
Abstract
Studies of climate change impacts on agricultural land use generally consider sets of climates combined with fixed socio-economic scenarios, making it impossible to compare the impact of specific factors within these scenario sets. Analysis of the impact of specific scenario factors is extremely difficult due to prohibitively long run-times of the complex models. This study produces and combines metamodels of crop and forest yields and farm profit, derived from previously developed very complex models, to enable prediction of European land use under any set of climate and socio-economic data. Land use is predicted based on the profitability of the alternatives on every soil within every 10’ grid across the EU. A clustering procedure reduces 23,871 grids with 20+ soils per grid to 6,714 clusters of common soil and climate. Combined these reduce runtime 100 thousand-fold. Profit thresholds define land as intensive agriculture (arable or grassland), extensive agriculture or managed forest, or finally unmanaged forest or abandoned land. The demand for food as a function of population, imports, food preferences and bioenergy, is a production constraint, as is irrigation water available. An iteration adjusts prices to meet these constraints. A range of measures are derived at 10’ grid-level such as diversity as well as overall EU production. There are many ways to utilise this ability to do rapid What-If analysis of both impact and adaptations. The paper illustrates using two of the 5 different GCMs (CSMK3, HADGEM with contrasting precipitation and temperature) and two of the 4 different socio-economic scenarios (“We are the world”, “Should I stay or should I go” which have contrasting demands for land), exploring these using two of the 13 scenario parameters (crop breeding for yield and population) . In the first scenario, population can be increased by a large amount showing that food security is far from vulnerable. In the second scenario increasing crop yield shows that it improves the food security problem.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
There are many different scales and approaches to modelling agricultural land use and ecosystems in Europe and the impact of climate change. A global equilibrium model such as CAPRI, (Britz (ed) 2005) divides the whole world into a number of regions and aims to model the progression of cropping and (equilibrium) prices due to trade over time, typically in response to future EU policies. Naturally the agricultural detail in a region, particularly outside Europe, cannot be as great as a regional model such as shown in Holman et al. (2005) which considers all the soils within a 5 km grid. Regional models need an alternative scheme to deal with trade and external prices. Audsley et al. (2006) adopt a compromise and model all the soil association polygons in Europe and use a scenario input parameter to indicate the influence of trade outside Europe. Morris et al. (2005) adopt a similar approach of calculating the land use within the UK given a scenario and demonstrating the contradictions between the consequences for imports and the scenario assumptions. A number of studies use the concept of modifying the gross margins of the crops on the farm to a scenario (Hanley et al. 2012).
It is therefore important to be clear as to the type of questions this study is aimed at addressing. This study aims to examine how non-urban land in Europe will be used over a timescale of 40+ years. Thus land which is not currently used for agriculture may become suitable so the study must consider the underlying property of the land, soil and climate, not its current cropping. In addition socio- and techno-economic changes may mean that more (or less) agricultural land is needed so that land which is currently marginal may be cropped or vice-versa, so the study must consider the profitability of the land. In consequence the objective of the model can be defined as to calculate the profitability of every piece of soil in Europe in any defined future.
Many studies of the impacts of climate change on agricultural land use have considered futures as sets of climates rigidly combined with (usually four!) socio-economic scenarios. (Hossell et al. 1996; Rounsevell et al. 2003; Holman et al. 2005; Rounsevell et al. 2005; Audsley et al. 2006; Lehtonen et al. 2006; van Meijl et al. 2006). However as individual reports it is impossible to compare the impact of specific factors within these scenario sets. Thus whether the effects observed are due to the change in rainfall, temperature, population, oil price, crop breeding or any of the other parameters of the scenario, is a matter of speculation. What-if questions by the reader cannot be answered.
It can also be impossible to carry out many iterations of a complex model as the run-times are prohibitively long. The work of Audsley et al. (2006) is an example of this problem. This analysis considered four socioeconomic-climate scenarios and iterated to a solution where production met the demand in each scenario. This required very long run-times so that any more detailed investigation of the impact of any specific factor was impossible or at best extremely limited.
The problem can be thought of as a balance between precision (number of distinct regions of the study area) and accuracy (detail and time step of the simulation) versus solution time. However in many cases there is very little difference between regions that are analysed, for example neighboring regions with much the same soil type and climate. Similarly a daily time step often considerably overstates the accuracy of the crop yield predictions, which are usually founded on soil moisture. The estimate of the yield in the future climate relative to the current climate is generally more accurate and fulfils a large part of the requirement from the model. Other estimates such as suitability for the crop can be derived from data that is no more detailed than monthly. Thus it ought to be possible to reduce solution time with only a small loss of precision and accuracy.
This study aims to allow rapid solutions and iteration. It takes the results of Audsley et al. (2006) and derives metamodels with very short run-times. Combined with forestry and water availability models, it enables examination of factors within the scenarios, and hence key sensitivities and adaptation strategies. The first section of the paper describes the modelling system, the second the metamodels and finally examples of using the modelling system.
2 Modelling system
2.1 Overview
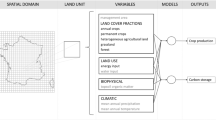
The overall objective is to predict agricultural land use under any scenario set of climate and socio- and techno-economic data. Profitability of each possible land use is modelled for every soil across the EU, the assumption being that in the timescale being considered (2,050), use will change to that which has become the most profitable. Metamodels of crop, forest yields, and optimal cropping and profit are derived from the outputs of the previously developed very complex models (Audsley et al. 2006; Keenan et al. 2011, Wimmer et al. 2014). Land use in a grid is then allocated based on profit, see Fig. 1. If profit is above a threshold it is intensive agriculture (arable or grassland). If profit is above a lower threshold it is extensive agriculture or managed forest and finally it is either unmanaged forest or abandoned land.

Example of soils in a grid being allocated to most profitable use by the models (A-arable, G-grassland, E-extensive, F-forest)
2.2 The complex models
The water and flood models are described elsewhere in (Wimmer et al. 2014, Mokrech et al., Submitted for publication in this special issue), so we concentrate here on the crop, forest and farm models.
The crop model (Audsley et al. 2006) is a daily time step simulation which predicts the average yield over 30 years with a) limited nitrogen and water, b) no limit to nitrogen and c) no limit to water and nitrogen, d) sowing date e) harvest date, if the crop was feasible. Output is available for soils across Europe and a range of future climates. The model simulates winter and spring wheat, barley and oilseed rape, potatoes, maize, sunflower, soya, cotton, grass and olives. Input consists of soil, climate and crop management data.
The forest model GOTILWA + (Growth Of Trees Is Limited by WAter), (Keenan et al. 2008, 2011); http://www.creaf.uab.es/GOTILWA±) is a process-based terrestrial biogeochemical model of forest growth developed to explore how forests are influenced by water stress, tree stand structure, management techniques, soil properties, and climate (including CO2) change. GOTILWA + simulates tree growth, and the associated carbon and water fluxes for different tree species in different environments, thus reflecting a site-species specific ecophysiological suitability. Stands can be even or uneven-aged. No bioclimatic limits are set, and indeed indirect bioclimatic limits can only be considered through the direct effect of climate on the physiological processes of the forest. Five species were simulated over a wide range of climate conditions: Pinus sylvestris, Pinus halepensis, Pinus pinaster, Quercus ilex and Fagus sylvatica with unmanaged forest and with uneven aged and even aged management. These were species which covered the range of climates across Europe.
The land use model (Annetts and Audsley 2002) is a mechanistic farm-based optimising linear programming model of long-term strategic agricultural land use. Crops are defined by their gross margin, the amount and timing of labour and machinery required, restrictions on crop rotations, and their sowing and harvest dates. Gross margins are determined from the yield, which is a function of soil and climate, and where relevant irrigation. Soil workability is also a function of soil and climate. Farmer uncertainty over actual prices and yields is simulated by 10 combinations of yields and prices, from which the average cropping represents the expected land use for this soil and climate. The decision variables are crop areas, crop rotations, operational timing within its feasible period and amount of labour and machinery, which determine the farm profit for the given soil and climate.
2.3 Soil input data
There are 23,871 10’ grids across the EU with 20+ soils per grid with more than 0.1 % (20 ha) in the grid (Panagos et al. 2012) which are reduced to a smaller number of distinct elements using a clustering procedure. The soil data file is derived from an intersection of the European soil database (eusoils.jrc.ec.europa.eu/data.html) with the CLIMSAVE 10’ grid. There are 143,955 soil type-grid combinations, with up to 47 different soil types (officially known as Soil Typological Units) within each grid square, and a total of 5,107 different soil types.
The soil attribute database for each soil type was reduced to those parameters required by the meta-models for crop yield, forestry and land use such as Available Water Capacity (AWC) at four suctions from Saturation to Permanent Wilting Point, stoniness, and soil texture. On this basis many soil types are identical and the total is reduced to 582 distinct soils.
A proportion of each grid can be identified as urban or not possible for agro-forestry using the CORINE database (for example the land use category Bare Rock) (Bossard et al. 2000). These categories were used to eliminate the no soil or very shallow soil types.
Finally a clustering procedure was applied to the soil data to produce 182 similar soil types. This used the Akaike Information Criteria (AIC) optimum for loss of information. However note that it is actually possible to cluster more or less tightly depending on run time desired.
2.4 Climate input data
The climate data per grid (Dubrovsky et al., Submitted for publication in this special issue) consists of the monthly precipitation, temperatures, evapotranspiration, radiation and wind. The data were processed to that required by the metamodels: summer and winter temperature, potential evapotranspiration, precipitation, and days (from 1st January) until average temperature > 0 °C and 6 °C. An analysis of key data split summer into April-June and July–Sept.
The same clustering procedure was applied to the baseline climate data for the 23,871 grid squares, which was assumed uniform over a grid, and produced 170 clusters (Supplement Fig. 4). As with soils it is possible to use more or fewer clusters than the AIC-defined optimum. Analysis of the clusters showed that there was very little loss of precision if the climate change was applied to all grids within a cluster. Thus it is assumed that all climates have the same clustering.
Combining the soil and climate clusters results in 6,714 distinct soil-climate elements to be analysed, representing a 97 % reduction in calculations required.
2.5 Scenario input data
The parameters used to define the socio-economic scenarios are typically expressed as either a percentage change from the current value or a change in the percentage. The linked models use other parameters such as level of flood defenses but those relevant to the land use model are listed in Table 1 with the values defined in two of the scenarios (Kok et al. 2014). They affect either demand for production, land available or level of production.
3 The metamodelling system
3.1 The metamodels
The complex crop model was simulated by a series of neural network models using a subset of the input and output data from the full model from the previous study (Audsley et al. 2006). The sampling of the calibration dataset used to develop the metamodels took into account values outside ± 1 standard deviation from the mean of each parameter (both input and output). From the interval between 1 and 2 standard deviations, two-thirds of the data were used for model calibration and of those data points above/below 3 standard deviations 90 % were used for model calibration. The procedure for the meta-model development first focused on the selection of the most suitable ANN design (e.g. input parameter selection, number of layers and hidden layers). One hundred iterations of the best design were then run and the top five performing artificial neural networks (ANN) were selected to increase robustness of the final estimate. When needed, the ANNs were combined with temperature thresholds to account for limiting factors not well covered by the input parameters. Using these criteria, the number of locations at which the meta-models under/over predicted possible crops decreased by more than 2/3. In order to ensure coherence, the models predicted first the unlimited yield and then the difference due to limitations. Supplement Fig. 5 illustrates the type of outcomes predicted by the model for 4 crops of different types for HadCM3 climate model (Dubrovsky et al., Submitted for publication in this special issue). Spring barley and winter wheat yields show relatively either no change or modest mean yield increases across the EU with both crops becoming suitable in the north of Europe. Yields are mostly affected by increased CO2 levels with relatively small impacts of expected drying in the south and wetter climate in the north. Large areas become suitable for grain maize under the future climate, and also soybean. The yields of grain maize decrease in some parts of southern Europe but increase in higher latitudes and over much of Central Europe. The MPEH5 climate leads to similar results.
In order to train the forest model neural network, around 1,000 cells were selected across Europe to explore the response of GOTILWA. Cells were selected to ensure the representativity of the range of climatic (environmental) conditions and to include the more extreme conditions by selecting the cells with higher and lower values for each input variable (Table 6.1). This selection allows extrapolation to be avoided because the climatic conditions of the predicted period are between the range of the climatic conditions used in the GOTILWA simulations. Simulations were run from 1,950 until 2,100 using climatic data from predictions of the GCM HadCM3 in the A1B emissions scenario. The span of predictions in the CLIMSAVE project is until 2,050. For each cell, simulations were conducted for all five species, all management regimes and with 5 different levels of effective soil volume to produce the key outputs including Carbon, Net Primary Productivity and the yield of timber from managed forests. The neural networks were built and run using the Cascade 2 algorithm from the Fast Artificial Neural Networks library (Nissen 2005). The Cascade2 algorithm starts with an empty neural network and then adds neurons one by one, while it trains the neural network. New neurons are trained separate from the real network, then the most promising of these candidate neurons is inserted into the neural network. Then the output connections are trained and new candidate neurons are prepared. The candidate neurons are created as shortcut connected neurons in a new hidden layer, which means that the final neural network will consist of a number of hidden layers with one shortcut connected neuron in each.
The predictions of the neural network were tested against data from cells not used for training. Although there is inevitable scatter, there is a strong 1:1 relationship (R 2 = 0.918) between the outputs of metaGOTILWA + and GOTILWA+. Supplement Figs. 6 and 7 show typical output from the metamodel.
The approach taken to develop the land use meta-model was to use the full SFARMOD-LP to systematically populate the input parameter space and then to create a meta-model that relates the input parameters to the SFARMOD-LP outputs. In order to fully cover the parameter input space, SFARMOD-LP was run with 20,000 randomly selected sets of input data:
-
gross margins for each crop
-
net precipitation used in the SFARMOD-LP workability formula
-
a summer temperature (which modifies the harvest and sowing dates for each crop)
Output included percentage of the area of each crop, number of dairy cows, fixed costs and profit per hectare. These 44,000 results were then used to create the meta-model. A number of approaches were taken to fit the meta-modelling but the most reliably successful proved to be a regression rather than a neural network approach. The regressions break the model into steps to allow the effect of scenario variables to be included. The steps estimate first the percentage of the area of each crop, then the costs of dairy cows (concentrates) then the fixed costs of labour and machinery and finally the profitability of this element. Regressions were fitted to key combinations of input parameters such as the ratio of gross margins. The regressions predict the nominal percentage of each crop, which are then scaled to 100 %. Regressions then predict the number of dairy cows as a function of the forage areas, yields and summer precipitation, predict the annual labour and machinery costs as a function of soil type and rainfall and finally predict the profit. (Full details of the regressions and goodness of fit are listed in the Electronic Supplement). Supplement Fig. 8 shows typical errors in fitting crop areas.
3.2 Procedure to predict land use
The crop model provides the yield with no irrigation, Y0 and the yield with no water limit, Ym. To determine the optimum level of irrigation, the yield for any level of irrigation is required. Yield due to irrigation I is assumed to follow the curve Y(I) = Y m (1-exp(−k(W + I))) where W is the water naturally available to the crop from soil and climate in this element. Fitted to the full model output, k = 0.0021 for potatoes. Given that Y(0) = Y 0 it is possible to combine this with Y(I) eliminating W, Y(I) = Y m (1-exp(−kI) (1-Y 0 /Y m )). To find the optimum gross margin, irrigation is increased in steps of 100 mm effective irrigation, taking account of the scenario efficiency factor.
The land use model then calculates the profitability (net farm profit before deducting non-operational farm costs such as rent) of each element as intensive arable or intensive grassland whichever is greater. If the profit is greater than €350/ha it is defined as intensive agriculture.
The forest profitability is the annual equivalent profit of a total Net Present Value (NPV), where V is calculated as V/(1−(1 + r)n), n is the life of the forest and r is the discount rate, taken as 3 %. The NPV of a cash flow P after n years is P/(1 + r)n. Prior to the final harvest there are a number of interventions when a proportion of the wood is harvested, the number being a function of the growth rate. The total NPV of the forest is the sum of the NPV of all these harvests and costs. The forest species and management with the highest profit is taken as the species that would be grown currently. If the forest or extensive grassland profit are greater than €150/ha, then the element is allocated to whichever gives greater profit. When calculating the Impact of a future (climate change) scenario, the basic assumption is that the species does not change, because the life of a forest is typically over 100 years. It is thus possible for the forest to become abandoned as unprofitable. An alternative assumption is that adaptation changes the forest to the best species (if any exists).
The remaining elements are unmanaged, and are allocated to unmanaged forest if the Net Primary Productivity (NPP) is positive and greater than the grass yield of extensive grass, else the land use is very extensive grass. Otherwise the elements are classed as abandoned. Note that the areas unsuitable for agriculture (such as bare rock) have previously been eliminated so this last class is often very small.
Finally the elements are allocated back to the 10’ grids to provide the proportion of each grid having each land use, the area of each crop, the average yield of each crop, the amount of irrigation and measures such as diversity. Figures 1 and 2 illustrates the detailed results produced by the modelling for one of the NUTS2 regions of Europe. In addition details of the crops, their yields and nitrate leaching exist at the same scale. The sum of the grids provides the total production of each commodity.

Illustration of detailed results for % land use by 10’ grid for one NUTS 2 region (AT12)
3.3 Calibration
The output from the system was compared with the yields and areas of crops and forest at a NUTS2 level from the Eurostat agricultural database (ec.europa.eu/Eurostat). Tests of the differences between these yields resulted in using a calibration procedure to scale the nutrient unlimited yields to allow for reduced inputs in CEEC countries, to allow for the effect of disease pressure on yields in high rainfall situations and to update the yields to modern levels. These are applied at a NUTS2 level, though as far as possible the factors are kept the same at a NUTS1 level. Note that forests in the data are not differentiated between managed and unmanaged. Not all the data for all the NUTS2 are available, for example Greece. The profit thresholds were also calibrated as 350 and 150. The resulting fit for arable and grassland use versus the NUTS2 level Eurostat data are shown in Supplement Fig. 9. Supplement Fig. 10 shows the map of intensive agriculture land use (arable and grassland) in Europe for the baseline conditions.
3.4 Scenario analysis
The analysis of a scenario proceeds in a number of steps. The first step is to determine the demand for each commodity type. Demand is proportional to population. Reduced ruminant meat preference reduces the grazed meat demand but increases other food demands. Reducing non-ruminant preference reduces the crop needed for livestock feed and increases food crops required. Reduced food imports increase the food production required. Bioenergy production increases the production of arable crops required.
Changes to yields and suitability lead to changes in the area of crops and EU total production and potentially under or oversupply. Similarly there could be too high a demand for irrigation water versus the amount available calculated by the water model (Wimmer et al. 2014). The model matches supply and demand by modifying crop prices and basin water price.
-
a)
Linked metamodels
-
1.
Other linked models calculate the change in the area of Urban and Flooded land (M. Mokrech et al., Submitted for publication in this special issue) which are deducted from the elements pro-rata. Flooded land is defined as either unusable for agriculture or restricted to grassland.
-
2.
For every element, the Crop metamodel calculates the yield of crops and the Forest metamodel calculates the yield of species as managed and unmanaged forest.
-
3.
The Water metamodel calculates the water available for irrigation in each water basin (Wimmer et al. 2014). Grids are pre-allocated to 91 water basins.
-
4.
The Protected Areas metamodel calculates the proportion of each grid which is protected and has to be extensive grassland, forest or abandoned land use.
-
1.
-
b)
Land use metamodel and iterative analysis
-
1.
The procedure (section 3.2) is used to calculate the land use in each grid for the given set of prices and hence total production of each commodity group.
-
2.
Total production of each commodity group is compared with the required demand, and prices adjusted. At the same time if water used for irrigation in any basin exceeds water available, the basin’s water price is increased. Crops are allocated to commodity groups: cereals, carbohydrate, protein, oil, cotton, milk, meat and timber.
-
3.
The model iterates (from 1) until demand is satisfied (or cannot be met) and basin water use is not more than is available. It is possible that demand cannot be met, for example due to a large increase in population, reduction in imported food or increase in land used for bioenergy.
-
1.
-
c)
Post modelling analysis
For each grid, in addition to the area and yield of each crop, the nitrate leaching, fertiliser and pesticide use are estimated. Food production is calculated as TJ output and kcal per person per day. Food output includes food which is subsequently fed to livestock such as pigs and chicken and is thus greater than kcal food required by a person. Finally a Shannon land use diversity index is calculated based on the 6 land use types.
4 Results
There are many ways to utilise this ability to do rapid What-If analyses of both impact and adaptation. What is the effect of using one of the five different GCMs? Or what is the effect of increasing or decreasing summer or winter temperature or precipitation? Or what is the effect of increasing population, oil price or bioenergy cropping? Or what is the effect of breeding higher yielding crops, of more efficient irrigation, reducing meat consumption, or of increasing the land set aside for biodiversity.
To illustrate this, two of the 5 different GCMs and two of the four different socio-economic scenarios were selected. HADGEM and CSMK3 GCMs are illustrated in Supplement Fig. 11. HADGEM shows much lower levels of precipitation and almost no areas with an increase, whereas CSMK3 shows much greater temperature increases in the North. The “We are the World” (WaW) socio-economic scenario (Table 1) has limited population growth, reduced meat consumption and increased crop yield potentials, whereas “Should I stay or Should I go” (SISOG) has increased population, increased meat consumption and reduced crop yields. Both reduce food imports. Figure 3 shows the impact. There is a clear shift of intensive land use to the north, but in WaW this is accompanied by a loss of production in the South. In SISOG intensive land use increases everywhere and in HADGEM the required production was impossible in spite of massive increases in the area used for intensive food production.

Intensive agricultural land use in 2,050 for two climates and two scenarios a) CSMK3+” We are the World” b) HADGEM+” We are the World” c) CSMK3 + “Should I Stay or Should I go” d) HADGEM + “Should I Stay or Should I go” e) c with yield +15 % f) b with population +25 %
How secure is food security in WaW? This can be examined by, for example, increasing population from its current 5 % level, to successively 15 %, 25 %, 33 % (the maximum allowed). In none of these cases is food security a problem, which suggests food security is not vulnerable in this scenario. Figure 3 shows that with a 25 % increase in population, intensive agriculture increases in most areas of Europe.
What will solve the food security problem in SISOG? One idea is to increase crop yields (more investment in breeding research) by 5, 15, 25, 35 %. Fig. 3 shows the effect of 15 % which solves the food security problem but still requires large increases in intensive land use. (+26 % of current)
Finally there is nothing about the models that requires them to be used at an EU 10’ grid scale. The models were applied to Scotland by replacing the input data by 5 km2 grid data for soils and climate. Supplement Fig. 12 shows the output baseline intensive agriculture for Scotland. A large amount here is extensive grassland agriculture.
5 Discussion and conclusion
Metamodels operating on clustered data have successfully replaced complex models in predicting land use. It can be estimated that clustering has reduced run-time by a factor of 36 and that metamodels using monthly not daily data have reduced time by a factor of about 3,000. One run of the crop and forest yield models on 6,174 cells requires 6.8 s on a 3Ghz Intel Core 2™ Duo and the farm model requires 0.5 s per iteration. The typical 20 s overall when added to the other modules is 4–5 times longer than desirable to be ‘interactive’.
Whilst there must be some loss of precision this is tempered by the fact that the complex models themselves are far from perfect in predicting yields and land use. Thus whilst it is possible to discover locations where the results are poor, it is far from obvious whether this is additional metamodelling error or complex model error. In fact the ability to view and analyse the results in great detail, which has become available due to this system, is in this respect both a benefit and a curse since results are open to severe scrutiny. Thus whilst the models do well when understanding the aggregate performance of the EU to climate change, there is great temptation for users to dwell on the fine scale of their own communities.
The study has shown the advantage of being able to carry out iterations rapidly and thus match supply and demand for food and water, even though the iterations have to be restricted to limit the time delay. However the system does not clearly indicate potential contradictions between the scenario assumptions and the results. The study calculates that WaW has considerable surplus land which would tend to generate more exports (fewer imports) than the scenario indicates. Conversely SISOG needs more production and hence would require more imports, contradicting the scenario value. However these are only potential contradictions since nothing is known about the rest of the world. It may be (and it is quite likely) that in WaW, world food supply is high and prices low and that in SISOG world food supply is in crisis.
Having the ability to examine many scenarios allows a user to examine the many parameters which make up the more common Forecasted Scenarios. During testing it has rapidly become clear that population, yield increase and imports have by far the biggest impact—greater than climate. Choice of climate model however can cause significant differences if vulnerability is close as with the SISOG scenario.
Having identified vulnerabilities, the system is easy to use to examine the level of vulnerability, for example increasing population by 20 % to try to generate a problem. Similarly with adaptations to solve problems such as by increasing yields. Note that this adaptation already exists in WaW and solves the food security problem identified in SISOG.
An obvious conclusion of any modelling study is the need to increase the scope or precision of the crop, forest and land use models. This need is long acknowledged by on-going projects such as AgMIP and MACSUR. For example, what if crops were bred more drought tolerant? This however ignores the 80–20 rule, that 80 % of the answer is obtained with 20 % of the effort and thus a lot more effort may be needed to increase precision, whilst providing little new information to policy. And this needs to be done without compromising speed of model solutions.
References
Annetts JE, Audsley E (2002) Multiple objective linear programming for environmental farm planning. J Oper Res Soc 53:933–943. doi:10.1057/palgrave.jors.2601404
Audsley E, Pearn KR, Simota C, Cojocaru G, Koutsidou E, Rounsevell MDA, Trnka M, Alexandrov V (2006) What can scenario modelling tell us about future European scale agricultural land use, and what not? Environ Sci Pol 9:148–162. doi:10.1016/j.envsci.2005.11.008
Bossard M, Feranec J, Otahel J (2000) CORINE land cover technical guide—addendum
Britz Wolfgang (Ed.), (2005) CAPRI Modelling system documentation
Dubrovsky M, Trnka M, Svobodova E, Dunford R, Holman IP (submitted for this issue) Creating a reduced-form ensemble of climate change scenarios for Europe representing known uncertainties. Climatic Change
Hanley N, Acs S, Dallimer M, Gaston KJ, Graves A, Morris J, Armsworth PR (2012) Farm-scale ecological and economic impacts of agricultural change in the uplands. Land Use Pol 29:587–597. doi:10.1016/j.landusepol.2011.10.001
Holman IP, Rounsevell MDA, Shackley S, Harrison PA, Nicholls RJ, Berry PM, Audsley E (2005) A regional, multi-sectoral and integrated assessment of the impacts of climate and socio-economic change in the UK. Clim Chang 71:9–41. doi:10.1007/s10584-005-5927-y
Hossell JE, Jones PJ, Marsh JS, Parry ML, Rehman T, Tranter RB (1996) The likely effects of climate change on agricultural land use in England and Wales. Geoforum 27:149–157. doi:10.1016/0016-7185(96)00005-X
Keenan T, Maria Serra J, Lloret F, Ninyerola M, Sabate S (2011) Predicting the future of forests in the Mediterranean under climate change, with niche- and process-based models: CO2 matters!: predicting the future of forests under climate change. Glob Chang Biol 17:565–579. doi:10.1111/j.1365-2486.2010.02254.x
Keenan T, Sabaté S, Gracia C (2008) Forest Eco-physiological models and carbon sequestration. In: Bravo F, Jandl R, LeMay V, Gadow K (eds) Managing forest ecosystems: The challenge of climate change. Springer, Netherlands, pp 83–102
Kok K, Bärlund I, Flörke M, Holman I, Gramberger M, Sendzimir J, Stuch B, Zellmer K (2014) European participatory scenario development: strengthening the link between stories and models. Climatic Change. doi:10.1007/s10584-014-1143-y
Lehtonen H, Peltola J, Sinkkonen M (2006) Co-effects of climate policy and agricultural policy on regional agricultural viability in Finland. Agric Syst 88:472–493. doi:10.1016/j.agsy.2005.07.005
Mokrech M, Kebede AS, Nicholls RJ, Wimmer F (submitted for this issue) Assessing flood impacts due to cross-sectoral effects of climate and socio-economic scenarios and the scope of adaptation. Climatic Change
Morris J, Audsley E, Wright IA, McLeod J, Pearn K, Angus A, Rickard S, (2005) Agricultural futures and implications for the environment
Nissen S (2005) Neural networks made simple. Softw 2:14–19
Panagos P, Van Liedekerke M, Jones A, Montanarella L (2012) European soil data centre (ESDAC): response to European policy support and public data requirements. Land Use Pol 29:329–338
Rounsevell MD, Annetts J, Audsley E, Mayr T, Reginster I (2003) Modelling the spatial distribution of agricultural land use at the regional scale. Agric Ecosyst Environ 95:465–479. doi:10.1016/S0167-8809(02)00217-7
Rounsevell MDA, Ewert F, Reginster I, Leemans R, Carter TR (2005) Future scenarios of European agricultural land use. Agric Ecosyst Environ 107:117–135. doi:10.1016/j.agee.2004.12.002
Van Meijl H, van Rheenen T, Tabeau A, Eickhout B (2006) The impact of different policy environments on agricultural land use in Europe. Agric Ecosyst Environ 114:21–38. doi:10.1016/j.agee.2005.11.006
Wimmer F, Audsley E, Malsy M, Savin C, Dunford R, Harrison PA, Schaldach R, Flörke M (2014) Modelling the effects of cross-sectoral water allocation schemes in Europe. Climatic Change. doi:10.1007/s10584-014-1161-9
Acknowledgments
This work was supported by the CLIMSAVE Project (Climate change integrated assessment methodology for cross-sectoral adaptation and vulnerability in Europe; www.climsave.eu) funded under the Seventh Framework Programme of the European Commission (Contract No. 244031).). The Czech participation was co-funded through Ministry of Education projects no. 7E10033 and KONTAKT II LD130030 with Jan Balek’s work being funded through project Building up a multidisciplinary scientific team focused on drought, No. CZ.1.07/2.3.00/20.0248
Author information
Authors and Affiliations
Corresponding author
Additional information
This article is part of a Special Issue on "Regional Integrated Assessment of Cross-sectoral Climate Change Impacts, Adaptation, and Vulnerability" with Guest Editors Paula A. Harrison and Pam M. Berry.
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 4296 kb)
Rights and permissions
About this article

Cite this article
Audsley, E., Trnka, M., Sabaté, S. et al. Interactively modelling land profitability to estimate European agricultural and forest land use under future scenarios of climate, socio-economics and adaptation. Climatic Change 128, 215–227 (2015). https://doi.org/10.1007/s10584-014-1164-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10584-014-1164-6