission from Springer Science+Business Media.
UN-ECE. (1998). Manual on methodologies and criteria for harmonized sampling, assessment, monitoring and analysis of the effects on air pollution on forests. Hamburg: Programme Coordinating Centres.
Wulff, S., Lindelöw, Å., Lundin, L., Hansson, P., Axelsson, A. L., Barklund, P., et al. (2011). Adapting forest health assessments to changing perspectives on threats—a case example from Sweden. Environmental Monitoring and Assessment. doi:10.1007/s10661-011-2130-7.
Acknowledgments
The study was funded by the Project “FutMon” (LIFE 07 ENV/D/00218). We thank the personnel of the National Forest Service for the data collection and all the colleagues who helped with the training and the data entry. We are also grateful to the referees, whose suggestions considerably helped to improve the article.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Gasparini, P., Di Cosmo, L., Cenni, E. et al. Towards the harmonization between National Forest Inventory and Forest Condition Monitoring. Consistency of plot allocation and effect of tree selection methods on sample statistics in Italy. Environ Monit Assess 185, 6155–6171 (2013). https://doi.org/10.1007/s10661-012-3014-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10661-012-3014-1