
Abstract
Purpose
Claims data may be a suitable source studying associations between drugs and cancer. However, linkage between cancer registry and claims data including pharmacy-dispensing information is not always available. We examined the accuracy of claims-based definitions of incident cancers and their date of diagnosis.
Methods
Four claims-based definitions were developed to identify incident leukemia, lymphoma, lung, colorectal, stomach, and breast cancer. We identified a cohort of subjects aged ≥65 (1997–2000) from Pennsylvania Medicare and drug benefit program data linked with the state cancer registry. We calculated sensitivity, specificity, and positive predictive values of the claims-based definitions using registry as the gold standard. We further assessed the agreement between diagnosis dates from two data sources.
Results
All definitions had very high specificity (≥98%), while sensitivity varied between 40% and 90%. Test characteristics did not vary systematically by age groups. The date of first diagnosis according to Medicare data tended to be later than the date recorded in the registry data except for breast cancer. The differences in dates of first diagnosis were within 14 days for 75% to 88% of the cases. Bias due to outcome misclassification of our claims-based definition of cancer was minimal in our example of a cohort study.
Conclusions
Claims data can identify incident hematologic malignancies and solid tumors with very high specificity with sufficient agreement in the date of first diagnosis. The impact of bias due to outcome misclassification and thus the usefulness of claims-based cancer definitions as cancer outcome markers in etiologic studies need to be assessed for each study setting.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Background
Health care utilization databases such as claims files from Medicaid, Medicare linked with pharmacy prescription programs, or large health maintenance organizations (HMOs) have been used to study the safety of drugs in pharmacoepidemiologic studies. New biologic immunomodifying drugs such as tumor necrosis factor (TNF)-α antagonists have raised concerns about an increased risk of cancers, especially lymphoproliferative malignancies [1, 2]. Large population-based datasets are required to examine the effect of infrequent exposures (e.g., TNF-α antagonists) on rare outcomes (e.g., lymphoma). Although the Surveillance Epidemiology and End Results (SEER)-Medicare dataset can provide large numbers of patients with valid cancer diagnosis, the SEER-Medicare dataset does not include prescription drug information. Furthermore, cancer registry data linkable to specific health care utilization data including pharmacy information are not often available, which leaves only health care utilization databases to identify incident cancers.
Previous studies have evaluated the accuracy of cancer diagnoses in Medicare claims data including breast, colorectal, endometrial, lung, pancreatic, and prostate cancers [3–9], but they did not include less frequent cancers such as hematologic malignancies, and the agreement of diagnosis dates between claims data and cancer registry data has not been understood since only month and year of diagnosis are available in SEER data. We sought to develop various claims-based definitions for incident lymphoma and leukemia as well as breast, lung, colorectal, and stomach cancer and assessed the accuracy of these definitions in comparison with registry data including the accuracy of the date of the clinical cancer diagnosis.
Methods
Data sources and study participants
Three data sources were used for this study. Health care utilization data were derived from Medicare claims data linked to pharmacy dispensing data from the Pharmaceutical Assistance Contract for the Elderly (PACE) in Pennsylvania between 1 January 1997 and 31 December 2000. Our gold standard cancer information was Pennsylvania State (PA) Cancer Registry data from 1 January 1989 to 31 December 2000. PACE provides comprehensive pharmacy coverage with only a co-payment of US $6 per prescription. The PA cancer registry is a population-based cancer registry that routinely collects data on patient demographics, date of diagnosis, primary tumor site, morphology, stage at diagnosis, first course of treatment, follow-up for vital status, and survival rates within each stage. The PA cancer registry is certified as “Gold”, the highest quality by the North American Association of Central Cancer Registries [10]. The Institutional Review Board of the Brigham and Women’s Hospital approved this study, and data use agreements were in place.
We identified a cohort of subjects’ age 65 or older who were continuously enrolled in PA Medicare and PACE between 1 January 1997 and 31 December 2000. To ensure subjects’ enrollment, we required all subjects to have at least one claim for any service and prescription during each 6-month period until subjects die, or until the study period ends. We also required all subjects to be enrolled, and have no cancer-related claims during the 6 months before 1 January 1997 to exclude subjects currently undergoing treatment for cancer.
Incident case definitions in medicare/PACE
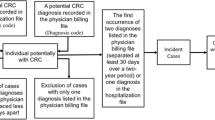
A panel consisting of epidemiologists, health services researchers, and clinical oncologists reviewed and developed four claims data-based definitions of incident cancer using (1) ICD-9 diagnosis codes, (2) Current Procedural Terminology (CPT) codes for screening procedures, surgical procedures, radiation therapy, chemotherapy, and nuclear medicine procedures, and/or (3) National Drug Code (NDC) prescription codes for medications used for cancer treatment available in PACE. The four definitions were developed based on our expectation that we will find some variation in sensitivity and specificity among these definitions. Using four claims data-based definitions (Fig. 1), we identified incident cases of lymphoma and leukemia, as well as breast, colorectal, stomach, and lung cancer diagnosed between 1997 and 2000 in the cohort. Definition 1 is based on combination of diagnoses and procedure codes, Definition 2 and 4 are based on only diagnoses codes, and Definition 3 is defined either as Definition 1 or 2. (Fig. 1) These definitions reflect how researchers typically defined diseases in administrative data. The index date for each case was defined as the earliest date of cancer diagnosis appearing in the health care utilization data. Diagnosis and procedure codes used are available upon request.

Health care utilization-based definitions for incident cancers
Incident case definition in the registry
Incident cancer cases in the registry were those recorded as having lymphoma and leukemia as well as cancers of breast, colorectal, stomach, and lung with the diagnosis date during the study period (1 January 1997–31 December 2000). We considered the cases identified in the registry as the gold standard for validating claims data-based definitions of cancers.
Characteristics of patients
Information on age, gender, race, adjusted net income, and death was obtained from PACE eligibility files and PA cancer registry data files. In addition, information on the stage of the cancer at diagnosis and procedures of diagnostic confirmation were obtained from the registry data.
Data linkage
Participants in the cohort from Medicare/PACE data were linked with the PA cancer registry data using social security number, gender, and date of birth. All person-specific identifiers were removed after successfully linking all the three data sources. Anonymously coded study numbers were used to identify subjects to protect the privacy of program participants.
Statistical analysis
Specificity, sensitivity, and positive predictive value
For the four claims data-based definitions of six types of cancers, we calculated the sensitivity (the number of cancer cases identified by a claims data-based definition that are also identified in the registry divided by the number of all cases with the cancer identified in the registry), specificity (the number of subjects without cancer using claims data-based definition, and the registry divided by the number of all subjects without cancer according to the registry), and PPV (the number of all cases identified by a claims data-based definition that are also identified in the registry divided by the number of cancer cases identified by claims data-based definitions) [11] We also assessed whether these measures varied among age categories (65–74, 75–84, 85+).
Misclassification of prevalent cases as incident cases in health care utilizations data
Contrary to registry information, health care utilization data do not record the onset of diseases. Therefore, we assessed the extent to which prevalent or recurrent cancer cases could be misclassified as incident cases in the health care utilization data depending on a required cancer-free period before the study period. For example, when we required a 6 months cancer-free period, patients had to have no claims with cancer diagnoses during the 6 months prior to 1/1/1997 but had to have at least one claims for any type of health service excluding cancer to ensure health system use. All analyses described above used the default of a 6-month, cancer-free period, but we subsequently varied the period from 0 to 36 months. Sensitivity, specificity and PPV as a function of the duration for the required cancer-free period were calculated with our preferred definition, Definition 3. We chose the preferred definition based on its specificity and relatively high sensitivity. Very high specificity in defining cancers is essential to obtain unbiased ratio estimates for epidemiologic studies assessing the risk of cancer [12]. Relatively high sensitivity is preferred to identify a large proportion of true cases to improve statistical efficiency of estimates, especially when studying rare outcomes.
Date of the onset of cancer
The first date of a cancer diagnosis appeared in the claims data was defined as the incident cancer diagnosis in the claims data. Among subjects who were identified as incident cancer cases by both the registry and Definition 3 in the Medicare claims data, we calculated the difference in days between the cancer diagnosis dates recorded in the two data sources (‘registry diagnosis date’−‘claims diagnosis date’).
Results
Characteristics of study population and cases identified by cancer registry
We identified 157,310 subjects in the cohort who were continuously enrolled in Medicare and PACE and had no cancer-related claims during the 6 months before the study period. The mean age of the study population was 79 years, 83% were women, 95% were white, 5% were black and 1% was of other race.
Table 1 shows demographic and clinical characteristics of cancer cases identified by the registry within the cohort. In general, the proportion of men and older patients was higher in cancer cases than in the entire cohort. The overall completeness of stage and diagnosis confirmation in the registry was greater than 90% and 98% respectively, and cancers were confirmed microscopically for 91% of cases. The estimated incidence of cancers identified by the registry within the cohort was similar to the age-specific SEER-reported incidence [13].
Specificity, sensitivity, and PPV claims data-based definitions
The number of cases, specificity, sensitivity and PPV of four claims data-based definitions are shown in Table 2. All definitions had very high specificity (greater than 98%), whereas sensitivity varied from 40% to 90%. Differences in specificity were minimal among Definitions 1 to 3, but sensitivity differed considerably among definitions (highest in Definition 4, and lowest in Definition 1). Very small differences in specificity affected PPVs considerably, which was most extreme for leukemia that also had the lowest prevalence among the six cancers in the study population. Definition 3 had very high specificity yet had relatively high sensitivity, and was used for the subsequent analyses. All subsequent analyses were limited to Definition 3. When we calculated sensitivity, specificity, and PPV as a function of age at cohort entry, we observed slight to moderate variability in these measures among age groups; however, no systematic trend was observed across six cancers.
Table 3 shows sensitivity, specificity, and PPV for incident cancers as a function of various cancer-free periods, ranging from 0 to 36 months. Specificity, sensitivity, and PPV were expected to improve as we lengthen the period since fewer prevalent or recurrent cancers would be misclassified as incident in the study period. Although all these measures were greatly improved by changing the required cancer-free period from 0 to 6 months, no meaningful improvement was achieved by further lengthening the period beyond 6 months.
Accuracy of diagnosis dates
The diagnosis date derived from Medicare data tended to come later than the date recorded in the registry data except for breast cancer. The median difference in days is close to zero (0 to 2 depending on cancer type), the mean differences were greater than 10 days (12–22 days) except for breast cancer (−1 day). Across different cancers, 21 to 46 % of the cases had their diagnoses recorded on the same day, and another 21 to 48% had their diagnoses recorded within ±7 days. The differences in the diagnosis dates were within ±14 days for 74.1% to 88.0%, and within ±60 days for 85.7% to 97.0% of the cases depending on cancer type.
Impact of residual misclassification of cancer as an outcome on pharmacoepidemiologic studies
We created data for a hypothetical cohort study evaluating the effect of Drug A on the risk of lymphoma (Table 4a–c). In these data, incident lymphomas were identified using claims data and the effect of Drug A on lymphoma was estimated. We then calculated the expected number of cases and a corrected risk ratio (RR) using estimated sensitivity, specificity, and PPV [14] and disease prevalence in the current study assuming non-differential disease misclassification. (Table 4a) This resulted in a small bias towards the null, which was calculated by subtracting the observed risk ratio (RR), from the corrected RR. Next, we decreased specificity by increasing the disease prevalence but kept the PPV constant to illustrate the impact of specificity and PPV on bias. (Table 4b–c) Although the low PPV observed in our study was a concern, there was not substantial bias when the disease prevalence was low and specificity was very high (Table 4a) However, as specificity decreased, the impact of the same low PPV (0.57) on bias became greater (Table 4b–c)
Discussion
We assessed agreement between Medicare claims-identified cancer cases and registry identified cancer cases, and calculated sensitivity, specificity, and PPV for four Medicare claim-based definitions of cancers using the population-based cancer registry cases as the gold standard. Our study showed that incident hematologic malignancies and solid tumors could be identified using claims data with very high specificity but relatively low sensitivity. We showed that the agreement in the cancer diagnosis dates was reasonably good between claims and registry data.
We also observed that possible misclassification of prevalent cases as incident cases improved most significantly by requiring a 6-month cancer-free period in the claims data but longer periods did not impact sensitivity, specificity and PPV. These findings supports the rationale of having a 6-month required cancer-free period when studying the association between medication use or other risk factors and the incidence of cancer using health care utilization databases. By lengthening the required cancer-free period, we expected that the specificity and PPV would improve as the number of prevalent and recurrent cases misclassified as incident cancer cases decrease. In addition to these improvements, we also observed some increase in sensitivity, because the size of the cohort (the denominator) decreased with longer cohort membership requirement and it decreased faster than the number of cases identified by a claims data-based definition. This fast decrease in sample size reflected high turnover of subjects in the PACE program and similar to what is observed in HMOs.
Cooper et al., [4] examined the sensitivity of Medicare claims for six common cancers (breast, colorectal, endometrial, lung, prostate, and pancreatic cancers) using the SEER-Medicare database. They found that the sensitivity of a corresponding cancer diagnoses or a cancer-specific procedure coded in outpatient or hospital files for lung, colorectal, and breast cancers was 80% to 90%. Freeman et al. [8] examined the sensitivity, specificity, and PPV of a prediction model for incident breast cancer in the SEER–Medicare database using logistic regression. Using their optimal cut-point, the sensitivity, specificity, and PPV were 90%, 99.9% and 70%, respectively. We found that the sensitivity, specificity, and PPV were 83%, 99.6%, and 75%, respectively, using the preferred definition for breast cancer, which is comparable to Freeman’s findings. Our results for lung, colorectal and breast cancers are consistent with these previous studies.
A few limitations of our study should be noted. Our findings of low sensitivity and PPV especially in hematologic cancers may be partly explained by incomplete ascertainment of cases by the PA cancer registry [15–19]. Although, cancer registries make every effort to capture all cases, the case ascertainment may not be 100% and cases captured by claims data may enhance the cancer surveillance [16, 18]. The impact of incomplete case ascertainment can be large especially in rare cancers and could underestimate their PPVs to a large extent. We illustrated this in a figure to show how sensitivity, specificity and PPV of the claims-based definition changes depending on the degree of case ascertainment of the registry (alloyed gold standard) assuming that the missed cases by the registry were captured by our claims-based definition (Fig. 2). When we assumed that the registry captures only 80% of the true cases [16, 18], the PPV for lymphoma using our preferred definition will be 74% (compared to 56% if the registry captures 100% of the true cases), whereas the estimates for sensitivity and specificity are not affected substantially.

Estimated sensitivity, specificity, and positive predictive values (PPV) for a claims-based definition (Definition 3) of lymphoma vary depending on the degree of incomplete case ascertainment by the registry in the main analyses, we assumed that there are no cases missed by the registry (% of true cases missed by the registry = 0) to calculate sensitivity, specificity and PPV of the claims-based definitions. When we vary the assumption of the percentage of cases missed by the registry, as the percentage of cases missed by the registry increases, the estimated values of these test characteristics measures increased. The change was the largest in PPV but smaller in sensitivity and much smaller in specificity
To calculate sensitivity, specificity, and PPV with our claims data-based definitions, we linked the subjects in the cohort sampled from Medicare/PACE with the registry data using person-specific identifiers. Because the subjects in our cohort were a subset of the entire Medicare population in PA, e.g., those also enrolled in the PACE program, whereas the registry data include all cases in PA, we could not assess how successful the linkage was. It was impossible to assess whether we had non-linked registry cases because of poor linkage or because they arose outside of the cohort. However, we had several personal identifiers available for linkage, and the successful linkage was indirectly supported by the findings of our study; incidence in the cohort was similar to that in the SEER database, and sensitivity, specificity and PPV in some of the cancers were compatible with previous studies. Any insufficiency in linkage would likely diminish specificity and PPV.
We conclude that claims data can identify incident hematologic malignancies and solid tumors with high specificity and but with relatively low to moderate sensitivity and PPVs. Within the cases identified by both the registry and the claims-based definition, the agreement in the first dates of cancer diagnosis was sufficient. Our claims-based definition resulted in relatively small bias in our example of a typical pharmacoepidemiologic study with drug A possibly causing lymphoma. However, the impact of bias due to misclassification and thus the usefulness of claims-based cancer definitions as cancer outcome markers in etiologic studies need to be assessed for each study setting.
Reference
Brown SL, Greene MH, Gershon SK, Edwards ET, Braun MM (2002) Tumor necrosis factor antagonist therapy and lymphoma development: twenty-six cases reported to the Food and Drug Administration. Arthritis Rheum 46(12):3151–3158
Setoguchi S, Solomon DH, Weinblatt ME et al (2006) Tumor necrosis factor alpha antagonist use and cancer in patients with rheumatoid arthritis. Arthritis Rheum 54(9):2757–2764
Warren JL, Feuer E, Potosky AL, Riley GF, Lynch CF (1999) Use of Medicare hospital and physician data to assess breast cancer incidence.[comment]. Medical Care 37(5):445–456
Cooper GS, Yuan Z, Stange KC, Dennis LK, Amini SB, Rimm AA (1999) The sensitivity of Medicare claims data for case ascertainment of six common cancers.[comment]. Medical Care 37(5):436–444
Solin LJ, Legorreta A, Schultz DJ, Levin HA, Zatz S, Goodman RL (1994) Analysis of a claims database for the identification of patients with carcinoma of the breast. J Med Syst 18(1):23–32
Solin LJ, MacPherson S, Schultz DJ, Hanchak NA (1997) Evaluation of an algorithm to identify women with carcinoma of the breast. J Med Syst 21(3):189–199
Leung KM, Hasan AG, Rees KS, Parker RG, Legorreta AP (1999) Patients with newly diagnosed carcinoma of the breast: validation of a claim-based identification algorithm. J Clin Epidemiol 52(1):57–64
Freeman JL, Zhang D, Freeman DH, Goodwin JS (2000) An approach to identifying incident breast cancer cases using Medicare claims data. J Clin Epidemiol 53(6):605–614
Penberthy L, McClish D, Manning C, Retchin S, Smith T (2005) The added value of claims for cancer surveillance: results of varying case definitions. Med Care 43(7):705–712
The North American Association of Central Cancer Registries, Inc. Official website (2004) (Accessed September, 9, 2005, at http://www.naaccr.org/.)
Fletcher RW, Fletcher SW (2005) Clinical Epidemiology: The Essentials. 4th edn. Lippincott Williams & Wilkins (ed)
Rothman KJ, Greenland S (1998) Modern Epidemiology. 2nd edn. Lippincott Williams & Wilkins
SEER Fast Stats (Accessed January 15, 2005, 2005, at http://seer.cancer.gov.)
Brenner H, Gefeller O (1993) Use of the positive predictive value to correct for disease misclassification in epidemiologic studies. Am J Epidemiol 138(11):1007–1015
Fanning J, Gangestad A, Andrews SJ (2000) National cancer data base/surveillance epidemiology and end results: potential insensitive-measure bias. Gynecol Oncol 77(3):450–453
Penberthy L, McClish D, Pugh A, Smith W, Manning C, Retchin S (2003) Using hospital discharge files to enhance cancer surveillance. Am J Epidemiol 158(1):27–34
Stang A, Glynn RJ, Gann PH, Taylor JO, Hennekens CH (1999) Cancer occurrence in the elderly: agreement between three major data sources. Ann Epidemiol 9(1):60–67
Wang PS, Walker AM, Tsuang MT, Orav EJ, Levin R, Avorn J (2001) Finding incident breast cancer cases through US claims data and a state cancer registry. Cancer Causes & Control 12(3):257–265
McClish DK, Penberthy L, Whittemore M et al (1997) Ability of Medicare claims data and cancer registries to identify cancer cases and treatment. Am J Epidemiol 145(3):227–233
Acknowledgments
The authors thank Jeffrey Peppercorn, MD, MPH, Assistant Professor of Medicine, Division of Hematology/Oncology, University of North Carolina at Chapel Hill for useful comments on the health care utilization data-based definitions for incident cancers and the draft version of this work.
The authors also thank Helen Mogun, MS for her contributions to linking the data of this work.
Financial Support: This project was support by a grant from the Engalitcheff Arthritis Outcomes Initiatives, Arthritis Foundation. Dr. Schneeweiss received support from the National Institute on Aging (RO1-AG021950, RO1- AG023178) and the Agency for Healthcare Research and Quality (2-RO1-HS10881), Department of Health and Human Services, Rockville, MD, and is principal investigator of the BWH DEcIDE Research Center funded by the Agency for Healthcare Research and Quality.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Setoguchi, S., Solomon, D.H., Glynn, R.J. et al. Agreement of diagnosis and its date for hematologic malignancies and solid tumors between medicare claims and cancer registry data. Cancer Causes Control 18, 561–569 (2007). https://doi.org/10.1007/s10552-007-0131-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10552-007-0131-1